Hallo
ich habe in rund 3h mal für einen VT100 Screen mit 80x24 das Game of
Live durchprogrammiert. Erstmal die Funktion. Klappt auch alles soweit,
außer dass das Ganze auf 3,9 Mhz ein Standbildsimulator ist. Die
Berechnung jeder generation dauert rund 5 Sekunden. Die Zeit wird in der
Analyse jeder einzelnen Zelle und ihrer Nachbarn verschwendet (1920
Punkte * 8 Nachbarn). Den Bildaufbau mache ich nur dort neu, wo sich was
ändert. Arbeit mit ziwe Tabellen, wo jeweils der neue Screen
eingeschrieben wird und dann der alte mit memcpy angeglichen. Ausgabe
ist mit ncurses. Startbildschirm ist Zufalllsmuster, was aber keine 20
Generationen überlebt, bis es ein Standmuster wird. Bewegung etc kommt
nie zustande :-(
Gibt es Optmierungstrategien für sowas? PC Simulationen sind ja auch
sehr schnell und haben viel größere Felder.
1
// Game of Life
2
3
#define MAX_X 79
4
#define MAX_Y 23
5
#define START_RANDOM 699
6
#define START_ZELLEN 400 // Anzahl der zum Start bevölkerten Felder
7
#define GENERATIONS 5000
8
9
#define DEAD_CELL 0
10
#define ALIVE_CELL 1
11
12
// Zustände der nächsten Generation
13
enum cell_stat {DEAD=0,ALIVE};
14
15
uint16_t randstart = 100;
16
uint16_t maxgens = 0;
17
18
// 2 Spielfelder
19
enum cell_stat feld_last[MAX_X+1][MAX_Y+1];
20
enum cell_stat feld_next[MAX_X+1][MAX_Y+1];
21
22
/*
23
Prüft was mit einer einzelnen Zelle passiert in der
Christian J. schrieb:> Startbildschirm ist Zufalllsmuster, was aber keine 20> Generationen überlebt, bis es ein Standmuster wird. Bewegung etc kommt> nie zustande :-(
Verwendest Du wirklich bei jedem Start ein anderes Zufallsmuster? Oder
verwendest Du bei jedem Durchlauf das exakt selbe Zufallsmuster wie es
Dein Code nahelegt, bei Verwendung eines Pseudozufallszahlengenerators
mit konstant feststehendem Startwert?
Im übrigen ist es so, dass nur ganz bestimmte Ausgangsmuster zu Bewegung
führen, sichtbar z.B. in diesem Youtube-Video:
https://www.youtube.com/watch?v=C2vgICfQawE
Es dürfte möglicherweise schwierig sein, geeignete Ausgangsmuster nur
mit reinem Zufall zu bekommen, die zu länger dauernden Bewegungen führen
und nicht bereits nach wenigen Generationen zu einem Stand-/Wechselbild.
Jürgen S. schrieb:> Verwendest Du wirklich bei jedem Start ein anderes Zufallsmuster? Oder> verwendest Du bei jedem Durchlauf das exakt selbe Zufallsmuster wie es> Dein Code nahelegt,
Hi,
habe den Code seit dem Posten schon verändert..
nee.... ich verwende da das sog. DRAM Refresh Register, was bei der CPU
ständig läuft ab Reset. Da die CPU aber nicht weiss, wann ich "Start"
drücke ist da immer ein anderer Wert zwischen 0...127 drin.
uint8_t rreg;
// Hole den zufälligen Wert des R Registers
uint8_t get_rreg() {
__asm
ld a,r
ld (_rreg),a
__endasm;
return (rreg);
}
....
srand(get_rreg()); // Zufall initialisieren mit R Register
Ich habe auch mit verschiedenen Strategien exoperimentiert wann wer lebt
und wann wer krepiert. Manche führen schnell zu einem leeren Feld,
andere zur Explosionsvermehrung, bis fest stehende Muster da sind.
PS:
Dieser supereinfache "Zufall" erzeugt übrigens grafisch völlig
ausreichende Muster mit einer guten Vertreilung. Ist natürlch nur ein
Standbild, ich sehe ja wie es sich aufbaut. Und deutlich schneller und
kürzer als rand()
#ifdef USE_SIMPLE_RANDOM
static uint16_t seed=1000;
void sprng(uint16_t start)
{
seed = start;
}
uint16_t prng(uint16_t max)
{
uint16_t result;
seed ^= seed<<7;
seed ^= seed>>9;
seed ^= seed<<5;
result = seed % max;
return (result);
}
#endif
Christian J. schrieb in Prozedur cell-status:
> for (y=ypos-1;y<=(ypos+1);y++) {> for(x=xpos-1;x<=(xpos+1);x++) {> // Eigenes Feld aussschliessen> if ((x!=xpos) && (y!=ypos)) {
Die booleschen Ausdrücke in der if-Abfrage sind für diesen Zweck logisch
falsch, denn die if-Bedingung lautet: Abfrage, wenn x nicht gleich xpos
UND y nicht gleich ypos. Damit werden nur die 4 Nachbarzellen diagonal
in den Ecken abgefragt. Die 4 Nachbarn über und unter sowie links und
rechts neben der Mittelzelle werden ausgelassen, denn da ist entweder
nur x nicht gleich xpos oder es ist nur y nicht gleich ypos.
Richtig wäre z.B. die Abfrage: if (!((x == xpos) && (y == ypos)))
Also: Abfrage, wenn NICHT (x gleich xpos UND y gleich ypos)
Oder andere Schleifen mit anderer Abfrage:
for (y = -1; y <= 1; y++) {
for(x = -1; x <= 1; x++) {
if (!((x == 0) && (y == 0))) {
if (cells_last[xpos + x][ypos + y] == ALIVE)
lebende_nachbarn++;
} } }
Mehr Bewegung koenntest du auch kriegen, wenn du 'randuebergreifend'
arbeitest. D.h der rechte Nachbar des am weitesten rechts liegenden
Feldes einer Zeile ist des Feld am Zeilenanfang. Sinngemaess fuer alle
anderen Richtungen.
Sinn der Sache ist es, dass zb ein Glider, der sich nach schraeg rechts
oben bewegt nicht einfach verschwindet, wenn er den physikalischen
Bildschirmrand erreicht, sondern einen Wrap-around macht, links wieder
reinkommt und seine Fahrt fortsetzt.
Die Modifikation klingt jetzt kompliziert, ist es aber nicht.
Mathematisch ist das ganze äquivalent zum vorgehen, wie wenn du die
linke znd rechte Kante eines Blattes Papier zusammenklebst und den so
entstandenen Zylinder oben und unten noch mal zusammenklebst, wodurch
sich ein Torus ergibt. Lass dich davon aber jetzt nicht verwirren, du
brauchst nur bei der Nachbarsuche einfach nur entsprechende
Modifikationen, so dass das rechte,linke,obere,untere Nachbarfeld hier
1
// Ränder ignorieren (-1 o. > MAX)
2
if((y>=0)&&(y<=MAX_Y)&&(x>=0)&&(x<=MAX_X)){
Immer existiert. Der rechte Nachbar in x Richtung des Feldes MAX_X ist
einfach das Mit dem Index 0. Der linke Nachbar des Feldes 0 ist MAX_X.
In y Richtung sinngemaess dasselbe.
Christian J. schrieb:> Gibt es Optmierungstrategien für sowas?
Natürlich.
Die erste hast du schon: Array statisch machen.
Dann:
Alle Überpüfungen auf dem inneren der Schleife rauswerfen,
also:
Keine Randfelderprüfung, Array einfach 2 grösser machen
und nur den inneren Bereich neu rechnen.
Statt 2-dimensionalem Array eindimensional.
Zugriff auf 8 Nachbarn ohne Schleife über ermittelten Offset
ptr zeigt auf aktuelles Feld
ptr[-MAX_X-1]+ptr[-MAX_X]+ptr[-MAX_X-1] + ptr[-1]+ptr[1] +
ptr[ MAX_X-1]+ptr[ MAX_X]+ptr[ MAX_X-1]
Ob die Ausgabe wirklich schneller wird, wenn du Änderungen
prüfst, sei dahingestellt, hängt vom System ab.
Die Analyse muesste sich beschleunigen lassen, indem du nicht fuer jede
Zelle einzeln die Anzahl seiner Nachbarn bestimmst, sondern die Sache
aus der Sichtweise einer Zelle siehst: zu welchen Zellen rund um mich
trage ich als Nachbar bei?
D.h. du hast ein entsprechendes 2D Array, in dem die Anzahl der lebenden
Nachbarzellen sukzessive entsteht und das mit Initialwerte 0 beginnt.
Jede momentan lebende Zelle erhoeht diesen Zaehler bei seinen 8 Nachbarn
um 1. Hast du auf die Art alle momentan lebenden Zellen durchgearbeitet,
ist in diesem Array fuer jede Zelle der naechsten Generation die Anzahl
der momentan lebenden Nachbarn entstanden, die du nur noch bewerten
musst.
>Den Bildaufbau mache ich nur dort neu, wo sich was ändert.
Das ist lieb gemeint, aber in Summe duerfte das langsamer sein, als wenn
du einfach alle Zeichen einer Zeile in einem String sammelst und dann
die Zeile in einem Rutsch als String ausgibst.
>PC Simulationen sind ja auch sehr schnell und haben viel größere Felder.
Dein Z80 laeuft mit rund 4Mhz, ein PC mit rund 4Ghz. Das alleine ist
schon ein Faktor von 1000, um den dein PC schneller ist.
(1) Darf ich davon ausgehen, dass du aus alter Gewohnheit unoptimiert
üersetzt?
(2) In Code der Art
for (y=ypos-1;y<=(ypos+1);y++)
passt der Grenzwert von y aus Sicht des Compiler nicht mehr sicher in
char, sondern ist int, weshalb der Vergleich in 16 Bits gerechnet werden
muss.
(3) Der Typ char hat ein Vorzeichen, womit die Z80 deutlich mehr
Probleme hat als ohne Vorzeichen.
PS: Das ist kein Kleinkram sondern gibt - beides mit Optimierung - sowas
wie
Karl Heinz schrieb:> Das ist lieb gemeint, aber in Summe duerfte das langsamer sein, als wenn> du einfach alle Zeichen einer Zeile in einem String sammelst und dann> die Zeile in einem Rutsch als String ausgibst.
Die Anzahl der über die Uart übertragenen Zeichen bleibt aber gleich. Es
werden nur VT100 Steuercodes gesendet. Ich habe mir das angeschaut, die
Zeit verschwindet in den Berechnungen, nicht im Bildaufbau.
Rainer V. schrieb:> Die booleschen Ausdrücke in der if-Abfrage sind für diesen Zweck logisch> falsch, denn die if-Bedingung lautet:
Ja, habe ich auch bemerkt, es entstanden falsche Ausgaben. Danke !
Weiterhion habe ich den Feldrand einfach "tot" gelassen, alle
Durchsuchungen lassen die äußeren Felder aus, das reduziert die
Durchlaufzeit um einiges.
Wie man es allerdings hinbekommen soll, dass zellen oben auswandern und
unten wieder rein weiss ich nicht ohne dass deutlich mehr Code nötig
ist. Ich könnte mir nur vorstellen, dass wenn eine Zelle in den toten
Rand hineinwachsen will ich die zum Schluss der Berechnung aufsammel an
allen vier Ecken und rüpber spiegele.
Christian J. schrieb:> Wo sind denn da welche?
In C wird mindestens in "int" gerechnet, zumindest dem Ergebnis nach.
Folglich kann y+1 auch 256 sein. Weshalb der Compiler auch wirklich eine
16-Bit Rechnung und einen 16-Bit Vergleich durchführen muss. Es sei denn
der Compiler kennt der realen Wertebereich von y und berücksicht das.
Was bei GCC hier anzunehmen ist, aber bei SDCC würde ich da nicht drauf
wetten.
A. K. schrieb:> Ohne Optimierung gibts halt keine Optimierung...
Die schalte ich nur bei "release" ein, das dauert 20 Minuten !!!! bis
der sdcc fertig ist mit "Optimierung".... AMD 3.8GHZ Quadcore. SDCC
nimmt aber nur 1 Core.
Bei abgeschalteter Optimierung wird jeder einzelne Zwischenschritt auch
in Code umgesetzt, oft mit Speichervariablen für Zwischenergebnisse.
Dementsprechend sieht der Code dann aus.
Es wird ja wohl auch eine Optimierung geben, in der er nicht alle
Permutationen von 1000 Befehlen einzeln durchprobiert.
Moin!
Beim Video ist mir aufgefallen, dass das Terminal mit 9600bps läuft. Da
wird das ganze nicht viel schneller angezeigt. Wie sieht es bei höheren
Bitraten aus?
StefanL schrieb:> Beim Video ist mir aufgefallen, dass das Terminal mit 9600bps läuft. Da> wird das ganze nicht viel schneller angezeigt. Wie sieht es bei höheren> Bitraten aus?
Die 38400 Baud kommen erst nächste Woche, wenn mir Conrad den 5.9 Mhz
Oscillator liefert, damit die SIO höher getaktet werden kann. Der MK3801
Uralt-Baustein kann nur 9600 derzeit. Hallo AK :-)
A. K. schrieb:> Waren wir zwischenzeitlich nicht bei 57600? Oder hast du den Loader> nicht wenigstens zeilenweise mit XOFFs bestückt bekommen, wie jemand> anregte?
Andere Baustelle... XON XOFF lief nicht. stty verweigerte es anzuhalten.
Und 56700 auch nicht wie Du weisst, weil das nur auf TX geht aber nicht
auf RX. Und mixen will ich nicht und geht nicht bei minicom. Die Ausgabe
auf 57600 war auch nicht deutlich schneller.
Christian J. schrieb:
> Feldrand einfach "tot" gelassen, alle Durchsuchungen lassen die> äußeren Felder aus, das reduziert die Durchlaufzeit um einiges.
Sehr zu empfehlen, wenn das Spielfeld Ränder hat und sofern genug RAM
verfügbar ist. Sonst ist das bei großen Spielfeldern nicht zu machen.
> ...zellen oben auswandern und unten wieder rein weiss ich nicht ohne> dass deutlich mehr Code nötig ist.
Soviel Code ist es nun auch wieder nicht.
> ...eine Zelle in den toten Rand hineinwachsen will ich die zum Schluss> der Berechnung aufsammel an allen vier Ecken und rüber spiegele.
Da wird nichts aufgesammelt oder gespiegelt. Es funktioniert, wie beim
Ringpuffer. Der hat weder Anfang noch Ende, ist aber ein normales Array.
Jede Dimension beginnt mit Index Null, auch der Ursprung für x und y ist
nicht (1;1), sondern (0;0). Der Nachbarzellen-Index errechnet sich aus
dem Mittelzellen-Index wie hier am Beispiel für die x-Dimension:
(x_Mittelzelle + x_Nachbarabstand + x_Array_Größe) % x_Array_Größe
Dieser Code erscheint umfangreich, aber dafür entfallen tote Ränder und
die Prüfungen, ob x und y noch innerhalb der Array-Dimensionen liegen.
Rainer V. schrieb
> dem Mittelzellen-Index wie hier am Beispiel für die x-Dimension:> (x_Mittelzelle + x_Nachbarabstand + x_Array_Größe) % x_Array_Größe
Wobei ich mir vorstellen koennte, dass hier explizite Vergleiche besser
sind, als eine Modulo Division
Danke!
Auch wenn ich noch nicht genau weiss, wie ich ein "gerolltes" Feld
programmtechnisch erfassen soll, da es ja "unendlich" ist. Die beiden
Ringbuffer bei mir sind für die Uart, RX und TX. % kann man ersetzen
durch ein "& mask" bei Vielfachen von 2. % brauccht viel Code und Zeit.
Der Index X =-1 beim Array (Abfrage des linken Nachbarn neben 0) muss ja
dann auch gerollt werden zu X = MAX usw.
|-----------------------|
-1 0 79
|---------------------------^
Karl Heinz schrieb:> Prev_x = ( x == 0 ) ? MAX_X : x - 1;> Next_x = ( x == MAX_X ) ? 0 : x + 1;> Prev_y = ( y == 0 ) ? MAX_Y : y - 1;> Next_y = ( y == MAX_Y ) ? 0 : y + 1;
So ist es, das da unten sind 22 Bytes Kot und sie "wandern vom einem End
zum Anderen" :-)
1
int8_t y,x;
2
uint8_t x1,y1;
3
4
for (y = ypos-1;y <= (ypos+1);y++) {
5
for(x = xpos-1;x <= (xpos+1);x++) {
6
7
// Abfangen der Ränder und Erweiterung auf Gegenüber
Christian J. schrieb:> ich habe in rund 3h mal für einen VT100 Screen mit 80x24 das Game of> Live durchprogrammiert. Erstmal die Funktion. Klappt auch alles soweit,> außer dass das Ganze auf 3,9 Mhz ein Standbildsimulator ist. Die> Berechnung jeder generation dauert rund 5 Sekunden. Die Zeit wird in der> Analyse jeder einzelnen Zelle und ihrer Nachbarn verschwendet (1920> Punkte * 8 Nachbarn). Den Bildaufbau mache ich nur dort neu, wo sich was> ändert. Arbeit mit ziwe Tabellen, wo jeweils der neue Screen> eingeschrieben wird und dann der alte mit memcpy angeglichen. Ausgabe> ist mit ncurses. Startbildschirm ist Zufalllsmuster, was aber keine 20> Generationen überlebt, bis es ein Standmuster wird. Bewegung etc kommt> nie zustande :-(>> Gibt es Optmierungstrategien für sowas? PC Simulationen sind ja auch> sehr schnell und haben viel größere Felder.
Ich habe jetzt mal eine Version aus dem Internet heruntergeladen und für
die Arduino-IDE angepasst. Ausgabe auf Serial-Terminalprogramm, mit
Löschung des Bildschirms zwischen den Generationen über
VT100-Steuercode.
Bei einer Größe von 79x24 dauert die Initialisierung mit anschließender
Berechnung von 100 Generationen und Ausgabe mit 115200 Baud knappe 25
Sekunden.
Also 4 Generationen Berechnen und Ausgeben in einer Sekunde.
Auf einem Atmega2560 mit 16 MHz Systemtakt.
Das Spielfeld wird "über den Rand" gerechnet, d.h. als Feld "rechts
außerhalb" wird das Feld vom linken Rand genommen, als Feld "unten
außerhalb" das Feld vom oberen Rand. Also wird so getan, als wenn das
Spielfeld in jeder Richtung mehr eine geschlossene Zylinderfläche
darstellt. Wodurch am Rand kein Massensterben stattfindet, sondern im
Gegenteil die Muster, die an einer Seite aus dem Spielfeld rauslaufen,
am anderen Ende wieder erscheinen.
Jedenfalls ist von der Anfangsbedingung ausgehend (ist in diesem Fall
immer dieselbe) nach 100 Generationen noch nichts ausgestorben, sondern
immer noch Leben drin.
Arduino Sketch habe ich drangehängt.
Damit jeder die Datei hier im Forum sehen kann, mit .c Dateiendung
hochgeladen (muss für Kompilierung mit Arduino mit "ino" Dateiendung
gespeichert werden).
Edit/Nachgerechnet: Bei 115200 Baud gehen 11520 Zeichen pro Sekunde über
die serielle Schnittstelle. D.h. das Senden von 80x24= 1920 Zeichen
dauert ca. 1920/11520= 0,167 Sekunden. Wenn das Berechnen+Ausgeben pro
Generation ca. 0,25s benötigt und das Ausgeben auf Serial alleine
bereits 0,167s, dann entfällt auf die Berechnung alleine 0,25s-0,167s =
unter 0,1s Berechnungsdauer pro Generation bei 16 MHz Controllertakt.
Naja, viel anders ist meine Lösung auch nicht aber 1 Generation dauert
eben locker 4s.
Kann sein dass der gcc besser ist, Atmega schneller usw. Aber auf die
gleiche Lösung bin ich auch gekommen und die ist eben etwa zäh, stirbt
aber auch nicht aus, wenn man über die Ränder gleiten läst. Meine
Viecher leben auch nach der 1000.ten Generation noch.
PS: Der Atmega hat 1 Befehl pro Takt! Der Z80 braucht deutlich mehr
Takte
für jeden Befehl! Unterm Strich sind das nicht mehr als vielleicht
700.000 Befehle/s.
Nettes Programmierspielzeug... anbei mein Code.
PS: Meine "Wraparound" Lösung ist deutlich kürzer und effizienter.
Ich probiers mal eben aus mit dem Arduino Mega....mal schauen.....
Ok, geht rasend schnell. Leider reagiert das eingebaute Terminal nicht
auf den Home Befehl.
Christian J. schrieb:> Könnte sein, ganz schön Code....> 219 ;life.c:86: for (y=1;y < MAX_Y;y++) {> 1EEB DD 7E 04 [19] 220 ld a,4 (ix)> 1EEE DD 77 EB [19] 221 ld -21 (ix),a
Compiler zu blöd, mach mal ALLE (funktions-lokalen) Variablen
statisch (oder global),
denn keine Funktion wird rekursiv aufgerufen und der strunzdumme
blickt das nicht.
MaWin schrieb:> Compiler zu blöd, mach mal ALLE (funktions-lokalen) Variablen> statisch (oder global),
Bei abgeschalteter Optimierung ist optimierter Code nicht zu erwarten.
Kann man dem Compiler keinen Vorwurf machen.
A. K. schrieb:> Bei abgeschalteter Optimierung ist optimierter Code nicht zu erwarten.> Kann man dem Compiler keinen Vorwurf machen.
Natürlich ist die Optimierung ein aber die reisst es auch aus dem
Leder..... der Code sieht trotzdem schlimm aus, weil der Compiler damit
nicht klar klommt eine hohe "cyclomatic complexity" zu haben. Und glaube
mir, bei meiner Hartnäckigkeit habe ich Stunden damit verbracht das zu
optmieren und alles global gemacht, das Zeiger Gedönse so gut es geht
raus.
Anbei der Asm Code..... das wird nicht besser, auch nicht bei 30 Minuten
"optimieren" bei 500.000 Permutationen.
Zuweisung an EINE Variable... Hallo?
Wo kann man den Arduino Asm Code anschauen? Keine Ahnung wo man den
findet in dem Verzeichnis Gestrüpp..
133 ;life.c:67: feld.last[x][y] = ALIVE;
002E 4A [ 4] 134 ld c,d
002F 06 00 [ 7] 135 ld b,#0x00
0031 69 [ 4] 136 ld l, c
0032 60 [ 4] 137 ld h, b
0033 29 [11] 138 add hl, hl
0034 09 [11] 139 add hl, bc
0035 29 [11] 140 add hl, hl
0036 29 [11] 141 add hl, hl
0037 29 [11] 142 add hl, hl
0038 01r00r00 [10] 143 ld bc,#_feld
003B 09 [11] 144 add hl,bc
003C 4B [ 4] 145 ld c,e
003D 06 00 [ 7] 146 ld b,#0x00
003F 09 [11] 147 add hl,bc
0040 36 01 [10] 148 ld (hl),#0x01
Das hier kann der sdcc, das ist guter Code, wenn er straight forward
ist, geringe Schachtelung oder gar keine aber wehe es kommen Schleifen,
indizierte Felder oder Zeiger Konstrukte... dann explodiert es.
1
; ---------------------------------
2
377 ; Function putchar
3
378 ; ---------------------------------
4
030F 379 _putchar_start::
5
030F 380 _putchar:
6
030F DD E5 [15] 381 push ix
7
0311 DD 21 00 00 [14] 382 ld ix,#0
8
0315 DD 39 [15] 383 add ix,sp
9
384 ;driver.c:177: while (tx.bytes_to_send >= BUF_SIZE);
10
0317 385 00101$:
11
0317 21 07 E9 [10] 386 ld hl, #(_tx + 0x0082) + 0
12
031A 66 [ 7] 387 ld h,(hl)
13
031B 7C [ 4] 388 ld a,h
14
031C D6 80 [ 7] 389 sub a, #0x80
15
031E 30 F7 [12] 390 jr NC,00101$
16
391 ;driver.c:180: CLI;
17
0320 F3 [ 4] 392 di
18
393 ;driver.c:181: if (tx.f_idle) {
19
0321 21 09 E9 [10] 394 ld hl,#_tx + 132
20
0324 7E [ 7] 395 ld a,(hl)
21
0325 B7 [ 4] 396 or a, a
22
0326 28 0A [12] 397 jr Z,00105$
23
398 ;driver.c:182: tx.f_idle = false;
24
0328 36 00 [10] 399 ld (hl),#0x00
25
400 ;driver.c:183: STI_UDR = c; // Int Erzeugung anstossen
Und was macht er hier? Das habe ich schon deutlich kürzer gesehen:
Ich habe nichts gegen den Z80, will auch das Forum hier nicht rebellisch
machen aber ich möchte wissen, ob es so geht oder ob ich wenn ich mal
viel Lust habe und nichts zu tun das Ganze mal in Asm kodieren soll.
Anjbei das elf File des Arduino Sketches, ich weiss nicht wie man das
wieder umwandeln kann, keine Werkzeuge für
Christian J. schrieb:> Und was macht er hier?> 00E7 DD 56 F5 [19] 255 ld d,-11 (ix)> 00EA DD 7E F5 [19] 256 ld a,-11 (ix)> 00ED 17 [ 4] 257 rla> 00EE 9F [ 4] 258 sbc a, a> 00EF 5F [ 4] 259 ld e,a
DE = signextend(..)
Ok, der zweite LD könnte D verwenden statt Mem, das ist nicht optimal.
Benötigst du hier eine Variable mit Vorzeichen? zeroextend ist auf Z80
deutlich billiger als signextend.
> 00F0 7D [ 4] 260 ld a,l> 00F1 92 [ 4] 261 sub a, d> 00F2 7C [ 4] 262 ld a,h> 00F3 9B [ 4] 263 sbc a, e> 00F4 E2rF9r00 [10] 264 jp PO, 00185$
Das ist ein 16-Bit Vergleich mit Vorzeichen.
Ich habe dir schon geschrieben, dass Vergleiche wie
x <= (xpos+1)
schlecht umsetzbar sind, weil (xpos+1) ein "int" ist. So ist C nun
einmal definiert und dem Compiler bleibt nichts übrig, als den Vergleich
in vollen 16 Bits durchzuführen. Sorry, das ist dein Fehler.
Ich habe dir auch geschrieben, was du tun muss, um das zu vermeiden.
Die Z80 CPU ist nicht optimal für C, denn C wurde für CPUs mit
mindestens 16 Bits definiert. AVR hat übrigens ähnliche Probleme, das
sieht da auch nicht so arg viel anders aus. Entweder man kennt die
Regeln und passt sich an, oder man nimmt mindestens eine 16-Bit CPU.
Christian J. schrieb:> PS: Der Atmega hat 1 Befehl pro Takt! Der Z80 braucht deutlich mehr> Takte> für jeden Befehl! Unterm Strich sind das nicht mehr als vielleicht> 700.000 Befehle/s.
Ach ja, ich schaue mir das Trauerspiel mit den vielen Taktzyklen pro
Befehl beim Z80 gerade mal auf http://www.fundus.org/pdf.asp?ID=6378 an.
Da ist die Architektur der AVR Atmega-Controller, einen Befehl auch in
einem Schritt auszuführen, natürlich ganz was anderes.
Christian J. schrieb:> Wo kann man den Arduino Asm Code anschauen? Keine Ahnung wo man den> findet in dem Verzeichnis Gestrüpp..
In der Arduino-IDE gar nicht. Die Arduino-IDE ist für Hobbyprogrammierer
wie mich gemacht, die der Meinung sind: "Wenn Du es vernünftig
programmierst, wird es auch schnell genug laufen".
Aber ich glaube, Du kannst die Arduino Core-Library auch unter AVR
Studio installieren, mit einer Erweiterung. Nennt sich wohl "Visual
Micro".
http://www.visualmicro.com/page/Arduino-for-Atmel-Studio.aspx
Und dann kannst Du in AVR-Studio/Visual Micro Debuggen und
Assembler-Code gucken, und dabei die vollständige Arduino Core-Library
verwenden, wenn es Dich interessiert.
Außer "Serial" verwendet mein Conway-Beispielprogramm allerdings nicht
viel von der Arduino Core-Library. Das Programm könnte man wohl auch
relativ einfach von den Arduino-typischen setup/loop-Funktionen auf eine
main()-Funktion umschreiben, wenn man die Serial-Ausgabe über andere
AVR-Serial Routinen macht.
Jürgen S. schrieb:> Da ist die Architektur der AVR Atmega-Controller, einen Befehl auch in> einem Schritt auszuführen, natürlich ganz was anderes.
Liegen ja auch bloss 2 Jahrzehnte dazwischen. Und während beim Design
der AVRs die Sprache C mit auf der Rechnung war, wenngleich sie es
hätten besser machen können, war das anno 8080/Z80 kein Thema.
Hej, das ist eben Retro. Mit allen Konsequenzen.
Wer wissen will, wie umständliches Programmieren wirklich aussehen kann,
der sollte sich mal den RCA 1802 ansehen. Was ein Spass. Z80 ist Luxus!
Jürgen S. schrieb:> Ach ja, ich schaue mir das Trauerspiel mit den vielen Taktzyklen pro> Befehl beim Z80 gerade mal auf http://www.fundus.org/pdf.asp?ID=6378 an.
Die liegen zwischen 4-8 und maximal 30 für die Blockbefehle. Ergo 3.6
Mhz / ~6-8 = ~500 khz Der Atmega mit INTERNEM ROM und RAM hämmert das
natürlich schneller weg, ist ja auch eine RISC CPU. habs grad auf meinem
Keil Board mit ARM7 LPC2368 mal kompiliert, bei 60 Mhz ohne Ausgabe, der
berechnet auch 200 Generationen in der Sekunde. Porsche gegen Käfer,
Asm Befehle auf C Compiler getrimmt.
Eine 6510 mit 2 Mhz schafft genauso viel weg, weil man da auf beiden
Flanken intern Aktionen durchführte, der Z80 aber nur auf einer intern
"schaltet". Darum war die 6502 mit Halbgas genauso schnell.
Vermutlich aber hat 1 Z80 Baustein die gleiche Rechenleistug wie alle
"Computer" des 2.ten Weltkrieges zusammen hatten....
A. K. schrieb:> Ich habe dir schon geschrieben, dass Vergleiche wie> x <= (xpos+1)> schlecht umsetzbar sind, weil (xpos+1) ein "int" ist. So ist C nun> einmal definiert und dem Compiler bleibt nichts übrig, als den Vergleich> in vollen 16 Bits durchzuführen. Sorry, das ist dein Fehler.
Allein das hier macht den Code an der Stelle schon um 80 Bytes kürzer.
Ich brauche signed char hier wegen des Rollens des Feldes. Oder mit 0xff
ginge es ggf auch.
/ Berechne den neue Zellstatus
static char cell_status(const int8_t xpos, const int8_t ypos)
int8 a1,b1,a2,b2;
a1=ypos-1;
b1=ypos+1;
a2=xpos-1;
b2=xpos+1;
livecells = 0;
foo = feld.last[xpos][ypos];
// Ermittle den Zustand der 8 Nachbarn
for (y = a1;y <= b1;y++) {
for(x = a2;x <= b2;x++) {
Wenn du schon Typen mit Vorzeichen verwenden musst, dann verwende lieber
==/!= als </>, wenn möglich. Die Z80 hat keine Sprungbefehle für
Vergleich mit Vorzeichen.
A. K. schrieb:> Wenn du schon Typen mit Vorzeichen verwenden musst, dann verwende lieber> ==/!= als </>, wenn möglich. Die Z80 hat keine Sprungbefehle für> Vergleich mit Vorzeichen.
Morgen..... muss ins Bett.... Vorzeichen sind auch weg, vergleiche auf
0xff als "-1". Die "Tierchen" bewegen sich schon schneller, morgen mache
ich ihnen dann richtig Beine.....
Noch was. Linke Indizes laufen besser aussen, rechte innen. Jedenfalls
in C. Nur in FORTRAN ist es andersrum. Also nicht
for (y = a1;y <= b1;y++) {
for(x = a2;x <= b2;x++) {
... feld[x][y]
sondern
for(x = a2;x <= b2;x++) {
for (y = a1;y <= b1;y++) {
... feld[x][y]
Und wenn der Compiler dann nicht schon selber merken sollte, dass die
Adressrechnung von feld[x] nun bezogen auf die innere Schleife invariant
ist, dann kannst du ihm auf die Sprünge helfen:
for(x = a2;x <= b2;x++) {
var_t *p = feld[x];
for (y = a1;y <= b1;y++) {
... p[y];
Spätestens dann fliegt obige langwierige Multiplikation mit 24 aus der
inneren Schleife raus.
Ich werde es mir merken...
das hier erzeugt jedenfalls guten Code, 120 Bytes weniger aber das hat
mit strukturierter Programmierung echt nichts mehr zu tun. Es läuft aber
spürbar schneller, gefühlt 30%.
Und wenn der Compiler dann nicht schon selber merken sollte, dass die
Adressrechnung von feld[x] nun bezogen auf die innere Schleife invariant
ist, dann kannst du ihm auf die Sprünge helfen:
Erzeugt 50 Bytes mehr Code.
Christian J. schrieb:> Erzeugt 50 Bytes mehr Code.
Ich dachte, dich interessiert die Laufzeit. Schleifeninvariante Rechnung
aus der Schleife rauszuwerfen verkürzt die Laufzeit, nicht die Länge.
In deinem letzten Beispiel gibts auch einiges Zeug, was bezogen auf die
innere Schleife invariant ist, nämlich der Kram mit y/y1. Hoffe mal,
dass der Optimizer vom SDCC das selber spitz kriegt.
Christian J. schrieb:> Die "Tierchen" bewegen sich schon schneller, morgen mache> ich ihnen dann richtig Beine.....
Und, rennen Deine Tierchen heute?
Ich habe mir mal überlegt, was man am Algorithmus machen kann, um die
Anzahl der Rechenoperationen drastisch zu verringern und ohne dass dabei
massenhaft RAM-Speicher benötigt wird, wie es wohl bei schnellen
Algorithmen im Internet a la "Hashlife" der Fall ist.
Meine Idee ist dabei folgende:
Statt bei einem Spielfeld mit 2000 Zellen mit allen 2000 Zellen einzeln
die 8 umgebenden Felder abzusuchen und dadurch die Anzahl der Nachbarn
jeder Zelle zu ermitteln (= 16000 Programmaktionen), habe ich mir
überlegt, dass es auf jedem Spielfeld nur sehr viel weniger lebende
Zellen als Zellen insgesamt gibt.
Mal angenommen, nur 25% der Zellen leben, dann hätte ein Spielfeld mit
2000 Zellen nur 500 lebende Zellen. Wenn man nun einfach nur bei den 500
lebenden Zellen jeweils einen "Nachbarschaftspunkt auf die 8
Nachbarzellen" verteilen würde, könnte man anschließend in einem
weiteren Schleifendurchlauf genau die Anzahl der Nachbarzellen jeder
Zelle sehen.
Statt beim traditionellen Algorithmus 2000 Zellen mal 8
Nachbarschaftzellen nachschlagen = 16000 Programmaktionen würde man nur
bei 500 lebenden Zellen je 8 Nachbarschaftspunkte auf die Nachbarzellen
verteilen und anschließend in einem erneuten Durchlauf durch alle 2000
Zellen genau sehen, wieviele Nachbarn jede Zelle hat. Macht 500*8+2000=
6000 Programmaktionen.
Unter der Annahme, jede Programmaktion des traditionellen und des auf
lebende Zellen optimierten Algorithmus würde gleich lange dauern, ließe
sich die Laufzeit reduzieren auf 6000/16000 = 0,375 = 37,5% der Laufzeit
des ursprünglichen Algorithmus (mit der Annahme, dass 25% aller Zellen
leben).
Circa und Plus/Minus Pi mal Daumen.
Und ich bin mir eigentlich sicher, dass das auf einem Z80 ebenso als
Optimierung funktionieren würde wie auf einem Arduino, und auch, dass es
noch nicht das Ende der Fahnenstange bei der Optimierung sein muss.
Ggf. mache ich auch dazu mal eine Demo-Implementierung für Atmega2560.
Hast Du spaßeshalber mal den gestern von mir für Arduino geposteten Code
nach Z80 portiert und getestet, welche Laufzeit der Code für die
Berechnung einer neuen Generation hat? Ist der Code schneller oder
langsamer als Dein "life.c" Code, den Du gestern selbst gepostet hast?
Hi,
war heute 600km unterwegs auf der Autobahn und bin nicht daheim, daher
heute kein Code. Zurück erst am 3.1.2015. Den Arduino Code brauche ich
nicht portieren, der ist genauso wie meiner auch. Ich hatte auch mal
jede Zelle als x,y in einem Array abgespeichert und nur diese inkl.
ihrer Nachbarn betrachtet, da sich nurdort was tun kann, wo mindestens 1
Zelle ist. Der neue Code frisst die Ersparnis gleich wieder auf, man
muss suchen. Um das Suchen kommt man nicht herum. Eine Idee ist noch die
Rasterung des Feldes in ca 10x5er Blöcke und nur dort wo man was findet
durch Summerung rechnet man auch.
Für mich ist das ganze Problem eines für binäre Bäume. Das schreit
geradezu danach und ist eine gute Programmierübung, die noch interessant
ist. Haslife ist sehr komplex, das erkennt auch Blinker usw. und
berechnet sie nicht neu. Da steckt ne Professur hinter.
Anbei mein Zoo, aussterben tut der erst nach über 1000 Generationen.
2s pro Generation, mein ARM7 mit 80Mhz schafft locker 100 pro Sekunde
:-)
Christian J. schrieb:> war heute 600km unterwegs auf der Autobahn und bin nicht daheim, daher> heute kein Code. Zurück erst am 3.1.2015.
Na dann weiterhin gute Reise und komme gut durch die winterlichen
Straßenverhältnisse!
> Den Arduino Code brauche ich> nicht portieren, der ist genauso wie meiner auch.
Ich mache Dir mal bei Gelegenheit einen schnelleren Code mit einem
anderen Algorithmus. Mal schauen.
> Ich hatte auch mal> jede Zelle als x,y in einem Array abgespeichert und nur diese inkl.> ihrer Nachbarn betrachtet, da sich nurdort was tun kann, wo mindestens 1> Zelle ist. Der neue Code frisst die Ersparnis gleich wieder auf, man> muss suchen. Um das Suchen kommt man nicht herum.
Nein, was mir vorschwebt, funktioniert ohne Suchen und mit praktisch
derselben Datenstruktur: Ein aktuelles Spielfeld und ein als nächstes
berechnetes Spielfeld.
Wobei der Unterschied ist: Bei Standard-Algorithmus wird auf dem
nächsten Spielfeld gleich jede Zelle DEAD oder ALIVE gesetzt, nachdem
vorher jedes der 8 Nachbarfelder abgesucht wurde. Bei dem von mir
geplanten Algorithmus werden auf dem nächsten Spielfeld in einem ersten
Durchgang nur von dem ALIVE Zellen aus "Nachbarschaftspunkte" verteilt
und erst in einem zweiten Durchgang die Summe der Nachbarschaftspunkte
auf jedem Feld ausgewertet. Auf einem Spielfeld mit 2000 Zellen führt
das dann zu einem Vorteil, wenn mindestens 2000/8= 250 Zellen tot sind
und höchtens 1750 Zellen leben. Typischerweise leben auf einem Spielfeld
sehr viel weniger Zellen und deshalb werde ich da einen drastischen
Zuwachs an Rechengeschwindigkeit rausholen, wenn ich den Algorithmus
ändere.
> Eine Idee ist noch die> Rasterung des Feldes in ca 10x5er Blöcke und nur dort wo man was findet> durch Summerung rechnet man auch.
Hört sich kompliziert an.
> Für mich ist das ganze Problem eines für binäre Bäume.
Für mich irgendwie nicht.
> Das schreit> geradezu danach und ist eine gute Programmierübung, die noch interessant> ist.
Mal schauen, vielleicht übe ich mit.
Auch unter Arduino kann etwas Übung beim Programmieren ja wohl nicht
schaden.
:-)
Jürgen S. schrieb:> Bei dem von mir> geplanten Algorithmus werden auf dem nächsten Spielfeld in einem ersten> Durchgang nur von dem ALIVE Zellen aus "Nachbarschaftspunkte" verteilt> und erst in einem zweiten Durchgang die Summe der Nachbarschaftspunkte> auf jedem Feld ausgewertet.
Das müsstest du nochmal genau erklären. Übrigens 1,70m Schneehöhe....
hier geht nix mehr auf dem Feldberg.
Beim Z80 gibt es einen Automatikbefehl CP <Bereich>, d.h. es kann über
ein Feld ein Compare durchgeführt werden, was sehr schnell geht, die CPU
macht das allein. Das Ausnullen von 64kb braucht grad mal 0,5s.
Binärbäume kann man sehr schnell rekursiv durchlaufen, das ist der
Vorteil. Und es stehen nur Infos drin die nötig sind, die Totzellen
braucht man gar nicht.
Generell muss man nur die ALIVE Felder betrachten mit +1, -1 Umfeld zu
jeder LIVE zelle. d.h. um einen Pulk legt man einen Ring, der 1 Zelle
Platz hat zur nächsten LIVE Zelle. Nur da kann sich was tun, überall
sonst nicht.
Christian J. schrieb:> Generell muss man nur die ALIVE Felder betrachten mit +1, -1 Umfeld zu> jeder LIVE zelle. d.h. um einen Pulk legt man einen Ring, der 1 Zelle> Platz hat zur nächsten LIVE Zelle. Nur da kann sich was tun, überall> sonst nicht.
Genau das meine ich, man braucht nur das direkte Umfeld um die aktiven
Zellen betrachten. Mal angenommen, ein 5x5 Spielfeld namens "board"
kennt nur DEAD "0" oder ALIVE "X" und habe drei lebende Zellen:
1
00000
2
0XX00
3
00X00
4
00000
Dann zählst Du auf einem neuen Spielfeld "newboard" nur die ringförmig
um die lebende Zelle liegenden "Nachbarschaftspunkte" zusammen.
In der ersten Runde verteile ich Nachbarschaftspunkte "für das X links
oben":
1
11100
2
10100
3
11100
4
00000
5
00000
In der zweiten Runde addiere ich die Nachbarschaftspunkte "für das X
rechts oben":
1
01110
2
01010
3
01110
4
00000
5
00000
In der dritten Runde addiere ich die Nachbarschaftspunkte "für das
untere X":
1
00000
2
01110
3
01010
4
01110
5
00000
Diese drei Schritte gleich aufeinanderaddiert ergibt für "newboard"
insgesamt:
1
12210
2
12220
3
13220
4
01110
5
00000
Dort steht jetzt quasi als Zahlenwert, wieviele lebende Nachbarn jede
Zelle des Spielfelds hat.
Und jetzt vergleiche ich "board" mit "newboard".
1. Wo bei "newboard" in der Matrix eine 2 steht, bleibt der alte Zustand
in "board" erhalten
2. Wo bei "newboard" in der Matrix eine 3 steht, wird die Zelle in
"board" ALIVE gesetzt
3. Wo bei "newboard" in der Matrix ein anderer Wert steht
(0,1,4,5,6,7,8), wird die Zelle in "board" auf DEAD gesetzt
Hast Du mal die Anzahl der Iterationen durchgerechnet? Nach altem
Muster sind für 5x5 = 25 Zellen nötig, 25 Zellen a 8 Nachbarn = 200
Tests
Dein Verfahren erfordert natürlich immer noch das Durchsuchen des ganzen
Feldes nach Zellen. Die "verbale Formulierung" klingt gut, nur wie sähe
die Umsetzung auf Code aus? Newboard muss auch wieder in einen oldboard
Zustand überführt werden, die zahlen müssen also wieder raus. Nachher
durchsuchst du die Felder 3-4 Mal.....
Ich formuliere das oben mal so:
oldboard [100][100]
newboard [100][100]
1. Suche in oldboard die erste ALIVE Zelle
2. "Umkreise" und setze alle umliegenden 8 Koordinaten in newboard =
newboard +1
3. Suche zweite ALIVE Zellem in oldboard
4. weiter bei 2 bis Feld durch
5. Werte newboard nach dem Muster aus, wie oben beschrieben und
verändere X und O in oldboard
D.h. newboard nimmt nur die Nachbarpunkte auf, oldboard enthält nur 1
und 0.
Vorteil: Das rechenintensive "Umkreisen" findet nur für ddie wenigen
Live Zellen statt, die toten werden ignoriert.
Ok?
Anbei mal ein Beispiel wieviele Zyklen Befehle beim Z80 brauchen. Das
ist die Zahl in den eckigen Klammern. So ein CALL ist schon ein
absolutes Schwergewicht. Der tatsächliche Durchsatz bei 4 Mhz dürfte
vermutlich so bei 500.000/s liegen.
Christian J. schrieb:> Ich formuliere das oben mal so:>> oldboard [100][100]> newboard [100][100]>> 1. Suche in oldboard die erste ALIVE Zelle> 2. "Umkreise" und setze alle umliegenden 8 Koordinaten in newboard => newboard +1> 3. Suche zweite ALIVE Zellem in oldboard> 4. weiter bei 2 bis Feld durch>> 5. Werte newboard nach dem Muster aus, wie oben beschrieben und> verändere X und O in oldboard>> D.h. newboard nimmt nur die Nachbarpunkte auf, oldboard enthält nur 1> und 0.>> Vorteil: Das rechenintensive "Umkreisen" findet nur für ddie wenigen> Live Zellen statt, die toten werden ignoriert.>> Ok?
Ja, im Prinzip. Aber irgendwie stört mich der Begriff "Suchen". Denn
tatsächlich handelt es sich um eine Schleife durch alle Felder. Nur
statt im Gegensatz zum alten Algorithmus "Umkreise" um jede Zelle des
Spielfelds zu bilden, werden diese "Umkreise" nur dann gebildet, wenn
die Zelle lebt.
Alter Algorithmus in Worten:
1
Loop über alle Zellen
2
{
3
8x Nachbarfelder auf lebende Zellen abzählen
4
neuen Wert setzen
5
}
Neuer Algorithmus in Worten:
1
Loop über alle Zellen
2
{
3
Wenn Zelle lebt, dann 8x Nachbarschaftspunkte verteilen
4
}
5
Loop über alle Zellen
6
{
7
neuen Wert setzen
8
}
Eingespart wird: Die "Umkreisaktion" bei allen toten Zellen, und das
sind auf einem typischen Spielfeld die Mehrzahl der Zellen.
Hinzu kommt: Eine zweite loop durch alle Zellen zum Setzen des neuen
Werts
D.h. aus einem One-Pass-Algorithmus wird ein Two-Pass-Algorithmus.
Und der Two-Pass-Algorithmus ist schneller, sobald auch nur eine geringe
Mindestanzahl an Zellen auf dem Spielfeld tot sind. Und da in der Praxis
eigentlich immer mehr als 50% der Zellen tot sind, hat man eigenlich
auch immer einen hohen Geschwindigkeitsvorteil.
So vom Gefühl her würde ich sagen: Für jede Zelle kommen zwei Aktionen
hinzu, und zwar eine Lebendigkeitsabfrage im ersten loop-Durchlauf und
der zweite loop-Durchlauf an sich. Eingespart werden 8x die
Umkreisaktion bei toten Zellen.
D.h. auf einem Spielfeld mit 2000 Zellen insgesamt, davon 1500 tote
Zellen, würde man:
1500*8 Aktionen einsparen
2000*2 Aktionen zusätzlich durchführen
12000 Aktionen einsparen - 4000 Aktionen zusätzlich = Nettoersparnis
8000 Aktionen
Ich habe das mal auf den Arduino umgesetzt und es sieht ganz gut aus.
Der weiter oben von mir gepostete Arduino-Code rechnet eine 79x24
Generation in ca. 83ms aus.
Mein neuer Code nach dem neuen Algorithmus und einigen anderen
Optimierungen liegt derzeitig bei ca. 10,5 ms Rechenzeit pro Generation
(ohne Ausgabezeit auf Serial). Wenn die Umsetzung auf Deinen Z80 @3.9MHz
geschätzte 50 mal langsamer läuft als auf einem Arduino @16MHz, würde
die Rechenzeit bei Dir von gut 4s pro Generation auf 0,525s pro
Genration sinken.
Ich teste mal noch etwas, ob ich nicht auch unter 10ms Rechenzeit pro
79x24 Generation auf dem Arduino kommen kann und poste dann nochmal eine
schnellere Version als oben.
Vielleicht lohnt es sich ja dann für Dich, den Arduino-Code auf Deinen
Z80-Compiler umzusetzen. Eigentlich sind ja nur zwei Dinge anzupassen,
um es auf einem anderen System/Compiler laufen zu lassen:
- die Ausgabe auf Serial zur Anzeige
- die Timing-Funktionen zur Zeitmessung
Jürgen S. schrieb:> Ich habe das mal auf den Arduino umgesetzt und es sieht ganz gut aus.> Der weiter oben von mir gepostete Arduino-Code rechnet eine 79x24> Generation in ca. 83ms aus.
Werde das heute abend mal, wenn die Kinder im Bett sind auch umsetzen.
Gucken was mein alter Z80 dazu sagt.
Die 2.te Tabelle dient bei dir nur für die Zahlen? Die erste enthält
dann nur 1 und 0.?
Aktuell suche ich übrigens eine Abbruch Routine. Bisher breche ich ab,
wenn ich 8 Mal die gleiche Anzahl "Veränderungen" habe aber es gibt auch
Blinker, die Modifikations = 20,30,20,30..... erzeugen und auch die
Gleiter erzeugen unterschiedliche.
In den Wert 0 oder 1 für LIVE und DEAD lassen sich auch noch Altersinfos
einbauen, zb statt 0,und 1, Gen. 2,3,4,5,5 usw. d.h. Zellen können auch
an Alterschwäche sterben. Bastle auch noch an "Jungbrunnen", d.h.
Punkten die wenn sie berührt werden eine starke Vemehrung erzeugen. Das
müsste das Wabern auf dem Feld noch mehr werden. Leider nur VT100 80x24,
mehr geht leider nicht.
1
/ Prüft, ob Feld nur noch aus unv. Strukturen besteht
Christian J. schrieb:> Die 2.te Tabelle dient bei dir nur für die Zahlen? Die erste enthält> dann nur 1 und 0.?
Ja, genau so.
> Aktuell suche ich übrigens eine Abbruch Routine. Bisher breche ich ab,> wenn ich 8 Mal die gleiche Anzahl "Veränderungen" habe aber es gibt auch> Blinker, die Modifikations = 20,30,20,30..... erzeugen und auch die> Gleiter erzeugen unterschiedliche.
Darüber habe ich mir noch gar keine Gedanken gemacht. Ich dachte, am
Ende ist immer die Anzahl lebender Zellen gleich, so dass meine erste
Idee war: Wenn drei Generationen hintereinander dieselbe Anzahl lebender
Zellen existiert, wird wohl nicht mehr viel passieren.
Ich dachte, dann gäbe es nur noch statische Blöcke und Blinker, die von
Generation zu Generation aber immer dieselbe Zahl lebender Zellen
besitzen. Von "Gleitern" habe ich jetzt gelesen, dass es sie gibt. Aber
mir ist unklar, ob es Gleiter gibt, die während des Gleitens die Anzahl
lebender Zellen variieren. Bisher habe ich mir nur den kleinsten Gleiter
aus 5 lebenden Zellen angesehen, der hat in jeder Phase immer 5 Zellen.
Anyway, darüber müßte ich mir nochmal Gedanken machen, was man als
sinnvolle Abbruchbedingung verwenden könnte.
Bis dahin schon mal mein relevanter Code mit den verwendeten
Datenstrukturen und der Funktion zum Neuberechnen einer Funktion.
1
#define BOARD_WIDTH 79
2
#define BOARD_HEIGHT 24
3
#define DEAD 0
4
#define ALIVE 1
5
#define NUMGENERATIONS 100 // number of generations
6
7
byteboard[BOARD_HEIGHT][BOARD_WIDTH];
8
bytenewboard[BOARD_HEIGHT][BOARD_WIDTH];
9
intlivingCells;
10
11
voidplayBoard()
12
{
13
/*
14
(copied this from some web page, hence the English spellings...)
15
16
1.STASIS : If, for a given cell, the number of on neighbours is
17
exactly two, the cell maintains its status quo into the next
18
generation. If the cell is on, it stays on, if it is off, it stays off.
19
20
2.GROWTH : If the number of on neighbours is exactly three, the cell
21
will be on in the next generation. This is regardless of the cell's current state.
22
23
3.DEATH : If the number of on neighbours is 0, 1, 4-8, the cell will
24
be off in the next generation.
25
*/
26
memset(newboard,0,sizeof(newboard));
27
28
if(board[0][0]==ALIVE)// linke obere Ecke lebt
29
{
30
newboard[BOARD_HEIGHT-1][BOARD_WIDTH-1]++;
31
newboard[BOARD_HEIGHT-1][0]++;
32
newboard[BOARD_HEIGHT-1][1]++;
33
newboard[0][1]++;
34
newboard[1][1]++;
35
newboard[1][0]++;
36
newboard[1][BOARD_WIDTH-1]++;
37
newboard[0][BOARD_WIDTH-1]++;
38
}
39
40
for(bytecol=1;col<BOARD_WIDTH-1;col++)// oberste Reihe ohne die Ecken
Auf einem 79x24 Spielfeld mit 1896 Zellen beträgt die Berechnungszeit
auf einem 16 MHz Atmega2560 nun ca. 7,2 ms pro Generation als Mittelwert
über 100 Generationen, wenn man das Brett anfangs zu ca. 25% mit
zufallsverteilten lebenden Zellen initialisiert.
Hi,
ich möchte aber jetzt nicht wissen welcher Code Wust da entstanden ist,
allein die Adressierung eines 2D Feldes kostet unheimlich. Es gibt ja
Schleifen :-) Ich werde wohl krank, habe schon Fieber, heute daher nicht
mehr....
PS;: Sieht aber schon ganz nett aus...
Gruss,
Christian
Christian J. schrieb:> ich möchte aber jetzt nicht wissen welcher Code Wust da entstanden ist,> allein die Adressierung eines 2D Feldes kostet unheimlich.
Ja, mit diesem Code kompiliert wird das Programm größer als vorher. Aber
das von Dir ausgegebene Optimierungsziel war ja eine möglichst geringe
Laufzeit und nicht eine besonders geringe Codegröße. Du kannst
normalerweise nur das eine oder das andere bekommen, aber nicht beides
gleichzeitig.
Mit dem jetzt geposteten Berechnungscode wird das komplette
Arduino-Programm mit VT100-Serial-Ausgabe und Zeitmessung der
Berechnungsfunktion ca. 8 KB statt 4 KB gross, dafür läuft es über 10x
schneller als das, was ich weiter oben gepostet habe.
> Es gibt ja Schleifen :-)
Wenn Du genau hinsiehst: Ich verwende Schleifen. Schleifen mit einer
8-Bit Zählervariablen. Überall dort, wo es sinnvoll ist.
Auf was ich bei der Berechnung verzichte:
1. Funktionsaufrufe
2. Fallunterscheidungen, ob eine Zelle am Rand oder an einer Ecke liegt
Wenn Du mal in Deinen eigenen Code reinschaust, dann machst Du bei jeder
möglichen Zelle des Spielfelds eine umfangreiche Fallunterscheidung mit
vier möglichen Fällen, bevor eine der acht Nachbarzellen ausgewertet
wird.
1
// Abfangen der Ränder und Erweiterung auf Gegenüber
2
if(x<0)
3
x1=MAX_X;
4
elseif(x>MAX_X)
5
x1=0;
6
elsex1=x;
7
8
if(y<0)
9
y1=MAX_Y;
10
elseif(y>MAX_Y)
11
y1=0;
12
elsey1=y;
Mein neuer Code verschwendet damit keinen einzigen Programmzyklus.
Mein neuer Code weiß immer, wo er sich gerade bei der Bearbeitung
befindet, und wenn der Code gerade eine Zelle in der Ecke, oder am
oberen/linken/rechten/unteren Rand bearbeitet wird, dann wird sogar mit
Konstanten als Array-Index gearbeitet, was besonders effektiv ist.
Probier's aus!
Auf dem Arduino mit GCC braucht die Berechnung einer Generation weniger
als ein Zehntel der Zeit wie bei meinem weiter oben geposteten Code.
> Ich werde wohl krank, habe schon Fieber, heute daher nicht> mehr....
Muss ja auch nicht gleich sein.
Der Code steht ja jetzt im Forum, da läuft er nicht weg.
Gute Besserung!
Jürgen S. schrieb:> Mein neuer Code verschwendet damit keinen einzigen Programmzyklus.
Dafür hat er aber auch keine Faltung des Feldes, das geht nur so.
Kostet nicht die Welt...
Hab noch mehr Speed und weniger Coddegrößer rausgekitzelt durch Zeiger,
da 2D Feldzugriffe endlos Code erzeugen, wenn sie mehrfach vorkommen. Da
geht sicher auch noch mehr.
1
// Aktualisiere das alte Feld mit neuen Informationen
Angeregt durch diesen Thread hier habe ich Game of Life auch für
meinen Rechner programmiert. Schaut mal rein in meinen Thread.
Beitrag "Re: 8bit-Computing mit FPGA"
@Juergen S.
Die Abbruchbedingung "keine Veränderungen" auf 16 gezählt funktioniert
bisher einwandfrei. Er hat heute nach 46 Durchgänge gemacht und
abgebrochen, wenn Blinker auftauchten.
heute kam der 4.9 Mhz Quarz, der mir 38400 baud ermöglicht und die CPU
+20% höher taktet. Bin ja mal gespannt....
PS: Huh, das ist wie ein Turbo :-) Jetzt läuft es richtig auf dem
Schirm.
Christian J. schrieb:> Flitz schon ganz gut :-)>> Ich habe den Code mal etwas "opmtiert", nur als als Tip dass das auch> deutlich kürzer geht:
Ja, es geht kürzer. Aber der kurze Code ist nicht der schnellste Code.
Mein Code beachtet natürlich die "Anschlusspunkte auf der anderen
Spielfeldseite", aber nicht mit "Prüfung der Randbedingung und Anpassung
einer Hilfsvariablen bei jedem einzelnen Punkt".
Die Geschwindigkeit bekommt mein Code, weil er die 9 verschiedenen Fälle
kennt, die zu behandeln sind, als da sind
1. Eckpunkt oben links
2. Punkt in der oberen Reihe (ohne Eckpunkte)
3. Eckpunkt oben rechts
4. Punkt am linken Rand
5. Punkt "in der Mitte" (kein Randpunkt, häufigster Fall)
6. Punkt am rechten Rand
7. Eckpunkt links unten
8. Punkt in der unteren Reihe (ohne Eckpunkte)
9. Eckpunkt rechts unten
Dadurch bekomme ich beim Neuberechnen die 9-fache Menge an Code, aber
ich spare beim Abfragen jedes einzelnen Punktes vier Vergleiche auf die
Randbedingungen (Rand oben, Rand rechts, Rand unten, Rand links). Und
weil bei jedem Punkt 4 Vergleiche gespart werden, wird der Code
schneller.
Denn wo die Ränder und Ecken sind, steht fest, da das Spielfeld eine
feste Größe hat. Zuerst wird immer auf ALIVE getestet, das lasse ich in
der nachfolgenden Beschreibung daher mal weg. Bei einem 79x24 Spielfeld
ergibt sich ansonsten etwa folgende Programmlogik beim Neuberechnen.
1
Eckpunkt oben links berechnen
2
77 Punkte in der oberen Reihe berechnen
3
Eckpunkt oben rechts berechnen
4
For-loop von zweiter Zeile bis vorletzter Zeile
5
- linken Randpunkt berechnen
6
- 77 Punkte der Reihe berechnen
7
- rechten Randpunkt berechnen
8
Ende der For-loop
9
Eckpunkt unten links berechnen
10
77 Punkte in der unteren Reihe berechnen
11
Eckpunkt unten rechts berechnen
Und ich muss nicht ein einziges mal abfragen, ob ein Punkt irgendwo am
Rand liegt oder nicht. Denn der Algorithmus weiß, welchen Punkt er
gerade berechnet, wo dieser liegt und wendet einen von 9 verschiedenen
Fällen an, um die umliegenden Fälle zu ermitteln.
Die Summe des Geschwindigkeitszuwachses kommt aus der Multiplikation der
Einzelmaßnahmen. Wenn Du eine Codeoptimierung machst, die die
Geschwindigkeit um Faktor 5 steigert und eine andere Codeoptimierung,
die die Geschwindigkeit um den Faktor 2 steigert, läuft das Programm
hinterher 5x2 = 10 mal schneller.
Da ich überhaupt kein Assembler kann, und mir die Arduino-IDE auch gar
kein Assembler anzeigt, fange ich beim Optimieren auch nicht beim
fertigen Assembler-Code an, sondern ich schaue mir den Algorithmus genau
an, wo dieser Ansätze bietet, durch eine alternative Herangehensweise
schneller und mit weniger Programmaktionen zu einem Ergebnis zu kommen.
Jürgen S. schrieb:> Und ich muss nicht ein einziges mal abfragen, ob ein Punkt irgendwo am> Rand liegt oder nicht. Denn der Algorithmus weiß, welchen Punkt er> gerade berechnet, wo dieser liegt und wendet einen von 9 verschiedenen> Fällen an, um die umliegenden Fälle zu ermitteln.
Das schaue ich mir nochmal an, werde da Faallunterscheidungen machen, da
die Ränder viel kleiner sind als das ganze Spielfeld. Allerdings mag ich
keinen Spaghetti Code, lieber das kürzeste Ergebnis auf dem Schirm.
Auch wenn es nicht speed optmiert ist.
So schaut es jetzt aus.... deutlich fixer als vorher. da ist auch ein
Gleiter bei 2:31 rechts, der später aufgefressen wird. Interessant ist,
dass oft wenn man meint, dass es gleich vorbei ist plötzlich wieder
viele neue Zellen entstehen, wenn zei Figuren zusammen stossen. Und aus
80 sind rukczuck wieder 250 Zellen geworden. Aktuell läuft generation
4500 und immer noch kein Ende in Sicht.
https://www.youtube.com/watch?v=DjO6rMPWEss&feature=youtu.be
Christian J. schrieb:> Das schaue ich mir nochmal an, werde da Faallunterscheidungen machen, da> die Ränder viel kleiner sind als das ganze Spielfeld. Allerdings mag ich> keinen Spaghetti Code, lieber das kürzeste Ergebnis auf dem Schirm.> Auch wenn es nicht speed optmiert ist.
Tja, ist ein relativ hoher Codeaufwand von mir, um Rechenzeit
einzusparen.
Ein Kompromiss wäre vielleicht, wenn Du zwei Funktionen machst:
- "cell_status_ohne(reihe,spalte)" (ohne die Randüberprüfung)
- "cell_status_mit(reihe,spalte)" (mit der Randüberprüfung)
In dem Fall kannst Du die Neuberechnung nach der Logik erschlagen:
1
// Oberste Reihe mit Ecken
2
for erste Spalte to letzte Spalte
3
wenn ALIVE dann cell_status_mit(0, spalte);
4
5
// Zweite bis vorletzte Reihe
6
for zweite Reihe to vorletzte Reihe
7
{
8
wenn ALIVE dann cell_status_mit(reihe, 0); // linker Rand
9
for zweite Spalte to vorletzte Spalte
10
{
11
wenn ALIVE dann cell_status_ohne(reihe, spalte);
12
}
13
wenn ALIVE dann cell_status_mit(reihe, BOARD_WIDTH-1); // rechter Rand
14
}
15
16
// Unterste Reihe mit Ecken
17
for erste Spalte to letzte Spalte
18
wenn ALIVE dann cell_status_mit(BOARD_HEIGHT-1, spalte);
Das sollte fast genau so schnell laufen wie mein komplett ausgerollter
Code, wenn Du die beiden Funktionen "static inline" deklarierst, und der
Compiler damit optimierungstechnisch etwas anfangen kann.
Bei meinem zuletzt geposteten Neuberechnungs-Code war ich auch davon
ausgegangen, dass Dein Compiler vielleicht "static inline"
Funktionsaufrufe nicht wegoptimieren kann und habe daher einen
Algorithmus verwendet, bei dem zur Neuberechnung kein einziger
Funktionsaufruf notwendig ist. Denn wie Du ja oben auch festgestellt
hast, schlagen Funktionsaufrufe auch mit besonders vielen Takten ins
Kontor.
P.S.: Array- und Schleifen-Indizes musst Du ggf. anpassen, die
verwendest Du irgendwie beim Deklarieren, Programmieren und
Schleifendurchläufen anders als ich.
P.P.S.: Das Youtube-Video "test" sieht inzwischen ja so aus, als wenn
die Berechnung zwischen den Generationen nun deutlich unter 4 Sekunden
benötigt.
;-)
Jürgen S. schrieb:> P.P.S.: Das Youtube-Video "test" sieht inzwischen ja so aus, als wenn> die Berechnung zwischen den Generationen nun deutlich unter 4 Sekunden> benötigt.> ;-)
Frohes Neues!
So, da hier das "Neujahrspringen" bei blauem Himmel das ganzjährig
verschlafene Dorf in ein Medienzentrum verwandelt hat halte ich mich mal
lieber daheim auf. Die Schanze sehe ich ja auch vom Balkon aus und höre
wenn der Krankenwagen kommt um wieder einen von der Bande abzukratzen
:-)
Mein GOL ist fertig, da ist alles gemacht was geht und für 10 Befehle
lohnt sich auch keine Fallunterscheidung mehr, die mir fast 500 Bytes
mehr im knappen EPROM wegfrisst. Der Abbruch ist auch ok, hat sich
niemals in einer Endlosschleife festgefressen bei jetzt über 100
Durchläufen. Leider keine Grafik aber VT100 hat leider keinen Pixel
Mode. Wäre cool aber gab es damals wohl nicht.
Mal schauen ob ich mit VT100 so eine Art Breakout Spiel hin bekomme oder
sowas wie Pac Man.
@Christian J. (hobel):
Das hört sich ja ganz nach Schonach an, ich wohne in Furtwangen.
Ich bin gerade am Assemblerprogrammieren, für meine LED-Spielereien,
alle auf AVR.
Dir noch viel Spaß beim Basteln und Tüfteln.
Mit freundlichem Gruß - Martin
Christian J. schrieb:> Mein GOL ist fertig, da ist alles gemacht was geht und für 10 Befehle> lohnt sich auch keine Fallunterscheidung mehr, die mir fast 500 Bytes> mehr im knappen EPROM wegfrisst.
OK, wenn schnell genug, dann schnell genug. Dann braucht man die letzten
Taktzyklen nicht mehr aufwändig rausoptimieren. Und dass Du auch knapp
mit Programmspeicher bist, wußte ich gar nicht.
> Der Abbruch ist auch ok, hat sich niemals in einer Endlosschleife> festgefressen bei jetzt über 100 Durchläufen.
Der Abbruch nach "keine Veränderungen auf 16 gezählt" ist allenfalls
"praktisch zu mehr als 99,99...% OK" und funktioniert fast immer. Aber
theoretisch können auch durch Zufall verschiedene blinkende Endmuster
entstehen, bei denen
- die Anzahl der lebenden Zellen rhythmisch schwankt
- die entweder an einer Stelle stehen (Oszillator)
- oder die über das Spielfeld wandern (Gleiter)
- und der Rhythmus kann 2, 3, 4 oder eine andere Zahl von Perioden sein
Lade Dir zum Beispiel mal diesen Pulsar auf das Spielfeld:
1
charconway_pulsar[16][17]={
2
" ",
3
" x x ",
4
" x x ",
5
" xx xx ",
6
" ",
7
" xxx xx xx xxx",
8
" x x x x x x ",
9
" xx xx ",
10
" ",
11
" xx xx ",
12
" x x x x x x ",
13
" xxx xx xx xxx",
14
" ",
15
" xx xx ",
16
" x x ",
17
" x x "};
Die Anzahl lebender Zellen ändert sich von Generation zu Generation.
Besser, man macht also nicht nur einen Test auf Änderungen, sondern
setzt auch eine MAX_GENERATIONS Maximalzahl an Generationen für einen
"sicheren" Abbruch nach einer Höchstzahl von Generationen. Falls man
zufällig doch mal einen mit wechselnder Zellenzahl lebenden Oszillator
oder Gleiter am Ende bekommt.
> Leider keine Grafik aber VT100 hat leider keinen Pixel> Mode. Wäre cool aber gab es damals wohl nicht.>> Mal schauen ob ich mit VT100 so eine Art Breakout Spiel hin bekomme oder> sowas wie Pac Man.
Mit VT100 kann zwar die Cursorposition unabhängig von einer Ausgabe
gesteuert werden, aber das ist relativ zeitaufwändig, weil dafür recht
viele Zeichen gesendet werden müssen.
Was aber möglich ist: Man kann das Terminal scrollen. Oder sogar
Teilbereiche auf dem Terminal als Scrollbereiche definieren, und bei
Ausgaben im Scrollbereich scrollt das Terminal automatisch, wenn der
Punkt rechts unten ausgegeben wird.
Was Du also rasend schnell hinbekommen könntest, wäre es, Bilder mit
einem eindimensionalen (einzeiligen) Zustandsautomaten zu generieren und
immer nur am Ende eine Zeile dazuzuschreiben, so dass nach dem
erstmaligen Bildaufbau jedes neue Bild wie folgt entsteht:
- das Bild schrollt eine Zeile nach oben
- am Ende wird die letzte (neu generierte) Zeile dazugeschrieben
Dadurch, dass Du für ein neues Bild nur eine einzige Zeile neu schreiben
musst und das Terminal die übrigen Zeilen alleine nach oben setzt,
bekommst Du auf einem Feld mit 24 Zeilen praktisch die 24-fache
Bildwiedergaberate wie bei Conway. Und bei einem entsprechenden
Algorithmus können dadurch ziemlich kaleidoskopartig-psychedelische
Muster auf dem Bildschirm entstehen.
Nur mal so als Idee für eine optisch schnelle Spielerei auf einem
langsamen Rechner. Bei Interesse könnte ich auch mal Code für so einen
1D-Zustandsautomaten raussuchen, der interessante Variationen ergibt, so
dass es am Ende nicht nur aussieht wie "Punkte laufen in eine Richtung"
oder "Punkte laufen symmetrisch auseinander bzw. aufeindander zu".
Auch der aus dem Film "Matrix" bekannte Effekt, nachgebildet in diversen
"Matrix Screensaver" Programmen, dürfte für Terminalausgabe leicht
nachbaubar sein und schnell ablaufen.
Auch Muster nach dem Prinzip "Kaleidoskop" sollten gut machbar sein: Man
teilt den Bildschirm in vier Bereiche, und diese vier Bereiche werden
spiegelsymmetrisch zueinander ausgegeben, zur Erzeugung dynamischer
Kaleidoskopeffekte.
Martin Schlüter schrieb:> @Christian J. (hobel):>> Das hört sich ja ganz nach Schonach an, ich wohne in Furtwangen.
Schönwald :-) Aber nur noch 7 Tage, dann auf Nimmerwiedersehen
"Schwarzwald", dieses Kapitel hier und eine gewisse Firma mit
orangenen Lettern am Dach möchte ich lieber vergessen.
@Christian J. (hobel):
Ja, das hört sich ja nach einer Leidensgeschichte an, ich wünsche Dir
viel Glück daß das wieder besser wird. Aber was soll ich da sagen, nach
22 Jahren ununterbrochener Berufstätigkeit nun seit 9 Monaten
arbeitslos, und nichts in Aussicht. Schönwald, und Schonach verwechsele
ich leider immer wieder mal. Schade, wieder ein Tüftler weniger im
Schwarzwald.
@all:
Auch wenn der Z80, und seine Emulatoren nicht so mein Thema sind, lese
ich hier begeistert mit. Zu meinen VC20 / C64 Zeiten war das 'Game of
Live' eine sehr beliebte Spielerei, mit der auch ich meinen Computer
tagelang beschäftigt habe. Nach dem Ende der Ära der Heimcomputer habe
ich mich dann den Mikrocontrollern zugewendet. Auf dem PC ist das
Programmieren, für mich, nicht soo reizvoll, da man sich um viel zu
viele Dinge kümmern muß, die mit der eigentlichen Idee gar nichts zu tun
haben.
Ich habe hier, für eins meiner LED Experimente, eine Lochrasterplatte
mit einem ATmega644P, per RS232 mit dem PC verbunden, vielleicht sollte
ich da mal Game of Live programmieren, nativ auf AVR, natürlich in
Assembler ...
Das mit der Abbruchbedingung ist so eine Sache, bei Verfahren, die nicht
zu 100% sicher sind, besteht ja nicht nur die Gefahr, daß sie gar nicht
abbrechen, sondern auch die Gefahr, daß zu früh abgebrochen wird. Nehmen
wir z.B. ein rechteckiges Spielfeld, 'randuebergreifend', wenn jetzt 2
Gleiter auf dem Spielfeld sind, Einer bewegt sich waagerecht, der Andere
senkrecht, dann ist das lange langweilig, und wird eventuell
abgebrochen. Durch die unterschiedlichen Umlaufzeiten der 2 Gleiter
werden die aber irgendwann kollidieren, und dann geht's rund. Eine
sichere Abbruchbedingung ist vermutlich nur durch den Vergleich von
kompletten Bildern möglich, wobei da der Zeit-, und Speicherverbrauch
ein echtes Problem ist. Die Perioden können ja recht lang sein. Eine
Idee ist, z.B. nur alle 500 Generationen ein Bild zu speichern, davon
immer die letzten 4 Bilder behalten, und jede neue Generation mit Diesen
zu vergleichen, dann wird eine Periodizität zwar verspätet erkannt, aber
sicher. Wenn man, mit den Bildern, auch die Zahl der lebenden Zellen
speichert, kann man den Vergleich oft abkürzen, Bilder mit
unterschiedlicher Anzahl lebender Zellen muß man nicht im Detail
vergleichen.
Ihr habt die Begeisterung für dieses Thema, bei mir, wieder geweckt ...
Mit freundlichen Grüßen - Martin
Hallo zusammen,
da ich das Forum nicht regelmäßig verfolge, habe ich erst heute den
Faden entdeckt.
Ich hab auch nicht viel beizutragen, ausser Erfahrungen meiner
Programmiererei vor 30 Jahren.
Damales hab ich LIFE ohne Assembler direkt in Maschinencode gehackt.
(Das war die beste Schule, um Assembler zu lernen...)
Auf 25x40 brauchte ein Durchlauf etwas weniger als eine Sekunde auf
einem 4MHz Z80 (Sharp MZ700). Von daher finde ich Deine Zeiten gar nicht
so langsam.
Bei meiner Lösung wurde ein grosser Teil der Rechenzeit verbraten, um
die Daten zwischen dem Generationswechsel zu kopieren.
Sowas wie Pointer kannte ich damals noch nicht.
Zum Glück habe ich den Block-Tranfer vom Z80 entdeckt,
der ganze Speicherbereiche in einem Rutsch kopieren kann.
Martin Schlüter schrieb:> Idee ist, z.B. nur alle 500 Generationen ein Bild zu speichern, davon> immer die letzten 4 Bilder behalten, und jede neue Generation mit Diesen> zu vergleichen, dann wird eine Periodizität zwar verspätet erkannt, aber
Es reicht wohl, wenn man einen CRC vom Bild speichert. Der CRC kann beim
Aufbau des Bilds nebenbei berechnet werden.
Martin Schlüter schrieb:> @Christian J. (hobel):>> Ja, das hört sich ja nach einer Leidensgeschichte an, ich wünsche Dir> viel Glück daß das wieder besser wird. Aber was soll ich da sagen, nach> 22 Jahren ununterbrochener Berufstätigkeit nun seit 9 Monaten> arbeitslos, und nichts in Aussicht. Schönwald, und Schonach verwechsele> ich leider immer wieder mal. Schade, wieder ein Tüftler weniger im> Schwarzwald.
Tja..... arbeitslos war ich auch, 4 Monate, davor 13 Jahre nicht. Und
ich kann jedem nur empfehlen niemals einen sicheren Arbeitsplatz in
einem rennomierten Gross-Konzern aufzugeben, nur um ein "Abenteuer" in
einer inhabergeführten Kleinfirma anzutreten - um dann festzustellen,
dass man das Gefühl hat auf die dunke Seite des Mondes gewechselt zu
haben und schon durch den fehlenden Dialekt eine Barriere besteht an
deren Beseitigung auch kein Interesse besteht. Man bleibt halt gern
unter sich im Ländle. Darum jetzt zurück in einen modernen global
operierenden Konzern :-)
Der Z80 ist eine Spielerei und auch dieses GOL eher eine
Programmierübung, wie Kreuzworträtsel lösen. Man muss sich halt Gedanken
machen auf einer langsamen Maschine, wenn 1 Generation ca 1s aktuell
dauert was mein ARM7 in 0,0001s erledigt ohne dass ich da auch nur eine
einzige Optimierung benutzt hätte.
Jedenfalls ist bei der Benutzung eines Kompilers, hier des sdcc darauf
zu achten, dass möglichst alles "global" ist, Ergebnisse in Hilfsvars
gespeichert werden. da zb feld[x][y] einen Wust an Code erzeugt,
jedesmal wenn es benutzt wird. Der Compiler merkt nicht, dass er den
Zugriff zwischenspeichern sollte.
Bisher klappt mein Abbruch einwandfrei aber ich werde versuche noch eine
Bildanalyse einzubauen, was jedoch nicht ganz einfach ist, da die CPU
nicht das sieht wie der Mensch es sieht nämlich das ganze Bild.
Interessante Idee, ich bin in der Mathematik nicht bewandert genug, um
sagen zu können, ob die Tatsache, daß einer CRC nicht eindeutig ein Bild
zugeordnet werden kann, ein Problem ist. Zu jeder CRC gibt es mehrere
mögliche Bilder, ob die aber in einem Game of Live Lauf vorkommen, wage
ich nicht zu beurteilen, das Verhalten dieses Systems ist doch recht
komplex. CRCs sind aber besser als die Anzahl lebender Zellen, und kaum
aufwendiger.
Mit freundlichen Grüßen - Martin
Konrad S. schrieb:> Es reicht wohl, wenn man einen CRC vom Bild speichert. Der CRC kann beim> Aufbau des Bilds nebenbei berechnet werden.
Nein, glaube ich nicht. Oszilatoren ändern sich periodisch und haben
unterschiedliche Zellzahlen. Mann muss die Zyklik erkennen können und
das geht eher so, dass man Zellzahl und "Modifikationen pro Bild"
auswertet. Das Muster wiederholt sich und Wiederholungen kann man
auswerten. Ich arbeite nur mit Diffenzbildern, niemals wird das ganze
Bild neu aufgebaut oder die ganze Matrix neu gemacht. Das Kopiern geht
ratzfatz mit dem LDIR Befehl, der SDCC kennt die Blockbfehle des Z80 und
wendet sie an. memcpy(Ziel, Quelle....) erzeugt genau 8 Bytes Code oder
memset(Ziel, Byte, Quelle).
@Christian J. (hobel):
Ja, wenn man vergleicht, was ein Mensch, mit einem Blick, an
Informationen aus einem Bild zieht, und was man da mit seinem Programm
erreicht, dann kommt man sich ganz klein vor. Technische
Bildverarbeitung war einer der Schwerpunkte in meinem Studium, und es
ist schon erschreckend wie viel Aufwand man da für Dinge treiben muß,
die für den Menschen trivial sind.
Mit freundlichem Gruß - Martin
Hi Juergen,
heute kam bei mir dieses Board mit der Post:
https://www.youtube.com/watch?v=l6KmvP-Kwro
Pixel/s : 3.5 Mio :-)
Die Demosoftware ist allerdings "erschlagend", mit "mal eben" geht da
nichts aber sobald ich da besser durchblicke werde ich das GOL mal auf
diesem superschnellen Rechner implementieren mit grafischer Ausgabe.
Dürfte ja nicht so schwer sein das Display anzusteuern, wenn die Lib
schon mit dabei ist.
Eckdaten sind beeindruckend: 2MB Flash onchip, 192 kb RAM on chip,
8MBit extern, 160 Mhz Risc CPU.
5 Uarts und 14 Timer müssten ausreichen.....erstmal :-)
Wegen Umzug aber erstmal Pause für 3-4 Wochen, danach kann es losgehen.
Hi,
ich merke eh grad, dass ich der Letzte bin, der dieses Board entdeckt
und ich werde mich hüten da noch einen Thread zu aufzumachen, da sonst
Steine fliegen dürften :-)
Trotzdem ist schon der Code-Umstieg vom "Z80" auf diesen supermodernen
Prozessor wieder eine Hürde. Ohne Libs wohl keine Chance. Der hat nicht
2 PLL MULT7DIV Register, nein sogar 4. Mein ARM7TDMI LPC2368 Board von
2009 scheint schon wieder völlig veraltet zu sein. Der lag noch gut in
der Hand, nicht zu komplex und nicht zu einfach, mit 80Mhz ein gutes
Rennpferd.
Habe grad erstmal "gelernt" dass man selbst für das Setzen eines IO Pins
beim STM32F4 eine Library braucht (kippausdenlatschen) und für den ADC
und die Uarts auch usw. Und natürlich für das LCD Display für die
Darstellung von Windows eine von SEGGER, deren Manual allein 350 Seiten
stark ist, in C++ geschrieben. Netterweise hat auch jemand eine für s/w
text und Pixel geschrieben, die etwas "schmaler" daherkommt.
Fieserweise hat ST aber die Firmware nur als HEX dabei gelegt, manches
auch nur als Object File. Audiocodecs der Demo usw. sind nicht im Set
mit drin.
Ok, ich wollte es ja so.....
Christian J. schrieb:> 5 Uarts
... aber wenn du die auf dem Board vorhandene/mögliche Peripherie
komplett nutzen willst, dann hast du nichtmal eine einzige freie UART!
Freud' und Leid eines gut ausgestatteten Dev-Boards eben.
Konrad S. schrieb:> ... aber wenn du die auf dem Board vorhandene/mögliche Peripherie> komplett nutzen willst, dann hast du nichtmal eine einzige freie UART!> Freud' und Leid eines gut ausgestatteten Dev-Boards eben.
Glaube es sind sogar 8 Uarts, zzgl der 14 Timer, Cryptoprozessor, Hash
Generator, blubberbla.....
Ich weiss nicht genau welche Philosophie dahinter steckt aber ich kann
mir nur denken, dass Silizium inzwischen nichts mehr kostet, so dass die
statt 10 Varianten lieber einen Typ bis zur Unterkante Oberlippe
vollpacken mit Gattern und wie man 1 und 0 noch in immer neue
Reihenfolgen bringen kann. Wenn ich allein an den Patterngenerator
denke, der die Chips durchtestet, müssen Milliarden Muster sein.
2MB Flash Speicher, leider nur 1000 Mal beschreibbar. Da er
self-programmingh beherrscht werde ich mal ne passende Lib raussuchen,
damit ich den nutzen kann. 192kb RAM..... verleitet fast dazu mit dem
Speicher verschwenderisch umzugehen.
Bus Matrix mit Weichen.... immer was Neues....
Christian J. schrieb:> 2MB Flash Speicher, leider nur 1000 Mal beschreibbar.
In der Praxis darf wohl wie üblich ein Faktor 10 eingerechnet werden.
Nur sollte man das Exemplar dann nicht für Produktion verwenden.
Dank genug RAM kann man ausserdem beim Debuggen erst einmal den Code ins
RAM legen und das Flash in Ruhe lassen.
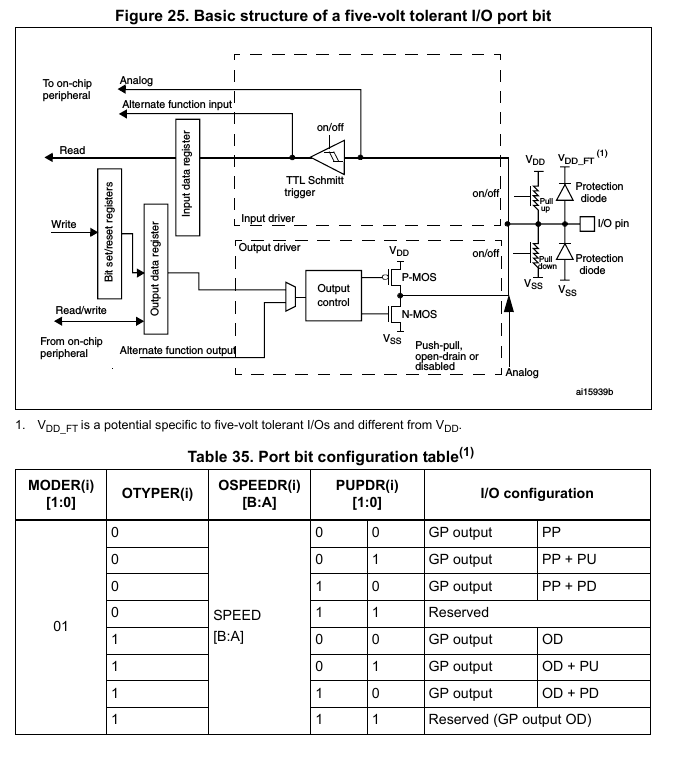
Each general-purpose I/O port has four 32-bit configuration registers
(GPIOx_MODER, GPIOx_OTYPER, GPIOx_OSPEEDR and GPIOx_PUPDR), two 32-bit
data registers (GPIOx_IDR and GPIOx_ODR), a 32-bit set/reset register
(GPIOx_BSRR), a 32-bit locking register (GPIOx_LCKR) and two 32-bit
alternate function selection register (GPIOx_AFRH and GPIOx_AFRL).
Meine Güte, was ist bloss aus den beiden Registern geworden, die beim
PIC ausreichen um einen Pin zu schalten.... ächz.
A. K. schrieb:> Dank genug RAM kann man ausserdem beim Debuggen erst einmal den Code ins RAM
legen und das Flash in Ruhe lassen.
Ja, das habe ich beim ARM7 auch gemacht, solange unter 32kb. Rowley
Crossworks hat einfach einen Switch "RAM Release, RAM Debug, ROM Debug"
usw, und wechselt im Hintergrund die Makefile, Startup Code usw aus.
A.K. (welchen Vornamen hast du eigentlich? ) ?
Hast du mit dem M4 Erfahrungen? IN dieser Zusammenstellung von STM?
Leider sehe ich die IDE wieder nur unter Windows, CooCox gibt es nicht
für Linux.
Christian J. schrieb:> Ich weiss nicht genau welche Philosophie dahinter steckt aber ich kann> mir nur denken, dass Silizium inzwischen nichts mehr kostet, so dass die> statt 10 Varianten lieber einen Typ bis zur Unterkante Oberlippe> vollpacken mit Gattern
Das ist schon lange so. Es gibt bei den STM32 Familien einige wenige
Basischips und haufenweise davon abgeleitete intern identische Modelle,
die sich durch reduzierte Kapazität, abgeschaltete Features und
unvollständige Bepinnung unterscheiden. Möglicherweise bei entsprechend
reduziertem Testprofil, was ja einen Teil der Kosten ausmacht.
A. K. schrieb:> Möglicherweise bei entsprechend> reduziertem Testprofil, was ja einen Teil der Kosten ausmacht.
Ich war 1999-2001 bei Renesas für V850 tätig..... das war einer der
Hauptkostenpunkte, dass jeder Chip komplett duechgeklappert werden
musste.
Wenigstens die Push Pull Stufe gibt es noch :-)
Christian J. schrieb:> A.K. (welchen Vornamen hast du eigentlich? ) ?
Einen der Standardvornamen meiner Generation, in der Grundschule waren
wir zeitweilig zu dritt.
> Hast du mit dem M4 Erfahrungen? IN dieser Zusammenstellung von STM?
M3 etwas ja, M4 nein (davor LPC2xxx). Ist aber schon ein paar Jahre her.
Mit Rowley Crossworks.
A. K. schrieb:> M3 etwas ja, M4 nein (davor LPC2xxx). Ist aber schon ein paar Jahre her.> Mit Rowley Crossworks, das gibts auch für Linux (150$). Ob Crossworks> das Debug-Interface des Boards unterstützt weiss ich nicht.
Hi Adolf? Alfred? Andreas? :-)
CW unterstützt eine Reihe von Wigglern und LPT1 Parallel Interface,
zumindest meine 2009 Version. Ich habe den Olimex USB Wiggler hier.
Das STM32F4 Board hat kein JTAG Interface, es ist ein STZ-Link V2
verbaut, welches über die USBN läuft und einen speziellen Treiber
braucht. Die JTAG Pins sind aber heraus geführt wie ich sehe aber nicht
konfiguriert als solche.
Blöde Frage:
Was muss man tun, um einen Pin einfach nur als Out oder In zu defieren?
Welche "Alternate Function" ist das? AF0?
Christian J. schrieb:> Meine Güte, was ist bloss aus den beiden Registern geworden, die beim> PIC ausreichen um einen Pin zu schalten.... ächz.
Warst du nicht derjenige, der den Z80 SIO für hoffnungslos kompliziert
und daher unbenutzbar hielt? Viel Spass in der Neuzeit. ;-)
Danke neuzeit war 2009 bei mir , da habe ich aufgehört mit 32
Bittern...... mein ARM Board liegt grad auf der Heizung, war mal kurz
unter der Dusche mit etwas Pril nach 3 Jahren auf dem Schrank und
Nikotin Dunst. Hoffe das hat es überlebt....
Christian J. schrieb:> Hi Adolf? Alfred? Andreas? :-)
Na also, geht doch. ;-)
> Was muss man tun, um einen Pin einfach nur als Out oder In zu defieren?> Welche "Alternate Function" ist das? AF0?
Keine.
Aber es gibt hier im Board irgendwo etwas Text zum STM32 und ich werde
den Teufel tun und dir alle Registerbits durchdeklinieren. Das darfst du
schön brav selber machen (oder musst jemand anderen finden). ;-)
A. K. schrieb:> Aber es gibt hier im Board irgendwo etwas Text zum STM32 und ich werde> den Teufel tun und dir alle Registerbits durchdeklinieren. Das darfst du> schön brav selber machen (oder musst jemand anderen finden). ;-)
Die Eingabe von "Discovery" oder "Disco" erzeugt hunderte Treffer, ich
werde mich hüten da noch was aufzumachen :-)
Die SIO hat nur 50 Seiten im Manual, die Eth aber fast 240 :-)
Christian J. schrieb:> Die Eingabe von "Discovery" oder "Disco" erzeugt hunderte Treffer, ich> werde mich hüten da noch was aufzumachen :-)
Jetzt gehst du erst einmal auf die Homepage dieser Site und schaust mal
was sich im linken oberen Eck so alles findet. Leider kriege ich den
Tonfall von der Sendung mit der Maus nicht hin, denk dir den dazu. ;-)
Oh mein Gott! Ich kann wieder sehen!
http://www.mikrocontroller.net/articles/STM32
:-)
Außerdem mache ich grad die wiss. Feststellung, dass Duschkopf und
"Schwarzkopf Schauma" eine nicht-schädigende Wirkung auf Hardware haben.
Das Schätzchen läuft noch, auch die DIY Grafikkarte, für die ich hier im
Forum mal ne Sammel gemacht habe, nur die Puffer Batterie ist leer.
Hi A.K. :-)
Nachdem ich mich den halben Tag mit dem "Disco Board" befasst habe und
mal das Manual quergelesen habe, fliegt das Ding in den
Gebrauchtwarenmarkt.
Einfach aus der Überlegung heraus, dass die Entwickler dieser CPU es
geschafft haben, selbst einfachste Dinge wie AD Wandler derart
kompliziert zu machen, dass die wenigen Stunden, die ich abends Zeit
habe sinnvoller verwendet werden sollten als sich neben dem Job den Kopf
mit etwas voll zu hauen, was ich nie beruflich brauchen werde, da ich da
nichts (mehr) mit CPUs am Hut habe, die Zeiten wo ich Produkt-Entwickler
war sind ein paar Jahre vorbei.
Und Hobbymaessig ist alles ausnahmlos mit Arduino, PIC und dem ARM7
LPC2368 erschlagbar, der noch gut durchschaubar ist und dazu sehr
schnell. 90% schlägt man sich beim M4 damit herum wie der Chip
konfiguriert werden muss, damit er einfachste Funktionen im Bastelkeller
ausführt, die genauso gut mit einer 8 Bit CPU zu machen sind.
Das ist "nur" die Init mit Hilfe einer Library, wie es "per Hand"
aussieht möchte ich schon gar nicht mehr wissen.
void P_ADC1s_InitADC(void)
{
ADC_CommonInitTypeDef ADC_CommonInitStructure;
ADC_InitTypeDef ADC_InitStructure;
// Clock Enable
RCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC1, ENABLE);
// ADC-Config
ADC_CommonInitStructure.ADC_Mode = ADC_Mode_Independent;
ADC_CommonInitStructure.ADC_Prescaler = ADC1s_VORTEILER;
ADC_CommonInitStructure.ADC_DMAAccessMode =
ADC_DMAAccessMode_Disabled;
ADC_CommonInitStructure.ADC_TwoSamplingDelay =
ADC_TwoSamplingDelay_5Cycles;
ADC_CommonInit(&ADC_CommonInitStructure);
ADC_InitStructure.ADC_Resolution = ADC_Resolution_12b;
ADC_InitStructure.ADC_ScanConvMode = DISABLE;
ADC_InitStructure.ADC_ContinuousConvMode = DISABLE;
ADC_InitStructure.ADC_ExternalTrigConvEdge =
ADC_ExternalTrigConvEdge_None;
ADC_InitStructure.ADC_DataAlign = ADC_DataAlign_Right;
ADC_InitStructure.ADC_NbrOfConversion = 1;
ADC_Init(ADC1, &ADC_InitStructure);
// ADC-Enable
ADC_Cmd(ADC1, ENABLE);
}
@ Christian J. (hobel)
>Einfach aus der Überlegung heraus, dass die Entwickler dieser CPU es>geschafft haben, selbst einfachste Dinge wie AD Wandler derart>kompliziert zu machen,>Und Hobbymaessig ist alles ausnahmlos mit Arduino, PIC und dem ARM7>LPC2368 erschlagbar, der noch gut durchschaubar ist und dazu sehr>schnell. 90% schlägt man sich beim M4 damit herum wie der Chip>konfiguriert werden muss, damit er einfachste Funktionen im Bastelkeller>ausführt, die genauso gut mit einer 8 Bit CPU zu machen sind
Lass das mal nicht den Moby hören, das ist pure Atomkernmunition für
ihn!!!
Falk Brunner schrieb:> Lass das mal nicht den Moby hören, das ist pure Atomkernmunition für> ihn!!!
Wer ist Moby? :-)
Der erste Schock ist überwunden .... ich werde dieses 25 Euro Teil
"bezwingen" und ihm beibringen wie es zu arbeiten hat.
Christian J. schrieb:> Nachdem ich mich den halben Tag mit dem "Disco Board" befasst habe und> mal das Manual quergelesen habe, fliegt das Ding in den> Gebrauchtwarenmarkt.
Hab ich so gemacht. Das Board ist zu allem fähig, aber zu nichts
wirklich zu gebrauchen.
Christian J. schrieb:> Der erste Schock ist überwunden .... ich werde dieses 25 Euro Teil> "bezwingen" und ihm beibringen wie es zu arbeiten hat.
Also doch wohl eher eine Frage des persönlichen Stolzes und Standings
hier im Forum ;-) Na ja, mir wär die Zeit zu schade für solche
Spielchen. Konzentrier Dich mal lieber auf konkrete Projekte. Wenn die
wirklich nach dem Aufwand/Leistung schreien will ich nichts gesagt
haben.
Falk Brunner schrieb:> das ist pure Atomkernmunition für> ihn!!!
... und die sollte jedem ernsthaft Interessierten zu denken geben.
Was bitte rechtfertigt diese Ausgeburt an Komplexität, wie jene
ADU-Initialisierung?
Moby schrieb:> ... und die sollte jedem ernsthaft Interessierten zu denken geben.> Was bitte rechtfertigt diese Ausgeburt an Komplexität, wie jene> ADU-Initialisierung?
Es gibt Leutchens, die den ganzen Tag bezahlt 8 Stunden darüber
nachdenken, wie sie das Rad noch runder machen können. Fast zwanghaft
arbeiten sie daran immer neue Ideen zu produzieren, wie man dem Kunden
immer neue Dinge aufschwatzen kann, die niemand wirklich braucht, wie zb
ein "Dual Trigger Mode" der ADC .... manches erinnert mich an "Windows".
Der wird ein Riesenaufwand getrieben "Windows 8", was auf einen Blick
"der letzte Shice" ist dem Kunden schmackhaft zu machen. Gebildeten
Leuten versuchen einzureden, dass dieser gekachelte Blödsinn das Non
Plus Ultra ist, was sie jetzt zu verwenden haben.
https://www.facebook.com/100000MenschenDieWindows8ScheisseFinden
Ich bewundere diese Leute, mir wäre meine Zeit zu schade dafür.
Christian J. schrieb:> neue Ideen zu produzieren, wie man dem Kunden> immer neue Dinge aufschwatzen kann, die niemand wirklich braucht, wie zb> ein "Dual Trigger Mode" der ADC ....
Irgendjemand wirds schon anwenden. Das Zeug soll hat flexibel auf Teufel
komm raus werden. Daß die resultierende Konfiguritis nicht nur den
Einarbeitungsaufwand, sondern auch die Fehlermöglichkeiten exponentiell
steigert (inklusive Verteuerung des nötigen Entwicklungs-Equipments),
scheint außerhalb des Sichtbereichs der Ingenieure geraten zu sein.
Route 66 schrieb im Beitrag #3956815:
> *FRECHHEIT!*>> Hier Werbung zu platzieren, ist unwürdig (oder aus mangelndem Wissen> eine Dummheit?).
Schlecht geschlafen?
Echt Hammer, was man damit machen kann:
https://www.youtube.com/watch?v=WkW55b-WQx4
@ Moby (Gast)
>Was bitte rechtfertigt diese Ausgeburt an Komplexität, wie jene>ADU-Initialisierung?
Naja, komplex ist das nicht wirklich, nur "zeitgemäß aufgebläht". Es
wird eine Init-Stukurtur Schritt für Schritt mir einzelnen Parametern
gefüttert, webei halt durch den struturellen Ansatz die Namen alle recht
lang sind. Am Ende sind es eine handvoll Infos, die in einer handvoll
Registern landen.
Aber ohne einen deratrigen Ansatz lassen sich solche Großkaliber nicht
mehr sinnvoll beherrschen. Und Assembler will man da auch nicht, auch
eine einige relegiöse Fanatiker da bestimmt gleich widersprechen ;-)
Christian J. schrieb:> ich habe in rund 3h mal für einen VT100 Screen mit 80x24 das Game of> Live durchprogrammiertChristian J. schrieb:> Nachdem ich mich den halben Tag mit dem "Disco Board" befasst habe und> mal das Manual quergelesen habe, fliegt das Ding in den> Gebrauchtwarenmarkt.
nur mal zum Vergleich :
im Anhang ein Projektfile vom GameOfLife
für das STM32F429 Board (das HEX-File ist auch dabei)
in unter 2Std programmiert
(natürlich ohne die Librarys :-)
die CPU rechnet und zeichnet 120 x 160 Zellen in ca 100ms
(ohne Optimierung oder sonstige Klimmzüge)
also gib dem STM nochmal eine chance,
so viel komplizierter ist der nicht.
Gruss Uwe
Uwe B. schrieb:> also gib dem STM nochmal eine chance,> so viel komplizierter ist der nicht.
Ich bin dabei aber ich kriege nicht mal die IDE (welche üperhaupt)
aufgesetzt und nerve das hale Forum damit, weil NICHTS klappt oder so
ist wie beschrieben, weil es sich schon wieder verändert hat. Selbst die
Flash Tools arbeiten mal, mal melden sie Fehler und scheinbar ist HEX
ein Fremdwort für viele, nur weil sie objcopy nicht kennen. Ich versuchs
mal zu brennen mit st-util....
ps: wo ist denn das Gamefile? Ich finde nur main.c und main.h...
pss: st-util und st-flash unter Linux zeigen auch seltsame
Erscheinungen. st-flash will gar nicht, zeigt interne Fehlermeldungen
oder erzeugt 0B grosse Dateien. Das ist alles ein sch..... Flickwerk
unter Linux wie es im Buche steht! Sorry.. musste mal so raus.
psss: Mit Cocox Flash liess sich das -elf dann brennen.... wahnsinn wie
fix GOL läuft! Irre!
Kannst Du mir nochmal das ganze projekt schicken? Mit den
Berechnungsfiles? Die sind leider nicht drin. Und vielleicht eine
release Version statt der Debug?
Anbei die Abruchbedingungen für das Spiel, die auf dem Z80 gut
funktioniert.... unter check_blinker wird ausgewertet wieviele
Modufikationen es pro Bild gibt und sobald die "Anzahl der Anzahl der
Modifikationen" < 4 wird springt er raus.
Da kriege ich wieder richtig Lust und würde gern den optimierten
Alopgorithmus, der nur die lebenden Zellen betrachtet auf dem STM
impelmentieren.
Hi nochmal,
falls das alles bei dir läuft (Linux? Windows?) können wir vieleicht mal
kurz telefonieren, damit ich etwas fixer zum Ergebnis komme als hier am
PC ständig alles tippen zu müssen und dann wider Stunden warte bevor
eine Antwort kommt?
Ich stehe kurz davor Rowley Crossworks zu kaufen aber wenn es
Alternative gibt, die wirklich funktionieren, dann immer her damit!
ps: Sie "leben" noch, das geht aber bestimmt noch schneller mit
optmiertem Code.
Wieviel Pixel hat eigentlich die ganze Zeile? Das sieht viel mehr aus
als 120x160 ....
Gruss,
Christian
Und nochmal :-)
Du bist der Uwe Berger, der diese schöne Wordpress Page hat merke ich
grad. Sagenhaft, Pacman lief prima, muss ne ganz schöne Arbeit gewesen
sein das zu programmieren. Würde ich schon 3-4 Wochen dransitzen mit
Konzept und Umsetzung. Klasse! Muss viel Zeit bei drauf gegangen sein,
kenne das ja von meinem (fast) fertigen Z80 Monitor System wo nur noch
die SD karte fehlt, die über den Arduino AVR angesteuert wird.
GOL Code habe ich gefunden, gut versteckt in ub_lieb. Da hast du ja auch
die Grafikroutinen drin. Hätte ich selbst direkt von Ardafruit
"geklaut", da es die auch für das Nokia Display so gibt. Nur die DMA
Geschichte ist mir neu aber Rom wurde auch nicht an einem Tag erbaut.
Dein GOL sucht stur durch sehe ich, Minimal Code. Es wird 5-10 Mal
schneller wenn man mit den "Nachbarschafts Punkten" arbeitet, da dann
nur die Live Felder betrachtet werden. Bei STm32 aber muss dann ggf
schon gebremst werden.
IDE: Linux scheidet aus, nicht mal die Flash Tools (st-util) laufen
wirklich. Eclipse ist unendlich langsam und die Errors beim Installieren
sind auch heute noch da. Atolic ist mit 32kb zu begrenzt.
Daher habe ich grad mit Rowley telefoniert, die würden das Board full
supporten, nur die ST Libs muss ich selbst einbauen.
Ganz wichtige Frage, wenn Du wieder am PC bist: Wieviel Schritte sind es
vom Kompilieren zum Debug Testen im Source Code und Probellauf? Hat
CooCox einen Sourcelevel Debugger, der einfach startbar ist? Bei Rowley
ist das ein Klick, ob Flash oder RAM Upload, dann lädt es, startet auf
und man kann debuggen.
Uwe B. schrieb:> die CPU rechnet und zeichnet 120 x 160 Zellen in ca 100ms> (ohne Optimierung oder sonstige Klimmzüge)>> also gib dem STM nochmal eine chance,> so viel komplizierter ist der nicht.
Uwe,
wollte mich nochmal bedanken, der Satz fiel mir heute wieder ein "also
gib dem STM nochmal eine chance".
Er hat seine Chance bekommen und der Z80 liegt derweil in der Ecke.
Inzwischen läuft auch mein GOL auf STm32F fast, obwohl die Portierung
vom Z80 Code doch etwas heftiger ist als gedacht, da ich völlig andere
Interfaces habe und das Spielfeld noch "doppelt gemoppelt" habe, also im
Videoram und in einem struct.
Aber die Geschwindigkeit.....BOAHHH EY! ;-)
PS: Zugegeben.... Tilen Majerle und Du habt aus dem System einen Arduino
gemacht, die Komplexität der Hardware ist völlig verborgen, zb die des
Displays, was ich selbst nie mit der StdPeriphLib hätte einstellen
können in akzeptabler Zeit.
@Christian,
habe den Thread jetzt erst wieder gesehen
(Uwe Berger ist ein Namensvetter...aber nicht ich)
super das du jetzt mit dem STM arbeiten kannst,
wie gesagt mach ein Schritt nach dem anderen