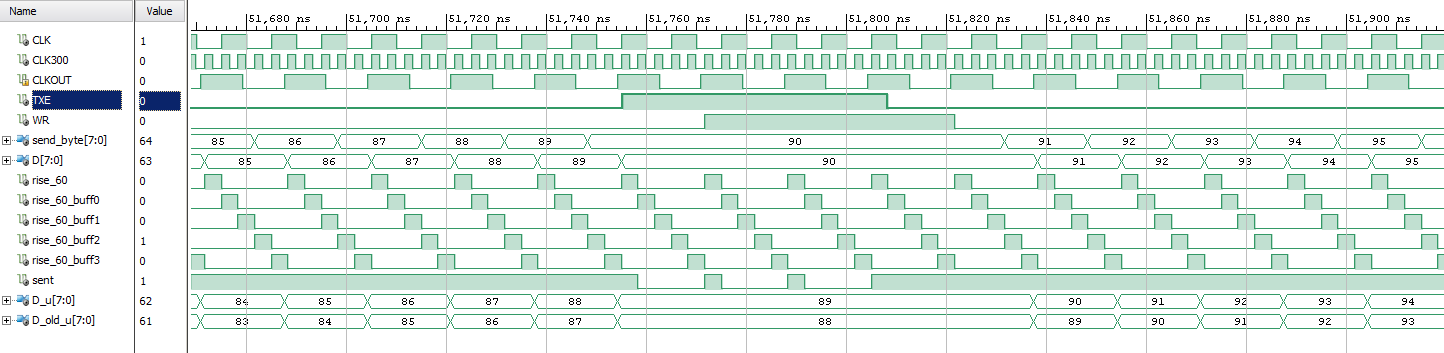
Hallo, mir ist klar, dass es ältere Threads zum Thema gibt, aber die haben mir nicht wirklich weitergeholfen. Ich möchte viele Daten über USB ausgeben, lesen ist mir egal, das brauche ich nie. Zuerst hab ich versucht die 60 MHz vom FT2232 im FPGA zu verwenden, aber die Daten kommen aus einer anderen Taktdomäne. Das ist eher kompliziert da den dual-clock-FIFO der ja dann auch einen Takt Latenz hat richtig anzuhalten wenn der FT2232H FIFO voll ist, das Timing ist halt doch eher hart für mich. So, jetzt habe ich das versucht indem ich im FPGA nur einen 300 MHz Takt verwende. Da kann (so dachte ich) man schön die Flanke der 60 MHz Clock erkennen und hat mehrere Takte Zeit Daten auszugeben und vom interen FIFO zu lesen. Also man kann in einem Takt prüfen ob der FT2232 FIFO nicht voll ist, dann vom FIFO im FPGA ein neues Byte lesen und das ausgeben. Eigentlich ganz schick. Habe natürlich auch ne Testbench gebaut die wie ich finde gut genug testet. TXE geht zwischen 1 und 7.15 ns nach CLKOUT auf Low oder High. Was ich nicht ganz verstehe im Datenblatt ist das t14, WR# setup Time to CLKOUT (WR# low after TXE# low) ist das jetzt die Zeit die WR# vor CLKOUT seinen Pegel geändert haben soll oder nach TXE#? Ich mache das so, dass wenn ich eine steigende Flanke von CLKOUT erkannt habe, ich WR# entsprechend zu TXE# setze. Aber natürlich funktioniert das nicht obwohl die Simulation gut aussieht. Ich würde mich freuen, wenn da mal Jemand drüberguckt. Vielen Dank!
Angehängte Dateien:
-

wave.png
24 KB
Ich würde es wahrscheinlich auch mit einem ansynchronem Übergang angehen, da bei 300 MHz das "bitgestreichel" schon gut losgeht. Aber bleiben wir doch mal bei deiner Variante. Wenn du Überabtastung mit einer eigenen Taktquelle umsetzt, dann benötigst du einsynchronisierte Signale bzw. einen einsynchronisierten Bus. Dies konnte ich auf dem ersten Blick nicht erkennen. Zweitens. Ist deine STA sauber? Gustl B. schrieb: > Habe natürlich auch ne Testbench > gebaut die wie ich finde gut genug testet :)
Klakx schrieb: > dann benötigst du einsynchronisierte > Signale bzw. einen einsynchronisierten Bus. Wieso? Also ich will damit ja nur Daten zum FT2232 hin ausgeben. Reicht es da nicht den 60 MHz Takt zu erkennen? Die anderen Signale verwende ich ja nicht direkt sondern immer nur als Enable ... wenn ich das mit mehreren FFs einsynchronisiere habe ich doch wieder Latenz. Derzeit "lese/sample" ich die Signale vom FT2232 und reagiere darauf indem ich selber Signale anlege. Klakx schrieb: > Ist deine STA sauber? Muss ich mir mal angucken ... gab zumindest keinen Fehler bisher.
Gustl B. schrieb: > Wieso? Also ich will damit ja nur Daten zum FT2232 hin ausgeben. Reicht > es da nicht den 60 MHz Takt zu erkennen? Die anderen Signale verwende > ich ja nicht direkt sondern immer nur als Enable ... wenn ich das mit > mehreren FFs einsynchronisiere habe ich doch wieder Latenz. Derzeit > "lese/sample" ich die Signale vom FT2232 und reagiere darauf indem ich > selber Signale anlege. Genau. Vollkommen richtig nur die Flanke zu erkennen und Enables zu nutzen. Aber die Flanke muss sauber auf der Taktdomäne sitzen. Im geposteten Code geht das USB-Takt "CLKOUT" direkt in einen kombinatorischen Flankendetektor. D.h. hier sollte input-constraints schonmal richtig gesetzt sein, damit es für die STA auch korrekt läuft. Metastabilität ist aber eben noch das größere Problem im Flankendetekor. Das mit der Latenz ist blöd, aber sowas kriegt man bei asynchronen Übergängen nunmal irgendwo mit rein. Synchronisier doch CLKOUT bevor es in die Logik geht mit 2 FFs auf CLK300. Ggf. müssen noch Eingangssignale angepasst/verzögert werden; vielleicht auch nicht. Bei einem Oversampling von 5 sollte es doch noch nicht so schlimm sein zwei Zyklen abzugeben?
Du hast mir sehr weitergeholfen! Habe mal in der Post-Implementation Timing Simulation (wusste gar nicht, dass VIVADO das kann) geguckt, und in der Tat, das ist mein Problem. Klakx schrieb: > D.h. hier sollte input-constraints > schonmal richtig gesetzt sein, damit es für die STA auch korrekt läuft. Constraints habe ich noch nie gebraucht (ausser um die IOs zuzuordnen mit Treiberstärke und so) und auch nichts diesbezüglich gelernt, leider. Muss ich nachholen. Klakx schrieb: > Im geposteten Code geht das USB-Takt "CLKOUT" direkt in einen > kombinatorischen Flankendetektor. Das habe ich noch nicht ganz verstanden. Ist das kombinatorisch, weil da nur ein FF verwendet wird um den alten Wert von CLKOUT zu speichern und dann im Vergleich auch direkt der Wert von CLKOUT verwendet wird ohne ein FF dazwischen? Ob das mit der Latenz der paar Takte gut geht wird sich zeigen, die Daten müssen eben rechtzeitig am FT2232 anliegen. Sollte aber funktionieren. Edit: Mit zwei FFs sieht es in der Tat gut aus, nur ist die Latenz enorm. Werde mal auf die fallende Flanke triggern, dann sollte es passen. Mir ist auch inzwischen klar wieso das falsch war. Und am Ende war es eben Dummheit. Hatte sogar zuerst die Methode von Lothar mit mehreren FFs drinnen, aber dann war mir die Latenz zu groß, so dass ich da einige rausgeworfen habe. In der einfachen Simulation sah das unverändert gut aus ...
So, also laut Simulation halte ich die Spec vom FT2232 nicht ganz ein, da kann TXE# auch noch 7,15 ns nach CLKOUT seinen Pegel ändern, ich checke das aber zuletzt grob 6,5 ns nach CLKOUT, aber, jetzt auch Hardware macht das keinen Ärger. Ich schaffe fast 42 MB/s ohne Fehler. Jetzt kommt noch ein FIFO ins FPGA und die Daten werden realistischer generiert, also nicht nur ein Zähler wie bisher. Jedenfalls vielen Dank!
Gustl B. schrieb: > Das > ist eher kompliziert da den dual-clock-FIFO der ja dann auch einen Takt > Latenz hat richtig anzuhalten wenn der FT2232H FIFO voll ist, das Timing > ist halt doch eher hart für mich. Der async FIFO kann man im Coregen auch weitere Ausgänge verpassen wie "gleuch voll" und/oder "gleich leer". Ab wann der das dann ausgibt ist auch einstellbar. Also zB "fast voll" wenn noch 8 Bytes reinpassen.
Das ist mir klar, aber wenn ich in jedem Takt zum FT232H hin schreibe und aus dem FIFO mit einem Takt latenz lese, kann passiert es, dass der FT232H das TXE# auf high zieht, ich aber noch einen Takt lang neue Daten aus dem FIFO bekomme. Wenn der FT232H dann wieder Daten annimmt, muss ich also zuerst die zwei Bytes dorthin schreiben die zuletzt noch aus dem FIFO kamen, aber noch nicht gesendet wurden und zwar in der richtigen Reihenfolge. Da muss man also Daten noch speichern für den Fall, dass der FT232H nixmehr entgegennimmt. Aber ja, werde ich mal bauen. Das mit den 300MHz macht beim BRAM irgendwie Probleme mit dem Timing ...
Gustl B. schrieb: > Aber ja, werde ich mal bauen. Das mit den 300MHz macht beim BRAM > irgendwie Probleme mit dem Timing ... Mittel- und langfristig hast Du mit Deinem bisherigen Ansatz unnötige Schwierigkeiten nicht nur dort. Scheinbar bist Du talentiert und befasst Dich intensiv damit. Die Frage ist daher, welche essentielle Information Dir noch fehlt. Du kannst kleine Teile des FPGAs (beispielsweise jene, die die state machines des besagten Interfaces darstellen) problemlos mit einem beliebigen externen Takt (beispielsweise mit dem des Interface-ICs) betreiben, insofern dieser sauber genug dafür ist. Ggf kann man ihn noch "sauber machen". Die Daten übergibst Du in beide Richtungen über jeweils eine FIFO. Siehe Beiträge oben.
Lars R. schrieb: > Scheinbar bist Du talentiert und befasst > Dich intensiv damit. Vielen Dank! Ist aber nur ein Hobby ... mal gucken, wenn man da als Seiteneinsteiger auch an Jobs kommt versuche ich das vielleicht mal. Aber zuerst Referendariat zwecks abgeschlossener Berufsausbildung. > Die Frage ist daher, welche essentielle Information > Dir noch fehlt. Eigentlich keine, nur die nötige Zeit. Und dann bin ich eben doch nicht allzu schlau ... Ja, richtig, mein Ansatz ist jetzt die 60 MHz von Extern zur Datenausgabe zu verwenden. Da könnte ich noch eine PLL intern drauf verwenden, aber der Takt sieht auch so gut genug aus. Für den Taktübergang habe ich mir jetzt ein Dual-Clock-FIFO erzeugen lassen, auf der einen Seite schreibe ich mit den 100 MHz rein die ich auch sonst im FPGA verwende und auf der anderen Seite lese ich eben mit den 60 MHz. Jetzt muss ich "nurnoch" die Logik erdenken/beschreiben die auf die externen Steuersignale reagiert. Also sowas wie "was passiert wenn ich Daten ausgebe, aber TXE# auf High geht?" Die Daten die ich also gerade eben angelegt habe an den Ausgang wurden nicht übernommen, die müssen gehalten werden und in dem Takt kommen neue Daten aus dem FIFO, die müssen auch "gemerkt werden" und dann wenn TXE# wieder Low wird zur richtigen Zeit ausgegeben werden. Alles nicht sooo einfach und das Datenblatt von FTDI ist im Timing-Diagramm auch nicht sehr hilfreich bei den seltsam eingezeichneten Zeiten. Am Wochenende werde ich da etwas Zeit drauf werfen ... Edit: Wieso nicht gleich mit 60 MHz sondern das rumprobiere mit den 300 MHz? Mit 60 MHz hatte ich angefangen, das lief auf einem Spartan 6, aber ohne Dual-Clock-FIFO und nur mit Testdaten, einem Zähler in der 60 MHz Domäne. Mit dem FIFO habe ich das da einfach nicht hinbekommen und auch nicht gesehen was nicht klappt. Jetzt verwende ich einen Artix und VIVADO, auch da war mir lange nicht klar dass es eine Post-Implementation-Simulation gibt (gab es die in ISE?) also hab ich zuerst mit 300 MHz angefangen weil ich dachte "da hast du genug Takte". Aber jetzt mit der wunderschönen Simulationsmöglichkeit werde ich das nochmal mit den 60 MHz testen.
Bei dem beknackten Timing des FT2232B kannst du nur hoffen dass nicht beide Werte den Worst Case gleichzeitig annehmen, denn dann hättest du für die Kombinatorik aus TXE und deinem Fifo Ready für das Write Enable nur 850ps im FPGA incl. IO Delays. Nicht machbar. Da der FTDI auch kein programmierbares Fifo Flag hat, ist das eigentlich unbrauchbar. Da kann man eben nur hoffen, denn meist klappt es ja. Wir verwenden u.a. deshalb die Cypress Chips, da hat man selbst beim Fx2 16 Bit und kann ganz entspannt mit 25MHz fahren und beim FX3, wo die Latenz sogar 2 Takte ist kann man die Fifo Flags programmieren. Das kriegt man dort alles sauber hin.
Christian R. schrieb: > denn dann hättest du > für die Kombinatorik aus TXE und deinem Fifo Ready für das Write Enable > nur 850ps im FPGA incl. IO Delays. Das verstehe ich nicht. Ich kann doch immer zu jeder steigenden Taktflanke vom 60 MHz Takt ein neues Byte anlegen wenn TXE# Low ist. Wenn TXE# High ist, muss ich damit aufhören bzw. merken dass gerade nix angekommen ist. Edit: So hatte ich das in Kombination mit dem Spartan 6 gemacht. Da war noch kein FPGA-internes FIFO dabei sondern die Testdaten waren nur ein Zähler. Aber das hat funktioniert soweit. /Edit. Der FX2 sieht für mich erstmal komplizierter aus, vor allem auch auf PC Seite. Da war der FTDI extrem einfach in C anzusprechen aber der FX2 hat da unterschiedliche Endpunkte und lauter Zeug um das man sich kümmern muss. Was ich aber generell nicht verstehe: Ich mach das nicht weil ich was lernen möchte, sondern weil ich Daten über USB ausgeben möchte. Ich würde da auch gerne was für kleines Geld kaufen wenn das geht. Klar Lernen ist auch gut und mache ich ja auch gerne, aber an dieser Stelle habe ich gerade keine Zeit dazu eigentlich. Also wieso haben die Hersteller von den Steinen nix im Angebot für Leute wie mich die einfach wollen dass es geht? Ein Stück VHDL und ein Stück C. Ist ja nicht so, dass ich hier etwas total exotisches mache, ich will ganz normale Funktion des Steins nutzen, das müssen die Hersteller doch auch mal gemacht habe. Aber wie auch immer, jetzt kostet es eben Zeit und ich lerne mal etwas (-:
Gustl B. schrieb: > Das verstehe ich nicht. Ich kann doch immer zu jeder steigenden > Taktflanke vom 60 MHz Takt ein neues Byte anlegen wenn TXE# Low ist. > Wenn TXE# High ist, muss ich damit aufhören bzw. merken dass gerade nix > angekommen ist. Ganz genau darum geht es ja. Nur ist die Zeit arschknapp. TXE reagiert im Worst Case 7. 15ns nach der letzten Flanke. OK, bleiben von den 16.66ns noch 9.51 übrig. Dann will WREN aber schon 8ns vor der nächsten Flanke den Pegelwechsel im Worst Case haben, dann hast du nur noch 1.51ns um die Signale im FPGA zu verknüpfen (ich hab oben die 0.66 unterschlagen und mit 16ns gerechnet), denn du musst ja das WREN inaktiv setzen. Klar, man kann jetzt drauf spekulieren dass schon nix passieren wird wenn man auf den vollen Fifo noch was schreibt, aber sauber ist das nicht. Um die interne Logik des FPGA zu stoppen und das Auslesen aus dem internen Fifo anzuhakten, sollte die Zeit aber reichen. Ich denke die meisten Designs arbeiten so. Das kannst du mit Constraints abtesten lassen. Der FX2 sieht nur auf den ersten Blick komplex aus, die liefern Firmware Beispiele mit, ich hab hier auch schon mal was gepostet an Quellcode. Auf der PC Seite kannst du auch dann den WinUSB oder LibUSB Treiber benutzen. Nachteil an den Cypress ist dass du eine USB Vendor ID brauchst.
Ah das meintest Du. OK das mag für Dich nicht sauber sein, aber wird sogar im Datenblatt so gemacht, da geht WR# auch erst mit der nächsten Taktflanke hoch. https://www.mikrocontroller.net/attachment/114971/burst.PNG Das sehe ich mal als Indiz dafür, dass das schon so funktioniert. Eine USB ID habe ich nicht.
Ah, na schau an. OK, dann scheint also nix zu passieren wenn du den Fifo überfüllst. Dann hast du auch mit 60MHz ksin Problem, die 16.66ns - 7.15ns reichen aus um intern zur Flanke zu stoppen.
So, zuerst wollte ich alles vom Lesen beim FPGA internen FIFO bis zur Ausgabe von den Daten zum FTDI alles in einen getakteten Prozess packen, aber das habe ich nicht geschafft weil ich da dann immer Latenz habe und echt viele Zustände beachten muss. Naja, also ... habe ich Kombinatorik dazugenommen. Ist auch schön übersichtlich und macht in der Verhaltenssimulation keine Fehler. Aber in der Post-Implementation-Timing-Simulation schon, aber selten. Und zwar nutze ich ja den externen 60 MHz Takt vom FTDI um intern am FPGA-FIFO zu lesen. Und do zwischen ist Latenz zwischen dem externen Takt und dann dem tatsächlichen Takt am FIFO. Naja, geht ja auch vom Pad erstmal rein in den Stein. Also eine PLL reingebaut. Die lockt auf die externen 60 MHz und dann sollte das passen. Jetzt ist es seltsam: Die Implementation sagt irgendwas von Timing Violations und zwar ist wohl ein Intra-Clock-Path verletzt mit einem Total Negative Slack von -947.579 ns. Was soll das? Wo kommt sowas her? Ich habe in meiner .xdc nur die beiden externen Takte constraint. Jedenfalls, trotz des Fehlers habe ich ja eine fertige Implementation und jetzt zeigt die Post-Implementation-Timing-Simulation keine Fehler mehr, aber weil die PLL Clock minimal Versatz zur externen FTDI-Clock hat schaffe ich die 8 ns Setup-Time der Daten und vom WR# nicht, sondern nur etwas über 7. Mal gucken was die Hardware sagt ... Edit: Sieht auch gut aus. Getestet mit etwas über 30 MB/s und keine Fehler. Aber muss ich mal länger laufen lassen. Edit2: Jetzt hab ich die PLL wieder draussen und es gibt auch keine Fehler auf Hardware. Das mit der PLL und der Simulation verstehe ich sowieso nicht. Ich meine ob jetzt der Takt von extern zu der Logik geht oder aus der PLL ist doch egal weil die Latenz zwischen Pad und Logik ja sowieso für alle Logikteile gleich ist. Und bei der PLL eben auch.
So, bei den grob 34MB/s wird der FPGA-integre 64kByte FIFO doch manchmal voll und es fehlen Bytes. Bei jetzt 25MB/s (ich brauche später nur 22MB/s) passiert das nur noch extrem selten. Zum Testen habe ich jetzt mal grob eine Stunde lang (4000s = 100GByte) Daten zum PC geschickt und habe jedes Mal nur so eine Hand voll Fehler bei denen anscheinend der FIFO voll war (es fehlen jeweils mehrere Bytes am Stück). Also sprich ich bin zufrieden, werde aber auch noch unter Linux testen, vielleicht sieht es da ja anders aus.
Wieso nicht? Wenn der PC eine Zeit lang nicht von USB liest läuft intern der FIFO voll. Ich erzeuge ohne Unterbrechung Daten weil das später in der Anwendung eben auch so seien wird.
Achso meinst du das. Deine Anwendung auf dem FPGA schreibt da zuviel rein. Wenn das erlaubt ist, ok. Bei Datenübertragung und den Worten Fehler und anscheinend bin ich sehr vorsichtig. Wenn sich der Overflow vermeiden lässt, würde ich lieber kontrolliert anhalten.
Was ist denn das für eine Anwendung? Für dauerhaftes Streaming ist BULK nicht geeignet. Das geht zwar am schnellsten, aber nur wenn auf dem Bus Platz ist. Für Streaming gibts isochronen Transfer. Da bekommst du 24MB/s garantiert, aber eben keine Datensicherheit. Kannst oder willst du den Datentransfer nicht anhalten? Wir machen das bei uns so ähnlich wie Speicher-Oszi, der Host PC fordert die Daten an, und wenn der PC halt beschäftigt ist, wird die Blindzeit zwischen zwei Messungen halt größer. Für Dauer-Streaming wirst du auch bei Linux nicht mehr Glück haben, USB und insbesondere BULK gibt das nicht her.
Also als Anwendung haben wir an der Uni ein Transmissionselektronenmikroskop (TEM). Das rastert mit dem Strahl über die Probe und hat also horizontale und vertikale Ablenkspannungen. Diese werden in einem Rechner mit einer Karte von NI und leider closed-source Software generiert. Die NI-Karte hab ich schon angeguckt und weis auch wo ich die 2x16 Bit + 4xClock abgreifen kann die also die Pixeladresse auf dem Bild sind. (Ich greife das vor den 2 AD-Wandlern ab). Bei sinnvollem Scanning bei dem die Bilder nicht allzu verrauscht sind ändert sich die Adresse jede us., also ich bekomme mit 1MHz jeweils einen neuen Pixel. Dann soll ja auch was gemessen werden und zwar mit 8 AD-Wandlern die jeweils 16 Bit liefern. Das soll synchron zu dem 1MHz Takt der Pixeladresse funktionieren damit ich also zu jedem Pixel so die "Farbinformation" bekomme. So, und dass soll möglichst stumpf zum PC übertragen werden und da sitzt dann eine Software die die Daten erkennt und in ein Bildarray schreibt oder auch nur auf Platte schreibt und später verrechnet. Übertragen muss ich die Pixeladresse und die 8x16Bit. Die Pixeladresse sind jedoch nicht die 2x16 Bit die an den AD-Wandlern ankommen sondern nur jeweils die oberen 11 Bit, denn mehr als 2048x2048 Pixel kann man in der Steuersoftware nicht einstellen. Macht zusammen 2x11Bit + 8*16Bit = 150Bit. Und damit ich im Datenstrom irgendwie den Anfang und das Ende eines Pixels erkennen kann habe ich mir das so gedacht: Das letzte Bit jedes Bytes ist '0' ausser wenn ein neues Paket anfängt. Damit brauche ich dann 22Bytes/Pixel. Macht 22MBytes/s die ich also übertragen muss. Anhalten kann ich nicht, weil ich keinen Zugriff auf die Interna der Steuersoftware habe. Aber ist auch egal. Man kann ja erkennen wenn Bytes fehlen weil die Pixeladresse nicht schön hochzählt oder sonst wie ein Paket unvollständig ist.
Hallo, finde dein Projekt super und will es nicht schlecht reden. Falls Du es noch schneller brauchst, dann kannst Du Dir den FT601 anschauen, fertigen FPGA Code gibt es wohl auch für Xilinx und Altera. http://www.ftdichip.com/Products/ICs/FT600.html
Vielen Dank! Schneller brauche ich das nicht aber ja, der Stein ist interessant. Derzeut verwende ich aber nicht den FT232H auf einer eigenen Platine, sondern die UM232H wo alles schon fertig drauf ist. Der FT232H wäre aber auch selber noch gut auf zweilagig zu layouten. Beim FT601 finde ich a) keine kompakte schöne fertige Platine die ich an den FPGA stecken könnte und b) sieht das zum selber layouten etwas anspruchsvoller aus. Vielleicht mache ich das mal wenn ein neues Projekt höhere Anforderungen hat ...
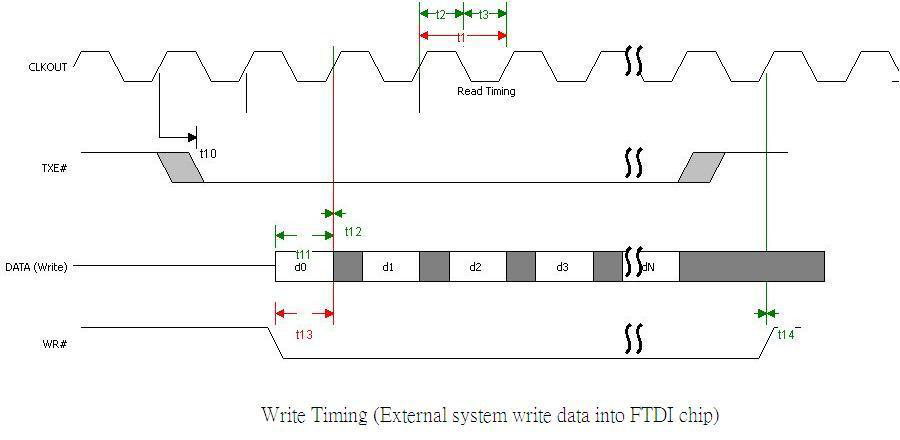
So, ich habe Probleme. Ich habe an dem mittlerweile deutlich größeren Projekt einige Dinge geändert und bekomme jetzt Fehler bei der Übertragung mit dem FT2232 Stein. Den Teil vom Code der mit dem FT2232H spricht habe ich aber nicht angefasst. Ich habe das so: In einer 100 MHz Domäne füttere ich einen independent Clock FIFO mit Daten und in der 60 MHz Dömäne (der Takt kommt da vom FT2232H) wird aus diesem FIFO gelesen. Das hat immer funktioniert, aber selbst wenn ich dem FIFO jetzt konstante Werte gebe passieren Fehler. Ich kann mir das nicht erklären, meine Simulation funktioniert wunderbar. Ich möchte mich jetzt in Constraints einarbeiten und das darüber lösen. Bisher habe ich nur Constraints für die 100 MHz Clock die direkt am FPGA angeschlossen ist. Da werden Periodendauer und Jitter mitgeteilt. Für die 60 MHz Clock vom FT2232H habe ich auch Periodendauer und Jitter eingestellt. Ich möchte jetzt weitere Constraints für die Kommunikation mit dem FT2232H angeben. Konkret geht es hier https://www.ftdichip.com/Support/Documents/DataSheets/ICs/DS_FT2232H.pdf um die Seite 41. Ich verwende nur die Richtung vom FPGA zum FT2232H, muss also nur das TXE# auswerten und WR# zusammen mit den Daten setzen. Welche Constraints brauche ich da? Vielen Dank!
Angehängte Dateien:
-

timing.jpg
160 KB
Jetzt habe ich meinen Code deutlich optimiert. Das sieht jetzt so aus:
1 | RD <= '1'; |
2 | SIWU <= '1'; |
3 | OE <= '1'; |
4 | WR <= not fifo_valid; |
5 | fifo_rd_en <= TXE nor fifo_empty; |
Die Daten kommen direkt aus dem FIFO und CLKOUT geht nur zum FIFO. Das bedeutet also, dass nur mit WR# ins FT2232 geschrieben werden wenn fifo_valid high ist. Und es wird nur vom FIFO gelesen wenn TXE# low ist und fifo_empty auch low ist. Das funktioniert auch in der Simulation ausser wenn mal eine Zeit lang nicht vom FIFO im FPGA gelesen wird. Wenn dann wieder mit dem Lesen begonnen wird, TXE# also auf low geht, wird das erste Byte das vom FIFO ausgegeben wird nicht übertragen. Wenn ich aber die CLKOUT invertiert an das FIFO im FPGA anschließe gibt es keine Fehler. Ich würde das trotzdem gerne mit Constraints machen habe aber keine Ahnung wie ich die Zeiten aus dem FT2232H Datenblatt mit Constraints abbilde.
Angehängte Dateien:
-

FT2232H_minimal.jpg
240 KB
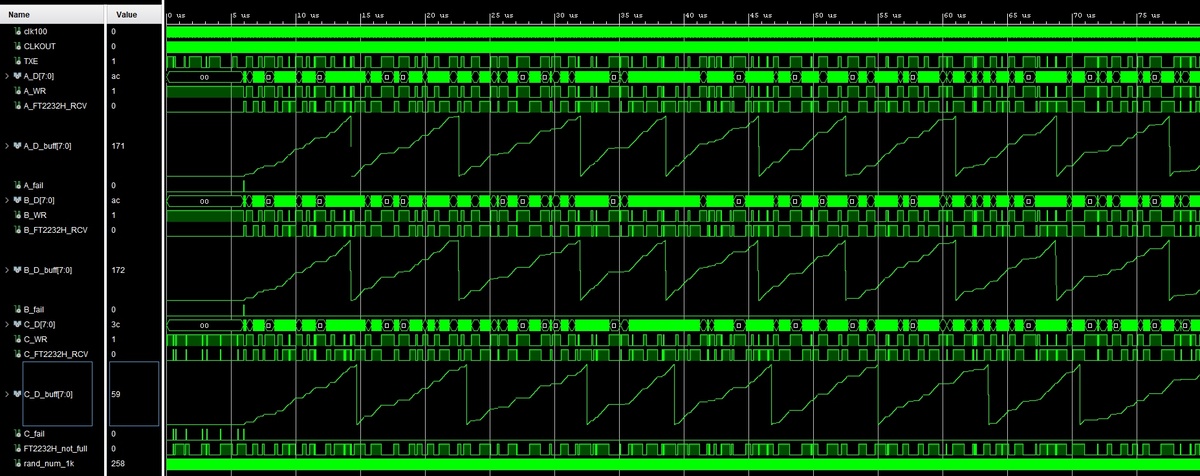
So, ich habe jetzt drei Lösungen die in der Simulation funktionieren, aber auf der Hardware nicht bzw. nur manchmal. Im Anhang ist ein Minimalprojekt. Da wird regelmäßig ein 256Byte Burst in einer 100MHz Domäne in einen Dual Clock FIFO geschrieben. Das sind die Bytes mit den Werten 0 bis 255. Auf der anderen Seite wird mit den 60MHz vom FTDI aus diesem FIFO gelesen. Die Testbench überprüft ob die gelesenen Werte aufsteigend sind. Die drei Lösungen habe ich mit A, B und C gekennzeichnet. Version A wurde von mir auf Hardware verwendet und lief bis vor einigen Wochen als ich das Projekt neu baute komplett problemlos. Sowohl mit Artix als auch mit Spartan3 und Spartan6. Auch komplett ohne Constraints. Mit meiner aktuellen 2018.3 Vivado Version schaffe ich es nichtmehr, dass es fehlerfrei funktioniert und bin jetzt auf der Suche nach einer Lösung. Habt ihr eine Idee? Die Hardware kann ich aussschließen weil alte Bitstreams weiterhin funktionieren.
Gustl B. schrieb: > Habt ihr eine Idee? Wenn Dinge "nur manchmal" funktionieren, liegt's ja höchstwahrscheinlich eher am (nicht eingehaltenen) Timing als am Code, wäre meine Annahme. Wenn das Timing nicht eingehalten wird und die Synthesetools das nicht merken und anmeckern, dann ist das Design wahrscheinlich nicht vollständig (oder nicht korrekt) constrained.
Das kann gut sein. Welche Constraints sollte ich denn setzen wenn ich nur dieses Minimalbeispiel auf die Hardware bringen möchte?
-gb- schrieb: > Das kann gut sein. Welche Constraints sollte ich denn setzen wenn ich > nur dieses Minimalbeispiel auf die Hardware bringen möchte? Eine vollständige Timing-Analyse (die die Voraussetzung für eine funktionierende "timing driven" Synthese ist) funktioniert nur (Vivado kenne ich nicht, aber ich nehme an, die Logik ist dieselbe wie bei TimeQuest), wenn mindestens sämtliche I/O-Ports constrained sind und die Tools Taktdomänenübergänge (als clock group oder false path) als solche erkennen (sich also nicht die Zähne daran ausbeissen, die synchronisieren zu wollen und sich stattdessen an wichtigeren Dingen verlustieren können). Aus meiner Sicht minimal notwendig ist also (neben den "echten" und virtuellen Clocks) ein set_input_delay für jeden Input und ein set_output_delay für jeden Output. Weil ich meist (aufgrund fehlender oder unvollständiger Dokumentation des angeschlossenen Hobby-Zeugs) reichlich ahnungslos bin, welche Werte ich da reinschreiben soll, beginne ich meist bei 0 ("Zeitfenster auf") und mache die Zeitfenster dann sukzessive enger, bis das Design bei erträglicher Synthesedauer zuverlässig funktioniert. So ziemlich jedes nicht-triviale Design hat (zumindest bei mir) den ein oder anderen kombinatorischen Pfad, der zu lang ist, als daß er bei gegebener Clock bereits an der nächsten (default-) Flanke ein Ergebnis liefern könnte. Wenn man das (evt. im Design über Enables abgesichert) dem Fitter als Multicycle mitteilt, gewinnt er Timing-Margin, die er an anderer Stelle sinnvoll verwenden kann.
Klar, die 60MHz Clock constraine ich und da gebe ich auch einen Input Jitter an. Das hat aber auch komplett ohne Constraints funktioniert, nur eben jetzt nichtmehr. Markus F. schrieb: > ein set_input_delay für jeden Input und ein > set_output_delay für jeden Output. OK, worauf bezieht sich das? Eine Eingangsverzögerung ist ja vermutlich relativ zu einem anderem Signal sonst wäre sie ja egal. Müsste ich da hier auf Seite 41 https://www.ftdichip.com/Support/Documents/DataSheets/ICs/DS_FT2232H.pdf t11 reinschreiben, also per Constraint mitteilen, wieviel TXE# nach CLOCKOUT anliegt?
Ich habe jetzt folgende Constraints geschrieben verstehe aber vielleicht nicht deren Bedeutung: set_input_delay -clock [get_clocks sys_clkout_pin] -max 7.15 [get_ports TXE] set_input_delay -clock [get_clocks sys_clkout_pin] -min 1.00 [get_ports TXE] set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 [get_ports WR] set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 [get_ports D] 1. sagt, dass TXE spätestens 7.15ns nach der Clock am sys_clkout_pin anliegt. 2. sagt, dass TXE frühestens 1ns nach der Clock am sys_clkout_pin anliegt. Mit 3. und 4. möchte ich vorgeben, dass WR und D spätestens 8ns nach der Clock stabil ausgegeben werden. Die Toolchain kann das Timing aber nicht einhalten, daher vermute ich ein Missverständnis. Die Minimallösungen von oben funktionieren komplett ohne Constraints auf der Hardware die ich hier zuhause habe. Die ist fast identisch mit der Zielhardware aber nicht ganz. Auf der Zielhardware habe ich diese Minimalbeispiele noch nicht getestet, das wird noch gemacht.
Angehängte Dateien:
-

path.jpg
110 KB

So, noch eine Lösung, dieses Mal mit einem zusätzlichen Register für die Daten. Die kommen also nicht direkt vom BlockRAM zu den Füßchen des FPGAs, sondern gehen jetzt zuerst in eine getaktete Registerstufe. Das mache ich weil ich da das Problem vermute. Der BRAM hat ja Latenz bis die Daten rausfallen und wenn ich in einem Takt die Adresse anlegen und die Daten im nächsten Takt schon an den Pins sein müssen ist das vielleicht etwas knapp. Mit diesem zusätzlichen Register handelt man sich aber Komplexität ein. Wenn der FTDI TXE hochnimmt, dann liegen Daten an den Pins an, neuere Daten sind im Register und ganz frische Daten kommen gerade aus dem BRAM, das ist eine Pipeline die man dann mühsam leeren muss wenn TXE wieder runter geht. Testweise habe ich darauf also verzichtet und überprüfe direkt ob ein Byte richtig zum FTDI geschrieben wurde. Dadurch drittelt sich die maximale Datenrate aber ... das ist zum Testen egal. Auf meiner Testhardware komme ich noch auf knapp 10 MBytes/s ohne Fehler. Tja, aber die Timingverletzung wird mit immernoch angezeigt. Irgendwie verstehe ich die Constraints nicht. Laut dem FTDI Datenblatt muss die Write DATA setup time mindestens 8 ns betragen. Das bedeutet doch, dass die Daten 8 ns vor der Taktflanke anliegen müssen. Als Constraint habe ich set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 [get_ports D] geschrieben. Laut UG949 Seite 228 https://www.xilinx.com/support/documentation/sw_manuals/ug949-vivado-design-methodology.pdf müsste das passen. -max gibt Setup und -min Hold an. Ich verstehe aber noch nicht ganz warum das jetzt verletzt wird. Ich habe einen independend Clock FIFO und dann noch ein Register die beide mit den 60 MHz vom FTDI getaktet werden. Da ist keine Logik dazwischen, das Register geht direkt auf die Pins und wird auch in jedem Takt zugewiesen. Was dauert da länger als 8 ns? Im Anhang das Bildchen zeigt, dass es vom Register zum Pin geht, dass Start und Ziel von gleichen Takt getaktet sind und dann stehen da noch echt große Zahlen. 4 ns Logic Delay ist ziemlich viel dafür dass da keine Logik zwischen Register und Pin ist. Das Requirement ist für mich auch völlig unklar. Ja, das ist die Periodendauer vom 60 MHz Takt, aber was bedeutet das? Wo wird was required? Die Signale sollen 8 ns vor der nächsten Taktflanke da sein.
Gustl B. schrieb: > Mit 3. und 4. möchte ich vorgeben, dass WR und D spätestens 8ns nach der > Clock stabil ausgegeben werden. > Die Toolchain kann das Timing aber nicht einhalten, daher vermute ich > ein Missverständnis. set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 [get_ports WR] set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 [get_ports D] Die beiden Statements sagen, dass WR und D (durch externes Delay, das ist das, was set_output_delay ausdrückt) bis zu 8ns brauchen, bis sie beim Empfänger ankommen. Die Toolchain "zielt" auf die nächste steigende Taktflanke, ist also der Meinung, sie müsste (damit das wieder zusammenpasst) die Daten spätestens 16,667 - 8 = 8,667 ns vor der nächsten Taktflanke stabil haben, damit sie rechtzeitig beim Empfänger sind. Und das schafft sie offensichtlich nicht.
OK, aber das ist doch auch das was das Datenblatt verlangt. Ich frage mich wieso die das nicht schafft. Kann man das irgendwo rausfinden? In dem Code ist da keine Kombinatorik im Weg, sondern mit einem Takt kommt D_out aus dem FIFO und geht mit einem weiteren Takt D <= D_out an die Pins. Da müssen nur die Daten vom Register an die Pins gegeben werden. Natürlich gibt es das schon fertig, z. B. hier https://github.com/RandomReaper/pim-vhdl/blob/master/hdl/rtl/ft245_sync_if/ft245_sync_if.vhd aber das ist echt viel Code im Vergleich zu der Lösung die bei mir jetzt echt lange problemlos funktioniert hat und das auf mancher Hardware immernoch tut. Das muss doch kürzer gehen, auch mit FIFO im FPGA.
Gustl B. schrieb: > OK, aber das ist doch auch das was das Datenblatt verlangt. Tatsächlich steht da - wenn ich das richtig sehe - Minimum 8, Maximum 16.67 ns für die Write Daten (was erklären würde, warum dein Design nur manchmal funktioniert). Im Idealfall würden die Daten beim Empfänger bei genau 8 + (16,67 - 8)/2 = 12,33 ns ankommen (dann hättest Du maximal Spielraum nach links und rechts). Warum verschiebst Du (PLL) deine FIFO Output Clock nicht genau dahin? Dann sind deine Constraints ganz einfach ...
Markus F. schrieb: > Minimum 8, Maximum > 16.67 ns für die Write Daten (was erklären würde, warum dein Design nur > manchmal funktioniert). Ja, das ist der Abstand zu der Taktflanke mit der sie im FTDI übernommen werden. Also sie dürfen frühestens 16,67 ns, und müssen spätestens 8 ns vor dieser Flanke anliegen. Markus F. schrieb: > Im Idealfall würden die Daten beim Empfänger bei genau 8 + (16,67 - 8)/2 > = 12,33 ns ankommen (dann hättest Du maximal Spielraum nach links und > rechts). Genau, also 12,33 ns vor der nächsten Flanke. Markus F. schrieb: > Warum verschiebst Du (PLL) deine FIFO Output Clock nicht genau dahin? > Dann sind deine Constraints ganz einfach ... Das kann ich machen, oder ich verwende die fallende Flanke. Aber wie muss ich dann constrainen? Das bezieht sich ja weiterhin auf die steigende Flanke der FTDI-Clock.
Gustl B. schrieb: > Das kann ich machen, oder ich verwende die fallende Flanke. Aber wie > muss ich dann constrainen? Du kannst die output delays auf OUTCLK beziehen (dann gilt das, was im Datenblatt steht) oder eine virtual clock mit den Parametern der verschobenen PLL-clock erzeugen und dich auf die beziehen - dann gilt das, was wir oben ausgerechnet haben.
OK, aber TXE# bleibt ja auf CLKOUT bezogen, das muss ich irgendwie auswerten. Also mit CLKOUT TXE# auswerten und mit einer leicht verschobenen CLKOUT die Daten und das WR# anlegen? Edit: CLKOUT to TEX# ist 1 ns bis 7,15 ns. Das bedeutet, dass bei der fallenden Flanke von CLKOUT TXE# schon stabil anliegen müsste. Dann kann ich mit dieser fallenden Flanke auch die Daten und WR# ausgeben, muss das aber so constrainen, dass es erst nach der ersten steigenden Flanke da ist.
Gustl B. schrieb: > Ja, das ist der Abstand zu der Taktflanke mit der sie im FTDI übernommen > werden. Also sie dürfen frühestens 16,67 ns, und müssen spätestens 8 ns > vor dieser Flanke anliegen. Das stimmt so nicht (und ich habe mich oben - offensichtlich verwirrt - auch nicht präzise ausgedrückt). Das ist nicht dein Spielraum, sondern der Spielraum, den sich dein MAX gönnt. Es kann ihm also durchaus einfallen, die Daten 16,67 ns vorher oder auch mal nur 8 ns vorher abzuholen. Deine Daten müssen also über dieses gesamte Zeitfenster hinweg stabil anliegen, damit dein Design zuverlässig funktioniert.
Angehängte Dateien:
-

timing.png
100 KB -

timing.jpg
200 KB
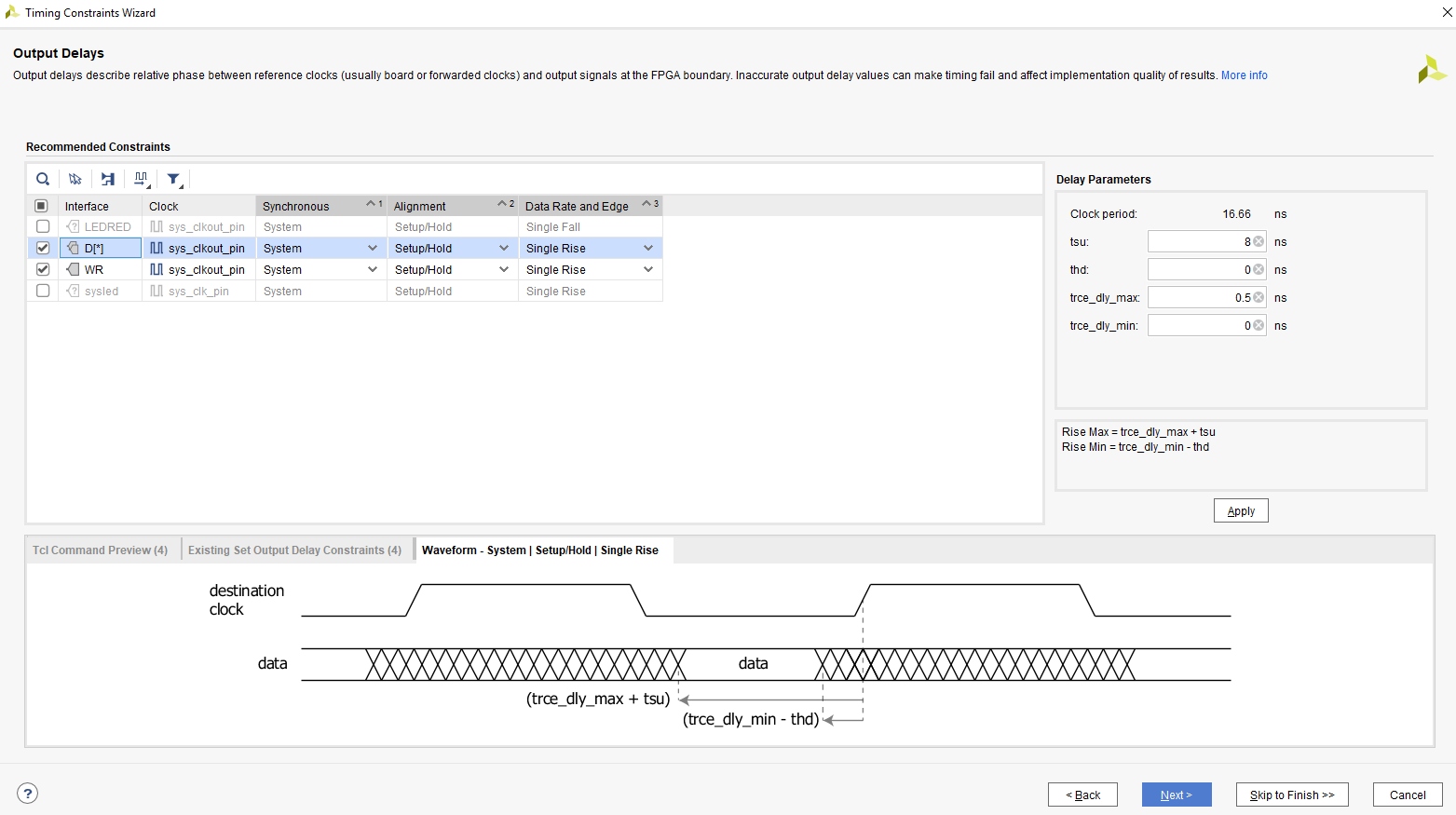
{kind=link}
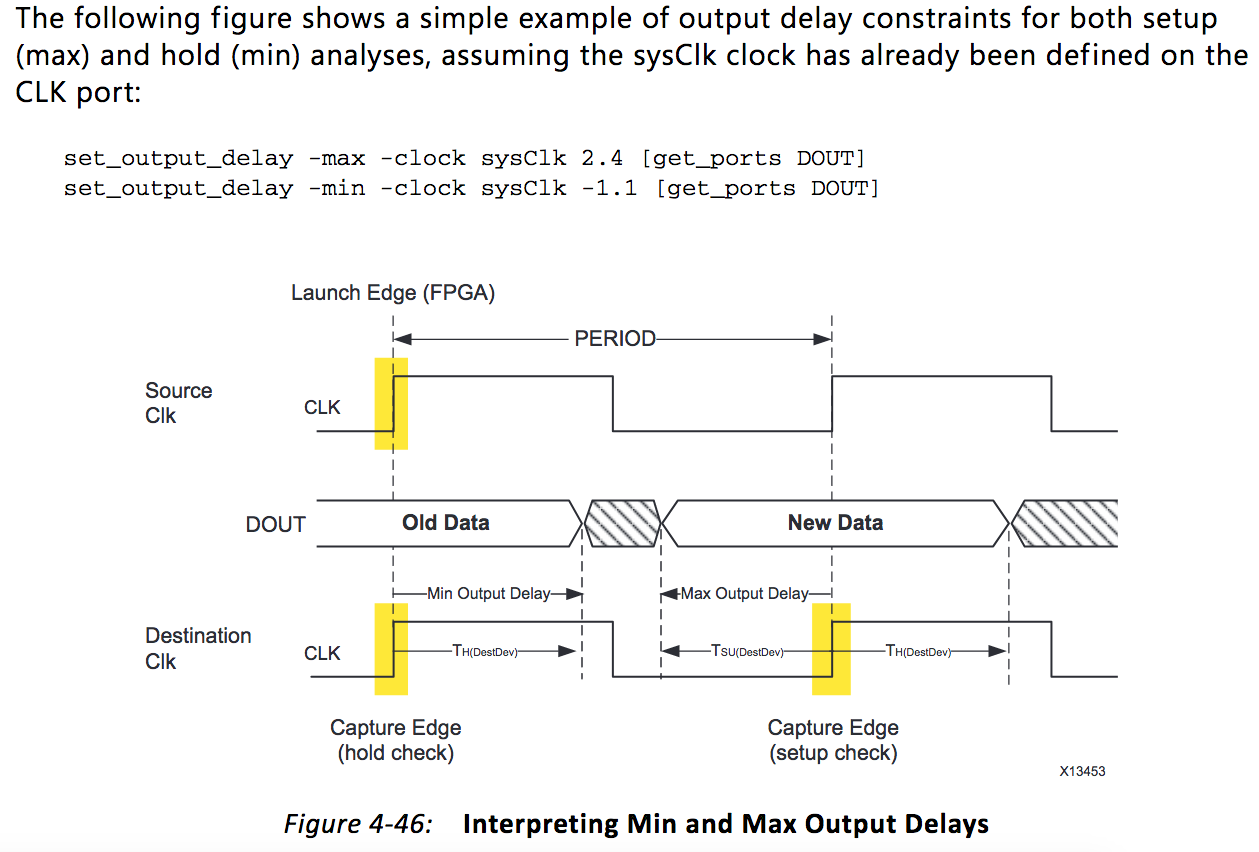
Sicher? "Write DATA setup time" hat den Maximalwert von 16,67 ns und den Minimalwert von 8 ns. Das bedeutet für mich, dass die Daten schon 16,67 ns vor der Flanke anliegen dürfen, aber erst 8 ns vor der Flanke anliegen müssen. So sieht das auch im Bildchen auf Seite 41 https://www.ftdichip.com/Support/Documents/DataSheets/ICs/DS_FT2232H.pdf aus. Also in dem Bild sind die Daten in der zweiten Takthälfte gezeichnet und in der ersten sind sie ausgegraut. Laut dem Bildchen oben gibt -max den Mindestabstand zur Flanke an, zu der die Daten anliegen müssen. -min gibt den Abstand zur vorherigen Flanke an ab dem die neuen Daten anliegen dürfen. So wie ich das verstehen wäre also set_output_delay -clock [get_clocks sys_clkout_pin] -max 8.000 -min 0.000 [get_ports D] richtig. Edit: Ein weiteres Bildchen zeigt den Timing Wizard. Da ist auch schön abgebildet für was welche Angabe steht. Der FTDI Stein will laut Datenblatt mindestend 8 ns Setup und 0 ns Hold. Oder muss ich das anders lesen? Für mich bedeutet Setup, dass die Daten bereitgestellt oder eingestellt werden. Wenn also eine maximale und eine minimale Setup Zeit angegeben ist, interpretiere ich das so, dass irgendwann zwischen diesen beiden Zeiten die Daten ankommen müssen und ab dann, also ab der minimalen Setup Zeit stabil anliegen müssen. Wenn da also Maximal 16,67 ns und Minimal 8 ns steht, dann dürfen die Daten nicht früher als 16,67 ns vor der Taktflanke, aber auch nicht später als 8 ns vor der Taktflanke ankommen. Sie müssen ab 8 ns vor der Flanke stabil anliegen.
Gustl B. schrieb: > Sicher? > denke schon. > Oder muss ich das anders lesen? Für mich bedeutet Setup, dass die Daten > bereitgestellt oder eingestellt werden. Wenn also eine maximale und eine > minimale Setup Zeit angegeben ist, interpretiere ich das so, dass > irgendwann zwischen diesen beiden Zeiten die Daten ankommen müssen und > ab dann, also ab der minimalen Setup Zeit stabil anliegen müssen. > Wenn da also Maximal 16,67 ns und Minimal 8 ns steht, dann dürfen die > Daten nicht früher als 16,67 ns vor der Taktflanke, aber auch nicht > später als 8 ns vor der Taktflanke ankommen. Sie müssen ab 8 ns vor der > Flanke stabil anliegen. Für die Setup-Zeit gilt m.E. (wenn im Datenblatt ein Minimum- und ein Maximum-Wert angegeben ist), daß im schlimmsten Fall die Eingangsschaltung des entsprechenden Flipflops den Maximum-Wert lange braucht, bis die Daten stabil sind. Wenn das stabil unter allen Betriebsbedingungen (kalt, warm, ...) funktionieren soll, mußt Du dich m.E. an den Maximum-Wert halten, auch wenn unter besten Bedingungen mal der Minimum-Wert erreicht würde. Wenn Du die Drive Strength deines Output-Pins hochdrehst, magst Du näher zum Minimum-Wert hinkommen, aber den Zusammenhang sehe ich auf den ersten Blick im Datenblatt nicht dokumentiert.
OK, ich lese das anders. Auch die Bildchen zeigen ja, dass sich die Daten bis zur minimalen Setupzeit noch verändern dürfen und danach bis zur Flanke stabil anliegen. Aber gut, ich kenne mich da leider zu schlecht aus. Ich habe jetzt ein Design, das FT2232H_minimal_D.vhd von gestern früh (siehe oben), das auch auf der Zielhardware läuft obwohl es die Timings nicht einhält. Oder sagen wir so: Tie Toolchain sagt, dass das Timing verletzt wird, aber wenn ich mir das angucke in der Timing Simulation sehe ich keine Verletzung. Es ist aber eben Langsam weil nicht als Burst geschrieben wird. Das muss ich noch einbauen. Gemessen schafft es knapp 20 MByte/s, das ist auch erwartbar weil es bei 60 MHz in jedem 3. Takt schreibt.
Hallo Gustl B., wir scheinen schon seit Jahren immer an sehr aehnlichen Aufgaben zu arbeiten, und haeufig auch mit den gleichen Problemen zu kaempfen. Wann immer ich ein Problem habe, brauche ich gar nicht selber einen Thread zu starten, sondern kann mich an einem deiner Diskussionsfaeden bedienen :) Ich kann Dir bei deinem konkreten Fall oben bezueglich der Constraints nicht weiterhelfen, wollte aber zwei Dinge loswerden, die eventuell auch hilfreich sind. Zuerst glaube ich, dass die Einsynchronisation von TXE nicht ganz so zeitkritisch ist, wie angenommen. So wie ich das Datenblatt verstehe, bedeutet TXE=high nicht sofort, dass der FIFO des FT2232H voll ist - eher, dass es nicht mehr leer ist. Nur, wenn TXE mehr als 400ns nicht wieder auf LOW wechselt, darfst Du nicht mehr weiterschreiben. Der von Dir geschilderte Fall, dass Du nach TXE=high noch ein weiteres Byte aus dem FIFO zu versenden hast, sollte demnach kein Problem darstellen. Darueberhinaus habe ich in meinem Fall (ich benutze den FT232H - nicht FT2232H - und lediglich im asynchronen 245 FIFO Mode zum einseitigen Bulk Transfer FPGA->PC, das ist also noch deutlich einfacher) ebenfalls festgestellt, dass ausgehend von einem absolut fehlerfreien Datentransfer auf einmal sporadische Fehler auftraten, nachdem ich von meinem Erstaufbau zu verschiedenen FPGA-Devboards, FT232H Boards, und unterschiedlichen Computern mit nicht von mir vorgenommenen d2xx Treiberinstallationen gewechselt habe. Aufgrund eines neu hinzugekommenen Analog-Teils habe ich teilweise den drive strength hinabgesetzt und den Pinmode auf "quiet-io" gesetzt, und auf einmal schien das Timing nicht mehr immer hinzuhauen, obwohl immer noch alle Bedingungen des Timingschemas aus dem FT232H Datenblatts erfuellt wurden. Vermutlich ist daher "Markus F." Aussage ueber den Zusammenhang Drive Strength/Minimum Time tatsaechlich gegeben. Hast Du mal analysiert, wie genau die sporadischen Fehler in der Datenuebertragung aussehen? In meinem Fall war das nicht zufaellig, sondern absolut systematisch - aber der Fall ist nicht ganz uebertragbar. Ich sende immer 16bit words, wobei der zeitliche Abstand zwischen zwei Bytes dem minimal erlaubten Abstand aus dem Timingschema entspricht, waehrend der Abstand zwischen zwei 16bit words geringfuegig laenger ist. Eine Analyse der sporadisch fehlerhaft uebertragenen Bytes hat ergeben, dass im Falle eines Fehlers immer das spaetere Byte eines Words 0x00 war. Eine Verlangsamung des Transfers durch Anlegen dieser Daten einen Clockcycle eher hat Abhilfe geschaffen - haette aber laut Timingdiagramm nicht noetig sein duerfen. Vielleicht haettte das FT(2)232H Datenblatt auch ruhig etwas konservativer geschrieben werden koennen? Gibts da Erfahrungen im Forum, inwiefern man mit perfektem Platinendesign, idealem Signalverlauf (Flankensteilheit, Reflexionen, ...) wirklich exakt den beworbenen Datendurchsatz erreichen kann? Viele Gruesse *edit: Mein Fehler. Die 400ns Regel fuer TXE scheint nur fuer den asynchronen FIFO mode zu gelten, das Datenblatt des FT2232H ist ja klar darin, dass TXE fuer jeden write cycle ueberprueft werden muss. Die Angabe der 400ns kam auch nicht, wie oben behauptet, aus dem FT232H Datenblatt, sondern ist in FTDIs "TN_167_FIFO_Basics" zu finden.*
Hm, vieleicht baust du ja zufällig genau das was auch ich baue? Angefangen hatte ich auch mit dem FT232H auf dem UM232H Modul. Aber jetzt verwende ich den FT2232H weil ich den sowieso habe. Der sitzt zweimal auf der Platine, einmal für UART und JTAG und einmal für den Sync-FIFO. Tja leider muss das TXE# überprüft werden, aber das geht. So wie in meinen ersten Lösungen hat es eigentlich immer gut funktioniert und tut es jetzt immernoch nur auf der einen Hardware nicht. Da werden auch dauerhaft >35 MBytes/s erreicht. Jetzt habe ich das ohne Burst gebaut und komme auf knapp 20 MByte/s ohne Fehler. Da müsste ich jetzt noch Bursts einbauen, also eine deutlich komplexere FSM die auch abgebrochene Bursts neu anfängt, wird eben deutlich komplexer, aber sollte funktionieren und ebenfalls eine hohe Datenrate schaffen. Den asynchronen FIFO habe ich nie verwendet, der war mir zu langsam, aber vielleicht nutze ich den bald auch mal. Ich habe nämlich eine Platine da ist nur ein FT2232H drauf. Ein Port macht JTAG und der andere Port soll UART machen oder eben auch diesen asynchronen FIFO, das geht ja gleichzeitig (JTAG+async-FIFO). Mal gucken ... die Hardware ist noch im Layout und wird eine große Lötherausforderung.
Gustl B. schrieb: > Tja, aber die Timingverletzung wird mit immernoch angezeigt. Irgendwie > verstehe ich die Constraints nicht. wie ist denn dein Screenshot oben (Timing-Verletzung) zustande gekommen? Irgendwie kriege ich den nicht mit deinen anderen Angaben auf die Reihe.
Hier ist es im Anhang. Die Beschreibung funktioniert auf allen meinen verschiedenen Hardwareversionen - ohne irgendwelche weiteren Constraints ausser für die beiden Takte. Das ist ohne Bursts, schafft also nur knapp 20 MByte/s. Das werde ich bald noch verbessern, habe aber gerade kaum Zeit.
So, es geht weiter (-. Ich habe jetzt mal gemessen: TXE# geht sehr konstant knapp 5ns nach CLKOUT nach high. Bis zur nächsten Flanke von CLKOUT bleiben dann also noch ca. 11 ns. Die Zeit hat man also um auf TXE# zu reagieren wobei das Signal natürlich erst ins FPGA rein muss und dann WR# auch wieder raus muss. Das könnte knapp werden und in der Tat, wenn ich im FPGA Daten mit der steigenden Flanke von CLKOUT ausgebe, dann erscheinen die extern auf den Pins erst sehr knapp vor der fallenden Flanke von CLKOUT. Das sind also viele ns Latenz. Wenn ich kombinatorisch auf TXE# reagiere und WR# setze erscheint WR# erst 1,5 ns vor der nächsten Flanke auf den Leitungen, das ist extrem knapp. Bei den Daten ist es minimal besser, aber auch da ist der Abatsnd kleiner 2 ns. Mein Fazit ist, dass man das Timing gut schafft, wenn man alles getaktet läuft. Ist eben ziemlich komplex die FSM wenn man wirklich immer schreiben will wenn TXE# low ist.
Wohoo! Ich habe jetzt mal Bursts eingebaut, aber nicht vollständig. Die FSM kann jetzt in einer Pipeline aus dem dual Clock FIFO lesen, das in ein Register schreiben und das ausgeben. Wenn TXE# high geht dann wird das gestoppt und sobald TXE# wieder low ist wird es rückabgewickelt, also die schon gelesenen Daten werden dann in der richtigen Reihenfolge geschrieben (zum FTDI). Die FSM darf jetzt zu einem beliebigen Zeitpunkt durch TXE# unterbrochen werden und auch der dual Clock FIFO darf zu einem beliebigen Zeitpunkt leer laufen. Was noch fehlt ist, dass während der Rückabwicklung schon wieder aud dem FIFO gelesen wird. Das hätte den Vorteil, dass wenn die Rückabwicklung fertig ist schon wieder neue Daten da sind. Das ist jetzt nicht der Fall, am Ende der Rückabwicklung geht es neu los und es kostet wieder ein paar Takte bis dann neue Daten in den FTDI Stein geschrieben werden. Das ist also noch nicht optimal, aber a) das ist vergleichsweise selten b) es kostet nur wenige Takte. Tja was kann das jetzt? Ein Artix7 erzeugt jetzt quasi dauernd statische Pakete (mit 40 Bytes, die sind so ähnlich wie ich sie für die Zielanwendung brauche) und schreibt die in den dual Clock FIFO im FPGA. Daraus liest dann der FT232H. Wenn ich mit meinem C Programm lese bekomme ich in 100 Sekunden 4879941632 Bytes, also deutlich über 40 MBytes/s. 4879941632 Bytes geteilt durch die 40 Bytes je Paket sind 121998540,8 Pakete. Wenn ich die Daten mit einem anderen C Programm teste bekomme ich 121998539 korrekte Pakete. Es gab also einen Fehler. Dieser Fehler ist ziemlich am Anfang. Ich bin damit sehr zufrieden, vor allem weil das eine getaktete Lösung ist die vom Timing her gut aussieht auf dem Oszi. WR# und Daten erscheinen ca. zur fallenden Flanke con CLKOUT auf den Leitungen. Im Anhang jetzt das Vivado Projekt. In der Testbench kann man selber TXE setzten wie man will und in der Komponente kann man über einen counter einstellen wieviele Daten geschrieben werden. Bei vielen Daten ist der FIFO dann nie leer, bei wenigen Daten wird der ab und zu mal leer. Es werden immer die Daten x"0A", x"0B", x"0C", x"0D" erzeugt, die Testbench überprüft ob die in irgendeiner richtigen Reihenfolge empfangen wurden. Ja, die FSM ist hässlich, aber egal^^
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.