Hallo,
ich werde noch wahnsinnig mit dem GCC :-( Jedesmal wenn ich
Hardwarefunktionen codieren, die einwandfrei laufen OHNE OPTIMIERUNG und
die dann einschalte kommt es zu seltsamen Dingen, meist einfach
"funktioniert nicht mehr" bis "Hard Fault" Exeption Handler.
Ich schreibe nicht erst seit gestern Programme ..... schnaub Mi dem
Keil habe ich nie solche Probs gehabt, den kan ich mir aber nicht mit
nach Hause nehmen, weil der der Firma gehört.
Wie kann es sein, dass dieser Compiler es nicht kapiert, dass die
Funktion so gemeint ist wie sie da steht?
In dem Code ist wirklich nichts geheimnissvolles aber schon die
Intialisierung schlägt fehl, aus der SPI kommt nich das raus, was
rauskommen soll.
Erst wenn ich das ganze Modul mit
#pragma GCC optimize ("O0")
"abtöte" klappt es.
Wenn dein Code nur ohne Optimierung funktioniert dann schreibst du
keinen standardkonformen Code, bzw. verlässt dich auf nicht zugesicherte
Eigenschaften.
An welcher Stelle z.B. funktioniert was nicht und wie stellst du das
fest?
le x. schrieb:> An welcher Stelle z.B. funktioniert was nicht und wie stellst du das> fest?
Ist nicht feststellbar ohne weiteres. Ich merke nur, dass das RF Modul
nicht reagiert, wenn ich seine Anwesenheit prüfe. Testweise habe ich die
Optimierung mal für SPI Routine und Init abgeschaltet und dann geht es
wieder. Das tritt auch bei Libs aus dem Netz auf, die geprüft sind, die
zig Leute verwenden.
__attribute__((optimize(0)))
muss bei SPI_Sendbyte stehen und bei der SPI_INIT, dann läuft es auch
aus dem Kaltstart heraus. Sonst kommt die Fehlermeldung, dass Gerät
nicht vorhanden.
definiert ist.
Das wär aber so ein typisches Optimierungsproblem:
der Compiler geht davon aus dass SPI_I2S_GetFlagStatus immer "1"
liefert, somit hast du eine Endlosschleife
Christian J. schrieb:> Mi dem Keil habe ich nie solche Probs gehabt
Hunderttausende andere Programmierer haben diese Probleme mit dem GCC
auch nicht.
Allerdings ist es anhand der vagen Beschreibung schwierig zu raten,
was du wohl falsch machst. Das muss ja nichtmal am Code liegen, es
kann auch der Linkerscript sein (woher stammt der, den du benutzt?).
Einen Hardfault kann man debuggen. Damit sollte man zumindest die
Ursache finden, dann bekommt man vielleicht auch eine Idee, woran
das liegt.
Jörg W. schrieb:> Christian J. schrieb:> Mi dem Keil habe ich nie solche Probs gehabt> Einen Hardfault kann man debuggen. Damit sollte man zumindest die> Ursache finden, dann bekommt man vielleicht auch eine Idee, woran das> liegt.
Um ein gescheiten Hardfault-Handler hat er sich ja vor kurzem schonmal
ewig drum herum geredet...
Aber was dieser Fred soll, wenn man nicht mal das Problem etwas präziser
beschreibt, sodass man helfen kann, sondern wieder nur GCC bashing drin
vorkommt, dann nervt es langsam wirklich. Zumal es zu 99,9% erneut nicht
an diesem liegen wird.
Horst schrieb:> Zumal es zu 99,9% erneut nicht> an diesem liegen wird.
Doch, natürlich liegt es am GCC. Richtiger Code kann ja nicht einmal
richtig und dann falsch sein. Und den Hard-Fault Zirkus fange ich gar
nicht erst an, erwarte davon auch keine neue Erkenntnis. Ichj schalte
die Optimierung partweise ab und damit soll es gut sein, wenn es keine
einfache Lösung gibt.
Christian J. schrieb:> Peter II schrieb:>> wer sagt denn das der Code richtig ist?>> Das Laufzeit Ergebnis
nein, das zeigt nur das es zufällig unter gewissen Optionen
funktioniert.
.... oder wer sieht da einen Fehler drin?
nein, aber das hat wenig zu sagen. Ich würde mich zumindest nicht damit
zufrieden geben.
Kannst du nicht alles absprecken und nur die SPI Send_byte aufrufen und
einfach mal ein Oszi anstecken und dann mit und ohne Optimierung
vergleichen?
Christian J. schrieb:>> wer sagt denn das der Code richtig ist?>> Das Laufzeit Ergebnis.
Nein, das besagt, dass es da einen Fehler gibt. Ansonsten hättest
du diesen Thread nicht eröffnet.
Wenn du lieber, statt den Fehler zu suchen (und ihn so in Zukunft
vermeiden zu können), den Rückzieher machst und irgendwas machst,
Hauptsache es klappt, dann ist das natürlich deine Entscheidung –
aber dann brauchst du hier nicht nach Ratschlägen zu fragen.
Es kann natürlich gut sein, dass dein schönes Kartenhaus im nächsten
Moment wieder zusammefällt, weil sich irgendwelche Bedingungen
geändert haben, und der „Trick“ dann nicht mehr klappt.
Tu, was du willst, aber meckere nicht über deine Werkzeuge, wenn du
zu faul bist, die Fehler auch zu suchen. Klar gibt es auch Fehler im
Compiler, aber in den allermeisten Fällen sitzt der Fehler immer noch
zwischen Tastatur und Stuhl.
Jörg W. schrieb:> Tu, was du willst, aber meckere nicht über deine Werkzeuge, wenn du> zu faul bist, die Fehler auch zu suchen.
Das ist in der Tat der Fall, daher kannst Du den Thread auch schliessen.
Ich habe mein Projekt grad von jemandem aus dem Netz mit dem Keil durch
compilieren lassen und der hat mir den Hex Code geschickt, auf maximaler
Optimierungsstufe. Er läuft einwandfrei durch. Darum wird jetzt das
Werkzeug ausgetauscht, auch wenn es etwas kostet.
Peter II schrieb:> Kannst du nicht alles absprecken und nur die SPI Send_byte aufrufen und> einfach mal ein Oszi anstecken und dann mit und ohne Optimierung> vergleichen?
Evtl. heute abend mal ..... da nur die SPI Routinen betroffen ist lässt
sich das evtl eingrenzen aber das sind alles Herstellerroutinen, die
eigentlich getestet sein sollten.
Christian J. schrieb:> Jörg W. schrieb:>> Tu, was du willst, aber meckere nicht über deine Werkzeuge, wenn du>> zu faul bist, die Fehler auch zu suchen.>> Das ist in der Tat der Fall, daher kannst Du den Thread auch schliessen.> Ich habe mein Projekt grad von jemandem aus dem Netz mit dem Keil durch> compilieren lassen und der hat mir den Hex Code geschickt, auf maximaler> Optimierungsstufe. Er läuft einwandfrei durch. Darum wird jetzt das> Werkzeug ausgetauscht, auch wenn es etwas kostet.
Ich würde das als Zeichen dafür interpretieren, dass der Keil ziemlich
mies optimiert...
Aber ernsthaft: Du verlässt dich darauf, dass der Compiler hier und da
etwas genau so macht, wie du es möchtest.
Im Gegenzug verlässt sich der Compiler aber darauf, dass du dich an die
Regeln hälst, wenn du ihm sagst, wie er es zu machen hat.
Wenn du dich nicht an Regeln hälst, brauchst du dich nicht wundern, wenn
der Compiler dich missversteht.
Ich behaupte, SPI_I2S_GetFlagStatus ist fehlerhaft. Vermutlich zieht
der GCC sie als inline rein und optimiert sie ganz raus. Zeig doch mal
die Implementierung davon.
Nase schrieb:> Ich behaupte, SPI_I2S_GetFlagStatus ist fehlerhaft. Vermutlich zieht> der GCC sie als inline rein und optimiert sie ganz raus. Zeig doch mal> die Implementierung davon.
hätte ich auch gedacht, Google liefert:
http://www.cs.indiana.edu/~bhimebau/f3lib/html/stm32f30x__spi_8c_source.html#l01298
Wenn du genauso umgesetzt ist, sollte da kein Fehler drin sein.
Der ASM code dafür sollte nicht allzu viel sein, eventuell ist es ein
Timing Problem. DAs es zu schnell ist.
Nase schrieb:> Wenn du dich nicht an Regeln hälst, brauchst du dich nicht wundern, wenn> der Compiler dich missversteht.
Was soll ich denn da noch machen außer -Wall einzuschalten ? :-) Und zu
sehen, dass da nichts bemeckert wird. Ja, ich verlasse mich da drauf,
dass der Compiler keine Hardwarezugriffe "verschluckt", wenn ich mit
volatile nur so um mich geworfen habe.
Die GCC Probs tauchen nur bei hardwarenahe Sachen auf, I2C, SPI, DMA
Sachen, niemals aber bei Berechnungen usw.
Christian J. schrieb:> Was soll ich denn da noch machen außer -Wall einzuschalten
-Wall ist doch kein Allheilmitteln. Es gibt genug Unsinn den man
schreiben kann ohne das eine Warnung kommt.
Schau Dir doch mal den ASM Output an, dann siehst Du schnell ob und was
weg optimiert worden ist und kannst vermutlich auch den Grund eruieren.
Die Wahrscheinlichkeit, dass der Fehler beim Compiler ist, ist limes 0.
Grüsse,
René
Christian J. schrieb:> Die GCC Probs tauchen nur bei hardwarenahe Sachen auf, I2C, SPI, DMA> Sachen, niemals aber bei Berechnungen usw.
Anders: die „GCC Probs“ tauchen nur bei dir auf.
Ich versichere dir, dass wir hier ein Vieltausendzeiler-Projekt
völlig problemlos mit dem GCC compilieren können. Ist kein STM32
sondern Atmel-SAM4, aber das ist dem Compiler ja herzlich egal.
Hardwarenah ist es auf jeden Fall, wir haben teils sehr strikte
Timings, synchronisiertes SPI (zwei Devices, die parallel von einem
Master getaktet werden können, deren MISO wiederum an zwei
unterschiedliche SPI/USART zum Controller geht). Das klappt klaglos,
mit GCC.
Ein einziges Toolchain-Problem hatten wir mal, da wurden
Gleitkommazahlen im printf() manchmal nicht richtig ausgegeben.
Das hat sich mit einem Upgrade der newlib von Version 2.1.0 auf
2.2.0 beheben lassen. Alle anderen Probleme, die wir bislang hatten,
haben sich immer wieder als auf Layer 8 befindlich herausgestellt.
Christian J. schrieb:>> Kannst du nicht alles absprecken und nur die SPI Send_byte aufrufen und>> einfach mal ein Oszi anstecken und dann mit und ohne Optimierung>> vergleichen?>> Evtl. heute abend mal ..... da nur die SPI Routinen betroffen ist lässt> sich das evtl eingrenzen aber das sind alles Herstellerroutinen, die> eigentlich getestet sein sollten.
GCC funzt hier auch einwandfrei.
Es macht auch Sinn, sich den erzeugten ASM-Code anzuschauen, um
eventuell Hinweise auf den Fehler zu finden, so schwer ist der
thumb-code nicht zu verstehen.
Asm-listing mit c-source kann man z.b. mit objdump -d -S aus dem ELF
File erzeugen.
Hallo Christian,
bin erst jetzt auf den Thread aufmerksam geworden ...
Warum nimmst du nicht die aktuellen CubeMx Bibliotheken ...
Ich nehme mal an, du hast die Ursache noch nicht gefunden.
Kannst du eigentlich mit deinem Code die Identification Register lesen?
Grüße,
Adib.
Ist jetzt nicht SPI aber bei DMAD2 hatte ich den Fall das man der
Pheripherie auch Zeit für ihre Zustandslogik lassen muß.Es taktet ja
nicht alles mit vollem Speed.
Bei sowas z.B.
while(!SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_RXNE)); // Warte
bis SPI komplett fertig...
while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_BSY)); // Wert
abholen...
können ein paar takte mehr im nicht optimiertem Code schon was
ausmachen.
m.f.G.
Dieter
Jörg W. schrieb:> Anders: die „GCC Probs“ tauchen nur bei dir auf.
Jörg, mach den Thread bitte zu. Da das alles nicht sein kann brauchen
wir es also auch nicht zu diskutieren. Ich komm schon klar, danke.
Dieter Graef schrieb:> können ein paar takte mehr im nicht optimiertem Code schon was> ausmachen.> m.f.G.> Dieter
Vermutlich war es das auch.... denn so läuft es. Sehr seltsam.
Christian J. schrieb:> Doch, natürlich liegt es am GCC. Richtiger Code kann ja nicht einmal> richtig und dann falsch sein.
Aber falscher Code kann so funktionieren wie erwartet; dadurch wird der
Code aber nicht korrekt.
rmu schrieb:> Es macht auch Sinn, sich den erzeugten ASM-Code anzuschauen, um> eventuell Hinweise auf den Fehler zu finden, so schwer ist der> thumb-code nicht zu verstehen.
so hab testweise gerade SPI_SendByte compiliert, da gibts keinen
Unterschied zwischen -O0, -Os und -O3, kommt immer der selbe
maschinencode raus.
gcc 5.2.1
Genauer gesagt reicht ein 1uS Delay an genau dieser Stelle aus zwischen
BSY = false und dem Auslesen des Wertes bei einer 1.3 Mhz SPI mit
Prescaler 64 ..... jetzt noch mal das Ganze mit Full Speed GPIO.
rmu schrieb:> rmu schrieb:>> Es macht auch Sinn, sich den erzeugten ASM-Code anzuschauen, um>> eventuell Hinweise auf den Fehler zu finden, so schwer ist der>> thumb-code nicht zu verstehen.>> so hab testweise gerade SPI_SendByte compiliert, da gibts keinen> Unterschied zwischen -O0, -Os und -O3, kommt immer der selbe> maschinencode raus.
Sei vorsichtig mit solchen "testweise"-Sachen.
Wenn du die Routine isoliert kompilierst, kommt möglicherweise was ganz
Anderes bei heraus. Gibts Link-Time-Opti?
Mach mal nur ein Delay an den Anfang der Routine bzw. an das Ende und
schau in das Listing vom ganzen Projekt. Ein- und Rücksprung könnten
noch durch den Optimierer beeinflusst werden.
Rene H. schrieb:> Mach mal ein diff der beiden.
Ist schwierig, wenn man sich das Disassembler-Listing nur ansieht.
Besser geht das, wenn man sich den vom Compiler erzeugten
Assemblercode ansieht (Option -S statt -c).
Rene H. schrieb:> Mach mal ein diff der beiden.
Weiss nicht wie das geht .... Windows 7 .... diem optimierte ist einiges
kürzer, sieht man ja. Und wo das Problem liegt weiss ich ja jetzt auch,
die CPU ist zu schnell.
Wie gesagt, ein Delay von wenigen Mikrosekunden genau vor diesem Befehl
behebt das Problem, auch bei doppelter SPI Geschwindigkeit (max 4 Mhz
darf ich). Das wirft für mich schon etwas die Frage auf, was denn die
Flags mir zu sagen haben, die ich extra agefragt habe, sogar zwei Stück,
nämlich "Data Receive Ready" und "SPI Busy". Denn ich hätte schon
erwartet, dass 1 Systick nach Ende der Warteschleife der Wert da ist.
(142) return SPI_I2S_ReceiveData(SPI1); // Wert abholen...
08002284 ldr r0, [pc, #8] ; (0x8002290 <SPI_SendByte+60>)
08002286 bl 0x8000db6 <SPI_I2S_ReceiveData>
Das sind zumindest für mich Sachen, deren Ursachen ich nur schwer
ergründen kann. Das gleiche Problem hatte ich mal bei I2C Routinen, auch
mit den Flags. Da half auch nur Optimierung aus.
Möglicherweise ist also der GCC nicht "schuldig", sondern der macht es
so gut, dass es eben zu schnell wird. Der STM32 ist ja nicht global
taktsyynchron sondern hat verschiedenen Clocks innen am werkeln, die
Pins schalten nicht so schnell wie die CPU.
PS.
Ein
GPIO_InitStruct.GPIO_Speed = GPIO_Fast_Speed;
statt
//GPIO_InitStruct.GPIO_Speed = GPIO_Medium_Speed;
behebt das Problem auch, auch ganz ohne Delay. Ok, sorry, wenn ich den
GCC im Verdacht hatte, das war wohl ei Schnellschuss aus dem Ärger
heraus. Dazugelernt, dass auch 1.3Mhz SPI lieber Full Speed GPIO
braucht. Wusste ich auch nicht, normale LED lassen sich mit Slow auch
schalten aber wohl keine Peripherien.
Tja..... und auch die I2C Routinen laufen jetzt, nachdem ich deren Pins
auf Fast umgestellt habe und wieder volle Optimierung zulasse.
Christian J. schrieb:> Möglicherweise ist also der GCC nicht "schuldig", sondern der macht es> so gut, dass es eben zu schnell wird.
Aber das macht ja nix, du hast dich ja schon für den Kauf von Keil
entschieden. Dann kannst du dich weiterhin an deinem langsamen Code
erfreuen, weil die Optimierung da ja scheinbar schlechter ist, als
diejenige des GCC.
Christian J. schrieb:> Möglicherweise ist also der GCC nicht "schuldig", sondern der macht es> so gut, dass es eben zu schnell wird.
Aus Simpsons zitiert: "Du bist wie Christoph Kolumbus, du hast etwas
entdeckt, das Millionen [hier eher 'viele'] Menschen schon vor dir
kannten." ;-P
Christian J. schrieb:> Dazugelernt, dass auch 1.3Mhz SPI lieber Full Speed GPIO braucht. Wusste> ich auch nicht, normale LED lassen sich mit Slow auch schalten aber wohl> keine Peripherien.
Naja, LED als Referenz ist schon ein bisschen lächerlich, meinst du
nicht?
Aber wenn es an dem GPIO-Speed läge, wäre es eine interessante
Entdeckung. Hast du mal ein Scope drangehalten? Kann es vielleicht auch
an einem Hardwaretechnischen Problem liegen, dass die begrenzten GPIOs
irgendwelche Kapazitäten oder so nicht schnell genug umladen? Oder
vielleicht PushPull für SPI vergessen?
Christian J. schrieb:> ein Delay von wenigen Mikrosekunden genau vor diesem Befehl> behebt das Problem
Falsch! Das Problem wird nicht behoben sondern verschoben!
Ein Delay ist praktisch nie die Lösung, sondern das Problem, und da
wette ich auch dieses mal drauf.
Christian J. schrieb:> die> Pins schalten nicht so schnell wie die CPU.
Ach... sag bloß. Hast du ganz vielleicht eventuell mal daran gedacht
einen blick in das Datenblatt zu werfen?
Nein! Doch! Oohh!
Horst schrieb:> Aber wenn es an dem GPIO-Speed läge, wäre es eine interessante> Entdeckung. Hast du mal ein Scope drangehalten? Kann es vielleicht auch> an einem Hardwaretechnischen Problem liegen, dass die begrenzten GPIOs> irgendwelche Kapazitäten oder so nicht schnell genug umladen? Oder> vielleicht PushPull für SPI vergessen?
Ich habe kein Scope hier. Nur so einen China-Lyzer und keine offenen
Kontakte zum anclipsen.
Bisher..... (!) ging ich davon aus, dass die Speed Einstellung etwas
damit zu tun hat, wie schnell der Pin nach dem Setzen des Bits im BRSS
sich wirklich umschaltet. Man findet im Netz auch was von wegen
Flankensteilheit. Bei einer 1.3Mhz SPI denkt man ja nun nicht, dass man
da die volle APB2 Speed von 1/2 Sycklock = 84 Mhz braucht. Bei I2C nch
weniger mit 100khz aber auch da half es grad alle Probleme zu
beseitigen.
Ich muss mich da mal schlau machen aber ist auch für mich neu.
und ein Wort an den Vorredner: Wenn Datenblätter alle Fragen beantworten
würden wäre dieses Forum total leer, wir wären alle glücklich mit
unseren Zettelchen, weil sie alle Fragen beantworten. Vielleicht sollte
ich Merkel mal den Tipp geben ins Datenblatt der EU zu schauen. ROFL.
Christian J. schrieb:> Bei I2C nch> weniger mit 100khz aber auch da half es grad alle Probleme zu> beseitigen.
Hmm, das klingt für mich schon wieder sehr unwahrscheinlich... Außerdem
hat die Slew-Rate eigentlich ja auch nichts mit dem anderen Delay-Fix zu
tuen. Ich vermute das Problem an noch anderer Stelle. Ich teste jetzt
gleich aber mal, ob ich einen Unterschied in der Slewrate messen kann.
Ich gehe mal davon aus, es handelt sich hier um einen ARM Core, richtig?
Der Compiler weis manchmal nicht, das sich Zugriffe auf Hardware
Komponenten nicht sofort auswirken, z.B. wenn ein Peripherie Gerät
langsamer als der Core läuft.
Konstrukte wie:
// irgend eine Aktion triggern.
device->Control = 1;
// Auf das Ergebniss warten.
while (! (device->Control & flag));
können manchmal einfach durch die Warteschleife laufen. Ob das so ist,
ist vom Core zu Core unterschiedlich. Mit STM32 hab ich da keine
Erfahrung, bei den LPC1xxx von NXP ist das aber schon der fall.
In diesen Fällen hilft es explizit dafür zu sorgen, das der Write auch
komplett ausgeführt wird bevor die Controlflags gelesen werden: z.B.
wiefolgt:
// irgend eine Aktion triggern.
device->Control = 1;
// Sicherstellen, das der Schreibzugriff auf Control auch ausgeführt
wird:
__DMB();
// Auf das Ergebniss warten.
while (! (device->Control & flag));
/Nils
Nils schrieb:> __DMB();>> // Auf das Ergebniss warten.> while (! (device->Control & flag));>> /Nils
Und dieses Konstrukt aus CMSIS bringt da etwas? Wieder was Neues...
/** \brief Data Memory Barrier
This function ensures the apparent order of the explicit memory
operations before
and after the instruction, without ensuring their completion.
*/
__attribute__( ( always_inline ) ) __STATIC_INLINE void __DMB(void)
{
__ASM volatile ("dmb");
}
Christian J. schrieb:> Bisher..... (!) ging ich davon aus, dass die Speed Einstellung etwas> damit zu tun hat, wie schnell der Pin nach dem Setzen des Bits im BRSS> sich wirklich umschaltet. Man findet im Netz auch was von wegen> Flankensteilheit. Bei einer 1.3Mhz SPI denkt man ja nun nicht, dass man> da die volle APB2 Speed von 1/2 Sycklock = 84 Mhz braucht. Bei I2C nch> weniger mit 100khz aber auch da half es grad alle Probleme zu> beseitigen.
Richtig, es geht schon um die Slewrate dabei. Ich habe das gerade aber
mal ohne Last auf meinem STM32F401-DISCO ausprobiert, und halte es für
ausgeschlossen, dass das wirklich das Problem ist, wenn Hardwaremäßig
alles in Ordnung ist.
Probes sind nicht die besten, und Scope hat auch nur 100MHz Bandwidth
und ich habe außerdem am Pinheader (aber mit Low Inductance Nädelchen
immerhin ^^) gemessen. Siehe Anhang. Und mit dem Ergebnis ist es wie
gesagt höchst unwahrscheinlich. Ich vermute daher noch was anderes...
Poste doch mal ein Bild von dem Aufbau.
Ich könnte mir vorstellen da ST den Zustand Schaltflanke bei den
unterschiedlichen Geschwindigkeiten intern mit waitstates hinterlegt ,wo
dann in der Logik nix passiert . Das ist aber nur ne Vermutung.
m.f.G.
Dieter
Du kannst viel zeit sparen wenn Du folgendes beachtest:
Die Wahrscheinlichkeit als durchschnittlicher oder auch
überdurchschnittlicher Programmierer (also das schließt jeden ein der
nicht den Status "Guru" hat) bei einem gut gereiften und vielgenutzten
Compiler wie dem gcc zufällig über einen bislang unbekannten
Compilerfehler zu stolpern ist nahezu null.
Du brauchst Du also gar nicht erst dran zu denken anzufangen dort etwas
zu vermuten.
Ursache 1: Flüchtigkeitsfehler (Software und/oder Hardware)
Ursache 2a: Eigenen Code nicht vollständig verstanden
Ursache 2b: Hardware nicht vollständig verstanden
Ursache 2c: Programmiersprache nicht vollständig verstanden
Ursache 3: Verwendete Tools nicht verstanden / falsch benutzt
Ursache 4: Hardware tatsächlich fehlerhaft (ja, das gibts auch)
...lange nichts
...immer noch nichts
Ursache n: Compilerfehler
In der Reihenfolge würd ich in Zukunft an die Fehlersuche gehen. Das
spart viel Zeit und Nerven.
Dieter Graef schrieb:> Ich könnte mir vorstellen da ST den Zustand Schaltflanke bei den> unterschiedlichen Geschwindigkeiten intern mit waitstates hinterlegt ,wo> dann in der Logik nix passiert . Das ist aber nur ne Vermutung.
Und was soll das für einen Sinn haben?
Meines Wissens sind die Geschwindigkeiten die Slewrates, wie die Messung
ja auch bestätigt. Und das ganze aus Stromspar und vor allem EMV
Gründen.
Horst schrieb:> Ich vermute daher noch was anderes...> Poste doch mal ein Bild von dem Aufbau.
Ähm.... also das ist eine Lochrasterkarte mit einem Disco Board und drum
herum sind die Module. Die Slew Rate wird es nicht sein aber
programmierre doch mal wie schnell du einen Pin toggeln kannst bei
verschiedenen Einstellungen. Ich vermute mal, dass das stark davon
abhängt welche Speed du eingestellt hast.
Also wie man da sie Slew Rate ändern soll frage ich mich schon.....
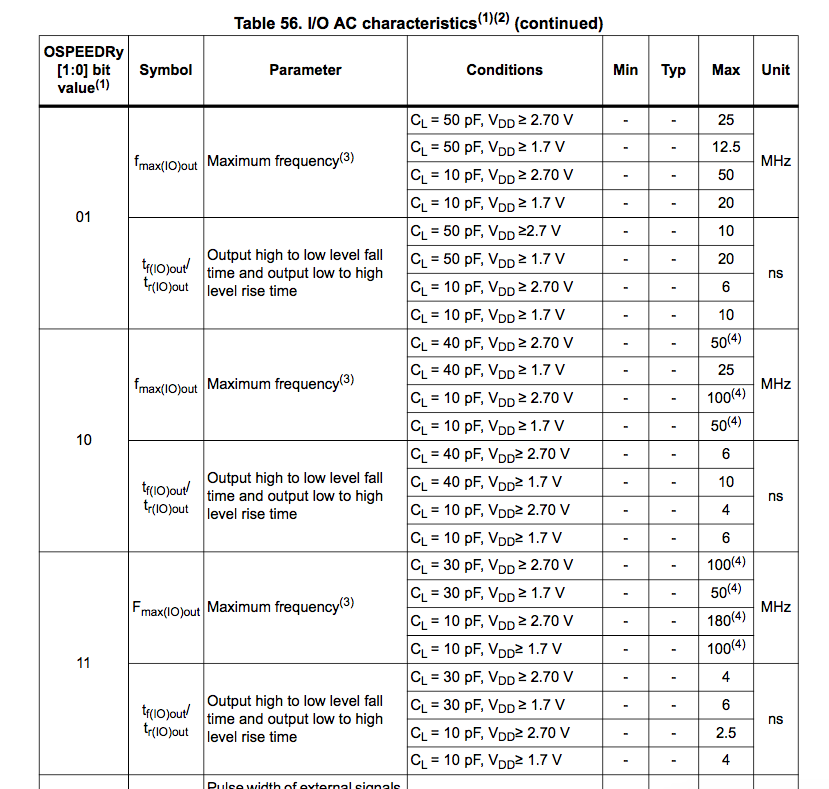
Und was OSPEEDR ist wird auch im datenblatt nicht wirklich erklärt.
These bits are written by software to configure the I/O output speed.
00: Low speed
01: Medium speed
10: Fast speed
11: High speed
Na, toll.....
Bernd K. schrieb:> bei einem gut gereiften und vielgenutzten> Compiler wie dem gcc zufällig über einen bislang unbekannten> Compilerfehler zu stolpern ist nahezu null.
Beim GCC ok, beim SDCC habe ich bereits 2 Bugs entdeckt und reported,
die auch bestätigt wurden.
Christian J. schrieb:> Und was OSPEEDR ist wird auch im datenblatt nicht wirklich erklärt.>> These bits are written by software to configure the I/O output speed.> 00: Low speed> 01: Medium speed> 10: Fast speed> 11: High speed
Ich weiß nicht welchen Controller du hast aber in meinem Datenblatt
stand was...
Horst schrieb:> Ich weiß nicht welchen Controller du hast aber in meinem Datenblatt> stand was...
Ich habe imj reference nach geschaut, Du im Data sheet. Ok, ja ... wie
ich sagte, die switching frequenz. D.h. ein gesetztes Bit schlägt sich
nicht sofort auf die Hardware nieder sondern erst im nächsten Buszyklus
des APB2. D.h. der Core ist schneller. Und ich lese ja etwas zurück was
vielleicht noch gar nicht fertig ist.
Sagen wir es mal so: Es funktioniert ja jetzt. Und solange soll es auch
gut sein.
Bernd K. schrieb:> Ursache 1: Flüchtigkeitsfehler (Software und/oder Hardware)> Ursache 2a: Eigenen Code nicht vollständig verstanden> Ursache 2b: Hardware nicht vollständig verstanden> Ursache 2c: Programmiersprache nicht vollständig verstanden> Ursache 3: Verwendete Tools nicht verstanden / falsch benutzt> Ursache 4: Hardware tatsächlich fehlerhaft (ja, das gibts auch)> ...lange nichts> ...immer noch nichts> Ursache n: Compilerfehler
diese Liste halte ich nach eigener Erfahrung für realistisch. Zwei
Punkte fehlen mir aber noch drin:
Fehler in fremder Bibliothek
Würde ich vermutlich zwischen 3 und 4 von Deiner Liste packen.
und
Unvollständige/Fehlerhafte Dokumentation der Hardware
Das würde ich auch vor 4 in Deiner Liste setzen
Christian J. schrieb:> Ich habe imj reference nach geschaut, Du im Data sheet
Siehe Anhang.
Christian J. schrieb:> wie> ich sagte, die switching frequenz. D.h. ein gesetztes Bit schlägt sich> nicht sofort auf die Hardware nieder sondern erst im nächsten Buszyklus> des APB2. D.h. der Core ist schneller. Und ich lese ja etwas zurück was> vielleicht noch gar nicht fertig ist.
Wo steht das? Ich habe das nirgendwo gelesen. Kann sein, aber alles was
ich noch gefunden habe, ist:
> All GPIOs are high-current-capable and have speed selection to better manage
internal noise, power consumption and electromagnetic emission.
Das klingt für mich aber nicht nach sinnlosen (oder was bringt das?)
Waitstates sondern nach der Slewrate...
Christian J. schrieb:> Sagen wir es mal so: Es funktioniert ja jetzt. Und solange soll es auch> gut sein.
Sagen wir es mal so: Ich wette in ein paar Tagen kommst du wieder an und
erzählst wie scheiße GCC ist, und dass der tolle Keil ja so viel besser
ist... Viele Open-Source-Software ist zum Teil wirklich Schrott weil sie
nur aus Hacks besteht. Aber der GCC ist das definitiv nicht, vor allem
bei so einfachem Zeug wie hier.
Andersrum.Wie erklärt man die offenbar nötige Pause nach der
Zustandsauswertung bei anderer als höchster Geschwindigkeit
ausschließlich mit der Slew Rate?
m.f.G.
Dieter
Dieter Graef schrieb:> Andersrum.Wie erklärt man die offenbar nötige Pause nach der> Zustandsauswertung bei anderer als höchster Geschwindigkeit> ausschließlich mit der Slew Rate?
Das verstehe ich ja auch nicht, aber würde es gerne rausfinden. Wenn du
weißt wo Waitstates dokumentiert sind, dann sag wo. Ich habs nicht
gefunden und wüsste auch nicht wozu die gut sein sollten..
Und dass die Slewrate sich auch ändert hab ich ja auch eindeutig messen
können.
Flipp nicht gleich aus aber ich bin immer noch dabei.... das hat auch
mit der "Link Time Optimization" was zu tun. Die ist das eigentliche
Problem, nicht die Einstellung Os, O1 usw. Nehme ich die weg läuft es
mit allen Stufen aber NUR, wenn da ein Delay drin ist bei der SPI. Die
Speed Einstellung hat nur Einfluss, wenn sie grob daneben liegt. D.h.
mit Prescaler = 2 und Speed = 2 Mhz klappt es natürlich nicht. Mit ein
googlen findet man, dass fast alle Beispielcodes immer auf Fast stehen
bei SPI und anderen Geräten.
Die Ursache ist einfach und lässt sich im Debugger nachvollziehen: Die
SPI wird schlicht immer zu 0 ausgelesen, d.h. es kann ja auch nicht
funktionieren.
Hallo Christian,
Ich benutze auch Keil. Ich hatte aber auch Probleme beim debuggen.
Die Flags wurden einfach nicht wie erwartet gesetzt.
Ohne debuggen ging es.
Die aktuellen Libraries von St, also die CubeMx Libraries funktionieren
auch mit GCC problemlos.
Grüße, Adib.
--
Horst schrieb:> und wüsste auch nicht wozu die gut sein sollten.
Waitstates ist vieleicht auch der falsche Begriff.Ich nenn es mal
Sperrzeiten in denen Zustandsänderungen nicht erlaubt sind.Mit solchen
Sperrzeiten kann ich Probleme die sich aus Phasenverschiebungen ergeben
(z.B. durch die konkrete Realisierung der Slew Raten)
vermindern.(falsche Zustandswechsel z.B.)
Christian hat halt den Zustandswechsel - Sendetakte losrattern in eine
solche Sperrzeit gesendet und nix passierte.Workaround hätte vieleicht
auch die Abfrage des Tx buffer empty flag (TXE) vor dem Senden sein
können. Muß man halt mal probieren.
Horst schrieb:> wo Waitstates dokumentiert sind
Es gibt eine Differenz zwischen dem was ist und dem was dokumentiert
ist.Diese Differenz bestimmt den Wert von ST. Es werden ja jetzt schon
Chips der STM32F100 Serie "geclont". Und die Jungs von ST wären blöd
auch noch den Rest ihres know hows auf dem Silbertablet zu präsentieren.
Christian J. schrieb:>> Das wäre viel Arbeit das alles umzuschreiben auf CubeMX :-(>
Die cubemx Libraries sehen schon etwas aufgeräumter aus als die
StdPeripheral Libraries. Die Konvertierung sollte nicht so schwer sein.
Schau auch mal im ST Forum nach deinem Problem.
Noch ein Hinweis: nach dem cs_low musst du eine DSB Instruktion
einfügen. Sonst ist nicht zwingend garamtiert, dass der Pin gesetzt ist,
wenn die spi anfängt zu takten
Dann hat die SenDByte Routine nach ein Problem: sie geht davon aus, das
rx Flag nicht gesetzt ist. Bei deinem Beispiel wirkt sich dass nicht
aus, da erst bei not bsy gelesen wird. Eigentlich muss man das rx Flag
selber löschen.
Grüße, Adib.
Christian J. schrieb:> Horst schrieb:>>> Aber wenn es an dem GPIO-Speed läge, wäre es eine interessante>> Entdeckung. Hast du mal ein Scope drangehalten? Kann es vielleicht auch>> an einem Hardwaretechnischen Problem liegen, dass die begrenzten GPIOs>> irgendwelche Kapazitäten oder so nicht schnell genug umladen? Oder>> vielleicht PushPull für SPI vergessen?>> Ich habe kein Scope hier. Nur so einen China-Lyzer und keine offenen> Kontakte zum anclipsen.
Sehr hardwarenah programmieren und kein Oszilloskop haben passt nicht
zusammen. Das ist durchaus ein Standardwerkzeug.
Adib schrieb:> Noch ein Hinweis: nach dem cs_low musst du eine DSB Instruktion> einfügen. Sonst ist nicht zwingend garamtiert, dass der Pin gesetzt ist,> wenn die spi anfängt zu taktenhttp://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0489c/CIHGHHIE.html
DSB oder DMB? Das wirft dann noch eine andere Frage auf: Muss ich nach
jedem Pinsetzen diesen Befehle einfügen? Denn es kann ja sein, dass die
SPI anfängt zu tackern, obwohl der Pin noch gar nicht "abgeholt" wurde,
d.h. die Info aus den Schattenregistern an den PP Pin gelangt ist. Wie
Du es ja sagtest. Das gilt grundsätzlic für alle "Chip Select", auch bei
Bitbanging. Das wäre natürlich sehr nervig. Der Compiler weiss das
nicht, evtl. weiss der Keil es aber, da er ja für den ARM entwickelt
wurde.
Es würde sich dann ja empfehlen jedes Pinsetzen als Makro zu defnineren:
#define CE_HIGH (do {GPIO_SetBits(GPIOD,CEPIN); __DSB;} while (0))
#define CE_LOW (do {GPIO_ResetBits(GPIOD,CEPIN); __DSB;} while (0))
um es in eine Zeile und ein Makro zu quetschen.
Mark B. schrieb:> Kann es vielleicht auch>>> an einem Hardwaretechnischen Problem liegen, dass die begrenzten GPIOs>>> irgendwelche Kapazitäten oder so nicht schnell genug umladen?Adib schrieb:> Eigentlich muss man das rx Flag> selber löschen.
Nein, das ist Read-Only und wird von der Hardware bedient. Genauer
gesagt müsste man eigentlich vor dem Senden den RX Buffer auslesen, um
es zu löschen.
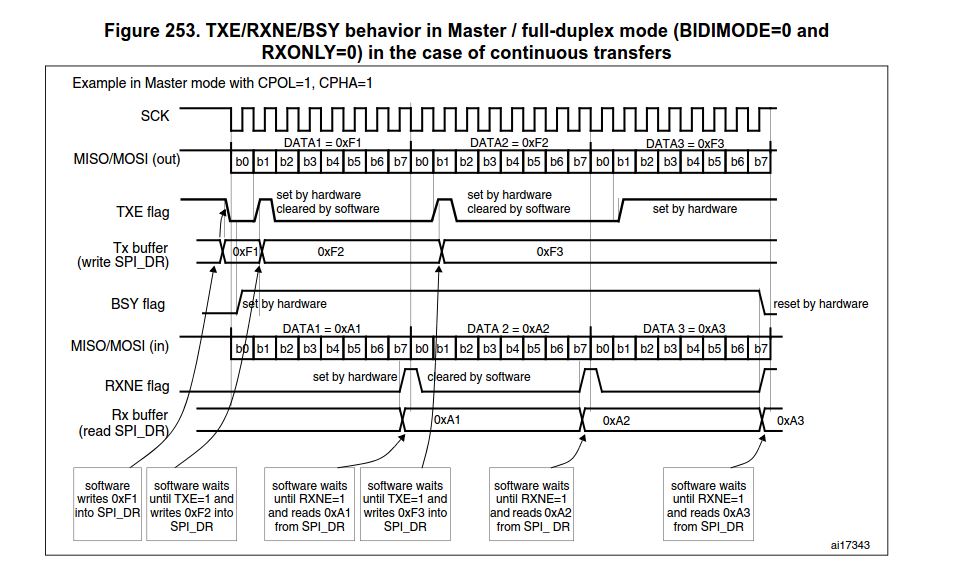
Receive sequence
For the receiver, when data transfer is complete:
• The Data in shift register is transferred to Rx Buffer and the RXNE
flag (SPI_SR
register) is set
• An Interrupt is generated if the RXNEIE bit is set in the SPI_CR2
register.
After the last sampling clock edge the RXNE bit is set, a copy of the
data byte received in
the shift register is moved to the Rx buffer. When the SPI_DR register
is read, the SPI
peripheral returns this buffered value.
Clearing of the RXNE bit is performed by reading the SPI_DR register.
1. Enable the SPI by setting the SPE bit to 1.
2. Write the first data item to be transmitted into the SPI_DR register
(this clears the TXEflag).
3. Wait until TXE=1 and write the second data item to be transmitted.
Then wait until RXNE=1 and read the SPI_DR to get the first received
data item (this clears the RXNE bit). Repeat this operation for each
data item to be transmitted/received until the n–1 received data.
4. Wait until RXNE=1 and read the last received data.
5. Wait until TXE=1 and then wait until BSY=0 before disabling the SPI.
This procedure can also be implemented using dedicated interrupt
subroutines launched at each rising edges of the RXNE or TXE flag.
Kann das mal jemand bestätigen, ob das eine korrekte SPI Routine ist,
die dem Datenblatt entspricht? Ob da nun ein SPI Enable rein muss weiss
ich nicht, halte es für wenig sinnig eine Hardware ewig ein und ab zu
schalten, wenn sie doch dauernd benutzt wird.
Für meine Anwendung ist es sinniger, wenn gewartet wird, bis alles raus
ist da ich immer die Antworten braucht, für andere 1 Kanal Apps kann das
egal sein, Byte abschicken und raus, ohne das Ende abzuwarten.
1
uint8_tSPI_SendByte(uint8_tdata)
2
{
3
uint8_tval;
4
5
SPI_Cmd(SPI1,ENABLE);
6
SPI_I2S_SendData(SPI1,data);// Sende Byte an SPI_DR
7
while(!SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_TXE));// Warte bis Byte raus und TXE Flag = 1
8
while(!SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_RXNE));// Warte bis Byte drin und RXNE = 1
9
val=SPI_I2S_ReceiveData(SPI1);// Hole RX Wert ab (Clearing RXNE)
10
while(SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_BSY));// Warte bis SPI fertig
Nase schrieb:> Sei vorsichtig mit solchen "testweise"-Sachen.>> Wenn du die Routine isoliert kompilierst, kommt möglicherweise was ganz> Anderes bei heraus. Gibts Link-Time-Opti?
Darum ja testweise. Wenn diese Funktion gleichen Maschinencode liefert
egal ob mit oder ohne Optimierung liegt das Problem woanders.
Christian J. schrieb:> Kann das mal jemand bestätigen, ob das eine korrekte SPI Routine ist,> die dem Datenblatt entspricht?
Wenn ich das richtig lese kommt RNXE vor TXE, auf TXE muss man nur
warten, wenn noch was weiteres gesendet wird. Also die Zeile mit "//
Warte bis Byte raus und TXE Flag = 1" gehört weg.
rmu schrieb:> Wenn ich das richtig lese kommt RNXE vor TXE, auf TXE muss man nur> warten, wenn noch was weiteres gesendet wird. Also die Zeile mit "//> Warte bis Byte raus und TXE Flag = 1" gehört weg.
Sorry, wenn ich da nochmal genau ins Detail gehe.
Es ist ja so, dass manchmal mehrere Bytes gesendet werden. Für das
Funkmodul zb wird ein Kommando gesendet, dann ein Dummy und mit dem
Dummy wird die Antwort gelesen. Daher muss ein Kontrolle her, dass die
SPI Rutsche frei ist. Ich bin mir nu nich ganz sicher, ob diese
Konzrolle mit dem Busy Flag erledigt ist, was ja zum Schluss abgefragt
wird.
Sicher, Du hast recht .... wozu warten, bis Byte raus ist aber eine
Bremse muss es geben, damit die SPI nicht zugemüllt wird.
Ich werde heute abend mal den Logic Analyzer anclipsen und mir das
anschauen und mit den Variationen spielen. Dann sieht man ja was dabei
raus kommt und ob es evtl. ein Zeitproblem gibt.
Ich warte noch auf den Poster oben, ob er das so machen würde, dass
hinter jedem PinSet dieses DSB oder DMB kommen muss.
#define CE_HIGH (do {GPIO_SetBits(GPIOD,CEPIN); __DSB;} while (0))
#define CE_LOW (do {GPIO_ResetBits(GPIOD,CEPIN); __DSB;} while (0))
Christian J. schrieb:> Ich warte noch auf den Poster oben, ob er das so machen würde, dass> hinter jedem PinSet dieses DSB oder DMB kommen muss.
Hallo Christian,
bei ARM gibt es 3 Synchronisationsbefehle, die sich auf die
Pipelineabarbeitung auswirken: DSB, ISB, DMB siehe
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0646a/CHDDGICF.html
Das Problem ist nicht unbedingt die Reihenfolge der Abarbeitung, sondern
wegen der uU verschiedenen Busse an dem der CS-Pin und das SPI Modul
hängt.
Die DSB Instruktion stellt sicher, dass die Daten auch in dem Modul
angekommen bzw. fertig abgeholt wurden befor der nächste Befehl
abgearbeitet wird. Ansonsten ist der GPIO IO Befehl und der SPI IO
Befehl zeitgleich auf der Reise während die CPU bereits den nächsten CPU
Befehl abarbeitet. Bin jetzt didaktisch nicht der Stärkste, aber das
Problem sollte ausreichend dargestellt sein.
Im speziellen kann es sein, wenn der CS Befehl an das GPIO Modul geht
und dann vom SPI gelesen wird. Dass bevor der Befehl am GPIO angekommen
ist, das SPI bereits beschrieben wurde. Pipelineeffekt,
unterschiedlicher Bustraffig, Geschwindigkeiten, etc.
Für deinen SPI Fall:
#define CE_HIGH (do {GPIO_SetBits(GPIOD,CEPIN); __DSB;} while (0))
#define CE_LOW (do {GPIO_ResetBits(GPIOD,CEPIN); __DSB;} while (0))
Beim Rücksetzen schützt es vor Zugriffen, die du evtl. auf dem gleichen
SPI mit unterschiedlichen Bausteinen machst.
HTH, Adib.
--
Nochmal ich,
im STM reference Manual steht das so drin (transmit / receive):
1. Enable the SPI by setting the SPE bit to 1.
2. Write the first data item to be transmitted into the SPI_DR register
(this clears the TXE flag).
3. Wait until TXE=1 and write the second data item to be transmitted.
Then wait until
RXNE=1 and read the SPI_DR to get the first received data item (this
clears the RXNE
bit). Repeat this operation for each data item to be
transmitted/received until the n–1
received data.
4. Wait until RXNE=1 and read the last received data.
5. Wait until TXE=1 and then wait until BSY=0 before disabling the SPI.
Die SendByte Funktion ist so implementiert:
1. Also man kann das DR Register schon nach SPI_I2S_FLAG_RXNE lesen.
2. Die Funktion stellt aber nicht zwingend sicher, dass auch zu Begin
RXNE false ist.
Also paranoiderweise würde man voranstellen:
Adib schrieb:> In der speziellen Implementierung sollte es aber keinen Fehler geben,> das ja nach BSY- Test erst gelesen wird.
Inzwischen läuft es, es führen mehrere Wege nach Rom. Es muss kein Busy
Flag abgefragt werden und ob die eingestreuten DSB es ja wirklich
beheben mag dahin gestellt sein. Entfernt man sie läuft es auch. Ich
habe sie nur bei CE und CSN Pin Setzen noch drin, wo sie wirklich Sinn
machen.
Was ich mich noch frage ist, ob es Sinn macht die SPI nach jedem ZUgriff
abzuschalten, sogar den Takt wegzunehmen. Oder ist das nur in
Anwendungen sinnvoll wo es auf jedes Mikroampere ankommt, weil sie mit
einer Batterie betrieben werden.
Das Funkmodul läuft jedenfalls prima. Und es hat sich gelohnt nicht auf
fertige Libs zurückzugreifen sondern alle Funktionen selbst zu
schreiben.
Allerdings ist das NRF24L01 nicht für Datenströme geeignet, nur halt für
für Datensätze zb von Sensoren.
1
uint8_tSPI_TransferByte(uint8_tdata)
2
{
3
while(!SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_TXE));// Warte bis TXE (SPI ist frei)
4
SPI_I2S_SendData(SPI1,data);// Byte senden...
5
__DSB();
6
while(!SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_RXNE));// Warte bis Byte empfangen worden
Adib schrieb:> 1. Also man kann das DR Register schon nach SPI_I2S_FLAG_RXNE lesen.> 2. Die Funktion stellt aber nicht zwingend sicher, dass auch zu Begin> RXNE false ist.> Also paranoiderweise würde man voranstellen:
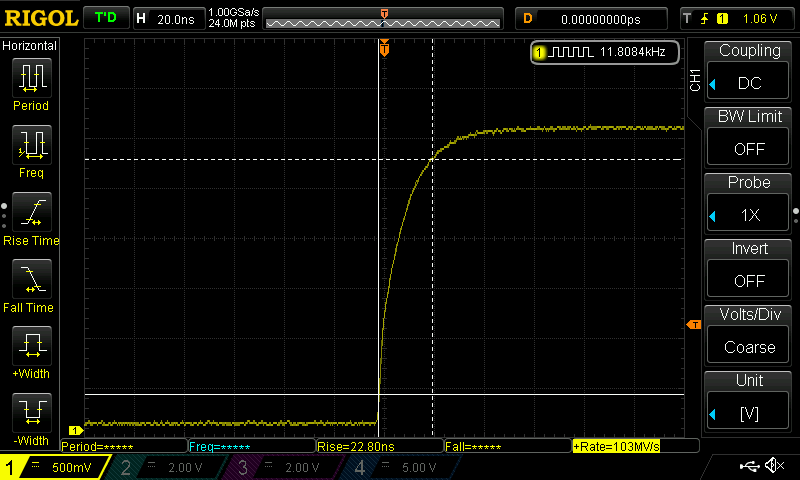
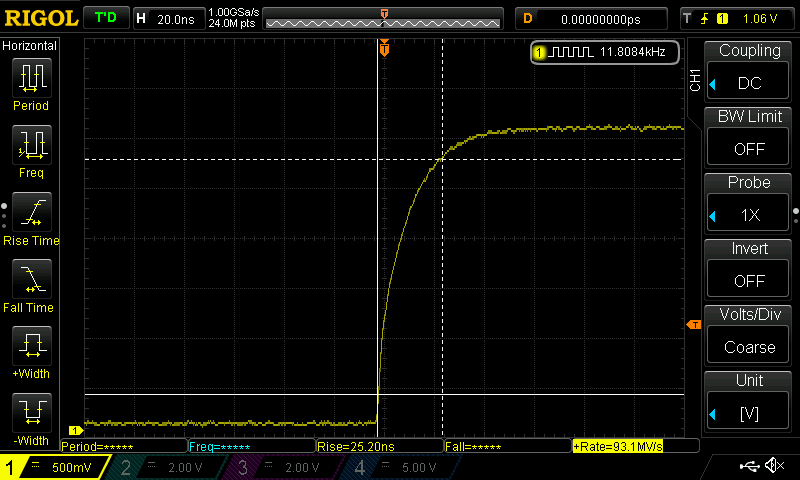
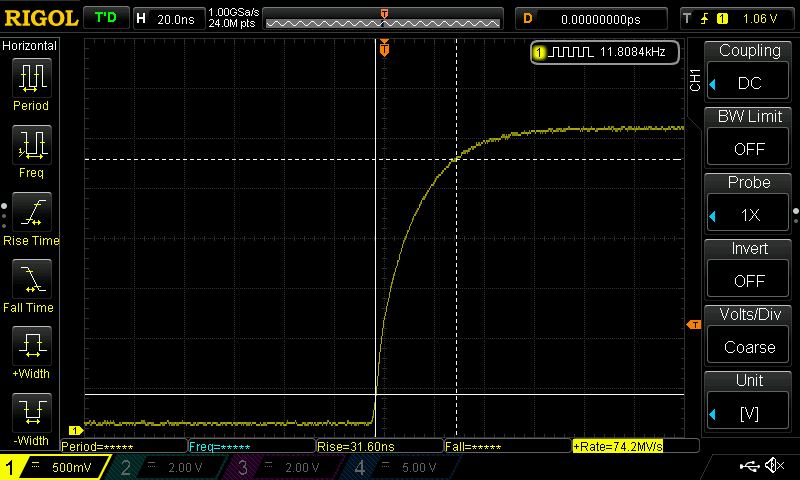
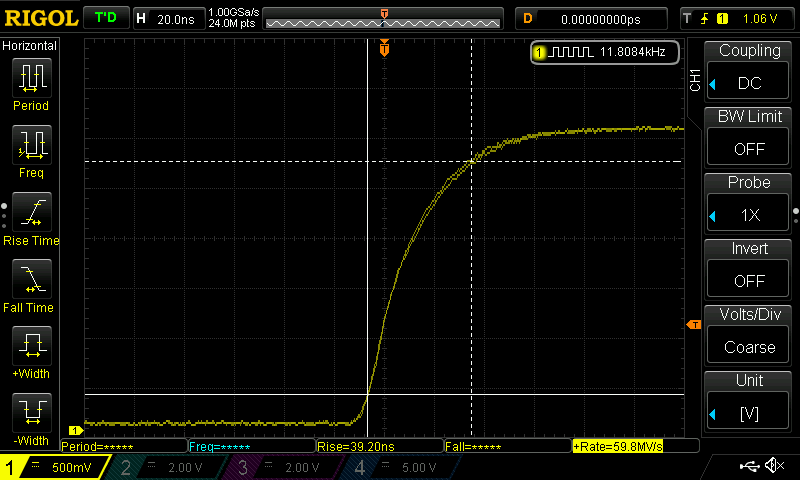
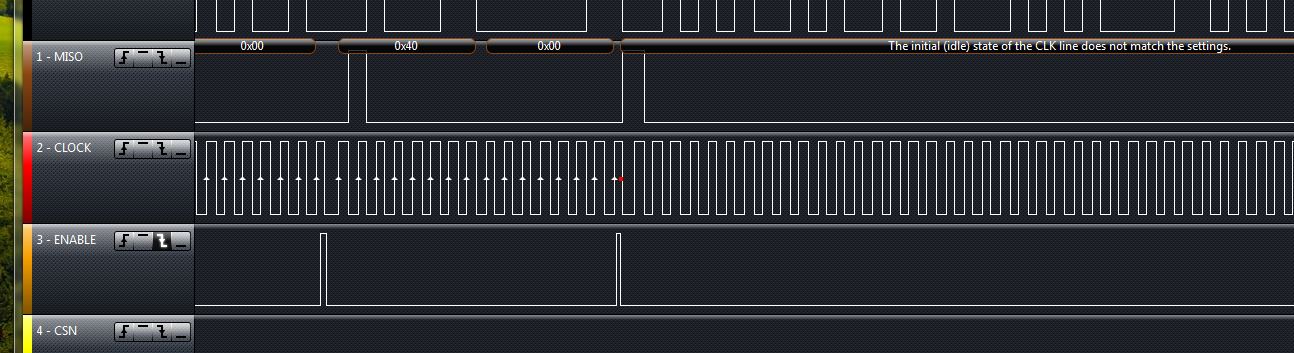
Anbei mal ein Logik Diagram, wo das Problem begraben ist. Habe mit
verschiedenen Geschwindigkeiten der SPI und der Pins herum
experimentiert.
Hier MUSS ein Delay vor. Da reicht auch ein DSB oder DMB nicht aus. Was
allerdings seltsam ist.
Delay(1);
return SPI_I2S_ReceiveData(SPI1);
Horst schrieb:> Dass die Speed-Einstellung aber immer noch auf High-Speed alle Probleme> behebt stimmt aber nicht mehr oder?
Nein. Bzw. ist deine Aussage richtig. Das klappte nur bei einer
speziellen Baurate der SPI. Ändert man diese Richtung langsamer kommt es
wieder.
Christian J. schrieb im Beitrag #4437701
> Anbei mal ein Logik Diagram, wo das Problem begraben ist. Habe mit> verschiedenen Geschwindigkeiten der SPI und der Pins herum> experimentiert.>
Christian, ich verstehe immer noch nicht gena, was das Problem ist.
Was genau bemängelst du denn an dem Diagramm?
Kannst du das Problem in einem Diagramm mit nur einer Übertragung von 2
Bytes zeigen?
Ach und welche mcu nimmst du und an welchen Pins hast du was
angeschlossen?
Danke Adib.
Christian J. schrieb:> Evtl. heute abend mal ..... da nur die SPI Routinen betroffen ist lässt> sich das evtl eingrenzen aber das sind alles Herstellerroutinen, die> eigentlich getestet sein sollten.
So die Theorie. Ich verstehe eigentlich gar nicht, wieso es bei
professioneller Software Bugfixes geben kann, wenn doch eigentlich alles
getestet sein sollte.
Adib schrieb:> Christian, ich verstehe immer noch nicht gena, was das Problem ist.> Was genau bemängelst du denn an dem Diagramm?> Kannst du das Problem in einem Diagramm mit nur einer Übertragung von 2> Bytes zeigen?>> Ach und welche mcu nimmst du und an welchen Pins hast du was> angeschlossen?>> Danke Adib.
Hi,
glaubst, Du dasss mir der Kopf pfeift, wenn man sich knapp 8h damit
befasst hat ein Problem zu suchen? Hälst Du mich für blöd, wenn ich dir
sage, dass der Ausdruck
#define CSN_LOW do { GPIO_ResetBits(CSN_PORT,CSN_PIN); __DSB(); }
while(0)
es war, der für die Abstürze sorgte? Seit ich das alles umgeschrieben
habe auf Funktionen läuft es nämlich durch. Das sollte eigentlich nur
eine Klammerung sein für das Makro.
Habe jetzt die Register direkt beschrieben, statt die StdLib Routinen zu
benutzen. Ist ja easy bei der SPi.
Das Thema __DSB() habe ich auch durch, das MUSS dahin. Man kann es
wirklich sehen auf dem Diagramm, dass teilweise der SCLK VOR dem CE
hochgeht, obwohl die beiden nacheinander stehen. Und das geht nicht, da
die Hardware nunmal Zeit braucht auf CE zu reagieren, was wiederum im
datenblatt steht, nämlich Tcc = 2ns. Da sieht wenig aus, ist es auch
aber -1ns (SCK VOR CE) ist eben schon Mist.
Ok, Schluss für heute....
Hallo Christian,
danke für deine Aufklärung.
Ich hatte mich inzwischen auch mal rangemacht. Anbei mein Code. Ich lese
das ID Register des L3GD20 auf dem F3Discovery.
Ich habe zuerst mit CubeMx programmiert und dann umgeschrieben auf reine
MPU-IO Befehle. Ich konnte mit Keil und Eclipse/GCC 5.2 keine Probleme
bei O0 und O3 feststellen.
Die aktuelle Lib kommt mit kompletten Transferfunktionen für Buffer.
Die gibt es auch für Interrupt und DMA Abarbeitung.
Ich denke es lohnt sich, das mal anzuschauen.
Viele Grüße und schönes WE.
Christian J. schrieb:> glaubst, Du dasss mir der Kopf pfeift, wenn man sich knapp 8h damit> befasst hat ein Problem zu suchen? Hälst Du mich für blöd, wenn ich dir> sage, dass der AusdruckAdib schrieb:> danke für deine Aufklärung.
LOL ^^
Respekt an Adib das einfach zu ignorieren. Hätte ich nicht gekonnt..
@Christian: wie sieht denn dein endgültiger Code jetzt aus, der immer
funktioniert? Aus den ganzen Fragmenten und dem ganzen Hin- und Her ist
das nicht so einfach zu rekonstruieren.
Mal sowas ganz abwegiges:
Gibts vielleicht ein Erratum zur SPI-Peripherie?
Christian J. schrieb:> Hälst Du mich für blöd, wenn ich dir> sage, dass der Ausdruck>> #define CSN_LOW do { GPIO_ResetBits(CSN_PORT,CSN_PIN); __DSB(); }> while(0)>> es war, der für die Abstürze sorgte? Seit ich das alles umgeschrieben> habe auf Funktionen läuft es nämlich durch.
Offen gestanden und wenn du so fragst, vermutlich ja, wir alle halten
dich für blöd, wenn es daran gelegen haben soll... Das liegt aber nicht
notwendigerweise daran, dass du blöd bist, sondern daran, dass du
blöd a.k.a. ungünstig schreibst.
Mit an Sicherheit grenzender Wahrscheinlichkeit ist es nicht der
Ausdruck, der für deine Abstürze sorgt. Sehr viel wahrscheinlicher ist
es, dass du dein Problem immer noch nicht zu fassen gekriegt hast. Die
ganzen Experimente mit DSB und Makro/Funktionen und Delays unsw. deuten
ganz extrem darauf hin, dass du immer noch um dein eigentliches Problem
herumkreist und kleine Änderungen z.B. im Timing schon für Funktion oder
Fehlfunktion ausreichen.
Nase schrieb:> Offen gestanden und wenn du so fragst, vermutlich ja, wir alle halten> dich für blöd, wenn es daran gelegen haben soll... Das liegt aber nicht> notwendigerweise daran, dass du blöd bist, sondern daran, dass du> blöd a.k.a. ungünstig schreibst.
Moin,
kann ich mir denken. Und Ich benutze ja das NRF24L01 Modul als Referenz
und gehe davon aus, dass das alles schhön und richtig macht, die Signale
stimmen usw!
Ich Idiot !!!!
Es war schon spät gestern aber diese ewigen völlig willkürlichen
Abstürze des Moduls gingen mir auf den Zünder. Ich polle in einer 1
Sekunden Schleife, da die Info nur alle 30s kommt.
Den Hinweis hätte mir etwas anderes schon geben können: Wie klappt das
nicht mit einer 250khz SPI? Da "Friert"es auch ein. Es müssen > 1MHz
sein. Hat dieses China Modul etwa gar kein statisches Design ???? Pollen
wir doch mal schneller (1mS) oder gleich per Interrupt.
Seit gestern nach 4 Uhr läuft es durch! Ohne einen Fehler ..... Das
Modul will Clocks sehen und das schnell, die Playload muss abgeholt
werden, sonst "wandern" da einige Bits etwas seltsam umher....
Hier haben sich also, um den Startbeitrag zubeantworten mehrere
Fehlerquellen vermengt. Der Compiler hat alles richtig gemacht aber er
weisss eben nichts von den Bussen und Clocks.
Arrrrgh.................... !!!!
Danke für die SPI Routine, baue ich mal direkt so ein....
So schaut es jetzt aus:
1
/* ------ SPI Low Level: Ein 8 Bit Datenwort senden und holen ------- */
Das DSB sorgt wohl dafür, dass in Val auch tatsächlich ein Wert drin
steht, weil der Memory Fetch abgeschlossen werden muss. Dieses
Pipelining und die Prefetch Queue können ganz schön für Ärger sorgen
glaube ich, hatte bisher nie CPUs die sowas hatten, nur 8 Bitter und
Z80.
Und eine Softr SPI, die vorher für einen Hard Fault sorgte sieht jetzt
so maus und läuft auch. Einfach mal drüber gestreut... schaden kann es
ja nicht.
1
voidtls_Set74HCT595(uint8_tdata)
2
{
3
for(uint8_ti=0;i<8;i++){
4
// Datenbit setzen
5
GPIO_SetPinValue(GPIOE,HCT595_DS,(data&0x80));__DSB();// Bit anlegen
6
GPIO_SetBits(GPIOE,HCT595_SHCP);__DSB();// SHCP -> High
Adib schrieb:> Hallo Horst, wie hättest du es denn geschrieben?Daniel A. schrieb:> Ist doch klar, so:return data[1] == 0xd4;
Exakt so wie Daniel ;)
Christian J. schrieb:> Ich Idiot !!!!Christian J. schrieb:> Der Compiler hat alles richtig gemacht
Wir kommen der Sache nun langsam näher :P
Christian J. schrieb:> So schaut es jetzt aus:/* ------ SPI Low Level: Ein 8 Bit Datenwort> senden und holen ------- */> uint8_t __attribute__((optimize(0))) SPI_TransferByte(uint8_t data)> {> uint8_t val;> while(!SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_TXE)); //> Warte bis TXE (SPI ist frei)> SPI_I2S_SendData(SPI1, data); // Byte> senden...> while(!SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_RXNE)); //> Warte bis Byte empfangen worden> val = SPI_I2S_ReceiveData(SPI1);> while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_BSY));> __DSB();> return val; // Wert abholen...> }
Ohne __DSB() gehts also nicht, ja?
Horst schrieb:> Ohne __DSB() gehts also nicht, ja?
Jein! Ob da ein Delay(1,2,3,...) steht oder was anderes ist egal.
Schreibe ich __DSB() jedenfalls genau da hin, exakt an diese Stelle,
dann kommen jedenfalls keine Fehlermeldungen mehr dass das Modul nicht
erkannt wurde oder plötzlich "weg" ist usw.
Hier auch eine sehr schöne Ausarbeitung des Themas
http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.07.23a.pdf
Darin steht für den Arm-v7 Core:
1 r1 = x;
2 if (r1 == 0)
3 nop();
4 y = 1;
5 r2 = z;
6 ISB();
7 r3 = z;
In this example, load-store control dependency ordering causes the load
from x on line 1 to be ordered before the store to y on line 4. However,
ARM does
not respect load-load control dependencies, so that the load on line 1
might well happen after the load on line 5. On the other hand, the
combination of the conditional branch on line 2 and the ISB instruction
on line 6 ensures that the load on line 7 happens after
the load on line 1.
Übersetzt heisst das, dass diese Folge von Befehlen nicht zwangsläufig
in der Reihenfolge ausgeführt wird, wie sie da stehen, sondern weil sie
alle in die Pipe geholt werden auch "gleichzeitig" oder eben in einer
anderen Reihenfolge.
Weiter heisst es:
If you are mainly a device driver developer, then examples (for
barriers) are fairly straightforward to find - whenever there is a
dependency in your code on a previous access having had an effect
(cleared an interrupt source, written a DMA descriptor) before some
other access is performed (re-enabling interrupts, initiating the DMA
transaction).
Hallo Christian,
Danke für den Link.
Habs noch nicht ganz studiert; das mit der code-Reordering macht
hoffentlich nur der C Compiler.
Derzeit hoffe ich noch, dass eine Sequenz auf volatile Speicher (auch
unterschiedliche Addressen) immer in dieser Sequenz ausgeführt wird.
Bezüglich der Barrieren gibt es auch von ARM Hinweise:
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/ka14041.html
und unten auf der Seite die App Note.
Mir hat mal jemand gesagt, dass evtl auch NOP im Core "wegoptimiert"
werden.
Man sollte also bei kurzen Delays sich was anderes einfallen lassen.
Timer verwenden oder mehrfach ein IO Register (volatile + IO Bus) lesen.
HTH, Adib.
Adib schrieb:> Mir hat mal jemand gesagt, dass evtl auch NOP im Core "wegoptimiert"> werden.
Man kann das NOP als "volatile" kodieren, dann bleibt es.
Reordering macht in erster Linie der Compiler, ja.
Aber "volatile" hat erstmal nichts mit dem Umsortieren von Anweisungen
zu tun.
Es sind Sätze wie diese, die mir Angst machen (mal abgesehen vom
derzeitigen Zustand Deutschlands....):
"The latest ARM processors can optimize the order of instruction
execution and data accesses. For example, an ARM architecture v6 or v7
processor could optimize the following sequence of instructions"
hier macht es noch Sinn, da STR kein Register hat, was auch LDR bedient,
also STR gleichzeitig oder vorgezogen werden kann.
LDR r0, [r1] ; Load from Normal/Cacheable memory leads to a cache miss
STR r2, [r3] ; Store to Normal/Non-cacheable memory
D.h. nichts anderes, als dass die CPU eigenmächtig entscheidet was sie
wann, wie und in welcher Reihenfolge macht. Sehr hardwarenahe
Programmierung über die Register kann in dem Fall zu unerfreulichen
Effekten führen.
GPIO_SetBits(GPIOC,GPIO_Pin_1);
GPIO_ResetBits(GPIOC,GPIO_Pin_1);
Man würde erwarten, dass da ein Peak am Port zu sehen ist. Habe jetzt
keinen Oszi hier aber viel wahrscheinlicher ist es doch, dass der BSRR
Befehl den BSSR direkt wieder aufhebt. Beide schreiben in
Schattenregister rein, die durch die interne Statemachine im Takte des
Bussses abgefragt und auf die phys. Register abgebildet werden. Ich
nehme an, dass ein Port in einem einzigen Rutsch abgebildet wird, d.h.
das aueinander folgende Setzen zweier Pins wird auf dem Oszi
gleichzeitig erfolgen. Was für ein CE bei einer Soft SPI ja schon fatal
ist, da CE VOR dem Clock kommen muss.
Ich müsste das jedenfalls erstmal testen bevor ich es verwenden weil ich
mir nicht sicher bin. Oder direkt eine Unmenge __DSB; DMB über den Code
streuen.
Für mich auf jeden Fall eine Bestätigung, dass meine Codieung, die kein
einziges Register selbst beschreibt sondern nur auf einem Hardware Layer
aufbaut weiter so gemacht wird, da ich "hoffe", dass Die HAL und wie sie
heissen die von den blassen Cracks in den dunklen Büros geschrieben
werden das berücksichtigen.
Christian J. schrieb:> D.h. nichts anderes, als dass die CPU eigenmächtig entscheidet was sie> wann, wie und in welcher Reihenfolge macht.
Das macht aber so ziemlich jede große CPU seit Pentium so...
Unabhängig davon, was der Compiler noch so umsortiert, um die Pipelines
voll zu kriegen.
Christian J. schrieb:> Sehr hardwarenahe> Programmierung über die Register kann in dem Fall zu unerfreulichen> Effekten führen.>> GPIO_SetBits(GPIOC,GPIO_Pin_1);> GPIO_ResetBits(GPIOC,GPIO_Pin_1);
Im Prinzip geht sowas schon auf nem popeligen AVR in die Hose: Zwischen
Pin schreiben und zurücklesen muss eine Nop eingefüllt werden, was aber
noch überschaubar ist, weil I/O-Takt und Systemtakt synchron sind.
Das ist auch so ein Grund, warum ich gerne immer noch einen kleinen AVR
einsetze, wenn er ausreicht, und nicht gleich einen ARM nehme, auch wenn
er nicht teurer ist.
Letztlich sollte dir deine Laufzeitumgebung aber die nötigen Primitive
anbieten, um Synchronisierung zu erreichen.
Das hört sich alles sehr mystisch an und ist schwer zu glauben. In den
Beschreibungen zu den memory barriers geht es um Mehrprozessorsystem,
Mutexes, Memory Remapping oder Selbstmodifizierenden Code, das liegt
hier doch nicht vor.
Eine plausible Ursache war doch das der CS und Clk zu nah beeinander
oder sogar in der falschen Reihenfolge zu sehen waren. Liegt das nicht
eher daran das SPI/GPIO an unterschiedlichen und sogar unterschiedlich
schnellen Bussen hängen? Hast du mal SPI2/3 probiert die auch am
AHB/APB1 hängen?
Jojo S. schrieb:> In den> Beschreibungen zu den memory barriers geht es um Mehrprozessorsystem,> Mutexes, Memory Remapping oder Selbstmodifizierenden Code, das liegt> hier doch nicht vor.
Dann hast Du das aber nicht ganz gelesen. Ein 32 Bit ARm Cortext v-7 ist
kein popeliger AVR, wo alles an einem Takt hängt und im Gleichschritt
maschiert. Guck dir mal an, wieviele Busse der intern allein hat. Und
eine CPU, die einen Instruction Cache hat, der PARALLEL abgearbeitet
wird ist nicht zu vergleichen mit einem AVR. Bevor "Setze Pin D1 = 1"
ganz unten ankommt, nämlich an dem Flipflop vor der PP Stufe passiert
eine ganze Menge. Der Compiler weiss nicht, ob Du eine App schreibst
oder zeitkritische Dinge.
Ich bin da auch erst reingeklaufen, bevor ich mich damit überhaupt erst
befasst habe an einem freien WE wie diesem :-(
>>Liegt das nicht eher daran das SPI/GPIO an unterschiedlichen und sogar >>unterschiedlich schnellen Bussen hängen?
Du hast es erfasst. Das und auch die "Optimerung" der Reihenfolge.
>>Hast du mal SPI2/3 probiert die auch >>am AHB/APB1 hängen?
Nö :-) Ich löte da nix mehr um.
ich habe hier auch mal STM32 Libs durchsucht, die DMB/DSB/ISB tauchen
nur an einer Stelle auf: beim beschreiben des Flash, sonst nirgends.
Und das habe ich auch mal schnell in den STM32F103 geschoben:
1
while(1){
2
GPIOB->BSRR=(1<<12);
3
GPIOB->BSRR=((1<<12)<<16);
4
}
Das erzeugt brav Pulse mit 30 / 200 ns. Mit dem Keil v5 kompiliert, aber
auch der erzeugt keine MB Befehle:
1
21: GPIOB->BSRR = (1 << 12);
2
0x08000164 F44F5080 MOV r0,#0x1000
3
0x08000168 491B LDR r1,[pc,#108] ; @0x080001D8
4
0x0800016A 6008 STR r0,[r1,#0x00]
5
22: GPIOB->BSRR = ((1 << 12) << 16);
6
0x0800016C 0400 LSLS r0,r0,#16
7
0x0800016E 6008 STR r0,[r1,#0x00]
8
19: while(1) {
Und dein DMB ist ja nicht nach Assemblerzeilen, sondern nach
Funktionsaufrufen die aus vielen Einzelbefehlen bestehen, wie soll die
CPU das umsortieren?
Christian J. schrieb:> Es sind Sätze wie diese, die mir Angst machen (mal abgesehen vom> derzeitigen Zustand Deutschlands....):>> "The latest ARM processors can optimize the order of instruction> execution and data accesses. For example, an ARM architecture v6 or v7> processor could optimize the following sequence of instructions"
die cortex-mx sind aber einfache architekture, die tun nichts reordern.
hat bei einer 3-stufigen pipeline auch nicht viel sinn.
Christian J. schrieb:> Beide schreiben in> Schattenregister rein, die durch die interne Statemachine im Takte des> Bussses abgefragt und auf die phys. Register abgebildet werden. Ich> nehme an, dass ein Port in einem einzigen Rutsch abgebildet wird, d.h.> das aueinander folgende Setzen zweier Pins wird auf dem Oszi> gleichzeitig erfolgen.
Diese Busse laufen teilweise ja mit konfigurierbaren Takten, und sind
nicht alle gleich schnell. Ein STMF401 kann die GPIOs alle 2 Takte
togglen.
Dass eine Bitsetz-Operation eine andere überholt kann es auf den
cortexen eigentlich nicht geben.
DSB und co sollte nur notwendig sein im Zusammenhang mit DMA oder
anderen externen Busmastern die auf den Speicher zugreifen können,
ansonsten sollte ein "nop" reichen, danach ist das bit gesetzt oder
nicht.
Je nach eingestellter Geschwindigkeit (=Treiberstärke) dauerts dann halt
noch bis der Portpin auf entsprechende Spannung hoch/runtergetrieben
ist.
Nase schrieb:> Im Prinzip geht sowas schon auf nem popeligen AVR in die Hose: Zwischen> Pin schreiben und zurücklesen muss eine Nop eingefüllt werden,
Hallo Nase, Wo kann ich das nachlesen? Danke.
Adib schrieb:> Nase schrieb:>> Im Prinzip geht sowas schon auf nem popeligen AVR in die Hose: Zwischen>> Pin schreiben und zurücklesen muss eine Nop eingefüllt werden,>> Hallo Nase, Wo kann ich das nachlesen? Danke.
Hallo Adib, im Datenblatt. Bitte.
Beim ATmega8 unter
> I/O Ports -> Ports as general digital I/O -> Reading the pin value
Da liegt es aber nicht am asynchronen Takt oder an Reodering, sondern
einfach am Aufbau der Ausgänge.
rmu schrieb:> Dass eine Bitsetz-Operation eine andere überholt kann es auf den> cortexen eigentlich nicht geben.
trotzdem ist es besser bei Bitbanging Routinen die Optimierung
abzuschalten, damit der Compiler auch nicht auf die Idee kommt da etwas
um zu stellen. Ich fahre damit inzwischen ganz gut bestimmmte Routinen
mit einem __attribute__optimize(0) davon auszunehmen. Auch die Option
"Link Time Optimiziation" sorgt bei mir hauptssächlich für Hard Faults,
was aber auch wohl damit zusammen hängt welche Libs man verwendet.
Bisher nehme ich den Nano-Branch, auch wenn ich noch 900kb freien Platz
habe.
Christian J. schrieb:> trotzdem ist es besser bei Bitbanging Routinen die Optimierung> abzuschalten, damit der Compiler auch nicht auf die Idee kommt da etwas> um zu stellen.
das tut der compiler nicht, zugriffe auf "volatile" deklarierte
variablen (z.b. die register) werden nicht umgestellt oder wegoptimiert.
Christian J. schrieb:> Auch die Option> "Link Time Optimiziation" sorgt bei mir hauptssächlich für Hard Faults,> was aber auch wohl damit zusammen hängt welche Libs man verwendet.
link-time-optimization ist u.U. wirklich buggy, funktioniert aber
normalerweise auch. man sollte dann halt alles mit lto optionen bauen,
und aufpassen dass die binutils auch mit den passenden plugins
aufgerufen werden. seltsame interaktionen sind mir da nur im
zusammenhang mit explizit "weak" definierten symbolen untergekommen.
irgendwo ist das aber so oder so ein hack.
code, dessen timing nur mit bestimmten optimierungsflags funktioniert
ist üblicherweise irgendwo falsch und kann einem mit einer neueren
compilerversion um die ohren fliegen.
Optimierung abschalten brauchte ich außer beim debuggen bis jetzt noch
nie.Sinnloscode einfügen um ein paar Takte Zeit zu schinden aber
schon.Z.B. bei DMA Transfers in Schleifen für die Textausgabe.
m.f.G.
Dieter
rmu schrieb:> das tut der compiler nicht, zugriffe auf "volatile" deklarierte> variablen (z.b. die register) werden nicht umgestellt oder wegoptimiert.
das ist m.E. nicht garantiert.
Zugriffe, bei denen der Compiler keinen ursächlichen Zusammenhang
erkennen kann (weil z.B. ein gelesener Wert für die weitere Berechnung
erforderlich ist), kann er umstellen (und wird er auch, wenn das in
schnellerem Code resultiert). Das verhindert eine "volatile"-Deklaration
nicht zuverlässig. Ich hatte beispielsweise mal einen Fall, bei dem ich
einen i2c Dummy-Read brauchte, um den FiFo zu leeren, bevor ich was
anderes mache. Der Compiler hat darauf bestanden, erst mal was anderes
zu machen ...
Dagegen hilft manchmal nur eine explizite memory barrier. Also ein
Markus F. schrieb:> das ist m.E. nicht garantiert.
Der Compiler darf die Zugriffe auf volatile-variablen jedenfalls nicht
über sequence-points hinweg umordnen. In welcher Reihenfolge aber die
Zugriffe beim Funktions-aufruf
volatile int* R1 = something;
volatile int* R2 = somethingelse;
value = function(R1, R2); // hier
auf R1 und R2 passieren kann man nicht sagen, genausowenig wie volatile
mit nicht-volatile-Zugriffen gereiht werden.
Die Sache mit dem i2c Fifo klingt nach Mischung aus Zugriff auf volatile
(I2C-Register) mit Zugriff auf "normale" Variable ("was anderes tun"),
das darf der Compiler umstellen, da brauchts dann eine Barriere.
Christian J. schrieb:> trotzdem ist es besser bei Bitbanging Routinen die Optimierung> abzuschalten, damit der Compiler auch nicht auf die Idee kommt da etwas> um zu stellen.
Der Compiler kann nichts von diesem Bitbanging umstellen weil alle
Peripherie-Register üblicherweise als volatile deklariert sind. Volatile
bedeutet für den Compiler soviel wie "Das ist eine von außen
beobachtbare Wirkung" und per Definition darf nur so optimiert und
umgestellt werden daß alle von außen beobachtbaren Verhaltensweisen und
Wirkungen des Programms genau so und in genau der Reihenfolge
eintreten wie es im Programmtext geschrieben steht.
Also die Optimierungen können an bleiben aber man muss sich stets im
klaren sein welche Teile das geschriebenen Programms als beobachtbare
Außenwirkung gelten und welche Teile des Programms nur private interne
Angelegenheiten sind der Compiler nach Herzenslust umstellen oder
weglassen darf solange er nur nicht die Außenwirkung verändert.
Mir wird es langsam ein wenig zu hoch, bzw. weiss ich nicht was der
Compiler alles so darf und was nicht ohne mich da in die Doku zu
vertiefen, die ich ohnehin nicht verstehe, weil zu viel Fachchinesisch.
Was müsste denn an diesem I2C Code verbessert werden, der auch nur ohne
Optmierung korrekt läuft? Bisher weiss ich nicht wo ich da eingreifen
muss.
Nase schrieb:> Beim ATmega8 unter>> I/O Ports -> Ports as general digital I/O -> Reading the pin value>> Da liegt es aber nicht am asynchronen Takt oder an Reodering, sondern> einfach am Aufbau der Ausgänge.
das ist so wenn man den Pin als Eingang einlesen will,
in dem zugrundeliegenden Beispiel
Christian J. schrieb:> GPIO_SetBits(GPIOC,GPIO_Pin_1);> GPIO_ResetBits(GPIOC,GPIO_Pin_1);
umgeschrieben auf AVR
wird aber kein PIN eingelesen,
PORTB |= 1;
PORTB &= ~1;
und mit Sicherheit ein Puls ausgegeben
Christian J. schrieb:> Was müsste denn an diesem I2C Code verbessert werden
Was soll der ganze Heckmeck mit dem ständigen Initialisieren und
Deinitialisieren?
Ich benutze Bit-Banging, das sollte auf jedem MC auf Anhieb gehen. Man
muß nur die Bit- und Direction-Setzfunktionen etwas anpassen und
vielleicht auch die Delayfunktion.
Ich habe meine I2C-Funktionen etwas anders aufgeteilt:
Beitrag "Re: I2C Problem mit Acknowledge Polling"
Die Optimierung darf keinen Einfluß haben, da ja Portzugriffe und Delays
volatile sind, d.h. unbedingt und an genau der Stelle ausgeführt werden
müssen.
Hallo Christian,
hab's erst jetzt gesehen;
Auch für das I2C kannst du die aktuellen CubeMx Routinen von ST nehmen.
Zumindest so mache ich es. die liefern komplette Api:
Die Memory Funktionen gibt es auch als xxx_IT und xxx_DMA.
Ich steuere damit einen I2C EEprom ohne Problem out of the box an.
... Nur so als Hinweis ...
Adib.
--
Peter D. schrieb:> Was soll der ganze Heckmeck mit dem ständigen Initialisieren und> Deinitialisieren?
Peter..... wenn Du eine MP5 Vollautomat Bleispritze hast nimmst Du doch
auch keinen Flitzebogen mehr? Wenn ich also eine I2c I/F habe was alles
hat und einen Riesentrumm an Konfigmöglichkeiten, dann nehme ich doch
kein Bitbanging, was bei einem STM32 ja auch wieder den Einsatz der
komplexen Timer notwendig macht. Da wird auch nichts ständig
initialisiert, das sind Abfragen von Eventflags.
Adib schrieb:> hab's erst jetzt gesehen;> Auch für das I2C kannst du die aktuellen CubeMx Routinen von ST nehmen.
Kann ich die parallel zu den StdLibs verwenden? Ich habe mich so an die
gewöhnt, möchte die eigentlich weiter benutzen, auch wenn sie
abgekündigt sind. Wahrscheinlich aber geht das wohl eher nicht, oder?
usw. usw.
Bitbanging hat den Charme, daß es kurz und knackig ist, sofort auf jedem
Target läuft und auch nicht länger braucht, als ein super duper HW-I2C.
Erst als Interrupt oder DMA ist ein HW-I2C schneller, aber im Polling
Mode mußt du genauso lange warten.
Adib schrieb:> Auch für das I2C kannst du die aktuellen CubeMx Routinen von ST nehmen.
Also bei 7 Argumenten würde ich besser einen Pointer auf eine Struct
übergeben. Insbesondere, da sich die meisten Parameter zwischen den
Aufrufen kaum ändern werden.
Christian J. schrieb:> Kann ich die parallel zu den StdLibs verwenden?
Nein, die Funktionen und Parameter sind nur "ähnlich".
Wenn du unter Win. arbeitest, bekommst du mit CubeMx zumindest ein
Gerüst gebaut, wo deine Hardware initialisiert ist.
Der codegenerator soll wohl mit C# programmiert sein. Der Rest in Java.
Für mich ist das ein guter Einstieg gewesen ...
Und für nicht Laufzeitkritische Sachen sind die Funktionen immernoch in
meinem Code
Hth, Adib.
Adib schrieb:> Wenn du unter Win. arbeitest, bekommst du mit CubeMx zumindest ein> Gerüst gebaut, wo deine Hardware initialisiert ist.> Der codegenerator soll wohl mit C# programmiert sein. Der Rest in Java.
CubeMX ist in Java geschrieben und läuft auch unter Linux
http://fivevolt.blogspot.de/2014/07/installing-stm32cubemx-on-linux.html
U.u. reicht dort mittlerweile auch ein java -jar path-to-cubemx.exe oder
über den Wine-Umweg
Ich darf vorausschicken, daß ich mit den STM's keine eigene Erfahrung
habe.
Trotzdem habe ich mir gerade das Manual angeschaut (schad' ja nix).
STMI2C_CheckEvent() kann anscheinend
(http://www.st.com/web/en/resource/technical/document/user_manual/DM00023896.pdf
S.313) "SUCCESS" zurückliefern, obwohl in den Statusregistern ein Fehler
geflaggt ist (weil eben nur die explizit angefragten Bits geprüft
werden).
Wenn das so richtig ist, dann wäre die Fehlerbehandlung in deinem Code
eher rudimentär bis nicht vorhanden und Du kriegstest womöglich gar
nicht mit, wenn ein Kommunikationsfehler aufträte (wenn Du
beispielsweise die Peripherie "überfahren" hättest)?