Christian B. schrieb:> unsigned long Wait1 = 40 * 1000;> unsigned long Wait2 = 40000;
Böse Stolperfalle in C. 40 und 1000 werden vom Compiler implizit als
int-Konstanten betrachtet und die Rechnung als int durchgeführt. Und der
Arduino-Compiler avr gcc definiert int als 16 Bit. Der Überlauf wird
stillschwiegend ignoriert. Allerdings warnen einige Compiler bei sowas.
Wenn es richtig laufen soll, muss man die Konstanten als long
definieren. Da macht man mit der Endung L oder UL (unsigend long)
> unsigned long Wait1 = 40UL * 1000;
Compiler für echte 32 Bit CPUs definieren int mit 32 bit, da besteht das
Problem so nicht, denn dort gilt sizeof(int)==sizeof(long).
Frag nicht, wer und warum er den Käse so erfunden hat.
G. 4. schrieb:>> Kann mir das jemand erklären?>> Die Multiplikation>>> 40 * 1000>> läuft über weil Du einen zu kleinen Datentyp verwendet hast.>> HTH
Die ist schon aufgefallen, dass beides eigentlich dasselbe Ergebnis
haben sollte?!
Wie sieht es aus, wenn du die Zahlen oder das Ergbnis der Rechnung auf
"unsigned long" castest?
Dann läge das "Problem" bei der print-Funktion.
Rahul D. schrieb:> Wie sieht es aus, wenn du die Zahlen oder das Ergbnis der Rechnung auf> "unsigned long" castest?
Nö. Denn erst wird gerechnet, dann konvertiert. Wenn die Rechnung schon
den Überlauf erzeugt, nützt der abschließende cast rein gar nichts.
Rahul D. schrieb:> Dir ist schon aufgefallen, dass beides eigentlich dasselbe Ergebnis> haben sollte?!
Sicher, hat er das so erwartet. Sonst hätte er nicht gefragt, warum es
anders ist.
Hier mal Schritt für Schritt, was im Programm passiert.
40 * 1000 = 40000
durch implizite Betrachtung als vorzeichenbehaftete 16 Bit
(40000 - 65536)= -25536 = 9C40
Die werden nach der Rechung in eine vorzeichenlose 32 Bit Variable
kopiert, allerdings wird dabei eine Vorzeichenerweiterung durchgeführt,
d.h. das MSB ganz links wird in die oberen 16 Bit kopiert.
9C40 -> FFFF9C40
print interpretiert das aber als vorzeichenlose 32 Bit Zahl
FFFF9C40 = 4294941760
Q.E.D.
Falk B. schrieb:> Böse Stolperfalle in C.
Danke euch allen.
Für Einen der von der Stringenz in Pascal verwöhnt ist, ist C eine
einzige Stolperfalle ... :(
LG
Christian
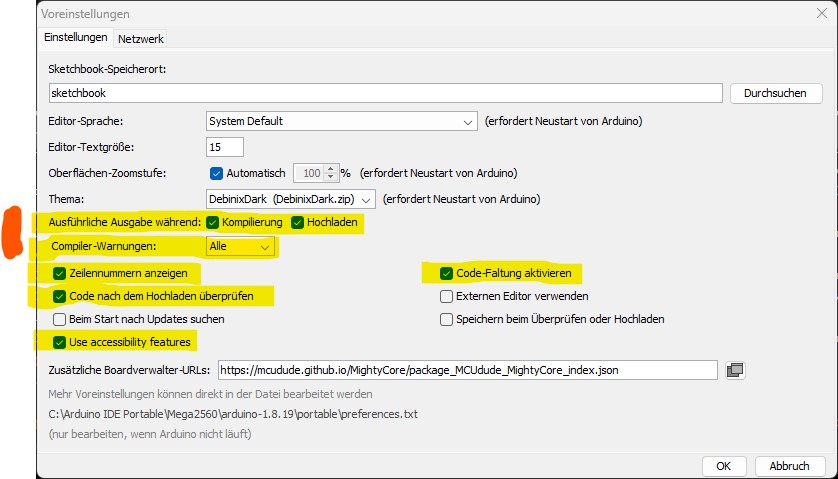
Hallo,
tätige einmal paar Einstellungen in der IDE siehe Screenshot. Danach
kompilierst du nochmal und guckst welche Warnungen erscheinen. Die 2
orange markierten sind für den Fall hier entscheidend.
Danach schreibst du einmal moderner
1
unsignedlongWait1{40*1000};
2
unsignedlongWait2{40000};
und kompilierst nochmal und schaust dir die Warnungen an.
gut zu wissen. muss ich nun gleich noch mal meinen Code durchchecken.
Der Fehler ist mir noch nicht aufgefallen. trifft das beim ESP32 mit
Arduino IDE auch zu, arbeitet ja mit 32 Bit?
Hallo,
wie Falk schon erklärt hat. Standardmäßig wird immer in 'int' gerechnet
wenn kein konkreter Datentyp angegeben oder bekannt ist. Je nach
Controller ist 'int' verschieden breit. Das heißt long ist je nach
Controller auch breiter wie int. Das heißt das Problem ist immer gleich
und verlagert sich nur in größere Datentypen und wird wohl beim testen
nie gesehen und erst das laufende Problem macht irgendwann komische
Sachen.
Alexander schrieb:> arbeitet ja mit 32 Bit?
Natürlich macht das im Detail einen Unterschied.
Aber das Prinzip bleibt das gleiche.
Denn das ist ja keine Spezialität des µC oder von Arduino, sondern eine
Spracheigenschaft.
Christian B. schrieb:> Für Einen der von der Stringenz in Pascal verwöhnt ist, ist C eine> einzige Stolperfalle ... :(
1. Es geht um C++, weil das Programm mit einem C++ Compiler üversetzt
wird (avr-g++).
2. Zeitgemäße Compiler warnen. Zum Beispiel avr-g++ v5.4 (Release
2015):
1
<location> Warning: integer overflow in expression [-Woverflow]
2
unsigned long a = 40 * 1000;
3
^
Ähnlich mit v8, v12, v13, v14 (andere Versionen hab ich grad keine da).
-Woverflow muss dabei **nicht** extra gesetzt werden, es gehört also zu
den default Warnings.
Wenn das nicht als Warning behandelt werden soll sondern als Fehler:
1
avr-g++ -Werror=overflow ...
Neuere Versionen sind dann noch etwas geschwätziger, v8:
1
<location> warning: integer overflow in expression of type 'int' results in '-25536' [-Woverflow]
Veit D. schrieb:> Standardmäßig wird immer in 'int' gerechnet> wenn kein konkreter Datentyp angegeben oder bekannt ist.
Steht aber auch eigentlich in den Büchern.
Und es ist hier keine Wertzuweisung, sondern eine Initialisierung. Wer
dann die brace-init-list benutzt bekommt auch die Warnungen für
einengende Umwandlungen.
Wilhelm M. schrieb:> Da ein integer-overflow UB ist, kann man den Fehler in einem> constexpr-Kontext sofort erkennen.> constexpr unsigned long a = 40 * 1000;
Auch ohne constexpr (also exakt so, wie der TE die Zeile geschrieben
hat), würde der Compiler eine Warnung ausgeben, wenn diese nicht
explizit mit -w komplett unterdrückt wird.
Genau das tut aber die Arduino-IDE, wohl um den Benutzer jeglicher
Chance zu berauben, einfache Fehler selber als solche zu erkennen und zu
beheben ;-)
Ich verstehe ja, dass -Wextra nicht defaultmäßig aktiviert wird, weil
damit die Menge der ausgegebenen Warnungen (inbesondere bei erst
halbfertigen Programmen) schnell sehr groß wird. Aber die Warnungen, die
auch ohne -Wextra und -Wall ausgegeben werden, sind nicht viele und IMHO
praktisch alle berechtigt und hilfreich. Sie sollten deshalb niemals
deaktiviert werden.
Bei den Warnungen in -Wall kann man sich streiten, ob sie für einen
Anfänger eher hilfreich oder eher verwirrend sind. Ich würde aber dazu
tendieren, in der Arduino-IDE auch -Wall defaultmäßig zu aktivieren. Um
die Verwirrung bei Anfängern etwas zu reduzieren, wäre es evtl.
sinnvoll, in der Ausgabe der Compilermeldungen die Warnungen von den
wirklichen Fehlern klarer zu trennen.
Wichtige Warnungen einfach zu unterdrücken, ist ganz großer Käse, wie
man in den Anfragen zum Thema Arduino hier im Forum immer wieder
feststellen kann.
Yalu X. schrieb:> Wichtige Warnungen einfach zu unterdrücken, ist ganz großer Käse, wie> man in den Anfragen zum Thema Arduino hier im Forum immer wieder> feststellen kann.
Auch wenn du recht haben magst....
Hier ist die falsche Adresse um sich darüber zu beschweren.
Netter weise sagt es bei Fehlern, dass man doch bitte die ausführlichen
Meldungen aktivieren soll.
Und ja, das sollte man (spätesten dann) tun!
Yalu X. schrieb:> Genau das tut aber die Arduino-IDE, wohl um den Benutzer jeglicher> Chance zu berauben, einfache Fehler selber als solche zu erkennen und zu> beheben ;-)
Das ist aktivierbar.
Niemand hat dir, oder einem anderen Benutzer der IDE, was geraubt.
Du übertreibst.
Übrigens:
Die IDE ist schlicht gehalten.
Es dauert keine 5 Minuten, alle Menüpunkte zu finden, und zumindest
oberflächlich zu untersuchen.
Kann sein, dass du und einige andere damit völlig überfordert sind.
Schade....
Yalu X. schrieb:> Bei den Warnungen in -Wall kann man sich streiten, ob sie für einen> Anfänger eher hilfreich oder eher verwirrend sind. Ich würde aber dazu> tendieren, in der Arduino-IDE auch -Wall defaultmäßig zu aktivieren. Um> die Verwirrung bei Anfängern etwas zu reduzieren, wäre es evtl.> sinnvoll, in der Ausgabe der Compilermeldungen die Warnungen von den> wirklichen Fehlern klarer zu trennen.
Mein Professor in der Uni pflegte stets zu sagen
"Es gibt keinen Grund Warnungen zu ignorieren!"
Wenn ich bedenke, wieviele Anwendungen ich funktionsfähig bekommen habe
nur indem ich mich lediglich um die Warnungen gekümmert hatte muss ich
heute sagen (damals ging mir das auch auf den Sack): Er hatte recht.
Yalu X. schrieb:> Auch ohne constexpr (also exakt so, wie der TE die Zeile geschrieben> hat), würde der Compiler eine Warnung ausgeben, wenn diese nicht> explizit mit -w komplett unterdrückt wird.
Genau. Und wenn man sie mit -Wno-overflow abschaltet, bekommt man in dem
von mir geschilderten Fall immer noch eine Fehlermeldung (keine
Warnung), weil ganz einfach integer-overflow UB ist - egal was man in
irgendeiner vermurksten IDE einstellt.
Christian B. schrieb:> Für Einen der von der Stringenz in Pascal verwöhnt ist, ist C eine> einzige Stolperfalle ... :(
Ich hatte damals, als die PCs noch mit 8MHz liefen, etwas in
Turbo-Pascal programmiert. Das Programm war nicht groß, dafür aber schon
recht lahm.
Ich habe es dann in Turbo-C umgeschrieben und der
Geschwindigkeitszuwachs war beeindruckend. Ich hab danach nie wieder
eine Zeile in Pascal geschrieben.
Peter D. schrieb:> Das Programm war nicht groß, dafür aber schon> recht lahm.
Ich habe - auch zu der Zeit der 8MHz-CPUs mit Basic und bald darauf
Assembler begonnen.
Am ersten PC kam dann Turbo-Pascal.
Inzwischen schreibe ich (wirklich große, umfangreiche) Programme in
Lazarus (Freepascal) und kann diese Beobachtung absolut nicht
bestätigen. Die Programme werden kompakt, laufen schnell (was bei der
heutigen Hardware ja auch kein Wunder sein sollte) und - das für mich
Wichtigste: Die Kompilierzeiten sind wie bei einem geölten Blitz.
Wenn ich da die - endlosen - Übersetzungszeiten der (mir bekannten) C++
Compiler anschaue kommt mir das kalte Grausen.
Schon die IDE ist flüssig und geschmeidig. Verglichen mit z.B.:
PlatformIO mit VSCode: Ein Traum!
Aber das ist - wie so Vieles - eben Geschmackssache und jeder muss für
sich das Passende finden.
Wilhelm M. schrieb:> Und wenn man sie mit -Wno-overflow abschaltet, bekommt man in dem> von mir geschilderten Fall immer noch eine Fehlermeldung (keine> Warnung), weil ganz einfach integer-overflow UB ist
Ein Integer-Overflow ist immer UB, unabhängig davon, ob davor ein
constexpr steht oder nicht. Warum GCC mit constexpr einen Fehler und
ohne constexpr nur eine Warnung ausgibt, verstehe ich auch nicht ganz.
Vermutlich hängt das, wie so oft, mit der Rücksichtnahme auf Legacy-Code
zusammen.
Christian B. schrieb:> Die Programme werden kompakt, laufen schnell (was bei der> heutigen Hardware ja auch kein Wunder sein sollte)
Du solltest für AVR kompilieren und dann mit dem Output eines C/C++
Kompilers vergleichen. Und nicht Äpfel mit Birnen.
Yalu X. schrieb:> Warum GCC mit constexpr einen Fehler und> ohne constexpr nur eine Warnung ausgibt, verstehe ich auch nicht ganz.
Das kann ich nicht bestätigen!
Es wirft Warnungen, aber keinen Fehler.
Problemstelle:
Arduino F. schrieb:> Das kann ich nicht bestätigen!> Es wirft Warnungen, aber keinen Fehler.
<source>:36:30: warning: narrowing conversion of '-25536' from 'int' to
'long unsigned int' [-Wnarrowing]
36 | constexpr unsigned long a{40 * 1000};
| ~~~^~~~~~
<source>:36:36: error: overflow in constant expression [-fpermissive]
36 | constexpr unsigned long a{40 * 1000};
| ^
<source>:36:36: error: overflow in constant expression [-fpermissive]
Compiler returned: 1
Yalu X. schrieb:> Ein Integer-Overflow ist immer UB, unabhängig davon, ob davor ein> constexpr steht oder nicht. Warum GCC mit constexpr einen Fehler und> ohne constexpr nur eine Warnung ausgibt, verstehe ich auch nicht ganz.
UB bedeutet (meistens) diagnostic-required, manches UB ist sogar NDR!
Welche MEldung kommt, entscheidet der Compiler-Hersteller.
In constexpr-Kontexten ist aber kein UB zugelassen. Deswegen kommt dort
definitiv ein Fehler. constexpr-Kontexte kann man gut als UB-Checker
nutzen. Compiler, die dort nicht abbrechen, sind einfach nicht
compliant.
Arduino F. schrieb:> Das ist aktivierbar.
Ja, aber nicht Default. Default Warnings per Default auszuschalten, um
den Arduino-User nicht zu verwirren, ist einfach nur daneben.
Da kann ich auch direkt neben einem 100m tiefen Loch das Warnschild
entfernen, um den Spaziergänger nicht zu verwirren.
Aber ich meine mich zu erinnern, dass man bei einer Neu-Installation
einer einigermaßen aktuellen Arduino-Version schon während der
Installation durchaus nach dem Warning-Level gefragt wird. Immerhin eine
Verbesserung. Ältere Versionen haben die Warnungen stillschweigend
abgeschaltet und haben den User wirklich in jede nur mögliche Falle
tappen lassen. Das war schon ärgerlich.
Arduino F. schrieb:> Du solltest für AVR kompilieren und dann mit dem Output eines C/C++> Kompilers vergleichen. Und nicht Äpfel mit Birnen.
Nein, nein.
Ich vergleiche gar nichts. Ich habe nur meine - bescheidenen -
Erfahrungen mit C/C++ beschrieben.
Ich finde es auch Phänomenal zu welchen Grundsatzdiskussionen diese -
eigentlich einfache Frage - geführt hat, aber es bestätigt mir auch ein
wenig meine Vorurteile über diese Sprache (und ihre Verwender) :)
Aber mir wurde (blitzschnell) geholfen und darüber freu' ich mich.
Alles andere überlasse ich den Spezialisten hier.
Schönen Nachmittag
Christian
Moin,
Warum macht das GCC eigentlich so? Bitte nicht lachen:-)
Man sollte meinen, daß der Compiler Präprozesser eigentlich aus der
Variablen Erstellung sich entsprechend verhalten könnte.
unsigned long Wait1 = 40 * 1000;
Ist da ein tieferer Grund dahinter, daß man die Konstanten sozusagen mit
"UL" "pimpen" muß? Warum wird da nach Erkennung von "unsigned long"
nicht so gerechnet? Die Logik könnte ja sein. OK, mein Herr und Gebieter
deklariert eine UL. Also wäre es vernünftig mit den denselben Datentypen
weiter zu machen. Dann kann auch nichts schief gehen:-)
Man sollte annehmen können, so eine Präprozessor Eigeniniative müsste
vertretbar sein.
Dieses Problem fühlt sich (mir als Werkzeugbenutzer) irgendwie
unerwartet und unintuitiv an. Da ich kein Computerscienceexperte bin,
frage ich mich halt.
Ob die anderen von mir verwendeten Compiler (CCS, CVAVR, KEIL) es auch
so machen, müsste ich erst testen. Mir ist das eigentlich auch nur in
GCC aufgefallen.
Mir kommt auch vor, daß das System mit jeder neuen Version scheinbar
weniger durchgehen lässt. Was vor 20 Jahren noch Fehler- und
Warnungsfrei war, ist heute nicht länger unbedingt der Fall.
Jedenfalls, habe ich mir schon lange angewöhnt bei GCC (und anderen)
alle Warnungen aktiviert zu halten und nach Möglichkeit zu beheben.
VG,
Gerhard
Gerhard O. schrieb:> Moin,>> Warum macht das GCC eigentlich so? Bitte nicht lachen:-)>> Man sollte meinen, daß der Compiler Präprozesser eigentlich aus der> Variablen Erstellung sich entsprechend verhalten könnte.>> unsigned long Wait1 = 40 * 1000;
Wie schon gesagt, der Präprozessor macht hier gar nix.
> Ist da ein tieferer Grund dahinter, daß man die Konstanten sozusagen mit> "UL" "pimpen" muß?
Jein: siehe C++-Standard
> Warum wird da nach Erkennung von "unsigned long"> nicht so gerechnet?
s.a. Promotionsregeln
> Die Logik könnte ja sein. OK, mein Herr und Gebieter> deklariert eine UL. Also wäre es vernünftig mit den denselben Datentypen> weiter zu machen. Dann kann auch nichts schief gehen:-)
Dein Herr und Gebieter ist der Sprach-Standard.
> Man sollte annehmen können, so eine Präprozessor Eigeniniative müsste> vertretbar sein.
Nein.
> Mir kommt auch vor, daß das System mit jeder neuen Version scheinbar> weniger durchgehen lässt. Was vor 20 Jahren noch Fehler- und> Warnungsfrei war, ist heute nicht länger unbedingt der Fall.
Ja, die Warnungen werden mehr und besser.
> Jedenfalls, habe ich mir schon lange angewöhnt bei GCC (und anderen)> alle Warnungen aktiviert zu halten und nach Möglichkeit zu beheben.
Sehr gute Idee!!!
Wilhelm, das ging ja schnell. Danke.
Ich fürchte nur, daß das Studieren der GCC Unterlagen eine recht
trockene und langwierige Angelegenheit sein wird.
Gibt es da eigentlich irgendein Werk, wo die wichtigsten "Fußangeln" in
Kurzform behandelt werden?
Tausende Seiten GCC Referenz Unterlagen durchgehen zu müssen und
Antworten zu finden, ist auch nicht jedermanns Sache. Manchmal weiß man
ja nicht einmal präzise wie die Frage im Kopf formuliert werden kann um
den Gegenstand der Frage zu finden.
Ich fing vor 25 Jahren an in der Firma mit dem PIC CCS Compiler an zu
arbeiten. Da war in einem 400+ Seiten Handbuch alles Wesentliche
dokumentiert und man konnte sich schnell orientieren und hatte nie
Probleme mit dem CCS zu arbeiten. Auch bei CVAVR oder Keil hatte ich
sehr selten Probleme. Ich arbeitete später auch viel mit ARM IAR und
fand deren Dokus eigentlich viel verdaulicher. Für mich war GCC immer
das am wenigsten erschließbare Werk.
Bei GCC dagegen fühlt es sich immer dagegen an Mt. Everest erklimmen zu
müssen. Irgendwie finde ich die GCC Dokus allgemein schwer verdaulich.
Man muß scheinbare Experte sein, um manche GCC Dokumentations-Aspekte
ausreichend verständlich lesen zu können. Die Terminologie ist (mir)
nicht immer leicht familiär.
Zum Glück gibt es in der Praxis, solange man in vertrauten Gewässer
navigieren kann, auch mit GCC wenig Probleme.
Gerhard
Gerhard O. schrieb:> Tausende Seiten GCC Referenz Unterlagen durchgehen zu müssen und> Antworten zu finden, ist auch nicht jedermanns Sache.
Du pinkelst den falschen Baum an.
Die Festlegung, wie diese Berechnungen zu behandeln sind, steht im C-
bzw. C++-Standard, und jeder Compiler, der sich C- bzw- C+++Compiler
nennen möchte, muß den Standard implementieren.
Jetzt kannst du die Standards lesen, oder aber jedes gute Lehrbuch zu C
bzw. C++, denn dort wird auch dieses Thema hier behandelt. Und auch wenn
es blöd klingt, muß man das halt einfach mal tun. Learning by doing oder
nach Gefühl programmieren funktioniert nicht, man muß eine
Programmiersprache lernen.
Oliver
Arduino F. schrieb:> Gerhard O. schrieb:>> GCC>> Es ist nicht der Gcc!> Sondern C und Cpp>> Du musst also in die Sprachdefinition schauen.> Nicht in die Compiler Doku
Ja. Danke.
Oliver S. schrieb:> Gerhard O. schrieb:>> Tausende Seiten GCC Referenz Unterlagen durchgehen zu müssen und>> Antworten zu finden, ist auch nicht jedermanns Sache.>> Du pinkelst den falschen Baum an.>> Die Festlegung, wie diese Berechnungen zu behandeln sind, steht im C-> bzw. C++-Standard, und jeder Compiler, der sich C- bzw- C+++Compiler> nennen möchte, muß den Standard implementieren.>> Jetzt kannst du die Standards lesen, oder aber jedes gute Lehrbuch zu C> bzw. C++, denn dort wird auch dieses Thema hier behandelt. Und auch wenn> es blöd klingt, muß man das halt einfach mal tun. Learning by doing oder> nach Gefühl programmieren funktioniert nicht, man muß eine> Programmiersprache lernen.>> Oliver
Ja. Das hört sich vernünftig an. Nur bin ich das (noch) nicht wirklich
gewöhnt. Damals stand in den kommerziellen Compiler Unterlagen alles
Wesentliche drin um sich orientieren zu können und man kam damit in der
Praxis zurecht. Damals bestand wenig Grund sich detailliert an den
Standards richtig zu müssen, weil KR in C einigermaßen ausreichte.
...
Nur ergänzend zu Wilhelms Anmerkungen:
Gerhard O. schrieb:> Warum macht das GCC eigentlich so?
Das macht nicht nur der GCC so, sondern muss jeder C/C++-Compiler so
machen. Sonst ist er kein C/C++-Compiler, sondern irgend etwas anderes.
> Ob die anderen von mir verwendeten Compiler (CCS, CVAVR, KEIL)
Die machen das auch so, da bin ich mir ziemlich sicher.
Diese Integer-Promotion-Rules haben einen signifikaten Vorteil: Dein
Programm "wächst" mit der Hardware mit und bleibt damit für größere
Hardware kompatibel.
(Unix-)Programme, die früher für eine PDP11 geschrieben wurden
(16-Bit-Integer) sind so meist so auch noch lauffähig auf späteren 32-
und auch 64-Bit-Prozessoren. Dabei können sie dann automatisch auch die
größeren zur Verfügung gestellen Speicher-Ressourcen nutzen - und das
meist auch bei weiterhin optimaler CPU-Nutzung. Denn es macht wenig
Sinn, auf einem AVR für alle Variablen immer 64-Bit-Breiten zu nutzen.
Umgekehrt werden viele 32-Bit-Prozessoren ausgebremst, wenn sie eine zu
kleine Wortbreite zum Rechnen verwenden. Ebensowenig macht es Sinn, für
verschiedene Prozessoren ein Programm mehrfach grundsätzlich neu zu
schreiben.
Meist ist ein Programm, dass sich von vornherein auf eine fixe
Variablen-Größe festlegt, irgendwann später obsolet. Von daher wird bei
nicht allzu hardware-nahen C-Programmen lieber mit generischen Größen
wie int, short, long gearbeitet statt mit konkreten Breiten.
Gerhard O. schrieb:> Ich fürchte nur, daß das Studieren der GCC Unterlagen eine recht> trockene und langwierige Angelegenheit sein wird.
Eine vereinfachte und besser zugängliche Form des C++-Standards (und des
C-Standards) findest Du unter:
https://en.cppreference.com/> Gibt es da eigentlich irgendein Werk, wo die wichtigsten "Fußangeln" in> Kurzform behandelt werden?
Eigentlich in jedem guten(!) C/C++-Buch, bspw. im Breymann.
Stark kondensiert findest Du das natürlich alles unter:
https://en.cppreference.com/w/cpp/language/implicit_conversion
Gerhard O. schrieb:> Damals bestand wenig Grund sich detailliert an den> Standards richtig zu müssen, weil KR in C einigermaßen ausreichte.
Die Regeln zu dem Thema, um das es hier geht, haben sich seit den
seligen Zeiten von K&R nicht großartig geändert. Das musste man damals
genauso wissen wie heute.
Oliver
Einfach unglaublich, dass eine Programmiersprache Standard ist, die so
viele Unlogiken hat. Man ist dauernd mit den Problemen der Eigenheiten
und Syntax beschäftigt, anstatt mit der Lösung des Problems. Manche sind
auch noch stolz darauf, das zu "beherrschen"! Entschuldigung, aber mit
BASIC habe ich keine solchen Probleme!
Gruss Chregu
Vielen Dank für Eure Hinweise.
Die Dokus der Werkzeuge mit denen ich damals zu tun hatte, befassten
sich nur mit den Zielarchitekturen der in Betracht kommenden uC. Da
dachte man eigentlich gar nicht daran über den Zaun zu schauen. Erst in
2010 befasste ich mit den STM32 unter Atollic. Wiederum spezialisierte
man sich dann auf jene. Das reichte um die damaligen Aufgaben zu
erfüllen. Das großartig zu studieren kam eigentlich gar nicht in den
Sinn, weil es nicht am Radar Horizont erschien. Die mitgelieferten Dokus
der kommerziellen Werkzeuge waren genug um damit ausreichend gut
arbeiten zu können, weil die Sprachumsetzung genau umrissen war. Und da
ich mir das Nötige selbst beibringen mußte, blieb mein Blick ins
Computersprachen-Universum etwas lückenhaft. War da von der UNI kam,
hatte ganz andere Voraussetzungen und Hintergründe und erhielt eine ganz
andere Einführung in die Materie.
Mit GCC schien das mehr die Domaine der UNIs und Computer Spezialisten
zu sein. Mit GCC kam ich eigentlich w.g. erstmals mit Atollic in
Berührung.
War eben so. Es hätte mir bestimmt gut getan, mir etwas Zeit dafür zu
nehmen, einschlägige Bücher durchzuarbeiten. Aber bei mir war halt die
Emphasis im Betrieb auf HW Design und nur gelegentliche FW Erstellung.
Oder nur Test FW Erstellung zum Testen der entwickelten HW. Anders herum
ausgedrückt, Mittel zum Zweck.
Aber solche Bücher durchzuwälzen hat nur dann Sinn, wenn man
gleichzeitig das Neugelernte am PC gleich praktisch ausprobiert und
testet. Zumindest bei mir bleibt sonst wenig haften. Lesen genügt für
mich nicht.
Vor 25 Jahren war auch die Welt des C/C++ Standards noch wesentlich
begrenzter wie heute.
Was Änderungen betrifft, merkt man das deutlich. Ich habe eine alte sehr
kompakte ASM Soft I2C Bibliothek für den AVR. Ab einer bestimmten GCC
Version geht sie nicht mehr richtig oder erzeugt unsägliche Fehler und
Warnungen. Mit der Version unter die diese LIB entwickelt wurde, ist
alles fehlerfrei. Auch umgeänderte Versionen funktionieren leider nicht
100% mit der aktuellen Version.
Man muß wirklich seine Werkzeuge einfrieren und notfallsmit VMs
arbeiten, wenn man über lange Zeit ein Design unterstützen muß. Ich
arbeite in einer Industrie wo der Einsatz und Wartbarkeit einer
industriellen Steuerung in Jahrzehnten gerechnet wird und
Neuentwicklungen wegen der strengen Zulassungen sehr viel Geld kosten.
Da ist Stabilität der notwendigen Werkzeuge von erster Bedeutung. Leider
denkt die übrige Welt nicht so und rennt nur ihrem Fortschritt nach, was
sicherlich gesamtbildlich gesehen für die Menschheit notwendig ist. Aber
für diejenigen, die lange Produktlebenszeit benötigen, ein Ärgernis,
wenn alle paar Jahre nichts mehr wie früher funktioniert. Zum Glück gibt
es VMs...
Auch HW hat ähnliche Probleme wegen der kurzlebigen Verfügbarkeit vieler
Komponenten.
Ich hätte da gleich eine Frage: GCC wird bekanntlich regelmäßig immer
neueren C/C++ Standards zugrunde gelegt. Kann man z.B. die neueste
Version so konfigurieren, daß sie noch kompatibel, z.B. zu V5.1.4 ist,
auch wenn es die neueste Version ist? Oder muß man sich eben ältere
Versionen archivieren?
Gerhard
Gerhard O. schrieb:> GCC wird bekanntlich regelmäßig immer> neueren C/C++ Standards zugrunde gelegt.
nö, man kann den Standard per Compilerschalter auswählen.
Neuere Compilerversionen sind oft penibler was Warnungen angeht, da
lohnt es sich den Quellcode nochmal zu überprüfen. Auch wenn er alt ist
und man meint es funktioniert alles.
Und man benutzt den Compiler oft im Bundle mit der C/C++ Runtime. Die
sind auch nicht immer Fehlerfrei, auch nicht wenn sie neuer sind. Dafür
lohnt es sich schon wenn man in seiner Entwicklungsumgebung die
toolchain einfach umschalten kann.
Gerhard O. schrieb:> Es hätte mir bestimmt gut getan, mir etwas Zeit dafür zu> nehmen, einschlägige Bücher durchzuarbeiten.
Wer will findet Wege, wer nicht will findet Gründe.
Gerhard O. schrieb:> GCC wird bekanntlich regelmäßig immer neueren C/C++ Standards> zugrunde gelegt. Kann man z.B. die neueste Version so konfigurieren,> daß sie noch kompatibel, z.B. zu V5.1.4 ist, auch wenn es die neueste> Version ist? Oder muß man sich eben ältere Versionen archivieren?
Ohne weitere angabe implementiert gcc/g++ eine bestimmte Version des
Standards bzw. eine Erweiterung dessen, genannt GNU-C oder GNU-C++.
Beim Start eines neuen Projektes sollte man auch klar haben, nach
welchen Kriterien entwickelt wird (welche Sprache, welche Version
derselben, Coding-Rules, etc,).
Die verwendete C-Version kann man zum Beispiel angeben mit -std=c99
-pedantic wenn man C99 will und keine dazu kompatiblen Erweiterungen,
oder -std=gnu99 wenn man GNU-C99 will etc.
https://gcc.gnu.org/onlinedocs/gcc-13.2.0/gcc/C-Dialect-Options.htmlhttps://gcc.gnu.org/onlinedocs/gcc-13.2.0/gcc/C_002b_002b-Dialect-Options.html
Bei Verwendung von avr-g++ sollte man sich auch darüber klar sein, dass
der C++ Support unvollständig ist.
Hallo,
Johann L. schrieb:> Bei Verwendung von avr-g++ sollte man sich auch darüber klar sein, dass> der C++ Support unvollständig ist.
In wie fern? Ist der Sprachumfang und/oder die Standardbibliothek
beschnitten?
rhf
Christian M. schrieb:> Einfach unglaublich, dass eine Programmiersprache Standard ist, die so> viele Unlogiken hat. Man ist dauernd mit den Problemen der Eigenheiten> und Syntax beschäftigt, anstatt mit der Lösung des Problems. Manche sind> auch noch stolz darauf, das zu "beherrschen"! Entschuldigung, aber mit> BASIC habe ich keine solchen Probleme!
"It is practically impossible to teach good programming to students that
have had a prior exposure to BASIC: as potential programmers they are
mentally mutilated beyond hope of regeneration."
https://en.wikiquote.org/wiki/Edsger_W._Dijkstra
Christian B. schrieb:> unsigned long Wait1 = 40 * 1000;
Wenn es dabei darum geht, eine leichter sichtbare Trennung der Nullen zu
haben, sollte man das so schreiben, sofern man einen Compiler hat, der
wenigstens C++14 beherrscht:
1
unsignedlongWait1=40'000;
Christian M. schrieb:> Einfach unglaublich, dass eine Programmiersprache Standard ist, die so> viele Unlogiken hat.
Was ist daran unlogisch? In C und C++ ist definiert, dass mathematische
Operationen mit dem Typ der Operanden durchgeführt werden. Falls die
Operanden unterschiedliche Typen haben, gibt es dafür genau definierte
Konvertierregeln, um den einen Operanden in den Typ des andern zu
konvertieren. Was dann im späteren Verlauf mit dem Ergebnis gemacht
wird, hat keinen Einfluss darauf. Hier sind 40 und 1000 von Typ int,
also ist auch das Ergebnis von diesem Typ. Und wenn int nur 16 Bit groß
ist, ist es zu klein für das Ergebnis. Das mag aus deiner Sicht
unintuitiv sein, aber unlogisch ist es absolut nicht.
Johann L. schrieb:> Gerhard O. schrieb:>> GCC wird bekanntlich regelmäßig immer neueren C/C++ Standards>> zugrunde gelegt. Kann man z.B. die neueste Version so konfigurieren,>> daß sie noch kompatibel, z.B. zu V5.1.4 ist, auch wenn es die neueste>> Version ist? Oder muß man sich eben ältere Versionen archivieren?>> Ohne weitere angabe implementiert gcc/g++ eine bestimmte Version des> Standards bzw. eine Erweiterung dessen, genannt GNU-C oder GNU-C++.>> Beim Start eines neuen Projektes sollte man auch klar haben, nach> welchen Kriterien entwickelt wird (welche Sprache, welche Version> derselben, Coding-Rules, etc,).>> Die verwendete C-Version kann man zum Beispiel angeben mit -std=c99> -pedantic wenn man C99 will und keine dazu kompatiblen Erweiterungen,> oder -std=gnu99 wenn man GNU-C99 will etc.
Allerdings sind neuere GCC-Versionen oft strenger als vorherige, d.h.
sie lassen weniger Fehler durchgehen. Da kann es natürlich sein, dass
das alte Programm auch mit den gleichen Einstellungen nicht mehr
compiliert. Das liegt dann aber eher daran, dass das Programm schon die
ganze Zeit fehlerhaft war und das nur bisher nicht bemerkt wurde.
Insofern ist es eigentlich ganz gut, dass solche Fehler dann endlich
behoben werden, auch wenn manche das als Gängelung durch die neue
Compiler-Version wahrnehmen.
40 * 1000 war nur ein Beispiel. Aber macht Sinn, es gibt ja auch
Situationen wo ein integer overflow durchaus gewollt ist. Daher nur eine
Warnung und keine Autokorrektur. Ich nutze z.B. ein Byte als Zähler der
sich so irgendwann selbst zurück setzt. (Weiß nur nicht ob bei 127 oder
255 - sollte es unsigned byte heißen?)
Alexander schrieb:> es gibt ja auch> Situationen wo ein integer overflow durchaus gewollt ist.
Ein gewollter Überlauf von vorzeichenbehafteten Zahlen?
Nee, so dumm kann man nicht sein!
1. Die Mathematik kann das nicht.
2. in C/C++ ist das verboten und mündet in ein UB
Georg M. schrieb:> "It is practically impossible
Dieses Zitat ist von 1975! Hast Du Dir schon mal ein modernes BASIC von
heutzutage angeschaut?
Gruss Chregu
Arduino F. schrieb:> Ein gewollter Überlauf von vorzeichenbehafteten Zahlen?> Nee, so dumm kann man nicht sein!
Das mit dem Vorzeichen wäre natürlich ungewollt. gibt es 'unsigned byte'
als Datentyp? Ich war mir nicht mehr sicher ob es 'char' oder 'byte'
sein muss, oder 'unsigned short'
Alexander schrieb:> gibt es 'unsigned byte'> als Datentyp?
byte ist unsigned char
Alexander schrieb:> Das mit dem Vorzeichen wäre natürlich ungewollt.
Genau darum dreht es sich im Eingangsposting.
Das Kernproblem dieses Threads, mal abgesehen von den antisozialen
Verirrungen.
Johann L. schrieb:> Hä?
Der Zahlenstrahl der vorzeichenbehafteten Zahlen ist in beide Richtungen
unendlich lang.
Da gibt es keinen Überlauf in der Mathematik.
Erst die Begrenzung durch die Variablenbreite bringt den Überlauf ins
Spiel.
Welcher dann in ein UB mündet.
Arduino F. schrieb:> byte ist unsigned char
Nunja, std::byte ist als scoped-enum implementiert, ganz einfach, weil
man der Natur eines Bytes als Sammlung von 8 Bits Rechnung tragen will.
Denn nicht immer sind 8-Bits als unsigned char (das ist leider(!) ein
arithmetischer Typ) zu interpretieren. Also: der underlying-type des
std::byte ist ein unsigend char, deswegen eignet er sich zur
memory-inspection wie auch unsigend char und dann eben auch ohne UB.
Aber es ist nicht dasselbe wie unsigend char, wie gerade erwähnt sind
die arithmetisch OP für std::byte sinnvollerweise nicht definiert.
Arduino F. schrieb:> Bla bla bla...
Sorry, dachte der Datentyp byte wäre gemeint.
> z.B. Der AVR-Gcc hat kein std::irgendwas im Lieferumfang.
Du kannst es Dir aber selbst definieren (der TO selbst schreibt nichts
von AVR ...)
Christian M. schrieb:> Dieses Zitat ist von 1975! Hast Du Dir schon mal ein modernes BASIC von> heutzutage angeschaut?
Auch nicht mehr viel anders als z.B. Phyton
Gibt es so ein modernes Basic auch für 8 Bit Controller?
Arduino F. schrieb:> Johann L. schrieb:>> Hä?>> Der Zahlenstrahl der vorzeichenbehafteten Zahlen ist in beide Richtungen> unendlich lang.> Da gibt es keinen Überlauf in der Mathematik.
Natürlich kann man das modellieren.
Nimm einfach Addition und Multiplikation in Z/256Z.
Im kleinsten nicht-negativen Restsystem ist das Arithmetik mit unsigned
8-Bit Wrap-Around. Im betragsmäßig kleinsten Restsystem bekommst du die
signed Variante.
Arduino F. schrieb:> Der Zahlenstrahl der vorzeichenbehafteten Zahlen ist in beide Richtungen> unendlich lang.> Da gibt es keinen Überlauf in der Mathematik.
Das hat mit dem Vorzeichen nichts zu tun. Es gibt meines Wissens
generell keinen Überlauf in der Mathematik. Was es höchstens gibt, ist
ein Definitionsbereich. Der wird aber eben definitionsgemäß nie
verlassen, so dass da auch nichts überlaufen kann.
> Erst die Begrenzung durch die Variablenbreite bringt den Überlauf ins> Spiel.> Welcher dann in ein UB mündet.
Das ist aber keine mathematische Regel, sondern eine der
Programmiersprache.
Übrigens gibt es auch in C(++) offiziell keinen Überlauf. Bei
vorzeichenbehafteten Zahlen ist eben undefiniert, was passiertm wenn man
versucht, den Wertebereich zu verlassen. Bei vorzeichenlosen Zahlen wird
die Berechnung definitionsgemäß modulo größter darstellbarer Wert + 1
durchgeführt, so dass auch dort kein Überlauf stattfindet.
Hallo,
es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete
Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln. Wenn man
einmal weiß wie ein vorzeichenloser Überlauf behandelt wird und sich
darauf verlassen kann, dann ist das schon blöd das man sich auf diesen
Automatismus bei vorzeichenbehafteten Zahlen nicht verlassen kann und
das in UB mündet.
Veit D. schrieb:> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln. Wenn man> einmal weiß wie ein vorzeichenloser Überlauf behandelt wird und sich> darauf verlassen kann, dann ist das schon blöd das man sich auf diesen> Automatismus bei vorzeichenbehafteten Zahlen nicht verlassen kann und> das in UB mündet.
Das besondere ist, dass sich alle Hardware bei einem unsigned über oder
unter Lauf identisch verhält.
Bei einem signed Über-Unterlauf ist das nicht der Fall. Da unterscheiden
sich die Systeme.
Hier zeigt sich die Hardwarenähe von C/C++
Veit D. schrieb:> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln. Wenn man> einmal weiß wie ein vorzeichenloser Überlauf behandelt wird und sich> darauf verlassen kann, dann ist das schon blöd das man sich auf diesen> Automatismus bei vorzeichenbehafteten Zahlen nicht verlassen kann und> das in UB mündet.
Das UB für signed Overflows stammt wohl noch aus Zeiten, wo es Rechner
mit Einerkomplementdarstellung gab. Die Modulo-2ⁿ-Arithmetik
funktioniert hardwareseitig aber nur mit Zweierkomplement.
Mittlerweile ist in den Standards nur noch Zweierkomplement zugelassen,
somit könnte das UB abgeschafft werden. Das ist aber bisher noch nicht
passiert, aus welchen Gründen auch immer.
Yalu X. schrieb:> aus welchen Gründen auch immer.
Eine Addition von zwei positiven Zahlen muss ein positives Ergebnis
bringen!
Alles andere wäre absurd.
Das wäre der Grund, warum ich das so beibehalten haben möchte.
Über das werfen einer Exception könnte man nachdenken, aber die
Überprüfung macht es langsamer.
Arduino F. schrieb:> Yalu X. schrieb:>> aus welchen Gründen auch immer.>> Eine Addition von zwei positiven Zahlen muss ein positives Ergebnis> bringen!> Alles andere wäre absurd.
Warum?
Man könnte in ähnlicher Weise argumentieren, dass die Summe zweier
positiver Zahlen mindestens so groß wie deren Maximum sein muss und
damit auch unsigned Overflows zum UB erklären. Das tut der C-Standard
aber nicht, folglich wäre es auch bei signed-Arithmetik nicht nötig.
In Haskell wird auf alle bounded Integrals Modulo-Arithmetik angewandt,
unabhängig davon, ob sie vorzeichenbehaftet sind oder nicht, und ich
habe noch nirgends Gemecker darüber gehört oder gelesen.
Hallo,
dann habe ich ja noch Hoffnung das bei vorzeichenbehafteten
Zahlen das UB irgendwann abgeschafft wird. :-)
Arduino F. schrieb:
> Eine Addition von zwei positiven Zahlen muss ein positives Ergebnis> bringen! Alles andere wäre absurd. Das wäre der Grund, warum ich das so> beibehalten haben möchte.
Der saubere Überlauf von vorzeichenlosen Zahlen ohne UB bleibt erhalten.
So verstehe ich Yalu. Es geht um die Möglichkeit der Abschaffung von UB
bei vorzeichenbehafteten Zahlen. Sodass der Überlauf hierbei genauso
logisch ist aus Programmierersicht.
Hallo,
von Durchsetzung war keine Rede. Wie sollte ich das auch tun. Es besteht
nur die Möglichkeit das es irgendwann geändert wird bzw. geändert werden
könnte. Genau das hoffe ich das ich es noch erleben darf ...
Veit D. schrieb:> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln.
Geht mit GCC auch, per -fwrapv.
Damit ist signed Overflow nicht UB sindern wird behandelt wie in Java.
Java-Unterstützung wurde zwar schon vor Jahren wieder aus GCC entfernt,
aber Flags wie -fwrapv haben überlebt :-)
https://gcc.gnu.org/onlinedocs/gcc-13.2.0/gcc/Code-Gen-Options.html#index-fwrapv
Veit D. schrieb:> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln.
Also auch bei vorzeichenbehafteten Zahlen die Modulo-Rechnung, also
wrap-around nach 0?
Rolf M. schrieb:> Veit D. schrieb:>> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete>> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln.>> Also auch bei vorzeichenbehafteten Zahlen die Modulo-Rechnung, also> wrap-around nach 0?
Nein, Arithmetik wie in Z / 2^nZ mit Restsystem -2^{n-1}..2^{n-1}-1 (2's
Complement). Bei n = 8 zum Beispiel Restsystem -128..127.
Hallo,
bin mir fast sicher das Rolf das Gleiche meint wie Xalu mit
"Modulo-2ⁿ-Arithmetik" und damit das Gleiche wie Johann. Wetten? :-)
Also konkret bspw. im char Wertebereich.
Nach 127 + 1 folgt -128 in Plusrichtung
und
nach -128 - 1 folgt 127 in Minusrichtung
und das alles definiert ohne UB.
Schön zu hören das es dafür ein Flag gibt. Danke.
Veit D. schrieb:> Nach 127 + 1 folgt -128 in Plusrichtung> und> nach -128 - 1 folgt 127 in Minusrichtung
Das wäre das, was man erwarten würde, aber es entspricht eben nicht dem,
was der Standard für unsigned definiert. Der sagt, dass es modulo
größter darstellbarer Wert + 1 gerechnet wird, und dann käme nach 127
eben 0.
Rolf M. schrieb:> Veit D. schrieb:>> Nach 127 + 1 folgt -128 in Plusrichtung>> und>> nach -128 - 1 folgt 127 in Minusrichtung>> Das wäre das, was man erwarten würde, aber es entspricht eben nicht dem,> was der Standard für unsigned definiert.
Es geht ja auch nicht um unsigned, sondern um siged.
> größter darstellbarer Wert + 1 gerechnet wird, und dann käme nach 127> eben 0.
Besser so formuliert, wie man zum Ergebnis kommt:
1) Berechne X als Summe, Differenz oder Produkt der beiden Werte über
den ganzen Zahlen.
2) Addiere solange ganzzahlige Vielfache des Moduls (bei n-Bit Zahlen
also 2^n) zu X, bis man einen Wert Y im Zielbereich erhält (zum Beispiel
Y∈[0,256) für 8-Bit Unsigned oder Y∈[-128, 128) für 8-Bit Signed).
3) Das Ergebnis der Operation ist Y.
Der einzige Unterschied zwischen Signed und Unsigned gleicher Breite ist
dann nur der Zielbereich.
Johann L. schrieb:> Es geht ja auch nicht um unsigned, sondern um siged.
Ich hatte auf diese Aussage geantwortet:
Veit D. schrieb:> es wäre jedoch für alle Zeiten sinnvoller gewesen vorzeichenbehaftete> Zahlen genau wie vorzeichenlose Zahlen in C/C++ zu behandeln.
Und wenn man das tut, dann kommt bei signed nach 127 die 0 und nicht,
wie man eher erwarten würde, die -128.
Johann L. schrieb:>> größter darstellbarer Wert + 1 gerechnet wird, und dann käme nach 127>> eben 0.>> Besser so formuliert, wie man zum Ergebnis kommt:
Ich habe mich darauf bezogen, wie es im Standard definiert ist. Wenn man
es anders definiert, kann man natürlich was geeignetes finden, aber dann
ist es nicht mehr "genau so", denn das war die obige Aussage.
Rolf M. schrieb:> Ich habe mich darauf bezogen, wie es im Standard definiert ist.
Im Standard ist es eben nicht definiert.
In C11 heißt zu zu + lapidar:
> The result of the binary + operator is the sum of the operands.
Dito für andere Operationen, hier wird also über den ganzen Zahlen
gerechnet. Jedoch braucht es noch eine Abbildung auf den Zieltyp, was
unter "Conversions / Signed and Unsigned Integers" zu finden ist, wo der
Signed "Überlauf" dann Implementation Defined ist.
Die Implementation wiederum schreibt dazu:
> * The result of, or the signal raised by, converting an integer to> a signed integer type when the value cannot be represented in an> object of that type (C90 6.2.1.2, C99 and C11 6.3.1.3).>> For conversion to a type of width N, the value is reduced> modulo 2^N to be within range of the type; no signal is raised.
Die Formulierung ist so, dass sie für unsigned der Festlegung im
Standard äquivalent ist, d.h. der einzige Unterschied zwischen Signed
und Unsigned steckt im "range of the type".
Ich weiß, dass Prognosen immer recht schwierig sind, insbesondere wenn
sie die Zukunft betreffen.
Glaube nicht, dass an C da noch gedreht wird.
Arduinofans und sonstige C++ Jünger bauen sich halt einen entsprechenden
Datentype mit dem gewünschten Verhalten.
Johann L. schrieb:> Rolf M. schrieb:>> Ich habe mich darauf bezogen, wie es im Standard definiert ist.>> Im Standard ist es eben nicht definiert.
Im aktuellen Draft in 6.2.5 Types:
"The range of representable values for the unsigned type is 0 to 2^N − 1
(inclusive). A computation involving unsigned operands can never produce
an overflow, because arithmetic for the unsigned type is performed
modulo 2^N."
Die Formulierung wurde offenbar mal geändert, denn vorher hieß es:
"A computation involving unsigned operands can never overflow, because a
result that cannot be represented by the resulting unsigned integer type
is reduced modulo the number that is one greater than the largest value
that can be represented by the resulting type."
Hallo,
nochmal wegen dem UB beim signed Overflow.
Wenn ich bspw. eine int8_t Variable ständig inkrementiere funktioniert
das komischerweise aktuell ohne und mit dem Flag 'fwrapv'. Kann man 'UB'
provozieren oder ist das rein Zufallsgesteuert? Wovon würde der Zufall
abhängen?
Was irgendwo in irgendeinem C Standard steht das interessiert nur wenn
man MISRA komform o.ä. abliefern muss, das hat im echten Leben keine
Bedeutung. Sagt ein Nichtprogrammierer.
Veit D. schrieb:> Wenn ich bspw. eine int8_t Variable ständig inkrementiere funktioniert> das komischerweise aktuell ohne und mit dem Flag 'fwrapv'. Kann man 'UB'> provozieren oder ist das rein Zufallsgesteuert?
Nicht exakt dein Beispiel aber ganz ähnlich:
1
$ cat overflowtest.c
2
#include <stdio.h>
3
4
int main(void) {
5
for (int i=0; i>=0; i+=1000000000)
6
printf("%d\n", i);
7
}
Erster Versuch mit -fwrapv:
1
$ gcc -O2 -fwrapv overflowtest.c -o overflowtest
2
$ ./overflowtest
3
0
4
1000000000
5
2000000000
Die Schleife bricht ab, weil i negativ wird.
Zweiter Versuch ohne -fwrapv (Standard-C):
Schleife läuft endlos weiter, obwohl i negativ wird. Das ist legal, weil
UB.
PS: Das ist vermutlich der Grund dafür, dass auch im C23-Standard noch
an UB für Signed-Overflows festgehalten wird: Eine Abkehr davon würde
dem Compiler darauf bezogene Optimierungen verwehren, die bisher möglich
waren.
Veit D. schrieb:> Hallo,>> nochmal wegen dem UB beim signed Overflow.> Wenn ich bspw. eine int8_t Variable ständig inkrementiere funktioniert> das komischerweise aktuell ohne und mit dem Flag 'fwrapv'. Kann man 'UB'> provozieren oder ist das rein Zufallsgesteuert?
UB heißt nur, dass der Standard nicht definiert, was passiert. Somit
kann beliebiges passieren, auch dass es "funktioniert", in dem Sinne,
dass es tut, was du erwartest. Es heißt nicht, dass der Compiler
verpflichtet ist, Blödsinn zu machen.
> Wovon würde der Zufall abhängen?
Zum Beispiel von der Prozessor-Architektur, dem Compiler, dessen
Version, den Optimierungseinstellungen, dem Datentyp, der spezifischen
Stelle im Code, u.s.w.