Ein Funktionspointer auf eine Funktion, die einen void-Pointer
zurückgibt:
1
typedefvoid*(*TimeoutHandler)(void);
Wie muss das Ding aussehen, wenn die Funktion statt einem void * einen
Funktionspointer auf eine Funktion des Typs zurückgibt, der mit dem
typedef definiert wird?
Uhu U. schrieb:> Ein Funktionspointer auf eine Funktion, die einen void-Pointer> zurückgibt:>
1
>typedefvoid*(*TimeoutHandler)(void);
2
>
>> Wie muss das Ding aussehen, wenn die Funktion statt einem void * einen> Funktionspointer auf eine Funktion des Typs zurückgibt, der mit dem> typedef definiert wird?
Zwei Typedefs?
Um einen Pointer auf einen Datentyp in sich selbst verwenden zu können
must du diesen erst als "incomplete type" deklarieren, also sagen das er
existiert, aber nicht, was er beinhaltet. Dies ist bei Funktionspointern
nicht möglich, bei structs und unions aber schon. Der folgende c code
kommt dem, was der TO sucht noch am nächsten:
1
typedefstructfunctionfunction;
2
structfunction{
3
function(*call)(void);
4
};
5
6
functionmyfunc(){
7
printf("test\n");
8
return(function){myfunc};
9
}
10
11
intmain(){
12
functionf=myfunc().call().call();
13
f.call();
14
return0;
15
}
In C++ könnte man jetzt noch den Funktionsoperator des structs function
überladen. ( Mein erster versuch in c++11 war "using f = f(*)();",
funktioniert leider nicht ).
Daniel A. schrieb:> In C++ könnte man jetzt noch den Funktionsoperator des structs function> überladen. ( Mein erster versuch in c++11 war "using f = f(*)();",> funktioniert leider nicht ).
Mit std::add_pointer sollte das machbar sein.
Arc N. schrieb:> // Ein Handler soll sein?> void IAmAHandler(void) { }
In Worten: eine Funktion, die einen Pointer auf sich selbst zurück gibt.
Mit einem typecast kann man das hin biegen, wenn die Funktion einen void
* zurück gibt:
Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll
so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf
sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Die Frage lautet also: wie kann man mit einem typedef [in c!] den
typcast (TimeoutHandler) in der ISR umgehen?
Uhu U. schrieb:> Die Frage lautet also: wie kann man mit einem typedef [in c!] den> typcast (TimeoutHandler) in der ISR umgehen?
Das ist in c einfach nicht möglich. Du kannst den Funktionstyp nicht
nutzen, bevor du ihn deklariert hast, und du kannst Funktionstypen nicht
unvollständig deklarieren. Somit kannst du den Funktionstyp den du
möchtest, nicht deklarieren und somit auch nicht definieren.
Uhu U. schrieb:> Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll> so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf> sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Das kann man sicher auch anders lösen. Zum Beispiel mit einem Flag.
> Die Frage lautet also: wie kann man mit einem typedef [in c!] den> typcast (TimeoutHandler) in der ISR umgehen?
In C? Gar nicht.
Uhu U. schrieb:> Sinn der Übung:
fraglich. Wenn du zu so seltsamen Konstrukten geführt wirst, stimmt
vermutlich was am Design nicht. Auch wenn du es funktionierend
hinbekommst, ist die Wartbarkeit nicht nerauschend.
> Die Frage lautet also: wie kann man mit einem typedef [in c!] den> typcast (TimeoutHandler) in der ISR umgehen?
Genauso wie in C++ auch: Alles in einen Struct packen und es werden
keine Casts mehr benötigt, hier in C99:
Rufus Τ. F. schrieb:> Johann L. schrieb:>> return (F) { func1 };>> Das ... kommt mir komisch vor.
Keine sorge, das ist ein ganz normales Compound literal, die Dinger sind
echt Praktisch. Man könnte das ganze natürlich auch Ausschreiben, aber
das ist nun-mal einer der Vorteile von C gegenüber C++, welcher ich auch
ganz gerne Verwende.
Johann L. schrieb:> Uhu U. schrieb:>> Sinn der Übung:>> fraglich. Wenn du zu so seltsamen Konstrukten geführt wirst, stimmt> vermutlich was am Design nicht. Auch wenn du es funktionierend> hinbekommst, ist die Wartbarkeit nicht nerauschend.
Wenn sich das auf deinen Beispielcode bezieht: ja, das ist wirklich
fraglich, weil einfach nur vergurkt.
Meine Anwendung ist in der ISR in
Beitrag "Re: Vertracktes typedef für Funktionspointer" skizziert.
Fazit: der typecast ist das kleinere Übel...
Uhu U. schrieb:> Johann L. schrieb:>> Uhu U. schrieb:>>> Sinn der Übung:>>>> fraglich. Wenn du zu so seltsamen Konstrukten geführt wirst, stimmt>> vermutlich was am Design nicht. Auch wenn du es funktionierend>> hinbekommst, ist die Wartbarkeit nicht nerauschend.>> Wenn sich das auf deinen Beispielcode bezieht: ja, das ist wirklich> fraglich, weil einfach nur vergurkt.
Das "Problem" (falls man hier überhaupt von einem Problem sprechen
kann), liegt darin, dass C keine rekursiven Typsynonyme (aka Typedefs)
zulässt. Deswegen gelingt die Definition rekursiver Datentypen nur über
einen benamsten (Hilfs-)Typ. In C sind die einzigen benamsten Typen
Structs und Unions. Deswegen ist der Weg, den Daniel und Johann
vorgeschlagen haben, nämlich den Funktionszeiger in einem Struct zu
verpacken, nicht vergurkt, sondern die einzige saubere Lösung.
Wenn, dann würde ich eher deine Casterei als vergurkt bezeichnen, zumal
du dabei auch noch unnötigerweise zwischen Daten- und Funktionszeigern
hin- und herkonvertierst, was zwar meist funktioniert, aber durch den
ISO-Standard nicht abgedeckt ist.
Da rekursive Datentypen normalerweise sowieso nur im Zusammenhang mit
Structs auftreten, würde es sich nicht lohnen, für die wenigen
Ausnahmefälle spezielle Sprachfeatures einzuführen. Das gilt nicht nur
für C, sondern für praktisch alle Programmiersprachen. Oder kennt von
euch jemand eine Sprache mit statischer Typisierung, in der der von Uhu
gewünschte Funktionstyp definiert werden kann?
Deswegen ist es auch in anderen Sprachen in solchen und ähnlichen Fällen
üblich, den Datenwert (in diesem Fall den Funktionszeiger) einfach in
ein benamstes Päckchen zu verpacken. Das erfordert nur unwesentlich mehr
Schreibaufwand und verursacht i.Allg. überhaupt keine Effizienzeinbußen.
Im Gegensatz zur Cast-Methode bleibt dabei aber die Typischerheit voll
erhalten.
Uhu U. schrieb:> Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll> so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf> sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Warum so kompliziert, gib einfach TRUE oder FALSE zurück.
Yalu X. schrieb:> Da rekursive Datentypen normalerweise sowieso nur im Zusammenhang mit> Structs auftreten,
Eher selbstbezüglich als rekursiv.
Das Problem hängt auch mit der vergurkten Syntax zu tun. Typedefs wurden
nachträglich regelrecht in die Sprache reingewürgt und da der Name des
Typs nicht das erste sondern das letzte syntaktische Element ist, kann
er vorher eben auch nicht bekannt sein. Müsste er aber, weil Typnamen in
C dummerweise eine Rolle ähnlich der von Keywords haben.
> euch jemand eine Sprache mit statischer Typisierung, in der der von Uhu> gewünschte Funktionstyp definiert werden kann?
Ohne auf konkrete Sprachen einzugehen: Bei so etwas wie
type T: pointer to F; //(1)
type F: function (p: T) returning T; //(2)
wäre (1) eine unvollständige Typdeklaration sowohl von T als auch von F,
die beide erst mit (2) vollständig werden. Dass F in (1) noch nicht
bekannt ist wäre an dieser Stelle kein Problem, weil anhand der
syntaktischem Position als (Typ)Name erkennbar.
In C gibts eine analoge Konstruktion nur bei "struct S" (sowie union).
A. K. schrieb:> Yalu X. schrieb:>> Da rekursive Datentypen normalerweise sowieso nur im Zusammenhang mit>> Structs auftreten,>> Eher selbstbezüglich als rekursiv.
Hast recht, zu Datentypen passt "selbstbezüglich" besser, auch wenn die
beiden Begriffe oft synonym verwendet werden.
> Das Problem hängt auch mit der vergurkten Syntax zu tun. Typedefs wurden> nachträglich regelrecht in die Sprache reingewürgt und da der Name des> Typs nicht das erste sondern das letzte syntaktische Element ist, kann> er vorher eben auch nicht bekannt sein.
Das spielt sicher auch eine Rolle. Ein wesentlicher Grund liegt aber
auch darin, dass selbstbezügliche Typsynonyme die Typprüfung durch den
Compiler arg erschweren. Deswegen sind sie bspw. auch in Pascal und
Haskell nicht zugelassen, obwohl bei beiden Sprachen der neue Typname
jeweils am Anfang der Deklaration steht:
Yalu X. schrieb:> Deswegen ist der Weg, den Daniel und Johann> vorgeschlagen haben, nämlich den Funktionszeiger in einem Struct zu> verpacken, nicht vergurkt, sondern die einzige saubere Lösung.
Das habe ich auch nicht behauptet. Vergurkt ist Johanns
Anwendungsbeispiel, aus dem er gleich großzügig ein Designproblem für
die ganze Geschichte herbeizaubert.
> Wenn, dann würde ich eher deine Casterei als vergurkt bezeichnen
...
> Da rekursive Datentypen normalerweise sowieso nur im Zusammenhang mit> Structs auftreten, würde es sich nicht lohnen, für die wenigen> Ausnahmefälle spezielle Sprachfeatures einzuführen.
Na ja...
Peter D. schrieb:> Warum so kompliziert, gib einfach TRUE oder FALSE zurück.> if (timeoutHandler && !timeoutHandler())> timeoutHandler = NULL;
Dat Dingens kann ja nu noch ein bischen mehr, als nur NULL zurückgeben.
Denkbar wäre ja auch die Adresse einer Folgefunktion, die den nächsten
Teiljob erledigt usw...
Uhu U. schrieb:> Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll> so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf> sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Das halte ich für "von hinten durch die Brust ins Auge".
Ich formuliere Deine Aufgabenstellung einfach mal um:
Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll
so lange alle 100 Ticks aufgerufen werden, wie sie 1 zurückgibt; beim
Rückgabewert 0 soll beendet werden.
Fertig. Warum einen Funktionspointer auf sich selbst zurückgeben? Der
aufrufenden Funktion ist der Funktionspointer doch längst bekannt!?!
Frank M. schrieb:> Fertig. Warum einen Funktionspointer auf sich selbst zurückgeben? Der> aufrufenden Funktion ist der Funktionspointer doch längst bekannt!?!
Vielleicht steht dahinter eine verkettete Liste. Und die Funktion gibt
den nächsten Eintrag zurück.
Nur könnte man die Liste natürlich auch ausserhalb des Funktionsaufrufs
abklappern.
A. K. schrieb:> Vielleicht steht dahinter eine verkettete Liste. Und die Funktion gibt> den nächsten Eintrag zurück.
Ja, okay. Ursprünglich schrieb Uhu aber, dass die Funkton einen Pointer
auf sich selbst zurückliefern würde. Erst heute vormittag erwähnt er,
dass auch "die Adresse einer Folgefunktion" denkbar wäre. Denkbar, aber
bisher nicht gefordert.
> Nur könnte man die Liste natürlich auch ausserhalb des Funktionsaufrufs> abklappern.
Eben. Warum soll eine Teilfunktion (als kleines Rädchen im Uhrwerk)
wissen sollen, welche Folgefunktion als nächstes kommt? Die Koordination
Teil1 -> Teil2 -> Teil3 ... -> TeilN
sollte der aufrufenden Funktion überlassen sein. Dann reicht als
Rückgabewert 0 oder 1:
1: Mach weiter
0: Stop!
Uhu U. schrieb:> Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll> so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf> sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Wieso übergibst du nicht die Variable mit der Callback-Adresse
by-Reference an die Funktion? Innerhalb der Funktion kannst sie dann
ggf. auf NULL setzen.
Uhu U. schrieb:> Jetzt driftet ihr ab. Es steht nicht zur Debatte, wie ich mein Programm> strukturiere.
Frage:
Wie bekomme ich mit einem Kreuzschraubendreher eine Mutter
festgezogen?
Antwort:
Nimm einen Schraubenschlüssel!
Reaktion:
Jetzt driftet Ihr ab, es steht nicht zur Debatte, welches Werkzeug
ich wähle.
Uhu U. schrieb:> Es steht nicht zur Debatte, wie ich mein Programm strukturiere.
Das muss auch zur Debatte stehen können, wenn man eine vernünftige
Lösung finden will.
Mark B. schrieb:> Das muss auch zur Debatte stehen können, wenn man eine vernünftige> Lösung finden will.
Jetzt lass mal die Kirche im Dorf. Der Cast in der Timer-ISR ist ein
Schönheitsfehler, mehr nicht.
Johann L. schrieb:> Wenn du zu so seltsamen Konstrukten geführt wirst, stimmt> vermutlich was am Design nicht. Auch wenn du es funktionierend> hinbekommst, ist die Wartbarkeit nicht nerauschend.
So seltsam finde ich das Konstrukt gar nicht, ganz im Gegenteil. Es ist
meine bevorzugte Variante, einen ereignisgesteuerten (event driven)
deterministischen endlichen Automaten (DFA: deterministic finite
automaton, gerne auch FSM: finite state machine) zu implementieren:
Jeder Zustand des DFA wird durch eine Funktion repräsentiert, die das
nächste Eingabesymbol als Parameter erhält, die entsprechend des daraus
resultierenden Zustandsüberganges notwendigen Aktionen ausführt und den
Folgezustand als Resultat zurück gibt. Diese wird dann in einer
Zustandsvariable bis zum Eintreffen des nächsten Eingabesymbols
gespeichert. Die Callback-Funktion wird dadurch extrem einfach:
1
voidonInput(Inputinput){
2
state=state(input);
3
if(!state)
4
terminateDFA();
5
}
Oder gerne auch frei laufend:
1
while(state){
2
state=state(getInput());
3
}
Das ist deutlich flexibler, sicherer und letztlich auch effizienter als
jede andere mir bekannte Methode.
Genau das hat der TO hier auch implementiert, allerdings hat sein DFA
(neben dem trivialen terminalen) nur einen einzigen nichttrivialen
Zustand. Insofern ist die Frage natürlich berechtigt, ob die Komplexität
des Problems einen solchen Aufwand rechtfertigt. Elegant finde ich den
Ansatz aber allemal.
A. H. schrieb:> Genau das hat der TO hier auch implementiert, allerdings hat sein DFA> (neben dem trivialen terminalen) nur einen einzigen nichttrivialen> Zustand. Insofern ist die Frage natürlich berechtigt, ob die Komplexität> des Problems einen solchen Aufwand rechtfertigt.
Um das Prinzip zu demonstrieren, reicht das doch völlig aus. Da stellt
sich die Frage nach der Berechtigtheit des Aufwandes nicht.
> Elegant finde ich den Ansatz aber allemal.
Nicht nur das. Man bekommt auch den Scheduler vom Anwendungscode sauber
getrennt und kann ihn unverändert weiterverwenden.
A. H. schrieb:> void onInput(Input input) {> state = state(input);> if (! state )> terminateDFA();> }>> Oder gerne auch frei laufend:>> while (state) {> state = state(getInput());> }
Kannst du dafür auch noch Kontext (vor allem Deklarationen) liefern? Mir
ist leider noch nicht ganz klar wie das im Ganzen aussieht.
Micha schrieb:> Kannst du dafür auch noch Kontext (vor allem Deklarationen) liefern? Mir> ist leider noch nicht ganz klar wie das im Ganzen aussieht.
Zwar C++, Lösung ist dieselbe wie die weiter oben im Thread mit typedef
struct
http://www.gotw.ca/gotw/057.htm
Micha schrieb:> A. H. schrieb:>> void onInput(Input input) {>> state = state(input);>> if (! state )>> terminateDFA();>> }>>>> Oder gerne auch frei laufend:>>>> while (state) {>> state = state(getInput());>> }>> Kannst du dafür auch noch Kontext (vor allem Deklarationen) liefern? Mir> ist leider noch nicht ganz klar wie das im Ganzen aussieht.
Das haben Daniel und Johann oben schon wunderbar gemacht. Dem ist
eigentlich nichts hinzu zu fügen, außer vielleicht, dass ich bei dieser
Interpretation entsprechend angepasste Namen verwenden würde. Also so
etwa (ungetestet):
1
typedefintInput;
2
typedefstructState{
3
structState(*next)(Input);
4
}State;
5
6
Statestate_0(Input);
7
Statestate_1(Input);
8
Statestate_2(Input);
9
...// more state deklarations
10
11
Statestate_0(Inputi)
12
{
13
switch(i)
14
{
15
case1:/* do somthing */return(State){state_0};
16
case2:/* do somthing */return(State){0};// terminate
17
case3:/* do somthing */return(State){state_2};
18
}
19
return(State){state_1};
20
}
21
22
...// more state definitions
23
24
25
Statestate=(State){state_0}:
26
27
voidonInput(Inputinput){
28
state=state.next(input);
29
if(!state.next)
30
terminateDFA();
31
}
32
33
while(state.next){
34
state=state.next(getInput());
35
}
PS: Ach so, mein ursprünglicher Code war als Pseudocode gedacht der
funktionieren würde, wenn C rekursive Typdeklarationen der Form
1
typedefState(*State)(Input);
erlauben würde. Sorry, falls das zu Missverständnissen geführt hat.
Vielen Dank für diesen Thread, besonders für die Idee mit den
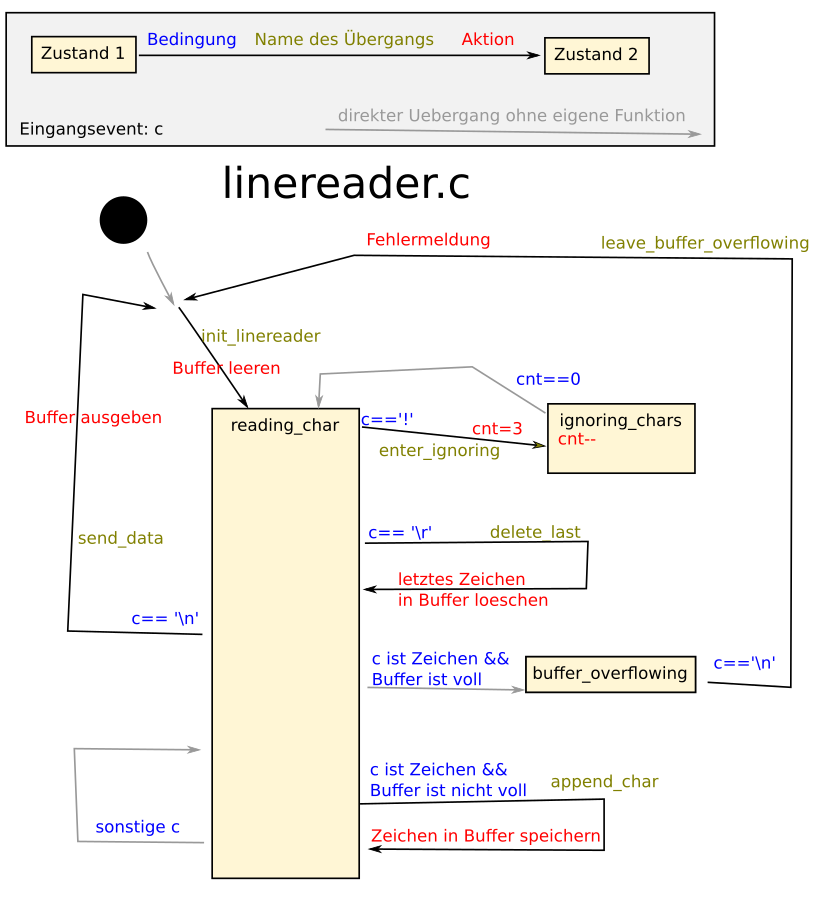
Zustandsautomaten. Um das Konzept zu verstehen, habe ich ein
Minibeispiel gebaut und in linereader.c weitergesponnen, bis in den
Zuständen nur Flusskontrolle passiert und die Aktionen in den Übergängen
geschehen, wobei die Übergänge ebenfalls Funktionen sind, die zum neuen
Zustand führen.
Nett finde ich dabei die kurzen, primitiven Funktionen und die
(scheinbare) 1:1-Beziehung zur grafischen Darstellung. Unschön ist die
wacklige Abstraktion und der höhere Aufwand, selbst wenn man wie hier
pragmatische Abkürzungen nimmt. Ob das ganze elegant oder albern ist,
ist mir noch nicht ganz klar.
Der Ansatz ohne die Übergangs-Funktionen ist der Vollständigkeit halber
in linereader2.c, ist aber insgesamt nicht viel kürzer.
Tom schrieb:> Vielen Dank für diesen Thread, besonders für die Idee mit den> Zustandsautomaten. Um das Konzept zu verstehen, habe ich ein> Minibeispiel gebaut und in linereader.c weitergesponnen, bis in den> Zuständen nur Flusskontrolle passiert und die Aktionen in den Übergängen> geschehen, wobei die Übergänge ebenfalls Funktionen sind, die zum neuen> Zustand führen.
Schön, dass wir Dich begeistern konnten. Aber bitte nicht der Versuchung
erliegen, eine neue Programmiertechnik einzusetzen, nur weil sie cool
ist (oder zumindest so erscheint). Am Anfang einer solchen
Implementierung steht immer der DFA. Der ist das Ergebnis eines eigenen
Entwicklungsprozesses, der auch gut dokumentiert sein sollte, denn er
ist wichtig für das Verständnis des Codes.
Ist der DFA vorhanden wird er einfach 1:1 in Code übertragen. (Das kann
unter Umständen sogar automatisch geschehen!) In der Regel sollte ein
DFA so wenige Zustände haben wie möglich. Es ist meist keine gute Idee,
zusätzliche Zustände einzuführen, nur weil das ein paar Zeilen Code
spart. Erfahrungsgemäß kommt es immer wieder mal zu Code-Teilen, die
sich in mehreren – gerne auch mal in den meisten – Zuständen eines DFA
wiederholen. Dann diese lieber in eine ganz normale Funktion
ausgliedern, die innerhalb einer Zustandsfunktion aufgerufen wird. Das
ist meist deutlich übersichtlicher.
Eine Funktion, die kein Eingabesymbol erhält, kann keine Transition
sein, weil ein Zustandsübergang immer das Ereignis eines eintreffenden
Zeichens voraussetzt. (Das Zeichen kann ggf. auch das leere Zeichen
sein, meist als Epsilon bezeichnet.) Die Funktionen, die Du in Deinem
Code als Transitions bezeichnest, sind letzten Endes ganz normale
Funktionen im obigen Sinn. (Ob sie in Deinem Fall wirklich etwas
bringen, sei einmal dahin gestellt.) Als solche ist es aber auch nicht
wirklich sinnvoll, den Folgezustand in ihnen festzulegen, den dieser ist
Teil des Modells des DFA, nicht des Teilproblems, was Du in der Funktion
löst.
Es gibt auch keinen Grund, zwischen Zustand und Transition zu
unterscheiden. Eine Zustandsfunktion ist beides: sowohl ein Zustand als
auch die Menge aller aus diesem Zustand heraus führenden Transitions.
(Genauer müsste man wohl formulieren, dass der Pointer auf die Funktion
der Zustand ist, die Funktion selber die Menge der Transitions.)
Zustände, die nur einen Folgezustand haben, machen in der Regel wenig
Sinn, es sei denn, Zustände werden genutzt, um etwas zu zählen. Das kann
im Einzelfall sinnvoll sein, meist ist aber eine explizite Zählvariable
die bessere Alternative.
Alles in allem gefällt mir die zweite Version Deiner Implementierung
(linereader2.c) deutlich besser.
Übrigens, Variablen, die innerhalb des DFA gebraucht werden, müssen
nicht global sein. Meist ist es übersichtlicher, sie in einer Struktur
zusammenzufassen und diese den Zustandsfunktionen als Referenz mit zu
übergeben. Genau genommen könnte sogar die Zustandsvariable (also der
Pointer auf den Folgezustand) Teil dieser Struktur sein. Der
Zustandsübergang wäre dann eine einfache Zuweisung innerhalb der
Zustandsübergangsfunktion. Das finde ich persönlich aber weniger
elegant, das es das Grundprinzip des DFA weniger offensichtlich macht.
Besser finde ich, ggfs. die Zustandsvariable gemeinsam mit der
Parameterstruktur in einer eigenen übergeordneten Struktur
zusammenzufassen. Diese kann dann je nach Bedarf global, lokal oder auch
dynamisch angelegt werden. Bei mehr als zwei gleichzeitig laufenden DFAs
ist das sogar zwingend erforderlich.
Uhu U. schrieb:> Sinn der Übung: die Funktion, die an ScheduleTimer2 übergeben wird, soll> so lange alle 100 Ticks aufgerufen werden, wie sie einen Pointer auf> sich selbst zurück gibt; beim Rückgabewert NULL soll beendet werden.
Und dafür läßt du die Köpfe aller Anwesenden derart rauchen?
Also, ich repetiere das mal:
Du brauchst eine Funktion, die was Anderes als NULL zurückgibt, wenn sie
nach 100 Ticks wieder aufgerufen werden soll?
Warum muß das unbedingt ein Zeiger auf sich selbst sein? Ein schlichtes
boolean würde den Zweck der Entscheidung doch auch erfüllen. Oder ist
das mit dem zurückgegebenen Funktionspointer ein besonderer Kick für
dich?
Noch einfacher wäre es, mit verzögerten oder geplanten Events zu
arbeiten. Dann hat der Systemtick die alleinige Arbeit und man kommt
ohne jegliche C-Akrobatik aus.
W.S.
Uhu U. schrieb:>> Also, ich repetiere das mal:>> Du kannst zwar schreiben, aber nicht lesen. Und auch im Spekulieren bist> du eine absolute Null.
Wenn Du Hilfe von anderen Leuten ersuchst, solltest Du vielleicht mal
verbal einen Gang zurück schalten.
Mark B. schrieb:> Wenn Du Hilfe von anderen Leuten ersuchst, solltest Du vielleicht mal> verbal einen Gang zurück schalten.
Wer zu faul zum lesen ist, der kann auch keine vernünftigen Ratschläge
geben. Insbesondere dann nicht, wenn die Frage bereits spätestens seit
14.05.2016 16:47 geklärt ist...
Uhu U. schrieb:> Du kannst zwar schreiben, aber nicht lesen.
Nicht so grob bitte.
Du rückst ja nur mit mit mikroskopisch kleinen Häppchen mit wichtigen
Einzelheiten heraus, bist also selber Schuld, wenn jemand etwas
überliest.
Dein Problem ist schon ziemlich an den Haaren herbeigezogen. Ich finde
eine Scheduler-Lösung viel besser und vor allem einfacher zu
durchschauen.
Peter D. schrieb:> Du rückst ja nur mit mit mikroskopisch kleinen Häppchen mit wichtigen> Einzelheiten heraus, bist also selber Schuld, wenn jemand etwas> überliest.
Es handelt sich nicht um ein Implementierungsproblem - die kann ich
durchaus schon selbst lösen - sondern um ein reines Sprachproblem mit
C.
Im Eingangsposting steht alles über das Problem. Man muss nur lesen.
Wozu ich das letzten Endes benutze, ist völlig irrelevant. Das zu
erfahren, befriedigt natürlich die Neugier - das geht auch in Ordnung.
Nur Ratschläge in der Art: "Das ist alles Unsinn, mach das so und so..."
sind nicht nur nutzlos und ärgerlich, sie signalisieren auch, dass der
Ratgeber die Frage nicht im Entfernten verstanden hat.
> Dein Problem ist schon ziemlich an den Haaren herbeigezogen.
Das kann man so sehen, muss man aber nicht. Ich will einen
wiederverwendbaren Scheduler, der völlig unabhängig von der jeweiligen
Anwendung in eine Lib verpackt wird und dann nur noch eingebunden und
aufgerufen wird. Um sowas sauber handhabbar zu machen, sollte man sich
schon etwas genauer mit der Problematik auseinandersetzen - das habe ich
gemacht.
> Ich finde eine Scheduler-Lösung viel besser und vor allem einfacher zu> durchschauen.
Ich weiß nicht, was du unter einer "Scheduler-Lösung" verstehst. Ich
finde, eine gut durchdachter Bibliotheksmodul ist allemal besser, als
Einwegcode, den man jedesmal neu hinschreibt.
Uhu U. schrieb:> Ich weiß nicht, was du unter einer "Scheduler-Lösung" verstehst.
Z.B. diese Lib:
Beitrag "Wartezeiten effektiv (Scheduler)"
Ich nehme sie sogar für einfache Blink-LEDs.
Oder für Timeouts von beliebigen Protokollen.
Peter D. schrieb:> Dein Problem ist schon ziemlich an den Haaren herbeigezogen. Ich finde> eine Scheduler-Lösung viel besser und vor allem einfacher zu> durchschauen.
Ein Scheduler und ein DFA sind zwei unterschiedliche Konzepte, sie
können sich aber sehr gut ergänzen.
Ein DFA schaltet immer auf Grund eines externen Ereignisses.(*) Das kann
z.B. ein Interrupt sein, wenn ein neues Eingabesymbol vorliegt, aber
auch der Ablauf einer bestimmten Zeit. (Das Eingabesymbol ist dann in
der Regel Epsilon.) Um das Schalten nach einer bestimmten Zeit zu
erreichen kann durchaus ein entsprechendes Ereignis im Scheduler
eingestellt werden.
Ein Scheduler, auf der anderen Seite, sorgt dafür, dass zu einer
bestimmten Zeit ein bestimmtes Ereignis getriggert wird. Das kann, muss
aber nicht, auch das Weiterschalten eines DFA sein.
(*) Natürlich werden DFAs auch zu anderen Zwecken wie der Syntaxanalyse
eingesetzt. Dann müssen sie in der Regel aber nicht ereignisgesteuert
sein und es würden sich andere Implementierungen anbieten.
Die Lösung mit dem Funktionspointer als Rückgabewert ist wohl deutlich
kompakter, als Peters Modell: es fallen eine Menge Funktionsaufrufe in
den Zustandsfunktionen ("handler") weg.
Zudem läßt sich das Interface sehr schlank gestalten, wenn man den
Tick-Wert 0 für eine Zustandsfunktion als "lösche den Eintrag"
interpretiert - was durchaus auf der Hand liegt.
Auch muss der Timeout für eine Kette von Zuständen bei vielen
Anwendungen nicht jedesmal geändert werden - das spricht - neben der
Eleganz - für die Lösung mit dem Funktionspointer als return-Wert. Das
reduziert auch die Größe der Scheduler-Tabelle.
Uhu U. schrieb:> Die Lösung mit dem Funktionspointer als Rückgabewert ist wohl deutlich> kompakter, als Peters Modell
Ich finde es im Gegenteil einfacher, wenn man für das Eintragen und
Löschen eine timed Calls zentrale Lib-Funktionen hat, als wenn sich
jeder selber um solchen Schrunz kümmern muß.
Auch kann man solche Funktionsaufrufe besser nachverfolgen, d.h. den
Code einfacher verstehen.
Ich hab da keine untere Grenze, selbst einfache Funktionen (Einzeiler)
zu modularisieren, wenn es sinnvoll ist.
Vielleicht hätte ich mich oben etwas präziser ausdrücken sollen: Der
Scheduler und der DFA sind zwei orthogonale Konzepte, die völlig
unterschiedliche Probleme lösen. Die Diskussion, welches Konzept besser
ist, ist müßig, weil es vom jeweiligen Problem abhängt. Das vom TO
gepostete Problem ist dazu erst recht nicht geeignet, das es so trivial
ist, dass es in der Praxis weder das eine, noch das andere benötigt. (Es
sollte ja aber wohl auch nur als theoretisches Beispiel dienen.)
Peter D. schrieb:> Ich finde es im Gegenteil einfacher, wenn man für das Eintragen und> Löschen eine timed Calls zentrale Lib-Funktionen hat, als wenn sich> jeder selber um solchen Schrunz kümmern muß.
Na rat mal, warum ich mir dafür eine Lib schreibe...
A. H. schrieb:> Der Scheduler und der DFA sind zwei orthogonale Konzepte, die völlig> unterschiedliche Probleme lösen.
Das kommt auf den Abstraktionsgrad an, unter dem man das Ganze
betrachtet - deswegen würde ich nicht sagen, die Konzepte seien
orthogonal.
Beispiel: Rampe für einen PID-Regler abfahren. Der Prozess wird von
außen durch eine Änderung des Sollwertes angestoßen - das ist eine
Eingabe - und läuft dann timergesteuert ab, sozusagen als Echo auf die
Eingabe.
Uhu U. schrieb:> A. H. schrieb:>> Der Scheduler und der DFA sind zwei orthogonale Konzepte, die völlig>> unterschiedliche Probleme lösen.>> Das kommt auf den Abstraktionsgrad an, unter dem man das Ganze> betrachtet - deswegen würde ich nicht sagen, die Konzepte seien> orthogonal.
Das sehe ich nicht so. Egal auf welcher Abstraktionsebene ich mich
bewege, auf ein und derselben Ebene sind Scheduler und DFA immer
orthogonal zueinander.
Ein DFA schaltet immer auf Grund eines externen Ereignisses. Wo das
Ereignis her kommt ist ihm egal, er kann es aber nicht selber erzeugen,
denn ein DFA wechselt nie spontan seinen Zustand (zumindest nach der mir
bekannten Definition des Models).
Ein Scheduler dagegen tut genau das, er erzeugt Ereignisse, mit denen er
dann Aktionen in Form von Callback-Funktionen triggert. Da er genau das
tut, was ein DFA nicht kann, kann er weder Teil des DFA sein noch ihn
ersetzen.
Auf der anderen Seite ist weder der Scheduler auf den DFA als
Ereignisempfänger, noch der DFA auf einen Scheduler als Ereignisquelle
beschränkt. Es gibt immer alternative Quellen bzw. Senken. Beide
Konzepte können also nicht die Funktion des jeweils anderen übernehmen,
sind aber frei miteinander kombinierbar und also in diesem Sinne
orthogonal zueinander.
Natürlich hat auch der Scheduler einen Zustand, der die aktuelle Zeit
repräsentiert. Man kann also auch die Implementierung des Schedulers als
DFA betrachten und das Voranschreiten der Zeit als Zustandsübergang.
Dann befinde ich mich aber auf einer anderen, eigenen Abstraktionsebene.
Auch auf dieser Ebene wird der DFA seinen Zustand nicht spontan ändern,
sondern ist auf eine externe Ereignisquelle angewiesen, in diesem Fall
einen Timer-Interrupt.
> Beispiel: Rampe für einen PID-Regler abfahren. Der Prozess wird von> außen durch eine Änderung des Sollwertes angestoßen - das ist eine> Eingabe - und läuft dann timergesteuert ab, sozusagen als Echo auf die> Eingabe.
In diesem Fall könnte man einen DFA mit zwei Zuständen konstruieren: Der
Initiale Zustand prüft, ob das Ereignis vom Timer oder von der Änderung
des Sollwertes herrührt. Im ersten Fall verharrt er in seinem Zustand,
im zweiten Fall geht er in den Ausgabezustand über. Hier zählt er bei
jedem Timer-Tick eine Index weiter und gibt den entsprechenden
Rampenwert aus. Nach n Ausgaben kehrt er in den Initialzustand zurück.
(Mathematisch betrachtet handelt es sich natürlich um einen DFA mit n+1
Zuständen, n Ausgabezustände plus einen Initialzustand. Aber niemand
würde dafür n Zustandsfunktionen implementieren.) Wie ein Ausgabezustand
auf eine weitere Änderung des Sollwertes regiert, bliebe noch zu
definieren.
Wenn dabei ein Scheduler im Spiel ist – ein Timer-Interrupt ist genauso
vorstellbar – dann übernimmt der die Rolle des Timers. Dann würde der
DFA bei jedem Übergang in den Ausgabezustand – auch von sich selbst aus
– das nächste Timer-Event registrieren. Anders als beim mathematischen
Modell, das bei jedem Zustandsübergang immer auch ein – möglicherweise
leeres – Ausgabesymbol ausgibt, ist es in der Praxis oft vorteilhafter,
ggfs. eine Aktion auszuführen. Diese Aktion kann man als Teil der
Ausgabefunktion betrachten. Das Registrieren eines neuen Timer-Events
wäre eine solche Aktion. In jedem Fall aber bleiben Ereignisquelle und
DFA sauber getrennt.