Hallo Leute,
OS: WinXP SP3
CPU: Intel Core2Duo E8500
RAM: 2GB
ich versuche mit awk ein einfaches Programm zu schreiben,
das einen vorhandenen Text (CAN-Datenstrom->Messung1.asc) ausliest und
ich einen einer
anderen Datei speichert. Allerdings sollen in der Ausgabedatei (Name
"4") die dritte Spalte mit einem x versehen werden, wenn
1. Ansatz
der Inhalt der dritten Spalte mehr als 4 Stellen hat.
Prog5.awk
1
Length ($3) > 4 {
2
printf "%s %s %10s %2s\n",$1, $2, $3"x", $4>4
3
}
2. Ansatz
der Inhalt der zweiten Spalte gleich 2 ist.
Prog2.awk
1
IF ($2 == 2)
2
{printf "%s %s %10s %2s\n",$1, $2, $3"x", $4>4}
Ich rufe den Interpreter über CYGwin mit folgendem Befehl auf:
"awk -f prog5.awk messung1.asc"
Das Ergebnis ist das alle Zahlen in der 3 Spalte mit einer X versehen
werden. So als ab die IF oder LENGTH-Anweisung gar nicht beachtet
werden.
Gruß
Andre
Andre schrieb:> Ich rufe den Interpreter über CYGwin mit folgendem Befehl auf:> "awk -f prog5.awk messung1.asc">> Das Ergebnis ist das alle Zahlen in der 3 Spalte mit einer X versehen> werden. So als ab die IF oder LENGTH-Anweisung gar nicht beachtet> werden.
Ich verstehe nicht recht, ob du jetzt eines oder beide
awk-Programme ausführen willst.
Aufgerufen wird doch offenbar nur das Prog5.awk, weil du auch nur
das angibst beim Aufruf.
Also kann das IF aus Prog2.awk nie aufgerufen werden.
Außerdem:
- awk unterscheidet zwischen groß/klein, also nicht IF sondern
if, length statt Length u.s.w..
- Eine awk-Anweisung besteht aus einem optionalen RE, um
die Auswahl der Zeilen einzugrenzen, und einer optionalen
Anweisung (-sfolge) in geschweiften Klammern.
Das Length ($3) > 4 ist wie gesagt schon mal falsch geschrieben
und müsste length ($3) > 4 heißen.
Davon abgesehen gehört es mit zur Anweisung, nicht in den
RE-Teil vor der geschweiften Klammer.
- Bei den Anweisungen würdest du mit ... > 4 die Ausgabe m.W. in
eine Datei namens "4" umleiten, das dürfte nicht deine Absicht
sein.
Was wirklich deine Absicht ist, verstehe ich nicht.
Ein Vergleich?
In der 4. Spalte stehen aber gar keine Zahlen, sondern
lauter "Rx". Wie soll man die mit 4 vergleichen?
Falls du einen Vergleich willst und der Kram versehentlich
in einer Datei umgeleitet wird, hilft es, den Ausdruck zu
klammern.
Ein zumindest formal wesentlich besseres awk-Programm wäre etwa:
Hallo Klaus,
vielen Dank für Deine Antwort.
Die zwei Programme haben beide das gleiche Ziel. Ich habe nur
unterschiedliche Ansätze (Programme) erstellt, weil ich mir nicht
erklären konnte warum es nicht funktionierte.
Jetzt läuft es. Danke für die Hilfe.
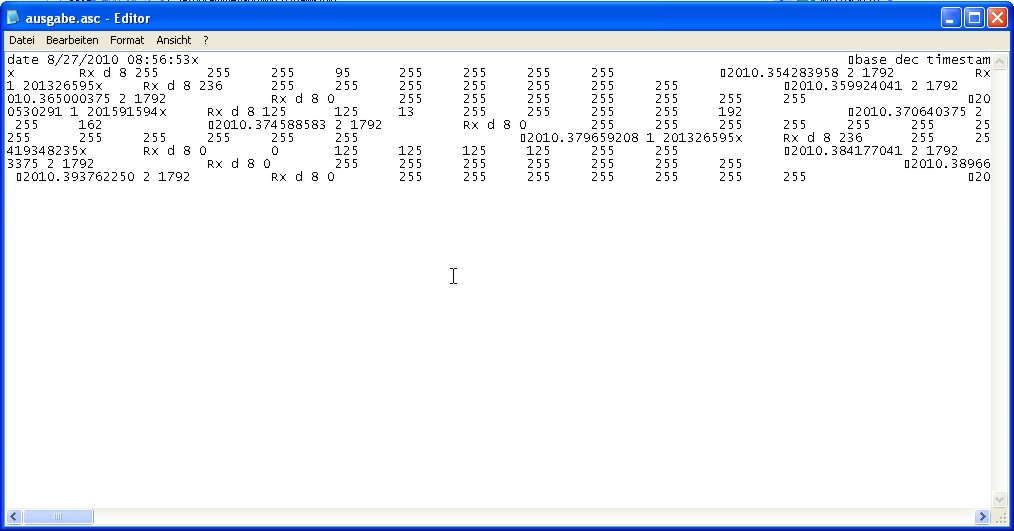
Anbei habe ich einmal das Ergegnis angehangen (Datei "ausgabe.asc")
Der Inhalt bzw. die Formatierungen sind falsch dargestellt.
Wenn ich die Ausgabe ohne Dateitype (einfach nur "ausgabe") schreibe,
dann
sieht die Formatierung dem des Originals schon sehr ähnlich.
Wie kann man die Ausgabe so formatieren, dass es wie das Orignal
(Messung1.asc) aussieht?
Den Interpreter rufe ich wie folgt auf:
"awk -f prog7.awk messung1.asc"
Vielen Dank im Voraus.
Gruß
Andre
Wenn ich dich jetzt richtig verstehe, ist das Problem nur
eines bzgl. Zeilenende.
Unter DOS, also auch unter der grafischen Benutzeroberfläche
von DOS, aka Windows, ist es üblich, daß an jedem Zeilenende
die beiden Bytes "carriage return" (CR, auch oft als \r
geschrieben) und "line feed" (LF, \n) stehen als Zeichen,
daß jetzt eine neue Zeile kommt.
Unter allen anderen interessanten Systemen spart man sich
eines davon. Deshalb wird unter allen Unix-ähnlichen auf
das CR verzichtet und nur das LF ans Zeilenende gestellt.
So wie es aussieht, hast du jetzt nur ein LF da stehen,
und einen Editor, der nicht damit klar kommt (das
Verhalten kann durchaus von der Dateiendung abhängen, je
nach Editor).
Jetzt kannst du entweder
- in deinem awk-Programm dafür sorgen, daß jeweils am
Ende jeder Zeile noch ein \r ausgegeben wird
- oder einen Editor nehmen, der nicht so doof ist
(wordpad glaube ich da etwas besser)
- oder mit einem Programm die Datei anpassen