Hallo, ich habe hier ein für mich unbekanntes Textformat. Kann mir jemand sagen was das für ein Format ist? Die Hex-Werte sind Originalen Daten. A4 CE 26 3D E5 9E D1 21 46 B2 60 = 'A.d.Bruchm}hle' 0E 64 9A B9 7E 20 A7 86 22 00 = 'Kleiner Markt' A2 70 E5 3D 8E 69 42 A0 = 'Am Karlshof' AC 34 F9 72 1E 4E 00 = 'Alicestr.' 1F 25 AE 43 64 64 00 = 'Beuneweg' Gruß Max
Ich hab so das Gefühl, dass du mit der Zuordnung etwas zu kämpfen hast. Einmal ist A als AC und einmal als A4 kodiert. Entweder verschlüßelt oder keine direkte 1zu1 Zuordnung.....
Nicht wirklich eine Lösung, aber ein erster Hinweis: Die Kodierung braucht definitiv weniger als 1Byte pro Zeichen. Ich hab mal ausgerechnet wieviel. Erst unter Zählung aller Bytes, dann nach weglassen der 0 Nibbles am Ende (in Klammern). 14Z in 11Bytes => 6,28bit/Zeichen (6bit/Zeichen) 13Z in 10B => 6,15bit/Zeichen (5,53bit/Zeichen) 11Z in 8B => 5,81bit/Zeichen (5,54bit/Zeichen) 9Z in 7B => 6,22bit/Zeichen (5,33bit/Zeichen) 8Z in 7B => 7bit/Zeichen (6bit/Zeichen) Könnte das Format vielleicht komprimiert sein? Eine direkte Zuordnung mit 5bit/Zeichen und mit 6bit/Zeichen funktioniert bei mir nicht. Evtl. ist aber auch die Reihenfolge der Bits anders als von mir angenommen.
Hast Du als Beispiel einen Strassennamen mit einer Buchstabenwiederholung?
Weniger als 8bit pro Zeichen klingt plausibel. Vielleicht ein Huffman-Code? Dann haette "A" wohl ein Symbol von hoechstens 4 Bit abgekriegt, weil "Am" und "Al" sich bereits im fuenften Bit unterscheiden (weitere Annahme: die Bits werden MSb-first in Bytes gesteckt). Um das zu pruefen, kannst Du ja mal Paare von Woertern mit gleichem Anfang schnappen und jeweils messen, in wie vielen fuehrenden Bits sie uebereinstimmen. Wenn "Alice-Schwarzer-Allee" und "Alicestr" weniger gemeinsame fuehrende Bits haben als "Alicestr" und "Ali-Baba-und-40-Raeuber-Strasse", ist meine Hypothese widerlegt.
Konrad schrieb: > Weniger als 8bit pro Zeichen klingt plausibel. Vielleicht ein > Huffman-Code? Dann haette "A" wohl ein Symbol von hoechstens 4 Bit > abgekriegt, weil "Am" und "Al" sich bereits im fuenften Bit > unterscheiden (weitere Annahme: die Bits werden MSb-first in Bytes > gesteckt). Das sehe ich genauso, man muss sich einfach mal das große A anschauen: A4 = 10100100 A2 = 10100010 AC = 10101100 Die einzige Übereinstimmung ist in den ersten 4 Bit, also A=1010. Auch die unterschiedlichen Verhältnisse von Zeichen pro Bit sprechen für eine Komprimierung à la Huffman. Wenn es Huffman ist, bekommt man das raus. Aber dafür reichen die obigen Daten nicht. EDIT: Wenn man sich den Punkt in "A.d.Bruchm}hle" anschaut, dann muss dieser 01001100 oder kürzer sein:
1 | 1010 01001100 11100 01001100 011110111100101100111101101000100100001010001101011001001100000 |
2 | A . d? . |
EDIT2: Dass das "ü" als "}" geschrieben wird, muss nicht verwundern. Das ist 7-Bit ISO646 für Deutsch.
Konrad schrieb: > Vielleicht ein Huffman-Code? Daran habe ich auch zuerst gedacht. Wenn der Code aber wirklich zwischen Groß- und Kleinbuchstaben unterscheidet, erscheinen mir die 4 Bits für das große "A" etwas wenig. Damit das "A" nach Huffman in 4 Bits kodiert werden kann, darf es in der Haufigkeitsstatistik allerhöchstens auf Platz 15 liegen. In diesem langen Text https://de.wikipedia.org/wiki/Liste_der_Baudenkm%C3%A4ler_in_Viersen_%28A%E2%80%93F%29 liegt es aber auf Platz 34, könnte also nicht einmal mit 5 Bits kodiert werden. Ok, bei Straßennamen ist die Verteilung eine andere, da generell mehr Großbuchstaben auftreten und speziell das "A" in Straßennamen der Form "Am ..." sehr häufig auftritt. Hier kann man eine Liste von deutschen Straßennamen herunterladen: http://www.datendieter.de/item/Liste_von_deutschen_Strassennamen_.csv In dieser Liste liegt das "A" immerhin schon auf Platz 24, was aber für eine Kodierung in 4 Bits immer noch nicht ausreicht. Es kann natürlich sein, dass der Ersteller des Huffman-Codes für die Straßennamen eine ganz andere Code-Basis zugrunde gelegt hat, die die reale Häufigkeitsverteilung aber schon arg verzerren müsste, damit das "A" auf einen der oberen Plätze kommt. Vielleicht hat er aber auch ein ganz anderes Kodierungsververfahren verwendet. Frank M. schrieb: > 1010 01001100 11100 01001100 011110111100101100111101101000100100001010001101011001001100000 > A . d? . Wenn der "." tatsächlich als 01001100 kodiert wird (was nach deinem Beispiel sogar sehr wahrscheinlich erscheint), müsste die "Alicestr." mit "1E 4C 00" statt mit "1E 4E 00" enden. Da sich die beiden Bitmuster aber nur ein einem einzigen Bit unterscheiden, könnte das evtl. auch ein Abtippfehler des TE sein. Das "d" liegt in den obigen Statistiken auf Platz 9 (Wikipedia-Text) bzw. auf Plaz 15 (Straßennamen), also deutlich vor dem "A", und sollte deswegen keinesfalls mehr Bits als das "A" beanspruchen. Aber auch hier könnte eine verzerrende Code-Basis eine Erklärung sein.
Yalu X. schrieb: > Wenn der "." tatsächlich als 01001100 kodiert wird (was nach deinem > Beispiel sogar sehr wahrscheinlich erscheint), müsste die "Alicestr." > mit "1E 4C 00" statt mit "1E 4E 00" enden. Witzig, an diesem Problem knabbere ich gerade auch. Da ist ein Bit gekippt... Andere Möglichkeit: der Punkt ist nur mit 6 Bits statt 8 Bits kodiert. Das halte ich aber für unwahrscheinlich. Obwohl... vielleicht wurde auch stark mit Punkten abgekürzt, so dass dieser gar nicht so unwahrscheinlich ist.
Kann der TE bestätigen, dass diese Daten aus derselben Datei sind? Nicht das am Ende jedesmal neu kodiert wurde, und jedesmal ein anderer Code verwendet.
Mein bisheriger Vorschlag: A: 101 B: 111 K: 1110 l: 01100 e: 100100 Wieviel das noch mit Huffmann zu tun hat müsste ich aber überprüfen. Edit: Ich merke gerade, dass das 'B' und 'K' nicht mehr unterscheidbar wären...
Operator S. schrieb: > K: 1110 Du hast die 4 führenden Nullen vergessen: 0E = 0000 1110 -> darin steckt das K > B: 111 Ähnliches gilt für das B: 1F = 0001 1111 -> darin steckt das B Ausserdem halte ich lediglich 3 Bits für A oder B für viel zu wenig.
Hey, vielen Dank für eure Hilfe! :-) anbei noch einige weitere Beispiele: 11 B5 62 76 B2 08 E5 C0 88 7B 57 20 = 'Friedr.Ebert-Pl.' 11 B5 62 76 B2 24 11 59 13 21 6B 90 = 'Friedr.-Eb.-Str.' 11 B5 62 6F 28 F9 00 = 'Friedhof' 11 C6 A7 B0 B7 01 59 20 = 'Feldstra~e' 11 C6 A7 B0 B7 6E E4 80 = 'Feldstrasse' 11 C3 72 C2 F1 F7 20 = 'Feuerwehr' 11 C3 72 C2 F1 F7 20 = 'Feuerwehr' 1A A6 27 96 FC 50 A9 = 'Kinderheim' 1A AB 49 FB 0B 76 EE 48 = 'Kirchstrasse' 1A AB 49 FB 0B 5C 80 = 'Kirchstr.' 1A AB 49 F9 20 = 'Kirche' 07 59 11 98 6E A4 F6 65 91 32 16 B9 00 = 'W.-Leuschner-Str.' 07 59 11 98 6E A4 F6 65 91 32 16 B9 00 = 'W.-Leuschner-Str.' 07 59 12 6E 83 F1 64 4C 85 AE 40 = 'W.-Rathe.-Str.' 26 56 C0 A4 85 E5 F3 21 6B 90 = 'Rostocker Str.' 26 E8 3D C6 EC 80 = 'Rathaus' A6 A6 A9 = 'Aldi' 1E E7 B0 21 1C B4 1C C4 24 = 'Bahn}bergang' 1E E7 B1 E5 1E 59 81 09 C8 = 'Bahnhof/S}d' 1E E7 B1 E5 1F B0 B5 C8 = 'Bahnhofstr.' 1E E7 B1 E5 1F B0 B7 6E E4 80 = 'Bahnhofstrasse' 0A C1 25 42 40 = 'Depot'
https://de.wikipedia.org/wiki/Varicode das ist die Codierung mit variabler Zeichenlänge, die in PSK31 verwendet wird. Da wird noch auf allgemeinere Verfahren verwiesen: https://de.wikipedia.org/wiki/Fano-Bedingung
Ansatz:
Beuneweg mit erster Stelle B und einem signfikanten Bitmuster.
00011111001001011010111001000011011001000110010000000000 ''
- Bruchm}hle hat 5. Stelle B.
- A ist 1,10,101 oder 1010 (o.g.)
- Zwei Wiederholungen von '.'
000001001100111000100110001111011110010110011110110100010010000101000110
1011001001100000
Ergibt die folgenden beiden Varianten:
A:101 .:0010011 d:001110 .:0010011 B:[0001111...
A:1010 .:010011 d:0011100 .:010011 B:[0001111...
Typische Kodierung wäre Tag+Value mit Tag 0*1 und davon abhängig die
Länge des Wertes.
A:1+010 .:01+0011 d:001+1100 .:01+0011 B:0001+111...
Bsp. Beuneweg:
B:0001+111 e:1+001 u:001+0110 n:1+011 e:1+001 w:00001+101 e:1+001
g:0001+1001 {0000000000}
Das scheint mt den Tags 1 (3 Bit Value) und 001 (4 Bit Value) zu
klappen.
Die anderen sind scheinbar mit variabler Länge (+/-1).
Bsp. Alicestr.:
A:1+010 l:1+100 i:001+1010 c:01+111 e:1+001 s:01+1100 t:1+000 r:01+1110
.=01+0011 {1000000000} 'Alicestr.'
Also c:01+111 aber .=01+0011. Da müsste man sich mal die Bitmuster
genauer anschauen.
Geht auch an versch. anderen Stellen nicht ganz auf. Jetzt muss ich aber
mal was richtiges machen... ;-)
Es scheint tatsächlich ein Art Huffman-Code zu sein, nur dass die Bitbreite der einzelnen Zeichen nicht unbedingt mit ihrer relativen Hüufigkeit korrelliert. Die Codes für die Straßennamen im ersten Beitrag habe ich inziwschen herausgefunden:
1 | ' ' 11 |
2 | 'A' 101 |
3 | 'e' 1001 |
4 | 't' 01000 |
5 | 'a' 01010 |
6 | 'n' 01011 |
7 | 'l' 01100 |
8 | 'h' 01101 |
9 | 's' 01110 |
10 | 'r' 01111 |
11 | 'o' 001010 |
12 | 'u' 001011 |
13 | 'i' 001101 |
14 | 'd' 001110 |
15 | 'c' 001111 |
16 | 'm' 0001001 |
17 | 'f' 0001010 |
18 | 'g' 0001100 |
19 | 'B' 0001111 |
20 | '.' 0010011 |
21 | 'k' 00001100 |
22 | 'w' 00001101 |
23 | 'K' 00001110 |
24 | 'M' 00010000 |
25 | 'ü' 000010100 |
26 | '\0' 1000 oder 10000 oder 100000 (Stringende) |
Diese Kodierung sind präfixfrei und stimmt für alle der im ersten Beitrag angeführten Straßennamen. Es scheint auch so (da bin ich mir allerdings nicht zu 100% sicher), dass das die einzigen mögliche Kodierung mit diesen Eigenschaften ist. Mit den neuen Beispielen kann man natrürlich noch ein paar mehr Zeichen erraten.
Zu erwähnen ist noch dass die hier aufgestellten Daten alle aus der selben Datei stammen. Am Anfang der Datei wird aufgelistet wie lang die "Streams" sind und an welcher Position sie sich befinden. Somit ist also in den Hex-Werten nicht hinterlegt wo der Text anfängt und endet.
Yalu X. schrieb: > Die Codes für die Straßennamen im ersten Beitrag > habe ich inziwschen herausgefunden: Gratuliere! Aus so wenig Daten soviel herausgeholt... Hast Du dafür ein Programm geschrieben, um dahinterzukommen oder hast Du das alles per Hand gemacht?
Entschuldigt bitte! Die Daten aus dem ersten Thread stammen aus einer anderen Grunddatei aus der ich nur die ersten 5 gezeigten Beispiele ausgelesen habe. Daher bitte nur noch mit den neuen Beispielen arbeiten.
Max S. schrieb: > Entschuldigt bitte! Die Daten aus dem ersten Thread stammen aus einer > anderen Grunddatei aus der ich nur die ersten 5 gezeigten Beispiele > ausgelesen habe. Daher bitte nur noch mit den neuen Beispielen arbeiten. Stimmt! Denn diese Daten:
1 | 11 B5 62 76 B2 08 E5 C0 88 7B 57 20 = Friedr.Ebert-Pl. 000100011011010101100010011101101011001000001000111001011100000010001000011110110101011100100000 |
2 | 11 B5 62 76 B2 24 59 13 21 6B 90 = Friedr.-Eb.-Str. 0001000110110101011000100111011010110010001001000101100100010011001000010110101110010000 |
3 | 11 B5 62 6F 28 F9 00 = Friedhof 00010001101101010110001001101111001010001111100100000000 |
passen nicht zu den Daten im Ursprungsposting. Yalus Tabelle lässt sich nicht darauf anwenden. Bringt Dir dann eine Decodierung überhaupt etwas, wenn Du alle paar Minuten eine neue Datei hast?
Die Datei bleibt die gleiche. Die ersten Beispiele stammten nur aus einer alten Datei mit welcher ich nicht mehr arbeite. Das Grundgerüst bleibt jetzt sozusagen gleich.
Angehängte Dateien:
-

TrT.PNG
6,2 KB
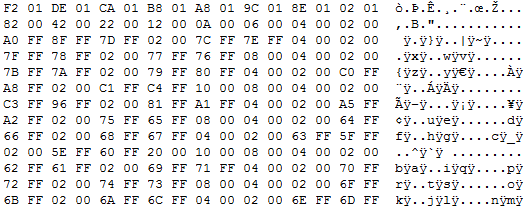
Angereizt durch die Bemerkung dass die Daten aus dem Ursprungspost nicht zu den neuen Beispielen passen habe ich mir weitere Bestandteile der Datei angeschaut und folgendes gefunden (siehe Anhang). Dort muss wohl die Codierung hinterlegt sein.
Frank M. schrieb: > Gratuliere! Danke :) > Aus so wenig Daten soviel herausgeholt... Hast Du dafür ein > Programm geschrieben, um dahinterzukommen oder hast Du das alles per > Hand gemacht? Von Hand. Ist ein Bisschen wie Sudokus Lösen :) Man fängt mit den Buchstaben an, die einfach erscheinen, wie bsp. das "A". In den Fällen,wo es zunächste mehrere Alternativen gibt, führen die meisten dieser Alternativen irgendwann zu einem Widerspruch, so dass sie ausschließen kann. Wenn man mit größeren Datenmengen arbeitet, wäre aber sicher besser, das Problem vom Computer lösen zu lassen. Nachdem nun ziemlich sicher um welche Art der Kodierung es sich handelt, werde ich mir vielleicht heute Abend mal etwas dazu überlegen. Max S. schrieb: > Entschuldigt bitte! Die Daten aus dem ersten Thread stammen aus einer > anderen Grunddatei aus der ich nur die ersten 5 gezeigten Beispiele > ausgelesen habe. Daher bitte nur noch mit den neuen Beispielen arbeiten. Und ich dachte schon, ich hätte mit der obigen Lösung völlig daneben gelegen ;-) Aber wenn die Kodierung in jeder Datei anders ist, müsste dann nicht auch die Codetabelle in der Datei enthalten sein? Oder wie weiß sonst ein Programm, das die Dateien benutzt, wie sie zu dekodieren sind? Max S. schrieb: > Angereizt durch die Bemerkung dass die Daten aus dem Ursprungspost nicht > zu den neuen Beispielen passen habe ich mir weitere Bestandteile der > Datei angeschaut und folgendes gefunden (siehe Anhang). Dort muss wohl > die Codierung hinterlegt sein. Ah, ok. Aber woran erkennst du das? Edit: Ich glaube, du hast recht. Ich habe da so einen Verdacht ...
Die Anwendung von ISO646-Code (Umlaute und ß), die Huffman-Codierung und die Codierungstabelle am Anfang erinnert mich stark an das alte Unix-Kommando "pack", was das Standard-Komprimierungsprogramm in den 70ern war, bevor compress, gzip, zip usw. dem pack den Rang abliefen. https://en.wikipedia.org/wiki/Pack_%28compression%29
Max S. schrieb: > Dort muss wohl die Codierung hinterlegt sein. So ist es tatsächlich. Der gepostete Hex-Dump enthält den Baum, mit dem die Bitmuster dekodiert werden. Es gibt 257 mögliche Zeichen, wobei das letzte (mit dem Huffman-Code 1001) das Stringendezeichen ist. Die Codetabelle habe ich angehängt, mehr zum Aufbau des Baum werde ich nachher noch schreiben.
So, hier sind wie angekündigt mehr Informationen zum Dekodierbaum: Zum Verständis ist es wichtig zu wissen, wie so ein Dekodierbaum prinzipiell funktioniert: Der Dekodierbaum ist ein Binärbaum, bei dem jeder Knoten ein 0-Kind und ein 1-Kind hat, und bei dem jedes Blatt einem Zeichen des dekodierten Alphabets entpricht. Um eine Bitfolge zu dekodieren, hangelt man sich von der Wurzel des Baums von Knoten zu Knoten, bis man ein Blatt erreicht. Dabei wählt man bei jeder Verzweigung entsprechend dem jeweils nächstem Bit in der Eingabe entweder das 0- oder das 1-Kind als nächsten Knoten. Das schließlich erreichte Blatt ist dann das dekodierte Zeichen. Sind nach dieser Aktion noch nicht alle Bits der Eingabe aufgebraucht, wiederholt sich das Spiel mit den restlichen Bits. Der Binärbaum wird in der Datei als Liste von 513 vorzeichenbehafteten 16-Bit-Zahlen im Zweierkomplement- und Little-Endian-Format dargestellt. Jede Zahl in dieser Folge repräsentiert einen Knoten (Zahl>0) oder ein Blatt (Zahl≤0). Die erste Zahl in der Folge ist der Wurzelknoten. Das 0-Kind eines Knotens ist sein direkter Nachfolger in der Liste, das 1-Kind der n-te Nachfolger, wobei n der Zahlenwert des betrachteten Knotens ist. Die Blätter haben als Zahlenwert den negierten Code des Zeichens, den sie repräsentieren. Im angehängten Python-Programm ist das bisher Geschriebene umgesetzt. Es enthält die Routinen readTree für das Einlesen der Zahlenfolge aus dem von Max geposteten Hexdump Max S. schrieb: > 24100001.txt und huffmanDecode für die eigentliche Dekodierung. Die 0/1-Strings in examples stammen von den Beispielen hier: Max S. schrieb: > anbei noch einige weitere Beispiele:
Vielen Dank für die Erklärungen und dem Python-Script. Leider habe ich mit dieser Sprache noch nicht gearbeitet, ausführen konnte ich ihn aber. Mit der von dir erstellte Tabelle "codetab.txt" konnte ich unter VBA/Excel eine Kodierung umsetzen. Nun würde ich gerne einen Dekodierbaum (wie in 24100001.txt) erstellen. Dabei soll aber der Ascii-Zeichensatz abgebildet werden. Mir ist bewusst dass damit natürlich der Sinn des Sparen von Speicherplatzes nicht erfüllt wird - es ist aber für mich das einfachste Lösung. Hast du da noch eine Lösung parat diesen zu erstellen?
Max S. schrieb: > Dabei soll aber der Ascii-Zeichensatz abgebildet werden. ASCII ist 7-Bit. Nicht mehr und nicht weniger. Genau damit sind die Daten kodiert, nämlich mit der deutschen Variante von ISO646 (DIN 66003). Hier bei werden die 6 deutschen Umlaute und das ß auf {[]}|\~ gemappt. Du meinst wahrscheinlich etwas anderes, nämlich 8-Bit, also zum Beispiel ISO8859-1 (ohne €-Zeichen) bzw. ISO8859-15 (mit €-Zeichen) - auch umgangssprachlich als "ANSI-Zeichensatz" (nicht ASCII!) bekannt. Literaturhinweise: https://de.wikipedia.org/wiki/ISO_646 https://de.wikipedia.org/wiki/DIN_66003 https://de.wikipedia.org/wiki/ISO_8859-1 https://de.wikipedia.org/wiki/DIN_66303 https://de.wikipedia.org/wiki/ISO_8859-15
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.