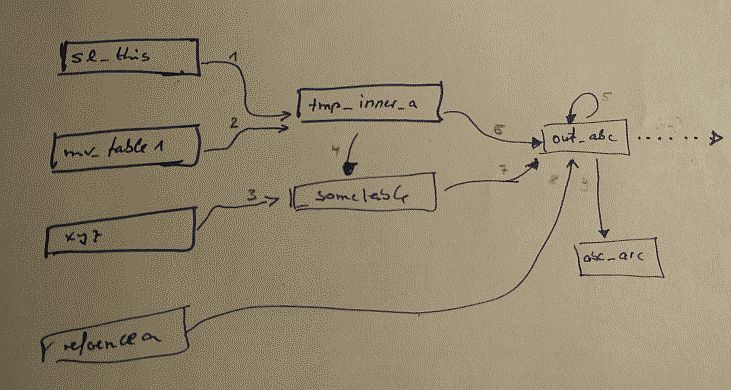
kennt jemand "einfache" Tools zur Datenfluss-Visualisierung? ich habe im Datawarehouse Umfeld häufiger mit umfangreichen (sql) Programmen zu tun, welche pro Modul (z.B. in einem Package) aus mehreren tausend Codezeilen bestehen, und dabei auf z.B. 20 verschiedenen Quell- bzw. Zielobjekten zugreifen (select, insert, update, delete, join etc). Ich möchte jetzt gerne "auf die Schnelle" die Datenfluss-Struktur erfassen, die sich bei der Code-Ausführung ergibt. Momentan mach ich sowas manuell, wenn ich mir den Code ansehe. Die Nummern an den Kanten geben die Reihenfolge vor, in welcher der Code abgearbeitet wird. Die Darstellung sollte nicht zu überladen sein, sondern halt nur die wesentlichen "globalen" Datenobjekte und ihre Zusammenhänge darstellen. "lokale" Objekte (z.B. Variablen, Cursor etc) brauche ich nicht zur direkten Darstellung bzw. Visualisierung --> Da gibts doch bestimmt elegantere Möglichkeiten, außer da händisch Bildchen zu malen? Nach welchen Stichwort bzw Produkt sollte ich denn da mal schauen?
Angehängte Dateien:
-

dataflow_diagram1.jpg
79 KB
:
Bearbeitet durch User
> --> Da gibts doch bestimmt elegantere Möglichkeiten, außer da händisch > Bildchen zu malen? Nach welchen Stichwort bzw Produkt sollte ich denn da > mal schauen? Graphviz
T2Graph schrieb: > Graphviz naja, es geht mir nicht hauptsächlich ums "schön malen" versus "von Hand malen" Ich suche eher nach etwas wie "oben (sql-) [*1] Code rein, unten Bild raus". Das Gesuchte sollte eine Code-Analyse machen, alle relevanten globalen Datenobjekte identifizieren, sowie deren Beziehungen untereinander, und dann zum Schluss visualisieren. Für den letzten Schritt kann man dann vermutlich tatsächlich Graphviz oder ähnliches mittels Objektimport "fürs malen" nehmen. das Beispiel Bildchen oben enthält Codefragmente wie : insert into tmp_inner_a select from sl_this join mv_table1 (-->Kante1, Kante2) on (irgendwas) where (irgendwas) (die 3 Knoten sl_this, mv_table_a und tmp_inner_a sind dadurch auch erkannt worden) ... update/delete out_abc set/where o.ä (->Kante5) usw Die Visualisierung erzeugt dann aus der vorliegenden Netztliste den Graphen von links nach rechts. - - - - - [*1] ein (großer) Teil von dem Zeug was ich da betrachte, besteht aus "reinem" sql code. Da scheint mir eine derartige Analyse/visualisierung "machbar". Die SQL Codedschnipsel sind eher groß (einige 1000 LOC) Darüber hinaus gibts aber auch noch Code-Teile, welche als Rahmenwerk aus Shell-Scripten bestehen, welche dann wiederum irgendwelches sql Zeug (inline oder per aufgerufenen seperaten sql-sqript) aufrufen. shell einige hundert LOC, SQL einige 100 LOC. Sowas kombinierters bringt vermutlich noch mal eine weitere Komplexitätsstufe rein (LOC = lines of code)
:
Bearbeitet durch User
>Das Gesuchte sollte...
Nix Da! So ein Programm würde doch 90% aller Software-Entwickler
arbeitslos machen.
Noch einer schrieb: > Nix Da! So ein Programm würde doch 90% aller Software-Entwickler > arbeitslos machen. Und für die restlichen 10% Arbeit, 100% Kassieren :D (Das waren noch Zeiten. Doku? Klar, hab ich im Kopf:)
Noch einer schrieb: >>Das Gesuchte sollte... > > Nix Da! So ein Programm würde doch 90% aller Software-Entwickler > arbeitslos machen. Warum sollte es das? Die Visualisierung des Datenflusses ist sicher nicht die Hauptaufgabe der meisten Software-Entwickler.
Also mit der Suche " sql dataflow visualization" finde ich in StackExchange den Beitrag http://dba.stackexchange.com/questions/144870/stored-procedure-logic-data-flow-visualization-tool der wiederum auf http://www.fatesoft.com/s2f/ verweist. Hast Du vermutlich aber schon gefunden.
Diese Tools sind nicht wirklich nützlich. Ist eine historisch gewachsene Software so umfangreich, dass man so ein Tool braucht, dann bekommt man nur ein Wand füllendes Spagetti-Muster.
Es gibt für UML ein Data modelling profile. Manche UML Tools unterstützen auch Reverse Engineering. ArgoUML hat auch ein SQL Modul.
Noch einer schrieb: > Diese Tools sind nicht wirklich nützlich. Stimmt. Das was ich da bei diesen Tools sehe, ist auch nicht wirklich das was ich benötige. Die "Innereien" eines Algorithmus interessieren mich nicht. Ich brauche es eine Stufe granularer, nämlich auf "Tabellen-Ebene". [*1] Für eine schnelle Gesamt-Betrachatung der Funktionalität eines Moduls reicht die "Tabellen" Sicht aus. Beispiel-Modul: Daten, enthalten Automarken mit irgendwelchen verschiedenen Modellen je Automarke werden "sortiert". Es gibt Eingangs-Tabellen, Ausgangstabellen, und Meta-Daten in Meta-Tabellen welche heran gezogen werden (VW > Opel, und Opel-astra > opel-corsa) Ich brauche halt nun "nur" die Beziehung der Tabellen zueinander. Ich muss wissen: Wo kommen DAten her, wo gehen sie hin. Wo gehen Daten rein, wo kommen sie raus. Vielleicht auch noch: welche Tabellen sind zwischendrin ---- [*1] Tabellen meint: tables, views, materialized views, synonyms, links etc. =========== Andreas R. schrieb: > Es gibt für UML ein Data modelling profile. Manche UML Tools > unterstützen auch Reverse Engineering. ArgoUML hat auch ein SQL Modul. MAchen die das auch in der Weise, wie ich es benötige? Kennst du ArgoUML, und kannst dazu einen Hinweis geben?
:
Bearbeitet durch User
Hmm... Wenn es eine KI gibt, die aus diesem Wust die wesentlichen Strukturen und den Sinn der Innereien rekonstruiert, dann dürfte dein Job nicht mehr lange existieren.
Thomas N. hat das Data Modelling Profile auf Argo portiert und da ging schon eine ganze Menge. Leider vieles noch nicht automatisch. Allerdings wurde da so einiges nur auf der Mailing-Liste geposted, und indet sich nicht in den Repositories mit den Sources. Ist schrecklich lange her, dass ich da bisserl mitgecoded hab. Ich glaub Rational hat das auch unterstützt, aber da reden wir halt von richtig Geld. Da gibt es auch ein Modul: https://sourceforge.net/projects/dbuml/
:
Bearbeitet durch User
Noch einer schrieb: > Wenn es eine KI gibt, die aus diesem Wust die wesentlichen > Strukturen und den Sinn der Innereien rekonstruiert, dann dürfte dein > Job nicht mehr lange existieren. Ich will ja nicht den "Sinn" der Innereien (=den Algorithmus) rekonstruieren, sondern "nur" die betroffenen Objekte und deren Beziehungen zueinander ermitteln. Was da mittendrin passiert, ist mir erst mal "egal" Beispiel: das folgende sql Statement sei Teil des Package "hauptschema.pkg_kundenanreicherung", als Prozedur-Einsprung wird pr_main() angenommen. irgendwo im pr_main() oder eine weitere durch pr_main aufgerufene Prozedur oder Funktion gibt es folgendes statement: insert into GESAMTERGEBNISLISTE select (irgendwelche_felder) from KLEINEKUNDENLISTE where (irgendeine_bedingung) --> folgende Objekte und ihre Beziehungen zuienander wurden identifiziert: GESAMTERGEBNISLISTE ist ein Zielobjekt. (Zielobjekt ist jedes Objekt, in dem geschrieben wird) GESAMTERGEBNISLISTE: typ=table , location=hauptschema.GESAMTERGEBNISLISTE KLEINEKUNDENLISTE ist ein Quellobjekt, hat keine (weiteren) Vorgänger (Quellobjekt ist jedes Objekt, aus dem nur gelesen wird) KLEINEKUNDENLISTE: typ=synonym,location=hauptschema.KLEINEKUNDENLISTE Das Objekt referenziert: typ=view, location=hauptschema.K_KUNDENLISTE, das Objekt referenziert typ=table, location=einanderesschema.ALLE_KUNDENLISTE KLEINKUNDENLISTE hat eine gerichtete Kante zu GESAMTERGEBNISLISTE nochmal, das "irgendeine_bedingung" des query interessiert mich nicht. Mir ist klr, dqaß dieses Beispiel-Query das einfachste ist, und daß es Besonderheiten gibt, welche erst "auf den zweiten Blick" sichtbar werden, z.B. insert into target select s1.field1 ,s2.field1 -- ,s3.field1 from source s1, source2 s2, source3 s3 Hier wird anscheinend source3 zwar im "from" aufgeführt, aber gar nicht genutzt, da auskommentiert: Also wird es "in Wirklichkeit" gar nicht genutzt, braucht auch nicht beachtet zu werden. ---- "händisch" greppe und lese ich mich bisher durch den Code, suche mir alle selcet, insert, update, delete etc raus, bis ich auf statische Datenobjekte treffe. Und dann male ich mir halt die Objekte und ihre Beziehungen auf ein Blatt. Beim ersten Erfassen wirds etwas chaotisch, meistens muß ich das Skizzierte noch mal neu aufmalen, um es etwas "besser lesbar" zu haben. Die detaillierte Knotenliste (Objekttyp etc) erstelle ich dann im Nachgang ---- Um zu begründen, wofür das gut sein soll: Bei Regressionstests stehe ich vor Aufgabenstellungen, dass "vorne was rein geht" und "hinten was raus kommt", und sich "in der Mitte" (im Algorithmus) manchmal was ändert. Ich möchte nun erst mal wissen, WO was rein kommt und raus geht. Ich spreche hier von mehreren hundert Modulen (packages), mit durchschnittlichen Größen von von bis zu mehreren Tausend Zeilen von Code. In jedem Modul werden 10 bis 100 Tabellen etc. als Quell- oder Zielobjekte verwendet -- "krasses" (etwas anders gelagertes) Beispiel: In der Mitte eines Packages befindet sich ein Sortieralgorithmus, und der wird nun ausgetauscht (xy-Sort wird durch pq-Sort ersetzt) Dann soll (Erwartung) bei gleichen Eingangsdaten die gleichen Ausgangsdaten rauskommen. Der Algorithmus mittendrin, also DASS da was in der Mitte sortiert, angereichert oder gefiltert wird, interessiert für den Regressions-Vergleich nicht. Im weiteren Regressions-Verlauf wurd dann ein Eingangs-Datenvektor injiziert (dazu muss ich halt wissen wo der Eingang ist), und der Ausgangsdatenvektor gesichert. Dann wird alles geleert, und der Mittelteil (package) ausgetauscht. Ein weiterer Lauf wird gestartet. Dann werden Eingangs- und Ausgangsdaten von Lauf1 und Lauf2 gegenüber gestellt
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.