Hallo zusammen, ich habe zu Lernzwecken einen Multiplizierer für signed Werte entworfen. Für unsigned gibt es ja recht viel, aber für vorzeichenbehaftete Werte wird es sehr dünn (da habe ich gar nichts gefunden, was lauffähig wäre!). Ich will explizit keinen HW-Block vom FPGA benutzen. Ich will es "zu Fuß" machen. Ich habe euch den Code angehängt und auch die Testbench dazu. Das funktioniert so wie man das in der Grundschule gemacht hat, also das schriftliche Multiplizieren. Für die negative Zahlen braucht man allerdings die Fallunterscheidung, sonst kommt ein falsches Ergebnis raus Allerdings ist das nur so, wenn der Operant_B negativ wird. Für Operant_A geht das auch direkt, wenn der negativ wird. Da bräuchte man die Fallunterscheidung noch nicht. Grund ist, dass der Operant_B für die Schiftoperation verwendet wird. Funktioniert auch soweit, wie ich es implementiert habe! :-) Die Frage ist, ob das schon die beste Lösung ist. Der Ressourcenverbrauch ist schon recht hoch, aber da fehlt mir noch das Bauchgefühl für. Kann man da insgesamt noch sparen oder eher nicht? Gibt es da noch Tricks, die man versuchen könnte? Kann man die Fallunterscheidung geschickter machen, da die ja nur gebraucht wird, wenn Operant_B negativ wird? Grüße, Jens
Angehängte Dateien:
-

Ressource_Estimation.PNG
7,5 KB
Jens W. schrieb: > Die Frage ist, ob das schon die beste Lösung ist. Die beste Lösung ist es, das den Synthesizer machen zu lassen. Denn gerade solche "Brot-und-Butter" Geschichten haben die FPGA-Hersteller penibelst auf ihre interne Struktur hin optimiert (z.B. durch die Nutzung von Carry-Chains und Multiplexern, auf die du so einfach gar keinen Zugriff hast). > Der Ressourcenverbrauch ist schon recht hoch, aber da fehlt mir noch das > Bauchgefühl für. Vergleich es mit dem Ressourcenverbrauch des selben Designs, wenn kein Multiplizierer-Block verwendet, sondern der Multiplizierer diskret aufgebaut wird. > Der Ressourcenverbrauch ist schon recht hoch, aber da fehlt mir noch das > Bauchgefühl für. Sieh dir den RTL-Schaltplan an. Hat der Synthesizer aus deiner VHDL-Beschreibung das gemacht, was du beschreiben wolltest? > Operant Meinst du "Operand"? Warum ist dein Multiplizierer überhaupt getaktet? So eine Multiplikation ist doch grundlegend mal ein rein kombinatorischer Vorgang, weil nur Addierer irgendwie verdrahtet werden. Und so wie du es geschrieben hast, ist der Multiplizierer nicht mal pipelinefähig. BTW: > use IEEE.STD_LOGIC_ARITH.ALL; > use IEEE.STD_LOGIC_SIGNED.ALL; Nimm doch besser die numeric_std statt der uralten Synopsys-Packages. Eine kleine Linksammlung dazu ist im Beitrag "Re: Einfacher VHDL Zähler"
Jens W. schrieb: > Die Frage ist, ob das schon die beste Lösung ist. Der > Ressourcenverbrauch ist schon recht hoch, aber da fehlt mir noch das > Bauchgefühl für. Wie Lothar schon geschrieben hat, schau dir mal das RTL Schematic an und frag dich, ob du das auch so etwa in der Art gebaut hättest. Um dein Bauchgefühl etwas zu trainieren guck dir mal deine eigene Beschreibung an und finde heraus wie viele FF die braucht:
1 | Generic (iBITWIDTH : integer range 0 to 18 := 18; |
2 | oBITWIDTH : integer range 0 to 36 := 36; |
3 | intBITWIDTH : integer range 0 to 36 := 36); |
4 | [...] |
5 | signal bitCounter: integer range 0 to intBITWIDTH+2; -- 6 bit Zähler |
6 | signal accu : std_logic_vector (intBITWIDTH-1 downto 0); |
7 | signal intOperant_A : std_logic_vector (intBITWIDTH-1 downto 0); |
8 | signal intOperant_B : std_logic_vector (intBITWIDTH-1 downto 0); |
9 | signal shiftOp : std_logic_vector(iBITWIDTH-1 downto 0); |
10 | signal sign : std_logic_vector(1 downto 0); |
11 | signal intbusy : std_logic; |
intBITWIDTH ist also 36 und wird in der Testbench auch nicht anders definiert. Dann braucht es für all die Aufgelisteten Signale (wenn alles Register wären) 153 FF. Im Report steht das 137 FF verbraucht wurden. Also sind nicht alle Signale Register oder der Synthesizer konnte hier also schon etwas optimieren (habe den Code nicht gelesen, der Synthesizer sagt dir im Report, was er optimiert hat).
So, hier eine Variante ohne Takt und ebenfalls ohne Multiplizierer. Wenn es aber besonders wenige Ressourcen verwenden soll, dann ist eine sequentielle Lösung mit nur einem Addierer optimal.
Hier mal noch ein kleines Minimalbeispiel zum untersuchen was der Synthesizer macht wenn man nicht zu Fuss geht:
1 | library IEEE; |
2 | use IEEE.STD_LOGIC_1164.ALL; |
3 | use ieee.numeric_std.ALL; |
4 | |
5 | |
6 | entity toplevel is |
7 | Generic( |
8 | iBITWIDTH: integer range 0 to 18:= 18; |
9 | oBITWIDTH: integer range 0 to 36:= 36 |
10 | );
|
11 | Port( |
12 | f1_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
13 | f2_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
14 | p_q : out std_logic_vector(oBITWIDTH-1 downto 0) |
15 | );
|
16 | end toplevel; |
17 | |
18 | architecture rtl of toplevel is |
19 | |
20 | signal f1 : signed(f1_in'range); |
21 | signal f2 : signed(f1_in'range); |
22 | |
23 | attribute use_dsp48 : string; |
24 | attribute use_dsp48 of rtl : architecture is "no"; |
25 | |
26 | begin
|
27 | |
28 | f1 <= signed(f1_in); |
29 | f2 <= signed(f2_in); |
30 | p_q <= std_logic_vector(f1 * f2); |
31 | |
32 | end rtl; |
Mit dem "yes" / "no" Switch kann man das entsprechend in einen DSP Slice packen oder eben zu "Fuss gehen". Wenn ich nenn Artix 7 auswaehle spuckt mir das Tool 345 verwendete LUTs aus.
Cool, danke! Das war mir noch nicht bekannt, dass man die Verwendung von DSPs verbieten kann. Dass der Synthesizer das prinzipiell bauen kann ohne DSPs wusste ich, auch die Division kann man einfach so hinschreiben und bekommt dann eine kombinatorische Lösung.
Attributes sind ein maechtges Werkzeug, leider auch manchmal etwas problematisch, gerade wenn man Designs unter den Herstellern portierbar halten moechte. Vll noch ein didaktisches Beispiel, bei dem man sieht, dass man auch ganz gezielt dem Synthesizer Anweisungen geben kann:
1 | library IEEE; |
2 | use IEEE.STD_LOGIC_1164.ALL; |
3 | use ieee.numeric_std.ALL; |
4 | |
5 | |
6 | entity toplevel is |
7 | Generic( |
8 | iBITWIDTH: integer range 0 to 18:= 18; |
9 | oBITWIDTH: integer range 0 to 36:= 36 |
10 | );
|
11 | Port( |
12 | f1_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
13 | f2_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
14 | p_q : out std_logic_vector(oBITWIDTH-1 downto 0); |
15 | f1opt_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
16 | f2opt_in : in std_logic_vector(iBITWIDTH-1 downto 0); |
17 | popt_q : out std_logic_vector(oBITWIDTH-1 downto 0) |
18 | );
|
19 | end toplevel; |
20 | |
21 | architecture rtl of toplevel is |
22 | |
23 | signal f1 : signed(f1_in'range); |
24 | signal f2 : signed(f1_in'range); |
25 | signal f1opt : signed(f1_in'range); |
26 | signal f2opt : signed(f1_in'range); |
27 | |
28 | attribute use_dsp48 : string; |
29 | attribute use_dsp48 of p_q : signal is "no"; |
30 | |
31 | begin
|
32 | |
33 | f1 <= signed(f1_in); |
34 | f2 <= signed(f2_in); |
35 | p_q <= std_logic_vector(f1 * f2); |
36 | |
37 | f1opt <= signed(f1opt_in); |
38 | f2opt <= signed(f2opt_in); |
39 | popt_q <= std_logic_vector(f1opt * f2opt); |
40 | |
41 | end rtl; |
Wenn ich nenn Cyclone 1 auswaehle kommen immer LUTs raus! So einfach kann das Leben sein.
Ein signed 27 x 27 braucht uebrigens 835 LEs auf einem Cyclone 1. Ein Cyclone 4 verwendet 7 9 x 9 Multiplizierer wenn er darf.
Angehängte Dateien:
-

Unbenannt1.PNG
5,3 KB -

Unbenannt2.PNG
4,1 KB


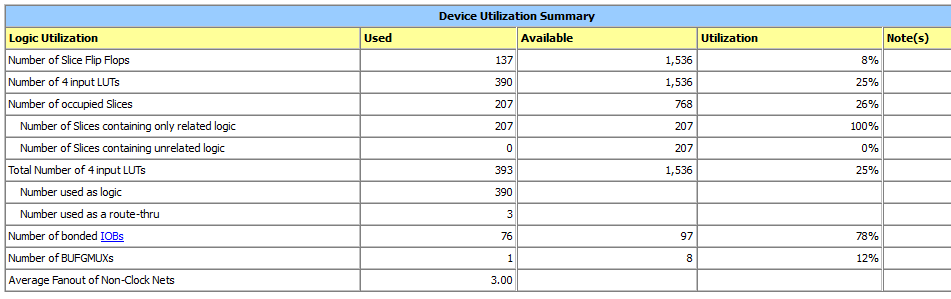
Hallo zusammen, vielen Dank für all eure Hinweise. Ich habe die verschiedenen Varianten mal versucht. Der Ressourcenverbrauch ist aber immer deutlich höher als bei meinem Versuch. Das wird daran liegen, dass das alles kombinatorische Lösungen sind. Und die verbrauchen eben deutlich mehr. Ich habe euch die Ergebnisse mal angehängt. Das erste Bild ist das Ergebnis von meinem Multiplizierer implementiert auf einem Spartan-6. Das zweite ist der Vorschlag von Gustl. Der Vorschlag von Tobias B liegt dazwischen (da habe ich jetzt nicht extra ein Bild gemacht). Viele Grüße, Jens
Jens W. schrieb: > Der Ressourcenverbrauch ist aber immer deutlich höher als bei meinem > Versuch. Auf was willst du denn optimieren? Soll das schnell sein oder wenige Ressourcen brauchen? Dann wäre eine Pipeline fein. Also getaktet und in jedem Takte eine Schiebeoperation und eine Addition. Soll das in einem Takt fertig werden ohne DSP? Dann ist das eine kombinatorische Lösung, die braucht aber viel Platz. Was man oder du da jetzt einbaut sollte sich daran orientieren was gefordert wird.
Irgendwie hinkt der Vergleich. Warum hat das erste Beispiel 4 IOBs mehr als das zweite? Einen fuer die Clock kann ich verstehen, aber woher kommen die uebrigen 3?
Hallo, @Gustl: Ich möchte gerne so wenig Ressourcen verbrauchen wie es geht. Es muss auch nicht in einem Takt fertig sein. Ich verwende in dem Design auch eine Division und die braucht pro Bit vom Eingangsvektor einen Takt. Also bei 32bit 32 Takte. Und selbst wenn es 64 Takte wären, dann wäre das auch noch ok. Schneller als die Division muss das nicht sein. Also ein Schieberegister mit Addition reicht bestimmt. Der Grund ist auch schnell erklärt. Ich möchte diese Design auf zwei Plattformen laufen lassen. Einmal auf einem Spartan-6 und einmal auf einem Spartan-3. Und da ist das Problem. Das Spartan-3 hat nur 4 Multiplizierer und die werden mir nicht reichen. Und wenn ich das zu Fuß machen und die Multiplikation alleine schon 25% der Ressourcen braucht, dann wird das nicht gehen. @Tobias: Vermutlich, da ich in meinem ursprünglichen Design noch reset, start und busy als Signale mit dabei habe. Die habe ich im Vergleich mit der anderen Lösung rausgenommen. Grüße, Jens
Jens W. schrieb: > Ich möchte gerne so wenig Ressourcen verbrauchen wie es geht. Es muss > auch nicht in einem Takt fertig sein. Dann nimm doch einen fertigen Multiplizierer und multiplexe den durch die Operanden. Wenn der Multiplizierer dann pro Takt eine Multiplikation schafft, kannst du während der Division mit dem einen Multiplizierer 32 Multiplikationen machen. Gustl B. schrieb: > Soll das in einem Takt fertig werden ohne DSP? Dann ist das eine > kombinatorische Lösung, die braucht aber viel Platz. Und möglicherweise wegen der langen kombinatorischen Addiererkette auch einen langsamen Takt. ;-)
So, noch zwei Versionen, einmal als Pipeline und einmal seriell mit einem Addierer. In Wirklichkeit sind das zwei Addierer weil ja auch die Takte gezählt werden. Viel Spaß!
Beitrag #6482083 wurde von einem Moderator gelöscht.
Gustl B. schrieb: > In Wirklichkeit sind das zwei Addierer weil ja auch die > Takte gezählt werden. Muss man die zählen? Nein. Es geht also auch mit nur einem Addierer.
Angehängte Dateien:
-

Unbenannt.PNG
5,3 KB

Hallo zusammen, @Gustl: Das ist besser! Mit deinem letzten Vorschlag kann man noch richtig was sparen im Vergleich zu meinem Design. Das verbraucht nur die Hälfte! Vielen, vielen Dank!!! @Lothar: Darauf wird es wohl hinaus laufen. Das mit dem Multiplizierer "zu Fuß" habe ich aus Neugier gemacht. Aber da gebe ich dir Recht, das wird für das Design nicht wirklich praktikabel sein. Ich hatte da auch schon dran gedacht, die Operanden zu multiplexen, aber das ist eine ganz andere Struktur. Wie macht man das richtig? Sagen wir ich habe eine Regelstrecke für einen DC Motor. Da gibt es dann mehrere Blöcke. PI Regler, PWM-Erzeugung, und vielleicht noch einen, der die Drehzahl berechnet anhand der Werte (das ist nur ein Gedankenexperiment) und sagen wir jedes der Module braucht einen Multiplizierer und ich habe aber nur einen in HW. Dann müsste ich doch alle Blöcke in einen großen zusammenfassen, damit ich alle Berechnungen auf dem einen Multiplizierer machen kann. Oder optimiert mir das der Synthesizer? Damit wird die Übersichtlichkeit nicht besser? Viele Grüße, Jens
Jens W. schrieb: > Dann müsste ich doch alle Blöcke in einen großen zusammenfassen, damit > ich alle Berechnungen auf dem einen Multiplizierer machen kann. Oder > optimiert mir das der Synthesizer? Ja, das musst du selber Designen. Der Synthesizer weiss nicht, wer, wann, wie oft mit welcher Priorität, diesen Multiplizierer nutzen kann. Jens W. schrieb: > Damit wird die Übersichtlichkeit nicht besser? Meistens nicht :-) Lothar hat in einem anderen Thread mal erzählt, wie er so etwas angeht, ohne gleich einen vollständigen Soft-Core Prozessor zu implementieren. Sein Ansatz kann übersichtlicher sein, als riesige State-Machines und ist auf jeden Fall schneller anzupassen/Fehler im Ablauf zu beheben: Beitrag "Re: Rumgefragt: Verwendung 'reiner' FPGA's heute (2020)"
Christoph Z. schrieb: > Ja, das musst du selber Designen. Der Synthesizer weiss nicht, wer, > wann, wie oft mit welcher Priorität, diesen Multiplizierer nutzen kann. Gibt es da nicht dieses resource sharing? Das findet er doch anhand seiner Zugriffslisten mit denen er auch checked, ob signale mehrfach getrieben werden.
Markus W. schrieb: > Gibt es da nicht dieses resource sharing? Ja, aber da werden 'nur' parallel genutzte Ressourcen optimiert. Duke
Ich meine, ein Altera-FAE habe sich mal gerühmt, dass "sein" Quartus erkennte, dass eine Resource zeitlich exklusiv verwendet werde, genau so, wie es erkennt, dass ein Signal aus 2 Prozessen geschrieben wird (was ja so lange gut geht, so lange diese exklusiv erfolgt).
Gerade noch etwas gefunden: Im Hauptdesign findet man bei anderen Multiplikationen, die breiter sind, folgenden Hinweis: **************************************************** DPOP #1 Warning DSP ...se/...xyz_reg output ...se/...xyz_reg/P[47:0] is not pipelined (PREG=0). Pipelining the DSP48 output will improve performance and often saves power so it is suggested whenever possible to fully pipeline this function. If this DSP48 function was inferred, it is suggested to describe an additional register stage after this function. If the DSP48 was instantiated in the design, it is suggested to set the PREG attribute to 1. **************************************************** Dazu ist zu sagen, dass alle Multiplikationen implizit über VHDL gehen, also keine DSPs instanziiert werden. Folglich kriegen die auch keine ausdrücklichen Optionen von mir mit. Interessanzt ist, dass diese Meldung weiter besteht, auch wenn ich weitere Register dahinter hänge. Kann es sein, dass für die "breite Multiplikation" kein PREG möglich ist? Oder macht die Synthese aus anderen Gründen das nicht richtig? Wie auch immer, deren Timing scheint nicht das Problem, weil diese Pfade geschafft werden! Interessant ist dabei, dass das kritische Register von oben nicht angemeckert wird, in Sachen mangelndem pipelining, er aber genau das nicht timen kann! Es ist seltsam: Diese Multiplier haben nicht mehr Register dahinter (zunächst sogar weniger) - er schafft aber das timing. Es ist daher um so verrückter, dass er ausgerechnet die Quadrierung von nur 10 Bits nicht hinbekommt. Die anderen Multis sind breiter, nur eben keine Quadrierungen. Zu wenige DSPs sind es nicht und auch ein placement-Problem würde ich ausschließen: Insgesamt stehen genug zur Verfügung, es sind keine 20% verbaut. Im isolierten Schaltungsdesign sind es < 10 Multiplier.
Markus W. schrieb: > Dazu ist zu sagen, dass alle Multiplikationen implizit über VHDL gehen, > also keine DSPs instanziiert werden. Und wer entscheidet das keine DSPs verwendet werden? Die Vivado Toolchain ist clever genug eine Multiplikation zu erkennen und entsprechend einen DSP zu instanzieren. Markus W. schrieb: > Dazu ist zu sagen, dass alle Multiplikationen implizit über VHDL gehen, > also keine DSPs instanziiert werden. Folglich kriegen die auch keine > Optionen von mir mit. Interessant ist, dass das kritische Register nicht > mehr angemeckert wird, in Sachen mangelndem pipelining. Deshalb wuerde ich auch empfehlen, nicht blind im Nebel rumzustochern, sondern sich das P&R Resultat anzusehen und mal den angemeckerten Pfad aus dem Timing Report zu verfolgen. Dann sollte eigentlich relativ schnell klar werden, wo das Problem liegt. Wie gesagt: die Randbedingungen sind ein Klacks fuer den besagten Artix. Das schreit nach einem unguenstigen Design und wenn du bereit bist mehr davon preiszugegeben (oder zumidnest mal ein aequivalentes Beispiel, welches das Problem reproduziert), kann man vll. sogar helfen. ;-)
Ich sehe gerade, dass meine Antwort hier gar nicht her gehört, sondern in den anderen thread. Daher bitte löschen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.