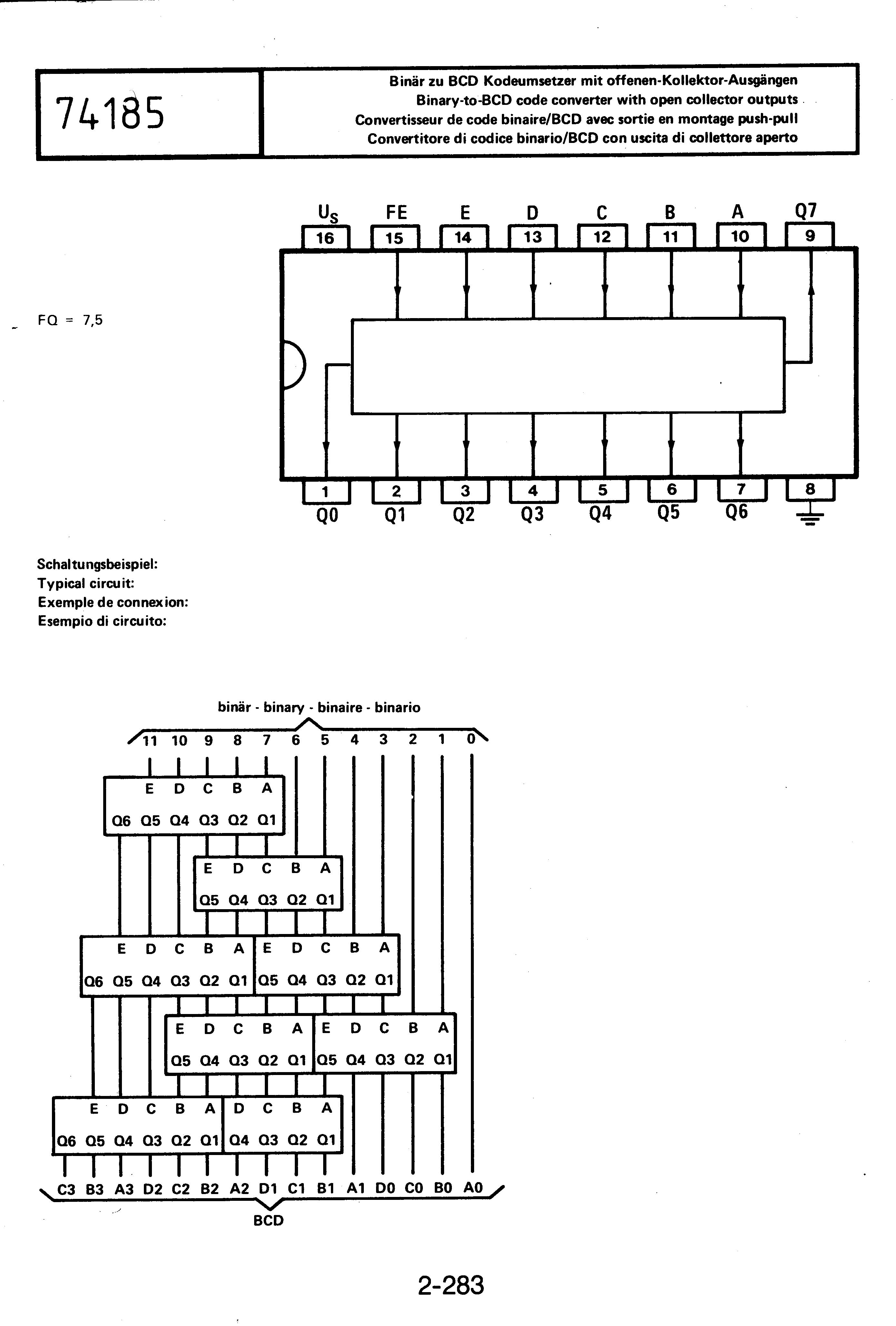
Hallo, kennt jemand von euch eine gute Implementierung des IC 74185(6-Bit Binary to BCD converter von TI)in VHDL mit Testbench,wenn möglich nicht taktgesteuert? Vielen Dank!
Ich habe in zwei Applikationsbüchern ( AT&T und ST) nachgeschaut, in denen TTL-Typpen als FPGA-Datei beschrieben sind, aber der 74185 war nicht darunter. Aber als 6 KV-Diagramme mit 5 Eingängen sollte sich der Konverter doch beschreiben lassen, das ist nicht viel. Im Texas-Datenblatt ist die Logiktabelle enthalten. Das unterste Bit0 wird direkt weitergegeben, es geht nur um Bits 1-5, die in 6 BCD-Ausgänge umgesetzt werden.
Hallo, >Ich habe in zwei Applikationsbüchern ( AT&T und ST) nachgeschaut, in >denen TTL-Typpen als FPGA-Datei beschrieben sind, aber der 74185 war >nicht darunter. Findet man diese Bücher Online? Gruß, Dirk
Die sind schon relativ alt, außerdem sind das nur Abbildungen und kurze Beschreibungen, die vermutlich zu einer FPGA-Entwurfssoftware gehören. In Xilinx Webpack oder Altera Quartus sind auch Beispiele enthalten, ich weiß aber nicht ob auch TTL-Emulationen darunter sind.
Vielen Dank an Christoph und Dirk für Euer Interesse an meinem Problem. Ich habe selbst nochmal im Netz gesucht und einige Anregungen gefunden. Habe inzwischen ein einfaches Design in reiner nebenläufiger (concurrency logic)Logik geschrieben,bezogen auf eine Instanz des IC.Jetzt kann ich mir durch Instanzierung entsprechende Converter selbst erstellen(siehe Datenblatt SN74185) Anbei vielleicht interessante Links: http://www.cse.secs.oakland.edu/hanna/cse378/378Lectures.htm (Codeconverter mittels Shiftoperation) http://www.doulos.com/knowhow/vhdl_designers_guide/models/binary_bcd/ (Umsetzung der App.Note XAPP029 für XILINX,allerdings taktgebunden)
"kennt jemand von euch eine gute Implementierung des IC 74185(6-Bit Binary to BCD converter von TI)in VHDL mit Testbench,wenn möglich nicht taktgesteuert?" Kann man das nicht einfach mit ein paar ANDs und NOTs zusammenschustern?
@Selma Wenn man verdammt viele NANDs nimmt kann man das. Will man aber kaum. @fpgakuechle Wäre es nicht einfacher und übersichtlicher, einfach die 64 Codes hinzuscheiben mittels Case ? MfG Falk
<Wäre es nicht einfacher und übersichtlicher, einfach die 64 Codes <hinzuscheiben mittels Case ? Case nehme ich für rein kombinat. Netzwerke ungern, da man schnell ein signal in der sensetivity list vergisst(case verlangt process) Das Äquivalent zum Case ohne process ist select, also wenn dann dieses. Dann schreib ich die Sachen gerne so das sie optimal in einen Xilinx-FPGA passen. Und das ist eben die Beschreibung in einzelen Gleichungen mit fanin 5, das passt in zwei LUTs mit F5MUX. Bei der Beschreibung als Tabelle 6Bit vector zu 8 bit vector muss das synthesetool schon etwas intelligent sein um nicht auf den Gedanken zu kommen ein ROM zu verwenden. ROM wäre schlecht da man alle Pfade zu einem Punkt und von diesem wieder weg führen müsste (timing/routing probs). Kurzum die Beschreibung in Gleichungen: y_n = f(x_n1,x_n2,X_n3,X_n4,x_n5) ist Hardwarenäher (FPGA,CPLD).
<@Selma <Wenn man verdammt viele NANDs nimmt kann man das. Will man aber kaum. Zumindest was FPGA's betrifft sind NAND/AND ausgestorben (fast). Das Grundelement eines FPGA sind (Xilinx,Altera) LookUpTables. Damit kann man beliebige Funktion mit 4 (Xilinx) und 6(?) (Altera) basteln. Notfalls auch ein NAND, aber in der Regel bleibt es bei der Komplexeren Funktion, sie wird nicht in NAND zerlegt.
@fpgakuechle Wo ist das Problem bei der Sensitivity List? Der Compiler meckert, man korrigiert es. Und wenn du alles Gleichungen schon "optimiert" hinschreibst, machst du die Arbeit des Compilers. Ist manchmal sinnvoll, wenn man maximalen Takt erreichen will und ein paar Optimierungen, für die der Compiler zu dämlich ist. In den meisten Fällen jedoch nicht. Und gerade in diesem Beispiel ist es a) wesentlich unübersichtlicher und b) fehleranfälliger und c) sind die Compiler heute schlau genug, den ROM (und nix weiter ist es) maximal zu optimieren. Probiers aus. Just my two cents. MfG Falk
Habs ausprobiert (siehe Artikel http://www.mikrocontroller.net/articles/TTL74185). Die Variante als ROM istetwas größer als in der Gleichungsvariante. Wenn ein ROM erkannt wird, wird ein ROM benutzt und eben nicht zu Gleichungen ungeformt. Woher sollen die Tools wissen was für den Anwender Optimal ist. Vielleicht will er ja einen kompakten Block (Flächenpartionierung). Warum soll man case verwenden wenn es mit select genauso getan ist. Mit select macht man weniger falsch. Und spätestens wenn die lieben Kollegen einen mit Modulen zuballern, übersieht man die kleinen warnings wegen der sense list. Mehrere Hundert warnings sind in der Praxis üblich. Und das sind die die man nicht wegbekommt.
@FPGAküchle Man kann bei ISE (und den meisten anderen Tools) einstellen, ob ROMs erkannt und in spezielle Hardwarefunktionen (BRAMS) umgewandelt werden sollen. Warum case anstatt select. Ganz einfach! Weil es übersichtlicher, weniger fehleranfällig und sinnvoller ist, dass dem Compiler die Arbeit gelassen wird, für die er da ist, nämlich Boolsche Algebra zu minimieren. Ausserdem wie kommst du darauf, dass die ROM-Variante grösser ist als die "Gleichungsvariante"? Da steht ein BRAM gegen X LUTs/LEs. Birnen und Äpfel. MfG Falk
Quatsch BRAM! XST sagt in der synthese deutlich was es erkennt, und das ist im zweiten Fall eine ROM-Struktur während er beim ersten zwei,drei kleinere ROM-Strukturen erkennt (siehe synthesereport *.syr) Diese "Strukturen" bauen XST und map dann aus den FPGA Elementen auf (memory-Slices (SRL16,distr. RAM), Logic-slices, CARRYMUX etc). Beim Beispiel verwendet er keine BRAM's sondern slices. Und lt. abschliessenenden report nach Place und Route verbraucht Variante 2 5 Slices und Variante 1 4 slices. Wie gesagt ich habs ausprobiert (kompletter Tooldurchlauf), ich theoretisiere nicht.
> abschliessenenden report nach Place und Route verbraucht Variante 2 5 > Slices und Variante 1 4 slices. Na dann sag das doch gleich. Trotzdem ist der Vergleich nicht ganz korrekt, schliesslich hast du im Beispiel 1 bcd_o(0) direkt verbunden während es in Beispiel 2 noch im Decoder drin ist. Was kommt in Beispiel zwei raus (Resourcenbedarf) wenn du bcd_0(0) direkt durchverbindest? Und mein Argument beleibt bestehen, Version 2 ist übersichtlicher/lesbarer und du machst die Arbeit die der Compiler in den meisten Fällen besser kann. Und dafür kann ich locker 1 Slice "opfern". Ist im Endeffekt die alte Diskussion wie Assembler vs. C. 90% der Logik kann man "einfach so" (Variante 2) hinschreiben und mit ein minimal suboptimalen Egebnis leben. Nur 10% oder weniger müssen bis aufs letzte ausgequetscht werden (Variante 1). MfG Falk
<Na dann sag das doch gleich. Steht doch im Artikel, lies den doch.
<Warum case anstatt select. Ganz einfach! Weil es übersichtlicher, <weniger fehleranfällig und sinnvoller ist, dass dem Compiler die Arbeit <gelassen wird, für die er da ist, nämlich Boolsche Algebra zu <minimieren. Ich hoffe mal wir reden aneinander vorbei. Case ist im Vergleich zu select weniger übersichtlich, länger und fehleranfälliger (wg. Process). Die beiden neuen Codebeispiele (behave3 select|behave4 case) im Artikel beweisen das. Wenn schon als ROM, dann als Konstantenfeld, eventuell noch select (obwohl ich da jetzt keine Vorteile erkenne). http://www.mikrocontroller.net/articles/TTL74185
Wieso bitte schön ist ein case wegen Process fehleranfälliger? Und ich die Formatierung ist nicht so, wie ich sie hinschrieben würde. Was spricht gegen 64 Zeilen, pro Zeile eine Zuweisung? Ausserdem, ich wiederhole mich, macht bei Variante 1 der Programmierer die Arbeit des Compilers. Denn die Kodierung der einzelnen Bits schreibt man nicht einfach so mal hin, da muss man sich schon auf Papier oder in Excel die Wahheitstabelle hinschreiben und dan per Hand "umcodieren". Alles unnötig, erst recht wenn gerade mal ein Slice dabei rausspringt. Aussederm sieht man in Vrsion 1 nciht das Ergebnis des Dekoders auf einen Blick, i allen anderen Versionen schon. Die Frage bleibt natürlich, ob der Compiler, wenn er eine ROM-Struktur erkannt hat, ob er dann noch versucht den ROM zu minimieren oder einfach faul den ROM 1:1 übernimmt. In diesem Fall wahrscheinlich letzteres. MfG Falk
<Wieso bitte schön ist ein case wegen Process fehleranfälliger? Weil man Fehler in der sensetivity list, z.B. fehlende Signale machen kann. Bei Select dagegen nicht, das ist ja der nebenläufige Counterpart zum sequentiellen Case, braucht also keinen prozess. Wenn man Code über tausende von Zeilen hat ist jede mögliche fehlstelle eine zuviel. Und wenn man nicht etliche Überstunden schrubben will ebenfalls. Synthese anwerfen, Viertelstunde warten, report nach warnings durchforsten ... . Jede zeile code die nicht geschrieben werden muss ist fehlerfrei.
Da ich ein Freund von parameterisierbaren Komponenten bin habe ich hier mal was hingetippert für beliebig breite Vektoren. Für eine Analyse hatte ich leider keine Zeit mehr. Der Eingangsvektor muss genauso breit sein wie der Ausgangsvektor. Also einfach ein paar Nullen beim Eingansvektor ranhängen sonst funktioniert das nicht. Gruß tobias
Scheint nach den ersten Durchschauen OK, ist leider nicht synthetisierbar ( die Division wird angemeckert). Aber uns fehlte ja eh noch die Testbench und dazu passt die Funktion ganz gut. Für bastler mit Hang zum Selbstversuch statt dunkler Theorie, anbei das VHDL File mit allen angesprochenen Architekturen. Bis auf die letzte passt alles durch die Synthese. Durch auskommentieren ganzer Blöcke kann man die einzelnen Variante testen. Oder man schreibt eine configuration (aber die mag der XST manchmal nicht).
@fpgakuechle SO ein Quark! Wer nicht mal EIN popeliges Signal in ne sensitivity list schreiben kann sollte besser die Strasse fegen und nicht VHDL Designer sein! Ausserdem schreibt kein Mensch tausende von Zeilen um dann (völlig erschöpft?) die Warnungen des Compilers zu ignorieren. Wer sooooo faul (unfähig?) ist, solls bleiben lassen. Und gerade WENN die Synthese ne Viertelstunde dauert (Monsterdesign) muss man erst recht schauen, dass überall die Warnugen vor allem bezüglich der Sensitivity list weg sind, sonst spinnt die Simulation. Und gerade bei so nem Mosnterdesign ist es vollkommen daneben, alles per Hand zu "optimieren". Lesbarkeit gegen null. Und Überstund schrubbst ja wohl eher DU, wenn du alles auf Papier "optimierst". "Jede zeile code die nicht geschrieben werden muss ist fehlerfrei." So ein Quark. Du klingst wie die alten, halsstarrigen Assembler-Freaks. Systematisches Design ist nicht dein Ding. MfG Falk
Es ist immer wieder schön, Diskussionspartner mit substantiellen Argumenten zu haben . .. Schönen Tag noch. Falk
ich denk ihr habt beide Recht... mir gefällt aber die Variante von fpgaküchle auch besser. Und zwar weil diese kleine Logik keine Schwierigkeit darstellt und es mir auf diese Weise mehr Spaß machen würde es umzusetzen. Schließlich ist es ja ein Hobby.
Also hobbymässige Bastelei/Herausforderung/Lernprojekt ja, aus professioneller Sicht nein. MFG Falk
mir geht grade eine Frage durch den Kopf. Wie es denn bei der case-Variante, falls man aus welchen Gründen auch immer mehr als 6 Bit abarbeiten muss? Der Aufwand steigt doch dann mit 2 hoch N. Bei 6 Bit sind es noch 64 Zweige. Bei einem Byte 256... also 256 "when"-Zweige? Ob das noch so praktisch ist...
Ja, es IST praktisch. Denn man schreibt einfach hin, welches Ergebnis bei welchem Eingangssignal gewünscht ist. Schön übersichtlich. Und man muss nicht per hand alles kodieren und optimieren. Das macht der Compiler, und das zu 95% sehr gut. MfG Falk
Naja, alles was nicht mehr auf den Bildschirm passt, ist auch unübersichtlich. Eleganter ist m.E. die Variante die im Anhang aufgezeigt ist. Einmal mehr nachgedacht und tausendmal weniger getippt. Grüße Rick
Ich hab das akademische Powerpoint sheet mal für Xilinx synthetisierbar umgeschrieben:
1 | ARCHITECTURE behave5 OF ttl74185 IS |
2 | BEGIN
|
3 | |
4 | bcd_o(0) <= binary_i(0); |
5 | |
6 | PROCESS(binary_i) |
7 | VARIABLE v_tmp : unsigned(12 DOWNTO 0); |
8 | BEGIN
|
9 | v_tmp := "0000" & unsigned(binary_i) & "000"; |
10 | |
11 | FOR i IN 0 TO 2 LOOP |
12 | IF v_tmp(9 DOWNTO 6) > unsigned'("0100") THEN |
13 | v_tmp(9 DOWNTO 6) := "0011" + v_tmp(9 DOWNTO 6) ; |
14 | END IF; |
15 | v_tmp( 12 DOWNTO 1) := v_tmp( 11 DOWNTO 0); |
16 | END LOOP; -- i |
17 | bcd_o(7 DOWNTO 1) <= STD_LOGIC_VECTOR(v_tmp(12 DOWNTO 6)); |
18 | |
19 | |
20 | END PROCESS; |
21 | |
22 | END behave5; |
Erstes ergebnis es braucht 5 slices. Find ich erst mal nicht so toll, schau ich mir später noch genauer an.
So ich habs in den Artikel eingearbeitet: http://www.mikrocontroller.net/articles/TTL74185 Also ich versteh (noch) nicht, warum das mit der 3er Addition zur BCD Wandklung taugt. Der Code stammt wahrscheinlich von einem Programmierer nicht Hardwerker. Die Initialisierung geht über drei Zeilen, da kennt einer das "&" nicht. Und der Code ist ohne Überarbeitung nicht synthesefähig. Der Vorteil dieser Variante liegt in der regelmäßigen und kompakten Struktur. Man kann einen generischen Wandler für beliebige Bitlängen bauen. Wahrscheinlich stammt dieser Entwurf aus der ASIC-Ecke, im FPGA bevorzugt man statt N Input zu M Output Komponenten N zu 1 Schaltungen (LUT). Strukturen mit mehren Ausgängen werden durch (platzgreifende) Parallelschaltung nachgestellt. Also funktional nicht (sofort) verständlicher Code, nicht optimal für FPGA aber einfach erweiterbar. Die behave5b ist ein test ob eine Strukturbeschreibung besser synthetisierbar ist. Da sie das nicht ist, ist die kompakte behave5a vorziehen. Persönlich würde ich einen 6bit Wandler mit Variante behave2 aufbauen, bei breiteren mit Erweiterungen von behave5a. Danke für das interessante Beispiel.
@Fpga Kuechle: Hmm. Bei mir ließ sich m.E. alle Beispiele ohne große Änderungen sofort synthetisieren (Xilinx und GHDL). Aber nagut. [Wandlung mit add 3] shift left add 6 und add 3 shift left ist dasselbe. Aber schön, daß es mit im Wiki erscheint. Ich hab mir nach sowas vor zwei Wochen den Wolf gesucht :) Rick
<Hmm. Bei mir ließ sich m.E. alle Beispiele ohne große Änderungen sofort <synthetisieren (Xilinx und GHDL). Aber nagut. Welche Xilinx Version? Ich habs mit der 8.2 versucht und die Operationen mit Konstanten Integer auf std_logic_vector wollten nicht. Xilinx scheint mit jeder neuen Version etwas weniger zu synthetisieren, was die 8.1 frißt ist der 8.2 unbekömmlich (z.B. array of array als generic). Oder es liegt an der benutzten Bibliothek. Wo has Du das Dokument gefunden? Liegt da vielleicht noch mehr?
Hallo, Vielen Dank noch mal an alle Beteiligten für die die vielen Anregungen bezüglich meiner Anfrage hier im Forum! Ich habe die Version der oakland university ebenfalls mit Xilinx ISE 7.1 synthetisiert. Leider hatte ich in meinem ersten Eintrag nicht erwähnt,das ich das Design in einen GAL von Lattice 18V10-15LP implementieren mußte. Mit der Version von ispLEVER kann ich zwar über Synplify synthetisieren aber nicht das physische Design der Synthese sehen,so wie bei XST. Ein Design habe ich nach der Original Beschreibung des Converters nur mit AND und OR beschrieben,jedoch war das Ergebnis in der Schaltung so ,das die Werte verdoppelt wurden! Die Original Beschreibung habe ich auf der Website von TI im Bereich der PLD gefunden.Es ist ein JEDEC File und eine Beschreibung für den ProLogic Compiler.Ob diese Version allerdings auf Lattice GAL läuft weiß ich nicht. Vielleicht hat jemand Erfahrung damit?
@Fpga Kuechle: Aktuelle Xilinx-Version (8.2.03i). Ja irgendwelche Typanpassungen mussten korrigiert werden. Quelle: http://www.cse.secs.oakland.edu/haskell/CSE378/Lectures/Winter2006/D4.5%20Binary2BCD.ppt Rick
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.