Hallo,
habe einen simplen Timer für meinen Belichter gebaut, der noch ein paar
weiße LEDs spendiert bekam, um auch als Leuchtpult dienen zu können.
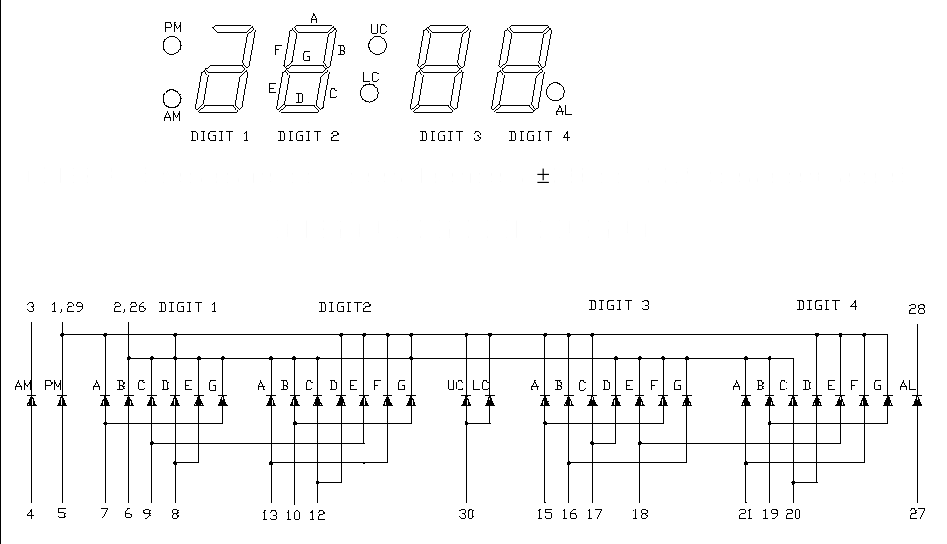
Als Display kommt eine Segmentanzeige von Pollin zum Einsatz (D120150),
bei der die Segmente "gemultiplext" werden müssen (Ansteuerung über 3
kaskadierte Schieberegister 74HC595 - ich habe den Schaltplan dem Archiv
beigepackt).
Die Bedienung habe ich auf einem Mega mit LCD-Anzeige ausprobiert und
wollte das Ganze jetzt auf einen ATtiny2313 bringen. Leider mit diesem
Ergebnis:
1
AVR Memory Usage
2
----------------
3
Device: attiny2313
4
5
Program: 2104 bytes (102.7% Full)
6
(.text + .data + .bootloader)
7
8
Data: 30 bytes (23.4% Full)
9
(.data + .bss + .noinit)
Ich meine, schon speichersparend gearbeitet zu haben, aber vielleicht
gibt es ja noch etwas Einsparpotential (hoffe ich mal).
Bin für jeden Tip dankbar.
Ok, hatte die falsche Toolchain (hasr Du nicht dazugeschrieben).
Die sdGenDisplay() ist sehr aufwändig durch die vielen case, die jedoch
alle praktisch den gleichen Code enthalten. Und natürlich kostet
32-Bit-Arithmetik.
Hier mal versuchen, die OR-Konstanten in ein Array zu packen und per
Index (h0,h1,m0,m1) drauf zuzugreifen.
Was machen die switches? Bastelst Du dort die Segmente einer
7-Segment-Anzeige zusammen?
In main() greifst Du sehr oft auf status zu. Da GCC die Adresse kennt,
macht er direkte Zugriffe, von denen jeder 4 Byte kostet.
Schreib das mal indirekt, also
1
typeof(status)*s=&status;
2
...
3
s->work.mode=...
GCC ist wahrscheinlich überschlau, trickst sich selber aus und macht
dennoch direkte Zugriffe (er kennt die Adresse immer noch!). Also: Im
Assembler-Out kontrollieren!
Falls da immer noch direkte Zugriffe stehen, kommt nach der Deklaration
ein
1
asm("":"+r"(s));
und der direkte Zugriff ist gegessen.
Ausserdem: oft verwendete Variablen wie .work.mode in lokalen Variablen
halten und Lesen/Schreiben vor/nach der Änder-Sequenz.
Am besten stückchenweise vortasten.
Santiago m. H. wrote:
> Ich meine, schon speichersparend gearbeitet zu haben, aber vielleicht> gibt es ja noch etwas Einsparpotential (hoffe ich mal).
Ja, die 7-Segment Ausgabe enthält noch viel Einsparpotential:
- Die 32Bit-Zugriffe sind nicht so der Brüller, da werden dann auch
Bytes angefaßt, die garnicht verändert werden.
Besser ist ein Array aus 3 Byte.
- Die switch-Anweisung kann auch nicht gut optimieren.
Besser die Segmentmuster mit Index aus ner Tabelle holen.
Hier mal ein Beispiel:
Beitrag "ADC mit Multiplexanzeige"
Danach sollte alles reinpassen.
Peter
Hallo,
herzlichen Dank für Eure Aufmerksamkeit und Unterstützung!
> Ok, hatte die falsche Toolchain (hasr Du nicht dazugeschrieben).
Sorry, ich kenne nur eine (avr-gcc). Was hätte ich dazu schreiben
sollen?
> Hier mal versuchen, die OR-Konstanten in ein Array zu packen und per> Index (h0,h1,m0,m1) drauf zuzugreifen.
Das war auch meine erste Idee. Habe die Funktion doppelt geschrieben und
es stellte sich heraus, dass die Array-Variante über 200 Bytes mehr
brauchte, abgesehen davon, dass der Speicher für das Array nicht
ausreichte.
> Was machen die switches? Bastelst Du dort die Segmente einer> 7-Segment-Anzeige zusammen?
Nein, die habe ich in der Header-Datei bereits zusammen gebaut. Das
Display ist so organisiert, dass es 2 gemeinsame Kathoden-Stränge gibt.
Dann sind die Anoden mancher Segmente auch zusammen gefasst ...
Mit den Switches baue ich die Bitfolgen für jeden Kathodenstrang
zusammen, der dann an die Schieberegister übertragen wird.
Da jede Ziffer anders angeschlossen ist, kann ich die Ziffern nicht
einheitlich verarbeiten.
> In main() greifst Du sehr oft auf status zu. Da GCC die Adresse kennt,> macht er direkte Zugriffe, von denen jeder 4 Byte kostet.
Irgendwo las ich, dass es effektiver wäre, globale Variablen in einer
Struktur zusammen zu fassen. Gilt die Aussage nicht für gcc?
Sollte ich besser ohne Struktur arbeiten?
Den Tip mit dem Zeiger statt der globalen Struktur verstehe ich noch
nicht. Was wird besser, wenn ich einen Zeiger verwende?
> - Die switch-Anweisung kann auch nicht gut optimieren.> Besser die Segmentmuster mit Index aus ner Tabelle holen.
Wie bereits geschrieben habe ich das ja bereits versucht.
Das ekelhafte ist, dass die Digits nicht gleich angesteuert werden
können, d.h. ich brauche für jede Ziffer ein Array.
Ich habe die Verdrahtung des Displays mal angehängt.
erster Erfolg:
> Ausserdem: oft verwendete Variablen wie .work.mode in lokalen Variablen> halten und Lesen/Schreiben vor/nach der Änder-Sequenz.
das hat schonmal 42 Byte (nur für mode) gebracht. Danke!
Hallo,
habe die Array-Variante nochmal überarbeitet, habe sie aber immer noch
nicht kleiner als die Switch-Version bekommen. Anbei mal die Sauce der
Array-Variante.
Statistik der Varianten:
1. Switch-Variante:
Santiago m. H. wrote:
> Hallo,>> herzlichen Dank für Eure Aufmerksamkeit und Unterstützung!>>> Ok, hatte die falsche Toolchain (hasr Du nicht dazugeschrieben).>> Sorry, ich kenne nur eine (avr-gcc). Was hätte ich dazu schreiben> sollen?
Ich verwende die alte (3.4.6) weil die bei meinen Projekten durchweg 10%
kleineren Code macht, und hatte erst mal nicht dran gedacht, daß es bei
der neuen 4.x viele tolle Optionen gibt, welche die alte noch nicht
kennt. Geht also auf meine Kappe.
>> Hier mal versuchen, die OR-Konstanten in ein Array zu packen und per>> Index (h0,h1,m0,m1) drauf zuzugreifen.>> Das war auch meine erste Idee. Habe die Funktion doppelt geschrieben und> es stellte sich heraus, dass die Array-Variante über 200 Bytes mehr> brauchte, abgesehen davon, dass der Speicher für das Array nicht> ausreichte.
Hmmm mal rechnen. Pro Ziffer braucht man 11 Einträge à 1 Byte: macht 44
Byte.
-- Byte für Ziffer 1 lesen
-- Byte für Ziffer 2 lesen
-- OR
-- Byte für Ziffer 3 lesen
-- Byte für Ziffer 4 lesen
-- OR
-- Ist wohl ein 2:1 MUX, also je nach MUX-Phase die unerwünschten Bits
rausUNDen
-- die beiden Bytes zu dem Long zusammenbasteln und weg damit
pro Bytelese-Aktion rechne ich mal 16 Byte Code, insgesamt sollten für
die Musterbildung 100-120 Bytes an Code reichen (ohne die Divisionen).
>> In main() greifst Du sehr oft auf status zu. Da GCC die Adresse kennt,>> macht er direkte Zugriffe, von denen jeder 4 Byte kostet.>> Irgendwo las ich, dass es effektiver wäre, globale Variablen in einer> Struktur zusammen zu fassen. Gilt die Aussage nicht für gcc?> Sollte ich besser ohne Struktur arbeiten?
Nein, das wäre die falsche Richtung. Der Zugriff würde sich zudem nicht
unterscheiden von einem struct-Zugriff. Ein struct/union hat aber den
Vorteil, daß die Komponenten im Speicher hintereinander liegen --
abgesehen davon, daß man nur eine Variable hat und nicht 1000
Kleingefuzzel an globalen Variablen.
> Den Tip mit dem Zeiger statt der globalen Struktur verstehe ich noch> nicht. Was wird besser, wenn ich einen Zeiger verwende?
Für AVR gilt: Ein indirekter Zugriff kostet 2 Byte Code im Gegensatz zu
den 4 Bytes bei direktem Zugriff. Die Ausführungsgeschwindigkeit ist
dabei identisch. Allerdings muss die Adresse erst in eines der
Adress-Register geladen werden, was Code kostet und ein 16-Bit-Register
belegt. Y- und Z-Register können mit festem Offset adressieren. Bei
vielen Zugriffen auf die gleiche Struktur kann es daher lohnend sein,
erst die Startadresse zu laden und dann indirekt zuzugreifen.
Ob das wirklich zu einem Codegewinn führt, muss man austesten. Falls der
Compiler auf die Idee kommt, die Startadresse zB in Register R15:R14
anzulegen, dann kopiert er die Adresse vor jedem Zugriff nach Y oder
(wahrscheinlicher) Z. Damit hätte man wieder 4 Byte Code (oder gar 6,
wenn kein MOVW geht) bei sogar 4 Ticks :-(
Versuchen kann man folgendes: Indirekte Zugriffe hinschreiben. Der
Compiler wird das wahrscheinlich zu direkten Zugriffen "optimieren",
also hat man nix gewonnen oder verloren, ausser etwas Zeitaufwand. Mit
dem asm kann man dann die "Optimierung" verhindern und schauen, ob es
einen Code-Schrumpf gibt. Wenn nicht, lässt man es bei den indirekten
Zugriffen, die der Compiler in direkte umwandelt und hat zumindest nix
an Code verloren.
Schön ist das nicht, aber schöne Lösungen kosten meist auch Platz.
>> - Die switch-Anweisung kann auch nicht gut optimieren.
Switch erweitert 8-Bit-Argumente zu 16-Bit. Ohne Sprungtabelle hat man
also für jedes Case einen unnötigen 16-Bit-Vergleich. Auch hier gilt:
mal eine explizite if-else-Orgie machen und schauen, ob der Code besser
wird (am besten im asm kontrollieren). Wiederum: der Code wird nicht
schöner...
das ergab den Durchbruch, bzw. nochmal 58 Byte Einsparung.
Mit der Switch-Variante bin ich jetzt bei 98% - damit kann ich loslegen
:)
> Switch erweitert 8-Bit-Argumente zu 16-Bit. Ohne Sprungtabelle hat man> also für jedes Case einen unnötigen 16-Bit-Vergleich. Auch hier gilt:> mal eine explizite if-else-Orgie machen und schauen, ob der Code besser> wird
Ok, werde ich auch nochmal durchprobieren - schließlich lerne ich ja was
dabei :)
> Ich verwende die alte (3.4.6) weil die bei meinen Projekten durchweg 10%> kleineren Code macht, und hatte erst mal nicht dran gedacht, daß es bei> der neuen 4.x viele tolle Optionen gibt, welche die alte noch nicht> kennt. Geht also auf meine Kappe.
Hm - das hat sich also nicht geändert? Ich habe eine Zeitlang Deinen
Fred zwecks Compiler-Vergleich mitgelesen, ihn dann aber aus den Augen
verloren.
Das heißt also, wenn man knackigen Code möchte, sollte man 3.4.6
verwenden?
Nochmals danke an alle die mitgeholfen haben.
Gruß Santi
Hallo,
das Umformulieren von swith in if...else ergab folgendes:
Der Switch vom mode auf die enum-Werte ergab 4 Byte Einsparung bei
if...else, der Switch von z.B. h0 auf 12 mögliche Werte ergab einen
Mehrverbrauch von 8 Byte.
Am Meisten brachte wieder die Verwendung eines Zeigers für den Zugriff
auf die Struktur (nachmal fast 20 Byte).
Mein Fazit:
Also die Verwendung von if...else macht somit nur in Einzelfällen Sinn
und die Einsparung ist nicht so groß, dass sich die "Verunstaltung" des
Codes generell rechtfertigen ließe. Im Einzelfall gilt es bei Bedarf zu
prüfen.
Ein Zeiger auf die globale Struktur macht dagegen generell Sinn.
Somit habe ich wieder viel dazu gelernt. Danke!
Du kannst ja mal testen, ob du den Code mit -mint8 zum laufen
bekommst(siehe Artikel AVR-Codeoptimierung).
Hat bei mir ziemlich viel rausgeholt (ich glaube, das waren fast 300
Byte).
Santiago m. H. wrote:
>> Ich verwende die alte (3.4.6) weil die bei meinen Projekten durchweg 10%>> kleineren Code macht, und hatte erst mal nicht dran gedacht, daß es bei>> der neuen 4.x viele tolle Optionen gibt, welche die alte noch nicht>> kennt. Geht also auf meine Kappe.>> Hm - das hat sich also nicht geändert? Ich habe eine Zeitlang Deinen> Fred zwecks Compiler-Vergleich mitgelesen, ihn dann aber aus den Augen> verloren.> Das heißt also, wenn man knackigen Code möchte, sollte man 3.4.6> verwenden?
Kann man so allgemein nicht sagen. Mein C-Code kommt nicht von nem
32-Bit-µC oder gar Host-Rechner, sondern ist direkt für AVR geschrieben.
Ausserdem kenn ich die avr-gcc-Interne bzw. GCC-Interna recht gut und
weiß, was dem Compiler schmeckt und was nicht.
Leider fehlt gcc ne Option wie -fsmart-code oder -fbraindead-code, womit
man einstellen könnte, wie geschickt programmiert wurde.
Ein C-Compiler will natürlich unabhängig sein zB von der speziellen
algebraischen Formulierung einzelner Ausdrücke. Man will ja portierbaren
Code und nicht für jede Plattform an der Quelle schnitzen.
Für Code aus nem Code-Generator (-fbraindead-code) würde ich mal
schätzen, daß 4.x besseren Code mach. Bei für avr-gcc 3.4.x mungerecht
geschriebenem C-Code ist das aber leider nicht so.
Einen neuen Anlauf, avr-gcc 4.3.x zu testen hab ich nicht gemacht. Weder
unter Win32 noch unter Linux. Wobei reizen würd es je schon, ein
bisschen die Quellen zu tunen...
Santiago m. H. wrote:
> Hallo,>> das Umformulieren von swith in if...else ergab folgendes:> [...]> Mein Fazit:> Also die Verwendung von if...else macht somit nur in Einzelfällen Sinn> und die Einsparung ist nicht so groß, dass sich die "Verunstaltung" des> Codes generell rechtfertigen ließe. Im Einzelfall gilt es bei Bedarf zu> prüfen.
In Deinem Fall liegen die case-Werte schön hintereinander, optimal für
jump-tables. Liegen die case verstreut, ist mit einer Tabelle nicht viel
zu wollen und die Vergleiche würden ausgetextet. Der Compiler hat dazu
intern Heuristiken, aber die GCC-Entwickler streuben sich leider
dagegen, switch auch für 8 Bit einzubauen, so daß bei expliziten
Vergleichen auf int-Ebene verglichen wird...
> Ein Zeiger auf die globale Struktur macht dagegen generell Sinn.
Wie gesagt, nicht generell. Aus hier gibt es zahlreiche Ausnahmen, zB
wenn viele Register gebraucht werden, oder gleichzeitig auf mehrere
solcher Strukturen zugegriffen werden soll. Leider hat AVR nur 2
wirklich brauchbare Adress-Register, von denen eines von avr-gcc schon
für den Frame-Pointer reserviert ist, also nur dann für "normalen" Code
allokierbar ist, wenn kein Framepointer gebraucht wird.
egberto wrote:
> Du kannst ja mal testen, ob du den Code mit -mint8 zum laufen> bekommst(siehe Artikel AVR-Codeoptimierung).
Nicht wundern, wenn dann keine 32-Bit-Arithmetik mehr geht...
>Nicht wundern, wenn dann keine 32-Bit-Arithmetik mehr geht...
Deswegen habe ich ja auch extra geschrieben "testen, ob du den Code mit
-mint8 zum laufen bekommst" und auf den passenden Artikel verwiesen.
Ob Aufwand und nutzen hier vernünftig sind, muß man dann halt
abschätzen.
Aber das Programm pass ja wohl schon in den Chip....
Schönes (Bastel)WE
Hallo Johann,
> Kann man so allgemein nicht sagen. Mein C-Code kommt nicht von nem> 32-Bit-µC oder gar Host-Rechner, sondern ist direkt für AVR geschrieben.
Wie meinst Du das?
Ich habe auch versucht, den C-Code direkt für den AVR zu schreiben.
Generiert ist da nix und 32-Bit µCs habe ich auch nicht - aber klar, ich
bin noch Anfänger im µC-Umfeld, von daher muss ich noch viel der
Eigenheiten lernen.
Also wenn Du noch einen Tip hättest, was ich besser machen könnte/sollte
- bin dankbarer Abnehmer :)
Wie sieht das denn mit App-Notes von Atmel bzgl. C-Programmierung aus?
Sind die übertragbar auf GCC, oder gelten die "nur" für den Intel
Compiler?
Gruß Santi
Santiago m. H. wrote:
> Hallo Johann,>>> Kann man so allgemein nicht sagen. Mein C-Code kommt nicht von nem>> 32-Bit-µC oder gar Host-Rechner, sondern ist direkt für AVR geschrieben.>> Wie meinst Du das?>> Ich habe auch versucht, den C-Code direkt für den AVR zu schreiben.> Generiert ist da nix und 32-Bit µCs habe ich auch nicht - aber klar, ich> bin noch Anfänger im µC-Umfeld, von daher muss ich noch viel der> Eigenheiten lernen.
Die Großzahl der Optimierungsalgorithmen in GCC ist maschinenunabhängig,
was Optimierung aber in Wirklichkeit fast nie ist. GCC zielt eben eher
auf 32-Bit-Architekturen und versucht näher an die Konkurrenten wie
Intel C-Compiler ranzukommen. Naja, und solche Optimierungen führen für
AVR dann manchmal zu schlechterem Code als ältere Compiler-Versionen.
Ein bisschen hatte ich auch im von Dir genannten Thema dazu geschrieben.
Aber GCC lernt bestimmt noch dazu. Das Potential an mächtigen
Optimierungen hat er zweifellos, es fehlt aber etwas an deren
zielgenauem Einsatz...
> Also wenn Du noch einen Tip hättest, was ich besser machen könnte/sollte> - bin dankbarer Abnehmer :)>> Gruß Santi
Sehr hilfreich finde ich, hin und wieder einen Blick ins erzeugte
Assembler zu werfen. Dazu gibt es mehrer Wege
http://www.roboternetz.de/wissen/index.php/Assembler-Dump_erstellen_mit_avr-gcc
Weit verbreitet ist, den Assembler ein List-File miterzeugen zu lassen.
Ich bevorzuge jedoch, direkt in die Compiler-Ausgabe zu schauen. Während
die avr-as-Ausgabe schon Maschinencode enthält, ist das bei der
Compiler-Ausgabe noch nicht der Fall. Dafür kann man andere
Informationen bekommen über die verwendeten Variablen oder welches
Pattern eine gewisse Befehlsfolge erzeugt hat
foo-gcc -save-temps -dp -fverbose-asm ...
-save-temps legt die .s-Datei im aktuellen Verzeichniss an anstatt als
tmp-Datei.
-dp ist recht speziell, die Zusatzinfos dienen eigentlich zum Debuggen
des Compilers... Ausserdem fin ich -g (Debug-Info) recht lästig. Ich
verwende die Option nicht, weil ich eh nicht debugge und -g die .s groß
und schlecht lesbar macht.
Die herkömmlich erzeigten lst/lss-Files sind aber auch ganz nett und
enthalten Quell-Info, so daß der Code zuortenbar bleibt.
Meistens genügt ein Blick ins List, um zu beurteilen, was gcc zu treibt.
Macht er viel überflüssiges Zeug, geht das idR auf Codegröße und auf
Speicherplatz.
Ein Kandidat wäre zB eines der ersten swich-Statements in der Ausgabe,
das 2x die Sequenz
1
h0=h/10;
2
h1=h%10;
3
m0=m/10;
4
m1=m%10;
enthält.
Wenn gcc gut ist, erkennt er das und legt den Code nur 1x an und
verzweigt so, wie man es händisch mit goto machen würde.
Wenn gcc den Code 2x anlegt, was bei -Os unerwünscht ist, kann man sich
unterschiedliche Strategien überlegen, das loszuwerden.
Noch was: Die Arrays S1Dig0[] ect. sind 32 Bit breit. Pro Ziffer reichen
aber doch 1 Byte. Es codiert für Bit 6..13 (Dig 1,2) bzw. für Bit 15..21
(Dig 3,4). Zusammenbasteln kann man das später. Das spart Platz in den
Arrays und beim Lesen!
Santiago m. H. wrote:
> habe die Array-Variante nochmal überarbeitet, habe sie aber immer noch> nicht kleiner als die Switch-Version bekommen.
Kein Wunder, sie ist ja immer noch 32-Bittig und das mag der GCC nicht
(gut optimieren).
Und da Du nur 24Bit brauchst, sinds schonmal 25% toter Code.
Du hast 4 Digits a 7 Segmente.
Also mach erstmal ein Array 4*7 für jedes Segment ein Byte (=28Byte
Flashverbrauch).
Das Byte enthält einmal die Bitnummer 0..23 (=5Bits) und die
Multiplexnummer 0..1 (= nochn Bit), die 6 Bits passen also in ein Byte.
Dann die nächste Tabelle mit 10 Einträgen für den 7-Segmentcode.
Dann ein Array (Display-RAM) im SRAM von 6 Byte (je 24 Bit für MUX0 und
MUX1).
So und nun ne Funktion, die in den Display-RAM ne Ziffer einstellt.
Diese Funktion setzt/löscht dann die Bits einer Ziffer auf einem Digit,
also 2 Argumente:
1
voiddigit_out(uint8_tdigit,uint8_tnumber);
Am besten als Schleife Bit für Bit, damit der Code klein bleibt.
Dauert zwar etwas länger als tausend Switches, aber der Mensch kann eh
nicht so schnell lesen.
Man sollte nicht schneller als 2..5 Werte je Sekunde ausgeben, damits
ergonomisch ist.
Und fertisch.
Peter
Hallo,
@Johann L.
Danke für die ausführlichen Erklärungen. Schätze, ich muss mich doch mit
Assembler auseinander setzen. Hatte mich bislang davor gedrückt.
@Peter
Also Deine Tips reißen mal wieder die Mundwinkel bis zu den Ohrläppchen.
Das muss ich mir langsam auf der Zunge zergehen lassen.
Also erstmal nen Kaffee holen und dann versuchen umzusetzen.
So wie es aussieht habbich wohl die Tina verärgert
(Beitrag "zum Abschied rauch ich eine"). Kann die Tips also
(vorerst) nur virtuell testen.
Nochmals ein Dankeschön Euch allen und ein angenehmes WE.
Gruß Santi
Santiago m. H. wrote:
> @Peter> Also Deine Tips reißen mal wieder die Mundwinkel bis zu den Ohrläppchen.> Das muss ich mir langsam auf der Zunge zergehen lassen.> Also erstmal nen Kaffee holen und dann versuchen umzusetzen.
Im Anhang hab ichs mal schnell geproggt (ohne Gewähr).
Die konstanten Daten kann man noch nach PGM verschieben, ich habs
erstmal im SRAM gemacht.
Das Array SEGMENT_TAB mußt Du noch mit den richtigen Anschlüssen
belegen.
Peter
Hallo Peter,
als ich las, dass Du es "mal schnell geproggt" hast, war ich erst
enttäuscht und dachte: wie langweilig.
Aber dann sagte ich mir, du musst es ja nicht gleich anschauen.
Also habe ich erst versucht, es selbst umzusetzen und dann erst Deinen
code angeschaut.
So knackig habe ich es natürlich nicht hinbekommen :) - war ja klar.
Aber die Ergebnisse meines Codes haben mich auch überrascht.
Zuerst habe ich glatt runtergeschrieben und den Display-Puffer als
32Bit-Werte gelassen.
Nach dem Übersetzen zeigte sich, dass die Array-Variante ca 40Byte mehr
an Code produzierte, als die Switch-Variante.
Dann habe ich den Display-Puffer in ein Char-Array umgewandelt und den
Code angepasst.
Ergebnis: 310 Byte Einsparung gegenüber der 32-Bit-Variante, bzw. 270
Byte weniger als die Switch-Variante. Das ist doch mal nicht schlecht.
Allerdings denke ich, dass ich die Codegröße gegen schlechtere Laufzeit
eintauscht habe - insbesondere beim Tiny2313 der keinen Multiplikator
hat.
Was meinst Du?
Santiago m. H. wrote:
> Allerdings denke ich, dass ich die Codegröße gegen schlechtere Laufzeit> eintauscht habe - insbesondere beim Tiny2313 der keinen Multiplikator> hat.
Der MC kann über 100-mal schneller Zahlen ausgeben, als der Mensch
ablesen kann. Daher hast Du keinerlei merkbare Laufzeiteinbuße.
Peter
Hallo Peter,
habe inzwischen auch Deinen Vorschlag umgesetzt und was soll ich sagen:
nochmals 140 Byte Einsparung.
Ich muss gestehen, so richtig habe ich es erst beim Abschreiben
verstanden.
Schon genial, Rechenoperationen in die Arraybelegung mit zu nehmen.
Schätze derlei Genialitäten lernt man nur, wenn man wirklich mit
begrenztem Speicher umgehen muss.
Ein Anwendungsentwickler, der sich nicht um die Größe des
Auslagerungsspeichers kümmern muss, würde nie auf so eine Idee kommen.
Da habe ich wohl noch viel zu lernen.
Danke für Deine Unterstützung.
Angenehmes WE wünscht
Santi
Hallo Peter,
> Ich hab nochn Fehler in meinem Code gefunden
Das finde ich sehr großzügig, dass Du meine Fehler auf Dir nimmst ;)
So wie der Typ in dem alten Schinken: "den Pups der Dame nehm ik auf
mir..."
Schätze Deine Variante, den Zähler runter zu zählen und die
Abbruchbedingung gegen 0 zu prüfen dürfte auch noch schneller sein.
Auf jeden Fall danke ich Dir für die extra Tips. Jetzt verstehe ich
auch, warum meine Variante so schlecht ist. Da sind jede Menge variable
Schiebeoperationen drin.
Anbei mal die vollständige Datei nach Deiner Vorlage.
Gruß Santi