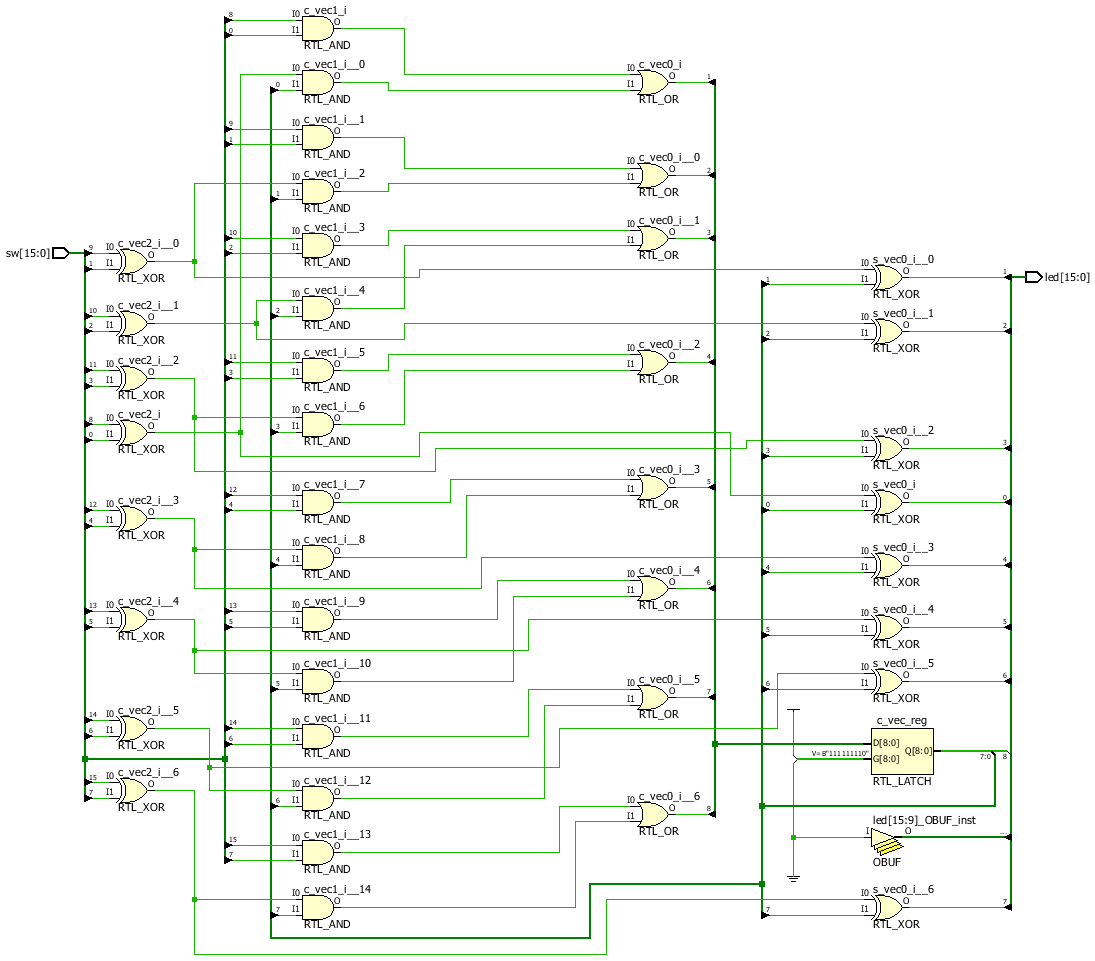
Ja, alle 9 Bits. Ist das aktuelle Vivado.
Aber:
Ich hatte das immer nur simuliert und das RTL Analysis > Schematic
angeguckt. Wenn man das wirklich implementieren lässt, dann kommt das
Gleiche bei raus. Immer 11 LUTs. Ist jedenfalls verwirrend ...
Gustl B. schrieb:> Ich hatte das immer nur simuliert und das RTL Analysis > Schematic> angeguckt.
Was sind dort das Enable-Signale (Latch-Signale) an diesen Latches?
Sind die statisch auf '1'/aktiv?
Dann dürfte das ein Automatismus sein, der erkennt, dass ein Signal auf
sich selbst zugewiesen wird. Und daraus reflexartig ein Latch bastelt,
das von nachfolgenden Optimierungsstufen auf normale Logik reduziert
wird...
Hier bleibt s(8) immer auf unknown 'U'. Steckt man die Zeile
s(8) <= c_vec(8);
aber mit in die loop, dann sieht es in der Simulation korrekt aus.
Wieso?
Wieder: Wenn man das als generate schreibt
dann passt es auch so in der Simulation. Ja, es kommt wieder identische
Hardware raus, aber ich möchte verstehen wieso sich die Simulation so
seltsam verhält.
Funktioniert auch wie gewünscht in der Simulation. Aber wieso muss diese
Zeile
s(8) <= c_vec(8);
überhaupt in den Process? Die sollte sich doch auch so in jedem
Simulationsschritt neu berechnet werden.
Gustl B. schrieb:> Funktioniert auch wie gewünscht in der Simulation.> Aber wieso muss diese Zeile s(8) <= c_vec(8); überhaupt in den Process?
Probier mal das hier noch aus:
Das ist das, was der Simulator aus der originalen nebenläufigen
Beschreibung macht. Und jetzt sieht man, dass da möglicherweise multiple
Treiber auftreten könnten (wenn man mal nicht auf den Bereich der
Laufvariable achtet).
Und dann weils grad so schön ist, probier das noch aus:
Lothar M. schrieb:> 'U' ist nicht Unknown, sondern Uninitialized.
Stimmt, ja ist klar, eine Unaufmerksamkeit meinerseits.
So, beide Beschreibungen erzeugen ein 'U' für s(8) in der Simulation.
Das simuliert so wie es soll, also kein 'U'. Aber was haben wir da jetzt
gelernt? Die Loop sollte doch exakt das Gleiche machen wie wenn man das
zu Fuß einzeln hinschreibt? (Dafür gibt es die doch.)
Gustl B. schrieb:> Aber was haben wir da jetzt gelernt?
Es gibt im Simulator ein Problem mit einer vermeintlichen Multisource,
wenn dem Vektor aus 2 Prozessen (oder eben 1 Prozess und 1 nebenläufigen
Zuweisung) zugewiesen wird. Wenn man sich das genau anschaut, ist dieses
Verhalten sogar "genormt"... :-/
Mit einem lokalen Signal zum Auftrennen dieser Zuweisung gehts dann
wieder (siehe Screenshot):
HM komisch. Ich hätte erwartet, dass ein std_logic_vector von der
Simulation nicht als ein Stück berechnet wird sondern als einzelne
std_logic. Hier wird das ja nicht als Speicher sondern nur als Kabelbaum
verwendet.
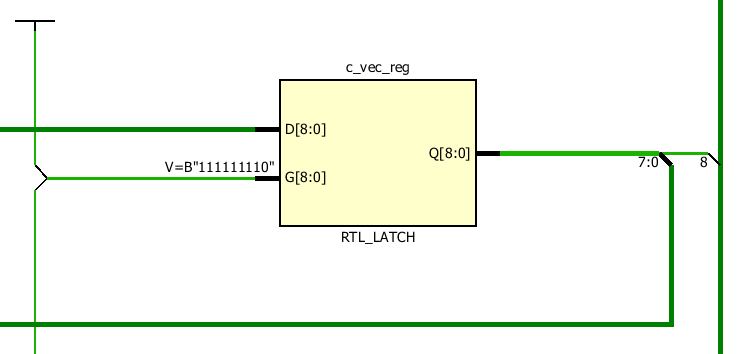
Nochmal zu den Latches:
Die Zuweisungen in Prozessen gehen der Reihe nach, Zeile für Zeile.
Generate baut dir eine normale Logikwolke.
Wenn eine Logikwolke gewollt ist -> generate.
Beim Prozess gibt es einen latch, weil c_vec(0) Im prozess nie
beschrieben wird, aber ausgelesen.
Daher muss er den Vektor Zwischenspeichern -> Latch.
Die Synthese erkennt aaber, dass das Murks ist und wirft die Lacthes
wieder raus.
Also mach mal:
Wobei s(8) <= c_vec(8); wieder im Process stehen muss. Ich finde das
seltsam weil in der loop werden nur s(7 downto 0) berechnet. Wieso
berechnet die Simulation s(8) nicht komplett eigenständig? Also gerne
einen Simulationsschritt später, dann hat sich c_vec(8) geändert und
somit ändert sich auch s(8). Irgendwie ist das unlogisch ausser man sagt
dass die Simulation std_logic_vector immer als ganzes berechnet.
Eigentlich soll die Simulation doch das zeigen was dann auch das FPGA
macht.
Die Post-Synthesis Simulation zeigt natürlich immer das richtige
Verhalten.
Na selbst wenn das im Process nacheinander berechnet wird, dann sollte
doch nach dem Durchlauf oder mehreren Durchläufen am Ende c_vec(8)
stabil sein. Und da s(8) nicht im process auftaucht sollte das doch dann
den Wert von c_vec(8) bekommen. Aber s(8) bleibt auf 'U'. Das finde ich
unlogisch.