Hi,
wie kann ich am schnellsten binär zu bcd wandeln (als c programm)
möglichst unabhängig. Ich mache das bisher immer so:
uint16_t Hex2Dez (uint16_t hex)
{
uint16_t dez=0;
while(hex>=10000)
{
hex-=10000;
}
while(hex>=1000)
{
dez+=0x1000;
hex-=1000;
}
while(hex>=100)
{
dez+=0x100;
hex-=100;
}
while(hex>=10)
{
dez+=0x10;
hex-=10;
}
while(hex>=1)
{
dez+=0x1;
hex-=1;
}
return dez;
}
aber ich denke es gibt besseres...
Vielen Dank für die Tips schonmal
T.
man sieht es ja auch hier: Beitrag "32 Bit binär in BCD umwandeln" das Modulo und Division nicht die beste Lösung für einen AVR bedeuten, dennoch frage ich mich ob es nicht noch einfacher und schneller geht... T.
ich meine ich hätte noch mal etwas schlaueres gesehen... hier ist auch nur das was man so kennt: http://www.mikrocontroller.net/articles/Festkommaarithmetik T.
Hi Abgesehen, das hier etwas fehlt > while(hex>=10000) > { > hex-=10000; > } ist das eine umständliche Methode für dez = hex. MfG Spess
>>Abgesehen, das hier etwas fehlt<< was denn? ist ein 16Bit Rückgabeewert... >>ist das eine umständliche Methode für dez = hex<< he? Ich meine ich hatte das Thema hier schon mal, ich werde das letzte While nun noch in eine addierung ändern und dann sollte es passen... T.
Hi >Ich meine ich hatte das Thema hier schon mal, ich werde das letzte While >nun noch in eine addierung ändern und dann sollte es passen... Dann reicht auch while(hex>=10000) { hex-=10000; } dez = hex; Der Rest ist überflüssig. MfG Spess
hmm, ne so würde in der Variablen dez nur binär ein Wert kleiner 0x10000 stehen... oder? T.
Aus meiner Snippet-Sammlung
1 | uint8_t itobcd(uint8_t i) |
2 | {
|
3 | uint8_t lo, hi = 0; |
4 | |
5 | //Fehler mit unmoeglicher Zahl "von aussen" erkennbar machen
|
6 | if(i > 99) |
7 | return(0xFF); |
8 | |
9 | //Division, entspricht "hi = i/10;"
|
10 | while (i > 9) |
11 | {
|
12 | hi++; |
13 | i -= 10; |
14 | }
|
15 | |
16 | //Der Rest der Division ist noch in "i", das ist der lo-Anteil
|
17 | //Der Compiler wird die Variable "lo" wegoptimieren
|
18 | lo = i; |
19 | |
20 | return((hi << 4) | lo); |
21 | }
|
Scheint also auch "nix neues im Westen" zu geben. mfg mf
Hey Minifloat,
das ist ja das Prinzip. Bei mir sieht es nun so aus:
uint16_t Hex2Dez (uint16_t hex)
{
uint16_t dez=0;
while(hex>=10000)
{
hex-=10000;
}
while(hex>=1000)
{
dez+=0x1000;
hex-=1000;
}
while(hex>=100)
{
dez+=0x100;
hex-=100;
}
while(hex>=10)
{
dez+=0x10;
hex-=10;
}
dez+=hex;
return dez;
}
Ich schätze schneller geht es wohl nicht. Wenn du dir das Geshifte und
Verknüpfe sparen willst, dann könnte man es auch so machen:
uint8_t itobcd(uint8_t i)
{
uint8_t dez=0
//Fehler mit unmoeglicher Zahl "von aussen" erkennbar machen
if(i > 99)
return(0xFF);
while(i>=10)
{
dez+=0x10;
i-=10;
}
//Der Rest der Division ist noch in "i",
dez+=i;
return(dez);
}
könnte das passen, naja, der Compiler macht warscheinlich eh das selbe
daraus :-)
Gruß,
T.
Hi >hmm, ne so würde in der Variablen dez nur binär ein Wert kleiner 0x10000 >stehen... oder? Ja. Genau wie bei deinem Programm. Dezimal und Hexadezimal sind nur verschiedene Schreibweisen. Keine verschiedenen Zahlen. MfG Spess
spess53 schrieb: >>Ich meine ich hatte das Thema hier schon mal, ich werde das letzte While >>nun noch in eine addierung ändern und dann sollte es passen... > > Dann reicht auch > > while(hex>=10000) > { > hex-=10000; > } > dez = hex; > > Der Rest ist überflüssig. > > MfG Spess ich denke da hast du was übersehen spess, in den anderen whiles paasiert noch mehr ...
Sorry, habe das wohl etwas falsch benannt. Mein Code erzeugt bcds im 16Bit Wert, sieht man nur nicht auf den ersten Blick, muss ich mal umbenennen in bintobcd oder my_itoa oder soetwas... T.
spess53 schrieb: > Dezimal und Hexadezimal sind nur > verschiedene Schreibweisen. Keine verschiedenen Zahlen. es geht nicht um dezimal sondern um BCD, die Hexzahl 0x10 ist in BCD z.B. 0x16
So,
das konnte man falsch verstehen, sorry.
Ich habe meine Routine nun noch mal überarbeitet:
uint16_t bintobcd (uint16_t bin)
{
uint16_t bcds=0;
while(bin>=10000)
{
bin-=10000;
}
while(bin>=1000)
{
bcds+=0x1000;
bin-=1000;
}
while(bin>=100)
{
bcds+=0x100;
bin-=100;
}
while(bin>=10)
{
bcds+=0x10;
bin-=10;
}
bcds+=bin;
return bcds;
}
Gruß,
T.
Hi >es geht nicht um dezimal sondern um BCD, >die Hexzahl 0x10 ist in BCD z.B. 0x16 Stimmt. Mir war das +=0x... entgangen. MfG Spess
wie kann ich mir eigentlich angucken wie die Funktion ins assembler aussieht, beim PIC gab es da immer das "absolut Listing".... Nutze AVR Studio und avrgcc. T.
Thorsten S. schrieb: > wie kann ich mir eigentlich angucken wie die Funktion ins assembler *.lss in "Other Files" mfg.
danke :-)
das ist sie also in asm code:
uint16_t bintobcd (uint16_t bin)
{
9c0: 02 c0 rjmp .+4 ; 0x9c6 <bintobcd+0x6>
uint16_t bcds=0;
while(bin>=10000)
{
bin-=10000;
9c2: 80 51 subi r24, 0x10 ; 16
9c4: 97 42 sbci r25, 0x27 ; 39
9c6: 27 e2 ldi r18, 0x27 ; 39
9c8: 80 31 cpi r24, 0x10 ; 16
9ca: 92 07 cpc r25, r18
9cc: d0 f7 brcc .-12 ; 0x9c2 <bintobcd+0x2>
9ce: 20 e0 ldi r18, 0x00 ; 0
9d0: 30 e0 ldi r19, 0x00 ; 0
9d2: 04 c0 rjmp .+8 ; 0x9dc <bintobcd+0x1c>
}
while(bin>=1000)
{
bcds+=0x1000;
9d4: 20 50 subi r18, 0x00 ; 0
9d6: 30 4f sbci r19, 0xF0 ; 240
bin-=1000;
9d8: 88 5e subi r24, 0xE8 ; 232
9da: 93 40 sbci r25, 0x03 ; 3
9dc: 43 e0 ldi r20, 0x03 ; 3
9de: 88 3e cpi r24, 0xE8 ; 232
9e0: 94 07 cpc r25, r20
9e2: c0 f7 brcc .-16 ; 0x9d4 <bintobcd+0x14>
9e4: 04 c0 rjmp .+8 ; 0x9ee <bintobcd+0x2e>
}
while(bin>=100)
{
bcds+=0x100;
9e6: 20 50 subi r18, 0x00 ; 0
9e8: 3f 4f sbci r19, 0xFF ; 255
bin-=100;
9ea: 84 56 subi r24, 0x64 ; 100
9ec: 90 40 sbci r25, 0x00 ; 0
9ee: 84 36 cpi r24, 0x64 ; 100
9f0: 91 05 cpc r25, r1
9f2: c8 f7 brcc .-14 ; 0x9e6 <bintobcd+0x26>
9f4: 03 c0 rjmp .+6 ; 0x9fc <bintobcd+0x3c>
}
while(bin>=10)
{
bcds+=0x10;
9f6: 20 5f subi r18, 0xF0 ; 240
9f8: 3f 4f sbci r19, 0xFF ; 255
bin-=10;
9fa: 0a 97 sbiw r24, 0x0a ; 10
9fc: 8a 30 cpi r24, 0x0A ; 10
9fe: 91 05 cpc r25, r1
a00: d0 f7 brcc .-12 ; 0x9f6 <bintobcd+0x36>
}
bcds+=bin;
return bcds;
}
a02: 82 0f add r24, r18
a04: 93 1f adc r25, r19
a06: 08 95 ret
00000a08 <_exit>:
a08: ff cf rjmp .-2 ; 0xa08 <_exit>
0xA08-0x90c=0xFC
Also 252 Intruktionen, klingt viel.
T.
Thorsten S. schrieb: > 0xA08-0x90c=0xFC > > Also 252 Intruktionen, klingt viel. und was ist mit den schleifen?
Ja - ha ha - man muss das Thema ja von 2 Seiten betrachten: 1)Wie schnell ist die Routine 2)Wie lang ist sie codeseitig In diesem Fall hat sie codeseitig 252 Instruktionen, die Menge der Ausgeführten Instruktionen hängt bei dieser Routine stark von dem Übergabeparameter ab. Interessant sind sicher Lösungen, die eine konstante Ausführungszeit haben, egal was übergeben wird, wenn also wirklich gerechnet wird, die dennoch weniger Speicherplatz benötigen. T.
...ich probiere jetzt gerade mal nur so zum Spass hiermit rum:
uint16_t bintobcd (uint16_t bin)
{
uint16_t bcds=0;
uint8_t i=0;
while(i<4)
{
bcds |= (bin % 10)<<(4*i);
bin/=10;
i++;
}
return bcds;
}
irgendwie hat das einen komischen Einfluss auf meine Displayausgabe, das
untersuche ich gerade noch.
uint16_t bintobcd (uint16_t bin)
{
9c0: cf 93 push r28
9c2: df 93 push r29
9c4: 9c 01 movw r18, r24
9c6: c0 e0 ldi r28, 0x00 ; 0
9c8: d0 e0 ldi r29, 0x00 ; 0
9ca: e0 e0 ldi r30, 0x00 ; 0
9cc: f0 e0 ldi r31, 0x00 ; 0
uint16_t bcds=0;
uint8_t i=0;
while(i<4)
{
bcds |= (bin % 10)<<(4*i);
9ce: c9 01 movw r24, r18
9d0: 6a e0 ldi r22, 0x0A ; 10
9d2: 70 e0 ldi r23, 0x00 ; 0
9d4: 0e 94 02 05 call 0xa04 ; 0xa04 <__udivmodhi4>
9d8: 0e 2e mov r0, r30
9da: 02 c0 rjmp .+4 ; 0x9e0 <bintobcd+0x20>
9dc: 88 0f add r24, r24
9de: 99 1f adc r25, r25
9e0: 0a 94 dec r0
9e2: e2 f7 brpl .-8 ; 0x9dc <bintobcd+0x1c>
9e4: c8 2b or r28, r24
9e6: d9 2b or r29, r25
bin/=10;
9e8: c9 01 movw r24, r18
9ea: 6a e0 ldi r22, 0x0A ; 10
9ec: 70 e0 ldi r23, 0x00 ; 0
9ee: 0e 94 02 05 call 0xa04 ; 0xa04 <__udivmodhi4>
9f2: 9b 01 movw r18, r22
9f4: 34 96 adiw r30, 0x04 ; 4
9f6: e0 31 cpi r30, 0x10 ; 16
9f8: f1 05 cpc r31, r1
9fa: 49 f7 brne .-46 ; 0x9ce <bintobcd+0xe>
i++;
}
return bcds;
}
9fc: ce 01 movw r24, r28
9fe: df 91 pop r29
a00: cf 91 pop r28
a02: 08 95 ret
00000a04 <__udivmodhi4>:
a04: aa 1b sub r26, r26
a06: bb 1b sub r27, r27
a08: 51 e1 ldi r21, 0x11 ; 17
a0a: 07 c0 rjmp .+14 ; 0xa1a <__udivmodhi4_ep>
00000a0c <__udivmodhi4_loop>:
a0c: aa 1f adc r26, r26
a0e: bb 1f adc r27, r27
a10: a6 17 cp r26, r22
a12: b7 07 cpc r27, r23
a14: 10 f0 brcs .+4 ; 0xa1a <__udivmodhi4_ep>
a16: a6 1b sub r26, r22
a18: b7 0b sbc r27, r23
00000a1a <__udivmodhi4_ep>:
a1a: 88 1f adc r24, r24
a1c: 99 1f adc r25, r25
a1e: 5a 95 dec r21
a20: a9 f7 brne .-22 ; 0xa0c <__udivmodhi4_loop>
a22: 80 95 com r24
a24: 90 95 com r25
a26: bc 01 movw r22, r24
a28: cd 01 movw r24, r26
a2a: 08 95 ret
00000a2c <_exit>:
a2c: ff cf rjmp .-2 ; 0xa2c <_exit>
Thorsten
Angehängte Dateien:
-

bintobcd.png
30 KB
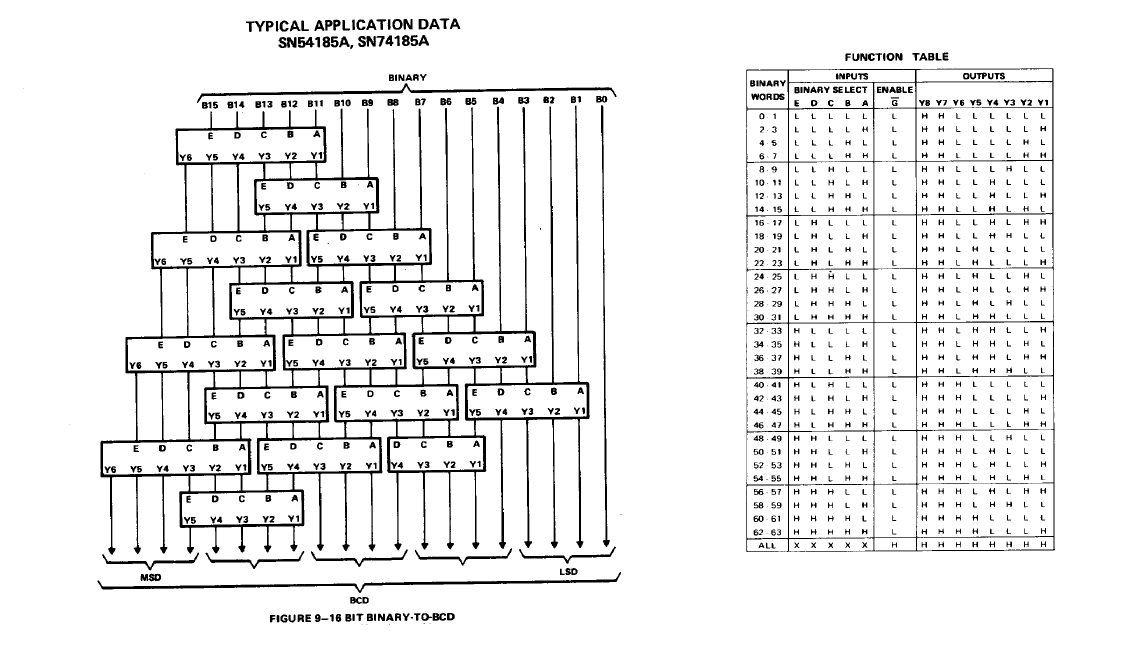
Hi, mir kam gerade noch das hier in den Kopf, aber da meine Funktion mir erstmal reicht und auch funktioniert bleibe ich erstmal dabei. Gruß, T.
Es geht noch schneller mit Peter Danneggers Routine, die abwechselnd subtrahiert und addiert, siehe Anhang. i muss auf jeden Fall signed sein, kann aber auch statt long nur int sein, dann wird es noch schneller. bcd kann unsigned int sein, falls nur 4 Stellen gewünscht sind. Der Startwert muss dann 65535 sein. Bei i>9999 geht die 10000er-Stelle ins Nirwana. Mit einer binären Suche geht es noch schneller, aber der Code ist länger.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.