Die Frage ist jetzt wenn ich im Interrupt die Länge lese => und was
damit machen möchte dann sehe ich hier ein großes Probleme. :-) Also ich
hoffe ihr versteht was ich meine und hoffe auch das ich da nicht
komplett falsch denke.
Im Kommentar der Artikel steht, dass es hier kein Lock braucht - ich
sehe das einfach aderst.
Ich möchte nicht immer
1
//in der main() loop: | in einem IRQ:
2
ISR_LOCK;
3
CBUF_Push(buffer,'a');|
4
CBUF_Push(buffer,'b');|CBUF_Len(buffer);
5
ISR_UNLOCK;
verwenden um sicher zu gehen.
Was ich noch gedacht habe ist das Makro umzubauen:
Die Makros bestehen NICHT aus einem einzelnen Assembler-Befehl. Wenn
eine ISR also auf die gleiche Struktur zugreifen kann, dann muss Gelockt
werden.
Du kannst das Locken und Unlocken auch in die Makros hineinschreiben.
Mag sein, dass in Sonderfällen ein Dazwischenfunken unschädlich ist,
aber darauf würde ich mich nicht verlassen. (Denkt jemand bei späteren
Erweiterungen noch daran?)
Okay ich muss was ergänzen, ich habe sehr viele Zufriffe wo ich eben nur
einzelne Bytes in die Queue schreiben möchte und dann kann ich diese
sozusagen schneller über eine Schnittstelle versenden. Bei mir immer 8
byte am Stück. Klar ist man mit einem Lock immer sicher, aber ich find
es halt unperfomant und bau nicht gerne locks ein.
Deshalb überlege ich immer genau, bis jetzt läuft seit 3 tagen bin mir
eben nur nicht ganz sicher ob ich falsch gedacht habe.
Also ich hab ja eigentlich nur einen single reader single writer
Zugriff, da muss ich nicht locken normal. Das Problem sehe ich eben nur
bei der Länge. Wenn ich es aber so wie unten mache müsste ich doch ohne
Lock auskommen sofern natürlich die idx++ atomar sind - oder?
Danke
Hat niemand hier noch eine Idee bzw. einen Kommentar dazu?
@ Thomas Z. :-) Danke aber das bezüglich makro und asm ist schon klar.
Ich habe meinen Assembler Code angeschaut => das Problem ist das es eine
Library ist und es sollte mit verschiedenen Compilern gehen, deshalb
kann ich mich nicht darauf verlassen.
aber immer isr lock und unlock ist doch auch schlecht
danke
clonephone82 schrieb:> sofern natürlich die idx++ atomar sind
Kommt auf die CPU an.
Auf einem CISC vielleicht, auf einem RISC (x++ = load,inc,store) auf
keinen Fall.
Die Namen Push,Pop definieren einen FILO (Stack), Dein Code sieht mir
aber ganz nach nem FIFO aus.
Die Größenbeschränkung auf 2-er Potenzen ist eine recht starke
Einschränkung, der Laufzeitvorteil aber nur äußerst minimal.
| ist ein OR und kein Kommentarzeichen, das irritiert extrem beim Lesen.
Besser ist //.
clonephon82 schrieb:> Was ich noch gedacht habe ist das Makro umzubauen:>> #define CBUF_Push( cbuf, elem ) (cbuf.m_entry)[ cbuf.m_putIdx & ((> cbuf##_SIZE ) - 1 )] = (elem); \> cbuf.m_putIdx++;>> #define CBUF_Pop( cbuf ) (cbuf.m_entry)[ cbuf.m_getIdx & ((> cbuf##_SIZE ) - 1 )]; \> cbuf.m_getIdx++;
Das ist genau die Variante, die ich nehmen würde.
Begründung: Durch das explizite Rausnehmen der ++ Operation ist sicher
gestellt, dass die auch tatsächlich als letztes passiert, nachdem alle
anderen Operationen abgeschlossen sind.
Ob du da rund um das ++ noch eine Interruptsperre brauchst oder nicht,
hängt auch davon ab, welchen Datentyp die Index Variablen haben. Wenn
das nur uint8_t sind, dann brauchst du keine, weil das Zurückschreiben
der Variablen dann atomar erfolgt.
Hmm. Mit diesen beiden Operationen, so wie die beiden implementiert
sind, ist das ganze allerdings ein Ringbuffer. Dann passt aber die
Längenfunktion nicht dazu. Die kommt mit der Ringbufferstruktur nicht
klar. In einem Ringbuffer kann es durchaus sein, dass der putIdx kleiner
als der getIdx ist. Deine Längenfunktion behauptet dann, dass sich eine
negative Anzahl an Elementen in deiner Queue befinden würden.
Allerdings interessiert einen bei so einer Queue die Anzahl der Elemente
meistens nicht wirklich. Die Operation, die man tatsächlich benötigt,
beantwortet die Fragestellungen: gibt es Elemente in der Queue? bzw. Ist
die Queue voll?
Und genau derartige Funktionen solltest du dir als Basis zur Verfügung
stellen. Genauso wie die Bezeichnungen "Push" und "Pop" irreführend
sind. Push und Pop sind ein Hinweis auf einen Stack und nicht auf eine
Queue. Bei einer Queue heissen die Funktionen traditionell "Enqueue" und
"Dequeue".
Wenn ich mir aus dem Web den Code für eine Queue suche und der
Programmierer nennt die Funktionen Push und Pop, dann klick ich bei
Google auf den nächsten Link.
Karl Heinz schrieb:> Das ist genau die Variante, die ich nehmen würde.
Äh. Die anderen natürlich. Die mit der Zwischenvariablen und der
do-while Makro Sicherung rundherum.
clonephon82 schrieb:> kein Lock braucht - ich> sehe das einfach aderst.
Was du übersiehst, das ist, das du das als Transaktion sehen musst. Du
machst du Zuweisungen und erst durch den ++ auf die putIdx Variable
(genauer, beim Zurückschreiben der Variablen), wird diese Aktion
abgeschlossen. Erst dann ist der Enqueue tatsächlich durch und die Daten
stehen in der Queue. Man könnte auch sagen: erst dann gilt es. Daher
brauchst du da auch keinen Lock, solange die putIdx Variable atomar
geschrieben werden kann, was im Falle eines uint8_t der Fall ist.
Solange dieses Zurückschreiben auf putIdx nicht erfolgt ist, sind für
jeglichen anderen Queue-verwendenden Code die Daten noch nicht in der
Queue. Der neue Queue-Eintrag hängt sozusagen in der Schwebe.
Mit einer Ausnahme natürlich: Es darf natürlich nie passieren, dass eine
Enqueue Operation durch eine anderen Enqueue Operation unterbrochen
wird. Den Fall hat man allerdings eher selten.
(Selbiges fürs rausnehmen und getIdx)
clonephone82 schrieb:> Also ich hab ja eigentlich nur einen single reader single writer> Zugriff, da muss ich nicht locken normal
vielleicht sehe ich da was falsch aber ein Lesen verschiebt doch die
Lesemarkierung - ist also auch ein Schreiben ...
Wenn 2 Leute unabhängig voneinander schreiben, dann kann man nur Locken
- oder Du synchronisierst diese beiden:
- Senden anhalten (Flag setzen) (dann holt die ISR keine neuen Bytes ab)
- viele einzelne Bytes schreiben
- Senden starten
In diesem Fall schreibt immer nur einer. Nachteil: Während des Füllens
wird nicht gesendet (verschmerzbar)
K.H. hat aber diesen Sonderfall (nur einer packt was hinein) super
erklärt. In diesem Fall braucht man kein Lock.
Thomas Z. schrieb:> clonephone82 schrieb:>> Also ich hab ja eigentlich nur einen single reader single writer>> Zugriff, da muss ich nicht locken normal>> vielleicht sehe ich da was falsch aber ein Lesen verschiebt doch die> Lesemarkierung - ist also auch ein Schreiben ...>> Wenn 2 Leute unabhängig voneinander schreiben, dann kann man nur Locken> - oder Du synchronisierst diese beiden:
Ja, aber den Fall hat er eigentlich nicht.
Er hat eher den Fall, dass der eine schreibt und dabei mit dem
Zeigefinger auf die Stelle zeigt, an die er schreibt. Erst nachdem er
vollständig geschrieben hat, wandert der Finger weiter zur nächsten
Stelle auf dem Papierstreifen um anzuzeigen, dass er beim nächsten mal
dort schreiben wird.
Der 'Leser' hat auch einen Finger, mit dem er auf die Stelle zeigt, von
wo er Lesen wird. Auf die Aufforderung hin, macht er das auch und
schiebt dann den Finger weiter.
Man muss nur aufpassen, wenn beide Finger auf dasselbe Feld zeigen. Dann
kann offenbar der Leser nichts sinnvolles lesen, wenn der Schreiber noch
nichts hingeschrieben hat. Sobald man aber aus diesem Stadium raus ist,
kann der Schreiber unabhängig vom Leser etwas auf den Papierstreifen
schreiben bzw. der Leser kann unabhängig vom Schreiber agieren. Die
beiden müssen daher nicht aufeinander achten. Und da beide den Finger
nur dann weiter schieben, wenn die eigentliche Aktion Schreiben bzw.
Lesen abgeschlossen ist, gibt es auch keinen gefährlichen
Zwischenzustand, solange nur sicher gestellt ist, dass das
Weiterschieben nicht unterbrochen wird. Das Schlimmste was passieren
kann ist, dass der Schreiber zwar seine Daten schon komplett
hingeschrieben hat, aber den Finger noch nicht weiter geschoben hat.
Blickt in diesem Moment der Supervisor auf die Situation, so stellt er
fest, dass nichts geschrieben wurde, da er sich nur am Finger
orientiert. Wird dir Infomation dazu benutzt, um dem Leser den Auftrag
zu geben zu lesen, dann findet das zu diesem Zeitpunkt daher noch nicht
statt, sondern wird auf das nächste mal Nachsehen vertagt.
Alles richtig K.H.
- erst Datenmanipulation (Lesen/Schreiben)
- dann Finger verschieben
Und wenn nur eine liest und nur einer schreibt ist alles gut.
Aber der TO wurde stutzig und ich auch, denn "sein" Macro:
1
Push:puffer[finger++&begrenzung]=wert;
Ob der Finger wirklich erst NACH der Zuweisung verschoben wird, kann ich
aus dem Hut nicht sagen. Für mich persönlich wäre ein
Hallo,
Vielen Dank für die Rückmeldungen.
@Peter Dannegger: Okay vielen dank.
Das werde ich das nächste mal anderst machen bezüglich | und //. Wollte
nur 2 Spalten simulieren. Momentan verwende ich die erste
Implementierung auf einem XE167 (C166) Kern 16Bit also RISC. Also 16Bit
Idx sind dann so wie du schreibst nicht atomar.
Bisher ging ich immer davon:
8Bit var => auf 8Bit CPU zumindest ++ atomar
16Bit var oder kleiner => auf 16Bit CPU zumindest ++ atomar
32Bit var oder kleiner => auf 32Bit CPU zumindest ++ atomar
meist reicht einem ja das wenn ++ atomar ist bei single reader und
writer speichern.
Später soll das dann auch auf einem CortexM4F von Infineon Verwendung
finden und auch auf einem STM32.
Okay also ich glaube es ist ein FIFO unabhängig vom Namen => ich mach
das immer mit #defines so wie ich es dann möchte siehe weiter unten.
Das mit den 2-er Potenzen ist mir klar - aber wenn ich nicht Modulo will
muss ich das doch immer so machen?
1
#ifndef COMM_RX_QUEUE_SIZE
2
#define COMM_RX_QUEUE_SIZE 512
3
#endif // #ifndef COMM_RX_QUEUE_SIZE
4
5
// check of the queue
6
#if COMM_RX_QUEUE_SIZE < 2
7
#error COMM_RX_QUEUE_SIZE is too small. It must be larger than 1.
8
#elif COMM_RX_QUEUE_SIZE > 32768
9
#error COMM_RX_QUEUE_SIZE is too large. It must be smaller than 32769.
@ Karl Heinz: Okay vielen dank.
Naja bin das nicht so arrogant was fremd Code angeht ich habe halt den
Artikel gelesen auf Embedded.com manchmal finde ich die ganz gut. Und
dann bin ich eben auf diese CBUF.h gekommen - was ich wirklich auch
nicht so schlecht finde. Ich verwende auch viel von Peter und Co aus
diesem Forum weil das einfach super Dinge sind - und man lernt einfach
viel. Also wie gesagt ich brauchte eine schnelle Implementierung eines
Speichers.
Ich mach das dann immer so:
So kann ich den Fremcode möglichst so belassen und wenn es mal eine neue
Version gibt einfacher austauschen => hier habe ich halt die xPush und
xPop => für extended dazugebaut. so wie auch von dir Empfohlen.
Meine Idx sind 16Bit jetzt -> später 32Bit das mache ich in Keil für den
C166 via Define und für die 32Bit varianten mit typeof:
Also bezüglich Länge => Also das ganze ist ein Fifo ich darf nicht
überschreiben das ist mir klar.
Das ist ja auch der Unterschied zu Fifo und Queue oder ?
Diese Schutz ist in den Makros nicht drin => aber das mach ich halt von
meiner SW aus.
@thomas: Vielen dank ja so habe ich das jetzt auch alles interpretiert.
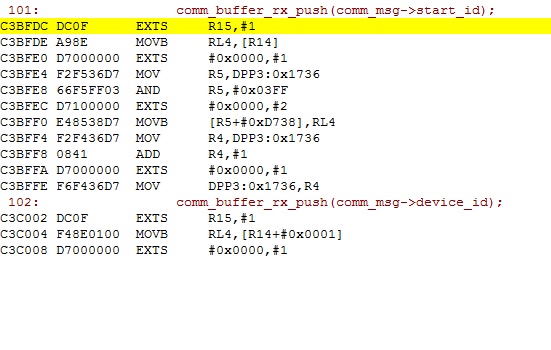
Anbei noch ein Bild von einem Push => ich gebe es zu ich kann echt ein
C166 Assembler brauchte es nie und finde es auch wirklich schwer zu
lesen mit diese blöden DPP´s aber so wie es aussieht ist es wirklich
load inc store über R4 und DPP3 also brauche ich wohl ein Lock um sicher
zugehen oder lese ich diesen Assembler falsch?
danke
sg
mathias
Hier noch das ganze CBuf.h mit meinen Änderungen. Habe auch noch
Funktionen mit Pointer ergänzt. CBUF_Pop2, CBUF_Len2 etc.
Werde das dann mal auf Github zurückgeben - vielliecht kanns es der
Autor ja brauchen.
sg
clonephon82 schrieb:> Das mit den 2-er Potenzen ist mir klar - aber wenn ich nicht Modulo will> muss ich das doch immer so machen?
Halt deine Compilerbauer nicht für Vollidioten. Wenn man eine
Modulo-Division durch eine andere Operation ersetzen kann, dann macht
das der COmpiler schon.
Einziger Unterschied:
1
uint8_tabc;
2
...
3
4
abc%=ANZAHL
funktioniert auch dann korrekt, wenn
1
#define ANZAHL 24
ANZAHL keine 2-er Potenz ist. Bei einer 2-er Potenz
1
#define ANZAHL 16
hingegen, wird dir der Compiler für
1
uint8_tabc;
2
...
3
4
abc%=ANZAHL
die Modulo-Division durch eine entsprechende Ver_Undung ersetzen, wenn
das auf der CPU schneller ist.
Solche Dinge machen Compiler seit mehr als 40 Jahren routinemässig.
Hallo Zusammen,
Ich wende mich nochmals an euch, weil ich aktuell einen komisch Fehler
hatte und ich glaube, dass das Problem in diesem Code steckt.
Also ich habe übersehen das diese Implementierung gar nicht
unterscheidet ob die Queue Voll oder Leer ist.
Len kann doch hier falsch sein => also putIdx und getIdx können ja
gleich sein und die Queue könnte voll oder leer sein. Wie vermeidet man
sowas normal? Also wie könnte ich diese Implementierung eurer Meinung
nach am besten anpassen. Weil eigentlich könnte ich das doch nur machen,
wenn ich die Idx´s begrenze und 1 Element Luft lasse.
Oder sonst sehe ich das jetzt gar nicht wie ich das lösen könnte.
Danke schon mal..
clonephon82 schrieb:> Len kann doch hier falsch sein => also putIdx und getIdx können ja> gleich sein und die Queue könnte voll oder leer sein.
Das ist bei der oben ersichtlichen Implementierung nur dann der fall,
wenn cbuff##_SIZE==(1<<sizeof(putIdx)) ist, also wenn cbuff##_SIZE==256.
> Wie vermeidet man sowas normal?
Dem buffer ne grösse von 1<<7 geben, also 128. Steht auch in den
kommentaren.
clonephon82 schrieb:> Ja das ist klar, aber das hat doch nicht damit zu tun das die idx´s> nicht mal auf UINT16T_MAX stehen können.>> Oder?
Ganz genau, deshalb ist es ja auch kein Problen, weil wenn es zum
Overflow von putIdx kommt und die buffergrösse < UINT16T_MAX bleibt die
differenz von putIdx zu getIdx maximal die buffergrösse. Also wenn du 0
elemente im buffer hast und getIdx=putIdx=UINT16T_MAX-2, und du legst
z.B. 4 elemente drauf, ist (putIdx=2)-(getIdx=UINT16T_MAX-2)=4. Und weil
die buffergrösse < UINT16T_MAX und buffergrösse=1<<x, wobei x ∈ N ist
ist der Spezialfall von putIdx-getIdx+1==0 erst nach (1<<x)-1
bufferoverflows möglich.