Hallo!
Habe hier 2 Lösungen für die selbe Aufgabe.
Ist es "reine Geschmackssache", oder gibt es bei der einen oder anderen
Lösung ernsthafte Einwände?
1
//_1________________________________________
2
voidEnergieRestAmpel(uint16_tRestZeit)
3
{
4
if(RestZeit>=ENERGIE_SCHWELLE_OBEN)
5
{
6
LED_ENERGIE_GN_ON;
7
return;
8
}
9
if(RestZeit<=ENERGIE_SCHWELL_UNTEN)
10
{
11
LED_ENERGIE_RT_ON;
12
return;
13
}
14
LED_ENERGIE_GE_ON;
15
}
16
17
//_2_________________________________________
18
voidEnergieRestAmpel(uint16_tRestZeit)
19
{
20
uint8_tPrio=3;
21
if(RestZeit>=ENERGIE_SCHWELLE_OBEN)Prio=2;
22
if(RestZeit<=ENERGIE_SCHWELL_UNTEN)Prio=1;
23
24
switch(Prio)
25
{
26
case1:
27
LED_ENERGIE_RT_ON;
28
break;
29
case2:
30
LED_ENERGIE_GN_ON;
31
break;
32
default:
33
LED_ENERGIE_GE_ON;
34
}
35
}
___________________________________________
Ich persönlich favorisiere die switch-Lösung aufgrund der tabellarischen
Übersicht. Vor allem wenn mehr als 2 Vergleiche erfolgen. Nur muss
einmalig die Priorität (von unten nach oben) festgelegt werden.
Such es Dir aus. Implementiere es. Du wirst im Laufe Deine Projekts
ohnehin noch das eine oder andere mehrmals ändern, weil Dir am Anfang
jede Woche die Vorteile der einen oder der anderen Lösung mehr liegen.
Lies das nochmal. Überlege welchen Sinn die Kombination >= und <= macht.
Und wie oft die markierte zeile ausgeführt wird.
Hint: findige Software-Ingenöre haben "else" erfunden
Michael R. schrieb:> Lies das nochmal. Überlege welchen Sinn die Kombination> >= und <= macht. Und wie oft die markierte zeile ausgeführt> wird.
???
Zuviel Blut im Kaffee?
Die markierte Zeile wird ausgeführt, wenn RestZeit (echt)
kleiner als ENERGIE_SCHWELLE_OBEN, aber noch (echt) größer
als ENERGIE_SCHWELLE_UNTEN ist.
Im Endeffekt machen beide Codes das Gleiche. Meiner Meinung nach ist es
Geschmackssache. Zitat von einem unserer Informatiker: "Code soll für
einen selbst übersichtlich und lesbar sein. Optimierung macht der
Compiler".
switch() case statements sind normalerweise für Auflistungen gedacht.
Mit enums kann man so z.B. eine Warnung generieren, wenn das 'case'
Statement für einen später eingefügten Fall fehlt. Sehr hilfreich.
Dein Codebeispiel ist ok, aber das 'return' mitten im Code is Spaghetti
und sollte vermieden werden. Wenn Du Jahre später mal am Ende der
Funktion code hinzufügst könntest Du das eventuell übersehen.
IMHO ist es so besser:
void EnergieRestAmpel(uint16_t RestZeit)
{
if (RestZeit >= ENERGIE_SCHWELLE_OBEN)
{
LED_ENERGIE_GN_ON;
}
else if(RestZeit <= ENERGIE_SCHWELL_UNTEN)
{
LED_ENERGIE_RT_ON;
}
else
{
LED_ENERGIE_GE_ON;
}
}
Die geschwungenen Klammern kannst DU dann auch weglassen, und die Idee,
die hinter der Formel steckt wird offensichtlicher. So würdest Du das
Problem umgangssprachlich wohl auch ausdrücken: Wenn die Restzeit
grösser ist, dann mach das, ansonsten wenn die Zeit kleiner ist, mach
jenes, und wenn keines der beiden zutrifft, mach sonstwas.
Michael R. schrieb:> Lies das nochmal.
Dito. Man könnte kritisieren, das die obere Schwelle
'ENERGIE_SCHWELLE_OBEN' heisst, während die untere
'ENERGIE_SCHWELL_UNTEN' heisst, da hat der Autor eben SCHWELL statt
SCHWELLE geschrieben. Das ist aber auch schon alles. Zwischen den
Schwellen passiert nun mal nichts.
__Son´s B. schrieb:> Habe hier 2 Lösungen für die selbe Aufgabe.> Ist es "reine Geschmackssache",
Fast, aber nicht ganz, würde ich sagen.
> Ich persönlich favorisiere die switch-Lösung aufgrund> der tabellarischen Übersicht. Vor allem wenn mehr als> 2 Vergleiche erfolgen.
Ja.
Die zweite Variante ist ein ziemlich universelles Muster,
wie man M Variablen auf N Fallklassen abbilden kann. Die
if-Abfragen oben ermitteln erstmal die Fallnummer; der
switch ruft dann den Handler für den jeweiligen Fall auf.
Ich verwende das immer dann, wenn ich eine einigermaßen
feststehende, a priori bekannte Anzahl von Fällen habe,
aus denen zu jedem Zeitpunkt genau einer zutrifft.
Die erste Konstruktion benutze ich für Abläufe (endliche
Automanten, "state machines"). In der Steuerungstechnik
kennt (kannte) man das als Schrittkette (Ablaufkette).
Hier kann man ziemlich viele Zustände haben, deren Anzahl
sich auch mal ändern kann; ich will dann kein switch
haben, was über mehrere Seiten geht.
Geschachtelte if-then-else verwende ich nie, dazu ist
mein IQ zu niedrig.
Was Du tust, ist 1) aus der RestZeit ein "Warnlevel" zu generieren und
2) das WarnLevel anzuzeigen.
Wenn man das übertrieben sauber trennen will, könnte man zuerst die
RestZeit in irgendeinen abstrakten Zustand übersetzen und dann diesen
irgendwie anzeigen. Dein zweiter Ansatz geht ein wenig in diese
Richtung, wobei mir die "Priorität" nicht ganz klar ist.
In diesem einfachen Fall ist das wahrscheinlich in dieser Form Quatsch.
Wenn es groß und kompliziert wird, macht man sich aber das Leben auf
Dauer einfacher, wenn man Aufgaben strikt auf Module aufteilt und
Querabhängigkeiten zwischen diesen vermeidet.
Peter D. schrieb:> Ich finde die extrem unlesbar.
Mit einer ordentlichen Programmiersprache sind die auch gut lesbar. Darf
man halt nicht diesen Klammermist nehmen.
Thomas H. schrieb:> Im Endeffekt machen beide Codes das Gleiche.
Die Varianten kompilieren durchaus unterschiedlich. Bei if ... else
stehen die auszuführenden Anweisungen direkt hinter dem Vergleich, dann
folgt der nächste Vergleich. Bei case stehen alle Vergleiche zusammen,
von dort wird zu den auszuführnenden Anweisungen gesprungen.
Ich hab auch schon ein Kompilat gesehen, wo ein case mit aufsteigender
Nummerierung (also a = 1, 2, 3) derart aufgelöst wurde, dass anhand a
eine Adresse einer Lookup-Table berechnet wurde, in der dann die
Sprungadresse zum auszuführenden Code stand. Das geht aber nur mit
Aufzählungen, nicht mit Bereichen oder <> Vergleichen.
Possetitjel schrieb:> Zuviel Blut im Kaffee?>> Die markierte Zeile wird ausgeführt, wenn RestZeit (echt)> kleiner als ENERGIE_SCHWELLE_OBEN, aber noch (echt) größer> als ENERGIE_SCHWELLE_UNTEN ist.
Ja. zuviel Blut im Kaffee ;-) sorry, überlesen
Michael R. schrieb:> Lies das nochmal. Überlege welchen Sinn die Kombination >= und <= macht.
Lies das nochmal.
ENERGIE_SCHWELLE_OBEN und ENERGIE_SCHWELL_UNTEN sind vermutlich
verschieden.
W.A. schrieb:> Lies das nochmal.> ENERGIE_SCHWELLE_OBEN und ENERGIE_SCHWELL_UNTEN sind vermutlich> verschieden.
Ja, schon gut :-) hab das analysiert. Mein Brain 1.9.68 hat Erkennung
von Wörtern in GROSSBUCHSTABEN auf char[15] definiert.
Und wo krieg ich jetzt ein Update her? Cheffe mein, 2.0 wäre nicht, zu
viele Subsysteme die das nicht mitmachen...
Peter D. schrieb:> Possetitjel schrieb:>> Geschachtelte if-then-else verwende ich nie, dazu ist>> mein IQ zu niedrig.>> Geht mir auch so.> Ich finde die extrem unlesbar.
Else If hat aber den Vorteil, dass man sofort sieht, dass sich beide
Segmente ausschließen.
Das ist mit zwei If hintereinander nicht sauber definiert.
Die Switch Case mit der vorherigen If Abfrage ist meiner Meinung nach
unschön, fehleranfällig und unübersichtlich. Es sollte zu jeder Zeit
klar sein was passiert, sprich man sollte grob die Funktion erkennen
können obwohl man maximal Zeile+-1 sieht.
BTW: Ich bin kein Fan von deutschen Bezeichnungen. ein UPPER_LIMIT bzw.
LOWER_LIMIT ist da schöner, kann man auch noch abkürzen usw. Energie
z.B. mit E reinnehmen. 40 Zeichen lange Defines will man ehrlich gesagt
nicht.
__Son´s B. schrieb:> Ist es "reine Geschmackssache", oder gibt es bei der einen oder anderen> Lösung ernsthafte Einwände?
Nicht nach meinem Geschmack ist auf jeden Fall das
> LED_ENERGIE_RT_ON;
Was soll das sein? Eine Konstante wie die meisten #defines ist es
jedenfalls nicht. Damit sich überhaupt etwas tut, muss es wohl eine
Funktion sein.
Dann würde ich das aber zumindest kenntlich machen:
LED_ENERGIE_RT_ON ();
Noch besser fände ich es allerdings, Funktionen nicht hinter #defines zu
verstecken.
Mit den ganzen -wo auch immer- deklarierten und initialisierten
Variablen und Funktionen ( wie JoQuis schon zutreffend anmerkte ) kann
das sowieso keine Sau richtig lesen!
Ich nenne sowas blah - blah - Code !!!
Egon N. schrieb:> Peter D. schrieb:>> Possetitjel schrieb:>>> Geschachtelte if-then-else verwende ich nie, dazu ist>>> mein IQ zu niedrig.>>>> Geht mir auch so.>> Ich finde die extrem unlesbar.>> Else If hat aber den Vorteil, dass man sofort sieht,> dass sich beide Segmente ausschließen.>> Das ist mit zwei If hintereinander nicht sauber definiert.
Da ich durch Tcl geprägt bin, würde ich sowieso in jedem
Fall schreiben:
if(bedingung1) {
aktion;
}
if(bedingung2) {
andere_aktion;
}
Nach meinem laienhaften Verständnis der C-Syntax müsste das
eindeutig sein.
Das sind halt zwei isolierte Statements und gut.
Das Problem bei if/elseif ist, dass es zwar syntaktisch
eine Anweisung bleibt, man aber mehrere unabhängige
Bedingungen abprüfen kann, und das ist Teufelswerk.
Ganz spaßig wird es, wenn man in den then-Zweigen weitere
if-Abfragen unterbringt -- das ist dann genau der Fall,
den Peter als unlesbar bezeichnet.
> Die Switch Case mit der vorherigen If Abfrage ist meiner> Meinung nach unschön, fehleranfällig und unübersichtlich.
Da bin ich eben komplett anderer Meinung.
Ein Problem, bei dem M Variablen zu N unterschiedlichen
Fällen führen, ist schon rein inhaltlich immer ein großer
Matschklumpen.
Ich finde es bei dieser Konstellation gut, erstmal zu
ermitteln "Welcher Fall liegt eigentlich vor?" (das passiert
in dem Block mit den if-Abfragen), und wenn man das weiss,
kann man den Fall anhand der Fallnummer behandeln, das macht
die switch-Anweisung.
Die Schnittstelle zwischen beiden besteht nur in der Fallnummer.
> Es sollte zu jeder Zeit klar sein was passiert, sprich man> sollte grob die Funktion erkennen können obwohl man maximal> Zeile+-1 sieht.
Das ist zwar wünschenswert, aber nicht realistisch.
Possetitjel schrieb:> Da ich durch Tcl geprägt bin, würde ich sowieso in jedem> Fall schreiben:>> if(bedingung1) {> aktion;> }>> if(bedingung2) {> andere_aktion;> }
Wenn "bedingung1" und "bedingung2" sich nicht gegenseitig ausschließen,
dann werden beide Aktionen ausgeführt. Das ist nicht überall gewünscht,
insbesondere hier nicht.
Außerdem muss in deinem Code "bedingung2" auch dann ausgewertet werden,
wenn "bedingung1" schon zutraf.
__Son´s B. schrieb:> Ich persönlich favorisiere die switch-Lösung aufgrund der tabellarischen> Übersicht.
Ich nicht. Ich finde es im Gegenteil vollkommen bescheuert, erst eine
Hilfsvariable per if-Kaskade zu setzen und dann ein switch() Statement
zur Auswertung der Hilfsvariable zu verwenden. Das führt garantiert zu
längerem Code und ist kein bißchen übersichtlich, weil man jetzt an
zwei Stellen nachsehen muß - wo die Hilfsvariable gesetzt wird und wo
sie ausgewertet wird.
Persönlich würde ich das als if .. else if ... else if ... else Kaskade
schreiben. Vernünfig eingerückt und geklammert ist das sehr gut lesbar -
zumindest so lange alles auf einen Bildschirmseite paßt. Das
standardmäßige switch() Statement paßt halt nicht, weil das nur gegen
Konstanten vergleichen kann. Auf eine gcc-Erweiterung sollte man im
Sinne der Portabilität verzichten.
Wenn es nicht auf eine Seite paßt; etwa weil doch mehr Code nach jedem
if kommt, und wenn das tatsächlich so verkapselt ist, daß es keinen
gemeinsamen Code nach der Verzweigung gibt, dann ist die Variante mit
abgeschlossenen if () { ...; return; } Blöcken auch ok. Das Argument
"Spaghetti" greift hier nicht, denn es geht ja nur darum, einen
Codeblock (den Funktionsrumpf) geordnet zu verlassen.
S. R. schrieb:> Possetitjel schrieb:>> Da ich durch Tcl geprägt bin, würde ich sowieso in jedem>> Fall schreiben:>>>> if(bedingung1) {>> aktion;>> }>>>> if(bedingung2) {>> andere_aktion;>> }>> Wenn "bedingung1" und "bedingung2" sich nicht gegenseitig> ausschließen, dann werden beide Aktionen ausgeführt. Das> ist nicht überall gewünscht, insbesondere hier nicht.
???
(Achtung -- kein C, sondern Tcl:)
1
2
set RestLaufzeit 0
3
4
if { $RestEnergie >= ENERGIE_SCHWELLE_UNTEN } then {
5
set RestLaufzeit 1
6
}
7
8
if { $RestEnergie >= ENERGIE_SCHWELLE_OBEN } then {
9
incr RestLaufzeit
10
}
Ich sehe das Problem nicht.
> Außerdem muss in deinem Code "bedingung2" auch dann> ausgewertet werden, wenn "bedingung1" schon zutraf.
Selbstverständlich. Soll ja.
Axel S. schrieb:> Ich finde es im Gegenteil vollkommen bescheuert, erst> eine Hilfsvariable per if-Kaskade zu setzen und dann> ein switch() Statement zur Auswertung der Hilfsvariable> zu verwenden.
Steht Dir frei. Alles kann, nichts muss ;)
> Das führt garantiert zu längerem Code
Mag sein -- aber auch zu intakteren Zähnen und Tischkanten.
(Zumindest bei mir.)
> und ist kein bißchen übersichtlich,
Sehr mutig, dass Du so genau weisst, was ich übersichtlich
finde.
> weil man jetzt an zwei Stellen nachsehen muß - wo die> Hilfsvariable gesetzt wird und wo sie ausgewertet wird.
Das ist für mich keine echte Komplikation.
In wirklich richtig komplizierten Fällen -- und nur über
die lohnt es sich zu diskutieren -- muss ich sowieso über
zwei getrennte Fragen nachdenken:
1. Woran erkenne ich den jeweiligen Fall?
2. Welche Aktion ist im jeweiligen Fall notwendig?
Der Quelltext widerspiegelt somit nur, wie mein Gehirn
funktioniert.
> Persönlich würde ich das als if .. else if ... else if ... else> Kaskade schreiben. Vernünfig eingerückt und geklammert ist> das sehr gut lesbar - zumindest so lange alles auf einen> Bildschirmseite paßt.
Im konkreten Beispiel stimmt das -- weil sich nämlich beide
Bedingungen auf dieselbe Variable beziehen. Es ist also aus
inhaltlichen Gründen sowieso sichergestellt, dass sich die
Fälle gegenseitig ausschließen.
Wenn mehrere Variablen mit voneinander abhängigen Bedingungen
eine Rolle spielen, ist das aber keineswegs mehr so.
Possetitjel schrieb:> Nach meinem laienhaften Verständnis der C-Syntax müsste das> eindeutig sein.> Das sind halt zwei isolierte Statements und gut.
Nach meinem Verständnis ist das Schrott. Die Statements gehören im
obigen Beispiel zusammen und dann kann man sie auch zusammen behandeln.
Das in mehrere ifs aufzuteilen ist nur fehleranfällig.
> Das Problem bei if/elseif ist, dass es zwar syntaktisch> eine Anweisung bleibt, man aber mehrere unabhängige> Bedingungen abprüfen kann, und das ist Teufelswerk.
Isses schon so schlimm wie goto, oder nur so schlimm wie upn?
Der GROSSE Vorteil von if ... else ist, dass man damit sehr effizient
Abfragen zusammenfassen kann, die der Compiler dann sehr effizient in
Maschinencode umsetzt. Wer diesen Vorteil gerade auf µCs nicht nutzt,
weil er davon Kopfschmerzen bekommt, sollte vielleicht besser Bäcker
werden.
> Ganz spaßig wird es, wenn man in den then-Zweigen weitere> if-Abfragen unterbringt -- das ist dann genau der Fall,> den Peter als unlesbar bezeichnet.
Aus aktuellem Anlass:
1
procedurertc_checksummer();
2
begin
3
ifrtc.summandRsauto<>0thenbegin// prüfen auf Flag Auto
4
ifrtc.wday=7thenbegin// wenn Sonntag
5
ifrtc.day>=$25thenbegin// wenn letzter Sonntag im Monat
6
ifrtc.month=$03thenbegin// wenn März, Umschalten auf Sommerzeit
7
if(rtc.summandRsumm)=0thenbegin//wenn Flag nicht gesetzt
8
ifrtc.hh=$02thenbegin
9
rtc.hh:=$03;
10
rtc.summ:=RsautoorRsumm;
11
rtc_setsummer();// Sommerzeit schreiben
12
end;
13
end;
14
endelseifrtc.month=$10thenbegin// wenn Oktober, Umschalten auf Winterzeit
15
if(rtc.summandRsumm)<>0thenbegin//wenn Flag gesetzt
16
ifrtc.hh=$03thenbegin
17
rtc.hh:=$02;
18
rtc.summ:=Rsauto;
19
rtc_setsummer();// Winterzeit schreiben
20
end;
21
end;
22
end;
23
end;
24
end;
25
end;
26
end;
Was bitte ist daran unlesbar? Und, schon Kopfschmerzen?
Karl schrieb:> Possetitjel schrieb:>> Nach meinem laienhaften Verständnis der C-Syntax müsste>> das eindeutig sein.>> Das sind halt zwei isolierte Statements und gut.>> Nach meinem Verständnis ist das Schrott.
Das ist keine sachlich begründete Aussage und daher nicht
hilfreich.
> Die Statements gehören im obigen Beispiel zusammen und> dann kann man sie auch zusammen behandeln.
Das ist zwar richtig, aber eine Besonderheit des konkretenBeispiels .
Es gibt jedoch Fälle, in denen das nicht so ist, und dann
ist die Formulierung als unabhängige Bedingungen nützlich.
Nichts anderes wollte ich ausdrücken.
>> Das Problem bei if/elseif ist, dass es zwar syntaktisch>> eine Anweisung bleibt, man aber mehrere unabhängige>> Bedingungen abprüfen kann, und das ist Teufelswerk.>> Isses schon so schlimm wie goto, oder nur so schlimm> wie upn?
Was ist upn?
Davon abgesehen: Dein gutes Gedächtnis beeindruckt -- aber
ich bin nicht sicher, inwieweit Du verstehst, was Du liest.
Es gibt einen sachlichen Zusammenhang zwischen der goto-
Diskussion und dieser hier.
Das war mir gar nicht aufgefallen; ich danke für den
Hinweis.
> Der GROSSE Vorteil von if ... else ist, dass man damit> sehr effizient Abfragen zusammenfassen kann, die der> Compiler dann sehr effizient in Maschinencode umsetzt.
Irrelevant. Optimierende Compiler existieren. Du bist auf
dem Stand von vor 50 Jahren stehengeblieben.
> Aus aktuellem Anlass:procedure rtc_checksummer();> begin> if rtc.summ and Rsauto <> 0 then begin // prüfen auf Flag Auto> if rtc.wday = 7 then begin // wenn Sonntag> if rtc.day >= $25 then begin // wenn letzter Sonntag im Monat> if rtc.month = $03 then begin // wenn März, Umschalten auf> Sommerzeit> if (rtc.summ and Rsumm) = 0 then begin //wenn Flag nicht> gesetzt> if rtc.hh = $02 then begin> rtc.hh := $03;> rtc.summ := Rsauto or Rsumm;> rtc_setsummer(); // Sommerzeit schreiben> end;> end;> end else if rtc.month = $10 then begin // wenn Oktober,> Umschalten auf Winterzeit> if (rtc.summ and Rsumm) <> 0 then begin //wenn Flag gesetzt> if rtc.hh = $03 then begin> rtc.hh := $02;> rtc.summ := Rsauto;> rtc_setsummer(); // Winterzeit schreiben> end;> end;> end;> end;> end;> end;> end;>> Was bitte ist daran unlesbar? Und, schon Kopfschmerzen?
Das ist nicht nur unlesbar, das ist hässlich. Dabei wäre es
so einfach, es besser zu machen.
1
2
set SwitchToSummertime true
3
...
4
if { rtc.wday != 7 } then { set SwitchToSummertime false }
5
if { rtc.day < 25 } then { set SwitchToSummertime false }
6
if { rtc.month != 3 } then { set SwitchToSummertime false }
7
...
Man kann ein wired-AND auf die unterschiedlichsten Arten
ausdrücken.
Possetitjel schrieb:> set SwitchToSummertime true> ...> if { rtc.wday != 7 } then { set SwitchToSummertime false }> if { rtc.day < 25 } then { set SwitchToSummertime false }> if { rtc.month != 3 } then { set SwitchToSummertime false }> ...
Danke. Wieder was gelernt.
Gibt es hierzu empfehlenswerte Bücher?
Possetitjel schrieb:> Das Problem bei if/elseif ist, dass es zwar syntaktisch> eine Anweisung bleibt, man aber mehrere unabhängige> Bedingungen abprüfen kann, und das ist Teufelswerk.
Warum?
>> Die Switch Case mit der vorherigen If Abfrage ist meiner>> Meinung nach unschön, fehleranfällig und unübersichtlich.>> Da bin ich eben komplett anderer Meinung.
Ich finde sie nur unnötig aufgebläht. Es steht quasi doppelt da.
> Ich finde es bei dieser Konstellation gut, erstmal zu> ermitteln "Welcher Fall liegt eigentlich vor?" (das passiert> in dem Block mit den if-Abfragen), und wenn man das weiss,> kann man den Fall anhand der Fallnummer behandeln, das macht> die switch-Anweisung.
"Fallnummer"? Also wenn man das so macht, dann sollte man (ähnlich wie
Tom es gezeigt hat) den Fällen auch Namen geben. Irgendwelche
Magic-Numbers machen es alles andere als übersichtlicher. Dann muss ich
beim Lesen des switch/case erst wieder oben nachschauen, welches
Ergebnis der if-Abfrage denn nun zu Fall Nummer 3 gehört, was den
Lesefluss meiner Meinung nach stark stört.
Possetitjel schrieb:> In wirklich richtig komplizierten Fällen -- und nur über> die lohnt es sich zu diskutieren -- muss ich sowieso über> zwei getrennte Fragen nachdenken:>> 1. Woran erkenne ich den jeweiligen Fall?> 2. Welche Aktion ist im jeweiligen Fall notwendig?>> Der Quelltext widerspiegelt somit nur, wie mein Gehirn> funktioniert.
Hmm, dann funktionieren unsere Gehirne verschieden ;-)
Wenn ich das im Kopf durchgehen würde, würde ich sagen:
Wenn der Wert kleiner ist als die Untergrenze, dann soll die rote LED
angehen. Wenn er stattdessen größer ist als die Obergrenze, soll die
grüne LED angehen, und sonst die gelbe. Das würde der if/else-Kaskade
entsprechen.
Die switch/case-Variante, die dann deiner Gehirnfunktion entsprechen
müsste, würde ich so lesen:
Wenn nichts anderes gilt, haben wir Fall 3. Wenn der Wert kleiner ist
als die Untegrenze ist, ist das Fall 1. Wenn er größer ist als die
Obergrenze, ist das Fall 2.
In Fall 1 mache die rote LED an, in Fall 2 die grüne und in Fall 3 die
gelbe.
Da hab ich ja im zweiten Satz schon vergessen, welcher Fall im ersten
Satz welcher Bedingung zugeordnet war.
> Im konkreten Beispiel stimmt das -- weil sich nämlich beide> Bedingungen auf dieselbe Variable beziehen. Es ist also aus> inhaltlichen Gründen sowieso sichergestellt, dass sich die> Fälle gegenseitig ausschließen.>> Wenn mehrere Variablen mit voneinander abhängigen Bedingungen> eine Rolle spielen, ist das aber keineswegs mehr so.
Ja, ab einer gewissen Komplexität ist die Trennung durchaus sinnvoll.
Aber zwingend ist für mich dann auch wieder, dass keine magischen
Fallnummern verwendet werden, sondern aussagekräftige Bezeichnungen.
FAZIT:
Vielen Dank für die vielen konstruktiven Gedanken, Geschmäcker,
Bemerkungen und Anregungen! Eure Ideen werden mich noch lange begleiten.
So macht Forum Spaß :-)
1| Rechtschreibfehler "SCHWELL vs. SCHWELLE" ist mir gar nicht
aufgefallen...
2| Da es sich um nur 2(+1) Abfragen handelt, werde ich if/else ohne
return verwenden.
Possetitjel schrieb:>> Persönlich würde ich das als if .. else if ... else if ... else>> Kaskade schreiben. Vernünfig eingerückt und geklammert ist>> das sehr gut lesbar - zumindest so lange alles auf einen>> Bildschirmseite paßt.>> Im konkreten Beispiel stimmt das -- weil sich nämlich beide> Bedingungen auf dieselbe Variable beziehen. Es ist also aus> inhaltlichen Gründen sowieso sichergestellt, dass sich die> Fälle gegenseitig ausschließen.>> Wenn mehrere Variablen mit voneinander abhängigen Bedingungen> eine Rolle spielen, ist das aber keineswegs mehr so.
Doch. Bei einer if ... else if ... else if ... Kaskade ist
sichergestellt daß maximal einer der Blöcke ausgeführt wird. Und wenn
es ein abschließendes else gibt, dann sogar genau einer. Vollkommen
egal, wieviele Variablen in die Test-Ausdrücke der if()'s einfließen.
Im Prinzip ist das genauso [1] wie eine switch() Anweisung, wo auch
immer nur einer der Blöcke ausgeführt wird. Nur daß man mit switch() nur
sehr begrenzte Tests hat - man kann nur eine Variable auf bestimmte
konstante Werte testen. if() hingegen kann beliebig komplexe Tests
ausführen. Nicht daß man Tests kompliziert machen sollte, aber bereits
die simple Unterteilung eines Bereichs in 3 Teile ist zu kompliziert für
switch(), aber trivial für if().
[1] genau genommen kann switch() mehr als das; wenn man am Ende eines
case: Blocks kein break hat, passiert ein fall through in den nächsten
Block. Das braucht man zwar selten, aber es sorgt regelmäßig für
Verwirrung.
Possetitjel schrieb:> Sehr mutig, dass Du so genau weisst, was ich übersichtlich> finde.
Stell dir einfach mal vor, der Code wäre länger. Es wären 10 Fälle und
das switch() enthielte so viel Code, daß der ganze Krempel 3
Bildschirmseiten braucht. Und jetzt suchst du einen Bug, der darin
besteht, daß case 42: ausgeführt wird, obwohl er eigentlich nicht
sollte.
Dann ist eine Kaskade von if()'s deutlich besser lesbar, weil
ausgeführter Code und die zugehörige Bedingung beieinander stehen. Und
nicht durch 2½ Bildschirmseiten Codewüste voneinander getrennt sind.
void EnergieRestAmpel(uint16_t RestZeit)
{
if(RestZeit >= ENERGIE_SCHWELLE_OBEN) LED_ENERGIE_GN_ON;
else if(RestZeit <= ENERGIE_SCHWELLE_UNTEN) LED_ENERGIE_RT_ON;
else LED_ENERGIE_GE_ON;
}
In diesem Zusammenhang verstehe ich folgende Fehlermeldung in beiden
else-Zeilen nicht;
'else' without a previous 'if'
Mit geschweifter Klammer läuft der Compiler sauber durch!
Code ist doch OK? Ist doch nur ein Anweisung hinter if(RestZeit...).
Moin,
__Son´s B. schrieb:> Ist doch nur ein Anweisung hinter if(RestZeit...
Die "Anweisung" scheint mir ein Macro zu sein (das aus mehreren
Statements bestehen kann und das wohl auch tut).
Gruss
WK
Dergute W. schrieb:> Moin,>> __Son´s B. schrieb:>> Ist doch nur ein Anweisung hinter if(RestZeit...>> Die "Anweisung" scheint mir ein Macro zu sein (das aus mehreren> Statements bestehen kann und das wohl auch tut).
ist mit sicherheit so. Phöse ;-)
Wenn man jetzt den "do { x; y; z; } while (0)" Trick empfiehlt, gibts
sicher wieder Geschrei ;-)
__Son´s B. schrieb:> void EnergieRestAmpel(uint16_t RestZeit)> {> if(RestZeit >= ENERGIE_SCHWELLE_OBEN) LED_ENERGIE_GN_ON;> else if(RestZeit <= ENERGIE_SCHWELLE_UNTEN) LED_ENERGIE_RT_ON;> else LED_ENERGIE_GE_ON;> }>> In diesem Zusammenhang verstehe ich folgende Fehlermeldung in beiden> else-Zeilen nicht;> 'else' without a previous 'if'> Mit geschweifter Klammer läuft der Compiler sauber durch!> Code ist doch OK? Ist doch nur ein Anweisung hinter if(RestZeit...).
Das kommt eben durch den Makromurks LED_ENERGIE_GN_ON usw.
Mit
void EnergieRestAmpel(uint16_t RestZeit)
{
if(RestZeit >= ENERGIE_SCHWELLE_OBEN) SchalteEnergieAmpel(GRUEN);
else if(RestZeit <= ENERGIE_SCHWELLE_UNTEN) SchalteEnergieAmpel(ROT);
else SchalteEnergieAmpel(GELB);
}
wär das kein Problem.
Der Vollständigkeit halber gäbe es auch noch die kompakte Lösung:
SchalteEnergieAmpel((RestZeit >= ENERGIE_SCHWELLE_OBEN)?GRUEN:
(RestZeit <= ENERGIE_SCHWELLE_UNTEN)?ROT:GELB);
Dergute W. schrieb:> Die "Anweisung" scheint mir ein Macro zu sein (das aus mehreren> Statements bestehen kann und das wohl auch tut).
Stimmt - übersehen oder verdrängt...
Jobst Q. schrieb:> Der Vollständigkeit halber gäbe es auch noch die kompakte Lösung:>> SchalteEnergieAmpel((RestZeit >= ENERGIE_SCHWELLE_OBEN)?GRUEN:> (RestZeit <= ENERGIE_SCHWELLE_UNTEN)?ROT:GELB);
Kompakt ist super, wenn man Speicherplatz für den Quellcode sparen muss,
oder an einem Wettbewerb für den dümmsten Programmierer teilnehmen will.
Ansonsten ist "kompakter Quellcode" sicher kein Ziel das man antreben
sollte. Versuchs mal mit lesbar und erweiterbar. Ist aber nur was für
Erwachsene.
Karl schrieb:> Isses schon so schlimm wie goto,....?
Goto könnte man auch für das erste Beispiel verwenden.
Dann würden sich die eingestreuten return Statements vermeiden lassen.
Michael R. schrieb:> Wenn man jetzt den "do { x; y; z; } while (0)" Trick empfiehlt, gibts> sicher wieder Geschrei ;-)
Natürlich!
Ich bevorzuge auch einzeln stehende if Statments, vor if/else Kaskaden.
Switch/case ist mir auch nicht unbedingt recht, da es einen weiteren
Block {} einführt. Und dazu noch Blöcke ohne {} beinhaltet.
Block Verschachtlungen bis zur Tiefe 2 sind für mich noch leicht zu
erfassen. Über eine Tiefe von 5 bis 7, ist Ende. Ins Besondere, wenn da
noch komplizierte Bedingungen im Spiel sind.
Das überlasse ich dann lieber Typen wie Chuck Norris.
Aber wie immer:
1. die konkrete Anwendung
2. die Firmen Richtlinie
3. persönliche Vorlieben
entscheiden.
Cyblord -. schrieb:> Jobst Q. schrieb:>> Der Vollständigkeit halber gäbe es auch noch die kompakte Lösung:>>>> SchalteEnergieAmpel((RestZeit >= ENERGIE_SCHWELLE_OBEN)?GRUEN:>> (RestZeit <= ENERGIE_SCHWELLE_UNTEN)?ROT:GELB);>> Kompakt ist super, wenn man Speicherplatz für den Quellcode sparen muss,> oder an einem Wettbewerb für den dümmsten Programmierer teilnehmen will.
Was hat die sinnvolle Benutzung des ternären Operators ?: in C mit
'duemmsten Programmierer' zu tun?
Walter K. schrieb:> Was hat die sinnvolle Benutzung des ternären Operators ?: in C mit> 'duemmsten Programmierer' zu tun?
Wer noch nicht mal den Kern der Kritik versteht sollte nicht versuchen
auch noch darüber zu diskutieren.
Cyblord -. schrieb:> Kompakt ist super, wenn man Speicherplatz für den Quellcode sparen muss,> oder an einem Wettbewerb für den dümmsten Programmierer teilnehmen will.> Ansonsten ist "kompakter Quellcode" sicher kein Ziel das man antreben> sollte. Versuchs mal mit lesbar und erweiterbar. Ist aber nur was für> Erwachsene.
Das stimmt einfach nicht. Wenn Du in größeren Projekten arbeitest, ist
Lesbarkeit das primäre Ziel. Und da hängt es von den projekt- und
teamspezifischen Gewohnheiten ab, ob lange Zeilen gut sind. Wenn die
IDE einzeilige Suchergebnisse liefert UND 80 Zeichen im Editor sichtbar
sind, dann musst Du schon lange knobeln um folgenden Code besser zu
machen:
Achim S. schrieb:> if( RestZeit >= ENERGIE_SCHWELLE_OBEN)> {SchalteEnergieAmpel(GRUEN);}> else if(RestZeit <= ENERGIE_SCHWELLE_UNTEN)> {SchalteEnergieAmpel(ROT);}> else> {SchalteEnergieAmpel(GELB);}
Bin ich der einzige der sich über ein cmp zwischen "RestZeit" und
"ENERGIE_SCHWELLE_*" wundert?
Allein das ist schon der nächste Punkt der Lesbarkeit. Man sollte nicht
nachschlagen müssen was welche Variablen machen...
Egon N. schrieb:> Bin ich der einzige der sich über ein cmp zwischen "RestZeit" und> "ENERGIE_SCHWELLE_*" wundert?
Naja, die Begriffe sind wie der Code (hoffentlich) sinnfreie Beispiele.
In meiner Antwort ging es z.B. nur um die Anordnung, daher originale
Namen. Eine echte Aufgabe (und damit sinnvolle Namen) kennen wir eh
nicht. Darum macht es beispielsweise (wie oben) auch keinen Sinn, über
Lösungen zu streiten, die einer ganz anderen if-Struktur bedürfen.
Egon N. schrieb:> Bin ich der einzige der sich über ein cmp zwischen "RestZeit" und> "ENERGIE_SCHWELLE_*" wundert?
Nein, da sind noch mindestens 4 Andere. Wenn mein Kollege wiederkommt,
sind es dann sogar 5.
Cyblord -. schrieb:> Kompakt ist super, wenn man Speicherplatz für den Quellcode sparen muss,> oder an einem Wettbewerb für den dümmsten Programmierer teilnehmen will.> Ansonsten ist "kompakter Quellcode" sicher kein Ziel das man antreben> sollte. Versuchs mal mit lesbar und erweiterbar. Ist aber nur was für> Erwachsene.
Eine verschachtelte bedingte Zuweisung ist genauso erweiterbar wie eine
if-else Konstruktion.
a = (b>c)? 1:
(d<e)? 2:
(f==g)? 3:
...
(y!=z)? 24:
0;
Kompakt ist auch super für die Lesbarkeit, für mich jedenfalls. Und ich
schreibe Quelltext für mich und den Compiler, nicht für den
Kindergarten.
Eine Zeile ist nun mal schneller zu überblicken als eine halbe Seite. Je
weniger Ballast und Redundanzen, umso schlechter können sich Fehler
verstecken.
Geschwätzigen Quellcode zu schreiben lohnt sich nur, wenn man nicht nach
Funktionalität, sondern nach Zeilen bezahlt wird.
Egon N. schrieb:> Bin ich der einzige der sich über ein cmp zwischen "RestZeit" und> "ENERGIE_SCHWELLE_*" wundert?
Ich finde es auch interessant, eine Energie mit einer Zeit zu
vergleichen. Besonders, wenn man bedenkt, dass jeder Vergleich eine
Subtraktion ist, denn dann steht da "Zeit-Energie"...
Die Lesbarkeit und Verständlichkeit eines Codes beginnt also tatsächlich
weit, weit vor der Diskussion über die Verwendung des ternären
Operators.
Curby23523 N. schrieb:> C) finde ich in so einem einfachen Fall am besten.
Ich nehme D)
1
inta=10;
2
boolb;
3
4
if(a==10)b=true;
5
elseb=false;
Man könnte aber auch E) nehmen:
1
inta=10;
2
boolb;
3
4
b=(a==10);
Denn das Ergebnis des == Operators ist schon bool...
Possetitjel schrieb:> Dabei wäre es> so einfach, es besser zu machen.>> set SwitchToSummertime true> ...> if { rtc.wday != 7 } then { set SwitchToSummertime false }> if { rtc.day < 25 } then { set SwitchToSummertime false }> if { rtc.month != 3 } then { set SwitchToSummertime false }> ...
Dein Ernst?
Das ist der totale Schrott!
Du willst sicher wieder eine Begründung:
Erstens: Muss der Controller hier alle if-Anfragen prüfen, obwohl er bei
meiner Abfrage schon in 6 von 7 Fällen bei der Sonntags-Abfrage
aussteigen kann. Unnötige Programmlaufzeit.
Zweitens: Wird damit erheblich mehr Code erzeugt. Unnötiger
Speicherbedarf.
Drittens: Braucht es dann noch zwei zusätzliche ifs und zwei zusätzliche
Variablen. Unnötig kompliziert.
Da wundert es mich nicht, dass die Leute rumjammern, dass sie mit dem
8-Bitter nicht auskommen und es der 32-Bitter sein muss, weil der
Speicher nicht reicht. Oder vielleicht doch lieber der Raspi, um die LED
zu schalten?
Wenn Du schon an so einfachen Programmkonstrukten scheiterst, wie sehen
dann umfangreichere Programme für Dich aus? Vielleicht doch das falsche
Hobby?
Curby23523 N. schrieb:> int a = 10;> bool b;>> if(a == 10)> b = true;> else> b = false;
geht kürzer:
bool b = true;
Wenn man a gerade 10 zugewiesen hat, wozu dann noch mit 10 vergleichen?
Jobst Q. schrieb:> Curby23523 N. schrieb:>> int a = 10;>> bool b;>>>> if(a == 10)>> b = true;>> else>> b = false;>> geht kürzer:>> bool b = true;
Ich finde es grausam, für sowas ein if einzusetzen.
Eher so:
1
inta=10;
2
boolb=10==a;
Ich setze bei Vergleichen meist die Konstante nach links.
Also so: if(10 == a)
und eher nicht: if(a == 10)
Um halt das evtl ungewollte if(a = 10) zu vermeiden.
Denn, wenn ich versehentlich if(10 = a) schreibe schimpft der Kompiler
mit mir, während er das versehentliche if(a = 10) klaglos schluckt.
Arduino F. schrieb:> Um halt das evtl ungewollte if(a = 10) zu vermeiden.> Denn, wenn ich versehentlich if(10 = a) schreibe schimpft der Kompiler> mit mir, während er das versehentliche if(a = 10) klaglos schluckt.
Nimm halt eine richtige Programmiersprache, dann passiert sowas nicht.
Oder ist der Algorithmus für Deine Einkaufsliste auch: Wenn Null ==
Bier, dann Nachkaufen?
Hochsprachen sollten eigentlich dazu dienen, den Maschinencode
menschenkombatibel zu machen. Also Algorithmen so formulieren zu können,
wie Menschen sie denken. Stattdessen sehe ich hier einen Haufen
Beispiele, die sich irgendwelcher Hilfskonstrukte bedienen, nur um
menschenkombatiblen Code zu vermeiden.
Da ist der Sinn einer Hochsprache irgendwie verfehlt.
Karl schrieb:> Nimm halt eine richtige Programmiersprache, dann passiert sowas nicht.
Du meinst besser Forth, als C++?
Vielleicht, sollte ich mal drüber nachdenken....
Bei sowas if(a = 10) kann man schon mal länger nach einem Fehler suchen.
Das Auge flutscht drüber weg, und der Kompiler jammert nicht.
if(10 == a) sieht vielleicht anfangs etwas komisch aus, aber man kann
sich daran gewöhnen und ist Funktional gleichwertig zu if(a == 10)
Also wohl wieder eher ein Fall von: "Was der Bauer nicht kennt, das
frisst er nicht"
Moin,
Man koennte dem compiler auch sagen, dass er halt mal ein Auge auf
solche Konstrukte haben soll und doch ein wenig grummeln, wenn er eins
findet:
Arduino F. schrieb:> Du meinst besser Forth, als C++?
Pascal, Ada...
> if(10 == a) sieht vielleicht anfangs etwas komisch aus, aber man kann> sich daran gewöhnen und ist funktional gleichwertig zu if(a == 10)
1
lds r16, a
2
cpi r16, 10
3
breq j10
4
rjmp j20
5
j10:
6
// if
7
j20:
8
// end if
Sieht auch komisch aus, kann man sich auch dran gewöhnen und funktional
ist es gleichwertig zu if a = 10.
Nochmal: Der Sinn einer Hochsprache ist, dass man sich eben nicht
komische Konstrukte ausdenken muss, sondern Algorithmen menschlich
verständlich schreiben kann. Sonst kannste auch Assembler schreiben -
was ich seit Jahren mache.
Wenn eine Sprache solche Konstrukte verlangt, dann isses vielleicht
keine Hochsprache, sondern ein besserer Makro-Assembler.
Karl schrieb:>> set SwitchToSummertime true>> ...>> if { rtc.wday != 7 } then { set SwitchToSummertime false }>> if { rtc.day < 25 } then { set SwitchToSummertime false }>> if { rtc.month != 3 } then { set SwitchToSummertime false }>> ...>> Das ist der totale Schrott!>> Du willst sicher wieder eine Begründung:>> Erstens: Muss der Controller hier alle if-Anfragen prüfen, obwohl> er bei meiner Abfrage schon in 6 von 7 Fällen bei der> Sonntags-Abfrage aussteigen kann. Unnötige Programmlaufzeit.
Wie oft wird die Funktion aufgerufen? Einmal pro Tag?
>> Zweitens: Wird damit erheblich mehr Code erzeugt. Unnötiger> Speicherbedarf.> Drittens: Braucht es dann noch zwei zusätzliche ifs und zwei> zusätzliche Variablen. Unnötig kompliziert.
Was nützen die beiden Punkte, wenn sich wegen fehlender
Übersichtlichkeit ein Fehler eingeschlichen hat?
Bei zeitkritischen Funktionen werde ich in Zukunft weiterhin mal
verschachteln. Ansonsten werde ich zugunsten der Lesbarkeit,
Zusatzoperationen in Kauf nehmen.
Ich durfte mich oft genug durch Code kämpfen, wo sich verschachtelte if
else Konstrukte über mehrere Bildschirmseiten erstreckten. Da hilft
selbst korrektes Einrücken wenig. Selbst bei obigem Beispiel brauche ich
wegen der Verschachtelung einfach länger.
Beitrag "Re: Art der if-Auswahl nur Geschmackssache?"
Karl schrieb:> Hochsprachen sollten eigentlich dazu dienen, den Maschinencode> menschenkombatibel zu machen.
Meinst du damit solche Ungetüme:
Karl schrieb:> Aus aktuellem Anlass:procedure rtc_checksummer();> begin> if rtc.summ and Rsauto <> 0 then begin // prüfen auf Flag Auto> if rtc.wday = 7 then begin // wenn Sonntag> if rtc.day >= $25 then begin // wenn letzter Sonntag im Monat> if rtc.month = $03 then begin // wenn März, Umschalten auf> Sommerzeit> if (rtc.summ and Rsumm) = 0 then begin //wenn Flag nicht> gesetzt> if rtc.hh = $02 then begin> rtc.hh := $03;> rtc.summ := Rsauto or Rsumm;> rtc_setsummer(); // Sommerzeit schreiben> end;> end;> end else if rtc.month = $10 then begin // wenn Oktober,> Umschalten auf Winterzeit> if (rtc.summ and Rsumm) <> 0 then begin //wenn Flag gesetzt> if rtc.hh = $03 then begin> rtc.hh := $02;> rtc.summ := Rsauto;> rtc_setsummer(); // Winterzeit schreiben> end;> end;> end;> end;> end;> end;> end;
Das ist wahrhaft menschencombatibel.
https://www.urbandictionary.com/define.php?term=combatible
Karl schrieb:>> set SwitchToSummertime true>> ...>> if { rtc.wday != 7 } then { set SwitchToSummertime false }>> if { rtc.day < 25 } then { set SwitchToSummertime false }>> if { rtc.month != 3 } then { set SwitchToSummertime false }>> ...>> Dein Ernst?
Selbstverständlich. Mein voller Ernst.
> Das ist der totale Schrott!
:)
> Du willst sicher wieder eine Begründung:
Ja, wenn sie sich nicht auf den Kernpunkt beschränkt,
dass ich eben dämlich bin, wäre eine Begründung ganz
nett...
> Erstens: Muss der Controller hier alle if-Anfragen> prüfen, obwohl er bei meiner Abfrage schon in 6> von 7 Fällen bei der Sonntags-Abfrage aussteigen> kann. Unnötige Programmlaufzeit.
Das stimmt.
Die Kette von Einzelbedingungen, die ich hingeschrieben
habe, wird immer komplett ausgewertet, das ist in der
Laufzeit etwas ungünstiger als geschachteltes if.
Das lässt sich aber sehr leicht abmildern.
> Zweitens: Wird damit erheblich mehr Code erzeugt.> Unnötiger Speicherbedarf.
Erheblich... naja.
Die Zahl der Vergleiche und der Sprünge wird nicht
(wesentlich) beeinflusst, nur die Variablenzuweisung
kommt neu dazu. Sind dann halt 21 statt 14 Befehle.
Auch das lässt sich sehr leicht abmildern, ohne meine
Grundidee aufzugeben.
> Drittens: Braucht es dann noch zwei zusätzliche ifs> und zwei zusätzliche Variablen. Unnötig kompliziert.
Ist im Regelfall nicht relevant.
> Da wundert es mich nicht, dass die Leute rumjammern,> dass sie mit dem 8-Bitter nicht auskommen und es> der 32-Bitter sein muss, weil der Speicher nicht> reicht. Oder vielleicht doch lieber der Raspi, um> die LED zu schalten?
Lächerlich.
Ich wollte ein Prinzip, eine Grundidee zeigen und habe
NATÜRLICH darauf verzichtet, sie durch Optimierung
zu verwässern.
Selbstverständlich KANN man das in der Praxis etwas
kompakter formulieren, ohne die Grundidee aufzugeben.
Dazu kommt noch: Die Bedingung ist in Deinem Beispiel
nur ein längliches UND aus mehreren Teilbedingungen;
ein strukturell so wenig komplexer Ausdruck lässt sich
auch anders als von mir vorgeschlagen behandeln.
> Wenn Du schon an so einfachen Programmkonstrukten> scheiterst,
Schätzungsweise definieren wir "scheitern" deutlich
verschieden.
> wie sehen dann umfangreichere Programme für Dich> aus?
So wie für alle anderen auch: Beschissen.
Zeige mir den Programmierer, der nicht viel lieber
selbst programmiert, als fremde Quelltexte zu lesen.
Karl schrieb:> Arduino F. schrieb:>> Um halt das evtl ungewollte if(a = 10) zu vermeiden.>> Denn, wenn ich versehentlich if(10 = a) schreibe>> schimpft der Kompiler mit mir, während er das>> versehentliche if(a = 10) klaglos schluckt.>> Nimm halt eine richtige Programmiersprache, dann> passiert sowas nicht.
Karl, das ist kindisches Gezänk, das bringt doch
niemanden weiter.
Die Diskussion hatten wir doch neulich schon: Nenne
bitte eine Programmiersprache, die es hinsichtlich
* Ressourceneffizienz,
* Portabilität,
* Ausdruckskraft
ungefähr mit C aufnehmen kann, aber nicht die zahlreichen
Macken von C hat!
Das Ergebnis war auch schon neulich: Es gibt keine.
Es ist völlig egal, ob man C eine "richtige Programmier-
sprache" oder nur einen "portablen Makroassembler" nennt --
der betrübliche Fakt ist der, dass man keine Alternative
hat.
Jobst Q. schrieb:> Kompakt ist auch super für die Lesbarkeit, für mich> jedenfalls.
Da schließe ich mich weitgehend an.
> Und ich schreibe Quelltext für mich und den Compiler,> nicht für den Kindergarten.
Hier nicht.
Ich denke, es ist ganz gut, dass wir keine Kollegen sind
und auch sonst nicht zusammen an einem Projekt arbeiten.
> Je weniger Ballast und Redundanzen, umso schlechter> können sich Fehler verstecken.
Aufgrund dieses fundamentalen Zusammenhanges sind Leute
wie C. E. Shannon, R. W. Hamming, die Herrn Reed und
Solomon usw. bis heute unbeachtete Spinner geblieben,
und Paritätsbits haben ihren vedienten Platz im
Kuriositätenkabinett der Technik gefunden... :)
Jobst Q. schrieb:> if((rtc.wday != 7)||(rtc.day < 25)||(rtc.min != 0)||(rtc.sec !=> 0))return;> if((rtc.mon == 3) && (rtc.h == 2)) rtc_set_summer();> if((rtc.mon == 10) && (rtc.h == 3)) rtc_set_winter();
Elegant, schnell, kompakt. Bravo
Für Karl sollten wir die Reihenfolge der ersten Zeile optimieren ;-)
if((rtc.min != 0)||(rtc.sec !=0)||(rtc.wday != 7)||(rtc.day <
25))return;
Begründung:
Wenn ich mich recht entsinne werden in C die Bedingungen von links
geprüft und sobald eine Oderbedingung true ist, wird zurückgesprungen.
min ist 1/60
sec ist 1/60
wday ist 1/7
day ist ca 1/6
Axel S. schrieb:>> Im konkreten Beispiel stimmt das -- weil sich nämlich beide>> Bedingungen auf dieselbe Variable beziehen. Es ist also aus>> inhaltlichen Gründen sowieso sichergestellt, dass sich die>> Fälle gegenseitig ausschließen.>>>> Wenn mehrere Variablen mit voneinander abhängigen Bedingungen>> eine Rolle spielen, ist das aber keineswegs mehr so.>> Doch. Bei einer if ... else if ... else if ... Kaskade ist> sichergestellt daß maximal einer der Blöcke ausgeführt wird.
Missverständnis. Meine Schuld. (s.u.)
> Im Prinzip ist das genauso [1] wie eine switch() Anweisung,> wo auch immer nur einer der Blöcke ausgeführt wird. Nur daß> man mit switch() nur sehr begrenzte Tests hat - man kann nur> eine Variable auf bestimmte konstante Werte testen. if()> hingegen kann beliebig komplexe Tests ausführen. Nicht daß> man Tests kompliziert machen sollte, aber bereits die simple> Unterteilung eines Bereichs in 3 Teile ist zu kompliziert> für switch(), aber trivial für if().
Die Verwandschaft zwischen if/elseif und switch/break ist
erstmal klar; bezüglich des letztlich ausgeführten Anweisungs-
blockes sind beides quasi 1-aus-N-Decoder.
Ich meinte aber etwas anderes:
Im Beispiel gibt es eine Variable (mit einem Wertebereich,
über dem eine Ordnungsrelation definiert ist), und es gibt
zwei Schwellwerte.
Da es zwei Schwellwerte gibt, existieren drei unterscheidbare
Teilintervalle, in denen der Variablenwert liegen kann.
Um die Steuervariable gegen die beiden Schwellwerte zu
testen, sind zwei Bedingungsausdrücke notwendig, die
logischerweise zwei Wahrheitswerte liefern.
Mit zwei Wahrheitswerten sind aber VIER Kombinationen
ausdrückbar!
Der scheinbare Widerspruch rührt natürlich daher, dass die
beiden Bedingungen nicht unabhängig sind, sondern sich auf
dieselbe Variable beziehen: Sie kann nur ENTWEDER im einen
ODER im anderen ODER im dritten Intervall liegen.
Die Kombination, dass sie KLEINER als die untere, aber
gleichzeitig GRÖSSER als die obere Schwelle ist, kann aus
inhaltlichen Gründen nicht auftreten, der Fall ist per se
ausgeschlossen.
Deswegen -- weil es zwar mehrere Bedingungen, aber nur ein
und dieselbe Steuervariable gibt -- ist die if/elsif-
Konstruktion im vorliegenden Fall machbar und sinnvoll.
Hochtrabend mengentheoretisch formuliert: Die möglichen
Fälle bilden inhaltlich eine Partition, und die if/elseif-
Konstrukion bildet diese Partition korrekt ab.
So. Jetzt mein Punkt: Es GIBT Fälle, in denen mehrere
Bedingungsausdrücke vorliegen, die sich aber NICHT ALLE
wie im Beispiel auf dieselbe Steuervariable beziehen,
sondern in denen mehrere verschiedene Steuervariablen in
unterschiedlicher Kombination vorkommen.
Überdies kann der Fall eintreten, dass sich die Bedingungen
für die unterschiedlichen Steuervariablen gegenseitig
beeinflussen ("Der Busfahrer kann männlich oder weiblich
sein; wenn es ein Mann ist, kann er einen Bart tragen oder
nicht. Wenn es eine Frau ist, interessiert der Bart nicht.")
In diesen -- und PRIMÄR in diesen -- Fällen ist meiner
unmaßgeblichen Meinung nach die geteilte Konstruktion mit
dem if-Abschnitt und der abschließenden switch-Anweisung
sinnvoll.
(Im Prinzip ist das nämlich nichts weiter wie eine Art
Normalform: Erstmal wird alles auf garantiert disjunkte
Basisfälle zurückgeführt; dann werden bei Bedarf im switch
die Basisfälle wieder gruppenweise zusammengefasst.)
> Possetitjel schrieb:>> Sehr mutig, dass Du so genau weisst, was ich übersichtlich>> finde.>> [...]>> Dann ist eine Kaskade von if()'s deutlich besser lesbar,> weil ausgeführter Code und die zugehörige Bedingung> beieinander stehen. Und nicht durch 2½ Bildschirmseiten> Codewüste voneinander getrennt sind.
Ich hoffe, mein Punkt ist klarer geworden: Wenn von vornherein
INHALTLICH disjunkte Fallklassen vorliegen, ist if/elseif
optimal, weil es genau das abbildet. (Das ist im Beispiel der
Fall.)
Das bedeutet aber im Umkehrschluss nicht, dass die diskutierte
if/switch-Konstruktion generell sinnlos ist: Da das eine Art
Normalformkonstruktion ist, ist sie gerade in komplizierten
Fällen nützlich, wenn man KEINE offensichtlich disjunkten
Fallklassen hat.
(Sie ist auch nützlich, wenn man SEHR VIELE diskjunkte Fälle
hat, aber das ist ein anderes Thema.)
Karl schrieb:> Der GROSSE Vorteil von if ... else ist, dass man damit sehr effizient> Abfragen zusammenfassen kann, die der Compiler dann sehr effizient in> Maschinencode umsetzt. Wer diesen Vorteil gerade auf µCs nicht nutzt,> weil er davon Kopfschmerzen bekommt, sollte vielleicht besser _Bäcker_> werden.
Der Bäcker der vermutlich seit dem letzten Wochenende zu späte Brötchen
backt, weil er versucht hat seine komplizierte Sommerzeitumstellung in
einem µC zu zu testen oder die Chance verpasst hat seine süße
Treppenkunst der 'Programmierung' auch in einem Feldversuch zu testen
hat sicherlich nichts von konventioneller Effizienz verstanden:
1
01:if rtc.summ and Rsauto <> 0 then begin // prüfen auf Flag Auto
2
02: if rtc.wday = 7 then begin // wenn Sonntag
3
03: if rtc.day >= $25 then begin // wenn letzter Sonntag im Monat
4
04: if rtc.month = $03 then begin // wenn März, Umschalten auf Sommerzeit
5
05: if (rtc.summ and Rsumm) = 0 then begin //wenn Flag nicht gesetzt
6
06: if rtc.hh = $02 then begin
7
07: rtc.hh := $03;
8
08: rtc.summ := Rsauto or Rsumm;
9
09: rtc_setsummer(); // Sommerzeit schreiben
10
10: end;
11
11: end;
12
12: end else if rtc.month = $10 then begin // wenn Oktober, Umschalten auf Winterzeit
13
13: if (rtc.summ and Rsumm) <> 0 then begin //wenn Flag gesetzt
14
14: if rtc.hh = $03 then begin
15
15: rtc.hh := $02;
16
16: rtc.summ := Rsauto;
17
17: rtc_setsummer(); // Winterzeit schreiben
18
18: end;
19
19: end;
20
20: end;
21
21: end;
22
22: end;
23
22:end;
Zeile 09: rtc_setsummer(); // Sommerzeit schreiben
Zeile 17: rtc_setsummer(); // Winterzeit schreiben
==> der Bäcker versucht dem Compiler mittels Kommentar den Code zu
erklären, während traditionelle Programmierer Kommentare dazu verwenden
den verwendeten (!) Code für Menschen lesbarer zu gestalten.
Natürlich kann ein Bäcker nicht wissen, dass praktisch (für Menschen)
selbsterklärender Code:
"wenn (rtc.tag.akt) größer (tag.36) dann evt. Umstellung" (Pascal "if
rtc.day >= $25 then") durch die Kommentierung mit einem Wochentag der
nicht in der Zeile vorkommt ("... Sonntag im Monat") nicht besser
funktioniert.
Die Frage:
>Was bitte ist daran unlesbar? Und, schon Kopfschmerzen?
die ein Bäcker bei so einem Kunstwerk an die Öffentlichkeit stellen
muss, da er naturgemäß keinen eigenen Zugriff auf den Quelltext hat,
verbietet diesem natürlich den Code leserlicher zu gestalten.
(etwas kreativ, u.U. nicht mit jedem Pascal-Compiler religiös vereinbar,
aber technisch identisch mit dem original Backwerk):
1
{$define th:=then } {$define th_:=then begin}
2
{$define el:=else } {$define el_:=else begin}
3
{$define _el:=end} {$define _th:=end}
4
5
01: if rtc.summ and Rsauto <> 0 // prüfen auf Flag Auto
6
02: th if rtc.wday = 7 // wenn Sonntag
7
03: th if rtc.day >= $25 // wenn letzter Sonntag im Monat
8
04: th if rtc.month = $03 // wenn März, Umschalten auf Sommerzeit
9
05: th_ if (rtc.summ and Rsumm) = 0 // wenn Flag nicht gesetzt
10
06: th if rtc.hh = $02
11
07: th_ rtc.hh := $03;
12
08: rtc.summ := Rsauto or Rsumm;
13
09: rtc_setsummer(); // Sommerzeit schreiben
14
10: _th;
15
11: _th
16
12: el if rtc.month = $10 // wenn Oktober, Umschalten auf Winterzeit
17
13: th if (rtc.summ and Rsumm) <> 0//wenn Flag gesetzt
18
14: th if rtc.hh = $03
19
15: th_ rtc.hh := $02;
20
16: rtc.summ := Rsauto;
21
17: rtc_setsummer(); // Winterzeit schreiben
22
18: _th;
23
24
// verkürzte Version mit gleichrangigen Bedingungen, um sowohl Kommentar
25
// als auch hexadezimale Brötchenfehler lesen zu können:
26
{$define a_:= and } {$define o_:= or }
27
28
01: if (rtc.summ and Rsauto <> 0 ) // wenn Flag=Auto
29
02: a_ (rtc.wday = 7) // und Sonntag
30
03: a_ (rtc.day >= $25) // und Tag > 37 (letzte Woche)
31
04: th if (rtc.month = $03) // dann wenn März,
32
05: th_ if ((rtc.summ and Rsumm) = 0) //dann wenn Flag nicht gesetzt
33
06: a_ (rtc.hh = $02 ) // und Stunde=2
34
07: th_ rtc.hh := $03;
35
08: rtc.summ := Rsauto or Rsumm; //'Umschalten' auf Szt
36
09: rtc_setsummer(); // Sommerzeit schreiben (ident mit WZ_write?)
37
10: _th; // flag !=rsumm & stunde = 2
38
11: _th // month $03
39
12: el if (rtc.month = $10) //sonst wenn Okt(Dez:10;Hex:$0a),
40
13: a_ ((rtc.summ and Rsumm) <> 0) //und Flag gesetzt
Vorteil: zumindest lesbarer als gleichrangige UND-Bedingungen als
abhängige "wenn ... dann"-Bedingung zu texten (i.A. werten Compiler ohne
spezielle Option es exakt gleich aus)
(Nebenvorteil: da viele Bäcker Angst haben einen µC mit ein paar Takten
zu viel zu überlasten, könnten diese den häufigsten Ausschlussgrund
(day<>7) an den Anfang der Abfrage stellen und so den µC etwas schonen)
Zusammenfassung: lesbarer Code kann zwar ein paar Takte 'kosten' aber
Karl der Bäcker bräuchte mehrere Zeitumstellungen bis er die Fehler in
seinem Code experimentell überprüfen könnte.
Umfangreiche Programmkonstrukte, wie eine Zeitumstellung vor Ende des 36
Tages im Monat, dürften Bäcker die Karl aus seinen Kopfschmerzen kennt
sicherlich überfordern. Umfangreiche Programme dürften für Bäcker wie
Karl wohl deutlich mehr "begin" "end" enthalten.
Arduino F. schrieb:> Um halt das evtl ungewollte if(a = 10) zu vermeiden.
technisch sehr sinnvoll, aber etwas inkompatibel mit dt./eng. Schreib
und wohl auch Denkmustern:
sprachlich: wenn der µC eine Spannung von 230V hat, dann liegt ein
Fehler vor.
umgekehrt: wenn eine Spannung von 230V der µC hat, dann ....auch Fehler
aber sprachlich wohl Jedi.
Beim programmieren:
if 230 = uC ... ok (aber Denkmurks)
if uC = 230 ... Bude fackelt ab ... (noch schlechter)
Es könnte sein, dass durch die damalige Sparmaßnahme beim
Zuweisungsoperator in C der Keim der Zerstörung mit angelegt wurde,
ähnlich dem Whitespace-Operator in C (u.U. etwas übertrieben für eine
so gefährliche Programmiersprache)
NB.: für den OP könnte es wohl Hoffnung mit C++20 geben (soll 2020 auf
den Markt kommen) da dann der Spaceship-Operator endlich Einzug in die
gefährliche Welt von C++ findet.
Rolf M. schrieb:> Possetitjel schrieb:>> Das Problem bei if/elseif ist, dass es zwar syntaktisch>> eine Anweisung bleibt, man aber mehrere unabhängige>> Bedingungen abprüfen kann, und das ist Teufelswerk.>> Warum?
Bei if/elseif schließen sich die (die Fälle behandelnden)
Anweisungsblöcke per Konstruktion aus. Bei unabhängigen
Bedingungen "überlappen" sich die Teilmengen jedoch inhalt-
lich.
Das Konstrukt der Hochsprache spiegelt somit formal einen
ganz anderen Fall vor, als letztlich inhaltlich vorliegt.
Beispiel: Gegeben seien die Bedingungen c1, c2 und c3,
die jeweils wahr oder falsch sein können. Es ergeben
sich formal acht Fallklassen.
Wenn alle acht formal denkbaren Fallklassen tatsächlich
inhaltlich verschieden sind, ist die Sache noch relativ
einfach: Man kommt mit if/then auf drei Ebenen durch die
Sache durch, muss aber Bedingungen mehrfach schreiben
(was nicht dramatisch, aber auch nicht schön ist -- "DRY").
Alternativ kann man auch if/elseif auf einer Ebene verwenden,
muss dann aber alle drei Bedingungen viermal negiert und
viermal nichtnegiert schreiben. Geht auch.
Die if/switch-Konstruktion sieht dort so aus:
1
2
set fallnr 0
3
if { $c1 } then { set fallnr 4 }
4
if { $c2 } then { incr fallnr 2 }
5
if { $c3 } then { incr fallnr 1 }
6
7
switch $fallnr {
8
...
9
}
Noch schlimmer wird es aber, wenn die formal denkbaren
Fälle inhaltlich NICHT alle unterschiedlich sind.
Bei der if/then/else- bzw. if/elseif-Variante schreibt
man entweder den die Fälle behandelnden Code mehrfach,
oder man lagern ihn in Funktionen aus, oder man versucht,
die Bedingungen umzuformulieren.
Letzteres ist gefährlich; es ist eine Konzentrationsübung,
dabei Vollständigkeit und Widerspruchsfreiheit abzusichern.
Verwendet man die if/switch-Konstruktion, muss man von der
Struktur her überhaupt nichts anpassen, sondern ändert
lediglich die Zuordnung der Fallnummern in der switch-
Anweisung.
Dieses Beispiel mit drei binären Bedingungen ist noch
ziemlich gutartig; wenn es drei Bedingungen mit drei,
drei und zwei Belegungen gibt, sind das formal schon
18 Fallklassen.
> "Fallnummer"? Also wenn man das so macht, dann sollte> man (ähnlich wie Tom es gezeigt hat) den Fällen auch> Namen geben. Irgendwelche Magic-Numbers machen es alles> andere als übersichtlicher. Dann muss ich beim Lesen des> switch/case erst wieder oben nachschauen, welches> Ergebnis der if-Abfrage denn nun zu Fall Nummer 3 gehört,> was den Lesefluss meiner Meinung nach stark stört.
Das stimmt -- aber hast Du einen besseren Vorschlag?
> Hmm, dann funktionieren unsere Gehirne verschieden ;-)
Das ist gut möglich :)
> Wenn ich das im Kopf durchgehen würde, würde ich sagen:> [...]>> Da hab ich ja im zweiten Satz schon vergessen, welcher> Fall im ersten Satz welcher Bedingung zugeordnet war.
Ja... das Beispiel ist ungünstig, weil für die LEDs die
if/elseif-Kette aus inhaltlichen Gründe die richtige
Konstruktion ist.
Das will ich auch gar nicht bestreiten; es ging mir nur
darum, dass der if/switch-Vorschlag nicht SO bescheuert
ist, wie er zunächst aussieht -- auch wenn er für das
konkrete Beispiel nicht gut passt.
>> Im konkreten Beispiel stimmt das -- weil sich nämlich beide>> Bedingungen auf dieselbe Variable beziehen. Es ist also aus>> inhaltlichen Gründen sowieso sichergestellt, dass sich die>> Fälle gegenseitig ausschließen.>>>> Wenn mehrere Variablen mit voneinander abhängigen Bedingungen>> eine Rolle spielen, ist das aber keineswegs mehr so.>> Ja, ab einer gewissen Komplexität ist die Trennung durchaus> sinnvoll. Aber zwingend ist für mich dann auch wieder, dass> keine magischen Fallnummern verwendet werden, sondern> aussagekräftige Bezeichnungen.
Ich bin für alle Ideen offen.
Die erstrebte Vereinfachung kommt ja dadurch zustande, dass
ich mit den Fallnummern rechne. Mir fällt aber nix ein, wie
man das mit Klartext-Bezeichnungen kombinieren könnte.
Bitfrickeln ist auch nicht schön; es kann ja drei oder fünf
Unterklassen je Steuervariable geben, dann würden Lücken in
den Fallnummern entstehen, was die Sache wieder verkompliziert.
Im Prinzip ist Dein Einwand aber gut; man braucht eine
idiotensichere (=für mich taugliche) Methode, die Fallnummern
auf Klartextbezeichnungen abzubilden.
Jobst Q. schrieb:> if((rtc.wday != 7)||(rtc.day < 25)||(rtc.min != 0)||(rtc.sec !=> 0))return;> if((rtc.mon == 3) && (rtc.h == 2)) rtc_set_summer();> if((rtc.mon == 10) && (rtc.h == 3)) rtc_set_winter();
Macht nur leider nicht das Gleiche wie mein Code.
Tom schrieb:> bool is_sunday = (rtc.wday == 7);> bool is_last_week_in_month = (rtc.day > 24); // only for months with 31> days (e.g. March and October)> bool is_last_sunday_in_month = is_sunday && is_last_week_in_month;>> bool is_march = (rtc.month == 3);> bool is_october = (rtc.month == 10);>> bool do_switch_to_summertime = is_march && is_last_sunday_in_month;> bool do_switch_to_wintertime = is_october && is_last_sunday_in_month;>> if (do_switch_to_summertime)> rtc_set_summer();> if (do_switch_to_wintertime)> rtc_set_winter();
Das hätte ich gern mal als ASM-Listing gesehen. Glaube kaum, dass 7
unnötige Zwischenvariablen effektiver umgesetzt werden als if-Abfragen.
Possetitjel schrieb:> Karl, das ist kindisches Gezänk, das bringt doch> niemanden weiter.
Ich empfinde es eher als kindisch, sich absonderliche Konstrukte
auszudenken, weil man mit der Struktur einer if .. else if.. else
Abfolge überfordert ist.
Ist das wirklich so schwierig? Bei den meisten der obigen "alternativen"
Konstrukte sage ich mir: Ja, kann man machen, aber: WARUM?
Karl schrieb:
> Ja, kann man machen, aber: WARUM?
Warum? Verschleiern, tarnen, täuschen, Finten setzen. Wozu? Um es
Anderen maximal zu erschweren oder am Besten unmöglich machen, den unter
Elend und Entbehrungen erzeugten Code zu entziffern.
Karl schrieb:> Macht nur leider nicht das Gleiche wie mein Code.
du hast als Betroffener sicherlich keinen direkten Zugang zu Deinem Code
und konntest den in einem µC testen, ansonsten wäre Dir die verpasste
Zeitumstellung bei Deinem umfangreichen Projekt aufgefallen.,
> Possetitjel schrieb:>> Karl, das ist kindisches Gezänk, das bringt doch>> niemanden weiter.>> Ich empfinde es eher als kindisch, sich absonderliche Konstrukte> auszudenken, weil man mit der Struktur einer if .. else if.. else> Abfolge überfordert ist.
Solche kindischen Empfindungen passieren wenn Karl überfordert ist
seinen fehlerhaften Problemcode aus seinem Zeitumstellungsprojekt
eigenständig zu überprüfen.
> Ist das wirklich so schwierig? Bei den meisten der obigen "alternativen"> Konstrukte sage ich mir: Ja, kann man machen, aber: WARUM?
Solche Selbstgespräche sind sicherlich nicht hilfreich wenn es darum
geht WARUM die Zeitumstellung bei Karl auch dieses Jahr nicht geklappt
hat.
Tom schrieb:> Lothar M. schrieb:>> if (a == 10) b = true;>> So wäre es noch konsequenter:if ( (a == 10) == true )> b = true;
Genfer Konvention sagt dir was? Solche Codekonstrukte wurden im gleichen
Atemzug mit chemischen Kampfstoffen verboten.
Dirk schrieb:> du hast als Betroffener sicherlich keinen direkten Zugang zu Deinem Code> und konntest den in einem µC testen, ansonsten wäre Dir die verpasste> Zeitumstellung bei Deinem umfangreichen Projekt aufgefallen.,
Der Code läuft seit Jahren in meiner Heizung und hat bisher noch jede
Zeitumstellung mitgemacht.
Wenn Du eine Packed-BCD-Zahl nicht als solche erkennst, solltest Du
Bäcker werden.
Possetitjel schrieb:>> Und ich schreibe Quelltext für mich und den Compiler,>> nicht für den Kindergarten.>> Hier nicht.
Hier halte ich mich an die Vorgaben der Fragesteller und der anderen
Teilnehmer, soweit es geht.
Das ist aber nur ein winziger Bruchteil der von mir geschriebenen
Quelltexte. Ich bin eben selbstständig und der einzige, der mit meinen
Quellen arbeiten muss. Also haben sich durch Erfahrungen von Jahrzehnten
Regeln herauskristallisiert, die für mich und meine Arbeit optimal
sind.Ich habe das Privileg, nicht berücksichtigen zu müssen, was andere
für optimal halten.
> Ich denke, es ist ganz gut, dass wir keine Kollegen sind> und auch sonst nicht zusammen an einem Projekt arbeiten.>
Warum? Dass ich nach eigenen Regeln programmiere, heißt ja nicht, dass
ich mich nicht nach anderen Regeln richten kann. Mit manchen könnte ich
mich sicher auf gemeinsame Regeln einigen, mit allen natürlich nicht.
>> Je weniger Ballast und Redundanzen, umso schlechter>> können sich Fehler verstecken.>> Aufgrund dieses fundamentalen Zusammenhanges sind Leute> wie C. E. Shannon, R. W. Hamming, die Herrn Reed und> Solomon usw. bis heute unbeachtete Spinner geblieben,> und Paritätsbits haben ihren vedienten Platz im> Kuriositätenkabinett der Technik gefunden... :)
Das soll wohl Ironie sein, aber in der Nachrichtentechnik hat Redundanz
eine ganz andere Bedeutung als in der Programmierung und die Fehler sind
ganz anderer Art.
Karl schrieb:> Jobst Q. schrieb:>> if((rtc.wday != 7)||(rtc.day < 25)||(rtc.min != 0)||(rtc.sec !=>> 0))return;>> if((rtc.mon == 3) && (rtc.h == 2)) rtc_set_summer();>> if((rtc.mon == 10) && (rtc.h == 3)) rtc_set_winter();>> Macht nur leider nicht das Gleiche wie mein Code.
Was dein Code macht, weiß leider keiner außer dir. Die Umgebung hast du
uns nicht mitgeteilt.
Karl schrieb:> Dirk schrieb:>> du hast als Betroffener sicherlich keinen direkten Zugang zu Deinem Code>> und konntest den in einem µC testen, ansonsten wäre Dir die verpasste>> Zeitumstellung bei Deinem umfangreichen Projekt aufgefallen.,>> Der Code läuft seit Jahren in meiner Heizung und hat bisher noch jede> Zeitumstellung mitgemacht.> Wenn Du eine Packed-BCD-Zahl nicht als solche erkennst, solltest Du> Bäcker werden.
das heisst du hast wirklich keine Möglichkeit eigenständig Deinen
veröffentlichten Code mit Hilfe einer Texterkennung nach "BCD" zu
untersuchen und bleibst als Abhängiger darauf beschränkt anderen
Menschen etwas 'empfehlen' zu müssen.
Du hast den Geschmack der Packed-BCD-Zahl sicherlich beim backen erlebt
und deswegen sind bei dir
>Zeile 09: rtc_setsummer(); // Sommerzeit schreiben>Zeile 17: rtc_setsummer(); // Winterzeit schreiben
weiterhin identisch.
Dirk schrieb:> deswegen sind bei dir>>Zeile 09: rtc_setsummer(); // Sommerzeit schreiben>>Zeile 17: rtc_setsummer(); // Winterzeit schreiben> weiterhin identisch.
Ja. Weil da nur die aktuelle Stunde aus rtc.hh und die Flags (Auto und
Sommerzeit) aus rtc.summ per TWI in die RTC geschrieben werden. Ist die
gleiche Funktion, warum sollte ich die zweimal unter verschiedenen Namen
haben?
Das Entscheidende ist die Zeile darüber, in der das Flag gesetzt wird,
welches dann stromausfallsicher in der RTC abgelegt wird.
Karl schrieb:> Dirk schrieb:>> deswegen sind bei dir>>>Zeile 09: rtc_setsummer(); // Sommerzeit schreiben>>>Zeile 17: rtc_setsummer(); // Winterzeit schreiben>> weiterhin identisch.>> Ja. Weil da nur die aktuelle Stunde aus rtc.hh und die Flags (Auto und> Sommerzeit) aus rtc.summ per TWI in die RTC geschrieben werden. Ist die> gleiche Funktion, warum sollte ich die zweimal unter verschiedenen Namen> haben?
das kannst du nicht wissen wenn du aus Unerfahrenheit generell fremde
Menschen wie mich für solche programmtechnischen Kleinigkeiten fragen
musst, aber auch Kommentare können falsch sein d.h. wenn der Kommentar
behauptet "Winterzeit schreiben" obwohl im Programm der jeweils aktuelle
Wert geschrieben wird, dann ist das ein eindeutiger Kommentarfehler.
>Zeile 09: rtc_setsummer(); // Wert schreiben>Zeile 17: rtc_setsummer(); // Wert schreiben
wäre zumindest nicht falsch und falls du einmal leslichen Code
schreiben möchtest anstatt vieler begin/end, dann wäre
>Zeile 09: rtc_setsummer(); // stromausfallsicher Flag setzen>Zeile 17: rtc_setsummer(); // stromausfallsicher Flag setzen
eine Option.
> Das Entscheidende ist die Zeile darüber, in der das Flag gesetzt wird,> welches dann stromausfallsicher in der RTC abgelegt wird.
Dein Programm wäre ohne Kommentare sicherlich leichter zu lesen, aber da
Du auf fremde Menschen angewiesen bist um diese nach einfachsten Sachen
zu fragen kannst du auch nicht lesen, dass auch das nicht im
Code/Kommentar steht.
Karl schrieb:>>> Dirk schrieb:>> das kannst du nicht wissen wenn du aus Unerfahrenheit generell fremde>> Menschen wie mich für solche programmtechnischen Kleinigkeiten fragen>> musst, aber auch Kommentare können falsch sein d.h. wenn der Kommentar>> behauptet "Winterzeit schreiben" obwohl im Programm der jeweils aktuelle>> Wert geschrieben wird, dann ist das ein eindeutiger Kommentarfehler.> Häh?
Menschen die nur hilflos fremde Menschen "Hä?" fragen können und keinen
Zugang zum Quelltext haben auf den sie reagieren, bleibt die
Unerfahrenheit mit der sie auf den Bäcker gekommen sind.
>Zeile 09: rtc_setsummer(); // Sommerzeit schreiben>Zeile 17: rtc_setsummer(); // Winterzeit schreiben
Ich finde das absolut gruselig!
Eine Funktion/Methode, mit "set" im Name ist für mich ein Setter, und
setSummer() setzt halt auf Sommerzeit. NIE würde ich auf die Idee
kommen, dass die gleiche Funktion auch die Winterzeit einstellt.
Eine solche Funktion würde ich sofort umbenennen!
z.B. in rtc_togglesummer()
Das kann man ja sonst nach 6 Monaten selber nicht mehr verstehen.
(es sei denn, es ist das einzige Programm, was man in der Zeit anfasst)
Cyblord -. schrieb:> Süß. Der Blinde möchte Picasso über Farbe belehren.
Mh, unter welchem Namen zeigst Du denn in diesem Forum mal was von
Deiner Kunst?
Und wenn Du selber mal ein großes Projekt betreust (nicht nur als Summe
vieler kleiner), dann wirst Du erfahren, dass einige Regeln für normale
Projekte nicht skalieren, an die Du (aus Deiner Erfahrung zurecht) noch
glaubst.
Jobst Q. schrieb:>> Ich denke, es ist ganz gut, dass wir keine Kollegen sind>> und auch sonst nicht zusammen an einem Projekt arbeiten.>>> Warum? Dass ich nach eigenen Regeln programmiere, heißt> ja nicht, dass ich mich nicht nach anderen Regeln richten> kann.
Naja, vor dem Hintergrund, dass Du ein Ein-Mann-Team bist,
wird Deine Bemerkung verständlicher.
Die Formulierung mit dem Kindergarten kam halt so 'rüber,
dass Dir völlig egal ist, ob andere Deine genialen Quell-
texte lesen können (wobei es durchaus sein kann, dass die
wirklich genial sind. Dein Codebeispiel für die Sommerzeit-
umstellung ist auch an Lesbarkeit schwerlich zu übertreffen.)
>>> Je weniger Ballast und Redundanzen, umso schlechter>>> können sich Fehler verstecken.>>>> Aufgrund dieses fundamentalen Zusammenhanges sind Leute>> wie C. E. Shannon, R. W. Hamming, die Herrn Reed und>> Solomon usw. bis heute unbeachtete Spinner geblieben,>> und Paritätsbits haben ihren vedienten Platz im>> Kuriositätenkabinett der Technik gefunden... :)>> Das soll wohl Ironie sein,
Richtig erkannt.
> aber in der Nachrichtentechnik hat Redundanz eine> ganz andere Bedeutung als in der Programmierung und> die Fehler sind ganz anderer Art.
Bei "andere Art der Fehler" stimme ich teilweise zu.
Redundanz bewirkt aber immer dasselbe: Aufblähung des
Datenvolumens -- und Möglichkeit zur Erkennung und
Korrektur von Fehlern.
Wenn Menschen für die redundanzfreie Kommunikation
geschaffen wären, würden wir alle immer und überall
Steno schreiben. Tun wir aber nicht.
Klare, kompakten Formulierungen im Quelltext sind
immer erstrebenswert -- aber die Kompaktheit sollte
nur soweit getrieben werden, wie sie der Klarheit
nicht widerspricht.
Dein eigener Dreizeiler oben ist ja ein gutes Beispiel
dafür.
Possetitjel schrieb:> Redundanz bewirkt aber immer dasselbe: Aufblähung des> Datenvolumens -- und Möglichkeit zur Erkennung und> Korrektur von Fehlern.
Ich hätte jetzt erwartet, dass da kommt: Möglichkeit zum Einbauen von
mehr Fehlern…
Possetitjel schrieb:> Bei "andere Art der Fehler" stimme ich teilweise zu.>> Redundanz bewirkt aber immer dasselbe: Aufblähung des> Datenvolumens -- und Möglichkeit zur Erkennung und> Korrektur von Fehlern.
Redundanz ist dann sinnvoll und nützlich, wenn man die Wahl hat zwischen
redundanten Blöcken und die Fehler vor der Wahl erkennen kann. Wie in
der Nachrichtentechnik.
In Programmen ist das aber nicht gegeben. Da wird einer der redundanten
Blöcke aufgerufen und wenn da ein Fehler drin ist, ist das ein Fehler
des ganzen Progamms, das dann evtl abstürzt.
Redundanzarme Programmierung mit gemeinsamen Funktionen oder Makros für
ähnliche Operationen bietet Fehlern weniger Möglichkeiten, sich zu
verstecken.
Die aufrufenden Funktionen werden kürzer und übersichtlicher, da kommt
man Fehlern schneller auf die Spur. Sind sie in der aufgerufenen
Funktion, werden sie schneller entdeckt, weil diese häufiger aufgerufen
wird.
Tom schrieb:> void doit(int mon, int day, int wday){> static struct {void (*a)(void); void (*b)(void);void (*c)(void); } F> = {set_summer, do_nothing, set_winter};> static void (**p)(void) = (void(**)(void)) &F + 1;> p[(mon==10 && wday==7 && day>24) - (mon==3 && wday==7 && day>24)]();> }
Hi,
ich vermisse hier noch die zeit/stunde, weil die uhr wird nicht um
mitternacht umgestellt.
schönes beispiel, man beachte die dereferenzierung durch eckige klammern
des functionspointers! daher anstatt *() = []
wieder was gelernt, danke mt!
Tom schrieb:> TI:07 schrieb:>> geht das auch ohne switch case oder if ?>> Also Funktionsaufruf über einen struct ?> Ohne if und mit struct :void set_summer(void) {printf("sommer\n");}> void set_winter(void) {printf("winter\n");}> void do_nothing(void) {;}>> void doit(int mon, int day, int wday){> static struct {void (*a)(void); void (*b)(void);void (*c)(void); } F> = {set_summer, do_nothing, set_winter};> static void (**p)(void) = (void(**)(void)) &F + 1;> p[(mon==10 && wday==7 && day>24) - (mon==3 && wday==7 && day>24)]();> }>> Sehr kompakt mit wenigen Zeilen und deshalb überaus lesbar.
Ich hab keine Ahnung was da passieren soll.
Wieso nicht einfach die Formel vom Gauss benutzen? Dadurch bekommt man
bequem den letzten Sonntag ermittelt.
https://de.wikipedia.org/wiki/Gau%C3%9Fsche_Wochentagsformel
> Sehr kompakt mit wenigen Zeilen und deshalb überaus lesbar.
Warum als struct und nicht gleich als Array?
Die Funktionen sind doch alle vom selben Typ.
Tom schrieb:> p[(mon==10 && wday==7 && day>24) - (mon==3 && wday==7 && day>24)]();
Ist denn sichergestellt, dass eine wahre Bedingung +1 als Ergebnis hat?
Soweit ich mich erinnere, ist nur Null und nicht-null festgelegt.
Jobst Q. schrieb:> Ist denn sichergestellt, dass eine wahre Bedingung +1 als Ergebnis hat?> Soweit ich mich erinnere, ist nur Null und nicht-null festgelegt.
passt!
boolische ausdrücke liefern 0=false oder 1=true zurück
UND
als bedingung wird alles ungleich 0 als true interpretiert.
mt
Egon N. schrieb:> Wieso nicht einfach die Formel vom Gauss benutzen? Dadurch bekommt man> bequem den letzten Sonntag ermittelt.
Wow! Zwei Modulos durch 100 und 400. Das heisst, mal eben noch
Ganzzahldivision reinschmeißen.
Der letzte Sonntag im Monat ist im März und Oktober IMMER der zwischen
25.* und 31. Iss so.
*) In Packed-BCD, wie es eine RTC wie die DS1307 liefert: $25
Egon N. schrieb:> http://www.instructables.com/id/The-Arduino-and-Daylight-Saving-Time-Europe/
Von da: if (dow == 7 && mo == 10 && d >= 25 && h == 3 && DST==1)
Das hatte ich so ähnlich für C auf dem ATmega. Das wurde bescheiden
umgesetzt, daraufhin habe ich das in die einzelnen ifs aufgelöst und es
wurde controllerfreundlich umgesetzt.
Das Problem war wenn ich mich recht erinnere, dass der Compiler bei
dieser Variante erstmal alle Variablen aus dem SRAM in Register lädt,
und diese dann vergleicht. Wobei jeder einzelne Vergleich im Controller
als compare+branch ausgeführt wird, geht ja nicht anders.
In ifs aufgelöst wird genauso mit compare+branch verglichen, nur dass
der Compiler nur die Variable lädt, die er für den Vergleich braucht,
und auch nur in ein Register. Was neben der unnötigen zusätzlichen
Laufzeit für das Laden auch Register spart. Was dazu führt, dass der
Compiler diese gesparten Register nicht pushen und poppen muss. Was
wiederum zu gespartem Speicherplatz führt.
Sämtliche anderen obigen Konstrukte benötigen genau die gleichen
compares+branches, egal ob über Hilfsvariablen oder über eine Structure.
Denn der Controller kann nunmal nur das: Einen Wert mit einem anderen
Vergleichen und darauf ein Ergebnisregister auf true oder false setzen.
Zusätzlich benötigen diese Konstrukte aber weiteren Speicherplatz,
müssen Variablen schreiben und lesen, oder benötigen zuätzliche
Register, die gepushed und gepoppt werden müssen. Kann mir keiner
erzählen, dass das effizienter ist. Schlechter lesbar ist es noch dazu.
Deswegen hätte ich ja gern mal die vom Compiler erzeugten
Assemblerlistings zu obigen Konstrukten gesehen. Aber dafür reichts dann
wieder nicht.
Karl schrieb:> dass der Compiler bei> dieser Variante erstmal alle Variablen aus dem SRAM in Register lädt,> und diese dann vergleicht. Wobei jeder einzelne Vergleich im Controller> als compare+branch ausgeführt wird, geht ja nicht anders.
So blöd ist gcc nichtmal mit -O0.
Jobst Q. schrieb:> Redundanz ist dann sinnvoll und nützlich, wenn man> die Wahl hat zwischen redundanten Blöcken und die> Fehler vor der Wahl erkennen kann. Wie in der> Nachrichtentechnik.>> In Programmen ist das aber nicht gegeben. [...]
Wir haben unterschiedliche Dinge im Blick.
Dass man auf Block- oder Anweisungsebene keine
Redundanz haben will, ist klar ("DRY").
Quelltexte sind aber nicht nur Mittel zur Mensch-
Maschine-Kommunikation, sondern auch zur Mensch-
Mensch-Kommunikation -- und sei es nur, dass ich
den Quelltext verstehen will, den ich vor drei
Jahren geschrieben habe.
Der redundanzfreie Operatorwahn, den C auslebt, ist
da meiner Meinung nach wahrnehmungspsychologisch nicht
hilfreich.
Wenn die Menschen für redundanzfreie schriftliche
Kommunikation geeignet wären, würde wir alle immer
und überall Steno schreiben. Tun wir aber nicht.
Die normale Schriftsprache enthält reichlich
Redundanz, und das ist auch gut so [TM].
Hallo allseits,
obwohl die Diskussion in diesem Thread langsam programmier-esoterisch
geworden ist, möchte ich gerne nochmals auf den OT zurückkommen (konnte
leider nicht früher posten). Ich habe den Code mal auf Verdacht mit ein
paar defines ergänzt, damit er kompilierbar wird, und dann dem
Compiler-Explorer von Mats Godbolt (https://godbolt.org/) zum Fraß
vorgeworfen:
Was ich jetzt wirklich interessant finde, ist, dass er mit -O3 übersetzt
für beide Funktionen identischen Code liefert. Hier das Ergebnis für den
ARM64-Compiler, für AVR waren die beiden Funktionen ebenfalls gleich,
andere habe ich nicht versucht:
1
EnergieRestAmpel1(unsigned short):
2
uxth w0, w0
3
cmp w0, 4
4
bgt .L6
5
cmp w0, 1
6
ble .L7
7
mov x0, 20484
8
mov w1, 1
9
strh w1, [x0]
10
ret
11
.L6:
12
mov x0, 20480
13
mov w1, 1
14
strh w1, [x0]
15
ret
16
.L7:
17
mov x0, 20482
18
mov w1, 1
19
strh w1, [x0]
20
ret
21
EnergieRestAmpel2(unsigned short):
22
uxth w0, w0
23
cmp w0, 4
24
bgt .L9
25
cmp w0, 1
26
bgt .L10
27
mov x0, 20482
28
mov w1, 1
29
strh w1, [x0]
30
ret
31
.L9:
32
mov x0, 20480
33
mov w1, 1
34
strh w1, [x0]
35
ret
36
.L10:
37
mov x0, 20484
38
mov w1, 1
39
strh w1, [x0]
40
ret
Das heißt, dass alle Überlegungen sich wirklich ausschließlich auf die
Lesbarkeit beschränken können, in Puncto Laufzeit ist jegliche
Diskussion überflüssig. :)
Gruß
Herby
Herbert P schrieb:> Das heißt, dass alle Überlegungen sich wirklich ausschließlich auf die> Lesbarkeit beschränken können, in Puncto Laufzeit ist jegliche> Diskussion überflüssig. :)
... der beweis geht fehl, weil kein induktiver beweis vorliegt, die
schnelle verallgemeinerung ist hier eher wunsch als realität.
z.b. meine erfahrung mit gcc und avr ist, das bei umfangreichen
bedingungen ich zwar regelmäßig switch/case bzgl. lesbarkeit mir wünsche
aber if/else oft bessere code size liefert.
ich probier deshalb ab einer gefühlten mächtigkeit der vorliegenden
bedingungen beide varianten bzgl. code size. die laufzeit war nie thema.
ich bin ansonsten ein switch/case kind, weil da mache ich weniger fehler
...
und habe irgenwie einen besseren überblick was sache ist.
mt
Apollo M. schrieb:> die laufzeit war nie thema.
Das ist das Problem mit den Softwerkern. Am Besten vor dem Vergelcih
noch einen Cast auf einen 64-Bit-Float. So bekommt man jeden GHz-Boliden
langsam...
Possetitjel schrieb:> Quelltexte sind aber nicht nur Mittel zur Mensch-> Maschine-Kommunikation, sondern auch zur Mensch-> Mensch-Kommunikation -- und sei es nur, dass ich> den Quelltext verstehen will, den ich vor drei> Jahren geschrieben habe.
Das will ich auch.
>> Der redundanzfreie Operatorwahn, den C auslebt, ist> da meiner Meinung nach wahrnehmungspsychologisch nicht> hilfreich.
Da habe ich wohl eine andere Wahrnehmung als du.
(x+1)*y habe ich schneller und sicherer überblickt als
Addiere 1 zu x und multipliziere das Ganze mit y.
Dass C sparsam mit Schlüsselwörtern umgeht und stattdessen lieber
einfache Zeichen nimmt, sehe ich als einen seiner größten Vorteile. Über
die Zeichen nehme ich die Struktur wahr und die Buchstaben bleiben
größtenteil für den Inhalt (Variablen und Funktionen) reserviert.
Wörter wie begin und end sind weder redundanter noch verständlicher als
{ und }. Als unbedarfter Leser von Pascal-Quelltexten würde ich mich
wundern, warum man dem Programm zigmal sagen muss, dass es anfangen soll
und ebenso oft, dass es aufhören soll.
Solche unnötigen Buchstabenwüsten zähle ich auch nicht unter Redundanz,
sondern unter Ballast.
Hilfreiche Redundanz kenne ich auch. So habe ich mir angewöhnt, bei
größeren Blöcken die schließenden Klammern mit den Bedingungen ihres
Anfangs zu kommentieren.
}// for(i=0;i<NSets;i++)
}// while(*s)
}// else zu if(r != l)
#endif // #ifdef ARM
Jobst Q. schrieb:> So habe ich mir angewöhnt, bei> größeren Blöcken die schließenden Klammern mit den Bedingungen ihres> Anfangs zu kommentieren.> }// for(i=0;i<NSets;i++)> }// while(*s)> }// else zu if(r != l)
Und das ist weniger als ein begin...end?
Es gibt moderne IDE, die haben sowas wie Autovervollständigen oder
intelligente Klammerung. So wie ein C die } automatisch nach der {
gesetzt werden kann, geht das in Pascal auch. Nervt manchmal, aber in
Pascal sehe ich ein irrtümlich gesetztes end; eher als eine irrtümlich
gesetzte Klammer in C.
Ganz häßlich sind in C Folgen von )})}.
Abgesehen davon kann man sowohl in C begin...end anstatt {} verwenden
als auch in Pascal {} statt begin...end, wenn man sich das hindefiniert.
Das ist nicht der entscheidende Unterschied.
Apollo M. schrieb:> Herbert P schrieb:>> Das heißt, dass alle Überlegungen sich wirklich ausschließlich auf die>> Lesbarkeit beschränken können, in Puncto Laufzeit ist jegliche>> Diskussion überflüssig. :)>> ... der beweis geht fehl, weil kein induktiver beweis vorliegt, die> schnelle verallgemeinerung ist hier eher wunsch als realität.
Mein Post war weder Verallgemeinerung noch der Versuch eines Beweises
sondern beschränkte sich ausschließlich auf das publizierte Codestück.
Es ist richtig, dass komplexere Konstrukte nicht ganz so einfach zu
betrachten sind, aber in der Regel werden bei einer Handvoll Vergleichen
(ich hab das mal bis zu 10 untersucht) if-else-Ketten und vergleichbare
Switch-Awnweisungen zu gleichem Maschinenencode übersetzt bei
Optimierung. Bei mehr Fällen macht switch in der Regel dann
Sprungtabellen, außer odie Löcher werden zu groß.
Bei Sonderfällen oder extremen Konstrukten treten dann auch schnell
Unterschiede zwischen den Compilern auf, so dass man hier eigentlich gar
nicht verallgemeinern kann.
Gruß
Herby
Jobst Q. schrieb:> Hilfreiche Redundanz kenne ich auch. So habe ich mir angewöhnt, bei> größeren Blöcken die schließenden Klammern mit den Bedingungen ihres> Anfangs zu kommentieren.>> }// for(i=0;i<NSets;i++)> }// while(*s)> }// else zu if(r != l)
Verwende da lieber einen Editor. (nicht "Editor" von Windows;-). Der
Kommentar veraltet zu schnell.
Lothar M. schrieb:> Am Besten vor dem Vergelcih> noch einen Cast auf einen 64-Bit-Float.
Gut lesbarer Code ist selten Grund für Laufzeitprobleme. Ein solcher
Cast wäre Gift für beides. Im Gegenteil: Wenn ich einen Code gut lesen
kann, erkenne ich solchen Unsinn eher und es wird ... nur besser.
Jobst Q. schrieb:> Da habe ich wohl eine andere Wahrnehmung als du.
Mag sein...
> (x+1)*y habe ich schneller und sicherer überblickt als>> Addiere 1 zu x und multipliziere das Ganze mit y.
Nun ja, das liegt mMn einfach daran, dass die(se) mathe-
matischen Operatoren in C im großen und ganzen dieselbe
Bedeutung haben wie in der Mathematik, und die Arithmetik
hat man schon einige Jahre in der Grundschule trainiert...
> Dass C sparsam mit Schlüsselwörtern umgeht und stattdessen> lieber einfache Zeichen nimmt, sehe ich als einen seiner> größten Vorteile.
Hmm. Du machst mich nachdenklich. Vielleicht habe ich mir
einfach die falsche Begründung für meine Beobachtung
zurechtgelegt.
Bescheuert finde ich z.B., dass sowohl "=" als auch "=="
belegt -- und i.d.R. auch im selben Kontext zulässig sind,
so dass automatische Prüfung durch den Compiler schwierig
ist.
Die Verwendung von "*" für Pointer ist auch so ein Beispiel;
wieso muss ich einen "Mal"-Punkt schreiben, wenn ich gar
nicht multiplizieren will?
Von "++" und "--" schweigen wir lieber. Ich gestehe aber
zu, dass das nix mit den Operatoren an sich zu tun hat,
sondern damit, wie man sie in Ausdrücken verwenden darf
(--> Seiteneffekte).
Es gibt noch weitere Beispiele; "&&" etwa, was ein
Etikettenschwindel ist, weil boolesches AND kommutativ
ist, && aber nicht.
> Über die Zeichen nehme ich die Struktur wahr [...]> Wörter wie begin und end sind weder redundanter noch> verständlicher als { und }.
...wobei mir in diesem Zusammenhang eine hübsche Ironie
aufgefallen ist: Wenn man die Programmstruktur primär
über "{" und "}" wahrnimmt -- warum schreibt dann niemand
Blocksatz mit 72 Zeichen je Zeile?
Warum wird dann -- teils erbittert -- über die Formatie-
rung von Quelltexten gestritten?
Die Wahrheit ist: Alle "konventionellen" Programmier-
sprachen sind auch "graphische" Programmiersprachen; die
Klammern sind für den Compiler, die Einrückung für den
Menschen. :)
Das nur als Anmerkung; in der Sache gebe ich Dir Recht.
> Hilfreiche Redundanz kenne ich auch. So habe ich mir> angewöhnt, bei größeren Blöcken die schließenden Klammern> mit den Bedingungen ihres Anfangs zu kommentieren.>> }// for(i=0;i<NSets;i++)> }// while(*s)> }// else zu if(r != l)>> #endif // #ifdef ARM
Das finde ich witzig, denn das mache ich auch.
Die Gefahr, dass der Kommentar veraltet, besteht zwar, ist
aber meiner Erfahrung nach nicht übermäßig groß, weil ich
bei Änderungen an der Steuerstruktur sowieso die Einrückung
und Klammerung anpassen muss; da fällt das Korrigieren des
Kommentars mit ab.
Possetitjel schrieb:> Bescheuert finde ich z.B., dass sowohl "=" als auch "=="> belegt -- und i.d.R. auch im selben Kontext zulässig sind,> so dass automatische Prüfung durch den Compiler schwierig> ist.> Die Verwendung von "*" für Pointer ist auch so ein Beispiel;> wieso muss ich einen "Mal"-Punkt schreiben, wenn ich gar> nicht multiplizieren will?> Von "++" und "--" schweigen wir lieber. Ich gestehe aber> zu, dass das nix mit den Operatoren an sich zu tun hat,> sondern damit, wie man sie in Ausdrücken verwenden darf> (--> Seiteneffekte).https://de.wikibooks.org/wiki/C-Programmierung:_Liste_der_Operatoren_nach_Priorit%C3%A4t
Hast du bei einer Zeile Code keine Ahnung was der Operator macht auf den
ersten Blick - richtig klammern! Ist das nicht sofort ersichtlich ist
der Code als Müll zu betrachten.
Karl schrieb:> Jobst Q. schrieb:>> So habe ich mir angewöhnt, bei>> größeren Blöcken die schließenden Klammern mit den>> Bedingungen ihres Anfangs zu kommentieren.>> }// for(i=0;i<NSets;i++)>> }// while(*s)>> }// else zu if(r != l)>> Und das ist weniger als ein begin...end?
Wieso "weniger"?
Längere Blöcke mit mehreren Schachtelungsebenen übersieht
man selbst auf dem Monitor nicht mehr so einfach. Ich sehe
da NICHT mehr auf einen Blick, welche schließende zu welcher
öffnenden Klammer gehört; da sind diese Kommentare schon
hilfreich.
> Es gibt moderne IDE, die haben sowas wie Autovervollständigen> oder intelligente Klammerung. So wie ein C die } automatisch> nach der { gesetzt werden kann, geht das in Pascal auch.
Das hilft gar nix, wenn man bemerkt, dass man NACH einem
bestimmten Anweisungsblock noch eine Anweisung einfügen muss,
und beim Ändern den falschen Block (=die falsche schließende
Klammer) erwischt.
Die Kommentare sind sinnvoll für's Ändern -- nicht für's
Neu-Schreiben.
> Ganz häßlich sind in C Folgen von )})}.
Schließende geschweifte Klammern markieren ein Block-Ende;
das bekommt eine Zeile für sich.
Possetitjel schrieb:> Längere Blöcke mit mehreren Schachtelungsebenen übersieht> man selbst auf dem Monitor nicht mehr so einfach. Ich sehe> da NICHT mehr auf einen Blick, welche schließende zu welcher> öffnenden Klammer gehört; da sind diese Kommentare schon> hilfreich.
Welchen Editor verwendest du? Diese Software muss ich unbedingt meiden,
scheint ja gar nichts zu können.
Possetitjel schrieb:> Längere Blöcke mit mehreren Schachtelungsebenen übersieht> man selbst auf dem Monitor nicht mehr so einfach...
Auch wenn es bei mir abgeschaltet ist, weil ich es nicht nutze: Moderne
IDE haben Codefaltung auf mehreren Ebenen.
Ebenso markieren diese IDE schließende zusammen mit öffnenden Klammern,
ebenso das zu einem "end" gehörige "begin" und umgekehrt.
Possetitjel schrieb:> Schließende geschweifte Klammern markieren ein Block-Ende;> das bekommt eine Zeile für sich.
Das machst Du vielleicht so, aber es gibt genug Code wo das nicht
gemacht wird.
Possetitjel schrieb:> Wenn man die Programmstruktur primär> über "{" und "}" wahrnimmt -- warum schreibt dann niemand> Blocksatz mit 72 Zeichen je Zeile?> Warum wird dann -- teils erbittert -- über die Formatie-> rung von Quelltexten gestritten?
Hier gibt es eine Redundanz: Der Blocksatz UND die Klammern bestimmen
die Struktur, genauso wie bei begin/end.
Bei Python ist es nur der Blocksatz, was m.E. "fragil" ist.
Bei C stört {/} einfach weniger als begin/end, weil es einfach schneller
erfassbar ist.
In der Mathematik haben wir uns daran gewöhnt, dass die schnelle
Erfassbarkeit wichtig ist. Wir erkennen es nichtmal. Operatoren,
Ziffern, Variablen, etc. sind meist nur je ein Zeichen. Daneben noch
Schreibweisen, die weiter Einkürzen (z.B. 3E7). Eine Formel y=2x wäre
nacht Wirth wohl sowas wie "FunktionsWERT IST Zwei MAL
FunktionsARGUMENT". Den Vergleich kann man für witzig oder blöd halten,
Fakt ist, dass selbst Schulkinder (aus gutem Grund) y=2*x normal finden.
Karl schrieb:> Possetitjel schrieb:>> Längere Blöcke mit mehreren Schachtelungsebenen übersieht>> man selbst auf dem Monitor nicht mehr so einfach...>> Auch wenn es bei mir abgeschaltet ist, weil ich es nicht> nutze: Moderne IDE haben Codefaltung auf mehreren Ebenen.
Ja, stimmt, ... die boshafte Frage des Vorposters zielte
ja auch in diese Richtung.
> Ebenso markieren diese IDE schließende zusammen mit> öffnenden Klammern, ebenso das zu einem "end" gehörige> "begin" und umgekehrt.
Das macht selbst der (von mir i.d.R. verwendete) mcedit;
das hilft aber nix, wenn ein Papierausdruck vor mir liegt.
Und -- ja! Ich verwende Papierausdrucke für (informelle)
Code-Reviews.
> Possetitjel schrieb:>> Schließende geschweifte Klammern markieren ein>> Block-Ende; das bekommt eine Zeile für sich.>> Das machst Du vielleicht so, aber es gibt genug> Code wo das nicht gemacht wird.
Sicher -- aber man kann ja die Programmiersprache nicht
für JEDE Unsitte verantwortlich machen.
Possetitjel schrieb:> Die Wahrheit ist: Alle "konventionellen" Programmier-> sprachen sind auch "graphische" Programmiersprachen; die> Klammern sind für den Compiler, die Einrückung für den> Menschen. :)
Signaturverdächtig. ;-)
Achim S. schrieb:> Possetitjel schrieb:>> Wenn man die Programmstruktur primär>> über "{" und "}" wahrnimmt -- warum schreibt dann niemand>> Blocksatz mit 72 Zeichen je Zeile?>> Warum wird dann -- teils erbittert -- über die Formatie->> rung von Quelltexten gestritten?>> Hier gibt es eine Redundanz: Der Blocksatz UND die Klammern> bestimmen die Struktur, genauso wie bei begin/end.
Naja, was heisst "bestimmen"?
Wie schon geschrieben: Die Klammern sind für den Compiler,
die Einrückung ist für den Menschen.
> Bei Python ist es nur der Blocksatz, was m.E. "fragil" ist.
Ja, ich halte das auch für keine gute Idee.
Besser eine IDE, die automatisch gemäß der Klammerung einrückt,
als ein Interpreter, der gemäß der Einrückung klammert :)
> Bei C stört {/} einfach weniger als begin/end, weil es> einfach schneller erfassbar ist.>> In der Mathematik haben wir uns daran gewöhnt, dass die> schnelle Erfassbarkeit wichtig ist. Wir erkennen es nichtmal.> [...]
Jaja...
Jobst hat mich schon bei meiner ersten Antwort unsicher
gemacht. Wer nach Noten singen oder musizieren kann, der
weiss ja aus eigener Erfahrung, dass man auch einen sehr
speziellen Code mit ziemlich merkwürdigen Zeichen flüssig
lesen lernen kann.
Es können also nicht die Sonderzeichen an sich sein, die
mich an C stören, es muss irgend etwas anderes sein.
> Operatoren, Ziffern, Variablen, etc. sind meist nur je> ein Zeichen. Daneben noch Schreibweisen, die weiter> Einkürzen (z.B. 3E7). Eine Formel y=2x wäre nacht Wirth> wohl sowas wie "FunktionsWERT IST Zwei MAL FunktionsARGUMENT".> Den Vergleich kann man für witzig oder blöd halten, [...]
Nee, weder -- noch.
Ich denke, der Vergleich ist ungerecht gegenüber Wirth.
Die Grundrechenarten werden in Pascal genauso codiert wie
im normalen Leben; das ist nicht der Punkt. Die Sache mit
der Zuweisung (":=") ist mMn deutlich vernünftiger als in C.
Einzig unrühmliche Ausnahme ist begin/end; das hätte nicht
sein müssen.
Ihr habt mich (teilweise) bekehrt: Das Problem ist offen-
sichtlich NICHT, dass viele Operatoren durch Sonderzeichen
codiert werden -- das funktioniert ja in anderen Programmier-
sprachen und auch gänzlich außerhalb des Computers recht gut.
Also muss das Problem in den Operatoren selbst liegen. Hmm.
Mal überdenken.
Sheeva P. schrieb:> Possetitjel schrieb:>> Die Wahrheit ist: Alle "konventionellen" Programmier->> sprachen sind auch "graphische" Programmiersprachen; die>> Klammern sind für den Compiler, die Einrückung für den>> Menschen. :)>> Signaturverdächtig. ;-)
:)
Karl schrieb:> Possetitjel schrieb:>> aber man kann ja die Programmiersprache nicht>> für JEDE Unsitte verantwortlich machen.>> Bei C? Doch!
Man muss nicht alles machen, was nicht verboten ist.
Und man muss auch nicht alles verbieten, was unsinnig ist.
Scharfes Werkzeug ist immer auch gefährlich. Aber es bringt auch nichts,
deshalb mit stumpfem Werkzeug zu arbeiten.
Und es kommt auch auf die Ebene an. Von einer Fräsmaschine kann man
einige Sicherheitsvorkehrungen erwarten, von einem einfachen Stechbeitel
nicht.
Possetitjel schrieb:> Also muss das Problem in den Operatoren selbst liegen. Hmm. Mal> überdenken.
Da sind deine Argumente ja richtig. * für prt, ++ für +=1 (und das für
...).
Das lässt sich wohl nur erklären, wenn man auf damaliger Tastaturen
schaut. Die trigraphen geben einen ersten Hinweis.
Wenn Buchstaben ausscheiden, und möglichst wenige Schlüsselwörter, ...
If(*x+++++y)...
Bernd N schrieb:> Code mit Code kommentieren :-) auweia, C Legasteniker.
Peinlich. Bevor man andere als Legastheniker beschimpft, sollte man sich
erkundigen, wie es geschrieben wird.
Bernd N schrieb:>> }// for(i=0;i<NSets;i++)>> }// while(*s)>> }// else zu if(r != l)>> Code mit Code kommentieren :-) auweia, C Legasteniker.
Den Zweck nicht verstanden? Bei #ifdefs mache ich das immer. Wenn man
davon mehrere im Code hat, wird das sonst sehr unübersichtlich, vor
allem, weil man bei denen ja in der Regel keine Einrückung zur
Gliederung des darin enthaltenen Codes nutzt.
Bei XML ist es sogar vorgeschrieben, beim Schließen des Tags dessen Name
nochmal zu wiederholen.
Achim S. schrieb:> Possetitjel schrieb:>> Also muss das Problem in den Operatoren selbst liegen. Hmm. Mal>> überdenken.>> Da sind deine Argumente ja richtig. * für prt, ++ für +=1 (und das für> ...).
Bevor ich C genutzt habe, fand ich x = x + 1 irgendwie etwas
umständlich, aber es gab nichts anderes, also war das eben so. Und es
ist ja nun auch wirklich kein Hexenwerk, die Bedeutung von ++ und += zu
lernen.
> If(*x+++++y)...
Manche betätigen sich damit ja geradezu künstlerisch:
Jobst Q. schrieb:> Von einer Fräsmaschine kann man> einige Sicherheitsvorkehrungen erwarten, von einem einfachen Stechbeitel> nicht.
Leider montieren einige den Stechbeitel an einen 10kW-Motor, den sie auf
einen Handkarren laden, fahren damit in der Gegend rum und sagen: Guck,
meine Fräsmaschine.
Ich bin ja immer wieder beeindruckt, wenn darauf hingewiesen wird, dass
man mit C doch AUCH guten Code schreiben könnte.
Warum wird es dann nicht gemacht?
Wenn man sich so die üblichen Einfallstore in Software anschaut: Strings
schreiben über den definierten Bereich, beim Laden eines Bildes
schreiben Metadaten über den erlaubten Bereich hinaus, Pointer zeigen
auf ausführbaren Speicher... das sind so Sachen, da würde Dir ein
Pascal- oder Ada-Compiler schon beim Kompilieren auf die Finger klopfen
oder spätestens beim Ausführen eine Exception werfen, aber nicht einfach
Schadcode ausführen als wäre nix dabei.
*** Vorsicht: im Anschluss folgt ein längerer Text der entscheidbare,
faktenfähige Inhalte enthalten könnte **
edit: ist wohl noch etwas längerer geworden: besondere Vorsicht
*** bitte nur lesen/reagieren, wenn ganze Sätze im Kontext gelesen und
bei Reaktionen genannt werden können **
Possetitjel schrieb:> Ihr habt mich (teilweise) bekehrt: Das Problem ist offen-> sichtlich NICHT, dass viele Operatoren durch Sonderzeichen> codiert werden -- das funktioniert ja in anderen Programmier-> sprachen und auch gänzlich außerhalb des Computers recht gut.
es ist vermutlich schlimmer: Du hast es (nachweisbar durch die Nennung
eigener Beispiele) selber (aktiv) verstanden und wurdest nicht (passiv)
bekehrt...
> Also muss das Problem in den Operatoren selbst liegen. Hmm.> Mal überdenken.
... zumindest fast. Also ich persönlich hab bspw. ein Problem Pilze zu
essen, aber das Problem muss nicht in den Pilzen sein und ganz häufig
ist es noch nicht einmal ein Problem d.h. solange Du nicht aus
Umweltgründen (bspw. finanzielle Engpässe) dazu gezwungen bist die
Operatoren zu benutzten (C-Programme schreiben) ist "das Problem" ein
Nil-Pointer auf eine völlig unstrukturierte Variable.
Dein Beispiel für eine falsche Kodierung des Schlüsselwortes "Redundant"
dürfte sich damit vom Ergebnis her erledigt haben, aber ich hatte das
als Konzept für eine Erklärung eingeplant, deswegen nochmal kurz:
Prüfung "Redundanz" Duden: "überflüssige Information": kann weg, muss
aber nicht d.h. die Information erzeugt selber keinen Fehler UND
implizit: es existiert auch eine Information, die beim weglassen der
'redundanten' übrig bleibt.
1
C:
2
int i;// das 'Schlüsselsymbol' " " ist redundant und könnte mit:
3
int i;
vereinfacht werden.
Pascal:
1
Var i:integer;;// ein ";" ist redundant.
2
Var i::integer;;// geht nicht: die aus C bekannte Redundamnz wird von P. nicht unterstützt (und umgekehrt beim
3
";")
Reduntante Blöcke Klammerungen:
1
if bedingung
2
then begin // Information: Anweisungen a b werden
3
begin // entweder beide oder nicht ausgeführt
4
anw_a; // ? ist eine Information reduntant
5
anw_b; // ! mind. eine Information kann wegegelassen
6
end; // werden UND wenn alle begin ... end weggelassen werden,
7
end; // dann ändert sich die Aneisungsausführung ==> redundant
8
9
if bedingung
10
then begin // kein Block/eine(1) Anweisung
11
anw_a; // begin ... end kann weg, aber
12
end; // wenn alle begin ... end entfernt werden
13
begin // ändert sich nichts ==> nicht redundant,
14
anw_b; // sondern nur überflüssig OHNE Information
15
end;
Praxistest redundante Seilbahn:
a) Kabine hängt an 3 Seilen. 2 fallen aus: Kabine vom Boden entfernt.
3 Ausfälle: Kabine erreicht Bodenkontakt
b) Kabine ist bereits abgestürzt. 3 Seile sind gespannt. 3 Ausfälle:
Kabine behält Bodenkontakt: für die
betroffene Kabine waren die 3 Seile vor dem Ausfall nicht einmal
redundant
im Beispiel aus der Füllstoffindustrie "Aus aktuellem
Anlass:"(Ausschnitt)
1
if rtc.month = $03 then begin // 'fasst' if (rts.sum)... zusammen
2
if (rtc.summ and Rsumm) = 0 then begin // 'fasst' if (rtc.hh)... zusammen
3
if rtc.hh = $02 then begin // Information:
4
rtc.hh := $03; // hh / sum sollen
5
rtc.summ := Rsauto or Rsumm;//zusammen ausgeführt werden
6
end;
7
end;
8
end;
9
10
if rtc.month = $03 then
11
if (rtc.summ and Rsumm) = 0 then
12
if rtc.hh = $02 then begin
13
rtc.hh := $03;
14
rtc.summ := Rsauto or Rsumm;
15
end;//keine Änderung
16
17
1:1 Kopie Pascal (Füllstoff)==> C (Füllstoff):
18
void rtc_checksummer();
19
{if (rtc.summ and Rsauto != 0) { // prüfen auf Flag Auto
20
if (rtc.wday == 7) { // wenn Sonntag
21
if (rtc.day >= $25 { // wenn letzter Sonntag im Monat
22
if (rtc.month == $03) { // wenn März, Umschalten auf Sommerzeit
23
if ((rtc.summ and Rsumm) == 0 ) { //wenn Flag nicht gesetzt
24
if (rtc.hh == $02) {
25
rtc.hh = $03;
26
rtc.summ = Rsauto or Rsumm;
27
rtc_setsummer(); // Sommerzeit schreiben
28
};
29
};
30
} else if (rtc.month == $10) { // wenn Oktober, Umschalten auf Winterzeit
31
if ((rtc.summ and Rsumm) != 0) { //wenn Flag gesetzt
32
if (rtc.hh == $03) {
33
rtc.hh = $02;
34
rtc.summ = Rsauto;
35
rtc_setsummer(); // Winterzeit schreiben
36
};
37
};
38
};
39
};
40
};
41
};
42
};
==> für C Ungewohnte könnte die überflüssige und nicht redundante
Klammerung noch(!) unleserlicher sein, aber unnötige Nichtinformation
ist in beiden Sprachen ziemlich sicher unleserlicher
Häufig gibt es für exakt die gleiche Anweisung unterschiedliche
Schreibweisen:
1
inc(x) <=> x=x+1 kann aber den Zweck verdeutlichen.
2
Bei C ist nach definiertem Standard:
3
if ( bed_1 && bed_2) Anweisung;
EXAKT, für die Ausführung, identisch mit
if (bed_1)
if (bed_2) Anweisung;
[/code]
Pascal hat keine offizielle Festlegung, aber praktisch alle Compiler
benutzen SC als Vorgabe.
Mit
1
If (tag=24)and (monat=24) then heiligabend:
ist leslich: vom Prinzip könnte monat=24 zuerst geprüft werden, aber
faktisch wird tag zuerst abgefragt. Falls sich herausstellen sollte,
dass die Abfrage tag=24 sehr 'teuer' ist, dann lässt sich das leserliche
Programm sehr einfach an die - in dem speziellen Fall wohl eher
unwahrscheinlichen - Gegebenheiten anpassen in dem die
beiden Bedingungen vertauscht werden.
Beim umgekehrten Fall
1
if pW<>nil then if pw^=flag_hlg then heiligabend:
wird deutlich, dass pw<>nil erfüllt sein MUSS und nicht nur aus
performance Gründen zuerst geprüft wird. Vom
Prinzip ist ein bekanntes Pascal Konstrukt:
if (pW<>nil) and ( pw^=flag_hlg) then heiligabend:
ziemlich unleserlich und nur durch Gewohnheit, weil es vielfach so
verwendet und beim Kontakt mit Fremdcode wohl unbewusst gelernt wird
oder weil es kürzer ist, halbwegs lesbar.(genaue Ursache und ob
überhaupt, ist nicht sicher),
Bei u.U. gewünschten Seiteneffekten ("function SE_toll:boolean") könnte
es kompliziert werden:
Pascal:
1
if se_toll or true then ok; //u.U. könnte ein Compiler se_toll als Voreinstellung weg-optimieren
C:
1
if (se_toll or true) ok; //der Compiler darf ohne Optimierungsoption se_toll nicht vergessen, obwohl das Ergebnis mathematisch im Voraus [code]
2
berechnet werden könnte.
Bei anderen Sprachen u.U. etwas vorsichtig sein: VB kennt zumindest
and_then als schnellen Vergleich. VBA nicht (stammt aus einem nicht ganz
freiwilligem Experiment bzgl. Programmiersprache an dem ich mal
teilgenommen hab und kann natürlich durch Erinnerungsfehler etwas anders
sein)
Tom's Code im Beitrag #5367644:
> Sehr kompakt mit wenigen Zeilen und deshalb überaus lesbar.
ist nicht unbedingt wegen der wenigen Zeilen lesbar und ob die
komischen Zeichen lesbar sind hängt extrem am
Lesenden, ABER dadurch dass die fehlende Uhrzeit
Apollo M. schrieb:
> ich vermisse hier noch die zeit/stunde, weil die uhr wird nicht um
> mitternacht umgestellt.
nachweislich lesbar war ist ein sicherer Beweis für eine lesbare
Fehlererkennung erbracht worden.
Der Fehler könnte in der Praxis je nach Implementierung sogar recht
unterhaltsame Folgen bspw. wenn set_summer: byte hh;hh=hh+1 definiert
ist und die Uhr am Tag der geplanten Umstellung mit maximaler
Prozessorgeschwindigkeit die Uhr vorstellt, dann ist durch die
Begrenzung auf ein Byte eine traditionelle Uhrzeit im Bereich 0..23 nur
noch mit einer Wahrscheinlichkeit von unter 10% zu erwarten. Bei
automatischer Tagumstellung nach 23:59 wäre die maximale Länge des
letzten Sonntags nur durch die Prozessorgeschwindigkeit begrenzt
gewesen.... :-)
vereinfacht: Fehler können Spass machen und wenn die nicht so bedrohlich
wirken, dann können die wohl auch einfacher zu lesen sein. ==> Indiz für
lesbaren Quelltext.
Ein netter möglicher Fehler ergäbe sich noch aus
Jobst Q. schrieb:> Ist denn sichergestellt, dass eine wahre Bedingung +1 als Ergebnis hat?> Soweit ich mich erinnere, ist nur Null und nicht-null festgelegt.
neuerdings ist mit C99 =>stdbool.h =>true=1 die Frage für eine seriöse
Fehlerdarstellung wohl zu definiert, aber rein theoretisch falls Tom
einen C95 Compiler /64bit mit true=-1 benutzt, dann
ließe sich sicher ein versuchter Sprung aus dem Programmspeicher
vorhersagen--> praktisch optimaler Fehler
Durch die Analyse von Tom's lesbaren Code ... [gekürzt].... , aber wenn
das SZ-flag als begründbar sicherer Bestandteil des Datums implementiert
wird, bspw. bit 7 in hh, dann wären sowohl lesbarer Code als auch
performanterer Code praktisch unvermeidbar.
Begründung:
- lesbar:die zusammenhängenden Ereignisse 2_WZ-=>3_SZ bzw 3_SZ-=> 2_WZ
ließen sich nur so auffällig trennen, sodass selbst ein unbewusster
Vorsatz zu offensichtlich würde.
- Prozessorlast: der Spitzenwert an Vergleichen am Anfang der beiden
Umstellungstage sinkt um %20
Falls das Programm an anderen Stellen ebenfalls Performance kritische
Stellen hat, dann kann eine u.U.
aufwändige Bitmaskierung natürlich Probleme verursachen, aber ohne
Kenntnis halbwegs definierter Problemstellen lässt sich keine
Gesamtbelastungsbeurteilung erstellen.
Die Chance auf Realisierung für den Fall, dass der Betroffene eine
Verbesserung eigentlich gern gesehen hätte
lässt sich mit
> Deswegen hätte ich ja gern mal die vom Compiler erzeugten> Assemblerlistings zu obigen Konstrukten gesehen. Aber dafür reichts dann> wieder nicht.
ziemlich sicher auszuschließen, da wenn es schon für die
Anschaffung/Bedienung eines Compilers nicht reicht obwohl der
realisierbare Wunsch besteht die von einem Compiler erzeugten
Assemblerlistings zu obigen Konstrukten zu sehen, dann dürften weitere
Barrieren bei der Umsetzung von Wünschen vorhanden sein.
Zwischenbilanz: der aktuelle Text ist ziemlich sicher zu lang und
eigentlich wollte ich nur auf:
Jobst Q. schrieb:> Redundanzarme Programmierung mit gemeinsamen Funktionen oder Makros für> ähnliche Operationen bietet Fehlern weniger Möglichkeiten, sich zu> verstecken.>> Die aufrufenden Funktionen werden kürzer und übersichtlicher, da kommt> man Fehlern schneller auf die Spur. Sind sie in der aufgerufenen> Funktion, werden sie schneller entdeckt, weil diese häufiger aufgerufen> wird.
antworten, aber es gab da ein paar Zwischentexte.
Also die Kombination Aufrufhäufigkeit mit Parametern die eine
automatische Fehlerentdeckung verursachen hat mit Sicherheit zu viele
Seiteneffekte d.h. u.a. geplantes häufiges Aufrufen hat eine mögliche
Performancerelevanz zur Folge, damit steigt die
Untersuchungswahrscheinlichkeit und die Fehlerwahrscheinlichkeit sinkt,
aber für zwei andere Hypothesen habe ich Indizien
a) ein nicht überprüfbares Experiment: Kurzfassung in Stichpunkten
- Teilnahme an einer Fortbildung B.Eng u.a. Datenverarbeitung
- Versuchsteilnehmer: überwiegend Studenten die DV (in der Fortbildung
nur eines von sehr unterschiedlichen
Modulen) eher kritisch distanziert verstehen
- ein TN der auch aus Unterhaltungsgründen ruhig in 3 Gruppen (einmal
offiziell, 2*IM) teilnimmt und die Verwaltung des Programmcodes für alle
3 Gruppen übernommen hat, aber - und das war das Interessante an dem
Versuch - zweimal den persönlichen Programmierstil für den
Prüfungsbeauftragten unleserlich im Sinne einer persönlichen
Handschrifterkennung im Computerprogramm gestalten musste.
Resultat 1:
- offizielle Gruppe hatte ca. 5 Seiten Programmcode (passte grob mit
der Erwartungshaltung, keine Überraschung)
- die beiden IM-Gruppen ca. 20 Seiten (leichte Überraschung: Zielgröße
langes Listing ohne wirklich auffälligen Leerraum kann überraschend
schwierig werden)
- die nicht genau untersuchten Vergleichsgruppen müssen von einem
Papierhersteller gesponsert gewesen sein (subjektiv gemessen)
Resultat 2: ein Ausfall in einer IM Gruppe (..manchmal gehen halt
bestimmte Sachen nicht), aber ansonsten korrelierte sogar bei den
individuellen Feedbackergebnissen vom unabhängigen Prüfungsbeauftragten
der Performanceindikator mit der Papiermenge (weniger war in dem Fall
bessere Note)
Für mich einerseits ein guter Indikator, dass zumindest in Grenzen (gar
kein Code ist sicher falsch ...bis ... deutlich unterdurchschnittlich
lang) ein gewisses Optimum für unbekannt viele Möglichkeiten liegen
könnte,
andererseits kenne ich natürlich den klassischen Messfehler:
Apollo M. schrieb:> z.b. meine erfahrung mit gcc und avr ist, das bei umfangreichen> bedingungen ich zwar regelmäßig switch/case bzgl. lesbarkeit mir wünsche> aber if/else oft bessere code size liefert.> ich bin ansonsten ein switch/case kind, weil da mache ich weniger fehler> ...> und habe irgendwie einen besseren überblick was sache ist.
auf deutsch: mit geeigneten Wahrnehmungen lassen sich sehr einfach die
passenden Wünsche/Ergebnisse messen
ohne dass es auffällt.
Versuchsgruppen zu klein + undokumentiert + viele mögliche Messfehler
==> eigentlich allenfalls als nette Story oder für interne Zwecke
brauchbar, aber durch den zufälligen Fund eines mutmaßlich
unveröffentlichten Freischaltcodes aktuell plausibler geworden (s.u.)
Bis hier bis auf den langen Text nichts wirklich belastbar
interessantes, aber letztes WE ist mir eine Überraschung passiert, die
mutmaßlich begründbar auch andere überraschen könnte:
- hobbymäßige µC Basteleien u.a. Lichtdeko.
- meine 'Standard' µC für alles Schaltbare waren 2313tiny 8k-14bit-pwm +
8K digital
- geplantes Update 4312, weil sich rgb-kanäle als dekorativ
herausgestellt haben und durch den verdoppelten Speicher 15PWM Kanäle
relativ problemlos möglich sind bzw. sein sollten
- anderseits wenn schon so viel Speicher vorhanden ist, dann sollten
mehrere lut uvm. in den Speicher und dann wurde es wg. Interpolation
etc. knapp mit Zeit. Sehr interessante Zusammenhänge.
vereinfacht: Situation in der viele Schritte viele kleine Verbesserungen
bringen und alles komplizierter machen bis an anderen Stellen
versehentlich Randbedingungen verletzt werden.
Eine Versuchsmöglichkeit: teilweise Problemübertragung auf Unbeteiligte
d.h. eine Spekulation wenn das Problem bei einem simulierten Mega
ähnlich ist, dann wurde entweder der problematische Code mit simuliert
und lässt sich evtl. dort finden, ansonsten in der konkreten
Implementation auf dem Ziel-Tiny (so etwas kann klappen, aber es ist
keinerlei Wahrscheinlichkeit annähernd schätzbar)
Resultat: 16bit PWM mit 32Kanälen==>ca. 40% Auslastung, bei sauber
strukturiertem hübsch sortierten Code, zig Registern etc.,--> sehr
uneindeutig.
Nächster Versuch: aus Spass eine vom Prinzip nicht performance kritische
Zielgröße probiert: Dateigröße bzw. Leserlichkeit: max. EINE Datei,EINE
Textseite, keine Einzeloptimierungen
Resultat==>10%: irgendwie überraschend gut und extrem überraschend
simpel. hmm.
Prüfliste für eine mögliche Verallgemeinerung:
Anz 8bit timer =1 : erfüllen alle mir bekannten AVR
Anz Register= 4 'hohe' d.h ein Indexregister wird 'verbraucht' + 2
'vollwertige' aus R16..31 + r0 r15 (tw. lässt sich das zu lasten
anderer Kriterien optimieren) )
Speicher: 24byte sram/port
Flash=600b
Interrupts= 1, aber keine sonstigen erlaubt
ok
==> sicher induktiv beweisbar, dass für alle mir bekannten AVR eine
Freischaltung aller 16bit-PWM Kanäle mit maximaler (untere Bits) bzw.
F/4000 Frequenz (höhere bits) mit vertretbarem Aufwand möglich ist.
Extremfall Atmega (??) mit 5 Ports ca. 15% Auslastung.
Max. F/2000 geht auch mit grob 3x% beim 5-port mega.
Also mit 20 MHZ *AtMega*: 34 *PWM-Kanäle* / *16*-*Bit* / 10KHz /
ca.30% Auslastung* mEn. interessant.
Anhand einiger Beiträge aus dem Forum (bspw. einfache 12bit 16k pwm für
3euro als Tipp bei einem vorhandenen 32K - praktisch wohl 31 -
16bit-PWMM Mega mit deutlich reduzierter Flackerleistung) lässt sich
plausibel begründen, dass der einfache Freischaltcode (Textdatatei 50*80
Zeichen mit Zielgröße Lesbarkeit, also max. 3 Befehle/Zeile, sofern
nicht bspw. nop nop nop nop o.ä. einfach lesbar wiederholt werden)
ziemlich unbekannt ist.
Noch ein paar kurze Checks:
- ist eine absichtliche Geheimhaltung des Freischaltcodes wahrscheinlich
plausibel?
Konzerne die 12pwm vermarkten: mutmaßlich genug anderen Spielkram im
Portfolio--> eher nicht
Micochip bzw. Atmel (hätte genug Zeit zur Veröffentlichung gehabt):
könnten u.U. mehr Chips insgesamt, aber weniger mit mehreren
Hardware-PWM verkaufen.
==> albern
- kommerzielle Vermarktungsmöglichkeit?
==> eher Deko
kurz: ich glaube, dass es a) sehr wenige Menschen gibt die den
Freischaltcode kennen, aber auch dass
b) dieses nur aus reinem Zufall so ist.
Da der Code vermutlich noch nicht öffentlich ist bietet sich mit diesem
Beitrag bis in den April zur geplanten Veröffentlichung eine sehr
seltene Gelegenheit sich ohne die Gefahr eines Selbstbetruges zu testen,
was bei anderen unkontrollierten Situationen praktisch unvermeidbar ist.
Jeder Interessierte der etwas (AVR) Assembler kann und damit überhaupt
die 'Codeanalysen' in den Beiträgen verstehen kann , kann daran
teilnehmen. ALLE Versuche können ohne Hilfe mit eigenem heimischen PC am
Simulator überprüft werden. ASM ist nicht so gefährlich wie C und nicht
so geschwätzig wie Pascal, kann aber beliebig macrodiert werden, sodass
keine Verzerrungen zu erwarten sind. Vermutlich (interessante Hypothese)
könnten alle die den Zugang gefunden haben verschlüsselt miteinander
kommunizieren, wüssten aber nicht wie und warum (etwas Spass, bestimmte
Aussagen lassen sich vermutlich wirklich öffentlich austauschen, sodass
die Beteiligten sich gegenseitig über die Kenntnis vergewissern könnten
ohne dass 'Unwissende', also Späteinsteiger, Informationen zum
Freischaltcode erhalten)
Im folgenden meine ich mit "die" Lösung nicht eine wirklich spezifische
"die" Lösung, sondern eine die ungefähr mit dem Freischaltcode
vergleichbar ist oder die aktuell am Freischaltcode ablesbar ist, formal
ist eine Lösung ohne passendes Problem natürlich keine Lösung, aber ugs.
wird es so verwendet und im Kontext sollte die etwas ungenaue Definition
auch genug lesbar sein, um entscheidbare Kriterien zu haben.
An der Textversion lassen sich viele tw. mutmaßliche Eigenschaften
ablesen:
- es ist sicher, dass es nicht die optimale Lösung ist, da im
Freischaltcode sehr einfach Änderungsmöglichkeiten zu sehen sind, die
aber sicher die Leserlichkeit stark beeinträchtigen würden und damit
zumindest per Umfrage eine Situation 'beweisen' könnten die (zumindest
tw. von diesen Beiträgen gelesen) eher ungewöhnlich ist: einfache
Optimierung nur zu lasten der Leserlichkeit? zumindest interessant
- an anderen Stellen lässt sich ablesen, dass eine Verringerung der
Latenz (max. Zyklenzahl im Interrupt) auf die Gesamtlast geht (u.U. eine
Zielgröße die ansonsten gerne vergessen wird)
generell müssen bei der Lösung natürlich (?) andere Interrupts
ausgeschlossen sein, aber max. Latenzen von <100T könnten in vielen
Fällen das Performance-Problem relativeren.
nette Vorhersagen:
- Menschen die eine 14+bit BAM PWM implementiert haben, werden
begründbar wahrscheinlich eine klassische Informatiker Problemsituation
erlebt haben, aber das mutmaßliche Problem ist wahrscheinlich ein Teil
der Lösung (getestet mit n=1)
- die Anzahl der Informationen im Sinne von ... schwierig zu definieren
praktisch Konzept für eine einfache Änderung... damit die meisten ASM
Programmieren den Freischaltcode selber schreiben könnte, dürfte ca. 4
sein.
Vom Prinzip sehr einfach sobald Punkte klar sind, nur vorher mutmaßlich
schwierig.
Ich hoffe das ist ein interessantes Ostersuch Problem mit guter
Unterhaltung, auch wenn der Text wohl seine zulässige Gesamtlänge
maximal überschritten hat.
Viel Spass
Karl schrieb:> Ich bin ja immer wieder beeindruckt, wenn darauf hingewiesen wird, dass> man mit C doch AUCH guten Code schreiben könnte.>> Warum wird es dann nicht gemacht?
Natürlich wird es gemacht. Der Anteil schlechten Codes an der gesamten
Programmierung in C ist minimal, auch wenn du dich darauf spezialisiert
hast, nur diese wahrzunehmen.
Aus der Tatsache, dass es Verkehrsunfälle gibt, kann nicht geschlossen
werden, dass Unfälle generell nicht vermieden werden. Erst wenn die
Anzahl Unfälle in Beziehung gesetzt wird zu den unfallfrei gefahrenen
km, kann man eine realistische Aussage dazu treffen.
Dirk B. schrieb:> Pascal hat keine offizielle Festlegung, aber praktisch alle Compiler> benutzen SC als Vorgabe.> Mit If (tag=24)and (monat=24) then heiligabend:> ist leslich
Mit der richtigen Typedef von monat würde Dir Pascal für die folgende
Zeile sagen: Warning: unreachable code
Liebe Kinder, leider fällt die Bescherung für die nächsten Jahre aus.
Dirk B. schrieb:> für C Ungewohnte könnte die überflüssige und nicht redundante> Klammerung noch(!) unleserlicher sein, aber unnötige Nichtinformation> ist in beiden Sprachen ziemlich sicher unleserlicher
Die Klammerung mag Dir überflüssig erscheinen, aber mit richtiger
Klammerung wäre das hier:
http://cdn3.spiegel.de/images/image-662536-860_poster_16x9-erjl-662536.jpg
nicht passiert.
Jobst Q. schrieb:> Der Anteil schlechten Codes an der gesamten> Programmierung in C ist minimal, auch wenn du dich darauf spezialisiert> hast, nur diese wahrzunehmen.
Nur weil Code größtenteils funktioniert heisst das noch nicht dass er
nicht schlecht ist.
Karl schrieb:> Die Klammerung mag Dir überflüssig erscheinen, aber mit richtiger> Klammerung wäre das hier:
so ein Knausern an Zeilen oder Zeichen ist echt nur von 1 oder 2
Leerzeichen Einrückung zu toppen.
Bei uns hätte lint gemeckert.
Und wenn man so kleine Monitore hat, dass man den Scheiß nicht im
Blocksatz machen kann (der dann auch viel schneller prüfbar ist), dann
sind die selber schuld.
Achim S. schrieb:> so ein Knausern an Zeilen oder Zeichen ist echt nur von 1 oder 2> Leerzeichen Einrückung zu toppen.
Zwei Zeichen Einrückung ist doch optimal. Nicht zu übersehen, aber doch
noch zu überblicken.
Ich stell mir gerade Karls Treppenmonstercode mit 4 oder 8 Zeichen
Einrückung vor. Gruselig. Da bräuchte man einen halbrunden Bildschirm
und Fischaugen, um es zu überblicken.
Ich werfe dazu einfach mal einen Buchtitel ein:
Clean Code: A Handbook of Agile Software Craftsmanship (Robert C.
Martin)
(gibt es meines Wissens nach auch als PDF)
Sehr lesenswert. Gerade wegen diesen riesen if-Monstern über mehr als
fünf Ebenen. Dann erübrigt sich auch die Eingangsfrage.
Mit freundlichen Grüßen,
N.G.
N. G. schrieb:> Clean Code: A Handbook of Agile Software Craftsmanship (Robert C.> Martin)> (gibt es meines Wissens nach auch als PDF)> Sehr lesenswert.
Echt jetzt? Ich hab mal die als pdf verfügbaren "free sample chapters"
überflogen: Ein Haufen Geschwätz, witzige Bildchen und zusammengetragene
Zitate von diversen "Software-Gurus".
Nicht ein einziges Beispiel, wo man mal sieht worum es dem Typen geht.
Wenn ich Computer-Belletristik will, hole ich mir ein Buch von Elsberg
oder Suarez.
Karl schrieb:> N. G. schrieb:> Clean Code: A Handbook of Agile Software Craftsmanship (Robert C.> Martin)> (gibt es meines Wissens nach auch als PDF)> Sehr lesenswert.>> Echt jetzt? Ich hab mal die als pdf verfügbaren "free sample chapters"> überflogen: Ein Haufen Geschwätz, witzige Bildchen und zusammengetragene> Zitate von diversen "Software-Gurus".>> Nicht ein einziges Beispiel, wo man mal sieht worum es dem Typen geht.> Wenn ich Computer-Belletristik will, hole ich mir ein Buch von Elsberg> oder Suarez.
Signalwort agile sollte da doch schon alles sagen, spätestens bei
Craftsmanship hättest das Lesen aufhören können.
Karl schrieb:> Ich hab mal die als pdf verfügbaren "free sample chapters"> überflogen: Ein Haufen Geschwätz, witzige Bildchen und> zusammengetragene Zitate von diversen "Software-Gurus".
Vielleicht hättest Du mehr als das Vorwort lesen sollen.
Wobei: Niemand soll gezwungen werden dazuzulernen, auch Du
nicht.
Possetitjel schrieb:> Wobei: Niemand soll gezwungen werden dazuzulernen, auch Du> nicht.
Die Frage ist: WILL man sich mit einer Sprache und einer solch häßlichen
Syntax und Regeln für diese, die einem Würfelspiel gleichen, wirklich
den Kopf vollstopfen? Normalerweise will man doch einen Algorithmus in
einen Quelltext überseztzen und sich nicht mit einer Diva von
Programmiersprache um jedes Sonderzeichen streiten.
Großer Zeh schrieb:> Possetitjel schrieb:>>> Wobei: Niemand soll gezwungen werden dazuzulernen,>> auch Du nicht.>> Die Frage ist: WILL man sich mit einer Sprache und> einer solch häßlichen Syntax und Regeln für diese,> die einem Würfelspiel gleichen, wirklich den Kopf> vollstopfen?
Nun ja, was heisst "wollen"?
C hat ein paar Alleinstellungsmerkmale, und wenn man
die benötigt, hat man keine Wahl. Das ist ja inzwischen
oft genug durchdiskutiert worden.
Ich akzeptiere das auch ohne Groll, denn ich lerne
allmählich unterscheiden, was echte Ausdruckskraft
ist und was unnützer syntaktischer Zucker (wobei die
Zuschreibung "unnütz" natürlich subjektiv ist.)
> Normalerweise will man doch einen Algorithmus in> einen Quelltext überseztzen und sich nicht mit einer> Diva von Programmiersprache um jedes Sonderzeichen> streiten.
Sicher -- nur wenn man das Können der Diva braucht,
muss man die Gage halt bezahlen.
Wenn nicht, dann nicht.
Großer Zeh schrieb im Beitrag #5372248:
> Soll man wirklich eine Programmiersprache erlernen, die die Fähigkeit,> sich normal auszudrücken, so sehr zerstört?
Wieso gehst Da davon aus, dass er überhaupt eine Programmiersprache
kann? Das ist ein Philosophiestudent im 20. Semester, der aus Versehen*
über die Feiertage in der Unibibliothek eingeschlossen wurde.
*) über das "aus Versehen" können wir noch diskutieren.
Possetitjel schrieb:> C hat ein paar Alleinstellungsmerkmale, und wenn man> die benötigt, hat man keine Wahl.
Als da wären?
Typecast geht sogar unter Ada, wenn auch nicht so locker flockig ohne
Prüfung aus der Hand.
Karl schrieb:> Possetitjel schrieb:>> C hat ein paar Alleinstellungsmerkmale, und wenn man>> die benötigt, hat man keine Wahl.>> Als da wären?
Das Zusammentreffen von
- Normung,
- Trennung von Sprachkern und Standardbibliothek,
- "kleinem" Sprachkern und
- "unvollständiger" Abstraktion.
Das prädestiniert C für den unübersehbaren Zoo von
mittelgroßen, kleinen und kleinsten Maschinen.
All das wurde hier aber schon x Mal durchgekaut.
Wichtig ist, Programme so zu schreiben, daß der Leser versteht, was man
dem Compiler sagen wollte.
Das gilt auch für Texte, deren Inhalt nicht an Compiler übergeben werden
soll. Manche "Schriftsteller" schreiben aber so, daß es keiner lesen
will/kann und sollten sich dann nicht wundern, wenn ihre Gedanken nicht
verstanden werden.
Kurz: wer klare Programmiersprachen fordert, sollte keine "Dirk"-Texte
schreiben.
Possetitjel schrieb:> Das Zusammentreffen von...
Ja und? Ist doch in anderen Sprachen auch möglich. Das ist kein
Alleinstellungsmerkmal.
Du glaubst nur, dass das nur in C geht, weil Du es nur in C kennst.
Die Syntax einer Programmiersprache prägt das Denken m.E. nicht so sehr.
Das wird erkennbar, wenn man sich von Details löst und einen etwas
breiteren Hintergrund sucht. Ob man Sonderzeichen schüttelt oder
Keywords ist wenig relevant, solange das Paradigma der Sprache sich
nicht ändert. Und da fallen imperative Sprachen wie C, Pascal und auch
Fortran alle in die gleiche Kategorie.
Diese Ähnlichkeit von Sprachen, über deren Unterschiede sich viele Leute
streiten wie die Kesselflicker, fällt besonders dann auf, wenn man in
Sprachen reinschnuppert, die nicht dazu gehören. Ein krasser Fall aus
der Vorzeit ist beispielsweise Prolog. Da kommt man mit prozeduralem
Denken nicht weit, weil gibts nicht, der Quelltext beschreibt keine
Abläufe. Erfahrungen mit imperativen Sprachen nützen hier nichts.
Wer es weniger krass und etwas aktueller haben will, der schaue sich
funktionale Sprachen an.
A. K. schrieb:> Die Syntax einer Programmiersprache prägt das Denken m.E. nicht so sehr.> Das wird erkennbar, wenn man..
..alles in einen so großen Rahmen stellt, daß sämtliche Details verloren
gehen.
Nee, wie sehr gerade C das Denken und die Denkfähigkeit beeinträchtigt,
kann man hier in diesem Forum sehr gut beobachten.
Das eigentlich Erstaunliche dabei ist, wie sehr sich gerade C
ausgebreitet hat. Ausgerechnet diese Krücke, und das bei Anwesenheit von
besseren Alternativen.
Jetzt könnte man darüber räsonnieren, ob es der Drang nach der Heldentat
ist, der die Programmierer zu C getrieben hat, oder ob es der Wunsch
war, etwas möglichst kryptisches zu betreiben, wo der Chef und alle
anderen möglichst wie das berühmte Schwein ins Uhrwerk schauen.
Schlichtweg der Drang nach Geheimniskrämerei zwecks persönlicher
Vorteile.
W.S.
Possetitjel schrieb:> Was ist upn?
97
3+
4*
ergibt 400
Zu jung, um einen HP-Taschenrechner gekannt zu haben?
Ich benutze sowas in leicht abgeänderter Weise gern für Steuersequenzen
zwischen PC und µC per seriell oder USB, weil man damit atomare
Operationen hat, die sich gut erweitern lassen und weil das Ganze im µC
leicht dekodierbar ist. Zum Beispiel beim Wobbler:
3500000A1000S300N2W
Das wobbelt das 80M Band mit 1kHz Schritten 2x durch.
klaro?
W.S.
W.S. schrieb:> ..alles in einen so großen Rahmen stellt, daß sämtliche Details verloren> gehen.
Das Prinzip dahinter nennt sich Abstraktion. Liegt nicht jedem.
Mir ist es für die Denkweise in einer Sprache ziemlich egal, ob
if (...) { ... }
oder
if ... then ... endif
verwendet wird.
Zur Erinnerung: Ich schrieb ausdrücklich über die Syntax.
Arduino F. schrieb:> Hat auch seinen Reiz, finde ich....
Ist aber in diesem Fall genauso imperativ, sieht also nur anders aus,
arbeitet aber gleich. Interessant wird es bei FORTH, wenn man die
Dynamik der Sprache in Rechnung stellt, d.h. sich damit inkrementell
eine eigene Sprache schafft.
Immerhin können FORTH Worte bereits zur Zeitpunkt der Übersetzung aktiv
werden, nicht erst mit der Ausführung, was von Worten wie IF/THEN zur
Umsetzung in den internen Code genutzt wird. Dann schafft sich das
Programm quasi eine eigene anwendungsbezogene Syntax.
W.S. schrieb:> Possetitjel schrieb:>> Was ist upn?>> 97> 3+> 4*> ergibt 400
Klar. Kann mich nur nicht entsinnen, mal mit Karl über
"Umgekehrte polnische Notation" diskutiert zu haben;
seine Referenz auf "goto" dagegen war mir verständlich.
> Zu jung, um einen HP-Taschenrechner gekannt zu haben?
Nein -- auf der falschen Seite der Mauer gelebt.
A. K. schrieb:> , d.h. sich damit inkrementell> quasi eine eigene Sprache schafft.
In C muss man das Problem solange durchkauen, bis man es in der Sprache
abhandeln kann.
In Forth wird die Sprache solange modifiziert, bis sie das Problem
optimal widerspiegelt.
Meinst du das so, in etwa?
Arduino F. schrieb:> Meinst du das so, in etwa?
Schau dir beispielsweise mal an, wie Strings in FORTH übersetzt werden.
Da steht beispielsweise
." Text"
im Quelltext. Aber es gibt keine zentral in einem Übersetzer fixierte
Syntax dazu, denn das Word
."
wird bei der Übersetzung sofort ausgeführt, liest den Quelltext bis zum
" ein, und macht daraus die interne Darstellung. Es wird also Teil des
Übersetzungsprozesses.
Da der Quelltext hinter ." ausschliesslich vom Code in diesem ."
bestimmt wird, und ein Programm beliebig andere solcher Worte definieren
kann, kann also die Syntax des Quelltextes in hohem Mass von Programm
selbst definiert werden.
W.S. schrieb:> Das eigentlich Erstaunliche dabei ist, wie sehr sich gerade C> ausgebreitet hat. Ausgerechnet diese Krücke, und das bei Anwesenheit von> besseren Alternativen.
Dann zeige doch mal eine einzige, die auf µC, hardwarenah oder einfach
(Beschreibung/Umsetzung/zuverlässigkeit) auch nur annähernd heranreicht.
Bis dahin fürchte ich, hat Frau Merkel recht mit ihrem Alternativlos.
Ein gutes Argument wäre z.B., wenn die Sprache in ihrem Kern sich im
Wesentlichen selber übersetzt, und nicht per C-Compiler Assembler-Code
erzeugt.
Dirk B. schrieb im Beitrag #5372848:
> Programmierte die noch nicht so> eine eigene Denkfähigkeit haben die Denkfähigkeit beeinträchtigt,
Zwar sind Parser natürlicher Sprachen wesentlich flexibler als die von
Programmiersprachen, kommen aber trotzdem manchmal an ihre Grenzen.
Achim S. schrieb:> Ein gutes Argument wäre z.B., wenn die Sprache in ihrem Kern sich im> Wesentlichen selber übersetzt, und nicht per C-Compiler Assembler-Code> erzeugt.
Womit wir wieder bei FORTH wären. Denn genau das geschieht da.
Jobst Q. schrieb:> Achim S. schrieb:>> so ein Knausern an Zeilen oder Zeichen ist echt nur von 1 oder 2>> Leerzeichen Einrückung zu toppen.>> Zwei Zeichen Einrückung ist doch optimal. Nicht zu übersehen, aber doch> noch zu überblicken.>> Ich stell mir gerade Karls Treppenmonstercode mit 4 oder 8 Zeichen> Einrückung vor. Gruselig. Da bräuchte man einen halbrunden Bildschirm> und Fischaugen, um es zu überblicken.
Wenn du das Problem hast, sind deine Funktionen zu kompliziert. Wobei 8
Zeichen wirklich übertrieben ist. Zwei sind mir aber dann doch zu wenig.
Ich hab für mich 4 als Optimum gefunden.
A. K. schrieb:> Aber es gibt keine fixierte Syntax dazu,
Naja, es ist schon etwas vermessen, bei Forth von einer Syntax zu reden.
Mit fallen da nur wenige Regeln ein...
1. Forth Worte werden durch WhiteSpaces voneinander getrennt.
2. Es können nur Worte genutzt werden welche vorher definiert wurden.
Zu 2 gibt es die 1/2 Ausnahme, z.B. dass das Wort RECURSIVE, üblicher
weise, das Attribut IMMEDIATE hat, also zur Kompilezeit ausgeführt wird.
RECURSIVE kompiliert einen Aufruf auf das Wort, welches gerade
kompiliert wird in den Code.
A. K. schrieb:> Schau dir beispielsweise mal an, wie Strings in FORTH übersetzt> werden.
." ist ein kompilierendes Wort.
Es hat auch das Attribut IMMEDIATE
Mein Decompiler sagt, dass ." bei mir so definiert ist:
1
:." COMPILE (.")," ; IMMEDIATE
Mein Decompiler sagt zu if:
1
:IF?COMPHERE2CELLS-@DUPlitCOMPILE=SWAPlitLIT
2
=OR0=HERECELL-@litDUP=AND
3
IFCELLNEGATEALLOTCOMPILE-?BRANCH
4
5
ELSECOMPILE?BRANCH
6
THEN>MARK2;IMMEDIATE
Ich sage es gerne so....
Forth Worte haben Attribute:
1. Sie haben einen Namen (darüber werden sie im Vocabulary gefunden)
2. Sie haben ein Laufzeitverhalten
3. Sie haben ein Kompilezeitverhalten.
4. Sie tragen Werte/Parameter in sich
1 ist immer der Fall
2 bis 4 muss nicht unbedingt zum tragen kommen
-------
A. K. schrieb:> Achim S. schrieb:>> Ein gutes Argument wäre z.B., wenn die Sprache in ihrem Kern sich im>> Wesentlichen selber übersetzt, und nicht per C-Compiler Assembler-Code>> erzeugt.>> Womit wir wieder bei FORTH wären. Denn genau das geschieht da.
Sehe ich auch so!
Rolf M. schrieb:> Wenn du das Problem hast, sind deine Funktionen zu kompliziert. Wobei 8> Zeichen wirklich übertrieben ist. Zwei sind mir aber dann doch zu wenig.
Ich bin kein Freund von langen Treppen und weiß auch wie sie zu
vermeiden sind. Siehe:
Beitrag "Re: Art der if-Auswahl nur Geschmackssache?"
Aber manchmal hab ich längere Funktionen, die nur mit großem Aufwand
aufzuteilen wären. In denen sind dann bis zu 6 Einrückungen, da wär mir
mit 4 Zeichen Einrückung der Text schon manchmal unangenehm breit,zumal
ich in dem Alter bin, wo man große Schriften bevorzugt.
> Ich hab für mich 4 als Optimum gefunden.
Ist ja auch ok.Ich will mein Optimum ja auch nicht anderen vorschreiben.
Possetitjel schrieb:>Warum wird dann -- teils erbittert -- über die Formatie->rung von Quelltexten gestritten?
eine plausible Erklärung wäre: weil es für Formatierungen keine (in
Grenzen) keine entscheidbar besser/schlechter/richtig/falsch geben kann
und somit jeder Recht hat und alle anderen die falsche Formatierung
benutzen (ungefähr) und vor allem ist das Risiko erkennbar falsch zu
liegen sicher 0.
Mein Beitrag mit dem Vorschlag 32 16bit zum Suchspiel zu nutzen wurde
wohl völlig anders verstanden als es gemeint war (und ist wohl auch sehr
unglücklich formuliert) aber wenn die Erbitterung es verbietet einfach
den Autor in ganzen Sätzen anzuschreiben, dann fallen solche Fehler
nicht auf und erzeugen wohl zig Geschwafel Lawinen.
Dirk B. schrieb im Beitrag #5372848:
> In diesem Forum können...
..schwafel...schwafel...
> beeinträchtigt,
Mein lieber Junge, es kommt nicht drauf an, wieviele sinnlose Wörter man
aneinanderreihen kann, um irgend etwas zu ignorieren.
Ich bevorzuge klare und prägnante Sätze.
Aber um sowas zu können, mußt du noch sehr üben.
Da fällt mir der gute Herbert ein (Wehner), über den sich mal ein
Kabarettist etwa so ausgelassen hat:
"Meine Damen und Herren,
mir wird hier des Öfteren vorgeworfen, ich übte Polemik.
Nein.
ICH habe das nicht nötig.
Sie, meine Damen und Herren, müssen das noch üben."
W.S.
Achim S. schrieb:> Dann zeige doch mal eine einzige, die auf µC, hardwarenah oder einfach> (Beschreibung/Umsetzung/zuverlässigkeit) auch nur annähernd heranreicht.
Dazu ist es so etwa 30 Jahre zu spät. Man hätte Pascal oder noch früher
Algol nehmen können. Aber dafür ist es JETZT zu spät.
Vergleiche doch mal sowas:
1
#define FIOPIN (*((volatile unsigned long *) 0x3FFFC014))
2
3
var
4
FIOPIN:dwordabsolute$3FFFC014;
Merkst du, was für eine elende Cast-Hampelei das in C ist?
Aber mir ist hier nicht danach, wieder das alte Gezänk
heraufzubeschwören. Also merken wir uns eines: Daß nämlich
Fehlentscheidungen irgendwann nicht mehr korrigierbar sind.
W.S.
W.S. schrieb:> Man hätte Pascal oder noch früher> Algol nehmen können. Aber dafür ist es JETZT zu spät.
Warum? Mit Ada ging und geht das durchaus. Aber in Ada kann man halt
nicht so schön wild rumcasten und rumpointern.
Und für Pascal gibt es durchaus brauchbare Compiler für Mikrocontroller.
Hab gerade ein komplettes Projekt für AVR von C nach Pascal
transferiert. Das macht richtig Spass.
Und auf ARM und ARM Embedded läuft zur Zeit auch Einiges in Pascal. Das
muss sich hinter C keineswegs verstecken.
Das Einzige, was die Leute an C bindet ist ihr eigener begrenzter
Horizont.
Teo D. schrieb:> Ich dachte nämlich, ich lerne hier noch ein paar Eigenheiten von C> kennen. :(
Die paar Eigenheiten von C die du schon kennst wären da für einige
Menschen eine interessante Information, da C häufig zur Programmierung
genutzt wird und etwas mit eigenen Eigenheiten sich nicht dafür eignet.
Karl schrieb:> Du meinst so lustige Sachen wie:
Du meinst so falsche Sachen wie...
Karl schrieb:> Na, wie gehts nach dem if weiter? Ist der Vergleich True oder False?
Die Frage stellt sich nicht, eben weil der Code fehlerhaft ist. Und
jeder Compiler wird dir das sagen. Hör doch auf mit den konstruierten
beispielen...
Michael R. schrieb:> Die Frage stellt sich nicht, eben weil der Code fehlerhaft ist. Und> jeder Compiler wird dir das sagen.
Der Compiler-Explorer meldet keinen Fehler, der bringt nur eine Warnung.
Und witzigerweise bringt der die Warnung nur bei char, uint8_t oder
int8_t. Und nur bei der Zuweisung, nicht beim Vergleich.
int16_t c2; c2 = ~0x8000; wird klaglos akzeptiert, obwohl es genauso
einen Overflow erzeugen würde.
> Hör doch auf mit den konstruierten> beispielen...
Wenn Du C auf AVR programmieren würdest, wüsstest Du, dass eine
Zuweisung mit ~(1 << 7) zum Setzen aller Bits ausser Bit 7, oder zum
Löschen von Bit 7 per AND völlig normal und gängige Praxis ist. Und
genau das ist ~0x80.
Karl schrieb:> Der Compiler-Explorer meldet keinen Fehler, der bringt nur eine Warnung.> Und witzigerweise bringt der die Warnung nur bei char, uint8_t oder> int8_t. Und nur bei der Zuweisung, nicht beim Vergleich.>> int16_t c2; c2 = ~0x8000; wird klaglos akzeptiert, obwohl es genauso> einen Overflow erzeugen würde.
Das was du Zuweisung nennst ist eine Operation mit nachfolgender
Zuweisung. Da du den type von 0x80 nicht definiert hast nimmt der
Compiler einfach eine Standardeinstellung her (in deinem Fall uint16_t).
Somit ist dein ~0x80 nicht 0x7F sondern 0xFF7F, und das parst der
compiler dir nicht sauber in uint8_t, deswegen die Warnung.
Karl schrieb:> Wenn Du C auf AVR programmieren würdest, wüsstest Du, dass eine> Zuweisung mit ~(1 << 7) zum Setzen aller Bits ausser Bit 7, oder zum> Löschen von Bit 7 per AND völlig normal und gängige Praxis ist. Und> genau das ist ~0x80.
Dein Bitshift wird anders behandelt als die Zahl, der bekommt vom
compiler den minimal möglichen Datentyp, und das ist nun mal uint8_t in
deinem Fall, würdest du um 9 bits shiften, dann wäre es ein uint16_t.
Sepp schrieb:> Das was du Zuweisung nennst ist eine Operation mit nachfolgender> Zuweisung.
Ach,
ldi r24,lo8(127)
std Y+1,r24
ist keine Zuweisung?
Sepp schrieb:> Dein Bitshift wird anders behandelt als die Zahl, der bekommt vom> compiler den minimal möglichen Datentyp
Wird er nicht: c1 = ~(1<<7); liefert genau die gleiche Warnung und im
Compilat genau das gleiche falsche Ergebnis.
Bei
1
uint16_t c1;
2
c1 = ~(1<<15);
3
if (c1 == ~(1<<15)) {
4
is_true();
5
} else {
6
is_false();
7
}
8
uint8_t c2;
9
c2 = ~(1<<7);
10
if (c2 == ~(1<<7)) {
11
is_true();
12
} else {
13
is_false();
14
}
im GCC liefert der erste Fall true, der zweite Fall false.
Karl schrieb:> Ach,> ldi r24,lo8(127)> std Y+1,r24> ist keine Zuweisung?>lo8(x)
ist die Operation (das Parsen) vor der Zuweisung und entspricht
((x)&0xff)
>lo8(127)
zeigt aber, dass das nicht alles ist, denn
>~0x80
ergibt in dem von dir erwähnten Fall nie
>127
sondern 65407.
Ich denke du mischt 8 und 16-Bit AVRs.
Denn den Fehler bekommst du so bei einem 16bit AVR und dein Compilat in
der Form bei einem 8bit AVR.
Karl schrieb:> Wenn Du C auf AVR programmieren würdest, wüsstest Du, dass eine> Zuweisung mit ~(1 << 7) zum Setzen aller Bits ausser Bit 7, oder zum> Löschen von Bit 7 per AND völlig normal und gängige Praxis ist. Und> genau das ist ~0x80.Karl schrieb:> Wird er nicht: c1 = ~(1<<7); liefert genau die gleiche Warnung und im> Compilat genau das gleiche falsche Ergebnis.
Also ist ~(1<<7) doch nicht ~0x80 wie vorher behauptet?
Sepp schrieb:> Dein Bitshift wird anders behandelt als die Zahl
Nein. (1<<7) ist vom Type her stets identisch mit 0x80. Aber (1<<15) ist
nicht notwendigerweise identisch mit 0x8000.
Sepp schrieb:> Also ist ~(1<<7) doch nicht ~0x80 wie vorher behauptet?
Doch. Aber (int)(uint8_t)~0x80 ist nicht gleich ~0x80.
Karl schrieb:> Der Compiler-Explorer meldet keinen Fehler, der bringt nur eine Warnung.
Der Code ist ja auch nicht illegal, sondern höchstens unsinnig.
> Und witzigerweise bringt der die Warnung nur bei char, uint8_t oder> int8_t. Und nur bei der Zuweisung, nicht beim Vergleich.
Der GCC meckert mit -Wextra auch den Vergleich an:
1
warning: comparison is always false due to limited range of data type [-Wtype-limits]
> int16_t c2; c2 = ~0x8000; wird klaglos akzeptiert, obwohl es genauso> einen Overflow erzeugen würde.
Auf dem PC liefert der GCC dabei die gleichen Warnungen wie oben. Auf
dem AVR natürlich nicht, weil dort int16_t = int ist und somit keine
Konvertierung erfolgt, die einen Überlauf auslösen könnte.
Yalu X. schrieb:> Auf dem PC liefert der GCC dabei die gleichen Warnungen wie oben. Auf> dem AVR natürlich nicht, weil dort int16_t = int ist und somit keine> Konvertierung erfolgt, die einen Überlauf auslösen könnte.
Ja, der gleiche Schmonz funktioniert aber auch auf 32bit CPUs mit int32
vs. int16, oder auf 64bit CPUs. Das ist kein AVR-spezifisches Problem.
Yalu X. schrieb:> Der Code ist ja auch nicht illegal, sondern höchstens unsinnig.
Warum ist es unsinnig, um beim AVR-Beispiel zu bleiben, Bits auf diese
Weise zu selektieren, oder auf ein Bitmuster zu prüfen?
Der Code ist hier vereinfacht, aber c1 könnte seine Daten aus einem
low-aktiven Tastenfeld haben und dann mit ~auf gedrückte Tasten prüfen.
Die Werte könnten auch per #define irgendwo anders festgelegt werden.
Karl schrieb:> Yalu X. schrieb:>> Der Code ist ja auch nicht illegal, sondern höchstens unsinnig.>> Warum ist es unsinnig, um beim AVR-Beispiel zu bleiben, Bits auf diese> Weise zu selektieren, oder auf ein Bitmuster zu prüfen?
Ich bezog mich auf das da:
Karl schrieb:> char c1;> c1 = ~0x80;> if (c1 == ~0x80)> // True oder False?> Der Code ist hier vereinfacht, aber c1 könnte seine Daten aus einem> low-aktiven Tastenfeld haben und dann mit ~auf gedrückte Tasten prüfen.
Ok, aber was erwartest du bei einem Vergleich zwischen zwei verschieden
breiten Integertypen?
Es gibt im Wesentlichen drei Möglichkeiten, mit diesem Fall umzugehen:
1. Einer oder beide der beiden Typen werden zu einem gemeinsamen Typ
erweitert, so dass sie vergleichbar werden. Im konkreten Fall wird
das char unter Beibehaltung des numerischen Werts zu einem int
erweitert. So wird das in C bei der impliziten Typkonvertierung
gehandhabt.
2. Einer oder beide der beiden Typen werden zu einem gemeinsamen Typ
beschnitten, so dass sie vergleichbar werden. So hättest du es in
deinem Beispiel wohl gerne. Im konkreten Fall c1==~0x80 würde ~0x80
in ein char konvertiert, wobei sich der Wert von -129 in +127 ändert
und der Vergleich deswegen wahr wird, da c1 ebenfalls gleich +127
ist. Implizites Beschneiden und damit u.U. verbundene Änderungen des
Werts ist aber in den allermeisten Fällen unerwünscht, da es eine
Fehlerquelle bei numerischen Berechnungen darstellt.
3. Der Vergleich wird wegen der verschiedenen Datentypen gar nicht erst
zugelassen. Im konkreten Fall würde der Compiler mit einem Fehler
abbrechen, weil char und int nicht vergleichbar sind. Das wäre die
sauberste Alternative, es gibt aber nur wenige Programmiersprachen,
deren Typprüfung so streng ist (z.B. Haskell).
Man muss sich in C (wie auch in neueren Pascals und vielen anderen
Sprachen) bewusst sein, dass implizite Typkonvertierungen manchmal zu
Problemen führen. Solche Probleme lassen sich im Zweifelsfall meist
durch explizite Typkonvertierungen umgehen. Schreibt man im konkreten
Fall c1==(char)~0x80 statt c1==~0x80, ist das Ergebnis das von dir
erwartete.
Yalu X. schrieb:> 3. Der Vergleich wird wegen der verschiedenen Datentypen gar nicht erst> zugelassen. Im konkreten Fall würde der Compiler mit einem Fehler> abbrechen, weil char und int nicht vergleichbar sind. Das wäre die> sauberste Alternative, es gibt aber nur wenige Programmiersprachen,> deren Typprüfung so streng ist (z.B. Haskell).
Und C++ seit der 2011er Version, wenn man die Initialisierung mit {}
nutzt.
Da sagt z.B. der gcc bei diesem Programm
1
intmain()
2
{
3
charc{~0x80};
4
}
folgendes:
1
0x80.cpp: In function ‘int main()’:
2
0x80.cpp:3:20: error: narrowing conversion of ‘-129’ from ‘int’ to ‘char’ inside { } [-Wnarrowing]
Yalu X. schrieb:> Ok, aber was erwartest du bei einem Vergleich zwischen zwei verschieden> breiten Integertypen?
Sowas?
1
# [47] c1 := not($80);
2
ldi r18,127
3
# [48] if c1 = not($80) then begin
4
cpi r18,127
5
brne .Lj16
Die Typen sind nicht verschieden breit. Die sind genau ein Byte. Und ein
Not eines Bytes ist wiederum genau ein Byte. Ein Byte wird durch ein Not
nicht zu zwei Byte.
Das ist nur eine Eigenheit von C, welches erstmal versucht alles in 16
Bit zu quetschen.
Rolf M. schrieb:> Und C++ seit der 2011er Version, wenn man die Initialisierung mit {}> nutzt.> Da sagt z.B. der gcc bei diesem Programmint main()> {> char c { ~0x80 };> }> folgendes:0x80.cpp: In function ‘int main()’:> 0x80.cpp:3:20: error: narrowing conversion of ‘-129’ from ‘int’ to> ‘char’ inside { } [-Wnarrowing]
Ähnliches sagt ja auch der C-Compiler bei der Initialisierung, nur dass
der lediglich eine Warnung ausspricht.
Karl schrieb:> Yalu X. schrieb:>> Ok, aber was erwartest du bei einem Vergleich zwischen zwei verschieden>> breiten Integertypen?>> Sowas?# [47] c1 := not($80);> ldi r18,127> # [48] if c1 = not($80) then begin> cpi r18,127> brne .Lj16
Das sieht nach Pascal aus, aber welcher Dialekt bzw.Compiler? (W.S. hat
diese Frage weiter oben auch schon gestellt)
Da gibt es nämlich große Unterschiede. Mit deinem Compiler wird der
Ausdruck not($80) offensichtlich zu 127, mit Free Pascal (PC-Version)
aber zu -129 ausgewertet. Dort würde der Vergleich false liefern.
Karl schrieb:> Die Typen sind nicht verschieden breit. Die sind genau ein Byte. Und ein> Not eines Bytes ist wiederum genau ein Byte. Ein Byte wird durch ein Not> nicht zu zwei Byte.
wo steht das 0x80 ein Byte ist? Ist es nämlich nicht, es ist ein Integer
(und ein integer heißt nicht 16 bit)
aber selbst wenn du aus 0x80 ein Byte machst, ist das "not" davon wieder
ein Integer. Blöd, eh?
> Das ist nur eine Eigenheit von C, welches erstmal versucht alles in 16> Bit zu quetschen.
16 Bit ist falsch, Integer wäre richtig.
Für dich mag es eine Eigenheit sein, C-Programmierer haben das Kapitel
"Integral Promotion" in ihrem C-Buch gelesen ;-)
Michael R. schrieb:> Für dich mag es eine Eigenheit sein, C-Programmierer haben das Kapitel> "Integral Promotion" in ihrem C-Buch gelesen ;-)
Das nützt aber Nichts, wenn in dem "guten C-Buch" des Anderen wieder
etwas Anderes steht. Eine Sprache, bei der eine 50:50 Chance besteht,
daß das richtige Ergebnis einer Operation erzielt wird...
Ich weiß nicht so recht...
Bär Luskoni schrieb:> Ich weiß nicht so recht...
Aber ich!
Denn:
Den individuellen Irrtum eines Buchautors, einer Sprache anzulasten, ist
mindestens ungerecht.
Karl schrieb:> Yalu X. schrieb:>> Der Code ist ja auch nicht illegal, sondern höchstens unsinnig.>> Warum ist es unsinnig, um beim AVR-Beispiel zu bleiben, Bits auf diese> Weise zu selektieren, oder auf ein Bitmuster zu prüfen?
Zahlen vergleicht man mit == ,Bitmuster prüft man mit &.
if (! (c & 0x80))...
gibt immer das richtige Ergebnis,unabhängig von der Bitbreite der
Variablen und der Implementierung.
Das Bitmuster 0x81 ist also gleich dem Bitmuster 0x80?
Da muss man sich nicht wundern, dass Software in C so schlecht ist, wenn
C-Programmierer nicht mal die einfachsten Vergleiche hinbekommen.
Leute, ist es denn echt so schwer einfach zuzugeben: Ja, der C-Compiler
baut hier Scheisse, das ist leider so, weil das irgendwann mal so
angefangen wurde und wir das jetzt wegen der Abwärtskombatibilität so
beibehalten müssen.
Stattdessen Verrenkungen um Verrenkungen, um zu erklären, warum die
Scheisse in C jetzt doch die Sachertorte ist.
Karl schrieb:>> aber selbst wenn du aus 0x80 ein Byte machst, ist das "not" davon wieder>> ein Integer. Blöd, eh?>> Ach, wirklich? https://en.wikipedia.org/wiki/Bitwise_operation#NOT
Schön, dass du dir die Mühe gemacht hast, 'Integral Promotion' zu
recherchieren, und versucht hast, das auch nur ansatzweise zu verstehen
;-)
Karl schrieb:> Ja, der C-Compiler> baut hier Scheisse, das ist leider so, weil das irgendwann mal so> angefangen wurde und wir das jetzt wegen der Abwärtskombatibilität so> beibehalten müssen.
Wenn du die Promotion verstanden hättest, wüsstest du auch wo deren
Vorteile liegen, dass das weder Sch**sse noch Abwärtskompatibilität ist.
So aber wirst du wohl bei deiner $FavoriteProgrammingLanguage (welche
eigentlich?) bleiben müssen... das ist aber ok, damit hat niemand ein
Problem, eher im Gegenteil ^^
Karl schrieb:> Autsch!> c1 = 0x81;> if (c1 & 0x80) {> is_true();> } else {> is_false();> }> Das Bitmuster 0x81 ist also gleich dem Bitmuster 0x80?
if (c1 & 0x80) fragt ab, ob Bit7 gesetzt ist. Das ist bei c = 0x81 der
Fall. Also richtig.
Wenn du abfragen willst ob Bit7 und Bit0 gesetzt ist, geht das so:
if ((c1 & 0x81)==0x81)...
Deinen Mangel an Kenntnissen von Bitoperationen kannst du nicht C
anlasten.
Karl schrieb:> Scheisse wird nicht dadurch schmackhafter, dass man ihr einen tollen> Namen gibt.
Hmmm... ich finde Gabelstapler total Scheisse. Ich kann mit denen
überhaupt nicht umgehen...
Jobst Q. schrieb:> Deinen Mangel an Kenntnissen von Bitoperationen kannst du nicht C> anlasten.
Das gilt aber definitiv nicht für Gabelstapler ;-)
Jobst Q. schrieb:> if (c1 & 0x80) fragt ab, ob Bit7 gesetzt ist. Das ist bei c = 0x81 der> Fall. Also richtig.
Das ist nicht das, was Du oben behauptet hast.
Karl schrieb:> Jobst Q. schrieb:>> if (c1 & 0x80) fragt ab, ob Bit7 gesetzt ist. Das ist bei c = 0x81 der>> Fall. Also richtig.>> Das ist nicht das, was Du oben behauptet hast.
"Bitmuster prüft man mit &." hatte ich gesagt. Und 0x80 ist nunmal als
Bitmuster in 0x81 enthalten.
Karl schrieb:> Michael R. schrieb:>> aber selbst wenn du aus 0x80 ein Byte machst, ist das "not" davon wieder>> ein Integer. Blöd, eh?>> Ach, wirklich?
Ja, wirklich.
> https://en.wikipedia.org/wiki/Bitwise_operation#NOT
Schön. Du hast rausgefunden, wie eine boolesche Invertierung
funtkioniert. Was hat das jetzt damit zu tun, von welchem Datentyp die
Konstante 0x80 und damit auch ~0x80 in C ist?
> Da muss man sich nicht wundern, dass Software in C so schlecht ist, wenn> C-Programmierer nicht mal die einfachsten Vergleiche hinbekommen.
Schließe doch bitte nicht von dir auf andere.
Karl schrieb:> if (c1 == ~0x80)> // True oder False?
Weder noch, sondern einfach Unsinn. Die einzig sinnvolle Verwendung des
bitweisen NOT '~' ist das Zurücksetzen von Bits zusammen mit dem
bitweisen AND '&'.
flags &= (~0x80);
Dabei ist es nicht von Nachteil, wenn die vom Compiler gewählte Größe
der '~'-Konstruktion größer ist als die betroffene Variable. Alle
zusätzlichen Bits sind gesetzt, haben also mit dem '&' keine Wirkung.
Rolf M. schrieb:> Was hat das jetzt damit zu tun, von welchem Datentyp die> Konstante 0x80 und damit auch ~0x80 in C ist?
Die Konstante hat sinnvoller Weise die Länge, die angegeben ist. 0x80
sind ein Byte, 0x0080 sind 2 Byte. Gerade bei Hex ist das doch total
simple und seit Jahrhunderten bewährt.
Ich sag doch: Die Crux bei C ist, dass es erstmal alles auf seine
mindestens 16 Bit presst, auch wenn das für 8-Bit-Systeme nicht sinnvoll
ist.
Jobst Q. schrieb:> Die einzig sinnvolle Verwendung des> bitweisen NOT '~'...
... die Du Dir vorstellen kannst. Für Deinen beschränkten Horizont kann
ja sonst keiner was.
Karl schrieb:> Die Konstante hat sinnvoller Weise die Länge, die angegeben ist. 0x80> sind ein Byte, 0x0080 sind 2 Byte. Gerade bei Hex ist das doch total> simple und seit Jahrhunderten bewährt.
Ach ist das süß ;-) Hex ist also ein Sonderfall... wie macht man das
dezimal, oktal?
> [...] dass es erstmal alles auf seine mindestens 16 Bit presst [...]
ah, mindestens... er lernt^^
Karl schrieb:> Die Konstante hat sinnvoller Weise die Länge, die angegeben ist. 0x80> sind ein Byte, 0x0080 sind 2 Byte.
In C hängt die Länge vom Wert und von der Basis ab.
Michael R. schrieb:> Ach ist das süß ;-) Hex ist also ein Sonderfall... wie macht man das> dezimal, oktal?
Stimmt aber. Der Typ einer lexikalischen Konstanten hängt zwar vom Wert
ab, nicht von der Länge im Quelltext, aber das bestimmt sich oktal/hex
tatsächlich anders als dezimal. Bei dezimaler Angabe werden die
vorzeichenlosen Typen übergangen, weshalb 32768 in einer 16-Bit Umgebung
"long" ist, 0x8000 aber "unsigned".
Ach, wenn unser Karl sich wenigstens darüber beschweren würde, dass ein
Byte auch mal 9 Bit breit sein darf, dann hätte ich ja halbes
Verständnis.
Aber so....
Denn das Verhalten von C ist eigentlich recht klar definiert.
Sicher kann man diese Definitionen in Zweifel ziehen, oder sich fragen
ob sie geschickt definiert sind.
Es macht allerdings keinen Sinn darüber zu schimpfen, denn die
Definition kann man nicht ändern. Das ist, wie darüber jammern, dass man
nass wird, wenn es regnet.
Man/Karl könnte sich eine andere Sprache suchen, wenn man/Karl C nicht
mag. Aber deswegen anderen die Sprache madig machen...?
Neee...
Ich selber bin auch kein C Fan.
Habs eher mit OOP, also wenn, dann C++ auf meinen AVR Zwergen.
Michael R. schrieb:> Hex ist also ein Sonderfall... wie macht man das> dezimal, oktal?
Naja, oktal in C ist ja noch bescheuerter: 010 ist ein Oktalzahl. Was
haben die geraucht, um auf sowas zu kommen?
Michael R. schrieb:> ah, mindestens...
Falls Du damit wieder auf die vergötterte Integer-Promotion ansprichst:
Wenn ein NOT aus einem Byte zwei Byte macht, ist das keine
Integer-Promotion, sondern einfach nur bescheuert. Das Ergebnis von
einem NOT auf ein Byte ist wiederum nur ein Byte. Genauso wie das
Ergebnis ein Byte AND ein Byte wieder nur ein Byte ist. Bitweise
Operatoren. Wie soll sich da die Anzahl der Bits erhöhen?
Nein, was Du für Integer Promotion hältst ist einfach nur die Eigenheit,
erstmal alles in 16 Bit zu pressen, weil 16 Bit damals(TM) halt hipp
waren. Das ist schlichtweg ein Designfehler von C, den man immer weiter
mitschleifen muss.
Arduino F. schrieb:> Man/Karl könnte sich eine andere Sprache suchen, wenn man/Karl C nicht> mag. Aber deswegen anderen die Sprache madig machen...?
Done!
Allerdings ist es im Gegenteil eher so, dass die C-Fans anderen "ihre"
Sprachen madig machen wollen, weil C und dessen Derivate das einzig
Wahre sind und man nur in C richtig programmieren könne.
Witzig zu sehen ist allerdings, wie krampfhaft die "Eigenheiten" sprich
Designfehler von C verteidigt werden, anstatt einfach mal zuzugeben: Ja
ok, das war damals eine Fehlentscheidung, mit der wir heute leider leben
müssen.
Karl schrieb:> Nein, was Du für Integer Promotion hältst ist einfach nur die Eigenheit,> erstmal alles in 16 Bit zu pressen, weil 16 Bit damals(TM) halt hipp> waren. Das ist schlichtweg ein Designfehler von C, den man immer weiter> mitschleifen muss.
wir müssen damals im selben Kommunikationstraining gewesen sein...
"Blamiere dich täglich" war der Wahlspruch, aber du übertreibst es
etwas... dabei warst du schon beim "mindestens".
es wird mitnichten auf 16 bit, sondern auf die native Wortbreite (aber
mindestens 16 bit) erweitert. Und das nicht weil es hipp ist oder war,
sondern weil es in der Mehrzahl der Fälle sinnvoll ist. Deswegen ist es
auch kein Designfehler, sondern wurde absichtlich so definiert, weil es
eben Vorteile bietet. Das damit ein paar Fallstricke für Anfänger
verbunden sind, damit hast du recht. Aber C hatte (im Gegensatz zu zB
Pascal) niemals den Anspruch, eine Anfänger-Sprache zu sein.
Karl schrieb:> Naja, oktal in C ist ja noch bescheuerter: 010 ist ein Oktalzahl. Was> haben die geraucht, um auf sowas zu kommen?
Oktale Darstellung war in der Phase ziemlich gebräuchlich, in der C
erfunden wurde. Wenn man die binäre Codierung der Befehle der PDP11 und
anderer Maschinen dieser Ära ansieht, dann weiss man auch warum.
> Falls Du damit wieder auf die vergötterte Integer-Promotion ansprichst:> Wenn ein NOT aus einem Byte zwei Byte macht,
Tut es nicht. ~0x80 macht aus einer "int" eine "int", denn 0x80 ist
schon eine "int". ~ ändert also nicht den Typ. Auch in
uint8_t c = 0x80;
... ~c ...
erweitert nicht speziell der ~ Operator die variable "c" auf "int",
sondern der Umstand, dass "c" im Kontext einer Expression verwendet
wird. Aber auch da wird "c" vor der Berechung erweitert, also nicht
durch den Operator.
> Nein, was Du für Integer Promotion hältst ist einfach nur die Eigenheit,> erstmal alles in 16 Bit zu pressen,
Da wird nichts gepresst. Konstanten, die nicht in 16 Bits passen, werden
nicht reduziert. Der Typ passt sich an, mindestens aber "int", was per
Definition mindestens 16 Bits sein muss.
C ist definitiv nicht die bestmögliche aller Welten. Muss man nicht
mögen, ist aber so und wird so verwendet. Deutsch ist auch nicht die
einfachste aller Sprachen, wird aber von uns trotzdem verwendet.
Michael R. schrieb:> KaUnd das nicht weil es hipp ist oder war,> sondern weil es in der Mehrzahl der Fälle sinnvoll ist.
Es war damals nicht unüblich, Bytes seitens der Maschine automatisch zu
einem Wort zu erweitern, wenn sie aus dem Speicher geladen wurden - mal
vorausgesetzt, es gab überhaupt Byteadressierung. So auch die PDP11, die
in der Entstehungsphase eine nicht unmassgebliche Rolle spielte.
Karl schrieb:> Jobst Q. schrieb:>> Die einzig sinnvolle Verwendung des>> bitweisen NOT '~'...>> ... die Du Dir vorstellen kannst. Für Deinen beschränkten Horizont kann> ja sonst keiner was.
Natürlich kann ich mir mehr vorstellen, aber eben nichts sinnvolles.
Invertieren kann man auch mit XOR '^', sogar ganz beliebige Bits.
c^=0xFF;
Invertiert genau ein Byte, ohne dass die Typlänge eine Rolle spielt.
A. K. schrieb:> C ist definitiv nicht die bestmögliche aller Welten. Muss man nicht> mögen, ist aber so und wird so verwendet.
Ein wahres Wort!
Um nochmal bei Karl zu bleiben: Karl mag C nicht. Ich mag Python nicht.
Karl wird seine Gründe haben, zwischen mir und Python steht (vor allem)
die off-side rule (Einrückung). Damit kann ich nicht.
Ich würde aber nie so weit gehen, das als Design-Fehler zu bezeichnen.
Es ist nur ein (legitimes) Design welches mir nicht gefällt.
Weil ich Python nicht mag, verwende ich es nicht. Weil ich es nicht
verwende, weiß ich nichts (oder nur sehr wenig) drüber. Weil ich nichts
drüber weiß, schreibe ich nicht in Python-Threads mit (und schon gar
nicht mokiere ich mich dort über Design-Fehler).
Bei Karl scheint da irgendwas anders zu sein ;-)
Nun, ich mag Python auch nicht, genau aus genanntem Grund.
Im Gegensatz zum Einrücken bei Python, welches offensichtlich ist, ist
obiger Fehler in C eben nicht offensichtlich.
Der Compiler macht hier etwas, was zu einer der Intention - nicht zu
Verwechseln mit Indention - des Codes widersprechenden Aussage führt,
aufgrund einer Typwandlung, die im Verborgenen erfolgt.
Da weiter oben der FPC erwähnt wurde: Der FPC auf dem PC kompiliert das
gar nicht erst, man müsste ihn durch einen expliziten Typecast dazu
zwingen. Und der FPC für Embedded AVR kompiliert das plattformkonform
mit 8 Bit, und das Ergebnis ist korrekt.
Geht also durchaus.
Mutter Teresa sagte mal:
> Wenn du die Menschen verurteilst,> hast du keine Zeit, sie zu lieben.
Das gilt natürlich auch, im übertragenen sinne, für vieles andere.
z.B. für Computersprachen.
(auch wenn sie das nicht direkt damit gemeint haben sollte)
Michael R. schrieb:> Karl schrieb:>> Nein, was Du für Integer Promotion hältst ist einfach nur die Eigenheit,>> erstmal alles in 16 Bit zu pressen, ...>> ...> es wird mitnichten auf 16 bit, sondern auf die native Wortbreite (aber> mindestens 16 bit) erweitert.
Genau dieses "aber mindestens 16 bit" ist jedoch ein Punkt, wo ich Karl
teilweise recht gebe.
Der ursprüngliche Grund, die Größe von int und damit den defaultmäßigen
Wertebereich für Integer-Berechnungen an die Wortbreite des verwendeten
Prozessors anzugleichen, liegt schlicht im Wunsch nach maximaler
Performanz. Von diesem Standpunkt aus gesehen müsste bei einem
AVR-C-Compiler int 8 bit breit sein, denn ein AVR rechnet in 8-Bit-
Arithmetik deutlich schneller als in 16 Bit.
Der Grund, warum für int trotzdem mindestens 16 Bit vorgeschrieben sind,
liegt IMHO vor allem darin, dass einige als int deklarierte Funktionen
der Standardbibliothek (bspw. fgetc) einen Wertebereich von mehr als
0..255 voraussetzen. Die Signatur dieser Funktionen wurden bereits
festgelegt lange bevor der erste C-Compiler für einen 8-Bit-Prozessor
geschrieben wurde.
Dieses Problem wurde dadurch umgangen, dass 16 Bit als minimale Größe
von int festgesetzt wurde. Das führte bei den ersten C-Compilern für
8-Bit-Prozessoren tatsächlich zu Performanzeinschränkungen, die aber in
neueren, stark optimierenden Compilern weitgehend behoben sind.
Dennoch bleiben ein paar wenige Fälle, wo auf 8-Bit-Prozessoren die
Integer-Promotion lästig ist. Da diese Fälle selten sind und i.Allg.
durch Umschrieben des betreffenden Ausdrucks oder Einfügen von Casts
leicht abgehandelt werden können, besteht für mich keinerlei Grund, auf
8-Bit-Prozessoren in einer anderen Sprache als C (oder allenfalls noch
Assembler) zu programmieren.
An dem von Karl angeprangerten Fall
1
irgendwas1==~irgendwas2
störe ich mich überhaupt nicht, da ich einen solchen Ausdruck noch nie
gebraucht habe, obwohl schon seit vielen Jahren Mikrocontroller aus
vielen unterschiedlichen 8-, 16- und 32-Bit-Familien in C programmiere.
Übrigens kann man beim AVR-GCC die int-Größe mit -mint8 auf nicht 8 bit
einstellen. Dann verhält er sich wie von Karl gewünscht, allerdings ist
er damit nicht mehr ISO-konform, und die Standardbibliothek kann nicht
mehr verwendet werden bzw. müsste angepasst und neu gebaut werden.
@Karl:
Bisher hast du dich ja um die Beantwortung der bereits mehrfach
gestellten Frage nach dem von dir verwendeten Compiler erfolgreich
herumgedrückt:
W.S. schrieb:> Meinst du Mikroe oder was anderes?Yalu X. schrieb:> Das sieht nach Pascal aus, aber welcher Dialekt bzw.Compiler?Arduino F. schrieb:> Zeige mir bitte deinen eigenen "besseren" Kompiler.
Aber so langsam scheint Licht ins Dunkel zu kommen:
Karl schrieb:> Da weiter oben der FPC erwähnt wurde: Der FPC auf dem PC kompiliert das> gar nicht erst, man müsste ihn durch einen expliziten Typecast dazu> zwingen. Und der FPC für Embedded AVR kompiliert das plattformkonform> mit 8 Bit, und das Ergebnis ist korrekt.
Du arbeitest also mit dem AVR-FPC?
Michael R. schrieb:> Weil ich Python nicht mag, verwende ich es nicht. Weil> ich es nicht verwende, weiß ich nichts (oder nur sehr> wenig) drüber. Weil ich nichts drüber weiß, schreibe> ich nicht in Python-Threads mit (und schon gar nicht> mokiere ich mich dort über Design-Fehler).
Das ist menschlich gesehen zwar nobel, sachlich aber
nicht zielführend: Der Fortschritt wird durch die
Unzufriedenen erzwungen :)
> Der Fortschritt wird durch die Unzufriedenen erzwungen
Ich vertrete ja eher die Ansicht, dass Fortschritt meisten zufällig
passiert und der Versuch, ihn zu erzwingen, meistens scheitert.
Yalu X. schrieb:> Der ursprüngliche Grund, die Größe von int und damit den> defaultmäßigen Wertebereich für Integer-Berechnungen an> die Wortbreite des verwendeten Prozessors anzugleichen,> liegt schlicht im Wunsch nach maximaler Performanz.
Der Gedanke lässt sich weiterspinnen:
Wenn die Performanz allein das entscheidende Argument
(gewesen) wäre, hätte sich C nicht so weit verbreiten
dürfen -- dann hätte man nämlich bei Assembler bleiben
müssen.
Es ist daher nicht unsinnig zu vermuten, dass auch die
anderen Eigenschaften von C -- wie die im Vergleich zum
Assembler höhere Abstraktion und die bessere Portabili-
tät -- eine wichtige Rolle gespielt haben.
Spätestens hier sollte aber auffallen, dass logisch
widersprüchliche Ziele vorliegen: Man kann nicht
gleichzeitig maximale Performance (die optimale
Ausnutzung maschinenspezifischer Besonderheiten
erfordert) und maximale Portabilität (die maximale
Unabhängigkeit von maschinenspezifischen Besonder-
heiten notwendig macht) haben -- wenigstens nicht ohne
zusätzlichen Aufwand.
Stefan U. schrieb:>> Der Fortschritt wird durch die Unzufriedenen erzwungen>> Ich vertrete ja eher die Ansicht, dass Fortschritt> meisten zufällig passiert und der Versuch, ihn zu> erzwingen, meistens scheitert.
Unsere Aussagen sind vollständig kompatibel.
Von den 100 Unzufriedenen, die versuchen, den Fortschritt
zu erzwingen, scheitern 99, und nur einer hat Erfolg.
Trotzdem wird der Fortschritt von den Unzufriedenen
getragen -- die anderen haben nämlich kein Motiv, etwas
zu ändern :)
Yalu X. schrieb:> Der ursprüngliche Grund, die Größe von int und damit den defaultmäßigen> Wertebereich für Integer-Berechnungen an die Wortbreite des verwendeten> Prozessors anzugleichen, liegt schlicht im Wunsch nach maximaler> Performanz.
Nö.
Ich verbuche sowas unter Geburtsfehler, von denen C eine Menge hat.
Immerhin versemmelt man sich genau damit aus Sicht der zu lösenden
Probleme jegliche Sicherheit, Allgemeingültigkeit und Portierbarkeit.
Und um die "Performanz" sollte sich der Compiler bzw. dessen Architekt
kümmern.
Die Sicherheit, daß ein Datentyp eben genau definiert ist, sollte man
nicht unterschätzen. Das grundsätzliche Ziel einer Programmiersprache
oberhalb des Assemblers ist es ja gerade, dem Programmierer eine
Sicherhait für seine problemabhängigen Algorithmen zu geben und nicht
etwa, daß er sich mit maschinenabhängigen Besonderheiten herumschlagen
muß. Das ist Obliegenheit der Tools.
Die Sichtweise in C ist da mal wieder nicht die Sicht aus
Anwenderperspektive, sondern die Sicht des Compiler-Erfinders.
Nochwas: Die Maschinen, die ich damals programmiert hatte, konnten
überhaupt keinen byteweisen Zugriff. Der Speicher bestand kompletissimo
aus 16 Bit WORD's und wenn man Text (7 Bit) speichern wollte, dann mußte
man das selbst per Swap in diese 16 Bits einpassen.
So ging das damals - mit Kernspeicher-Maschinen.
W.S.
W.S. schrieb:> Yalu X. schrieb:>> Der ursprüngliche Grund, die Größe von int und damit den defaultmäßigen>> Wertebereich für Integer-Berechnungen an die Wortbreite des verwendeten>> Prozessors anzugleichen, liegt schlicht im Wunsch nach maximaler>> Performanz.>> Nö.
Gibt es deiner Ansicht nach denn einen anderen möglichen Grund für die
maschinenabhängige Größe von int? Oder haben dei C-Entwickler diese
Entscheidung etwa völlig grundlos getroffen?
> Ich verbuche sowas unter Geburtsfehler, von denen C eine Menge hat.
C hat zwar tatsächlich einige Geburtsfehler, aber die maschinenabhängige
int-Größe gehört definitiv nicht dazu.
> Immerhin versemmelt man sich genau damit aus Sicht der zu lösenden> Probleme jegliche Sicherheit, Allgemeingültigkeit und Portierbarkeit.
Sprachen mit guter Portabilität (bspw. Fortran) oder guter Performanz
(Assembler) gab es bereits. C sollte ein guter Kompromiss aus beiden
Kriterien werden. Das ist es IMHO auch geworden, aber es ist und bleibt
eben ein Kompromiss, der in keinem der Kriterien das absolute Optimum
erreicht.
Wem heute bei High-Level-Anwendungen Portabilität über alles geht,
programmiert nicht in C, sondern bspw. in Java. Maschinennahe Software,
hingegen (bspw. ein Betriebssystem) ist per se nur eingeschränkt
portabel, so dass andere Kriterien in den Vordergrund treten, in denen
Java wiederum ganz schlecht abschneidet.
Die Programmiersprache, die für alle Anwendungen vom PID-Regler auf
einem 8-Bit-Controller bis hin zum hochkomplexen KI-System gleichermaßen
optimal geeignet ist, gibt es leider noch nicht und wird es vermutlich
auch nie geben.
> Und um die "Performanz" sollte sich der Compiler bzw. dessen Architekt> kümmern.
Werden die Basisdatentypen erst einmal ungünstig festgelegt, kann das
auch der beste Optimierer nicht mehr richten. Man muss auch sehen, dass
in den 70ern die Compilertechnik noch nicht so weit fortgeschritten war
wie heute, und starke Optimierer, wie wir sie heute gewohnt sind, die
RAM-Kapazität der damaligen Rechner um Größenordnungen sprengen würden.
Yalu X. schrieb:> störe ich mich überhaupt nicht, da ich einen solchen Ausdruck noch nie> gebraucht habe
Ich auch nicht. Das ist ein Beispiel, an dem das Problem kurz und
prägnant deutlich wird.
Die "Zutaten" zu diesem Beispiel allerdings gibt es durchaus: Ein NOT,
um eingelesene low-aktive Pins zu wandeln, eine Konstante, die irgendwo
definiert eine Maske der verwendeten Pins enthält, Prüfen ob keiner der
Pins gesetzt ist, oder alle, oder...
Das ist auch nicht mein Beispiel, das findest Du auf diversen Seiten,
und das ist nicht 8-Bit spezifisch, das funktioniert unter anderem
Systemen ebenso.
Yalu X. schrieb:> Übrigens kann man beim AVR-GCC die int-Größe mit -mint8 auf nicht 8 bit> einstellen.
Wovon mir, als das Thema vor einigen Monaten mal aufkam, vehement
abgeraten wurde, es würde zu vielen Problemen führen.
Damals ging es darum, dass C viele Operationen unnötigerweise auf 16 Bit
aufbläht, wenn 8 Bit auch reichen würden.
Karl schrieb:> Damals ging es darum, dass C viele Operationen> unnötigerweise auf 16 Bit aufbläht, wenn 8 Bit> auch reichen würden.
Das Problem hat FreePascal eine Etage höher (32bit
vs. 64bit) aber auch.
Ich bin grundsätzlich ein Freund starker Typisierung,
aber das Problem ist mMn damit nicht lösbar.
Karl schrieb:> Damals ging es darum, dass C viele Operationen unnötigerweise auf 16 Bit> aufbläht, wenn 8 Bit auch reichen würden.
Als C definiert wurde kam niemand auf die Idee, es wäre etwas für 8 Bit
Mikroprozessoren. Es gab keine. Die kleinste Klasse von Rechnern, auf
denen ein C Compiler sinnvoll schien, waren 16-Bit Minicomputer. Es
dauerte Jahrzehnte, bis sich C als Crosscompiler-Sprache für 8-Bit
Mikrocomputer verbreitete.
A. K. schrieb:> Karl schrieb:>> Damals ging es darum, dass C viele Operationen>> unnötigerweise auf 16 Bit aufbläht, wenn 8 Bit>> auch reichen würden.>> Als C definiert wurde kam niemand auf die Idee,> es wäre etwas für 8 Bit Mikroprozessoren. Es gab> keine.
Kopf-an-Kopf-Rennen:
C - 1972 erschienen
i8008 - 1972 erschienen
i8080 - 1974 erschienen
Z80 - 1976 erschienen
> Die kleinste Klasse von Rechnern, auf denen ein C> Compiler sinnvoll schien, waren 16-Bit Minicomputer.
Ja - wegen der klassischen Bindung von C an Unix.
> Es dauerte Jahrzehnte, bis sich C als Crosscompiler-> Sprache für 8-Bit Mikrocomputer verbreitete.
... was man als Beweis dafür ansehen kann, dass frühe
Fehlentscheidungen NICHT ewigen Bestand haben müssen,
sondern auch korrigiert werden können.
Karl schrieb:> Yalu X. schrieb:>> Übrigens kann man beim AVR-GCC die int-Größe mit -mint8 auf nicht 8 bit>> einstellen.>> Wovon mir, als das Thema vor einigen Monaten mal aufkam, vehement> abgeraten wurde, es würde zu vielen Problemen führen.
Ich habe zwar nicht viel Erfahrung mit -mint8, aber solange du in deinen
Programmen keinen Fremdcode benutzt, der nicht für eine int-Größe von 8
bit geschrieben ist (also auch nicht die AVR Libc), dürften IMHO keine
größeren Probleme entstehen.
Hier ist übrigens noch ein kleines Beispiel für den AVR-FPC, dessen
Verhalten auch nicht immer ganz der menschlichen Intuition entspricht:
1
procedure test;
2
var
3
w: word;
4
b: byte;
5
6
begin
7
8
{ Wegen $e0 + $40 > $ff wird die not-Operation 16-bit-breit ausgeführt }
9
w := not ($e0 + $40); { -> $fedf }
10
do_something_with(w);
11
12
{ Wird $e0 durch eine Byte-Variable mit gleichem Inhalt ersetzt, wird
13
die not-Operation nur noch 8-bit-breit ausgeführt }
14
b := $e0;
15
w := not ( b + $40); { -> $00df }
16
do_something_with(w);
17
18
end;
Vom FPC generierter Assemblercode (R1 hat den Inhalt 0):
1
PsTEST_ss_TEST:
2
ldi r24,-33
3
ldi r26,-2
4
mov r25,r26
5
call PsTEST_ss_DO_SOMETHING_WITHsWORD
6
ldi r18,-32
7
ldi r24,-33
8
mov r25,r1
9
jmp PsTEST_ss_DO_SOMETHING_WITHsWORD
Leider konnte ich in der Dokumentation des FPC keine Erklärung für
dieses Verhalten finden.
In C liefern beide Ausdrücke das gleiche Ergebnis:
Possetitjel schrieb:> Das Problem hat FreePascal eine Etage höher (32bit> vs. 64bit) aber auch.
Auf dem PC sehe ich ja ein, dass es sinnvoller ist die Bitbreite der
Matheunit voll auszunutzen, da geht eine Division mit 32 oder 64 Bit
auch schnell.
Allerdings ist Pascal hier wenigstens konsequent und sagt: Wenn wir auf
64 Bit Breite rechnen, dann alles, und wenn Du das anders willst musst
Du das explizit casten. C wandelt halt einfach nach Belieben.
Auf dem AVR hab ich mir meine eigenen Matheroutinen geschrieben. Da
Pascal Multiplikation oder Division immer auf gleicher Bitbreite macht,
wird unnötig viel Overhead erzeugt, genau wie bei C. Wenn ich aber nur
16bitx16bit=>32bit oder 32bit/8bit=>32bit brauche, spare ich enorm. Eine
Division in 5usec statt in 200usec ist schon ein Nummer.
Aber wenigstens versucht Pascal nicht meinem 8-Bitter unbedingt 16 Bit
aufzunötigen.
Was mir unter Pascal deutlich besser gefällt ist die Matheunterstützung.
Letztens hab ich einen - aktuellen - Beitrag über C gelesen, wo als Tipp
kam: Nehmen Sie mathematische Funktionen möglichst auseinander. Nur eine
Operation pro Zeile. Da dachte ich so: Echt jetzt? Euer Ernst? Leider
finde ich die Seite nicht mehr, vielleicht wurde sie aus Scham gelöscht.
War das bei heise...?
Karl schrieb:> Letztens hab ich einen - aktuellen - Beitrag über C gelesen, wo als Tipp> kam: Nehmen Sie mathematische Funktionen möglichst auseinander. Nur eine> Operation pro Zeile. Da dachte ich so: Echt jetzt? Euer Ernst?
Das denke ich auch ;-)
Bist du sicher, dass es um C und nicht um Bascom ging?
Bei letzterem muss man sogar für jede Rechenoperation eine eigene
Anweisung schreiben.
> Leider> finde ich die Seite nicht mehr, vielleicht wurde sie aus Scham gelöscht.
So wird es wohl sein ;-)
Yalu X. schrieb:> Hier ist übrigens noch ein kleines Beispiel für den AVR-FPC, dessen> Verhalten auch nicht immer ganz der menschlichen Intuition entspricht:
not($E0 + $40) gibt bei mir einen fetten range check error. Ich muss das
explizit auf uint16 casten. Und dann isses klar, einmal wird das Not auf
ein Word angewendet, einmal auf ein Byte, und dann erst auf ein Word
erweitert.
Karl schrieb:> Yalu X. schrieb:>> Hier ist übrigens noch ein kleines Beispiel für den AVR-FPC, dessen>> Verhalten auch nicht immer ganz der menschlichen Intuition entspricht:>> not($E0 + $40) gibt bei mir einen fetten range check error.
Stimmt, auch wenn "fett" etwas übertrieben ist, denn es erscheint
lediglich eine Warnung, die den Kompiliervorgang nicht abbricht.
Sie kommt daher, dass der Compiler das Ergebnis $fedf als negativ
ansieht, so dass es außerhalb des Wertebereichs von word liegt.
> Ich muss das explizit auf uint16 casten.
Die Warnung verschwindet auch ohne Cast, wenn man für w einen
passenderen Datentyp wählt. Ersetze also
1
w: word;
durch
1
w: smallint;
so dass w auch negative Werte annehmen kann. Die Ergebnisse sind aber
immer noch verschieden. Es ändert sich nicht einmal der generierte
Assemblercode.
Was nun?
Yalu X. schrieb:> Die Ergebnisse sind aber immer noch verschieden. Es> ändert sich nicht einmal der generierte Assemblercode.>> Was nun?
Naja, schätzungsweise ist "not" einfach überladen.
Anders ausgedrückt: "$E0 + $40" liefert dieser
Vermutung nach im ersten Beispiel nicht deswegen ein
word, weil es größer als 255 ist, sondern weil als
Ergebnis ein Word erwartet wird. (Die Konstanten
selbst haben ja in Pascal, wenn ich mich recht
entsinne, keinen Typ.)
Das kannst Du ja leicht prüfen: Sieh' einfach, was
bei "$30 + $50" passiert, und berichte.
Analog im zweiten Beispiel: Byte plus Konstante gibt
erstmal ein Byte; der unäre Operator "not" macht ein
Byte aus dem Byte, und die Zuweisung expandiert auf
das Word. Genau das kommt heraus.
Ich habe da jetzt nicht tiefer drübernachgedacht,
aber ich finde das auch völlig logisch so.
Possetitjel schrieb:> Analog im zweiten Beispiel: Byte plus Konstante gibt> erstmal ein Byte; der unäre Operator "not" macht ein> Byte aus dem Byte, und die Zuweisung expandiert auf> das Word. Genau das kommt heraus.
Ich bekomme hier noch eine Meise. Warum liefert...
1
program multest;
2
3
var b1, b2, b3 : byte;
4
w : word;
5
begin
6
b1:=100;
7
b2:=200;
8
b3:=1;
9
w:=not((b1*b2)+b3);
10
writeln('w=',w);
11
end.
... als Ergebnis "w=45534" (=0xB1DE)?
Meiner Theorie nach hätte Byte mal Byte plus Byte
wiederum Byte ergeben sollen, so dass ich ein
Ergebnis der Art "0x00??" erwartet hätte.
> Ich habe da jetzt nicht tiefer drübernachgedacht,> aber ich finde das auch völlig logisch so.
Ich nehme das frustriert zurück.
Karl schrieb:> Auf dem PC sehe ich ja ein, dass es sinnvoller ist die Bitbreite der> Matheunit voll auszunutzen, da geht eine Division mit 32 oder 64 Bit> auch schnell.
Dabei geht es nicht nur um (mathematische) Berechnungen; mWn profitieren
alle Register- und Speicheroperationen von der nativen Wortbreite.
> C wandelt halt einfach nach Belieben.
"nach Belieben" wäre mir noch nicht aufgefallen.
> Auf dem AVR hab ich mir meine eigenen Matheroutinen geschrieben.
Das kann aber nicht Sinn der Übung sein, oder?
> Was mir unter Pascal deutlich besser gefällt ist die Matheunterstützung.
Inwiefern? Grad vorher schreibst du, du hättest das alles selbst
geschrieben?
> Damals ging es darum, dass C viele Operationen unnötigerweise auf 16 Bit> aufbläht, wenn 8 Bit auch reichen würden.
ich mach jetzt doch schon einige Jahre in C, etwas kürzer auf dem AVR,
aber ich kann mich nicht erinnnern da auf signifikante Probleme gestoßen
zu sein (was nicht heißt dass solche nicht existieren).
Hast du mal ein wirklich konkretes Beispiel? Also nicht so ein
konstruiertes wie
1
irgendwas1==~irgendwas2
von dem du ja selbst schreibst dass du es noch nie gebraucht hast.
Karl schrieb:> Allerdings ist Pascal hier wenigstens konsequent und sagt: Wenn wir auf> 64 Bit Breite rechnen, dann alles, und wenn Du das anders willst musst> Du das explizit casten. C wandelt halt einfach nach Belieben.
Nein, C macht das gleiche. Gerade aus diesem Grund gibt es die
Integer-Promotion, die dich so stört, doch. Berechnungen werden immer in
int durchgeführt, es sei denn, die Eingangsdatentypen sind größer.
Gleiches gilt entsprechend für den Datentyp von Integerkonstanten.
Deshalb sollte int möglichst die native Breite der CPU sein. Es gibt
allerdings eben die Einschränkung, dass es mindestens 16 Bit breit sein
muss, was für den Spezialfall einer 8-Bit-CPU nicht ideal ist. Die
Compiler-Optimierungen sorgen aber dafür, dass der Impact auf Laufzeit
und Codegröße minimal ist.
Rolf M. schrieb:> Es gibt allerdings eben die Einschränkung, dass es mindestens 16 Bit> breit sein muss, was für den Spezialfall einer 8-Bit-CPU nicht ideal> ist.
...und deshalb dort meist abgestellt werden kann. Für optimierten
8-bit-code.
Wer portable(r) sein will, lässt es.
Possetitjel schrieb:> Kopf-an-Kopf-Rennen:> C - 1972 erschienen> i8008 - 1972 erschienen
1972 erschien das Buch, Sprache und Compiler entstanden logischerweise
vorher. Dass der Dennis Ritchie mit Intel unter einer Decke steckte darf
man wohl ausschliessen.
Aber ein C Compiler, der auf einem 8008 läuft, das wär schon eine
Vorstellung für 1972 ;-). Immerhin entstand C als Sprache eines
laufenden Systems, nicht als Crosscompiler-Sprache für Drittsysteme, wie
es heute bei Mikrocontrollern üblich ist.
Possetitjel schrieb:> Ich bekomme hier noch eine Meise. Warum liefert...> program multest;>> var b1, b2, b3 : byte;> w : word;> begin> b1:=100;> b2:=200;> b3:=1;> w:=not((b1*b2)+b3);> writeln('w=',w);> end.>> ... als Ergebnis "w=45534" (=0xB1DE)?>> Meiner Theorie nach hätte Byte mal Byte plus Byte> wiederum Byte ergeben sollen, so dass ich ein> Ergebnis der Art "0x00??" erwartet hätte.
Das zeigt doch schön, das dass grundsätzliche Problem weder bei C noch
bei Pascal liegt, sondern beim unären Operator 'not' bzw '~'. Sein
Verhalten ist naturgemäß typgebunden.
Wie ich schon weiter oben geschrieben habe, ist seine einzig sinnvolle
Anwendung das Zurücksetzen von Bits zusammen mit 'and' bzw '&', wodurch
die Typgebundenheit aufgehoben wird.
Wenn es um Invertierung geht, ist der binäre Operator 'xor' bzw '^'
immer die bessere und sicherere Wahl.
Possetitjel schrieb:>> Die kleinste Klasse von Rechnern, auf denen ein C>> Compiler sinnvoll schien, waren 16-Bit Minicomputer.>> Ja - wegen der klassischen Bindung von C an Unix.
Weniger. Sondern weil man oft nur den einen Rechner hatte, nämlich den
Zielrechner. Auf dem sollte der Compiler laufen, Unix oder nicht. So
wars bei mir Ende der 70er auch, Compiler (PL/65) und Assembler liefen
auf dem 6502 Rechner selbst. Einen anderen hatte ich nicht.
Mikrocontroller mit Entwicklungssystem auf einem PC gab es sinngemäss in
den 70ern zwar auch. Minicomputer mit Assembler und ggf. Compiler als
Entwicklungssystem für Mikrocomputer und Mikrocontroller. Aber in dieser
Szene war C völlig unbekannt.
Jobst Q. schrieb:> Das zeigt doch schön, das dass grundsätzliche Problem weder bei C noch> bei Pascal liegt, sondern beim unären Operator 'not' bzw '~'. Sein> Verhalten ist naturgemäß typgebunden.
Hier noch ein Beispiel ohne Bitoperationen, sondern nur mit gewöhnlichen
Additionen:
1
procedure test;
2
const
3
b1 = 100;
4
5
var
6
b2: byte;
7
i: smallint;
8
9
begin
10
i := b1 + 200; { -> 300 }
11
do_something_with(i);
12
13
b2 := 100;
14
i := b2 + 200; { -> 44 }
15
do_something_with(i);
16
end;
Wie es scheint, liegt dieses (zumindest für C-Programmierer seltsam
anmutende) Verhalten an der Auswertung konstanter Ausdrücke:
Solche Ausdrücke werden durch den Compiler ausgewertet, wobei ein
Wertebereich von -2⁶³..+2⁶⁴-1 (das ist die Vereinigung von int64 und
uint64) abgedeckt wird. Wird dieser Wertebereich überschritten, meldet
der Compiler einen Overflow-Error, ansonsten ist das Ergebnis immer
mathematisch korrekt. Anders als in C wird das Ergebnis also nicht auf
eine bestimmte Bitbreite beschnitten.
Beispiel:
1
Ausdruck: 1000 * 1000
2
AVR-FPC: -> 1000000
3
AVR-GCC: -> 16960 (= 1000000 mod 2¹⁶)
Erst nach der Auswertung des konstanten Ausdrucks wird sein Typ
bestimmt, und zwar abhängig vom berechneten Wert.
Beispiel:
1
Ausdruck Wert Typ
2
——————————————————————————————————————————————
3
10 + 10 20 uint8 bzw. byte
4
10 - 30 -20 int8
5
1000 * 1000 1000000 uint32 bzw. longword
6
usw.
7
——————————————————————————————————————————————
In einem Ausdruck, der auch Variablen enthält, werden zuerst die
konstanten Teilausdrücke ausgewertet und typisiert, dann kommen die in
der FPC-Dokumentation beschriebenen impliziten Typkonvertierungen zur
Anwendung (auf der Seite nach "type conversion" suchen):
https://www.freepascal.org/docs-html/current/ref/refsu4.html#x26-250003.1.1
In C wird für jede Teiloperation erst der Typ des oder der Operanden
bestimmt und danach mit einer von den Operandentypen abhängigen
Bitbreite das Ergebnis berechnet. Der Ablauf ist also genau andersherum
als in Free Pascal. Dieselbe Methode wird auch für variable Ausdrücke
angewandt, die erst zur Laufzeit berechnet werden.
Das führt letztendlich zu den folgenden Eigenschaften der beiden
Methoden:
Free-Pascal:
- Der Wert konstanter Ausdrücke ist immer richtig (oder der Compiler
bricht mit einer Fehlermeldung ab, wenn der Wert nicht mit 64 Bit
darstellbar ist, was aber selten passieren dürfte).
- Ausdrücke mit Variablen können zu abweichenden Ergebnissen führen, da
dort andere Auswertungsregeln gelten.
C:
- Der Wert wird bei Überläufen beschnitten und ist deswegen nicht immer
mathematisch korrekt.
- Das Ergebnis eines Ausdrucks hängt nur von dessen Operandenwerten und
-typen ab, ist aber unabhängig davon, ob es sich bei den Operanden um
Konstanten oder Variablen handelt.
Beide Sprachen haben also ein paar Überraschungen parat. Wenn man die
genannten Regeln genau kennt, kann man mit beiden Methoden gut leben.
Deswegen sollte man sich das Regelwerk einmal genau durchlesen, die
Frage ist nur, wo:
- Bei Free Pascal habe ich in der Dokumentation immer noch keine
Beschreibung der Auswertung und Typisierung konstanter Ausdrücke
gefunden, aber vielleicht habe ich auch einfach nur Tomaten auf den
Augen :)
Die ISO-Normen für Pascal und Extended Pascal stellen leider
keine Hilfe bei Fragen zu aktuellen Pascal-Implementationen dar.
- Für C gibt es viel mehr Informationsquellen (sowohl auf Papier als
auch im Netz). Im Zweifelsfall kann man die ISO-Norm zu Rate ziehen,
die solche (und andere) Dinge naturgemäß mit absoluter Präzision
beschreibt.
Jobst Q. schrieb:>> Meiner Theorie nach hätte Byte mal Byte plus Byte>> wiederum Byte ergeben sollen, so dass ich ein>> Ergebnis der Art "0x00??" erwartet hätte.>> Das zeigt doch schön, das dass grundsätzliche Problem> weder bei C noch bei Pascal liegt, sondern beim unären> Operator 'not' bzw '~'.
Hmm. Weiss nicht. Vielleicht ist das Problem nur mein
schlechtes Gedächtnis. Ich war GANZ sicher, das TurboPascal
bei
1
2
b1:=100;
3
b2:=200;
4
w:=b1*b2;
als Ergebnis "32" geliefert hätte. FreePascal liefert jedoch
20'000.
> Sein Verhalten ist naturgemäß typgebunden.
Sicher -- aber lt. Online-Hilfe ist "not" nur für Bytes (!)
definiert.
Im dargestellten Beispiel
1
2
b1:=100;
3
b2:=200;
4
b3:=1;
5
w:=not((b1*b2)+b3);
kommt lt. Test "w=45534" heraus, was das Negat von 20001 ist.
Wie kann es sein, dass in einem Ausdruck, der angeblich nur
aus Byte-Operanden und Byte-Operatoren besteht, bereits die
einzelnen Faktoren der Multiplikation (!!) auf 16bit erweitert
werden, obwohl in dem arithmetischen Ausdruck nichts steht,
das auch nur entfernt nach 16Bit aussieht?
Wer die integer promotion von C nicht mag - ist der Umgang von Free
Pascal mit ganzzahligen Rechnungen tatsächlich einfacher?
https://www.freepascal.org/docs-html/current/ref/refsu4.html#x26-260003.1.1Possetitjel schrieb:> Wie kann es sein, dass in einem Ausdruck, der angeblich nur> aus Byte-Operanden und Byte-Operatoren besteht, bereits die> einzelnen Faktoren der Multiplikation (!!) auf 16bit erweitert> werden, obwohl in dem arithmetischen Ausdruck nichts steht,> das auch nur entfernt nach 16Bit aussieht?
Das geschieht gemäss obiger Referenz, wenn die "native integer size" 16
Bits beträgt:
`Every platform has a ”native” integer size, depending on whether the
platform is 8-bit, 16-bit, 32-bit or 64-bit. e.g. On AVR this is 8-bit.
Every integer smaller than the ”native” size is promoted to a signed
version of the ”native” size. Integers equal to the ”native” size keep
their signedness.´
Wer das alles zu unintuitiv ist, der kann sich bei PL/I umsehen. Da legt
man bei der Deklaration von Variablen die Anzahl Bits vor und nach dem
Komma fest, "fixed binary (15,0)" ist eine 16 Bit Integer in binärer
Darstellung - das Vorzeichen geht extra, 15 Bits insgesamt, davon 0 nach
dem Komma.
Bei den Operatoren darf man dann kopfrechnen. Wenn man fixed(P,Q) und
fixed(R,S) addiert oder subtrahiert, dann kommt ein
fixed(MIN(N,1+MAX(P-Q,R-S)+MAX(Q,S)),MAX(Q,S)) raus, mit N als
implementiertem Maximum. Multiplikation ist natürlich einfacher:
fixed(MIN(N,P+R+1),Q+S). Also solange es in die Grenzen der
Implementierung passt gibts keinen Überlauf.
http://documentation.microfocus.com/help/topic/com.microfocus.eclipse.infocenter.studee60ux/BKPFPFEXPRMATHOPS.html
Bei Bitoperation war man ebenfalls sehr korrekt. Das macht man nicht mit
Zahlen, sondern mit Bitstrings deklarierter Länge. Und weil das eben
Strings sind, erweitern Operatoren auf Operanden unterschiedlicher Länge
den kürzeren String linksbündig. '10000'B | '01'B ergibt '11000'B
http://documentation.microfocus.com/help/topic/com.microfocus.eclipse.infocenter.studee60ux/BKPFPFEXPRS011.html
A. K. schrieb:> Das geschieht gemäss obiger Referenz,
Vielen Dank für den Link.
> wenn die "native integer size" 16 Bits beträgt:>> `Every platform has a ”native” integer size, [...]
Oh Gott. Nicht auch Pascal... !
Possetitjel schrieb:>> `Every platform has a ”native” integer size, [...]>> Oh Gott. Nicht auch Pascal... !
;-)
Nur dass Free Pascal auch 8 Bits als native integer zulässt.
Aber es ist schon ein wenig anders als in C. Komplizierter nämlich.
Beispielsweise weil es Ausnahmen gibt, etwa indem die Differenz zweier
vorzeichenloser Typen ein Vorzeichen hat. Und wenn man Typen mit und
ohne Vorzeichen mischt, kann es je nach Grösse auf ein Ergebnis
rauslaufen, das doppelt so gross ist. Beides ist nicht unlogisch, aber
kompliziert. Und natürlich ist das abhängig vom konkreten Pascal, Delphi
anders als Turbo Pascal.
Jobst Q. schrieb:> Wie ich schon weiter oben geschrieben habe, ist seine einzig sinnvolle> Anwendung das Zurücksetzen von Bits zusammen mit 'and' bzw '&', wodurch> die Typgebundenheit aufgehoben wird.
Ja klar, alle blöd ausser Du...
Die wohl berühmteste Routine des Forums:
https://www.mikrocontroller.net/articles/Entprellung#Timer-Verfahren_.28nach_Peter_Dannegger.29
Siehe unten bei C-Code.
Jobst Q. schrieb:> Wenn es um Invertierung geht, ist der binäre Operator 'xor' bzw '^'> immer die bessere und sicherere Wahl.
Schon deswegen nicht, weil xor immer eine Hilfsvariable braucht.
Michael R. schrieb:> Hast du mal ein wirklich konkretes Beispiel? Also nicht so ein> konstruiertes wie
Ich weiss ja nicht, ob Dir das konstruiert ist:
[code]void test(void) {
char a;
a = a * 4;
a = a << 2;
}
ldd r24,Y+1
lsl r24
lsl r24
std Y+1,r24
ldd r24,Y+1
clr r25
sbrc r24,7
com r25
lsl r24
rol r25
lsl r24
rol r25
std Y+1,r24[code]
Ich hab das damals mit uint8_t gemacht, aber das nimmt der GCC im
Codeexplorer nicht an, und AvrStudio 7 habe ich wegen exzessiver
Platzverschwendung von der Platte gehauen.
Yalu X. schrieb:> Erst nach der Auswertung des konstanten Ausdrucks wird sein Typ> bestimmt, und zwar abhängig vom berechneten Wert.
Und das ist gut so:
1
const
2
Cfcpu = 16000000; // 16MHz Quarz
3
...
4
const
5
fmul = 1 * Cfcpu div 1000000;
Bin ich ganz froh, das fmul hier nur ein Byte ist und nicht 4 Bytes.
A. K. schrieb:> Wer die integer promotion von C nicht mag - ist der Umgang von Free> Pascal mit ganzzahligen Rechnungen tatsächlich einfacher?
Ähm nein, da ist auch historisch viel Mist gewachsen. Deswegen verwende
ich für den AVR prinzipiell nur uint8, uint16, int8, int16. Auf dem PC
allerdings habe ich mir angewöhnt, dass ein Zähler von 1 bis 10 durchaus
integer sein darf, und damit je nach Maschine 32 oder 64 Bits, weil es
eh keinen Unterschied macht.
A. K. schrieb:> Da legt> man bei der Deklaration von Variablen die Anzahl Bits vor und nach dem> Komma fest, "fixed binary (15,0)" ist eine 16 Bit Integer in binärer> Darstellung - das Vorzeichen geht extra, 15 Bits insgesamt, davon 0 nach> dem Komma.
Ja und, Festkommazahl, geht bei Ada auch und für FreePascal gibts glaub
ich eine Lib für. Der AVR kann das ja sogar bedingt, allerdings scheint
es so ein Hirnkrampf für den Programmierer zu sein, dass es kaum jemand
nimmt.
Karl schrieb:> const> fmul = 1 * Cfcpu div 1000000;>> Bin ich ganz froh, das fmul hier nur ein Byte ist und> nicht 4 Bytes.
Verstehe ich nicht. Würde Dir die Hand abfaulen, wenn Du
Karl schrieb:> Ja und, Festkommazahl, geht bei Ada auch und für FreePascal gibts glaub> ich eine Lib für.
Es ging mir dabei weniger um die Nachkommastellen. Sondern darum, dass
das Ergebnis einer Addition von zwei 16-Bit Operanden ein Typ mit 17
Bits war. Das war die normale Integer-Rechnung, eine andere gab es
nicht.
Karl schrieb:> Und das ist gut so:> const> Cfcpu = 16000000; // 16MHz Quarz> ...> const> fmul = 1 * Cfcpu div 1000000;> Bin ich ganz froh, das fmul hier nur ein Byte ist und nicht 4 Bytes.
fmul ist eine Compilezeitkonstante. Die belegt auf dem Zielsystem kein
einziges Byte.
Michael R. schrieb:> Inwiefern? Grad vorher schreibst du, du hättest das alles selbst> geschrieben?
Beides.
Ich habe ein Projekt mit mehreren umfangreichen Berechnungen von C auf
Pascal übertragen und meiner Beobachtung nach produziert hier Pascal
besseren Code bzw. nutzt Register besser aus für die gleichen
Berechnungen.
Allerdings setzt Pascal genau wie C einige Berechnungen zu aufwändig um.
Für a32 = b16 x c16 muss zwingend b und c auf 32 Bit erweitert werden
und eine 32 Bit Multiplikation ausgeführt werden. Mit einer 16 Bit
Multiplikation ist a auch nur 16 Bit.
In Assembler kann ich aber b16 und c16 problemlos zu a mit 32 Bit
multiplizieren.
Nun müssen bei 32x32 Bit natürlich selbst unter Verwendung des
Hardware-Multiplizierers deutlich mehr Register rumgeschubst werden als
bei 16 x 16 Bit, einschließlich des pushens und poppens dieser Register,
der längeren Laufzeit und des größeren Speicherbedarfs. Da dauert die
Berechnung durchaus 20mal so lange. Bei Division ist es noch extremer,
da alles in Software.
Und nun kommts drauf an: Muss ich nur ab und zu einen Wert berechnen,
nehm ich die fertigen Routinen. Muss ich was in Echtzeit berechnen, über
viele Werte, sprich es muss einfach schnell sein, nehm ich die
optimierten Assembler-Routinen.
Karl schrieb:> Jobst Q. schrieb:>> Wenn es um Invertierung geht, ist der binäre Operator 'xor' bzw '^'>> immer die bessere und sicherere Wahl.>> Schon deswegen nicht, weil xor immer eine Hilfsvariable braucht.
Meistens keine Variable, sondern eine Konstante. Und mit dieser
Konstante kann man genau bestimmen, wieviele und welche Bits invertiert
werden. Unabhängig vom Compiler, vom Zielprozessor und von irgendwo
festgelegten Typen. Also nur Vorteile.
Jobst Q. schrieb:> Meistens keine Variable, sondern eine Konstante.
Es gibt kein xor mit Konstante auf dem AVR. Du musst eine Konstante
immer erst in ein Register laden und dann kannst Du das Register mit
Deinem Wert ver-xor-en.
Karl schrieb:> Allerdings setzt Pascal genau wie C einige Berechnungen zu aufwändig um.> Für a32 = b16 x c16 muss zwingend b und c auf 32 Bit erweitert werden> und eine 32 Bit Multiplikation ausgeführt werden.
Der AVR-GCC macht das schon seit geraumer Zeit besser, zumindest bei
Controllern mit Hardwaremultiplizierer. Johann, der auch hier im Forum
aktiv ist, hat's gerichtet:
https://gcc.gnu.org/ml/gcc-patches/2011-06/msg02114.html
Die selbstgeschriebene 16-Bit-Multiplikation mit 32-Bit-Ergebnis
benötigst du nur noch für Pascalprogramme.
Jobst Q. schrieb:> Und mit dieser Konstante kann man genau bestimmen,> wieviele und welche Bits invertiert werden.> Unabhängig vom Compiler, vom Zielprozessor und von> irgendwo festgelegten Typen. Also nur Vorteile.
Mit Verlaub -- aber da widerspreche ich.
Von einer Hochsprache, die den Namen verdient, erwarte
ich schon, dass ich die üblichen booleschen Operationen
einfach im Klartext (egal, ob Schlüsselwort oder
Sonderzeichen-Operator) hinschreiben kann -- und nicht
erst den Karnaugh-Plan im Kopf aufstellen muss. Als
"üblich" würde ich mal NOT, AND, OR, XOR auffassen.
(Auf der Siemens-S7-SPS geht das in AWL nicht so einfach;
es ist ein ziemlicher Krampf, dort einen Flankendetektor
zu formulieren, denn (NOT(alt) AND neu) funktioniert nicht.)
Vielleicht übersehe ich ja etwas, aber mir erschließt
sich das fundamentale Problem mit "NOT" nicht. Das ist
ein unärer Operator, der Datentyp des Ergebnisses kann
(=sollte) also derselbe wie der des Operanden sein.
A. K. schrieb:> Possetitjel schrieb:>>> `Every platform has a ”native” integer size, [...]>>>> Oh Gott. Nicht auch Pascal... !>> ;-)>> Nur dass Free Pascal auch 8 Bits als native integer> zulässt.
Naja, ich halte, drastisch formuliert, native integers
generell für Schwachsinn und einen Irrweg.
Hochsprachen sollten die Portabilität fördern -- und
nicht noch dazu einladen, die Plattformabhängigkeiten
gleichmäßig über den Quelltext zu verteilen.
> Beides ist nicht unlogisch, aber kompliziert. Und natürlich> ist das abhängig vom konkreten Pascal, Delphi anders als> Turbo Pascal.
Furchtbar.
Aber an die heilige Kuh, die seit Jahrzehnten tradierte
implizite Modulo-Arithmetik, hat sich wieder einmal niemand
herangetraut. Typisch.
Possetitjel schrieb:> Naja, ich halte, drastisch formuliert, native integers> generell für Schwachsinn und einen Irrweg.
Viele Prozessoren favorisieren bestimmte Datentypen. 32-Bit RISCs tun
sich bei Rechnungen mit 32-Bit Integers leichter als mit kleineren
Typen. Wenn eine Sprache also der Implementierung die Möglichkeit gibt,
in der favorisierten Breite zu rechnen ohne bei jedem Schritt auf
Einhaltung einer kleineren Breite zu bestehen, dann ist das schlicht ein
Tribut an die Effizienz.
A. K. schrieb:> Viele Prozessoren favorisieren bestimmte Datentypen. 32-Bit> RISCs tun sich bei Rechnungen mit 32-Bit Integers leichter> als mit kleineren Typen.
Ja, ich weiss. Das ist mir klar.
> Wenn eine Sprache also der Implementierung die Möglichkeit> gibt, in der favorisierten Breite zu rechnen ohne bei jedem> Schritt auf Einhaltung einer kleineren Breite zu bestehen,> dann ist das schlicht ein Tribut an die Effizienz.
Sicher -- aber dazu ist kein "native integer" notwendig.
Es wäre völlig ausreichend, wenn man beim Definieren
der Variablen keinen "Typ", sondern außer dem Hinweis
"integer" noch den notwendigen Wertebereich angeben könnte:
1
2
var
3
menuepunkt : integer range(1..20);
Das würde genau denselben Effekt erzielen; der Compiler
wäre völlig frei in seiner Entscheidung, auf welchen
plattform-eigenen Typ er diese Variable abbildet -- aber
es wäre dennoch vollständig portabel.
Possetitjel schrieb:> Hochsprachen sollten die Portabilität fördern -- und> nicht noch dazu einladen, die Plattformabhängigkeiten> gleichmäßig über den Quelltext zu verteilen.
in Ergänzung zu A.K.s richtigem Kommentar meine ich, dass "native
integers" genau das tun - Portabilität fördern.
Wenn ich schreibe
1
for(inti=42;i>0;i--){
2
magic_smoke(i)
3
}
dann möchte ich dass auf einer 64-bit-CPU i 64 bit hat, detto mit 32, 16
(mal abgesehen davon dass der hochoptimierende Compiler noch eingreift)
Possetitjel schrieb:> Von einer Hochsprache, die den Namen verdient, erwarte> ich schon, dass ich die üblichen booleschen Operationen> einfach im Klartext (egal, ob Schlüsselwort oder> Sonderzeichen-Operator) hinschreiben kann -- und nicht> erst den Karnaugh-Plan im Kopf aufstellen muss. Als> "üblich" würde ich mal NOT, AND, OR, XOR auffassen.
Die Probleme treten ja nicht bei den boolschen (logischen) Operatoren
auf, sondern bei den Bitoperatoren. C unterscheidet das aus gutem Grund
mit unterschiedlichen Zeichen. ! && || für die Logik und ~ & | ^ für die
Bitmanipulationen.
Bei den Bitoperatoren ist das NOT ~ als unärer ein typabhängiger
Sonderfall. Es hängt vom Typ ab, wieviele Bits betroffen sind. Bei den
binären Operatoren AND, OR und XOR wird das von den Operanden bestimmt.
Deshalb würde ich das ~ vermeiden, so gut es geht, aus Gründen der
Vorhersehbarkeit und der Portabilität, die du ja auch sehr schätzt.
Possetitjel schrieb:> (Auf der Siemens-S7-SPS geht das in AWL nicht so einfach;> es ist ein ziemlicher Krampf, dort einen Flankendetektor> zu formulieren, denn (NOT(alt) AND neu) funktioniert nicht.)
Wieso?
U Neu; UN Alt; = PosFlanke;
UN Neu; U Alt; = NegFlanke;
U Neu; X Alt; = Aenderung;
...
U Neu; = Alt;
Michael R. schrieb:> Possetitjel schrieb:>> Hochsprachen sollten die Portabilität fördern -- und>> nicht noch dazu einladen, die Plattformabhängigkeiten>> gleichmäßig über den Quelltext zu verteilen.>> in Ergänzung zu A.K.s richtigem Kommentar meine ich,> dass "native integers" genau das tun - Portabilität> fördern.
Nur in speziellen Fällen.
> Wenn ich schreibe> for (int i = 42; i> 0; i--) {> magic_smoke(i)> }
Das darf man m.W. in Pascal nicht schreiben; diese
"inline-Deklaration" war zumindest bisher nicht erlaubt.
> dann möchte ich dass auf einer 64-bit-CPU i 64 bit hat,> detto mit 32, 16 (mal abgesehen davon dass der> hochoptimierende Compiler noch eingreift)
Bei allem gebotenen Respekt glaube ich, dass Du EIGENTLICH
etwas anderes willst: Den Integer-Datentyp, der
1. maximale Rechengeschwindigkeit ermöglicht und
2. den notwendigen Zahlbereich abdeckt.
Oder möchtest Du im (leicht modifizierten) Beispiel:
1
2
for (int i = 300; i> 0; i--) {
3
magic_smoke(i)
4
}
auf einer 8-bit-Maschine einen Compilerfehler bekommen?
Ich würde das nicht wollen.
Possetitjel schrieb:> var> menuepunkt : integer range(1..20);> Das würde genau denselben Effekt erzielen; der Compiler> wäre völlig frei in seiner Entscheidung, auf welchen> plattform-eigenen Typ er diese Variable abbildet -- aber> es wäre dennoch vollständig portabel.
Eine solche Spezifikation geht am Problem vorbei. Denn das Problem
besteht nicht in der Breite der Speicherung von Variablen. Sondern in
der Breite der Berechnung von Ausdrücken, die Variablen verwenden. Wenn
du dieses Regelwerk nur von solchen Deklarationen abhängig machst, dann
landest du ungefähr beim erwähnten PL/I, also mit individuellen
Rechenbreiten für jeden Rechenschritt. Nur eben in Wertebereichen, statt
wie in PL/I in Bits oder Digits.
Die Multiplikation zweier [1..100] Variablen ergäbe also ein
Zwischenergebnis [1..10000] und müsste somit mit mindestens 16 Bits
stattfinden. Denn du wirst mit Variablen, die als [1..100] deklariert
sind, wohl kaum meinen, dass dies auch auf das Produkt zutreffen sollte.
Weitere Rechenschritte führen dann zu weiteren möglichen Änderungen in
der Rechenbreite. Wird dabei von der Implementierung vorgegebene
Maximalbreite überschritten - und das ist bei Multiplikationen schnell
der Fall - dann dürfte nicht implizit abgeschnitten werden, denn das
wäre ja nicht portabel. Es liefe also darauf hinaus, bei vielen
Rechenausdrücken für einzelne Zwischenschritte jeweils explizit die
Rechenbreite im Programm anzugeben. Also sowas wie
x *[0..50000] y
statt
x * y
um dem Compiler mitzuteilen, dass er nur mit diesem Wertebereich rechnen
muss, auch wenn die Teilrechnungen hinter x und y eigentlich eher eine
nicht vorhandene 256-Bit Multiplikation erzwängen.
Bei Operationen auf Bits gibts das ähnlich, nämlich bei Linksshifts,
wenn die rechte Seite nicht konstant ist. Da lässt sich die
erforderliche Rechenbreite im Programm nur schlecht statisch aus den
Typen der Teilausdrücke ableiten, so dass auch hier der Programmierer
bei jeder einzelnen solchen Operation explizit abgeben müsste, wie breit
sie durchgeführt werden muss.
Alternativ wären ausschliesslich Berechnungen der Form
a = b <op> c
und
a = <op> c
mit Variablen a,b,c zulässig, weil sich dann aus dem Typ von a,b,c die
Breite der Berechnung ableiten liesse. Komplexere Rechenausdrücke
müssten entsprechend zerlegt werden. Also nix mit a = b * c - d.
Viel Spass.
Possetitjel schrieb:> Oder möchtest Du im (leicht modifizierten) Beispiel:> for (int i = 300; i> 0; i--) {> magic_smoke(i)> }> auf einer 8-bit-Maschine einen Compilerfehler bekommen?
In einer Sprache, in der sich der Typ von "i" aus dem Typ der
Initialisierung und der Verwendung ergibt, liesse sich das in diesem
Beispiel vermeiden. Allerdings müsste dann die interne Darstellung von
"i" in
for (integer i = 100; i > x; i--)
magic_smoke(i)
eigentlich vom Typ von "x" (kann -1000000 sein) und vielleicht auch von
der Parameterdeklaration von magic_smoke abhängen. In komplexeren
Beispielen blickt dann aber schnell niemand mehr durch.
In einem C Statement
for (int i = 300000; i > 0; i--)
würde ich es allerdings schon vorziehen, gewarnt zu werden, wenn int nur
16 Bits haben sollte. Du wirklich nicht?
A. K. schrieb:> Possetitjel schrieb:>> var>> menuepunkt : integer range(1..20);>>> Das würde genau denselben Effekt erzielen; der Compiler>> wäre völlig frei in seiner Entscheidung, auf welchen>> plattform-eigenen Typ er diese Variable abbildet -- aber>> es wäre dennoch vollständig portabel.>> Eine solche Spezifikation geht am Problem vorbei. Denn> das Problem besteht nicht in der Breite der Speicherung> von Variablen. Sondern in der Breite der Berechnung von> Ausdrücken, die Variablen verwenden.
Nee, Moment.
Ich kann Dir folgen -- aber das sind unterschiedliche
Teilprobleme.
Wir waren zwischendurch auf die "native Integers" abge-
schweift, darauf, dass ich sie für einen Irrweg halte, und
Deine Entgegnung, dass man sie aus Performancegründen
dennoch haben will.
Meine Erwiderung DARAUF ist: Die Typsysteme gängiger
Programmiersprachen spezifizieren z.T. das Falsche. Für
eine Laufvariable ist u.U. völlig wurscht, wievel Speicher
sie benötigt -- man will einfach, dass die Kiste schnell
und richtig rechnet. Man sollte daher eine Möglichkeit
schaffen, solche Variablen nach WERTEBEREICH und nicht
nach SPEICHERBEDARF zu deklarieren.
Das bringt nämlich die gegensätzlichen Forderungen nach
Performance und Portabilität unter einen Hut: Wenn den
Programmierer der Speicherbedarf nicht interessiert,
sondern nur ein bestimmter Wertebereich gefordert wird,
dann soll er gefälligst auch den Wertebereich angeben --
und nicht die Speichergröße!
Der Unterschied meines Vorschlages zum "native integer"
ist: Der Compiler kann prüfen, ob der Zahlbereich
ausreicht, und bei Portierung auf eine andere Plattform
mit anderer native-integer-Größe einen geeigenten
non-native-integer wählen!
Das hat aber mit der hauptsächlich diskutierten Frage
nach "integer promotion", impliziter Typkonvertierung
usw. nicht direkt zu tun, das war ein Seitenast.
Thomas H. schrieb:> Zitat von einem unserer Informatiker: "Code soll für> einen selbst übersichtlich und lesbar sein. Optimierung macht der> Compiler".
Sollte über (und unter) jedem Tutorial stehen.
A. K. schrieb:> In einer Sprache, in der sich der Typ von "i" aus> dem Typ der Initialisierung und der Verwendung ergibt,> liesse sich das in diesem Beispiel vermeiden.
Ich möchte nicht missverstanden werden: Es ging mir
nicht darum, die üblichen Typen generell abzuschaffen
und durch die Wertebereichs-Spezifikation oder irgend
eine Art von Heuristik zu ersetzen.
Der Vorschlag war nur, ZUSÄTZLICH eine Typspezifikation
über den Wertebereich zu haben, damit der Programmierer
die (plattformunabhängige) Kontrolle über den Wertebereich
behält, die Auswahl der internen Zahldarstellung aber dem
Compiler überlassen kann.
> Allerdings müsste dann die interne Darstellung von> "i" in> for (integer i = 100; i > x; i--)> magic_smoke(i)> eigentlich vom Typ von "x" (kann -1000000 sein) und> vielleicht auch von der Parameterdeklaration von> magic_smoke abhängen.
Naja, ich hatte eigentlich Pascal vor Augen, wo diese
on-the-fly-Deklarationen m.W. nicht erlaubt sind.
> In komplexeren Beispielen blickt dann aber schnell> niemand mehr durch.
Klar -- deswegen ja mein primitiver Vorschlag, den
gewünschten Wertebereich explizit durch Konstanten
anzugeben.
> In einem C Statement> for (int i = 300000; i > 0; i--)> würde ich es allerdings schon vorziehen, gewarnt zu> werden, wenn int nur 16 Bits haben sollte. Du wirklich> nicht?
Naja, in meinem Universum würde es das Problem nicht
geben, weil in
1
2
var
3
pixelcount : integer range(0..300000);
das "integer" nicht für einen spezifischen Datentyp
stehen sollte, sondern als Aufforderung an den Compiler,
aus den auf der jeweiligen Plattform zur Verfügung
stehenden Datentypen einen auszuwählen, der den geforderten
Zahlbereich -- im Beispiel also 1-300'000 -- abbilden kann.
Auf einer 32bit-Maschine und Optimierung auf Geschwindigkeit
wäre das ganz sicher ein 32bit-native-integer, auf einer
16-bit-Maschine sicherlich irgend etwas anderes.
Programme profitieren auf diese Art bei Portierung
"automatisch" von einer größeren Wortbreite, ohne dass bei
kleineren Prozessoren die Gefahr von unerkannten Überläufen
besteht.
Jobst Q. schrieb:> Possetitjel schrieb:>> (Auf der Siemens-S7-SPS geht das in AWL nicht so einfach;>> es ist ein ziemlicher Krampf, dort einen Flankendetektor>> zu formulieren, denn (NOT(alt) AND neu) funktioniert nicht.)>> Wieso?
Das weiss ich leider nicht mehr genau. Kann sein, dass es
nicht auf der S7, sondern der S5 war; bin nicht sicher.
Der Kernpunkt war jedenfalls, das "not(x)" durch "x xor 1"
nachgebildet werden musste. Natürlich geht das -- aber es
ist doch irgendwie Krampf. Muss das im dritten Jahrtausend
WIRKLICH noch sein?
Yalu X. schrieb:> Der AVR-GCC macht das schon seit geraumer Zeit besser, zumindest bei> Controllern mit Hardwaremultiplizierer. Johann, der auch hier im Forum> aktiv ist, hat's gerichtet:
Anscheinend 2011, der GCC 4.6.4 scheints nicht zu können, der ist von
2013.
Possetitjel schrieb:> Man sollte daher eine Möglichkeit> schaffen, solche Variablen nach WERTEBEREICH und nicht> nach SPEICHERBEDARF zu deklarieren.
Ist das (speziell bei Integer) nicht das Selbe? Zumindest bei mir im
Kopf ist das so... Die Wertebereiche von 8- und 16 bit signed/unsigned
hab ich eingebrannt, bei 32 Bit wirds schon eng ("irgendwas mit 4
vorne") und in 99.999% der Fälle muss ich nicht nachdenken ob ich 0..255
oder 0..65535 oder mehr brauche.
Aber wie oben schon richtig festgestellt wurde, Variablen sind nicht so
schwierig, komplexer sind Ausdrücke. Aber auch hier habe zumindest ich
keine Probleme mit der Art wie C das angeht. Die Fälle wo ich hier
Fehler suchen und durch einen cast beheben musste, kann ich vermutlich
an einer Hand abzählen.
Possetitjel schrieb:> Aber an die heilige Kuh, die seit Jahrzehnten tradierte> implizite Modulo-Arithmetik, hat sich wieder einmal niemand> herangetraut. Typisch.
Erklärst du mir was du hier meinst? Bezieht sich das auf pascal? (dann
muss ichs nicht verstehen, siehe ich & Python)
Karl schrieb:>> Hast du mal ein wirklich konkretes Beispiel? Also nicht so ein>> konstruiertes wie>> Ich weiss ja nicht, ob Dir das konstruiert ist:>>
1
>voidtest(void){
2
>chara;
3
>a=a*4;
4
>a=a<<2;
5
>}
6
>
>>
1
> ldd r24,Y+1
2
> lsl r24
3
> lsl r24
4
> std Y+1,r24
5
> ldd r24,Y+1
6
> clr r25
7
> sbrc r24,7
8
> com r25
9
> lsl r24
10
> rol r25
11
> lsl r24
12
> rol r25
13
> std Y+1,r24[code]
14
>
Wenn ich dein Beispiel so kompiliere, kommt nix raus, a wird nicht
verwendet und deshalb komplett rausoptimiert.
ich habs aber mal leicht modifiziert:
1
charKarl(chara)
2
{
3
a=a*4;
4
a=a<<2;
5
returna;
6
}
Daraus wird bei mir:
1
Karl:
2
swap r24
3
andi r24,lo8(-16)
4
ret
5
.size Karl, .-Karl
keine 16 bit, und optimaler code (ich denke das lässt sich auch von Hand
nicht mehr verbessern)
Das von dir beschriebene Ergebnis kriege ich, wenn ich mit -O0 (disable
all optimizations) kompiliere. Warum machst du das?
Karl schrieb:>> Der AVR-GCC macht das schon seit geraumer Zeit besser, zumindest bei>> Controllern mit Hardwaremultiplizierer. Johann, der auch hier im Forum>> aktiv ist, hat's gerichtet:>> Anscheinend 2011, der GCC 4.6.4 scheints nicht zu können, der ist von> 2013.
Auch -O0 ? Damit löst mein avr-gcc 4.8.1 (auch 2013) das auch noch nach
__mulhi3 auch, mit -Os (was eigentlich Standard auf AVR sein sollte)
aber sehr wohl nach __umulhisi3 (der 32=16*16 widening multiplication)
Possetitjel schrieb:> Der Vorschlag war nur, ZUSÄTZLICH eine Typspezifikation> über den Wertebereich zu haben, damit der Programmierer> die (plattformunabhängige) Kontrolle über den Wertebereich> behält, die Auswahl der internen Zahldarstellung aber dem> Compiler überlassen kann.
Das hatte ich schon verstanden. Aber du stelltest diese Datentypen
direkt in den Kontext deiner Ablehnung von native integers und eine
solche (sinnvolle) Typdeklaration ändert nichts daran, dass man Regeln
benötigt, in welcher Breite sowohl damit als auch mit normalen Integers
gerechnet werden soll.
Pascals native Integers sind kein Aspekt der Speicherung von Daten,
sondern betreffen nur die Breite der Berechnung in Ausdrücken. Mit einer
möglichen Wertebereichsdefinition von Variablen wirst du sie nicht los.
> Naja, ich hatte eigentlich Pascal vor Augen, wo diese> on-the-fly-Deklarationen m.W. nicht erlaubt sind.
Solche Details sind für Grundfragen zur Typisierung von Integers
irrelevant. In C geht das auch erst seit C99.
> stehenden Datentypen einen auszuwählen, der den geforderten> Zahlbereich -- im Beispiel also 1-300'000 -- abbilden kann.
Damit beschreibst du wieder die Festlegung von Variablen ...
> Auf einer 32bit-Maschine und Optimierung auf Geschwindigkeit> wäre das ganz sicher ein 32bit-native-integer, auf einer> 16-bit-Maschine sicherlich irgend etwas anderes.
... um sofort zur Breite der Berechnung von Ausdrücken umzuschwenken.
Denn eine 32-Bit Maschine kann (heute) Daten im RAM stets auch kleiner
speichern, tut sich aber im Umgang mit diesen Daten evtl leichter, wenn
sie dafür auf native integer erweitert werden.
Die sinnvolle Möglichkeit, [1..100] im Array als Byte zu speichern, in
einer explizit definierten lokalen Variable, die im Register liegt, aber
in voller Wortbreite, erspart nicht die Festlegung, in welche Breite man
mit diesen Daten umgehen sollte. Und da kommen die native integers in
Spiel.
A. K. schrieb:> PS: Da war doch was... Deine Wertebereichstypen gibts in Pascal doch> sowieso schon seit Anbeginn der Zeit.
Genau.
Und auch in C gibt es mit [u]int_fast<n>_t und [u]int_least<n>_t
flexible Datentypen, mit denen auf portable Weise Wertebereiche für
Variablen festgelegt werden können, zwar nicht so feingranular wie in
Pascal, dafür kann man mit "fast" oder "least" angeben, ob man lieber
Rechenzeit oder Speicherplatz sparen möchte.
Possetitjel schrieb:> A. K. schrieb:>> Eine solche Spezifikation geht am Problem vorbei. Denn>> das Problem besteht nicht in der Breite der Speicherung>> von Variablen. Sondern in der Breite der Berechnung von>> Ausdrücken, die Variablen verwenden.>> Nee, Moment.>> Ich kann Dir folgen -- aber das sind unterschiedliche> Teilprobleme.
Das erste Teilproblem, um das es dir schwerpunktmäßig geht, sehe ich in
Pascal und C als weitgehend gelöst an.
Das zweite, viel schwierigere Teilproblem hat A. K. diesem Beitrag sehr
gut umrissen:
A. K. schrieb:> Denn das Problem besteht nicht in der Breite der Speicherung von> Variablen. Sondern in der Breite der Berechnung von Ausdrücken, die> Variablen verwenden.> ...
Ich kenne keine (auch keine exotische) Programmiersprache, in der dieses
Problem zufriedenstellen gelöst wäre.
Interessant ist, dass selbst eine extrem "maschinenferne" Sprache wie
Haskell neben Integer-Typen mit fester und dynamischer Bitbreite einen
plattformspezifischen Integer-Typ (Int) hat. Im Gegensatz zu C wird Int
für Rechenoperationen aber nur dann verwendet, wenn auch die Operanden
von diesem Typ sind.
Yalu X. schrieb:> Ich kenne keine (auch keine exotische) Programmiersprache, in der dieses> Problem zufriedenstellen gelöst wäre.
ich denke das liegt auch daran, dass dieses Problem von Der Sprache bzw.
dem Compiler gar nicht gelöst werden kann; hier sehe ich den
Programmierer in der Pflicht. Nur er (oder sie) kann die Wertebereiche
abschätzen, und entsprechend reagieren.
Das zeigt sich schon bei einer einfachen Multiplikation: Die Bitbreite
des Ergebnisses ergibt sich aus der Summe der Bitbreiten der Operanden.
Wenn ich also zwei 16-bit-Werte multipliziere, müsste ich die Operation
in 32 bit ausführen, um sicher keinen Überlauf zu erhalten.
Wenn ich aber weiß (woher auch immer), dass das Ergebnis immer in 16
bit Platz finden wird, kann ich die Multiplikation in 16 bit ausführen,
was (zB am AVR) schneller und kürzer ist.
Dieses Wissen kann mir aber keine Sprache und kein Compiler abnehmen.
Possetitjel schrieb:> Jobst Q. schrieb:>>> Possetitjel schrieb:>>> (Auf der Siemens-S7-SPS geht das in AWL nicht so einfach;>>> es ist ein ziemlicher Krampf, dort einen Flankendetektor>>> zu formulieren, denn (NOT(alt) AND neu) funktioniert nicht.)>>>> Wieso?>> Das weiss ich leider nicht mehr genau. Kann sein, dass es> nicht auf der S7, sondern der S5 war; bin nicht sicher.>> Der Kernpunkt war jedenfalls, das "not(x)" durch "x xor 1"> nachgebildet werden musste. Natürlich geht das -- aber es> ist doch irgendwie Krampf. Muss das im dritten Jahrtausend> WIRKLICH noch sein?
Die AWL-Anweisungen sind nicht für alle CPUs gleich, nichtmal für die
Serien. Im Laufe der Zeit sind wohl einige dazugekommen.
Habe gerade gelesen, dass es zum Invertieren die Anweisungen INVI (16
Bit) und INVD (32 Bit) gibt, aber evtl erst ab S7-1500.
XOW und XOD gibt es aber wohl schon länger.
Michael R. schrieb:> ich denke das liegt auch daran, dass dieses Problem von Der Sprache bzw.> dem Compiler gar nicht gelöst werden kann;
Der aus dem Unix-Universum stammende "bc" kommt dem recht nahe. ;-)
Geht halt als Interpreter einfacher.
Michael R. schrieb:> Yalu X. schrieb:>> Ich kenne keine (auch keine exotische) Programmiersprache, in der dieses>> Problem zufriedenstellen gelöst wäre.>> ich denke das liegt auch daran, dass dieses Problem von Der Sprache bzw.> dem Compiler gar nicht gelöst werden kann; hier sehe ich den> Programmierer in der Pflicht.
Richtig. Man müsste dann für jede einzelne Rechenoperation den zu
erwartenden Wertebereich angeben, bspw. so:
A. K. schrieb:> x *[0..50000] y> statt> x * y
Aber das will man ja auch nicht wirklich.
A. K. schrieb:> Der aus dem Unix-Universum stammende "bc" kommt dem recht nahe. ;-)> Geht halt als Interpreter einfacher.
Das geht auch problemlos in kompilierten Sprachen (wird ja teilweise
tatsächlich auch gemacht), ist aber nicht unbedingt effizienzfördernd.
Yalu X. schrieb:> Richtig. Man müsste dann für jede einzelne Rechenoperation den zu> erwartenden Wertebereich angeben, bspw. so:>> A. K. schrieb:>> x *[0..50000] y>> statt>> x * y>> Aber das will man ja auch nicht wirklich.
Das reicht ja nicht mal!
ich konstruiere mal ein Beispiel: Länge eines Vektors der sich im
Inneren des Einheitskreises bewegt, bei auf 255 skaliertem
Einheitskreis. Basierend auf den Wertebereichen könnte der Vektor 360
lang werden, praktisch ist er aber nie größer als 255.
Oder anders gesagt: Immer wenn die Variablen nicht unabhängig sind,
können sich geringere Wertebereiche ergeben.
Yalu X. schrieb:> Das geht auch problemlos in kompilierten Sprachen (wird ja teilweise> tatsächlich auch gemacht),
Nur mit dynamischen Datentypen, deren Breite sich also zur Laufzeit
entwickelt. Klar, kann man als C++ Klasse machen und tut man sicherlich
auch. Angewandt auf alle normalen Integers der Sprache wäre das aber,
verglichen mit dem was man hier im Forum üblicherweise als Compiler
versteht, eher ein als Compiler getarnter Interpreter.
Michael R. schrieb:> Das reicht ja nicht mal!> ...> Oder anders gesagt: Immer wenn die Variablen nicht unabhängig sind,> können sich geringere Wertebereiche ergeben.
Genau deswegen braucht man ja die Wertebereichsangaben für die einzelnen
Rechenoperationen, für die A. K. die Syntax
<op>[<lo>..<hi>]
vorgeschlagen hat. Für dein Beispiel würde das so aussehen:
1
x, y, length: 0..255;
2
3
length := isqrt(sqr(x) +[0..65025] sqr(y))
Damit weiß der Compiler, dass die Addition nur 16- und nicht etwa
17-bit-breit ausgeführt werden muss, wie es bei unabhängigen x und y der
Fall wäre.
Entsprechendes gilt auch für Funktionsaufrufe. Wenn der Compiler nicht
von sich aus erkennt, dass der Aufruf von sqr([0..255]) einen
Wertebereich von [0..65025] hat, müsste der obige Ausdruck
folgendermaßen ergänzt werden:
Yalu X. schrieb:> <op>[<lo>..<hi>]
ok, das hatte ich falsch verstanden.
Yalu X. schrieb:> Ja, irgendwann ist ein Ausdruck dann so sehr mit Wertebereichshinweisen> gespickt, dass überhaupt keiner mehr durchblickt ;-)
Richtig, und diese (fiktive) Programmiersprache würde ich dann nicht
sooo gerne verwenden ;-)
Übrigens: Respekt, du hast mein (krudes) Beispiel besser verstanden als
ich selbst... der Trick liegt in der Addition, für die 16 Bit
ausreichend sind.
Michael R. schrieb:> Possetitjel schrieb:>> Man sollte daher eine Möglichkeit schaffen, solche>> Variablen nach WERTEBEREICH und nicht nach SPEICHERBEDARF>> zu deklarieren.>> Ist das (speziell bei Integer) nicht das Selbe?
Für den Menschen: Fast.
Für den Compiler: Nein.
> Zumindest bei mir im Kopf ist das so...
Ich weiss... anerkannte Berufskrankheit bei Programmierern :)
> Die Wertebereiche von 8- und 16 bit signed/unsigned> hab ich eingebrannt, bei 32 Bit wirds schon eng [...]
Nein, ich meine das anders: Wenn Du auf einer 8-bit-Maschine
einen kleinen endlichen Automaten mit - was weiss ich - 12
Zuständen programmierst, dann wirst Du für die Zustandsvariable
ein Byte wählen.
Wenn Du jetzt diesen Automaten auf einem ARM verwenden willst,
weil er super funktioniert, zwingst Du den Compiler, auch auf
dem ARM mit einem Byte zu operieren, obwohl ein 32bit-Wort viel
sinnvoller wäre.
Es gibt aber keine Möglichkeit, dem Compiler zu sagen: "Nimm
einen Dir passend scheinenden Integer-Typ, der (mindestens)
die Zahlen 1 bis 12 kennt".
Der Witz dieser Idee zeigt sich erst, wenn man sich einen
Zahlbereich 1..1000 und die Portierung in die umgekehrte
Richtung (vom ARM auf 8 bit) vorstellt: Theoretisch wäre
ein ja word (16bit) ausreichend.
Wenn es meine wertebereichsgesteuerte Typauswahl gäbe, würde
der Compiler auf dem ARM schätzungsweise ein longint wählen --
auf einer 8-bit-Maschine aber tatsächlich ein word, weil das
der kleinste Integer ist, der den Zahlbereich abdeckt.
Die Bereichsangabe 1..1000 ist vollständig portabel; dennoch
könnte vom Compiler immer der optimale Datentyp gewählt werden.
> Aber wie oben schon richtig festgestellt wurde, Variablen> sind nicht so schwierig, komplexer sind Ausdrücke.
Kommt darauf an. Fließkomma kann außer Betracht bleiben, weil
dort die niederwertigsten Bits (und nicht die höchstwertigen)
wegfallen. Das fällt in die Zuständigkeit der Numerik.
Bitoperationen spielen auch keine Rolle, weil die keinen
Überlauf erzeugen, und wenn sie vernünftig implementiert bzw.
definiert sind, auch keine versteckte Typabhängigkeit haben.
Als Problemfälle bleiben nur die Ganzzahl-Ausdrücke.
> Aber auch hier habe zumindest ich keine Probleme mit der> Art wie C das angeht. Die Fälle wo ich hier Fehler suchen> und durch einen cast beheben musste, kann ich vermutlich> an einer Hand abzählen.
Sicher eine Sache der Gewohnheit.
Ich bin der Meinung, dass
1. die Regeln EINFACH sein und
2. sich nicht dauernd ändern sollten.
Der Rest ist ziemlich wahlfrei.
Michael R. schrieb:> Possetitjel schrieb:>> Aber an die heilige Kuh, die seit Jahrzehnten tradierte>> implizite Modulo-Arithmetik, hat sich wieder einmal niemand>> herangetraut. Typisch.>> Erklärst du mir was du hier meinst?
Klar.
> Bezieht sich das auf pascal?
Nee.
Jeder hält es für normal, dass bei...
1
2
var b : byte;
3
...
4
b:=255;
5
incr(b);
... für b Null herauskommt.
Nicht nur, dass das mathematisch falsch und unter dem
Gesichtspunkt der Anwendungslogik häufig unsinnig ist, es
ist auch deshalb ärgerlich, weil der Prozessor intern den
Überlauf sehr wohl registriert, das Flag aber nicht an die
Hochsprache durchreicht.
Dass es auch anders geht, zeigen die diversen SIMD-Einheiten,
die (auch) eine Sättigungsarithmetik haben.
A. K. schrieb:> Das hatte ich schon verstanden. Aber du stelltest diese> Datentypen direkt in den Kontext deiner Ablehnung von> native integers und eine solche (sinnvolle) Typdeklaration> ändert nichts daran, dass man Regeln benötigt, in welcher> Breite sowohl damit als auch mit normalen Integers gerechnet> werden soll.>> Pascals native Integers sind kein Aspekt der Speicherung von> Daten, sondern betreffen nur die Breite der Berechnung in> Ausdrücken. Mit einer möglichen Wertebereichsdefinition von> Variablen wirst du sie nicht los.
Du hast Recht, ich zwei verschiedene Fragen vermischt.
Entschuldigung.
Mein zügelloses Wettern gegen "native integers" bezog sich
auf den "int"-Datentyp, wie er in C existiert. Während man
z.B. bei "uint8_t" gleichzeitig SOWOHL Speicherbedarf ALS
AUCH Wertebereich festlegt, legt man bei "int" außer der
Tatsache, dass es ganze Zahlen sein sollen, ÜBERHAUPT NICHTS
fest -- also Übertreibung in die andere Richtung.
Die Sachlage in Pascal ist anders; da geht es, wie Du richtig
bemerkst, um die Auswertung von Ausdrücken. Ich muss jetzt,
beim erneuten ruhigen Durchdenken, auch zugeben, dass die
implementierte Lösung einen gewissen Charme hat -- aber
ärgerlich ist sie andererseits doch, denn es entsteht eine
verdeckte Plattformabhängigkeit.
A. K. schrieb:> PS: Da war doch was... Deine Wertebereichstypen gibts> in Pascal doch sowieso schon seit Anbeginn der Zeit.
Die haben natürlich bei meinem Vorschlag Pate gestanden.
Ich weiss aber nicht, ob sie genau das leisten, was ich
haben will: Ich will ja keinen NEUEN Datentyp erzeugen, der
dann Pascal-typisch wieder nur zu sich selbst zuweisungs-
kompatibel ist -- ich will, dass der Compiler aus den
EXISTIERENDEN Integertypen einen passenden auswählt.
Aus meinen antiken Pascal-Büchern kann ich nicht heraus-
lesen, wie die Teilbereichstypen im Detail funktionieren.
Yalu X. schrieb:> Und auch in C gibt es mit [u]int_fast<n>_t und> [u]int_least<n>_t flexible Datentypen, mit denen> auf portable Weise Wertebereiche für Variablen> festgelegt werden können, zwar nicht so feingranular> wie in Pascal, dafür kann man mit "fast" oder "least"> angeben, ob man lieber Rechenzeit oder Speicherplatz> sparen möchte.
Ahh... richtig, da war was. Danke für die Erinnerung;
das war mir komplett entfallen.
> A. K. schrieb:>> Denn das Problem besteht nicht in der Breite der>> Speicherung von Variablen. Sondern in der Breite>> der Berechnung von Ausdrücken, die Variablen verwenden.>> ...>> Ich kenne keine (auch keine exotische) Programmiersprache,> in der dieses Problem zufriedenstellen gelöst wäre.
Ich weiss ja nicht, was für Dich "zufriedenstellend" ist.
Da Tcl überhaupt kein für den Programmierer zugängliches
Typkonzept kennt, ist in Tcl natürlich auch die Unterscheidung
verschieden langer Integers hinfällig.
Yalu X. schrieb:>> Oder anders gesagt: Immer wenn die Variablen nicht>> unabhängig sind, können sich geringere Wertebereiche>> ergeben.>> Genau deswegen braucht man ja die Wertebereichsangaben> für die einzelnen Rechenoperationen, [...]
Nee... die braucht man nur für die µC.net-typische
Übertreibung... :)
Es gibt doch erstmal drei separate Probleme:
- Portabilität,
- Auswertungsregeln, die Überlauf verhindern,
- Effizienz.
Mein Ausgangspunkt war gar nicht, dass ich immer und
überall den Überlauf zuverlässig verhindern will --
es ging mir nur darum, dass nicht plattformabhängig
mal ein Überlauf entsteht und mal nicht!
Anders ausgedrückt: Ich wollte keine plattformabhängigen
Auswertungsregeln.
Sicher gibt es keine ideale Sprache, die diesem Problem in Gänze gerecht
wird. Allerdings ist für mich C++ nah dran. Jeder C++-Programmierer
lernt / sollte lernen ziemlich am Anfang, dass eine der Ideen der
Sprache die (fast) Gleichbehandlung der primitive DT und UDT sind, mit
dem Hintergrund, sich ein domänenspezifisches Typsystem zu erzeugen
(nicht alles ist ein String oder ein int, es gibt Bytes, Meter, Volt,
etc. und entspr. Operationen).
Insofern adressiere ich das Problem mit Typen wie
[c]
uint_ranged<23, 57> x;
uint_ranged_NaN<0, 19999> y;
uint_circular<0, 15> z;
[\c]
Die notwendigen unterliegenden primitiven DT werden hier bspw. aus dem
Wertebereich bestimmt. Die Plattformabhängigkeit löst der Standard durch
uint_fast8_t, etc.
Statische Überläufe erkennt der Compiler, Laufzeitüberläufe als
Verlassen des Wertebereiches prüfen natürlich Assertionen (sind ja auch
abschaltbar).
Natürlich kann man sich mehr wünschen, aber so bin ich bzgl. Sicherheit
und Expressivität schon ein ziemliches Stück weiter als der "alles ist
ein unsigned char" Ansatz ...
Wilhelm M. schrieb:> Allerdings ist für mich C++ nah dran.
Endlich! Ich kaufe gleich Popcorn ein, für heute Abend und die nächsten
Wochen.
Wenn C++ ins Spiel kommt, wird es lustig.
F. F. schrieb:> Wilhelm M. schrieb:>> Allerdings ist für mich C++ nah dran.>> Endlich! Ich kaufe gleich Popcorn ein, für heute Abend und die nächsten> Wochen.
Ja, mich hat es auch schon gewundert, dass das noch keiner ins Spiel
gebracht hatte ... nun, ich muss ja meinem Ruf gerecht werden ;-)
Possetitjel schrieb:> Nein, ich meine das anders: Wenn Du auf einer 8-bit-Maschine> einen kleinen endlichen Automaten mit - was weiss ich - 12> Zuständen programmierst, dann wirst Du für die Zustandsvariable> ein Byte wählen.
Nein. Für die Zustandsvariable wähle ich eine Enumeration. Die kann man
auf einem AVR (allerdings per Compilerschalter) auch auf 8 Bit
eindampfen und wird je nach Wertebereich automatisch vergrößert.
> Es gibt aber keine Möglichkeit, dem Compiler zu sagen: "Nimm> einen Dir passend scheinenden Integer-Typ, der (mindestens)> die Zahlen 1 bis 12 kennt".
Doch, und in C nennt der sich "enum" (mit benannten Werten).
Außerdem kennt C solche Datentypen wie uint_fast8_t und uint_least8_t,
mit denen ich genau solch ein Verhalten ausdrücken kann.
> Die Bereichsangabe 1..1000 ist vollständig portabel; dennoch> könnte vom Compiler immer der optimale Datentyp gewählt werden.
CPUs arbeiten auf Vielfachen von Bytes, und außerdem durchgängig im
Binärsystem. Wenn ich einen Wertebereich von 1..1000 angebe, dann
erwarte ich auch, dass dieser immer und ausnahmslos eingehalten wird.
Das kostet entweder Performance zur Laufzeit oder ich kann mit Über-
oder Unterläufen ungültige Werte produzieren. Möchte ich nicht.
> Als Problemfälle bleiben nur die Ganzzahl-Ausdrücke.
Also genau das, wofür Computer gebaut werden - Rechenoperationen. :-)
Possetitjel schrieb:> [Modulo-Arithmetik]> Dass es auch anders geht, zeigen die diversen SIMD-Einheiten,> die (auch) eine Sättigungsarithmetik haben.
Man kann dank der Modulo-Arithmetik bestimmte Dinge sehr effizient
umsetzen, was mit sättigender Arithmetik nicht ginge. Zumal CPUs bei
normaler Integer-Arithmetik nicht sättigen können.
Alles, was du möchtest, gibt es in höheren Sprachen, bei denen die
Laufzeitkosten kein Problem darstellt. Im Extremfall steht dann sowas
wie coq, bei dem jede Operation passend bewiesen werden muss (und wo die
Laufzeitkosten wieder wegfallen).
Possetitjel schrieb:> Mein zügelloses Wettern gegen "native integers" bezog sich> auf den "int"-Datentyp, wie er in C existiert.
Wie es ihn auch in Pascal gibt, siehe oben.
Wie es ihn in so ziemlich jeder Programmiersprache gibt, denn wenn man
darauf verzichtet, muss man mit arbitrary precision logic arbeiten und
das kostet Performance und Speicher.
> Während man> z.B. bei "uint8_t" gleichzeitig SOWOHL Speicherbedarf ALS> AUCH Wertebereich festlegt, legt man bei "int" außer der> Tatsache, dass es ganze Zahlen sein sollen, ÜBERHAUPT NICHTS> fest -- also Übertreibung in die andere Richtung.
Das ist falsch. Ein "int" ist mindestens 16 Bit lang und auf der CPU
effizient. Das sind grundsätzlich sinnvolle Randbedingungen und etwas
völlig anderes als "nichts".
Und wie gesagt, du darfst auch mit den fastN- und leastN-Typen
hantieren. Oder dich bei Java umschauen, wo Integer ein Objekt ist (dort
gibt es "int" nur auf Performance-Gründen, nur signed und m.W. mit
relativ undefinierter Breite).
Was du möchtest, ist an sich nicht verkehrt, aber es ist für
maschinennahe/effiziente Programmierung (und für nichts anderes ist C
entwickelt worden) aus den genannten Gründen nicht optimal. Da sind
andere Kompromisse wichtiger.
Wilhelm M. schrieb:> Sicher gibt es keine ideale Sprache, die diesem> Problem in Gänze gerecht wird. Allerdings ist für> mich C++ nah dran.
Nun ja, ich bin dabei, C zu lernen. Zielpunkt sind
Mikrocontroller.
Wäre es tatsächlich hilfreich, statt C eine noch
wesentlich mächtigere und komplexere Sprache zu
wählen? Ich habe da Zweifel...
Possetitjel schrieb:> Wilhelm M. schrieb:>>> Sicher gibt es keine ideale Sprache, die diesem>> Problem in Gänze gerecht wird. Allerdings ist für>> mich C++ nah dran.>> Nun ja, ich bin dabei, C zu lernen. Zielpunkt sind> Mikrocontroller.>> Wäre es tatsächlich hilfreich, statt C eine noch> wesentlich mächtigere und komplexere Sprache zu> wählen? Ich habe da Zweifel...
C++ ist schon klasse und ich wollte das nicht verunglimpfen. Es gab
einmal einen Thread hier, da wurde ein Problem so über Wochen (glaube
das ging eine Weile) zerrissen und es kamen quasi täglich neue "Götter
der C++ Kunst" hinzu und der Thread wurde eher philosophisch (vielleicht
übertreibe ich ein bisschen, aber deshalb das Popcorn) und war nicht
mehr zu lesen.
Possetitjel schrieb:> Wilhelm M. schrieb:>>> Sicher gibt es keine ideale Sprache, die diesem>> Problem in Gänze gerecht wird. Allerdings ist für>> mich C++ nah dran.>> Nun ja, ich bin dabei, C zu lernen. Zielpunkt sind> Mikrocontroller.>> Wäre es tatsächlich hilfreich, statt C eine noch> wesentlich mächtigere und komplexere Sprache zu> wählen? Ich habe da Zweifel...
Die Sprache C++ ist zwar komplexer und wesentlich mächtiger als C, aber
nicht notwendigerweise schwerer zu lernen. Das wird leider oft in einen
Topf geworfen. Ja, C++ ist eine Multiparadigmensprache: imperativ /
prozedural, objektorientiert, generisch / meta-programmatisch,
funktional. Doch man muss nicht alles auf einmal benutzen, sondern man
kann sich je nach Einsatzzweck das Richtige heraussuchen.
Sich auf C als Sprache oder auf den C-Anteil in C++ allein zu
beschränken, macht m.E. keinen Sinn. In einer general-purpose Umgebung
wie *nix/Win$$ greift man gerne auf OOP zurück, in einer eingeschränkten
Umgebung wie bare-metal µC findet man schnell eine Kombination aus
prozedural und meta-programmatisch hilfreich, ggf. mit einer Prise OOP.
Ich finde die Sichtweise "alles ist ein Integer oder ein hoffentlich
null-terminiertes char-Array" sehr einengend. In meinen Augen sind
solche SW-Konstrukte extrem schwer zu lesen, zu warten oder weiter zu
entwickeln. Hingegen fördern die richtigen Abstraktionen die Lesbarkeit
bzw. Expressivität und verhindern zur Compile-Zeit viele Fehler, die man
sonst zu Laufzeit suchen muss. Zudem hilft ein reiches Typsystem dem
Compiler bei der Optimierungsarbeit.
Wilhelm M. schrieb:> Insofern adressiere ich das Problem mit Typen wie
Wobei Possetitjel damit auch den Platzbedarf optimieren wollte. Wie
macht man das in C++? Also dass der Programmierer nicht doch wieder
explizit den Grundtyp "uint" in "uint_ranged<23, 57>" angeben muss, egal
ob wie hier hardcoded, oder als Parameter vom Template. Sondern der
Compiler sich das aus dem angegeben Bereich selbst ableiten kann. Für
die frühen C++ Versionen fällt mir da nichts sinnvolles ein.
A. K. schrieb:> Wilhelm M. schrieb:>> Insofern adressiere ich das Problem mit Typen wie>> Wobei Possetitjel damit auch den Platzbedarf optimieren wollte. Wie> macht man das in C++? Also dass der Programmierer nicht doch wieder> explizit den Grundtyp "uint" in "uint_ranged<23, 57>" angeben muss, egal> ob wie hier hardcoded, oder als Parameter vom Template. Sondern der> Compiler sich das aus dem angegeben Bereich selbst ableiten kann. Für> die frühen C++ Versionen fällt mir da nichts sinnvolles ein.
Mit einer Meta-Funktion, etwa so:
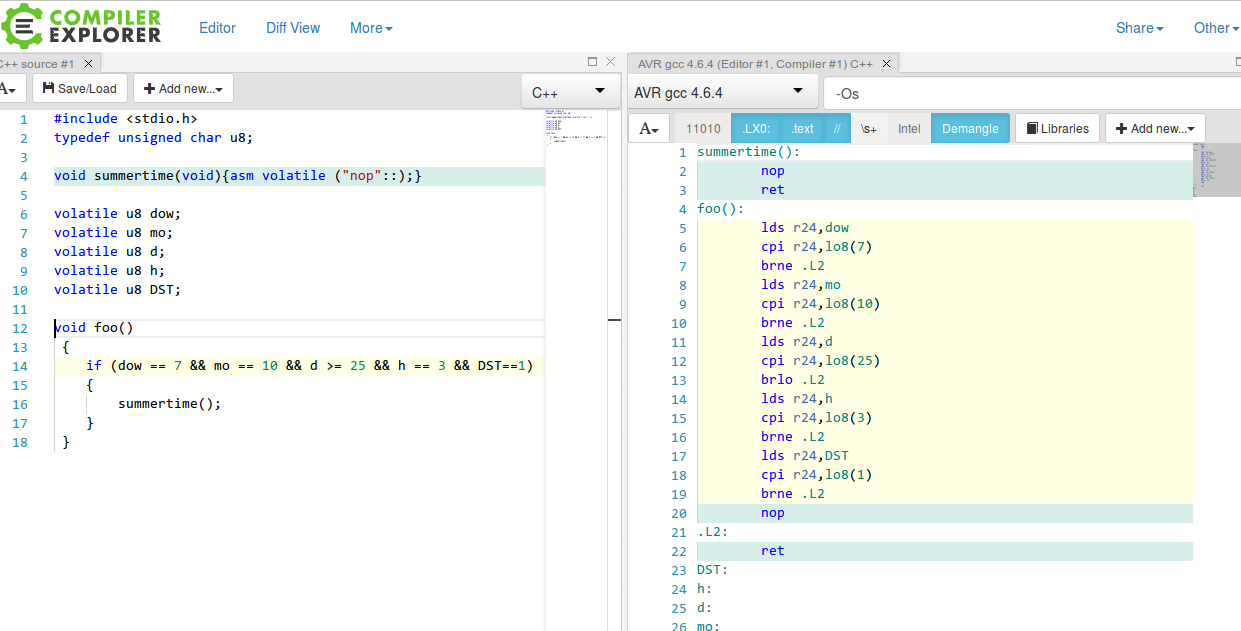
{kind=link}