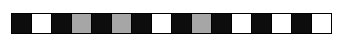
Guten Tag, ich habe folgende Anfängerfrage: Für ein Projekt wollen wir einen kleinen (d.h. einige mm großen) Barcode-Scanner bauen. Der Barcode befindet sich ca. 5mm vor dem Leser und soll die Zahlen von 1 bis 1.000.000 wiedergeben können. Die Länge des Barcodes soll maximal 10 cm betragen. Unser Problem ist, dass der Barcode manuell an dem Leser vorbei geführt wird, d.h. die Geschwindigkeit ist nicht bekannt und auch nicht konstant. Wir gehen von einer Geschwindigkeit von maximal 0,2m/s aus. Ein erster Lösungsansatz war die Verwendung des SFH9202 (Dokumentation ist als Anhang beigefügt) und die Kodierung der Informationen mit weißen und grauen (= 50% schwarzen) Feldern. Schwarze Felder würden dann als Separatoren zwischen den Informationsfeldern dienen. Ich habe dies in einem Beispiel im Anhang dargestellt. Das wäre z.B. "01101000" bzw. 22. Wird das so funktionieren? Welche besseren Techniken gibt es für unseren Anwendungsfall? Danke und viele Grüße Florian
Angehängte Dateien:
-

Barcode_sample.png
236 Bytes
Florian B. schrieb: > Welche besseren Techniken gibt es für unseren > Anwendungsfall? Das kommt darauf an, was man an Auswerteelektronik zur Verfügung hat. Barcode stellt natürlich sehr geringe Anforderungen an die Weiterverarbeitung, eine Alternative zum Barcode könne QR-Code sein. Kameras sind ja heutzutage recht klein geworden. https://www.sparkfun.com/products/14028
Hallo Joe, guter Hinweis, vielen Dank. Ich hatte noch vergessen zu erwähnen dass die Lösung billig (< 5 Euro) sein sollte, die Kamera ist leider zu teuer. An Auswerteelektronik ist derzeit ein Arduino Due geplant. Viele Grüße Florian
Die Idee sollte soweit funktionieren. Die 10cm Länge werden aber knapp. Ihr bräuchtet 20 Bits, wenn ich mich nicht verrechnet habe. Das macht 2,5mm pro Bit mit dem Trennzeichen, was schon relativ klein ist. Eine andere Idee wären zwei parallele Lochlinien. Eine permanent als "nun kommt das nächste Bit" Markierung und daneben dann ein Loch oder eben keines für 0/1. Auslesen könnte man es mit zwei kleinen Lichtschranken. Ich denke damit koennte man letztlich etwas kleiner werden als bei eurer Lösungsidee. Aber ob das wirklich zuverlässig funktioniert weiß ich auch nicht.
Hallo Baendiger, vielen Dank, diese Idee hatten wir auch schon. Der Barcode darf nicht höher als 5mm werden, da wird es knapp mit zwei Sensoren übereinander. Allerdings ist der Barcode auf eine durchsichtige Plastikkarte geklebt, wir könnten also die Daten von der einen Seite lesen und die permanente Spur von der anderen Seite, sofern das PLA-Plastik das IR-Signal durchlässt. Oder wir müssen die Sensoren ein bisschen kippen, so dass sie nebeneinander passen und trotzdem auf den gleichen Punkt zielen. "sollte soweit funktionieren" klingt auf jeden Fall schon mal gut. ;-) Viele Grüße Florian
Hi Da der Arduino Duo, zumindest Die, Die ich gefunden habe, allesamt um die 20Eu lagen - warum darf die Sensorik jetzt Nichts mehr kosten? Auch sehe ich den Ansatz, einen irgendwie gearteten Streifen zweizeilig auszulesen als - gewagt - an. Der Streifen muß dazu recht genau an dem Sensor vorbei geführt werden. Was soll 'Es' unterm Strich werden? Eine einzigartige Erkennung (oder eben bis 1Mio) würde ich dann eher in Richtung RFID aufbauen - da gibt es bereits fertige Komponenten und der Arduino hat bestimmt passende Bibliotheken griffbereit. Auch muß dabei der RFID-Tag nicht so genau getroffen werden - er muß nur vor die Spule. Wenn es ein reines Lern-Projekt ist, schauen wir aber auch in der Richtung weiter. Wenn Schwarz als Trenner erhalten bleibt, müssten wir 'nur' per ADC erkennen, wie hell die Fläche ich und damit die Bits zusammen schieben. Dabei ist die Durchzieh-Geschwindigkeit auch relativ egal - so flott ist der µC wohl gerade noch, wie Du zerren kannst :) MfG
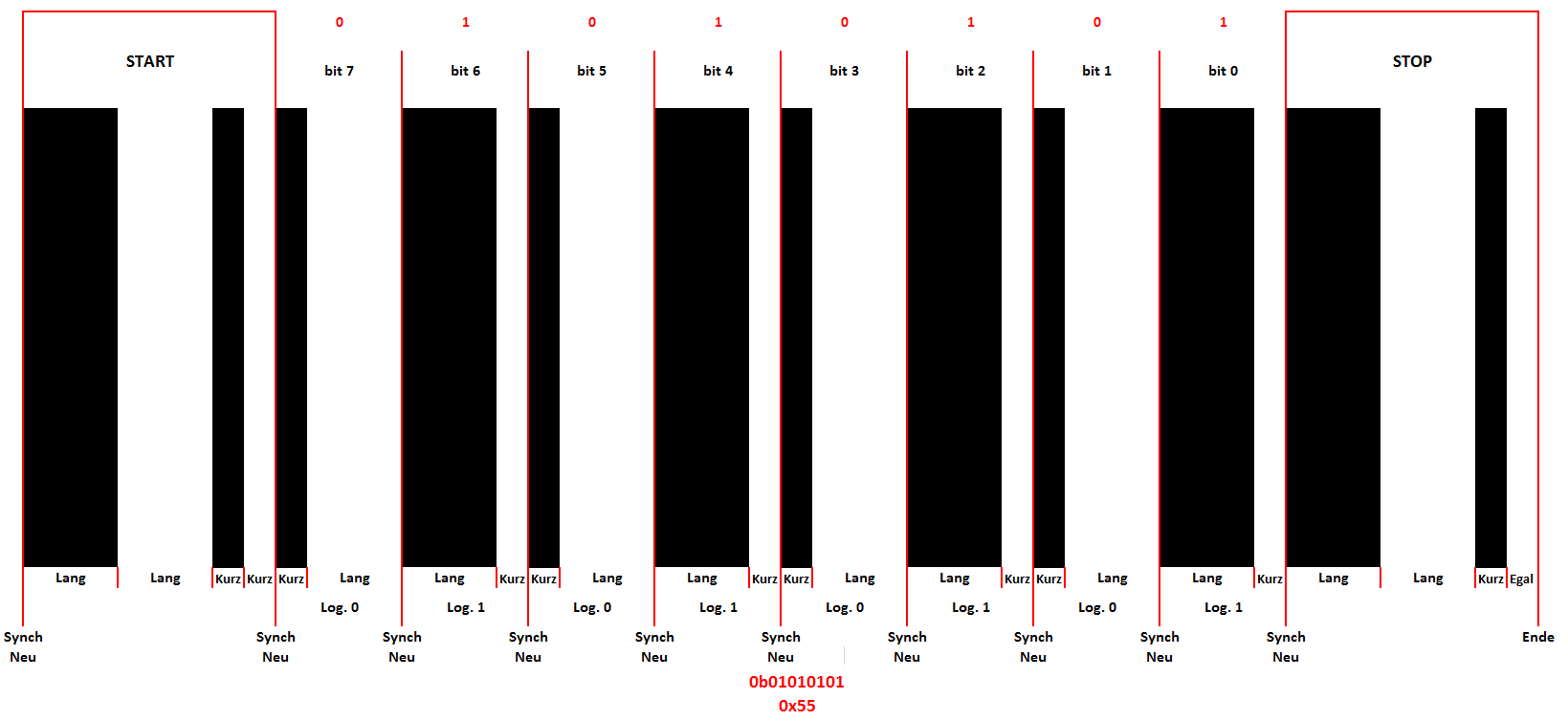
Florian B. schrieb: > Wird das so funktionieren? Welche besseren Techniken gibt es für unseren > Anwendungsfall? Ein normaler Mensch zieht den Scanner relativ gleichmässig über den aufgedruckten Code. Und auf 10cm ändert sich da auch nicht viel. Deswegen meine ich, dass so etwas wie Synchbalken am Anfang völlig ausreicht. Kurz Schwarz, lang Weiss, lang Schwarz, kurz Weiss als Startbit oder Synchbalken, danach 8 Datenbits. Jedes Bit fängt mit Schwarz an. Lang Schwarz / kurz Weiss ist Log. 1 Kurz Schwarz / lang Weiss ist Log. 0 Auf diese Weise wird jedes Bit auch neu synchronisiert. Man kann es auch umgekehrt machen, ist eigentlich egal.
Hallo Posti, die Sensorik darf nichts kosten, da wir sie relativ oft brauchen, also ca. 30 mal pro Gerät. RFID haben wir uns auch schon angeschaut, aber da sind - soweit ich das beurteilen kann - die Sensoren ja auch sehr teuer. Ich bin mir auch nicht sicher, inwieweit man einen Mindestabstand zwischen den ID-Tags einhalten muss, bzw. diese gegeneinander abschirmen muss, damit nicht der falsche Sensor die ID liest. posti schrieb: > Wenn Schwarz als Trenner erhalten bleibt, müssten wir 'nur' per ADC > erkennen, wie hell die Fläche ich und damit die Bits zusammen schieben. Ist denn der Abstand zwischen 0%, 50% und 100% schwarz "weit" genug, damit der Sensor ein fehlerfreies Ergebnis liefern kann? Wie exakt arbeiten solche Sensoren? Kann man das der technischen Dokumentation irgendwie entnehmen? Ich leider nicht ... :-( Viele Grüße Florian
1. Ihr braucht Fehlerkorrektur, oder zumindest eine zuverlässige Fehlererkennung. Ohne wird es nicht gehen. Der Nutzer muss wissen, ob der Scan erfolgreich war. Zu diesem Thema gibt es haufenweise Literatur. Stichworte sind BCH-Codes, Reed-Solomon, Hamming-Codes. Die Mathematik dahinter ist relativ heftig. 2. Hast Du schon mal darüber nachgedacht, was passiert, wenn der User den Code rückwärts scannt? Die industriell verwendeten Codes sind diesbezüglich eindeutig. 3. Wie wird der Code aufgebracht? Per Druck? Dann bräuchtest Du neben Schwarz eine weitere Sonderfarbe. Das Aufrastern (Halftoning) kann zum Problem werden, je nachdem, wie scharf der Leser fokussiert. Außerdem hast Du beim Druck immer das Problem, dass weiße Punkte beim Druck zulaufen, d.h. Dein Grau hat nicht 50%, sondern eventuell 70% effektive Helligkeit, und das kann im Druck selber schwanken. Bei Barcode ist Halftoning deswegen eine dumme Idee. Tipp: Schau, wie es die Profis machen. Es gibt ja Lesestifte für Barcodes wie diesen hier https://www.ico.de/ico-barcode-lesestift-typ-ii-mit-usb-anschluss-metallausfuehrung--bcrt2u Sowas funktioniert in der Praxis einwandfrei. Du brauchst eben geeignete Codes und clevere Software. Zu den Codes: Besorge Dir mal dieses Buch: https://www.amazon.de/Barcode-Das-Profibuch-optischen-Identifikation/dp/3935551045 fchk
posti schrieb: > Dabei ist die Durchzieh-Geschwindigkeit auch relativ egal - so flott ist > der µC wohl gerade noch, wie Du zerren kannst :) Kann man das auch anders herum rechnen: Wie klein darf ein Feld werden, wenn die Geschwindigkeit max. 0,2m/s beträgt? Also wie schnell liest der Sensor? Auch zu der "Abtastrate" (falls man das so nennt) bin ich aus der Dokumentation leider nicht schlauer geworden. :-( Viele Grüße Florian
Florian B. schrieb: > Kann man das auch anders herum rechnen: Wie klein darf ein Feld werden, > wenn die Geschwindigkeit max. 0,2m/s beträgt? Also wie schnell liest der > Sensor? Auch zu der "Abtastrate" (falls man das so nennt) bin ich aus > der Dokumentation leider nicht schlauer geworden. :-( Man kann auch die Antworten lesen, anstatt auf nutzlose Google Beiträge einzugehen. Manchen Leuten soltte man überhaupt nicht helfen. P.S. Leider kann ich meinen vorherigen Beitrag nicht mehr löschen, vielleicht kann der Moderator das für mich tun.
:
Bearbeitet durch User
Die Geschwindigkeit lässt sich immer mit etwas Rechenaufwand "heraus"-rechnen. Der Barcode, mit schwarz-grau/weiß liefert aber nur schwache Übergänge. Besser wäre ein Bi-Phase-Code, wie RC5 bei Fernbedienunungen. Für 20 Bit sind da auch nur 2 Breitenheiten pro Bit nötig: 100 mm / 2*20 = 2,5 mm pro Halb-Bit. Zur eindeutigen Erkennung von Anfang, Ende, Leserichtung und Plausibilität (!) kann man noch einige Dummy-schwarz-weiß-Wechsel vorn und hinten, sowie ein Parity-Bit anfügen. Macht etwa 25 Bit, also 2 mm pro Halb-Bit. 2 mm schwarz-weiß sollten besser zu detektieren sein, als 2,5 mm schwarz-grau-schwarz.
Hallo Marc, natürlich lese ich mir alle Antworten sehr genau durch, und ich habe auch auf fast jeden Post Bezug genommen. Marc V. schrieb: > Ein normaler Mensch zieht den Scanner relativ gleichmässig über den > aufgedruckten Code. Und auf 10cm ändert sich da auch nicht viel. Genau dies nehme ich nicht an, und das hatte ich ja in meinem ersten Post auch so geschrieben ("die Geschwindigkeit ist nicht bekannt und auch nicht konstant"). Deshalb bin ich nicht weiter auf Deine Antwort eingegangen, da für uns nur eine Technik in Frage kommt, bei der die Geschwindigkeit und deren Änderung nicht zu einem Fehler führen können. Viele Grüße Florian
Hi Wenn ich mich recht entsinne, war der ADC beim ATtiny spätestens nach 23 Takten fertig - wären bei 1MHz 0,000023 Sekunden (23µs). Wobei mir die Lösung mit der Bitcodierung nur aus SW und WS besser gefällt. Vorne und hinten eine eindeutige Kennung, damit der µC mitbekommt, wie rum gelesen wird. Wenn noch Platz ist, eine Prüfsumme/ein/mehrere Prüfbit einbeziehen. Wenn man auf die Halbfarben verzichtet, könnte sich als Sensor ein CNY70 eigen (5 Stk unter 5Eu auf eBay) und direkt digital eingelesen werden. Beim Anfahren an den Code werden die ersten zwei Blöcke zum Syncronisoeren genutzt, sollten also von Vorne wie von Hinten gesehen identisch sein. Sobald was erkannt wird, werden die Durchlaufzeiten der einzelnen Blöcke mitgehalten. Aus diesen Zahlen muß man nun schauen, ob sich daraus ein gültiger Code berechnen lässt. Dabei muß beim Ausdruck drauf geachtet werden, daß entweder der Druck oder das Papier reflektieren oder eben nicht - also nur Eines davon darf reflektieren. In der Software könnte man beide Varianten durchrechnen, ob davon Eine ein stimmiges Ergebnis bringt. Nicht ganz trivial, wenn nur eine Richtung möglich wäre, wäre es um Welten einfacher, aber Du kannst davon ausgehen, daß mindestens ein Aufkleber falsch rum gescannt wird und der ganze Betrieb dadurch ins Stocken kommt, wenn man das nicht beachtet :) MfG
Florian B. schrieb: > natürlich lese ich mir alle Antworten sehr genau durch, und ich habe > auch auf fast jeden Post Bezug genommen. > > Marc V. schrieb: >> Ein normaler Mensch zieht den Scanner relativ gleichmässig über den >> aufgedruckten Code. Und auf 10cm ändert sich da auch nicht viel. > > Genau dies nehme ich nicht an, und das hatte ich ja in meinem ersten > Post auch so geschrieben ("die Geschwindigkeit ist nicht bekannt und > auch nicht > konstant"). Deshalb bin ich nicht weiter auf Deine Antwort eingegangen, > da für uns nur eine Technik in Frage kommt, bei der die Geschwindigkeit > und deren Änderung nicht zu einem Fehler führen können. Manoman. Nicht nur lesen, auch verstehen. In meiner Antwort steht auch: Marc V. schrieb: > Auf diese Weise wird jedes Bit auch neu synchronisiert. Mit Startbit, 8 Databits, Stoppbit sind es 10 bit. 10cm / 10bit = 1cm/bit. Wieviel Schwankungen kann es auf 1cm geben ? Wenn kurz 0.25cm ist und lang 0.75cm dann ist das ein Verhältnis von 1:3, mit Schwankungen von 50% ist es immer noch 1:2. Also, wenn Abtastzeit Schwarz mehr als Abtastzeit Weiss ist, dann ist das ganz einfach eine Log.1, umgekehrt ist es eine Log. 0. Und der Fehler beim lesen wird nicht akumuliert, sondern gilt für jedes Bit einzeln, weil bei jedem Bit vom neuen synchronisiert wird. Natürlich kannst du auch unzählige Bücher darüber lesen, mit Tausenden von dazugehörigen Formeln. Oder ganz einfach Gehirn einschalten und es zumindest so versuchen. Und ich garantiere dir, dass es so geht, sogar wenn jemand mit Parkinson den Scanner bedient.
Angehängte Dateien:
-

barcode.png
7,8 KB
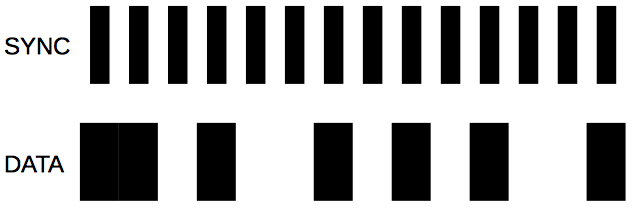
Florian B. schrieb: > wir könnten also die Daten von der einen Seite lesen und die permanente > Spur von der anderen Seite, sofern das PLA-Plastik das IR-Signal > durchlässt. Dann arbeite doch mit reinem schwarz/weiss. Auf der einen Seite sind die Datenbits (DATA) und auf der anderen Seite schmälere Schwarze Streifen zur Synchronisation (SYNC). Bei 20 Bits (plus sagen wir mal 4 Checksummen-Bits) auf 10cm sind das immerhin ca. 4mm pro Bit, das Sync-Pattern könnte dann 2mm weiss, 2mm schwarz sein. Das sollte mit einer Reflexionslichtschranke erkennbar sein. Im Anhang sind exemplarisch 14 Bit dargestellt.
:
Bearbeitet durch User
Marc V. schrieb: > Und ich garantiere dir, dass es so geht, sogar wenn jemand mit > Parkinson den Scanner bedient. P.S. Start und Stoppbit sollten gerade deswegen gleich sein, damit kannst du dann zuverlässig erkennen ob die Richtung stimmt.
:
Bearbeitet durch User
Angehängte Dateien:
-

Scanner.png
9,1 KB
Muss sowieso die Zeit totschlagen, hier ist auch ein Bild für dich weil ein Bild mehr als Tausend Worte sagt... P.S. Und die Sch...steuerung weicht immer noch zuviel ab - noch ein TestZyklus, noch eine Stunde.
:
Bearbeitet durch User
Ich würde eine optische Maus aufs Kreuz legen. Die gibt es billig und bis 4000DPI. Notfalls zerlegen oder gleich einen passenden Sensor besorgen. Dazu gibt es schon Projekte. Zum auswerten braucht man auch nicht alle Pixelwerte auslesen, sondern nur eine Zeile oder Spalte. Das braucht nicht so viel Rechenleistung für den seriellen Datenstrom.
Florian B. schrieb: > ca. 30 mal pro Gerät. RFID haben wir uns auch schon angeschaut, aber da > sind - soweit ich das beurteilen kann - die Sensoren ja auch sehr teuer. Healthcare Startup? "Sensoren sehr teuer"? Lasst mal Euren Kosteneinschaetzer neu kalibrieren, Sensoren im professionellen Umfeld sind normalerweise mindestens dreistellig im Nettopreis. Florian B. schrieb: > Marc V. schrieb: >> Ein normaler Mensch zieht den Scanner relativ gleichmässig über den >> aufgedruckten Code. Und auf 10cm ändert sich da auch nicht viel. > > Genau dies nehme ich nicht an, und das hatte ich ja in meinem ersten > Post auch so geschrieben ("die Geschwindigkeit ist nicht bekannt und > auch nicht > konstant"). Deshalb bin ich nicht weiter auf Deine Antwort eingegangen, > da für uns nur eine Technik in Frage kommt, bei der die Geschwindigkeit > und deren Änderung nicht zu einem Fehler führen können. Dann solltet Ihr allgemeine Betrachtungen (oder Versuche) anstellen, wie sehr sich die Geschwindigkeit aendern kann - das duerfte recht begrenzt sein. Danach solltet Ihr allgemeine Betrachtungen (oder Versuche) anstellen, wie man den "Datenmatsch" dann trotzdem noch auswerten kann. wendelsberg
wendelsberg schrieb: > Dann solltet Ihr allgemeine Betrachtungen (oder Versuche) anstellen, wie > sehr sich die Geschwindigkeit aendern kann - das duerfte recht begrenzt > sein. Das sollte doch selbstverständlich sein. Man printet auf 10cm etwa 40 - 50 senkrechte Linien gleicher Breite und lässt ein Paar Leute den Scanner mehrmals drüber ziehen. Dauert weniger als eine Minute und sagt sehr viel über Gleichmässigkeit aus. Aber herumrätseln macht auch Spass...
Schau mal in mein Buch Band 3, da habe ich etwas ähnliches als Experiment dokumentiert. http://stefanfrings.de/mikrocontroller_buch/index.html Ich nutze dort zwei Spuren.Eine für den Takt und eine für die Daten. So wird das Tempo des Einscannens völlig unkritisch und der Programmcode bleibt dennoch simpel. Deine Anforderungen zu den Abmessungen machen die Sache kompliziert, weil du dann IMHO nicht mehr die handelsüblichen Reflex-Lichtschranken in der Preisklasse um 1 Euro verwenden kannst. Auf graue Felder würde ich definitiv verzichten. Das hatte ich mal ausprobiert. Die Unterscheidung zwischen den drei Helligkeiten ist problematisch, vor allen bei dem geforderten Abstand. Handgeführte Barcode Scanner sind schwieriger zu programmieren. Die Entwicklung lohnt sich sicher nicht, da man das schon fertig kaufen kann. Ich nehem an, dass dein Entwicklungsbudget nicht ausreicht, um dieses ausgefuchste Rad neu zu erfinden.
Angehängte Dateien:
-

Barcode_CMYK.png
361 Bytes
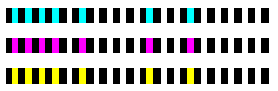
Vielen Dank an alle. Ich fand den Hinweis von Frank zum Halftoning sehr hilfreich. Ich würde es jetzt also erstmal mit einer dritten Druckfarbe versuchen, vielleicht habe ich ja Glück und eine der CMYK-Farben unterscheidet sich sehr gut von scharz und weiß. Mit 2mm Strichbreite bringe ich die 20 Informations-Bits plus 20 Separator-Bits auf den 10 cm ja ganz gut unter, und dann bleibt auch noch ein bisschen Platz für Prüfziffern. Startblöcke brauche ich bei konstanter Strichbreite ja keine, und die Leserichtung ist kein Problem da der Sensor in einer Schiene sitzt, und der Code daher nur von einer Seite eingeführt werden kann. Mit dem Vorschlag, unterschiedliche Strichbreiten zu verwenden kann ich mich leider immer noch nicht so richtig anfreunden. Aber das kann ich ja später einfach mal testen, die Hardware bleibt ja zumindest die gleiche. Zweispurige Verfahren sind auch interessant, um die Hardware aber möglichst einfach zu halten würde ich darauf nur zurückgreifen, wenn das einspurige Verfahren nicht klappt. Viele Grüße Florian
Angehängte Dateien:
-

manchester-barcode.png
17 KB
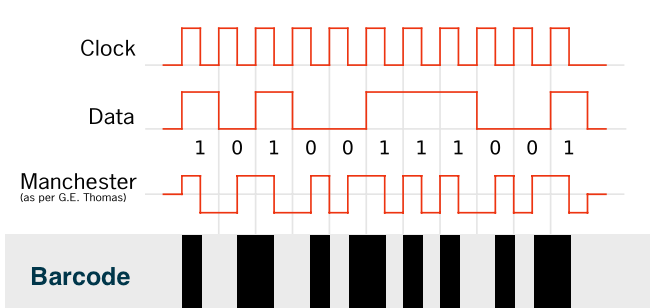
Graustufen/Farben halte ich eher für problematisch. Eine Codierung, die mit Barcode auf nur einer Seite auskommt, und trotzdem recht platzsparend ist wäre auch Manchester Code. Hier ist sichergestellt, dass pro Bit immer eine schwarze und eine weisse Fläche abwechseln, mit unterschiedlicher Phasenlage. In deinem Fall wären die Flächen dann jeweils ca. 2 oder 4mm breit. Die Clock kann aus den Datenbits regeneriert werden. https://en.wikipedia.org/wiki/Manchester_code
Hi Ob Du Dir mit den verschiedenen Farben einen Gefallen tust? Dort brauchst Du mindestens den ADC und darin 'Grauwerte' zu sehen. Wenn Diese weit genug auseinander sind, fertig. Wenn nicht, kannst Du mit einer RGB-LED und einen Foto-Transistor auf dem ADC die Farben durch die Helligkeit pro angeleuchteter Farbe erfassen - damit wurden schon Smarties sortiert :) Meine Wahl fiele weiter auf eine reine Schwarz-Weiß-Kombination mit verschieden langen Halb-Blöcken bei gleicher Gesamtlänge (also eine der Farben wesentlich länger als die Andere, jeweils pro Bit). Durch das Start/Stop-Bit kann erkannt werden, wie rum der Code liegt. Weiter kann daran die aktuelle Geschwindigkeit erfasst werden. Diese Geschwindigkeit ist 'das Maß' bei den nächsten Bits. Bei jedem Bit wird geprüft, wie lange das Durchziehen brauchte und daraus entschieden, ob's ein langer oder kurzer Bereich war. Hiermit kann ich auch mein Maß angleichen, da bekannt ist, wie lang der Bereich war und somit welche Zeit verbraucht hätte werden müssen. Dadurch dürften wir sehr störsicher werden. Bei einem Mehrstreifen-Code sehe ich noch das Problem, daß der Sensor schräg aufgesetzt werden kann - wir reden hier von 5Eu pro Sensor - da wird nicht mehr viel Geld für eine Führungsschiene über bleiben! Nur meine Gedanken - hoffentlich hältst Du uns auf dem Laufenden. MfG
Florian B. schrieb: > Ich würde es jetzt also erstmal mit einer dritten Druckfarbe versuchen, Was gefällt dir an deinem grauen oder bunten Ansatz so unglaublich gut, dass du die "handelsüblichen" Barcode-Konzepte, die täglich weltweit zigmilliarden Mal erfolgreich gelesen werden, gar nicht näher ansiehst? > vielleicht habe ich ja Glück Auf "Glück" in der Logistik verlässt sich kein seriöses Geschäft und keine Firma.
Joe F. schrieb: > Graustufen/Farben halte ich eher für problematisch. Das sind sie auch. Es gab genug Versuche, übliche Codierungen (allerdings vor allem 2D-Codes) mittels Einsatz von Graustufen oder Farben mit einer höheren Datendichte auszustatten. Rein garnix davon konnte sich auf breiter Front in der Praxis durchsetzen. Denn die gesteigerte Informationsdichte wird mit einem viel zu hohen Verlust bei der Informationssicherheit erkauft. Dazu kommen noch höhere Kosten für Sensoren, vor allem aber auch erheblich höhere Kosten für die Herstellung der Markierungen und deren oft deutlich geringere Widerstandsfähigkeit gegen Veränderungen durch Umwelteinflüsse. Kurzfassung: der Ansatz ist erwiesenermaßen ein Irrweg. > Eine Codierung, die mit Barcode auf nur einer Seite auskommt, und > trotzdem recht platzsparend ist wäre auch Manchester Code. Ja. Allerdings erfüllt auch der Manchester-Code nicht die (völlig idiotische, weil schon vom theoretischen Standpunkt unerreichbare) Forderung des TO nach einer seriellen Codierung, bei der völlig unabhängig von der Lesegeschwindigkeit fehlerfrei gelesen werden soll. Schon einfachste theoretische Überlegungen zeigen doch für jeden, dass das unmöglich ist. Man braucht sich doch z.B. bloß die Frage zu stellen: Wann genau soll denn eigentlich ein Leseergebnis vorliegen?. Und die Antwort anhand des Beispiels der Lesegeschwindigkeit 0 klärt dann allein schon hinreichend die grenzenlose Idiotie dieser Forderung... Jedem wissenschaftlich auch nur halbwegs gebildeten Menschen ist also allein schon anhand der rein theoretischen Betrachtung der Grenzfälle von vornherein klar, dass eine völlige Unabhängigkeit von der Lesegeschwindigkeit für ein serielles Verfahren ein Ding der Unmöglichkeit sein MUSS. Dazu braucht man keine Details der Hardware zu kennen oder der Software und sich schon gar keine Gedanken darüber machen, wie wohl ein Code aussehen könnte, der das Unmögliche möglich macht. Nö, man erkennt sofort, dass man genau das tun muss, was die Entwickler aller in Millarden Exemplaren erfolgreich verwendeten Barcodes auch gemacht haben: Man legt anhand der praktischen Erfordernisse/Gegebenheiten einfach sinnvolle Grenzen für die Lesegeschwindigkeit (und deren zulässigen lokale Änderungen) fest und entwirft dann Code, Hardware und Software so, dass sie innerhalb dieser sinnvollen Grenzen möglichst gut funktionieren.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.