Hi
Ich probiere zurzeit ein Schachengine zu programmieren.
Nachdem mein eigen geschriebener Algorithmus funktionierte (hab ich erst
später gemerkt das, dass ein minimax war), hab ich nach was besserem
gesucht, und hab den alpha beta gefunden. Leider funktioniert er nicht
ganz. Mein Programm zieht wirre Züge die nichts bringen. Der
Zuggenerator und die Bewertungfunktion funktioniert einwandfrei.
auf. Was ich genau bei alpha und beta einsetzen soll hab ich bisher noch
nicht verstanden, wie der Algorithmus funktioniert schon.
Move ist eine Klasse und hat die int Variablen To, From und Rating.
Das Prog hab ich mal im Anhang angehängt, dann sieht man was passiert.
Wenn man auf button1 drückt, zieht der Com einen Zug. Die checkbox
aktiviert das autom. ziehen nach dem eigenen Zug.
Samuel K. schrieb:> Das Prog hab ich mal im Anhang angehängt, dann sieht man was passiert
Und ich habe das mal gelöscht beovor hier wieder Paranoia ausbricht.
Bitte keine EXE anhängen, sondern lieber ein Compilierfähiges Program.
Samuel K. schrieb:> Was ich genau bei alpha und beta einsetzen soll hab ich bisher noch> nicht verstanden, wie der Algorithmus funktioniert schon
Schließt sich das nicht gegenseitig aus?
Samuel K. schrieb:> Der Zuggenerator und die Bewertungfunktion funktioniert einwandfrei
Meinst du oder hast du einen (Unit-)Test dafür geschrieben?
Läubi .. schrieb:> Meinst du oder hast du einen (Unit-)Test dafür geschrieben?
Nein, aber der Mnimax funktioniert auf akzeptabler Spielstärke.
Außerdem hab ich mein Projekt schon so oft debuggt, und dabei die
Funktionen getestet, das ist nicht der Fehler.
Läubi .. schrieb:> Schließt sich das nicht gegenseitig aus?
Naja vielleicht schon, ich bin mir nicht ganz sicher, aber damit
überhaupt etwas gefunden wird, sollte man einen niedriegen alpha nehmen,
und einen beta der darüberliegt.
Samuel K. schrieb:> gesucht, und hab den alpha beta gefunden. Leider funktioniert er nicht> ganz. Mein Programm zieht wirre Züge die nichts bringen.
Dann musst du rausfinden, warum.
Das nennt man dann debuggen.
Mach dich mit dem Gedanken vertraut, dass debuggen nicht nur bedeutet,
sich im Debugger in paar Variablen anzusehen.
Debuggen kann auch bedeuten:
File auf und dort zb eine Liste aller generierten Züge reinschreiben,
danach die relevanten Variablen mit ins File schreiben, damit man als
Programmierer nachvollziehen kann, wie genau es zur Entscheidung des
Programms gekommen ist, den Zug zu wählen, den es gewählt hat.
Bei derartigen Sachen ist es nicht ungewöhnlich, dass man sich
umfangreiche Debug-Dump-Funktionalität baut, die einem erlaubt den
Programmlauf im Nachhinein zu verfolgen und rauszufinden, was da
eigentlich passiert ist.
Mir kommt zb komisch vor, dass in deiner AlphaBeta Funktion zwar
innerhalb der for-Schleife ein return steht, aber niemals eine Zuweisung
an endmove erfolgt.
> Wenn man auf button1 drückt, zieht der Com einen Zug. Die checkbox> aktiviert das autom. ziehen nach dem eigenen Zug.
Schön.
Aber nutzlos.
Du betrachtest die Symptome. Da die Symptome aber aus einem komplexen
Zusammenspiel entstehen hilft es nichts. Du musst die Ursachen finden.
Und da man die in komplexen Systemen nur mehr sehr schwer erraten kann
(anders als bei 99% aller µC-Programme hier im Forum) musst du dir
Einblick verschaffen.
Auch das gehört dazu auf dem Weg zum Programmierer: Werkzeugbau. Sich
selbst die Werkzeuge zu bauen, mit denen man Sachverhalte rausfinden
kann.
Samuel K. schrieb:> Was ich genau bei alpha und beta einsetzen soll hab ich bisher noch> nicht verstanden
Beim Aufruf von AlphaBeta aus AB wird für alpha die schlechtest- und für
beta die bestmögliche Bewertung oder einfach eine riesige negative bzw.
positive Zahl übergeben.
Die Funktion Rate muss wissen, für welchen der beiden Spieler sie die
Stellung bewerten soll. Alternativ kann AlphaBeta in Abhängigkeit von
der aktuellen Rekursionstiefe (gerade oder ungerade) das Vorzeichen der
Bewertung umdrehen. Hast du das berücksichtigt? Wenn nicht, würde das
die wirren Züge erklären.
Ein Bericht über Debuggen brauche ich nicht. Ich weiß wie man debuggt,
ich hab es auch gemacht. Soll ich dann aufgeben, wenn ich es trotzdem
nicht zum laufen bekomme?
An das mit Rate hab ich wirklich nicht gedacht, danke. Rate gibt nämlich
einfach die Stellung zurück, und wenn Schwarz besser steht dann halt
negativ.
Das ist aber noch nicht alles, es zieht zwar anders, aber immer noch
schlecht,
endmove wird natürlich nur auf der ersten Ebene gesetzt, da ich ja den
ersten Zug der besten Variante möchte, nicht den fünften.
Samuel K. schrieb:> Ein Bericht über Debuggen brauche ich nicht.
Anscheinend doch
> Ich weiß wie man debuggt,> ich hab es auch gemacht.
Ach.
Ich seh in deinem Code keine einzige Ausgabe zwischendurch aus der sich
erschliessen würde:
welche Züge sind in der Zugliste
welche Bewertung hat jeder Zug
wie wirkt sich das auf Alpha bzw Beta aus
warum wird genau der Zug ausgewählt, der laut deiner Aussage 'wirr'
ist.
Keine einzige Ausgabe, mit der das auch nur annähernd nachzuvollziehen
wäre.
In einer Ausgabe in Tabellenform, in der alle Züge aufgefürt wären,
eingerückt ja nach Aufruftiefe, zusammen mit ihrem Rating würde man das
schön sehen.
Dauer der Implementierung: vielleicht 10 Minuten
Statt dessen lametierst du da jetzt schon mehr als 1 Tag rum. Das nenn
ich keineswegs effizientes Arbeiten.
> Soll ich dann aufgeben, wenn ich es trotzdem> nicht zum laufen bekomme?
Nein.
Du sollst deine Debugging Werkzeuge verbessern. Wenn du es nicht zum
Laufen bekommst heißt das, das du (noch) nicht genau verstehst, was im
Programm vor sich geht. Wie behebt man das? Indem man seine Debug
Werkzeuge darauf abstimmen, dass sich dieses Verständnis verbessert.
Und nein.
wenn du darauf vertraust, du könnest das alles mit dem integrierten
Debugger erledigen, dann sei versichert: bei rekursiven Funktionen wirst
du damit ganz schnell Schiffbruch erleiden. Warum? Weil man den
Überblick verliert, auf Grund welcher Kriterien die Funktion rekursiv
einsteigt und wie dann die Parameter sind; wieviele Aufrufhierarchien
auf ihren return warten und was mit dem return-Wert passiert bzw. welche
Aufrufstufe den jetzt wie weiterverarbeitet.
Samuel K. schrieb:> Ich weiß wie man debuggt, ich hab es auch gemacht.
Wenn man's genau nimmt, hast du das nicht getan, sonst wäre der Code
jetzt debugged, also die Bugs beseitigt ;-)
Und hättest du dir die Tipps von Karl Heinz zu Herzen genommen, hättest
du schon längst den Suchbaum (einer einfachen Stellung, damit er nicht
zu groß wird) mit den Knotenbewertungen in eine Datei schreiben lassen
und von Hand überprüft. Da du ja nach eigenen Angaben den Algorithmus
verstanden hast, hättest du damit ziemlich genau die Stelle im Programm
gefunden, an der es sich falsch verhält.
Hast du meinen anderen Hinweis bzgl. der Anfangswerte für alpha und beta
befolgt? Wenn du mit beliebigen Werten wie hier
1
AlphaBeta(depth,-2,10);
startest, wird die Suche zu stark eingeschränkt, und du bekommst
entweder falsche oder überhaupt keine Ergebnisse.
En passant, Rochade und Promotion fehlen übrigens auch noch ;-)
Yalu X. schrieb:> Und hättest du dir die Tipps von Karl Heinz zu Herzen genommen, hättest> du schon längst den Suchbaum (einer einfachen Stellung, damit er nicht> zu groß wird) mit den Knotenbewertungen in eine Datei schreiben lassen> und von Hand überprüft.
Wobei ich bei einem Schachprogramm sogar sagen würde:
Da lohnt es sich schon, den Suchbaum ein wenig ansprechend in einem
Fenster darzustellen. Komplett mit Bewertung aller Teilzüge aller
Zwischenebenen. In einem Tree-Widget, damit man einzelne Ebenen gezielt
ein und ausblenden kann. Wenn man dann den Baum auch noch drucken bzw.
in ein File speichern kann (zwecks Vergleich verschiedener
Programmversionen auf Unterschiede, wie sich zb eine andere
Bewertungsfunktion auswirkt) - noch besser.
Braucht man während der Entwicklung laufend, daher sollte man sich
dieses Debug-Werkzeug so komfortabel wie möglich machen. Als Entwickler
will ich nach einem Zug des Programms nachvollziehen können: Welche Züge
wurden untersucht, welches Rating hat jeder bekommen. Natürlich rekursiv
rein (also als Baum und nicht als Liste), so wie auch das Programm den
Suchraum absucht.
Welche anderen Informationen während der Zugsuche noch relevant sind,
kann man dann bei Bedarf immer noch entscheiden. Aber so eine
Baumdarstellung als Minimalversion als Debugging Werkzeug ... ohne würde
ich ein Schachprogramm gar nicht anfangen.
Ich hab auch nur die wichtgen Routinen gepostet. Meine ganze Chessklasse
hat inzwischen über 5 verschiedene Rechenalgorithmen die alle noch
andere verschiedene Methoden nutzen. Deswegen hab ich nur den
relevanten Code rauskopiert. Normalerweise packe ich ja auch nicht den
ganzen Code in Program.cs wie oben.
Yalu X. schrieb:> En passant, Rochade und Promotion fehlen übrigens auch noch ;-)
Weiß ich, wollte ich aber erst machen wenn der Rest Stimmt.
Was ist Promotion? Meinst du damit die Umwandlung?
Es fehlt noch die Matterkennung. außerdem muss ich noch Schach
implementieren. Der König ist zwar am meisten Wert, aber mit dem
Minimax-Engine, hat der eine den einen König angegriffen und der andere
hat den andern König auch angegriffen ;)
Ok, das mit der treeview müsste ich in 10 minuten haben.
Ich hab um es zu vereinfachen, mal eine Minimax mit alphabeta
algorithmus genommen.
Zufällig hab ich grad das Dateiding gemacht. Aber das bringt echt
nichts, das ist zu unübersichtlich.
Samuel K. schrieb:> Ok, das mit der treeview müsste ich in 10 minuten haben.
Gut.
Der wird dir noch gute Dienste leisten.
> Zufällig hab ich grad das Dateiding gemacht. Aber das bringt echt> nichts, das ist zu unübersichtlich.
Da könnte man sicherlich noch daran arbeiten.
Gerade bei rekursiven Sachen ist zb eine Einrückung je nach
Rekursionstiefe wichtig. Auf der anderen Seite möchte man dann aber
Kennzahlen nicht eingerückt sondern untereinander stehen haben. Von
daher kann das dann schon aufwändig werden, damit man da eine saubere
Form, mit der man auch etwas anfangen kann, reinkriegt.
a7-a6
a2-a3 +5000
a6-a5 -500
b7-b6 -800
b7-b5 -500
a2-a4 +6000
....
so sieht man dann auch welche (weiße) Züge als Antwort auf den
untersuchten (schwarzen) Zug betrachtet wurden und wie sie bewertet
wurden. Und damit kann man dann analysieren anfangen. Wie hat sich die
Bewertung +5000 bei a2-a3 ergeben? Aufgrund welches schwarzen Zugs (und
eventueller Zusatzinfo, die man in in derselben Zeile dazuschreibt) ist
es dazu gekommen. Wie war die Materialbewertung an dieser Stelle. Was
waren die anderen Bewertungskriterien an dieser Stelle
(Zentrumskontrolle bzw. was du dann sonst noch so in deiner Bewertung
drinnen hast)
Klar wird der Baum immens groß, sobald mehrere Suchtiefen im Spiel sind.
Aber genau das ist es ja, was beim Schach ein nicht unwesentliches
Problem (zumindest bei den heutigen Schachprogrammen) ausmacht.
Das könnte dann aber auch tatsächlich ein Problem darstellen: Der Baum
wird (bei genügend hoher Suchtiefe) so groß, das er den Speicher im
TreeView sprengt.
Samuel K. schrieb:> Weiß ich, wollte ich aber erst machen wenn der Rest Stimmt.> Was ist Promotion? Meinst du damit die Umwandlung?> Es fehlt noch die Matterkennung. außerdem muss ich noch Schach> implementieren. Der König ist zwar am meisten Wert, aber mit dem> Minimax-Engine, hat der eine den einen König angegriffen und der andere> hat den andern König auch angegriffen ;)
Dann stimmt an deinen Material-Bewertungsfunktionen etwas nicht.
Ein im Schach stehender König liefert so viele Minuspunkte, das
praktisch jeder Zug, der den König aus dem Schach herausbringt jedem
anderen Zug der dies nicht tut, der Vorzug gegeben wird. Gibt es keinen
derartigen Zug mehr, dann wird bei der Zugbewertung noch einmal ein
ordentlicher Malus draufgeschlagen, denn dann steht der König matt und
daher sollte dieser Teil des Zugbaums gar nicht betreten werden.
Karl heinz Buchegger schrieb:> Der König ist zwar am meisten Wert, aber mit dem>> Minimax-Engine, hat der eine den einen König angegriffen und der andere>> hat den andern König auch angegriffen ;)>> Dann stimmt an deinen Bewertungsfunktionen etwas nicht.
Die Bewertungsfunktion stimmt wahrscheinlich schon, aber man muss noch
weitere Dinge berücksichtigen:
Im Fall eines "geschlagenen" Königs muss die Suche in dem betreffenden
Suchzweig sofort abgebrochen werden, sonst kann es passieren, dass in
der betrachteten Zugfolge nacheinander beide Könige geschlagen werden,
was fälschlicherweise zu einer ausgeglichenen Bewertung führt.
Das Gleiche gilt für Mattsituationen. Wird ein Spieler mattgesetzt, ist
das Spiel verloren, auch dann, wenn er den Gegner im nächsten Zug selber
mattsetzen könnte.
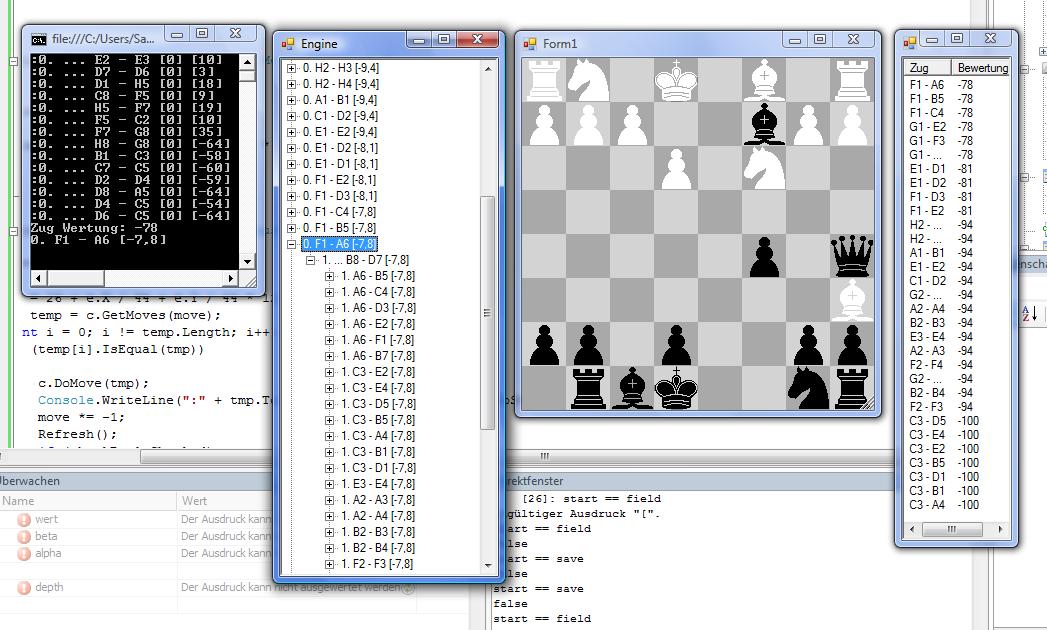
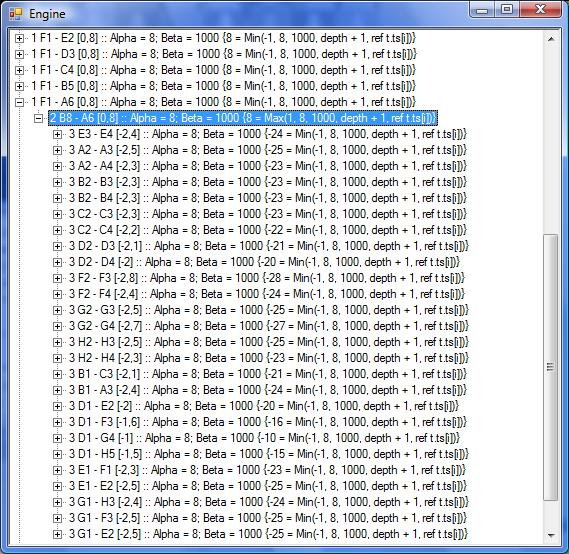
Im angehängten Bild sieht man, dass der Algo die wichtigen Zügen einfach
auslässt! Er realisiert gar nicht, dass man den Läufer einfach schlagen
kann. Ich hab da einfach ein paar züge gemacht und ihn dann mal ziehen
lassen. Hab ich da vielleicht irgendwas verwechselt? Irgendwie hört er
zu früh auf.
Aus deinem Baum sieht man eigentlich auch, dass nur die einzige
Alternative
B8-D7 durchgerechnet wird. Deren Bewertung ist offenbar so, dass du hier
if (wert <= alpha)
return alpha;
bzw. hier
if (wert >= beta)
return beta;
vorzeitig aus den Funktionen aussteigst. Zusätzlich dürfte es da eine
Interaktion mit den jeweilige Programmteilen
if (wert < beta)
beta = wert;
bzw.
if (wert > alpha)
alpha = wert;
geben, die ja dem jeweiligen Partner ein anderes Alpha bzw. Beta
vorgeben.
Lass dir doch bei jedem Move zzusätzlich noch den aktuellen Alpha bzw.
Beta Wert mit wegspeichern und zeig dir die mal an.
PS: color
Was ist bei dir weiß? -1 oder 1
(Oder anders gefragt: Womit gehts los, wenn der Rechner am Zug ist? Mit
Min oder mit Max?)
Mit deinen depth Werten scheint auch irgendwas nicht zu stimmen. Sollte
die 2.te Einrückebene nicht vorne eine 2. stehen haben?
Oder aber dein Zuggenerator versagt bei einer Farbe aus irgendeinem
Grund.
-1 .. +1
mit
0 .. 1
verwechselt?
Edit: Nein, bei Drüberscrollen sieht das gut aus.
Weiß ist 1 und Schwarz ist -1, ist zur vereinfachung, der minimax
routine so.
Danke, beim Zähler hab ich was vergessen.
EDIT: Ich habe eine was gefunden: Ab dem von dem ... 1. auf den 2. Zug
ändert sich die Wertung, irgendwie wird die nachträglich Wertung nicht
übernommen. Außerdem Beta wird nie gesetzt.
Nochmal den aktuellen Code bitte.
Da stimmt was nicht.
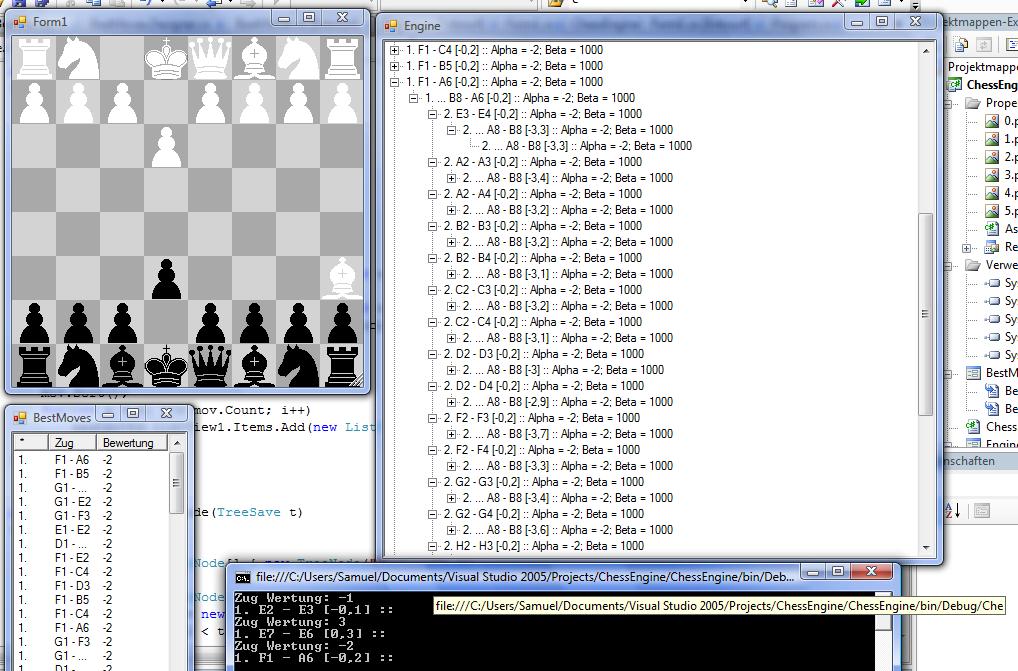
alpha beginnt mit -1000. d.h. im Baum müssten beim ersten Teilbaum ganz
am Blatt (bei B8-A6 E3-E4 A8-B8) die -1000 auftauchen.
Deine Tiefennummerierung stimmt immer noch nicht und warum zb das Blatt
A8-B8 ineinandergeschachtelt doppelt auftaucht, dem solltest du auch
nachgehen.
Lass es fürs erste bei einer maximalen Zugtiefe von 2 bewenden. Sonst
hast du so viele Daten zu analysieren.
Wenn das System den Schwarzen Zug sucht, welches ist dann die
Einstiegsfunktion: Max oder Min?
Hmm
Ich denke du beschickst in Move_AB die Min bzw. Max Funktionen mit
falschen Werten
if (color == 1)
wert = Max(color, -1000, 1000, 0, ref ts);
else
wert = Min(color, 1000, -1000, 0, ref ts);
Angenommen der erste Aufruf wäre zu Min und maxdepth wäre 1
dann ist in Min alpha gleich 1000
In Min wird die Zugliste generiert und für jeden Zug wird Max
aufgerufen. Da maxdepth erreicht ist, berechnet Max einfach nur die
Wertung und gibt die zurück. So eine Wertung ist zb -37
Jetzt kommt in Min die Abfrage
if (wert <= alpha)
return alpha;
alpha war 1000 und wert war -37. Der Vergleich ist true und du steigst
aus der Funktion aus.
if (color == 1)
wert = Max(color, -1000, 1000, 0, ref ts);
else
wert = Min(color, -1000, 1000, 0, ref ts);
Nichts desto trotz ist deine Baumausgabe noch fehlerhaft. Schau sie dir
genau an und korrigiere sie.
Hmmm.
Sieht ok aus.
Und trotzdem sind die Werte im Baum seltsam.
Geh im Debugger mal Single-Step mässig beginnend bei Move_AB den Code
durch und sieh nach, wie es dazu kommt, das alpha an dieser Stelle
gleich -2 ist. Das ist für mich momentan nicht erklärbar.
Karl heinz Buchegger schrieb:> alpha beginnt mit -1000. d.h. im Baum müssten beim ersten Teilbaum ganz> am Blatt (bei B8-A6 E3-E4 A8-B8) die -1000 auftauchen.
In der aktuellen Verion tut es das.
> Deine Tiefennummerierung stimmt immer noch nicht und warum zb das Blatt> A8-B8 ineinandergeschachtelt doppelt auftaucht, dem solltest du auch> nachgehen.
Die Tiefe wird wie im Schach angezeigt, d. h. ein Zug ist vorbei wenn
beide gezogen haben:
1. e2e4
1. ... e7e5
2. f2f4
2. ... d7d5
Ich hoffe das stört dich nicht.
> Lass es fürs erste bei einer maximalen Zugtiefe von 2 bewenden. Sonst> hast du so viele Daten zu analysieren.
Werd ich mal machen.
> Wenn das System den Schwarzen Zug sucht, welches ist dann die> Einstiegsfunktion: Max oder Min?
Das hab ich gerade korrigiert. Ich multipliziere nun Rate mit
startcolor. Dann kann ich alles mit der selben funktion aufrufen.
Karl heinz Buchegger schrieb:> Geh im Debugger mal Single-Step mässig beginnend bei Move_AB den Code> durch und sieh nach, wie es dazu kommt, das alpha an dieser Stelle> gleich -2 ist. Das ist für mich momentan nicht erklärbar.
Kann ich dir vielleicht gleich beantworten. Das ganz oben ist nicht der
erste Eintrag der Liste, sondern der 25.
Samuel K. schrieb:> Karl heinz Buchegger schrieb:>> alpha beginnt mit -1000. d.h. im Baum müssten beim ersten Teilbaum ganz>> am Blatt (bei B8-A6 E3-E4 A8-B8) die -1000 auftauchen.>> In der aktuellen Verion tut es das.
Gut
>> Deine Tiefennummerierung stimmt immer noch nicht und warum zb das Blatt>> A8-B8 ineinandergeschachtelt doppelt auftaucht, dem solltest du auch>> nachgehen.>> Die Tiefe wird wie im Schach angezeigt, d. h. ein Zug ist vorbei wenn> beide gezogen haben:> 1. e2e4> 1. ... e7e5> 2. f2f4> 2. ... d7d5>> Ich hoffe das stört dich nicht.
Mich nicht. Aber dich wird es irgendwann stören.
In der Baumanzeige willst du die Dinge so haben, wie sie intern
ablaufen. Das ist dein Fenster zu dem was das Programm errechnet.
Benutzerinterface Dinge eines Schachspielers interessieren hier wenig.
Hier geht es darum möglichst gut nachzuvollziehen, welche Wege dein
Programmlauf genommen hat. Und deshalb ist es auch nicht sehr glücklich,
dass du die Wetrung einmal mit Kommazahl / 10 anzeigst und einmal als
Integer. Mir ist das egal, du musst damit klarkommen. Und mit du ist der
Programmentwickler 'du' gemeint und nicht der Schachspieler 'du'.
die geraden Tiefennummern sind die Züge von (schwarz) die ungeraden die
von (weiß) [oder umgekehrt]. Dann braucht man auch nicht lange
nachdenken ob an dieser Stelle im Baum der Max oder der Min die Subdaten
zusammengefasst hat und ob in der Ebene darüber sich jetzt das Alpha
oder das Beta verändern müsste und wonach man die Liste absuchen muss,
wenn man festellen will, warum ein bestimmter Zug jetzt in der
Baumhierarchie mittendrinn nicht genommen wurde.
Aber wie gesagt: Mir ist das egal. Ich muss das Ding ja nicht debuggen
bzw. mich später mit Bewertungsfunktionen und deren Werten und deren
Auswirkungen auf den Baum herumschlagen.
> Werd ich mal machen.>>> Wenn das System den Schwarzen Zug sucht, welches ist dann die>> Einstiegsfunktion: Max oder Min?>> Das hab ich gerade korrigiert. Ich multipliziere nun Rate mit> startcolor. Dann kann ich alles mit der selben funktion aufrufen.
Es muss aufjedenfall etwas kaputt sein mit der Seite von der Aus
Berechnet wird, denn:
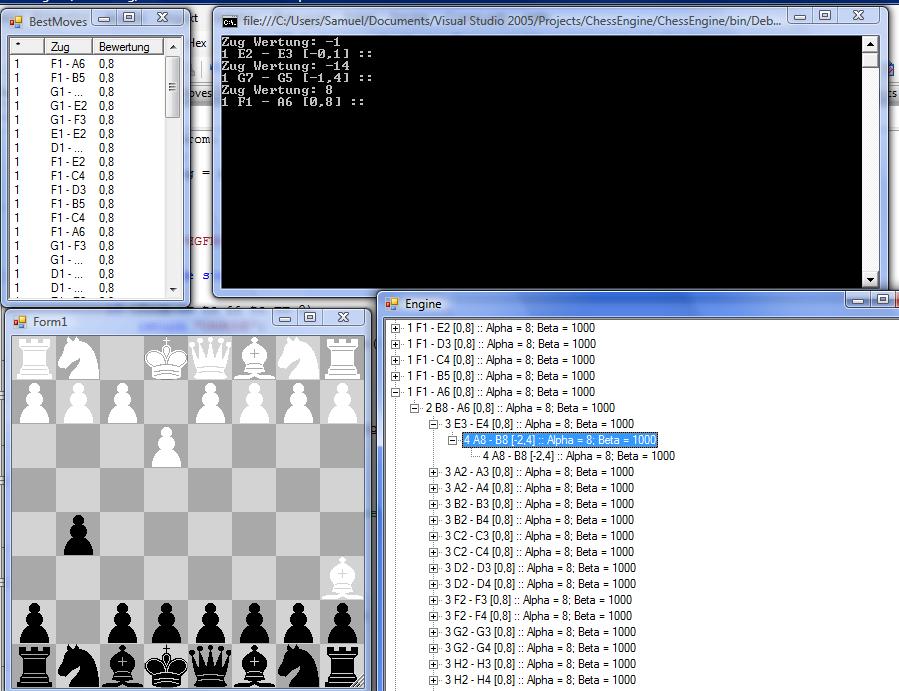
Wenn Weiß den Läufer (Anhang) auf h6 zieht, sieht man trotzdem in der
Liste das Weiß allerdings realisiert, dass er sofort geschagen wird. Der
einzigste Zug, alle anderen werden nämlich abgeschnitten. Wenn man nun
eine Ebene weiter geht, sieht man sofort wie die Bewertung runter geht,
aber sie geht nicht (wie sie sollte nach ganz unten).
Allerdings schlägt schwarz nicht (selbes Problem). Die Wertung wird
nicht richtig weitergeleitet.
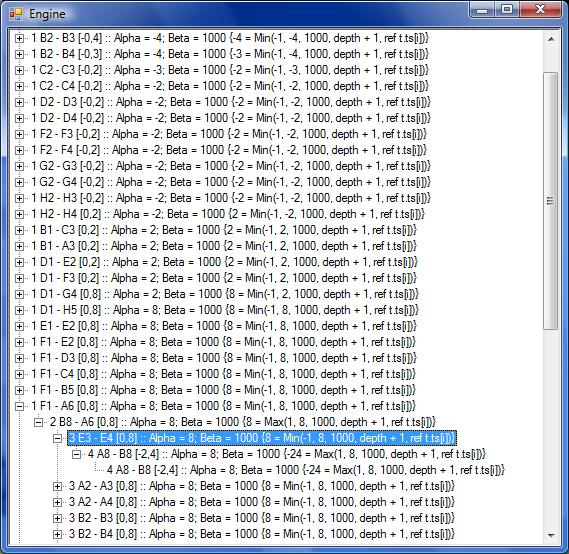
Hier sieht man jetzt genau, dass alpha zu schnell zu groß wird. Da Alpha
8 ist lässt es einen Wert kleiner als 8 nicht zu. Also wird statt 24 8
zurückgegeben und die Wertung ist kaputt. Allerdings wird in das so in
allen Quellen, die ich gesehen habe so gemacht.
Im Algorithmus sind (mindestens) zwei Fehler.
Den einen hat Karl Heinz schon genannt: Die Startwerte für alpha und
beta müssen alpha = -1000 und beta = 1000 sein, egal ob Min oder Max als
erstes aufgerufen wird. Also:
Der andere liegt in den Funktion Min: Liefert hier der Aufruf von Max
einen Wert schlechter als alpha, ist es zwar richtig, dass dann der Rest
des Unterbaums nicht mehr untersucht werden muss. Der Wert dieses
Unterbaums ist aber nicht alpha, sondern bestenfalls der gerade
gefundenen schlechtere Wert. Also sollte dieser Wert anstelle von alpha
zurückgegeben werden:
1
if(wert<=alpha)
2
// return alpha; // falsch
3
returnwert;// richtig
Entsprechendes muss auch in der Funktion Max korrigiert werden:
1
if(wert>=beta)
2
// return beta; // falsch
3
returnwert;// richtig
Übrigens kannst du dir das color-Argument in Min und Max sparen, da Min
immer mit -1 und Max immer mit +1 aufgerufen wird.
Ich hoffe, ich habe jetzt zu späterer Stunde und nach dem Genuss von
vergorener Gerste keinen Müll geschrieben ;-)
Yalu X. schrieb:> Der andere liegt in den Funktion Min: Liefert hier der Aufruf von Max> einen Wert schlechter als alpha, ist es zwar richtig, dass dann der Rest> des Unterbaums nicht mehr untersucht werden muss. Der Wert dieses> Unterbaums ist aber nicht alpha, sondern bestenfalls der gerade> gefundenen schlechtere Wert. Also sollte dieser Wert zurückgegeben> werden:
Das hab ich auch schon probiert gehabt, aber das ist dasselbe in grün.
Wenn ich das so ändere wie du es sagst, zieht schwarz von rechts unten
immer den ersten Zug der möglich ist. Also Springer raus und dann mit
dem Turm pendeln.
Das Color Argument kann ich mir leider nichtsparen, da ich sonst der
Zuggenerator sonst nicht weiß für wen er die Züge generieren soll.
> Das hab ich auch schon probiert gehabt, aber das ist dasselbe in grün.
Stimmt, da liegt wohl noch mehr im Argen.
Wenn in der Max-Funktion alpha nicht erhöht wird, weil alle untersuchten
Züge schlechter als alpha sind, sollte nicht alpha, sondern ein
beliebiger Wert kleiner als alpha zurückgegeben werden (bspw. alpha-1
oder -1000). Wie wär's damit:
In Min:
1
boolbetachanged=false;
2
//...
3
if(wert<=alpha)
4
returnwert;
5
if(wert<beta)
6
{
7
beta=wert;
8
betachanged=true;
9
}
10
}
11
12
returnbetachanged?beta:1000;
In Max:
1
boolalphachanged=false;
2
//...
3
if(wert>=beta)
4
returnwert;
5
if(wert>alpha)
6
{
7
alpha=wert;
8
alphachanged=true;
9
}
10
}
11
returnalphachanged?alpha:-1000;
Wenn das immer noch nicht geht, geb ich's für heute auf :)
Ich habe vor Urzeiten auch einmal ein Schachprogramm geschrieben. Es hat
zwar schlecht gespielt, aber zumindest das von dir beschriebene Problem
trat nicht auf. Wenn ich irgendwo noch den Quellcode finde, sag ich dir,
wie ich das Alpha-Beta damals implementiert habe.
> Das Color Argument kann ich mir leider nichtsparen, da ich sonst der> Zuggenerator sonst nicht weiß für wen er die Züge generieren soll.
Der Zuggenerator (GetMoves) wird aus Min immer mit color=-1 und aus Max
immer mit color=1 aufgerufen. Du kannst also diese Werte als Konstanten
übergeben.
Ich habe den Quellcode meines Schachprogramms wiedergefunden und die
Alpha-Beta-Suche auf das Wesentliche zusammengestaucht, da in den
Algorithmus noch etliche Optimierungen und die Sonderbehandlung von
Schachsituationen eingeflochten waren, die das Ganze etwas unübersicht-
lich machten (die Originalfunktion ist knapp 200 Zeilen lang). Folgendes
ist übrig geblieben:
if(suchtiefe_erreicht(zug))// Die Suchtiefe wird dynamisch festgelegt
11
erg=stellungsbewertung();
12
else{
13
zug_vor(zug);
14
erg=-such_zug(-beta,-alpha,tiefe+1,stufe);
15
zug_zurueck();
16
}
17
if(erg>alpha){
18
maxerg=erg;
19
alpha=erg;
20
if(maxerg>=beta)
21
break;
22
}
23
zug++;
24
}
25
returnmaxerg;
26
}
Auf den ersten Blick würde ich sagen, dass der Algorithmus deinem mit
den in meinem letzten Beitrag geposteten Änderungen entspricht, aller-
dings sind Min und Max wie in deinem ersten Beitrag in einer Funktion
zusammengefasst.
Statt der booleschen Variablen alphachanged und betachanged in meinem
letzten Beitrag gibt es die Variable maxerg, die den gleichen Wert wie
alpha hat, wenn ein Zug mit einer Bewertung geößer als alpha gefunden
wurde. Wurde kein solcher Zug gefunden, ist maxerg = -20000. Die
Funktion gibt nicht alpha, sondern maxerg zurück, was ähnlich wie die
Version mit den booleschen Variablen dein Problem beheben sollte.
Auch beim Abbruch der Schleife (maxerg > beta) wird maxerg zurückgegeben
(und nicht beta).
Samuel K. schrieb:> Es muss aufjedenfall etwas kaputt sein mit der Seite von der Aus> Berechnet wird, denn:>> Wenn Weiß den Läufer (Anhang) auf h6 zieht, sieht man trotzdem in der> Liste das Weiß allerdings realisiert, dass er sofort geschagen wird.
Aber nur über einen Umweg.
Dadurch dass in der enstehenden Stellung der Läufer nicht mehr vorhanden
ist, ist der reine Materialwert der enstehenden Stellung etwas geringer.
Dein Verfahren hat gar nicht realisiert, dass da eine Figur geschlagen
wird, sondern dass der Materialwert in der enstehenden Stellung ein
wenig geringer ist.
Wenn du in die Bewertungsfunktion einbaust, dass ein Bauer der eine
höherwertige Figur schlagen kann, einen Bonus bekommt, dann wird dieser
Zug dann auch ausgewählt werden (wenn die Bewertung richtig den Baumast
hochläuft). Genauso auch umgekehrt: Wird eine Figur bedroht, so bekommt
sie einen Malus. Ist eine Figur von einer anderen gedeckt, so dass sie
nicht straffrei geschlagen werden kann, so bekommt sie wieder einen
Bonus. usw. usw.
Und damit sind wir dann in der Welt der Schachprogrammierung. Klar ist
diese ganze Baumsucherei wichtig, damit man möglichst viele Stellungen
untersuchen kann. Aber die Stärke eines Schachprogramms liegt in den
Bewertungsfunktionen, die eine entstehende Stellung beurteilen.
Du erwartest momentan viel zu viel von deiner Minimal-Bewertung. Die ist
noch lange nicht geeignet um damit ein sinnvolles Schachspiel machen zu
können.
Alpha-Beta ist nur eine Methode aus der Wust der Züge anhand der
jeweiligen Bewertung einen guten rauszusuchen. Aber die Güte der Züge
steckt in der Bewertungsfunktion und nicht im Alpha-Beta
Daher hat es auch keinen Sinn, wenn du momentan dem Programm wie ein
Schachspieler auf die Finger schaust. Du musst wie ein Programmierer
arbeiten: Werden die entstehenden Informationen korrekt weitergegeben,
werden Minima, Maxima korrekt berechnet. Wandert die Information korekt
den Baum hinauf.
Das sind die Dinge, auf die du jetzt dein Augenmerk richten musst, egal
ob der Zug jetzt sinnvoll ist oder nicht. Es geht um die reine
Datenverarbeitung.
Die Züge sinnvoll und spielstark zu machen, kommt dann später. Dazu muss
die Baumbearbeitung schon korrekt funktionieren. Versuchst du dich um
alles gleichzeitig zu kümmern, dann verzettelst du dich. Man kann
natürlich Dinge, die einem jetzt auffallen in die Bewertungsfunktion mit
einbauen solange sie relativ trivial machbar sind. Aber sonderlich
großes Augenmerk würde ich da jetzt noch nicht drauf legen.
> Der> einzigste Zug, alle anderen werden nämlich abgeschnitten. Wenn man nun> eine Ebene weiter geht, sieht man sofort wie die Bewertung runter geht,> aber sie geht nicht (wie sie sollte nach ganz unten).
Dann musst du etwas dagegen tun.
Um die Bumfunktionen zu testen und zu debuggen würde ich auch hergehen
und den Zuggenerator modifizieren, so dass der nicht mehr alle Züge
liefert sondern nur eine Handvoll. Zb von jeder Figur nur einen
möglichen Zug und nicht alle. Sinn der Sache ist es, die Datenwust
während des Debuggings zu drücken um nicht in einem Meer von
Bewertungen, Alphas und Betas zu stehen und nicht zu wissen: wo
anfangen.
Wenn die Werte sauber den Baum hinauf wandern kann man ja diese
Beschränkung wieder aufheben, aber wenn es nur darum geht zu überprüfen
ob die Bewertungen korrekt miteinander verrechnet werden, geht das
genausogut mit einer eingeschränkten Zugliste.
Wieder: Jetzt ist Arbeiten an der Datenverarbeitung angesagt. Ob das was
da rauskommt schachtechnisch gesehen Sinn macht, steht auf einem ganz
anderen Blatt. Darum gehts noch gar nicht (oder nur sehr eingeschränkt)
Yalu X. schrieb:> immer mit color=1 aufgerufen
Ich hab zwar nicht so die Ahnung von Schachprogrammen, hatte nurmal so
ein Uraltes Ding für MS-DOS was mich immer besiegt hat, aber aus
Programmierersicht würde ich auch ganz dringen einfach mal eine
Konstante für den "magischen Wert 1" einsetzen ;)
Ansonsten ist es wie Karl heinz Buchegger schreibt, "sinnvoll" gibt es
für ein Programm nicht.
So ein Problem ist doch optimal für einen Unit-Test geeigent. Lege dir
eine Menge von Eingabewerten fest, und definiere die erwarteten
Ausgabewerte.
Das muss durchlaufen ohne Fehler! Und zwar für jede Funktion unabhängig.
Dann kannst du immer weiter "nach oben" gehen.
Und wenn das alles klappt... ja dann kannst du das ganze mal in der GUI
spielen...
Läubi .. schrieb:> Ansonsten ist es wie Karl heinz Buchegger schreibt, "sinnvoll" gibt es> für ein Programm nicht.
Das ganze ist ja im jetzigen Stadium ein Informationstheoretisches
Problem
Man hat einen Baum
o
|
+----------+------------+----------+
| | | |
o o o o
| | | |
+-------+ +-------+ +-------+ +--------+
| | | | | | | |
o o o o o o o o
| | | | | | | |
+--+ +--+ +---+ +---+ +----+ +--+ +---+ +---+---+
| | | | | | | | | | | | | | | | |
o o o o o o o o o o o o o o o o o
Jeder o steht für eine Stellung.
An den unteren Enden des Baumes, den Blättern, werden Werte eingesetzt.
Diese Werte werden dann den Baum hoch verarbeitet und miteinander
verrechnet (Minum/Maximum einer jeden Ebene geht eine Stufe höher). Hat
man das für alle Zweige gemacht, dann sucht man sich aus der 2. Ebene
den mit der Maximalbewertung raus und das ist dann der Zug der gemacht
wird.
Das ist reine Datenverarbeitung und hat mit Schach erst mal nicht das
geringste zu tun.
Das Problem das man hat ist, das der Baum extrem schnell extrem breit
wird. Daher sucht man nach cleveren Strategien, wie man möglichst
schnell entscheiden kann, dass ein Teilbaum gar nicht bis zu seiner
vollen Tiefe aufgespannt werden muss, sondern dass man vorzeitig
abbrechen kann. Und da kommt dann Alpha/Beta ins Spiel.
Alpha/Beta ist eine Technik mit der der Baum zurechtgestutzt wird. Mit
Spiellogik oder dergleichen hat das überhaupt nichts zu tun. Es geht
einzig und alleine, aus dem Baum möglichst viele Teiläste von vorne
herein auszuschliessen.
Daher ist auch das Betrachten, ob ein Spielzug sinnvoll ist oder nicht,
zum jetzigen Zeitpunkt völlig uninteressant. Es geht einzig und alleine
darum: An den Blättern werden Werte injeziert, wandern die den Baum
korrekt hoch, bzw. wird der entsprechende Teilbaum bei den richtigen
Kriterien (wiederrum erkennbar an den Kennzahlen der Werte und dem
jeweiligen Alpha bzw. Beta) vorzeitig richtig abgebrochen.
Ob die Kennzahlen (=die Bewertung) an sich Sinn macht oder nicht, ob die
gut sind oder nicht - das ist zum jetzigen Zeitpunkt nicht das Thema.
> So ein Problem ist doch optimal für einen Unit-Test geeigent. Lege dir> eine Menge von Eingabewerten fest, und definiere die erwarteten> Ausgabewerte.
Jau.
Reproduzierbarkeit (und zwar einfach erreichbar) ist oberstes Gebot in
der Debugphase.
Samuel mag ein guter Schachspieler sein, das weiß ich nicht - will ich
auch gar nicht wissen. Aber zum jetzigen Zeitpunkt ist er zuviel
Schachspieler und zu wenig Softwareentwickler. Er achtet auf die
falschen Dinge. Wenn da ein Turm pendelt, dann mag das zwar die
Horrorvorstellung für einen Schachspieler sein, für einen Programmierer
bedeutet das aber nur: Handelt es sich dabei um einen Programmfehler,
wird irgenetwas falsch zusammengezählt, oder geben die momentan unten im
Baum injezierten Werte einfach nicht mehr her. Wenn sich aus den Werten
unten an den Blättern dieses Verhalten ergibt und eine Analyse zeigt,
dass diese Werte korrekt den Baum hochwandern und sich daraus dann eben
ergibt, dass der Turm pendelt, dann ist das eben so. Aus Sicht des
Programmierers.
Das ein Alpha/Beta Programm einem Minimum/Maximum Programm überlegen
ist, hängt ja nicht damit zusammen, dass Alpha/Beta dem Programm
besondere Intelligenz einhaucht. Die höhere Spielstärke resultiert
daraus, dass mehr Teilbäume von vorneherein gar nicht abgeklappert
werden, und daher Rechenzeit frei wird, mit der man die restlichen
Teilbäume tiefer absuchen kann. Das ist im Großen und Ganzen das ganze
Geheimnis von Alpha/Beta, der einzige Zwecke warum es geht: Teilbäume
vorzeitig ausschliessen. Und ob das korrekt funktioniert kann ich nicht
daran festmachen, ob zu guter letzt der (meiner Meinung nach) richtige
Zug ausgewählt wird, sondern nur daran, indem ich mir die Zahlen ansehe
und zwar vom ganzen Baum und entscheide ob sich die Werte der höheren
Baumebene korrekt aus den Werten der eine Stufe tiefer liegenden
Baumebene ergibt.
Und daher braucht man auch eine derartige Ausgabe zu Debugzwecken, damit
man den Baum als ganzes überblicken kann. Wenn dann zuätzlich das
Programm auch noch in einer Datei mitprotokolliert, in welcher
Reihenfolge sich welche Werte ergeben haben, welche Teilbäume aus
welchem Grund abgebrochen wurden, wie und aus welchem Grund sich die
Werte für Alpha und Beta verändert haben, ist man schon fast am Optimum
dessen, was an Debug-Funktionalität in dieser speziellen
Programmsituation möglich und brauchbar ist.
Aber eines muss auch klar sein: Da ist man dann schon in einer komplexen
Geschichte gefangen. Mit 3 Variablen ansehen und entscheiden ob die die
richtigen Werte haben ist da nicht mehr viel. Debuggen heisst da, die
Protokolle analysieren, eventuell mit dem Quelltext daneben das
Protokoll durchgehen und im Quelltext die Stellen wiederfinden, im
Quelltext Abläufe verfolgen wobei einem das Protokoll hilft, Dinge die
man nicht weiß (wie zb wie Vergleiche ausgegangen sind) zu ergänzen.
Einfach nur einen Blick drauf werfen und "schön" sagen, ist zu wenig.
Karl heinz Buchegger schrieb:> Aber eines muss auch klar sein: Da ist man dann schon in einer komplexen> Geschichte gefangen. Mit 3 Variablen ansehen und entscheiden ob die die> richtigen Werte haben ist da nicht mehr viel. Debuggen heisst da, die> Protokolle analysieren, eventuell mit dem Quelltext daneben das> Protokoll durchgehen und im Quelltext die Stellen wiederfinden, im> Quelltext Abläufe verfolgen wobei einem das Protokoll hilft, Dinge die> man nicht weiß (wie zb wie Vergleiche ausgegangen sind) zu ergänzen.> Einfach nur einen Blick drauf werfen und "schön" sagen, ist zu wenig.
Nur mal so als Beispiel.
Im Anhang ist ein Dump unserer CAD Software. Wir brauchen solche Dumps
um Fehler in den Datenstrukturen zu finden, Fehler in den einzelnen
Bearbeitungsprogrammteilen zu finden, rauszukriegen ob
Geometrieverknüfungen untereinander korrekt sind, ob Zusammenhänge
sauber umgesetzt wurden etc. Kurz und gut: eine textuelle Beschreibung
dessen, was sich für den Benutzer auf der GUI lediglich als ein paar
Striche manifestiert.
Die zugehörige Geometrie ist in der Anzeige relativ simpel. Und trotzdem
ist der Dump 77k gross. Hilft nichts, wenn man Nachvollziehen will,
warum eine Operation ein falsches Ergebnis liefert, welches sich erst 5
Bearbeitungsschritte später bemerkbar macht, dann heißt es oft: Dump
davor, Dump danach. Welche Unterschiede gibt es? Was ist miteinander
falsch verknüpft worden? Im Programmcode durchegen und den Dump daneben:
Welcher Wert wird wo ausgelesen, stimmt der überhaupt noch? etc. etc.
Oh. Und das ist nicht der einzige Dump, den wir jederzeit von der
inneren Datenstruktur ziehen können. Für spezielle Situationen gibt es
wieder andere Dumps, mit speziellem Augenmerk auf irgendeinen Umstand,
wie zb Polygonanalyse, etc. Teilweise sind die Dumps auch dergestalt,
dass in einem Extrafenster die Geometrie rausgezeichnet wird mit den
relevanten Kennwerten an den Punkten und Kanten, etc.
Also, da kann schon einiges an Aufwand in solchen Dumps stecken.
Aber es ist Aufwand der sich lohnt. 3 Stunden in die Erstellung eines
ordentlichen Dumps investiert, kann dir viele Zig Stunden Fehleranalyse
erleichtern bzw. einsparen.
Yalu X. schrieb:> Wenn in der Max-Funktion alpha nicht erhöht wird, weil alle untersuchten> Züge schlechter als alpha sind, sollte nicht alpha, sondern ein> beliebiger Wert kleiner als alpha zurückgegeben werden (bspw. alpha-1> oder -1000). Wie wär's damit:
Das war wirklich der Fehler, und jetzt hat das Ding auch eine akzeptable
Spielstärke (aber nur wenn man gegen ihn spielt, gegen sich selbst
spielt es grauenhaft!).
Karl heinz Buchegger schrieb:> Wenn da ein Turm pendelt, dann mag das zwar die> Horrorvorstellung für einen Schachspieler sein, für einen Programmierer> bedeutet das aber nur: Handelt es sich dabei um einen Programmfehler,> wird irgenetwas falsch zusammengezählt, oder geben die momentan unten im> Baum injezierten Werte einfach nicht mehr her. Wenn sich aus den Werten> unten an den Blättern dieses Verhalten ergibt und eine Analyse zeigt,> dass diese Werte korrekt den Baum hochwandern und sich daraus dann eben> ergibt, dass der Turm pendelt, dann ist das eben so. Aus Sicht des> Programmierers.
Hab ich nicht dazu gesagt, dass der d.h. der erste Zug vom Zuggenerator
wird immer genommen?
Das ist jetzt auch egal, den Rest kann man zum Glück aus schachlicher
Sicht betrachten.
Aber ob ich das Programm so optimiert bekomme, dass es auf einem
atmega644 mit 16Mhz läuft? Eigentlich wollte ich erstmal ein
Schachprogramm für den PC programmieren (erstmal weil man genügend Ram
und Leistung hat) und dann für den µC. Gut die meisten Variablen kann
man durch uint8 ersetzen. Die Bewertung müsste man als uint16
definieren. Aber ich frage mich ob das dann von der Leistung reicht?
Läubi .. schrieb:> ein Uraltes Ding für MS-DOS
Das Programm lief auf einem 8Mhz 286er mit 1MB RAM, das sollte man mit
einem AVR doch wohl schlagen können ;P
Irgendwo im Forum gab es auch mal einen Link auf eine uC kompatible
Schach Implementierung
> Ich korrigiere mich: nur weiß spielt stark schwarz nicht.
Ja und? Sollen jetzt wieder alle dir alles aus der Nase ziehen? Hast du
den eine Vermutung, und was bedeutet "stark"...
Ich hab das auch inzwischen korrigiert. Mit stark meinte ich richtig, da
war noch ein bug. Ich kenne auch eine Seite auf der alles mögliche
darüber steht. Aber das wäre doch ingerdwie langweilig - ich baue einen
Schachcomputer und nehme dafür das Programm eines anderen. Wo liegt da
der reiz? Ich möchte das Programm wenn dann selber schreiben und
verstehen.
Ich hab mal eine ganz blöde Frage:
Auf
http://www.schach-computer.info/wiki/index.php/Fidelity_Elite_Avantgarde_Versionen
steht
>> Um eine Stellung in den Hash Tables zu speichern, braucht man 8 Bytes RAM.
Kann mir einer erklären wie das geht???
Ich komme auf 32 Byte Ram pro Stellung:
0 | a | b | c | x | y | z | Wechsel //Feldangabe
1 | h | i | j | k | ? | ? | ? //Nächste Figur
abc = Feld - X - Kordinate
xyz = Feld - Y - Kordinate
Wechsel = Nächste Figur ist die nächste in der Liste
hij = Figurentyp
k = Farbe
Zuerst ein Bit das angibt ob die folgende Angabe, ein Feld angibt oder
den Figurentyp.
Der figurentyp wird dann einfach als zahl angegeben.
Als Feld braucht man 6bit = 64 Felder.
Dazu noch 1bit ob ein Wechsel zur nächten Figur stattfindet nach der
Liste:
Weißer Bauer, W. Springer, W. Läufer ...
Grundstellung wäre dann:
8 weiße Bauern:
<----X----Feld----Y--->
0 | 0 | 0 | 0 | 0 | 0 | 1 | 0
0 | 0 | 0 | 1 | 0 | 0 | 1 | 0
0 | 0 | 1 | 0 | 0 | 0 | 1 | 0
0 | 0 | 1 | 1 | 0 | 0 | 1 | 0
0 | 1 | 0 | 0 | 0 | 0 | 1 | 0
0 | 1 | 0 | 1 | 0 | 0 | 1 | 0
0 | 1 | 1 | 0 | 0 | 0 | 1 | 0
0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 //Wechsel zu Springer
2 Könige wäre dann z.b.:
1 | KÖ | N | IG | WEIß
0 | D | AS | F | E | L | D | 0
1 | KÖ | N | IG | SCHWARZ
0 | D | AS | F | E | L | D | 0
Also 8 byte kann doch irgendwie nicht gehen, auf
http://de.wikipedia.org/wiki/Schach steht, dass es geschätzt 2.28 ^ 46
Stellungen geben soll, also braucht man einen 160bit Interger um die
Zahl zu fassen = 20 Byte.
Also 8 Byte kann ich mir auch nicht vorstellen, zumindest nicht wenn man
die vollständige Information der Stellung speichern will, vielleicht ist
aber garnicht alles relevant.
Z.b. muss man sich nur max. 32 Positionen merken, daraus kann man die
leeren Positionen ableiten
Es gibt m.W. etwa 10^50 unterschiedliche Stellungen, das entspricht bei
optimaler Kodierung 166 Bits oder 21 Bytes, bei halbwegs rechenzeit-
freundlicher Kodierung mindestens 24 Bytes.
Ein Eintrag in der Hashtable enthält aber nicht die komplette Stellung,
sondern einen Hashcode, der bspw. 64 Bits lang ist (GNU Chess). Dabei
besteht natürlich die Gefahr, dass zwei unterschiedliche Stellungen als
gleich angesehen werden, weil sie den gleichen Hashcode haben. Die Wahr-
scheinlichkeit dafür ist aber nur 2^-64. Selbst wenn ein schneller Rech-
ner während einer Partie 10 Billionen Stellungen¹ durchrechnet, ist die
Fehlerwahrscheinlichkeit nur 5·10^-7, also vernachlässigbar.
Jeder Hashtable-Eintrag enthält aber neben dem Hashcode noch die Stel-
lungsbewertung und weitere Informationen. Ist bei den Fidelity-Schach-
computern der komplette Eintrag tatsächlich nur 8 Bytes groß, müssen die
Hashcodes entsprechend kürzer sein, also bspw. 48 Bits. Da diese alten
Kisten aber im Vergleich zu einem aktuellen PC nicht besonders schnell
waren und entsprechend weniger Stellungen durchrechneten, bestand trotz
des kürzeren Hashcodes praktisch keine Gefahr einer Kollision.
Wenn man hundertprozentig sicher gehen will, kann man, bevor ein Zug auf
dem Brett ausgeführt wird, die berechnete Zugfolge noch einmal bewerten,
was ja sehr schnell geht. In den extrem seltenen Fällen, wo man dabei
einen Fehler feststellt, wird einfach die komplette Zugberechnung noch
einmal ohne Hashtable wiederholt.
¹) Das wären bei einer 3-Stunden-Partie etwa 1ns pro Stellung, was schon
sehr schnell ist.
Wie macht man das dann am effektivsten? Nimmt man für die Hashtabelle
eine Sortedlist?
Und kennst du zufällig einen Hashcodealgorithmus? Das wäre der nächste
Schritt zur Geschwindigkeitsoptimierung.
In GNU Chess gibt es zur Berechnung des Hashcodes für jede Kombination
aus Farbe, Figur und Position ein zufällig generiertes 64-Bit-Muster.
Der Hashcode einer Stellung ist die XOR-Verknüpfung der Bitmuster der
einzelnen Figuren. Damit kann der Hashcode einer Stellung beim Ausführen
eines Zugs sehr schnell aktualisiert werden und muss nicht jedesmal
komplett neu berechnet werden.
Die Tabelle selbst ist als Array organisiert. Der Index für den Zugriff
ergibt sich aus den unteren n Bits des Hashcodes.
Das Hash-Verfahren ist damit zweistufig: Die XOR-Verknüpfung der Bitmus-
ter aus dem ersten Abschnitt ist die Hash-Funktion zur Identifizierung
der Stellungen, die Extraktion der untersten n Bits aus dem Hashcode die
Hash-Funktion für das schnelle Auffinden der Stellungen in der Tabelle.
Hast du dazu eine Quelle? Die Hashfunktion würde ich mir gerne anschauen
(die Tabellen auch). Leider bekommt man bei 4KB Ram nur 500 Stellen hin
und da ich evtl. eine Endspieldatenbank und ein Eröffnungsbuch per
SD-Karte hinzufügen würde, bräuchte ich noch 512Byte Puffer + die
Readfunktionen -> Also so ca. 700B Ram extra. Da kann ich dann nur ca.
350 Stellungen benutzen.
Wie wärs wenn du erst mal deine Bewertungsfunktion vernünftiger machst,
anstatt dich da jetzt in irgendwelche Optimierungen zu verlaufen.
Deine Bewertungsfunktion ist ein Witz. Von vernünftiger Spielstärke kann
da überhaupt keine Rede sein.
Samuel K. schrieb:> Hast du dazu eine Quelle?
Ja natürlich. Das Ding würde wahrscheinlich kein GNU im Namen tragen,
wenn der Quellcode nicht öffentlich wäre:
http://www.gnu.org/software/chess/
Der Quellcode ist knapp, aber gut dokumentiert. Etwas ausführlicher
dokumentiert ist dieses deutlich leistungsstärkere Programm (eine
Weiterentwicklung des berühmten "Cray Blitz"):
http://www.craftychess.com/> Leider bekommt man bei 4KB Ram nur 500 Stellen hin und da ich evtl.> eine Endspieldatenbank und ein Eröffnungsbuch per SD-Karte hinzufügen> würde, bräuchte ich noch 512Byte Puffer + die Readfunktionen -> Also> so ca. 700B Ram extra. Da kann ich dann nur ca. 350 Stellungen> benutzen.
Die Eröffnungen und die Hastables brauchst du nicht unbedingt gleichzei-
tig, so dass die 512 Bytes des SD-Lesepuffers auch für die Hashtables
zur Verfügung stehen. Aber selbst bei 500 Einträgen dürfte die Treffer-
wahrscheinlichkeit noch so gering sein, dass der daraus resultierende
Geschwindigkeitszuwachs durch den zusätzlichen Aufwand für die Berech-
nung der Hashcodes usw. aufgefressen wird.
Auf Grund ihrer geringen Größe greifen die Hashtables dann höchstens im
Endspiel, wenn außer den Königen noch maximal eine oder zwei Figuren im
Spiel sind. Für diese Situationen gibt es aber meist einfach zu program-
mierende Algorithmen, die die Alpha-Beta-Suche und damit auch die Hash-
tables überflüssig machen.
Außerdem muss dein Programm das Endspiel erst einmal erreichen, insofern
ist der Einwand von Karl Heinz schon berechtigt ;-)
Die in deinem Link von oben
http://www.schach-computer.info/wiki/index.php/Fidelity_Elite_Avantgarde_Versionen
beschriebenen Fidelity-Schachcomputer verwenden 128KiB bis 2MiB für 16Ki
bis 256Ki Hashtable-Einträge. Mit den größeren davon lässt sich schon
eher etwas anfangen. Von den RAM-armen 8-Bit-Schachcomputern hatte m.W.
keiner Hashtables. Auf dem AVR würde ich sie nur dann vorsehen, wenn
massiv externer Speicher zur Verfügung steht.
Ich habe mir gerade noch einmal die Alpha-Beta-Suche aus deinem ersten
Beitrag angesehen, weil ich nicht so richtig glauben konnte, dass sie
fehlerhaft ist, denn sie entspricht ja ziemlich genau der in Wikipedia
und anderen Quellen beschriebenen Variante.
Dabei ist mir aufgefallen, dass du in Ebene 0 alle bewerteten Züge erst
nach Abschluss der Suche sortierst. Das führt zu dem von dir beschriebe-
nen Fehler, da alle Züge, die nach dem stärksten untersucht werden,
unabhängig von ihrer Stärke die gleiche Bewertung wie der stärkste Zug
bekommen. Da die Sort-Methoden in C# laut diesem Link
http://www.csharp411.com/c-stable-sort/
nicht stabil sind, kann es also passieren, dass einer der schwachen Züge
bei der Sortierung an die erste Stelle rückt.
So sieht deine ursprüngliche AlphaBeta-Methode aus:
In Wikipedia steht zwar, wie der Wert des besten Zugs berechnet, nicht
aber, wie der Zug selbst gefunden wird. Und genau an dieser Stelle hat
sich der Fehler eingeschlichen.
Diese Variante der Alpha-Beta-Suche nennt sich übrigens Fail-Hard. Das,
was ich damals in meinem eigenen Schachprogramm realisierte (mein Bei-
trag vom 20.08.2010 01:09), ist hingegen die Fail-Soft-Variante, was ich
aber auch erst heute gelernt habe :)
Die Fail-Soft-Variante beschneidet den Suchbaum noch stärker als die
Fail-Hard-Variante und ist deswegen dieser praktisch immer vorzuziehen.
Mehr dazu:
http://chessprogramming.wikispaces.com/Alpha-Betahttp://chessprogramming.wikispaces.com/Fail-Hardhttp://chessprogramming.wikispaces.com/Fail-Soft
Dass ich damals die bessere der beiden Varianten gefunden habe, liegt
wohl hauptsächlich daran, dass ich nicht den fertig programmierten
Alpha-beta-Algorithmus, sondern nur eine unpräzise textuelle Beschrei-
bung davon zur Verfügung hatte, wodurch ich gezwungen war, mir die
Details selber zu überlegen.
Deswegen ist es generell vorteilhaft, bei der Implementierung nichttri-
vialer Algorithmen in folgenden Schritten vorzugehen:
1. den Algorithmus anhand einer Veröffentlichung versuchen zu verstehen
2. die Veröffentlichung beiseite legen
3. den Algorithmus ohne Nutzung einer Vorlage programmieren
4. solange debuggen, bis der Algorithmus fehlerfrei funktioniert
5. die eigene Implementation mit denen anderer (Open-Source) vergleichen
6. bei Unterschieden überlegen, ob und warum die eigene oder die andere
Variante besser ist
Danach hat man i.Allg. den Algorithmus wirklich verstanden. Oftmals
fehlt einem aber leider die Zeit für dieses Vorgehen, was dann gerne zu
schnell zusammengepappten Murksprogrammen führt.
Oh.
Und eines noch:
Du solltest deine Anzeigeroutine so umändern, dass das Feld A1 links
unten ist, bzw. wenn du das Brett aus der schwarzen Sicht zeigen willst
rechts oben.
Das war am Anfang des Threads schon etwas ungewohnt, deine
Zugbezeichnungen mit der Grafik in Übereinstimmung zu bringen.
Yalu X. schrieb:> denn sie entspricht ja ziemlich genau der in Wikipedia> und anderen Quellen beschriebenen Variante.
Da hast du recht. Alle Varianten, die ich gesehen habe waren gleich.
Entweder Wiki hat kopiert oder die anderen. Ich hab auch mal eine
Javachess variante versucht auseinander zunehmen, aber die hatte fast
nur globale Variablen und da hatte ich dann überhupt kein Durchblick
mehr.
Sam schrieb:> Javachess variante versucht auseinander zunehmen, aber die hatte fast> nur globale Variablen und da hatte ich dann überhupt kein Durchblick> mehr.
Es gibt keine globalen Variablen in Java... sicher das dir da nicht dser
durchblick in Java gefehlt hat als der Durchblick an sich? ;)
Läubi .. schrieb:> Es gibt keine globalen Variablen in Java... sicher das dir da nicht dser> durchblick in Java gefehlt hat als der Durchblick an sich? ;)
Sicher? Ich hab das Programm jetzt nochmal durchgeschaut - so viele
globale Variablen sind doch nicht drin, allerdings find ich das PRogramm
trotzdem verwirrend:
http://library.thinkquest.org/C001348/
Praxis -> Abschlussarbeiten
Ich hab übrigens wirklich noch nie Java programmiert, außer einmal fürs
Handy.