Hat sich hier schon mal jemand mit den Transputer-Prozessoren aus den 1980ern auseinandergesetzt? https://de.wikipedia.org/wiki/Transputer Würde es Sinn machen, die Prinzipien zur Parallelverarbeitung direkt auf die heutigen MCUs zu übertragen? Da diese ziemlich billig sind, könnte man ja viele miteinander verbinden. Transputer gab es von ST wohl in verschiedenen Wortbreiten: http://transputer.classiccmp.org// T225 16-bit Transputer T425 32-bit Transputer ST20450 32-bit Transputer T400 32-bit Low cost Transputer T805 32-bit Floating Point Transputer T9000 32-bit Floating Point Transputer
:
Verschoben durch Moderator
Das limitierende ist die Kommunikation zwischen den Nodes. Deshalb packt man die Recheneinheiten sehr nah zusammen, und gibt denen gemeinsamen Speicher mit hoher Bandbreite. Z.B. auf einer Grafikkarte, wo x-tausend CUDA-Cores gleichzeitig vor sich hin werkeln.
Beitrag #7955399 wurde von einem Moderator gelöscht.
Ernst schrieb:
>Das limitierende ist die Kommunikation zwischen den Nodes.
Es wird von 10-20MBIt/s gesprochen. Das ist eine Geschwindigkeit, die
man z.B. mit zwei PiPicos auf einer Platine gut erreichen sollte.
Mich interessiert, ob es Sinn machen würde, verschieden Prinzipien auf
z.B. die PiPicos zu übertragen.
Moin, Christoph M. schrieb: > Mich interessiert, ob es Sinn machen würde, verschieden Prinzipien auf > z.B. die PiPicos zu übertragen. Es wird wohl stark davon abhaengen, was du mit deinen PiPicos berechnen willst. Es ist ja nicht verboten, viele von den Dingern miteinander kommunizieren zu lassen. Aber es ist auch nicht immer dringend noetig. Gruss WK
Enge Kopplung über gemeinsamen Speicher ist wesentlich umgänglicher in paralleler Programmierung, als kommunikative Kopplung wie bei Transputern. Der Aufwand der Kommunikation ist beträchtlich. Da man heute hunderte leistungsfähiger und speichergekoppelter Nodes in einem Modul unterbringen kann, Tendenz weiter steigend, fehlt der Sinn der Parallelisierung der Transputer, unterhalb der Ebene von HPC in Saalgrösse.
:
Bearbeitet durch User
Christoph M. schrieb: > Es wird von 10-20MBIt/s gesprochen. Das ist eine Geschwindigkeit, die > man z.B. mit zwei PiPicos auf einer Platine gut erreichen sollte. Immerhin hatten die Transputer wesentliche Elemente der Kommunikation in Hardware gegossen, bis hin zur Signalisierung damit in Verbindung stehender Tasks. Das fehlt hier.
Christoph M. schrieb: > T9000 32-bit Floating Point Transputer Randinfo: Dessen exorbitanter Abstand zwischen Ankündigung und Fertigstellung schloss das Kapitel ab. Schon die hardwaregestützte Kommunikation innerhalb grösserer Gebilde wurde zum Problem, d.h. wenn nicht nur direkte Nachbarn miteinander kommunizieren. Und das Arbeitsprinzip der Architektur, der Stack, war problematisch, weil es sich verfahrensbedingt nur mit damals hohem Aufwand signifikant beschleunigen liess. Bald kamen erste superskalare Architekturen auf, die also mehrere unabhängige Operationen parallel bearbeiteten, was in dieser Phase der Implementierungen aufgrund der Abhängigkeit aufeinanderfolgender Befehle einer Stack-Architektur wenig bringt.
:
Bearbeitet durch User
Angehängte Dateien:
-

TransputerLink.png
160 KB

von (prx) A. K. (prx) >Immerhin hatten die Transputer wesentliche Elemente der Kommunikation in >Hardware gegossen, bis hin zur Signalisierung damit in Verbindung >stehender Tasks. Das fehlt hier. Wenn ich das richtig verstehe, werden beim Transputer Link auf einer Leitung 11Bit gesendet, dann wird die Richtung umgeschaltet und auf das 2Bit Acknowledge gewartet. Das lässt sich wohl mit der PiPico PIO machen: https://github.com/blackjetrock/picoputer
Xmos mit den Links geht in diese Richtung, es gibt/gab auch ein Board mit 64 Einheiten welche untereinander verbunden waren. Als sie sich noch nicht auf Audio fokussierten gab es zwei unterschiedliche Architekturen, eine low cost, LX glaube ich und eine teure, gx. Diese hatten inkompatible HW links und token damit man diese leider nicht kombinieren könnte.
Chris S. schrieb: > Xmos mit den Links geht in diese Richtung Was wenig verwundert, wenn man sich ansieht, welcher Name dahinter steht.
Hier gibt es noch das Video zum PiPico-Transputer Link: https://retrocomputingforum.com/t/raspberry-pi-pico-transputer-emulator/2068
:
Bearbeitet durch User
Christoph M. schrieb: > Würde es Sinn machen, die Prinzipien zur Parallelverarbeitung direkt auf > die heutigen MCUs zu übertragen? Es gibt ja Multicore-MCUs (z.B. ESP32, manche STM32, TriCore) die primär über shared-memory kommunizieren. Das scheint sich so wohl mehr durchgesetzt zu haben als Transputer. Tatsächlich geht es dabei auch weniger um das Erreichen höherer Rechenleistung, sondern Entkopplung von nebenläufigen Vorgängen. Will man mehr Rechenleistung, nimmt man größere Prozessoren (z.B. Cortex-A). Das kann man ziemlich weit treiben (z.B. AWS Graviton). Oder die erwähnten GPUs, APUs.
Da schneidest du ein heisses Thema an. Mit dem Inmos T800 habe ich mich mal auseinandergesetzt, irgendwo liegt noch ein Scan des TRM. Das Problem an der Architektur: Sie war zu frueh dran. Das naechste: Die Entwicklungstools exotisch (Occam wollte einfach vor allem missverstanden werden). Auf jeden Fall keine schlechte Idee, sich mit dem verwaisten Knowhow zu beschaeftigen, denn die Transputerkonzepte findet man - abseits von XMOS - doch oefters in FPGA-Designs wieder, wo Software und Hardware ineinander uebergeht. Nur bei MCUs finde ich es eher fragwuerdig. Sinn macht das Ganze sowieso nur, wenn man alles in die Simulation stecken kann, denn sequentielles Debugging ist da nicht mehr zielfuehrend.
Martin S. schrieb: > Auf jeden Fall keine schlechte Idee, sich mit dem verwaisten Knowhow zu > beschaeftigen, Bei Hobbys ist die Sinnfrage meist nutzlos. Martin S. schrieb: > denn die Transputerkonzepte findet man - abseits von XMOS > - doch oefters in FPGA-Designs wieder, Alles Exoten.... Auch der GA144 von Green Arrays verwendet sowas wie das Transputer Link Konzept.
Martin S. schrieb: > Das Problem an der Architektur: Sie war zu frueh dran. Sie kam immerhin zu einem Zeitpunkt, der zu allerlei Projekten an Universitäten einlud. Da kommen exotische Ideen gut an. Sie war aber engstirnig ausschliesslich auf Programmierung in Occam konzipiert. Was Occam nicht benötigte, das gab es nicht. Was einem bei der Implementierung anderer Programmiersprachen auf die Füsse fiel.
:
Bearbeitet durch User
Martin S. (strubi) 23.10.2025 16:15 >Das Problem an der Architektur: Sie war zu frueh dran. Das naechste: Die >Entwicklungstools exotisch (Occam wollte einfach vor allem >missverstanden werden). Hier gibt es ein interessantes Video zur Entstehung des Transputers: https://www.youtube.com/watch?v=qJVStORkjnM Das interessante: Es wurde zuerst die Programmiersprache "Occam" für parallel arbeitende Prozessoren und danach die dafür optimierte Prozessorarchitektur des Transputers entwickelt. Heraus kam dann eine gemischte Architektur (laut Video, ich habe mir den Befehlssatz noch nicht genau angesehen) aus Stackmaschine und Registermaschine. Dass eine Stackmaschine ziemlich optimiert in ein FPGA passen kann, zeigt Exacamera mit der J1: https://excamera.com/sphinx/article-j1a-swapforth.html
Christoph M. schrieb: > T225 16-bit Transputer > T425 32-bit Transputer > ST20450 32-bit Transputer > T400 32-bit Low cost Transputer > T805 32-bit Floating Point Transputer > T9000 32-bit Floating Point Transputer Da hast du die "Multimedia-Transputer" noch übersehen, die wie der ST20450 zur ST20-Serie gehören, und neben ihrem Transputerkern noch reichlich Peripherie für Audio und Video mitbringen. Wenn man wollte, gab es dafür sogar Betriebssysteme wie OS20, OS21 oder OSPlus. Die Typenbezeichnungen deuten keine Verwandtschaft an: ST51xx, ST77xx, und sicher noch ein paar mehr. Mit 32 bit, Taktraten von ca. 250 MHz, und Single-Cycle-Befehlen dürften die auch jeden Pico leicht an die Wand rechnen. ☺
Angehängte Dateien:
-

ST20450.png
120 KB
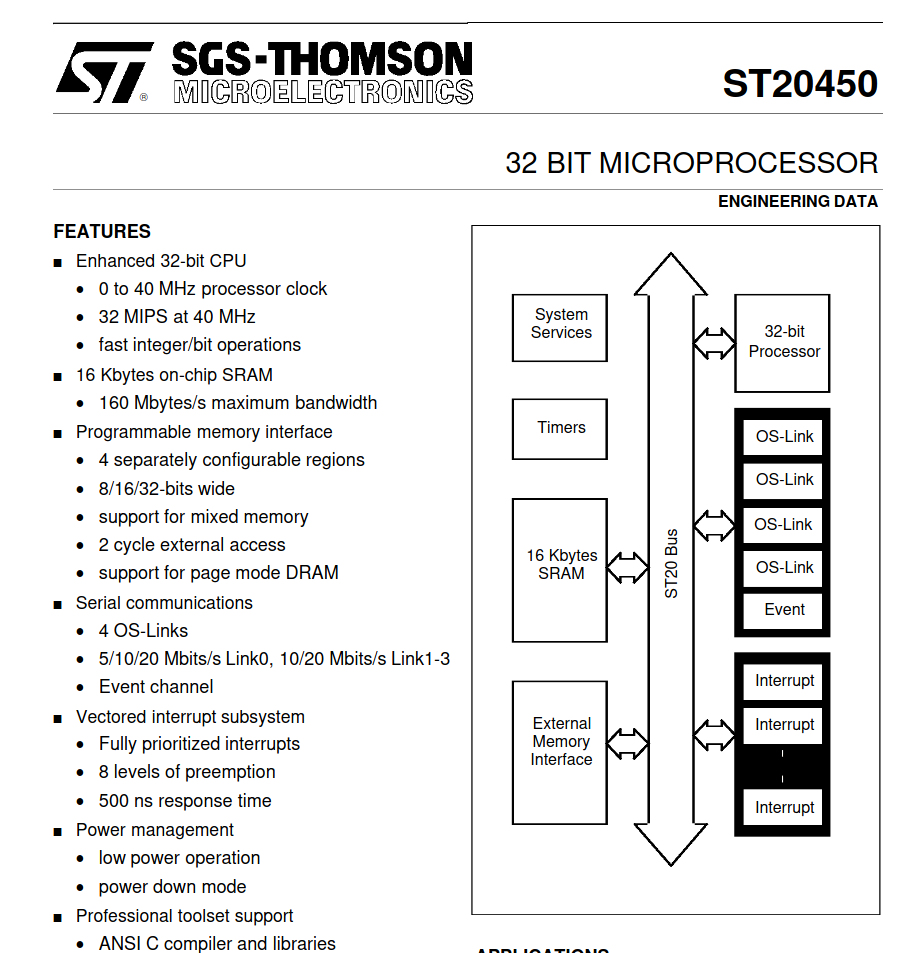
>Da hast du die "Multimedia-Transputer" noch übersehen, die wie der >ST20450 Hmm, 40MHz .. https://transputer.net/ibooks/dsheets/st20450.pdf Sind aber wahrscheinlich auch ziemlich historisch.
Christoph M. schrieb: > Würde es Sinn machen, die Prinzipien zur Parallelverarbeitung direkt auf > die heutigen MCUs zu übertragen? In dem Zusammenhang könnte dich der Parallax Propeller interessieren, den man tatsächlich noch kaufen kann. https://www.parallax.com/propeller/
Cartman E. (cartmaneric) 23.10.2025 17:03 >Mit 32 bit, Taktraten von ca. 250 MHz, und Single-Cycle-Befehlen >dürften die auch jeden Pico leicht an die Wand rechnen. Das könnte eng werden. Wenn ich es Recht weiß, lässt sich der RP2350 auf 400MHz übertakten. Er hat zwei Kerne, deutlich mehr Register und immerhin 512kRam im Direktzugriff.
Nemopuk (nemopuk) 23.10.2025 17:26 >In dem Zusammenhang könnte dich der Parallax Propeller interessieren, >den man tatsächlich noch kaufen kann. Ich habe noch 10 Stück rumliegen .. Architektonisch sehr interessant, aber eher in der C64 Ära anzusiedeln. Der Propeller1 hat nur Integer Arithmetik und nur 2K COG-Memory.
Cartman E. schrieb: > Mit 32 bit, Taktraten von ca. 250 MHz, und Single-Cycle-Befehlen > dürften die auch jeden Pico leicht an die Wand rechnen. ☺ Bei den klassischen Transputern wie T4xx waren Taktfrequenzvergleiche mit den aufkommenden RISC Architekturen völlig wertlos. Die Transputer benötigten für die gleiche Aufgabe erheblich mehr Befehle.
Angehängte Dateien:
-

STI55xx.png
31 KB

Christoph M. schrieb: >>Da hast du die "Multimedia-Transputer" noch übersehen, die wie der >>ST20450 > > Hmm, 40MHz .. > https://transputer.net/ibooks/dsheets/st20450.pdf > Sind aber wahrscheinlich auch ziemlich historisch. Die ST-55xx haben auch noch eine PLL zum vervielfachen. Im Beispiel von einem STi-55xx. Es gibt noch schnellere, deren DB mir nicht vorliegt. Ich habe hier zwei Boards die mit 243 MHz (9 * 27 MHz) CPU-Takt laufen.
:
Bearbeitet durch User
Martin S. schrieb: > Da schneidest du ein heisses Thema an. Mit dem Inmos T800 habe ich mich > mal auseinandergesetzt, irgendwo liegt noch ein Scan des TRM. Gehörtest Du etwa zu den wenigen 100 Leuten, die damals eine ATW800 hatten?
Christoph M. schrieb: > Hat sich hier schon mal jemand mit den Transputer-Prozessoren aus den > 1980ern auseinandergesetzt? Ja. > Würde es Sinn machen, die Prinzipien zur Parallelverarbeitung direkt auf > die heutigen MCUs zu übertragen Nein. Alles fürchterlich langsam. CUDA lernen ist klüger.
Michael B. schrieb: > CUDA lernen ist klüger. Habe neulich erst damit begonnen, CUDA auf einem AT90S1200 zu implementieren. Sobald ich damit fertig bin, dann sofort auf 'nem Tiny.
Was mich ein wenig wundert beim Transputerlink: Es gibt jeweils eine Link-Out und einen Link-IN, aber es wird z.B. für jeden Link die Richtung umgeschaltet, um das Acknowledge zurück zu senden. Wäre es nicht sinnvoller gewesen, die Richtung beizubehalten und wie bei einer seriellen Leitung das Acknowledge per RX zurück zu senden?
Hmmm schrieb: > Martin S. schrieb: >> Da schneidest du ein heisses Thema an. Mit dem Inmos T800 habe ich mich >> mal auseinandergesetzt, irgendwo liegt noch ein Scan des TRM. > > Gehörtest Du etwa zu den wenigen 100 Leuten, die damals eine ATW800 > hatten? Leider nein, aber es stand mal die dumme Idee im Raum, das Ding auf einem FPGA nachzubauen. Wurde dann stattdessen ein DSP. Falls aber hier jemand noch eine ATW800 rumstehen hat - ich wuerde immer noch verliebt auf einige Fotos davon glotzen. Christoph M. schrieb: > Dass eine Stackmaschine ziemlich optimiert in ein FPGA passen kann, > zeigt Exacamera mit der J1: Von der J1 gibt es einige Klone, die spezifische Aufgaben sehr gut erledigen, wie z.B. einen Gigabit-UDP-Stack mit niedriger Latenz. Habe es mir nicht genau angesehen, aber der Forth-Code duerfte aus derselben Quelle stammen. Es gibt schon eine gewichtige, absolut non-exotische Berechtigung, kleine Mehrkern-Stackmaschinen einzusetzen: Anstatt eines dicken RISC-V mit Multitasking ist es 'guenstiger', ein paar ZPU-Kerne per Task zu instanzieren - das allerdings in Custom-Logik, wie ein FPGA. Die ZPU kann man sehr gut mit Transputer-Logik aufbohren, ein Addressbit wird dann ploetzlich Teil des Opcodes. Fuer spezifische Aufgaben ist das viel resourcensparender als die Zynq-Kanone und deutlich leichter zu verifizieren - bei Safety-Aspekten erst recht. Ich bin kein Kybernetikhistoriker, aber wuerde mal behaupten, dass der Transputerkiller schliesslich die MIPS-R4k-Schiene von Silicon Graphics war, da sie die gleiche tolle Grafik 'in gruen' rechnen konnte, und die Tools gut waren. Und das nicht-wollende Ende dieses Mainstreams findet man nun im Chaos von RISC-V-Derivaten wieder...
Apropos: Demnächst findet wieder ein Vintage-Computer Festival statt: https://vintagecomputerfestival.ch/ Vermutlich wird es kein Transputer geben, aber es ist trotzdem sehr interessant (besonders für die Schweizer unter uns ;-) ). Das Enter-Museum ist bezüglich historischer Computer sehr zu empfehlen.
Hmmm schrieb: > Martin S. schrieb: >> Da schneidest du ein heisses Thema an. Mit dem Inmos T800 habe ich mich >> mal auseinandergesetzt, irgendwo liegt noch ein Scan des TRM. > > Gehörtest Du etwa zu den wenigen 100 Leuten, die damals eine ATW800 > hatten? Ich glaube, die T800-Karte der C'T war ziemlich verbreitet. Ich hatte selber einen recht ansehnlichen T800-Cluster und auch eigene Platinen-Designs. Tiefe 9HE Europakarten. Da ging was drauf. Ich wurde mal gefragt, ob ich einen Parsytek-Cluster nach Ost-Berlin verschieben würde. Das war mir dann doch zu heiß. 4 Wochen später ist die Einheit ausgebrochen. Das hätte spätestens dann niemanden mehr gejuckt. Gerhard
Christoph M. schrieb: > Würde es Sinn machen, die Prinzipien zur Parallelverarbeitung direkt auf > die heutigen MCUs zu übertragen? Der Trend geht eher Richtung Vereinfachung und nicht weiterer Verkomplizierung. Die grössten Rechenzeitverbraucher sind ja heutzutage Datacenter für generative Künstliche Intelligenz und da eignet sich künftig wohl "Stochastic computing" besser. https://en.wikipedia.org/wiki/Stochastic_computing Video zum Thema: This Huge Breakthrough Can Change Computing Forever https://youtu.be/w6RztFN36Vo?si=tu8hJFMb3WQROZvd
:
Bearbeitet durch User
Johnny B. schrieb: > Der Trend geht eher Richtung… …Lesen und Verstehen des Titels: …für heutige MCUs Sowie der weiteren Beachtung der Tatsache, dass dies im Unterforum: Mikrocontroller und Digitale Elektronik steht.
Norbert (der_norbert) 24.10.2025 11:38 >…Lesen und Verstehen des Titels: …für heutige MCUs >Sowie der weiteren Beachtung der Tatsache, dass dies im Unterforum: >Mikrocontroller und Digitale Elektronik >steht. Du hast zwar Recht und ich habe auch schon überlegt, ob ich mich ärgern soll. Aber andererseits ist es ja auch interessant, was es sonst so für neue Ansätze gibt.
Christoph M. schrieb: > Cartman E. (cartmaneric) > 23.10.2025 17:03 >>Mit 32 bit, Taktraten von ca. 250 MHz, und Single-Cycle-Befehlen >>dürften die auch jeden Pico leicht an die Wand rechnen. > > Das könnte eng werden. Wenn ich es Recht weiß, lässt sich der RP2350 auf > 400MHz übertakten. Er hat zwei Kerne, deutlich mehr Register und > immerhin 512kRam im Direktzugriff. Dem würde ich gelassen entgegensehen. Der RP2350 wäre ja aber nicht mehr der "Pico". Dem mangelt es ja schon an einer richtigen 32 bit Multiplikation mit einem langen Ergebnis. Die STi55xx die hier rennen, können auch Single- und Doublefloat, und haben u.a. eine integrierte Grafikeinheit mit 4 Grafiklayern. Mehrkernig sind sie eigentlich auch, nur das die Cores eine spezialisierte Verwendung haben. ☺ Das hängt nur davon ab, ob man die gebrauchen kann. Die Zielgruppe ist eben deutlich andere als der Pico. Für mich waren sie damals ein interessanter Ausflug in die Transputerwelt, at "No Cost". ☺
Angehängte Dateien:
-

RP2350_Price.png
40 KB
>Die STi55xx die hier rennen, können auch Single- und Doublefloat, >Der RP2350 wäre ja aber nicht mehr der "Pico". Dem mangelt es ja schon >an einer richtigen 32 bit Multiplikation mit einem langen Ergebnis. https://de.wikipedia.org/wiki/SGS-Thomson_ST20 : "Der Prozessor ist auf Integer-Arithmetik (bis zu 64 Bit) optimiert und enthält keine Gleitkommaeinheit." Dagegen PiPico2 ARM Cortex M33: https://en.wikipedia.org/wiki/ARM_Cortex-M#Cortex-M33 Architecture and classification Microarchitecture ARMv8-M Mainline Instruction set Thumb-1, Thumb-2, Saturated, DSP, Divide, FPU (SP), TrustZone, Co-processor
:
Bearbeitet durch User
Cartman E. schrieb: > Der RP2350 wäre ja aber nicht mehr der "Pico". Der ist auf Platinen drauf, die mit "Pico2" beschriftet sind.
Kann man stacken und mit den üblichen verdächtigen Softwarepaketen bestücken: https://parallella.org/board/ https://www.suzannejmatthews.com/private/Parallella_setup.pdf https://www.parallella.org/docs/parallella_manual.pdf
Christoph M. schrieb: >>Die STi55xx die hier rennen, können auch Single- und Doublefloat, >>Der RP2350 wäre ja aber nicht mehr der "Pico". Dem mangelt es ja schon >>an einer richtigen 32 bit Multiplikation mit einem langen Ergebnis. > > https://de.wikipedia.org/wiki/SGS-Thomson_ST20 : > > "Der Prozessor ist auf Integer-Arithmetik (bis zu 64 Bit) optimiert und > enthält keine Gleitkommaeinheit." Ja, das ist die Generation ST20-C1. Die ich meine, sind ST20-C2+ und folgen der Spezifikation ST20-C24. > Dagegen PiPico2 ARM Cortex M33: > > https://en.wikipedia.org/wiki/ARM_Cortex-M#Cortex-M33 > Architecture and classification > Microarchitecture ARMv8-M Mainline > Instruction set Thumb-1, Thumb-2, > Saturated, DSP, > Divide, FPU (SP), > TrustZone, Co-processor Ja, dass kann ja alles sein. Nur verwende ich schon lieber Controller/Signalprozessoren, die in ihrem Ahnenbaum wenigstens den Abglanz eines richtigen DSP haben. Die gibt es, die habe ich, und die verwende ich auch. Die kommen bei mir von der "Rolle", und ich wüsste nicht, warum ich da nun wechseln sollte. Zumal deren spezielle Erweiterungen ihres nativen Befehlssatzes ganz vorzüglich genau in meine Konzepte passen. 2 unabhängige, allerdings unsymmetrische Cores haben die nebenbei auch. Ein M33 wäre für diese Fälle nur eine Gehhilfe.
Christoph M. schrieb: > Nemopuk (nemopuk) > 23.10.2025 17:26 >>In dem Zusammenhang könnte dich der Parallax Propeller interessieren, >>den man tatsächlich noch kaufen kann. > > Ich habe noch 10 Stück rumliegen .. > Architektonisch sehr interessant, aber eher in der C64 Ära anzusiedeln. > Der Propeller1 hat nur Integer Arithmetik und nur 2K COG-Memory. Naja, beim Propeller steckte vor allem die Idee dahinter, dass man sich selbst möglichst flexible, intelligente Peripherie schaffen kann. Denn es ist kein Timer, keine UART - einfach nichts vorhanden! Die Kommunikation läuft über den Hauptspeicher, aber erst, wenn man an der Reihe ist! Auf Multiprocessing war das Ding weniger ausgelegt, auch wenn man das machen kann. Dazu macht jeder Core nur max. 20 Mips bei 80MHz Schlimm finde ich außerdem, dass per default der Interpreter läuft, aus dem man sich frei kämpfen muss um selber die Kontrolle über die Cores zu bekommen. Als ich mich in den 80ern mit Apfelmännchen beschäftigte, rückten Transputer kurz in den Fokus. Schien es doch die richtige Plattform für dieses Problem zu sein, für das damalige Computer z.T. Tage für einen Bildausschnitt tief aus der Menge benötigten. Für mich als Jungendlicher aber nicht leistbar und damit dann auch recht schnell wieder vom Tisch. Ich habe dann allerdings auf der Cebit einen Kontakt zu einem INMOS-Vertreter hergestellt, der auch Interesse daran hatte dies umzusetzen. Aber dann musste ich feststellen, dass der gar keine Ahnung von Programmierung hatte (Was mich heute gar nicht mehr wundern würde, es damals aber tat.) Außerdem war die Kommunikation damals eben noch recht zäh. Telefon (ohne Mobilfunk) und Brief. So ist das dann auch wieder recht schnell eingeschlafen. Danach habe ich mich nie wieder damit beschäftigt. Gruß Jobst
Angehängte Dateien:

{kind=link}
Jobst M. (jobstens-de) 25.10.2025 20:11 >Als ich mich in den 80ern mit Apfelmännchen beschäftigte, rückten >Transputer kurz in den Fokus. Schien es doch die richtige Plattform für >dieses Problem zu sein, für das damalige Computer z.T. Tage für einen >Bildausschnitt tief aus der Menge benötigten. Das Apfelmänchen ist auch wirklich die ideale Anwendung für Parallelcomputing. Einzelne Bereiche können vollständig separat berechnet werden und der Kommunikationsaufwand zwischen den Transputer ist gering. Es gibt ja 4 Links an den Transputern und deshalb konnte man die einfach schachbrettartig ohne extra Speicher auf der Platine anordnen (siehe Bild). Ich habe aber den starken Verdacht, dass diese Schachbrettvernetzung bei größeren Prozessorclustern nicht mehr ganz aktuell ist und man dort eher andere, vielleicht Baumstrukturen zur Vernetzung nimmt. Es gibt ja auch ein Problem, wenn z.B. ein Transputer der Master sein soll und alle anderen schnell mit neuen, gleichen Daten versorgt werden sollen.
Christoph M. schrieb: > Das Apfelmänchen ist auch wirklich die ideale Anwendung für > Parallelcomputing. Einzelne Bereiche können vollständig separat > berechnet werden und der Kommunikationsaufwand zwischen den Transputer > ist gering. Ja, ca. 20 Jahre ist das schon her, da konnte man die Shader-Units der nvidia-Grafikkarten dafuer wunderbar missbrauchen. Christoph M. schrieb: > Ich habe aber den starken Verdacht, dass diese Schachbrettvernetzung bei > größeren Prozessorclustern nicht mehr ganz aktuell ist und man dort eher > andere, vielleicht Baumstrukturen zur Vernetzung nimmt. Zum Stichwort NoC (Network on a chip) findet man eine Menge akademischer Exkursionen auf grossflaechigen FPGAs, geht oft in Richtung der GreenArray-Ansaetze. Der guenstigste Kleber ist meiner Meinung nach ein TDP (True dual port) Block, weil damit im Grunde alles abgehakt werden kann typischerweise endet es doch in einer Queue). Baumstruktur ist halt auf dem Silizium abgesehen von Clock-Netzen nicht so wirklich schmalspurig. Fuer Synchronisation zwischen entlegenen Kernen kann man sonst notfalls TDM-Prinzipien a la i2s nutzen und allenfalls Clock-Netze dafuer missbrauchen. Wo man wohl von wegkommen muss, ist gleichzeitige Versorgung aller Kerne mit denselben Bulk-Daten, das gewinnt schlicht nicht gegenueber einer harten Pipeline. Alles eine eigentlich heisse Sache, wenn die de-facto-Standard-Tools und Sprachen dafuer ausgelegt waeren. Aber wenn ich schon sehe wie manche viel Zeit mit manueller Plazierung verbraten oder Einarbeitung in komplett exotische Forth-Paradigmen investieren, wird das Fragezeichen sehr gross.
Wenn Du die Prinzipien ausprobieren willst, ist vielleicht TinyGo was für Dich. Go implementiert mit dem Channel-Konzept genau das, was die Transputer-Links in Hardware waren. Sowohl Occam und später GO nutzen das CSP (Communicating Sequential Processes) sowohl für multi-thread/-process Kommunikation als auch als Mittel zur Prozess-/Thread-Synchronisation Es werden auf jeden Fall ziemlich viele MCUs unterstützt. Sogar goroutinen und channels werden unterstützt (getestet auf https://play.tinygo.org ):
1 | package main |
2 | |
3 | import ( |
4 | "fmt" |
5 | ) |
6 | |
7 | func main() {
|
8 | ch := make(chan string) |
9 | |
10 | go func() {
|
11 | ch <- "ping" |
12 | }() |
13 | |
14 | msg := <-ch |
15 | fmt.Println(msg) // Output: ping |
16 | fmt.Println("Hello, TinyGo")
|
17 | } |
Was jetzt aber noch fehlt ist, einen channel auf einem Hardware-Port zu platzieren. Dafür gab es in Occam (und Inmos C) eine Placement-Postprocessor, den man nach dem Linker noch starten musste. Da wurden einige der benannten Channels auf die Hardware Links platziert. Gleichzeitig hat man dann auch mehrere Binaries auf einem Transputer starten können und via Channels (in-Memory) kommunizieren lassen. Alles in allem eine sehr elegante Lösung um auch inhomogene Hardwaretopologien realisieren zu können.
:
Bearbeitet durch User
Martin S. (strubi) 26.10.2025 11:39 >Zum Stichwort NoC (Network on a chip) findet man eine Menge akademischer >Exkursionen auf grossflaechigen FPGAs, geht oft in Richtung der >GreenArray-Ansaetze. Apropos GreenArray: Frage mich, ob deren Produkte noch irgendwo eingesetzt werden, oder ob die Firma den Bach runter geht. Es wäre ja mal interessant, ein Evaluationboard zu haben, aber knapp 500$ sind ein wenig viel um zu spielen: https://www.greenarraychips.com/home/products/index.php Gibt es irgendwo eine Applikationsliste die zeigt, wo deren Prozessoren wirklich erfolgreich eingesetzt werden? Ihr letztes News-Update ist von 2024: https://www.greenarraychips.com/home/news/index.php "We have finished moving our offices and lab onto a very small farm in Northern Missouri. Thanks to the continuing audacious and life-enhancing achievements of men like Elon Musk and Jeff Bezos, we've concluded it is now practical to operate a high tech business in a beautiful," Sie erwähnen Musk und Bezos aber es ist völlig unklar, ob die was investieren.
Christoph M. schrieb: > Apropos GreenArray: Frage mich, ob deren Produkte noch irgendwo > eingesetzt werden, oder ob die Firma den Bach runter geht. Ich glaube, weder noch. Ersteres hoechstens in einer Nische, nicht dem Entwickler-Mainstream, kein Disti duerfte einen GA144 im Programm haben. Der auf Bezos und Musk gemuenzte Nebensatz duerfte eher satirischen Beiwert haben. Soweit ich das verstanden habe, besteht die Firma aus einer relativ kleinen Gruppe aus Nerds, die wie in den 80ern Forthung ('Forschung' mit Lispel-sch) betreiben und denen dicker Profit und Marketing-Geblubber inkl. Fake-it-b4-u-make-it zuwider ist. Forth hatte schon immer noch den besten Nerd-Faktor, neben Oberon und dem Risc5 (nicht RISC-V) von Niklaus Wirth. In der Forschung gabs in den US genuegend Nachfrage danach, das koennte sich allerdings unter dem orangen Idioten auch aendern.
Martin S. schrieb: > und denen dicker Profit und Marketing-Geblubber inkl. > Fake-it-b4-u-make-it zuwider ist Und dann Musk und Bezos zitieren? Naja...
Christoph M. schrieb: > Gibt es irgendwo eine Applikationsliste die zeigt, wo deren Prozessoren > wirklich erfolgreich eingesetzt werden? Wirst Du Du wohl nicht trivial finden. Deren Hauptkunden sind an gewisser Publicity nur bedingt interessiert. Aber wenn Du mal ein bisschen "rumbohren" willst: Einer der Greenarray Gründer (Moore) hatte vorher mal ein Design an Harris verkauft, das es zu einer gewissen Bekanntheit gebracht hat: https://de.wikipedia.org/wiki/RTX2010 Ansonsten ist der Witz der GA144 ja wohl eher der, dass sie weitgehend asynchon arbeiten. Da muss man als normalsterblicher "Synchrondesigner" im Kopf erstmal massiv umdenken ;) Aber das Konzept hat durchaus Charme, finde ich. Martin S. schrieb: > Forth hatte schon immer noch den besten Nerd-Faktor Was ist ein Nerd-Faktor? Wenn ich mal eine spezielle CPU im FPGA brauche dann kriege ich ein kleines Forth dafür in ein paar Tagen zum laufen (btdt). Und dann laufen auch die meisten Libs wieder. Also (im Prinzip) wie mit C-Libs. Wenn Du eben mal "schnell" einen C-Compiler portierst... Der praktische Unterschied: Ich habe relativ schnell eine funktionierende Lösung und die große Gemeinde der "Ich nehme nur zertifizierte C-Compiler" muss sich (meist teuer) etwas anderes aufschwatzen lassen ;) Aber zugegeben: Forth ist eine andere "Denke". Darum wird den Leuten auch immer zuerst das Buch "Thinking Forth" (https://www.forth.com/wp-content/uploads/2018/11/thinking-forth-color.pdf) empfohlen. Danach ist die anfängliche Verwirrung meist verflogen. /regards
Andreas H. schrieb: > Wenn ich mal eine spezielle CPU im FPGA brauche Was braucht man denn für spezielle CPUs, für die man nicht eine existierende Architektur mit existierendem C-Compiler nutzen kann? Und wenn man Forth als Abstraktion drüber legt, kann man die Besonderheiten dieser CPU dann auch (effizient) nutzen? Und warum Forth und nicht ein Emulator für eine Architektur mit C-Compiler, oder eine JVM o.ä.? Andreas H. schrieb: > , dass sie weitgehend asynchon arbeiten. Da muss man als > normalsterblicher "Synchrondesigner" im Kopf erstmal massiv umdenken ;) Bei gewöhnlichem SMP ist doch auch alles asynchron...
:
Bearbeitet durch User
Niklas G. schrieb: > Was braucht man denn für spezielle CPUs, für die man nicht eine > existierende Architektur mit existierendem C-Compiler nutzen kann? Na, z.B. alle Arten von "intelligenten" Peripherieprocessoren.Fiktives, dafür einfaches, Beispiel: Der PP holt verschlüsselte Daten via RMII von einem externen System, kontroliert die Validität der einzelnen Pakete, holt sie ggf. erneut, entschlüsselt sie, speichert dann das komplette (!) Packet via DMA im RAM und signalisiert das Ende des Transfers an den Hauptprozessor. > Und warum Forth und nicht ein Emulator für eine Architektur mit C-Compiler, oder eine JVM o.ä.? Zeig mir mal bitte sowas in 8 KByte ;) Ausserdem ist Forth ein interaktives System. Man kann also beim Entwickeln direkt (ohne Compile/Load cycle) Änderungen machen. Ähnlich wie wenn Du bei ARM im Keil beim debuggen ein HW-Register änderst. Nur das Du in Forth auch den Code selber ändern kannst oder eine Wegwerf-Testfunktion schreiben & ausführen. Aber, wie gesagt, das ist eine "eigene" Designphilosophie. Man baut aus einem Minimalsystem genau das was man braucht, soweit wie man es braucht. Und natürlich kann man auch in Forth extrem schnell unwartbaren Code schreiben. > Bei gewöhnlichem SMP ist doch auch alles asynchron... Ich bezog mich auf die digitale HW, nicht auf die Ebene "CPU-Prozesse". Die Hardware auf der das läuft ist synchron aufgebaut, d.h. alles bezieht sich auf eine HW-Clock und beim wechseln in eine andere Clock-Domain werden die Signale einsynchronisiert. Das ist wohl bei der GA144 nicht so. Ich muss aber zugeben, dass ich mir nie die Zeit genommen habe da tiefer einzusteigen. Aber $500 für das Devkit sind ja schon eine Nummer^^ /regards
Andreas H. schrieb: > Na, z.B. alle Arten von "intelligenten" Peripherieprocessoren Und warum braucht man dafür eine besondere Architektur, und nicht 8051 oder so? Andreas H. schrieb: > Ausserdem ist Forth ein interaktives System. Könnte man aber auch auf einer Standard-Architektur laufen lassen, hat aber dann die Flexibilität alles mögliche andere ebenfalls drauf zu starten...
Niklas G. (erlkoenig) Benutzerseite >Und warum braucht man dafür eine besondere Architektur, und nicht 8051 >oder so? Man kann Forth so ziemlich auf jeder CPU laufen lassen. Forth ist Stack basiert und benötigt einen Data- und einen Return-Stack. Man erreicht aber eine optimale Ausnutzung des Transistor-Counts und der Geschwindigkeit nur, wenn die CPU speziell für Forth designed ist, d.h. die Basis Befehle sowie die Stacks in Hardware vorhanden sind. Aus diesem Grund hatte es Green-Array auch geschafft, 144 Kerne auf einer damals relativ kleinen Chipfläche unterzubringen. Auch beim Transputer wurde wie schon oben erwähnt auch zuerst die Programmiersprache und dann der dafür passende Prozessor entwickelt.
Christoph M. schrieb: > Man kann Forth so ziemlich auf jeder CPU laufen lassen. Forth ist Stack > basiert und benötigt einen Data- und einen Return-Stack Das ist doch etwas zirkuläre Logik "Man kann auf dem speziellen Peripherie-Prozessor kein C nutzen und muss Forth implementieren weil die Architektur so speziell ist, weil sie für Forth entwickelt wurde". Hätte man sich von Anfang an für C entschieden bräuchte man auch nur einen Stack...?
Niklas G. schrieb: > Hätte man sich von Anfang an für C entschieden Du hast was gegen Forth... Das ist OK. Aber das macht Forth nicht schlechter, nur weil du ein Forth System nicht verstehst. Ein paar Compiler, mindestens 2 Interpreter und gerne noch ein Assembler in wenigen KByte. Das ganze System zur Laufzeit modifizierbar. Das kann C als Compilersprache einfach nicht leisten.
Arduino F. schrieb: > Du hast was gegen Forth... Nö. Aber mir ist die Argumentation nicht schlüssig, warum man extra eine eigene spezielle Architektur entwickelt, auf der Forth läuft aber explizit nichts anderes, wenn man auch eine existierende Architektur nutzen könnte, die beides unterstützt. Arduino F. schrieb: > Ein paar Compiler, mindestens 2 Interpreter und gerne noch ein Assembler > in wenigen KByte. Ist es denn wirklich nötig das Forth Programm auf dem Target System zu kompilieren, Cross-Compilation nicht möglich? Wie greift man überhaupt interaktiv auf einen Peripherie Prozessor im FPGA zu, hat der eine dedizierte serielle Schnittstelle? Arduino F. schrieb: > Das ganze System zur Laufzeit modifizierbar. Das ist eigentlich das einzige Argument, das kann aber jeder andere Interpreter auch. Für cross-kompilierte Sprachen könnte man sich sowas auch basteln, einzelne Codeschnipsel on-the-fly kompilieren, in den RAM schreiben und von da ausführen. Hab noch nicht gesehen dass das wer so machen würde...
Niklas G. >Nö. Aber mir ist die Argumentation nicht schlüssig, warum man extra eine >eigene spezielle Architektur entwickelt, auf der Forth läuft aber >explizit nichts anderes, wenn man auch eine existierende Architektur >nutzen könnte, die beides unterstützt. Hier geht es um Prozessordesign, Routing, Flächen- und Geschwindigkeitsoptimierung. Um da etwas zu verstehen, muss man sich ein paar Jahre damit befasst haben, das ist nicht deine Spielwiese. Ich hatte es oben schon erwähnt: Hoch optimierte Strukturen mit geringer Transistoranzahl aber hoher Geschwindigkeit haben andere Anforderung als du das von der abstrahierten C-Programmierung kennst. Und es wurde auch oben schon erwähnt, dass die Grenn-Arrays im Bereich AeroSpace (und vermutlich nicht erwähnt: Military) eingesetzt waren.
Niklas G. schrieb: > Ist es denn wirklich nötig das Forth Programm auf dem Target System zu > kompilieren, Ja, ja und nochmal ja! Der Bau von Compilern, zur Laufzeit, gehört zur üblichen Beschäftigung, wenn man mit Forth Systemen hantiert. Es ist oft einfacher einen weiteren spezialisierten Compiler zu bauen, als mit den vorhandenen Mitteln drum rum zu arbeiten. Niklas G. schrieb: > Cross-Compilation nicht möglich? Schon... Aber dann brauchste immer noch einen Compiler im System, also nix damit gewonnen. Niklas G. schrieb: > wenn man auch eine existierende Architektur > nutzen könnte, die beides unterstützt. Soweit ich weiß hat man das beim 6502 gemacht. Den gibts/gabs mit spezialisiertem Rechenwerk/Microcode für Forth. Im Grunde tuts Forth auf fast jedem Kesselchen. Nur eben nicht optimal/ideal.
"The benefit of having a stack reserved for return addresses was that the other stack could be used freely for parameter passing, without having to be "balanced" before and after calls." Zitat Kopie aus diesem Text: https://dl.acm.org/doi/pdf/10.1145/234286.1057832
:
Bearbeitet durch User
Arduino F. schrieb: > Soweit ich weiß hat man das beim 6502 gemacht. > Den gibts/gabs mit spezialisiertem Rechenwerk/Microcode für Forth. > Im Grunde tuts Forth auf fast jedem Kesselchen. > Nur eben nicht optimal/ideal. Nein, die 6502 hatte keinen Microcode. Das Forth gab es für sie als onchip-ROM. Waren glaub 8KB. Vom Aufwand/Nutzen-Verhältnis war die 6502 ziemlich optimal für die damalige Zeit. Ich mochte sie allerdings nicht. A.K. könnte sich sicher darüber länglich auslassen.
R65F11/12 war der Chip: https://web.archive.org/web/20201129230955if_/http://archive.6502.org/datasheets/rockwell_r65f11_r65f12_forth_microcomputers.pdf
:
Bearbeitet durch User
Christoph M. schrieb: > Um da etwas zu verstehen, muss man sich ein paar Jahre damit befasst > haben, das ist nicht deine Spielwiese. Und dann darf man keine Fragen stellen? Christoph M. schrieb: > Ich hatte es oben schon erwähnt: Hoch optimierte Strukturen mit geringer > Transistoranzahl aber hoher Geschwindigkeit Für mich waren Interpreter, oder nicht-optimierende Compiler immer eher langsamer als optimierende kompilierte Sprachen. Da man mit C oder C++ ja fast an die Performance von handgeschriebenem Assembler herankommt, war mir nicht klar, dass Forth da noch besser sein kann. Christoph M. schrieb: > Flächen Wenn die Fläche das Argument ist weil Standard-Architekturen zu groß sind (auch sowas wie Picoblaze?), würde man dann C nehmen wenn es einen Compiler gäbe? Oder doch Forth weil dessen Interpreter noch schneller ist bzw. der Compiler effizienteren Code erzeugt? Arduino F. schrieb: > Ja, ja und nochmal ja! > Der Bau von Compilern, zur Laufzeit, gehört zur üblichen Beschäftigung, > wenn man mit Forth Systemen hantiert. Heißt also, auf dem Zielsystem kompilieren zu müssen/wollen ist eine Eigenschaft von Forth, aber nicht etwas, was für Forth an sich spricht. Arduino F. schrieb: > Aber dann brauchste immer noch einen Compiler im System Wieso das? Arduino F. schrieb: > Soweit ich weiß hat man das beim 6502 gemacht. Wie praktisch dass ARM vom 6502 inspiriert ist 🙃 Rbx schrieb: > without having to be "balanced" before and > after calls." Muss der Stack bei traditionellen Architekturen (mit Software Stack, wie z.B. x86 oder ARM) ja eigentlich auch nicht sein; die Funktion muss nur wissen, wo ihre Parameter aufhören. Gerade beim ARM mit dem LR lässt sich das auch so erreichen, außer man möchte dass eine Funktion jenseits ihrer Parameter auf die internen Daten des Aufrufers zugreifen können soll. Apropos ARM: Mit der Jazelle hatte ARM ja auch eine hart verdrahtete Logik zur Beschleunigung von JVM Code, aber längst wieder abgeschafft, weil's sich nicht lohnt...
Niklas G. schrieb: > "Man kann auf dem speziellen > Peripherie-Prozessor kein C nutzen und muss Forth implementieren weil > die Architektur so speziell ist, weil sie für Forth entwickelt wurde" Man WILL kein C benutzen, u.a. weil es meist keinen Compiler gibt. Und man entwickelt die Architektur nicht FÜR, sondern MIT Forth. Klein, überschaubar, kompakt. Ganz simpel ;) Hier mal ein (altes, aber verfügbares) Beispiel von James Bowmanns PR2 Roboter: https://www.forth.org/svfig/kk/11-2010-Bowman.pdf Und das ist 15 Jahre alt. Niklas G. schrieb: > Wie greift man überhaupt interaktiv auf einen Peripherie Prozessor im > FPGA zu, hat der eine dedizierte serielle Schnittstelle? Im Prinzip genau wie bei jeder anderen Sprache auch. Entweder baut man einen UART ein oder man benutzt Segger RTT oder ähnliches. Das wird z.B. auch von OpenOCD unterstützt. /regards
Niklas G. schrieb: > Christoph M. schrieb: >> Um da etwas zu verstehen, muss man sich ein paar Jahre damit befasst >> haben, das ist nicht deine Spielwiese. > > Und dann darf man keine Fragen stellen? Das war hoffentlich ironisch gemeint ;) /regards
Niklas G. schrieb: > Arduino F. schrieb: >> Aber dann brauchste immer noch einen Compiler im System > > Wieso das? Wie will man denn sonst die Anwendung entwickeln? Neue Worte bauen? Forth ist nicht wirklich eine Sprache! Es ist wenn überhaut eine niedrige Sprache, dank des Assemblers, den es in der Regel mit sich trägt. Nein, es ist eine Hochsprache! U.A. weil es OOP kann und Background Prozesse. OK,OK, es gibt Standards, wie Fig79, oder F83. Aber die sind eher Empfehlungen, schon nützlich, aber nicht in Stein gemeißelt. Wenn einem ein Wort nicht gefällt, kann man sich jederzeit ein neues mit gleichem Namen bauen. Beispiel, zugegeben, ein seltsames: Angenommen mir gefällt die 5 nicht mehr. Dann baue ich mir eine eigene 5 : 5 42 ; Wenn ich jetzt mit der 5 rechne, dann passiert sowas: 5 6 + . 48 ok Nach einiger Zeit stelle ich fest, dass das wirklich eine dumme Idee war, die 5 umzustricken. Einfache Lösung: forget 5 Und das Vokabular wird auf den Stand gesetzt, bevor die 5 definiert wurde.
:
Bearbeitet durch User
Andreas H. schrieb: > Man WILL kein C benutzen, u.a. weil es meist keinen Compiler gibt. Für klingt das eher nach einem Fall von "man KANN kein C benutzen"... Andreas H. schrieb: > Hier mal ein (altes, aber verfügbares) Beispiel von James Bowmanns PR2 > Roboter: https://www.forth.org/svfig/kk/11-2010-Bowman.pdf Interessantes Beispiel, das beantwortet immerhin endlich einigermaßen meine ursprüngliche Frage: Niklas G. schrieb: > Was braucht man denn für spezielle CPUs, für die man nicht eine > existierende Architektur mit existierendem C-Compiler nutzen kann? Gängige Architekturen sind wohl eher für ASICs optimiert, wo man einfacher komplexe CPUs mit hoher Geschwindigkeit implementieren kann, wo eine Minimal-CPU hinter den Möglichkeiten zurück bleiben würde. Was mich noch interessieren würde - wie kann die "J1" CPU aus dem Beispiel mit 100 MIPS Funktionsaufrufe in einem einzigen Prozessortakt ausführen, während z.B. ARM Cortex-M immer mindestens 2 Takte für Speicherzugriffe brauchen? Wie erreicht die J1 100 MIPS (vermutlich?) ohne Pipeline, während selbst 8bit-MCUs für eine Handvoll MIPS schon mehrere Pipeline-Stages benötigen? Wobei sich dann die Gegenfrage stellt, ob man für so eine Minimal-CPU nicht auch einen C/C++/Rust... -Compiler entwickeln könnte, und ob das Einzige, was dagegen spricht, der Aufwand ist. Andreas H. schrieb: > Im Prinzip genau wie bei jeder anderen Sprache auch. Entweder baut man > einen UART ein oder man benutzt Segger RTT oder ähnliches Diese Hardware, plus dem Compiler, Interpreter, Text-User-Interface, Dictionary-Verwaltung, Assembler verbraucht dann immer noch weniger Chipfläche als eine Standard-Architektur? Andreas H. schrieb: > Das war hoffentlich ironisch gemeint ;) Weiß man ja nicht, wenn man sich schon solche Sprüche anhören muss. Arduino F. schrieb: > Wie will man denn sonst die Anwendung entwickeln? > Neue Worte bauen? In allen gängigen Sprachen kann ich das auf dem PC machen, ohne spezielle Zusatz-Hardware. Arduino F. schrieb: > Wenn einem ein Wort nicht gefällt, kann man sich jederzeit ein neues mit > gleichem Namen bauen. Das ist erstmal nur syntaktischer Schall-und -Rauch, das geht in vielen Sprachen, auch in kompilierten. Meistens nur mit Text-Wörtern und nicht mit reinen Ziffern-Folgen, wobei das, wie du schon sagst, vermutlich eh eine blöde Idee wäre.
:
Bearbeitet durch User
Niklas G. schrieb: > das geht in vielen > Sprachen Nein! Da kann man die 5 nicht umdefinieren und ein forget gibt es auch nicht. Niklas G. schrieb: > In allen gängigen Sprachen kann ich das auf dem PC machen, ohne > spezielle Zusatz-Hardware. Wozu der PC? Forth Dinger brauchen nur ein Terminal, keinen externen Compiler keinen Programmer nix.
:
Bearbeitet durch User
Niklas G. schrieb: > Andreas H. schrieb: >> Man WILL kein C benutzen, u.a. weil es meist keinen Compiler gibt. > > Für klingt das eher nach einem Fall von "man KANN kein C benutzen"... ÄH..geht das nicht etwas genauer? TCC ist ja nun auch so ein Fall, der weit über meinen Horizont hinausgeht. Nicht dass ich nicht verstehe, was da in etwa abgelaufen sein muss - aber selber würde ich sowas für einen FPGA Cpu-Modell eher nicht hinbekommen. Überhaupt: Beschäftige dich mal damit: https://smunix.github.io/dev.stephendiehl.com/fun/WYAH.pdf und https://upload.wikimedia.org/wikipedia/commons/a/aa/Write_Yourself_a_Scheme_in_48_Hours.pdf Eventuell bohrt das dein Verständnis für Forth ein wenig auf ;)
Niklas G. schrieb: > Andreas H. schrieb: >> Man WILL kein C benutzen, u.a. weil es meist keinen Compiler gibt. > Für klingt das eher nach einem Fall von "man KANN kein C benutzen"... Nene, das ist genau so gemeint. Wenn ich nicht beabsichtige IM FPGA-Design direkt zu entwickeln/debuggen, dann kann ich ja auch eine RISCV nehmen, die dann natürlich in C(++) programmiert wird. Alles eine Frage der Aufgabe. > Gängige Architekturen sind wohl eher für ASICs optimiert, wo man > einfacher komplexe CPUs mit hoher Geschwindigkeit implementieren kann, > wo eine Minimal-CPU hinter den Möglichkeiten zurück bleiben würde. Umgekehrt. Je einfacher die CPU, desto besser kriegst Du sie in einen ASIC. Die kombinatorischen Pfade sind meist deutlich kürzer was einen höheren Takt ermöglicht. Man muss also, wenn überhaupt, seltener pipelinen. > Wobei sich dann die Gegenfrage stellt, ob man für so eine Minimal-CPU > nicht auch einen C/C++/Rust... -Compiler entwickeln könnte, und ob das > Einzige, was dagegen spricht, der Aufwand ist. Der Aufwand ist MASSIV höher. Schau Dir mal nur die Testsuite für den GCC an^^ Ausserdem verlierst Du die Möglichkeit des interaktiven Arbeitens. Und das ist schon sehr angenehm. Wenn man sich das schon antut, dann eher nicht nur für ein Projekt, sondern für eine größere Produktlinie. Und da willst Du Dir, genau umgekehrt, nicht die Möglichkeiten durch eine Minimal-CPU einschränken, oder? /regards
Andreas H. schrieb: > Ausserdem verlierst Du die Möglichkeit des interaktiven Arbeitens. Und > das ist schon sehr angenehm. Mit gdb kann man per JTAG/In Circuit-Emulation auch wunderbar interaktiv arbeiten. In den meisten Faellen will ich eigentlich auf dem System selber keinen Compiler, ueber den man elegant Schadcode einschleusen kann. Was das Thema Schadcode und Safety angeht, koennte man eine lange Diskussion Registermaschinen versus Stackmaschinen fuehren. Fuer Space ist es sicherlich interessant, wenn man einerseits hohe Fail-Safety jedoch primitive remote-Update-Funktion hat. Aber ist halt 'Nische'.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.