Hallo Zusammen, Ich habe seit langem ein "RFID System" am laufen. Im Prinzip auf Basis des Pollinbausatzes. Da speichere ich die Karten ID als 5 byte Hex in eine Datenbank. Wenn eine Karte mal nicht mehr lesbar war(defekt), habe ich die aufgedrucke Nummer (dezimal) in Hex umgerechnet und damit in der DB nach der Karte gesucht. Ich stellte fest, dass die aufgedruckte Dezimalzahl immer 10stellig ist und nur die ersten 3 Byte der KartenID in Hex ergeben. Das fand ich zwar nicht optimal aber um die defekte oder nicht leserliche Karte in der DB zu finden, reichte das. Nun habe ich mir einen Reader gekauft: https://www.amazon.de/gp/product/B018OYOR3E/ref=ask_ql_qh_dp_hza Dieser fungiert unter Windows als Tastatur und tippt die ID einer gescannten Karte in ein aktives Textefeld. Soweit so gut. Jedoch spuckt dieser Reader auch nur die 10stellige, aufgedruckte ID aus. Das hat mich erst zweifeln lassen, ob ich vor 8 Jahren vllt nen groben Schnitzer gemacht habe aber ich habe überall nur von 5 Byte ID gelesen (bei EM40XX). Kann mich einer aufklären? Würde diesen günstigen Reader gerne nutzten, jedoch hätte ich schon gerne alle 5 Bytes der KartenID Besten Dank und Gruß!
:
Bearbeitet durch User
Angehängte Dateien:
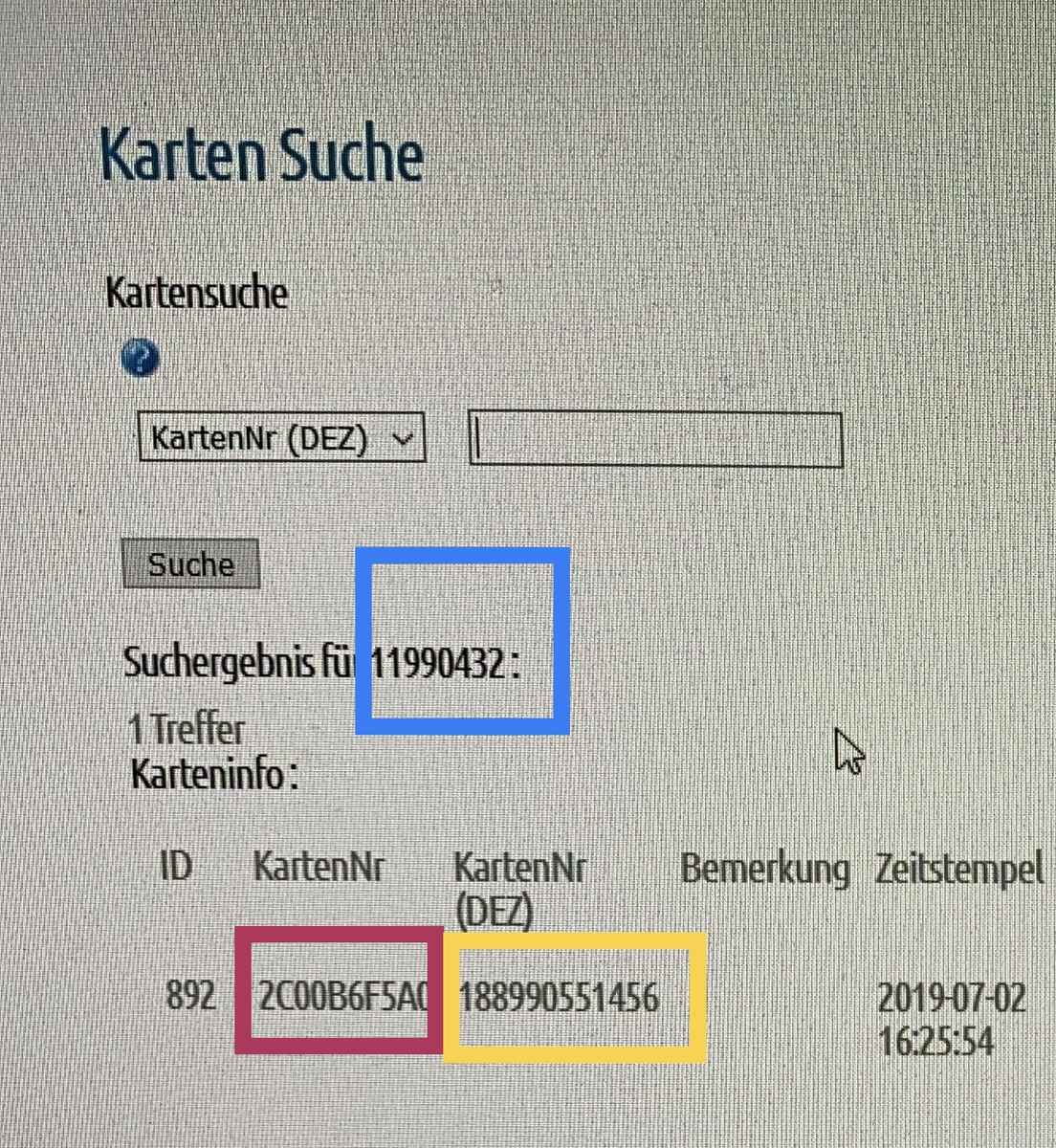
Hier ein Beispiel, zu Verdeutlichung. Das Bild zeigt im -blauen Kästchen: die aufgedruckte Nummer, mit der gesucht wird und die auch aus dem USB Reader herauskommen. -roten Kästchen: die gespeicherte 5Byte ID in HEX. -gelben Kästchen: die gespeicherte ID in Dezimal umgerechnet (debuginfo). Zum finden einer Karte ist das ja ok, wenn ich jedoch mit dem Reader eine neue/unbekannte Karte in die DB erstpeichern möchte, habe ich ja nur 3 Byte zu Verfügung. Oder bedarf es einer anderen Umrechnung um auch mit der 10stelligen Zahl auf 5 Bytes zu kommen?
Christian P. schrieb: > Oder bedarf es einer anderen Umrechnung um auch > mit der 10stelligen Zahl auf 5 Bytes zu kommen? Nein, diese Dezimal-Schreibweisen schnippeln eigentlich immer etwas ab. Beim ersten Byte kann man noch darüber streiten (Versions-/Herstellerangabe, meistens 0x0a), aber spätestens diese Variante wäre für mich ein Grund, einen Bogen um den Reader zu machen.
Evtl. hilft Dir das da zum Verständnis: http://www.priority1design.com.au/em4100_protocol.html Die 10-stellige Dezimalzahl, die auf den Tags aufgedruckt ist (und offenbar von Deinem neuen Reader ausgespuckt wird) entspricht den "32 Data Bits". Der grösste Wert, den man mit 32 Bit darstellen kann, ist "FF FF FF FF" = 0xFFFFFFFF = 4294967295. In Dezimalschreibweise also eine 10-stellige Zahl, um jeden möglichen Wert dieses Feldes als Dezimalzahl darstellen zu können, benötigt man im Maximalfall also zehn dezimale Ziffern. Auf den Tags wird der vollständige Wert der "32 Data Bits" als Dezimalzahl aufgedruckt, aber immer mit den 10 maximal benötigten Stellen, bei kleinen Zahlen also mit entsprechend vielen führenden 0en. Mal an dem Beispiel, das Du da als Screenshot gepostet hast: - Das RFID-Tag, das Du da ausprobiert hast, enthält tatsächlich den Wert "00 B6 F5 A0" als Wert des "32 Data Bits"-Feldes - Das entspricht "00 B6 F5 A0" = 0x00B6F5A0 = 11990432 dezimal. Auf der Karte aufgedruckt ist der dezimale Wert, mit führenden 0en auf 10 Stellen aufgefüllt, also "0011990432". - Dein neuer RFID-Reader liefert die vollständigen "32 Data Bits", als Dezimalzahl - aber offenbar ohne die führenden Nullen, also 11990432. Dieser Wert passt zwar in drei Byte, aber wenn vier Byte nötig wären, würde Dein neuer RFID-Reader garantiert auch die ausgeben. Hier ist das vierte, höchstwertige Byte halt 00, wie bei vielen (oder sogar fast allen?) EM4100-RFID-Tags. Was Dein neuer Reader offenbar tatsächlich einfach nicht liefert, ist den Inhalt des ersten, ein Byte umfassenden Feldes, das in dem oben genannten Link als "8 bit version number or customer ID" bezeichnet wird. Dieses Feld enthält bei der Karte aus dem Screenshot offenbar den Wert 0x2C, aber Dein neuer Reader gibt den Wert dieses 1-Byte-Feldes nicht aus, sondern nur den Wert des eigentlichen "32 Data Bits"-Feldes. Streng genommen enthält ein EM4100-RFID-Tag also ein 1-Byte-"version number or customer ID"-Feld und eine 4-Byte-"Data Bits"-Feld, Du hast diese beiden Werte/Felder aber zu einem einzigen 5-Byte-Wert zusammengefasst, als "Karten ID" bezeichnet und so in Deiner Datenbank gespeichert. Besser wäre vermutlich gewesen, Du hättest diese beiden Felder/Werte als zwei separate Werte in zwei separate Felder der Datenbank geschrieben. Nun aber die gute Nachricht: In der verlinkten Amazon-Artikelbeschreibung Deines neuen Readers ist ein Screenshot zu sehen, der darauf hindeutet, dass Du den Reader umkonfigurieren kannst, so dass er die Daten in einem anderen Format ausgibt. Da gibt es garantiert auch Optionen, die alle 5 Bytes enthalten.
:
Bearbeitet durch User
Angehängte Dateien:
-

Unbenannt.JPG
63 KB
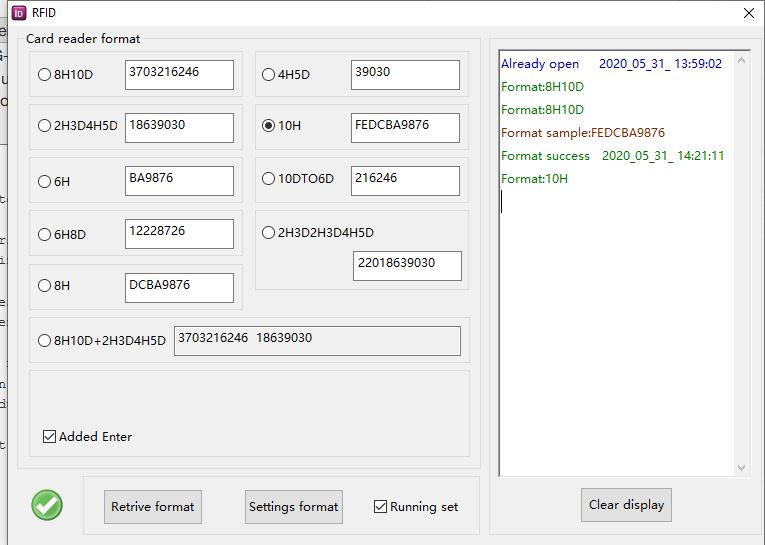
Lieber Joachim, Als ich deine Antwort heute morgen las... offenbarte sich eine perfekte Antwort - WOW! On point, ausführlich, verständlich, bemüht und freundlich. Das hat mich wirklich beeindruckt. Jetzt war davon nicht alles neu für mich, aber hier schauen ja hoffentlich auch in Zukunft noch Suchende vorbei ;) Aber dass ich tatsächlich nichts von dem Link/der Software mitbekommen habe und statt desssen hier nen thread aufmache **BrettVormKopf*. Um so erfreulicher, dass du das gecheckt hast! Ich danke dir für die Zeit die du dir genommen hast und dass du dein Verständnis geteilt hast ;) Im Anhang ein Screenshot der Software. Da gibt es viele Einstellungen die die Ausgabe der ID verkürzen aber immerhin eine, die die "vollen" 5 Bytes ausgibgt. Dann aber nur in Hex. Für mein bestehendes System passt das, denn ich nutze dort ja in der DB ohnehin schon HEX Zahlen. Aber bei der Entwicklung seinerzeit habe ich nicht daran gedacht, dass so eine Karte ja auch mal defekt gehen kann und die aufgedruckte Nummer von Interesse werden kann. Eine Frage würde ich dann noch in den Raumstellen. Würde die 4 Byte UID reichen um unique Karten im System zu garantieren oder kann es dann(unwahrscheinlich) passieren, dasss ich von Hersteller A eine Karte mit UID 0x 03 00 12 34 56 und vom Hersteller B eine Karte mit UID 0x 01 00 12 34 56 bekomme? und daher es durchaus sinnvoll ist, das 5 Byte zu nutzen? Dann ist es aber weiterhin so, dass bei einer defekten Karte mit der aufgedruckten Kartennr (10stellig Dezimal) nur nach 4 Bytes der 5 suchen kann. Ich ich weiß, dass es vermutlich in diesem Leben nicht passieren wird, dass ich zwei Karten erwische die sich nur im höchsten Byte unterscheiden und im Zweifel muss ich dann nur noch aus 2-3 Treffern wählen. Aber in der Umsetzung macht es ja auch einen kleinen unterschied ob ich 5 ByteZahlen mit 5 Byte suche oder mit 4Bytes. Vorallem wenn man die 5 Byte in mysql als binary ablegt. Da funktioniert die Suche mit "like" nämlich nicht. Also falls jemand mal da hängt. Ich finde passende 5Byte-Binary-Hex Eintrag mit kürzenen "Suchnummern" mit folgendem mysql query:
1 | elseif(strcmp($suchtyp,"KartenNr (DEZ)")==0) |
2 | {
|
3 | $sucheingabe_hex= base_convert($sucheingabe, 10, 16); |
4 | //tollerante suche (mit weniger stellen suchen) |
5 | $querystring= "SELECT *, HEX(`KartenNr`) AS `KartenNr` FROM `Karten` WHERE INSTR(KartenNr,UNHEX('".$sucheingabe_hex."')) > 0";
|
6 | |
7 | }elseif(strcmp($suchtyp,"KartenNr (HEX)")==0) |
8 | {
|
9 | //tollerante suche (mit weniger stellen suchen) |
10 | $querystring= "SELECT *, HEX(`KartenNr`) AS `KartenNr` FROM `Karten` WHERE INSTR(KartenNr,UNHEX('".$sucheingabe."')) > 0";
|
11 | |
12 | //exakte suche |
13 | //$querystring= "SELECT *, HEX(`KartenNr`) AS `KartenNr` FROM `Karten` WHERE `KartenNr` = UNHEX('".$sucheingabe."')";
|
14 | |
15 | } |
Angehängte Dateien:
-

20200531_175039.jpg
210 KB -

20200531_175048.jpg
200 KB
Der von dir verlinkte RFID reader hat sehr wahrscheinlich im inneren Löt brücken um die verschiedenen ausgabe modies einzustellen, ich stand mal wie du vor dem gleichen problem und konnte es so lösen. Mache gerade mal ein foto von meinem.
:
Bearbeitet durch User
Joachim S. schrieb: > - Das RFID-Tag, das Du da ausprobiert hast, enthält tatsächlich den Wert > "00 B6 F5 A0" als Wert des "32 Data Bits"-Feldes Joachim S. schrieb: > das in dem oben > genannten Link als "8 bit version number or customer ID" bezeichnet > wird. Dieses Feld enthält bei der Karte aus dem Screenshot offenbar den > Wert 0x2C Ich bin da etwas skeptisch, weil die meisten Tags mit 0x0a zu beginnen scheinen, was hier passen würde, wenn man die Reihenfolge der Nibbles umdreht. In dem Fall wäre in dem, was der Reader liefert, also das Versions-/Hersteller-Byte enthalten, während ein anderes (signifikanteres) fehlt. Christian P. schrieb: > Würde die 4 Byte UID reichen um unique Karten im System zu garantieren Nein. Im Datenblatt steht auch explizit: "The header is followed by 10 groups of 4 data bits allowing 100 billion combinations [...]"
Danke für deine Einwände. Also (vorausgesetzt, ich habe keine Dreher) fuer ist das abgehakt. Bekomme meine 5 Bytes. Und der Reader spuckt die selbe ID aus, welche auch mein Pollin-Style reader die seit Jahren in die Db schreibt. Also müssten der erkaufte Reader und meine selbst gebauter den selben Fehler machen. Hmmm schrieb: > Ich bin da etwas skeptisch, weil die meisten Tags mit 0x0a zu beginnen > scheinen, was hier passen würde, wenn man die Reihenfolge der Nibbles > umdreht. Das es die unteren 4 Byte waren ist gewiss. Denn ich hab damit ja nach den Karten in der DB gesucht. Ich würde der Aussage „meisten Tags mit 0x0a“ erstmal widersprechen. Habe mittlerweile über tausend karten in der DB und kann mich nicht an eine solche Auffälligkeit erinnern. Kann da gerne mal nach der Verteilung des höchsten Bytes nachschauen. Aber wenn es das Hersteller byte ist, ist es ja auch ehr unwahrscheinlich oder unlogisch, wenn das immer 0x0a waere oder?! Beste Grüße!
Christian P. schrieb: > Ich würde der Aussage „meisten Tags mit 0x0a“ erstmal widersprechen. > Habe mittlerweile über tausend karten in der DB und kann mich nicht an > eine solche Auffälligkeit erinnern. Kann da gerne mal nach der > Verteilung des höchsten Bytes nachschauen. > Aber wenn es das Hersteller byte ist, ist es ja auch ehr > unwahrscheinlich oder unlogisch, wenn das immer 0x0a waere oder?! Da mit dem "meistens 0x0a" würde ich auch eher für einen Zufall oder so halten. Ich habe eben testweise mal alle meine EM4100-RFID-Tags überprüft: Ich habe 4 Karten im Scheckkartenformat, die haben als höchstes/erstes Byte alle den Wert 0x03. Ausserdem habe ich noch 6 Tags im Schlüsselanhänger-Format. Da habe ich 1x den Wert 0x28, 2x den Wert 0x08 und 3x den Wert 0x01. Unter'm Strich also kein einziges Mal der Wert 0x0A. Das zweite Byte, also höchstwertige Byte des "Data Bits"-Feldes, ist übrigens bei allen meinen Karten tatsächlich immer 0x00.
Christian P. schrieb: > Also > müssten der erkaufte Reader und meine selbst gebauter den selben Fehler > machen. Das wäre nicht einmal wirklich ein Fehler. Aus Datenblatt-Perspektive sind das einfach nur Datenbits in 4-Bit-Gruppen zzgl. Parity, die Darstellung ist nicht genormt. Christian P. schrieb: > Ich würde der Aussage „meisten Tags mit 0x0a“ erstmal widersprechen. > Habe mittlerweile über tausend karten in der DB und kann mich nicht an > eine solche Auffälligkeit erinnern. Ich habe hier neben ein paar einzelnen noch eine Datenbank mit ebenfalls rund 1000 Karten, wo es überall zutrifft - wobei letztere auch tatsächlich vom gleichen Hersteller stammen dürften. Deshalb stach mir das in Deinem Screenshot ins Auge. Aber da Du jetzt alle 40 Nutzdaten-Bits bekommst, bist Du ohnehin auf der sicheren Seite. Selbst wenn ein Clone-Hersteller sich nicht um Hersteller-IDs kümmert, ist die Gefahr einer Kollision minimal. Christian P. schrieb: > Kann da gerne mal nach der > Verteilung des höchsten Bytes nachschauen. Das wäre wirklich mal interessant zu wissen. Christian P. schrieb: > Aber wenn es das Hersteller byte ist, ist es ja auch ehr > unwahrscheinlich oder unlogisch, wenn das immer 0x0a waere oder?! Kommt darauf an, wie diese Bits in der Praxis verwendet werden. Ich könnte mir vorstellen, dass Grosskunden eigene IDs bekommen können, damit ihre Systeme nicht mit fremden Karten laufen, und ansonsten bestimmte Standard-IDs verwendet werden.
Joachim S. schrieb: > Das zweite Byte, also höchstwertige Byte des "Data Bits"-Feldes, ist > übrigens bei allen meinen Karten tatsächlich immer 0x00. Das kann ich wiederum auch bestätigen, dann sieht es hier doch nach der üblichen Reihenfolge aus, und das 0xa0 am Ende war bloss Zufall.
Hmmm schrieb: > Ich habe hier neben ein paar einzelnen noch eine Datenbank mit ebenfalls > rund 1000 Karten, Was machst du denn? Haben wir das gleiche gemacht? xD Schade das du nur Gast warst/bist. Hätte dir gerne mal ne PM geschcikt.
Angehängte Dateien:
-

Unbenannt.JPG
35 KB
{kind=link}
{kind=link}
Hmmm schrieb: > Christian P. schrieb: >> Kann da gerne mal nach der >> Verteilung des höchsten Bytes nachschauen. > > Das wäre wirklich mal interessant zu wissen.
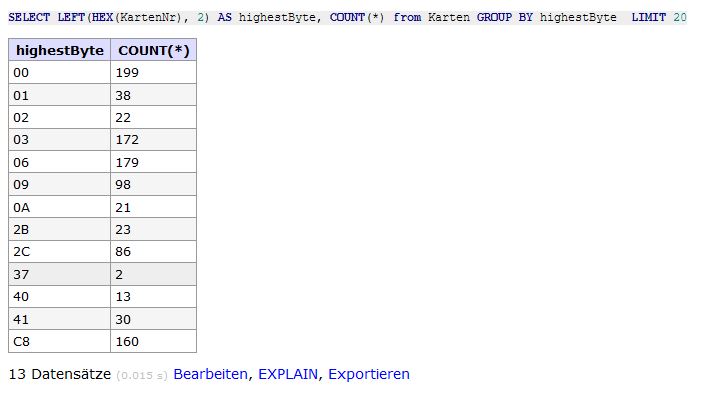
Ah, da taucht das nächste Fragezeichen auf... Diese Counts zusammen addiert ergeben 1043 Karten. In meiner Tabelle sind aber 1046 eingetragen... Also entweder hat meine Countabfrage 3 Karten nicht erfasst (wohl kaum) oder ich habe eine Lücke in den fortlaufenden ID Nummer in der KartenTabelle. Bekomme ich das Checken auf eine Lücke unter den ID auch in mysql hin? Also das zählen der ID ist klar... Meine das Aufspüren der Stellen wo die Lücken sind.
:
Bearbeitet durch User
1 | SELECT (t1.id + 1) as gap_starts_at, |
2 | (SELECT MIN(t3.id) -1 FROM Karten t3 WHERE t3.id > t1.id) as gap_ends_at |
3 | FROM Karten t1 |
4 | WHERE NOT EXISTS (SELECT t2.id FROM Karten t2 WHERE t2.id = t1.id + 1) |
5 | HAVING gap_ends_at IS NOT NULL |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.