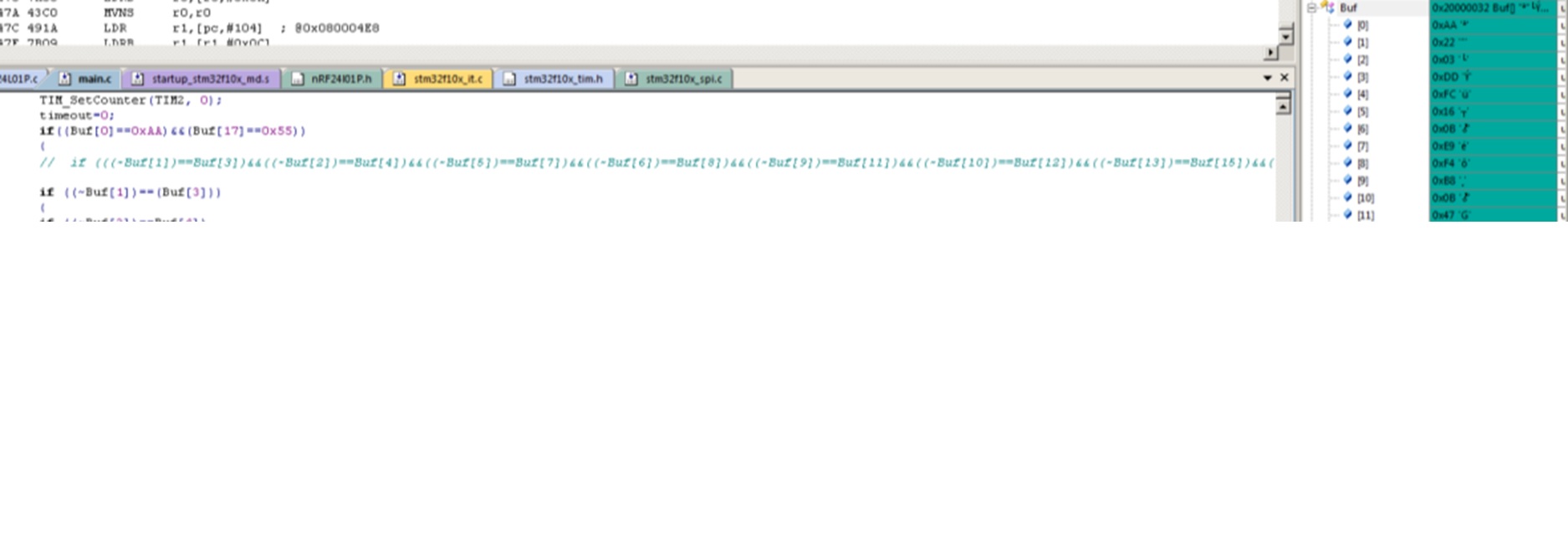
Hallo, ich stehe gerade auf dem Schlauch... Kann mir jemand sagen warum mein Controller den Vergleich "if((~Buf[1])==(Buf[3]))" nicht erfolgreich ausführt? in Buf[3] befindet sich exakt das invertierte von Buf[1] siehe debugger. Danke! Gruß Micha
Angehängte Dateien:
-

Unbenannt.jpg
88 KB
Hmm, das ist ja ein bösartiger Fehler. Schau dir das mal im Assemblerfenster an und führe es dort Schritt für Schritt aus. Die CPU läd das Byte in ein Register, da steht also jetzt 0x00000022 drin. Dann wird das Register negiert. Danach steht 0xFFFFFFDD drin. Dann wird das zweite Byte in ein anderes Register geladen, da ist dann 0x000000DD drin. Und dann werden 0xFFFFFFDD und 0x000000DD verglichen. :(
Das ist ganz normales Verhalten eines C-Compilers, dass Variablen beim Vergleich auf 32 Bit erweitert werden.
Antimedial schrieb: > Das ist ganz normales Verhalten eines C-Compilers, dass Variablen beim > Vergleich auf 32 Bit erweitert werden. Aber ist es auch ganz normales Verhalten eines Compilers, das char beim invertieren auf 32 Bit erweitert werden?
Detlef Kunz schrieb: > Aber ist es auch ganz normales Verhalten eines Compilers, das char beim > invertieren auf 32 Bit erweitert werden? Ja, das sagte ich doch!
Siehe hier: http://www.elektronikpraxis.vogel.de/softwareengineering/programmiersprachen/articles/426198/
Detlef Kunz schrieb: > Workaround: > if((char)(~buf[1])==(buf[3])) Hmm, ich hab das mal jetzt auf mit dem C-Compiler im Linux probiert. Das gleiche Verhalten. Ganz, ganz böse. Nochmal zum Workaround: Du musst natürlich den Cast machen, der zum Typ von Buf gehört. Bei Keil schein es egal zu sein, ob man (unsigned char) oder (char) einsetzt, aber ein Testprogramm mit dem C-Compiler auf dem Linux-PC funktionierte nur mit dem richtigen Typ. Sollte bei sauberer Programmierung sowieso kein Thema sein ;) Ich habs nur mal ausbropiert, weil ich deinen Typ von Buf nicht wusste.
Na der Compiler und µC macht genau das was du programmiert hast. Das das nicht das ist was du haben Willst steht auf einem anderen Blatt. Also der STM ist ein 32 Bit µC. Das heißt Registerbreite und Datenbreite ist 32 Bit. Wenn du da jetzt eine UChar reinlegst belegst du genau 8 Bit von diesen 32. Bei der Verarbeitung im Register wird vom Datenbus genau diese 8 Bit in das 32 Bit Register geladen. Dann kommt : (~Buf[1]) ==> Negiere ALLE Bits des Registers. und damit wird aus 0x00000022 eben 0xFFFFFFDD. Es fehlt für den Compiler die Anweisung das er diesen Wert überall als UChar behandeln MUSS. ==> Cast Somit geht der Compiler auf die optimale Verarbeitung. Das heißt die das Register vollständig nutzen. Dies erspart einige Assemblerbefehle bei der Verarbeitung.==> Laufzeit. Alternativ lässt sich die Negierung auch auf anderem Weg machen. Dann besteht diese Problem NICHT. Das ist ein XOR mit 0xFf für 8Bit Variablen, 0xFFFF für 18Bit und 9xFFFFFFFF für 32 Bit. Das ist kein Workaround sondern die bessere Variante. In dem Fall wäre es also dann ( Buf[1] ^ 0xFF ) anstelle von (~Buf[1]) Damit wird aus 0x00000022 ==> 0x000000DD Solche Fehler lassen sich wunderbar automatisiert finden. Es gibt Tools die den Source Code nach MISRA Regeln prüfen. Dabei gibt genau eine solche Programmierung einen Fehler der auf exact dieses Verhalten hinweißt. Die Misra Fehlernummer müsste ich jetzt allerdings mal raus suchen. Beim 8Bitter passiert das an der Stelle nicht da ja Registerbreit 8 Bit ist. Liegt aber nicht daran das 8 Bitter besser sind, sondern ist purer Zufall aus der Entwcklungshistorie. 16 Bitter haben übrigens hier das gleiche Problem.
Eigentlich müsste schon: "if(~(Buf[1])==Buf[3])" ... falls ich den Befehl als (~Var1==Var2) richtig interpretiere, gehen.
Amateur schrieb: > Eigentlich müsste schon: > > "if(~(Buf[1])==Buf[3])" > > ... falls ich den Befehl als (~Var1==Var2) richtig interpretiere, gehen. Nein, das hab ich vor dem Cast ausprobiert.
Dann liegt's am "Stretching" von Variablen, also wie erweitere ich eine Char-Variable auf ein größeres Format. Zwei Bleistifte: (char)50 == (char)80 --> 8-Bit 00110010 == 01010000 (char)50 == (char)80 --> 16-Bit 0000000000110010 == 0000000001010000 Der erste Fall klappt. (char)180 == (char)80 --> 8-Bit 10110100 == 01010000 (char)180 == (char)80 --> 16-Bit 1111111110110100 == 0000000001010000 Im zweiten Falle macht sich die Erweiterung von vorzeichenbehafteten Zahlen ins nächste Format bemerkbar. Das oberste Bit wird als Vorzeichen betrachtet. Analog funktioniert der 32-Bit-Vergleich. Wenn dann noch "~" dazu kommt, ändert sich das Prinzip nicht. Also erst Erweiterung und dann "~".
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.