Hallo, ich möchte ein 13 MHz Taktsignal mit 500 ps Auflösung verzögern und habe hierfür angedacht, mir die Laufzeit eines Inverters zu nutze zu machen. Die Idee ist, das Signal auf eine Inverterkette (Serie mehrerer Inverter) zu legen und zwischen den einzelnen Invertern abzugreifen. Die Abgriffe sollen über einen Multiplexer ausgewählt und auf den Ausgang gelegt werden können. Bisher habe ich mich in Quartus und ISE mit Schematics versucht, aber die Simulation gibt nichts sinnvolles aus. Würde mich freuen, wenn ihr Tipps für mich hättet, welche Optimierungsmechanismen ich deaktivieren muss oder wie ich das Ganze angehen sollte, um tatsächlich die Laufzeit durch einen Inverter ausnutzen zu können. Danke schonmal! Gruß Peter PS: Das Delay könnte natürlich auch über Delay-Lines realisiert werden, aber davon bräuchte ich dann recht viele.
also ich habe mal etwas ähnliches versucht im rahmen einer DCO (digital clock oscillator). Leider war das dieses konzept wegen diversen schwierigkeiten mit der inverterkette nicht realisierbar. das haptsächliche problem was ich hatte war, das im FPGA die inverter ja keine echten inverter sind, sondern im normalfall durch LUT's dargestellt werden. und ich habe damals die sache auf basis eines Spartan3E aufgebaut und mich an den FAE von Xilinx gewand. Dieser hat mir das Problem bestätigt, dass, zumindest bei den xilinx bausteinen, die LUT's nicht delaystabil arbeiten. sprich, man kann nich von einer definiert festen verzögerung ausgehen. bei mir hatte das den effekt, das die erzeugte frequenz schwankte. dadurch waren keine genauen frequenzen einstellbar. das zweite problem war, dass das synthesewerkzeug, die inverterkette für die verzögerung als unnütze logik angesehen und einfach wegoptimiert hat. hab dann die verzägerung über eine kombination aus UND und ODER glieder realisiert und dem synthesewerkzeug gesagt "Keep hirarchie", dann hat er es beibehalten. vielleicht helfen dir diese beschreibungen meiner problematiken etwas.
Vielen Dank schonmal für Deine Antwort! Ich dachte schon ich bin nur zu blöd die Optimierung komplett zu deaktivieren. Genau das Problem der LUT habe ich auch als Ursache für meine nicht statischen Delayzeiten angesehen. Das "wegoptimieren" konnte ich leider bisher weder bei Altera noch bei Xilinx komplett verhindern. Scheint ähnlich wie bei Dir zu sein. Könntest Du mir noch paar Details zu Deinem Ansatz "...Verzögerung über eine Kombination aus UND und ODER Glieder..." verraten? - Hast Du hierbei mit Schematic gearbeitet oder direkt VHDL? - Welche Werte von Verzögerungen konntest Du so erreichen? - Hast Du ebenfalls ausgewählt welches Delay auf den Ausgang soll, oder fest eingestellte Werte durchgeschleift? (mein Delay soll im Betrieb änderbar sein...) Danke und Grüße Peter
Ich weiß nicht genau ob das für deine Anwendung geht, aber hast du mal darüber nachgedacht ob du ein DCM (gibts bei Xilinx FPGAs) nutzen kannst? Weil damit kann man ein Clocksignal mit einem variablen Phase Shift erzeugen.
Angehängte Dateien:
-

delay.JPG
31 KB
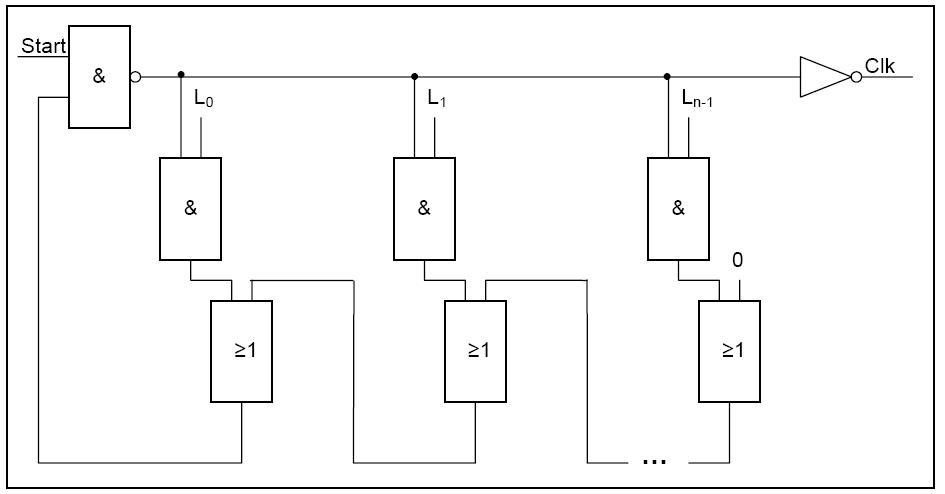
so, hab mal das blockschaltbild reingestellt. hab aber selber alles direkt in VHDL geschrieben. das START-Singal ist dabei das "enable" der frequenzerzeugung. mit dem L-Signal wählt man dann die Kettenlänge aus, darauf is zu beachten, das nur eine einzige Stelle aktiviert sein darf. diese stelle ist dann das letzte glied der kette. ich habe es so aufgebaut, das ich 128 glieder aneinander schlaten konnte, wobei ein glied aus jeweils einem UND und einem ODER besteht. der periodische aufbau sollte erkennbar sein.
achim, DCM's sind zwar schön und machen eine stabile frequenz, aber lassen sich leider nicht mehr zur laufzeit manipulieren. damit kann man sich schön eine grundfrequenz erstellen, die man dann weiterbearbeitet, aber dann kommt wieder die unregelmäßige gatterlaufzeit mit ins spiel.
DCM stellen keine hoch genuge Auflösung zur Verfügung und somit lässt sich damit kein entsprechend kleines Delay realisieren. (Trotzdem DANKE für die Idee!) Danke Nephilim für das Blockschaltbild! Funktion ist klar und sieht vielversprechend aus. Werde mich gleich mal dran machen und das umsetzen! Nochmal meine Frage: Was für ein Delay-Auflösung hast Du hiermit erreichen können?
welchen delay man damit erzeugt ist natürlich bausteinabhängig und dann noch in gewissen bereich schwankend. also ist das nich direkt definierbar. ich hatte mit diesem ringoszillator frequenzen zwischen 120MHz und 20MHz herzeugt, aber tiefer geht immer. wenn man eine höhere frequenz will bräuchte man einen anderen baustein. in kombination mit der ganzen regelung (war ein teil einer vollständig digitalen PLL) war nich mehr drin. aber war auch nur ein Spartan3E. mit nem virtex würde man noch einiges mehr rauskitzeln können. ach ja, und das ding mit dem simulieren wollt bei mir auch nich so richtig. in einer behaviorsimulation gehts eh nich, weil dort ja keine timing informationen enthalten sind, aber auch in einer Post-Route&Place simulation kamen immer falsche werte raus. musste es dann direkt aufm fpga mitm oszilloskop debuggen.
"keine hoch genuge " Was ist das für ein Konstrukt? Meine Sprachsynthese optimiert das zu "keine ausreichend hohe" :D Solche Delaygeschichten funktionieren eigentlich nur mit externen Partnern zusammen wirklich stabil. Ich habe da auch einige Versuche hinter mir. Das einfachste ist ein HF-Quarz an einem Pin, das durch ein Signal angetriggert wird und definiert zurückschwingt, was über einen Pin wieder eingelesen und per kaskadierten SR gezählt wird: Jede Kaskade des SR kriegt dabei den Ausgang vom vorherigen - verundet mit dem Quarztakt. Dabei nutzt jedes 2.Register den negierten Takt. Den braucht man über verschiedene Leitungen, damit die Synthese es nicht wegkillt. Im Prinzip schalten dann für die Synthese alle Stufen innerhalb eines Clocks, real rattert die Kombinatorik durch - aber eben synchronisiert mit dem Quarz. So kriegt man es auf einige 10ppm genau. Habe das mit einem 866MHz Quarz hinbekommen: Die Schaltfreuqenz je Stufe beträgt dann 0,6 ns. Das entspricht etwa der Verzögerung durch das SR-Gatter.
>"keine hoch genuge" Süddeutsch, oder? So würde ich auch reden... ;-) Schreiben würde ich aber "keine genügend hohe"... >...500 ps... Die Gatterlaufzeiten und die zusammenaddierten Zeiten aus dem Synthesereport sind Maximalzeiten. Bei den richtigen Temperaturen sind die Bausteine wesentlich schneller. Ich habe da mal einfach einen Oszillator über eine kombinatorische Schleife gebaut und anschliessend ausgemessen. Die Frequenz hängt dann im wesentlichen von den Gatterlaufzeiten ab, und war von FPGA zu FPGA deutlich unterschiedlich. Insgesamt konnte damit dann auch sehr schön die Temperatur gemessen werden. Wenn du also irgendwelche Zeiten über Gatter- und Routinglaufzeiten einstellst, sollten deine Anforderungen an die Genauigkeit nicht allzu hoch sein.
Hi zusammen, Glaube, ich habe hier was verpaß, denn ich versteh' nicht, wieso die DCM keine genügend hohe Auflösung bereitstellen soll ? In der ersten Anfrage geht es NUR darum das Eingangssignal definiert zu verzögern, oder ? Ganau das nennt man "Phase Shifting" Laut ds312-2 v3.7 Seite 37 läßt sich die Phase dynamisch in Schritten von tPS = PHASESHIFT/256 (PHASESHIFT = -255..+255) einstellen ! Bei 13 MHz sind dies ca 150 ps ! OK, 500 ist kein ganzzahliges Vielfaches von 150 - aber Schritte von 450 ps sind auch nicht schlecht, oder? da ganze läßt sich auch dynamisch (zur Laufzeit) ändern ! Gruß Jochen
Hallo Jochen, jetzt muss ich Dir Recht geben! Da hab ich wohl das Datenblatt etwas zu schnell überflogen. Ich hatte nur etwas von 0° (no phase shift), 90° (¼ period), 180° (½ period), 270° (¾ period) gelesen und war davon ausgegangen, dass nur Phaseshifts um jeweils eine Viertelperiode möglich sind. Da werde ich direkt mal weiter lesen, welche Delays hier tatsächlich möglich sind! Der Abschnitt "Variable Phase Shift increment or decrement unit" = 1/256th of CLKIN Period (degrees) Würde für mich von der Auflösung her ausreichen. Es geht auch nicht um den Wert 500 ps, sondern lediglich um eine Genauigkeit in mindestens diesem Bereich. Also vielen Dank für diesen Tipp und verzeih, dass ich Deine Idee so abgeschmettert habe :) Grüße Peter PS: Wir können alles, ausser Hochdeutsch :P
Achtung, die DCM funktioniert nicht mit so tiefen Frequenzen wie 13 MHz! Bei Spartan-3 braucht es mindestens 24 MHz.
"Spartan-3E and Spartan-3A/3AN/3A DSP DLLs support input clock frequencies as low as 5 MHz, whereas the Spartan-3 DLL requires at least 18 MHz." Danach bin ich davon ausgegangen, dass zumindest die 3E Version bei 13 MHz funktionieren sollte. Oder verwechsel ich da mal wieder was?
Das ist ja alles sehr interessant. Kann mal einer die Lösung mit den DCM ausprobieren und zur verfügung stellen. Möchte es dann aauch mal testen.
Kann mir einer mal ein Butterbrot schmieren und zusenden? Hätte ein klein wenig Hunger :-)
Also bevor das hier ausartet :P möchte ich mich für eure hilfreichen Tipps bedanken! Ich habe inzwischen ein Spartan-3E Eval-Board bestellt und beschäftige mich derzeit mit Datenblatt-Theorie. Parallel dazu behalte ich die Kette aus AND und OR Gliedern im Auge - diese habe ich jedoch leider nicht sinnvoll simulieren können - aber das bekomme ich auch noch hin. Also herzlichen Dank an dieser Stelle an alle Beitragenden! Butter hab ich in den Kühlschrank gelegt, als kleines Dankeschön! (geh nachschauen - da liegt wirklich Butter in Deinem Kühlschrank ;-)
Hallo zusammen, Ich hab mich jetzt mal mit VHDL auseinander gesetzt und Nephilim's Idee umgesetzt (oder der Versuch unternommen). Leider bekomme ich weder den Compiler bei Altera Quartus noch bei Xilinx ISE dazu, den von mir geschriebenen Code direkt zu übernehmen. @Nephilim - falls Du noch mitließt würde ich mich freuen, wenn Du mir bei dem Code Hilfestellung geben könntest. Danke schonmal im Voraus Grüße Peter Im Anhang ein PDF mit meiner Idee und den Bezeichnungen für den VHDL-Code Und hier mein VHDL-Code:
1 | Library IEEE; |
2 | use IEEE.Std_Logic_1164.all; |
3 | |
4 | entity Delay_Stufe is |
5 | |
6 | port ( Eingang,Zero : IN STD_LOGIC; |
7 | Ausgang : OUT STD_LOGIC; |
8 | Delay : IN STD_LOGIC_VECTOR(3 DOWNTO 1) |
9 | );
|
10 | |
11 | end Delay_Stufe; |
12 | |
13 | architecture Verhalten of Delay_Stufe is |
14 | |
15 | Signal Signal_Innen : STD_LOGIC; |
16 | Signal AND_Aus : STD_LOGIC_VECTOR(3 DOWNTO 1); |
17 | Signal OR_Aus : STD_LOGIC_VECTOR(3 DOWNTO 1); |
18 | |
19 | |
20 | begin
|
21 | |
22 | AND_1: process (Delay(1), Signal_Innen) |
23 | begin
|
24 | if (Signal_Innen = '1' AND Delay(1) = '1') then |
25 | AND_Aus(1) <= '1'; |
26 | else
|
27 | AND_Aus(1) <= '0'; |
28 | end if; |
29 | end process; |
30 | |
31 | AND_2: process (Delay(2), Signal_Innen) |
32 | begin
|
33 | if (Signal_Innen = '1' AND Delay(2) = '1') then |
34 | AND_Aus(2) <= '1'; |
35 | else
|
36 | AND_Aus(2) <= '0'; |
37 | end if; |
38 | end process; |
39 | |
40 | AND_3: process (Delay(3), Signal_Innen) |
41 | begin
|
42 | if (Signal_Innen = '1' AND Delay(3) = '1') then |
43 | AND_Aus(3) <= '1'; |
44 | else
|
45 | AND_Aus(3) <= '0'; |
46 | end if; |
47 | end process; |
48 | |
49 | OR_1: process (AND_Aus(1), OR_Aus(2)) |
50 | begin
|
51 | if (AND_Aus(1) = '1' OR OR_Aus(2) = '1') then |
52 | OR_Aus(1) <= '1'; |
53 | else
|
54 | OR_Aus(1) <= '0'; |
55 | end if; |
56 | end process; |
57 | |
58 | OR_2: process (AND_Aus(2), OR_Aus(3)) |
59 | begin
|
60 | if (AND_Aus(2) = '1' OR OR_Aus(3) = '1') then |
61 | OR_Aus(2) <= '1'; |
62 | else
|
63 | OR_Aus(2) <= '0'; |
64 | end if; |
65 | end process; |
66 | |
67 | OR_3: process (AND_Aus(3), Zero) |
68 | begin
|
69 | if (AND_Aus(3) = '1' OR Zero = '1') then |
70 | OR_Aus(3) <= '1'; |
71 | else
|
72 | OR_Aus(3) <= '0'; |
73 | end if; |
74 | end process; |
75 | |
76 | |
77 | |
78 | Signal_Innen <= NOT Eingang AND OR_Aus(1); |
79 | Ausgang <= NOT Signal_Innen; |
80 | |
81 | |
82 | end Verhalten; |
oha, das sieht ja irgendwie aufwendiger aus als es eigentlich ist. ich zeig dir mal wie ich es gemacht habe. also der teil, der sich quasi immer wieder wiederholt habe ich extra geschrieben.
1 | entity v_glied is |
2 | Port ( clk_in : in STD_LOGIC; |
3 | ueberlauf : in STD_LOGIC; |
4 | clk_out : out STD_LOGIC; |
5 | enable : in STD_LOGIC); |
6 | end v_glied; |
7 | |
8 | architecture Behavioral of v_glied is |
9 | signal int_1 : std_logic; |
10 | begin
|
11 | |
12 | int_1 <= clk_in and enable; |
13 | clk_out <= int_1 or ueberlauf; |
14 | |
15 | end Behavioral; |
diesen teil habe ich dann als Komponente über eine generic anweisung eingebunden, da ich nicht manuell 127 instanzen schreiben wollte. ;)
1 | v_glieder: for i in 127 downto 0 generate |
2 | gl1: if i = 127 generate |
3 | u1: v_glied PORT MAP( |
4 | clk_in => clk_int, |
5 | ueberlauf => '0', |
6 | clk_out => clk_int_out(i), |
7 | enable => Teiler_int(i) |
8 | );
|
9 | end generate; |
10 | gl2: if i < 127 generate |
11 | u2: v_glied PORT MAP( |
12 | clk_in => clk_int, |
13 | ueberlauf => clk_int_out(i+1), |
14 | clk_out => clk_int_out(i), |
15 | enable => Teiler_int(i) |
16 | );
|
17 | end generate; |
18 | end generate v_glieder; |
und dazu dann noch das bissl logik aussen drum
1 | clk_int <= not (RST and clk_int_out(0)); |
2 | Clk_out <= clk_out_2; |
3 | clk_out_2 <= not clk_int; |
jor, das wars im grunde auch schon. finde das übersichtlicher und auch einfacher wenn man z.b. mal am verzögerungsglied (wie es bei mir heisst) mal was ändern muss, dann muss mans nur einmal machen.
Ööööh wie Du vielleicht an meinem Code gesehen hast, bin ich alles andere als fit in Sachen VHDL... Ich hab das ganze so verstanden, wie hier als Schematic im Anhang dargestellt. Der "innere" Block wird mehrfach durchlaufen und abhängig vom externen Teiler_int wird das Enable gesetzt. Umsetzung um Deinen Code einzubauen sieht so aus:
1 | Library IEEE; |
2 | use IEEE.Std_Logic_1164.all; |
3 | |
4 | entity v_glied is |
5 | Port ( clk_in : in STD_LOGIC; |
6 | ueberlauf : in STD_LOGIC; |
7 | clk_out : out STD_LOGIC; |
8 | enable : in STD_LOGIC); |
9 | end v_glied; |
10 | |
11 | architecture Behavioral of v_glied is |
12 | signal int_1 : std_logic; |
13 | begin
|
14 | int_1 <= clk_in and enable; |
15 | clk_out <= int_1 or ueberlauf; |
16 | end Behavioral; |
17 | |
18 | architecture Behavioral2 of v_glied is |
19 | component Comp |
20 | generic (n : integer := 127); |
21 | Port ( RST : in STD_LOGIC; |
22 | clk_out : out STD_LOGIC; |
23 | Teiler_int : in STD_LOGIC_VECTOR(n DOWNTO 0) |
24 | );
|
25 | end Comp; |
26 | |
27 | signal clk_out_2 : std_logic; |
28 | signal clk_int_out : std_logic_vector(127 DOWNTO 0); |
29 | |
30 | begin
|
31 | |
32 | v_glieder: for i in 127 downto 0 generate |
33 | gl1: if i = 127 generate |
34 | u1: v_glied PORT MAP( |
35 | clk_in => clk_int, |
36 | ueberlauf => '0', |
37 | clk_out => clk_int_out(i), |
38 | enable => Teiler_int(i) |
39 | );
|
40 | end generate; |
41 | gl2: if i < 127 generate |
42 | u2: v_glied PORT MAP( |
43 | clk_in => clk_int, |
44 | ueberlauf => clk_int_out(i+1), |
45 | clk_out => clk_int_out(i), |
46 | enable => Teiler_int(i) |
47 | );
|
48 | end generate; |
49 | end generate v_glieder; |
50 | |
51 | clk_int <= not (RST and clk_int_out(0)); |
52 | clk_out <= clk_out_2; |
53 | clk_out_2 <= not clk_int; |
54 | |
55 | end Behavioral2; |
Ich dank Dir schonmal ganz herzlich für Deine Hilfe und die Teile auf Deinem Code! Würde mich freuen, wenn Du mir nochmal Nachhilfe geben würdest. :)
Angehängte Dateien:
-

rueckseite.jpg
130 KB
Peter Flender wrote:
> Hier der Anhang!
Hier die Auswertung:
Sehr interessant ;-P
Ich verstehe zwar nicht, was interessant an der Rückseite von meinem Schmierzettel sein soll, aber sag mir Deine Anschrift und ich sende Dir ein paar fehldrucke zu! Aktenvernichter-Spaghetti bekommste auch gratis dazu!
@Peter. Falls die Rückseiten Deiner Schmierzettel immer so unverfänglich sind, dass man sie der ganzen Welt zeigen kann, dann ist ja OK. Bei uns werden aus Vorsicht alle Ausdrucke mit selbstproduzierten Vernichtet. An Papierstreifen habe ich also genug ;-). Gruß DaMicha.
Hallo, vielleicht dann doch noch mal was Konstruktives. Ich hab die Oszillator-Schaltung mal umgesetzt (Siehe Anhang). Ziel Architektur war ein Xilinx Spartan 2E50. Das sollte aber egal sein. Sie funktioniert soweit, sobald man mit Timinginformationen simuliert. Also bestenfalls eine Post-Place & Route Simulation. Es sind jedoch ein paar Dinge zu beachten: Auf dem internen Clock Signal (clk_int) und dem overflow Signal (overflow) muss ein Keep gesetzt werden (Siehe Quellcode). Falls nicht, versucht die ISE eine parallele Logic Struktur aufzubauen und die Pfade durch die einzelnen Verzögerungsstufen werden alle annähernd gleich lang. Wer möchte kann das ja mal ausprobieren und im RTL Schematic nachschauen. Falls man in meinem Design die Konstante für die Länge der Kette ändert, muss man auch unter Modelsim in der Post-Place & Route Simulation das Designfile nocheinmal bauen, da sonst die Konstate für die Kettenlänge nicht aktualisiert wird und die Testbench nicht läuft. Das Reset für Schaltung muss wenigstens die halbe Dauer der maximal möglichen Periode (längste Kette) haben, da sonst die Schaltung Amok läuft. Und noch eine Anmerkung. Die Frequenz der Schaltung sollte von der Temperatur und dem verwendeten FPGA (auch zwischen FPGAs gleichen Typs) und eigentlich allem Möglichen abhängig sein. Ich würde so eine Schaltung nicht verwenden wollen. Gruß DaMicha.
Angehängte Dateien:
-

xil_vhdl.JPG
21 KB
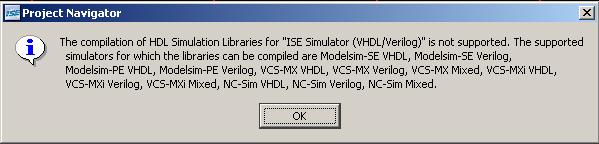
Hallo DaMicha, danke schonmal für Deine Hilfe! habe Deinen Code mal in ISE geladen, bekomme jedoch bei der Post-Place & Route Simulation einen Fehler bzw eine Meldung (siehe Anhang). Wenn ich den Simulator umstelle, tuts aber auch nicht. Ich kann mit dem Fehler recht wenig anfangen - weisst Du hier Rat? Im Quartus habe ich den Code prima zum laufen bekommen und kann hier auch eine Simulation starten. Du hast natürlich recht mit den auftretenden Schwankungen! Ziel dieses Aufbaus war ja eigentlich auch nicht eine Frequenz zu erzeugen, sondern vielmehr eine einstellbare Verzögerung des Eingangs zu erreichen. Male sehen, ob und wie ich das hiermit realisieren kann.... Danke und Grüße Peter
Hallo. Wahrscheinlich hast Du den ISE Simulator eingestellt. Wenn Du im Sources View mit der rechten Maustaste auf das Taget (FPGA Typ) klickst und Properties auswählst kannst Du das auf Deine Modelsim Version ändern. Warum der Fehler auftritt kann ich aber leider nicht sagen, da es bei mir mit dem ISE Simulator funktioniert. Vielleicht sind es Versionsunterschiede zwischen dem freien Webpack und der ISE Foundation Kaufversion. Gruß DaMicha.
Servus, wollte nur mitteilen, dass ich das Ganze mit dem DCM zum Laufen bekommen habe. Danke für eure Hilfe und eure Tipps hier! Dimulieren lässt sich das ganze eher nicht, aber die Messungen sind vielversprechend. Grüße
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.