Hallo zusammen,
Ich habe hier nach längerem Suchen nun ein Problem lokalisiert, welches
mir sehr seltsam vorkommt: ein mit ISE8.1 implementiertes Projekt kann
mit ISE9.1 nicht korrekt implementiert werden. Es handelt sich um ein
voll synchrones VHDL Design mit einem DPRAM drin. Der Clock beträgt
48MHz.
Bei der Implementierung werden die definierten Timing constraints
eingehalten, es gibt ein paar Warnings die ich als unkritisch erachte,
aber keine Fehlermeldungen.
Das Verhalten ist nun so, dass die mit ISE8.1 erstellte Version
funktioniert, bei der mit ISE9.1 erstellten Version beim DPRAM Zugriff
irgend etwas schief geht. Was genau führt hier wohl zu weit.
Den VHDL Source Code habe ich mit ModelSIM XE II 5.8c simuliert und
keinerlei Probleme festgestellt. Ich habe jedoch nur "Simulate
Behavioral Model" durchgeführt, da ich bisher davon ausgegangen bin,
dass dies genügt, wenn die genügend scharf eingestellten Timing
Constraints eingehalten werden.
Die Timing Constraints sind wie folgt eingestellt:
# Timing
NET "uC_CLK" TNM_NET = "uC_CLK";
TIMESPEC "TS_uC_CLK" = PERIOD "uC_CLK" 15 ns HIGH 50 %;
OFFSET = IN 5 ns BEFORE "uC_CLK" ;
OFFSET = OUT 15 ns AFTER "uC_CLK" ;
TIMESPEC "TS_P2P" = FROM "PADS" TO "PADS" 12 ns;
Das Signal uC_CLK ist ein CLK_OUT vom Controller, das ganze FPGA
arbeitet synchron mit diesem Clock.
Angehängt ist die Log-Ausgabe beim Implementieren des Designs mit ISE8.1
Fragen:
- Hat sonst schon mal jemand ähnlichen Ärger mit unterschiedlichen ISE
Versionen gehabt?
- Auf was muss ich achten, dass Simulation und Realität
übereinstimmen/was habe ich vergessen?
- Habe ich noch Timing Constraints vergessen?
Danke und Gruss,
Martin
Mir erscheint ein wenig seltsam, dass der Takt mit 15 ns spezifiziert
ist, und dass die Ausgangsdaten erst 15 ns nach dem Takt gültig sein
müssen. Damit bleibt ja kein Fenster übrig, wo die Daten sauber
übernommen werden können.
Klaus
Dieser Wert ist unkritisch, da die aus dem FPGA hinausführenden Signale
nirgends schneller verfügbar sein müssen (keine externen kritischen
Timings). Das habe ich überprüft.
Ich werde den Wert mal heruntersetzen und schauen was die Implementation
dazu sagt.
Das löst aber mein ISE Problem noch nicht, denn der im 9.1 nicht
funktionierende Teil befindet sich definitiv NUR intern, also
timingmässig nur von PERIOD abhängig. Und da sollte sicher nichts schief
gehen, da ja PERIOD auf 15ns->66MHz definiert ist, der Systemtakt aber
nur 48MHz->20.8ns beträgt.
Martin
Entschuldige, hatte übersehen, dass DPRAM == interner Dual Port BRAM.
Da bewirken die OFFSET OUT constraints natürlich nichts.
Möglichkeiten :
- Alle möglichen Service Packs aufspielen
- ISE 9.2 versuchen
- Ein bischen erzählen, was denn nun genau der Fehler ist.
Grüße
Klaus
@ Klaus Falser (kfalser)
>- ISE 9.2 versuchen
Oder einfach nur wirklich dann eine neue ISE-Version verwenden, wenn es
WIRKLICH nötig ist (weil ein neuer Baustein in der alten nicht
unterstützt wird).
Diesen Versionswahnsinn mach ich schon lange nicht mehr mit.
Never Change a Running System!
MFG
Falk
Danke für die Antworten. Dann wollen wir mal...
Zum "bisschen mehr erzählen":
Das System sieht so aus, dass auf der einen Seite synchron mit einem
8051er Controller kommuniziert wird (alles am gleichen Takt). Auf der
anderen Seite befindet sich eine Reihe Digitaler Ein- und Ausgänge (je
12).
Auf beiden Seiten werden alle Signale abgeclockt (sollten alles IOB FF's
sein).
Das Modell besteht aus einer ganzen Reihe von Einzelfunktionen, welche
alle auf Basis der abgecklockten DIO Signale arbeiten und über einen
internen Bus mit dem externen Controller-Bus verbunden sind.
Eine dieser Einzelfunktionen macht nun Ärger. Dieser sog. "Reader" liest
über zwei Inputs einen Drehgeber und legt bei Eintreffen von positiven
oder negativen Flanken auf einem weiteren Eingang (der "Lesespur") die
aktuelle Drehgeberpotition im DPRAM ab.
Dieser Reader-Teil ist so aufgebaut, dass die Positionserfassungslogik
nur schreibend auf das DPRAM zugreift, das Interface auf den internen
Bus auf der anderen Seite nur lesend. Es werden 14Bit-Worte abgelegt,
das DPRAM ist daher als 16Bit Speicher ausgelegt. Im Speicher sollen nun
bis zu 512 dieser Datenworte abgelegt werden, was zu einem 256x16bit
Speicher führt. Auf der Leseseite werden die Daten 32Bit breit
ausgelesen.
BEEEEPPPP!!!!!
Hier liegt wohl der Hund begraben! Ich habe gerade bemerkt, dass die
Adressbereiche bei der DPRAM Definition einen Fehler aufweisen!
Heute komme ich nicht mehr dazu, zu prüfen, ob sich da der Fehler
befindet, aber ich frage mich nun, warum es denn mit der Version 8.1
funktioniert hat.
Mehr dazu dann wohl nächste Woche.
Gruss, Martin
Hallo zusammen,
Da bin ich wieder. Der Fehler ist immer noch vorhanden, die Vermutung im
letzten Postin hat sich als falsch herausgestellt.
Korrektur der vorherigen Angaben:
" Im Speicher sollen nun bis zu 512 dieser Datenworte abgelegt werden,
was zu einem 256x16bit Speicher führt."
--> führt natürlich zu einem 512x16Bit Speicher, insgesamt also 1kByte
pro Spur
Ich poste hier mal den VHDL Code des fraglichen Moduls (siehe Anhang).
Die Funktionsweise:
- Schreiben 16bit Worte auf Seite A, Adressbit AA(1) entscheidet, ob in
RAM_L oder RAM_H geschrieben wird
- DA(15..0) schreiben, wenn WEA gesetzt
- lesen 32Bit Worte auf Seite B, zusammengesetzt aus je 16Bit H und L
Version 8.1 erstellt mir daraus zwei Block RAM zu je 256x16, in Version
9.2 wird nur ein Block RAM zu 256x16 erstellt.
Siehe die nächsten beiden Postings für Details dazu
Noch eine weitere Information:
Im Modell sind insgesamt 4 dieser Lesespuren vorhanden, es sollten also
insgesamt 4kByte Block RAM verwendet werden, aufgeteilt in 8x 256x16Bit.
Die Synthese in 9.2 liefert mir nun im Abschnitt "HDL Synthesis"
folgende Ausgabe:
1
Synthesizing Unit <ReadThroughRAM>.
2
Related source file is "//achstinf02/kohlmart/SCM_fox/KMC2600/KUSB/I-O_Flex/FPGA_01/VHDL/READERMemoryReadThroughRAM.vhd".
3
Found 256x16-bit dual-port RAM <Mram_RAM_L> for signal <RAM_L>.
4
Found 256x16-bit dual-port RAM <Mram_RAM_H> for signal <RAM_H>.
5
Found 32-bit tristate buffer for signal <INT_D>.
6
Found 8-bit register for signal <AB>.
7
Summary:
8
inferred 2 RAM(s).
9
inferred 8 D-type flip-flop(s).
10
inferred 32 Tristate(s).
11
Unit <ReadThroughRAM> synthesized.
Das wäre noch richtig, es werden für die eine Spur 2x 256x16Bit
verwendet.
Auch der Synthesis Report sieht gut aus:
Und nun kommt folgende Ausgabe bei den "Advanced HDL Synthesis":
1
Loading device for application Rf_Device from file '3s250e.nph' in environment C:\Programme\Xilinx_92i.
2
INFO:Xst:2737 - Unit <ReadThroughRAM> : The RAM <Mram_RAM_L>, combined with <Mram_RAM_H>, will be implemented as a BLOCK RAM, absorbing the following register(s): <AB>.
Warum werden hier RAM_L und RAM_H zu einem einzigen Block RAM 256x16Bit
zusammengefasst? Das darf doch so nicht sein?
Im Anhang befindet sich die Log-Ausgabe, aus welcher ich die obigen
Angaben entnommen habe.
Sieht jemand, wo das konkrete Problem liegt?
Danke für die Antworten.
Hier ist wohl tatsächlich ein Bug in der ISE-Software.
So geht es übrigens:
if (WEA = '1' and AA(1) = '0') then
RAM_L(conv_integer(AA(9 downto 2))) <= DA(15 downto 0);
elsif(WEA = '1' and AA(1) = '1') then
RAM_H(conv_integer(AA(9 downto 2))) <= DA(15 downto 0);
end if;
Kann das sonst noch jemand bestätigen, dass es ein Fehler in der ISE
9.2.03i Software ist?
Die Variante von Xenu habe ich nun umgesetzt, die funktioniert.
Können bei Xilinx Fehlermeldungen irgendwie eingespeist werden?
...Weißt Du, wie man BlockRAM instantieert? ;-)
Wenn ja, dann mache es den Xilinx-Tools nicht so schwer, sondern
instantieere zwei blockrams und nicht irgendwie mit einem Process und
mehreren Enable-Signalen
if WEA = '1' then
if AA(1) = '0' then
RAM_L(conv_integer(AA(9 downto 2))) <= DA(15 downto 0);
else
RAM_H(conv_integer(AA(9 downto 2))) <= DA(15 downto 0);
end if;
end if;
Wenn Du alles schön aufsplittest, dann wird es auch funktionieren. Zur
Zeit ist es wohl für die Tools zu kompliziert, daraus zwei BlockRAMs zu
machen. Wieso auch? Es kommt ein WRite-Enable Signal und von einem
Signal wird auch die Adresse abhängen, wo es hin geschrieben wird.
Quartus macht daraus zwar 2 Blockrams, aber es kann genausogut einer
sein, denn Du hast nur einen SchreibPort und einen Leseport (doppelt so
groß).
RAM_Type würde ich auch von 0 to 255 definieren und nicht umgekehrt.
Also: kein Fehler in ISE sondern ein Feature ;-)
Grüße,
Kest
Kest wrote:
> ...Weißt Du, wie man BlockRAM instantieert? ;-)>> Wenn ja, dann mache es den Xilinx-Tools nicht so schwer, sondern> instantieere zwei blockrams und nicht irgendwie mit einem Process und> mehreren Enable-Signalen
Grund: es wurde mir mal empfohlen, das generisch so zu machen mit dem
ram_type anstelle des herstellerspezifischen Block RAM Konstrukts.
Wie es Xilinx-spezifisch gemacht werden müsste würde ich wohl wieder
herausfinden.
Das dem-Tool-so-schwer-machen darf aber so oder so nicht zu einem
ungültigen Resultat führen, wie es aber in 9.2 geschehen ist.
Gruss, Martin
Gerade "generisch" geht es mit 0 to 255. Ich meinte ja auch nicht
CoreGen oder so, da hast Du mich falsch verstanden.
Den Grund habe ich Dir genannt: das Resultat ist nicht ungültig sondern
sehr wohl gültig. So wie ich das sehe, hast Du nur einen Blockram
implementiert. Punkt. Dass in der anderen Version 2 dabei rausgekommen
sind liegt daran, dass die Tools "nocht nicht so schlau" waren.
Grüße,
Kest
Es ist mir schon klar, dass das Tool auch nur ein Block RAM machen kann.
Dieses sollte dann aber bitte die korrekte Grösse haben, was es aber
eben nicht hat.
Ich schreibe mit 10 Adressleitungen (AA9..1) je 16Bit breit ins RAM, das
ergibt nun mal 1024x8Bit oder 512x16Bit, aber sicher nicht 256x16Bit, so
wie es ISE9.2 implementiert. Da ist sehr wohl etwas faul.
Oder habe ich jetzt komplett Tomaten auf den Augen??
Gruss, Martin
Das ist definitiv ein Fehler in der Software, weil er zwei 256x16-RAMs
auf ein 256x16-RAM zusammenstaucht.
Und in der 8.1er Version ging es ja wohl auch noch.
Doch, trotzdem Fehler!
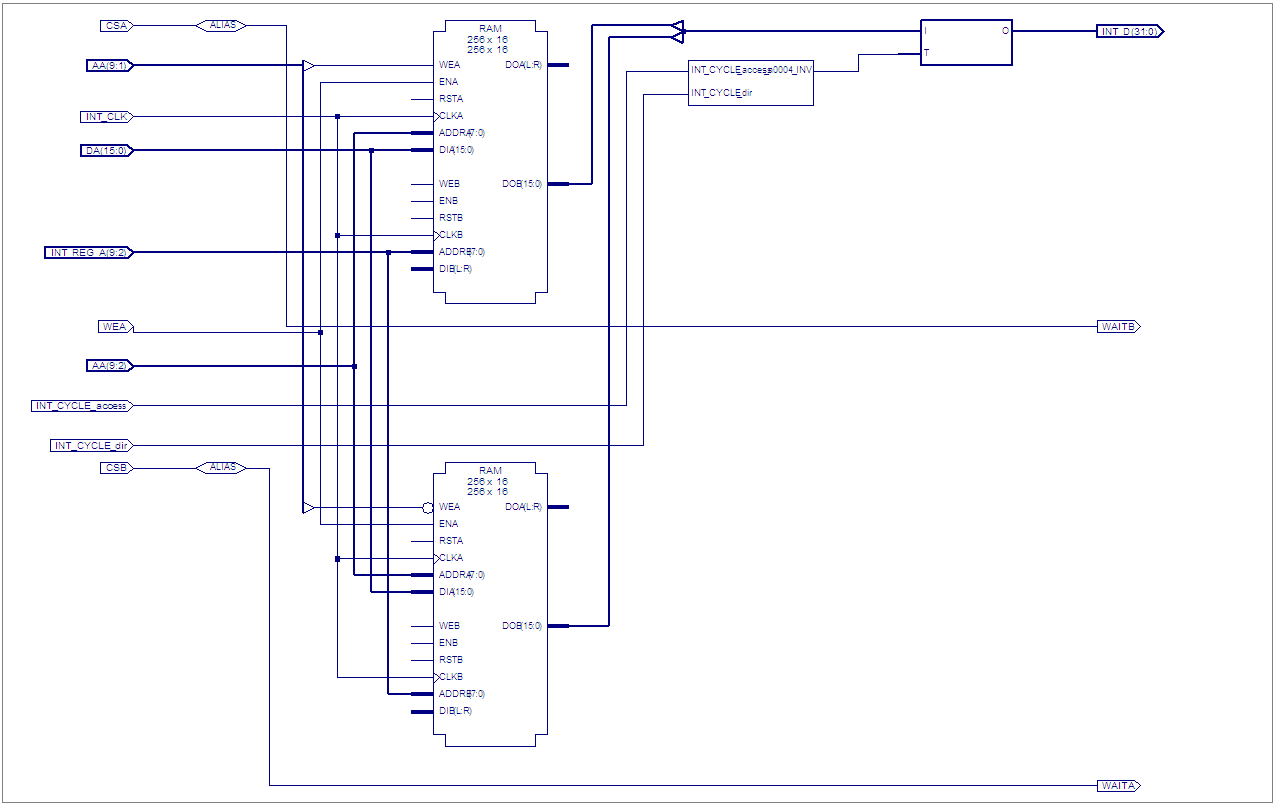
Schaue er bitte das Bild mit schwarzem Hintergrund ein paar Postings
höher an.
Da sieht man, dass DOA(15:0) und DOB(15:0) zu INT_D(31:0)
zusammengefasst werden.
Der Data Out Port A hat hier aber definitiv nichts verloren, weil dieser
ja mit der Schreib-Seite adressiert wird, ich aber mit der Lese-Seite
INT_REG_A resp. AB adressieren will.
Das im Bild gezeigte Verhalten entspricht genau dem in der Realität
gemessenen Fehler: Beim Lesen auf INT_D waren die unteren 16Bit immer
konstant, (da AA zum Zeitpunkt des Auslesens konstant war).
Und noch ein Einwand:
Original:
1
ifWEA='1'then
2
ifAA(1)='0'then
3
RAM_L(conv_integer(AA(9downto2)))<=DA(15downto0);
4
else
5
RAM_H(conv_integer(AA(9downto2)))<=DA(15downto0);
6
endif;
7
endif;
korrigiert von Xenu:
1
if(WEA='1'andAA(1)='0')then
2
RAM_L(conv_integer(AA(9downto2)))<=DA(15downto0);
3
elsif(WEA='1'andAA(1)='1')then
4
RAM_H(conv_integer(AA(9downto2)))<=DA(15downto0);
5
endif;
Warum sollte die Korrektur von Xenu den Fehler verhindern? Er hat ja nur
die verschachtelte if-Abfrage anders gestaltet. Die Wahrheitstabelle für
die Ausführung der einzelnen Statements blieb gleich.
Gruss, Martin
Gut... da muss man analytisch vorgehen ;-)
Zunächst mal, würde ich an Deiner Stelle alles so umschreiben, dass in
einem IF Zweig jeweils ein BlockRAM adressiert (beschrieben) wird. Ich
habe jetzt leider keine Möglichkeit selber zu synthetisieren, aber
eventuell ist STD_LOGIC ein Problem. Was passiert, wenn AA(1)=='Z' ist?
Die Implementation von Xenu ist eben eindeutiger.
Grüße,
Kest
Wenn du mit "nochmal da drunter" die zweite identische Zeile meinst:
Ich schätze, dass die erste Zeile Port A und die zweite Zeile Port B
angibt, in diesem Fall ist das Block RAM auf beiden Seiten 256x16
organisiert.
Das wäre richtig, nur bräuchte ich eben zwei davon ;-)
Was willst du "besser sehen"?
Ich schreibe, was ich sehe. Und was ich sehe ist, dass Du in der VHDL
Datei einen BlockRAM implementierst... Noch Mal langsam:
PortA: da kommen Deine Daten rein (8 Bit Breit). Jeweils Low und Hi
Bytes... Richtig? Diese werden in einer Zeile zu 16 Bit abgelegt.
PortB: da kommen Deine Daten raus (16 Bit Breit)... Richtig?
Nun erklär mir mal, wieso Du zwei BlockRAMS erwartest? Ich habe ja schon
gesagt, wieso die Größe nicht stimmt, kapiere ich es (noch) nicht, aber
wieso nur ein BlockRAM rauskommt schon.
Grüße,
Kest
Kest wrote:
> PortB: da kommen Deine Daten raus (16 Bit Breit)... Richtig?
Fast.
Auf INT_D habe ich schlussendlich einen 32Bit Vektor. Dieser wird
zusammengesetzt aus den unteren 16Bit aus ram_L und den oberen 16Bit aus
ram_h.
Ob nun die Synthese ram_L und ram_H in ein einziges Block RAM integriert
oder nicht ist mir ja prinzipiell wurscht, solange das Resultat der
Beschreibung entspricht. Aber das tut sie ja eben nicht.
Diese Statements werden nicht so umgesetzt, dass alle 32Bit auf DB von
INT_REG_A = AB abhängen:
Kest wrote:
> Alle Ausgänge hängen doch von AB ab! Weiß gar nicht, was Du meinst.>>> Kest
Du hast meine Beiträge oben schon gelesen, hoffentlich?
Ca. 8 Postings weiter oben habe ich nämlich geschrieben:
"Schaue er bitte das Bild mit schwarzem Hintergrund ein paar Postings
höher an.
Da sieht man, dass DOA(15:0) und DOB(15:0) zu INT_D(31:0)
zusammengefasst werden. Der Data Out Port A hat hier aber definitiv
nichts verloren, weil dieser ja mit der Schreib-Seite adressiert wird,
ich aber mit der Lese-Seite
INT_REG_A resp. AB adressieren will."
Im VHDL-Code hängt, alles von DB ab, ja - sehr scharf erkannt! Bravo.
Aber das ist ja genau der Punkt! Die Implementation von ISE9.2 stimmt
nicht mit dem VHDL Code überein, das ist doch genau das, was ich schon
länger mitzuteilen versuche.
Im VHDL Code ist DB einzig abhängig von jeweils 16Bit aus den zwei
Arrays ram_H und ram_L, adressiert über AB. Insgesamt also alles Seite
B, bei mir die Leseseite.
In der Realität (schaue er BITTE nochmals das schwarz hinterlegte Bild!)
hängt aber DB(31:0) von DOA(15:0) und DOB(15:0) ab.
DB darf aber nicht von der Schreibseite A abhängen, da diese ja nicht
über AB sondern über AA adressiert wird.
> Weiss gar nicht was du meinst
scheint tatsächlich so zu sein, ja.
Schaus noch mal an und vergleiche den VHDL-Code mit dem schwarz
hinterlegten RTL Schematic des Moduls.
Und bitte nicht nochmals so fundierte Abklärungen wie im letzten
Posting.
Gibts sonst noch jemanden hier, der es so sieht wie ich?
Xenu? Ein klärender Beitrag von dir? seufz
Das habe ich schon verstanden und das Bild habe ich auch angeschaut,
bevor ich gepostet habe.
Mal von der Bezeichnung der POrts abgesehen ist das Bild stimmig:
Eingang: 16 Bit, Ausgang 32 Bit. Wie die Ausgangsports nun tatsächlich
belegt sind, ist zunächstmal egal (alles Definitionsfrage).
Du baharrst darauf, dass Port B nur von der INT_REG_A abhängig ist.
Tatsächlich aber sind sowohl Port A, als auch Port B (beide Read Ports)
davon abhängig! Anders kanns auch nicht sein, so stehts auch in der VHDL
Implementierung.
Aus Erfahrung kann ich sagen, dass der Fehler (falls überhaupt einer
vorliegt) meistens trivial ist. Auf die Tools zu schieben ist zwar
heutzutage "in", aber man muss auch zugeben, dass bei so komplexen
Sachen den Tools alles "vorgekaut" werden soll. Deshalb habe ich auch
von Anfang an Dir geraten alles strukturierter zu schreiben.
Ich hoffe Du findest den Fehler und klärst uns alle auf :-) Sollte ich
irgendwelche andere Ideen haben, melde ich mich. Ansonsten weiß ich
nicht weiter. Viel Erfolg,
Kest
>Xenu? Ein klärender Beitrag von dir?
Wie gesagt, das ist ein Bug. Schreib am besten einen Fehlerbericht an
Xilinx und sag denen auch, dass esi mit der alten ISE-Version noch
funktioniert hat.
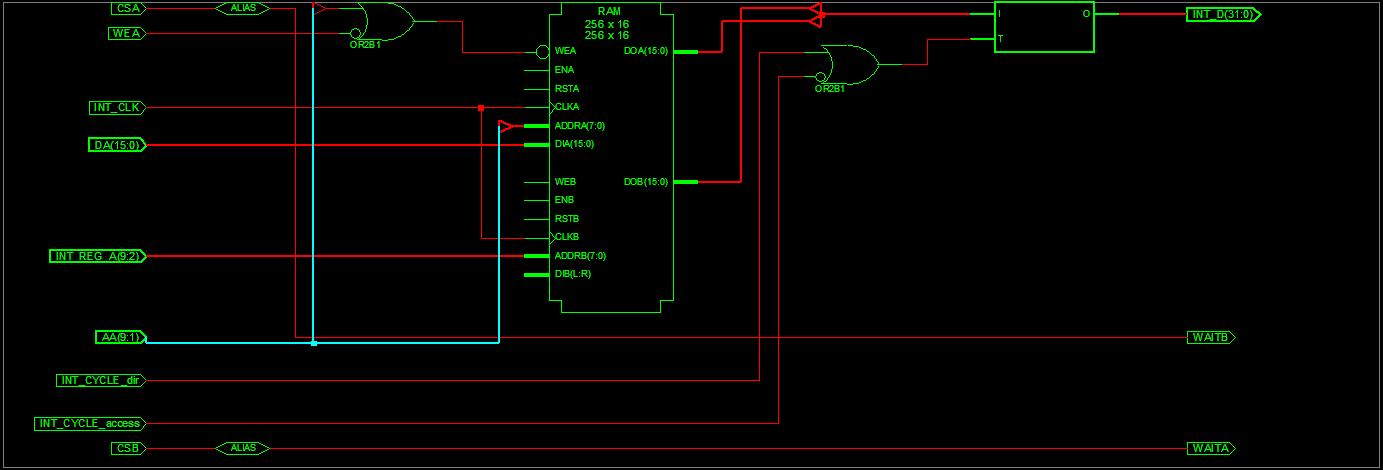
Ich hab den Code mal spaßeshalber mit Quartus für einen Cyclone II
synthetisiert, siehe Bild.
Wieso ist das ein Bug?
Hast Du mal die RTL-Ansichten verglichen? Ich würde fast sagen, sie
ähneln sich sehr. In der 9.2 Version ist das bloß zusammengepackt in
einem BlockRAM und nicht in 2 aufgeteilt. Nur dir Größe kann ich mir
nicht erklären.
Laut VHDL Beschreibung sind das keine zwei dual-Ports Rams. Wenn man
genau hinschaut, dann ist das nur einer! Geschrieben wird nur ein Mal
(entweder Lo oder Hi) und gelesen auch nur ein Mal (32 Bit zusammen).
Ich habe das Gefühl, dass ihr einfach alles so hintrimmen wollt, damit
RTL-View so aussieht, wie ihr es haben wollt. Wenn das so ist, ist Deine
(Xenu) Beschreibung der Enable-Signalen "richtiger", weil wahrscheinlich
ISE das nicht optimieren kann.
Ich frage mal frech, wenn Simulation funktioniert, funktioniert auch die
Synthese? Also die Hardware? (unabhängig davon, dass die Größe nicht
erklärbar ist)
Grüße,
Kest
Ach...
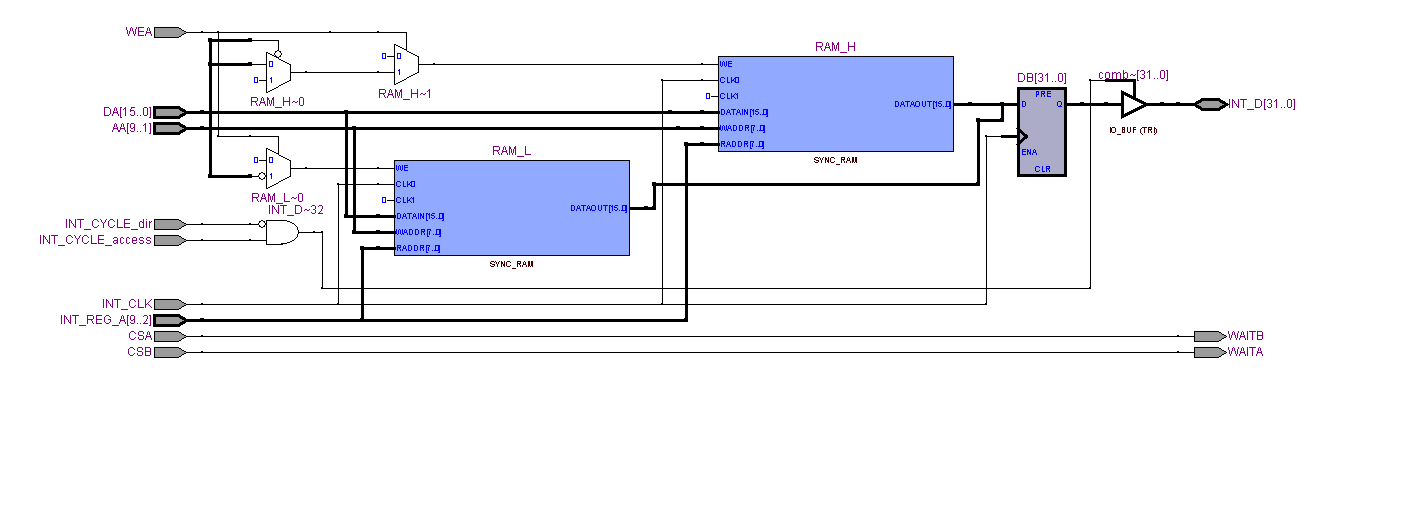
Gut, ich habe die ISE 9.2 RTL-Schematic Ausgabe ein wenig modifiziert
(siehe Anhang).
- über Write_ADDR, Write_DATA und WEA wird das RAM beschrieben
- über Read_ADDR und READ_DATA wird das RAM gelesen
Nun sieht man, dass READ_DATA nicht nur von Read_ADDR (gelber Pfeil),
sonder auch von Write_ADDR (pink Pfeil) abhängt.
Das stimmt definitiv nicht mit dem VHDL Code überein
wo gilt:
DB => Read_DATA
AB => Read_ADDR
AA => Write_ADDR hat im Read_DATA Vektor nichts zu suchen.
Klarer kann und will ich meinen Punkt nicht mehr erläutern. Ich gehe
nach wie vor von einem Fehler im Tool aus und warte auf Antwort des
Xilinx FAE (welchen ich schon kontaktiert habe). Danke an Xenu für die
Unterstützung.
Gruss, Martin
Kest wrote:
> Ich habe das Gefühl, dass ihr einfach alles so hintrimmen wollt, damit> RTL-View so aussieht, wie ihr es haben wollt. Wenn das so ist, ist Deine> (Xenu) Beschreibung der Enable-Signalen "richtiger", weil wahrscheinlich> ISE das nicht optimieren kann.
Absolut nicht. Ich will überhaupt nicht RTL trimmen. Hätte ich sonst ein
möglichst generisches Konstrukt für das RAM gewählt?
> Ich frage mal frech, wenn Simulation funktioniert, funktioniert auch die> Synthese? Also die Hardware? (unabhängig davon, dass die Größe nicht> erklärbar ist)
Und ich antworte hoffentlich nicht allzu frech:
Die Simulation funktioniert, ja. Sie liefert mir auch die benötigten
insgesamt 1kByte RAM. Das Schreiben und Herauslesen funktioniert in der
Testbench tadellos.
Die Synthese/Hardware funktioniert eben NICHT. Und sie funktioniert
genau so falsch wie es die 9.2 RTL-View zeigt.
Ich schreibe z.B. folgende Daten ins RAM, 16bit breit:
A: D:
0: 0000
1: 1111
2: 2222
3: 3333
4: 4444
5: 5555
6: 6666
7: 7777
8: 8888
9: 9999
Nach dem Schreibvorgang wird die Schreibadresse wieder auf 0 gestellt.
Während dem Auslesen bleibt die definitiv auf 0 (ablaufbedingt).
Ich lese dann folgende Daten aus dem RAM (32Bit breit)
0: 0000 0000
1: 0000 2222
2: 0000 4444
3: 0000 6666
4: 0000 8888
Man sieht, dass die höherwertigen 16Bit konstant sind und die auf
Schreibseite Adresse 0 geschriebenen Daten liefern, unabhängig von der
auf der Leseseite eingestellten Adresse.
Die RTL-View und die Realität stimmen überein, sind also "gleich
falsch".
Gruss, Martin
Hi Allerseits,
denke, es ist ein XST-Bug, aber....
1) Precision RTL baut 2 BRAMs
dies is noch kein Beweis, aber...
XST 9.2 hat wohl ein Problem, weil es feststellt, daß Du Ressourcen
verschwendest: 1 BRAM kann 1024 x 16 Bit fassen (zumindest die aktuellen
ARCHITEKTUREN9 - also passen da locker 2 x 256 Worte a 16 Bit rein.
XST-Gedanke: ich nehm 1 BRAM und verwende 1inen Port für RAM_L und einen
Port für RAM_H.
Soweit toll - coole Lösung.
Problem: XST scheint zu "übersehen", daß die Leseadresse unabhängig von
der Schreibadresse ist - und produziert Schrott.
--Schade: manchmal sind die Tools zu intelligent
Aber => DIE LEHRE:
1) Achte auf Deinen Coding-Style - mach es den Tools nicht zu schwer,
bzw.
lauf auf "ausgetretenen Wegen" - exotische Codierung testet die Qualität
der Tools, führt aber auch dazu, daß Du der erste biste, der den Bug
bemerkt !!!!
2) überpüfe, ob Du die Addressierung nicht so abändern kannst, daß
tatsächlich EIN BRAM ausreicht, um 'wertvolle' Ressourcen für andere
Funktionen zu sparan..
Gruß
Joko
P.S.
bitte poste die Antwort Deines FAEs - würde mich interessieren
Joko wrote:
> bitte poste die Antwort Deines FAEs - würde mich interessieren
Das werde ich tun.
Die Anordnung habe ich so gewählt, weil ich auf der Schreibseite mit
16Bit daher komme und diese auf der Leseseite mit 32Bit auslesen will.
Mit den beiden separaten RAM kann ich die beiden 16Bit Vektoren bequem
zusammensetzen ohne mich um High/Low 16Bit Byte ... kümmern zu
müssen.
In einem gewissen Sinne ist es wohl Bequemlichkeit.
Wie wäre denn dein Vorschlag, mein RAM zu beschreiben?
Momentan ist die Xenu-Variante implementiert und läuft auch.
Gruss, Martin
@Kest:
Bei den Xilinx-Dual-Port-RAMs hast Du zwei Leseports und einen
Schreibport. Allerdings nur zwei Adressen: einen zum Lesen, den anderen
zum Lesen+Schreiben. Du kannst also bei einem BRAM nicht gleichzeitig
beide Ports lesen und zusätzlich auch schreiben (ausser Schreibadresse =
Leseadresse). Das ist aber genau das was Martin macht, und deshalb
braucht er zwei BRAMs. Ob er die für seine Anwendung wirklich braucht
sei mal dahingestellt, aber Deine Behauptung, dass der Code auch ein
512x16-RAM darstellt ist falsch, weil es so ein Dreiadress-BRAM (noch)
nicht gibt.
Und deshalb ist das ein Bug im Synthesizer, weil er - wie JoKo so schön
beschrieben hat - etwas optimiert, was nicht zu optimieren ist.
Ich habe verstanden was Du meinst, doch Du irrst Dich.
Wenn ein DualPortRAM 32 Bit breit ist, dann kann man von einer Seite
(mit 9 Bit) nur 16 Bit beschreiben und auf der Leseseite 32 Bit mit der
8 Bit-Adresse auslesen.
Es ist somit nicht niotwendig 2 Ports zu schreiben, wozu auch -- Xilinx
fasst beide zu 32 Bit zusammen und man hat einen 32 Bit Port, aber durch
die Adressierung werden nur 16 Bit beschreiben.
Das ist keine Hexerei oder sowas, das habe ich zig Mal gemacht. Wenn die
VHDL-Beschreibung strukturiert ist und man sich an Style-Guide hält
(z.B. nur ein Write-Enable-Signal und nicht verschachtelte IF-Then),
dann funktioniert alles so, wie gedacht.
Grüße,
Kest
Update in dieser Sache:
Der FAE meinte, dass es wirlich nicht klar sei, ob das Problem wegen
einem ISE Fehler oder schlechtem Coding Style auftaucht und hat mir
empfohlen, bei Xilinx einen WebCase zu eröffnen.
Das hat jedoch noch nicht geklappt, weil die meinen Request vorerst mal
abgelehnt haben.
Ich werde weiter berichten, wenn ich mehr weiss (und gehe bis auf
weiteres immer noch von einem ISE Problem aus ;-) )
Gruss, Martin
Update:
Nach einigem Email-Verkehr mit dem Xilinx-Mitarbeiter habe ich heute
folgende Nachricht erhalten:
"After running some further tests and after taking a closer look, you
are correct, it does affect the functionality. When Synplify Pro is used
for the synthesis, the design synthesizes correctly. I will file a
Change Request against this bug."
Schönen Gruss an den User "Kest" ;-)
Gruss, Martin
Danke.
Ich habe bei mir auch ein DPRAM im Design. Der ist genau so beschrieben,
wie es im XST-Guide steht.
ISE 9.1 macht es richtig. ISE 9.2 will distributed RAM draus machen und
der darf aber keine zwei Ports haben :(
Also: Während des Projektes nur ein Update machen, wenn man die alte
Version noch in der Hinterhand hat!
Rick
@Martin Kohler (mkohler):
Danke für die Grüße! :-)
Was lernen wir also daraus?
a) Xilinx ist voller Bugs
b) hättest Du von Anfang an VHDL-DP-Ram anders beschrieben (ein Blockram
pro Process, wie im XST-Guide steht), wäre es nicht passiert
Es war eigentlich auch zu erwarten, ich meine, nicht umsonst gibt es
Tools, die besser mit solchen Sachen umgehen können (die kosten aber
auch Geld). Na ja.
Grüße zurück aus Berlin,
Kest
> Was lernen wir also daraus?
Mit XST weiterfahren und die Resultate weiterhin kritisch hinterfragen -
auch wenn andere einem nicht glauben wollen, dass das Tool einen Fehler
gemacht hat.
> a) Xilinx ist voller Bugs
Ja.
> b) hättest Du von Anfang an VHDL-DP-Ram anders beschrieben (ein Blockram> pro Process, wie im XST-Guide steht), wäre es nicht passiert
Darum ging es nicht. XST hatte einen Fehler, was du bestritten hast.
> Es war eigentlich auch zu erwarten,
Was genau? dass es trotzdem ein Bug war? Ein klammheimlicher
Meinungsumschwung also ;-)
> Tools, die besser mit solchen Sachen umgehen können (die kosten aber> auch Geld). Na ja.
Ist bekannt.
Gruss, Martin
Mein Fehler war, dass ich RTL-View falsch interpretiert habe (nähmlich,
dass man Read und Write-Ports untereinander vertauschen kann). Müsste
ich selber so ein RTL-Diagramm zeichnen, würde es auch so aussehen, wie
von XST (fehlerhaft) :-/
Zu der Sache, dass es Dir "niemand glauben wollte, dass XST einen Bug
hat":
Du hast hier gepostet, weil Du ein Problem hattest. Das ist ja okay,
aber Du kannst natürlich nicht erwarten, dass jetzt jeder Dir zustimmt
und sagt, "ja, es ist ein Bug". Es ist mehr wichtiger, dass man Dir dann
aufzeigt, dass es auch anders sein kann. Denn nur so kannst Du dann
selber, wie Du schreibst, kritisch hinterfragen, ob das wirklich so ist.
Man stelle sich nur vor, wenn jemand das gleiche Design mit der gleichen
Version von Xilinx XST bei sich synthetisiert hätte und es wäre das
Richtige rausgekommen? :-o Dass es ein Bug ist, ist einfach zu sagen und
mich befriedigt soetwas fast nie. Ich gehe Sachen gerne auf den Grund.
Ansosten kann man große (FPGA) Designs nicht mache -- wer weiß, was
später noch auftaucht.
Viel Erfolg,
Kest
Kest wrote:
> Du hast hier gepostet, weil Du ein Problem hattest. Das ist ja okay,> aber Du kannst natürlich nicht erwarten, dass jetzt jeder Dir zustimmt> und sagt, "ja, es ist ein Bug".
So soll es sicher nicht sein. Nur warst du der einzige, der sich
mehrfach dagegen aussprach, dass es ein Bug ist. Obwohl ich die Sachlage
ja hinreichend dokumentiert hatte.
Erst die Nachricht von Xilinx hat den Meinungsumschwung bewirkt.
> Es ist mehr wichtiger, dass man Dir dann> aufzeigt, dass es auch anders sein kann. Denn nur so kannst Du dann> selber, wie Du schreibst, kritisch hinterfragen, ob das wirklich so ist.
Ack. Nur darf das Aufzeigen des anderen nicht das ursprüngliche Problem
überdecken.
> Man stelle sich nur vor, wenn jemand das gleiche Design mit der gleichen> Version von Xilinx XST bei sich synthetisiert hätte und es wäre das> Richtige rausgekommen? :-o> Dass es ein Bug ist, ist einfach zu sagen und
Hätte ich nachgehakt bei Xilinx wenn ich es mir einfach machen wollte?
Nein! Sonst hätte ich gleich sofort den Xenu-Workaround benutzt.
> mich befriedigt soetwas fast nie. Ich gehe Sachen gerne auf den Grund.> Ansosten kann man große (FPGA) Designs nicht mache -- wer weiß, was> später noch auftaucht.
Ack.