Hallo Mitstreiter, wie einige von euch bereits wissen entwickelt "Bernd Wiebus alias dl1eic " eine KiCad-Bibliothek mit Norm-Schaltzeichen und anderen speziellen Schaltzeichen für KiCad. Ich habe mich vor 1 Monat dem Projekt angeschlossen und nun sind wir beide am überlegen wie man die Bibliothek ambesten aufbauen sollte um dem zukünftigen Anwender natürlich ein flinkes arbeiten zuermöglichen. Hier könnt ihr eure Vorschläge, Ideen, Erfahrungen posten und zur Diskussion stellen. Viele Grüße, Rene
Hallo, das is jetz nur gefährliches halbwissen meinerseits, aber imho arbeiten die entwickler gerade daran, das komplette lib-system von kicad umzubauen, nicht dass ihr euch dann jetzt viel mühe gebt und die arbeit dann umsonst war.. falls meine info falsch sein sollte, bitte den beitrag einfach überlesen ;)
Hallo Adlerauge, kannst du diese Information bitte noch mit einer Quellenangabe versehen. Denn dies wäre eine schon entscheidende Information. VG, Rene
Hallo, gefunden habe ich das auf der neuen seite der entwickler, bei launchpad. unter blueprints, https://blueprints.launchpad.net/kicad ist von einem neuen library-system die rede. der link von dort führt auf die (alte?) sourceforge seite, auf der änderungen aufgelistet werden, es scheint aber alles noch nicht besonders weit gediegen..ich hab das auch nur durch zufall entdeckt, weil mich halt interessiert wie sich da alles entwickelt (is ja vielversprechend..) ich hoffe das hilft..
Besten Dank Adlerauge. Ich werde das mal unter die Lupe O.O nehmen und versuchen ein paar Informationen zu ergattern ;).
Ich habe mir das jetzt mal geschaut und kann dies etwas entkräften. An einem neuen Library-System wird scheinbar nicht gearbeitet. Denn das Änderungsdatum von der alten Sourceforge-Seite lautet: http://kicad.sourceforge.net/wiki/index.php/New_Library_System_Spec >> unten links
1 | This page was last modified 15:16, 4 November 2009 |
Der Eintrag bei Launchpad ist ebenfalls schon sehr alt: https://launchpad.net/~kicad-testing-committers/+related-software (obere Seite) https://blueprints.launchpad.net/kicad/+spec/kicad-library-system (Eintrag) >> oben rechts
1 | Registered by Manveru on 2009-10-14 |
Dafür habe ich einen interessanten BUG-Report gefunden, bei welchem es anscheinend um die Problematik des Library_Transportes geht und es Schwierigkeiten bei gleicher Symbolbenennung in 2 verschiedenen Libraries bei gemeinsamer Nutzung geht. https://bugs.launchpad.net/kicad/+bug/575810
Wie würdet ihr eine Bibliothek in KiCad aufbauen? Alle Symbole in eine Datei, damit man alles schnell zur Hand hat oder bevorzugt ihr eine bestimmte Strucktur & Sortierung?
Rene B. schrieb: > Wie würdet ihr eine Bibliothek in KiCad aufbauen? Alle Symbole in eine > Datei, damit man alles schnell zur Hand hat oder bevorzugt ihr eine > bestimmte Strucktur & Sortierung? Ich hab vor ner Weile meine eigene Eagle-Bibliothek mal auf Vordermann gebracht. Dort halte ich das etwa so: - B (Gleichrichter) - C (Kondensatoren, unterteilt in polar, bipolar, tantal) - CON-molex - CON-pin (Stiftleisten) - IC-avr - IC-com (Kommunikation, Bus) - IC-memory - IC-opv (Opamps) - IC-ttl - IC-vreg (Schaltregler, Linearregler) - L - R - R-pot (Potis) - T (Transistoren) usw. Wo zutreffend, nach Typ gruppiert, sonst nach Bauart, also nicht für jeden Wert ein eignes Bauteil.
Ich hatte mir for längere Zeit mal etliche Libs von Basista glaube ich (Leiterplattenhersteller Berlin) heruntergezogen, nur Layout ohne Symbole, und die 4.x version. Darin enthalten war auch eine Ellenlange Nomenklaturerklärung. Habe viel mit den Libs gearbeitet, auch aus dem Grund, daß viele Symbole, welche in Eagle std-libs mit 6Mil Rules waren, dort mit 8 mil rules zu finden waren, ohne DRC verletzung. Sollte es die libs nicht mehr geben, kann ich die gerne posten. Trotzdem wäre ev. auch eine ofizielle Anfrage nicht schlecht, da es ja ein Tool für die Konvertierung von Eagle->Kikad gibt, ob man nicht die Libs offiziell konvertieren und als Kikad Libs freigeben könnte. Könnte die File frühestens Dienstag posten, trotzdem wäre die ofizielle Anfrage nicht schlecht und ich fand die umfangreichen Nomenklatur auch nicht schlecht, bzw. könnte ev. ein Ausgangspunkt werden.
- Frei eingebbare Tags ermöglichen, damit jeder seine Bibliothek nach eigenen Wünschen filtern kann. (Z.B. nach den Namen von Projekten, nach Datum, nach Sachgruppen usw.) - Sämtliche auf MK upgeloadete .sch- und .brd-Dateien mit einem Script auf die verwendeten Bauteile absuchen und diese auflisten (mit Tag "mk"). Das entspricht dann dem, worüber hier auf der Plattform geredet wird. - Liste nach Häufigkeit der Nutzung sortieren oder gruppieren, so dass man das, was man immer wieder braucht, besonders schnell findet. - Eine Funktion schaffen, mit der man alle schon einmal in einem eigenen Projekt genutzten Bauteile filtern kann. "Das hatte ich doch schon mal, aber wie hieß das Teil doch noch?"
Angehängte Dateien:
-

Screenshot_01.png
3,9 KB
Das Projekt von euch finde ich echt super!! Ich weiss nicht ob du splan kennst, aber evtl. wäre das ja ein Bibliotheksabfbau für euch (siehe Screenshot)
Also ich find, es gibt nix Hinderlicheres beim Arbeiten, als solch ellenlange Bezeichnungen. Mich hat das in der Target-Bibliothek schon immer gestört, drum hab ichs bei meinen Bibliotheken anders gemacht und nur noch kurze, knackige Präfixe benutzt. Bisher gabs noch keine Namenskollisionen ;-)
Guten Abend, sowie ich das sehe ist eine eine Katalogisierung durch Kategorien unerlässlich um eine erste Übersicht zugewährleisten. Die Idee von Sven P. (haku) mit kurzen Knackigen Präfixen finde ich ganz gut. Man könnte kurze Präfixe mit einer längeren Bezeichnung kombinieren um bei öfterer Nutzung nicht immer alles lesen zu müssen und bei neuer Suche nach einem Symbol kann man in Ruhe lesen, das finde ich einen guten Kompromiss. @ Chris (Gast) Eine Nutzung von anderen Symbolen durch eine Konvertierung ist nicht ganz trivial, weil das Urheberrecht beim Ersteller dieser liegt. @ didadu (Gast) Dies sind auch gute Ideen jedoch etwickeln wir den Bibliotheks-Browser nicht. Wir erstellen hauptsächlich Symbole & Footprints für KiCad. @ Andreas A. (elw-2) Ich habe mit SPLAN nur kurz gearbeitet. Ich werde es die Tage mal wieder ausgraben und mir den Aufbau dort anschauen. Besten Dank an alle für die ersten Tips.
Nett wären auch ein paar fertige Module: - Spannungswandler inkl. Kondensatoren - Schaltwandler inkl. passiven Bauteilen für die häufigsten Anwendungsfälle - Prozessoren inkl. Blockern, Quarz, Reset-R usw. für die häufigsten Anwendungsfälle - SD-Card-Anbindung komplett - Verschiedene häufig verwendete Sensoren - Verschiedene häufig verwendete Aktoren - usw. Die Idee dabei ist, dass bestimmte Sachen immer und immer wieder auftreten, von Neulingen (und anderen) immer wieder dieselben Fragen gestellt und Fehler gemacht werden, und fertige "Modul-Bausteine" könnten die Arbeit vielleicht erleichtern und beschleunigen. Wenn man dann nur noch einen "Baustein" laden muss, der sogar schon in sich geroutet ist, dann muss man nur noch die Leitungen zwischen den Bausteinen anschließen und das Projekt ist fertig.
Hallo didadu > Nett wären auch ein paar fertige Module: > - Spannungswandler inkl. Kondensatoren Gährt hier zur Zeit experimentell. In der KiCAD user group ist schon eine Sammlung experimenteller Building Blocks. Allerdings nur LM317 Schaltungen in (fast) allen Perversionen. Hier liegt eine zu einem viertel fertige Dokumentation, wie man rationell das hierarschische Schaltplansystem von KiCAD verwendet, um daraus schnell Schaltpläne aufzubauen. Sie mal hier http://www.mikrocontroller.net/wikifiles/4/41/BuildingBlocksKiCAD-EXPERIMENTELL.zip Es ist ein Beispielprojekt enthalten: Das File KiCAD-HierarchischeSchaltplaene+buildingBlocksRevA_Vorlaeufig.pdf, ist eine vorläufige Beschreibung dazu. Es fehlt noch die Übersetzung und die Bebilderung. Im Ordner Experimentalprojekt23052010 findet sich ein weiterer Ordner BuildingBlocksExperimental. Dieser enthält VoltageRegulatorBuildingBlock.sch mit VoltageRegulatorBuildingBlock-cache.lib und VoltageDetectorBuildingBlock.sch mit VoltageDetectorBuildingBlock-cache.lib. Die Projektdateien .pro sind nur der Vollständigkeit und zur leichteren Bearbeitung zugefügt. Aus VoltageDetectorBuildingBlock.sch und VoltageRegulatorBuildingBlock.sch wurde im übergeordneten Ordner das Projekt VoltageRegulatorBuildingBlock.pro zusammengesetzt. NICHT VERGESSEN DIE CACHE.LIB EINZUBINDEN! Sonst gibt es nur Fragezeichen statt Bauteile. Erzähl mal einer, wie es funktioniert hat. Das Beispielprojekt enthält eine 24V Unterspannungsüberwachung für einen Bleiakku, die zwei 12V Gruppen überwacht. Nicht elegant, aber hoffentlich robust. :-) > - Schaltwandler inkl. passiven Bauteilen für die häufigsten > Anwendungsfälle > - Prozessoren inkl. Blockern, Quarz, Reset-R usw. für die häufigsten > Anwendungsfälle > - SD-Card-Anbindung komplett > - Verschiedene häufig verwendete Sensoren > - Verschiedene häufig verwendete Aktoren > - usw. Gemach, Gemach..... > > Die Idee dabei ist, dass bestimmte Sachen immer und immer wieder > auftreten, von Neulingen (und anderen) immer wieder dieselben Fragen > gestellt und Fehler gemacht werden, und fertige "Modul-Bausteine" > könnten die Arbeit vielleicht erleichtern und beschleunigen. Sooooo einfach ist es leider nicht. Zum Beispiel die Spannungsregeler aus dem Beispiel. Es gibt Fälle, wo der Kühlkörper nötig ist, und Fälle, wo er stört. Egal, ob ich eine Bibliothek mit oder ohne Kühlkörper bereitstelle, der Anwender muss sich immer überlegen, ob er einen benötigt oder nicht, und entsprechend zufügen oder löchen. Stelle ich zwei Bibliotheken zu Verfügung, muss er sich überlegen, welche er nimmt. Ein weiterer Punkt sind Schnittstellen.....ich muss mir immer genau ansehen, wie sie im Detail ansehen, wie sie aufgebaut ist. Beispiel: Ich würde in einem Ausgang irgendwo einen RC Tiefpass verwenden. Durch das Paralellschalten der Ausgänge könnte der C mehrfach auftreten.......oder ein anderer Eingang mit ebenfalls RC-tiefpass. Zwei tiefpässe würden durch das blinde aneinanderfügen der Building blocks hintereinandergeschaltet. Das kann schon zu viel sein. Wenn ich sie weglasse, wo? Am Eingang? Am Ausgang? Ganz weglassen? Dann muss auch das der Anwender wissen und gegebenenfalls selber zufügen. Solche Systeme können nur eine Arbeitserleichterung sein, aber keinesfalls das selber denken ersetzten. Im übrigen ist das ganze zur Zeit auch noch recht gefährlich. Es ist nur eine Möglichkeit, die eigentlich so nicht angedacht war. KiCAD stellt dazu keine Werkzeuge zur Verfügung, und das ganze lebt vom manuellen umkopieren und umbenennen von Dateien. Und immer schön auf die ~-cache.lib achten. Weil in den Blocks können ja Symbole sein, die man selber nicht im System hat......oder anders, mit gleichem Namen.....gaaaanz übel. Vertippt man sich, kann man sich ganz leicht ganz weit wegschiessen. z.b. Wenn durch einen Fehler beim Umbenenen der Unterschaltpläne ein Unterschaltplan anfängt sich selber zu enthalten.....:O) > > Wenn man dann nur noch einen "Baustein" laden muss, der sogar schon in > sich geroutet ist, dann muss man nur noch die Leitungen zwischen den > Bausteinen anschließen und das Projekt ist fertig. "in sich geroutet......". Tja....so weit ist KiCAD leider noch nicht. Bis jetzt (25.05.2010) geht das ganze nur Brechstangenmäßig mit Schaltplänen, nicht mit Boards. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Nachtrag: >> Die Idee dabei ist, dass bestimmte Sachen immer und immer wieder >> auftreten, von Neulingen (und anderen) immer wieder dieselben Fragen >> gestellt und Fehler gemacht werden, und fertige "Modul-Bausteine" >> könnten die Arbeit vielleicht erleichtern und beschleunigen. > Sooooo einfach ist es leider nicht. Zum Beispiel die Spannungsregeler > aus dem Beispiel. Es gibt Fälle, wo der Kühlkörper nötig ist, und Fälle, > wo er stört. Egal, ob ich eine Bibliothek mit oder ohne Kühlkörper > bereitstelle, der Anwender muss sich immer überlegen, ob er einen > benötigt oder nicht, und entsprechend zufügen oder löchen. Stelle ich > zwei Bibliotheken zu Verfügung, muss er sich überlegen, welche er > nimmt.~~~~~~ Achja....den Spannungsteiler zum justieren des LM317 muss er sich auch immer noch selber ausrechnen. Ihm im 0,1V Abstand Buildingblocks bereitzustelln wäre etwas überkandidelt....mal abgesehen, daß ich es manchmal mag, den Abgleich auf mehr als zwei Widerstände im Spannungsteiler zu verteilen. Tekade hat früher vergleichbares zur Resteverwurstung gemacht, und wenn ich Ausschlachtmaterial verwende, oder nur eine eingeschränkte E6 Widerstandsreihe in der Tasche habe, kann das nützlich sein. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
didadu schrieb: > - Frei eingebbare Tags ermöglichen, damit jeder seine Bibliothek nach > eigenen Wünschen filtern kann. (Z.B. nach den Namen von Projekten, nach > Datum, nach Sachgruppen usw.) Die Idee hatte ich vor einiger Zeit auch schonmal. Hab sogar ne Mail an die Entwickler geschickt. Leider nie was davon gehört http://www.elektronik-projekt.de/thread.php?threadid=6244
Praktisch wäre auch eine "API" zur Anbindung an die eigene Bauteilebibliothek. Und zwar so, dass man alle (und nur) die Teile angezeigt bekommt, die man auch hat. In die umgekehrte Richtung wäre eine Funktion praktisch, die für eine von extern (z.B. hier aus dem Forum) geholte, gerade geöffnete Schaltung (und eine "Anzahl Exemplare, die ich bauen will") zwei Listen generiert: "Diese Bauteile hast Du in Deiner Sammlung" und "Diese Bauteile musst Du bestellen". Für die Bestellung wäre noch eine Funktion nützlich, die beim (bzw. bei den) bevorzugten Elektronikhändler einen Warenkorb generiert, den man dann nur noch bestätigen muss. (Das erfordert ggf. eine Zusammenarbeit mit denen, damit die dortige API überhaupt existiert.) Zur Auswahl von "Modulen": Wenn ich hier im Wiki auf die Seite "Konstantstromquelle" gehe, finde ich mehrere Schaltungsvorschläge. Jeder hat seine Vorteile und seine Nachteile. Die sollten natürlich als Auswahlhilfe angegeben werden. Ob nun nur die Schaltung oder auch ein Board-Element in das Projekt importiert wird, erscheint mir eher wie eine Frage des schrittweisen Vorgehens. Bei layoutkritischen Sachen (HF, Leistungs-Schaltelektronik) ist ein Vorlayout natürlich hilfreich.
Bernd Wiebus schrieb: > den Spannungsteiler zum justieren des LM317 muss er sich auch > immer noch selber ausrechnen Warum nicht die Formeln mit implementieren? Bei Aufruf des Moduls oder beim Anklicken eines "Formel"-Ankers im Schaltplan wird das geöffnet (als Dialog), was sonst immer irgendwo einer als Javascript zum Selbst-Berechnen ins Web gestellt hat -- aber wo war das man noch? Gerade beim jeweiligen Modul wäre das doch am Besten aufgehoben. Wenn so eine Möglichkeit für den User erstmal gegeben ist, das selbst (per "Scripting") zu implementieren, wird es sicher Leute geben, die solche Module für alle bauen. > "Gemach, Gemach..." Schon klar, aber es geht ja hier um Konzeptideen, also das "wie stelle ich mir die ideale Arbeitsumgebung vor". Noch eine Idee: Eine Datenblattverwaltung, die sowohl an meine Inventarliste (Inventar-Bauteilebibliothek) als auch an die Layoutprogramm-Bauteilebibliothek angebunden ist. Es ist ja toll, dass es die ganzen PDFs heute alle im Internet gibt, aber da sie manchmal nur etwas manuell-umständlich (und aus nicht immer ganz klarer Quelle) auffindbar und herunterladbar sind (unter teilweise sehr undeutlichen Dateinamen), fände ich eine geeignete PDF-Verwaltung hilfreich. Vor allem sollten die Schlüsseldaten nicht nur als PDF vorliegen, sondern auch direkt in den Bauteilebibliotheken abrufbar sein.
didadu schrieb: > Noch eine Idee: Eine Datenblattverwaltung, Ist die nicht schon drin? Habe sowas in Erinnerung, aber bisher nicht benutzt.
Hallo didadu und guido >> den Spannungsteiler zum justieren des LM317 muss er sich auch >> immer noch selber ausrechnen > > Warum nicht die Formeln mit implementieren? Aeeehm......es geht hier um Symbol Bibliotheken ZUR EINBINDUNG in KiCAD, nicht um KiCAD selber und etwaige zukünftige Scripte. Ansonsten ist die Idee nicht schlecht, abgesehen von den ganzen Sonderfällen.....:O) > Noch eine Idee: Eine Datenblattverwaltung, die sowohl an meine > Inventarliste (Inventar-Bauteilebibliothek) als auch an die > Layoutprogramm-Bauteilebibliothek angebunden ist. Es ist ja toll, dass > es die ganzen PDFs heute alle im Internet gibt, aber da sie manchmal nur > etwas manuell-umständlich (und aus nicht immer ganz klarer Quelle) > auffindbar und herunterladbar sind (unter teilweise sehr undeutlichen > Dateinamen), fände ich eine geeignete PDF-Verwaltung hilfreich. Vor > allem sollten die Schlüsseldaten nicht nur als PDF vorliegen, sondern > auch direkt in den Bauteilebibliotheken abrufbar sein. >> Noch eine Idee: Eine Datenblattverwaltung, >Ist die nicht schon drin? Habe sowas in Erinnerung, >aber bisher nicht benutzt. Nicht wirklich. Ich verwende dafür lieber Jabrev, um Tags und Bibtex Einträge an meine PDFs zu pappen, und ansonsten eine desktop suche. Das ist NOCH flexibler und universeller...... Ausserdem ist sie bei KiCAD vor allem an Module, weniger an Symbole gebunden. Eigentlich auch nicht für Datenblattsuche, sondern zum Betrachten und Suchen in den Footprints..... Jedenfalls ist das Hauptproblem, das Du generische Bauteile nicht explizit an herstellergebundene Datenblätter binden möchtest. Und was ist, wenn Du Deine PDF Dateien umgruppierst? Dann brauchst Du zwei Ordnersysteme. Einmal das originale, was Du nach herzenslust umgruppieren kannst, und ein fixes, nur mit den Dateien, die Du für KiCAD brauchst. (Das mache ich nur zum Schluss, wen ich die Daten rausgebe....... ) Oder halt wieder ein Indexsystem, wie bei der Desktop suche...... Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Bernd Wiebus schrieb: > Jedenfalls ist das Hauptproblem, das Du generische Bauteile nicht > explizit an herstellergebundene Datenblätter binden möchtest. Doch doch, ich möchte das. Ich habe z.B. das Problem, dass ich die Spannungsfestigkeit einer Spule herausfinden will. Wenn ich dann nicht Zugriff auf verschiedene (!) Datenblätter der Hersteller (und ggf. deren Adressen) habe, dann wird es sehr langwierig. Weitere Ideen: Es gibt eine Menge libraries, die im Web verstreut sind. Natürlich gibt es z.B. http://www.kicadlib.org/, wo man sicher viel "findet" ... wenn man das Gewünschte denn findet, nach dem meiner Meinung nach doch recht umständlichen Suchen. Mein erster Ansatz wäre daher immer, erstmal alles Bestehende zu sammeln (Herunterladen, Auspacken, alle Dateinamen, Bauteilenamen, Download-URLs usw. in eine DB, möglichst auch die jeweiligen Lizenzen!), dann mir eine Schnittstelle zu machen, um das alles möglichst einfach und schnell abzurufen. (Sowas ist mit Python, einem lokalen Ad-hoc Server und sqlite3 recht schnell gemacht.) Dann kann man erstmal überhaupt gucken, was es denn schon alles gibt. Sicher eine ganze Menge. Wenn man mehr braucht, geht man über google und sucht nach Stichwörtern, die auf weitere Bibliotheken führen, wo man dann noch mehr runterladen kann (inurl:.lib oder so), den URL und am Besten die E-Mail immer mit abspeichern! Der nächste Schritt wäre die Anbindung an Kicad selbst, also der einfach Export der von mir selbst gewünschten Listen. Wenn man einen Schritt weiter gehen möchte, organisiert man eine gemeinsame Anstrengung, eine weltweite Datenbank aller Bauteile aufzubauen, die mögilchst allen Ansprüchen und Wünschen gerecht wird. Erst dann wird es wirklich ein Projekt, das langfristig allen viel Zeit und Mühe spart. Da wären dann z.B. auch Übersetzungen der Beschreibungen hilfreich. Man könnte automatisch alle Lib-Ersteller (die das nicht sowieso unter GPL o.ä. gestellt haben) anschreiben und ihnen anbieten, die Daten mit in die Datenbank aufzunehmen. (Wo sie für den persönlichen Gebrauch eh schon sind, aber eben noch nicht öffentlich.)
Hallo didadu. > Wenn man einen Schritt weiter gehen möchte, organisiert man eine > gemeinsame Anstrengung, eine weltweite Datenbank aller Bauteile > aufzubauen, die mögilchst allen Ansprüchen und Wünschen gerecht wird. Wie wahr. Leider werden meine Fähigkeiten diesen Anforderungen nicht gerecht. Ich fürchte, ich werde diese kleine Aufgabe Dir überlassen müssen. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Bernd Wiebus schrieb: > ich werde diese kleine Aufgabe Dir überlassen müssen Wir danken für das uns ausgesprochene Vertrauen :-D Ich bin aber auch nur einer. Wie alle anderen auch.
Rene B. schrieb: > doch etwickeln wir den Bibliotheks-Browser > nicht. > Wir erstellen hauptsächlich Symbole & Footprints für KiCad. Ich verstehe noch nicht ganz, wie ihr vorgeht. Es gibt ja schon so viele Dinge, wollt ihr also das Rad neu erfinden? Oder wollt ihr etwas vereinheitlichen? Oder etwas aktualisieren, erneuern? Etwas neu kategorisieren? Etwas vervollständigen? Was genau ist es, das ihr verbessern wollt?
Mir scheint außerdem, dass es verschiedene Schaltsymbol-Stile gibt. Also z.B. einen europäischen, einen amerikanischen, vermutlich noch weitere. Dann gibt es alte und neue Darstellungsnormen (z.B. bei Logikbauteilen). Das alles beeinflusst die Darstellung (Footprint im Schaltplan) ein- und desselben Bauteils, und es gibt da sicher benutzerspezifische Präferenzen. Ich bin mir nicht sicher, dass es dafür Umschaltmöglichkeiten in den existierenden Schaltplaneditoren gibt, also muss man das Programm umgehen und entsprechende Umschaltungen in den bereitgestellten Footprint-Libraries machen. Im Übrigen gibt es noch erhältliche Bauteile und mehr oder weniger historische Bauteile (die man aber in Altgeräten finden und evtl. nutzen möchte). Auch da bieten sich Umschaltmöglichkeiten in der Library-Verwaltung an. Weiters gibt es verschiedene Bezeichnungen und Synonyme für Bauteile und Bauteilekategorien. Das ist eine Frage der ALIASE und der Übersetzungen. Wenn man seine Bibliothek gut kennt, hat man die direkten Bauteile-Bezeichnungen im Kopf, aber es ist eine große Hürde am Anfang und wenn man ein Bauteil sucht, das man nicht so gut kennt oder erstmals verwendet. Da ist eine Suchhilfe nützlich, und möglichst viele Aliase, die den Weg zum Bauteil ermöglichen. Dabei steht auch die Usability im Vordergrund, z.B. dass bei Eingabe eines Anfangsbuchstabens sofort die ganzen Auswahlmöglichkeiten erscheinen, oder auch Symbole zum Anklicken, oder mehrere unterschiedliche Kategorisierungen. Das alles läuft meiner Meinung nach auf eine Kicad-externe Bauteilverwaltung heraus, die dann jeweils das gewünschte Bauteile-Set in der vom jeweiligen User bevorzugten Form an die richtige Stelle im Verzeichnisbaum des Rechners mit dem richtigen Namen exportiert, um es dann in Kicad zu nutzen.
Hier noch ein paar Pointer für Interessierte: Libraries: Offizielle "contribs": http://www.kicadlib.org/ DARC: http://www.darc.de/distrikte/l/02/dateien/dl1eic/SymbolsSimilarEN60617+oldDIN617-RevC-en.lib Umgewandelte Eagle-Libraries: http://library.oshec.org/ More: http://www.google.de/search?q=kicad+libraries Script zum Umwandeln von Eagle-Symbolen (wo das rechtlich unproblematisch ist) in Kicad-Symbole: eagle2kicad-0.9b.ulp Quick KICAD Library Component Builder: http://kicad.rohrbacher.net/quicklib.php Gibt es eigentlich auch ein Tool für die Umwandlung KiCad=>Eagle? Wäre vielleicht auch interessant. Mich nervt das Gesuche in den Libraries so sehr (egal ob Eagle oder KiCad) -- das ist ein echter Turn-Off --, dass ich mir wohl ein Such-Tool dafür mache, und zwar ungefähr so wie oben angegeben. Wie in OSS üblich, besteht die Tendenz ja immer darin, alle Formate in alle anderen umwandeln zu können. Das sehe ich auch so. Warum soll man nicht EINE Datenbank der Teiledaten haben, die dann für ALLE Tools Exporte machen kann? Die Grunddaten sind ja dieselben, nur die konkrete Codierung variiert. Einlesen, Verarbeiten und Exportieren der KiCad-Daten sehe ich unproblematisch, das sind alles Text-Files. Selbst einen Parser und Checker könnte man noch bauen (für manuell erstellte Dateien). Aber hat jemand eine Beschreibung des Eagle-Formats? Außerdem fände ich es sinnvoll, wenn man auch in KiCad schon bei der Bauteile-Auswahl eine Gehäuse-Auswahl machen könnte. Dann hat man es in einem Arbeitsgang schon erledigt, das erscheint mir einfach praktischer. Wahrscheinlich könnte man in den Libraries entsprechende bevorzugte Gehäuseformen als Kommentar eingeben und dann nach der Schaltplanerstellung mit einem Script eine Verknüpfungsdatei (vor-)erstellen, die auf diesen Angaben basiert.
Hier noch ein paar Pointer für Interessierte: Libraries: Offizielle "contribs": http://www.kicadlib.org/ DARC: http://www.darc.de/distrikte/l/02/dateien/dl1eic/SymbolsSimilarEN60617+oldDIN617-RevC-en.lib Umgewandelte Eagle-Libraries: http://library.oshec.org/ More: http://www.google.de/search?q=kicad+libraries Script zum Umwandeln von Eagle-Symbolen (wo das rechtlich unproblematisch ist) in Kicad-Symbole: eagle2kicad-0.9b.ulp Quick KICAD Library Component Builder: http://kicad.rohrbacher.net/quicklib.php Gibt es eigentlich auch ein Tool für die Umwandlung KiCad=>Eagle? Wäre vielleicht auch interessant. Mich nervt das Gesuche in den Libraries so sehr (egal ob Eagle oder KiCad) -- das ist ein echter Turn-Off --, dass ich mir wohl ein Such-Tool dafür mache, und zwar ungefähr so wie oben angegeben. Wie in OSS üblich, besteht die Tendenz ja immer darin, alle Formate in alle anderen umwandeln zu können. Das sehe ich auch so. Warum soll man nicht EINE Datenbank der Teiledaten haben, die dann für ALLE Tools Exporte machen kann? Die Grunddaten sind ja dieselben, nur die konkrete Codierung variiert. Einlesen, Verarbeiten und Exportieren der KiCad-Daten sehe ich unproblematisch, das sind alles Text-Files. Selbst einen Parser und Checker könnte man noch bauen (für manuell erstellte Dateien). Aber hat jemand eine Beschreibung des Eagle-Formats? Außerdem fände ich es sinnvoll, wenn man auch in KiCad schon bei der Bauteile-Auswahl eine Gehäuse-Auswahl machen könnte. Dann hat man es in einem Arbeitsgang schon erledigt, das erscheint mir einfach praktischer. Wahrscheinlich könnte man in den Libraries entsprechende bevorzugte Gehäuseformen als Kommentar eingeben und dann nach der Schaltplanerstellung mit einem Script eine Verknüpfungsdatei (vor-)erstellen, die auf diesen Angaben basiert. Und gEDA <=> KiCad geht dann vielleicht auch noch irgendwann.
[Sorry für den Doppelpost, da war eine Fehlermeldung, die mich schließen ließ, dass der Server busy ist und der Post nicht ankam.] Hier die gEDA Filespecs: http://www.geda.seul.org/wiki/geda:file_format_spec
Guten Abend alle miteinander, wie ich sehe gibt es neue Ideen ^^. didadu schrieb: > Mir scheint außerdem, dass es verschiedene Schaltsymbol-Stile gibt. Also > z.B. einen europäischen, einen amerikanischen, vermutlich noch weitere. > Dann gibt es alte und neue Darstellungsnormen (z.B. bei Logikbauteilen). > Das alles beeinflusst die Darstellung (Footprint im Schaltplan) ein- und > desselben Bauteils, und es gibt da sicher benutzerspezifische > Präferenzen. didadu schrieb: > Weiters gibt es verschiedene Bezeichnungen und Synonyme für Bauteile und > Bauteilekategorien. Richtig! Dies ist vorallem von der jeweiligen Norm des entsprechenden Fachgebietes abhängig. didadu schrieb: > Das alles läuft meiner Meinung nach auf eine Kicad-externe > Bauteilverwaltung heraus, So ist es! Hier setzen wir an, in dem wir nach unseren gegebenen Möglichkeiten der Norm entsprechnden Symbole als auch Hersteller spezifische Symbole und Footprints erstellen. Zudem versuchen wir diese wiederum mit einer aussagekräftigen Nomenklatur zuversehen. Man bedenke bitte auch das nicht jede Kopie (Symbol oder Footprint) eines anderen Erstellers auch nach dem Recht des jeweiligen Landes einfach so in jedem Arbeitsbereich oder Komerzielle Zwecke verwendet werden darf! Nicht in allen Bereichen ist nur eine Anleitung zum Einschalten eines Gerätes nötig. Wir schaffen die Basis ;). > die dann jeweils das gewünschte Bauteile-Set > in der vom jeweiligen User bevorzugten Form an die richtige Stelle im > Verzeichnisbaum des Rechners mit dem richtigen Namen exportiert, um es > dann in Kicad zu nutzen. Dies impliziert für mich eine Datenbank als Verwaltungssystem von Symbolen und Footprint sowie anderen zugehörigen Daten. Ich persöhnlich kenne mich mit Datenbanksystemen nicht sehr gut aus. Ich weis durch andere Quellen das ein solches System nicht trival ist, da ja eine stetige Konsistenz der Daten gewährleistet werden muss/soll und Änderungen bei falschen Einträgen ohne großen Aufwand kaum zubeheben sind. Ich befürchte ebenso ein, das dadurch eine kunter bunte Bibliothek entsteht in der es zwar alles geben mag aber es kein einheitliches Konzept der Zeichnung gibt. Jede Linie, Abstände, Anschlüsse wie es der Ersteller bevorzugt. Dies ist für den einfachen Bastler nicht so schlimm aber solbald es ein Gruppenprojekt wird und man auf den Austausch von Schaltungsunterlagen angewiesen ist wird es auch optisch ganz schnell murks und der Überblick ist nicht mehr gegeben. Die Konzeptideen sind ansich alle sehr gut, diese beinhalten aber auch eine Verpflichtung auf mehrere Jahrzehnte und müssten noch ausgiebigeren Prüfungen unterzogen werden ;). Ich selbst programmiere keine Anwendungsprogramme dieser Art, nur Automatisierungs- & Messsoftware mit LabView und besitze dementsprechend nicht ganz so den Einblick in die Materie. Ein µC ist da viel harmloser und einfacher zu programmieren ;). --- VG, Rene
Hallo, haette da auch noch ein paar Ideen/Anmerkungen: didadu schrieb: > ... > Wie in OSS üblich, besteht die Tendenz ja immer darin, alle Formate in > alle anderen umwandeln zu können. Das sehe ich auch so. Warum soll man > nicht EINE Datenbank der Teiledaten haben, die dann für ALLE Tools > Exporte machen kann? Die Grunddaten sind ja dieselben, nur die konkrete > Codierung variiert. Einlesen, Verarbeiten und Exportieren der > KiCad-Daten sehe ich unproblematisch, das sind alles Text-Files. Selbst > einen Parser und Checker könnte man noch bauen (für manuell erstellte > Dateien). > Am Beispiel des Quick KICAD Library Component Builder kam mir mal vor laenger folgende Idee: Jeder soll online einen Baustein eingeben und fuer andere abspeichern koennen. So fuellt man mal die Datenbank. Der naechste Schritt ist die Sicherung eines Standards und der Qualitaet, deshalb muesste sich jemand um das eigentliche Format und die Verifizierung kuemmern. Schreit nach Web-Anwendung, nicht? Zu dem omnipotenten Datenformat, das du ansprichst: Ich habe noch nicht den Einblick in die allgemeine Formatvielfalt, aber wuerde mal schwer wetten, dass man mit XML relativ weit kommt: von XML kommt man in relativ linear aufgebaute Formate recht gut mit XSLT-stylesheets (ich generiere hier z.B. C-Code aus komplexen XML-Beschreibungen). Wenn nicht, muss man halt einen Translator selbst schreiben (z.B. in Python keine Hexerei). Das grosse Problem ist nun, sich ein schlaues XML-Format zu ueberlegen, was moeglichst alle Format-Eigenheiten abstrahiert. Zurueck zur Ambition der umfassenden, schrittweise perfektionierbaren Bibliothek: Ich habe vor der Komplexitaet solcher Anforderungen erst mal kalte Fuesse bekommen, sprich: fuer mich waere es utopisch, das mal in vernuenftiger Zeit umsetzen zu koennen. ABER: Wenn es jemand hinbekommt, einen Library-Server aufzusetzen und mit einem Authoring-Tool a la KICAD component builder plus Datenbankvernetzung und einem Bewertungs-System ("Design verifiziert", etc.) dem Designervolk zugaenglich macht, muesste das eigentlich sogar laengerfristig Marktwert haben, sobald man eine Community hostet, die fuer einen arbeitet. Also nochmal in der Zusammenfassung die "Utopia": 1. XML-Format definieren, Translator sheets schreiben (zunaechst Kicad, Eagle) 2. Web-Interface schreiben, Datenbank designen (wie sortiert man diese Unzahl an Bausteinen) 3. Eventuelle Schnittstellen zu Authoring-Tools zusaetzlich entwickeln 4. Die Community die Datenbank aufbauen lassen (Gehaeuse, 3D-Daten, Schema/Pinmaps/Gehaeusevarianten, Kreuzverweise) Ich wette, dass Farnell sowas in der Richtung anstreben wird - aus irgend einem Grund hat man ja wohl Cadsoft eingekauft. Das Projekt muesste irgendwie zu einem Selbstlaeufer werden, damit es laengerfristig funktioniert (und die Initianten nicht von der Komplexitaet her auffrisst). Finanzieren soll es sich auch koennen, das koennte dadurch funktionieren, dass kommerzielle Anbieter die Daten fuer ihre Tools lizenzieren koennen, bzw. die Entwicklung der Translator (XML->Anbieterformat) finanzieren. > Aber hat jemand eine Beschreibung des Eagle-Formats? Leider nein. Aber vielleicht waere das auch ueber die ULP-Schnittstelle nicht noetig? > > Außerdem fände ich es sinnvoll, wenn man auch in KiCad schon bei der > Bauteile-Auswahl eine Gehäuse-Auswahl machen könnte. Dann hat man es in > einem Arbeitsgang schon erledigt, das erscheint mir einfach praktischer. > Wahrscheinlich könnte man in den Libraries entsprechende bevorzugte > Gehäuseformen als Kommentar eingeben und dann nach der > Schaltplanerstellung mit einem Script eine Verknüpfungsdatei > (vor-)erstellen, die auf diesen Angaben basiert. Dem kann ich mich auch anschliessen. Anhand der wuenschenswerten Web-Datenbank sollte man die Listen mit den verfuegbaren Packages zum Baustein generieren koennen (d.h. den Package-Filter). Soweit mal mein Senf, ich werde das mal auf jeden Fall mitverfolgen.. Gruesse, - Strubi
Wie du schon schön geschrieben hast ist die Datenbank durch ihre vielen Parametern und deren x-Verknüpfungen unter einander eine mehr Jahresprojekt ohne das irgendwelche Massen an Symbolen und Footprintserzeugt werden müssen, das kommt dann von allein. Von der Verifizierung der Eingabedaten mal ganz abgesehen ;). Das Farnell so etwas auf die Beine stellt glaub ich nicht außer es rappelt grad einen beim durchlesen hier ;). Thema: "Instandhaltung" wird abschrecken, denke ich. Ich würde hier eher Leutz von Multisim[NI] vermuten, die sind so Größenwahnsinnig ^^. Wundern tut mich das "Tina" von Designsoft, so klein ist trotz [TI] im Rücken. Diese Software hat meiner Meinung auch das Potential für solch ein Projekt. KiCad fehlt leider noch die Kopplung zur Simulation. So nun muss ich aber noch bissel was zeichnen ;). ---- VG, Rene
So, hier ist mal eine sortierte Liste der auf www.gedasymbols.org (die Site ist etwas unübersichtlich...) befindlichen Footprints und Symbole. Angegeben sind als Tablist jeweils Typ (Footprint ODER Symbol), der Dateiname und der URL zum Aufrufen der Seite mit dem Download-Link. Vielleicht hilft das den ;-) Bibliothekaren, den Inhalt der dort auffindbaren Objekte einzuschätzen. Eine Symboldatei beispielsweise sieht dann etwa so aus:
1 | v 20081231 1 |
2 | P 0 200 200 200 1 0 0 |
3 | {
|
4 | T 100 250 5 8 0 1 0 6 1 |
5 | pinnumber=1 |
6 | T 100 150 5 8 0 1 0 8 1 |
7 | pinseq=1 |
8 | T 100 250 9 8 1 1 0 0 1 |
9 | pinlabel=+ |
10 | T 250 200 5 8 0 1 0 2 1 |
11 | pintype=pwr |
12 | } |
13 | P 700 200 500 200 1 0 0 |
14 | {
|
15 | T 600 250 5 8 0 1 0 0 1 |
16 | pinnumber=2 |
17 | T 600 150 5 8 0 1 0 2 1 |
18 | pinseq=2 |
19 | T 450 200 9 8 0 1 0 6 1 |
20 | pinlabel=2 |
21 | T 450 200 5 8 0 1 0 8 1 |
22 | pintype=pwr |
23 | } |
24 | T 350 450 8 10 1 1 0 3 1 |
25 | refdes=B? |
26 | T 0 1700 5 10 0 0 0 0 1 |
27 | device=Battery |
28 | T 0 700 5 10 0 0 0 0 1 |
29 | author=Stefan Salewski |
30 | T 0 900 5 10 0 0 0 0 1 |
31 | description=Battery |
32 | T 0 1100 5 10 0 0 0 0 1 |
33 | numslots=0 |
34 | T 0 1300 5 10 0 0 0 0 1 |
35 | dist-license=GPL |
36 | T 0 1500 5 10 0 0 0 0 1 |
37 | use-license=unlimited |
38 | L 200 400 200 0 3 0 0 0 -1 -1 |
39 | L 300 300 300 100 3 0 0 0 -1 -1 |
40 | L 400 400 400 0 3 0 0 0 -1 -1 |
41 | L 500 300 500 100 3 0 0 0 -1 -1 |
Man findet dort auch Abbildungen der Objekte, und sonstige Tools.
Hier ist die Beschreibung des Dateiformats der KiCad Schaltsymbol-Libraries: http://en.wikibooks.org/wiki/Kicad/file_formats#Schematic_Libraries_Files_Format Konkretes Beispiel:
1 | EESchema-LIBRARY Version 2.3 Date: 20/2/2009-09:35:03 |
2 | # |
3 | # SW_DIP_1 |
4 | # |
5 | DEF SW_DIP_1 SW 0 40 Y Y 1 F N |
6 | F0 "SW" 0 125 60 H V C C |
7 | F1 "SW_DIP_1" 0 -125 60 H V C C |
8 | DRAW |
9 | S 50 20 120 -20 0 1 0 F |
10 | P 4 0 1 0 130 30 130 -30 130 -30 130 -30 F |
11 | P 4 0 1 0 -130 30 -130 -30 -130 -30 -130 -30 F |
12 | P 4 0 1 0 -130 30 -130 -30 -130 -30 -130 -30 F |
13 | P 4 0 1 0 130 30 130 -30 130 -30 130 -30 F |
14 | S 50 20 120 -20 0 1 0 F |
15 | S -175 50 175 -50 0 1 0 N |
16 | S -140 30 140 -30 0 1 0 N |
17 | S -140 30 140 -30 0 1 0 N |
18 | X ~ 1 425 0 251 L 50 50 1 1 B |
19 | X ~ 2 -425 0 251 R 50 50 1 1 B |
20 | ENDDRAW |
21 | ENDDEF |
22 | # |
23 | # SW_DIP_2 |
24 | # |
25 | DEF SW_DIP_2 SW 0 40 Y Y 1 F N |
26 | F0 "SW" 0 175 60 H V C C |
27 | F1 "SW_DIP_2" 0 -175 60 H V C C |
28 | DRAW |
29 | S 50 -30 120 -70 0 1 0 F |
30 | P 4 0 1 0 130 -20 130 -80 130 -80 130 -80 F |
31 | P 4 0 1 0 -130 -20 -130 -80 -130 -80 -130 -80 F |
32 | P 4 0 1 0 -130 -20 -130 -80 -130 -80 -130 -80 F |
33 | P 4 0 1 0 130 -20 130 -80 130 -80 130 -80 F |
34 | S 50 -30 120 -70 0 1 0 F |
35 | S 50 70 120 30 0 1 0 F |
36 | P 4 0 1 0 130 80 130 20 130 20 130 20 F |
37 | P 4 0 1 0 -130 80 -130 20 -130 20 -130 20 F |
38 | P 4 0 1 0 -130 80 -130 20 -130 20 -130 20 F |
39 | P 4 0 1 0 130 80 130 20 130 20 130 20 F |
40 | S 50 70 120 30 0 1 0 F |
41 | S -140 80 140 20 0 1 0 N |
42 | S -140 80 140 20 0 1 0 N |
43 | S -140 -20 140 -80 0 1 0 N |
44 | S -140 -20 140 -80 0 1 0 N |
45 | S -175 100 175 -100 0 1 0 N |
46 | X ~ 1 425 -50 251 L 50 50 1 1 B |
47 | X ~ 2 425 50 251 L 50 50 1 1 B |
48 | X ~ 4 -425 -50 251 R 50 50 1 1 B |
49 | X ~ 3 -425 50 251 R 50 50 1 1 B |
50 | ENDDRAW |
51 | ENDDEF |
Sieht also so ähnlich aus wie die gEDA-Symbole. Würde mich wirklich wundern, wenn man das nicht recht einfach zusammenführen könnte. Auch die Formatbeschreibungen sind überschaubar.
Hi, ich schmeisse nochmal lose ein paar Inputs rein: - Habe mal mit phpmyadmin und einer MYSQL Datenbank plus nem Python script eben etwas rumgespielt. Die Datenbank als solche systematisch aufzubauen, duerfte, sobald das Framework steht, keine riesen Sache sein. Siehe Anhang. - Zum Framework: Mit PHP und einigen Masken kann man mal weitermachen und Daten einzugeben (mit phpmyadmin eher muehsam). - Ich denke, geda, kicad, eagle, und alle anderen Formate abzudecken, schreit nach einem erweiterbaren Meta-format, da faellt mir erst mal nur XML ein. Es kann sein, dass man im Zuge der Entwicklung feststellt, dass die Struktur des Formats nicht optimal ist. Der Vorteil beim XML ist, dass man einen Formatkonverter relativ schnell geschrieben hat, und alle bestehenden Daten schoen automatisch in das "neue" Format umkonvertiert hat (Stichwort XSLT stylesheets) - XML laesst sich sehr schoen mit dem freien XMLmind XML Editor (xxe, in Java) editieren. Die Beschreibung des eigentlichen Meta-Formats fuer Komponentendaten geschieht ebenfalls in Stylesheets (XSD). Um den Beduerfnissen und der Systematik allen Usern gerecht zu werden, müsste man dem Nutzer erlauben, per Script die lokale library entsprechend aus der Online-Datenbank zu generieren (und zwar nur die gewuenschten/abonnierten Komponenten). Das waere mal das zu loesende PULL-Problem (koennte einfach ueber einen direkten mysql-Zugang gehen). Die Systematik von User "haku" finde ich schon mal einen guten Ansatz a la "keep it simple", die wuerde ich schon mal so in die Datenbank uebernehmen. Das PUSH-Problem ist das naechste: Wie werden die Daten im Meta-Format erzeugt, was fuer Autorentools muessen geschrieben werden? Wie einfach ist es, z.B. aus kicad ein "Meta-Format" auszugeben, oder gibt es allenfalls bessere Tools? (bei der Part-Verwaltung hat kicad ein paar fiese Boecke, es darf an der gleichen Position nicht mehr als einen Pin geben) Ja, und dann die Aufgabenverteilung: Der, der sich den Managerhut anzieht, muesste auch fast gleich Wiki und Datenbank zur Verfuegung stellen, sonst sieht's mit der Kooperative schon mal schwierig aus, und die Diskussion wird ausufern, bevor ueberhaupt ein Prototyp laeuft. Meiner Meinung nach muessten sich also verschiedene Profis verschiedene Aufgabenbereiche krallen: 1) PHP/Datenbank/Eingabemaske (bestehende Tools nutzen? kicadlib, Component Builder) 2) Format-Design (XML), erste XML-Formatkonverter-Prototypen fuer kicad, geda, Eagle, usw. 3) Tools zum Erstellen der Rohdaten, also Pinlisten, und Package-Design (online? kicad-Export in XML?) 4) Community management Die Sache ist riesig komplex, aber ich wuerde mir spasseshalber mal Teil 2) unter die Lupe nehmen. Der Erfolg oder das Scheitern eines solchen Projekts haengt nach meiner Erfahrung meist im Endeffekt von Punkt 1) und einem guten Web-Interface, spaeter von Punkt 4), also des Willens einer Usergruppe, Daten zu konvertieren/eingeben, ab. Alles andere fiele unter schrittweise Iteration.. Gruesse, - Strubi
Martin S. schrieb: > ich wuerde mir spasseshalber mal Teil > 2) unter die Lupe nehmen. Wenn Du für jedes Format einen Parser geschrieben und verstanden hast, wozu die verschiedenen Befehle und Werte benutzt werden, dann wird Dir auch klar, was in die Metadaten muss. (Es macht ja keinen Sinn, sich aus der hohlen Hand ein XML-Format auszudenken.) Mein erster Schritt wäre, alle bekannten Symbole im Originalformat in eine DB einzulesen (jeweils mit genauer Herkunftsangabe und dem Typ (also "KiCad", "gEDA" usw.) und dann ein Script zu machen, das mir die Bilder generiert, damit man überhaupt mal sehen kann, was es da gibt (und um sich mit dem Parsen vertraut zu machen). Außerdem ein Script, das mir alle verfügbaren Metadaten aus den jeweiligen Formaten extrahiert, in eine separate Tabelle schreibt und per Suche erschließt. Wenn ich einen kleinen Pinheader suche, möchte ich z.B. mir mal eben schnell alle Teile anzeigen lassen, die 2 Pins haben. Oder alle, wo ein Pin "MISO" heißt. Oder alle, die einer bestimmten Norm genügen (das müsste man dann als neues Metadatenfeld dazutragen). Oder einen bestimmten Autor haben. Oder zu einer bestimmten Firma gehören. Oder ein bestimmtes Package haben. Usw. Mit solchen Funktionen dürfte das Vergleichen, Neukategorisieren und Ausmisten hoffentlich erleichtert werden. Als Parserschreiber hat man ja die Datenformate komplett begriffen, dann dürften die Exporte also auch keine große Hürde mehr sein. Bei gEDA sind übrigens die Kategorien (wichtige Metadaten für eine thematische Suche) teilweise in separaten Dateien enthalten, die man teilweise in den Archiven von den Websites mit runterlädt und also ebenfalls auswerten sollte. So komplex finde ich das alles gar nicht, nachdem ich in die Dateien geschaut und mir die verfügbaren Erläuterungen (s.o. die Links) durchgelesen habe. Eher unerwartet simpel.
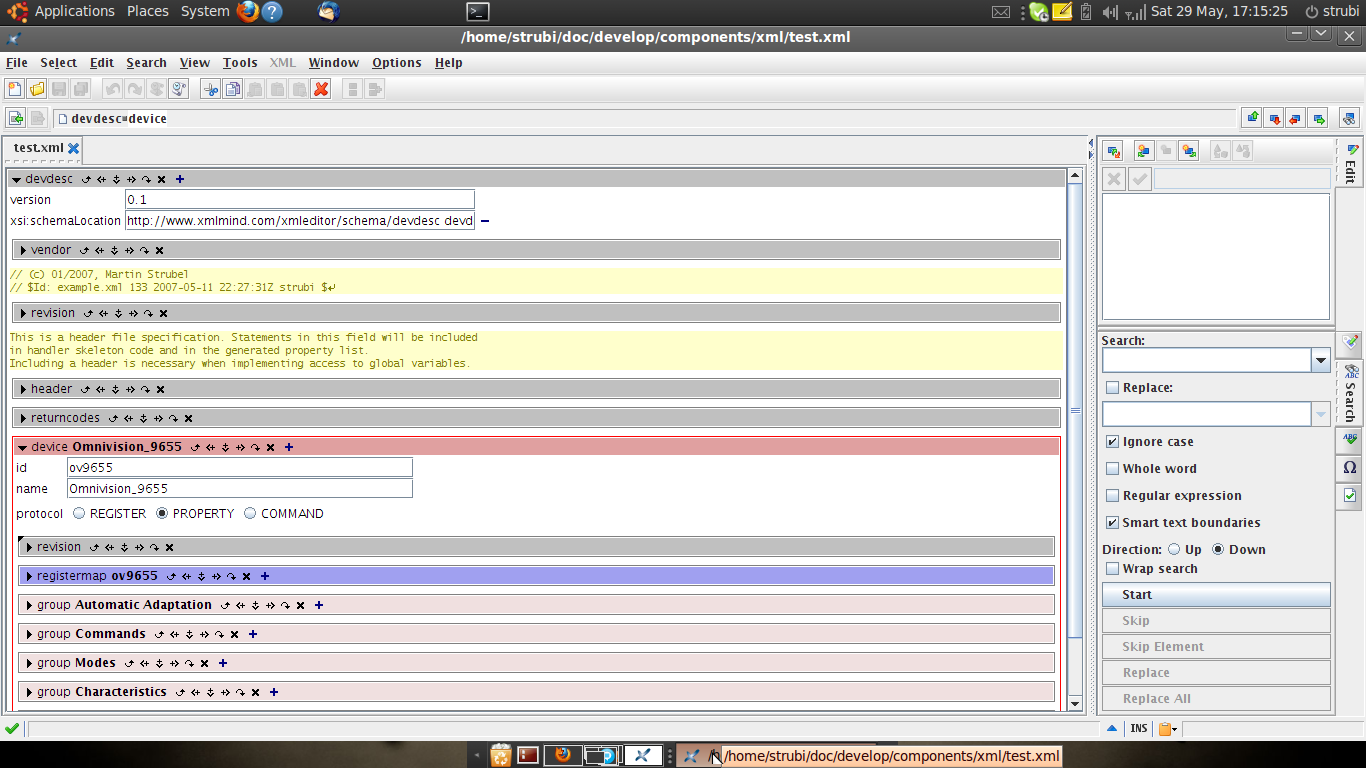
didadu schrieb: > Wenn Du für jedes Format einen Parser geschrieben und verstanden hast, > wozu die verschiedenen Befehle und Werte benutzt werden, dann wird Dir > auch klar, was in die Metadaten muss. (Es macht ja keinen Sinn, sich aus > der hohlen Hand ein XML-Format auszudenken.) Nee, ich wuerde gerade eben vermeiden, einen Parser fuer alle erdenklichen Formate zu schreiben, das kann uebelst ausarten. Das Meta-Format soll ja moeglichst simpel sein, und nicht zwingend alle Schweinereien der End-Formate enthalten - zumindest nicht als erstes. Aber natuerlich muss man verstanden haben, welche Eigenschaften ein Format abdeckt. Habe mal testweise meine device-beschreibungs-sprache (normalerweise fuer register genutzt) aufgebohrt. Das sieht dann per Baustein so aus:
1 | <device id="FT2232H" name="FT2232H" protocol="PROPERTY"> |
2 | <revision> |
3 | <major>0</major> |
4 | |
5 | <minor>1</minor> |
6 | </revision> |
7 | <schematic name="FT2232H" unitcode="U"> |
8 | <schematic:part name="A"> |
9 | <schematic:pin id="1" name="VCC"> |
10 | <schematic:geometry orientation="LEFT"> |
11 | <schematic:coordinate x="250" y="500" /> |
12 | </schematic:geometry> |
13 | </schematic:pin> |
14 | |
15 | <schematic:pin id="2" name="GND"> |
16 | <schematic:geometry orientation="RIGHT"> |
17 | <schematic:coordinate x="750" y="500" /> |
18 | </schematic:geometry> |
19 | </schematic:pin> |
20 | </schematic:part> |
21 | </schematic> |
22 | </device> |
Laesst sich bereits in eine rudimentaere kicad lib uebersetzen, es fehlen halt nur noch einige Optionen. Wenn Metadaten in Custom-Formaten in mehreren Files verteilt sind, sollte das auch kein grosses Problem sein, diese mit den XSLT's zu extrahieren. Wenn sich dann eben rausstellt, dass es fuer ein weiter hinzukommendes Format unerlaesslich ist, den XML-Dialekt zu aendern, dann tut man das halt, konvertiert die "Legacy" und zaehlt die Versionsnummer hoch, damit man auch Kompatibilitaeten abdecken kann. In der Tat nicht ganz so wild, aber bis es dann funktioniert, braucht es schon einige Mannmonate an vereinten Kraeften. Nu warte ich mal ab, was sonst noch an Ideen zusammenkommen.. Gruesse, - Strubi
Martin S. schrieb: > ich wuerde gerade eben vermeiden, einen Parser fuer alle > erdenklichen Formate zu schreiben, das kann uebelst ausarten. Ich verstehe nicht, wie Du die Daten in das XML-Neuformat überführen willst, wenn Du sie nicht parst. > Das > Meta-Format soll ja moeglichst simpel sein, und nicht zwingend alle > Schweinereien der End-Formate enthalten Es soll vor allem keine Informationen verlieren. Die Leute haben sich die Mühe gemacht, die Symbole zu erstellen, das würde ich nicht missachten wollen. Außerdem würde ich lieber gleich Nägel mit Köpfen machen (die Symbole sind ja nicht gerade sehr kompliziert gestrickt: Kästen, Linien, Bögen, Text), als ewig lange mit mehrfachen Formatänderungen rumzuhuddeln. Andererseits will ich auch niemanden abhalten, es zu tun, wie sie es für richtig hält. :-) Wenn man sich die Daten lange genug anschaut, hat man ja schon (selbst) gar keine großen Fragen mehr, um seine Bauteile zu finden/zu erstellen, womit sich so ein Projekt für einen selbst dann natürlich mehr oder weniger erübrigt. Es ist dann halt nur noch ein Projekt für die folgenden Erstwanderer im Bauteilwald. Die ursprüngliche Absicht hier war ja anscheinend auch eher, komplett neue Symbole nach bestimmten Richtlinien zu erstellen. Das ist ja noch mal wieder ein anderes Feld als das "Jagen und Sammeln" des Vorhandenen.
didadu schrieb: > Ich verstehe nicht, wie Du die Daten in das XML-Neuformat überführen > willst, wenn Du sie nicht parst. Na ganz einfach ein gut wiederverwertbares Exporter-Plugin fuer die diversen Tools schreiben. Wer lieber einen Parser baut, kann das ja ebenfalls tun. > Die ursprüngliche Absicht hier war ja anscheinend auch eher, komplett > neue Symbole nach bestimmten Richtlinien zu erstellen. Das ist ja noch > mal wieder ein anderes Feld als das "Jagen und Sammeln" des Vorhandenen. Das stimmt eigentlich schon. Aber meiner Meinung nach sollte man bei solchen Projekten gerne mal ein bisschen in die Infrastruktur klotzen, sonst bleibt die gute Idee meist auf halber Strecke stecken, weil die Community fehlt. Ohne "Standard" werden viele User nicht auf den Zug aufspringen und weiter ihre eigene Suppe kochen. Gruss, - Strubi
Hallo didadu. > Wenn Du für jedes Format einen Parser geschrieben und verstanden hast, > wozu die verschiedenen Befehle und Werte benutzt werden, dann wird Dir > auch klar, was in die Metadaten muss. (Es macht ja keinen Sinn, sich aus > der hohlen Hand ein XML-Format auszudenken.) Mmmh. Zum Thema XML und Platinen: Was ist mit IPC-2581? Siehe: http://webstds.ipc.org/2581/documents/IPC-2581pubv1.0.pdf Leider habe ich zur Zeit wenig Zeit, mich so Richtig darum zu kümmern......und ich kann nicht programmieren. :-( Jedenfalls habe ich angefangen, Symbole und Module/footprints für KiCAD zu erstellen, weil sie mir fehlten. Einen universellen Dateibrowser mit Konvertierungsfeatures für alle gängige PCB-Layout Programme zu erstellen, ist für mich drei Hutnummern zu groß. :O) Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Hallo Martin S. und Sven P. > Nee, ich wuerde gerade eben vermeiden, einen Parser fuer alle > erdenklichen Formate zu schreiben, das kann uebelst ausarten. Das mit dem ausarten kann ich verstehen. ;-) >Das > Meta-Format soll ja moeglichst simpel sein, und nicht zwingend alle > Schweinereien der End-Formate enthalten - zumindest nicht als erstes. Nicht als erstes.....weil alles fängt klein an. Aber es wird darauf hinauslaufen müssen. Viel kleiner: Was ich als erstes nützlich finden würde, wäre ein tool, das es erlaubt, die Bauteile in unterschiedlichen .libs / .mods hin und her zu schieben und umzuverteilen, sowie eine Möglichkeit, komplette Gruppen von Symbolen umzubenennen, und zum Beispiel mit einem Versionssufix / Datecodesufix zu versehen. Es sollte ein Sufix sein, und kein Prefix, weil KiCAD Alphanumerisch nach Namen im Symbol/Modulbrowser sortiert, der User das aber erst in zweiter Linie wissen will/ wissen muss. Diese Info im Namen ist aber wichtig, weil KiCAD Symbole/Module nach dem Namen in die Schaltung bindet. Aenderst Du die Version, aber den Namen nicht, und öffnest eine älteres Projekt mit einer neueren library Version, kann es unliebsame Überraschungen geben. Die Situation ist unter der Verwendung der -cache.lib, die zum Projekt gehört, rettbar, aber es ist mühselig, und der Ärger ist persistent, wenn Du nicht nur die -cache.lib verwenden willst, sondern auch eine aktuelle .lib, weil Du an dem Projekt etwas ändern möchtest, und die aktuelle .lib eine neue Version des Symbols unter gleichem Namen enthält.... Zu sven P.: >Also ich find, es gibt nix Hinderlicheres beim Arbeiten, als solch >ellenlange Bezeichnungen. Mich hat das in der Target-Bibliothek schon >immer gestört, drum hab ichs bei meinen Bibliotheken anders gemacht und >nur noch kurze, knackige Präfixe benutzt. >Bisher gabs noch keine Namenskollisionen ;-) Ich kann Deinen Einwand verstehen, aber Versionssufix / Datecodesufix werden den Namen noch länger machen. Und wenn ich die Symbole auswählen will, ohne immer in der Tiefe rumsuchen zu müssen, wüsste ich eben schon gerne am Namen schnell, was es ist. Und zwar auch bei einem Symbol / Modul, das ich seit snderthalb Jahren nicht angepackt habe. Ich gestehe, das ich auch gelegentlich die Fenster in den Symbol/Modul Browsern von KiCAD etwas knapp finde, aber letztlich ist es für mich das kleinere Übel. Obiges hypothetisches Tool könnte die Situation entschärfen, weil man sich damit schnell eine individuelle "Buddys" .lib schaffen könte, wo der Widerstand nur "R" heißt. Kürzer und knackiger gehts dann kaum. ;-) >Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Hallo alle zusammen, für kristallisieren sich hier 2 Projekte heraus. Wie von "didadu" bereits das schön herrausgestellt hat. 1. Das eretellen von neue Symbole nach bestimmten Richtlinien. 2. Das Jagen und Sammeln des Vorhandenen und Neuem. Im Bezug auf das XML-Format und einer simplen einfachen Umsetzung kann ich mir folgenden TAG-Aufbau vorstellen. > <device id="FT2232H" name="FT2232H" protocol="PROPERTY"> > <revision> > <major>0</major> > <minor>1</minor> > </revision> im Oberern Teil werden wichtige Daten von Hand über ein Interface eingegeben, voerst. > <KiCad-Lib> eingefügter verweis zum Speicherort der KiCad-Lib > </Kicad-lib> > <Eagle-Lib> eingefügter verweis zum Speicherort der KiCad-Lib > </Eagle-lib> > <Geda-Lib> eingefügter verweis zum Speicherort der KiCad-Lib > </Geda-lib> > <Other-Lib> eingefügter verweis zum Speicherort der KiCad-Lib > </Other-lib> > </device> Das ganze dann noch nach entsprechender Norm (noch nnicht durchgewälzt) wäre perfekt, denke ich. >Mmmh. Zum Thema XML und Platinen: Was ist mit IPC-2581? >Siehe: http://webstds.ipc.org/2581/documents/IPC-2581pubv1.0.pdf Einauslesen von diversen verschiedenen Parametern in verschiedenen eigenständigen Formaten halte ich für Overkill. Wenn die CAD-Softwarehersteller ihr eigenes Format verändern muss auch das entsprechende Auslesetool angepasst werden. Dies beinhaltet eine Feste Regelungsstrucktur, welche sich ausschließen um diese Problemtaik kümmern muss um damit eine perfekte Schnittstelle zum sammeln Daten bereit zustellen. Mein Vorschlag zielt darauf ab eigenständige Formate der jeweiligen Hersteller nicht zu analysieren zu müssen (vorerst) und zusätzliche wichtige/interessante Informationen mit zuspeichern. Daraus lässt sich ebenso schnell erkennen welche Angaben benötigt werden, welche sich im späteren Verlauf der Projektentwicklung auch automatisiert aus den Cad-Software spezifischen Formaten auslesen lassen sollten. So kann man dann hergehen und die Programmierer der jeweiligen CAD-Software anschreiben und diese bitten die gesuchten Informationen mit in aufzunehmen und in einer entsprechenden Strucktur in ihrem Format abzulegen. Zudem findet auch eine Kommunikation beider Parteien statt, statt eines reinen Reagieren auf eine Vielfalt & Änderungen von Parametern, sowie Formaten ansich. Zu bedenken ist natürlich das diese ganzen gesammelten Information noch in keinster Weise in der jeweiligen CAD-Software zur Verfügung stehen! Dies ist ebenso Aufgabe der Programmierer der CAD-Software ;). Nun ist die Frage wo man denn als Erstes ansetzt? PS: Große Hobbies kann man haben, nur die Frage ob man die Zeit hat? --- VG, Rene
Hallo Rene B. > für kristallisieren sich hier 2 Projekte heraus. Wie von "didadu" > bereits das schön herrausgestellt hat. > > 1. Das eretellen von neue Symbole nach bestimmten Richtlinien. > 2. Das Jagen und Sammeln des Vorhandenen und Neuem. > Ich sehe darunter sogar drei verschiedene Projekte: 1. Das erstellen von neuen Symbolen (und footprints) speziell für KiCAD. 2. Das Jagen und Sammeln vorhandener Symbole, und deren Erfassung in einer Datenbank (universell für unterschiedliche PCB-Layout Programme). Diese Datenbank soll auf ein PDF Archiv mit Datenblättern Und Applikationen verweisen. 3. Das Erstellen einer Symbol- und Footprintbibliothek in einem hochflexiblen und offenem Format, welches es erlaubt, mit einer noch zu erstellenden Konverter Toolchain die verschiedenen offenen und proprietären (wenn sie denn bekannt sind) Formate zu importieren und zu exportieren. Gleichzeitig soll eine Datenbank existieren, welches die einzelnen Symbole und Footprints und deren Versionen untereinander und mit einem Kommentar- und Datenblatt- und Applicationsarchiv verknüpft. Ich persönlich werde mich auf Punkt 1 konzentrieren. Diese Aufgabe ist in Bezug auf Symbole unter einigen Nebenbedingungen für mich fast abgeschlossen. Ich wollte eine Symbolbibliothek ähnlich EN60617 / DIN617 für diskrete elektronische Bauteile. Sprich Symbole für R, C, L, diverse Dioden, Transistoren, Thyristoren, Stecker, Relais......also das, was ich neben den ICs auf jeden Fall brauche, und die ich (persönlich) auch gerne in einer einzigen Symbolbybliothek vereine. Die habe ich nun. Noch ein paar Sachen dazugepackt, die sich als praktisch herausstellten, und jetzt noch an den Feinheiten feilen...... Symbole für ICs sind wieder ein anderes Kapitel, Footprints sowieso. Der Sinn von Punkt 2 erschliesst sich mir nicht wirklich. Weil das habe ich bisher zu eigener Zufriedenheit mit einer Dateiverwaltung und einer Desktopsuche (Beagle) erledigt. Wenn ich meine, das an PDF Dokumente noch Bibtext Einträge gehören, mache ich die mit Jabrev. Richtig, bezüglich Jabrev hätte ich auch noch Wünsche offen, aber es funktioniert gut. ;-) Punkt 3 ist eine Herkules Aufgabe. Schreib doch einer mal eine E-mail an Donald Knuth. Vieleicht braucht der ja abends Abwechslung, wenn er den ganzen Tag an tex gewartet hat. ;-) Persönlich stehe ich ja auf dem Standpunkt: Besser machen heisst Selber machen. Leider stosse ich dabei eben oft an meine Grenzen, was meine Zeit und auch meine Fertigkeiten angeht. > PS: Große Hobbies kann man haben, nur die Frage ob man die Zeit hat? Richtig. Manchmal ergänzt sich aber das eine oder andere auch mit dienstlichen Aufgaben. :-) >Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Bernd Wiebus schrieb: >> PS: Große Hobbies kann man haben, nur die Frage ob man die Zeit hat? > > Richtig. Manchmal ergänzt sich aber das eine oder andere auch mit > dienstlichen Aufgaben. :-) Genau so sehe ich das auch. Mir persöhnlich ging das schon so bei der Fage nach dem einarbeiten überhaupt in KiCad selbst. Bernd Wiebus schrieb: > Ich wollte eine Symbolbibliothek ähnlich EN60617 / DIN617 > für diskrete elektronische Bauteile. Sprich Symbole für R, C, L, diverse > Dioden, Transistoren, Thyristoren, Stecker, Relais......also das, was > ich neben den ICs auf jeden Fall brauche, und die ich (persönlich) auch > gerne in einer einzigen Symbolbybliothek vereine. Die habe ich nun. Noch > ein paar Sachen dazugepackt, die sich als praktisch herausstellten, und > jetzt noch an den Feinheiten feilen...... Das fand & finde ich einfach klasse eine Bibliothek mit genormten Schaltzeichen nutzen zukönnen. Mein Anliegen ist ja ebenso diese mit weiteren Symbolen zu füllen. Denn dies ist die Basis die man immer brauch ;-). In Punkto IC's & Footprints ist das meisten eine individuelle Geschichte je nachdem am welchen Projekt man gerade arbeitet, da füllt sich eine Bibliothek mit der Zeit. Da ich nicht über 1000 Pdfs besitze erledigt bei mir eine einfache Ordnerstrucktur und die Software "Mendeley" die Dokumenten Verwaltung. Von daher hält sich mein Eifer in dieser Sache eine Perfektion anzustreben für direkte Zugriffe von der Cad-Software "KiCad" über DB's auch in Grenzen, eher "nice to have". Das Thema Zeit ist für mich wichtig, weil ich noch andere berufliche Pläne verfolge und mein Hobby ein kleines Hobby ist!, wenn ich denn mal Zeit habe. --- VG, Rene
Hi Bernd, Bernd Wiebus schrieb: > Viel kleiner: > Was ich als erstes nützlich finden würde, wäre ein tool, das es erlaubt, > die Bauteile in unterschiedlichen .libs / .mods hin und her zu schieben > und umzuverteilen, sowie eine Möglichkeit, komplette Gruppen von > Symbolen umzubenennen, und zum Beispiel mit einem Versionssufix / > Datecodesufix zu versehen. > Es sollte ein Sufix sein, und kein Prefix, weil KiCAD Alphanumerisch > nach Namen im Symbol/Modulbrowser sortiert, der User das aber erst in > zweiter Linie wissen will/ wissen muss. Diese Info im Namen ist aber > wichtig, weil KiCAD Symbole/Module nach dem Namen in die Schaltung > bindet. Aenderst Du die Version, aber den Namen nicht, und öffnest eine > älteres Projekt mit einer neueren library Version, kann es unliebsame > Überraschungen geben. Momentan loese ich das Versions-Problem per SVN (dafuer habe ich separat ein Repository fuer alle lokalen Libraries): - Ich lege einen Projektfolder $(PCBDIR)/project1 fuer ein neues Projekt an - Setze einen svn:externals auf mein library-repository mit Ziel $(PCBDIR)/project1/lib und checke die aktuelle Version aus - Gibt es Aenderungen an der Library von anderen Projekten aus, committe ich die einfach und update die Projekte, wo ich die Updates jeweils brauche. Und muss natuerlich ev. Anpassungen vornehmen. - Wenn ich ein Projekt einfriere (Platine mache), wird der external auf eine explizite Library-Revision festgefroren, oder zusaetzlich im Sheet die Revision-Nummer der Library notiert. Heisst, jeder Projektordner hat einen versionskontrollierten lib/-Unterordner. Das kicad so gut mit SVN funktioniert, macht es eigentlich echt unschlagbar fuer Gruppenarbeiten. Ich wuerde in so einem Fall auch nicht versuchen, eine eigene Versionskontrolle zu erfinden, sondern eher Schnittstellen zu SVN oder git in kicad einbauen, um die jetzige Handarbeit noch bequemer zu machen. Die Frage ist nur, ob man wirklich eine Versionskontrolle PER Baustein innerhalb der Library braucht. Hier wuerde ich eher sagen: Keep it simple, man legt sich einfach mehrere Libraries mit ev. denselben Objekten an, und schaut, dass man die Versionsnummern im Griff hat. Allerdings ist eben das Herumschieben von Symbolen wie Du sagst, etwas muehsam, man muss echt aufpassen, dass man die Komponente aus der richtigen Library importiert, wenn man mit mehreren Versionen arbeitet. Kommt bei mir gottseidank nicht so oft vor. > Punkt 3 ist eine Herkules Aufgabe. Schreib doch einer mal eine E-mail an > Donald Knuth. Vieleicht braucht der ja abends Abwechslung, wenn er den > ganzen Tag an tex gewartet hat. ;-) Das stimmt. Aber ich haette das Framework dazu auf einer andern Baustelle fertig (nennt sich "netpp" und ist eine universelle Library zum Fernsteuern von beliebigen registerbasierten Geräten, Chips, etc.). Muss dazu etwas ausholen: Die Komplexitaeten von XML nach irgendwas zu konvertieren waeren damit so ziemlich "im Griff" - in obigem Fall ist es C-Code, Dokumentation, VHDL-Registertabellen, usw. Du erstellst also eine XML-Datei mit der Geraetebeschreibung, heraus kommt nach dem "make" eine Bibliothek, die auf Geraeteseite mit dem geraeteunabhaengigen Frontend (PC) ueber beliebige Interfaces kommuniziert und komplett mit der Hardware synchronisiert ist. Das laesst sich genauso auf eine Schematic-Bibliothek uebertragen, sei es per peer-to-peer oder ueber einen Format-Translator (Es gibt ja XMLRPC, UPnP und Konsorten, aber die sind weit vom Attribut "leichtgewichtig und universell" entfernt). Man muss sich wirklich nur noch die Format-Erweiterung fuer Schematic-Entities ueberlegen (also: "Was muss noch alles rein"). Ich will das Teil nach 7 Jahren Einsatz demnaechst opensourcen, insofern waeren das zwei Fliegen mit einer Klappe. ABER: Was noch fehlt, ist die Datenbank, um alle Geraete zu erfassen und kategorisieren. Da mir eben auch die Zeit wie allen fuer solche Spaesse begrenzt ist, sehe ich eben nur die Chance, eine Community (oder schon mal 5 talentierte Hacker) dafuer zu begeistern. Insofern ist das Hauptproblem an der Sache, diese zig Beduerfnisse verschiedener User unter einen Hut zu kriegen, sprich, einen "Standard" zu schaffen. Ich habe miterlebt, wie muehsam das innerhalb der EMVA sein kann (Stichwort GenICam-Standard, der das obige spezifisch fuer Industriekameras angegangen hat), den firmenpolitischen Ballast haetten wir hier ev. nicht. Prinzipiell spricht ja nichts dagegen, erst mal mit kicad anzufangen, und sich dann als naechstes fuer die fertige, standardisierte und freie library-collection zu ueberlegen, wie man das ganze in eine Datenbank quetscht und es auch anderen usern im kommerziellen Bereich (also in anderen Formaten) zugaenglich macht. Mit Versionshistory, und was dazugehoert. Die bessere Investition faende ich allerdings immer noch die Datenbank/Plattform, auf der man den "Standard" im Rahmen einer Usergruppe prototypen und weiteroptimieren kann. Sonst lohnt sich zumindest fuer mich das Projekt erst mal nicht, da ich mit den bestehenden Symbolen soweit arbeiten kann. Wo ich eher Zeit sparen wuerde, waeren die komplexen Chips mit vielen Pins, die vermutlich einige User im Component Builder generieren, aber nie anderen zur Verfuegung stellen (koennen). Im Prinzip waere ich schon mit reinen Pin-Listen zufrieden (bei manchen Chips parse ich die BSDL-Files um ein rohes .LIB-File zu generieren, und drehe dann die Pins manuell hin). Mal sehen, vielleicht wird der Winter wieder kalt, bis dann werd ich mir spaetestens das Datenbankproblem unter die Lupe genommen haben. Wenn aber jemand mitmachen will und gut PHP kann (und Zeit hat), soll er laut HIER schreien :-) Gruesse, - Strubi
Nochmal an Bernd: Wo wir gerade beim Thema SVN sind: Habt ihr euch schon ueberlegt, einfach mal das Projekt auf dem hiesigen (mikrocontroller.net sei dank) SVN-Server zu starten? Wenns ausartet und manche User Mist committen, kann man's spaeter immer noch regeln :-) Gleichzeitig koennten diverse User dann auch noch ihre Tools und Hilfs-Scripte hochladen, und wir merken dann ev. so nach und nach, was das Projekt noch braucht. Gruesse, - Strubi
An Rene, der in Beitrag #1726853 schrob: >> <KiCad-Lib> > eingefügter verweis zum Speicherort der KiCad-Lib >> </Kicad-lib> > >> <Eagle-Lib> > eingefügter verweis zum Speicherort der KiCad-Lib >> </Eagle-lib> Eigentlich nur eine kleine Anmerkung: Alles herstellerspezifische würde ich so als eigenstaendigen tag moeglichst vermeiden, sondern eher was a la: <liburl vendor="kicad">/pfad/zur/datei</liburl> machen. Spezifische Meta-Daten ebenfalls in was wie: <meta vendor="kicad" delim=";"> optionX=blabla; optionY=gnagna; </meta> Sonst muss man fuer jeden hinzugekommenen "vendor" den Dialekt aufblaehen. Rene B. schrieb: > Einauslesen von diversen verschiedenen Parametern in verschiedenen > eigenständigen Formaten halte ich für Overkill. Wenn die > CAD-Softwarehersteller ihr eigenes Format verändern muss auch das > entsprechende Auslesetool angepasst werden. Dies beinhaltet eine Feste > Regelungsstrucktur, welche sich ausschließen um diese Problemtaik > kümmern muss um damit eine perfekte Schnittstelle zum sammeln Daten > bereit zustellen. > > Mein Vorschlag zielt darauf ab eigenständige Formate der jeweiligen > Hersteller nicht zu analysieren zu müssen (vorerst) und zusätzliche > wichtige/interessante Informationen mit zuspeichern. Wenn das nach beim kurzen Ueberfliegen des IPC-Dingens richtig verstanden hab, soll das aber nur ein Standard anstelle von Gerber sein, richtig? Also in kicad-Sprache, nur die MOD-Seite abdecken, aber nicht die LIB. Ich wuerde hierbei die Komplexitaet des IPCschiessmichtot erst mal meiden, und erst spaeter versuchen, den eigenen XML-Dialekt dem Standard anzunaehern.
Martin S. schrieb: > An Rene, der in Beitrag #1726853 schrob: > > >>> <KiCad-Lib> >> eingefügter verweis zum Speicherort der KiCad-Lib >>> </Kicad-lib> >> >>> <Eagle-Lib> >> eingefügter verweis zum Speicherort der KiCad-Lib >>> </Eagle-lib> > > Eigentlich nur eine kleine Anmerkung: Alles herstellerspezifische würde > ich so als eigenstaendigen tag moeglichst vermeiden, sondern eher was a > la: > > <liburl vendor="kicad">/pfad/zur/datei</liburl> > > machen. Spezifische Meta-Daten ebenfalls in was wie: > > <meta vendor="kicad" delim=";"> > optionX=blabla; > optionY=gnagna; > </meta> > > Sonst muss man fuer jeden hinzugekommenen "vendor" den Dialekt > aufblaehen. Ich kenne mich mit XML wie gesagt nicht so aus. Die Idee besteht darin voerst nur Verweise zu den original Daten einzusetzen um es simpel zuhalten. Für Tag-Schreibweisen und Optimierung kommst du ins Spiel, wie du gut aufgezeigt hast ;). Dies bezieht sich natürlich rein auf das sammeln von Daten. Die Meta-Daten dachte ich vorerst von Hand einzugegeben, durch ein fest vordefiniertes Interface. Das ist ja auch nicht anders als wie beim Erstellen in KiCAd selbst auch. Martin S. schrieb: > Wenn das nach beim kurzen Ueberfliegen des IPC-Dingens richtig > verstanden hab, soll das aber nur ein Standard anstelle von Gerber sein, > richtig? Also in kicad-Sprache, nur die MOD-Seite abdecken, aber nicht > die LIB. > > Ich wuerde hierbei die Komplexitaet des IPCschiessmichtot erst mal > meiden, und erst spaeter versuchen, den eigenen XML-Dialekt dem Standard > anzunaehern. >>(noch nicht durchgewälzt) Hier noch eine kleine Info. didadu hat noch eine kleine Brücke in anderer Richtung geschlagen :). didadu schrieb: > Re: Teile-Verwaltung für elektronische Bauteile > > Autor: > didadu (Gast)> > Datum: 29.05.2010 10:02 > > > Schaut doch bitte mal hier rein: > Beitrag "[KiCad] Bibliotheksaufbau - Konzeptideen gesucht" > Vielleicht lassen sich da sinnvolle Verknüpfungen schaffen. > > Interessant wäre auch mal eine öffentliche, lizenzfreie Datenbank ALLER > existierenden (auch historischen) Elektronikkomponenten. > Das ließe sich sicher vereinfachen, wenn die Benutzer solcher > Datenbanken, die in diesem Thread das Thema sind, eine Funktionen > hätten, um alle unterschiedlichen Teile in eine Liste zu exportieren, > die dann irgendwer sammelt und allen zur Verfügung stellt. > > Wenn man dann noch sowas wie "popularity contest" (s. Debian) einbaut, > wüsste man, welche Teile am häufigsten eingesetzt werden, um eine > Richtlinie zu haben, in welcher Priorität man Footprints erstellt, seine > Bauteilesammlung erweitern kann, usw. Wenn ich den bisherigen Content hier im Thread so betrachte, vorallem den Input von den Programmierern, muss ich teileise ganz schön staunen, was so in Runde eingebracht wird. Einerseits sehr zukunftsorientiert und zugleich irgendwie selbstverständlich, "das wird irgendwie schon" bzw. die Basis ist schon versteckt fertig. --- VG, Rene
Nochmal n Gedanke:
das mag jetzt nach Schnellschuss und schrecklicher Aufblaehung des
eigentlichen Projekts klingen, aber da die Utopie schon laenger gaert,
muss der Furz nun raus (wer nicht wagt, gewinnt auch nix):
Zur Embedded World Messe (ich glaube ungefaehr Maerz 2011, Nürnberg)
gibt es ja die Moeglichkeit, Workshops zu organisieren, und auch Papers
einzureichen. Vielleicht hat ja jemand Lust, an einem Konzeptpapier
mitzuarbeiten, was mit viel Glueck an der Embedded eventuell etwas
Aufmerksamkeit bekommen koennte. Abgesehen davon koennte man probieren,
einen Raum fuer einen Workshop zu bekommen. Ob und wieviel das kostet,
muesste man erst nach dem Einreichen des Abstract und nach einem
wohlwollenden Echo (kann ja auch als "Bullshit" abgeschmettert werden)
mal feststellen.
Da es nicht das erste Mal ist, dass sich so ein Furz (entschuldigt mir
die burschikose Sprache) zu einem echten Standardkommittee entwickelt,
finde ich, wir sollten das wagen. Allerdings muss man echt aufpassen,
dass einem die grossen Hersteller nicht in den Napf spucken und die
guten Ideen absahnen.
Zudem ist die Zeit recht knapp:
* Submission of abstracts: September 17, 2010
* Notification of authors: October 27, 2010
* Final proceeding papers: January 12, 2011
Siehe auch:
http://www.embedded-world.eu/call-for-papers/abstract-submission-form.html
Bis dahin sollte man also etwas vorzuweisen haben...
Gruesse,
- Strubi
Dies wäre der 1. Meilenstein ;). VG, Rene
Martin S. schrieb: > Die Komplexitaeten von XML nach irgendwas zu konvertieren waeren damit > so ziemlich "im Griff" - in obigem Fall ist es C-Code, Dokumentation, > VHDL-Registertabellen, usw. Du erstellst also eine XML-Datei mit der > Geraetebeschreibung, heraus kommt nach dem "make" eine Bibliothek, die > auf Geraeteseite mit dem geraeteunabhaengigen Frontend (PC) ueber > beliebige Interfaces kommuniziert und komplett mit der Hardware > synchronisiert ist. Seid Ihr sicher, dass XML gegenüber einer recht einfach gehaltenen Textdatei wirklich so große Vorteile bringt? Allein die Notwendigkeit, zusätzlich noch einen (meist fetten und langsamen) XML-Parser nutzen zu müssen, die nicht mehr wirklich gegebene Lesbarkeit in einem normalen Editor und der fehlende echte Mehrwert haben mich immer wieder von XML abgehalten. Das Schlimmste ist aber, dass man mit Fehlern bei den Tags große Datenbereiche der Datei "korrumpieren" kann, was bei einfacher strukturierten Textdateien wesentlich unwahrscheinlicher ist.
Angehängte Dateien:
-

Screenshot-2.png
110 KB
Hi Gastino, Gastino G. schrieb: > Seid Ihr sicher, dass XML gegenüber einer recht einfach gehaltenen > Textdatei wirklich so große Vorteile bringt? Ja :-) Zumindest für das Prototyping von Formaten. Die taegliche Anwendung in einem Programm ist ne andere Sache. > Allein die Notwendigkeit, > zusätzlich noch einen (meist fetten und langsamen) XML-Parser nutzen zu > müssen, die nicht mehr wirklich gegebene Lesbarkeit in einem normalen > Editor und der fehlende echte Mehrwert haben mich immer wieder von XML > abgehalten. Du hast schon recht. Ich vermeide auch tendentiell die Verwendung von XML-Dialekten in Work-Dateien. Aber deren IFF-Format in XML beschreiben macht wiederum Sinn. Wegen der Lesbarkeit: Du brauchst schon einen guten XML-Editor, der mit Schemas (xsd, oder kraenkeres :-) ) umgehen kann. > Das Schlimmste ist aber, dass man mit Fehlern bei den Tags große > Datenbereiche der Datei "korrumpieren" kann, was bei einfacher > strukturierten Textdateien wesentlich unwahrscheinlicher ist. Das passiert dir z.B. mit XXE (XMLMind XML Editor) nicht. Hab mal eben nen Screenshot angetackert. Das Ding ist wirklich ne Meisterleistung, da alle Eingaben validiert werden, bzw. du nur das einfuegen kannst, was nach Schema-Beschreibung erlaubt ist, kannst Du als Autor kaum Mist bauen. Die ganzen Eingabemasken kannst du mit CSS-Stylesheets anpassen. Fuer jedes andere objektorientierte Format muesstest du Parser, Handler und Translator schreiben, und das mit einem Mehraufwand (zumindest fuer mich, denn ich bin generell faul) gegenueber einem XSLT-Sheet. Es gaebe allerdings einen recht kranken Ansatz mit Python und dem pickle-Modul, aber das wuerde zu weit fuehren. Der eigentliche Knackpunkt ist, dass das Format dauernd erweitert werden koennen muss, und sowohl abwaerts als auch aufwaertskompatibel bleibt. Das ist ein ziemlicher gordischer Knoten, und mir ist sonst nur ein Binaerformat bekannt, welches das in etwa hinbekommt. Gruss, - Strubi
So, hier sind drei Listen der Inhalte der Felder "Value", "Device" und "Package" der exportierten BOMs aller .sch-Dateien (also von Schaltplänen), die hier auf MK als öffentliche Attachments gepostet wurden (ca. 470 Stück). Nicht berücksichtigt wurden .sch-Dateien, die in ZIP-Archiven o.ä. gepostet wurden (einfach weil es ein Stück mehr Aufwand gewesen wäre). Es wäre interessant zu wissen, welchen Anteil der Projekte man deshalb nicht erfasst. Diese Listen erstrecken sich also über einige Jahre und die verschiedensten Projekte. Alle drei Listen sind sortiert nach Häufigkeit des Auftretens des jeweiligen Elements (die Häufigsten zuerst). Ich hoffe, dass dies hilft, besser zu verstehen, mit was für Teilen wir hier so umgehen und was in einer Datenbank benötigt wird.
Hier auch noch die "Descriptions". Die geben eine stärker aggregierende Aussage über die verwendeten Teile.
Da auch noch andere Analysen interessant sein können ("Welche Werte
verwenden die Leute bei Bauteile im Package X"), für die mehrere Felder
einer Zeile erforderlich sind, poste ich hier auch noch die Gesamtliste
für Interessierte.
Nützliche commandline-Befehle zum schnellen Auswerten sind: cut, sort,
uniq, grep, less und |
Das gibt dann Zeilen, die in etwa so aussehen:1 | cat All.txt | cut -f 3 | grep -v DIEWILLICHNICHT | sort | uniq -c | sort -n -r | less |
Nabend, mir ist gerade Idee gekommen das man im Bezug auf Datenblätter eine Kooperation mit einer der großen Sammelmaschinen a la "Datasheetcatalog" oder "AllDataSheet" eingehen könnte. Gibt natürlich ein paar kleine Probleme wie Aktualität, Vollständigkeit + andere Erfahrungen. Im einfachsten Falle könnte man das aus der Datenbank ausgewählte Bauelement bei einer solchen Sammelmaschine über den Namen des Bauteils suchen lassen und dann die angezeigten Ergebnisse 3-4 Pdfs zur Auswahl stellen in dem diese direkt verlinkt sind. Sonst müsste man meiner Meinung nach Kooperationen mit den Herstellern selbst aufbauen um nicht wieder manuelle Aktualisierungen der Datenbank betreiben zu müssen. --- VG, Rene
Hi Rene, einen Link zum PDF mit aufzunehmen finde ich sowieso schon mal gut. Dass der dann ins Leere zeigt, wenn der Hersteller das PDF verschiebt, muesste man einfach mit einplanen. Weiss nicht, wieviel Kooperation mit den Herstellern das braucht, man muesste pro Hersteller ev. den link fuers http get generieren und nur eine Datenbank ID abspeichern. So hat man bei Aenderungen schnell alles wieder unter Kontrolle. Kann man meiner Meinung auch alles spaeter mal verbessern. Die Datenblatt-Kraken sind, glaube ich, fast alle asiatisch... Das Problem, ein Datenblatt schlussendlich aufzufinden, finde ich nicht so kritisch. Gruesse, - Strubi
Martin S. schrieb: > Dass der dann ins Leere zeigt, wenn der Hersteller das PDF verschiebt Ich würde die PDF ja gleich herunterladen. Das sollte man eh bei jedem Teilekauf machen (die Daten sind Bestandteil des Produkts, ohne die es relativ wertlos ist), wenn man nicht später im Regen stehen will. Dann kann der Hersteller seine Dateien verschieben wie er lustig ist. Bei einer Webdatenbank könnte es da rechtliche Zwangsjacken geben, aber wenn die DB lokal auf dem Rechner ist (ist sowieso zu empfehlen - im Web dann vielleicht ein Clearinghouse), dann geht das wohl. Da es aber zahlreiche Datasheet-Kataloge gibt, sind die Hersteller vermutlich eher offen für die Weitergabe. Das spart ihnen ja Traffic-Kosten, und auch ihnen eine langfristige Pflege der Datenblattbereithaltung, wenn sie auf die Lieferung bestimmter Produkte keine Lust mehr haben (aka "nicht wirtschaftlich ist").
Hallo Martin, Gastino und Rene. >> Beitrag #1726735: >> Viel kleiner: >> Was ich als erstes nützlich finden würde, wäre ein tool, das es erlaubt, >> die Bauteile in unterschiedlichen .libs / .mods hin und her zu schieben >> und umzuverteilen, sowie eine Möglichkeit, komplette Gruppen von >> Symbolen umzubenennen, und zum Beispiel mit einem Versionssufix / >> Datecodesufix zu versehen. > Momentan loese ich das Versions-Problem per SVN (dafuer habe ich separat > ein Repository fuer alle lokalen Libraries): 1) Das ist nicht nur so ein Versionsproblem, weil die NAMEN der Symbole in der Library selber enthalten sind, und zwar vier mal pro Symbol, plus einmal für die komplette Library. Gerade das ist ja das Problem, nur die Librarys anhand ihres Dateinamens zu trennen langt nicht. 2) Local könnte mir SVN natürlich weiterhelfen, aber was ist, wenn ich die Librarys weitergebe, und zwei unterschiedliche Revisionen z.B. B und C existieren, wo Symbole mit gleichem Namen, aber versetztem Ankerpunkt existieren? Wenn, in der Reihenfolge des einlesens, zuerst die falsche Library gewählt wird, "hüpfen" mir die Symbole oder Module durch die Gegend. Das Problem ist mir leider nicht unbekannt. > > Heisst, jeder Projektordner hat einen versionskontrollierten > lib/-Unterordner. Das kicad so gut mit SVN funktioniert, macht es > eigentlich echt unschlagbar fuer Gruppenarbeiten. > > Ich wuerde in so einem Fall auch nicht versuchen, eine eigene > Versionskontrolle zu erfinden, sondern eher Schnittstellen zu SVN oder > git in kicad einbauen, um die jetzige Handarbeit noch bequemer zu > machen. > Schon Richtig. Ich habe seit gut einem Monat ein SVN Repository auf meinem Rechner, aber habe es zeitlich noch nicht hinbekommen, mich in SVN einzuarbeiten. Im Gegensatz zu Euch fehlen mir eigentlich alle Informatik Grundlagen, und ich muss mich dort erst einarbeiten. Ich bin einer der letzten, der noch mit einem Rechenschieber in Klausuren gegangen ist, und einen ausgemusterten XT habe ich dann 95 zu meiner Diplomarbeit geschenkt bekommen.....vorher hatte ich keinen PC (Nein, ich bin nicht aus der EX-DDR) und jetzt, im Alter, lernt es sich eben nicht mehr so schnell. > Die Frage ist nur, ob man wirklich eine Versionskontrolle PER Baustein > innerhalb der Library braucht. Hier wuerde ich eher sagen: Keep it > simple, man legt sich einfach mehrere Libraries mit ev. denselben > Objekten an, und schaut, dass man die Versionsnummern im Griff hat. Richtig. Aber wie oben gesagt, es langt nicht, nur die Librarys umzubenennen. Aber es würde langen, an den Symbolnamen per Suffix einen Datecode anzupappen bzw. zu aktualisieren......aber dazu fehlt eben das handliche Tool. Um Module aus verschiedenen Modulbibliotheken selektiert zusammenzufassen, wird vorgeschlagen, sie in ein Dummyboard einzufügen und abzuspeichern. KiCAD legt dann eine separate Modulbibliothek nur für das Board an, wo alles ausgewählte enthalten ist. Siehe: http://tech.groups.yahoo.com/group/kicad-users/message/7612 (Nicht vom Titel irritieren lassen) Das geht grundsätzlich mit Schaltplänen genauso. Es fehlt allerdings der Button, um das Schreiben der Cache Bibliothek zu erzwingen. Sie wird aber automatisch angelegt, wenn Du den Schaltplan schliesst. Das ist ein halbwegs bequemer Workaround zur Erstellung einer individuellen "Buddy-library", aber nicht zum Umbenennen...... > Wo wir gerade beim Thema SVN sind: Habt ihr euch schon ueberlegt, > einfach mal das Projekt auf dem hiesigen (mikrocontroller.net sei dank) > SVN-Server zu starten? Wenns ausartet und manche User Mist committen, > kann man's spaeter immer noch regeln :-) > Gleichzeitig koennten diverse User dann auch noch ihre Tools und > Hilfs-Scripte hochladen, und wir merken dann ev. so nach und nach, was > das Projekt noch braucht. Ich hatte eine Mail an Andreas losgeschickt, und er hat mir am Samstag auch geantwortet. Er fragt, ob das denn soviele Dateien sind, daß das nötig ist......ich werde das mit ihm wohl noch diskutieren müssen. Die KiCAD Dateien, die ich selber angelegt habe, Projekte, Bibliotheken, Dokumentation, Librarys (Symbole und Module), building Blocks sind hier bei mir etwas 1100 Dateien. Nach aufräumen werden wohl 500-600 übrigbleiben, von denen 50-100 für die Gruppe hier relevant sind...... Das, was im Wiki liegt, ist meist schon komprimiert.......schau mal in das Modul Zip file, wieviele Einzeldateien schon darin sind.....und da fehlt leider noch meistens die Doku, genau wie für die Symbole. Jedenfalls würde ich Andreas bitten, mindestens Rene und Dich mit auf die Liste zu setzten, weil ich vorläufig mit SVN überhaupt noch nicht wirklich umgehen kann. :O) Der Rest mit Bedarf möge sich melden...... Zu Gastino: >>> Die Komplexitaeten von XML nach irgendwas zu konvertieren waeren damit >>> so ziemlich "im Griff" - in obigem Fall ist es C-Code, Dokumentation, >>> VHDL-Registertabellen, usw. Du erstellst also eine XML-Datei mit der >> Geraetebeschreibung,~~~~~~~~~~~~~~ >> Seid Ihr sicher, dass XML gegenüber einer recht einfach gehaltenen >> Textdatei wirklich so große Vorteile bringt? Allein ~~~~~~~~~Das >> Schlimmste ist aber, dass man mit Fehlern bei den Tags große >> Datenbereiche der Datei "korrumpieren" kann, was bei einfacher >> strukturierten Textdateien wesentlich unwahrscheinlicher ist. > Das passiert dir z.B. mit XXE (XMLMind XML Editor) nicht. > Hab mal eben nen Screenshot angetackert. Das Ding ist wirklich ne > Meisterleistung, da alle Eingaben validiert werden, bzw. du nur das > einfuegen kannst, was nach Schema-Beschreibung erlaubt ist, kannst Du > als Autor kaum Mist bauen. Die ganzen Eingabemasken kannst du mit > CSS-Stylesheets anpassen. Mmmmh. So rein aus meinem Bauch und meiner Erfahrung heraus würde ich bei zwei sonst gleichwertigen Verfahren, bei denen eine "Sicherheitsfunktion" einmal inhärent im Dateiformat und einmal im tool, mit dem die Datei bearbeitet wird, liegt, ersteres vorziehen. Persönlich würde ich auch ein Cabrillo-Style ähnliches Textformat vorziehen......aber das hängt vieleicht auch damit zusammen, das ich auch kein XML kann. Cabrillo ist nicht elegant, aber ungemein fehlertolerant. Ich arbeite mich hier zur Zeit eben nicht nur in KiCAD ein, sondern auch in Latex (wegen der Doku) und in Gambas (primitivst mögliche Programiersprache für den angedachten Fall (Das Umbenenn-Tool) und unter Linux) ein. Das ich Fortran, C und Pascal gemacht habe, ist 20 Jahre her, und GFA-Basic sogar 25 Jahre. :-( Das SVN habe ich darum auch erstmal schleifen lassen....... Zu Rene: >einen Link zum PDF mit aufzunehmen finde ich sowieso schon mal gut. Richtig. Als Idee toll....... > Dass der dann ins Leere zeigt, wenn der Hersteller das PDF verschiebt, >muesste man einfach mit einplanen. Dass ist schon eher ein Problem, weil das klappt bei mir schon mit Jabrev nicht, weil ich die Datenblätter am Dienstrechner unter Windows habe und privat unter Linux. Immerhin habe ich die Ordnerstruktur immer identisch, und weiss also sofort, wo ich nachsehen muss, wenn es unter dem einen Pfad nicht gefunden wird. :-) Allerdings kocht das Problem sofort hoch, wenn ich meine Ordnerstrucktur ändere. Jabrev kann nicht selbstständig Ordnerbäume durchsuchen....Dann gehe ich mit dem Beagle ran. Dienstlich geht das wiederum nicht. > Weiss nicht, wieviel Kooperation mit > den Herstellern das braucht, man muesste pro Hersteller ev. den link > fuers http get generieren und nur eine Datenbank ID abspeichern. Wenn Die kooperieren, dann nur zu ihren Bedingungen. D.h. Du arbeitest mit einem Hersteller zusammen, und kommst mit dem nächsten in Konflikt.....So aus dem Bauch heraus würde ich da für strikte Unabhängigkeit plädieren. > Datenblatt-Kraken sind, glaube ich, fast alle asiatisch... > Das Problem, ein Datenblatt schlussendlich aufzufinden, finde ich nicht > so kritisch. Oh doch. Speziell bei musealem Kram......:-) Einige Firmen versehen Datenblätter für obsolete Bauteile mit einem Stempel, andere geben Sie nur noch auf Anfrage heraus: "Ich bräuchte für ein Redesign.....gut wenn man einen Firmennamen im Rücken hat...." Ich speichere Grundsätzlich jedes Datenblatt, das mir in die Finger kommt. So steht man auch in der Firma nicht dumm da, wenn gerade mal das Internet oder auch einfach das Firmeninterne Netzwerk nicht geht. Von meiner 8,5 Gb großen PDF-Sammlung sind 7,2Gb E-Technik relevant (Beim Rest ist immer noch Physik und Mathe enthalten). Davon sind 1,2 Gb Datenblätter und 500Mb Applikationsberichte. Würde ich gerne zur verfügung stellen, aber ich fürchte, da sind oft Copyrights drauf. Und das ist nicht einheitlich, darum sitzten die Datenblattkraken ja auch in Asien..... Wenn also jemand freien Serverplatz, gute Jurakenntnisse und Spass an gerichtlichen Auseinandersetzungen hat, soll er sich melden.......O)
Ich würde so eine Bauteileverwaltung wie schon beschrieben mit Python + sqlite3 + websercer + CGI machen. Lerne mal Python, Bernd! Du wirst über die Klarheit der Programmiesprache überrascht sein, und wie schnell man sich damit Werkzeuge programmieren kann. Die Standard-Tutorials sind sehr gut, einfach mal ein bisschen einlesen. Auch wenn es vielleicht neu für Dich ist, ich kann es nur wärmstens empfehlen. Mit Hintergrund in C und Pascal sollte das ziemlich leicht sein. Es ist für KiCad-Libs gut geeignet, weil das alles recht einfache Textfiles sind. Mir fehlt momentan die Zeit, das zu programmieren, aber sehr schwer ist es nicht. Mit etwas Glück packt mich der Rappel und ich mache es trotzdem einfach mal...
Hier ist ein Beispiel für die von mir vorgeschlagene Methode. Das ist gemacht mit einem Ad-hoc-Webserver mit CGI von hier: http://user.baden-online.de/~pjanssen/ad-hoc-server/index.html Dafür habe ich dann mit Python ein einfaches CGI-Script erstellt, das man lokal (oder auch im LAN) über diesen Webserver aufrufen kann. Dieses Script scannt ein Basisverzeichnis mit KiCad-Libraries ab und listet alle Symbole auf, die in diesen Dateien definiert werden, erstellt eine Liste, usw. Dieses Ergebnis wird dann im Browser angezeigt. Die Datei beispiel.html zeigt das Ergebnis. Um dieses Methode zu verwenden: - Python installieren (ist bei Linux meist schon vorhanden). - serve-from-here_withcgi.py in ein Verzeichnis tun. Die Datei muss ausführbar gemacht werden. - Unterverzeichnis "cgi" erstellen. - Die Datei index.py in das gerade erstellten Verzeichnis "cgi" tun. Sie muss ausführbar gemacht werden. - In der Datei index.py das Basisverzeichnis der Library-Dateien einstellen. Damit ist die Installation abgeschlossen. Aufruf: - Die Datei serve-from-here_withcgi.py starten. - Mit dem Browser den URL "localhost:8008/cgi/index.py" aufrufen.
Hi Bernd, Bernd Wiebus schrieb: > 2) Local könnte mir SVN natürlich weiterhelfen, aber was ist, wenn ich > die Librarys weitergebe, und zwei unterschiedliche Revisionen z.B. B und > C existieren, wo Symbole mit gleichem Namen, aber versetztem Ankerpunkt > existieren? Wenn, in der Reihenfolge des einlesens, zuerst die falsche > Library gewählt wird, "hüpfen" mir die Symbole oder Module durch die > Gegend. Das Problem ist mir leider nicht unbekannt. Ja, das ist garstig. Deswegen knuepfe ich jedes Projekt an eine bestimmte Revision der library fest. Ich vergass noch, in dem Zuge einen weitere Unschoenheit zu erwaehnen: Wenn man diese lokal aus SVN ausgecheckte fixe Revision ins Projekt einbinden will, traegt kicad in der .pro-Datei die absoluten Pfade ein. Ich habs bisher nur ueber Modifikationen mit dem Texteditor hinbekommen, relative Pfade zu benutzen. Deswegen waere mein Vorschlag - auch wenn ein SVN-Repo fuer ein-zwei Files zunaechst unsinnig erscheint - gleich mit der ersten Prototypen-Version im SVN loszulegen. In neue Tools einlernen ist zugegebenermassen garstig, koennte dir aber den "Tortoise SVN"-Client empfehlen, das macht die Sache einfacher. Da du bei SVN alles zurueckdrehen kannst, sehe ich auch kein Problem, einfach mal blindlings loszuschweinigeln, die Dateistruktur kann man spaeter verbessern. Vielleicht kristallisiert sich dann auch besser heraus, wie man optimal mit verschiedenen Library-Revisionen arbeitet. Ich koennte mir vorstellen, dass sich einige Extensions hacken lassen, um wenigstens den Revision-Tag in die Library mit aufzunehmen, und eine Synchronisation mit dem Schematic/PCBdesign zu erzwingen oder Warnungen zu schmeissen. Was du zum Thema Unabhaengigkeit von den Herstellern sagst, stimmt eigentlich komplett. Ich unterschreibe das mal. Soweit dazu, muss mir nu mal euern weiteren Input erst reinziehen und verstehen. Gruesse, - Strubi
Das klingt sehr nach "dependency hell". Die wurde in Debian erst mit der Paketverwaltung gelöst, die die Abhängigkeiten selbstständig auflösen kann. Wenn man die KiCad-Module hackt, um Symbol- (oder Library-)Revisionen zuzulassen, muss man auch in der Benutzeroberfläche die Möglichkeit haben, diese auszuwählen und zu ändern (falls die Revision nicht stimmt). Das klingt nach größerem Aufwand. Wenn ein Symbol neue Ansatzpunkte hat, müssen die auch neu "verschaltet" werden. Sonst könnte es ganze fiese Fehler mit vertauschten Anschlüssen geben, die aber nicht ohne weiteres bemerkt werden... Was relativ einfach ginge, wäre eine Aufnahme einer Revisionsnummer als Kommentarzeile in den Libraries. Das stört KiCad nicht, aber man kann dann damit arbeiten, indem man sich Listen erstellen lässt, die kann man dann mit seiner Datenbank abgleichen und ggf. Abweichungen, die Aufmerksamkeit brauchen, anzeigen lassen.
Hallo didadu. > So, hier sind drei Listen der Inhalte der Felder "Value", "Device" und > "Package" der exportierten BOMs aller .sch-Dateien (also von > Schaltplänen), die hier auf MK als öffentliche Attachments gepostet > wurden (ca. 470 Stück). Zu Devices.text: An erster Stelle steht R-EU_0207/10. Standard Widerstand im 10mm Raster. Throuhole ist hier immer wohl noch das gängigste. An zweiter Stelle steht LED5mm . Das sind die ganzen Uhren mit den vielen LEDs. :O) Dann an vierter Stelle R-EU_R0805. SMD ist also auch im Selbstbau gut im kommen. An fünfter Stelle "Device" und an sechster Stelle nur Leerzeichen, was zeigt, das die Leute bei Erstellung eigener Devices nicht besonders phantasievoll in der Namensgebung sind. :O) > Lerne mal Python, Bernd! Du wirst über die Klarheit der > Programmiesprache überrascht sein, und wie schnell man sich damit > Werkzeuge programmieren kann. Die Standard-Tutorials sind sehr gut, > einfach mal ein bisschen einlesen. Auch wenn es vielleicht neu für Dich > ist, ich kann es nur wärmstens empfehlen. Mit Hintergrund in C und > Pascal sollte das ziemlich leicht sein. Bevor ich mich Gambas zuwendete, habe ich mich an Python versucht.....mein Problem bin ich selber, und das ich bei Objektorientierung einfach an der Grenze meiner Intelligenz bin. :-( Dummerweise verstehe ich weniger als ein viertel Eurer Diskussion über Datenbanken. Ich habe da schlichtweg kein bisschen Ahnung von. Und ich habe oft das Gefühl, hier an den anderen Diskussionsteilnehmern vorbeizureden und zu verstehen. > Hier ist ein Beispiel für die von mir vorgeschlagene Methode. > Das ist gemacht mit einem Ad-hoc-Webserver mit CGI von hier: > http://user.baden-online.de/~pjanssen/ad-hoc-serve... > Dafür habe ich dann mit Python ein einfaches CGI-Script erstellt, das > man lokal (oder auch im LAN) über diesen Webserver aufrufen kann. > ~~~~~~~~~~ HERZLICHEN DANK! Ich habe das Python Package noch von meinen eigenen Python versuchen stehen..... Ich fürchte aber, ich werde erst am nächsten WE dazu kommen. Und vorher muss ich mich erkundigen was CGI ist......:-( Ich bin zimlich aus der Zeit gefallen denke ich. > Wenn man die KiCad-Module hackt, um Symbol- (oder Library-)Revisionen > zuzulassen, muss man auch in der Benutzeroberfläche die Möglichkeit > haben, diese auszuwählen und zu ändern (falls die Revision nicht > stimmt). Das kann man. In der tat. Oben unter "Einstellungem", und dann "Bibliotheken". In älteren Versionen hies es noch "Extras", und dann "Bibliotheken und Pfade". Allerdings wählt KiCAD und Symbole und Module nach SYMBOL-NAMEN und MODUL-NAMEN aus den angegebenen Librarys in den angegebenen Pfaden aus. Hat man mehr als eine Library, und befinden sich dort in unterschiedlichen Librarys Symbole oder Module mit gleichem NAMEN, so wird das erste gefundene benutzt. Das ist eigentlich kein Problem, wenn man die Librarys immer passend an das Projekt bindet. Was übrigens automatisch nach Auswahl einer Library passiert. Es wird aber zum Problem, wenn man an einer Schaltung arbeitet, mit schon gewählter Library, und dann als hierarchischen Unterschaltplan einen externen Schaltplan einbindet, und auch dessen -cache.lib verwendet. Enthält diese Library nun ein Symbol oder Modul mit gleichem NAMEN wie in den verwendeten Librarys das aus einer anderen Version stammt, hängt es vom NAMEN der Librarydatei ab, welche in alphabetischer Reihenfolge zuerst dran sind unf folglich verwendet werden. Wollte man die -cache.lib nicht verwenden, hat man u.U. nicht alle Symbole oder Module parat. > Was relativ einfach ginge, wäre eine Aufnahme einer Revisionsnummer als > Kommentarzeile in den Libraries. Das stört KiCad nicht, aber man kann > dann damit arbeiten, indem man sich Listen erstellen lässt, die kann man > dann mit seiner Datenbank abgleichen und ggf. Abweichungen, die > Aufmerksamkeit brauchen, anzeigen lassen. Es ist weniger sinnvoll, die Versionsbezeichnung, oder einen Datecode in einen Kommentar zu schreiben, als in den Namen des SYMBOLS oder MODULES! Weil im NAMEN KANN KiCAD das auswerten, und dann entsteht das Problem nicht. ;-) Im obigen Falle häette dann das Symbol/Modul den Suffix "RevG5" oder "16042010" als aktuellen Datecode. In der -cache.lib oder der Projekt.mod stände der gleiche Name mit anderem Suffix "RevF3" oder Datecode "25022009". Es gibt mit Sicherheit smartere Lösungen, aber der Momentane Entwicklungsstand von KiCAD legt diese Vorgehensweise nahe. Mit freundlichem Gruß: Bernd wiebus alias dl1eic http://www.dl0dg.de
> was CGI ist
CGI heißt "Common Gateway Interface" und bezeichnet eine Methode, wie
Daten, die vom Webbrowser an den Webserver geliefert werden, vom
Webserver an eigene Programme weitergegeben werden -- und zurück --,
sodass die eigenen Programme letztlich, vermittelt durch den Webserver,
mit dem Webbrowser kommunizieren können.
Anders gesagt, wenn ich am Webbrowser klicke, soll mein Programm die
Daten bekommen, und wenn mein Programm "print" sagt, soll es im Browser
angezeigt werden.
Wegen der Objektorientierung würde ich mir auch keine großen Gedanken
machen. Einfach mal in die Software reinschauen, vieles dürfte dann
schon mehr oder weniger intuitiv einleuchten.
---
Das Seltsame ist, dass ich selbst bisher kaum mit KiCad gearbeitet habe,
weil Eagle halt etwas bequemer ist und eine etwas flachere Lernkurve zu
haben scheint. Warum mache ich also hier mit? Weil ich grundsätzlich
freie Software besser finde und eigentlich lieber benutzen möchte.
Eine Hürde für mich war, dass ich die Symbole nicht fand. Die zweite war
die Sache mit der nachträglichen Package-Auswahl und -Zuordnung, das war
mir irgendwie zu unflüssig (dazu kommt aber auch, dass ich lange kaum
mit Elektronik gearbeitet habe, und das Feld hat sich doch verändert).
Und was ist überhaupt "back-annotation"? Die dritte Hürde war mangelnde
Erfahrung mit dem Layouten überhaupt.
Nun kenne ich aber schon etwas Eagle, also ist die Hürde 3 schon fast
genommen. Allerdings kann ich auch mit Eagle nicht wirklich flüssig
arbeiten... So gesehen nähert sich das an. Problem 2 ist in Eagle gut
gelöst: Umschalten auf 1 Klick, hin und her. Bequemer geht's nicht. Da
lässt KiCad zu wünschen übrig. Und Problem 1 habe ich mit Eagle auch.
Also auch hier: Annäherung.
Ich muss mir das Programm wohl mal wieder anschauen. Möglicherweise
zeigen sich dann noch weitere Probleme... Vielleicht mit dem Drucken?
Na, ich werd's ja sehen.
Kann man KiCad eigentlich scripten? Gibt's eine API für
KiCad-Funktionen, z.B. mit Python-Bindings?
Ein weiterer Punkt ist aber auch: Wie könnte man mehr User zu KiCad
kriegen? Je mehr es sind, desto eher werden auch Probleme gelöst,
Tutorials geschrieben usw. Ideen dafür:
- Die genannten Probleme lösen.
- Manche Dinge so gut machen, dass sie schon in sich ein Zugpferd sind.
(Ideen dafür?)
- Mehr große und attraktive Platinen entwickeln und hier reinstellen,
damit die Leute KiCad nehmen, um sie nachbauen und verändern zu können.
- Einen Leitfaden erstellen: "KiCad für Eagle-Nutzer", so nach dem
Prinzip "Linux für Umsteiger von Windows", der die Äquivalenzen und
Workarounds für die Unterschiede nennt.
- Eine Liste der jeweiligen Vorteile und Nachteile der Softwares
erstellen. Nicht ideologisch, sondern rein pragmatisch geschrieben.
- Sämtliche Eagle- (und andere) Schaltpläne dieser Website umwandeln in
KiCad und eine tolle indizierte Sammlung mit Index und Bildern anlegen,
die NUR die KiCad-Versionen zeigt.
- Import-Funktion für Eagle2KiCad in KiCad bauen. Oder zumindest einen
Export aus Eagle mit einem Eagle2KiCad.ulp, um den Umstieg zu
erleichtern.
- Werbung machen mit einer benutzerfreundlichen, modernen Website.
Bernd Wiebus schrieb: > Es ist weniger sinnvoll, die Versionsbezeichnung, oder einen Datecode in > einen Kommentar zu schreiben, als in den Namen des SYMBOLS oder MODULES! > Weil im NAMEN KANN KiCAD das auswerten, und dann entsteht das Problem > nicht. ;-) Im obigen Falle häette dann das Symbol/Modul den Suffix > "RevG5" oder "16042010" als aktuellen Datecode. In der -cache.lib oder > der Projekt.mod stände der gleiche Name mit anderem Suffix "RevF3" oder > Datecode "25022009". Lass mich es mal anders formulieren: Zum eindeutigen identifizieren des Moduls brauchen wir einen weiteren "key" (da kuerzer als "schluessel" nehme ich mal die englische Version). In der Datenbank (bzw dem Satz aus Lib-Files) duerften dann durchaus mehrere Komponenten mit dem gleichen Namen vorkommen, aber Name und Revision macht die Komponenteninstanz eindeutig. Im EESchema kann man ja bereits einen Fields-Eintrag pro Symbol mit einer Revisions-Nummer versehen. Diese Revisionsnummer muss zum Symbol passen, sonst Warnung. Problem: Es gibt momentan keine Felder per Komponentendefinition fuer einen $Rev:$-SVN-Tag (zur Erlaeuterung: Wenn entsprechend per svn:keywords konfiguriert, traegt SVN in Textfiles mit einem solchen $Rev:$-Tag während des "svn commit" die Revision ein, also steht da dann z.B.: "$Rev: 42 $") Das einfach in eine extra Text-Definition einzutragen, klappt ansich (siehe attachte chip.lib), aber die $Rev: $ wird im EEschema/Lib editor nicht richtig angezeigt (zumindest in meiner Version). Und anzeigen wollen wir es schlussendlich wohl auch nicht. Was nu also in kicad fehlt, waere eine vernuenftige Erweiterung, am besten generisch formuliert, d.h. die Moeglichkeit fuer den User, einen weiteren "key" zum Auffinden von Symbolen in den Libraries hinzuzufuegen. So, und wer programmiert uns das in kicad rein? Zu didadu: habe mal dein Script ausprobiert, funktioniert 1a. Du hast Dir damit den Schuh mit dem Parser fast schon angezogen :-) Die Datenbank bekaemen wir also wohl irgendwie gefuellt - und fuer's erste Fuellen ist es wohl zunaechst wirklich besser, eine gut designte Kicad-Lib in was auch immer zu uebersetzen. Habe nur noch ueber einen Aspekt sinniert: Der Gag an einem Online-Tool a la Kicad Component Builder ist ja, dass die erstellten Rohdaten gleich in eine Datenbank gespeichert werden koennten. Ein User, der sich Library-Daten runterlaedt und lokal verbessert, aber nicht wieder hochlaedt (ja, auch ich bin oft so faul), dient der Gemeinschaft nicht unbedingt. Das schreit also fuer das weitere Unterhalten und Auffuellen der Datenbank nach einem Online-Tool... Habe leider keine Emailadresse von dem Autor des KiCoBu, sonst haette ich den schon mal gepiesackt, was er von einer Erweiterung haelt, oder ob er den Source rausgibt.
Martin S. schrieb: > Schuh mit dem Parser Naja, der "Parser" ist bisher kaum mehr als ein "grep DEF" in Python-Form. Der nächste Schritt wäre das Herstellen von Grafiken, um auch mal was zu sehen. Ansonsten das Einlesen in eine DB. (Aber dann geht's los mit der Verwalterei, vor allem beim Neueinlesen, bei Updates usw., da muss man dann alles immer wieder vergleichen und mit Konflikten umgehen.) Martin S. schrieb: > Kicad Component Builder Vielleicht will er gerne selbst die Daten sammeln... (und für sich behalten? so wie google und so viele andere klautsourcer). Man kann ja höflich anfragen. Vielleicht steuert er ja die Bibliotheken zu so einem Projekt bei. (Wer weiß, vielleicht liest er hier mit.) Dieser Builder baut anscheinend hauptsächlich ICs. Aber was ist mit den anderen Komponenten? Gerade da ist die Arbeit des Selbststrickens ja nerviger. Und mit "Componenten" meint er wohl auch nur "Symbole", nicht Footprints. Eine Sammlung aller Footprints wäre auch nicht schlecht. Aber die sind nicht in den .lib drinnen, die auf der Website generiert werden (wohl nur als Default-Footprint referenziert). Dieser Symbol-Builder ist somit nicht sehr schwer nachzubauen, denke ich. Und man kann es besser machen. Dann könnte man mehr Zulauf kriegen ... um die Daten zu sammeln. Fairerweise könnte man ein Klickfeld vorsehen -- standardmäßig markiert -- das sagt: "Symbol in öffentliche Bibliothek aufnehmen". (Oder die Nutzungsbedingungen des besseren Builders ausdrücklich in diesem Sinne ankündigen.)
Martin S. schrieb: > leider keine Emailadresse von dem Autor des KiCoBu Tipp: whois => http://www.pagesjaunes.fr/ (Name, Vorname, Ort) => Anrufen
Ich habe mal weiter am Parsen gearbeitet. (Die beiden Scripts müssen BEIDE in das "cgi"-Verzeichnis (s.o.) getan werden.) Nun erscheinen beim Scannen der Libraries zusätzlich solche Infos:
1 | ======================================== EESchema-LIBRARY Version 2.3 Date: 4/5/2007-07:37:04 |
2 | Device: LM339 (Units: 4) |
3 | Aliase: ['LM139', 'LM239', 'LM2901', 'LM3302'] |
4 | Polyline (4 points): (-200,200) (200,0) (-200,-200) (-200,200) |
5 | Pin 3: V+ (Power In), unit 0 (-100,400) |
6 | Pin 13: ~ (Output), unit 4 (500,0) |
7 | Pin 2: ~ (Output), unit 1 (500,0) |
8 | Pin 1: ~ (Output), unit 2 (500,0) |
9 | Pin 14: ~ (Output), unit 3 (500,0) |
10 | Pin 10: - (Input), unit 4 (-500,-100) |
11 | Pin 4: - (Input), unit 1 (-500,-100) |
12 | Pin 6: - (Input), unit 2 (-500,-100) |
13 | Pin 8: - (Input), unit 3 (-500,-100) |
14 | Pin 9: + (Input), unit 3 (-500,100) |
15 | Pin 11: + (Input), unit 4 (-500,100) |
16 | Pin 5: + (Input), unit 1 (-500,100) |
17 | Pin 7: + (Input), unit 2 (-500,100) |
18 | Pin 12: GND (Power In), unit 0 (-100,-400) |
19 | ---------------------------------------- |
20 | ================================================================================ |
Bei mir tauchen bei einigen Bibliotheken ein paar Fehler auf, die kann man auf der Ausgabeseite schnell mit "***" finden. Neu ist dabei übrigens die Ausgabe der ALIAS-e, die in den Libs definiert sind.
didadu schrieb: > Neu ist dabei außerdem auch die Ausgabe der (ggf.) definierten Footprints. Footprints: ['SO16E', 'SO16N', '16DIP300', '16DIP-ELL300', 'SOJ28_WIDE', '28dip300', 'CP*', 'SM*', 'R?', 'SM0603', 'SM0805', 'C?', 'SM*', 'R?', 'SM0603', 'SM0805']
Hier eine verbesserte Version des Library-Parsers. Die Fehler treten nicht mehr auf. Er scannt jetzt alle meine Libs, auch die umfangreiche neue SymbolsSimilarEN60617+oldDIN617-RevD3-en.lib "AKTUELLE Version!" von hier http://www.mikrocontroller.net/articles/KiCAD#Bibliotheken
Mir fällt beim durchgehen der Ergebnisse auf, dass in der Bibliothek SymbolsSimilarEN60617+oldDIN617-RevD3-en.lib die T-Zeilen nicht der Beschreibung auf der Seite http://en.wikibooks.org/wiki/Kicad/file_formats#T_record_.28Text.29 entsprechen. Dort steht als Definition: T direction posx posy text_size text_type unit convert text * direction = Direction of text(0=Horizintal, 900=Vertical(default)) * text_size = Size of the text * text_type = ??? * text = Text to be displayed. All ~ characters are replaced with spaces. In der Lib treten aber mehr Felder auf, und zwar NACH dem Feld "text", das nach der Beschreibung das letzte sein sollte, z.B.: T 0 800 450 60 0 0 0 AC Normal 0 C C Stimmt die Lib nicht, oder ist die Beschreibung unvollständig? Wo gibt es eine richtige Beschreibung? Mit welchem Tool wurde die Lib erstellt? Dazu fällt mir ein, dass ein validierender Parser vielleicht nützlich wäre. Dazu braucht man aber eine definitive Definition der Formate. (Und die gibt's vermutlich direkt oder indirekt auf dem KiCad SVN.)
Libraries auf Launchpad: https://code.launchpad.net/~kicad-lib-committers/kicad/library "How can I contribute custom footprints to the project?" => https://answers.launchpad.net/kicad/+question/106798
Hier gibt's auch Symbole, einfach mal eine Rubrik anklicken: http://ftp.sunet.se/geda/tools/symbols/library/index.html Schön gemacht! Sowieso sind bei dem Programm schon zahlreiche Symbole und Footprints dabei, und auch kategorisiert.
Und hier sind noch ein paar mehr Programme, die vielleicht auch konvertierbare Symbole haben: http://en.wikipedia.org/wiki/Wikipedia:WikiProject_Electronics/Programs
Martin S. schrieb: > Bernd Wiebus schrieb: >> Es ist weniger sinnvoll, die Versionsbezeichnung, oder einen Datecode in >> einen Kommentar zu schreiben, als in den Namen des SYMBOLS oder MODULES! >> Weil im NAMEN KANN KiCAD das auswerten, und dann entsteht das Problem >> nicht. ;-) Im obigen Falle häette dann das Symbol/Modul den Suffix >> "RevG5" oder "16042010" als aktuellen Datecode. In der -cache.lib oder >> der Projekt.mod stände der gleiche Name mit anderem Suffix "RevF3" oder >> Datecode "25022009". > Im EESchema kann man ja bereits einen Fields-Eintrag pro Symbol mit > einer Revisions-Nummer versehen. Diese Revisionsnummer muss zum Symbol > passen, sonst Warnung. Problem: Es gibt momentan keine Felder per > Komponentendefinition fuer einen $Rev:$-SVN-Tag (zur Erlaeuterung: Wenn > entsprechend per svn:keywords konfiguriert, traegt SVN in Textfiles mit > einem solchen $Rev:$-Tag während des "svn commit" die Revision ein, also > steht da dann z.B.: "$Rev: 42 $") > Das einfach in eine extra Text-Definition einzutragen, klappt ansich > (siehe attachte chip.lib), aber die $Rev: $ wird im EEschema/Lib editor > nicht richtig angezeigt (zumindest in meiner Version). Und anzeigen > wollen wir es schlussendlich wohl auch nicht. > > Was nu also in kicad fehlt, waere eine vernuenftige Erweiterung, am > besten generisch formuliert, d.h. die Moeglichkeit fuer den User, einen > weiteren "key" zum Auffinden von Symbolen in den Libraries > hinzuzufuegen. Jap,Kann ich nur zustimmen ! Sehr schöne Idee mit dem SVN-Tag. > So, und wer programmiert uns das in kicad rein? Hm, ich. Nicht ganz ;). Ich habe eine andere Idee die mir schneller durch den Kopf geschossen ist beim lesen deiner ersten Zeilen. Achtung, ich hol mal aus.
Guten Abend, Ich habe eine Frage zur Realisierbarkeit mit Python. @didadu (Python-Crack ^^) und alle anderen auch ;-). PS: installiert ist es aber noch nie benutzt :)! Grundidee: (noch nicht ausgereift !!!, irgendwas hab ich bestimmt noch nicht bedacht) (Manuell) svn:keywords im ersten Ordner des SVN-Projekarchives definieren (rekursiv natürlich). Somit kann man bei allen Dateien die Revisionsnummer, Autor, Datum usw. abfragen. Python-Script vor dem 1. Übertragen (nicht das aller allererste zwingend) zum SVN-Projektarchiv: ------------------------------------------------------------------------ ----------------------------------------------------------- >>>1.Schritt einfügen/ersetzen der Standard-SVN-Tags # # CPC1017N $Id$ <--- # DEF CPC1017N U 0 0 Y Y 1 F N F0 "U" 0 350 60 H V C CNN F1 "CPC1017N" 0 -357 60 H V C CNN DRAW ----- EESchema-DOCLIB Version 2.0 Date: 04/03/2010 11:31:51 # $CMP CPC1017N D opto mos $Id$ <--- K SWITCH OPTO F opto/cpc1017n.pdf $ENDCMP # >>>2.Schritt die Dateien per Kommandozeile auf das SVN Projektarchiv übertragen -> dadurch werden die Tags mit Informationen gefüllt/ersetzt, wie ihr wollt :-)! >>>3.Schritt die Dateien vom SVN Projektarchiv wieder auschecken zum auslesen der SVN-Taginformationen -> Taginformationen in den Dateien enthalten. ----- $Tag: dateiname Revisionsnummer Datum Uhrzeit Autor $ ----- # # CPC1017N $Id: analog_switches.lib 13 2010-06-02 15:00:52Z PC-Username $ <--- hier stört es Kicad überhaupt nicht! (reine Praxisbestätigung ;) ) # DEF CPC1017N U 0 0 Y Y 1 F N F0 "U" 0 350 60 H V C CNN F1 "CPC1017N" 0 -357 60 H V C CNN DRAW ----- EESchema-DOCLIB Version 2.0 Date: 04/03/2010 11:31:51 # $CMP CPC1017N D opto mos $Id: analog_switches.dcm 13 2010-06-02 15:00:52Z PC-Username $ <--- (ebenso) K SWITCH OPTO F opto/cpc1017n.pdf $ENDCMP # ------ >>>4.Schritt Dateien erneut einlesen (Dateinamen merken!) und SVN-Taginformation auslesen >>>5.Schritt ausgelesene SVN-Taginformation als Suffix in dazugehörigen Dateinamen schreiben >>>6.Dateien zum SVN-Projektarchiv übertragen >>>7.Fertig :-)) Beim übertragen könnte man für die genauen vielleicht auch noch die Revisierung beachten damit diese nicht so schnell in die Höhe schießt. Immer wenn man fertig ist mit dem Bearbeiten Kicad-libs führt man das Python-Script aus und die Magie nimmt ihren lauf und man hat am Ende auf dem SVN-Server (oder im Projektarchiv, offline) sowie im aktuellen Arbeitsordner seine Kicad-libs mit zusätzlichen Revisionsinformationen in den Dateien und im Dateinamen. Zudem erscheint die veränderte Description in Kicad in der Unteren Statuszeile im Bibliothekseditor, Shematic & Layout beim anklicken das jeweiligen Symbols. Dieses Script könnte man bestimmt mit dem Analyse Script so kombinieren das man 2 Fliegen mit einer Klappe schlägt. Sammeln und richtiges Revisieren. Tests: ----- Die .lib & .dcm Dateien werden immer zur selben Zeit erstellt, außer man editiert selbst mit einem Editor in den Dateien. Die Informationen bleiben bei Bearbeitung der Dateien & erneutem abspeichern erhalten. Damit umgeht man Kicad ansich zwar ganz schön aber es würde die Problemstellung der direkten Revisierung und Benennung von Kicad-Dateien oder auch zukünftigen anderen Dateien lösen. So nun dürft ihr meckern und Einwände bringen oder Probs aufzeigen. Tipps wären auch gut ;). --- VG, Rene
Angehängte Dateien:
Hier noch ein Bild mit veränderter Description in Kicad. --- VG, Rene
Es geht auch noch ein weiteren Hack, der aber nicht richtig funktioniert. Du editierst mit einem Texteditor die F1-Zeile:
1 | DEF CHIP U 0 40 Y Y 1 F N |
2 | F0 "U" 0 0 60 H V C CNN |
3 | F1 "CHIP_$Rev: 5 $" 0 300 60 H V C CNN |
Damit kannst du explizit die Revision im Namen verankern. Das geht auch
beim ersten Mal Laden, dann wird leider intern in der cache.lib der Text
aus der F1-Zeile, also "CHIP_$Rev: 5 $" in die DEF-Zeile uebernommen,
und der Parser motzt, da er die DEF nicht richtig einlesen kann, da dort
die Anfuehrungszeichen fehlen und der Rev-Schlonz wie mehrere Argumente
erscheinen. Das passiert auch beim Editieren mit dem Library-Editor,
dann ist das Bauteil ploetzlich weg aus der Auswahl-Liste (wegen obigem
Parserproblem).
Diese Art Versionstagging per Lib-Datei hat ein echtes Minus: Bei jeder
Aenderung einer Komponente in der Lib muss man alle anderen Symbole die
derart "hart" codiert (mit Name-Rev-Schluessel) sind, im Schematic
nachfuehren, auch wenn sie sich gar nicht geaendert haben. Das ist echt
Kaese.
Abgesehen davon, dass es nicht richtig tut, finde ich es deswegen immer
noch einfacher, eine lokale Kopie der Library im Projektverzeichnis zu
unterhalten. Wobei mir allerdings die Uebersicht, welche Komponenten
geaendert wurden, verloren gehen kann, und ich mit svn diff alles
ueberpruefen muss, wenn ich eine aktualisierte lib ("svn up") in einem
anderen Projekt nachfuehren will.
Wenn man das also sauber mit SVN machen wollte, muesste jedes Symbol in
ein einzelnes File, damit man pro Symbol eine Revisionsnummer kriegt.
Oder man kriegt kicad dazu, mit einem internen "diff" festzustellen,
welches Symbol sich geaendert hat, und die zur Library zugehoerigen
Revision-IDs werden automatisch fuer die unveraenderten Symbole
synchronisiert. Bei den anderen heissts: Bitte updaten, wurde geaendert.
Ich muss zugeben, ich schmeisse erst mal den Bettel vor solchen
Revisionierungsfragen, das ist mir auf der Ebene zu komplex, deswegen
eben auch der Gedanke, das von einer Datenbankseite (kicad-unabhaengig)
aus mal aufzuziehen.
Oder die Frage mal den kicad-Entwicklern vorlegen.
Vielleicht muessten wir diese SVN-Tricks auch mal gesammelt
dokumentieren (auf englisch).
Gruesse,
- Strubi
>Wenn man das also sauber mit SVN machen wollte, muesste jedes Symbol in >ein einzelnes File, damit man pro Symbol eine Revisionsnummer kriegt. Davon bin ich ausgegangen. Nach meinem Kenntnissstand werden fast alle Bibliotheken so in der Entwicklung gehandhabt um eine maximale Flexibilität zu erzielen. Größere Teilbiliotheken wie es zum Beispiel Bernd hier im Forum einstellt sind komplett Bibliotheken mit einer festen Versionsnummer (tag). Ich würde die einzelnen Datei ebnso wieder per Script und entsprechnder Ordnerstruckter im SVN-Projektarchiv automatisert erstellen lassen. Bei der ~Cache.lib im jeweiligen Projekt sehe ich das genauso. Diese bildet einen festen Stand des Projektes wieder. Eine Veränderung am Projekt ist eine Instandhaltung/Wartung. Zudem ist hierbei auch immer ein Nutzereingriff erforderlich, sei nur die Prüfung auf Richtigkeit. Das Kicad mit ~Cach.lib arbeitet und die Informationen nicht direkt im .sch speichert sondern wieder comp einfügt ist ansich mist. Somit wirds nur komplizierter. --- VG, Rene
>Datenbankseite (kicad-unabhaengig) Hm, ich würde eher eine Datenbank aufsetzen welcher per SVN oder andere Quele mit einer festen Bibliotheksversion geüllt wird. Diese an Kicad angubunden als Ersatz für ~cache.lib. Dazu eine entsprechende Anpassung in Kicad so dass man unabhängig vom Projekt oder Schaltplan usw. auf alle Symbole und Footprints zugreifen kann und somit Konflikte durch manuelles hin- & herkopieren vermeidet. Zudem könntet ihr man die Ideen der Key-erweiterung zu den .libs einbauen. Das wäre ein echt guter Mehrwert. Später könnte ma die editoren vieleicht von Kicâd loslösen und auf einer Website einbinden für weitere Aquisen. Eine unabhängigkeit von Kicad ist ansich natürlich perfekt für die Marktplatziereung. Mir ist momentan nicht bekannt wo eine solche Datenbank ebenso sehr nützliche wäre, nach dem Motto es reicht so wie es ist aufgrund der längeren Entwicklungszeiten der auf dem Markt verfügbaren CAD-Produkte. Ich gebe dir Recht wir sollten mal einpaar Sachen in ein Dokument bannen. --- VG, Rene
Gibt es eigentlich außer diesem Thread eine Art Homepage, wo Bernd's Projekt etwas detaillierter beschrieben ist bzw. wo die ganzen Infos, Quellen und Diskussionen verfügbar sind?
Damit der Thread nicht ganz einschlaeft: Ich versuche grade in Zeit, die neben dem "serioesen" Arbeiten bleibt, mich ein bisschen in diverse Frameworks einzuspielen, die Datenbank/Userverwaltung usw. vereinfachen. Herrn Rohrbacher, der den kicad library component builder geschrieben hat, habe ich kontaktiert. Vielleicht liest er hier auch mal mit. Wenn sich jemand hier gut mit typo3, Zope, oder sonstigen CMS, die man leicht um Lagerverwaltungen erweitern kann, auskennt, soll er sich doch melden. Ich bin ansich fuer den Job nicht der Richtige, versuche nur gerade mit geringstem Widerstand und hoffentlich groesstmoeglicher Amortisation was zum Laufen zu kriegen. Wie ist denn der Status mit dem SVN? Apropos, ich hab noch etwas Doku zum SVN hochgeladen, bisher allerdings nur im englischen Wiki: http://kicad.sourceforge.net/wiki/index.php/Version_control_of_KiCad_files Vielleicht sollten wir die Diskussion auch auf den Wiki verlagern und unsere gesammelte Expertise dort manifestieren. Gruesse, - Strubi
Ob Andreas Lust hat, auf dem MK.net-Server eine Datenbank-API für sowas
einzurichten, mit der User-Programme zur Bibliothekenverwaltung
kommunizieren können?
Das müsste nicht sehr umfangreich sein, es reicht ja, wenn man sie nach
Teilen durchsuchen ('SELECT name FROM bauteile WHERE name LIKE
"%suchbegriff%" AND type = "KiCad"'), abrufen ('SELECT libdata FROM
bauteile WHERE name = "<name>" AND type = "KiCad"') und Teile hochladen
('INSERT INTO bauteile VALUES name, libdata') kann. Wenn das dann direkt
den Text als Text ausgibt, reicht es für User der Webschnittstelle, und
die Tools können auch recht einfach damit arbeiten. Der Traffic bleibt
damit vielleicht auch überschaubar.
Dann können wir Scripte machen, die für die Synchronisation der eigenen
neuen Teile mit der Zentrale sorgen.
Wenn irgendwann zuviele Leute zu lange Listen absaugen, könnte man
einfach ab und zu die Gesamtbibliothek, nach Software sortiert, bei
Sourceforge als Gesamtpaket abladen. Auf diese Download-Möglichkeit
könnte man in einer zusätzlichen Kommentarzeile ('#Parts data from
mikrocontroller.net\n#You can download the complete database for your
software from http://partslib.sourceforge.net/files";, oder wie der
richtige URL dort dann heißen wird) am Anfang der Teile-libdaten
hinweisen.
Das Backend könnte man ihm komplett liefern, wenn er es aus
Arbeitsüberlastungsgründen nicht selbst machen möchte, aber das Projekt
unterstützt.
Die Hauptfrage wäre dann ein Sinnvolles und eindeutiges
Benennungsschema.
Hi didadu, Die mysql-db plus serverspace koennte ich auch sponsorn, die Jungs von MC haben sicher genug am Hals. Mir geht's vor allem aber um ein benutzbares Front-End. Wenn du denkst, der Zeitpunkt waere schon gekommen, mit einer zentralen DB zu experimentieren, kein Problem, nen DB-User fuer vollen Zugriff (auf die 'components' datenbank) kann ich ad-hoc einrichten. Traffic ist kein Problem. Schick mir einfach ne PM, dann richte ich das mal mit ner rohen DB ein und du kriegst ne userid. Werde mal heute Abend noch nach Lagerverwaltungs-Systemen googeln, da muss es doch was geben, was sich irgendwie aufbohren laesst. Gruss, - Strubi
Strubi schrieb: > Werde mal heute Abend noch nach Lagerverwaltungs-Systemen googeln, da > muss es doch was geben, was sich irgendwie aufbohren laesst. Würde das nicht schon gehen: Part-DB RW - Lagerverwaltung - gerd
Hi Strubi,
Natürlich könnte ich das Python-Script weiter aufbohren, sodass es die
ganzen Daten gleich mit dieser DB abgleicht. Dann könnte man mal etwas
intensiver Teiledaten sammeln.
Allerdings überrollt mich das jetzt gerade alles etwas...
Aber ich denke trotzdem schon mal etwas weiter.
- Das Programm (KiCad, gEDA, Eagle) sollte man unbedingt angeben.
- Die Version ("KiCad-LibDBsync_v0.1") des Upload-Programms auch, damit
man, wenn man mal was ändern will an der API bzw. dem Datenformat, das
serverseitig mit Plugin-Modulen für unterschiedliche Formate richtig
sortieren kann, wenn man später merkt, dass es notwendig wird, aber die
Leute natürlich nicht alle gleich die neue Software verwenden.
- Für Testzwecke sollten wir vielleicht zunächst ein "Test"-Flag
einführen? (Oder man erschlägt das gleich mit der Version, s.o.)
Und Richtlinien für eine einheitliches Benennungsschema wären auch nicht
schlecht.
Was mir auch noch gefallen würde, wäre die Einbindung von Daten zum
leichten und schnellen Auffinden von Vergleichstypen. Also in etwas das
Prinzip, dass ein "BC237" einfach nur ein "TUN" ist (das kenne ich aus
der elektor-Terminologie). Etwas genauer könnte man es aber schon haben.
Ich stelle mir das so vor, dass man bei einer Schaltung ja nicht
unbedingt einen bestimmten Typ braucht, sondern eine Anforderung
vorliegt wie: "Ich brauchen einen bipolaren PNP-Transistor mit einem ß
zwischen 25 und 28, der einen maximalen Kollektorstrom von 35 mA
aushält, bei einer Spannungsfestigkeit von X Volt." Optional mit "im
Gehäuse soundso". Dann kann er mir auswerfen, welches Teil in meinem
Lager oder in der Datenbank meiner Lieferanten auch geeignet wäre. Je
gröber die Mindestanforderungen in einer Schaltung sind, desto mehr
Auswahl hat man, und muss nicht lange suchen. Gerade auch interessant
bei Lieferengpässen. :-/
Interessant wäre auch eine Funktion/Ein Script, die aus einer ganzen
Schaltung ein Bauteil macht. Also ein .sch inklusive Board in eine .lbr
umwandelt. Dann kann man sich leichter Elektronik-LEGOs definieren. Man
muss dann nur die Anschlusspunkte möglichst sinnvoll definieren UND im
Board platzieren, damit man diese Module, die dann in der Lib sind,
leicht miteinander verbinden kann. Offensichtliche Kandidaten sind ja:
"ATmegaXXX inkl. Quarz, pF-Cs, Reset-R, ADC-L, ADC-C", "Spannungsregler
inkl. Anschlussklemmen, C-Elko und 2 Kerkos", usw.
Hilfreich wäre vielleicht auch, wenn man sich in KiCad solche Scripte
auf Buttons oder Menüpunkte legen kann, also ein Erweiterungsframework.
Vielleichts gibt's das alles schon; ich habe danach noch nicht so genau
gesucht.
didadu schrieb: > Elektronik-LEGOs Die Frage wäre dabei für mich (momentan), wie leicht man so eine "Modul-Lib" wieder in die Einzelkomponenten (aber nicht weiter!) aufsplitten kann, wenn man Teile davon umrouten will (vor allem auf dem Board, das man routet). D.h., ob die GUI von KiCad für sowas eine geeignete Funktion bereitstellt oder man da noch was implementieren müsste.
gerd schrieb: > Würde das nicht schon gehen: Part-DB RW - Lagerverwaltung Why not. Ich mag allerdings Python lieber als PHP. Da braucht man gar nichts installieren (außer Python), und einen Webserver und sqlite hat das auch schon integriert. Ich wünsche mir für so eine Parts-DB auch eine Importfunktion, die aus den elektronischen Bestätigungs-E-Mails oder Rechnungen der Lieferanten die Bauteilemengen und -bezeichnungen extrahieren kann, damit ich sie per Mausklick updaten kann (oder direkt eine API beim Lieferanten kontaktiert). Wie mir scheint, geben die Hersteller von Bauteilen auch gewisse Daten raus. Z.B. Simulartordaten und Footprints für bestimmte Programme. Vielleicht auch komplette Bauteilelisten. Vielleicht kann man da ja Converter für schreiben. Ich hoffe, derartige Daten sind kostenlos und frei verfügbar. Müsste mal jemand anfragen und auf den Homepages gucken, wie das so läuft. Vielleicht hat auch hier schon einer Ahnung davon und kann es einfach sagen, oder gar Listen hier hochladen.
gerd: Danke fuer den Hinweis - wieso sehe ich das jetzt erst? Mal damit rumspielen. Scheint nur keine User-Verwaltung zu haben, aber das duerfte das geringste Problem sein. didadu: Einige Hersteller geben BSDL- oder UCF-Files raus, die lassen sich in Pin-Listen parsen. Generiere hier auch rohe LIB files draus, die muss ich nur selber manuell in parts splitten. Lohnt sich fast schon ab LQFP-44. Wenn ich dich richtig verstehe, willst du quasi ein hierarchisches Schema mit exportierten PinSheets in eine LIB-Komponente backen. Ich denke, das kriegt man auch mit nem Python-Script relativ einfach hin. Weiter objektorientiert geht das ganze vermutlich nur mit grundlegenden architektonischen Veraenderungen an kicad, da gaebe es noch die Knackpunkte der Annotation. Ich schau mal, wie leicht ich die part-db mit footprints gefuellt bekomme... Gruesse, - Strubi
Followup in Kuerze: - parts-db angeschaut: Ist wirklich gut gemacht, aber die Komplexitaet "unserer" Datenbank wuerde das Framework sprengen. Dummy-Datensaetze aus kicad-LIB-Verzeichnissen generieren: Siehe index.py (didadu's aufgebohrtes Script). - Mal in div. Python-CMS reingeschnuppert: web2py, django, ev. kommt noch pylons dazu. - typo3 (PHP) hat einige Shop-Systeme als Extensions verfuegbar. So etwas eignet sich IMHO am ehesten zum Aufbohren. Warte noch auf den Experten, der schreit: Nimm DAS, damit geht's. - Vorteil der Python-Loesungen scheint mir: Datenbankstruktur wird im Script selber beschrieben, Aenderungen/Migrationen also leichter. Favorisiere ebenfalls Python, der Code ist einfach generell wiederverwertbarer. Aber fuer die Python-CMS habe ich noch kein adaequates Shop-System im OpenSource gefunden. Gruesse, - Strubi
Strubi schrieb: > Mal in div. Python-CMS reingeschnuppert: web2py, django, ev. kommt > noch pylons dazu. Die würde ich alle nicht verwenden. Ich habe mir solche Systeme auch schon mehrmals angeschaut, um sie evtl. für ein Projekt zu benutzen, aber letztlich jedes Mal verworfen. Da kommt eine Komplexität und eine Abhängigkeit von den externen Entwicklungen ins Projekt, die ziemlich nerven kann, man verbringt dann mehr Zeit damit, Das System(TM) zu verstehen, als seine eigene Funktionalität zu programmieren. Das ist wohl eher was für Leute, die damit beruflich immer wieder neue Websites machen, also ständig damit zu tun haben und eh auf dem Stand bleiben. Sowas ist meiner Meinung nach hier gar nicht nötig, da die gebrauchten Funktionen eher überschaubar sind.
didadu schrieb: > Die würde ich alle nicht verwenden. > Ich habe mir solche Systeme auch schon mehrmals angeschaut, um sie evtl. > für ein Projekt zu benutzen, aber letztlich jedes Mal verworfen. Da > kommt eine Komplexität und eine Abhängigkeit von den externen > Entwicklungen ins Projekt, die ziemlich nerven kann, man verbringt dann > mehr Zeit damit, Das System(TM) zu verstehen, als seine eigene > Funktionalität zu programmieren. Das ist wohl eher was für Leute, die > damit beruflich immer wieder neue Websites machen, also ständig damit zu > tun haben und eh auf dem Stand bleiben. Verstehe deine Bedenken. Finde allerdings web2py auf den ersten Blick ueberschaubar. > Sowas ist meiner Meinung nach hier gar nicht nötig, da die gebrauchten > Funktionen eher überschaubar sind. Welche Alternative gibt es denn? Ohne Framework wuerde ich die Sache nicht anfangen, das wird erfahrungsgemaess sehr schnell sehr komplex, die Einarbeitung in ein CMS amortisiert sich spaetestens, wenn du 10 Features auf der Wunschliste hast. Die Community wird sehr schnell haben wollen, was sie z.B. auf der Farnell-Webseite bekommt. Wenn du dann anfangen musst, erst mal die erfundenen Raeder rund zu kriegen, springen dir die User ab. Habe allerdings keine Einwaende dagegen, wenn du alles "standalone" schreiben wuerdest, wenns schoen modular ist und einen HTML-Writer oder andere 'abstraction layer' fuer die Ausgabe benutzt, laesst es sich ja einbinden. Gruesse, - Strubi
Strubi schrieb: > Die Community wird sehr schnell haben wollen, was sie z.B. auf der > Farnell-Webseite bekommt. Ähhhh ... was schwebt Dir denn da vor? Ich vermute, wir sind gerade out of sync. Ich dachte an eine viel einfachere Sache: Und zwar einfach an ein DB-Backend zum gemeinschaftlichen Sammeln der existierenden Symbole/Footprints und zum gegenseitigen Synchronisieren. Also gar keine große Weboberfläche, sondern nur ein DB-System zum Hoch- bzw. Herunterladen von Listen und Textdateien ohne Formatierung. Die GUI wäre dann primär der Simpel-Webserver auf dem lokalen Rechner. Evtl. könnte man auf dem Server noch ein Webformular mit Suchmaske vorsehen, der als Ergebnis eine Liste von Teilen ausgibt und Symbole und Footprints anzeigt, aber auch das ist eigentlich kaum nötig, weil der lokale Access-Client das schon leistet. Abgesehen von der Grafikanzeige (und die muss man nicht gleich zu Anfang machen) wäre das Webserver-Backend eine kurze php-Datei. Gespeichert würden die Daten dann ja sowieso auch noch mal lokal (sqlite). Also KISS. Quick and ... clean. Wenn die Community viel mehr haben will, muss man vielleicht auch ein paar Mitarbeiter dafür finden. Aus meiner Sicht hat das momentan eine einfache aggegierende und explorative Funktion ("mal schauen, was es bei den Usern so gibt und wie wir das gemeinsam nutzen können"). Was im Web so zu finden ist, fand ich nicht gerade sehr umfangreich, und ich denke, wenn es KiCad-User gibt, dann gibt es auch einige mehr Teile, als ins Web gestellt werden. Je aufwandsfreier und je weniger intrusiv es möglich ist, seine Arbeit mit anderen zu teilen, desto mehr Leute werden das hoffentlich tun. Außerdem erfährt man so -- macht man so für alle sichtbar -- wo die Usercommunity gemeinschaftlich steht. Eine Schwierigkeit ist ja, dass die Libverwaltung der Softwares sich heutzutage noch zu viel um den jeweils eigenen Bauchnabel dreht, d.h. nicht auf Austausch mit anderen optimiert sind. Das ist ok, aber den Austausch-Layer kann man hinzufügen. Der sammelt und zentralisiert das, was der User in zahlreichen unübersichtlichen Dateien auf seinem Rechner hat und hilft ihm damit schon mal selbst, was ein Grund ist, so eine Software zu nutzen, und die zu schaffende Austauschfunktion erschließt (auf Wunsch) alle diese Daten für alle und verbindet die Robinsons mit einem größeren Ganzen, mit dem man dann schneller gemeinsam weiterbauen kann. Aufbohren für einen komfortableren Direktzugriff kann man so ein Backend später immer noch. Aber selbst da frage ich mich, wozu eigentlich, wenn man die Daten eh schon mit dem lokalen Client durchsuchen, auswählen und anzeigen kann?
Die benötigte Funktionalität ist doch diese: - Ich will was bauen mit einem Teil. - Wo ist das Teil in der Lib? - Die Sucherei beginnt, und fängt schnell an zu nerven. - Hm, gibt es das überhaupt schon? - Anscheinend nicht. - Na, schauen wir mal im Internet. - Mehrere Seiten, alle unterschiedlich, teilweise nicht sehr praktisch. Ob es da was Neues gibt seit dem letzten Besuch, ist praktisch nicht zu erkennen. Gibt es neue Seiten? Mal schauen mit google. - Mist, ich muss es selbst machen. Na ok. - Man macht es. Baut seine Schaltung, ist zufrieden. - Alle anderen: Genauso. - Und alle bleiben dabei. - Wenn ein Neuer mal was sucht und in einem Forum fragt, wird er mehr oder weniger unwirsch auf das oben beschriebenen Verfahren verwiesen. Soll er doch selbst suchen. - Und so, viel Zeit geht verloren mit Sucherei und nochmals Sucherei. Es geht ja nur darum, diesen Prozess abzukürzen und zu vereinfachen. Also den Computer und das Web für das zu nutzen, für das sie gemacht sind: dem Menschen zu dienen, statt ihn in neue Labyrinthe zu werfen. Wenn die Software das leistet, reicht es. Alles andere ist meiner Meinung nach nicht wirklich erforderliches Beiwerk.
Strubi schrieb: > index.py (4,9 KB, 1 Downloads) > partdb.py (900 Bytes, 1 Downloads) Hab mir das jetzt mal angeschaut. Das ist also ein Importer, mit dem man die Bezeichnungen der Teile, die in den auf dem eigenen Rechner vorhandenen Libs definiert werden, in die PartsDB einliest. Dazu fallen mir mehrere Dinge ein: - Sowas macht man nicht nur einmal, sondern aller Voraussicht nach mehrmals. Dann muss der Importer also mit dem vorhandenen Inhalt abgleichen können, damit man keine Dubletten erhält. - Wenn man Libs aus dem Web von unterschiedlichen Leuten hat, haben die Teile keine einheitlichen Bezeichnungen. Mal ist die volle Bezeichnung inkl. Varianten genannt, mal nur der grobe Typ. Der eine schreibt "C" vor seine Cs, der andere nur MKP 10 µ, der eine mit Spaces, der andere ohne, usw. Das tiefere Problem dahinter ist, einmal mehr, die babylonische Sprachverwirrung der Leute. Jeder benennt die Dinge anders. Der kanonische ("offizielle") Name wäre die volle Bezeichung des Herstellers. Also seine Bestellnummer. Bei LEDs enthält das sogar die Bins... Dann wären die Teile eindeutig identifiziert. Diese Bezeichnungen sind aber unhandlich und nicht allen Usern bekannt. Außerdem verwenden die Händler meist eigenen Bezeichnungen, mehr oder weniger verkürzend, die den Usern möglicherweise geläufiger sind. Man braucht also im Prinzip ein Mapping der unterschiedlichen geläufigen Bezeichnungen auf die realen Teile. Hinzu kommt, dass den Usern teilweise egal ist, was für ein Teil sie GENAU haben. Also ob der C von Hersteller X oder Hersteller Y kommt. Er will nur "einen Elko mit 220 µ 35 V". Anschlussfrage: "Wie groß ist der eigentlich?", und da geht's dann wieder los. Radial oder axial? Hersteller? usw. Der Bastler, der es gewohnt ist, in seine Teilekiste zu greifen, ist schnell überfordert mit Detailangaben. Ihm muss man sie möglichst verbergen, bzw. die Auswahl so intuitiv wie möglich halten, vor allem immer mit Bildern und Abmessungen der Symbole und Footprints. Derartige Auswahlmöglichkeiten sollten möglichst nur einmal nötig sein. Also nicht einmal lange suchen, um den C zu finden, und dann in einem späteren Programmteil WIEDER rein in die Bibliotheken, um WIEDER lange den Footprint zu suchen. Ändern ist ok, aber zweimal den Nerv, bitte nicht. Der Profi hingegen wird wohl wissen, was er genau will. Er nutzt sein Toll ja auch häufiger und kennt sich somit besser aus. Da ist der Detailreichtum ein Plus. Aber auch er würde eine Auswahlmöglichkeit zu schätzen wissen, aber dazu müssen die Hersteller- bzw. Händlerdaten integriert (bwz. integrierbar) sein, und dann ist es auch für ihn ein Vorteil und sogar eine Arbeitsbeschleunigung, sofern es gut gemacht ist. Die Auswahl erfolgt immer hierarchisch. Dabei gibt es jedoch unterschiedliche Hierarchien. Der eine denkt: C - 10n - Rasterabstand 2 Lochrasterpunkte Eine andere: C - Wima MKP - 630V - wie groß? sind die Werte zwischen 10 und 47n? Noch ein anderer: Ich hab hier diesen C in der Hand, der genau passt, und brauche mal schnell den Footprint dazu. Also will er klicken auf: C - Radial - 2 Rasterpunkte Abstand (Hersteller egal, Wert sekundär, weil ja erstmal nur zum Probieren getestet wird). Wenn man diese unterschiedlichen Hierarchien in eine einzige Bezeichnung pressen muss, wird immer der jeweils andere Teil der User eine nichtoptimale Suche haben und seine Teile nicht finden, also genervt sein. Wenn man ein simples Klickinterface haben will, muss man also nacheinander über verschiedene Stufen seine Parameter auswählen können. Eine Art parametrische Suche als Klickhierarchie. Mit Klick geht sicher schneller als mit diesen Listenfeldern auf den Webseiten. Das geht deswegen, weil die Fragestellung eine andere ist. Man sucht ja weniger, welches Teil überhaupt passt, sondern versucht, das Abbild der schon ausgewählten Realität in der Lib zu finden. Um da hinzukommen, muss man die existierenden Daten in den Libs allerdings neu aufbereiten, also entsprechend kategorisieren. Das kann man wohl zum Teil automatisieren, wenn man erstmal eine Suchfunktion hat und ein ergonomisches Klickinterface für die Kategorisierung, aber vermutlich bleibt ein manueller Teil. All mein Gelaber wieder mal nur, um die Konzeption der Sache möglichst klar im Kopf zu haben. ;-) Aus dem Gesagten folgt auch, dass man für jeden Hersteller bzw. Lieferanten diese Kategorien herausarbeiten muss, um sie den Libs so automatisch wie möglich (Qualersparnis) zuordnen zu können.
Illustration: Auch sowas kann man parsen und gemeinschaftlich verfügbar machen, um eine Bauteiledatenbank herzustellen:
1 | Vielen Dank für Ihre Bestellung, [...] |
2 | Folgende Daten haben Sie an uns übermittelt: |
3 | |
4 | Ihre I-Net Nummer (bei Rückfragen bitte angeben): XXXXXX |
5 | |
6 | [...] |
7 | Gesamtpreis |
8 | Artikelnummer Bezeichnung Anzahl |
9 | ________________________________________________________________________________ |
10 | TMC 428-PI24 Schrittmotor-Controller SO-24 1 12,95 Euro |
11 | SA 56-11 RT 7-Segment-Anzeige, rot, 14,2mm, gem. 10 4,50 Euro |
12 | TORX 173 Toshiba LWL-Empfänger, Simplex 2 6,60 Euro |
13 | TOTX 173 Toshiba LWL-Sender, Simplex 2 7,30 Euro |
14 | LWL TOS 8 2X Toslink-Stecker, Ø= 5,0mm, 5,0 Met 2 6,60 Euro |
15 | 1N 5822 Schottky Diode, DO201AD, 40V, 3A 10 2,10 Euro |
16 | 1N 5819 Schottky Diode, DO41, 40V, 1A 10 0,60 Euro |
17 | 1N 5818 Schottky Diode, DO41, 30V, 1A 10 0,60 Euro |
18 | FIN 40.52.6 12V Bistabiles Steckrelais, 12V, 2 Wechsl 1 5,60 Euro |
19 | LM 393 DIP Comparator, DIP-8 5 0,75 Euro |
20 | LM 393 D SMD Comparator, SO-8 5 0,95 Euro |
21 | BF 245A Transistor HF N-FET TO-92 30V 0,025A 10 1,50 Euro |
22 | 2W DRAHT 0,33 Draht-Widerstand 2W, 10% 0,33 Ohm 5 1,15 Euro |
23 | BUZ 171 Transistor P-FET TO-220AB 50V 8A 40W 3 8,25 Euro |
24 | SB 540 Schottky Diode, DO201, 40V, 5A 5 1,50 Euro |
25 | FT 114-61 Ferritring 5961001001 1 2,50 Euro |
26 | FT 82-61 Ferritring 5961000601 1 1,50 Euro |
27 | RIK 10 Ringkern aus Ferroxube, N30 1 0,71 Euro |
28 | RIK 12 Ringkern aus Ferroxube, N27 1 0,77 Euro |
29 | RIK 20 Ringkern aus Ferroxube, N30 1 1,40 Euro |
30 | T 106-26 Eisenpulver-Ringkern 5 5,75 Euro |
31 | BC 337-40 Transistor NPN TO-92 45V 0,5A 0,625W 10 0,40 Euro |
32 | KUPFER 0,5MM Kupferlackdraht, Ø 0,5mm, Länge: 23M 1 1,65 Euro |
33 | ENC 28J60-I/SO Ethernet Controller, Stand-Alone, SOI 1 2,55 Euro |
34 | ENC 28J60-I/SP Ethernet Controller, Stand-Alone, S-D 1 2,60 Euro |
35 | SMD-0805 27,0 SMD-Chip-Widerstand, Bauform 0805, 27 10 0,82 Euro |
36 | SMD-0805 270 SMD-Chip-Widerstand, Bauform 0805, 27 10 0,82 Euro |
37 | L-0805F 10µ SMD-Induktivität, 0805, Ferrit, 10µ 5 1,10 Euro |
38 | BAT 43 SMD Schottky Diode SMD, Mini-Melf, 30V, 0 10 1,00 Euro |
39 | BAT 43WS SMD-Schottky-Dioden, SOD323F, 30V, 0, 10 0,50 Euro |
Da bräuchte man natürlich für jeden Hersteller (und jede Änderung seiner Verfahren) ein Modul. Dann hat man die Teile in seiner Inventur und kann ihnen die Bauteile-Libs zuordnen. S. meine vorangehende Mail. Man kann mit Python auch Mailboxen auslesen. Wenn jemand also viel bestellt und die Bestätigungs-Emails in seiner Mail-Software nicht löscht, kann man da einiges zusammenbekommen -- vollautomatisch. Man kann sich gut vorstellen, dass gerade diese Bezeichnungen für viele User die geläufigsten sind, mit denen sie ihre Teile am leichtesten finden würden. (Und wem gehört die Sprache? Man muss sie miteinander teilen dürfen, um überhaupt präzise miteinander über die Dinge kommunizieren zu können.) Hilfreich wäre also auch ein Filterkriterium "gekauft bei", und das Einscannen solcher Bestelllisten wird aufgrund des Aspekts der sprachlichen Gewöhnung an bestimmte Bezeichnungen ja fast zu einer Notwendigkeit. Im Grunde wäre es nett, wenn die Händler für ihre User die Footprints aller Teile auf der Website vorrätig hielten. Als Service könnten sie mit den Bestätigungs-Emails sogar einfach immer alle Daten mitschicken. (Ggf. auf Wunsch) Warum sollte die Community nicht ein Tool für sowas bereitstellen, das die Lieferanten dann auf ihrem Webserver installieren bzw. in ihren Ablauf integrieren können? Jeder Hersteller und Händler kann hier seine Listen posten, das würde dem Projekt helfen. Es müssen ja nicht gleich alle Infos drinstehen (und Preise sind eh variabel), aber man sieht ja eh, dass sie uns, den vergleichenden Marktteilnehmern, kollektiv gesehen doch nicht entgehen. Warum dann nicht den Usern helfen, die Teile auch rationell zu nutzen? Am Ende verkaufen sie vermutlich insgesamt alle mehr, weil dann auch mehr (weil einfacher) damit gebaut werden kann. Also, postet eure Listen hier! Ich wünsche mir Listen mit: Bestellbezeichnung - Beschreibung - exakte Herstellerbezeichnung - Gehäuse. Dann können unsere Tools die Teile und somit deren Libs und Footprints für die Verwendung in Schaltplan und Platinen leicht auffindbar machen. Und am besten gleich die Libs dazu, falls existent. Die Händler sollten sie selbst bei ihren Lieferanten anfordern! Eine entsprechende Nachfrage führt dann vielleicht dazu, dass diese Dinge von den Herstellern gleich mitgeliefert werden, wie ja auch schon die Datenblätter.
didadu schrieb: > - Sowas macht man nicht nur einmal, sondern aller Voraussicht nach > mehrmals. Dann muss der Importer also mit dem vorhandenen Inhalt > abgleichen können, damit man keine Dubletten erhält. Haste voll recht. War ja erst mal ein "billiger Hack" :-) Den anderen Aspekten des Suchens stimme ich voll zu - nebenbei: Farnell treibt trotz seiner Komplexitaet des oefteren zur Verzweiflung, weil man manche Dinge einfach nicht findet. Genau da steckt der Teufel im Detail, und es ist teuflich schwer, bei all dem Wildwuchs benutzerfreundlich zu bleiben/werden. Da fuer dieses Projekt erwartungsgemaess kein allwissender Datenbankorganisator existieren wird (oder naja, wir werden uns eventuell an Bernds Kicad-Library-Schema orientieren), wird es im Endeffekt bei der Community liegen, sinnvolle Daten zu generieren. Die Mammutaufgabe, einen "Google-Algorithmus" fuer die gespeicherten Parts/Footprints zu schreiben, haette ich auch hinten angestellt, wie auch die Feinheiten, die du beschreibst - denn das koennte man ja alles auch per Google auffinden. Prinzipiell will ein Kicad-Library-User, der morgen seinen Platinenprototyp fertig haben will, ja nur folgendes: 1. Symbol 2. Zugehoeriger Footprint Welche Teile darauf passen, muessen IMHO in eine andere Tabelle. Also: Bauteil XY-1234 (id) vom Hersteller (->hersteller) passt zu: (->symbol,->footprint). Die ganzen Eigenschaften unterzubringen, ist tierischer Sisyphos, wuerde ich einfach an die Hersteller auslagern (und nur ein Link-Interface zur Distributor-Webseite implementieren) Um die ganzen User-spezifischen Klassifizierungs-Schluessel zu ermitteln, wuerde ich erst mal eine Moeglichkeit vom Framework her schaffen, einen Datensatz zu taggen. Beispiel: Als fixe Eigenschaften eines Kondensators in der Tabelle: [Wert] [Footprint] [Hersteller] [Bauform] [MaxVolt] [Typ] [Tags] 1uF 0604 (42) (SMD) 16 (Ceramic) (cheap), (low esr) Die Eintraege in () waeren ueber weitere Tabellen indiziert. Die Tags-Tabelle muss irgendwer mal saeubern und klassifizieren. Um nach und nach eben diese ganzen Wunschfeatures einzufuehren, wollte ich mich moeglichst wenig mit Details wie Dropdown-Boxen und Tagging-Mechanismen beschaeftigen, sondern das moeglichst an ein CMS-Framework auslagern. Dann hat man auch eher die Moeglichkeit, Erweiterungen einzufuehren, dass sich jeder User mit seiner Herangehensweise "zuhause" fuehlt. Genau dort steckt, denke ich, der Hirnschmalz der diversen CMS-Systeme. Da ich das ganze wie erwaehnt ja an einer andern Baustelle (Verwaltung von unzaehligen Geraetebeschreibungen) eh einsetzen will, wuerde ich sagen, wir prototypen einfach mal munter weiter, und schauen, was rauskommt, bevor wir uns zu sehr den Kopf zerbrechen.
Hallo, ich habe mir den Thread durchgelesen und finde das Projekt schon sehr interessant, allerdings habe ich durch viele Details ein bisschen den Überblick verloren. Ich würde mir von dem Vorhaben folgendes versprechen: - Eine Internetdatenbank für Bauteile, die zwar primär für Kicad aufgebaut wird, theoretisch aber auch von anderen Programmen verwendet werden kann. - Eben eine Anbindung an Kicad, wobei ich aus der Internetdatenbank meine eigene lokale Library für meine Zwecke zusammenbauen kann. Die parametrische Suche sollte aber immer noch möglich sein. - Einbindung möglichst vieler Bauteileparameter und Zusammenfassung von Bauteiltypen (z.B. Widerstände, Transistoren, Operationsverstärker) für eine parametrische Suche (um z.B. das Finden von Ersatztypen zu erleichtern) - Was aber meiner Meinung ein absolutes No-Go ist, dass Bauteile gleichen Types verschiedene Symbole haben. Ein Bipolartransistor beispielsweise soll in meinem Design immer gleich aussehen! Man müsste also auch eine getrennte Symboldatenbank führen, bei denen man sich seine Lieblingssymbole für diese Standardbauteile heraussuchen kann. In der Bauteildatenbank wird also für solche Standardteile nur eine Referenz hinterlegt. Bei komplexeren Bauteilen macht das natürlich keinen Sinn mehr. Soviel zur Datenbank. Ist Bernd eigentlich noch aktiv hier? Er hat schon ewig nichts mehr geschrieben. Für ihn wären nämlich dann noch die folgenden Ausführungen (die werde ich aber vielleicht bei Gelegenheit auch direkt an die Kicad-Entwickler wenden): Was mich an der Bauteileverwaltung bei Kicad auch noch stört: - Ich möchte das Bauteilfenster als Dialog immer offen haben und nicht als modalen Dialog eingebunden haben. Ist sicher Geschmackssache, aber sollte als Option möglich sein. - Die parametrische Suche fehlt (wie ja schon erwähnt). - Die Größenverhältnisse der Symbole sind absolut irrsinnig (Kondensatoren und Widerstände sind z.B. viel zu groß) Und wer hat sich eigentlich das Konzept ausgedacht, dass Power-Pins wie Bauteile gehandhabt werden? Ist ja bei Eagle genauso. Ich kenne Systeme, da ist das viel eleganter gelöst: Man hat eine eigene Symbolgruppe für Power-Pins und globale Signale (letzteres gibt es bei Kicad ja). Diese kann man dann nach Belieben benennen. Man ist also nicht auf die festen Power-Benennungen angewiesen. Das ist ganz nett, wenn man zum Beispiel mit mehreren galvanisch getrennten Bereichen arbeitet und diese mit einem Suffix kennzeichnen möchte.
Hier ist ein Parser für Bestelllisten eines (bestimmten) Lieferanten. Meine Vorstellung ist, dies dazu zu nutzen, um entweder: - seine entsprechenden E-Mails durch Kopieren-Einfügen in ein Textfeld des Browser-Interfaces zu übertragen und dann in die DB einzulesen (wenn die Bestellbestätigungen eintreffen und man sie checkt) oder: - einen Mailfolder, in dem man seine Bestellungen speichert, automatisch auszulesen, um die Datenbank mit den früheren Bestellungen zu füllen. Offensichtlich braucht man für jeden Lieferant so einen "Connector".
Strubi schrieb: > wird es im Endeffekt bei der Community liegen, sinnvolle Daten zu generieren. Bingo. Die Lieferanten sind alles "nur" Leute, die das für Geld machen. Also machen sie das, was für sie selbst notwendig ist, und das, was für den Verkauf unerlässlich (oder gesetzlich vorgeschrieben) ist. Jeder Lieferant wieder neu und für sich. Organisieren und in eine übergreifende Struktur müssen wir es bringen, weil da jeder sein eigenes Pflänzen hegt. Ist ja auch legitim, jede Firma hat eigene Vorstellungen, und Freiheit bringt das mit sich. Aber vergessen wir nicht, dass sie uns so nebenbei ihre Sprachverwirrung aufzwingen, was uns bis zur Vereinheitlichung zahlreiche Probleme bereitet und einen gewissen Teil unseres Lebens (sicher meist ohne böse Absicht) zu einer Hölle macht, die sie nicht sein müsste, wenn man gleich etwas gemeinsames organisiert. Stichwort "Formatkrieg" (s. Wikipedia, z.B. Edison/Westinghouse). > Die Mammutaufgabe, einen "Google-Algorithmus" fuer die gespeicherten Parts/Footprints zu schreiben, haette ich auch hinten angestellt, wie auch die Feinheiten, die du beschreibst - denn das koennte man ja alles auch per Google auffinden. Nun ja, ich stehe bei jedem Entwurf konkret vor dem Problem, die Symbole und Footprints zu finden. Daher wird das wohl eher eine meiner ersten Ansätze Prioritäten sein. > ein Kicad-Library-User Ich will mich da nicht nur auf KiCad festlegen. gEDA ist vielleicht auch nicht schlecht. Da gibt's immerhin Simulatoren. Auch für KiCad? Eine Teilebibliothek ist an sich nicht vom CAD-Programm abhängig, da sich alle Daten zunächst nur auf die Teile beziehen: Herstellerbezeichnung, Aussehen (Foto/3D-Datei), Symbol, Footprint, Pinzahl, elektrische Eigenschaften, usw. Das Programm kommt erst am Schluss. Also müsste im Grund auch ein programmunabhängiges Format für das alles her. Da das aber (für mich) momentan mangels Überblick zu schwierig ist, optiere ich dafür, erstmal die freien Bibliotheken zu sammeln und die Teiledaten im jeweiligen Format zu speichern, wobei man ich sie kennzeichnen will, um sie zu unterscheiden. > Eigenschaften eines [Teils] in der Tabelle Ja, so in etwa. Ich würde aber erstmal nichts indizieren, sondern einfach alles im Klartext eintragen, weil die Programmierung sonst so umständlich wird. Die Normalformen der DBs würde ich erst in einem späteren Schritt herstellen. Man ist ja eh erstmal noch am groben Sammeln der wichtigsten Daten. Ich würde aber immer auch Benutzertags zulassen wollen. Von mir aus soll ein Komitee sich da was schlaues ausdenken, aber mit eigenen Tags kann ich sowas sehr leicht an meine Bedürfnisse anpassen und für meine Projekte oder sonstwas kategorisieren. > Details wie Dropdown-Boxen Geht mir genauso. Aber man kann auch mit Klicklinks arbeiten, solch Programmcode ist einfacher und übersichtlicher. Vor allem: es ist für den Benutzer übersichtlicher, weil man die ganze Liste im Blick hat. Ok, immer ist das nicht die beste Lösung, aber ... mal sehen. > wir prototypen einfach mal munter weiter, und schauen, was rauskommt Genau :-)
> Ein Bipolartransistor > beispielsweise soll in meinem Design immer gleich aussehen! Man müsste > also auch eine getrennte Symboldatenbank führen, bei denen man sich > seine Lieblingssymbole für diese Standardbauteile heraussuchen kann. In > der Bauteildatenbank wird also für solche Standardteile nur eine > Referenz hinterlegt. Ja, würde ich auch so sehen. Es gibt ja z.B. unterschiedliche Normen. Da sollte man vielleicht einen allgemeinen Schalter vorsehen (das erschlägt sicher die meisten Fälle), aber warum nicht auch persönliche Präferenzen ermöglichen. Es würde ja z.B. schon reichen, wenn die Symbole immer in der Häufigkeit der eigenen Verwendung aufgelistet werden. Dann stehen die Lieblingsteile immer oben in der Liste. > Die Größenverhältnisse der Symbole sind absolut irrsinnig Könnte ein Programm evtl. automatisch normalisieren. Oder halbautomatisch. Halbautomatisch ist aber immer mehr aufwand, weil man sich ein Benutzerinterface überlegen und programmieren muss. Man könnt auch Tests machen, z.B. ob Teile alle auf einem bestimmten Raster liegen. KiCad und gEDA arbeiten (zum Glück beide) mit mil (1/1000 Zoll). Da braucht man z.B. nur durch 200 zu teilen und sich den Rest anschauen, um zu wissen, ob ein Teil auf 2-Loch-Raster ist. Wäre doch ein praktisches Auswahlkriterium. :-)
didadu schrieb: > Ja, würde ich auch so sehen. Es gibt ja z.B. unterschiedliche Normen. > Da sollte man vielleicht einen allgemeinen Schalter vorsehen (das > erschlägt sicher die meisten Fälle), aber warum nicht auch persönliche > Präferenzen ermöglichen. Es würde ja z.B. schon reichen, wenn die > Symbole immer in der Häufigkeit der eigenen Verwendung aufgelistet > werden. Dann stehen die Lieblingsteile immer oben in der Liste. Ja, oder man stellt standardisierte Symbolsätze bereit. Mein Hauptanliegen an der Stelle ist eben nur, dass man Bauteile nicht fest auf Symbole verlinkt, da man sonst 100 Transistoren mit 10 verschiedenen Symbolen in der Internetdatenbank liegen hat - je nachdem wer das Bauteil gerade erstellt hat. didadu schrieb: > Könnte ein Programm evtl. automatisch normalisieren. > Oder halbautomatisch. Halbautomatisch ist aber immer mehr aufwand, weil > man sich ein Benutzerinterface überlegen und programmieren muss. Zur Not geht manuell anpassen ja auch, wenn man sich sowieso einen eigenen Symbolesatz wie oben erwähnt zusammenstellen kann. Ich denke mal, dass in den Standards auch die Symbolgrößen festgelegt sind, daran könnte man sich ja auch orientieren.
Hier ein weiterer Parser als Beispiel und Anleitung. Die State-Machine ist hier etwas einfacher und logischer, also besser. Ich habe einfach einen Lieferanten ausgewählt, der Bestellbestätigungen als html-Mail verschickt, da das etwas einfacher zu parsen ist, und weil ich die Bauteil in den Libs haben will, aber nur mühsam gefunden habe. Die zwei Bestellzeilen hätte ich natürlich einfach eintippen können. Aber dann hätte ja sonst niemand was davon gehabt. Diese Art Script kann direkt von der Commandline aus aufgerufen werden und parst dann die Beispieldaten im Script und gibt sie wieder aus (als Test). Es kann aber vor allem als Modul in ein anderes Python-Script importiert werden, sodass man die einheitlich benannten Funktionen als erweiterbares Modulsystem nutzen kann. Somit können wir unsere Parser miteinander teilen, um unsere Bestelllisten einfacher in unsere DBs zu importieren und die Zuordnungen und neuen Libs leichter gegenseitig zu komplettieren. Das Schreiben eines Parsers ist im Grunde eine Sache des Lieferanten, da er die Datenstruktur erstellt und am Besten weiß, wie man die Felder voneinander trennt. Wenn sie sowas schreiben und zur Verfügung stellen MÜSSTEN, würden die Hersteller sich vermutlich bald zusammentun, um einheitliche, wiederverwertbare Parser bereitzustellen -- wenn sie halt selbst die Kosten ihrer Babylonismus tragen müssten. Aber vielleicht schaffen wir ja mit so einem System einen Anreiz zur rationelleren Zusammenarbeit mit den Kunden. Manche Hersteller haben wohl auch Web-APIs (RPCs) für solche Zwecke. Aber das gibt's (bisher!!!) wohl noch nicht für Endkunden. Wird halt Zeit, dass ... ;-)
Die Versionsnummer bezieht sich übrigens nicht auf die Scriptversion, sondern auf die Version des Datenformats, das geparst wird. Ein Bugfix des Scripts führt also nicht zur Erhöhung dieser Nummer, sondern eine Änderung der Bestätigungsmails.
In eine komfortable Library-Verwaltung gehört natürlich auch eine Funktion zum Erstellen von Platinenheizungen. ;-) Siehe hier: Beitrag "Re: Platine als Flächenheizung" (Script und Beispiel). Ich will damit sagen, dass man sowas im Prinzip sehr leicht einbauen kann. Für diesen Fall ist die wesentliche Arbeit schon erledigt. Man bräuchte nur noch einen kleinen cgi-Wrapper, müsste den Footprint mit einem Symbol verknüpfen und dann das erstellte Teil an einem geeigneten Ort in der Datenbank speichern. (Allerdings habe ich noch keine Infos über das Footprint-Format und wie das mit dem Symbol zusammengestrickt wird.)
Hallo zusammen. Nachdem Rene die undankbare Aufgabe erledigt hat, die Ankerpunkte von unten links in die Nähe des Symmetriepunktes zu verschieben und Fehler zu beseitigen, bin ich hier gerade dabei, die Symbole alle umzubenennen und etwas Doku zu machen. Die ganzen "Big" fliegen raus in eine eigene library, für die, die gerne Plakate malen. :-) Beim Rest verschwindet das "Small", und alle, auch die "BIG" (die auch Ihr "Big" behalten), erhalten einen Suffix der Form Tiefstrich REV aktuelle Revision Tiefstrich DATE Tag als Zahl monat als abgekürzter Name Jahreszahl. Beispiel: "_REVE_DATE15JUN2010". Dann gibt es wenigstens keinen Ärger, wenn unterschiedliche Symbole mit gleichem Namen durcheinanderfliegen. Einschub an sven P.: >Also ich find, es gibt nix Hinderlicheres beim Arbeiten, als solch >ellenlange Bezeichnungen. Mich hat das in der Target-Bibliothek schon >immer gestört, drum hab ichs bei meinen Bibliotheken anders gemacht und >nur noch kurze, knackige Präfixe benutzt. >Bisher gabs noch keine Namenskollisionen ;-) Hast Du mal Beispiele? Wie liesse sich das in KiCAD umsetzten, ohne Kollisionsfälle zu schaffen? Einschub Ende Die EN60617 Library wird noch mal in vergleichbarem Umfange wie vorher veröffentlicht. Wenn die "BIG" rausfliegen, ist sie gleich viel handlicher, und ich gehöre zu denen, die gerne alles zusammen bei Hand haben. Für die Organisationsfreaks werde ich gleichzeitig aber auch Abspaltungen daraus herstellen: Einmal nur die EN60617 Symbole, und den Rest als "Needfull" library. Um die EN60617 Biblothek nicht so furchtbar Aufzublähen, würde ich am liebsten auch die "array" Versionen, als Klemmen, widerstandsarrays, Dip-schalter ec, in eine extra Bibliothek auslagern......mal sehen. Die ICs und Trafos bleiben erstmal so (bis das die auch den Suffix bekommen). Sind ja noch nicht viele, und eine weitere Library mit ein paar Optokopplern. Die Doku wird wohl so aussehen, das ich alle Symbole der jeweiligen Library in Schaltpläne packe, die in SVG audgebe, Kommentare dazu schreibe (wenn nötig), sollte bei den EN60617 nicht nötig sein, aber bei den "Needfull Things" bestimmt. Weil der Sinn und Zweck von z.B. Dummy Symbolen sich Anfängern eben nicht immer von selber erschliesst. Danilo Ucelli hätte für seine Website mit KiCAD Bibliotheken gerne eine Beschreibung als Text....ich grüble, ob da ein "Readme" langt...... Über die Organisation der Footprints habe ich mir noch nicht so große Gedanken gemacht. Wärend ich die Symbolbibliothek für mich persönlich als fast komplett ansehe (weil IC sind schnell gemacht, Kasten, Pinne dran und benahmsen), sehe ich noch riesen Lücken in den Footprints. Insbesondere bei SMD. Und ich habe ein paar Ideen bezüglich "universalfotprints" um auf Experimentierplatinen das einzusetzten, was gerade da ist, oder wenn man aus ausschlachtmaterial was Bastelt. z.B. Extrem langezogene Keilförmige Pads, die für 0602 über 0805 bis 1206 gehen. vieleicht noch Thruhole Löcher für 10mm Rastermass dazu..... Universalfootprints für z.b. gleichzeitig für 8 Pinnig DIL oder SOIC sind problematischer als ich dachte. Ich muss mir dazu noch mal was überlegen und vieleicht auch testen. Desweiteren noch ein paar Montagelöcher ohne Restring.....für die, die dabei Bauchschmerzen haben. Es fehlen noch weitere Wago-Klemmen und vor allem Mate-N-Lock und Mini-Mate-N-Lock Stecker. Hallo Puffel. > Gibt es eigentlich außer diesem Thread eine Art Homepage, wo Bernd's > Projekt etwas detaillierter beschrieben ist bzw. wo die ganzen Infos, > Quellen und Diskussionen verfügbar sind? Es gibt hier im Mikrocontroller Net einen Artikel: http://www.mikrocontroller.net/articles/KiCAD Einiges von meinem Kram landet auch noch hier: http://www.darc.de/distrikte/l/02/con_technik_beitraege.shtml Der Update erfolgt aber recht langsam......es ist nicht meine Seite. Und natürlich in der KiCAD-User Group bei Yahoo. Dort findet nicht nur eine diskussion statt, es können, für angemeldete Nutzer, auch files abgelegt werden. Persönlich bin ich in Punkto Perogrammieren, Networking und Datenbanken nicht wirklich kompetent. Darum habe ich mir eine eigene HP bis jetzt verkniffen. Zusammen mit den librarys werde ich meine Notitzensammlung noch veröffentlichen. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic
Hallo Bernd, ich poste gleich mal hier rein. Zum aktuellen Sand meinerseits. > Im Moment bin ich gerade dabei mich etwas in Python einzulesen und > > meinen Vorschlag zur Versionierung von einzelnen KiCad-Symbolen selbst > > umzusetzen. > > > > Beitrag "Re: [KiCad] Bibliotheksaufbau - Konzeptideen gesucht" > > > > An neuen Symbolen sind ein paar Operationsverstärker nach IEC60617 mit > > unterschiedlichen Pinnummer in Arbeit, welche ich ganz gerne beisteuern > > würde. Bernd: Beim Rest verschwindet das "Small", und alle (auch die "BIG" erhalten einen Suffix der Form Tiefstrich REV aktuelle Revision Tiefstrich DATE Tag als Zahl monat als abgekürzter Name Jahreszahl. Beispiel: "_REVE_DATE15JUN2010". Dann gibt es wenigstens keinen Ärger, wenn unterschiedliche Symbole mit gleichem Namen durcheinanderfliegen. Rene: > Das ist gut. Es würde mir reichen wenn du dies nur innerhalb der > Bibliothek machst. Bernd: Die EN60617 Library wird noch mal in vergleichbarem Umfange wie vorher veröffentlicht. Wenn die "BIG" rausfliegen, ist sie gleich viel handlicher, und ich gehöre zu denen, die gerne alles zusammen bei Hand haben. Für die Organisationsfreaks werde ich gleichzeitig aber auch Abspaltungen daraus herstellen: Rene: Mein Vorschlag. Erstelle nur die große Bibliothek das separieren von einzelnen Symbolen mache ich per Script (mein 1. Schritt mit Python) denn ich kenn den Aufwand dies von Hand durchzuführen ;-). Nach einer 1/2 Stunden hast du keine Lust mehr darauf ;-).Ich schick dir die einzelnen Dateien wieder und du brauchst diese nur noch umbennen (suffix-erweiterung), fertig. Später gibts das script hier sowieso. PS: Python-Crackheads, lasst mich was lernen und postest nicht voreilg ;-). Bernd: Danke für Deine Mühe, die Ankerpunkte zu verschieben. Allerdings ist es nicht immer einfach, eine Symmetrie zu finden, bzw. zu treffen. In einigen Fällen scheint es sinnvoller zu sein, Lediglich die symmetrie bezüglich der Pinne zu beachten. Aber das hängt am Einzelfall und auch an persönlichen Vorlieben..... Was sich als unglücklich herausgestellt hat, ist, wegen der Symmetrie vom 50mil Raster abzuweichen. Hier würde ich sagen, Raster geht vor Symmetrie. Es ist mehr Klickarbeit, das Raster zum Anschliessen zu ändern, als ein Symbol etwas zu verschieben. Wie siehst Du das? Rene: Ich habe versucht maximal nur eine Rastestufe runter zugehen, so dass man entweder 50mil oder 25mil vorfindet. Ich gebe dir recht das dies nicht ganz so optimal ist aufgrund des stetigen Raster umschaltens. Ich schlage vor alles auf 50mil anzupassen und gut ist. Das ist am einfachsten und geht am schnellsten zu verdrahten. Um Symetrie mache ich mir keine Sorgen weil diese manchmal auch hinderlich sein kann bzw. ein Ankerpunkt unten Rechts idealer gewesen wäre. Den Ankerpunkt sollten einfach nach Erfahrung setzen und erst bei größerer Nachfrage ändern. Wir setzen den ja nicht sonst wohin. Du musst den Anker aber nicht gleich bei allen ändern und die 50mil Anpassung drchführen. Ich würde mich da wieder dran beiteiligen! Bernd: Hast Du irgendwelche Ideen zur Dokumentation? Die Doku wird wohl so aussehen, das ich alle Symbole der jeweiligen Library in Schaltpläne packe, die in SVG audgebe, kommentare dazu schreibe (wenn nötig), sollte bei den EN60617 nicht nötig sein, aber bei den "Needfull Things" bestimmt. Weil der Sinn und Zweck von z.B. Dummy Symbolen sich Anfängern eben nicht immer von selber erschliesst. Rene: Prinzipiell würde ich OpenOffice verwenden wollen. Wobei ich beruflich leider MS arbeiten muss und da entsprechend fixer bin aber en Video-Tutorial für OO ist unterwegs. Kleine Bildchen der Symbole & Footprints ansich ist immer gut, auch für eine zukünftige Datenbank als Vorschau zum Beispiel. Dies muss ich aber noch anschauen wie man das Zeit sparend umsetzten kann, diese Bilder zugenerien.(Mach ich heut Abend mal!) Das muss ich alles mal noch sichten bzw. genauer unter die Lupe nehmen. -> >Über die Organisation der Footprints habe ich mir noch nicht so große >Gedanken gemacht. Wärend ich die Symbolbibliothek mür mich persönlich >als fast komplett ansehe (weil IC sind schnell gemacht, Kasten, Pinne >dran und benahmsen), sehe ich noch riesen Lücken in den Footprints. >Insbesondere bei SMD. Und ich habe ein paar Ideen bezüglich >"universalfotprints" um auf Experimentierplatinen das einzusetzten, was >gerade da ist, oder wenn man aus ausschlachtmaterial was Bastelt. z.B. >Extrem langezogene Keilförmige Pads, die für 0602 über 0805 bis 1206 >gehen. vieleicht noch Thruhole Löcher für 10mm Rastermass dazu..... >Universalfootprints für z.b. gleichzeitig für 8 Pinnig DIL oder SOIC >sind problematischer als ich dachte. Ich muss mir dazu noch mal was >überlegen und vieleicht auch testen. >Desweiteren noch ein paar Montagelöcher ohne Restring.....für die, die >dabei Bauchschmerzen haben. >Es fehlen noch weitere Wago-Klemmen und vor allem Mate-N-Lock und >Mini-Mate-N-Lock Stecker. >Kennst Du >http://www.mikrocontroller.net/wikifiles/4/41/BuildingBlocksKiCAD-EXPERIMENTELL.zip >und wenn ja, was hälst Du davon? Nun aber erstmal etwas schaffen. VG, Rene
Moin, wie ist denn der SVN-Status zu den kicad-Files? Kann man schon was auschecken/angucken, und wenn ja, wo? Ich bin hier auch etwas weitergekommen. Habe mit dem web2py-Framework experimentiert und die Datenkbankstruktur soweit mit allen Kreuzreferenzen lose festgeklopft. web2py ist zwar etwas schwergewichtiger, aber macht Datenbank-Migrationen und Erweiterungen zu einem Klacks, da die Struktur der Datenbank im Code selbst beschrieben wird. Scheint mir bisher relativ Fehler-unanfaellig zu sein (zumindest mit sqlite3). Fazit, die Wahl ist auf web2py gefallen, das System ist wirklich extrem durchdacht. Ich arbeite gerade noch am Aufschalten einer ersten Testversion, das Problem liegt noch bei meinem Provider mit fehlender Unterstuetzung fuer Apache und Python, momentan laesst sich das ganze nur per CGI aufrufen und hat noch ein paar Boecke mit Permissions. Wenn jemand das ganze mit Apache/WSGI und VirtualHosts hosten mag und kann, bitte laut schreien. Das Parsing von kicad->XML ist fuer Libraries schon relativ weit fortgeschritten, dank SimpleParse. Kann/sollte bald mal ins SVN... Gruesse, - Strubi
Angehängte Dateien:
-

kicad-symbole.png
4,8 KB
{kind=link}
Ich habe noch eine kleine Anmerkung zu den Bauteilen: Man solle bei einigen Standardbauteilen vielleicht auch die Möglichkeit geben, direkt zusätzliche Parameter anzugeben, die man sich dann auf dem Schaltplan anzeigen lassen kann. Manuell geht das ja (siehe Screenshot im Anhang), aber es wäre wünschenswert, wenn es dafür schon eine Voreinstellung gibt.
Moin Gemeinde, ich habe mal eine Sandbox aufgeschaltet als Beispiel fuer eine Datenbank - damit sich die Spam- und Crawlerbots da nicht gerade reinhaken: http://dclib dann kommt ein punkt, dann: station5.ch/parts/ Was leider noch nicht online funktioniert, ist die Konversion von kicad nach XML-files, da mein Hoster die Installation von eigenen Python-Binaries nicht erlaubt. Im Prinzip geht das so, dass man sich einloggt, eine kicad-.lib hochlaedt, diese wird in einzelne Elemente geparst und die Datenbank mit den XML-Daten gefuellt. Anschauen kann man bisher nur die "Symbols". Braucht einen SVG-faehigen Browser, getestet ist nur Firefox, auf anderen laden vermutlich die Symbol-Grafiken nicht. Und ohne Javascript keinen Spass. Die Grafiken werden aus den XML-Daten erzeugt, Bounding Box stimmt noch nicht, und es kann dauern, da die Aufrufe ueber CGI gehen. Bitte keine langen Fehlerlisten oder Feature requests posten, das ganze ist eine langsam voranschreitende Baustelle (wir haben ja auch alle noch ein undankbares, wahres Leben). Nehme gerne weitere Parser-Module an, und baue sie testweise ein. Alles was in pur-Python geht, laesst sich prima einbauen um die Datenbank zu fuellen. Gruesse, - Strubi
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.