Hi, ich bin auf der Suche nach Informationen zu FAT16. Da ich im Internet fast ausschließlich Informationen zu FAT32 finden konnte, dachte ich mir, ich frage mal nach ob hier jemand eine gute Seite kennt, die sich mit FAT16 beschäftigt. So etwas ähnliches wie http://www.pjrc.com/tech/8051/ide/fat32.html wäre super. PS: Mir ist bewusst, dass es bereits einige FAT16 Implementierungen gibt, dennoch möchte ich gerne verstehen wie die Daten in dem Filesystem abgelegt werden.
:
Verschoben durch User
http://lmgtfy.com/?q=FAT16+aufbau erster Treffer. gruß Mobius P.S.: Die Ablage ist genauso wie bei FAT32. Nur die Zahl der Sektoren ist begrenzt auf 65535 (16bit halt, wer hätte das erwartet ;) )
Bernhard B. schrieb: > ich bin auf der Suche nach Informationen zu FAT16. Da ich im Internet > fast ausschließlich Informationen zu FAT32 finden konnte, dachte ich > mir, ich frage mal nach ob hier jemand eine gute Seite kennt, die sich > mit FAT16 beschäftigt. Wie hast Du das geschafft ? Google platzt doch fast vor Links zum Thema FAT16 ! Oder soll es wieder fertiger Quellcode genau für Deine Anwendung sein ?
Angehängte Dateien:
-

fat16.png
4,2 KB
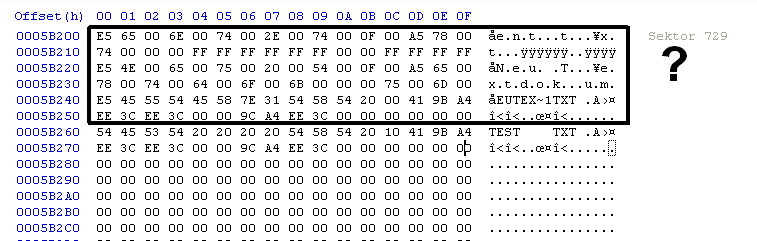
Ok, dann eine konkrete Frage: Wenn ich eine Datei mit dem Namen "TEST.txt" auf einer frisch formatierten FAT16 SD Karte erstelle, dann müsste doch ein 32 byte langer Directory-Eintrag im Root-Directory der SD Karte auftauchen. Bei mir wird da jedoch im Root-Directory für die Datei "TEST.txt" ein Eintrag erstellt, der um einiges größer als 32 Byte ist. Zuerst hab ich vermutet, dass es vielleicht dieser "Long-File-Zusatz" ist, doch mein Dateiname besteht ja nur aus 4.3 Zeichen. Kann mir jemand erklären was diese Bytes, die ich im Bild mit einem Fragezeichen markiert habe, zu bedeuten haben? Lg
Du hast die Text-Datei auf der SD-Karte erstellt und dadurch hatte die Datei erstmal den Namen "Neu Textdokument.txt". Die hast du dann umbenannt in TEST.TXT. Dadurch hast du erst die beiden (nicht mehr gültigen) Einträge für den langen Dateinamen und dannach den mit dem kurzen Namen, die beide auf den selben Dateieintrag zeigen
>des is ne gelöschte datei mit dem namen "Neu Textdokument.txt" Jupp. >Bei mir wird da jedoch im Root-Directory für die Datei "TEST.txt" ein >Eintrag erstellt, der um einiges größer als 32 Byte ist. Der gehört nicht zu deiner Datei. Das sind Reste von einer anderen Datei.
Achso, jetzt wird mir einiges klar. Danke euch Dreien! Noch eine Frage: Werden diese nicht mehr gültigen Einträge eigentlich irgendwann gelöscht/überschrieben?
Bernhard B. schrieb: > Noch eine Frage: Werden diese nicht mehr gültigen Einträge eigentlich > irgendwann gelöscht/überschrieben? Ja, leg' einfach noch ein paar Dateien an und sieh Dir das Directory dann nochmal an.
Und arbeite nicht mit einer Windows-Umgebung mit LFN-Support und dem Explorer. Mehr Mist kann man ja nicht sammeln.
Rufus t. Firefly schrieb: > Ja, leg' einfach noch ein paar Dateien an und sieh Dir das Directory > dann nochmal an. Danke!
Bei den meisten Dateisystemen werden Dateien nicht sofort gelöscht sondern nur als gelöscht markiert, bzw. der Speicherplatz als frei. Erst wenn der Bereich wieder neu beschrieben wird, verschwindet die alte Datei endgültig.
Troll schrieb: > Bei den meisten Dateisystemen werden Dateien nicht sofort gelöscht > sondern nur als gelöscht markiert, bzw. der Speicherplatz als frei. Erst > wenn der Bereich wieder neu beschrieben wird, verschwindet die alte > Datei endgültig. Gut zu wissen, danke für die Info. Aufgrund deines Tipps hab ich mir den Aufbau der Root-Directory-Einträge nochmal genauer angeschaut: "0xE5: Entry has been previously erased and is available. File undelete utilities must replace this character with a regular character as part of the undeletion process." Quelle: http://en.wikipedia.org/wiki/File_Allocation_Table Das klingt doch ganz gut. Das muss ich mir nachher genauer im Hex-Editor ansehen. Danke nochmals für den Hinweis!
Hi, ich bin gerade dabei eine FAT16 Lesefunktion zu implementieren, die eine beliebige Datei auf der SD Karte öffnet und deren Inhalt ausgibt. Im Moment gehe ich so vor: Ich hol mir aus der Directory Table den Startcluster der zu lesenden Datei. Den Startcluster wandle ich in eine Sektoradresse um und lese anschließend den kompletten Cluster (meine SD Karte hat 16 Sectors per Cluster) aus. Das funktioniert prinzipiell ganz gut, aber nur solange alle Sektoren in einem Cluster mit Daten gefüllt sind. Jetzt gibts aber auch den Fall, dass meine zu lesende Datei so klein ist, dass diese nicht den kompletten Cluster (also 16 Sektoren) verwendet, sondern nur 5 Sektoren. Wenn ich jetzt den kompletten Cluster auslese, dann kommt am Anfang der Inhalt der Datei und dann nur mehr Datenmüll, der nicht mehr zur Datei gehört. Meine Frage ist nun: Wie erkenne ich am effizientesten das die Datei nur einen Teil des Clusters belegt? Mein Ansatz wäre: In jedem 32 Byte langen Directory-Entry gibts 4 Byte die die Größe der Datei in Bytes angeben - diese werte ich aus und berechne mir die Anzahl der Sektoren die ich lesen muss, bis das Ende des Files erreicht wurde. Ist der Ansatz ok, oder gibts einen besseren?
Bernhard B. schrieb: > Ist der Ansatz ok, oder gibts einen besseren? Genauso hat es DOS letzten Endes auch gemacht.
Karl heinz Buchegger schrieb: > Bernhard B. schrieb: > >> Ist der Ansatz ok, oder gibts einen besseren? > > Genauso hat es DOS letzten Endes auch gemacht. Danke für den Hinweis. Dann werd' ich das auch mal so probieren.
Das ist der sinnvollste Ansatz. Bei Textdateien findet man manchmal ein aus der Urzeit stammendes Relikt, das Steuerzeichen Ctrl-Z als Dateiendekennung, aber auf so etwas sollte man sich nicht verlassen, denn neuzeitliche Texteditoren verzichten auf so etwas.
Rufus t. Firefly schrieb: > Das ist der sinnvollste Ansatz. > Bei Textdateien findet man manchmal ein aus der Urzeit stammendes > Relikt, das Steuerzeichen Ctrl-Z als Dateiendekennung, aber auf so etwas > sollte man sich nicht verlassen, denn neuzeitliche Texteditoren > verzichten auf so etwas. Mit dem Gedanken hab ich am Anfang auch gespielt, war mir aber nicht sicher ob es ein Steuerzeichen gibt, welches wirklich von jedem OS und jedem Texteditor als letztes Zeichen eingefügt wird... Danke für den Hinweis! Ich hab jetzt die Leseroutine fertig und würde gerne ein paar Meinungen zur Performance einholen. Um den Code möglichst übersichtlich zu gestalten, hab ich mir viele kleine Routinen geschrieben, die gewisse Teilaufgaben übernehmen. So wird zum Beispiel jedes Mal wenn ich die Adresse des Bootsectors benötige, diese erneut von der SD Karte gelesen. Performanceschonender wärs wahrscheinlich die Adresse in einer globalen Variable abzulegen und bei Bedarf auf diese zuzugreifen. Aber da ich möglichst auf globale Variablen verzichten möchte, bleibt mir nichts anderes übrig als den Wert jedes Mal von der SD Karte zu lesen. Lange Rede, kurzer Sinn: Ich hab mal einen Lesevorgang von der SD Karte durchgeführt und würde gerne wissen wie schlecht meine Performance ist. Ich bin mir dessen bewusst, dass ich sicherlich kein neues FAT16 Performancewunder erschaffen werde, dennoch hätte ich gerne eine Routine die halbwegs flink arbeitet. Die Daten: .) Die zu lesende Datei ist 40kB groß .) SPI Taktrate: 4MHz .) CPU taktet mit 8MHz .) Benötigte Zeit, um die Datei zu lesen: 28 Sekunden Mit ist klar, dass ich sowohl die CPU als auch SPI schneller takten kann, aber ich möchte meinen schlechten Programmierstil nicht dadurch wettmachen, dass ich einfach den Takt erhöhe. Ich glaub das wäre der falsche Ansatz... Was meint ihr? Ist die Lese-Performance akzeptabel oder grottenschlecht? Hab leider keine Ahnung welche Richtwerte man da erwarten soll/kann/muss...
Ich hab jetzt ein wenig recherchiert und bin draufgekommen, dass meine Lesegeschwindigkeit extrem schlecht ist. Ich vermute mal, dass ich in dieser Funktion ziemlich viel Zeit herschenke:
1 | struct FAT_struct fat16_get_fs_info(){ |
2 | struct FAT_struct FAT_values; |
3 | |
4 | //only if the last two bytes of the MBR are 0x55 and 0xAA
|
5 | if((mmc_read_byte(0,510) == 0x55) && (mmc_read_byte(0,511) == 0xAA)){ |
6 | FAT_values.error_flag = 0; |
7 | |
8 | //get bootsector address
|
9 | FAT_values.bootsector = mmc_read_byte(0,457) << 24; |
10 | FAT_values.bootsector += mmc_read_byte(0,456) << 16; |
11 | FAT_values.bootsector += mmc_read_byte(0,455) << 8; |
12 | FAT_values.bootsector += mmc_read_byte(0,454) << 0; |
13 | |
14 | FAT_values.fat_type = mmc_read_byte(0, 450); //read from sector 0 byte 450 = file system type |
15 | |
16 | //get bytes per sector
|
17 | FAT_values.bytes_per_sector = mmc_read_byte(FAT_values.bootsector, 12) << 8; |
18 | FAT_values.bytes_per_sector += mmc_read_byte(FAT_values.bootsector, 11) << 0; |
19 | |
20 | //get sectors per cluster
|
21 | FAT_values.sectors_per_cluster = mmc_read_byte(FAT_values.bootsector, 13); |
22 | |
23 | //get reserved sectors
|
24 | FAT_values.reserved_sectors = mmc_read_byte(FAT_values.bootsector, 15) << 8; |
25 | FAT_values.reserved_sectors += mmc_read_byte(FAT_values.bootsector, 14) << 0; |
26 | |
27 | |
28 | //get sectors per FAT
|
29 | FAT_values.sectors_per_fat = mmc_read_byte(FAT_values.bootsector, 23) << 8; |
30 | FAT_values.sectors_per_fat += mmc_read_byte(FAT_values.bootsector, 22) << 0; |
31 | |
32 | //get number of FATs
|
33 | FAT_values.number_of_fats = mmc_read_byte(FAT_values.bootsector, 16); |
34 | |
35 | //get max. number of root entries
|
36 | FAT_values.max_root_entry = mmc_read_byte(FAT_values.bootsector, 18) << 8; |
37 | FAT_values.max_root_entry += mmc_read_byte(FAT_values.bootsector, 17) << 0; |
38 | }
|
39 | |
40 | else{ //otherwise: set error flag! |
41 | FAT_values.error_flag = 1; |
42 | }
|
43 | return FAT_values; |
44 | }
|
Diese Funktion wird jedes Mal aufgerufen, wenn ich einen Wert (Anzahl der Sektoren, Anzahl der Root-Einträge...etc) daraus benötige. Das heißt: Wenn ich z.B: die Adresse des Bootsectors in der Funktion test benötige, dann schreibe ich:
1 | void test(){ |
2 | struct FAT_struct FAT; |
3 | FAT = fat16_get_fs_info(); |
4 | FAT.bootsector = tu_irgendwas_damit; |
5 | }
|
Bei jedem Aufruf der Funktion mmc_read_byte werden 512 Byte (also ein Sektor) gelesen und dann wird das jeweilige Zeichen, welches der übergebenen Position entspricht, zurückgegeben. Eine Möglichkeit wäre nun, die Werte in globale Variablen abzulegen und die Funktion zur Berechnung dieser Werte nur einmal auszuführen. Die Frage, die sich mir dabei stellt: Ist das ein guter Programmierstil, wenn ich all diese Werte in globale Variablen ablege?
Ok, ich hab meinen Code jetzt mal so umgebaut wie oben beschrieben, also auf globale Variablen. Um eine 40kB große Datei zu lesen, benötige ich jetzt nur noch ca. 2 Sekunden. Mit so einem großen Performancegewinn hätte ich nie gerechnet. Einziger Nachteil: Der Code ist durch die zahlreichen globalen Variablen nicht immer einfach zu lesen...da muss ich mir noch etwas überlegen. Hat vielleicht jemand nen Tipp wie man das schöner lösen könnte?
Es empfiehlt sich sehr, mindestens den letzten gelesenen Sektor komplett zu puffern. Deine mmc_read_byte-Funktion kann nachsehen, ob die ihr übergebene Sektornummer die des bereits gelesenen Sektors ist, und kann dann den Lesevorgang überspringen. Nur bei einer abweichenden Sektornummer muss erneut gelesen werden. Wenn ausreichend viel Speicher zur Verfügung steht, können auch mehrere Sektoren zwischengespeichert werden, beim Lesezugriff ist dann in der Liste der gelesenen Sektoren nachzuschauen, ob der gewünschte Sektor bereits im Speicher vorliegt. Beim Nachladen von noch nicht bekannten Sektoren ist dann sinnvollerweise ein Alterungsmechanismus zu verwenden, um zu bestimmen, welcher Sektor aus dem Speicher 'rausgekippt wird. Gewiss, um so etwas zu implementieren, braucht man irgendwo irgendwelche Variablen. Das kann man mit globalen Variablen erledigen, das kann man aber auch mit statischen, nur aus einem C-Modul heraus sichtbaren Variablen erledigen. Das nicht zu tun, nur um globale Variablen zu scheuen wie der Teufel das Weihwasser, ist offensichtlich ineffizient.
Rufus t. Firefly schrieb: > Es empfiehlt sich sehr, mindestens den letzten gelesenen Sektor komplett > zu puffern. Deine mmc_read_byte-Funktion kann nachsehen, ob die ihr > übergebene Sektornummer die des bereits gelesenen Sektors ist, und kann > dann den Lesevorgang überspringen. Nur bei einer abweichenden > Sektornummer muss erneut gelesen werden. > > Wenn ausreichend viel Speicher zur Verfügung steht, können auch mehrere > Sektoren zwischengespeichert werden, beim Lesezugriff ist dann in der > Liste der gelesenen Sektoren nachzuschauen, ob der gewünschte Sektor > bereits im Speicher vorliegt. Beim Nachladen von noch nicht bekannten > Sektoren ist dann sinnvollerweise ein Alterungsmechanismus zu verwenden, > um zu bestimmen, welcher Sektor aus dem Speicher 'rausgekippt wird. > Danke, die Idee ist echt nicht schlecht! > Gewiss, um so etwas zu implementieren, braucht man irgendwo irgendwelche > Variablen. Das kann man mit globalen Variablen erledigen, das kann man > aber auch mit statischen, nur aus einem C-Modul heraus sichtbaren > Variablen erledigen. Das nicht zu tun, nur um globale Variablen zu > scheuen wie der Teufel das Weihwasser, ist offensichtlich ineffizient. Ich meinte eigentlich eh statische Variablen, die nur in einem C-Modul sichtbar sind. Ich hab diese Variablen bisher immer fälschlicherweise als globale Variablen bezeichnet. Mein C-Modul sieht so aus: fat16.c:
1 | //Include-Files
|
2 | |
3 | //statische Variablen
|
4 | static uint32_t bootsector; |
5 | static uint8_t fat_type; |
6 | static uint8_t error_flag; |
7 | static uint16_t bytes_per_sector; |
8 | static uint8_t sectors_per_cluster; |
9 | static uint16_t reserved_sectors; |
10 | static uint16_t sectors_per_fat; |
11 | static uint8_t number_of_fats; |
12 | static uint16_t max_root_entry; |
13 | |
14 | //Hier kommen dann die Funktionen
|
15 | [....]
|
Ich weiß, dass ich langsam am ursprünglichen Topic vorbeischieße, ich möchte aber keinen neuen Thread eröffnen. Deshalb stelle ich die Fragen hier. Ich hoffe man nimmt es mir nicht übel. Und zwar: .)Ist es besser(übersichtlicher?), die statischen Variablen in das Headerfile auszulagern oder können die ruhig im C-File stehen? .)Gibt es einen Standard um statische Variablen (also jene Variablen die innerhalb eines kompletten C-Moduls gelten) bereits im Namen zu kennzeichnen? Also das man bereits am Variablennamen erkennt, dass sich der Gültigkeitsbereich der Variablen über das komplette C-Modul erstreckt.
Bernhard B. schrieb: > .)Ist es besser(übersichtlicher?), die statischen Variablen in das > Headerfile auszulagern oder können die ruhig im C-File stehen? Das ist die falsche Frage. Die richtige Frage muss lauten: Geht es ausserhalb deines SD-Moduls irgendjemanden etwas an, dass du da ein paar globale Variablen hast und ist es ok, wenn sich da jemand mit einem "extern" an diese Variablen klemmen kann? Wenn die Antwort ja lautet, dann darfst du die Variablen nicht static machen und ein extern Eintrag kommt ins Header File. Lautet die Antwort aber nein, dann gehören die Variablen ins *.c File und im Header File taucht kein Sterbenswörtchen über diese Variablen auf. Bei dir lautet die Antwort, wie meistens, nein! > .)Gibt es einen Standard um statische Variablen (also jene Variablen die > innerhalb eines kompletten C-Moduls gelten) bereits im Namen zu > kennzeichnen? Eine zeitlang habe ich die Variablen mit einem vorangestelltem s als Modul-static gekennzeichnet. Aber im Grunde genommen, braucht man kaum eine derartige Kennzeichnung. Aus dem Zusammenhang und der Verwendung ist normalerweise relativ klar, welche Variablen Modulglobal sind und welche nicht.
Karl heinz Buchegger schrieb: > Die richtige Frage muss lauten: > Geht es ausserhalb deines SD-Moduls irgendjemanden etwas an, dass du da > ein paar globale Variablen hast und ist es ok, wenn sich da jemand mit > einem "extern" an diese Variablen klemmen kann? > > Wenn die Antwort ja lautet, dann darfst du die Variablen nicht static > machen und ein extern Eintrag kommt ins Header File. > > Lautet die Antwort aber nein, dann gehören die Variablen ins *.c File > und im Header File taucht kein Sterbenswörtchen über diese Variablen > auf. Wieder etwas gelernt. Alles klar, dann werd' ich die statischen Variablen im C-File belassen. Karl heinz Buchegger schrieb: > Eine zeitlang habe ich die Variablen mit einem vorangestelltem s als > Modul-static gekennzeichnet. Aber im Grunde genommen, braucht man kaum > eine derartige Kennzeichnung. Aus dem Zusammenhang und der Verwendung > ist normalerweise relativ klar, welche Variablen Modulglobal sind und > welche nicht. Ok, dann werd' ich diese auch nicht weiter kennzeichnen. Ich hab mir gedacht, dass es vielleicht einen Standard gibt, den man bei der Namensgebung unbedingt beachten muss. Aber so wie ich das aus deinem Beitrag herauslese, dürfte da jeder Programmierer seinen eigenen "Stil" haben. Danke für die ausführliche Erklärung!
Bernhard B. schrieb: > Aber so wie ich das aus deinem > Beitrag herauslese, dürfte da jeder Programmierer seinen eigenen "Stil" > haben. Dürfen ja, solange es nur der Programmierer mit dem Code zu tun bekommt ist das auhc OK. Ich hab mir jedoch angewöhnt Variablen zu kennzeichnen damit, wenn mein Code von jemand anderen gelesen wird der keine Ahnung von meinem Stil hat, sich schnell reinfinden kann.
Angehängte Dateien:
-

fat16_schreiben.png
17 KB
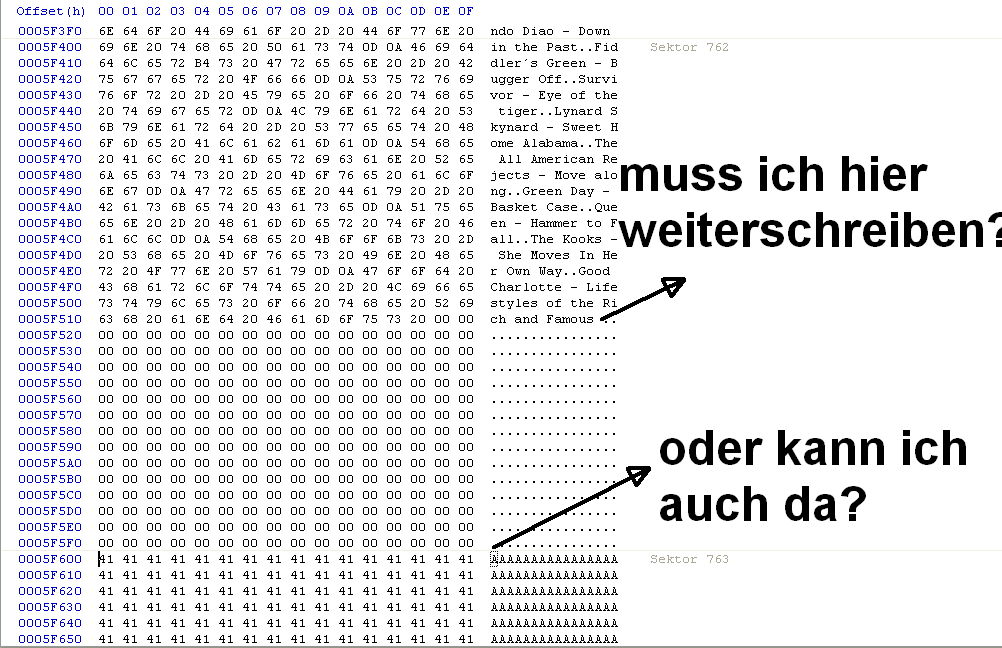
Hi, ich bin gerade dabei meine Schreibroutine zu implementieren und dabei ist noch eine Frage aufgetaucht: Mir ist klar, dass ich die SD Karte immer nur sektorweise beschreiben kann. Aber was mach ich, wenn eine Datei öffne, die nur 1,5 Sektoren belegt und ich bei dieser etwas ergänzen möchte? Ein konkretes Beispiel: Ich öffne eine Datei mit 798 Byte. In einen Sektoren passen 512 Byte (zumindest bei meiner SD Karte), das heißt: 798Byte / 512 Byte_per_sector = 1,55... Das heißt, ein Sektor ist komplett beschrieben und der andere nur etwa zur Hälfte. Jetzt möchte ich diese Datei öffnen und etwas hineinschreiben. Muss ich jetzt unmittelbar hinter dem halbbeschriebenen Sektor weiterschreiben oder kann ich nen neuen Sektor anfangen? Ersteres wäre ziemlich umständlich, da ich jedes Mal den letzten Sektor komplett lesen müsste, um zu überprüfen ob wirklich alle 512 Byte belegt sind. Wenn dies nicht der Fall ist, dann müsste ich die fehlenden Bytes ergänzen und den Sektor wieder auf die SD Karte schreiben. Zur besseren Verdeutlichung hab ich nen Screenshot angehängt. Mein erster Versuch war, einen komplett neuen Sektor zu beschreiben (siehe die vielen 'A's im Screenshot), aber das hat irgendwie nicht ganz geklappt. Falls man unmittelbar hinter dem halbbeschriebenen Sektor weiterschreiben muss: Wie macht man das am effizientesten? Die einzige Möglichkeit wäre wie gesagt, dass ich den Sektor komplett lese und überprüfe ob dort wirklich alle 512 Byte belegt sind. Falls nur 500 Byte belegt sind, dann häng ich an die 500 Byte 12 Byte dran und schreib den Sektor nochmals auf die SD Karte. Gibts nen eleganteren Weg? Jedes Mal den letzten Sektor lesen kostet halt schon etwas an Zeit...
Bernhard B. schrieb: > Das heißt, ein Sektor ist komplett beschrieben und der andere nur etwa > zur Hälfte. Jetzt möchte ich diese Datei öffnen und etwas > hineinschreiben. Muss ich jetzt unmittelbar hinter dem halbbeschriebenen > Sektor weiterschreiben oder kann ich nen neuen Sektor anfangen? Du musst dort im Sektor weiterschreiben, wo die Datei vorher aufgehört hat. Bernhard B. schrieb: > Ersteres > wäre ziemlich umständlich, da ich jedes Mal den letzten Sektor komplett > lesen müsste, um zu überprüfen ob wirklich alle 512 Byte belegt sind. Wieso das? Wofür gibt es im Directory eine Dateilängenangabe? Die modulo 512 sagt Dir, wieviele Bytes im letzten genutzten Sektor der Datei noch nicht genutzt sind. Bedenke hierbei, daß FAT mehrere Sektoren zu Clustern ("Zuordnungseinheit") zusammenfasst und daß eine Datei immer eine ganzzahlige Anzahl von Clustern belegt. Auch eine Datei, in der nur ein einziges Byte belegt ist, belegt einen vollständigen Cluster, der wiederum mehrere Sektoren groß sein kann (Anzahl ist eine Zweierpotenz). Für Deine Dateiendebetrachtung musst Du also zuerst Dateigröße modulo Clustergröße anwenden, um herauszufinden, wo im Cluster die Datei endet. Diesen Wert musst Du nun noch durch die Anzahl der Sektoren pro Cluster teilen (hier kommen die oben erwähnten Zweierpotenzen sehr praktisch ins Spiel), um die Nummer des Sektors im Cluster zu erhalten, und dann kannst Du wie oben bereits beschrieben die Anzahl der genutzten Bytes in diesem Sektor ermitteln. Beim Beschreiben des letzten Sektors musst Du in der Tat den bisherigen Inhalt lesen, und an der korrekten Position die neuen Daten anhängen. Dadurch, daß Du durch die im Verzeichniseintrag gespeicherte Dateilänge kennst, kannst Du diese Position ja berechnen. Das musst Du sogar - wie wolltest Du bei einer Datei, die binären Krempel enthält, sonst ihr Ende bestimmen?
Rufus t. Firefly schrieb: > Du musst dort im Sektor weiterschreiben, wo die Datei vorher aufgehört > hat. Alles klar, danke! Rufus t. Firefly schrieb: > Wieso das? Wofür gibt es im Directory eine Dateilängenangabe? Die modulo > 512 sagt Dir, wieviele Bytes im letzten genutzten Sektor der Datei noch > nicht genutzt sind. Da hab ich mich etwas schlecht ausgedrückt. Ich hätte schon vorher mit modulo 512 überprüft, wieviele Bytes im letzten genutzten Sektor der Datei noch nicht genutzt sind. Ich wollte mir das komplette Lesen des letzten Sektors sparen, indem ich einfach nen neuen Sektor beschreibe. Das wäre glaub ich schneller gegangen und auf die paar ungenutzten Bytes wär es mir auch nicht angekommen. Rufus t. Firefly schrieb: > Bedenke hierbei, daß FAT mehrere Sektoren zu Clustern > ("Zuordnungseinheit") zusammenfasst und daß eine Datei immer eine > ganzzahlige Anzahl von Clustern belegt. > > Auch eine Datei, in der nur ein einziges Byte belegt ist, belegt einen > vollständigen Cluster, der wiederum mehrere Sektoren groß sein kann > (Anzahl ist eine Zweierpotenz). Das ist mir soweit klar. Einzig das "Anzahl ist eine Zweierpotenz" wusste ich bisher nicht. Rufus t. Firefly schrieb: > Für Deine Dateiendebetrachtung musst Du also zuerst Dateigröße modulo > Clustergröße anwenden, um herauszufinden, wo im Cluster die Datei endet. > > Diesen Wert musst Du nun noch durch die Anzahl der Sektoren pro Cluster > teilen (hier kommen die oben erwähnten Zweierpotenzen sehr praktisch ins > Spiel), um die Nummer des Sektors im Cluster zu erhalten, und dann > kannst Du wie oben bereits beschrieben die Anzahl der genutzten Bytes in > diesem Sektor ermitteln. Mit dieser Erklärung komme ich nicht ganz klar (ich hätte es nämlich etwas umständlicher berechnet). Mal angenommen wir haben eine Datei die 160000 Byte groß ist. Deine Berechnung hab ich so verstanden: Dateigröße % Clustergröße = Dateigröße % (Bytes_per_Sector * Sectors_per_Cluster) = 160000 % (512 * 16) = 4352 4352 / Sectors_per_Cluster = 4352 / 16 = 272 <-- was sagt dieser Wert(also die 272) jetzt eigentlich aus? Das kapier ich nicht ganz. Ich hätte es so berechnet: Dateigröße / Bytes_per_Sector = 160000 / 512 = 312,5 Sektoren (wird aufgerundet, da Sektoren immer ganzzahlig sind) Diese 313 Sektoren werden dann durch Sectors_per_Cluster dividiert, um die Anzahl der Cluster zu berechnen. --> 313 / 16 = 19 Cluster 19 Cluster * 16 (Sectors_per_Cluster) = 304 Sektoren 313 Sektoren - 304 Sektoren = 9.Sektor Das heißt das Dateiende liegt im letzten (19.) Cluster an der 9. Sektorposition. Die Byteposition innerhalb dieses Sektors würde ich mir dann mit Dateigröße % Bytes_per_Sector = 160000 % 512 = 256 berechnen. Bin mir aber nicht ganz sicher ob der Ansatz in der Praxis auch funktioniert bzw. ob das praktikabel ist.
Rufus t. Firefly schrieb: > Diesen Wert musst Du nun noch durch die Anzahl der Sektoren pro Cluster > teilen (hier kommen die oben erwähnten Zweierpotenzen sehr praktisch ins > Spiel), um die Nummer des Sektors im Cluster zu erhalten, und dann > kannst Du wie oben bereits beschrieben die Anzahl der genutzten Bytes in > diesem Sektor ermitteln. Da habe ich tatsächlich Unfug geschrieben. Richtig ist: Diesen Wert musst Du noch durch die Anzahl Bytes pro Sektor teilen ... [Nachtrag] Da die Sektorgröße selbst auch eine Zweierpotenz ist, wird das Teilen sehr einfach.
Rufus t. Firefly schrieb: > Richtig ist: > > Diesen Wert musst Du noch durch die Anzahl Bytes pro Sektor teilen ... Damit geht die Berechnung tatsächlich um einiges weniger umständlich. Vielen Dank! Rufus t. Firefly schrieb: > [Nachtrag] > Da die Sektorgröße selbst auch eine Zweierpotenz ist, wird das Teilen > sehr einfach. Aber man verwendet da weiterhin den Divisionsoperator, oder gibts da nen programmiertechnischen Kniff um den zu umgehen? Irgendwie liest sich dein abschließender Satz so, als wäre dem so...
Sofern der C-Compiler was taugt, muss man sich nicht darum kümmern, eine Alternative zum Divisionsoperator zu verwenden, jedenfalls nicht, wenn mit einer Konstanten als Divisor gearbeitet wird. Die Alternative ist eine Schiebeoperation: x = y >> 1; entspricht x = y / 2; und x = y >> 9; entspricht x = y / 512; Wie gesagt, wenn der Compiler auch nur halbwegs was taugt, dann macht der das bei konstanten Divisoren, die Zweierpotenzen sind, sowieso selbst.
Bernhard B. schrieb: > Aber man verwendet da weiterhin den Divisionsoperator, oder gibts da nen > programmiertechnischen Kniff um den zu umgehen? Irgendwie liest sich > dein abschließender Satz so, als wäre dem so... Normalerweise genau so mit Divisionsoperator. Man könnte auch den shift Operator nutzen, ist bei Zweierpotenzen schneller. Aber solange Du die Optimierungen im Compiler nicht abschaltest, ist der meist schlau genug daß auch selbst zu erkennen.
Wichtig ist dann aber mit unsigned werten (oder besser gleich den t_uint..) zu arbeiten, da für signed werte diese äquivalenz nicht gilt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.