Hi, Es gibt im Bereich der embedded Software Entwicklung noch einige unbekannte Bereiche, in der ich mich noch einarbeiten muss. Ein großer Teil davon ist der Linkerscript. Ich finde da noch keinen Startpunkt, wo ich ansetzen kann um mich damit zu beschäftigen. Wenn ich Linkerscripts von verschiedenen Controllern ansehe und vergleiche, dann sehe ich bis auf die Sections kaum bzw. wenige Gemeinsamkeiten. Habt ihr Tipps oder Anregungen für mich, wie ich mich in dieses Thema einarbeiten kann? Mein Ziel ist es, dass ich anhand von Datenblättern eines Mikrocontrollers selber den Linkerscript sowie eigene Sektionen schreiben kann.
Ali K. schrieb: > Habt ihr Tipps oder Anregungen für mich, wie ich mich in dieses Thema > einarbeiten kann? Mit der Doku des betreffenden Linkers?
Ali K. schrieb: > Habt ihr Tipps oder Anregungen für mich, wie ich mich in dieses Thema > einarbeiten kann? Einfach sich ein Manual zu Gemüte führen. Daneben liegend vielleicht ein Beispiel eines Linkerscripts, oder auch mehrere. Hier mal ein Manual: https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_chapter/ld_3.html Wenn du allerdings noch etwas Anderes machen willst ausser dich mit solchen Problemen herumzuschlagen dann lasse dir für deine Anwendung ein Linkerscript generieren und verändere es ggf. nach deinen Bedürfnissen. Geht schneller und reicht im Allgemeinen.
Beitrag #7487400 wurde von einem Moderator gelöscht.
Ali K. schrieb: > Ich finde da noch keinen Startpunkt, wo ich ansetzen kann um mich damit > zu beschäftigen. Was hier einiges an Heiterkeit auslöst, den zum Verstehen des Linker Skripts braucht es auch den Start(up) Code. Meistens ist der in Assembler. Dort werden die meisten der Symbole verwendet, u.a. um den Stack Pointer aufzusetzen oder das Datensegment vom Flash in den Ram kopieren zu können. Bei µC kommen dann noch plattformspezifische Symbole z.B. für Interrupts hinzu - wobei im Linker Skript oftmals nur die Adresse der Interrupt Tabelle definiert wird.
Beitrag #7487413 wurde von einem Moderator gelöscht.
Ali K. schrieb: > Ein großer Teil davon ist der Linkerscript. Warum? Der weitaus größte Teil der Programmierer braucht es nicht. Sie installieren eine Toolchain und wählen darin das gewünschte Target aus. Irgendein Linkerscript bekommen sie nie zu Gesicht, wozu auch. Es reicht völlig, den Build-Button zu klicken. Willst Du selber ein Linkerscript erstellen, mußt Du erstmal festlegen, für welche Toolchain und für welches Target. Da kocht nämlich jeder Compilerhersteller sein eigenes Süppchen. P.S.: Ich hab auch noch nie ein Linkerscript erstellt oder gelesen.
Wenn es wenig Speicher gibt, dann ist das Linkerfile meistens übersichtlich. Aber bei so Boliden wie STM32H7 mit mehreren Speichern an verschiedenen Bussen sieht das schon anders aus. Da muss man das schon genau steuern was wohin soll. Und bei Keil/gcc/IAR sehen die komplett anders aus und auch die Nutzung der sections im Code hat eine unterschiedliche Syntax.
Wastl schrieb: > Ali K. schrieb: >> Habt ihr Tipps oder Anregungen für mich, wie ich mich in dieses Thema >> einarbeiten kann? > Wenn du allerdings noch etwas Anderes machen willst ausser dich > mit solchen Problemen herumzuschlagen dann lasse dir für deine > Anwendung ein Linkerscript generieren und verändere es ggf. > nach deinen Bedürfnissen. Geht schneller und reicht im > Allgemeinen. Mit welchem Tool lässt sich ein Linkderscript generieren? Das liest sich interessant! Peter D. schrieb: > Warum? > Der weitaus größte Teil der Programmierer braucht es nicht. Sie > installieren eine Toolchain und wählen darin das gewünschte Target aus. > Irgendein Linkerscript bekommen sie nie zu Gesicht, wozu auch. Es reicht > völlig, den Build-Button zu klicken. > > Willst Du selber ein Linkerscript erstellen, mußt Du erstmal festlegen, > für welche Toolchain und für welches Target. Da kocht nämlich jeder > Compilerhersteller sein eigenes Süppchen. > > P.S.: > Ich hab auch noch nie ein Linkerscript erstellt oder gelesen. Naja, wenn man z.B. ein Bootloader schreibt, dann kommt man schon mit einem Linkerscript in Berührung. Toolchain ist die Arm-GCC für Cortex-M Controller. Um das Warum noch zu beantworten. Einfach so, weil es mich interessiert.
Ali K. schrieb: > Mit welchem Tool lässt sich ein Linkderscript generieren? Das geht heute mit jeder modernen IDE praktisch automatisch. Siehe auch Pedas Beitrag: Peter D. schrieb: > Warum? > ................ Also eine IDE braucht man schon dazu, die Toolchain (Make, Compiler, Linker, ...) allein reicht nicht.
Wastl schrieb: > Ali K. schrieb: >> Mit welchem Tool lässt sich ein Linkderscript generieren? > > Das geht heute mit jeder modernen IDE praktisch automatisch. ... > Also eine IDE braucht man schon dazu, die Toolchain (Make, > Compiler, Linker, ...) allein reicht nicht. Quatsch mit Soße. Selbstverständlich geht es auch ohne irgendeine IDE. Das Linkerscript ist meist Teil der Standardlib. Oder wer auch immer den Startup-Code beisteuert. Weil wie gesagt dieser Code und das Linkerscript Hand in Hand arbeiten (müssen). Für arm-gcc gibt es da auch reichlich Auswahl. Ich mag beispielsweise libopencm3. Da ist eine Menge an Linkerscripten dabei. @TO: such dir eine "bare metal" Einführung in die Programmierung. Die schreiben meist ihren Startup-Code und das Linkerscript selber. Z.B. https://vivonomicon.com/2018/04/02/bare-metal-stm32-programming-part-1-hello-arm/
Wastl schrieb: > Hier mal ein Manual: > https://ftp.gnu.org/old-gnu warum nicht etwas aktuelleres? https://sourceware.org/binutils/docs-2.41/ Übrigens: außer Linker und Compiler braucht man für den Anfang nichts weiter. Und eine IDE schon überhaupt nicht, die verwirrt nur und ist schlecht bis garnicht dokumentiert. Es wird auch sehr viel übersichtlicher, wenn man die Unterstützung für C++ weg lässt.
Bei den ARM Cortex-M Controllern von STM kommt normalerweise das zur Serie passende "Firmware" Paket zum Einsatz. Es enthält die CMSIS Header (mit den Registern), diverse CMSIS Bibliotheken und die HAL Bibliotheken. Im CMSIS Verzeichnis befinden sich Beispiele für Linker Scripte und zugehöriger Startup Code. Diese Dateien taugen gut als Vorlage, falls man keine IDE verwenden will.
Eine interessante Spielwiese fuer Startupcode und Linkerscript sind die MIPS-Prozessoren. Die haben z.B. so Sonderlocken wie einen 65k grossen RAM-Bereich den sie mit "kurzen" Befehlen adressieren koennen. Da reichen dann selbst die Ausdrucksmittel des Linkerscripts nicht mehr, und folgerichtig gibt es spezielle Optionen fuer den Linker nur fuer den MIPS. Geruechteweise tauchen manche davon nichtmal in der Dokumentation auf. :) Und automatisch geht da auch nichts. Wenn man sie nicht kennt, wird man keinen Build zustandebringen. Mehrere RAM-Bereiche sind dagegen eher normales Business bei Renesas SH-2/3/4/RX-6x und besseren ARMen.
> Der weitaus größte Teil der Programmierer braucht es nicht. Sie > installieren eine Toolchain und wählen darin das gewünschte Target aus. > Irgendein Linkerscript bekommen sie nie zu Gesicht, wozu auch. Solange man nur blinkende Weihnachtsbaeume programmiert mag das stimmen. Aber jeder der ernsthaft Embedded programmier braucht das irgendwann, nicht taeglich, aber regelmaessig. Die Gruende dafuer sind immer sehr unterschiedlich. Bootloader, Anpassung an verschiedene Speicherlagen, Sondercode der z.B im Ram laufen muss und es gibt sicherlich noch mehr Gruende die mir gerade nicht einfallen. Es ist also sicher nicht das erste was man als Embeddedprogrammierer lernen muss, aber irgendwann kommt der Tag... Vanye
Angehängte Dateien:
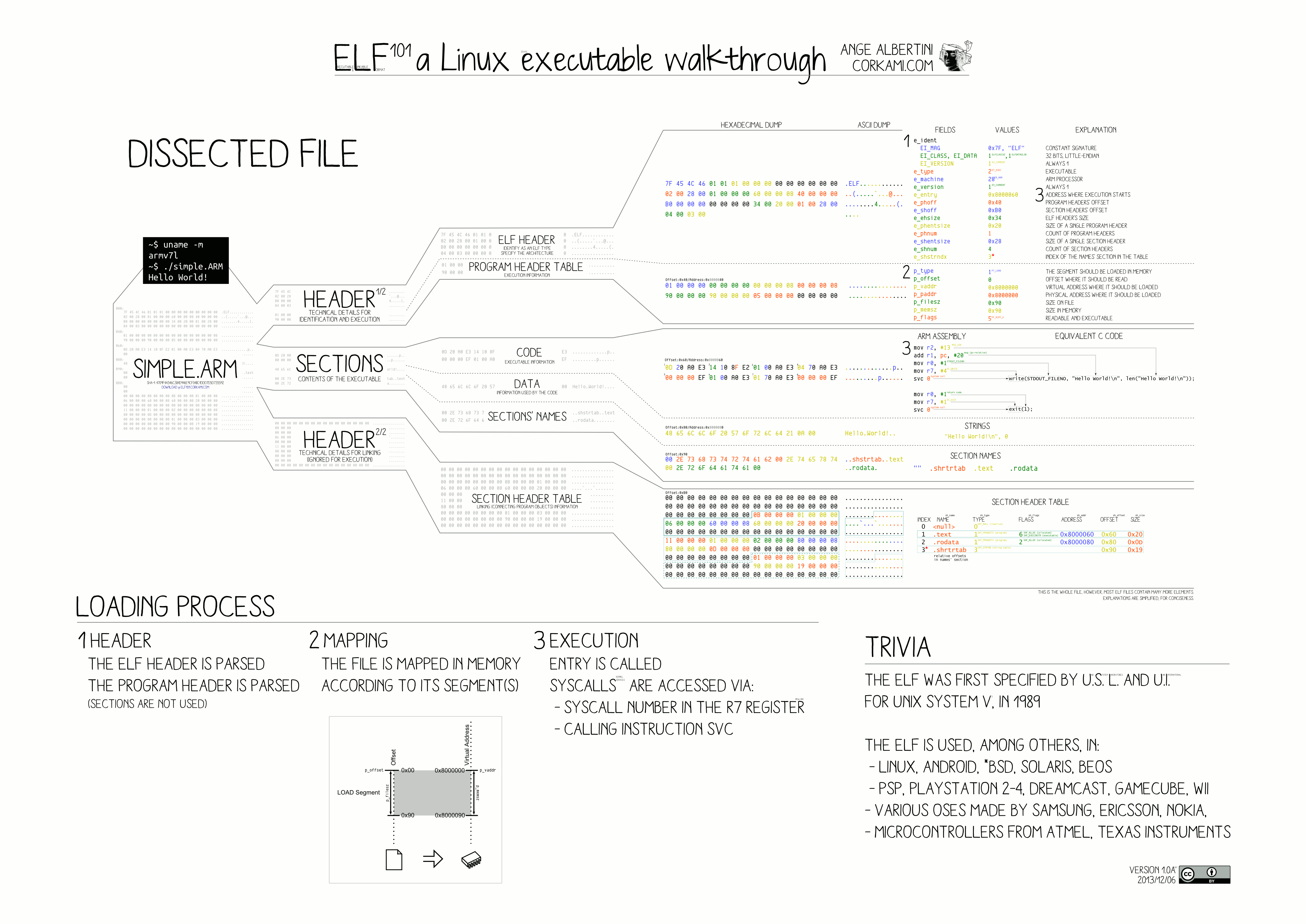
> Wenn ich Linkerscripts von verschiedenen Controllern ansehe und > vergleiche, dann sehe ich bis auf die Sections kaum bzw. wenige > Gemeinsamkeiten. > Habt ihr Tipps oder Anregungen für mich, wie ich mich in dieses Thema > einarbeiten kann? Mancher lernt viel über ein Tool sobald er seine Comfortzone verlässt und statt dem Tool "seine eigene Hände" verwendet und das Ganze "händisch" macht. In der Computerrei bedeudet"Händisch" das man binaries also bytes mit einem Hex-Editor anschaut resp bearbeitet. Manchmal ist so ein Hexeditor/-viewer noch Bestandteil der IDE, manchmal nicht. Den Haufen "magic numbers" im HexEditor muss man natürlich erstmal entschlüsseln. Da hilft vielleicht eine zweite Lernregel, die sagt, * Lerne von der Geschichte. Also steig erst mal bei einfachen binary-Formaten rein, wie eben das historische .COM oder .EXE Format (statisch gelinkt) bevor es an Finessen wie dynamisches Linken etc. geht. https://github.com/qb40/exe-format Wenn dann klar ist was so ein Linker grundsätzlich macht (File-Header, Speicheraddressen berechnen schreiben, boot code erzeugen) sollte man sich Lehrbücher/-literatur zu den häufigsten Format (ELF) besorgen und das Exzerpueren (abschreiben resp. Notizen in eigener Sprache dazu machen). Anbei ein Ausschnitt aus einem ARM-ELF wie in der .en WP verlinkt. https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
Vanye R. schrieb: > Bootloader, Anpassung an verschiedene Speicherlagen, Sondercode der z.B > im Ram laufen muss und es gibt sicherlich noch mehr Gruende die mir > gerade nicht einfallen. Mag sein, daß es bei den heutigen Boliden etwas komplexer ist, aber die 8-Bitter sind recht einfach gestrickt. Da muß man keine Wissenschaft draus machen, um externen RAM einzubinden oder die Applikation hinter dem Bootloader zu plazieren. Z.B. beim 8051 hat man zum Testen oft die Applikation in externen SRAM ab 0x8000 geladen. Flash gab es ja erst viel später, so ab 1994 und der war auch erstmal nicht ISP/IAP. Da hat es dann gereicht, in der "startup.a51" die magische Zeile "CSEG AT 8000H" einzufügen und dem Linker in der Kommandozeile "INTVECTOR(0x8000)" zu sagen. Das ist alles im C51 Manual gut erklärt. In der Regel gibt es auch vom Compilerbauer fertige Beispiele, die man einfach übernehmen kann. Vanye R. schrieb: > Es ist also sicher nicht das erste was man als Embeddedprogrammierer > lernen muss, aber irgendwann kommt der Tag... Nimmt man eine professionelle Toolchain (z.B. IAR, Keil), kommt dieser Tag jedoch nie.
Emil S. schrieb: > In der Computerrei bedeudet"Händisch" das man binaries > also bytes mit einem Hex-Editor anschaut resp bearbeitet. Das ist vielleicht was für Gamer, um die Charaktere stärker zu machen oder ihnen seltene Rüstungen und Waffen anzulegen. Der ernsthafte Entwickler braucht sowas nicht, der arbeitet nur mit den Sourcen.
> Das ist vielleicht was für Gamer, um die Charaktere stärker zu machen > oder ihnen seltene Rüstungen und Waffen anzulegen. Der ernsthafte > Entwickler braucht sowas nicht, der arbeitet nur mit den Sourcen. Es geht nicht ums "Arbeiten am Fliessband der Codierschweine", es geht ums "Lernen und Verstehen". Und für das Verständniss ist es schon hilfreich, wenigstens einmal ein Gerät respektive binary "zerlegt" (aufgeschraubt) und so "hinter die Frontblende" geschaut zu haben. Da eine IMHO brauchbare Labor-Anleitung für linkerscripte: https://users.informatik.haw-hamburg.de/~krabat/FH-Labor/gnupro/5_GNUPro_Utilities/c_Using_LD/ldLinker_scripts.html https://users.informatik.haw-hamburg.de/~krabat/FH-Labor/gnupro/7_GNUPro_Embedded_Development/embThe_linker_script.html
Eine IDE ist ja kein Hexenwerk oder eine Blackbox, wo alles im Geheimen abläuft. Alle Abläufe werden in einem Ausgabefenster angezeigt, was man auch in eine Datei umleiten kann. Da stehen dann alle expandierten Aufrufe mit ihren Fehlermeldungen drin. Prinzipiell kann man daher alles, was die IDE ausführt, auch selber auf der Kommandozeile machen oder in eine Batch schreiben.
Emil S. schrieb: > Und für das Verständniss ist es schon > hilfreich, wenigstens einmal ein Gerät respektive binary "zerlegt" > (aufgeschraubt) und so "hinter die Frontblende" geschaut zu haben. Dafür kann man sich doch bequem die Sourcen nach Assembler übersetzen oder ein List-File ausgeben lassen. Dazu muß man nicht langwierig im von Symbolen und Quelltext befreiten Binary rumrätseln.
Peter D. schrieb: > Vanye R. schrieb: >> Es ist also sicher nicht das erste was man als Embeddedprogrammierer >> lernen muss, aber irgendwann kommt der Tag... > > Nimmt man eine professionelle Toolchain (z.B. IAR, Keil), kommt dieser > Tag jedoch nie. Unsinn. So einen Schmarrn erzählen nur Leute die einfach immer den dicksten verfügbaren Controller einbauen und hoffen das er schon irgendwie die Anforderungen packen wird. Spätestens wenn es darum geht die Verfügbaren Speicherbereiche effizient und sinnvoll zu nutzen (müssen) kommt man um Linkerscripts nicht umhin. Interessant wirds auch bei Firmwareupdates "Over The Air". Klar kann man hoffen das der Toolchain-Entwickler das irgendwie im Griff hat, aber sobald es Probleme damit gibt ist man denen auf Gedeih und Verderb ausgeliefert. Da ists schon besser wenn man das selbst unter Kontrolle hat statt auf deren Support zu hoffen.
Peter D. schrieb: > Emil S. schrieb: >> Und für das Verständniss ist es schon >> hilfreich, wenigstens einmal ein Gerät respektive binary "zerlegt" >> (aufgeschraubt) und so "hinter die Frontblende" geschaut zu haben. > > Dafür kann man sich doch bequem die Sourcen nach Assembler übersetzen > oder ein List-File ausgeben lassen. Dazu muß man nicht langwierig im von > Symbolen und Quelltext befreiten Binary rumrätseln. Um die Arbeitsweise eines Linkes zu verstehen ist es hilfreich, sich das Ergebniss eines Linkerlaufes resp. den Output eines Linkers anzuschauen. Und das ist nun aber nicht ein *.asm-file. Und in einem *.lst steht eher debug-info als tatsächlicher output. Und *.obj ist auch eher Input als output des linkers. Ein linker erzeugt lätzlich einen Speicherabbild, das die CPU's abarbeiten. Und die CPU's brauchen nun mal keine Symbole oder Quelltext. > P.S.: > Ich hab auch noch nie ein Linkerscript erstellt oder gelesen. Dann sind deine Beiträge hier vollkommen fehl am Platze. Bitte einen Mod diese umgehend zu löschen.
Peter D. schrieb: > Eine IDE ist ja kein Hexenwerk oder eine Blackbox, wo alles im Geheimen > abläuft. Doch, eine IDE ist eine Blackbox desen wesentliches Merkmal der sogenannte "one-button-push-compile-flow" ist. > Prinzipiell kann man daher > alles, was die IDE ausführt, auch selber auf der Kommandozeile machen > oder in eine Batch schreiben. Ja klar kann man. Macht aber keiner. IMHO versteht man einen commandLine oder eben auch "BareMetal" Designflow besser, wenn man einen solchen anhand der Doku und Lehrtexte/Tutorials "from the scratch" aufsetzt. Man kann natürlich auch eine IDE dekonstruieren und anhand der logs versuchen, deren Arbeitsweise zu nachzustellen resp. nach zu äffen. Aber dann wird der eigene flow eben nicht besser als der der IDE und mit den "Feature/Fehlern" in der IDE muss man auch leben. Ich erinerre mich da an ein Problem mit dem Pinzuweisungseditor von Infineons XMC-IDE ("dave"?) bei der es partout nicht möglich (der design rule check meckerte wegen einem "Fehler" vor keiner war) war den zweiten Uart als sekundäre pin-Option zu nutzen. Da musste man sich dann selbst die konfiguration der Peripheral-Pin-Crossbar aus dem Datenblatt erarbeiten.
Emil S. schrieb: > Um die Arbeitsweise eines Linkes zu verstehen ist es hilfreich, sich das > Ergebniss eines Linkerlaufes resp. den Output eines Linkers anzuschauen. Ich wüßte nicht, welche Erkenntnisse mir das bringen soll. Der Linker linkt ja nur, wie der Name schon sagt. Er ist also nicht an der Codegenerierung beteiligt und hat demzufolge auch keinen Einfluß auf die Effizienz meines Codes. An welcher Adresse welche Funktion oder Variable steht, kann mir doch herzlich egal sein, solange sie gültig ist. Ich weiß, man kann Code im RAM ein Fitzelchen schneller laufen lassen. Aber ich bin nicht der Typ, der die CPU bis aufs letzte % ausquetschen läßt. Ich designe Projekte immer so, daß sie noch reichlich Reserven für zukünftige Erweiterungen haben. Die Erfahrung zeigt, daß der Kunde immer noch mehr Funktionen implementiert haben will.
Peter D. schrieb: > Emil S. schrieb: >> Um die Arbeitsweise eines Linkes zu verstehen ist es hilfreich, sich das >> Ergebniss eines Linkerlaufes resp. den Output eines Linkers anzuschauen. > > Ich wüßte nicht, welche Erkenntnisse mir das bringen soll. Bist du überhaupt nicht neugierig? Hast du noch nie etwas auseinander gebaut? > Der Linker linkt ja nur, wie der Name schon sagt. Er ist also nicht > an der Codegenerierung beteiligt und hat demzufolge auch keinen > Einfluß auf die Effizienz meines Codes. An welcher Adresse welche > Funktion oder Variable steht, kann mir doch herzlich egal sein Bei 8-Bittern wohl, aber schon bei kleineren Cortex-M4 ist Flash 64, 128 oder 256 Bit breit. Der Linker kann dann für das passende Alignment sorgen, z.B. für Interrupt-Routinen. Der Linker kann Tabellen im Flash bauen. Damit kann ich einzelne Funktionen nach Bedarf dazu linken (oder nicht), ohne einen Quelltext zu ändern, z.B. für eine Mini-Kommandozeile. Oder Daten für Zeitzonen oder Sprachen. Oder einfach nur für einen Header mit Version und Checksum. Feiglinge füllen gerne unbenutzte Flash-Bereiche, z.B. mit Breakpoint- oder UDF-Befehlen (Permanently Undefined Instruction) oder einfach mit 0xFF statt 0. > Aber ich bin nicht der Typ, der die CPU bis aufs letzte % ausquetschen > läßt. Das ist natürlich richtig und vernünftig.
Peter D. schrieb: > Ich wüßte nicht, welche Erkenntnisse mir das bringen soll. Der Linker > linkt ja nur, wie der Name schon sagt. Er ist also nicht an der > Codegenerierung beteiligt und hat demzufolge auch keinen Einfluß auf die > Effizienz meines Codes. Und schon reingefallen. Je nach Architektur fügt ein Linker sehr wohl Instruktionen in den Code ein, z.B. beim AVR8 oder 8051 wo der Compiler nämlich nur Dummy-Sprungbefehle hinterlegt und der Linker erst später die passenden Instruktionen dazu generiert. Und dann wäre da noch das Thema LTO, wo der Linker die Hauptarbeit der Codeoptimierung durchführt bishin zur komplett Elimination von Funktionsaufrufen. Mal davon abgesehen, das die Anordnung des Codes/Daten im RAM sehr wohl einen Einfluss hat, da sprechen wir von mittleren zweistelligen Performancezuwächsen. Oder glaubst Du wirklich, das ein mit Zero-Waitstate und vollem Prozessortakt angebundenes DTCM nur ein bischen schneller als ein mit halben CPU Takt laufendes SRAM hinter einem Multimasterfähigen Crossbarswitch ist? Peter D. schrieb: > Ich weiß, man kann Code im RAM ein Fitzelchen schneller laufen lassen. Die Ausage ist allgemein so auch falsch. Interrupt Entry wird bei Cortex-M sogar langsamer wenn man die Funktionen im gleichen RAM wie die Variablen hat. (Um genau zu sein, wenn der RAM der Daten am gleichen Busport wie der RAM für den Code hängt, was bei Standard-Linkerscripten immer der Fall ist) Peter D. schrieb: > Ich designe Projekte immer so, daß sie noch reichlich Reserven für > zukünftige Erweiterungen haben. Die Erfahrung zeigt, daß der Kunde immer > noch mehr Funktionen implementiert haben will. Wenn Deine Kunden das bezahlen... Nun, wir designen unsere Software so das sie auch auf einem 17 Jahre altem SoC ein ähnliches Performanceniveau wie das aktuelle System liefert. Wenn man einem Kunden dann für ein 15 Jahre altes Produkt ein Update auf den aktuellen Stand per Software anbieten kann, naja Du kannst Dir vorstellen wer das nächste Projekt dann bekommt...
Es gibt schon viele Gründe, sich mit dem Linkerscript auseinanderzusetzen. Viele davon wurden ja schon genannt. Was neben Bootloader dazukommt, und bei mir in der Praxis schon passiert ist: - Wichtigen Code in das Tightly Coupled Memory (ITCM) schieben. Hab ich für den STM32F7 gemacht. Das Linkerscript von ST brachte da von Haus aus nichts mit. - Teile des Codes und .rodata im Flash komprimiert ablegen und während des Systemstarts ins RAM dekomprimieren um Flash zu sparen. Ist beides ohne Anpassung des Linkerscripts nicht zu machen. Auf dem STM32F7 gab es noch ein anderes Schmankerl: Der Flash war über zwei Addressbereiche ansprechbar. Der eine ging durch den Code-Cache, der andere durch den Flash Accelerator. Default war Code-Cache. Das heist, der Flash Accelerator lag die ganze Zeit Brach und machte nichts. Durch geschicktes Partitionieren war es möglich, große Teile des RTOS und Interrupt Routinen durch den Flash Accelerator anzusprechen. Dadurch sinkt im System insgesammt die Latenz, da normaler "User"-Code und Hintergrund Interrupts sich nicht mehr um die gleichen Cache-Lines streiten.
Hallo Zusammen, es sind sehr viele Tipps und Hinweise gekommen, wo ich anfangen kann mich einzulesen. Danke dafür. Max H. schrieb: > Es gibt schon viele Gründe, sich mit dem Linkerscript > auseinanderzusetzen. Viele davon wurden ja schon genannt. > > Was neben Bootloader dazukommt, und bei mir in der Praxis schon passiert > ist: > > - Wichtigen Code in das Tightly Coupled Memory (ITCM) schieben. Hab > ich für den STM32F7 gemacht. Das Linkerscript von ST brachte da von Haus > aus nichts mit. > > - Teile des Codes und .rodata im Flash komprimiert ablegen und während > des Systemstarts ins RAM dekomprimieren um Flash zu sparen. > > Ist beides ohne Anpassung des Linkerscripts nicht zu machen. > > Auf dem STM32F7 gab es noch ein anderes Schmankerl: Der Flash war über > zwei Addressbereiche ansprechbar. Der eine ging durch den Code-Cache, > der andere durch den Flash Accelerator. Default war Code-Cache. Das > heist, der Flash Accelerator lag die ganze Zeit Brach und machte nichts. > Durch geschicktes Partitionieren war es möglich, große Teile des RTOS > und Interrupt Routinen durch den Flash Accelerator anzusprechen. Dadurch > sinkt im System insgesammt die Latenz, da normaler "User"-Code und > Hintergrund Interrupts sich nicht mehr um die gleichen Cache-Lines > streiten. Genau, das ist der Hauptgrund, wieso ich mich mit Linkerscripten beschäftigen möchte. Danke für weitere Anregungen.
Max H. schrieb: > Durch geschicktes Partitionieren war es möglich, große Teile des RTOS > und Interrupt Routinen durch den Flash Accelerator anzusprechen. Dadurch > sinkt im System insgesammt die Latenz, da normaler "User"-Code und > Hintergrund Interrupts sich nicht mehr um die gleichen Cache-Lines > streiten. Wenn man die Lust und vor allem viel Zeit übrig hat, kann man sich gerne an Mikrooptimierung aufreiben. In der Praxis habe ich sowas allerdings noch nirgends erlebt. Als Kunde von Geräten ist man heilfroh, wenn sie das machen, was sie sollen und dabei nicht abstürzen. Auch bei uns wird nicht noch weiter rumoptimiert. Sobald das Gerät läuft und alle Tests bestanden sind, geht es raus. Läuft etwas zu langsam, nimmt man die üblichen Optimierungsansätze (Umstellung des Programmablaufs, effizientere Algorithmen bzw. Libs, wiederkehrende Berechnungen aus Schleifen ziehen, teure Berechnungen seltener ausführen usw.). Früher zu Assemblerzeiten habe ich auch noch viel rumprobiert. Als ich mir dann mal angesehen habe, welche Tricks die Compilerbauer drauf hatten, habe ich damit aufgehört. Die eigenen Lösungen brauchten mehr Code und liefen langsamer. Assemblerkenntnisse sind durchaus nützlich, um mal im Listing zu erkennen, wo man dem Compiler etwas unabsichtlich kompliziert gemacht hat.
Peter D. schrieb: > Max H. schrieb: >> Durch geschicktes Partitionieren war es möglich, große Teile des RTOS >> und Interrupt Routinen durch den Flash Accelerator anzusprechen. Dadurch >> sinkt im System insgesammt die Latenz, da normaler "User"-Code und >> Hintergrund Interrupts sich nicht mehr um die gleichen Cache-Lines >> streiten. > > Wenn man die Lust und vor allem viel Zeit übrig hat, kann man sich gerne > an Mikrooptimierung aufreiben. Bullshit. Hier geht es nicht um kleinst-Optimierung sondern um Systemarchitektur. Und die Nutzung von caches verbessert den Datendurchsatz um mehrere 100%. > In der Praxis habe ich sowas allerdings > noch nirgends erlebt. Als Kunde von Geräten ist man heilfroh, wenn sie > das machen, was sie sollen und dabei nicht abstürzen. > Auch bei uns wird nicht noch weiter rumoptimiert. Na klar, wenn das Grundwissen um Stabilitätsverbesserung fehlt, muß man sich und dem Kunden alle Bemühungen in dieser Richtung ausreden.
Emil S. schrieb: > Na klar, wenn das Grundwissen um Stabilitätsverbesserung fehlt, muß man > sich und dem Kunden alle Bemühungen in dieser Richtung ausreden. Wie kommst Du darauf, daß wir dem Kunden was ausreden? Das Hauptaugenmerk liegt darauf, daß die gesamte Anwendung stabil läuft. Eine höhere Datenrate würde der Benutzer nichtmal bemerken.
Bei einem Controller wo es einen RAM Block gibt muss man sich sicher selten mit dem Linkerscript auseinandersetzten. Bei z.B. einem F407 der noch 64 kB DTCM RAM hat kann man schon überlegen was man da für schnellere Zugriffe reinpackt, eine section im Code und dann im Linkerscript festlegen ist kein Hexenwerk. Beim H7 und komplexeren Projekten mit zig kB Framebuffer und DMA und/oder Netzwerk wird es eben aufwändiger. DMA und Cache arbeiten da nur halbautomatisch zusammen, die Cache Pflege muss manuell erfolgen oder man schaltet den Cache in der MPU ab. Trotzdem wird man große Arrays gezielt an fixe Adressen legen wollen, auch um eben die Cache Einstellungen für diese Speicherbereiche machen zu können. Für den Cache möchte man den Speicher zudem noch 32 Byte aligned haben (jedenfalls bei den F7/H7 mit 32 Byte Cache Lines). Das geht für statische oder Stackvariablen, für Speicher vom Heap war die newlib da lange Zeit Fehlerhaft, die Funktion war nicht komplett implementiert. Beim Keil sah (sieht?) es noch schlechter aus. Also ist auch hier die Kontrolle per Linkerscript gut. Fies ist nur wenn man im Code eine Section anlegt, aber nicht im Linkerscript festnagelt oder durch einen Schreibfehler einen anderen Namen vergibt. Das führt zu keiner Warnung/Fehlermeldung und man kann schön suchen. Zur Kontrolle prüfe ich daher das Mapfile wenn ich solche sections verwende. Da hilft auch die IDE nicht weiter, die kann überlichweise nur ein default Script für den Start erstellen, da wird ein Template verwendet und die vorhandenen Speichergrößen eingesetzt. Das kann der Linker übrigens auch, da gibt es auch einen Preprozessor der Symbole erstmal auflösen kann. Und wie sehr man mit der IDE und den fehlenden Einstellungen auf die Nase fliegen kann zeigt CubeMX generierter lwip Code, da sind viele manuelle Änderungen nötig.
Peter D. schrieb: > Prinzipiell kann man daher > alles, was die IDE ausführt, auch selber auf der Kommandozeile machen > oder in eine Batch schreiben. Aber Peter, sowas darfst Du doch hier nicht sagen. Pure Blasphemie, da kommen dann gleich Leute mit Silberkugeln und Holzpflöcken. Okay, ich habe keine Angst vor denen und sag das trotzdem. Nicht selten artet das dann in ebenso wort- wie emotionsstarke Dispute aus, die mich belehren, daß die IDE xy das unschlagbare Feature z hat, und überhaupt: ohne IDE müßte man ja diese Befehle alle in die Kommandozeile eingeben, sowas geht natürlich gar nicht. Auf meine Hinweise, daß mein GNU Emacs das Feature z schon vor drölfzig Jahren hatte, man diese Befehle auch von Buildsystemen wie GNU make(1), oder schlimmstenfalls erst einmal mit einem Shellskript ausführen kann, reagieren Silberkugel- und Holzpflockfreunde dann oft aggressiv... Aber eine maximale Provokation für diese Sorte Mensch scheint die Aussage zu sein, daß man ohne IDE besser verstünde, was passiert. Hüte Dich, sonst sind die Credits für Deine Entprellung (danke) schnell vergessen! ;-)
> Wenn man die Lust und vor allem viel Zeit übrig hat, kann man sich > gerne an Mikrooptimierung aufreiben. In der Praxis habe ich > sowas allerdings noch nirgends erlebt. Das mag jetzt fuer dich gelten. ICh mach aber Sachen wo jedes Milliwatt zaehlt. Wenn du glaubst dich da auf die faule Haut legen zu koennen dann ist dein PRodukt halt kacke weil die Konkurrenz mehr kann. Oder du bekommst ploetzlich Probleme mit der Atexzertifizierung weil du zuviel Abwaerme hast. Wie ich schon sagte, man muss nicht oft oder gar immer ins Linkerscript, aber manchmal schon. Vanye
Peter D. schrieb: > Der ernsthafte > Entwickler braucht sowas nicht, der arbeitet nur mit den Sourcen. Kannte mal einen, der hat nichts anderes getan, als für Banken auf S-390/System Z die laufende Software binär zu patchen, wenn irgendwelche Probleme auftraten. Der hat sich damit dumm und dämlich verdient - haben die ihn auch nur einmal drangelassen, mussten sie ihn immer wieder holen.
Sheeva P. schrieb: > Peter D. schrieb: >> Prinzipiell kann man daher >> alles, was die IDE ausführt, auch selber auf der Kommandozeile machen >> oder in eine Batch schreiben. > > Aber Peter, sowas darfst Du doch hier nicht sagen. Pure Blasphemie, da > kommen dann gleich Leute mit Silberkugeln und Holzpflöcken. > > Okay, ich habe keine Angst vor denen und sag das trotzdem. Nicht selten > artet das dann in ebenso wort- wie emotionsstarke Dispute aus, die mich > belehren, daß die IDE xy das unschlagbare Feature z hat, und überhaupt: > ohne IDE müßte man ja diese Befehle alle in die Kommandozeile eingeben, > sowas geht natürlich gar nicht. > > Auf meine Hinweise, daß mein GNU Emacs das Feature z schon vor drölfzig > Jahren hatte, man diese Befehle auch von Buildsystemen wie GNU make(1), > oder schlimmstenfalls erst einmal mit einem Shellskript ausführen kann, > reagieren Silberkugel- und Holzpflockfreunde dann oft aggressiv... Aber > eine maximale Provokation für diese Sorte Mensch scheint die Aussage zu > sein, daß man ohne IDE besser verstünde, was passiert. Hüte Dich, sonst > sind die Credits für Deine Entprellung (danke) schnell vergessen! ;-) Moment, verstehe ich deinen Beitrag richtig? Mit make kann nan eigene Speichersektionen im RAM und FLASH erstellen und somit gezielt Variablen oder Funktionen in diese Sektionen legen? Du erzählst ein Märchen!
Ich habe für meinen letzten Post 2x negative Bewertung bekommen. Kann jemand hier aufklären, wieso es kein Märchen ist? Ich habe als Test eine Funktion ins RAM verlegt. Durch Objdump und Readelf konnte ich verifizieren, dass die Funktion wirklich im RAM liegt (Adresse liegt bei irgendwo ab 0x20000000). Des Weiteren habe ich die Ausführungszeit in Tick der Funktion bei FLASH vs RAM verglichen. Im RAM ist sie 20 Ticks langsamer. Wieso? ich nutze diesen Nucleo Bord "NUCLEO-L432KC"
Ali K. schrieb: > Ich habe für meinen letzten Post 2x negative Bewertung bekommen. > Kann jemand hier aufklären, wieso es kein Märchen ist? Die negative Bewertung von mir hast du bekommen, weil du in deinem Post vollkommen zusammenhanglosen Mist laberst. > Ich habe als Test eine Funktion ins RAM verlegt. > Im RAM ist sie 20 Ticks langsamer. > Wieso? Nun, bestimmt nicht weil der Compiler von make anstatt von der IDE aufgerufen wurde ...
Axel S. schrieb: > Ali K. schrieb: >> Ich habe für meinen letzten Post 2x negative Bewertung bekommen. >> Kann jemand hier aufklären, wieso es kein Märchen ist? > > Die negative Bewertung von mir hast du bekommen, weil du in deinem Post > vollkommen zusammenhanglosen Mist laberst. > >> Ich habe als Test eine Funktion ins RAM verlegt. >> Im RAM ist sie 20 Ticks langsamer. >> Wieso? > > Nun, bestimmt nicht weil der Compiler von make anstatt von der IDE > aufgerufen wurde ... Nimmst du mich gerade auf den Arm? Wo ist der Unterschied, wenn make den Compiler aufruft oder die IDE? Die Inputs und Outputs wären die gleichen!?
Ali K. schrieb: > Nimmst du mich gerade auf den Arm? Das habe ich mich bei Lesen von Beitrag "Re: Linkerscript verstehen lernen - Wo fängt man an?" auch gefragt. Wie gesagt vollkommen inkoherentes Geschwafel von dir. >>> Ich habe als Test eine Funktion ins RAM verlegt. >>> Im RAM ist sie 20 Ticks langsamer. >>> Wieso? >> >> Nun, bestimmt nicht weil der Compiler von make anstatt von der IDE >> aufgerufen wurde ... > > Wo ist der Unterschied, wenn make den Compiler aufruft oder die IDE? Ja. Eben. Und jetzt lies nochmal, was du da zitiert hast.
Ali K. schrieb: > Im RAM ist sie 20 Ticks langsamer. > Wieso? Ganz einfach, weil Code und Daten (Stack) jetzt im selben RAM liegen und deswegen nur nacheinander darauf zugegriffen werden kann. Wenn der Code im Flash liegt, dann er kann er Code lesen und parallel dazu Daten lesen oder schreiben. Lege die Funktion mal in SRAM2 statt SRAM1 und miss nochmal. Schau dir mal im Referenzmanual (RM0394) die "Figure 1" an, dann verstehst Du warum. https://www.st.com/resource/en/reference_manual/rm0394-stm32l41xxx42xxx43xxx44xxx45xxx46xxx-advanced-armbased-32bit-mcus-stmicroelectronics.pdf Du wirst vermutlich aber trotzdem keinen großen oder gar keinen Vorteil daraus ziehen, die Funktion in den RAM zu legen. Bei 80MHz können die meisten internen Flashspeicher eigentlich noch ganz gut mithalten, vor allem wenn Du den ART aktivierst. Der Microcontroller ist ja eher gemütlich unterwegs, kein Wunder ist ja ein "Low-Power" Modell. Ein F405 geht bis 168MHz, da wird das schon interessanter.
Ali K. schrieb: > Mein Ziel ist es, dass ich anhand von Datenblättern eines > Mikrocontrollers selber den Linkerscript sowie eigene Sektionen > schreiben kann. Das naheliegenste sind immer noch Assembler und Make-Automatismen verstehen - wie natürlich auch die Hardware selber. Und dort, also bei der Hardware, dann auch nach Gemeinsamkeiten suchen. Der nächste Schritt wäre dann noch der eingesetzte Programmcode beim aktuellen und lokalen Skript. Das ist auch kein Thema, welches man mal eben an einem Nachmittag abhandelt. 8 Wochen Lern-Zeit solltest du dir schon lassen.
Andreas M. schrieb: > Ali K. schrieb: >> Im RAM ist sie 20 Ticks langsamer. >> Wieso? > > Ganz einfach, weil Code und Daten (Stack) jetzt im selben RAM liegen und > deswegen nur nacheinander darauf zugegriffen werden kann. Wenn der Code > im Flash liegt, dann er kann er Code lesen und parallel dazu Daten lesen > oder schreiben. > > Lege die Funktion mal in SRAM2 statt SRAM1 und miss nochmal. > > Schau dir mal im Referenzmanual (RM0394) die "Figure 1" an, dann > verstehst Du warum. > https://www.st.com/resource/en/reference_manual/rm0394-stm32l41xxx42xxx43xxx44xxx45xxx46xxx-advanced-armbased-32bit-mcus-stmicroelectronics.pdf > > Du wirst vermutlich aber trotzdem keinen großen oder gar keinen Vorteil > daraus ziehen, die Funktion in den RAM zu legen. Bei 80MHz können die > meisten internen Flashspeicher eigentlich noch ganz gut mithalten, vor > allem wenn Du den ART aktivierst. Der Microcontroller ist ja eher > gemütlich unterwegs, kein Wunder ist ja ein "Low-Power" Modell. Ein F405 > geht bis 168MHz, da wird das schon interessanter. In SRAM2 ist sie nur marginal langsamer (6 Tick langsamer) als im FLASH. Ich habe nochmal ins Manual geschaut. Scheinbar gibt es die Möglichkeit, noch mehr Performance aus dem SRAM1 herauszuholen. In Kapitel 2.4 Embedded SRAM. "The CPU can access the SRAM1 through the system bus or through the ICode/DCode buses when boot from SRAM1 is selected or when physical remap is selected (Section 9.2.1: SYSCFG memory remap register (SYSCFG_MEMRMP) in the SYSCFG controller). To get the maximum performance on SRAM1 execution, physical remap should be selected (boot or software selection)" @RBX: Ich habe Zeit und Bock drauf ;)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.