So, jetzt siehts gut aus. Ich habe die Änderungen nun doch direkt ins
SVN geladen, mit "RabbitVCS" ist das ja echt komfortabel :-)
Da der Footprint Ordner "zzz_obsolete" nun nicht mehr gebraucht wird,
habe ich den gelöscht (bzw. RabbitVCS ist dran, sofern er sich nicht
aufgehängt hat^^)
Ich hoffe jetzt mal dass das Update bei allen einwandfrei funktioniert
und die Footprints immernoch korrekt angezeigt werden.
Übrigens haben Bert (b.r.) und ich heute mal Gedanken zu einigen
geplanten Änderungen (Footprints, Dateiupload, ...) gemacht. Ich werde
in unseren Issues auf Google Code noch reinschreiben wie wir uns das so
vorstellen.
Ausserdem werde ich beim Footprint-Issue noch vermerken was ich jetzt
schon gemacht habe und was noch fehlt.
P.S.
Mit den Variablennamen hatte ich manchmal ein ganz schönes
Durcheinander. Meiner Meinung nach würde es nicht schaden, wenn wir die
Variablen etwas aussagekräftiger gestalten würden ;-)
Jap hört sich alles gut an schaue es mir heute Abend an, die Alten FP
gibt es ja noch als Archiv im DL bereich, also raus damit.
Irgentwas muss trotzdem an den FP Parser geändert werden ab 40 Listen
einträgen scheitert das ganze an der PHP-Runtime (30s), das ist extrem
langsam, man sieht das recht gut an der Demo-DB.
Die Tage habe ich auch wieder etwas Zeit, auf Arbeit ist so gut wie
nichts zu tun gut das ich fast unkündbar bin, da werde ich mir dann
wieder mit der Part-DB die Zeit vertreiben.
@tb-netbook
An welcher Stelle ist das mit dem FP-Parser zu finden? Vielleicht finde
ich beim schnellen Drüberschauen das Problem.
@Urban
Es bezog sich ja auf den aktuellen Stand meiner Umsetzung :-)
tb-netbook schrieb:> Irgentwas muss trotzdem an den FP Parser geändert werden ab 40 Listen> einträgen scheitert das ganze an der PHP-Runtime (30s), das ist extrem> langsam, man sieht das recht gut an der Demo-DB.
Das liegt daran, dass momentan die Footprint-Bilder noch im ganzen
tools/footprints Ordner rekursiv gesucht werden. Da haben Bert und ich
aber auch eine Lösung parat, ich schreib sie nachher gleich in unsere
Issues Liste hinein.
Udo Neist schrieb:> @Urban>> Es bezog sich ja auf den aktuellen Stand meiner Umsetzung :-)
OK das habe ich nun vermutet :-D
Urban B. schrieb:> tb-netbook schrieb:>> Irgentwas muss trotzdem an den FP Parser geändert werden ab 40 Listen>> einträgen scheitert das ganze an der PHP-Runtime (30s), das ist extrem>> langsam, man sieht das recht gut an der Demo-DB.>> Das liegt daran, dass momentan die Footprint-Bilder noch im ganzen> tools/footprints Ordner rekursiv gesucht werden. Da haben Bert und ich> aber auch eine Lösung parat, ich schreib sie nachher gleich in unsere> Issues Liste hinein.
Mit folgendem Code durchsuche ich ein Verzeichnis rekursiv nach Dateien.
Das geht recht fix, da die Funktion sich bei jedem Unterverzeichnis
wieder selbst aufruft. Hab ich irgendwo im Netz gefunden. Die Funktion
ist aus einer Klasse, daher das "$this->" ;-)
1
function readDir($path = '.',$search = '',$options=array('mime'=>array(),'recursive'=>true,'onlyfiles'=>false)) {
2
/*
3
Durchforstet das übergebene Verzeichnis rekursiv nach Dateien
4
5
* Variablen
6
$this -> files (array): Container für Dateien
7
$path (string): Suchpfad (Default: .)
8
$search (string): Suchmuster für preg_match()
9
$options (array):
10
recursive (bool): Rekursiv suchen
11
onlyfiles (bool): Nur Dateien
12
mime (string): Mimetyp
13
14
* Rückgabe
15
$this -> files (array): Liste der Ergebnisse mit absoluten Pfad
16
17
* Anforderung
18
Kein Datenbanklink erforderlich!
19
20
* Anmerkung
21
Der Punkt ist das aktuelle Verzeichnis, ".." kennt man als "Verzeichnis höher" und "dir/" als "Verzeichnis tiefer".
22
23
*/
24
25
// $this->files wird initialisiert, falls noch nicht geschehen
26
if (!is_array($this -> file)) $this -> file = array();
27
28
// Pfad setzen
29
$dir = dir($path);
30
// Pfad durchsuchen
31
while (($file = $dir->read()) !== false) {
32
// Verzeichnisebenen überspringen
33
if ($file =='.' || $file =='..') continue;
34
if (is_dir($path."/".$file) && $options['recursive']===true) {
35
// Falls Verzeichnis, dann rekursiv die Funktion nochmal aufrufen
So, ich denke das Wichtigste aus der Diskussion von Bert und mir hab ich
jetzt in unsere Issues übertragen. Es geht um die Issues 12 und 14.
@Udo Neist
Danke für den code, aber ich denke der ist nicht notwendig, weil eben
eigentlich gar nicht mehr nach den Bildern gesucht werden muss, sobald
die noch anstehenden Änderungen durchgeführt wurden.
Hallo Udo,
Udo Neist schrieb:> Der Server> erlaubt keine Ausführung von shell_execute(). Ich habe die Funktion> durch folgendes ersetzt:
Die Zeichenkette in .svn/entries ist leider nicht das selbe wie
"svnversion".
Auf einem Webspace, wo das Projekt nur ausgecheckt und nicht verändert
wird passt es. Aber lokal zeigt mir svnversion z.B. Folgendes an:
1
$ svnversion
2
476M
Vielleicht kann man erst prüfen, ob shell_exec geht und dann in
.svn/entries reinschauen?
Grüße
b
Udo Neist schrieb:> An welcher Stelle ist das mit dem FP-Parser zu finden? Vielleicht finde> ich beim schnellen Drüberschauen das Problem.
In lib.php.
Das Problem bisher ist, die Footprints sind über einige Verzeichnisse
verteilt und müssen über den Dateinamen gesucht werden. Und das kann bei
vielen Einträgen/langen Listen dauern.
Urban und ich arbeiten aber gerade an dem Problem. Der Fundort wird
demnächst mit in der Datenbank abgelegt. Dann sollte das
Geschwindigkeitsproblem erledigt sein.
Grüße
b
Das mit der Datenbank wäre auch meine Idee. Einmal über ein Menüpunkt in
den Einstellunge und bei der ersten Inbetriebnahme das Verzeichnis
scannen und dann dürfte das auch schneller gehen. Diese Daten dürften
sich ja nicht sonderlich oft ändern.
Udo Neist schrieb:> Mit folgendem Code durchsuche ich ein Verzeichnis rekursiv nach Dateien.
Es wird momentan schon rekursiv gesucht. Wo alles noch in einem
Verzeichnis lag, war das auch akzeptabel. Wie gesagt, es wird dran
gearbeitet :-)
b
Urban B. schrieb:> P.S.> Mit den Variablennamen hatte ich manchmal ein ganz schönes> Durcheinander. Meiner Meinung nach würde es nicht schaden, wenn wir die> Variablen etwas aussagekräftiger gestalten würden ;-)
Nur zu!
Udo Neist schrieb:> Bei mir steht nur das Grundgerüst und die ersten Umstellungen. Ich kam> diese Woche noch nicht dazu weiter zu machen.
Wie wäre es, wenn Du die Template-Geschichte als Branch im
SVN-Repository anlegst? Da bleibt der Code an einer zentralen Stelle und
per "svn switch" kann man ihn auch schnell mal ausprobieren.
Grüße
b
Udo Neist schrieb:> Ich hab mit SVN und Co leider kaum gearbeitet. Wenn mir das einer mal> kurz erklärt, dann gerne :)
Womit entwickelst Du? Linux? Mac? Windows?
Diverse Tutorials gestern da durch's Netz...
b
Unter Linux. Ich hatte mal ein SVN eingerichtet, aber kaum genutzt.
Bisher hab ich immer mindestens zwei Kopien gehabt und kein Repo
benötigt.
Ich werde mir aber mal ein paar Howtos anschauen. Eventuell habt ihr ja
ein vernünftiges, da ja so mancher Schrott im Inet existiert.
@b.r und an alle :-)
Ich habe jetzt in der tools/footprints.php die Checkbox zum
hinzufügen/löschen von Footprints vorübergehend mal deaktiviert.
Ich denke es ist besser, wenn wir die Funktion erst wieder aktivieren
wenn es eine gescheite Sicherheitsabfrage beim Löschen gibt :-)
Und eine Anpassung an die neue Datenbankstruktur (Spalte "filename") ist
auch noch notwendig.
@Udo Neist
Ich habe heute auch zum ersten mal mit SVN gearbeitet. Dazu habe ich im
Internet "RabbitVCS" gefunden, das integriert sich in Nautilus und macht
es einem echt leicht, kann ich nur empfehlen :-)
Ich hab hier Dolphin (KDE4) und irgendwo ein kdesvn. Aber sowas mach ich
am liebsten von der Konsole aus :-)
Ich denke, ich brauch auch noch Zugangsdaten?
Udo Neist schrieb:> Ich hab hier Dolphin (KDE4) und irgendwo ein kdesvn. Aber sowas mach ich> am liebsten von der Konsole aus :-)
Ich nehm auch (fast) immer die Konsole. Außer unter Windows. Da
integriert sich TortoiseSVN sehr gelungen in den Explorer.
> Ich denke, ich brauch auch noch Zugangsdaten?
Frag mal bei K.J.
Evtl. geht es nur mit goole-Account.
Grüße
b
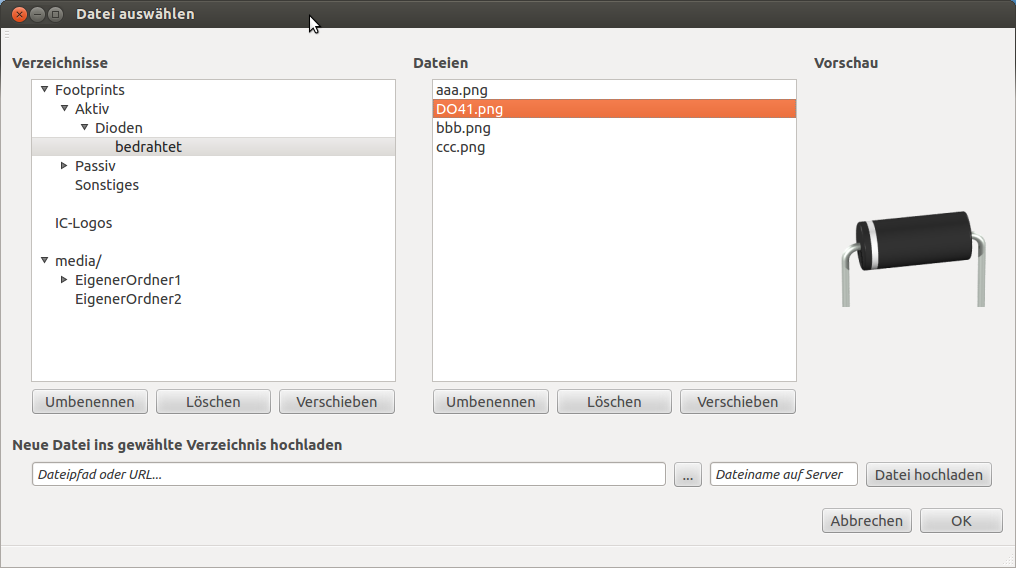
Kennt von euch zufälligerweise jemand einen Datei-Öffnen-Dialog, bei dem
man eine Datei, die auf dem Server liegt, auswählen kann?
Bilder sollen wenn möglich auch gleich im Dialog angezeigt werden,
sofern eine Bilddatei angewählt wird.
Im Internet finde ich überhaupt nichts derartiges...
Urban B. schrieb:> Kennt von euch zufälligerweise jemand einen Datei-Öffnen-Dialog, bei dem> man eine Datei, die auf dem Server liegt, auswählen kann?> Bilder sollen wenn möglich auch gleich im Dialog angezeigt werden,> sofern eine Bilddatei angewählt wird.>> Im Internet finde ich überhaupt nichts derartiges...
Ist mir auch keines bekannt. Mach ich über eine Listbox, die ich zuvor
gefüllt habe.
Also für die Zuweisung eines Bildes zu einem Footprint brauchen wir
jetzt ja einen Dialog, bei dem man die Serververzeichnisse durchsuchen
kann. Da man dafür wohl am besten gleich den Dialog für den universellen
Dateiupload (der noch nicht existiert xD) benutzt, habe ich mir mal
Gedanken gemacht wie der etwa aussehen könnte (siehe Anhang).
Kritik/Verbesserungsvorschläge sind erwünscht.
Der Dialog müsste beim Schliessen einfach dem aufrufenden Fenster den
Dateipfad der markierten Datei übermitteln.
Ich hab mal selber ein bisschen probiert sowas zu bauen, aber mit meinen
mageren php-Kenntnissen wird das nichts ;-)
Gibts Freiwillige? :-D
EDIT:
Ach ja, das Umbenennen/Löschen/Kopieren/Hochladen ist nur im Ordner
media/ erlaubt. Auf die anderen beiden Ordner hat der User nur
Lesezugriff.
Sowas wäre wohl ein Fall für Ajax (Javascript) :-) Das wäre dann auch
der Grund für die Beseitigung der Frames (sind obsolete und sollen
irgendwann von den Browsern nicht mehr unterstützt werden).
Udo Neist schrieb:> Sowas wäre wohl ein Fall für Ajax (Javascript) :-) Das wäre dann auch> der Grund für die Beseitigung der Frames (sind obsolete und sollen> irgendwann von den Browsern nicht mehr unterstützt werden).
Okay, also definitiv nichts für mich :-)
Ich habe übrigens jetzt (r479) unter Konfiguration/Datenbank die
Möglichkeit eingefügt, direkt ein Backup von der Datenbank zu erzeugen
und auf dem Server unter backup/ abzulegen. Auch kann man jedes
existierende Backup herunterladen oder löschen.
Ich hoffe das funktioniert bei euch auch ;-)
Ist ja richtig ruhig hier im Moment :-D
Ich war mal wieder fleissig am Arbeiten, und ich muss schon sagen, so
langsam fang ich an PHP zu mögen :-)
Die Umstellung auf die vollständigen Dateinamen habe ich jetzt ins SVN
geladen (r480). Die Footprintbilder werden jetzt nicht mehr im ganzen
footprint-Ordner gesucht, sondern es wird direkt die Datei genommen,
deren Pfad in der Datenbank abgelegt ist (beim entsprechenden
Footprint).
Das Laden der Liste sollte jetzt also einiges schneller gehen.
Nach dem Update funktionieren kurzfristig jedoch alle Footprint-Bilder
nicht mehr. Aber keine Panik, das ist nicht schlimm :-) Auf der
Startseite sollte gleich der Hinweis kommen, dass es fehlerhafte
Dateinamen für die Footprintbilder gibt. Unter Bearbeiten/Footprints
werden all diese fehlerhaften Footprints aufgelistet und falls
vorhanden, gleich passende Dateien vorgeschlagen.
Eigentlich müsst ihr diese Vorschläge gar nicht überprüfen. Wenn ihr
einfach auf "Alle Übernehmen" klickt sollte nachher alles wieder genau
so sein wie vor der Umstellung. Dass einige Pfade gelöscht werden sieht
zwar schlimm aus, ist es aber nicht, da die entsprechenden Footprints
schon vorher kein Bild sollten gehabt haben.
Wenn ihr aber auf "markierte übernehmen" klickt, werden schonmal alle
Footprints, die vorher ein Bild hatten, wieder mit dem richtigen Bild
verknüpft. Danach habt ihr gleich noch eine Liste von Footprints, die
schon vorher kein Bild hatten. Diese können dann mit den Dropdown-Listen
ganz einfach mit einem Bild verknüpft werden, falls gewünscht.
Ich habe es bei mir gründlich durchgetestet, und ich konnte keine Fehler
mehr entdecken. Eine Datenbanksicherung vor der Übernahme kann aber
trotzdem nicht schaden ;-)
mfg
Ich hab mir die 479er gezogen und werde die Änderungen dort einpflegen.
Die Version 12 der Datenbank habe ich auch schon als create.sql
gesichert, damit man nicht erst die alte Version installieren und dann
updaten muss. Ich werde wohl noch eine install.php erstellen, die die
Ersteinrichtung erleichtert.
Wenn ich die Migration von 446 auf 479 abgeschlossen habe, werde ich
diese dann auch ins SVN kopieren.
Grüße
Udo
Udo Neist schrieb:> Ich hab mir die 479er gezogen und werde die Änderungen dort einpflegen.
Heisst das, die Änderungen von r480 sind dann wieder weg?
Die Revision 480 ist eigentlich relativ wichtig, da dort das neue
Footprintsystem mehr oder weniger fertig implementiert ist (sobald der
neue Upload-Dialog vorhanden ist, muss der noch mit dem Footprintsystem
"verknüpft" werden, aber sonst ist es soweit fertig).
Ich wäre noch froh um Feedback ob die Umstellung aufs neue
Footprintsystem problemlos funktioniert hat, und vor allem ob nun die
Auflistung vieler Teile viel schneller geht als vorher (einige hatten ja
Probleme dass bereits Timeouts eingesetzt haben, die hatte ich jedoch
nicht).
mfg
ah okay das wär nicht schlecht ;-)
Oder auch gleich r481, aber da hab ich nur der Hinweis bei den
Footprints eingefügt, dass es empfohlen wäre vor dem automatischen
Korrigieren der Dateinamen eine Datenbanksicherung durchzuführen :-D
Den hab ich sicherheitshalber mal eingefügt damit man theoretisch wieder
aufs alte System wechseln könnte, falls irgendwas schiefgelaufen wäre.
Ach ja, sofern niemand reklamiert ich hätte mit r480 seine Datenbank
zerschossen, werde ich das SVN in nächster Zeit in Ruhe lassen ;-) Du
kannst also deine Migration durchführen ohne dass ich wieder dazwischen
funke ;-)
Udo Neist schrieb:> Warum nicht gleich bei einem Update der Datenbank ein Backup> durchführen? Da muss der User nicht das per Hand anwerfen.
Die Idee hatte ich auch schon. Aber die Revision 480 beinhaltet gar kein
Datenbankupdate, würde dann also keine automatische Sicherung auslösen
;-)
Und extra ein DB-Update "simulieren" finde ich nicht sehr schön...
Die Umstellung der Footprint-Dateinamen auf vollständige Pfadangaben
passiert ja eh nicht automatisch, sondern muss manuell durchgeführt
werden. Daher denke ich reicht auch ein kleiner Hinweis inkl. Link auf
die Seite, auf der man jetzt ja ganz einfach per Mausklick eine
Sicherung erstellen lassen kann.
Urban B. schrieb:> Udo Neist schrieb:>> Warum nicht gleich bei einem Update der Datenbank ein Backup>> durchführen? Da muss der User nicht das per Hand anwerfen.>> Die Idee hatte ich auch schon. Aber die Revision 480 beinhaltet gar kein> Datenbankupdate, würde dann also keine automatische Sicherung auslösen> ;-)
Ich würde in dem Fall zwei DB-Updates definieren. Ein Major-Update mit
Versionsänderung und ein Minor-Update mit Änderungen auf
System-/Datenebene.
> Und extra ein DB-Update "simulieren" finde ich nicht sehr schön...
Geht schneller als man denkt. Einfach ein mysqldump vor dem Update auf
der Kiste durchführen und nach dem Update schauen, ob alles geht. Wenn
nicht einfach den Dump mit "mysql <dump.sql" zurückspielen (User,
Passwort und Datenbank angeben nicht vergessen). Dazu braucht man kein
phpMyAdmin.
Udo Neist schrieb:> Ich würde in dem Fall zwei DB-Updates definieren. Ein Major-Update mit> Versionsänderung und ein Minor-Update mit Änderungen auf> System-/Datenebene.
Wär auch eine Möglichkeit. Ich notier das mal in unseren Issues.
> Geht schneller als man denkt. Einfach ein mysqldump vor dem Update auf> der Kiste durchführen und nach dem Update schauen, ob alles geht. Wenn> nicht einfach den Dump mit "mysql <dump.sql" zurückspielen (User,> Passwort und Datenbank angeben nicht vergessen). Dazu braucht man kein> phpMyAdmin.
Jo, stimmt. Eine Sicherung durchführen geht jetzt ja auch schon ohne
phpMyAdmin, falls du das noch nicht mitgekriegt hast ;-) Die
Möglichkeit, eine Sicherung wiederherzustellen kommt auch noch.
Ich habe heute die Revision 483 angefangen umzustellen und bereits einen
Teil geschafft. Nur klappt es mit dem Anlegen eines Branches nicht.
Google wirft mich mit Fehler 405 raus. Ich denke, man müsste mich noch
in die Liste der Committer aufnehmen :(
Nachdem ich ein paar Infos über Googlecode und Subversion gelesen und
noch einen Gmail-Account erstellt habe, werde ich beim Kopieren des
Hauptzweiges in ein Branch bzw. beim Import mit "access forbidden"
rausgeworfen. Ich arbeite auf der Konsole.
Ich hab die Revision 483 in der Version 20120711 nach
http://part-db.googlecode.com/svn/branches/uneist/ hochgeladen (->
Revision 484) und versuche gerade die Version 20120713 als Update
einzustellen. Noch klappt das nicht, bin mit svn noch am kämpfen.
Update erfolgreich. Version 20120713 als Revision 485 gespeichert.
Die Anleitungen zu svn sind teilweise unbrauchbar oder schwer
verständlich. Warum schreibt denn niemand was vernünftiges? Arbeitskopie
ist die lokale Kopie, die nach dem ersten Checkout entsteht. Führt zur
Verwirrung, wenn man die Begriffe nicht kennt.
Hier mal ein kurze Zusammenfassung meiner Vorgehensweise für
Konsolenfanatiker ;-)
A. Erster Import (wichtig, falls man neu beginnt)
1
svn import LOCALDIR URL
B. Kopie (Fork, Branch) erstellen (wenn man mit einer bestehenden
Revision starten will)
1
svn copy URL URL2
Startet man komplett neu und hat bereits ein Repo angelegt (z.b. bei
googlecode.com), so würde man mit Variante A beginnen. Startet man einen
neuen Zweig, so würde sich Variante B anbieten.
Anschliessend erfolgt der erste Checkout.
1
svn checkout URL LOCALDIR
Für die tägliche Arbeit sind die nachfolgenden Schritte einzuhalten.
1. Einbindung neuer Dateien/Verzeichnisse im lokalen Verzeichnis
1
svn add * --force
2. Löschen einer Datei oder eines Verzeichnisses im lokalen Verzeichnis
1
svn delete FILE/DIR
3. Synchronisiert des lokalen Verzeichnises mit der URL (wird durch das
Checkout gespeichert)
1
svn update
4. Freigabe des Updates
1
svn commit -m COMMENT
Die Schritte 1 und 2 werden nur benötigt, wenn sich im Verzeichnisbaum
was ändert. Ändert man nur bestehende Dateien, so kann man direkt mit
Schritt 3 beginnen. Allerdings gilt bei mehreren Committer im gleichen
Zweig, dass man den Schritt 3 zuerst ausführt, um Änderungen im Repo
auch in die eigene Arbeitskopie einfliessen zu lassen. Konflikte müssen
dann mit den Werkzeugen von svn aufgelöst werden, bevor man weiter
arbeitet. Danach führt man die Schritte 1 bis 4 aus.
Links: http://svnbook.red-bean.com/nightly/de/svn-book.html
Ich hoffe, ich habe die üblichen Schritte für svn recht gut rüber
gebracht. Man könnte natürlich auch einen Wiki-Artikel daraus machen, da
es hier ja auch einen svn -Server gibt.
Ich habe heute abend mal die partDB installiert und finde sie wirklich
prima. Super easy aufzusetzen und einfach zu durchschauen. Bis auf
Kleinigkeiten ist es genau das, was ich immer gesucht habe !
Ich werde mal die "Kleinigkeiten" in loser Abfolge auflisten, so dass
sich evtl. eine Diskussion über deren Sinnhaftigkeit ergibt.
- Footprint (1): das Bild in der ersten Spalte nervt -mich zumindest und
an dieser Position- sehr, da immer wenn die Maus auf dem Weg zum Eintrag
darüber kommt, das Bild groß aufpoppt und dann im Weg steht. Evtl.
könnte das in die letzte Spalte verschieben.
- Footprint (2): Da an sich immer Abbildungen fehlen werden (SC70, SC74,
MLF, Diode in 0603, ...) und nicht jeder Wert auf eine Abbildung legt,
wäre ein alternatives Eingabefeld sinnvoll; damit kann man auch ohne
Vorhandensein eines Footprints das Gehäuse für die Listenansicht
spezifizieren.
- Eingabefeld Preis: ich hätte gern noch eine Menge, auf die sich der
Preis bezieht. Prima wäre zusätzlich zum Preisfeld noch ein Feld
'Kalkulationspreis' und 'Kalkulationsmenge', sowie 'Bestellmenge'. Dann
könnte man eingeben: 49 Euro je 100 Stück, bei Bestellmenge 4000 Stück.
Wenn sich der Stückpreis dann automatisch aus 49/100 ergibt, ware das
nicht uncool ;)
- Ich wünschte mir eine Art Log, das anzeigt, wann und wie viele einer
Baugruppe gebucht wurden. Dort könnte man eine Buchung -hoffentlich-
auch rückgängig machen, sofern man aus Versehen mal 'was Falsches
eingegeben hat.
Eine Frage noch: wenn man spendet, wem kommt das zu gute ?
Gruß, Stefan
Udo Neist schrieb:> Die Anleitungen zu svn sind teilweise unbrauchbar oder schwer> verständlich.
Deshalb nutze ich lieber GUIs, da braucht man keine Anleitung, da kann
man einfach mal wild drauflosklicken und schauen was passiert :-D Und
wenn sich der SVN-Client sogar noch in den Dateibrowser integriert und
bei jeder einzelnen Datei anzeigt ob sie der aktuellsten SVN-Revision
entspricht, ist das sogar auch noch sehr nützlich :-D
Stefan schrieb:> - Footprint (1): das Bild in der ersten Spalte nervt -mich zumindest und> an dieser Position- sehr, da immer wenn die Maus auf dem Weg zum Eintrag> darüber kommt, das Bild groß aufpoppt und dann im Weg steht. Evtl.> könnte das in die letzte Spalte verschieben.
Okay, das wäre dann also eine zusätzliche Konfigurationsmöglichkeit. Da
die Konfiguration sowieso aus der config.php verschwinden und in die
SQL-Datenbank verschoben werden soll, denke ich wir warten noch mit
diesem Feature.
Da käme mir nämlich gerade eine ganz coole Idee in den Sinn: Es soll ja
in Zukunft auch eine Benutzerverwaltung geben. Das würde dann
ermöglichen, dass jeder Benutzer seine Spalten selber konfigurieren
kann. Ich denke danach sollte jeder zufrieden sein mit der Tabelle :-)
Stefan schrieb:> - Footprint (2): Da an sich immer Abbildungen fehlen werden (SC70, SC74,> MLF, Diode in 0603, ...) und nicht jeder Wert auf eine Abbildung legt,> wäre ein alternatives Eingabefeld sinnvoll; damit kann man auch ohne> Vorhandensein eines Footprints das Gehäuse für die Listenansicht> spezifizieren.
Ich denke das ist eine eher weniger gute Idee. Mal abgesehen davon, dass
es etwas mühsam/unschön zum programmieren ist, hat man einige Nachteile.
Wenn du nämlich mehreren Bauteilen den gleichen Footprint per manueller
Eingabe zuordnest, sind sie voneinander völlig unabhängig, obwohl es
immer um den gleichen Footprint geht. Du kannst also den Footprint nicht
bei allen betroffenen Bauteilen auf einmal umbenennen, oder falls später
mal das fehlende Bild dazukommt, kannst du es nicht direkt allen
betroffenen Bauteilen zuordnen. Viel besser ist es, wenn du beim Anlegen
eines neuen Bauteiles das Eingabefeld rechts benutzt um gleich einen
neuen Footprint anzulegen. Das geht genau so einfach wie das von dir
gewünschte Feature, hat aber die genannten Nachteile nicht.
Stefan schrieb:> Eingabefeld Preis: ich hätte gern noch eine Menge, auf die sich der> Preis bezieht. Prima wäre zusätzlich zum Preisfeld noch ein Feld> 'Kalkulationspreis' und 'Kalkulationsmenge', sowie 'Bestellmenge'. Dann> könnte man eingeben: 49 Euro je 100 Stück, bei Bestellmenge 4000 Stück.> Wenn sich der Stückpreis dann automatisch aus 49/100 ergibt, ware das> nicht uncool ;)
Die Angabe der Stückzahl habe ich auch schon im Sinn gehabt. Ich denke
das lässt sich so einbauen. Wie der Preis dann in den Tabellen angezeigt
wird ist halt Geschmackssache. Vermutlich wäre das beste, wenn dort nur
der Einzelpreis steht, ohne Stückzahl. Das mit der Bestellmenge wird
dann etwas komplizierter, wenn man es mit dem Preis verknüpfen will.
Dann müsste es eigentlich ja fast die Möglichkeit geben, pro Bauteil
mehrere Preise anzugeben (für verschiedene Bestellmengen). Wäre sicher
nützlich für den professionellen Einsatz, aber gibt viel Aufwand. Mal
schauen ob das was wird ;-)
Stefan schrieb:> - Ich wünschte mir eine Art Log, das anzeigt, wann und wie viele einer> Baugruppe gebucht wurden. Dort könnte man eine Buchung -hoffentlich-> auch rückgängig machen, sofern man aus Versehen mal 'was Falsches> eingegeben hat.
Keine schlechte Idee, vorallem auch im Bezug auf die Benutzerverwaltung
die ja noch kommen soll. Dann könnten die "Admins" auch nachvollziehen
was andere Leute so in der Datenbank "rumfummeln" und können
Fehlbuchungen rückgängig machen. Würde ich als durchaus nützlich
betrachten.
Stefan schrieb:> Eine Frage noch: wenn man spendet, wem kommt das zu gute ?
Gute Frage ;-) Ich denke die Frage geht an K.J.
Danke für die Vorschläge, ich nehme sie mal in unsere TODO-Liste auf.
mfg
> Das würde dann ermöglichen, dass jeder Benutzer seine Spalten selber> konfigurieren kann. Ich denke danach sollte jeder zufrieden sein mit der> Tabelle :-)
Würde ich auch als die beste Lösung betrachten. Zumal sich mein Problem
mit den Abbildungen der Footprints wahrscheinlich eh' erledigt hat.
> Du kannst also den Footprint nicht bei allen betroffenen Bauteilen auf> einmal umbenennen, oder falls später mal das fehlende Bild dazukommt,> kannst du es nicht direkt allen betroffenen Bauteilen zuordnen.> ...> Viel besser ist es, wenn du beim Anlegen eines neuen Bauteiles das> Eingabefeld rechts benutzt ...
Also 'Bild hochladen' erzeugt einen neuen Footprint ? Dann ist ja alles
in Ordnung. Ich finde -und jetzt nicht böse sein- dass hier eh' zu viel
Wert auf die Abbildungen gelegt wird; 2/3 des Threads scheinen sich mit
Footprints auseinanderzusetzen. Da ich weiß, wie ein 0603er oder ein
MSOP10 aussieht, reicht mir die Angabe des FP im Klartext, also
KERKO_0402 oder KERKO_0603. Deshalb werde ich einfach weiße-1-pixel-gifs
als FP benutzen. Damit sollte sich dann auch meine Problematik mit den
aufpoppenden Bildern erledigt haben.
Also mehrere Preise brauche ich nicht; alternative Bauteile anderer
Hersteller könnte ich ggf. in den Kommentaren unterbringen, nur ist eben
die Preisangabe so wie bisher umgesetzt, eher auf den Reichelt-Besteller
ausgerichtet. Das soll nicht abwertend sein (!), sondern nur
verdeutlichen, dass andere Anwender auch andere Anforderungen haben :)
Bei der von mir vorgeschlagenen Erweiterung handelt es sich im Grunde
genommen ja auch nur um 3 neue Datenbankfelder und Minimalarithmetik.
Jedoch geben viele Anbieter den Preis bezogen auf 100 an. Und zu
vermerken, ab welcher Stückzahl der genannte Preis gilt, ist immer
hilfreich, da Mouser, Farnell, Digikey, Schukat und eigentlich alle
außer Reichelt mit Staffelpreisen arbeiten.
Btw: kann man eigentlich einstellen, dass der Preis in Cent angegeben
wird ? 0.0011 Euro liest sich einfach bescheiden. Da muss ich immer
erst lange nachdenken, bevor ich weiß, was das Bauteil wirklich kostet
;)
Eine Log-Tabelle für abgebuchte Baugruppen, mit Korrekturmöglichkeit,
halte ich für sehr wichtig und würde für die Implementierung auch
bezahlen.
André hat geschrieben:
> Mich hatt es gestört, dass ich die Datenblätter nicht vom aktuellen> Rechner hochladen konnte, sodass ich den Code in Anlehnung an die Bilder> umgeändert habe, so dass man zusätzlich Datenblätter in den Ordner> hochladen kann der in der config.php als datasheet_path angegeben ist.> Es wäre bei den Datenblättern noch gut, wenn man einen Titel eingeben> könnte (der originale Dateiname würde meist schon reichen), vielleicht> passe ich das noch an. (datasheet.patch)
Stört mich auch sehr. Ich habe die V2.2 installiert, bei der diese
Funktion leider nicht vorhanden ist. Ist dieser Patch nie eingeflossen ?
Urban B. schrieb:> Stefan schrieb:>> Eine Frage noch: wenn man spendet, wem kommt das zu gute ?>> Gute Frage ;-) Ich denke die Frage geht an K.J.>> Danke für die Vorschläge, ich nehme sie mal in unsere TODO-Liste auf.>> mfg
Hm ist bis jetzt noch nicht Passiert ;-) da hab ich mir noch keine
Gedanken drum gemacht, ich würde es einfach erstmal sammeln,
ursprünglich war es gedacht damit ich damit meinen Server Finanzieren
kann jetzt wo so viele andere mitmachen müsste man sich da was
überlegen.
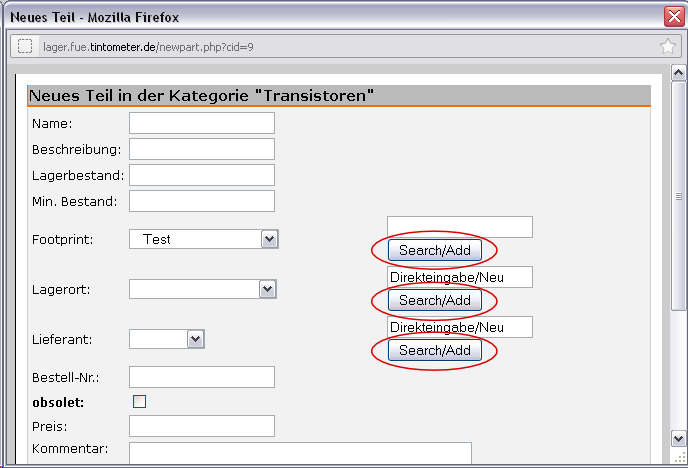
Stefan --- schrieb:>> Du kannst also den Footprint nicht bei allen betroffenen Bauteilen auf>> einmal umbenennen, oder falls später mal das fehlende Bild dazukommt,>> kannst du es nicht direkt allen betroffenen Bauteilen zuordnen.>> ...>> Viel besser ist es, wenn du beim Anlegen eines neuen Bauteiles das>> Eingabefeld rechts benutzt ...> Also 'Bild hochladen' erzeugt einen neuen Footprint ? Dann ist ja alles> in Ordnung.
Nein, nicht "Bild hochladen". Wenn du ein neues Bauteil anlegst gibt es
auf der rechten Seite die Möglichkeit den gewünschten Footprint in das
Feld "Direkteingabe/Neu" einzutippen. Ist der eingetippte Footprint
schon in der Datenbank vorhanden (ob mit oder ohne Bild) wird dieser dem
Bauteil zugewiesen. Ist der Footprint noch nicht vorhanden, wird er
direkt neu angelegt und dann dem Bauteil zugewiesen. Verstehst du wie
ich meine? Oder habe ich dich irgendwie falsch verstanden?
Footprint und Footprint-Bild haben erstmal nichts miteinander zu tun,
das wissen viele nicht. Die Footprintverwaltung ist einfach dazu da,
dass die Footprints auch gescheit mit den Bauteilen verknüpft sind. Also
dass alle Bauteile im DIP08 Gehäuse auf den genau gleichen Footprint
zeigen. Optional kann man den Footprints dann aber zusätzlich auch noch
Bilder zuweisen, damit sie direkt in den Tabellenansichten als Icon
erscheinen. Das ist kein muss sondern ein dürfen.
> Ich finde -und jetzt nicht böse sein- dass hier eh' zu viel> Wert auf die Abbildungen gelegt wird; 2/3 des Threads scheinen sich mit> Footprints auseinanderzusetzen. Da ich weiß, wie ein 0603er oder ein> MSOP10 aussieht, reicht mir die Angabe des FP im Klartext, also> KERKO_0402 oder KERKO_0603. Deshalb werde ich einfach weiße-1-pixel-gifs> als FP benutzen. Damit sollte sich dann auch meine Problematik mit den> aufpoppenden Bildern erledigt haben.
Naja ich persönlich finde die Bilder sehr nützlich. Man sieht schon auf
den ersten Blick gleich bildlich mit was man es zu tun hat. Aber wie
gesagt, die Bilder sind ja freiwillig - du musst sie nicht benutzen. Du
musst aber auch kein eigenes weisses Bild hochladen, wenn du ein
Footprint wählst der kein Bild hat, dann wird auch kein Bild in der
Tabelle angezeigt.
Stefan --- schrieb:> Also mehrere Preise brauche ich nicht; alternative Bauteile anderer> Hersteller könnte ich ggf. in den Kommentaren unterbringen, nur ist eben> die Preisangabe so wie bisher umgesetzt, eher auf den Reichelt-Besteller> ausgerichtet. Das soll nicht abwertend sein (!), sondern nur> verdeutlichen, dass andere Anwender auch andere Anforderungen haben :)> Bei der von mir vorgeschlagenen Erweiterung handelt es sich im Grunde> genommen ja auch nur um 3 neue Datenbankfelder und Minimalarithmetik.> Jedoch geben viele Anbieter den Preis bezogen auf 100 an. Und zu> vermerken, ab welcher Stückzahl der genannte Preis gilt, ist immer> hilfreich, da Mouser, Farnell, Digikey, Schukat und eigentlich alle> außer Reichelt mit Staffelpreisen arbeiten.
Jo aber ich denke wenn wir jetzt noch die zusätzlichen Felder einbauen
wird früher oder später auch der Wunsch kommen, pro Lieferanten mehrere
Preise (für unterschiedliche Stückzahlen) eingeben zu können. Ausserdem
macht es das ganze viel professioneller. Wer weiss, vielleicht habe ich
später mal eine eigene kleine Firma, und dann möchte ich auch ein
"richtiges" Lagerverwaltungssystem haben :-D
> Btw: kann man eigentlich einstellen, dass der Preis in Cent angegeben> wird ? 0.0011 Euro liest sich einfach bescheiden. Da muss ich immer> erst lange nachdenken, bevor ich weiß, was das Bauteil wirklich kostet> ;)
Bisher noch nicht. Aber könnte man ja noch einbauen.
Stefan --- schrieb:> Eine Log-Tabelle für abgebuchte Baugruppen, mit Korrekturmöglichkeit,> halte ich für sehr wichtig und würde für die Implementierung auch> bezahlen.
Ich habe es in unsere ToDo-Liste geschrieben, aber es wird wohl schon
ein Weilchen dauern bis das implementiert ist ;-)
Stefan --- schrieb:> Stört mich auch sehr. Ich habe die V2.2 installiert, bei der diese> Funktion leider nicht vorhanden ist. Ist dieser Patch nie eingeflossen ?
Der Upload aller möglichen Dateien wird eh noch umgebaut, da tut sich
also schon noch was. Bezüglich Version: Du solltest dir jeweils die
neuste per SVN herunterladen, die Archive sind nicht sehr aktuell:
http://code.google.com/p/part-db/source/checkout
> Ist der Footprint noch nicht vorhanden, wird er direkt neu angelegt und> dann dem Bauteil zugewiesen. Verstehst du wie ich meine? Oder habe ich> dich irgendwie falsch verstanden?
Hallo,
du hattest mich schon richtig verstanden. Da diese Felder nicht
bezeichnet waren und die Zuordnung mir als nicht eindeutig erschien,
habe ich erst einmal nichts damit probiert. Aber vielen Dank für die
Info, das wird es in Zukunft einfacher machen.
> wenn du ein Footprint wählst der kein Bild hat, dann wird auch kein Bild in> der Tabelle angezeigt.
Funktioniert - bin zufrieden, vielen Dank !
> die Archive sind nicht sehr aktuell:> http://code.google.com/p/part-db/source/checkout
Damit bin ich dann doch überfordert :(
im Terminal eingeben, dann wird die neuste Version nach ~/part-db/
heruntergeladen. Eventuell musst du erst noch das Paket "subversion"
installieren. Bei Debian oder Ubuntu mit
1
sudo apt-get install subversion
Bei Windows weiss ich grad nicht wie das geht, müsstest mal nach einem
SVN Client für Windows suchen.
> Was für ein Server hast du? Linux? Windows?
Im Moment läuft das auf irgendeinem Webspace; da hab' ich leider keinen
Konsolenzugriff. Ich muss mal bei uns auf dem lokalen Server eine VM mit
Linux einrichten und die DB dort einspielen.
Sollten nicht im Interesse aller die nicht an der Entwicklung beteiligt
sin von Zeit zu Zeit mal Archive aktualisiert werden ?
Stefan --- schrieb:>> Was für ein Server hast du? Linux? Windows?>> Im Moment läuft das auf irgendeinem Webspace; da hab' ich leider keinen> Konsolenzugriff. Ich muss mal bei uns auf dem lokalen Server eine VM mit> Linux einrichten und die DB dort einspielen.
Dann kannst du auch bei dir lokal eine Kopie aus dem SVN herunterladen,
und diese Dateien dann auf den Webspace hochladen.
> Sollten nicht im Interesse aller die nicht an der Entwicklung beteiligt> sin von Zeit zu Zeit mal Archive aktualisiert werden ?
Ja wäre nicht schlecht, aber das geht halt gerne ein bisschen vergessen
:-) Wobei ich jetzt aber gar nicht weiss wie alt das letzte Archiv
eigentlich ist. In unserer ToDo-Liste steht aber auch schon eine
Updatemöglichkeit direkt aus Part-DB heraus, das wär dann das
Non-Plus-Ultra wenn das was wird ;-)
Es stehen einige schöne Dinge in unserer ToDo-Liste, aber wir können
halt auch nicht zaubern ;-)
> Dann kannst du auch bei dir lokal eine Kopie aus dem SVN herunterladen,> und diese Dateien dann auf den Webspace hochladen.
Genau das habe ich eben nicht hin bekommen ...
Die letzte Version ist vom 12. Juni, wenn ich mich recht erinnere.
Danke für die Hilfestellung !
Stefan --- schrieb:>> Dann kannst du auch bei dir lokal eine Kopie aus dem SVN herunterladen,>> und diese Dateien dann auf den Webspace hochladen.> Genau das habe ich eben nicht hin bekommen ...
Wo liegt denn das Problem? Für Windows müsstest du halt mal schauen was
es da für SVN-Clients gibt. Mit einem gescheiten Programm sollte es
eigentlich keine grosse Sache sein part-db aus dem SVN zu beziehen.
> Die letzte Version ist vom 12. Juni, wenn ich mich recht erinnere.
Okay, das geht ja noch. Aber auch seit dem 12. Juni hat sich schon
wieder einiges getan.
> Danke für die Hilfestellung !
Kein Problem ;-)
@Udo Neist
Ich habe mir dein branch mal angeschaut. Scheint wirklich nicht so
kompliziert zu sein wie ich mir das vorgestellt habt. Im Grunde genommen
trennt man ja einfach html und php.
Was ich aber noch nicht verstanden habe: Ist es nicht auch der Sinn von
Templates, dass man für die gleiche Seite mehrere (verschiedene) *.tmpl
Dateien erstellen kann, um dann eben ein anderes "Design" zu erreichen?
Oder soll es nur ein einziges Template geben?
Falls es mehrere Templates geben soll, sollte man doch im Ordner
templates/ noch Unterordner für die verschiedenen Templates erstellen
oder?
Im Ordner /class/vlib/ sind keine part-db spezifischen Dinge drin, das
ist so unverändert "aus dem Internet heruntergeladen" nehme ich an? Geht
uns quasi also überhaupt nichts an was da drin ist?
Und was schätzt du, wie lange brauchtst du noch bis du fertig bist?
Also ich wäre dafür, dass wir dann den branch in den trunk übernehmen,
sobald du fertig bist. Ich weiss momentan auch gar nicht wo ich meine
Änderungen einpflegen soll, die ich noch gemacht habe.
Übrigens habe ich mal die JavaScript Dialoge wie confirm() und alert()
angeschaut. Die sind ja extrem einfach anzuwenden, damit könnte man
locker unsere komischen Weiterleitungen ersetzen.
Kleines Beispiel: Dieser Button
<input type="submit" name="delete_file" value="Löschen" onclick="return confirm('Achtung!\nDas Backup wird unwiederruflich gelöscht.')">
Und schon hat man eine Sicherheitsabfrage per JavaScript Dialog drin ;-)
Von mir aus kann ich das überall noch einbauen. Aber ich warte erstmal
noch ab wie es mit dem branch von Udo weitergeht.
> Ich habe mir dein branch mal angeschaut. Scheint wirklich nicht so> kompliziert zu sein wie ich mir das vorgestellt habt. Im Grunde genommen> trennt man ja einfach html und php.
Jau, ist eigentlich sehr simple. Vorallem sieht man dann den Code mal
wieder und muss sich nicht durch HTML-Wust durchwühlen ;-)
> Was ich aber noch nicht verstanden habe: Ist es nicht auch der Sinn von> Templates, dass man für die gleiche Seite mehrere (verschiedene) *.tmpl> Dateien erstellen kann, um dann eben ein anderes "Design" zu erreichen?> Oder soll es nur ein einziges Template geben?> Falls es mehrere Templates geben soll, sollte man doch im Ordner> templates/ noch Unterordner für die verschiedenen Templates erstellen> oder?
Man kann es so machen, aber Sinn von dieser Templates ist eigentlich nur
die Trennung von Code und Darstellung. Das Design würde ich ganz CSS
überlassen. Die Basis stellt standard/partdb.css dar. Alle Varianten
werden zusätzlich geladen und ergänzen/überschreiben die vorherigen
Definitionen. Wenn es gewünscht wäre, könnte man neben dem CSS auch noch
die Templates freigeben und würde dann analog zum CSS ein
Unterverzeichnis in templates/ anlegen.
> Im Ordner /class/vlib/ sind keine part-db spezifischen Dinge drin, das> ist so unverändert "aus dem Internet heruntergeladen" nehme ich an? Geht> uns quasi also überhaupt nichts an was da drin ist?
Da ist die Template-Engine drin. Zusätzlich noch vlibDate und
vlibMimeMail, die hier zwar nicht gebraucht werden, aber zu der Engine
gehören. Gibts so im Paket.
> Und was schätzt du, wie lange brauchtst du noch bis du fertig bist?> Also ich wäre dafür, dass wir dann den branch in den trunk übernehmen,> sobald du fertig bist. Ich weiss momentan auch gar nicht wo ich meine> Änderungen einpflegen soll, die ich noch gemacht habe.
Ich werde diese Woche im Büro noch die Änderungen machen. Könnte bis
Ende der Woche klappen, je nach Arbeit.
> Übrigens habe ich mal die JavaScript Dialoge wie confirm() und alert()> angeschaut. Die sind ja extrem einfach anzuwenden, damit könnte man> locker unsere komischen Weiterleitungen ersetzen.>> Kleines Beispiel: Dieser Button>
> onclick="return confirm('Achtung!\nDas Backup wird unwiederruflich
3
> gelöscht.')">
> Und schon hat man eine Sicherheitsabfrage per JavaScript Dialog drin ;-)
Eventuell einfach ein div-Element bauen, das die Dialoge aufnimmt. So
können wir die nicht immer gerade hübschen Dialoge der Browser umgehen.
Wäre dann auch für die PopUps nutzbar. Nur lasse ich das erstmal weg.
Die Änderungen dazu würden erstmal stören.
> Von mir aus kann ich das überall noch einbauen. Aber ich warte erstmal> noch ab wie es mit dem branch von Udo weitergeht.
Naja, muss so einiges noch aufräumen. Hier mal den HTML-Code außerhalb
von PHP, dort mal mit print() ausgegeben. Manche Routinen rufen sich
selbst wieder auf und ich muss da erstmal die Ausgabe abfangen und
aufarbeiten. Erst wenn ich alles gemacht habe, kann ich diese Dinge
umbauen. Was ich in dem Zug auch noch machen werde, ist die Aufteilung
der lib.php in verschiedene Bibliotheken. Wird dann übersichtlicher :)
Udo Neist schrieb:> Man kann es so machen, aber Sinn von dieser Templates ist eigentlich nur> die Trennung von Code und Darstellung. Das Design würde ich ganz CSS> überlassen. Die Basis stellt standard/partdb.css dar. Alle Varianten> werden zusätzlich geladen und ergänzen/überschreiben die vorherigen> Definitionen. Wenn es gewünscht wäre, könnte man neben dem CSS auch noch> die Templates freigeben und würde dann analog zum CSS ein> Unterverzeichnis in templates/ anlegen.
OK. Aber wenn es theoretisch möglich ist, durch vlib verschiedene
Templates zu erstellen, würde es vielleicht auch nicht schaden wenn man
das soweit schonmal vorbereiten würde. Also einfach das, was jetzt im
template/ Ordner liegt, einfach noch eine Ebene tiefer schieben, also
z.B. template/standard/. Sollte ja nicht weiter stören, würde aber eine
spätere Nachrüstung von zusätzlichen Templates erleichtern.
> Eventuell einfach ein div-Element bauen, das die Dialoge aufnimmt. So> können wir die nicht immer gerade hübschen Dialoge der Browser umgehen.> Wäre dann auch für die PopUps nutzbar. Nur lasse ich das erstmal weg.> Die Änderungen dazu würden erstmal stören.
Stimmt, im IE sehen die Dialoge nicht gerade hübsch aus. Im FF finde ich
sie aber eigentlich sehr schön.
> Naja, muss so einiges noch aufräumen. Hier mal den HTML-Code außerhalb> von PHP, dort mal mit print() ausgegeben. Manche Routinen rufen sich> selbst wieder auf und ich muss da erstmal die Ausgabe abfangen und> aufarbeiten. Erst wenn ich alles gemacht habe, kann ich diese Dinge> umbauen. Was ich in dem Zug auch noch machen werde, ist die Aufteilung> der lib.php in verschiedene Bibliotheken. Wird dann übersichtlicher :)
Daran habe ich auch schon gedacht, die lib.php ist echt schon ziemlich
umfangreich. Auch würde ich vielleicht noch ein paar Dateinamen ändern,
z.B. config_page.php ist ein etwas komischer Name für diese Seite.
Urban B. schrieb:> OK. Aber wenn es theoretisch möglich ist, durch vlib verschiedene> Templates zu erstellen, würde es vielleicht auch nicht schaden wenn man> das soweit schonmal vorbereiten würde. Also einfach das, was jetzt im> template/ Ordner liegt, einfach noch eine Ebene tiefer schieben, also> z.B. template/standard/. Sollte ja nicht weiter stören, würde aber eine> spätere Nachrüstung von zusätzlichen Templates erleichtern.
Kann ich machen, ist ja kein großes Thema. Ich werde dann aber die
Variable $css in $theme umbenennen.
> Stimmt, im IE sehen die Dialoge nicht gerade hübsch aus. Im FF finde ich> sie aber eigentlich sehr schön.
Am besten mal in die ToDo-Liste aufnehmen, das man die Dialoge/PopUps
ändern sollte. Auch gleich mal daran denken, die Frame-Sache
umzustellen, da diese ja schon seit Jahren als Auslaufmodell gelten und
irgendwann nicht mehr unterstützt werden. Per XMLHttpRequest lässt es
sich leichter arbeiten (GET, POST) und in ein DIV-Element reinschreiben
(Suchbegriff: Ajax)
> Daran habe ich auch schon gedacht, die lib.php ist echt schon ziemlich> umfangreich. Auch würde ich vielleicht noch ein paar Dateinamen ändern,> z.B. config_page.php ist ein etwas komischer Name für diese Seite.
setup_db.php und setup_system.php?
Udo Neist schrieb:> Kann ich machen, ist ja kein großes Thema. Ich werde dann aber die> Variable $css in $theme umbenennen.
Wie würdest du die Idee finden, wenn wir die CSS-Dateien gleich in die
jeweiligen template-Ordner verschieben würden? Dann hat quasi jedes
Template (falls es mal noch andere geben wird) seine eigenen
CSS-Dateien. So wäre man dann relativ flexibel was die Gestaltung
angeht.
Muss ja nicht sein dass es mal noch andere Templates gibt. Aber ich bin
da jeweils der Meinung man sollte sich alle Möglichkeiten offenhalten.
Was im jetztigen Moment nur eine kleine Änderung bedeutet, kann später
mal vier Arbeit geben das umzurüsten.
Udo Neist schrieb:> Am besten mal in die ToDo-Liste aufnehmen, das man die Dialoge/PopUps> ändern sollte. Auch gleich mal daran denken, die Frame-Sache> umzustellen, da diese ja schon seit Jahren als Auslaufmodell gelten und> irgendwann nicht mehr unterstützt werden. Per XMLHttpRequest lässt es> sich leichter arbeiten (GET, POST) und in ein DIV-Element reinschreiben> (Suchbegriff: Ajax)
Kann ich so mal in die ToDO-Liste aufnehmen.
Udo Neist schrieb:> setup_db.php und setup_system.php?
Ja, oder noch näher ans Menü angelehnt config_db.php und
config_system.php
Vielleicht könnte man das auch für die anderen Dateien so übernehmen,
also edit_footprints.php, edit_supplier.php usw.
Urban B. schrieb:> Wie würdest du die Idee finden, wenn wir die CSS-Dateien gleich in die> jeweiligen template-Ordner verschieben würden? Dann hat quasi jedes> Template (falls es mal noch andere geben wird) seine eigenen> CSS-Dateien. So wäre man dann relativ flexibel was die Gestaltung> angeht.>> Muss ja nicht sein dass es mal noch andere Templates gibt. Aber ich bin> da jeweils der Meinung man sollte sich alle Möglichkeiten offenhalten.> Was im jetztigen Moment nur eine kleine Änderung bedeutet, kann später> mal vier Arbeit geben das umzurüsten.
Ich habe es derzeit so umgesetzt, das CSS und Templates getrennt sind.
Aber ich kann prüfen, ob es in den Templates auch eine partdb.css gibt
und die zusätzlich zum Standard laden. Alternativ wird die
standardmäßige CSS-Datei in die Theme-CSS integriert und man lädt in der
vlib_head.tmpl nur noch ein CSS.
>> Am besten mal in die ToDo-Liste aufnehmen, das man die Dialoge/PopUps>> ändern sollte. Auch gleich mal daran denken, die Frame-Sache>> umzustellen, da diese ja schon seit Jahren als Auslaufmodell gelten und>> irgendwann nicht mehr unterstützt werden. Per XMLHttpRequest lässt es>> sich leichter arbeiten (GET, POST) und in ein DIV-Element reinschreiben>> (Suchbegriff: Ajax)>> Kann ich so mal in die ToDO-Liste aufnehmen.
:-)
>> setup_db.php und setup_system.php?>> Ja, oder noch näher ans Menü angelehnt config_db.php und> config_system.php> Vielleicht könnte man das auch für die anderen Dateien so übernehmen,> also edit_footprints.php, edit_supplier.php usw.
config_db.php existiert bereits. Darin hab ich die
Datenbankkonfiguration ausgelagert, um schneller zwischen verschiedenen
Rechner/Datenbanken umswitchen zu können (entwickel ja nicht nur hier zu
Hause ;-) ).
Udo Neist schrieb:> Ich habe es derzeit so umgesetzt, das CSS und Templates getrennt sind.> Aber ich kann prüfen, ob es in den Templates auch eine partdb.css gibt> und die zusätzlich zum Standard laden. Alternativ wird die> standardmäßige CSS-Datei in die Theme-CSS integriert und man lädt in der> vlib_head.tmpl nur noch ein CSS.
Oder man macht es wie bisher, aber man soll dann in der Konfiguration
Template und CSS separat, voneinander unabhängig wählen können. Zuerst
dachte ich man soll einfach Template und CSS gleichnamig machen um sie
so quasi miteinander verknüpfen zu können, aber das ist auch nichts weil
es dann auch für jede CSS ein eigenes Template geben muss...
Udo Neist schrieb:> config_db.php existiert bereits. Darin hab ich die> Datenbankkonfiguration ausgelagert, um schneller zwischen verschiedenen> Rechner/Datenbanken umswitchen zu können (entwickel ja nicht nur hier zu> Hause ;-) ).
Ah ja daran habe ich gar nicht gedacht dass es die Datei schon gibt.
Allerdings wenn man sich überlegt dass der grösste Teil der
Konfiguration eh in die Datenbank ausgelagert werden soll, würde
schlussendlich eh nur noch die Datenbankkonfiguration übrig bleiben, und
die könnte man ja in der config.php belassen.
Urban B. schrieb:> Oder man macht es wie bisher, aber man soll dann in der Konfiguration> Template und CSS separat, voneinander unabhängig wählen können. Zuerst> dachte ich man soll einfach Template und CSS gleichnamig machen um sie> so quasi miteinander verknüpfen zu können, aber das ist auch nichts weil> es dann auch für jede CSS ein eigenes Template geben muss...
Ich habe jetzt CSS und Template zusammengeführt. Das Thema "Greenway"
setzt das Thema "standard" vorraus. Wenn man das CSS eines Themas
anpassen will, so sollte man jetzt ein neues Thema erstellen (kopieren
des alten). Ein Alternativ-CSS geht derzeit nicht.
> Ah ja daran habe ich gar nicht gedacht dass es die Datei schon gibt.> Allerdings wenn man sich überlegt dass der grösste Teil der> Konfiguration eh in die Datenbank ausgelagert werden soll, würde> schlussendlich eh nur noch die Datenbankkonfiguration übrig bleiben, und> die könnte man ja in der config.php belassen.
Ich würde nicht alles in die Datenbank auslagern, sondern eine
Basisinstallation machen. Damit ist das System immer lauffähig und zudem
hat man die Defaults für einen neuen User auch gleich :)
PS: Revision 486 ist zwar hochgeladen, aber irgendwas ist schief
gelaufen. Da fehlen einige Dateien :(
Udo Neist schrieb:> Ich würde nicht alles in die Datenbank auslagern, sondern eine> Basisinstallation machen. Damit ist das System immer lauffähig und zudem> hat man die Defaults für einen neuen User auch gleich :)
Also wenn ich mir die config.php (aus dem trunk) so anschaue, sehe ich
da ausser dem Datenbankzeugs und dem Zeichensatz keine wichtigen
Einstellungen. Die Seite würde auch ohne diesen ganzen Kram laufen, also
auch wenn die Einstellungen in der Datenbank fehlen würden. Viele von
diesen Einstellungen würden vor allem auch benutzerbezogen Sinn machen,
also müssten sie sowieso aus der config.php raus. Und defaults können
direkt bei der Auswertung gesetzt werden, so ist es jetzt ja
(teilweise?) auch schon gemacht. Ist eine Einstellung in der config.php
nicht vorhanden, wird einfach ein default-Wert genommen. Theoretisch
könnte man dazu sogar noch eine zusätzliche Datei defaults.php anlegen,
in der die Standardwerte stehen (und da drin hat der User nichts zu
suchen).
Bei der Benutzerverwaltung würde es Sinn machen wenn man den Gruppen
alle benutzerspezifischen Einstellungen zuordnen kann. Wird dann ein
neuer Benutzer angelegt, soll man bei jeder benutzerspezifischen
Einstellung wählen können ob die Einstellung von der entsprechenden
Gruppe übernommen werden soll, oder ob man die Einstellung manuell
setzen möchte.
Urban B. schrieb:> Ist eine Einstellung in der config.php> nicht vorhanden, wird einfach ein default-Wert genommen. Theoretisch> könnte man dazu sogar noch eine zusätzliche Datei defaults.php anlegen,> in der die Standardwerte stehen (und da drin hat der User nichts zu> suchen).
In einer defaults.php könnten wir alle Überprüfungen der Einstellungen
einbauen und mit den gültigen Möglichkeiten vergleichen. Alles was nicht
passt oder fehlt wird dort entsprechend gesetzt.
> Bei der Benutzerverwaltung würde es Sinn machen wenn man den Gruppen> alle benutzerspezifischen Einstellungen zuordnen kann. Wird dann ein> neuer Benutzer angelegt, soll man bei jeder benutzerspezifischen> Einstellung wählen können ob die Einstellung von der entsprechenden> Gruppe übernommen werden soll, oder ob man die Einstellung manuell> setzen möchte.
Was Gruppen- und was Userrechte sein sollen, das müssen wir eh noch
zusammentragen. Dann erst sehen wir, was über die config.php geladen
wird und was wir über die Benutzerverwaltung an Variablen setzen müssen.
Solange macht es keinen Sinn, über diese Baustelle zu reden.
Udo Neist schrieb:> In einer defaults.php könnten wir alle Überprüfungen der Einstellungen> einbauen und mit den gültigen Möglichkeiten vergleichen. Alles was nicht> passt oder fehlt wird dort entsprechend gesetzt.
Klingt gut. Aber ich frage mich gerade was da drin dann noch landet wenn
eh fast alle Einstellungen in der Datenbank stehen. Diese Einstellungen
werden dann ja eh über eine Funktion, so wie jetzt in der lib.php, an
einer zentralen Stelle aus der Datenbank gelesen. Würde in der Datenbank
was fehlerhaftes stehen, würde dies gleich in dieser Funktion drin
korrigiert werden.
Udo Neist schrieb:> Was Gruppen- und was Userrechte sein sollen, das müssen wir eh noch> zusammentragen. Dann erst sehen wir, was über die config.php geladen> wird und was wir über die Benutzerverwaltung an Variablen setzen müssen.> Solange macht es keinen Sinn, über diese Baustelle zu reden.
Ja, ich wollte nur mitteilen, dass ich es als wenig sinnvoll betrachte
die Konfiguration auf zwei verschiedene Dateien aufzuteilen, wenn es
später eh nur noch eine handvoll hardgecodete Einstellungen geben wird.
Dann wäre die config_db.php wieder frei für die Einstellungsseite der
Datenbank :-D
Revision 487 mit den obigen Änderungen und einigen weiteren Umstellungen
auf Templates hochgeladen :-) Ich werde noch die IC-Logos und Footprints
heute umstellen. Dann ist für heute Feierabend.
Letztes Update für heute ;-) Revision 488 mit den geänderten
footprints.php und iclogos.php. Bei letzterem würde ich auch eine
Übertragung in die Datenbank empfehlen, denn dann könnte man mehrere
Dinge machen:
- Ausgabe der Logos in einer Schleife anstelle einer statischen Datei
- Mehrere Logos einer Firma in einer Zeile ausgeben
- Zuordnung von Bauteilen zu einer Firma, insbesondere wenn ganz
bestimmte Eigenschaften dieses Bauteils wichtig sind und kein 2nd Source
gewünscht ist (Projektverwaltung)
Ab morgen werde ich die restlichen Dateien auf Templates umstellen und
dann die Funktionen noch bereinigen. Ich werde abends das Ergebnis
hochladen und hier kurz beschreiben, was geändert wurde.
Ja, das wäre keine schlechte Idee mit den Herstellerlogos. Eigentlich
könnte man doch da mehr oder weniger das Footprintsystem einfach
kopieren oder?
Es soll nicht nur auf die Hersteller beschränkt sein, von denen wir die
Logos haben. Es sollen auch eigene Hersteller hinzugefügt werden können.
Meine Rede :-)
Noch ein paar Ideen zu den IC-Logos:
- Webseite
- Info zu welcher Firma die Firma jetzt gehört oder ob sie nicht mehr
existiert
Daneben können wir doch noch die Logos und Footprints mit einer
Versionsnummer versehen und per Updatefunktion holen. Die Infos kann man
in der Datenbank unterbringen. Die Webseite selbst gibt alle Versionen
in einer Liste aus und ein Script lädt aufsteigend bis zur letzten
Version alle Updates. Das lässt sich eventuell auf der Konsole per
cronjob automatisieren.
Udo Neist schrieb:> Meine Rede :-)>> Noch ein paar Ideen zu den IC-Logos:> - Webseite> - Info zu welcher Firma die Firma jetzt gehört oder ob sie nicht mehr> existiert
Hab daraus mal "Issue 26" gestrickt.
Udo Neist schrieb:> Daneben können wir doch noch die Logos und Footprints mit einer> Versionsnummer versehen und per Updatefunktion holen. Die Infos kann man> in der Datenbank unterbringen. Die Webseite selbst gibt alle Versionen> in einer Liste aus und ein Script lädt aufsteigend bis zur letzten> Version alle Updates. Das lässt sich eventuell auf der Konsole per> cronjob automatisieren.
Das versteh ich jetzt nicht ;-)
Die Bilder werden ja durch das SVN stets aktualisiert?
Und wozu soll eine Versionsnummer gut sein?
Urban B. schrieb:>> Noch ein paar Ideen zu den IC-Logos:>> - Webseite>> - Info zu welcher Firma die Firma jetzt gehört oder ob sie nicht mehr>> existiert>> Hab daraus mal "Issue 26" gestrickt.
:-)
> Das versteh ich jetzt nicht ;-)> Die Bilder werden ja durch das SVN stets aktualisiert?> Und wozu soll eine Versionsnummer gut sein?SVN ist gut, aber nicht zu allem zu gebrauchen. In der Praxis wird man
einmal installieren und über eine Update-Funktion auf dem Laufenden
bleiben wollen. Hier sind die meisten doch eher konservativ und wollen
nur von uns freigebene Versionen haben. Das SVN gibt aber nur die
Entwicklerversion her, das ist denen zu unsicher. Mit den Updates von
Script, Logo und Footprints in getrennten Aktionen haben wir zudem auch
noch Vorteile bei der Bandbreite. Und ob wir nur Script oder auch noch
die Grafiken als weiteres Update anbieten, dürfte doch kein Problem
sein. Die Versionsnummer ist nur für den Abgleich gedacht. Kann ja auch
einfach nur das Releasedatum des Paketes sein. Zudem können wir ja auch
ein Release aus der Datenbank herausnehmen und ein Downgrade
veranlassen.
So in etwa werden auch AddOns bei diversen Softwarepaketen gehandhabt
:-)
Ah, so meinst du das. Das würde dann zum Issue 4 gehören
(http://code.google.com/p/part-db/issues/detail?id=4).
Ich würde dann schon eher nur das Releasedatum der Pakete als
Versionskontrolle nehmen, jedes Bild / jede Datei einzeln finde ich
übertrieben.
Genau. Es ist Teil des Updates. Ich meinte aber nicht das jedes einzelne
Bild upgedatet wird. Wäre irrsinnig. Ne, wenn ein Update bei den Logos
oder Footprints gemacht werden soll, dann werden alle neuen Grafiken in
ein (!) Update-Archiv gepackt. So gibt es entweder zwei Updatevarianten
(Script und Grafiken) oder drei (Script, Logos, Footprints). Damit man
aber weiß, welche Grafikpakete installiert sind, sollen diese Pakete
eine unabhängige Nummer bekommen. Ein Update des Scripts erzwingt dann
aber auch eine Aktualisierung der Grafiken.
Ein Beispiel:
Installiert sind Script R488, Logo R3, Footprints R3. Es stehen Script
R495, Logo R5 und Footprints R8 zur Verfügung. Das Script-Update holt
R495, die Logos R4 bis R5 und die Footprints R4 bis R8. Würde man nur
die Grafiken updaten, würden R4 bis R5 bzw. R4 bis R8 geladen.
Ich hoffe, es ist verständlich geworden :)
Naja aber da würde ich dann nur ein einziges Update anbieten, und zwar
gleich für alles zusammen. Ich finde es macht keinen Sinn nur ein Teil
von Part-DB zu aktualisieren. Das macht es doch nur unnötig kompliziert.
Ist ja nur ein Vorschlag von mir :-) Ich entscheide ja nicht, was ihr zu
machen habt. Ich bin ja der Neuling in eurem Projekt.
Ich hab noch einen Fehler entdeckt. Die Funktion get_svn_revision()
läuft anscheinend nach der Änderung vor einigen Tagen immer noch nicht
richtig. Ich teste gleich mal ein Bugfix aus.
Udo Neist schrieb:> Ist ja nur ein Vorschlag von mir :-) Ich entscheide ja nicht, was ihr zu> machen habt. Ich bin ja der Neuling in eurem Projekt.
Naja so viel länger bin ich auch nicht dabei ;-)
Bezüglich automatisches Update habe ich mir mal ein paar Gedanken
gemacht:
In einer Funktion wird eine Textdatei direkt von Google Code
heruntergeladen. In dieser Textdatei steht die Versionsnummer des
aktuellsten zur Verfügung stehenden Pakets, und die URL zum Paket. Ist
die Versionsnummer neuer als die installierte Version, wird das gepackte
Archiv heruntergeladen. Danach einfach per exec("gzip ...") entpackt und
alle veralteten Dateien werden mit den neuen überschrieben.
Stelle ich mir das zu einfach vor, oder wäre das so tatsächlich möglich?
gzip sollte eigentlich ziemlich jeder Hoster anbieten oder?
So etwa dachte ich mir das auch. Ob gzip auf jedem Server installiert
ist, kann ich nicht beurteilen. Man sollte vielleicht mehrere Archive
anbieten?
Mir fällt gerade noch was ein. Warum sind eigentlich die Grafiken im
Verzeichnis tools und nicht in img?
Das mit den Mouse-Over Footprints stört mich ehrlich gesagt auch etwas.
Vielleicht kann das das Mouse-Over durch einfache Links ersetzen?
Wenn das mit der Benutzerverwaltung fertig ist erübrigt sich ja eine
"einfache" Upgradefunktion, da ein normaler User damit dann ja nichts
mehr zu tun hat. Die Upgrades würden dann ja von den Entwicklern
eingepflegt nachdem diese getestet wurden.
Stefan schrieb:
> - Ich wünschte mir eine Art Log, das anzeigt, wann und wie viele einer> Baugruppe gebucht wurden. Dort könnte man eine Buchung -hoffentlich-> auch rückgängig machen, sofern man aus Versehen mal 'was Falsches> eingegeben hat.
Ja, das wäre praktisch.
Urban B. schrieb:
> Keine schlechte Idee, vorallem auch im Bezug auf die Benutzerverwaltung> die ja noch kommen soll. Dann könnten die "Admins" auch nachvollziehen> was andere Leute so in der Datenbank "rumfummeln" und können> Fehlbuchungen rückgängig machen. Würde ich als durchaus nützlich> betrachten.
Naja, die User hätten doch eh alle ihre eigenen Lagerplätze und
Stückzahlen, somit hätten die Admins damit ja garnichts zu tun.
Die Admins hätten ja nur damit was zu tun, was "global" benutzt wird
(Footprints, Datasheets, usw.), aber Benutzerspezifische Dinge wie
"Lagerort oder Stückzahl" ändert ja jeder User nur für sich selber.
Christian R. schrieb:> Naja, die User hätten doch eh alle ihre eigenen Lagerplätze und> Stückzahlen, somit hätten die Admins damit ja garnichts zu tun.> Die Admins hätten ja nur damit was zu tun, was "global" benutzt wird> (Footprints, Datasheets, usw.), aber Benutzerspezifische Dinge wie> "Lagerort oder Stückzahl" ändert ja jeder User nur für sich selber.
Es müssen ja nicht die eigentlichen Admins eingreifen, es könnten ja
auch Gruppenadmins geben, die das für ihren Bereich dürfen.
Aber was genau soll ein Gruppenadmin da dann machen?
Wenn ein User seinen Bestand 330-Ohm-Widerstände von 100 auf 50 ändert
oder seine Lagerfächer umstrukturiert ist das doch seine Sache, das
betrifft auch nur den User selber. Wenn ein User hingegen den
Conrad-Preis dieses Widerstandes ändert, sich dabei jedoch vertan hat,
dann betrifft das alle User ...und somit ist das ein Fall für die
Admins.
Udo Neist schrieb:> Mir fällt gerade noch was ein. Warum sind eigentlich die Grafiken im> Verzeichnis tools und nicht in img?
Das weiss ich auch nicht. Würde eigentlich Sinn machen, das nach img zu
verschieben...
Christian R. schrieb:> Wenn das mit der Benutzerverwaltung fertig ist erübrigt sich ja eine> "einfache" Upgradefunktion, da ein normaler User damit dann ja nichts> mehr zu tun hat. Die Upgrades würden dann ja von den Entwicklern> eingepflegt nachdem diese getestet wurden.
Naja die meisten Leute werden wohl ihre Lagerverwaltung auf ihrem
eigenen Server laufen lassen wollen, für diejenigen sind sie
Update-Pakete gedacht.
Christian R. schrieb:> Naja, die User hätten doch eh alle ihre eigenen Lagerplätze und> Stückzahlen, somit hätten die Admins damit ja garnichts zu tun.> Die Admins hätten ja nur damit was zu tun, was "global" benutzt wird> (Footprints, Datasheets, usw.), aber Benutzerspezifische Dinge wie> "Lagerort oder Stückzahl" ändert ja jeder User nur für sich selber.
Die Benutzerverwaltung soll (wie ich finde) in erster Linie dazu da
sein, dass man seine eigene Part-DB-Installation auch anderen Leuten
(Kumpels, Mitarbeiter, ...) zur Verfügung stellen kann. Und vor allem
für den (mehr oder weniger) professionellen Einsatz in einer (kleinen)
Firma ist es unverzichtbar, da sollen nunmal Einkäufer, Verkäufer,
Lagerist und Elektroniker unterschiedliche Rechte haben, und der
Lagerist soll nachvollziehen (und rückgängig machen) können, was die
anderen (falsch) gemacht haben :-)
Achso, dann habe ich das falsch verstanden.
Ich dachte dabei halt an myparts.info , wo eine große Datenbank von
vielen vielen Usern genutzt werden soll. Die meisten der User werden
vermutlich normale "Hobbyelektroniker" sein, welche keinen Server haben
und ein relativ kleines Lager.
Für die professionelle Anwendung sieht das natürlich wieder ganz anders
aus.
Japp. Wir müssen beide Fälle betrachten. Im Normalfall wird es also nur
eine Gruppe geben, in der auch nur ein User arbeitet (Standalone). Hier
brauchen wir keine Benutzerverwaltung. In einer Firma wird es
unterschiedliche Gruppen geben, die unterschiedliche Arbeiten tun
sollen. Das Lager bearbeitet nur Lager und kennt die Baugruppen nicht.
Auf unserem Server müssen wir quasi eine Firma nachbilden, in der es
nicht nur eine Gruppe mit verschiedenen Rechten gibt, sondern mehrere.
Wobei in einer Gruppe alle Personen mit gleichen Rechten und in einer
anderen verschiedene Rechte bzw. Rollen geben könnte.
Mir schwebt sowas wie folgt vor:
1
- Firma bzw. Projekt
2
-> Entwicklergruppe/Projekt bzw. Unterprojekt
3
-> Rolle (Lagerist, Einkäufer, Entwickler, Verkäufer etc.)
Dann gibt es aber noch den dritten Fall, für den ich extra myparts.info
registriert habe.
Das ist für "Normal-User", die sich eine Datenbank teilen.
Da ist eine Benutzerverwaltung ebenfalls erforderlich.
Geplant ist das ja so:
Ein User meldet sich an und kann dann auf die vorhandene Datenbank
zugreifen. Er sieht viele bereits angelegten Bauteile (samt Footprints,
Datenblätter, Preise,...) und braucht nur noch seine Lagerfächer
einzurichten und die Stückzahlen einzugeben. Solle er Bauteile haben
welche noch nicht angelegt sind gibt es entweder die Möglichkeit dass er
das Bauteil selber anlegen kann, oder dass er es auf eine Liste schreibt
und Moderatoren dieses dann anlegen. Das war noch nicht geklärt wie man
das dann handhaben will.
Auf jeden Fall hat das gegenüber der Einzelversion folgende Vorteile:
-Ein User benötigt keinen Webspace und auch keinen virtuellen Server
-Ein User erspart sich eine Menge Arbeit beim anlegen der Bauteile, der
Suche nach dem Datenblatt, Zuordnung der Footprints usw. , denn diese
sind größtenteils schon angelegt.
-Wenn ein User einen Preis aktualisiert profitieren alle User davon,
somit sind die Daten allgemein aktueller.
Revision 491: orderparts.php umgeschrieben. Infolge dessen auch die
lib.php angepasst. print_http_charset() wird nach dem Umschreiben
entfallen, da diese Funktion als Variable in vlib_head.tmpl steckt.
So, ein kleines Update für die Reihenfolge der Arbeit mit SVN:
Arbeitskopie mit dem Server abgleichen
1
svn up
Konflikte mit den Mitteln von SVN lösen und ggfs. in die eigene
Arbeitskopie einpflegen.
Backupdateien löschen (mein Editor ist Quanta+ und der legt Backups mit
der Tilde am Ende an)
1
find . -name "*~" -exec rm {} \;
Neue Dateien und Verzeichnisse aufnehmen
1
svn add * --force
Commit der Version mit COMMENT als Kommentar
1
svn commit -m "COMMENT"
Arbeitskopie mit dem Server abgleichen, um die Revision upzudaten. Gibt
sonst ein Konflikt bei einem weiteren commit.
@Christian R.
Ja, ich weiss dass diese Art von Benutzerverwaltung noch geplant ist.
Aber ich denke in erster Linie sollte es mal eine Benutzerverwaltung für
den Einsatz in einer kleinen Firma geben. Du musst etwas Geduld haben,
es dauert halt bis neue Features eingebaut werden ;-D
@Udo Neist
hmm jetzt hast du für das greenway-css extra ein neues Template erzeugt?
Eigentlich wollte ich das vermeiden weil es umso aufwändiger wird eine
Änderung einfliessen zu lassen... Deshalb dachte ich man sollte auch
mehrere CSS-Dateien zu einem Template zuordnen können, das würde die
Wartung einfacher machen.
Übrigens habe ich festgestellt, dass auf Win7 (IE und FF) das Suchfeld
nur gerade etwa halb so gross ist wie auf Linux (FF). Könnt ihr das auch
nachvollziehen?
Ich habe nämlich extra mal die Feldlänge ein bisschen reduziert damit
das Feld und der "Los"-Button noch nebeneinander Platz haben. Wenn es
jetzt aber auf Win7 einfach viel zu kurz ist, ist das auch nicht das was
ich erreichen wollte ;-)
Ich habe heute wiedermal ein bisschen um Part-DB herumstudiert. Zwei
Sachen haben mich beschäftigt:
Einerseits denke ich es wäre von (grossem) Vorteil, wenn wir auf
objektorientierte Programmierung umrüsten. Das würde das Ganze viel
übersichtlicher, weniger fehleranfällig und einfacher wartbar machen
(denke ich zumindest :-). Für die ganzen Klassen könnten wir gleich das
Verzeichnis class/ benutzen, dass Udo für die vlib angelegt hat. Dann
könnten wir unsere lib.php durch folgende Dateien ersetzen:
1
class/footprint.php
2
class/storeloc.php
3
class/supplier.php
4
usw.
Und dann habe ich mir noch ein paar Gedanken zur Benutzerverwaltung
gemacht. Aus den Gedanken heraus sind dann die zwei Tabellen im Anhang
entstanden.
Für die Rechte habe ich mir überlegt, wir machen das ähnlich wie bei den
Unix-Dateirechten. Diese sind aber eher nicht passend genug für unseren
Einsatz um sie einfach 1:1 zu übernehmen. Stattdessen dachte ich, es
soll statt der drei Attributen (Lesen, Schreiben, Ausführen) diese sechs
Attribute geben:
1
- Erben von übergeordnetem Element (schliesst die nachfolgenden Attribute aus)
2
- Betrachten
3
- Bearbeiten
4
- Erstellen
5
- Löschen
6
- Verschieben
Mit diesen Attributen könnten wir schon sehr viel erreichen. Dort wo es
nicht genügt und spezielle Attribute notwendig sind (oder eine feinere
Unterteilung möglich sein soll) (wie z.B. bei den "perms_parts_*")
verwendet man halt für jedes einzelne Element eine Datenbankspalte.
Ich finde es wichtig, dass man das Attribut "Erben" einstellen kann. So
kann man einer Gruppe die Rechte zuteilen, und jeder Benutzer dieser
Gruppe erhält automatisch die selben Rechte (sofern "Erben" eingestellt
ist).
Diese Attribute könnten wir wie beim Unix-Rechtesystem einfach als
Integer in der Datenbank abspeichern. Wie es genau codiert werden soll
(Reihenfolge) habe ich noch nicht festgelegt. Im Anhang habe ich noch
den Wert "-1" für das Attribut "Erben" und "255" für "vollumfängliche
Rechte" verwendet, ist aber erstmal uninteressant wofür das nun stehen
soll.
Für die Benutzerverwaltung für myparts.info habe ich mir überlegt, man
soll jedem Benutzer (bzw. Gruppe) die Tabellen für Baugruppen, Lagerorte
usw. zuordnen können. Dazu sind die "dataset_*" Einträge da. Für die
Kategorien, Lieferanten und Footprints wird es auf myparts.info
vermutlich nur ein solches Datenset für alle Benutzer geben
(Vollständigkeitshalber habe ich sie trotzdem mal als "variabel"
angenommen und in die Tabelle aufgenommen). Man könnte aber auch einer
Gruppe ein anderes Datenset zuweisen, dann teilen nur die User innerhalb
dieser Gruppe alle Datensätze.
Das Datenset sollte übrigens besser nur beim Anlegen eines Benutzers
zugewiesen werden. Wird nachträglich was verändert an diesen IDs, wird
es zu einem ziemlichen Durcheinander kommen.
Natürlich fehlt in meinen Überlegungen noch einiges (z.B. die Anpassung
der bestehenden Tabellen an das DatenSet-System). Vielleicht habe ich
sogar noch einen groben Überlegungsfehler gemacht, so dass das System
gar nicht so funktionieren kann wie ich es hier beschreibe.
Ich wäre froh wenn ihr euch das mal kurz (oder besser lange :-)
anschauen könntet und berichtet was ihr davon haltet.
mfg
EDIT: Die Gruppe "Administratoren" könnte man auch löschen. Würde ich
schöner finden :-) Der Benutzer "admin" braucht ja nicht unbedingt eine
Gruppe denke ich...
Urban B. schrieb:> Übrigens habe ich festgestellt, dass auf Win7 (IE und FF) das Suchfeld> nur gerade etwa halb so gross ist wie auf Linux (FF). Könnt ihr das auch> nachvollziehen?
Lag wohl daran dass die Anzahl Zeichen als Breite angegeben war. Die
Breitenangabe in Pixel soll da zuverlässiger sein (im Internet gelesen),
hab das nun mal so ins SVN geladen. Bei mir funktionierts jetzt
jedenfalls auf Win7 (FF / IE) und Linux (IE).
Bitte melden wenns bei jemanden nicht passt, dann machen wir das Feld
halt noch ein bisschen schmaler.
Die Aufteilung der lib.php sollte man schon angehen. Für den Anfang
würde ich die Teile der lib.php in ein neues Verzeichnis lib/
unterbringen und später die OO-Teile in die Klasse verschieben. Für die
Übergangszeit würde in der libs/xxx.php dann ein Wrapper für die
entsprechende Klasse existieren, bis dieser Aufruf dann aus allen
Bereichen auf OO umgestellt wurde. So haben wir einen Überblick über die
Umstellung.
Ich habe mich noch nicht mit der Datenbankstruktur befasst, daher kann
ich zur Benutzerverwaltung noch nichts konkretes beisteuern. Ich habe
bisher eine Hierachie genutzt, bei der Gruppen nur für die Eingrenzung
der Datensätze gedacht waren. Ob es sich lohnt, jeder Gruppe eigene
Tabelle(n) zu geben oder nur einfach pro Ebene eine Spalte mehr nimmt,
weiß ich nicht. Man könnte ja eine Arbeitsgruppe 1 mit Untergruppen 1, 2
und 3 haben, die ihren jeweiligen Bestand bearbeiten, aber die anderen
UG nur einsehen können. Das könnte man auch auf Arbeitsgruppen
ausweiten, so dass am Ende die nächst höhere Instanz alle Bereiche
unterhalb sehen kann. Das wäre eine Zuordnungstabelle für die
Arbeitsgruppen bzw. noch eine für die Hierachie und zwei Spalten in den
anderen Tabellen. Der Nutzer könnte innerhalb der Hierachie auch UGs aus
verschiedenen AGs angehören und beim Einloggen die passende UG wählen.
So in etwa funktioniert auch meine Chemiekalienverwaltung.
Hab noch keine weiteren Änderungen machen können. Wahrscheinlich kann
ich morgen die nächste Version hochladen.
Udo Neist schrieb:> Die Aufteilung der lib.php sollte man schon angehen. Für den Anfang> würde ich die Teile der lib.php in ein neues Verzeichnis lib/> unterbringen und später die OO-Teile in die Klasse verschieben. Für die> Übergangszeit würde in der libs/xxx.php dann ein Wrapper für die> entsprechende Klasse existieren, bis dieser Aufruf dann aus allen> Bereichen auf OO umgestellt wurde. So haben wir einen Überblick über die> Umstellung.
Naja ich weiss nicht ob es sinnvoll ist, jetzt noch eine Übergangslösung
anzugehen. Da würde ich lieber noch einen Moment warten und dann die
Umstellung auf OO gleich in einem Mal machen.
Udo Neist schrieb:> Ich habe mich noch nicht mit der Datenbankstruktur befasst, daher kann> ich zur Benutzerverwaltung noch nichts konkretes beisteuern. Ich habe> bisher eine Hierachie genutzt, bei der Gruppen nur für die Eingrenzung> der Datensätze gedacht waren. Ob es sich lohnt, jeder Gruppe eigene> Tabelle(n) zu geben oder nur einfach pro Ebene eine Spalte mehr nimmt,> weiß ich nicht.
Eigene Tabellen würde ich nicht machen, finde ich "unschön", dann
explodiert unsere Datenbank für myparts.info. Mit den Datensets dachte
ich einfach an eine zusätzliche Spalte in den bestehenden Tabellen, mit
der ID des Datensets, dem die Einträge angehören.
Ich denke, das was ich "Datenset" nenne ist mehr oder weniger das, was
du unter "Arbeitsgruppe" verstehst. Dass ein User auch mehreren
Datensets angehören kann (und dieses beim Einloggen wählt), daran dachte
ich bisher noch gar nicht. Würde eigentlich Sinn machen, da hast du
recht.
Wir müssen nur aufpassen, dass es durch die Datensets kein Durcheinander
gibt. Ein Bauteil muss dann z.B. nicht mehr nur die ID des Footprints
haben, sondern auch noch die ID des Datensets der entsprechenden
Footprint-Datensätzen. NACHTRAG: wobei, wenn die ID des Footprints ja
eindeutig ist, bräuchte es das gar nicht. Die zusätzliche Spalte in der
Footprint-Tabelle aber natürlich schon.
Es wird auf jeden Fall nicht ganz trivial :-D
Übrigens habe ich eine Seite gefunden, auf der es ziemlich coolen
Ajax/DHTML Kram gibt, auch unter der GPL Lizenz:
http://dhtmlx.com/docs/products/dhtmlxTree/index.shtml
Viellecht können wir davon in Zukunft noch was gebrauchen (Sichworte:
Dateiupload-Dialog, Frames)
Urban B. schrieb:> Naja ich weiss nicht ob es sinnvoll ist, jetzt noch eine Übergangslösung> anzugehen. Da würde ich lieber noch einen Moment warten und dann die> Umstellung auf OO gleich in einem Mal machen.
Solange das in meinem Branch passiert, wäre das ja kein Problem. Erst
wenn die Umstellung komplett ist, würde das dann in die offizielle
Version einfliessen. Schliesslich müssen wir nicht alle Dinge im
Hauptzweig testen.
Udo Neist schrieb:> Solange das in meinem Branch passiert, wäre das ja kein Problem. Erst> wenn die Umstellung komplett ist, würde das dann in die offizielle> Version einfliessen. Schliesslich müssen wir nicht alle Dinge im> Hauptzweig testen.
Ja, das habe ich mir auch irgendwie so vorgestellt.
Stefan --- schrieb:> wenn ich mit TortoiseSVN auf http://part-db.googlecode.com/svn/trunk/> part-db> einen 'Fully Recursive' Checkout mache, bekomme ich folgende> Fehlermeldung:> URL 'http://part-db.googlecode.com/svn/trunk/%20part-db'; doesn't exist>> Hat jemand einen Tip für mich ?
Ja, den Befehl, den ich dir oben mal geschickt habe, hat nach dem
Internetpfad noch ein Leerzeichen, und dann kommt der lokale Ordner wo
das Zeug heruntergeladen werden soll. So gibt man das im Terminal ein
für den "svn checkout" Befehl. Ich denke mal bei TortoiseSVN brauchst du
den lokalen Pfad nicht, sondern nur die reine URL:
Also ich habe mal mit den Klassen angefangen. Vor allem an einer Klasse
für den Datenbankzugriff habe ich gearbeitet. Dazu habe ich was ziemlich
nützliches gefunden: http://www.peterkropff.de/site/php/pdo.htm
Diese Klasse macht es möglich, dass wir später auch ganz einfach andere
Datenbanken einsetzen können. Ausserdem gibt es einige Features, die SQL
Injections stark erschweren.
Alles in allem denke ich wäre das eine gute Basis für unsere
Datenbankklasse. Ein Nachteil ist halt, dass es mindestens PHP 5.1
voraussetzt. Da aber seit PHP5 das ganze OOP nochmal verbessert wurde,
denke ich es macht schon wegen den Klassen Sinn, dass wir nun halt PHP4
nicht mehr unterstützen.
Ich denke damit kann man leben. Wer hat denn heutzutage noch PHP4? ;-)
Was mir aber noch ein bisschen Kopfzerbrechen macht, sind
Datenbankeinträge mit Zeichen wie " oder ' im Namen. Irgendwo gibts
einfach immer Konflikte. Sei es beim JavaScript Menü oder bei HTML
Elementen.
Momentan werden alle Datenbankeinträge ja noch mit
mysql_real_escape_string() bearbeitet. Aber brauchts das eigentlich? So
wie ich die Klasse momentan programmier habe, kann man problemlos
Variablen mit " und ' im Namen in der Datenbank ablegen. Die werden dann
in phpmyadmin auch genau so angezeigt, also ohne Backslashes. Auch das
holen von diesen Daten ist kein Problem. Ein Problem gibts erst wenn so
ein String als HTML Code ausgegeben wird ;-)
Einfach diese beiden Zeichen verbieten finde ich aber nicht so toll, es
kann sicher mal vorkommen dass man solche Zeichen auch wirklich
verwenden will.
Weiss jemand wie man sowas am besten löst? Vor allem wenn beide von
diesen Zeichen erlaubt sind sehe ich ein Problem. Würde man nur eines
davon verbieten, könnte man gezielt das andere Zeichen abfangen, das
wäre wohl kein grosses Problem mehr.
Normalerweise reicht das Escapen bei den Zeichen aus, um diese zu
speichern. Wenn nicht, dann als HTML kodieren und übertragen. Als letzte
Möglichkeit wäre BLOB mit base64 oder ähnliches, nur das halte ich für
übertrieben.
Ich selbst habe mir auch eine eigene Datenbankklasse geschrieben. PDO
ist dort allerdings noch ein Dummy. Die SQL-Statements werden in meiner
Klasse in ein Array gespeichert und von der Klasse dann zusammen
gesetzt. Somit wären auch Prepared Statements möglich.
Ich glaub das mit dem escapen schaue ich mir später nochmal an, dafür
habe ich keine Nerven mehr...
Übrigens habe ich jetzt mal einen neuen Branch "kami89" angelegt für die
Entwicklung der Klassen. So könnt ihr schonmal schauen was ich gemacht
habe.
Diese Version dort ist soweit lauffähig dass die ganze Startseite
aufgebaut wird inklusive dem Kategorien-Menü. Mehr läuft noch nicht.
Damit diese Kleinigkeit aber überhaupt läuft, müsst ihr eure config.php
etwas abändern (siehe template) und per phpmyadmin die Spalte
'parentnode' von der Tabelle 'categories' in 'parent_id' umbenennen ;-)
(Grund siehe class/structural_db_element.php)
In dieser Datei habe ich ein paar Notizen gemacht die mir beim
programmieren einfach so eingefallen sind.
Die wichtigsten Dateien, an denen ich gearbeitet habe, sind system.php,
database.php, structural_db_element.php und category.php. Anhand dieser
Dateien solltet ihr erkennen wie ich mir das ganze System etwa
vorstelle.
In nav.php seht ihr wie die Klassen dann später verwendet werden.
Ich arbeite noch nicht lange mit OOP (und schon gar nicht mit php^^),
also meldet euch einfach wenn euch komische Sachen auffallen :-)
Ahja, wie die Datenbank-Klasse verwendet wird ist am Anfang vielleicht
etwas schwierig zu verstehen. Es ist jetzt halt nicht mehr nur ein
mysql_query() mit dem man auf die Datenbank zugreift (und jeder weiss
wie es geht).
In meiner Klasse gibt es jetzt zwei Funktionen: exec() für Anfragen, bei
denen man keine Datenrückgabe erwartet, und query() für Anfragen mit
Datenrückgabe (also eigentlich nur SELECT).
Da es schnell passiert ist, dass man die Rückgabewerte nicht ganz sauber
verarbeitet (z.B. 0 und false nicht getrennt behandelt), habe ich
vorgefertigte Funktionen für die wichtigsten Anfragen [insert(),
delete_record(), set_data_field(), ...] erstellt. Bei diesen muss man
dann nur noch auf false oder true prüfen, was anderes geben die nicht
zurück.
Ein Nachteil davon, dass in der Klasse alles mit prepared statements
erledigt wird, ist halt dass eine Abfrage nur noch Fragezeichen als
Platzhalter für Werte enthält, und die Werte selber dann separat
übergeben werden. Ich denke aber damit kann man leben (es kommt ja auch
der Sicherheit zugute).
Ich habe an der editpartsinfo.php und startup.php gearbeitet. Die
Autoren hab ich in eine authors.php reingeschoben, damit diese in einer
Schleife in startup.php verarbeitet werden können. Das mit den Themen
ist jetzt auch geändert. Man kann eine alternative CSS in css/ angeben,
wobei diese Datei nach dem entsprechenden Thema genannt werden muss,
z.B. Greenway -> css/Greenway.css. -> Revision 498
Deine Arbeiten an der Datenbankklasse übernehme ich später, wenn ich die
Templates fertig habe.
Ich habe mal auf die schnelle eine neues Install-Script (install.sh)
geschrieben, dass das Anlegen der Datenbank (in der Version 12)
vereinfacht. In dem SQL-Script habe ich die Befehle für die Erstellung
und Rechtevergabe eingebaut.
1
DROP DATABASE IF EXISTS `DB_NAME`;
2
CREATE DATABASE `DB_NAME` DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
3
GRANT USAGE ON *.* TO `DB_NAME`@`DB_HOST` IDENTIFIED BY "DB_PASS";
4
GRANT ALL PRIVILEGES ON `DB_NAME`.`*` TO `DB_USER`@`DB_HOST`;
5
USE `DB_NAME`;
Die vier Platzhalter DB_NAME, DB_HOST, DB_USER und DB_PASS werden im
Script definiert und durch den sed (Stream EDitor) ersetzt und dann
MySQL übergeben. Das SQL-Script muss mit passenden Rechten aufgerufen
werden (Create, Grant). Es läuft unter Linux, dürfte aber auch auf
anderen Un*xen laufen.
Ist ja richtig viel los hier, sind denn alle in den Ferien? :-)
Ich könnte mal eure Hilfe gebrauchen. Und zwar will ich das neue System,
dass man einem Bauteil mehrere Lieferanten+Preise zuordnen kann, gleich
in die neuen Klassen einbauen.
Jetzt habe ich gedacht, für diese Einkaufsinformationen benutze ich
einfach die Tabelle "preise" und ändere dessen Name in "orderdetails" ab
(dann sind auch gleich alle Tabellennamen englisch^^). Da drin können
dann also pro Bauteil mehrere Einträge vorhanden sein.
Soweit, sogut. Nur muss ich jetzt mit einem Datenbankupdate die Spalten
"id_supplier" und "supplierpartnr" aus der Tabelle "parts" in diese (bis
jetzt) "preise" Tabelle hineinkriegen, ohne dass dabei etwas kaputt
geht.
Da bis jetzt in der Tabelle "preise" nur Einträge von Teilen existieren,
denen mal ein Preis zugewiesen wurde, müssen jetzt teilweise also auch
neue Einträge angelegt werden, für diejenigen Teile denen zwar ein
Lieferant, aber kein Preis zugewiesen wurde. Bei Teilen mit Preis muss
der bereits vorhandene Eintrag in "preise" einfach überschrieben werden.
Tja, nun kenne ich mich mit SQL leider etwas zu wenig aus um das
hinzukriegen. Kann mir da jemand auf die Sprünge helfen?
Die Spalten "id_supplier" und "supplierpartnr" existieren
interessanterweise schon in der Tabelle "preise", haben aber kein
Inhalt...Ob da wohl schonmal was vorbereitet wurde für genau das, was
ich jetzt machen will?
Zum Thema Klassen:
So langsam nimmt das Ganze Form an. Allerdings ist es gar nicht so
einfach, eine saubere objektorientierte Programmierung hinzubekommen
ohne dass die Performance stark leidet. Die ganzen (komplizierten)
SQL-Abfragen, wie sie bisher genutzt werden, sind halt performancemässig
einfach unschlagbar.
Ich möchte nun aber eigentlich viel mehr mit Objekten herumhantieren
statt nur mir den Daten (Arrays), die von den SQL-Abfragen zurückkommen.
Und da kommt halt schnell mal einiges an Overhead zusammen.
Naja, ich habs jetzt mal so gemacht dass die zeitintensiven Funktionen
wirklich erst bei Bedarf aufgerufen werden, und dann bis zum nächsten
Abrufen zwischengespeichert werden. Zum Beispiel die Attribute "level"
oder "full_path" von den Kategorien, Footprints usw. werden beim
Erzeugen eines neuen Objektes noch nicht zugewiesen. Erst wenn diese
Attribute das erste Mal abgerufen werden, dann werden sie "berechnet"
und auch gleich gespeichert bis zur nächsten Abfrage.
Damit kann man schon noch einiges an Zeit sparen, da häufig halt auch
ganze Objekt-Arrays erzeugt werden bei denen viele Objektattribute
nachher gar nie abgefragt werden.
Oder habt ihr da eine bessere Idee? Ich lad gleich nochmal die neuste
Version in meinen SVN Branch damit ihr meinen aktuellen Stand seht.
Ach ja, wofür ist eigentlich die Tabelle "pending_orders"? Ist die bei
euch auch leer? Die wird doch (noch?) gar nicht benutzt, oder?
Ich hab mal noch ein UML Diagramm erstellt damit man ein bisschen den
Überblick über die Klassen hat. Es entspricht nicht ganz dem aktuellen
Stand des Codes. Und die Klassen User und Group sind nicht komplett.
Die meisten Funktionen haben natürlich Argumente und Rückgabewerte, sind
aber einfach im Diagramm nicht eingezeichnet.
Ausserdem habe ich nur die Verbindungen für die Vererbungen
eingezeichnet.
P.S.
Ich wäre echt froh wenn mir noch jemand wegen dem Datenbankupdate für
die Lieferinformationen (siehe letzter Beitrag) helfen könnte.
HTMLTable? Das ganze wird doch über die vlibTemplate-Klasse abgebildet
und benötigt keine weitere Kapselung. Genauso kann die
build_html_tree()-Funktion durch eine einfach Array-Rückgabe ersetzt
werden, denn die LOOP-Funktion in den Templates braucht einfach ein
Array des Typs
1
$array[x]['name']
Dabei ist x eine Zählvariable (kann durch [] beim Aufbau ersetzt werden,
was ein Anhängen der Daten an das Array bewirkt) und 'name' der Name
(Schlüssel).
Ansonsten sieht das gut aus :-) Ich werde morgen mal wieder an die
Templates rangehen, dann können wir anfangen, beide Versionen zu
verschmelzen.
Udo Neist schrieb:> HTMLTable? Das ganze wird doch über die vlibTemplate-Klasse abgebildet> und benötigt keine weitere Kapselung. Genauso kann die> build_html_tree()-Funktion durch eine einfach Array-Rückgabe ersetzt> werden, denn die LOOP-Funktion in den Templates braucht einfach ein> Array des Typs> $array[x]['name']>> Dabei ist x eine Zählvariable (kann durch [] beim Aufbau ersetzt werden,> was ein Anhängen der Daten an das Array bewirkt) und 'name' der Name> (Schlüssel).
Ach so, okay das ist natürlich super! Ich habe selber auch schon gedacht
dass da teilweise noch etwas zu viel HTML drin ist in den Klassen.
Aber bezüglich HTMLTable hatte ich eben noch eine spezielle Idee, das
mit unserem Issue 22
(https://code.google.com/p/part-db/issues/detail?id=22) zusammenhängt:
Ich dachte da bei der HTMLTable an eine Klasse, der man einfach ein
Array aus Objekten (v.a. Teile und Bestellinformationen), den Typ der
Tabelle (showparts, orderparts, nopriceparts,...) und eine Referenz auf
den aktuellen Benutzer übergeben kann. Wie in Issue 22 beschrieben, soll
ja jeder Benutzer seine Tabellenspalten individuell gestalten können.
Und genau das soll dann diese Klasse HTMLTable erledigen. Damit könnte
man dann also extrem individuelle Tabellen erzeugen lassen.
Allerdings bin ich selber auch noch nicht ganz zufrieden mit diesem
System, weil dann eben die Tabellen nicht durchs Templatesystem
gestaltet werden.
Hast du grad eine gescheite Idee wie wir das am besten lösen?
Urban B. schrieb:> Aber bezüglich HTMLTable hatte ich eben noch eine spezielle Idee, das> mit unserem Issue 22> (https://code.google.com/p/part-db/issues/detail?id=22) zusammenhängt:> Ich dachte da bei der HTMLTable an eine Klasse, der man einfach ein> Array aus Objekten (v.a. Teile und Bestellinformationen), den Typ der> Tabelle (showparts, orderparts, nopriceparts,...) und eine Referenz auf> den aktuellen Benutzer übergeben kann. Wie in Issue 22 beschrieben, soll> ja jeder Benutzer seine Tabellenspalten individuell gestalten können.> Und genau das soll dann diese Klasse HTMLTable erledigen. Damit könnte> man dann also extrem individuelle Tabellen erzeugen lassen.>> Allerdings bin ich selber auch noch nicht ganz zufrieden mit diesem> System, weil dann eben die Tabellen nicht durchs Templatesystem> gestaltet werden.>> Hast du grad eine gescheite Idee wie wir das am besten lösen?
Da die einzelnen Tabellen ja in den Templates vorhanden sind, brauchen
wir ja nur das Array und die Tabelle zu übergeben und die HTML-Klasse
würde das entsprechend veranlassen. Genauso können wir dann Kopf- und
Fußzeilen übernehmen.
1
$html -> put_html_header($meta)
2
$html -> put_html_table($template,$array)
3
$html -> put_html_footer()
In dem Beispiel würde also zuerst der Header generiert ($meta ist ein
Array und enthält alle Kopfdaten, die derzeit alle per Hand über
$tmpl->setVar() gesetzt werden), dann die Templatevorlage geladen und
mit den Array verbunden und am Schluss noch der Footer ausgegeben.
Intern kann die Klasse die einzelnen Templates in privaten Funktionen
(nur innerhalb der Klasse sichtbar) bearbeiten, um es übersichtlicher zu
halten. Ich kann ja mal morgen eine HTML-Klasse erzeugen, die obiges
implementiert.
Die Benutzerklasse würde ihre Daten in eine Session kopieren und diese
Daten stehen global allen Klassen und Funktionen zur Verfügung. Die
SQL-Abfragen würden dann auf $_SESSION zurückgreifen, um die Userdaten
einzubauen. Sowas nutze ich in meinem eigenen CMS-Framework.
Für unsere eigenen Klassen- und Funktionsbenennung sollten wir auf alle
Fälle ein festes Namensschema einführen, sonst kommen wir irgendwann
durcheinander. Da du hier schon angefangen hast, wäre also
Kleinschreibung und Trennung mit "_" für alle verbindlich? Zudem könnten
wir auch Maintainer für die einzelnen Bereiche benennen :-) Templates
und Benutzerverwaltung wäre dann wohl meine Sache? Das Tabellendesign
bis auf die eigentliche Usertable und die Anforderungen an die anderen
Tabellen überlasse ich dann anderen.
Udo Neist schrieb:> In dem Beispiel würde also zuerst der Header generiert ($meta ist ein> Array und enthält alle Kopfdaten, die derzeit alle per Hand über> $tmpl->setVar() gesetzt werden), dann die Templatevorlage geladen und> mit den Array verbunden und am Schluss noch der Footer ausgegeben.> Intern kann die Klasse die einzelnen Templates in privaten Funktionen> (nur innerhalb der Klasse sichtbar) bearbeiten, um es übersichtlicher zu> halten. Ich kann ja mal morgen eine HTML-Klasse erzeugen, die obiges> implementiert.
Also ich habe jetzt nicht alles zu 100% verstanden, aber ich denke mal
das kommt gut so :-) Das wäre super wenn du da mal eine solche Klasse
bauen könntest.
Udo Neist schrieb:> Die Benutzerklasse würde ihre Daten in eine Session kopieren und diese> Daten stehen global allen Klassen und Funktionen zur Verfügung. Die> SQL-Abfragen würden dann auf $_SESSION zurückgreifen, um die Userdaten> einzubauen. Sowas nutze ich in meinem eigenen CMS-Framework.
OK dazu kann ich noch nicht viel sagen, von Sessions usw. habe ich noch
nicht viel Ahnung.
Udo Neist schrieb:> Für unsere eigenen Klassen- und Funktionsbenennung sollten wir auf alle> Fälle ein festes Namensschema einführen, sonst kommen wir irgendwann> durcheinander. Da du hier schon angefangen hast, wäre also> Kleinschreibung und Trennung mit "_" für alle verbindlich?
Ja das wäre sicher vorteilhaft wenn wir uns da einigen. Da bisher der
grösste Teil der Funktionen nach diesem Schema benannt wurde, habe ich
das einfach mal so übernommen. Die Klassennamen habe ich aber gross
geschrieben, ich denke das hat sich ja mehr oder weniger so
eingebürgert.
Übrigens muss ich in den nächsten paar Wochen die Zeit fürs
Programmieren etwas reduzieren, es sind bald Semesterprüfungen... ;-)
Ich bin aber eigentlich eh der Meinung dass wir jetzt an der ultimativen
Version Eins Punkt Null (Part-DB v1.0) arbeiten, und Gut Ding will ja
bekanntlich Weile haben :-D
Update auf Revision 505: class_html.php erstellt.
Die HTML-Klasse (nicht HTMLTable wie im Schema, da einfach zu
universell) kapselt jetzt die vlibTemplate-Klasse und stellt einige
Funktionen bereit.
function set_html_loop ($key = '',$array = array())
8
function unset_html_loop ($key = '')
9
function clr_html_loop ()
10
function print_html_header ()
11
function print_html_footer ()
12
function load_html_template ($template = '')
13
function parse_html_template ($template = '',$array = array())
14
function parse_html_table ($array = array())
15
function print_html_template ()
16
function print_error_state ($error = 0)
17
}
Ich habe die startup.php und config_system.php auf diese Klasse
umgeschrieben. Beide Scripte zeigen dabei die zwei Ansätze, wie man die
neue Klasse benutzen kann. Erstes Script nutzt statt der vlib-Funktionen
setVar()/setLoop() die neuen Funktionen set_html_*().
set_html_variable() ist zudem noch etwas mächtiger als setVar():
optional kann man den Variablentyp setzen (wird beispielhaft gesetzt)
oder die Formatierung nach number_format() oder sprintf() nutzen. Das
andere Script verwendet parse_html_template(), welches
load_html_template(), set_html_*() und print_html_template()
zusammenfast.
Den HTML-Kopf wird durch print_html_header() ausgegeben, der Abschluss
durch print_html_footer().
In der Klasse sind die Funktionen erklärt.
Okay, sieht ja ganz gut aus, aber wie man damit nun individuelle
Tabellen zeichnen kann, habe ich noch nicht verstanden :-)
Übrigens ist mir noch aufgefallen dass du deutsche, und ich englische
Kommentare verwende. Vielleicht sollten wir uns da auch noch einigen.
Also ich bevorzuge eigentlich englisch, weil es halt einfach DIE Sprache
für Programmierer ist, und für ein OpenSource Projekt sowieso. Und
ausserdem kann ich so mein bescheidenes Englisch noch ein bisschen
verbessern :-)
Und übrigens, in der config.php solltest du noch das define "LANGUAGE"
in Anführungszeichen setzen (bekomme immer eine Fehlermeldung deswegen).
Was hat es damit eigentlich auf sich? Soll das ermöglichen, dass part-DB
in verschiedenen Sprachen angezeigt werden kann? Das wäre ja cool! Aber
wo würde man dann die verschiedenen Übersetzungstexte definieren?
Ich habe nochmal ein neues Klassendiagramm angehängt, diesmal mit
Parametern und Rückgabewerte. Ausserdem ist jetzt die Klasse "File" neu.
Diese soll alle möglichen Dateianhänge von irgendwelchen Objekten
vereinheitlichen. Man könnte dann also jedem Subelement von
"FilesContainingElement" unbeschränkt viele Dateien anhängen.
Und die Klasse "Export" ist dazu gedacht, dass man die mit allen
möglichen Objekten befüllen kann (Teile, Bestellinformationen,
Lagerorte,...), ein Exportformat wählt, und dann eine CSV-Datei oder was
auch immer bekommt. Später wäre natürlich dann noch schön wenn man
bequem eigene Exportformate definieren kann, ist bisher aber noch nicht
vorgesehen.
Nachtrag:
Ach ja, und die class_html.php würde ich noch in html.php umbenennen,
dann hättest du das gleiche Namensschema wie ich. Die Dateien liegen ja
eh alle im Ordnert "class", sollte also eh klar sein dass es sich dort
um Klassen handelt.
Urban B. schrieb:> Okay, sieht ja ganz gut aus, aber wie man damit nun individuelle> Tabellen zeichnen kann, habe ich noch nicht verstanden :-)
An dieser Stelle bin ich noch nicht. Aber ich hatte es so vorgesehen,
das man den Namen des Templates zusammen mit einem Array übergibt und
die entsprechende Funktion die Tabelle erzeugt. Im Grunde macht das
print_html_table() ja schon, in dem ich dort das Template fest auf
"vlib_table.tmpl" setze und der Aufruf von load_html_template() den
Scriptnamen in den Pfad übernimmt.
> Übrigens ist mir noch aufgefallen dass du deutsche, und ich englische> Kommentare verwende. Vielleicht sollten wir uns da auch noch einigen.> Also ich bevorzuge eigentlich englisch, weil es halt einfach DIE Sprache> für Programmierer ist, und für ein OpenSource Projekt sowieso. Und> ausserdem kann ich so mein bescheidenes Englisch noch ein bisschen> verbessern :-)
Man kann ja die Kommentare später übersetzen :) Solange lass ich die
erstmal in Deutsch.
> Und übrigens, in der config.php solltest du noch das define "LANGUAGE"> in Anführungszeichen setzen (bekomme immer eine Fehlermeldung deswegen).
Erledigt.
> Was hat es damit eigentlich auf sich? Soll das ermöglichen, dass part-DB> in verschiedenen Sprachen angezeigt werden kann? Das wäre ja cool! Aber> wo würde man dann die verschiedenen Übersetzungstexte definieren?
Erstmal ist das nur für LC_ALL
(http://php.net/manual/de/function.setlocale.php) interessant, später
könnte man damit auch die Templates internationalisieren. Nur wer
übersetzt die Templates in andere Sprachen? gettext() wäre zwar
interessant, aber für mich noch eine Spur zu hoch.
> Nachtrag:> Ach ja, und die class_html.php würde ich noch in html.php umbenennen,> dann hättest du das gleiche Namensschema wie ich. Die Dateien liegen ja> eh alle im Ordnert "class", sollte also eh klar sein dass es sich dort> um Klassen handelt.
Umbenennen geht immer :-) Ist eine Angewohnheit von mir, die Klassen und
Libraries mit "class_" bzw. "class." oder "lib_" bzw. "lib." noch extra
zu kennzeichnen, um Verwechselungen zu vermeiden. Könnte ja jemand
meinen, Libraries und Klassen gehören in das gleiche Verzeichnis ;-)
Ich habe config_page.php auch auf mod_xsendfile erweitert. Noch
funktioniert es nicht perfekt, aber wenn, dann lohnt es sich das in die
File-Klasse zu verschieben.
Okay alles klar :-)
Das mit der Internationalisierung können wir ja mal machen wenn uns
langweilig ist ;-) Momentan stehen aber wichtigere Sachen an...
Hast du eigentlich schon Erfahrung mit Doxygen? Meinst du, es würde sich
lohnen bzw. Sinn machen den Sourcecode mit Doxygen zu dokumentieren? Ich
bin mir nicht sicher ob das vielleicht erst bei viel grösseren Projekten
beginnt Sinn zu machen.
Und kennst du dich eigentlich mit SQL gut aus? Könntest du mir beim
Datenbankupdate fürs neue Lieferantendetails-System helfen? :-)
Anbei übrigens nochmal eine neuere version des Klassendiagrammes.
Ich hab irgendwann mal mit Doxygen experimentiert, hab dann aber mal ein
anderes System getestet. Hat mich beides nicht überzeugt. So hab ich die
gesamte Doku über Dokuwiki gemacht, das keine Datenbank benötigt.
SQL ist für mich kein Buch mit sieben Siegeln, auch wenn ich nicht jede
Möglichkeit kenne oder nutze.
Bin gerade an der print_table_row() aus der lib.php dran. Wenn das
funktioniert, kann ich die beiden Aufrufe aus search.php und
showparts.php auf die LOOPs umschreiben. Dann sieht man die Vorteile der
neuen HTML-Klasse. Derzeit wird der Output abgefangen und als fertiger
HTML-Block einfach eingefügt.
Udo Neist schrieb:> SQL ist für mich kein Buch mit sieben Siegeln, auch wenn ich nicht jede> Möglichkeit kenne oder nutze.
Das heisst, du könntest mal probieren ein Datenbankupdate zu schreiben?
:-) Was man machen müsste, habe ich ja hier geschrieben:
Beitrag "Re: PART-DB RW 1.2"Udo Neist schrieb:> Bin gerade an der print_table_row() aus der lib.php dran. Wenn das> funktioniert, kann ich die beiden Aufrufe aus search.php und> showparts.php auf die LOOPs umschreiben. Dann sieht man die Vorteile der> neuen HTML-Klasse. Derzeit wird der Output abgefangen und als fertiger> HTML-Block einfach eingefügt.
OK das würde mich interessieren wie das dann ausschaut. Ich finde es
einfach wichtig, dass man so eine Tabelle mit Objekten wie "Part",
"Orderinformations", "Footprint", "File" usw. erzeugen kann. Dann muss
man noch entscheiden, was für ein Tabellentyp es sein soll
(nopriceparts, obsoleteparts, defectfilenamefiles, ...), und die
Tabellenspalten werden dann in Abhängigkeit vom aktuellen Benutzer
gestaltet (Sichtbarkeit und Reihenfolge der Spalten).
Urban B. schrieb:> Udo Neist schrieb:>> SQL ist für mich kein Buch mit sieben Siegeln, auch wenn ich nicht jede>> Möglichkeit kenne oder nutze.>> Das heisst, du könntest mal probieren ein Datenbankupdate zu schreiben?> :-) Was man machen müsste, habe ich ja hier geschrieben:> Beitrag "Re: PART-DB RW 1.2"
Schaue ich mir die Tage mal an :-)
> OK das würde mich interessieren wie das dann ausschaut. Ich finde es> einfach wichtig, dass man so eine Tabelle mit Objekten wie "Part",> "Orderinformations", "Footprint", "File" usw. erzeugen kann. Dann muss> man noch entscheiden, was für ein Tabellentyp es sein soll> (nopriceparts, obsoleteparts, defectfilenamefiles, ...), und die> Tabellenspalten werden dann in Abhängigkeit vom aktuellen Benutzer> gestaltet (Sichtbarkeit und Reihenfolge der Spalten).
Ganz so einfach geht das nicht. Zwar kann man die Reihenfolge der
Spalten fast beliebig machen, aber dazu muss man das Template anders
aufbauen und viele Funktionen in den Code überführen. Das würde derzeit
ich in die ToDo- oder Wunschliste aufnehmen. Ich würde es bei im Moment
bei den jetzigen Tabellen belassen. Durch die Templates wird so manches
entschlackt, aber nicht an jeder Stelle flexibel.
Udo Neist schrieb:> Schaue ich mir die Tage mal an :-)
Danke :-)
Udo Neist schrieb:> Ganz so einfach geht das nicht. Zwar kann man die Reihenfolge der> Spalten fast beliebig machen, aber dazu muss man das Template anders> aufbauen und viele Funktionen in den Code überführen. Das würde derzeit> ich in die ToDo- oder Wunschliste aufnehmen. Ich würde es bei im Moment> bei den jetzigen Tabellen belassen. Durch die Templates wird so manches> entschlackt, aber nicht an jeder Stelle flexibel.
Hmm okay. Naja, Voraussetzung für die flexiblen Tabellen ist ja sowieso
die Implementierung der Benutzerverwaltung, und die braucht ja noch ein
bisschen Zeit.
Revision 506: search.php und showparts.php sind auf Templates
umgestellt. Die Funtion print_table_row() gibt nur noch ein Array von
Daten zurück.
Kurze Einführung in die HTML-Klasse:
Der HTML-Kopf ist in der vlib_head.tmpl gespeichert und ist in
print_html_header() fest kodiert. Die verschiedenen Variablen werden
durch set_html_meta() gesetzt.
1
$html = new HTML;
2
$html -> set_html_meta ( array(
3
'title' => 'Deviceinfo',
4
'http_charset' => $http_charset,
5
'theme' => $theme,
6
'css' => $css,
7
'menu' => true,
8
'popup' => true,
9
'hide_id' => $hide_id
10
)
11
);
12
$html -> print_html_header();
Das Herzstück der Klasse ist die Behandlung der einzelnen Templates. Es
werden zwei Herangehensweisen unterstützt. Wer mit vlibTemplates schon
vertraut ist, der kennt die Funktion setVar(). Diese wird durch
set_html_variable() ersetzt. Zusätzlich beherrscht sie einige
Formatierungen mittels number_format() und sprintf(). Die kürze und
etwas elegantere Methode nutzt parse_html_template(). Man übergibt den
Namen des Templates und ein assoziatives Array. Ist der Wert eines
Paares ein Array, so wird dieses als Loop für die Templates
interpretiert. Ein Beispiel ist folgender Code aus showparts.php:
Die Alternative parse_html_table() ist für Loops vorgesehen, die
vollständige Blöcke (bei Tabellen müssen die table-tags im Template
vorhanden sein) erzeugen. Teilausgaben müssen mit parse_html_template()
Vorlieb nehmen.
Den Abschluss der Webseite gibt print_html_footer() aus. Die
dazugehörige Datei ist vlib_foot.tmpl.
> Udo Neist schrieb:>> Ganz so einfach geht das nicht. Zwar kann man die Reihenfolge der>> Spalten fast beliebig machen, aber dazu muss man das Template anders>> aufbauen und viele Funktionen in den Code überführen. Das würde derzeit>> ich in die ToDo- oder Wunschliste aufnehmen. Ich würde es bei im Moment>> bei den jetzigen Tabellen belassen. Durch die Templates wird so manches>> entschlackt, aber nicht an jeder Stelle flexibel.
Wuaah... Was hab ich da denn geschrieben?
Nochmal: Das würde ich derzeit in die ToDo- oder Wunschliste aufnehmen.
Ich würde es bei den jetzigen Tabellen belassen.
In der index.php steht ja ein require ('mobil/mobil.php') drin. Da es
dieses Script nicht gibt, würde ein Aufruf von einem Tablet-PC unter
Umständen ins Leere laufen. Wäre es da nicht sinnvoll vorerst ein
"Sorry, wird derzeit nicht unterstützt" anzuzeigen und später einfach
ein angepasstes Thema (dafür sind ja gerade die Templates so genial) zu
laden?
Ich war so frei und hab zumindest ersteres implementiert.
Udo Neist schrieb:> Nochmal: Das würde ich derzeit in die ToDo- oder Wunschliste aufnehmen.
Da ist es schon drin ;-)
> Ich würde es bei den jetzigen Tabellen belassen.
Ja vorerst kein Problem, aber ich dachte halt ich baue gleich schon so
eine Klasse, damit man später nicht nochmal alles total umbauen muss.
Ich hätte jetzt die Tabellengestaltung noch nicht benutzerspezifisch
gemacht, aber halt einfach alles schonmal so vorbereitet dass man dann
nur noch diese eine Klasse anpassen muss, sobald die Benutzerverwaltung
steht.
Udo Neist schrieb:> In der index.php steht ja ein require ('mobil/mobil.php') drin. Da es> dieses Script nicht gibt, würde ein Aufruf von einem Tablet-PC unter> Umständen ins Leere laufen. Wäre es da nicht sinnvoll vorerst ein> "Sorry, wird derzeit nicht unterstützt" anzuzeigen und später einfach> ein angepasstes Thema (dafür sind ja gerade die Templates so genial) zu> laden?
Statt einem Hinweis können wir doch einfach die ganz normale Seite
anzeigen lassen? Also ich hätte lieber eine Seite, die nicht auf
Mobilgeräte angepasst ist, als gar keine Seite :-)
check_mobile() in der index.php ist Geschichte. Man muss nicht alles in
Funktionen giessen, wenn der Aufruf nur einmal im gesamten Kontext
erfolgt. Folgende Variante ersetzt die Funktion komplett und verwendet
eine while()-Schleife. In der index.php habe ich auf die Klammern
verzichtet, um die Schleife als Zweizeiler zu bekommen. Ausgeschrieben
läuft das so ab:
1
$agents = array(
2
'Windows CE', 'Pocket', 'Mobile',
3
'Portable', 'Smartphone', 'SDA',
4
'PDA', 'Handheld', 'Symbian',
5
'WAP', 'Palm', 'Avantgo',
6
'cHTML', 'BlackBerry', 'Opera Mini',
7
'Nokia', 'PSP', 'J2ME'
8
);
9
10
$mobile = false;
11
if (isset($_SERVER["HTTP_USER_AGENT"]))
12
{
13
while(list($agent) = each($agents) && !$mobile)
14
{
15
if (strpos($_SERVER["HTTP_USER_AGENT"], $agent))
16
{
17
$mobile = true;
18
}
19
}
20
}
while() wird solange durchlaufen, bis die Bedingung ein false ergibt.
Enthält das Array ein Elemente hat und die Stringfunktion innerhalb der
Schleife hat keinen Treffer ergeben, so bleibt die Variable $mobile auf
false und wird durch die Negierung true. Die UND-Verknüpfung ergibt
damit true. Ist das Array durchlaufen oder ein Treffer im Array
gelandet, so wird die UND-Verknüpfung false und while() beendet sich.
Man erspart sich das break.
Geht man noch eins weiter, kann man die äußere IF-Abfrage in die
while()-Bedingung einfliessen lassen.
> Udo Neist schrieb:>> In der index.php steht ja ein require ('mobil/mobil.php') drin. Da es>> dieses Script nicht gibt, würde ein Aufruf von einem Tablet-PC unter>> Umständen ins Leere laufen. Wäre es da nicht sinnvoll vorerst ein>> "Sorry, wird derzeit nicht unterstützt" anzuzeigen und später einfach>> ein angepasstes Thema (dafür sind ja gerade die Templates so genial) zu>> laden?>> Statt einem Hinweis können wir doch einfach die ganz normale Seite> anzeigen lassen? Also ich hätte lieber eine Seite, die nicht auf> Mobilgeräte angepasst ist, als gar keine Seite :-)
Ich hab beim Vergleich der Branches festgestellt, das es die Meldung
bereits gab und ich die schon vor längerem entsorgt habe.
Das Problem der Mobilgeräte ist die beschränkte Größe des Screens. Da
kann man das Menü und den Content praktisch nicht nutzen. Man müsste das
Menü auslagern. Sind die Frames mal verschwunden, lässt sich das Menü
ganz einfach ausblenden (CSS: "display:none;"), damit der Inhalt
angezeigt wird und umgekehrt. Das könnte man dann sehr simple mit einem
Switch im Template freischalten. Genauso könnte man dann auch
Nicht-Fullscreen-Fenster der Browser behandeln. Beides würde ein
Javascript-Schnipsel machen.
Pseudocode:
1
var menu_on = {TMPL_IF NAME="menu_on"}1{TMPL_ELSE}0{/TMPL_IF};
2
3
if (menu_on == 1) div.menu.style="display:block";
4
if (menu_on == 0 and browser.width<=1024) div.menu.style="display:none";
Ich habe in meinem Branch einen neuen Ordner "documentation" erstellt.
Ich denke, den können wir später auch für die Dokumentation (für
Anwender und Entwickler) verwenden, z.B. für Hilfedateien.
Darin habe ich den Unterordner "UML" erstellt, in dem ich das
Klassendiagramm abgelegt habe. So werden die Versionen auch gleich vom
SVN verwaltet, und es ist immer schnell erreichbar.
Das jeweils aktuelle PDF ist unter dieser Adresse erreichbar:
https://part-db.googlecode.com/svn/branches/kami89/documentation/UML/class_diagram.pdf
Hallo Community,
ich war seit Januar 2012 auf der Suche nach einer Lagerverwaltung für
mich in der Firma. Nur durch Zufall bin ich über die PArt-DB gestolpert
und fand die auf Anhieb recht gut programmiert. Vor einem Monat dann
haben wir angefangen in unserem Lager Ersatzteile jeglicher Art
aufzunehmen. Mir ist im vornherein bewusst dass ich die Part-DB dafür
zweckentfremde, da diese ja eigentlich nur für
Kleinstelektronikkomponenten ausgelegt ist.
Was ich super finden ist, dass die GUI sehr sauber und einfach gehalten
ist. Allderdings stört mich z.b. der Footprint in den einzelnen
Bauteilen. Diesen kann ich nicht verwenden. Gibt es eine Möglichkeit
diesen rauszunehmen? Vielleicht könnt ihr da zukünftig was Einbauen wo
man den Punkt einfach per Checkbox ausblenden kann.
Aufgrund der Massen an Ersatzteilen merke ich dass wir nach und nach
Probleme bekommen. Die Funktion mit den Bildern zu den Artikeln ist
genial allerdings wird bei Kategorien mit vielen Teilen die Auflistung
sehr träge.
Aktuell schaue ich fast täglich in die Google codes Projektseite
allerdings ist die Entwicklung fast ausschließlich hier im Gange.
Ich selbst bin leider programmiertechnisch nicht soo fit, was mich aber
nicht abhält auch mal Codeschnipsel nach Anleitung zu ändern.
Ich würde mich gerne aber als Tester bereit erklären euch zu helfen.
Was sich sehr gut bewährt hat ist die Hardware mit der ich arbeite. Die
Datenbank und der Webserver läuft auf einer Synology DS 107. Von daher
kann ich auf SVN´s verzichten und kann von mehreren Rechner
unproblematisch auf die Datenbank zugreifen. Ich weiss nicht ob das von
euch schon jemand getestet hat.
Keep the work going on!
Gruß Kirkdis
Hallo kirkdis,
> ich war seit Januar 2012 auf der Suche nach einer Lagerverwaltung für> mich in der Firma. Nur durch Zufall bin ich über die PArt-DB gestolpert> und fand die auf Anhieb recht gut programmiert. Vor einem Monat dann> haben wir angefangen in unserem Lager Ersatzteile jeglicher Art> aufzunehmen.
Cool, dass unser Projekt bereits den Weg in eine Firma gefunden hat :-)
Darf man fragen, wie viele Arbeiter auf die Part-DB zugreifen? Bisher
ist Part-DB allerdings noch nicht für die Verwendung in einer Firma
ausgelegt. Das soll sich aber noch ändern, es wird in Zukunft z.B. eine
Benutzerverwaltung (mit Rechtevergabe) geben.
> Was ich super finden ist, dass die GUI sehr sauber und einfach gehalten> ist. Allderdings stört mich z.b. der Footprint in den einzelnen> Bauteilen. Diesen kann ich nicht verwenden. Gibt es eine Möglichkeit> diesen rauszunehmen? Vielleicht könnt ihr da zukünftig was Einbauen wo> man den Punkt einfach per Checkbox ausblenden kann.
Eine solche Idee hatte ich auch schon. Ich dachte da an eine Einstellung
für die Kategorien, also quasi um anzugeben ob es sich bei einer
Kategorie um Bauteile mit Footprints handelt. Ich habe bei mir z.B. eine
Kategorie "Werkstatt" in dem ich Werkzeuge und Verbrauchsmaterialien
verwalte. Und da machen die Footprints auch wenig Sinn. Daher wäre es
wünschenswert, wenn man bei ausgewählten Kategorien die Footprints
deaktivieren kann.
Da wir aber momentan an einem relativ grossen Umbau arbeiten (Einführung
eines Templatesystems und Umbau auf objektorientierte Programmierung),
denke ich, werden wir diese neue Funktion erst in die neue Version
aufnehmen. Heisst also, es wird noch etwas dauern bis diese Funktion zur
Verfügung stehen wird.
> Aufgrund der Massen an Ersatzteilen merke ich dass wir nach und nach> Probleme bekommen. Die Funktion mit den Bildern zu den Artikeln ist> genial allerdings wird bei Kategorien mit vielen Teilen die Auflistung> sehr träge.
Von wievielen Teilen in der Auflistung reden wir hier etwa? Wie viele
davon haben ein Bild zugeordnet? Footprint wird keines der Bauteile
zugeordnet haben, oder? Und welche Version von Part-DB verwendest du
(hast du das Archiv v0.2.2 installiert, oder die neuste SVN-Revision)?
> Ich würde mich gerne aber als Tester bereit erklären euch zu helfen.
Das können wir immer gebrauchen :-)
> Was sich sehr gut bewährt hat ist die Hardware mit der ich arbeite. Die> Datenbank und der Webserver läuft auf einer Synology DS 107. Von daher> kann ich auf SVN´s verzichten und kann von mehreren Rechner> unproblematisch auf die Datenbank zugreifen. Ich weiss nicht ob das von> euch schon jemand getestet hat.
Hmm was meinst du damit, dass du aufs SVN verzichten kannst? Übers SVN
ist einfach immer die allerneuste (Entwickler-)Version erhältlich. Diese
können aber durchaus auch mal einige Fehler enthalten. Die erhältlichen
Archive sind etwas älter, aber sollten dafür stabiler/erprobter sein.
Und dass man von mehreren Rechnern auf Part-DB zugreifen kann, ist
eigentlich der Sinn einer Webapplikation :-)
Gruss
Urban
kirk disen schrieb:> Aufgrund der Massen an Ersatzteilen merke ich dass wir nach und nach> Probleme bekommen. Die Funktion mit den Bildern zu den Artikeln ist> genial allerdings wird bei Kategorien mit vielen Teilen die Auflistung> sehr träge.
Eventuell können wir hier recht schnell eine Abhilfe schaffen, denn das
Abschalten der Footprints bzw. eine Option für Thumbnails oder reinen
Textlink sind ja nur kleine Änderungen. Erstes könnte man in den
Kategorien selbst unterbringen (zusätzliche Option beim Erstellen einer
Kategorie) und das andere wäre etwas für die Einstellungen in config.php
(und später für die Benutzer-/Gruppenverwaltung).
> Aktuell schaue ich fast täglich in die Google codes Projektseite> allerdings ist die Entwicklung fast ausschließlich hier im Gange.
Das Projekt ist hier ja auch entstanden und viele Interessierte haben
diesen Thread auch abonniert. Das wir auf Google Codes das Wiki mal
überarbeiten sollten, ist mir schon in den Sinn gekommen :-)
> Ich selbst bin leider programmiertechnisch nicht soo fit, was mich aber> nicht abhält auch mal Codeschnipsel nach Anleitung zu ändern.>> Ich würde mich gerne aber als Tester bereit erklären euch zu helfen.
Ich schliess mich da Urban an. Tester kann man immer gebrauchen. Wir
Entwickler sehen ja nur einen Teil der möglichen Probleme und Fehler.
> Was sich sehr gut bewährt hat ist die Hardware mit der ich arbeite. Die> Datenbank und der Webserver läuft auf einer Synology DS 107. Von daher> kann ich auf SVN´s verzichten und kann von mehreren Rechner> unproblematisch auf die Datenbank zugreifen. Ich weiss nicht ob das von> euch schon jemand getestet hat.
Bei mir gibt es derzeit drei Systeme, auf denen ich die Entwicklung
mache, einer ist öffentlich zugänglich und erhält die Updates meines
Branches, wenn ich sie für stabil halte. Ich schätze, ich bin bei ca.
70% des Umbaus auf Templates angelangt.
> Keep the work going on!
Wir sind dabei :-)
also so wie ich das im überflug gelesen habe handelt es sich bei svn um
eine version für windows die eine datenbank und einen webserver
emuliert. gut vielleicht verwechsle ich da grad was hab den ellenlangen
threat zu meiner entschuldigung auch nicht ganz gelesen. aber so wie
sich jetzt herausstellt handelt es sich dabei wohl um die neuste version
eures entwicklerteams.
synology stellt miniaturwebserver her. google mal danach sind echt feine
geräte.
aktuell läuft bei mir die 0.2.2. würde alternativ eure mal ebenbei
laufen lassen oder gibts da bekannte probleme mit der datenbank wenn
zwei scripte darauf zugreifen. will mir auf keinen fall die sql db
zerschiessen. falls die db von 0.2.2 mit eurer neuesten svn kompatibel
ist werd ich mich montag mal drüber machen die parallel laufen zu
lassen.
artikel haben wir aktuell ca 2500 eingetragen. wieviele davon mit bild
kann ich nicht genau sagen werds aber mal checken am montag und
berichten.
nur so nebenbei aktuell verwalten wir mit eurem system 2 kardex
hochregallager. wobei da eine wichtige funtkion gerade noch fehlt. habt
ihr in eurer neuesten bereits etwas integriert wo ich nach lagerplatz
sortieren kann?
gruss kirkdis
kirk disen schrieb:> also so wie ich das im überflug gelesen habe handelt es sich bei svn um> eine version für windows die eine datenbank und einen webserver> emuliert. gut vielleicht verwechsle ich da grad was hab den ellenlangen> threat zu meiner entschuldigung auch nicht ganz gelesen. aber so wie> sich jetzt herausstellt handelt es sich dabei wohl um die neuste version> eures entwicklerteams.SVN ist ein Versionsverwaltungssystem:
https://de.wikipedia.org/wiki/Apache_Subversion
Google Code ist z.B. so ein SVN-Server, deshalb wird unser Projekt dort
verwaltet.
> aktuell läuft bei mir die 0.2.2. würde alternativ eure mal ebenbei> laufen lassen oder gibts da bekannte probleme mit der datenbank wenn> zwei scripte darauf zugreifen. will mir auf keinen fall die sql db> zerschiessen. falls die db von 0.2.2 mit eurer neuesten svn kompatibel> ist werd ich mich montag mal drüber machen die parallel laufen zu> lassen.
Bezüglich Datenbank zerschiessen würde sich sowieso ein gelegentliches
Backup anbieten. Vorallem im professionellen Einsatz sollte man
unbedingt regelmässige Backups der Datenbank machen.
Du kannst nicht verschiedene Versionen von Part-DB auf die gleiche
Datenbank zugreifen lassen, da einige Updates die Datenbankstruktur
verändern. Auch ein Downgrade ist nicht mehr einfach so ohne weiteres
möglich.
Ich würde dir empfehlen, dass du erstmal deine komplette Datenbank
sicherst (z.B. über phpMyAdmin oder mysqldump). Dann lädst du die neuste
Version aus dem SVN herunter. Den Link dazu gibts hier:
https://code.google.com/p/part-db/source/checkout und Anleitungen findet
man über Google.
Einfach die alten Dateien mit den neuen aus dem SVN überschreiben.
Danach kannst du die Version austesten, schauen ob alles so läuft wie es
soll. Ich habe immer die neuste SVN-Version als Produktivsystem
installiert und hatte noch nie wirklich Probleme.
Bei der neusten Version gibts übrigens auch gleich die Möglichkeit,
direkt aus Part-DB heraus eine Datenbanksicherung durchzuführen.
Wenn irgendwas nicht richtig funktioniert mit der SVN-Version von
Part-DB spielst du einfach wieder das Datenbank-Backup der Version 0.2.2
und die alten 0.2.2er-Dateien ein, und du hast wieder genau deinen
jetztigen Stand.
> artikel haben wir aktuell ca 2500 eingetragen. wieviele davon mit bild> kann ich nicht genau sagen werds aber mal checken am montag und> berichten.
Naja ich wollte eigentlich wissen, wie viele Einträge in den Kategorien
vorhanden sind, die schon sehr lange zum Laden brauchen. Die Ladezeit
beim Anzeigen einer Kategorie hängt vielmehr von der Anzahl der
anzuzeigenden Teile, als von der Gesamtanzahl Teile ab. Vorallem die
Bilder brauchen vermutlich viel Zeit, deshalb wollte ich wissen wie
viele (ungefähr) Bilder aufgelistet werden. Also z.B. "100 Teile in
einer Kategorie, 30 davon mit Bild, Ladezeit 10 Sekunden".
Übrigens spielt die Grösse der Bilder wahrscheinlich auch noch eine sehr
grosse Rolle. Wenn jedes Teil ein 1MB grosses Bild hat, wird es sehr
lange dauern z.B. 50 davon aufzulisten.
Vielleicht müssen wir da mit Thumbnauls arbeiten, damit die Ladezeiten
sich in Grenzen halten bei Kategorien mit vielen (grossen) Bildern.
> nur so nebenbei aktuell verwalten wir mit eurem system 2 kardex> hochregallager. wobei da eine wichtige funtkion gerade noch fehlt. habt> ihr in eurer neuesten bereits etwas integriert wo ich nach lagerplatz> sortieren kann?
Ist bereits in der Wunschliste, aber noch nicht eingebaut. Zur Zeit
musst du dich halt mit der Suchfunktion begnügen, die findet ja auch
Lagerorte.
Vielleicht hast du auch Glück und jemand baut die Funktion nächstens mal
ein, so eine grosse Sache wär das gar nicht. Ich habe aber leider in den
nächsten paar Wochen nicht viel Zeit zum programmieren
(Semesterprüfungen...).
Urban B. schrieb:> Vielleicht müssen wir da mit Thumbnauls arbeiten, damit die Ladezeiten> sich in Grenzen halten bei Kategorien mit vielen (grossen) Bildern.
Lohnt sich auf alle Fälle. So 64 oder 96 Pixel, je nach Qualität.
Update auf Revision 510
- Fehlerbehandlungsklasse eingeführt (error.php: class _exception)
- HTML-Klasse mit Exceptions versehen
- HTML-Klasse nimmt Defaults für Thema, CSS und Charset aus der
config.php, braucht nicht mehr mit angegeben zu werden (kann aber
überschrieben werden)
- startup.php auf HTML->parse_html_template() umgestellt
PS: Die englischen Kommentare müssten noch überarbeitet werden ;-)
Ich habe mal die Copyright-Info überarbeitet und hoffe, es ist euch
recht so.
1
part-db version 0.1
2
Copyright (C) 2005 Christoph Lechner
3
http://www.cl-projects.de/
4
5
part-db version 0.2+
6
Copyright (C) 2009 K. Jacobs and others (see authors.php)
7
http://code.google.com/p/part-db/
8
9
This program is free software; you can redistribute it and/or
10
modify it under the terms of the GNU General Public License
11
as published by the Free Software Foundation; either version 2
12
of the License, or (at your option) any later version.
13
14
This program is distributed in the hope that it will be useful,
15
but WITHOUT ANY WARRANTY; without even the implied warranty of
16
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
17
GNU General Public License for more details.
18
19
You should have received a copy of the GNU General Public License
20
along with this program; if not, write to the Free Software
21
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA
Aktuelle Änderungen (ist noch nicht im SVN, da ich obige Änderung nicht
ohne Zustimmung übernehmen will)
1
- Lizenzinfo in die einzelnen Scripte reinkopiert bzw. aktualisiert
2
- error.php entsprechend dem Namensschema umgeschrieben
3
- Einige Variablen aus der config.php in das Array $conf verschoben
4
- html.php angepasst
5
- install.sh geändert: Lizenz und Abfrage ob diese akzeptiert wird, sowie Abfrage der Daten zur Installation der Datenbank
6
- SQL-Script an install.sh angepasst
Ich hänge mal die install.sh hier an. Bitte testet die mal bei euch aus
(läuft unter Bash) und gebt mir Rückmeldung, ob sie sauber funktioniert.
Ich möchte nämlich die INSTALL.txt bzw. auch das Thema im Wiki
überarbeiten.
Udo Neist schrieb:> list_backup_files() liest dazu aus $db['backup_path'] rekursiv und gibt> alles als Array zurück. Download und Löschen muss ich noch anpassen.
list_backup_files() gibt jetzt den Pfad unterhalb der Installation
zurück. Download und Löschen ergänzen dann noch zu einem absoluten Pfad,
um darauf zurückgreifen zu können. Beim Download wird nur der Dateiname
genutzt.
@Udo Neist
Du gibst ja richtig Gas beim programmieren :-D
Also wenn du mich fragst, ich finde das neue Copyright gut, da man sieht
dass das ursprüngliche Projekt von uns "weitergeführt wurde. Aber K.J.
ist hier der Chef :-) Scheint aber momentan irgendwie nicht sehr aktiv
zu sein, oder ist er vielleicht in den Ferien?
Übrigens, hast du das "Problem" mit dem Datenbankupdate fürs neue
Preissystem mal angeschaut?
Wenn es nicht einfach so direkt per SQL-Anweisung möglich ist, dann
müssten wir halt dafür etwas PHP Code schreiben, der dann das Update
durchführt. Aber so mächtig wie SQL ist, wirds bestimmt auch ohne PHP
möglich sein :-)
Ich habe mal wieder meinen Branch aktualisiert. Auch das Klassendiagramm
wurde aktualisiert
(https://part-db.googlecode.com/svn/branches/kami89/documentation/UML/class_diagram.pdf).
Ich habe mal angefangen die Benutzerverwaltung einzubauen. Ich stelle
mir das so vor, dass man bei jedem Objekt, das man anlegt, eine Referenz
auf den aktuell angemeldeten Benutzer übergibt. Die Berücksichtigung der
Rechte würde dann direkt innerhalb der einzelnen Klassen stattfinden.
Zuerst dachte ich es wäre besser wenn die Überprüfung auf die
notwendigen Rechte ausserhalb der Klassen passieren würde. So könnte man
auch besser auf fehlende Rechte reagieren und entsprechend eine
Fehlermeldung ausgeben. Allerdings bin ich mir noch nicht sicher ob
früher oder später einzelne Klassenmethoden doch noch eine Information
über die vorhandenen Rechte brauchen werden. Und ausserdem wird so die
Überprüfung der Rechte nur an einer zentralen Stelle durchgeführt und
muss nicht für jede Seite extra programmiert werden.
Um trotzdem gescheite Fehlermeldungen ausgeben zu können, habe ich bei
den Klassen eine Funktion "get_last_error()" eingebaut. Versucht ein
Benutzer z.B. den Namen eines Bauteils abzuändern, kann man einfach
"set_name()" ganz normal aufrugen, und direkt nach diesem Aufruf halt
noch per "get_last_error()" überprüfen ob ein Fehler aufgetreten ist.
Falls ein String zurückkommt, wird direkt dieser String als
Fehlermeldung ausgegeben.
Irgendwann müssen wir ja unsere zwei Branches ja noch miteinander
verschmelzen. Momentan sind meine Klassen aber noch nicht wirklich
fertig, eigentlich möchte ich sie zuerst möglichst fertig kriegen bevor
wir die Branches zusammenschnüren. Nur wird es voraussichtlich noch ca.
5 Wochen dauern bis es soweit ist, weil ich eben momentan zu wenig Zeit
zum programmieren habe. Ist das für dich ein Problem, oder hast du in
dieser Zeit selber noch genug zu tun mit den Templates?
Was sicher nicht schaden würde, ist wenn du mein Klassendiagramm einfach
ein bisschen studierst, damit du ungefähr weisst wie das ganze aufgebaut
ist. Nicht dass es später noch böse Überraschungen gibt beim
Verschmelzen unserer Branches.
Urban B. schrieb:> @Udo Neist>> Du gibst ja richtig Gas beim programmieren :-D
Ich hab an diesem WE nichts vor, bis jetzt jedenfalls ;-)
> Also wenn du mich fragst, ich finde das neue Copyright gut, da man sieht> dass das ursprüngliche Projekt von uns "weitergeführt wurde. Aber K.J.> ist hier der Chef :-) Scheint aber momentan irgendwie nicht sehr aktiv> zu sein, oder ist er vielleicht in den Ferien?
Ich warte ab. Er muss ja zustimmen.
> Übrigens, hast du das "Problem" mit dem Datenbankupdate fürs neue> Preissystem mal angeschaut?
Nein, ich habe mich heute Abend an ein Online-Update der Datenbank
versucht. Bisher läuft es mit lokalen Daten. Hier fehlt noch der
Download des entsprechenden Archivs.
Kurzfassung zum Prinzip: Es wird die Datenbankversion ausgelesen, auf
dem Server nach einem Update-Archiv für diese Version geschaut, geladen
und installiert. Das Archiv beinhaltet eine PHP-Datei mit einem Array
für einen Gültigkeitscheck und eine Datei mit den SQL-Befehlen.
Möglichst eine Zeile pro SQL-Befehl, wird anhand des Semikolons
getrennt. Eventuell müsste ich da noch ein alternatives Trennzeichen
einführen, falls irgendwo bei den Daten selbst ein Semikolon vorhanden
ist.
> Wenn es nicht einfach so direkt per SQL-Anweisung möglich ist, dann> müssten wir halt dafür etwas PHP Code schreiben, der dann das Update> durchführt. Aber so mächtig wie SQL ist, wirds bestimmt auch ohne PHP> möglich sein :-)
Ich will mir das auf alle Fälle noch anschauen, bevor ich mich dazu
äußere. Also einfach noch ein bisschen liegen lassen ;-)
> Zuerst dachte ich es wäre besser wenn die Überprüfung auf die> notwendigen Rechte ausserhalb der Klassen passieren würde. So könnte man> auch besser auf fehlende Rechte reagieren und entsprechend eine> Fehlermeldung ausgeben. Allerdings bin ich mir noch nicht sicher ob> früher oder später einzelne Klassenmethoden doch noch eine Information> über die vorhandenen Rechte brauchen werden. Und ausserdem wird so die> Überprüfung der Rechte nur an einer zentralen Stelle durchgeführt und> muss nicht für jede Seite extra programmiert werden.
Es gibt bestimmt Notwendigkeiten in den verschiedenen Klassen, auch mal
die Benutzerrechte zu testen. Ich lasse schon im eigentlichen Script
prüfen, ob jemand überhaupt berechtigt ist, diese Funktion zu nutzen.
Die Klassenfunktionen brauchen hier dann nur noch das tun, für das sie
gedacht sind.
> Um trotzdem gescheite Fehlermeldungen ausgeben zu können, habe ich bei> den Klassen eine Funktion "get_last_error()" eingebaut.
Gute Idee. Im Prinzip mache ich das ähnlich. Entweder gibt es einen
Zahlencode für verschiedene Fehler und man kann den dann als Klartext
zurückbekommen oder, wenn es extrem wichtige Funktionen sind, es gibt
eine Exception und die Ausführung wird abgebrochen.
> Irgendwann müssen wir ja unsere zwei Branches ja noch miteinander> verschmelzen. Momentan sind meine Klassen aber noch nicht wirklich> fertig, eigentlich möchte ich sie zuerst möglichst fertig kriegen bevor> wir die Branches zusammenschnüren. Nur wird es voraussichtlich noch ca.> 5 Wochen dauern bis es soweit ist, weil ich eben momentan zu wenig Zeit> zum programmieren habe. Ist das für dich ein Problem, oder hast du in> dieser Zeit selber noch genug zu tun mit den Templates?
Meine Idee war es, erstmal beide Konzepte soweit zu entwickeln, dass sie
nutzbar sind. Die fehlenden Templates sind in vielleicht zwei Wochen
erstellt, wenn ich nicht wieder irgendeine Idee zu einem Issue hab ;-)
> Was sicher nicht schaden würde, ist wenn du mein Klassendiagramm einfach> ein bisschen studierst, damit du ungefähr weisst wie das ganze aufgebaut> ist. Nicht dass es später noch böse Überraschungen gibt beim> Verschmelzen unserer Branches.
Da sehe ich weniger ein Problem. Ich würde einfach Klasse für Klasse in
meinen Branch integrieren. Wenn du die Klassen so geschrieben hast, das
die Funktionen der lib.php praktisch identisch in einer Klasse
existieren, so macht der Umstieg kaum Ärger. Ich integriere die
Templates auch erstmal so, das nur der HTML-Teil vom Rest getrennt wird.
Ist das Template funktionstüchtig, nehme ich mir i.d.R. auch die
dortigen Routinen vor. Gibt so manches, was man sinnvoller umsetzen
kann.
Ich sehe in deinem Klassendiagramm, das du Objekte einsetzt. Ich muss
gestehen, ich hab mit Objekten bei PHP noch nicht gearbeitet.
Meine Klassendefinition habe ich mal als Text-Datei erstellt. Sie
umfasst meine eigenen drei Klassen html.php, error.php und pack.php.
EDIT: Korrigierte Klassendefinition (zweite Datei laden)
Udo Neist schrieb:> Wenn du die Klassen so geschrieben hast, das> die Funktionen der lib.php praktisch identisch in einer Klasse> existieren, so macht der Umstieg kaum Ärger.
Naja praktisch identisch ist es sicher nicht ;-) Die neuen Funktionen
sind natürlich voll auf OOP ausgelegt, geben also z.B. keine Arrays von
SQL-Querys mehr zurück, sondern Objekte.
Udo Neist schrieb:> Ich sehe in deinem Klassendiagramm, das du Objekte einsetzt. Ich muss> gestehen, ich hab mit Objekten bei PHP noch nicht gearbeitet.
Das verstehe ich jetzt nicht^^ Arbeitet man mit Klassen, so arbeitet man
doch automatisch auch mit Objekten ;-) Ansonsten machen die Klassen bzw.
OOP nicht viel Sinn...
Ich hab nicht gesagt, ich hätte noch nicht mit Objekten zu tun gehabt.
Nur unter PHP halt noch nicht, deswegen kenne ich die Zugriffe darauf
noch nicht. Klassen sind der Weg zu Objekten, aber nach meinem
Wissensstand haben Objekte auch noch Eigenschaften. Bisher habe ich
Klassen nur Variablen zur Verarbeitung übergeben und vielleicht hier und
da einen Ansatz zu Objekten drin gehabt.
Ob jetzt eine Funktion aus der lib.php ein String, Integer oder Bool
zurück gibt oder eine Klasse ein Objekt, das die gleichen Infos liefert,
macht keinen Unterschied. Es ist nur ein anderer Zugriff auf die Daten.
Wir werden sehen, wie man beide Branches zusammenbringen werden. Ich bin
zuversichtlich, dass es uns gelingen wird.
Ich habe gerade die partsinfo.php auf Templates umgestellt. Dabei ist
mir aufgefallen, das die Auflistung eine Schleife enthält, die aber wohl
nur einen Datensatz durchläuft.
1
$result = parts_select( $_REQUEST["pid"]);
2
while ( $data = mysql_fetch_assoc( $result))
3
{
4
...
5
}
Wenn ich das System richtig verstehe, kann PID nur einen Wert annehmen,
da parts_select() nur ein Ergebnis zurückliefert. Die Schleife wird also
nur einmal durchlaufen. Somit ist sie überflüssig. Liege ich da richtig
in meiner Annahme?
Udo Neist schrieb:> Ich hab nicht gesagt, ich hätte noch nicht mit Objekten zu tun gehabt.> Nur unter PHP halt noch nicht, deswegen kenne ich die Zugriffe darauf> noch nicht. Klassen sind der Weg zu Objekten, aber nach meinem> Wissensstand haben Objekte auch noch Eigenschaften. Bisher habe ich> Klassen nur Variablen zur Verarbeitung übergeben und vielleicht hier und> da einen Ansatz zu Objekten drin gehabt.
Ach so, okay :-)
Naja schwierig ist es nicht, einfach wie bei anderen Sprachen mit dem
"new" Operator neue Objekte anlegen usw. Ich selber habe ja bis vor
kurzem nichtmal PHP programmiert, und jetzt habe ich 22 Klassen erstellt
in PHP (und das was ich bisher getestet habe, funktioniert auch :-)
Eigentlich ist ja vieles sehr änlich wie in C++, vorallem der
objektorientierte Teil. Und wenn man sich mal etwas nicht sicher ist,
findet man im Internet für fast alles eine Erklärung.
Udo Neist schrieb:> Wenn ich das System richtig verstehe, kann PID nur einen Wert annehmen,> da parts_select() nur ein Ergebnis zurückliefert. Die Schleife wird also> nur einmal durchlaufen. Somit ist sie überflüssig. Liege ich da richtig> in meiner Annahme?
Würde ich jetzt auch meinen, ja. Es darf ja keine zwei Teile mit der
gleichen ID geben.
Übrigens kommt mir noch in den Sinn, dass ich mal daran dachte die
device.php zu löschen, und deren Aufgabe auch in die deviceinfo.php
einzubauen. Dann bräuchte das JavaScript-Menü der Baugruppen nicht mehr
zwei unterschiedliche Links (device.php oder deviceinfo.php). Das
JavaScript-Menü wird bei mir nun ja in der Klasse "StructuralDBElement"
erzeugt, und ist somit für Footprints, Kategorien, Baugruppen usw.
verwendbar, aber das System muss natürlich einheitlich sein. Da sind
solche "Extrawürste" wie zwei unterschiedliche URLs nicht erwünscht.
Vielleicht könntest du das ja noch bei Gelegenheit einbauen? Übrigens
würde ich dann vielleicht die deviceinfo.php auch gleich showdevices.php
nennen, das ist aussagekräftiger und wird ja bereits bei der
showparts.php verwendet.
Urban B. schrieb:> Ach so, okay :-)> Naja schwierig ist es nicht, einfach wie bei anderen Sprachen mit dem> "new" Operator neue Objekte anlegen usw. Ich selber habe ja bis vor> kurzem nichtmal PHP programmiert, und jetzt habe ich 22 Klassen erstellt> in PHP (und das was ich bisher getestet habe, funktioniert auch :-)> Eigentlich ist ja vieles sehr änlich wie in C++, vorallem der> objektorientierte Teil. Und wenn man sich mal etwas nicht sicher ist,> findet man im Internet für fast alles eine Erklärung.
Ich hab mir die PHP-Interpretation angeschaut. Im Prinzip hab ich das ja
schon in den Klassen drin. Nur noch nie so betrachtet :-)
C++ hab ich mal angefangen, aber bin nicht weit gekommen. Ich hab
irgendwo die C++-Bibel, nur finde ich die gerade nicht. Hab mir die
ganzen Sachen selbst beigebracht :-)
> Würde ich jetzt auch meinen, ja. Es darf ja keine zwei Teile mit der> gleichen ID geben.
Ich nehme das mal raus. Überflüssiges müssen wir nicht mitschleppen.
> Übrigens kommt mir noch in den Sinn, dass ich mal daran dachte die> device.php zu löschen, und deren Aufgabe auch in die deviceinfo.php> einzubauen. Dann bräuchte das JavaScript-Menü der Baugruppen nicht mehr> zwei unterschiedliche Links (device.php oder deviceinfo.php). Das> JavaScript-Menü wird bei mir nun ja in der Klasse "StructuralDBElement"> erzeugt, und ist somit für Footprints, Kategorien, Baugruppen usw.> verwendbar, aber das System muss natürlich einheitlich sein. Da sind> solche "Extrawürste" wie zwei unterschiedliche URLs nicht erwünscht.>> Vielleicht könntest du das ja noch bei Gelegenheit einbauen? Übrigens> würde ich dann vielleicht die deviceinfo.php auch gleich showdevices.php> nennen, das ist aussagekräftiger und wird ja bereits bei der> showparts.php verwendet.
Ich bin auch dafür, möglichst viel zu vereinheitlichen. Wenn es sinnvoll
ist, warum auch nicht. Ich werde beides mal umsetzen :-)
So... deviceinfo.php ist erstmal ein Wrapper für showdevices.php. Sobald
ich das auf vlibTemplate umgeschrieben habe, werde ich mir device.php
schnappen und integrieren.
Die deviceinfo.php ist in showdevices.php umbenannt und schätzungsweise
zu 50% auf vlibTemplate umgestellt.
Anmerkungen:
1) Mir ist aufgefallen, dass manche Beschreibungen bzw. Überschriften
der Funktionsblöcke auf der Webseite zu Verwirrungen führen können. Auf
Anhieb hätte ich nicht gewußt, dass "Benötigte Teile abfassen" die
Entnahme eines oder mehrerer kompletten Bausatzes/Bausätze bedeutet. Es
wäre hilfreich, wenn man die Hilfe auch in Form von Tooltips anbieten
würden. Man könnte am rechten Rand der Überschrift ein kleines
Fragezeichen einbauen, welches dann den Tooltip präsentiert.
2) Warum bei "Zugeordnete Bauteilen" rechts das Kästchen für "Entfernen"
markieren und dann über den Button "Löschen" löschen? Das könnte man
doch in die Funktion hinter "Übernehmen" integrieren. Schließlich will
man ja das als Änderung übernehmen. Etwas unlogisch nach meiner Meinung.
3) Die Javscript-Funktion validatePosIntNumber() erlaubt keine Änderung
per "Backspace", "Ins", "Del" oder den Cursortasten. Mein Vorschlag:
Udo Neist schrieb:>> Vielleicht könntest du das ja noch bei Gelegenheit einbauen? Übrigens>> würde ich dann vielleicht die deviceinfo.php auch gleich showdevices.php>> nennen, das ist aussagekräftiger und wird ja bereits bei der>> showparts.php verwendet.>> Ich bin auch dafür, möglichst viel zu vereinheitlichen. Wenn es sinnvoll> ist, warum auch nicht. Ich werde beides mal umsetzen :-)
Wunderbar, danke :-)
Udo Neist schrieb:> 1) Mir ist aufgefallen, dass manche Beschreibungen bzw. Überschriften> der Funktionsblöcke auf der Webseite zu Verwirrungen führen können. Auf> Anhieb hätte ich nicht gewußt, dass "Benötigte Teile abfassen" die> Entnahme eines oder mehrerer kompletten Bausatzes/Bausätze bedeutet. Es> wäre hilfreich, wenn man die Hilfe auch in Form von Tooltips anbieten> würden. Man könnte am rechten Rand der Überschrift ein kleines> Fragezeichen einbauen, welches dann den Tooltip präsentiert.
Klingt gut. Wenn es aber mal noch eine richtige Dokumentation geben
wird, würde ein Link auf die entsprechende Stelle in der Doku ja auch
genügen.
Udo Neist schrieb:> 2) Warum bei "Zugeordnete Bauteilen" rechts das Kästchen für "Entfernen"> markieren und dann über den Button "Löschen" löschen? Das könnte man> doch in die Funktion hinter "Übernehmen" integrieren. Schließlich will> man ja das als Änderung übernehmen. Etwas unlogisch nach meiner Meinung.
Jup, das finde ich auch. Ausserdem verbraucht die "Löschen"-Spalte
extrem viel Platz, obwohl nur kleine Kästchen drin stehen. Vielleicht
könnte man auch da noch etwas verbessern, also den Platz besser
ausnutzen.
Udo Neist schrieb:> 3) Die Javscript-Funktion validatePosIntNumber() erlaubt keine Änderung> per "Backspace", "Ins", "Del" oder den Cursortasten. Mein Vorschlag:
Jo, wenns funktioniert --> einbauen :-)
Ich habe vor 2 Wochen zu Testzwecken auch mal die Datenbank (Version
0.2.2) in der Firma/Abteilung) installiert.
Wir sind eine 7 Mann große Entwicklungsabteilung und haben unser
Bauteilellager bisher mit Excel 'gepflegt'. Ich habe dann mal so vor 2
Wochen den Vorschlag gemacht sich diese Datenbank mal anzusehen.
Was ich bisher so von den Kollegen gehört habe klang sehr positiv.
Bevor ich jetzt aber unsere Excel-Tabelle in die Datenbank überführe
würde mich interessieren, wann ihr meint in etwa mit dem Zusammenführen
eurer Branches fertig zu sein. Wenn das jetzt nur so 2-3 Wochen dauert,
würde ich noch warten ;-)
Wenn ich das richtig verstanden habe ist es in der neuen Version dann
möglich einem Bauteil mehreren Lieferanten zuzuordnen?
Macht es vielleicht auch Sinn einem Bauteil mehrere Hersteller zuordnen
zu können?
Dann ist uns aufgefallen das beim anlegen von Bauteilen ein zweites
Fenster aufpoppt wenn man neue Footprints/Lagerorte anlegt, kann man
nicht da zum bereits offenem Dialog wieder zurückkehren?
Eine Suche nach Preis oder die Splate Preis bei den Suchergebnissen
währe sicher sehr hilfreich.
Wenn ihr noch jemandem zum Test braucht, kann ich euch da auch gerne
weiterhelfen. Ich habe die Datenbank in einer XEN-Domu am laufen und
kann die schnell klonen und so auch Tests mit einer umfangreichen
Datenbank machen.
Mit PHP und MySQL kenn ich mich auch etwas aus, kleinere Aufgaben kann
ich auch gerne übernehmen.
M. K. schrieb:> Ich habe vor 2 Wochen zu Testzwecken auch mal die Datenbank (Version> 0.2.2) in der Firma/Abteilung) installiert.>> Wir sind eine 7 Mann große Entwicklungsabteilung und haben unser> Bauteilellager bisher mit Excel 'gepflegt'. Ich habe dann mal so vor 2> Wochen den Vorschlag gemacht sich diese Datenbank mal anzusehen.> Was ich bisher so von den Kollegen gehört habe klang sehr positiv.
Das freut uns natürlich :-)
M. K. schrieb:> Bevor ich jetzt aber unsere Excel-Tabelle in die Datenbank überführe> würde mich interessieren, wann ihr meint in etwa mit dem Zusammenführen> eurer Branches fertig zu sein. Wenn das jetzt nur so 2-3 Wochen dauert,> würde ich noch warten ;-)
Also ich von meiner Seite würde sagen, dass ich in ca. 5 Wochen die
Klassen einigermassen fertig habe. Ab dann wird es aber sicher nochmal 1
bis 2 Wochen dauern bis die beiden Branches zusammengeführt und
lauffähig sind. Bis dann ein neues Downloadarchiv rauskommt (also eine
als "stabil" bezeichnete Version) wird es dann aber nochmal ein weilchen
dauern, die neue Version muss ja erst noch gründlich getestet und Fehler
ausgemerzt werden.
Aber warten musst du ja eigentlich nicht, du kannst auch die Version
0.2.2 oder die aktuelle SVN Version benutzen bis die "brandneue" Version
rauskommt. Danach kannst du einfach deine Version aktualisieren, das ist
kein Problem, die Datenbankstruktur wird automatisch angepasst. Part-DB
ist so gebaut, dass man problemlos immer auf die neuste Version
aktualisieren kann.
M. K. schrieb:> Wenn ich das richtig verstanden habe ist es in der neuen Version dann> möglich einem Bauteil mehreren Lieferanten zuzuordnen?
Jup, genau. Und auch den Bezug der Preise auf eine bestimmte
Bestellmenge wird dann vermutlich möglich sein.
> Macht es vielleicht auch Sinn einem Bauteil mehrere Hersteller zuordnen> zu können?
Hmm...Also ich würde da jetzt nicht direkt einen Sinn erkennen. Ich
würde ähnliche Bauteile (genau gleich werden sie ja kaum sein), die von
anderen Herstellern stammen, als separate Bauteile abspeichern. Dieses
hat dann ja auch wieder andere Bestellnummern, andere Lieferanten,
andere Preise. Gemeinsamkeiten unter den verschiedenen Teilen gibt es
dann ja kaum noch (softwaretechnisch betrachtet, nicht die Bauteile an
sich verglichen).
Wenn du aber einen guten Grund hast, warum diese Funktion Sinn machen
würde, dann immer her damit :-)
M. K. schrieb:> Dann ist uns aufgefallen das beim anlegen von Bauteilen ein zweites> Fenster aufpoppt wenn man neue Footprints/Lagerorte anlegt, kann man> nicht da zum bereits offenem Dialog wieder zurückkehren?
Entweder habe ich dich falsch verstanden, oder dieses Verhalten ist in
der aktuellen SVN-Version nicht mehr so vorhanden. Ich habe leider grad
keine 0.2.2er Version installiert, kann es also grad nicht testen.
Wenn die Online-Demo funktionieren würde, könntest du es dort rasch
probieren. Aber irgendwie scheint der ganze Server momentan ein Problem
zu haben, sogar auf der normalen Seite von K.J. kommen MySQL Fehler. Ich
schreib ihm mal eine PN...
M. K. schrieb:> Eine Suche nach Preis oder die Splate Preis bei den Suchergebnissen> währe sicher sehr hilfreich.
Es ist geplant, dass die Tabellen(spalten) individuell anpassbar werden
sollen. Allerdings wird das noch eine ganze Weile dauern, da wir zuerst
die Benutzerverwaltung brauchen. Wenn es dringend ist, müsstest du es
halt selber einbauen, oder nochmal hier nachfragen ob es jemand von uns
machen kann (also nur für dich, nicht allgemein). Sollte keine grosse
Sache sein.
M. K. schrieb:> Wenn ihr noch jemandem zum Test braucht, kann ich euch da auch gerne> weiterhelfen.
Wie ich schon weiter oben einmal geschrieben habe: Tester kann man immer
brauchen :-) Alles was wir uns von euch wünschen, ist Feedback :-)
Speziell wenn Part-DB beruflich eingesetzt wird, sind die
Anforderungen/Erwartungen an die Software ja anders als bei privater
Nutzung. Da Part-DB vermutlich (noch?) nicht stark im beruflichen Umfeld
genutzt wird, sind die Feedbacks von solchen Benutzern speziell wichtig.
Gruss
Urban
Urban B. schrieb:> Ich würde dir empfehlen, dass du erstmal deine komplette Datenbank> sicherst (z.B. über phpMyAdmin oder mysqldump). Dann lädst du die neuste> Version aus dem SVN herunter. Den Link dazu gibts hier:> https://code.google.com/p/part-db/source/checkout und Anleitungen findet> man über Google.>> Einfach die alten Dateien mit den neuen aus dem SVN überschreiben.> Danach kannst du die Version austesten, schauen ob alles so läuft wie es> soll. Ich habe immer die neuste SVN-Version als Produktivsystem> installiert und hatte noch nie wirklich Probleme.
Steig da grad bei der Struktur auf Google code nicht ganz durch.
Muss ich da die einzelnen Branches einfach nachinstallieren, oder gibts
da irgendwo ein komplettarchiv dass ich dann einfach komplett einspiele?
Wollte da grad mal loslegen aber da habperts schon weil ich bei google
code nur einzelne files runterladen kann, vielleicht hab ich da auch nur
was übersehen?!?
kirk disen schrieb:> Muss ich da die einzelnen Branches einfach nachinstallieren, oder gibts> da irgendwo ein komplettarchiv dass ich dann einfach komplett einspiele?> Wollte da grad mal loslegen aber da habperts schon weil ich bei google> code nur einzelne files runterladen kann, vielleicht hab ich da auch nur> was übersehen?!?
Du brauchst einen SVN Client (ein Programm) um das komplette Projekt
herunterladen zu können.
Für Windows gibts dieses hier: http://tortoisesvn.net/
Für Linux muss das Paket "subversion" installiert sein.
Mit diesem Programm können dann die Dateien heruntergeladen werden. Du
musst das Programm einfach mit diesem Link füttern:
1
http://part-db.googlecode.com/svn/trunk/
Wie TortoiseSVN genau funktioniert weiss ich nicht, da ich Linux
verwende. Aber es sollte genügend Anleitungen dazu geben im Internet.
Die Verzeichnisse "uneist" und "kami89" unterhalb von
http://part-db.googlecode.com/svn/branches/ sind aktuell in Entwicklung
und sollen nach der Zusammenführung die neue Version von Part-DB werden.
Ich schätze, es dürfte Weihnachten werden, bis wir soweit sind. Das
Update wird auf alle Fälle so unkompliziert wie möglich gemacht. Wir
sind dabei, einen Update-Mechanismus dafür zu entwickeln :-)
Danke erstmal mti dem Tipp zum Tortoise SVN. Aber warum so kompliziert?
wäre es denn nicht sinnvoll einfach ein aktuelles Package mit den ganzen
Files online zu stellen? Bin ansich kein Freund von Client Programmen
weshalb ich auch so erfreut über eure offene Part-DB bin. Einziger
Vorteil den ich aktuell sehe durch das SVN ist dass Traffic gespart wird
falls neue Versionen rauskommen wobei das bei der aktuellen Nutzerzahl
wohl eher unwichtig ist. Das soll ja die neue Version von Part-DB
selbstständig managen können so wie ich das aktuell lese. Erklär mir
jetzt bitte noch wie man dem "umständlichen" SVN das verklickert die
Files in nem Ordner zu laden. hab das grad beim 3. versuch immernoch
nicht hinbekommen...
kirk disen schrieb:> Aber warum so kompliziert?> wäre es denn nicht sinnvoll einfach ein aktuelles Package mit den ganzen> Files online zu stellen?
Das SVN ist eigentlich nur für die Entwickler gedacht, nicht für die
"Endkunden". Mit dem SVN können wir nämlich sehr bequem und schnell
Änderungen in Google Code hochladen, Branches erstellen, Branches
verschmelzen, Versionen verwalten, Änderungen nachvollziehen usw. Es
gibt eine Menge Vorteile für uns Entwickler. Gerade auch wenn eben
mehrere Personen am gleichen Projekt arbeiten. Und natürlich kann man
eben seine eigene, lokal installierte Testversion ganz einfach immer
aktuell halten.
Der "Nachteil" ist aber, dass die (aktuellste) SVN-Version nicht immer
stabil läuft, noch Fehler enthält usw. weil eben mehrere Leute dran
"rumfummeln" und sich auch mal gegenseitig in die Quere kommen können.
Ist also wirklich nicht für die Endkunden gedacht, das würde nur Ärger
geben.
Zwischendurch, wenn wir der Ansicht sind dass die aktuelle SVN-Version
stabil und fehlerfrei läuft, stricken wir ein Archiv zusammen, das dann
in Google Code unter "Downloads" erscheint. Das ist dann die offizielle
stable-Version die für die Endkunden bestimmt ist.
Da aber unser Projekt noch einigermassen überschaubar ist (verglichen
mit anderen SVN Projekten), nicht zu viele Leute dran rumschrauben und
die aktuelle SVN-Version gar nicht schlecht läuft, "darf" man momentan
auch die SVN-Version benutzen wenns sein muss.
kirk disen schrieb:> Das soll ja die neue Version von Part-DB> selbstständig managen können so wie ich das aktuell lese.
Genau. Das würde das Updaten dann sehr bequem machen.
kirk disen schrieb:> Erklär mir> jetzt bitte noch wie man dem "umständlichen" SVN das verklickert die> Files in nem Ordner zu laden.
Was willst du genau machen? Die Dateien aus dem SVN herunterladen? Wie
gesagt, bei TortoiseSVN kenne ich mich überhaupt nicht aus.
Bei Linux geht es sehr bequem mit einem einzigen Terminalbefehl:
Udo Neist schrieb:> Das> Update wird auf alle Fälle so unkompliziert wie möglich gemacht. Wir> sind dabei, einen Update-Mechanismus dafür zu entwickeln :-)
Das hört sich sehr gut an. Dann werde ich erst einmal bei Version 0.2.2
bleiben und mich dann auf die nächste Version freuen ;-)
Urban B. schrieb:> M. K. schrieb:>> Dann ist uns aufgefallen das beim anlegen von Bauteilen ein zweites>> Fenster aufpoppt wenn man neue Footprints/Lagerorte anlegt, kann man>> nicht da zum bereits offenem Dialog wieder zurückkehren?>> Entweder habe ich dich falsch verstanden, oder dieses Verhalten ist in> der aktuellen SVN-Version nicht mehr so vorhanden. Ich habe leider grad> keine 0.2.2er Version installiert, kann es also grad nicht testen.
Ich habe mal ein Bild angehangen, wenn man auf die rot eingekreisten
Buttons klickt öffnet sich ein neues Popup mit der selben Maske wo dann
nur die DropDown-Listen aktualisiert sind.
Es scheint nur den Internet Explorer (IE 8.0) zu betreffen der Firefox
12 macht dies nicht.
Ein paar Fragen zu dem CSV-Import:
Im Beispiel wird vor den Daten eine Zeile mit den Spaltennamen
angegeben, sind in dem Beispiel alle Spalten aufgeführt die es gibt und
das # am Anfang muss auch sein?
Hier nochmal das Beispiel von der Seite:
Wenn ich die Vorschaubilder(Footprints) benutzen möchte muss ich bei
Footprint exakt den Namen des Vorschaubildes angeben?
Die Lagerorte haben bei uns Unterkategorien, wie kann ich die in der
CSV-Datei angeben? z.B. Schubladenkästen -> S-0123
Das gleiche bei den Bauteilkategorien.
M. K. schrieb:> Ich habe mal ein Bild angehangen, wenn man auf die rot eingekreisten> Buttons klickt öffnet sich ein neues Popup mit der selben Maske wo dann> nur die DropDown-Listen aktualisiert sind.> Es scheint nur den Internet Explorer (IE 8.0) zu betreffen der Firefox> 12 macht dies nicht.
Ah ja, stimmt, beim IE läuft da was falsch :-)
Ich habe den Fehler auch schon gefunden und lade ihn gleich noch ins SVN
hoch. Wer nicht auf die SVN-Version aktualisieren will, kann die
Änderungen auch selber durchführen.
Dazu einfach die folgenden Dateien herunterladen und die alten Dateien
damit überschreiben:
https://part-db.googlecode.com/svn-history/r512/trunk/editpartinfo.phphttps://part-db.googlecode.com/svn-history/r512/trunk/newpart.php
Dann muss man in der newpart.php die Zeile 145
1
$p_footprint = footprint_add( $NewFootprint, '');
ersetzen durch diese Zeile:
1
$p_footprint = footprint_add( $NewFootprint);
Und ausserdem muss in der alten partinfo.php eine neue Zeile (Nr. 54)
eingefügt werden:
54: <base target="_self" /> <!-- Diese Zeile ist neu -->
7
55:</head>
@Udo
Kannst du diese Änderungen auch gleich in deinen Branch übernehmen? Und
natürlich sollte der Header immer vor der ersten Ausgabe geschrieben
werden, was in der editpartinfo.php momentan nicht so ist. Da habe ich
etwas "gebastelt", da es eh nur eine Übergangslösung ist (die Seite wird
ja eh noch auf Templates umgestellt).
M. K. schrieb:> Ein paar Fragen zu dem CSV-Import:> Im Beispiel wird vor den Daten eine Zeile mit den Spaltennamen> angegeben, sind in dem Beispiel alle Spalten aufgeführt die es gibt und> das # am Anfang muss auch sein?
Ja es sind alle Spalten aufgeführt, die existieren. Und alle Zeilen mit
einem # am Anfang werden einfach ignoriert, das sind nur Kommentare
(brauchts also nicht).
M. K. schrieb:> Wenn ich die Vorschaubilder(Footprints) benutzen möchte muss ich bei> Footprint exakt den Namen des Vorschaubildes angeben?
Ja, in Version 0.2.2 ist das noch so. Die aktuelle SVN-Version
unterscheidet nun zwischen Footprint-Name und Dateiname (sind also
unabhängig voneinander). Allerdings ist das Zuweisen eines Bildes noch
nicht sehr bequem möglich, mann muss direkt den Dateinamen inkl. Pfad
angeben. Es gibt aber immerhin einen Trick: Einfach den Dateinamen (ohne
Pfad) eingeben, und so speichern. Danach ist dieser Footprint unter
"Fehlerhafte Dateinamen" aufgelistet (mit einem Vorschlag als
Dateinamen) und man muss nur noch bestätigen, dass der neue Pfad
übernommen wird.
Das ist halt alles noch ein bisschen provisorisch weil uns der neue
Uploadmanager noch fehlt (bzw. der Programmierer, der ihn programmiert)
;-)
M. K. schrieb:> Die Lagerorte haben bei uns Unterkategorien, wie kann ich die in der> CSV-Datei angeben? z.B. Schubladenkästen -> S-0123> Das gleiche bei den Bauteilkategorien.
Das automatische Anlegen von Kategorien funktioniert meines Wissens
nicht mit Unterkategorien. Alle noch nicht existierenden Kategorien
werden unter der Kategorie "Import" abgelegt.
Existieren die Kategorien aber bereits, dann brauchst du nur den
direkten Kategorienamen anzugeben (ohne Pfad), das müsste funktionieren.
Allerdings funktioniert das nur dann zuverlässig, wenn es nur eine
einzige Kategorie mit diesem Namen gibt!
Für deinen Fall wäre die einzig gescheite Lösung also, dass du alle
Kategorien schon vorher von Hand anlegst. Wäre das zu aufwändig (hast du
viele Kategorien)? Dann könnte vielleicht auch jemand das Importscript
so abändern, dass man auch ganze Pfade angeben kann, und die dann auch
so angelegt werden...
Urban B. schrieb:> Für deinen Fall wäre die einzig gescheite Lösung also, dass du alle> Kategorien schon vorher von Hand anlegst. Wäre das zu aufwändig (hast du> viele Kategorien)? Dann könnte vielleicht auch jemand das Importscript> so abändern, dass man auch ganze Pfade angeben kann, und die dann auch> so angelegt werden...
Soviele sind es nicht, diese vorher per Hand anzulegen dürfte recht gut
gehen. Die Lagerorte sind eindeutig, die Bauteilkategorien sollten auch
eindeutig sein, wenn nicht lässt sich da sicher ein wenig tricksen.
Mehr Arbeit habe ich im Moment sowieso damit die Daten aus Excel
aufzubereiten :-/
Urban B. schrieb:>> Macht es vielleicht auch Sinn einem Bauteil mehrere Hersteller zuordnen>> zu können?>> Hmm...Also ich würde da jetzt nicht direkt einen Sinn erkennen. Ich> würde ähnliche Bauteile (genau gleich werden sie ja kaum sein), die von> anderen Herstellern stammen, als separate Bauteile abspeichern. Dieses> hat dann ja auch wieder andere Bestellnummern, andere Lieferanten,> andere Preise. Gemeinsamkeiten unter den verschiedenen Teilen gibt es> dann ja kaum noch (softwaretechnisch betrachtet, nicht die Bauteile an> sich verglichen).>> Wenn du aber einen guten Grund hast, warum diese Funktion Sinn machen> würde, dann immer her damit :-)
Darüber haben wir gerade nochmal überlegt, dann ist uns aufgefallen das
es überhaupt keine Spalte für den Hersteller gibt. :D
Wahrscheinlich reicht es uns wenn wir solche Bauteile dann doppelt
anlegen.
Was aber öfters vorkommt ist, das wir 2 Bauteile an 2 Lagerorten haben.
Eine kleine Menge in unseren Schubladenkästen für Prototypen und eine
größere Menge die wir evtl. unseren Bestücker für die erste Serie
beistellen. Manchmal passen die Teile auch nicht in eine Schublade dann
wird das auf 2 oder 3 Schubladen aufgeteilt.
Man kann dafür zwar auch mehrere Bauteile anlegen, wenn sich dann aber
der Preis, Bestellnummer, Datenblatt ändert muss man halt daran denken
bei allen die Änderung durchzuführen.
M. K. schrieb:> Darüber haben wir gerade nochmal überlegt, dann ist uns aufgefallen das> es überhaupt keine Spalte für den Hersteller gibt. :D> Wahrscheinlich reicht es uns wenn wir solche Bauteile dann doppelt> anlegen.
Ja, noch gibt es keine solche Spalte, aber die kommt noch :-)
M. K. schrieb:> Was aber öfters vorkommt ist, das wir 2 Bauteile an 2 Lagerorten haben.> Eine kleine Menge in unseren Schubladenkästen für Prototypen und eine> größere Menge die wir evtl. unseren Bestücker für die erste Serie> beistellen.
Hmm ja, ich denke darüber lässt sich nachdenken. Mal schauen ob wir das
so einbauen werden.
Urban B. schrieb:> @Udo> Kannst du diese Änderungen auch gleich in deinen Branch übernehmen? Und> natürlich sollte der Header immer vor der ersten Ausgabe geschrieben> werden, was in der editpartinfo.php momentan nicht so ist. Da habe ich> etwas "gebastelt", da es eh nur eine Übergangslösung ist (die Seite wird> ja eh noch auf Templates umgestellt).
Ich habe die Änderungen gerade eingepflegt :-) Meine aktuelle Version
stelle ich heute abend ins SVN, unabhängig von der Freigabe der neuen
Lizenzinfo.
Von meiner Seite ist es auch geplant, die Popups auf Pseudo-Popups
(DIV-Blöcke, die über die Seite gelegt werden und wie neue Fenster
aussehen) zu ändern. Aber lasst mich erstmal die Templates erstellen und
die Klassen zusammen mit Urban integrieren :-)
Udo Neist schrieb:> Ich habe die Änderungen gerade eingepflegt :-) Meine aktuelle Version> stelle ich heute abend ins SVN, unabhängig von der Freigabe der neuen> Lizenzinfo.
Wunderbar :-) Ich habe K.J mal eine PN geschickt, auch deine
Lizenzänderung habe ich erwähnt. Jedoch hat er bisher nicht geantwortet.
Es erstaunt mich dass dieser Bug erst jetzt gemeldet wurde, es war ein
extrem nerviges Verhalten wenn man den IE verwendet. Es waren nicht nur
die genannten drei Buttons betroffen, es gab auch noch andere
Situationen in denen unnötig neue Popups geöffnet wurden. Naja
vielleicht arbeitet einfach kein Mensch mehr mit dem IE ;-)
Udo Neist schrieb:> Von meiner Seite ist es auch geplant, die Popups auf Pseudo-Popups> (DIV-Blöcke, die über die Seite gelegt werden und wie neue Fenster> aussehen) zu ändern.
Klingt gut, bin gespannt wie das aussehen wird :-)
Revision 513:
- neue Lizenzinfo in den Scripten, abgesehen von externen
Third-Party-Modulen
- diverse Templates erstellt, darunter für die Tools
- Änderung von validatePosIntNumber()
- Erstes Updatesystem für die Datenbank: soll auf einem spezifierten
Server nach einem Update für die Datenbank suchen und installieren
- Bugfix (siehe ein paar Posts weiter oben)
Infos zum Updatesystem:
Das Updatesystem prüft auf einem spezifizierten Server, ob zur
installierten Datenbank ein passendes Update vorliegt. Die aktuelle
Datenbank trägt die Version 12. Das neue System verlangt eine Version,
Subversion und Revision. Dafür legt die derzeitige update.php über das
mitgelieferte update/part-db_update_rev12.zip zwei zusätzliche Einträge
dbSubversion und dbRevision in der Tabelle internal an. Damit
können wir sehr genau steuern, welche Version wir zum Update anbieten.
Treten Fehler in unseren Versionen auf, soll ein passender Mechanismus
ein Rollback und ein neues Update ermöglichen. Geplant ist es, die
betreffenden Tabellen bzw. die gesamte Datenbank zuvor zu sichern.
Ob das Updatesystem auch ein Online-Update der Scripte/Templates
ermöglicht, das kann man zum jetzigen Zeitpunkt noch nicht sagen.
Udo Neist schrieb:> Das Updatesystem prüft auf einem spezifizierten Server, ob zur> installierten Datenbank ein passendes Update vorliegt. Die aktuelle> Datenbank trägt die Version 12. Das neue System verlangt eine Version,> Subversion und Revision. Dafür legt die derzeitige update.php über das> mitgelieferte update/part-db_update_rev12.zip zwei zusätzliche Einträge> dbSubversion und dbRevision in der Tabelle internal an. Damit> können wir sehr genau steuern, welche Version wir zum Update anbieten.
Das verstehe ich nicht ganz. Wir sollten kein Durcheinander mit dem
Update der Datenbank, und dem Update des Systems (die Dateien) machen.
Die Updatefunktion der Datenbank finde ich so wie sie momentan ist,
eigentlich sehr gut. Es ist total unkompliziert und vorallem aber prüft
sie quasi immer, ob das aktuell installiere System (die Dateien) eine
neuere Datenbankversion braucht als die aktuell installierte. Es ist so
quasi ein sehr selbstständiges und unkompliziertes System. Und
ausserdem, was ich auch noch sehr wichtig finde: Wenn jemand die
Updatefunktion des Systems nicht nutzen will oder kann, aber trotzdem
eine aktuelle Version haben will, der kann weiterhin problemlos die
neuen Dateien einfach von Hand auf den Server laden. Ein eventuell
notwendiges Datenbankupdate wird dann automatisch durchgeführt wenn die
db_update.php mit einer neueren Version überschrieben wurde.
Daher denke ich wir sollten es nicht unnötig kompliziert machen. Also
das Datenbankupdate und das Systemupdate sollen unabhängig voneinander
funktionieren, und das tun sie wenn wir das Datenbankupdate genau so
lassen wie es jetzt ist.
Beim Systemupdate dachte ich, dass ein Updatearchiv einfach alle neuen
(geänderten) Dateien enthalten soll, auch Footprint-Bilder usw. Durch
ein einfaches Entpacken werden dann alle Dateien überschrieben. Und
damit man auch Dateien löschen, verschieben usw. kann, wäre vielleicht
ein im Archiv enthaltenes Shell-Script eine einfache, aber sehr flexible
Lösung. Dieses Skript soll sich vielleicht nach einem erfolgreichen
Ausführen gleich automatisch Löschen, dann bräuchten wir nichtmal zu
überprüfen ob das Skript bereits ausgeführt wurde, oder ob es noch
ausgeführt werden muss.
EDIT: Oder man benutzt genau das gleiche Prinzip wie beim
Datenbankupdate. Das Skript enthält ein switch-case, mit einem case pro
Systemversion. Das wäre meiner Meinung nach eine gut geeignete Lösung.
> Treten Fehler in unseren Versionen auf, soll ein passender Mechanismus> ein Rollback und ein neues Update ermöglichen. Geplant ist es, die> betreffenden Tabellen bzw. die gesamte Datenbank zuvor zu sichern.
Für die Datenbank soll es dazu in meiner Datenbankklasse ja die
Funktionen backup() und restore() geben. Fürs System müsste man wohl
zuerst alle Dateien sichern (zippen?), um sie auch wiederherstellen zu
können. Zumindest die Systemdateien (ohne Bilder, das wäre wohl zu viel
des Guten).
Ach übrigens, K.J. hat auf meine PN geantwortet und schrieb dass die
Lizenzänderung so in Ordnung sei.
Hmm nach einigem Nachdenken gefällt mir mein Vorschlag zwar auch nicht
mehr so gut, also vergiss diesen Teil meines letzten Beitrages einfach
wieder^^
Ich bin noch ein bisschen am überlegen wie man es besser machen
könnte...
Das Prinzip neue Softwareversion = neue Datenbankversion bleibt ja
weiterhin bestehen. Dieser Mechanismus soll dafür sorgen, das zur
jeweiligen Software auch immer die richtige Datenbankversion installiert
ist. Wenn es ein Fehler in der Datenbank gibt, können wir den Bugfix auf
diese Weise zur Verfügung stellen. Der jetzige Ansatz bedingt ja, das
wir die Änderungen immer in der db_update.php einbauen. Das wird aber
nicht in jedem Fall auch funktionieren. Nicht jeder hat Zugriff auf die
Dateien von Part-DB und muss daher eine passende Updatefunktion für
Datenbank und System besitzen.
Switch oder If-Sequenzen für jede einzelne Datenbankversion? Das wird
irgendwann unwartbar werden.
Udo Neist schrieb:> Der jetzige Ansatz bedingt ja, das> wir die Änderungen immer in der db_update.php einbauen. Das wird aber> nicht in jedem Fall auch funktionieren. Nicht jeder hat Zugriff auf die> Dateien von Part-DB und muss daher eine passende Updatefunktion für> Datenbank und System besitzen.
Warum hat nicht jeder Zugriff auf die Dateien von Part-DB? Direkten
Dateizugriff hat nicht jeder, das ist klar. Aber ein Update wird ja
nicht vom Benutzer durchgeführt, sondern vom Webserver (auf Linux
standardmässig ja die Gruppe "www-data"). Der Webserver sollte ja in
jedem Fall Zugriff auf die Dateien haben. Hat er kein Schreibrecht im
ganzen Part-DB Ordner, kann man ein automatisches Update natürlich
vergessen, da keine Dateien aktualisiert werden können.
Und per separaten Updates nur die Datenbank zu aktualisieren halte ich
für unnötig. Entweder gibts das ganze Update-Programm oder nix :-)
Aber eigentlich sollte es ja kein Problem darstellen, dass man dem
Benutzer "www-data" Schreibrechte für den ganzen Ordner von Part-DB gibt
oder?
Udo Neist schrieb:> Switch oder If-Sequenzen für jede einzelne Datenbankversion? Das wird> irgendwann unwartbar werden.
Ja das denke ich eben momentan auch gerade. Es wäre schon nicht
schlecht, wenn jedes Update immer nur diejenigen Updateschritte enthält,
die für dieses Update notwendig sind. Das Problem ist dann allerdings,
dass das System wirklich nur noch Version für Version aktualisiert
werden darf. Wenn man immer die Online-Updates benutzt ist das kein
Problem. Will man aber nur manuelle Updates machen, und das nur einmal
im Jahr, dann müsste man ja alle in dieser Zeit veröffentlichten
Update-Pakete separat herunterladen, nacheinander auf den Server
kopieren und jedesmal nach dem Kopieren die Seite im Browser
aktualisieren damit die Updateschritte durchgeführt werden ;-)
Oder hast du für dieses Problem auch eine Lösung? :-)
Urban B. schrieb:> Ja das denke ich eben momentan auch gerade. Es wäre schon nicht> schlecht, wenn jedes Update immer nur diejenigen Updateschritte enthält,> die für dieses Update notwendig sind. Das Problem ist dann allerdings,> dass das System wirklich nur noch Version für Version aktualisiert> werden darf. Wenn man immer die Online-Updates benutzt ist das kein> Problem. Will man aber nur manuelle Updates machen, und das nur einmal> im Jahr, dann müsste man ja alle in dieser Zeit veröffentlichten> Update-Pakete separat herunterladen, nacheinander auf den Server> kopieren und jedesmal nach dem Kopieren die Seite im Browser> aktualisieren damit die Updateschritte durchgeführt werden ;-)>> Oder hast du für dieses Problem auch eine Lösung? :-)
Wenn man das ganze mal weiter spinnt, wäre folgendes wohl sinvoller:
Statt einem Update gäbe es Sammelupdates, also ein Paket von x
SQL-Scripte. Die PHP-Datei würde dann eine Zuordnung SQL-Script zur
Datenbank- und Part-DB-Version beinhalten. Wir würden also zur
Datenbankversion 12 ein Paket anbieten, zur 13 ein anderes, zur 14
wieder ein anderes. Die Updatefunktion durchsucht das Array in der
PHP-Datei nach gültigen Updates für sich und spielt die ein. Im Prinzip
könnten wir so auch die Installation der Datenbank durchführen,
sozusagen als Update Nummer 0 ;-)
So in etwa stelle ich mir das vor:
1
$up2date[12]['sqlscript'][]=12-0-0.sql;
2
$up2date[12]['required'][]=511;
3
$up2date[12]['sqlscript'][]=12-0-1.sql;
4
$up2date[12]['required'][]=553;
5
$up2date[12]['sqlscript'][]=12-0-2.sql;
6
$up2date[12]['required'][]=599;
7
$up2date[12]['sqlscript'][]=12-0-3.sql;
8
$up2date[12]['required'][]=615;
Das Update der Datenbank selbst wäre ja eher ein Sonderfall. Ich kann
mir vorstellen, dass wir das in Richtung Update von Logos, Footprints
u.ä. weiter"spinnen". Es wären also nicht nur SQL-Scripte in dem Archiv,
sondern auch Dateien, die ins System kopiert werden. Wenn man so will,
wäre das das Systemupdate, was wir wollen :-)
Hi, wollte mich mal kurz melden um einiges zu erwähnen:
- Das mit der Lizenz ist ok find auch das jeder der was dran macht sich
ja auch da unter verewigen kann in etwa wie folgt wen nur ich da stehe
ist das irgendwie blöd:
"- Nick Art der Änderungen Datum"
Ansonsten die Demo DB ist erstmal bis Mo. nicht funktionsfähig, leider
gab es eine Sicherheitslücke im Plesk des Servers, also werde ich den am
WE neu aufsetzen müssen, diesmal ohne Admin Interface ;-)
So ich glaub das war es erstmal, ansonsten per Mail wen was wichtiges
ist (die gmail. addy)
K. J. schrieb:> Hi, wollte mich mal kurz melden um einiges zu erwähnen:>> - Das mit der Lizenz ist ok find auch das jeder der was dran macht sich> ja auch da unter verewigen kann in etwa wie folgt wen nur ich da stehe> ist das irgendwie blöd:>> "- Nick Art der Änderungen Datum"
Gute Idee :-) Ich denke, das sollten wir im offiziellen
Entwicklungszweig einführen und, wenn die beiden Zweige von Urban und
mir zusammengeführt sind, entsprechend neu starten. Ist ja fast ein
kompletter Rewrite des Codes.
Ich führe in meinem Zweig ein kurzes Logfile, welches die wichtigsten
Änderungen zusammenfasst.
> Ansonsten die Demo DB ist erstmal bis Mo. nicht funktionsfähig, leider> gab es eine Sicherheitslücke im Plesk des Servers, also werde ich den am> WE neu aufsetzen müssen, diesmal ohne Admin Interface ;-)
Aus diesem Grund hab ich auf jegliche Adminoberfläche verzichtet und
nutze nur wenige Webtools. Alles andere geht über die Konsole :-)
Udo Neist schrieb:> Das Update der Datenbank selbst wäre ja eher ein Sonderfall. Ich kann> mir vorstellen, dass wir das in Richtung Update von Logos, Footprints> u.ä. weiter"spinnen". Es wären also nicht nur SQL-Scripte in dem Archiv,> sondern auch Dateien, die ins System kopiert werden. Wenn man so will,> wäre das das Systemupdate, was wir wollen :-)
Jo, ein Updatepaket soll alles mögliche beinhalten: Die neuen
PHP-Dateien, Footprints, IC-Logos, Dokumentation, Updateanweisungen für
exec() und Datenbankupdate.
Wenn wir jetzt die Updatepakete so minimal bauen, dass damit die Version
immer nur um eine erhöht wird, wäre das schlussendlich für das
automatische Update wohl das Beste, da die Pakete dadurch immer nur so
gross sind wie nötig. Und ausserdem ist es zuverlässiger, da nicht die
unmöglichsten Versionssprünge überwunden werden müssen, sondern wirklich
immer nur die jeweils nächstneuere. Also ich meine jetzt dateitechnisch
ist es so sicherer, weil keine Dateivsersionen übersprungen werden
können.
Für die Manuell-Updater müssten wir dann halt ab und zu mal komplette
Updatearchive anbieten, mit denen dann auch grössere Versionssprünge auf
einmal gemacht werden können. Ist halt leider schon wieder ein
zusätzlicher Aufwand für uns Entwickler, aber man muss ja nicht bei
jedem neuen Einzelupdate auch ein Komplettupdate anbieten.
Man könnte vielleicht ja auch der Versionsbezeichnung eine Bedeutung
zuweisen. also wenn die Versionsbezeichnung wie die 0.2.2 aus drei
Zahlen besteht, ist die erste Zahl die Hauptversion, die zweite Zahl
entspricht den Komplettupdatepaketen und die dritte Zahl den
Einzelupdates. Ist aber nur mal ein Vorschlag...
Für die Updates könnte man vielleicht einen neuen Ordner anlegen, z.B.
"updates/". Die Dateien darin sind genau nach der jeweiligen
Versionsnummer benannt, z.B. "0.2.3.inc" (oder php, wie auch immer...).
In den Einzelupdatepaketen ist jeweils nur eine solche Datei vorhanden,
in den Komplettupdatepaketen ist für jede Version, die mit dem Archiv
überwunden werden kann, eine Datei vorhanden. Bei den Komplettupdates
kann es ja auch vorkommen, dass eine gewisse Version Voraussetzung ist,
um problemlos updaten zu können. Also wenn man v0.2.2 installiert hat,
und dann das Komplettpaket v0.4.0 installieren will, das aber unbedingt
v0.3.3 voraussetzt, muss das System merken dass die Update-Dateien für
die Versionen 0.2.2 bis v0.3.3 gar nicht vorhanden sind.
In den jeweiligen Updatedateien sind dann vielleicht folgende
Informationen enthalten:
- Version, die vorausgesetzt wird (normalerweise immer eine Version
tiefer als die von der Datei, aber für Sprünge von z.B. 0.2.9 auf 0.3.0
ist diese Information wichtig)
- Version, die installiert wird (könnte man ev. auch weglassen, da der
Dateinamen diese Information ja schon enthält)
- Kurze Zusammenfassung des Updates (Changelog, der dem Benutzer auch
gezeigt wird damit man weiss was neu ist)
- Eine Updatefunktion, der eine Referenz auf das PDO meiner
Datenbankklasse übergeben wird (und ev. noch weitere Parameter)
- In dieser Funktion sind dann direkt die kompletten Datenbankupdates
enthalten, also nicht nur die SQL-Querys. Dies hat den Vorteil, dass man
einfach flexibler ist. Man kann auch mal ein kompliziertes
Datenbankupdate durchführen, bei dem eine PHP Schleife notwendig ist
oder sowas, da man über das PDO den direkten Vollzugriff auf die
Datenbank hat.
- In der Funktion können auch per exec() noch spezielle Sachen gemacht
werden, wie z.B. nicht mehr benötigte Dateien löschen, Dateien
verschieben usw. Da ist man dann eigentlich völlig frei was man hier
noch machen will.
So, und jetzt lese ich das gleich nochmal ein paarmal durch und finde
bestimmt wieder einige Aspekte die ich noch vergessen habe :-)
K. J. schrieb:> - Das mit der Lizenz ist ok find auch das jeder der was dran macht sich> ja auch da unter verewigen kann in etwa wie folgt wen nur ich da stehe> ist das irgendwie blöd:>> "- Nick Art der Änderungen Datum"
Jo, das finde ich gut. So kann man nämlich sehr schnell nachvollziehen
wer welche Änderung gemacht hat, das ist ab und zu mal nützlich. Wenn
ich einen Vorschlag machen darf, würde ich aber das Datum zu vorderst
schreiben, so dass es dann eine schöne, nach Datum sortierte Liste gibt
:-)
die updatefunktion ist schon schön allerdings muss ich gestehen dass
meine partdb aktuell ohne internetleitung auskommt und das möchte ich
auch ungern ändern schon allein wegen der datensicherheit. updatepakete
wären toll. beim ersten start kann dann das script prüfen ob die
datenbank auf dem neuesten stand ist.
Was mich noch freuen würde wenn man auch andere einheiten benutzen kann
als nur stückzahlen. aktuell ist es so dass wir im lager auch kabel
verwalten da geht et z.b. um meter, oder habt ihr schon eine lösung
bezüglich teile die nicht stückzahlabhängig geführt werden? die
problematik die ich aktuell habe sind dann so sachen wie aderendhülsen
die in massen im lager liegen. wir behelfen uns momentan damit dass wir
einfach 999999 als stückzahl eingeben, allerdings schlägt sich das in
der statistik nieder. im vergleich mit anderen "professionellen"
lagerverwaltungssystemen ist ich die partdb um längen voraus. gibts
schon eine lösung die footprints auszublenden? ich weiss ihr seid voll
im wuseln mit der updateroutine. falls ihr mal ein aktuelles package zum
testen habt das ohne grobe bugs läuft wäre es schön wenn ihr dass mal
irgendwo online stellen könnt. ich würde das dann mal versuchen bei uns
im alltag einzusetzen, da findet man am ehesten fehler und bugs..
gruß
kirk disen schrieb:> die updatefunktion ist schon schön allerdings muss ich gestehen dass> meine partdb aktuell ohne internetleitung auskommt und das möchte ich> auch ungern ändern schon allein wegen der datensicherheit. updatepakete> wären toll. beim ersten start kann dann das script prüfen ob die> datenbank auf dem neuesten stand ist.
Es wird natürlich weiterhin möglich sein, die Updates manuell
einzuspielen. Man lädt sich dann halt die Updatepakete selber im
Internet runder, entpackt sie und kopiert die neuen Dateien auf den
Webserver. Das Update der Datenbank führt dann das System selber durch.
kirk disen schrieb:> Was mich noch freuen würde wenn man auch andere einheiten benutzen kann> als nur stückzahlen. aktuell ist es so dass wir im lager auch kabel> verwalten da geht et z.b. um meter, oder habt ihr schon eine lösung> bezüglich teile die nicht stückzahlabhängig geführt werden?
Daran habe ich noch gar nie gedacht, ist aber natürlich eine sehr gute
Idee. Wird aber wohl auch noch ein Weilchen dauern bis wir das eingebaut
haben. Bis dahin musst du dir halt z.B. bei Kabel einfach vorstellen es
wäre nicht die Stückzahl, sondern die Anzahl Meter ;-)
kirk disen schrieb:> im vergleich mit anderen "professionellen"> lagerverwaltungssystemen ist ich die partdb um längen voraus.
Ja das ist natürlich klar, hier arbeiten keine 50 gut bezahlte Leute je
8 Stunden am Tag an dem Programm :-)
Und die Versionsnummer 0.2.2 sollte auch darauf hinweise, dass es noch
eine sehr frühe Version ist, also noch nicht wahnsinnig fortgeschritten.
kirk disen schrieb:> gibts> schon eine lösung die footprints auszublenden? ich weiss ihr seid voll> im wuseln mit der updateroutine. falls ihr mal ein aktuelles package zum> testen habt das ohne grobe bugs läuft wäre es schön wenn ihr dass mal> irgendwo online stellen könnt. ich würde das dann mal versuchen bei uns> im alltag einzusetzen, da findet man am ehesten fehler und bugs..
Also ich habe dir zuliebe mal rasch eine Funktion eingebaut, damit man
die Footprints deaktivieren kann. Es ist aber keine 100% saubere Arbeit
sondern eher eine Übergangslösung bis es dann in der nächsten Version
richtig eingebaut wird.
Ich habe mal die aktuellste SVN-Version mit diesem neuen Feature hier
angehängt (dann musst du dich nicht auch noch mit dem SVN
auseinandersetzten :-)
Einfach wieder die config.php_template als config.php kopieren und die
Einstellungen setzen. Die neue Variable $disable_footprints müsstest du
dann auf "true" setzen.
kirk disen schrieb:> die updatefunktion ist schon schön allerdings muss ich gestehen dass> meine partdb aktuell ohne internetleitung auskommt und das möchte ich> auch ungern ändern schon allein wegen der datensicherheit. updatepakete> wären toll. beim ersten start kann dann das script prüfen ob die> datenbank auf dem neuesten stand ist.
An sowas hab ich schon gedacht. Es wird zwei Optionen geben: On- oder
Offlineupdate (aus einem lokalen Verzeichnis).
> Was mich noch freuen würde wenn man auch andere einheiten benutzen kann> als nur stückzahlen. aktuell ist es so dass wir im lager auch kabel> verwalten da geht et z.b. um meter, oder habt ihr schon eine lösung> bezüglich teile die nicht stückzahlabhängig geführt werden?
Könnte man in der Kategorie lösen. Dort würde ich quasi die verwendete
Verpackung hinterlegen, z.B. Stk, VE, Meter, Trommel oder einfach nur
ein Schalter für "Vorhanden/Bestellt/Nicht verfügbar". Letzeres wäre für
Massenartikel wie die Aderendhülsen.
Ich habe mir zudem überlegt, ob Part-DB nicht auch Platinen oder Gehäuse
aufnehmen sollte. Damit wären dann die Baugruppen soweit komplett.
> gibts schon eine lösung die footprints auszublenden? ich weiss ihr seid> voll im wuseln mit der updateroutine. falls ihr mal ein aktuelles> package zum testen habt das ohne grobe bugs läuft wäre es schön wenn ihr> dass mal irgendwo online stellen könnt. ich würde das dann mal versuchen> bei uns im alltag einzusetzen, da findet man am ehesten fehler und bugs..
Wenn ich die Tage Zeit finde, kann ich mal schauen, ob ich eine schnelle
Lösung dafür finde. Quick&Dirty wäre das Ein- und Ausschalten der
Footprints per Konfiguration. Besser wäre es, wenn wir die Grafiken
anders präsentieren. Mir schwebt vor, die Grafiken entweder
user-/gruppengebunden bzw. in der Kategorie schaltbar zu machen oder per
Tooltip bzw. Popup anzuzeigen. Mal schauen :-)
Zu den Updates:
Kann man es nicht so machen, dass man Zum einen immer aktuelle Pakete
bereit stellt und zu anderen (z.B. für diejenigen die eine langsame
Internetverbindung haben) eine Update-Funktion.
Die Update-Funktion könnte ich mir so vorstellen dass zuerst einmal die
aktuelle Version ausgelesen wird (z.B. 2.0.1). Das Update soll nun auf
2.0.5 updaten, also erst einmal auf 2.0.2 , dann auch 2.0.3 usw.
Wird die Update-Funktion zu groß, dann setzt man ab da die Version x.x.x
voraus, welche man dann halt komplett herunterladen muss.
So wären die Updatefunktionen überschaubar und man müsste nicht immer
gleich "alles" herunterladen.
Auch denkbar wäre eine Funktion, die immer wenn man Part-DB startet auf
Updates prüft und wenn verfügbar, dann eine Meldung erscheint.
In dem Fall könnte es dann so aussehen, dass man in einem Webordner alle
Updates ablegt. Part-DB schaut nun in den Webordner (bei jedem start)
und listet die Dateien auf, welche mit einer bestimmten Ziffernfolge
beginnen (z.B. PDBU020005 --> Part DB Update 2.0.5) und vergleicht das
mit der eigenen Version. Ist irgendeine Datei im Webordner größer als
die vorhandene, dann wird stückweise geupdatet. Das könnte dann so
aussehen:
Vorhandene Version = 2.0.0 , neuste Version im Webordner 2.0.5 ...
Da ich mich mit PHP nicht auskenne schreibe ich es einfach mal grob auf:
1. Dateien auslesen
2. PDBU aus den Dateinamen filtern und die Dateiendung entfernen, so
dass nur noch die Zahl übrig bleibt, davon die höchste Nummer merken
(neustesUpdate)
3. Hat nichts mit PHP zu tun, soll nur grob erklären wie ich es meine:
Version := aktuelleVersion
While (neustesUpdate > Version) (Schleife bis alle Dateinamen überprüft
sind)
{
update := Version + 1
if (exist Update) { ;püfen ob dieses Update existiert
Gosub Updateroutine Update ;Updateroutine mit Update als Param.
}
Version := neueVersion
}
So könnte man das vollautomatisch machen (zumindest für diejenigen die
einen Internetzugang haben).
Da ich mich mit php leider nicht auskenne weiß ich natürlich nicht ob
das so einfach realisierbar ist wie mit anderen Programmiersprachen,
aber es soll ja auch nur ein Vorschlag sein.
Christian R. schrieb:> Zu den Updates:> Kann man es nicht so machen, dass man Zum einen immer aktuelle Pakete> bereit stellt und zu anderen (z.B. für diejenigen die eine langsame> Internetverbindung haben) eine Update-Funktion.
Und warum soll eine Update-Funktion eine weniger schnelle
Internetverbindung benötigen als wenn man es von Hand herunterlädt?
Ich verstehe nicht richtig was du meinst...
Aber keine Angst, es wird sicher eine gescheite Lösung rauskommen ;-)
Es wird ganz sicher die Möglichkeit geben, dass man zwischen manuellem
und automatischen Update wählen kann.
Diejenigen, deren Webserver die technischen Voraussetzungen für ein
automatisches Update haben, können direkt aus Part-DB heraus ein Update
durchführen lassen. Dabei soll das System natürlich immer selber
überprüfen ob eine neurere Version verfügbar ist.
Und für die, deren Webserver aus technischen oder sonst irgendwelchen
Gründen kein Update durchführen können oder wollen, die können die
Updatepakete einfach von Hand im Internet runterladen und auf den
Webserver kopieren.
Udo Neist schrieb:>> gibts schon eine lösung die footprints auszublenden? ich weiss ihr seid>> voll im wuseln mit der updateroutine. falls ihr mal ein aktuelles>> package zum testen habt das ohne grobe bugs läuft wäre es schön wenn ihr>> dass mal irgendwo online stellen könnt. ich würde das dann mal versuchen>> bei uns im alltag einzusetzen, da findet man am ehesten fehler und bugs..>> Wenn ich die Tage Zeit finde, kann ich mal schauen, ob ich eine schnelle> Lösung dafür finde. Quick&Dirty wäre das Ein- und Ausschalten der> Footprints per Konfiguration.
Genau das habe ich ja schon gemacht, guckst du SVN Revision 514 ;-)
Das ist entspricht in etwa meiner Vorstellung:
- ein Listbefehl auf einen FTP oder einem lokalen Verzeichnis loslassen
und alle Updatepakete ab eigener Version in ein Array aufnehmen
- Update in der Reihenfolge bis zum letzten Version innerhalb der
Majorversion vornehmen
Die Beschreibungsdatei jedes Updatearchivs sagt, was wohin kopiert
werden soll und welche SQL-Scripte in welcher Reihenfolge ausgeführt
werden müssen.
Könnte wie folgt aussehen:
Die erste Ebene im Array $up2date enthält die Versionsnummer, für die
die folgenden Anweisungen gelten:
- copy : Welche Datei wohin kopiert wird, wobei das Ziel als Backup
gesichert wird
- delete : Welche Datei gelöscht wird (darf nur nach copy ausgeführt
werden)
- sql : SQL-Scripte
- cleanup : Macht eine Bereinigung der automatisch angelegten
Backupdateien (true) oder nicht (false). Bei false wäre sogar ein
Rollback der Scripte möglich.
- version : Ändert die Versionsnummer auf die angegebene
- stable : Damit können wir bestimmte Versionen als stabil
kennzeichnen und dem User damit sagen, das dieses Update "gefahrlos"
ist. Wer bis auf das letzte stabile System updaten will, der durchläuft
dann aber auch alle unstable Versionen.
Weitere Befehle wären z.B.:
- mkdir
- rmdir
- chmod
Mit einem solchen System könnte man sogar Sammelupdates für Systeme
anbieten, die keine Internetverbindung haben oder nur selten upgedatet
werden soll.
Programmtechnisch wäre das also ein Interpreter für eine Art
Scriptsprache. Wenn jetzt jemand sagt, db_update.php beinhaltet doch
sowas schon, dem kann ich sagen jein. Hier werden ja nur SQL-Befehle
in der Reihenfolge wie im Array gespeichert ausgeführt. Die
Versionsabfrage verläuft statisch per switch(). Vorrausetzung ist
allerdings, das die Datenbank nicht mehr eine eigene Versionsnummer
besitzt, sondern die (SVN-)Version von Part-DB nutzt. Für uns Entwickler
bedeutet es, dass wir die zur Vorversion geänderte Dateien in diese
Liste eintragen müssen. svn diff nimmt uns zum Glück etwas Arbeit ab
und gibt die Änderungen zum Repository aus. Dabei benötigen wir ja nur
die Dateinamen selbst:
Urban B. schrieb:>> Wenn ich die Tage Zeit finde, kann ich mal schauen, ob ich eine schnelle>> Lösung dafür finde. Quick&Dirty wäre das Ein- und Ausschalten der>> Footprints per Konfiguration.>> Genau das habe ich ja schon gemacht, guckst du SVN Revision 514 ;-)
Eine Baustelle weniger ;-)
Udo Neist schrieb:> - ein Listbefehl auf einen FTP oder einem lokalen Verzeichnis loslassen> und alle Updatepakete ab eigener Version in ein Array aufnehmen> - Update in der Reihenfolge bis zum letzten Version innerhalb der> Majorversion vornehmen>> Die Beschreibungsdatei jedes Updatearchivs sagt, was wohin kopiert> werden soll und welche SQL-Scripte in welcher Reihenfolge ausgeführt> werden müssen.>> Könnte wie folgt aussehen:
Ich finde so eine Lösung aber irgendwie ziemlich aufwändig und
unflexibel.
Ausserdem, wozu sollen die neuen Dateien noch manuell herumkopiert
werden? Das kann man doch direkt mit dem Entpacken eines Updatesarchiv
erledigen, in nur einem einzigen Befehl.
Nehmen wir mal an, ein Update v0.2.3 beihaltet eine neue lib.php, ein
neues Dioden-Footprintbild, und die Informationen zum Update.
Ein Updatepaket könnte dann in etwa so aussehen:
1
part-db_v0.2.3.tar.gz:
2
- update/0.2.3/updateinfo.inc
3
- update/0.2.3/update.tar.gz:
4
- lib.php
5
- tools/footprints/Aktiv/Dioden/SMD/neuediode.png
Die neuen Dateien sind also nochmal separat in einem Archiv
zusammengefasst.
In einem ersten Schritt würde Part-DB alle verfügbaren Updates nach
update/ herunterladen. Wenn man die automatischen Updates nicht
aktiviert hat, legt man die Pakete einfach von Hand in diesen Ordner,
mehr muss man nicht machen.
Das System merkt jetzt, dass im Ordner update/ Archive für neuere
Versionen als die momentan installierte verfügbar sind. Einfach anhand
der Dateinamen der Archive, mehr brauchts nicht.
Sind neue Dateien vorhanden, beginnt das System sich zu aktualisieren.
Als erstes werden alle neuen Archive einfach mal entpackt. Dann entsteht
für jedes Update ein Ordner wie z.B. update/0.2.3/, in dem eine
Infodatei und das Update an sich (als Archiv) liegen.
Jetzt wird die Datei updates/x.x.x/updateinfo.inc ausgelesen. Darin
stehen:
- Version des Updates
- Vorausgesetzte Version
- Status (stable, unstable, ...)
- Checksumme des Archives "update.tar.gz", um auf Beschädigung zu prüfen
- Changelog, der dem Benutzer schon vor dem Update gezeigt werden kann
- Eine Funktion, die noch alle zusätzlich notwendigen Schritte enthält
Und genau diese Funktion ist das Geniale: Darin kann man einfach ALLES
machen, was man möchte. Man hat nicht nur ein Array zur Verfügung, das
man mit vordefinierten Befehlen befüllen kann. Nein, man hat vollen
Zugriff auf das PDO Objekt, kann also auch Querys durchführen, Schleifen
einbauen usw. Und für Systemoperationen kann man direkt den exec()
Befehl benutzen.
Der nächste Schritt ist nun stinkeinfach, erledigt aber schon fast
alles: Einfach nur das Archiv update/x.x.x/update.tar.gz der
nächstneueren Version ins Hauptverzeichnis entpacken. Die Dateien sind
jetzt schon alle auf dem neusten Stand, mit nur einem einzigen Befehl.
Danach wird dann noch die oben beschriebene Funktion aufgerufen, die ein
Datenbankupdate, exec() Anweisungen oder was auch immer enthalten kann.
Wäre das nicht ein sehr einfaches, aber extrem flexibles und dadurch
mächtiges Updatesystem?
Urban B. schrieb:> Ich finde so eine Lösung aber irgendwie ziemlich aufwändig und> unflexibel.> Ausserdem, wozu sollen die neuen Dateien noch manuell herumkopiert> werden? Das kann man doch direkt mit dem Entpacken eines Updatesarchiv> erledigen, in nur einem einzigen Befehl.>> Nehmen wir mal an, ein Update v0.2.3 beihaltet eine neue lib.php, ein> neues Dioden-Footprintbild, und die Informationen zum Update.> Ein Updatepaket könnte dann in etwa so aussehen:part-db_v0.2.3.tar.gz:> - update/0.2.3/updateinfo.inc> - update/0.2.3/update.tar.gz:> - lib.php> - tools/footprints/Aktiv/Dioden/SMD/neuediode.png> Die neuen Dateien sind also nochmal separat in einem Archiv> zusammengefasst.
Funktioniert aber nur dort, wo auch tar zur Verfügung steht. Windows
kennt den Befehl von Haus aus nicht. GNU tar reagiert anders als die
Versionen auf anderen Unices. ZIP (über zlib) müsste von PHP auf allen
Plattformen laufen, sofern das Modul existiert. Statt dem copy-Befehl im
Array ginge natürlich auch ein unpack :-) Mir wäre es lieber, wenn wir
die PHP-Funktionen anstelle der Shell nehmen, denn einige Provider
verbieten exec() und ähnliches.
> In einem ersten Schritt würde Part-DB alle verfügbaren Updates nach> update/ herunterladen. Wenn man die automatischen Updates nicht> aktiviert hat, legt man die Pakete einfach von Hand in diesen Ordner,> mehr muss man nicht machen.
Geschenkt ;-) Wichtig ist, das nur alle Updates für die aktuelle Version
und höher geladen werden. Alle vorherigen Updates wären überflüssig beim
Download. Deshalb ja der List-Befehl auf einen FTP angewendet und
durchforsten.
> Das System merkt jetzt, dass im Ordner update/ Archive für neuere> Versionen als die momentan installierte verfügbar sind. Einfach anhand> der Dateinamen der Archive, mehr brauchts nicht.> Sind neue Dateien vorhanden, beginnt das System sich zu aktualisieren.> Als erstes werden alle neuen Archive einfach mal entpackt. Dann entsteht> für jedes Update ein Ordner wie z.B. update/0.2.3/, in dem eine> Infodatei und das Update an sich (als Archiv) liegen.>> Jetzt wird die Datei updates/x.x.x/updateinfo.inc ausgelesen. Darin> stehen:> - Version des Updates> - Vorausgesetzte Version> - Status (stable, unstable, ...)> - Changelog, der dem Benutzer schon vor dem Update gezeigt werden kann> - Eine Funktion, die noch alle zusätzlich notwendigen Schritte enthält>> Und genau diese Funktion ist das Geniale: Darin kann man einfach ALLES> machen, was man möchte. Man hat nicht nur ein Array zur Verfügung, das> man mit vordefinierten Befehlen befüllen kann. Nein, man hat vollen> Zugriff auf das PDO Objekt, kann also auch Querys durchführen, Schleifen> einbauen usw. Und für Systemoperationen kann man direkt den exec()> Befehl benutzen.
Letzteres geht nicht auf allen Servern! myparts.info lässt den
Shell-Zugriff nicht zu. Und ich würde auf irgendwelche Scripte im
Updatesystem verzichten oder willst du eine Hintertür erlauben? Ein paar
Zeilen eingeschmuggelt und schon hat jemand anderes eine komplette
Datenbank. cURL braucht nur ein paar Zeilen Code. Und es steht einem
Angreifer zudem alle Möglichkeiten offen, die im Kontext des Webservers
möglich sind.
> Der nächste Schritt ist nun stinkeinfach, erledigt aber schon fast> alles: Einfach nur das Archiv update/x.x.x/update.tar.gz der> nächstneueren Version ins Hauptverzeichnis entpacken. Die Dateien sind> jetzt schon alle auf dem neusten Stand, mit nur einem einzigen Befehl.>> Danach wird dann noch die oben beschriebene Funktion aufgerufen, die ein> Datenbankupdate, exec() Anweisungen oder was auch immer enthalten kann.>> Wäre das nicht ein sehr einfaches, aber extrem flexibles und dadurch> mächtiges Updatesystem?
Nein, denn es scheitert an eventuell fehlenden Rechten bei PHP, die man
oft nicht ändern kann (safe_mode, open_basedir, disable_functions,
disable_classes), fehlende Programme auf der Plattform, Manipulation von
Daten über die Shell (falls Zugriff möglich) und so manch anderes
Problem. Part-DB muss den Systemrichtlinien der IT-Abteilungen von
Firmen standhalten und erst recht im Internet funktionieren. Ansonsten
können wir das Projekt myparts.info gleich wieder beerdigen.
Cross-site-Scripting, SQL-Injections, Auslesen verschiedener
Systemdateien, Backdoor installieren und so weiter... DNS umbiegen ist
auch beliebt. Die Liste der möglichen Angriffe ist lang.
Wenn du deinen Vorschlag umsetzen willst, dann denk auch gleich über
eine Signierung der Archive nach und wie man die Gültigkeit überprüft.
Nicht vertrauenswürdige Schlüssel bzw. Signaturen sind dann ein Grund,
ein Update zu verweigern.
Ich will hier nicht deine Ideen zerreden, aber ich bin nicht erst seit
gestern Admin von einigen Servern im Inter- und Intranet. Musste hin und
wieder mal Bots entfernen, die sich über schlechte PHP-Scripte
eingeschlichen hatten. Geht ja erstmal ums Prinzip und darum, den
gangbarsten Weg zu finden. Ich werde erstmal einen Interpreter erstellen
und diesen zur Diskussion stellen.
Udo Neist schrieb:> Funktioniert aber nur dort, wo auch tar zur Verfügung steht. Windows> kennt den Befehl von Haus aus nicht. GNU tar reagiert anders als die> Versionen auf anderen Unices. ZIP (über zlib) müsste von PHP auf allen> Plattformen laufen, sofern das Modul existiert.
OK kein Problem, dann halt ZIP :-) Das ist ja auch wurscht, hauptsache
irgend ein Archiv.
> Statt dem copy-Befehl im> Array ginge natürlich auch ein unpack :-) Mir wäre es lieber, wenn wir> die PHP-Funktionen anstelle der Shell nehmen, denn einige Provider> verbieten exec() und ähnliches.
Ebenfalls kein Problem, da man ja in der Funktion, die ich oben
erwähnte, ja so flexibel ist und die Befehle einbauen kann, die man
möchte :-)
Was eben noch ein Hintergedanke von mir ist:
Es könnte ja mal vorkommen, dass wir ein Datenbankupdate durchführen
müssen, das nicht mehr nur durch reine SQL Querys machbar ist, sondern
zwingend über einen individuellen PHP-Code gemacht werden muss. Man kann
dann aus dieser Funktion heraus auch auf alle meine Klassen zugreifen,
und mit Objekten arbeiten usw.
Und vielleicht tauchen ja mal noch irgendwelche andere Probleme auf, die
wir nur duch einen individuellen Codeblock lösen können, an die wir
momentan nicht denken.
Udo Neist schrieb:> Geschenkt ;-) Wichtig ist, das nur alle Updates für die aktuelle Version> und höher geladen werden. Alle vorherigen Updates wären überflüssig beim> Download. Deshalb ja der List-Befehl auf einen FTP angewendet und> durchforsten.
Ja, es werden natürlich immer nur die neueren Versionen runtergeladen.
Und jedes Updatearchiv beinhaltet nur gerade die neuen Dateien, also nur
die, die sich verändert haben. So kann ein Update sogar aus nur einer
einzigen PHP Datei bestehen, wenn z.B. ein Fehler in der lib.php behoben
wurde. (Also natürlich würde sich diese lib.php dann auch zusammen mit
einer Updateinfo-Datei in einem Archiv befinden)
Udo Neist schrieb:> Letzteres geht nicht auf allen Servern! myparts.info lässt den> Shell-Zugriff nicht zu. Und ich würde auf irgendwelche Scripte im> Updatesystem verzichten oder willst du eine Hintertür erlauben? Ein paar> Zeilen eingeschmuggelt und schon hat jemand anderes eine komplette> Datenbank. cURL braucht nur ein paar Zeilen Code. Und es steht einem> Angreifer zudem alle Möglichkeiten offen, die im Kontext des Webservers> möglich sind.
Das mit der Shell bzw. exec() ist nun klar das geht wohl nicht, ist aber
auch egal (war ja nur ein Beispiel. Ich hätte auch eine PHP Funktion als
Beispiel nehmen können xD).
Wie will jemand ein paar Zeilen in die Updatefunktion einschmuggeln?
Dazu gäbe es doch nur zwei Möglichkeiten: Entweder der "Angreifer" hat
FTP-Zugriff auf dem Webserver, dann hilft aber jegliche
Sicherheitsfunktion nichts mehr. Oder aber per DNS umbiegen oder sowas
könnte man das Updatepaket von einer anderen Seite holen lassen, aber
auch da kann man dann nichts mehr dagegen machen, denn dann müsste man
ja nur z.B. eine neue, startup.php (die was Böses enthält) ins
gefälschte Updatearchiv legen, und schon wird das böse Skript sogar bei
jedem Aufruf der Seite, und nicht nur einmalig beim Update ausgeführt
:-)
Somit sehe ich dieses Updatesystem nicht als Sicherheitslücke, zumindest
nicht unsicherer als dein System (sofern ich deines richtig verstanden
habe).
Udo Neist schrieb:> Wenn du deinen Vorschlag umsetzen willst, dann denk auch gleich über> eine Signierung der Archive nach und wie man die Gültigkeit überprüft.> Nicht vertrauenswürdige Schlüssel bzw. Signaturen sind dann ein Grund,> ein Update zu verweigern.
Das wäre doch eigentlich gar keine schlechte Idee!
Wie gesagt, ich denke auch jedes andere Updatesystem, das sich Daten von
anderen Webserver holt ist eigentlich ja schonmal nicht 100%tig sicher.
Somit wäre eine Signatur wohl sowieso für jedes Updatesystem eine sehr
gute und nützliche Sicherheitseinrichtung.
Udo Neist schrieb:> Ich will hier nicht deine Ideen zerreden, aber ich bin nicht erst seit> gestern Admin von einigen Servern im Inter- und Intranet.
Jo kein Problem, wir diskutieren ja hier um eine Lösung zu finden, mit
der möglichst alle Beteiligten zufrieden sind :-)
Und dass ich keine grosse Erfahrung mit dem Sicherheits-"Kram" von
Servern habe, das ist halt so. Aber ich kann ja trotzdem Vorschläge
machen, dann lerne ich auch gleich noch was dabei wenn du gute
Gegenargumente bringst :-)
Urban B. schrieb:> Udo Neist schrieb:>> Funktioniert aber nur dort, wo auch tar zur Verfügung steht. Windows>> kennt den Befehl von Haus aus nicht. GNU tar reagiert anders als die>> Versionen auf anderen Unices. ZIP (über zlib) müsste von PHP auf allen>> Plattformen laufen, sofern das Modul existiert.>> OK kein Problem, dann halt ZIP :-) Das ist ja auch wurscht, hauptsache> irgend ein Archiv.
ZIP hab ich auch schon in meiner Packer-Klasse drin :-)
> Was eben noch ein Hintergedanke von mir ist:> Es könnte ja mal vorkommen, dass wir ein Datenbankupdate durchführen> müssen, das nicht mehr nur durch reine SQL Querys machbar ist, sondern> zwingend über einen individuellen PHP-Code gemacht werden muss. Man kann> dann aus dieser Funktion heraus auch auf alle meine Klassen zugreifen,> und mit Objekten arbeiten usw.> Und vielleicht tauchen ja mal noch irgendwelche andere Probleme auf, die> wir nur duch einen individuellen Codeblock lösen können, an die wir> momentan nicht denken.
Ich wüsste nicht, welche Probleme wir noch mittels Script lösen müssen.
Thumbnails erzeugen oder ähnliches geht auch mit entsprechend geänderten
Scripte, die über das normale Update rein kommen. Sollte doch mal was
gemacht werden, so wäre es am Besten, wenn der User aufgefordert wird
oder mittels Redirect ein Post-Update-Script aus dem Archiv laufen zu
lassen. Perfekt ist diese Lösung zwar nicht, aber man kann zumindest
dieses Script je nach Wichtigkeit absichern (md5, sha1 oder was auch
immer).
> Das mit der Shell bzw. exec() ist nun klar das geht wohl nicht, ist aber> auch egal (war ja nur ein Beispiel. Ich hätte auch eine PHP Funktion als> Beispiel nehmen können xD).
War das schlechteste Beispiel g> Wie will jemand ein paar Zeilen in die Updatefunktion einschmuggeln?
Die Leute, die einem schaden wollen, die sind sehr erfinderisch. Und PHP
gilt nicht als die sicherste Sprache, also lieber ein paar mehr
Prüfungen rein als notwendig.
> Dazu gäbe es doch nur zwei Möglichkeiten: Entweder der "Angreifer" hat> FTP-Zugriff auf dem Webserver, dann hilft aber jegliche> Sicherheitsfunktion nichts mehr. Oder aber per DNS umbiegen oder sowas> könnte man das Updatepaket von einer anderen Seite holen lassen, aber> auch da kann man dann nichts mehr dagegen machen, denn dann müsste man> ja nur z.B. eine neue, startup.php (die was Böses enthält) ins> gefälschte Updatearchiv legen, und schon wird das böse Skript sogar bei> jedem Aufruf der Seite, und nicht nur einmalig beim Update ausgeführt
Im schlechtesten Fall wäre das ganze System ohne Überprüfung und würde
direkt den Code beim Updaten mit ausführen. Lässt man keinen Code zu, so
muss der Angreifer die Scripte manipulieren. Hat man Checksummen wie
sha1 und gibt die dem Updatesystem mit, so ist eine Hürde mehr drin. Man
kann zu jedem Update-Archiv ein zweites anbieten, das Checksummen und
ähnliches vorhält.
> Somit sehe ich dieses Updatesystem nicht als Sicherheitslücke, zumindest> nicht unsicherer als dein System (sofern ich deines richtig verstanden> habe).
Zumindest wären bei mir keine direkten Zugriffe möglich. Wäre in der
Form noch ein include() nötig, aber ich möchte auch darauf verzichten
und so eine Art INI-Datei oder XML nutzen. Die lassen sich nicht mit
include(), require() oder eval() ausführen. Da braucht man einen
Interpreter. Und wenn man genauer hinschaut, brauchst du auch einen
solchen, ansonsten könntest du die Variablen nicht verabeiten. Für uns
Entwickler würde ich passende Scripte schreiben, die das Zusammenbauen
(weitgehends) erledigen.
> Udo Neist schrieb:>> Wenn du deinen Vorschlag umsetzen willst, dann denk auch gleich über>> eine Signierung der Archive nach und wie man die Gültigkeit überprüft.>> Nicht vertrauenswürdige Schlüssel bzw. Signaturen sind dann ein Grund,>> ein Update zu verweigern.>> Das wäre doch eigentlich gar keine schlechte Idee!> Wie gesagt, ich denke auch jedes andere Updatesystem, das sich Daten von> anderen Webserver holt ist eigentlich ja schonmal nicht 100%tig sicher.> Somit wäre eine Signatur wohl sowieso für jedes Updatesystem eine sehr> gute und nützliche Sicherheitseinrichtung.
GPG wäre ja eine gute Lösung, aber PHP unterstützt es nicht direkt. Und
sowas selbst zu Entwicklen ist overkill. sha1 für Checksummen (wird in
einer anderen Datei gespeichert, die man auch noch downloaden muss) ist
schon recht gut.
> Jo kein Problem, wir diskutieren ja hier um eine Lösung zu finden, mit> der möglichst alle Beteiligten zufrieden sind :-)> Und dass ich keine grosse Erfahrung mit dem Sicherheits-"Kram" von> Servern habe, das ist halt so. Aber ich kann ja trotzdem Vorschläge> machen, dann lerne ich auch gleich noch was dabei wenn du gute> Gegenargumente bringst :-)
Es heißt nicht umsonst im PHP-Umfeld: Drum prüfe, was du bekommst. In
den wenigsten Teilen habe ich vernünftige Prüfungen der übergebenen
Daten gesehen. $_REQUEST ist fast immer falsch, $_GET oder $_POST ist
besser. $_GET für die Sachen, die man darstellen will, $_POST für die
Formulare. $_REQUEST unterscheidet nicht, woher die Daten kommen.
Desweiteren ist Part-DB ziemlich anfällig was SQL-Injections betrifft.
Viele Variablen werden gar nicht auf den Typ geprüft. IDs sind entweder
numerisch oder ein String. Fehlt eine Prüfung, kann aus einem harmlosen
Select auch schnell mal ein Truncate oder Drop werden, denn ein
Semikolon und ein Kommentarzeichen an der richtigen Stelle, schon wars
das. Hier und da ein paar settype() reingeschrieben, noch ein paar
Wertebereiche geprüft und die Daten möglichst noch escaped. Wobei man so
oder so auf Prepared Statements setzen sollte.
Ich habe in meiner HTML-Klasse die Variablen im Konstruktor typisiert.
Prüfungen des Inhalts gibt es kaum/keine, sind zum Teil auch gar nicht
durchführbar, manches wird von vlibTemplate abgefangen. Sicher kann ich
hier also auch nicht wirklich sein, was die übergebenen Daten angeht.
Zumindest prüfe ich einige Daten und werfe bei Fehlern ein Exception.
Das kann man erweitern und aus einem Abbruch mit Fehlermeldung noch
zusätzlich ein Warning bei problematischen Parametern/Inhalten ausgeben.
Gute Nacht :-)
Udo Neist schrieb:> Ich wüsste nicht, welche Probleme wir noch mittels Script lösen müssen.> Thumbnails erzeugen oder ähnliches geht auch mit entsprechend geänderten> Scripte, die über das normale Update rein kommen. Sollte doch mal was> gemacht werden, so wäre es am Besten, wenn der User aufgefordert wird> oder mittels Redirect ein Post-Update-Script aus dem Archiv laufen zu> lassen. Perfekt ist diese Lösung zwar nicht, aber man kann zumindest> dieses Script je nach Wichtigkeit absichern (md5, sha1 oder was auch> immer).
OK hier mal ein Beispiel, das zwar keinen Sinn macht, technisch aber
tatsächlich so ein Fall für eine PHP-Funktion statt einem SQL-Query ist:
Es sollen bei allen Footprint-Datensätzen, deren Bilddateiname ungültig
sind, der Dateiname gelöscht werden.
Per SQL-Query kann man wohl kaum überprüfen, ob ein Datenbankeintrag
einen Pfad zu einer existierenden Datei darstellt, oder nicht.
Wäre also ein Fall für PHP statt für SQL.
Oder:
Momentan ist es noch möglich, in einer Kategorie mehrere Unterkategorien
mit dem selben Namen zu haben. Dies soll später verboten werden, da es
z.B. für den Teile-Import notwendig ist, dass die Pfade zu Kategorien,
Footprints usw. eindeutig sind.
Sobald dieses Update eingespielt wird, muss die Datenbank auf solche
doppelten (gleichnamigen) Kategorien durchsucht werden. Sind solche
doppelte Einträge vorhanden, wäre es am besten wenn die Updatefunktion
z.B. gleich sein eigenes PopUp mitliefert, in dem alle doppelt
vorkommenden Kategorien aufgelistet werden, mit der Möglichkeit die
Kategorien gleich umzubenennen.
Solche Überprüfungen in die Systemdateien einzubauen ist, wie du schon
selber geschrieben hast, ziemlich unschön und sollte vermieden werden.
Ist man beim Update so flexibel dass man sogar solche Sachen wie "Popups
öffnen um Benutzereingaben zu erfassen" machen kann, wäre das sehr
vorteilhaft und eine saubere Implementierung (alles ist da, wo es
hingehört).
Übrigens wäre die von mir genannte updateinfo.inc eine normale PHP
Datei, das ".inc" habe ich nur geschrieben weil ich diese Datei nicht
als ganz normale PHP Datei betrachte, sondern als Include-Datei für die
Systemdatei (z.B. update.php), die das Update durchführt :-) Vielleicht
verwirrt es aber auch zu sehr und sie sollte doch besser in ".php"
umbenannt werden xD
Udo Neist schrieb:> Im schlechtesten Fall wäre das ganze System ohne Überprüfung und würde> direkt den Code beim Updaten mit ausführen. Lässt man keinen Code zu, so> muss der Angreifer die Scripte manipulieren. Hat man Checksummen wie> sha1 und gibt die dem Updatesystem mit, so ist eine Hürde mehr drin. Man> kann zu jedem Update-Archiv ein zweites anbieten, das Checksummen und> ähnliches vorhält.
Also ich sehe da keinen Unterschied, ob man nun Code zulässt oder nicht.
Schafft es ein Angreifer, ein Updatepaket zu manipulieren (bzw. zu
fälschen), stehen ihm sowieso alle Tore offen und er kann machen was er
will. Ich meine, einem Update kann nicht verboten werden, die
Systemdateien zu überschreiben, sonst kann man damit schlecht ein Update
durchführen ;-) Der Angreifer hat also sowieso die Möglichkeit,
Systemdateien zu überschreiben, warum soll er sich dann nur die
Updatedatei unter denn Nagel reissen, wenn er das ganze System
manipulieren kann?
OK was man an meiner Version noch ändern könnte, wäre folgendes:
Die updateinfo.inc wird aufgeteilt in zwei Dateien. Eine davon ist nur
eine Textdatei, die es nicht ermöglicht, Code auszuführen. In einer
anderen Datei ist dann die eigentliche Updatefunktion, die es erlaubt
PHP Code auszuführen.
Zuerst wird dann nur die Textdatei gelesen, die PHP-Datei wird noch gar
nicht includet. Erst wenn die Angaben aus der Textdatei die Gültigkeit
des Updates bestätigen (per Hash oder sowas), wird die PHP-Datei mit der
Updatefunktion includet.
Udo Neist schrieb:> Für uns> Entwickler würde ich passende Scripte schreiben, die das Zusammenbauen> (weitgehends) erledigen.
Daran dachte ich auch schon, das wäre natürlich für meine Updatevariante
genau so gut möglich wie für deine.
Udo Neist schrieb:> GPG wäre ja eine gute Lösung, aber PHP unterstützt es nicht direkt. Und> sowas selbst zu Entwicklen ist overkill. sha1 für Checksummen (wird in> einer anderen Datei gespeichert, die man auch noch downloaden muss) ist> schon recht gut.
Was bringt es denn, wenn man die Checksumme noch separat herunterlädt?
Wenn ein Angreifer ein Paket fälschen kann, kann er das doch auch mit
einer Checksumme machen.
Udo Neist schrieb:> Es heißt nicht umsonst im PHP-Umfeld: Drum prüfe, was du bekommst. In> den wenigsten Teilen habe ich vernünftige Prüfungen der übergebenen> Daten gesehen.
Viele solcher Überprüfungen müssen später gar nicht mehr in den PHP
Dateien der einzelnen Seiten gemacht werden, da meine Klassen bei jeder
Zuweisung von neuen Daten diese zuerst auf Gültigkeit überprüft. Diese
Variante halte ich eh für sinnvoller, da dann die Überprüfung nur noch
an einer zentralen Stelle (in der Klasse) überprüft werden müssen, und
nicht in jeder einzelnen Datei, die diese Klasse verwendet.
Udo Neist schrieb:> Desweiteren ist Part-DB ziemlich anfällig was SQL-Injections betrifft.> Viele Variablen werden gar nicht auf den Typ geprüft. IDs sind entweder> numerisch oder ein String. Fehlt eine Prüfung, kann aus einem harmlosen> Select auch schnell mal ein Truncate oder Drop werden, denn ein> Semikolon und ein Kommentarzeichen an der richtigen Stelle, schon wars> das. Hier und da ein paar settype() reingeschrieben, noch ein paar> Wertebereiche geprüft und die Daten möglichst noch escaped. Wobei man so> oder so auf Prepared Statements setzen sollte.
Hast du schonmal meine Datenbankklasse angeschaut? Dort stelle ich ja
die zwei Funktionen execute() und query() zur Verfügung für die
Benutzung der Datenbank. ALLE Datenbankzugriffe von ganz Part-DB laufen
schlussendlich über eine dieser beiden Funktionen. Und dort werden dann
genau Prepared Statements verwendet. Voraussetzung ist natürlich, dass
man diesen Funktionen die Parameter richtig übergibt, also den
Query-String mit Fragezeichen als Platzhalter und dann die Variablen
separat.
Ich denke damit ist die Gefahr einer SQL Injection ziemlich stark
gesunken.
Udo Neist schrieb:> Gute Nacht :-)
Ebenfalls :-)
P.S.
Versteh mich bitte nicht falsch: Ich zweifle nicht an der
Funktionsfähigkeit oder Sicherheit deiner vorgeschlagenen
Updatefunktion.
Nur habe ich das Gefühl, dass:
1. Irgendwann die Flexibilität deiner Methode nicht mehr ausreicht, und
ab und zu extra für Updates umgebaut/erweitert werden muss
2. Es auch einfacher geht :-)
Urban B. schrieb:> OK hier mal ein Beispiel, das zwar keinen Sinn macht, technisch aber> tatsächlich so ein Fall für eine PHP-Funktion statt einem SQL-Query ist:> Es sollen bei allen Footprint-Datensätzen, deren Bilddateiname ungültig> sind, der Dateiname gelöscht werden.> Per SQL-Query kann man wohl kaum überprüfen, ob ein Datenbankeintrag> einen Pfad zu einer existierenden Datei darstellt, oder nicht.> Wäre also ein Fall für PHP statt für SQL.
Lässt sich in der entsprechenden Funktion dauerhaft einbauen. Somit ist
es unabhängig von eventuell technischen Problemen auf dem Server. Könnte
ja sein, das die Bilder auf einer anderen Partition liegen. Zudem könnte
man die Datenbank per Admintool von "Leichen" befreien. Das ist
sinnvoller als sowas per Update machen zu wollen.
Und der Datenbank macht das nichts, wenn sie ein paar unnütze Daten mehr
drin hat :-) Ich glaube kaum, das Part-DB jemals TB von Daten verwalten
wird.
> Oder:> Momentan ist es noch möglich, in einer Kategorie mehrere Unterkategorien> mit dem selben Namen zu haben. Dies soll später verboten werden, da es> z.B. für den Teile-Import notwendig ist, dass die Pfade zu Kategorien,> Footprints usw. eindeutig sind.> Sobald dieses Update eingespielt wird, muss die Datenbank auf solche> doppelten (gleichnamigen) Kategorien durchsucht werden. Sind solche> doppelte Einträge vorhanden, wäre es am besten wenn die Updatefunktion> z.B. gleich sein eigenes PopUp mitliefert, in dem alle doppelt> vorkommenden Kategorien aufgelistet werden, mit der Möglichkeit die> Kategorien gleich umzubenennen.
Geht per SQL-Script ebenso. Wenn man den SQL-Scripten im Update eine
Flag für Rückgabewerte (show, question oder ähnliches) mitgibt, läuft
das auch ohne Script. Wenn das nicht als SQL-Statement geht, dann als
Stored Procedure :D
Zudem sollte man alle Vorkommnisse beim Updaten mitloggen und auch zum
Ausdrucken anbieten. So kann der User entsprechende Meldungen per Hand
beseitigen.
> Solche Überprüfungen in die Systemdateien einzubauen ist, wie du schon> selber geschrieben hast, ziemlich unschön und sollte vermieden werden.> Ist man beim Update so flexibel dass man sogar solche Sachen wie "Popups> öffnen um Benutzereingaben zu erfassen" machen kann, wäre das sehr> vorteilhaft und eine saubere Implementierung (alles ist da, wo es> hingehört).
Ich meinte nicht die üblichen Tests auf fehlerhafte Eingaben oder
unlogische Datensätze, sondern eher das typische Wartungsaufgaben wie
ein Update nichts darin verloren haben. Das gehört in die Kategorie
Admintools und sind Sonderaufgaben mit eigenen Scripten.
> Übrigens wäre die von mir genannte updateinfo.inc eine normale PHP> Datei, das ".inc" habe ich nur geschrieben weil ich diese Datei nicht> als ganz normale PHP Datei betrachte, sondern als Include-Datei für die> Systemdatei (z.B. update.php), die das Update durchführt :-) Vielleicht> verwirrt es aber auch zu sehr und sie sollte doch besser in ".php"> umbenannt werden xD
Ich würde das gar nicht als PHP-Datei machen, sondern als Pseudo-Sprache
definieren. Damit hast du wohl das größte Problem aus der Welt: ein
Fehler im Updatescript und der User steht höchstwahrscheinlich mit einer
unbenutzbaren Part-DB-Installation da. Und warum für jedes Update dann
ein eigenes Script schreiben wollen? Zeitverschwendung! Alle wichtigen
Funktionen in eine Update-Klasse und falls notwendig, wird diese dann
ersetzt, bevor das eigentliche Update läuft. Stichwort:
Stapelverarbeitung (Batch-Datei, Bash-Script etc. nur nicht so mächtig
wie diese).
> Hast du schonmal meine Datenbankklasse angeschaut? Dort stelle ich ja> die zwei Funktionen execute() und query() zur Verfügung für die> Benutzung der Datenbank. ALLE Datenbankzugriffe von ganz Part-DB laufen> schlussendlich über eine dieser beiden Funktionen. Und dort werden dann> genau Prepared Statements verwendet. Voraussetzung ist natürlich, dass> man diesen Funktionen die Parameter richtig übergibt, also den> Query-String mit Fragezeichen als Platzhalter und dann die Variablen> separat.> Ich denke damit ist die Gefahr einer SQL Injection ziemlich stark> gesunken.
Ich gehe erstmal von der offiziellen Version aus. Das die neue Version
etliche Probleme schon jetzt beseitigt hat, das denke ich mir.
Nicht jede Überprüfung sollte zudem in eine Klassenfunktion ausgelagert
werden. Funktionen sollten die übergebenen Daten auf Gültigkeit für
ihren Scope prüfen. Das Hauptscript prüft, ob die Funktion überhaupt
gebraucht wird. Welche Funktion kostet am wenigsten?
1) Wert -> Funktion -> Wert falsch -> Rückgabe Wert nicht verwertbar
2) Wert falsch -> Nächste Funktion
> P.S.> Versteh mich bitte nicht falsch: Ich zweifle nicht an der> Funktionsfähigkeit oder Sicherheit deiner vorgeschlagenen> Updatefunktion.> Nur habe ich das Gefühl, dass:> 1. Irgendwann die Flexibilität deiner Methode nicht mehr ausreicht, und> ab und zu extra für Updates umgebaut/erweitert werden muss> 2. Es auch einfacher geht :-)
Jede Updatefunktion ist nie perfekt und muss immer wieder neu
geschrieben werden. Aber warum jedesmal ein neues Script erstellen, wenn
man eine Klasse mit den üblichen Funktionen bereits hat und diese
vielleicht alle x Updates überarbeiten muss?
Aktuell wären folgende "Befehle" in der Updateklasse nötig (private
Funktionen, wird vom Interpreter aufgerufen):
- copy
- delete
- mkdir
- rmdir
- chmod
- log
- unpack
- sync (Gleicht Datenbank mit Verzeichnis ab, z.B. Grafiken)
- sql
Diese Funktionen sind übergeordnete Funktionen und werden von update.php
direkt aufgerufen:
- check_version (Prüft die installierte Version gegen dem Update)
- check_updates (Überprüft auf Updates)
- get_updates (Holt die Updates)
- parse (Der eigentliche Interpreter)
Sind halt zwei Positionen die wir hier einnehmen und beide haben in
verschiedenen Fragestellungen wahrscheinlich ihren Vorteil. Wir müssten
einfach mal jeder ein Beispielupdate erstellen und dann kann man
schauen, was wir von welchem System übernehmen sollten.
Grüße
Udo
Urban B. schrieb:> Christian R. schrieb:>> Zu den Updates:>> Kann man es nicht so machen, dass man Zum einen immer aktuelle Pakete>> bereit stellt und zu anderen (z.B. für diejenigen die eine langsame>> Internetverbindung haben) eine Update-Funktion.>> Und warum soll eine Update-Funktion eine weniger schnelle> Internetverbindung benötigen als wenn man es von Hand herunterlädt?> Ich verstehe nicht richtig was du meinst...
Ich habe mich ungünstig ausgedrückt. Mit Pakete meinte ich eigentlich
ein komplettes Archiv aller Dateien, also für jemanden der neu auf
Part-DB stößt. So kann diese Person gleich die aktuellste Version
herunterladen anstatt Version XXX welche dann gleich auf YYY geupdatet
werden kann.
Bei automatischen Updates kommt es letztendlich aufs gleiche hinaus,
aber aus eigener Erfahrung fühlt es sich besser an die "aktuellste
Version" herunterladen zu können, statt eine "veraltete" die dann
aktualisiert werden muss.
Udo Neist schrieb:> Das ist entspricht in etwa meiner Vorstellung:>> - ein Listbefehl auf einen FTP oder einem lokalen Verzeichnis loslassen> und alle Updatepakete ab eigener Version in ein Array aufnehmen> - Update in der Reihenfolge bis zum letzten Version innerhalb der> Majorversion vornehmen
Genau so meinte ich das.
Urban B. schrieb:> Ausserdem, wozu sollen die neuen Dateien noch manuell herumkopiert> werden? Das kann man doch direkt mit dem Entpacken eines Updatesarchiv> erledigen, in nur einem einzigen Befehl.
Durch manuelles kopieren kann man die zu überschreibenden Dateien
sichern um notfalls die Ursprungsversion wieder herzustellen falls doch
mal irgendetwas nicht klappt.
Udo Neist schrieb:> Urban B. schrieb:>> OK hier mal ein Beispiel, das zwar keinen Sinn macht, technisch aber>> tatsächlich so ein Fall für eine PHP-Funktion statt einem SQL-Query ist:>> [...]>> Lässt sich in der entsprechenden Funktion dauerhaft einbauen.
Ja klar lässt sich das dauerhaft einbauen, aber:
- Wer sagt uns dass nachher nicht bei jedem 3. Update nochmal eine
zusätzliche, spezielle Funktion gebraucht wird? In Version 3.x.x Platzt
dann doch die Update-Klasse aus allen Nähnten, weil darin noch 20
Funktionen für irgendwelche Updates rumliegen, die nur ein einziges Mal
gebraucht wurden. Und nach jedem Update wieder die nicht mehr benötigten
Funktionen aus der Update-Klasse zu löschen zeugt auch nicht grad von
einem durchdachten System ;-)
- Wozu sollen Funktionen, die nur ein einziges Mal (beim Update)
gebraucht werden, ins System integriert werden? Die haben dort nichts zu
suchen, die wurden geschrieben um Version x.x.a auf x.x.b zu
aktualisieren, also gehören sie zum Update x.x.b und nicht ins System.
> Somit ist> es unabhängig von eventuell technischen Problemen auf dem Server. Könnte> ja sein, das die Bilder auf einer anderen Partition liegen.
Was für technische Probleme auf dem Server? Meine Variante wäre sicher
nicht fehleranfälliger als deine Variante. Da die Updatefunktion ja zum
Ausführen includet werden muss, hat sie somit auch Zugriff auf den
ganzen Rest von Part-DB (Einstellungen aus der config.php,
Datenbankklasse, ...).
Dort, wo Part-DB die Bilder sucht, dort sucht sie auch meine
Updatefunktion, egal ob das nun auf einer anderen Partition liegt oder
nicht.
> Zudem könnte> man die Datenbank per Admintool von "Leichen" befreien. Das ist> sinnvoller als sowas per Update machen zu wollen.
Um sich von Leichen zu befreien, dazu soll natürlich ein Admintool
vorhanden sein, das ist richtig. Das habe ich nämlich schon mit den
Dateien vor, es soll möglich sein die Datenbank nach Dateien zu
durchforsten die nicht (mehr) existieren.
Aber: Es gibt auch Funktionen, die wirklich nur ein einziges mal beim
Update ausgeführt werden müssen, und nachher für den Benutzer nicht
erreichbar sein sollen. Und genau für solche (und nur für solche)
Funktionen wäre meine individuelle Updatefunktion gedacht.
>> Oder:>> Momentan ist es noch möglich, in einer Kategorie mehrere Unterkategorien>> mit dem selben Namen zu haben. Dies soll später verboten werden, da es>> z.B. für den Teile-Import notwendig ist, dass die Pfade zu Kategorien,>> Footprints usw. eindeutig sind.[...]>> Geht per SQL-Script ebenso. Wenn man den SQL-Scripten im Update eine> Flag für Rückgabewerte (show, question oder ähnliches) mitgibt, läuft> das auch ohne Script. Wenn das nicht als SQL-Statement geht, dann als> Stored Procedure :D
Ja logisch geht es. Aber es muss extra wieder in die Updatefunktion
eingebaut werden, das bläht die Updatefunktion immer stärker auf und
wird unnötig kompliziert.
Das ist ja genau das, was ich dir versuche mitzuteilen :-) Natürlich
kann man mit deiner Methode auch alles bewerkstelligen was zu
bewerkstelligen ist. Aber es macht die Update-Klasse immer komplizierter
wegen Features, die nur ein einziges Mal bei einem Update gebraucht
wurden und nachher kein Mensch mehr braucht.
Ich bin einfach der Meinung: Updateroutinen sind von Update zu Update
individuell und sollen daher immer mit dem jeweiligen Update
mitgeliefert werden. Individuelle Updateroutinen gehören nicht ins
System, und eine Allgemeine, flexible Updateroutine die ALLES machen
kann, das die Updates jemals brauchen könnten, macht die Updateklasse
viel zu aufwändig, zu kompliziert und daher evtl. auch noch
fehleranfällig.
> Zudem sollte man alle Vorkommnisse beim Updaten mitloggen und auch zum> Ausdrucken anbieten. So kann der User entsprechende Meldungen per Hand> beseitigen.
Sowas könnte man natürlich auch in meiner Variante einbauen. Die
Log-Funktion gehört dann natürlich ins System, da sie bei jedem Update
gebraucht wird. In der Updatefunktion, die im Updatearchiv daherkommt,
müsste dann z.B. nur noch ein Array mit den Meldungen gefüllt werden, so
ähnlich wie in den case-Blöcken der momentanenen db_update.php.
> Ich meinte nicht die üblichen Tests auf fehlerhafte Eingaben oder> unlogische Datensätze, sondern eher das typische Wartungsaufgaben wie> ein Update nichts darin verloren haben. Das gehört in die Kategorie> Admintools und sind Sonderaufgaben mit eigenen Scripten.
Ja, wie bereits oben erwähnt: Typische Wartungsarbeiten sollen natürlich
ins System integriert werden. Individuelle Funktionen, die wirklich nur
ein einziges Mal beim Update ausgeführt werden müssen, gehören da aber
nicht rein, und das sind ja genau die, von denen ich die ganze Zeit
spreche.
> Ich würde das gar nicht als PHP-Datei machen, sondern als Pseudo-Sprache> definieren.
Dann wäre mein Ziel, es möglichst einfach, unkompliziert und flexibel zu
gestalten, aber total verfehlt ;-)
> Damit hast du wohl das größte Problem aus der Welt: ein> Fehler im Updatescript und der User steht höchstwahrscheinlich mit einer> unbenutzbaren Part-DB-Installation da.
Dafür soll es ja dann eine Rollback-Funktion geben -> Problem gelöst.
> Und warum für jedes Update dann> ein eigenes Script schreiben wollen? Zeitverschwendung!
Also für ein normales Update, bei dem nur Dateien überschrieben und
SQL-Befehle ausgeführt werden, ist das Skript ziemlich kompakt (siehe
"update_bsp2.php" im Anhang). Und die Grundstruktur kann man natürlich
immer wieder übernehmen fürs nächste Update. Wenn man mal mehr machen
möchte als nur SQL Befehle ausführen, könnte das z.B. etwa so aussehen
wie in der "update.php" im Anhang.
> Ich gehe erstmal von der offiziellen Version aus. Das die neue Version> etliche Probleme schon jetzt beseitigt hat, das denke ich mir.
Ach so, ja das stimmt zum Teil. Aber ich denke es wäre Zeitverschwendung
wenn wir diese Version noch umbauen würden.
> Nicht jede Überprüfung sollte zudem in eine Klassenfunktion ausgelagert> werden. Funktionen sollten die übergebenen Daten auf Gültigkeit für> ihren Scope prüfen. Das Hauptscript prüft, ob die Funktion überhaupt> gebraucht wird. Welche Funktion kostet am wenigsten?>> 1) Wert -> Funktion -> Wert falsch -> Rückgabe Wert nicht verwertbar>> 2) Wert falsch -> Nächste Funktion
Jup, das macht natürlich Sinn.
> Jede Updatefunktion ist nie perfekt und muss immer wieder neu> geschrieben werden. Aber warum jedesmal ein neues Script erstellen, wenn> man eine Klasse mit den üblichen Funktionen bereits hat und diese> vielleicht alle x Updates überarbeiten muss?
Bei meiner Variante existiert natürlich auch eine Klasse die die Updates
durchführt. Diese kümmert sich ums Backup vor dem Update, ums Rollback
bei einem Fehler, verarbeitet die Logs usw. Das ist ja immer das selbe
und gehört ganz klar ins System integriert.
> Sind halt zwei Positionen die wir hier einnehmen und beide haben in> verschiedenen Fragestellungen wahrscheinlich ihren Vorteil. Wir müssten> einfach mal jeder ein Beispielupdate erstellen und dann kann man> schauen, was wir von welchem System übernehmen sollten.
Ja, das wäre nich schlecht. Momentan habe ich dazu aber nicht die Zeit.
Allerdings habe ich mal so auf die schnelle ein Beispiel-Updatepaket
erstellt, so wie ich mir das in etwa vorstelle. Ich denke, daran
erkennst du viel mehr als wenn ich hier 500 Zeilen Text schreiben würde.
Kurze Beschreibung:
In einem Updatepaket gibt es immer diese Elemente:
- Datei "info.ini": Eine nicht ausführbare Datei, die alle wichtigen
Informationen zum Update enthält
- Datei "update.php": Die Datei, die die notwendigen Updateschritte
enthält. Allerdings ist hier nichts drin, was das Überschreiben der
alten Systemdateien mit den neuen Dateien betrifft.
- Ordner "files/": Hier sind alle neuen Systemdateien enthalten (also
alle, die sich seit der letzten Version geändert haben). Die
Ordnerstruktur darin ist genau so wie es nachher auch sein muss.
Die Updatefunktion des Systems entpackt das Updatepaket erstmal nach
updates/0.2.3/. Dann wird die info.ini ausgelesen und entschieden, ob
dieses Update durchgeführt werden kann/darf.
Ist das Update in Ordnung, wird das Verzeichnis updates/0.2.3/files/
nach Dateien durchsucht. Von allen momentan installieren Systemdateien,
die auch in diesem files/ Ordner enthalten sind, werden nun Backups
angelegt. Auch von der Datenbank wird ein Update angelegt.
Dann kann das Update losgehen:
Die Update-Klasse kopiert einfach alle Dateien aus dem Ordner
update/0.2.3/files/ ins Systemverzeichnis. Jetzt sind schonmal alle
Dateien aktuell.
Dann wird noch die Datei update/0.2.3/update.ini includet und die darin
enthaltene Funktion ausgeführt. Diese nimmt dann das Datenbankupdates
oder sonst irgendwelche speziellen Updateroutinen vor.
Meldet diese Funktion Erfolg, ist das Update fertig. Meldet sie ein
Fehler, wird direkt ein Rollback der alten Systemdateien und der
Datenbank gemacht.
Christian R. schrieb:> Ich habe mich ungünstig ausgedrückt. Mit Pakete meinte ich eigentlich> ein komplettes Archiv aller Dateien, also für jemanden der neu auf> Part-DB stößt. So kann diese Person gleich die aktuellste Version> herunterladen anstatt Version XXX welche dann gleich auf YYY geupdatet> werden kann.
Ah so meinst du das. Naja das weiss ich jetzt nicht ob wir bei jedem
kleinsten Update extra noch ein vollständiges Paket schnüren. Inklusive
Footprints wären das auch jedesmal wieder 100MB Daten.
Was ich mir aber vorstellen könnte, wären Sammelupdates. Also dass man
sich zwar eine nicht ganz aktuelle Part-DB runterlädt, und dann noch ein
Updatearchiv das alle Updates bis zur aktuellsten Version enthält. Das
wären dann also im schlimmsten Fall zwei Pakete die man runterladen
müsste.
Aber eigentlich ist es momentan noch unwichtig, wie wir das dann genau
machen. Ich denke wir sind alle der Meinung, dass die Updatepakete für
das automatische Update immer nur diejenigen Dateien enthalten, die sich
seit der Vorversion geändert haben. Sammelupdates wären dann also ein
Thema das überhaupt keinen Einfluss auf die Updateroutine hat, das würde
alles ausserhalb von Part-DB geschehen.
Christian R. schrieb:> Urban B. schrieb:>> Ausserdem, wozu sollen die neuen Dateien noch manuell herumkopiert>> werden? Das kann man doch direkt mit dem Entpacken eines Updatesarchiv>> erledigen, in nur einem einzigen Befehl.>> Durch manuelles kopieren kann man die zu überschreibenden Dateien> sichern um notfalls die Ursprungsversion wieder herzustellen falls doch> mal irgendetwas nicht klappt.
Das kann man auch so machen wie ich es oben beschrieben habe. Die
Updatefunktion des Systems merkt selbst, welche Dateien durch das Update
überschrieben werden und welche nicht.
OK eine kleine Unschönheit gibt es da bei meiner Variante: Löscht man im
Updateskript eine Datei, so wird sie vom System nicht gesichert weil sie
sich nicht im files/ Ordner befindet. Dazu sind aber die Funktionen
backup() und restore() in der update.php gedacht. Hier kann man die
Backup- und die Restore-Funktion des Systems ergänzen mit
individuellen Befehlen, die auf das jeweilige Update zugeschnitten sind.
Die Update- und Restorefunktion des Systems wird aber natürlich trotzdem
auch ausgeführt, so muss man sich wirklich nur noch ganz selten um ein
paar wenigen Dateien kümmern, alles andere übernimmt das System völlig
automatisch.
puuh das ist jetzt ganz schön viel Text geworden, sorry ;-)
Ich schlage einfach mal vor, dass wir beide unsere Updatevarianten am
Beispiel des Updates von der offiziellen Version auf unser eigenen
Branch vorstellen. Tests:
1) Update erfolgreich
2) Fehler beim Kopieren einer Datei und Behandlung dieses Fehlers
3) Datenbankupdate wird durchgeführt (einfach ein Update auf die Tabelle
internal mit dem Einfügen und Ändern von Dummyvariablen)
Udo Neist schrieb:> Ich schlage einfach mal vor, dass wir beide unsere Updatevarianten am> Beispiel des Updates von der offiziellen Version auf unser eigenen> Branch vorstellen. Tests:>> 1) Update erfolgreich> 2) Fehler beim Kopieren einer Datei und Behandlung dieses Fehlers> 3) Datenbankupdate wird durchgeführt (einfach ein Update auf die Tabelle> internal mit dem Einfügen und Ändern von Dummyvariablen)
Können wir machen, muss aber noch mindestens 3 Wochen warten :-)
Sorry wenn ich langsam nerve^^ aber irgendwie konnte ich einfach noch
kein richtiges Argument von dir lesen, das gegen meine Variante sprechen
würde. Deshalb halte ich natürlich an meiner Variante fest :-)
Dass es weniger sicher ist, das glaube ich nicht. Speziell jetzt, wo das
Update vor dem Includen der Updatedatei erstmal verifiziert wird.
Dass man übertrieben viel Code schreiben muss für ein Update finde ich
auch nicht. Man kann ja die Funktionen execute() und query() aus der
Datenbankklasse nutzen, dann wird das sehr kompakt. Natürlich ist es ein
bisschen mehr als nur ein Array das man befüllt, darf es aber auch sein
wenn man dadurch enorm viel flexibler ist.
Allerdings sehe ich zwei grosse Vorteile bei meiner Variante:
- Flexibilität (es kann später noch kommen was will, alles kein Problem)
- Saubere Strukturierung (Funktionen, die häufiger genutzt werden kommen
ins System, Funktionen speziell auf ein Update angepasst kommen nur ins
Updatepaket, sind also "Einweg-Skripte")
Speziell die Flexibilität finde ich wichtig. Es ist ziemlich nervig,
ständig das eigene System umzubauen / zu erweitern nur weil man früher
nicht an alle möglichen Konstellationen gedacht hat. Ich jedenfalls
programmiere ein Progemm lieber nur einmal, und zwar so dass man es
möglichst flexibel nutzen kann, dann gibts später auch viel weniger
Anpassungen.
Mein Stand der Updatefunktion habe ich angehängt. Die Datei
update_r1000.ups enthält die Updatebefehle und ist Bestandteil eines
fiktiven Archivs part_db_r1000.zip, welches bereits in
update/part_db_r1000 extrahiert wurde. Wie die Scriptdatei später heißen
wird, das habe ich noch nicht festgelegt. Die Klasse ist ein
Proof-Of-Concept und sollte, abgesehen von kleineren - teilweise schon
bekannten - Fehlern, laufen. Einige Funktionen sind noch nicht benannt
(z.B. für den Online-Krams) oder nur ohne Inhalt.
Prinzipielle Vorgehensweise (hier als Online-Update):
1
$update = new update;
2
...
3
$files = $update -> get_update_list();
4
foreach ($file in $files)
5
{
6
$update -> get_update_file( $file ); // Holt das File
7
if ( is_readable( $file ) $archiv = $update -> f_unpack( $file ); // Entpackt das file
8
if ( is_readable( $archiv.'/update.ups' ) && $update->load_script( $archiv.'/update.ups' ) $update->parse_script(); // Parst das File
9
10
}
Die Funktion update->parse_script() interpretiert die zuvor mit
update->load_script(DATEINAME) in einen Array eingelesene Datei. Jedes
Element enthält Kommando, festgelegtes Trennzeichen (hier ein " :: ")
und ein oder mehrere Optionen (mit Leerzeichen getrennt). Die
Reihenfolge im Script entspricht auch der im Array und baut daher
aufeinander auf. Das Schlüsselwort "critical :: false" sorgt dafür, die
bis zum nächsten "critical :: true" vorhandenen Befehle ohne Rücksicht
auf einen Fehler auszuführen. "critical :: true" dagegen bricht die
Ausführung des Updates sofort ab. Ein Log wird (ist noch auf der
ToDo-Liste) immer mitgeschrieben. Es können mit der log-Anweisung auch
individuelle Texte eingefügt werden.
Meine Update-Klasse funktioniert soweit schon. Noch sind nicht alle
Befehle vorhanden, aber immerhin :-) Das Proof-Of-Concept konnte wegen
etlichen (flüchtigen) Fehlern - war ja auch nicht wirklich zum Austesten
gedacht - nicht laufen.
Zum System:
Das Script update.php von Part-DB lädt die update-Klasse, holt dann die
Updates von einem Server (die Funktionen download_*() und check_script()
sind hier nur Dummies), entpackt diese und parst die Datei dort
enthaltene "update.ups".
1
require_once ('lib.php');
2
require_once ('class/update.php');
3
4
$update =& new update;
5
6
// downloading a list of updates from url and get some files
7
$update -> download_list( 'ftp://' );
8
$update -> download_file( 'part-db_up515.zip' );
9
10
// parse an update script
11
$update -> check_script(515);
12
$update -> load_script('update/update.ups');
13
$update -> parse_script();
14
if ( ! $update -> get_debug() ) $update -> show_report();
In dem Script "update.ups" werden die Befehle in der Reihenfolge von
oben nach unten ausgeführt.
1
log :: update to revision xxx
2
copy :: authors.php
3
chmod :: authors.php 0755
4
#chmod :: update 0775
5
mkdir :: tmp 0775
6
rmdir :: tmp
7
critical :: false
8
sql :: part-db_update_rev12.sql
9
critical :: true
10
sql :: part-db_update_rev12.sql
Es sucht die notwendigen Dateien im Unterverzeichnis "files/". Die
Dateistruktur entspricht dabei der von Part-DB selbst.
1
part-db/update # l *
2
-rw-r--r-- 1 xxx xxx 1234 4. Aug 20:43 part-db_update_rev12.zip
3
-rw-r--r-- 1 xxx xxx 170 9. Aug 22:36 update.sh
4
-rw-r--r-- 1 xxx xxx 228 12. Aug 16:58 update.ups
5
6
files:
7
insgesamt 68
8
drwxr-xr-x 2 xxx xxx 54 12. Aug 17:58 ./
9
drwxrwxr-x 4 xxx xxx 93 12. Aug 17:58 ../
10
-rw-r--r-- 1 xxx xxx 1831 4. Aug 14:40 authors.php
11
-rw-r--r-- 1 xxx xxx 255 12. Aug 14:26 part-db_update_rev12.sql
Schlägt ein Kommando fehl, so wird in Abhängigkeit des Status "critical"
die Ausführung abgebrochen und ein Rollback veranlasst oder die
Ausführung ausgeführt. Der Status "critical" ist standardmässig ein und
lässt sich mit dem Befehl "critical :: (true|false)" beeinflussen.
1
loading update/update.ups...
2
executing log => update to revision xxx
3
executing copy => authors.php
4
- backup authors.php
5
- copying /update/files/authors.php to /authors.php
6
executing chmod => authors.php 0755
7
- chmod /srv/www/htdocs/part-db/authors.php to 0755
copy file /update/files/authors.php to /authors.php: success
30
chmod file "authors.php" to 0755: success
31
mkdir tmp: success
32
rmdir : success
33
executing sql: INSERT INTO `part-db`.`internal` (`keyName`, `keyValue`) VALUES ('dbSubversion', '0')
34
sql state: error => Duplicate entry 'dbSubversion' for key 'keyName'
35
executing sql: INSERT INTO `part-db`.`internal` (`keyName`, `keyValue`) VALUES ('dbRevision', '0')
36
sql state: error => Duplicate entry 'dbRevision' for key 'keyName'
37
executing sql: UPDATE `part-db`.`internal` SET `keyValue` = '1' WHERE `keyName` = 'dbSubversion'
38
sql state: ok
39
executing sql: INSERT INTO `part-db`.`internal` (`keyName`, `keyValue`) VALUES ('dbSubversion', '0')
40
sql state: error => Duplicate entry 'dbSubversion' for key 'keyName'
41
stop executing sql-script!
In folgenden Report ist die Datei authors.php umbenannt in author.php
und lässt sich daher nicht finden:
1
loading update/update.ups...
2
executing log => update to revision xxx
3
executing copy => authors.php
4
5
something getting wrong, stop executing script!
6
7
at least executing cleanup...
8
report:
9
10
comment: update to revision xxx
11
copy file /update/files/authors.php to /authors.php: failed -> file not found
12
something getting wrong, stop executing script!
Damit lassen sich auch die Installation oder auch eine Reparatur von
Part-DB bewerkstelligen. Einfach eine "install.ups" oder "repair.ups"
erstellen, die entsprechende Anweisungen enthält. Dazu müsste noch ein
Befehl "base :: PFAD" integriert werden, der relativ zum
Installationspfad liegt, um z.B. wichtige SQL- oder Systemscripte finden
zu können. Falls es dennoch notwendig werden sollte, spezielle
PHP-Scripte aufrufen zu müssen (ich hab bisher noch keine Beispiele
gelesen, für die man sowas braucht), so könnte man das hier auch noch
einbauen. Die meisten Updates benötigen das nicht. Entpacken, kopieren
von Dateien, Verzeichnisse erzeugen, Rechte wechseln, und Datenbank
updaten sind praktisch allen Fällen die einzigen Funktionen beim Update
und mit dieser Lösung schon abgedeckt.
Die Erstellung der UPS-Scripte lassen sich mit einem Batch-Script
vereinfachen (z.B. svn diff auswerten und damit copy-Befehle erzeugen,
wie ich schon weiter oben beschrieben hatte).
Im übrigen ist diese Klasse nicht auf Part-DB beschränkt und könnte auch
in anderen Projekten ihren Dienst versehen :-)
also hab gerade mal versucht die neueste r512 version auf den ftp
hochzuladen vorher ne kopie von der datenbank angelegt und aktuell hab
geht es
hatte vorher nen fehler...
"Unknown column 'footprints.filename' in 'field list'
ein datenbankupate wurde so wie ich das gesehen habe nicht
durchgeführt...
weiß einer rat?
aktuell habe ich noch die kategoriesturktur da aber keine artikel
mehr..."
habe gerade manuell über konfiguration die datenbank geupdatet...
scheint jetzt wieder alles zu gehen... werd morgen mal bisl rumtesten...
ein fehler steht aber noch an:
auf der Hauptseite steht oben unter part-db 0.2.1 SVN REV512:
Warning: shell_exec(): Cannot execute using backquotes in Safe Mode in
/volume1/web/lager/lib.php on line 536 Warning: shell_exec(): Cannot
execute using backquotes in Safe Mode in /volume1/web/lager/lib.php on
line 536
wie bekomme ich das weg? ansich funktioniert alles die meldung hatte ich
auch schon vorher bei der offiziellen part-db
hier nochmal ein Screenshot von der Hauptansicht der part-db mit der
Fehlermeldung.
Footprints ausblenden geht soweit auch. allerdings ist die Spalte
footprints in der Artikelauflistung noch vorhanden. Stört aber soweit
gerade nicht.
DANKE!
kirk disen schrieb:> also hab gerade mal versucht die neueste r512 version auf den ftp> hochzuladen vorher ne kopie von der datenbank angelegt und aktuell hab> geht es
r512 ist nicht die neuste Version, die neuste wäre r514. Welche davon
hast du nun installiert?
kirk disen schrieb:> Footprints ausblenden geht soweit auch. allerdings ist die Spalte> footprints in der Artikelauflistung noch vorhanden. Stört aber soweit> gerade nicht.
Aleo wenn das Footprint ausblenden geht, müsstest du r514 haben, denn
vorher ging das noch nicht. Dann sollte aber auch die Footprint-Spalte
nicht mehr angezeigt werden (bei mir funktioniert das).
Bist du dir ganz sicher dass das Installieren der neuen Version auch
alles sauber funktioniert hat? Überschreib mal deine lib.php und
showparts.php mit den neusten Versionen aus dem SVN:
https://part-db.googlecode.com/svn-history/r514/trunk/lib.phphttps://part-db.googlecode.com/svn-history/r514/trunk/showparts.php
Falls dann das Problem behoben ist, scheint bei der Installation deiner
Version etwas schief gelaufen zu sein (wobei da eigentlich gar nicht
viel schief laufen kann...). Dann würde ich sicherheitshalber gleich
nochmal das ganze System neu installieren.
Wenn das auch nicht geholfen hat, schreib einfach nochmal, dann müssen
wir den Fehler genauer lokalisieren :-)
@Udo
Hättest du vielleicht auch noch Zeit und Lust, mal mit dem universellen
Dateiupload zu beginnen? :-)
Es würde mir sehr helfen wenn dieser bald mal existieren würde, da meine
Klassen bereits auf das neue Dateiverwaltungs-System ausgerichtet sind,
bei dem man allen möglichen Objekten (Teile, Footprints, Lieferanten,
...) Dateien zuordnen kann.
Aber ist nur so eine Idee, kam mir einfach in den Sinn dass mir das sehr
helfen würde. Ich will dich natürlich nicht hetzen :-)
Oder hast du mit Ajax auch zu wenig Erfahrung um einen hübschen solchen
Dialog zu erstellen?
Vielleicht würden sich dazu ein paar Komponenten von dieser Seite
anbieten:
http://dhtmlx.com/docs/products/dhtmlxTree/index.shtml
Schön wäre, wenn man den Upload-Dialog vielleicht ungefähr so verwenden
könnte:
1
$dialog = new UploadDialog(/* ein paar Parameter */);
2
$filename = $dialog->open(); // Öffnet den Upload-Dialog (ein Popup) und gibt den Dateinamen der markierten Datei zurück
Ein paar Informationen wären hier noch aufgelistet:
https://code.google.com/p/part-db/issues/detail?id=14
Der letzte genannte Punkt (rekursive Eindeutigkeit der Dateinamen) wird
aber vermutlich nicht nötig sein. Auch eine Abfrage, ob ein grosses Bild
verkleinert werden soll wird es nicht brauchen wenn später sowieso mit
Thumbnails gearbeitet wird.
mfg
Stimmt das Archiv dass ich installiert hatte war die 514. allerdings
zeigt der mainscreen Rev 512 an. es war das archiv von urban b. das er
hier gepostet hat.
also die footprint spalte ist z.b. in den Baugruppen noch vorhanden.
Stört aber aktuell nicht weiter. falls die funktion später im konfig
menü per checkbox an bzw abgewählt werden kann wäre das super...
habe auch nochmal die beiden files geupdatet. soweit funktioniert alles
aktuell...
kirk disen schrieb:> Stimmt das Archiv dass ich installiert hatte war die 514. allerdings> zeigt der mainscreen Rev 512 an. es war das archiv von urban b. das er> hier gepostet hat.
Ups das ist vermutlich mein Fehler ;-) Ich hätte wohl erst noch ein "SVN
checkout" machen sollen bevor ich das Paket geschnürt habe, damit dann
auch die richtige Version angezeigt wird. Und eigentlich hätte ich
gleich alls .svn Ordner löschen können, aber es ist mir gar nicht in den
Sinn gekommen dass die vorhanden sind, da man sie ja nicht sieht (im
Dateibrowser unter Linux sind alle Dateien/Ordner mit einem Punkt am
Anfang unsichtbar).
Naja ist eigentlich aber nicht weiter schlimm. Aber jetzt weiss ich
wenigstens welche Version du hast :-)
kirk disen schrieb:> also die footprint spalte ist z.b. in den Baugruppen noch vorhanden.> Stört aber aktuell nicht weiter. falls die funktion später im konfig> menü per checkbox an bzw abgewählt werden kann wäre das super...
Ach so, bei den Baugruppen meinst du. Stimmt, das habe ich irgendwie
vergessen. Hab gedacht ich hätte es dort auch eingebaut...
Ich habs noch schnell eingebaut, hier gibts die neuste Version der
entsprechenden Datei:
https://part-db.googlecode.com/svn-history/r515/trunk/deviceinfo.php
was mir noch aufgefallen ist... wenn man mit paketen updatet kommt
eigentlich nur das überschreiben der alten dateien in frage, da die
ganzen artikelbilder im unterordner img liegen. hätte fast den fehler
gemacht und alles gelöscht und auf die neue datenbank verlinkt in der
config. die problematik die ich da aber sehe ist dass dabei wohlmöglich
alte dateileichen die nicht mehr benötigt werden erhalten bleiben. ist
in der updateroutine schon etwas eingebaut dass den ganzen dateistamm
checkt während des updates und unnötige dateien löscht?
zu dem footprint ausblenden: wenn man über die suchfunktion teiel sucht
taucht das footprint auch wieder als spalte rechts in der auflistung mit
auf. direkt über die kategorien ist es aber schön ausgeblendet...
bin aktuell noch bei der r514...
kirk disen schrieb:> zu dem footprint ausblenden: wenn man über die suchfunktion teiel sucht> taucht das footprint auch wieder als spalte rechts in der auflistung mit> auf.
Ist jetzt auch behoben :-)
https://part-db.googlecode.com/svn-history/r516/trunk/nav.phphttps://part-db.googlecode.com/svn-history/r516/trunk/search.phpkirk disen schrieb:> was mir noch aufgefallen ist... wenn man mit paketen updatet kommt> eigentlich nur das überschreiben der alten dateien in frage, da die> ganzen artikelbilder im unterordner img liegen. hätte fast den fehler> gemacht und alles gelöscht und auf die neue datenbank verlinkt in der> config. die problematik die ich da aber sehe ist dass dabei wohlmöglich> alte dateileichen die nicht mehr benötigt werden erhalten bleiben. ist> in der updateroutine schon etwas eingebaut dass den ganzen dateistamm> checkt während des updates und unnötige dateien löscht?
Ja, man soll einfach immer die alten Dateien mit den neuen
überschreiben. Dass Dateileichen entfernt werden, ist momentan nicht
möglich. Ausser du aktualisierst dein Verzeichnis direkt per SVN, dann
sollten zumindest die Systemdateien, die nicht mehr gebraucht werden,
gelöscht werden (meine ich zumindest).
Oder wenn man das ganze System löschen will, dann löscht man halt alles
ausser dem img-Ordner. Sonst sollten sich ja nirgens vom Benutzer
erstellte Dateien befinden (ausser die config.php noch).
Später soll das Löschen von Dateileichen natürlich die Updatefunktion
des Systems übernehmen. Auch soll etwas mehr Ordnung eingeführt werden,
was die selbst hochgeladenen Dateien betrifft. Für hochgeladene Dateien
gibt es dann ein Verzeichnis "media/", in dem alle hochgeladenen Dateien
landen (und nur in dem!). Also alles, was sich ausserhalb von media/
befindet gehört zum System und wird durch die Updatefunktion sauber
gehalten. Und für alles was sich dann in media/ befindet, ist der
Benutzer selbst verantwortlich (es könnte aber vom System eine Funktion
geben, die nicht benutzte Dateien im media-Verzeichnis aufspürt und dem
Benutzer das Aufräumen vereinfacht).
Urban B. schrieb:> Ja, man soll einfach immer die alten Dateien mit den neuen> überschreiben. Dass Dateileichen entfernt werden, ist momentan nicht> möglich. Ausser du aktualisierst dein Verzeichnis direkt per SVN, dann> sollten zumindest die Systemdateien, die nicht mehr gebraucht werden,> gelöscht werden (meine ich zumindest).
Im Prinzip hab ich das bei mir in meinem Update-System so vorgesehen.
Entweder wird das schon im Update-Script (update.ups) durch ein delete
gemacht (bevorzugt) oder cleanup() überprüft anhand einer aktuellen
Dateiliste, welche Systemdateien vorhanden sein müssen. Die speziellen
Listen bzw. die repair.ups würden bei Bedarf automatisch ersetzt und
abgearbeitet.
> Oder wenn man das ganze System löschen will, dann löscht man halt alles> ausser dem img-Ordner. Sonst sollten sich ja nirgens vom Benutzer> erstellte Dateien befinden (ausser die config.php noch).
Da die config.php irgendwann nur noch die Zugangsdaten der Datenbank
enthält, wäre die grundsätzlich beim Update nicht überschreibbar
(Blacklist).
Urban B. schrieb:> @Udo>> Hättest du vielleicht auch noch Zeit und Lust, mal mit dem universellen> Dateiupload zu beginnen? :-)> Es würde mir sehr helfen wenn dieser bald mal existieren würde, da meine> Klassen bereits auf das neue Dateiverwaltungs-System ausgerichtet sind,> bei dem man allen möglichen Objekten (Teile, Footprints, Lieferanten,> ...) Dateien zuordnen kann.>> Aber ist nur so eine Idee, kam mir einfach in den Sinn dass mir das sehr> helfen würde. Ich will dich natürlich nicht hetzen :-)>> Oder hast du mit Ajax auch zu wenig Erfahrung um einen hübschen solchen> Dialog zu erstellen?
Ich habe meist das dojo-Framework genutzt. Nach meiner Kenntnis gibt es
da kein Multiupload, den man direkt nutzen kann. Aber ein asynchroner
Dateiupload hatte ich damit schon hinbekommen. Ich werde mich aber
erstmal nicht damit beschäftigen, sonst werden Templates und meine
Update-Klasse niemals fertig.
Udo Neist schrieb:> Ich habe meist das dojo-Framework genutzt. Nach meiner Kenntnis gibt es> da kein Multiupload, den man direkt nutzen kann. Aber ein asynchroner> Dateiupload hatte ich damit schon hinbekommen.
Hmm das dojo Framework sieht ja ziemlich cool aus. Ich würde es sehr
begrüssen wenn irgendwann mal (in ferner Zukunft^^) ganz Part-DB mit so
einem System (muss ja nicht dojo sein) realisiert wird. Dann hätte man
eigentlich ein vollwertiges Programm, als wäre es eine lokale
Installation. Also ich meine wegen den vielen neuen Möglichkeiten, die
so ein Framework bieten. Konkret meine ich damit solche Sachen wie
Drag&Drop, Kontextmenüs usw, die die Bedienung viel komfortabler
gestalten. Aber momentan haben wir wichtigere Sachen zu tun :-)
Bezüglich Lizenz-Kram bin ich nicht gerade ein Profi. Ich habe mal
Wikipedia etwas bemüht, und ich habe den Eindruck dass die von dojo
angebotene BSD-Lizenz zu unserem Projekt passen würde oder? Die scheint
sogar "noch freier" als GPL zu sein wenn ich das richtig verstanden
habe?
Ich finde es halt einfach wichtig, dass wir keine Komponenten verwenden,
die dann plötzlich lizenztechnische Einschränkungen für Part-DB
darstellen könnte.
Ach ja, was meinst du genau mit Multiupload? Dass man mehrere Dateien
gleichzeitig uploaden kann? :-)
> Ich werde mich aber> erstmal nicht damit beschäftigen, sonst werden Templates und meine> Update-Klasse niemals fertig.
Jop, das ist natürlich kein Problem :-)
GPL und BSD kann man zusammen nutzen. Ist allerdings etwas umstritten,
ob beide Lizenzen kompatibel sind. Ich meine ja. Vielleicht hier und da
nicht perfekt, aber es geht ja (siehe die meisten Linux-Distris, die
auch sehr viele Tools mit BSD-Lizenz nutzen).
bei der r514 fällt mir auf dass es in der Artikelauflistung nicht mehr
möglich ist die Unterkategorien auszublenden. Das ging definitiv vorher
mal. ist das Absicht oder gibt es ne andere Möglichkeit die
Unterkategorien auszublenden?