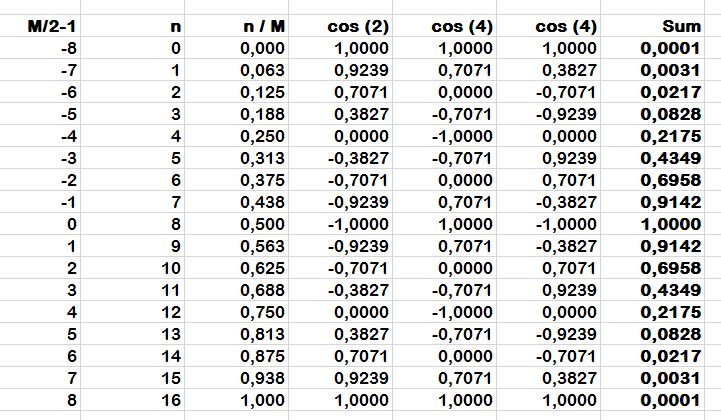
Gerade wird hier diskutiert, wie ein Blackman-Fenster einzusetzen wäre. Beitrag "Re: Ergebnisse einer FFT zusammen fassen" Dazu habe ich eine Frage zur Nummerierung: In der WP wird von der Zahl der digitalen Samples 'M' gesprochen und der Index einmal von 0 ... M-1 und einmal von -M/2 ... M/2 - 1 laufen lassen. https://de.wikipedia.org/wiki/Fensterfunktion In beiden Fällen ergibt sich mit den COS-Funktionen der Fenster z.B. Hamming und Blackman ein gleicher Verlauf. Allerdings sehe ich ein Problem mit den Indizes: Benutze ich das Beispiel aus der WP mit "M = 16" dann ergibt sich die Tabelle, die ich angehängt habe. Ich habe die Formel aus dem Beitrag von oben genommen, sie sind aber mit denen aus der WP gleich. Wie jeder sieht, schließt die Cosinusfunktionen bei 0 und 16 genau auf der Achse ab. Die Vielfachen von 2*PI*n tun das logischweise auch. Das sind aber 17 Werte!!! In der WP wird davon gesprochen, dass bei allen diesen Funktionen der erste Wert n=0 wegzulassen wäre(?), bzw. zu "0" wird und deshalb in den Darstellungen nicht vorhanden sei. Abgesehen davon, dass der Finalwert nicht exakt 0 gibt, sondern 0.001 ergibt sich dann ein Symmetrieproblem, wenn 16 Koeffizientenwerte für 16 samples genutzt werden, weil der letzte denselben Wert wird der 0te hat, aber drin bleibt. Das gleiche hat man, wenn 0 ... M-1 genutzt werden. Wie passt das zusammen? Bei einer großen Zahl von Audiosamples, z.B. 1024 ist es wahrscheinlich egal, wenn es einen shift, gibt, aber ich hätte totale Symmetrie erwartet. Welche Koeffizienten wären bei 16 samples zu benutzen?
Angehängte Dateien:
-

blackman_values.gif
22 KB
Audiologe schrieb: > Das sind aber 17 Werte!!! > ... > Welche Koeffizienten wären bei 16 samples zu benutzen? Bedenke mal, daß eine Filterfunktion, wenn sie denn Signale symmetrisch darstellen soll, ein Sample haben, was in der Ergebnis-Gegenwart liegt. Im Prinzip geht deine Verarbeitung immer so: - vom ADC kommt ein Sample, das wird an das fernste Ende der Zukunft gelegt und alle bisherigen Samples rutschen einen Platz in Richtung Vergangenheit. Das letzte Sample verschwindet im Nirwana. - Das Filter betrachtet die Samples als zu gleicher Zahl in der Zukunft liegend und in der Vergangenheit liegend. Und ein Sample (das in der Mitte) liegt direkt in der Gegenwart. Folglich: Filterkernel sollten immer eine ungerade Anzahl von Samples groß sein. Natürlich gehen auch Filterkernel mit gerader Anzahl, aber dann liegt die Gegenwart in der Mitte zwischen den beiden mittleren Samples. Für Speicherobliegenheiten ist sicherlich eine Zählung 0..16 in Ordnung, aber zur Berechnung der Taps zählt man besser -8..0..+8. W.S.
W.S. schrieb: > Für Speicherobliegenheiten ist sicherlich eine Zählung 0..16 in Ordnung, > aber zur Berechnung der Taps zählt man besser -8..0..+8. Das ist an der Stelle ja gleichwertig und macht noch keinen Unterschied für die Werte. Ich sehe aber nicht, wie das stimmen soll: Muss ich dann immer 17 Werte reinwerfen?
Audiologe schrieb: > Muss ich dann immer 17 Werte reinwerfen? Nein, natürlich nicht. Du kannst (sofern du es kannst) Filterkernel beliebiger Größe berechnen. Ist eben abhängig von deiner Anwendung. Man kann auch asysmmetrische Filter berechnen, die haben dann eben Eigenarten, die ich nicht weiter betrachten will. Aber weswegen "17 Werte reinwerfen"? Das verstehe ich nicht. Wenn du deinen ADC eine Weile arbeiten läßt, dann kriegst du Abertausende von Samples - und die wollen alle verarbeitet sein. Sowas kostet Rechenzeit und du wirst wohl immer einen Kompromiß eingehen müssen zwischen Rechenzeit bzw. Takte zwischen 2 Samples und dem Filterergebnis, was man damit erzielen kann. W.S.
Audiologe schrieb: > Muss ich dann immer 17 Werte reinwerfen? I.d.R. ist es deutlich einfacher, bei der gegebenen Zahl Samples zu bleiben und statt dessen das Fenster um ein halbes Sample zu "verschieben", es also auf diese Weise symmetrisch zu machen. Im Verlaufe dieses Threads: Beitrag "Audio Spektrum Analyzer mit ATtiny85" Habe ich genau das getan. Die dadurch bewirkte Verbesserung kann man hier sehen: Beitrag "Re: Audio Spektrum Analyzer mit ATtiny85" Ist kein sehr großer Sprung in der Qualität, aber doch eine deutlich nachweisbare Verbesserung. Bei dem Thread ging es zwar um eine Sache mit Goertzels, das funktioniert aber bei einer FFT ganz genauso.
Angehängte Dateien:

{kind=link}
{kind=link}
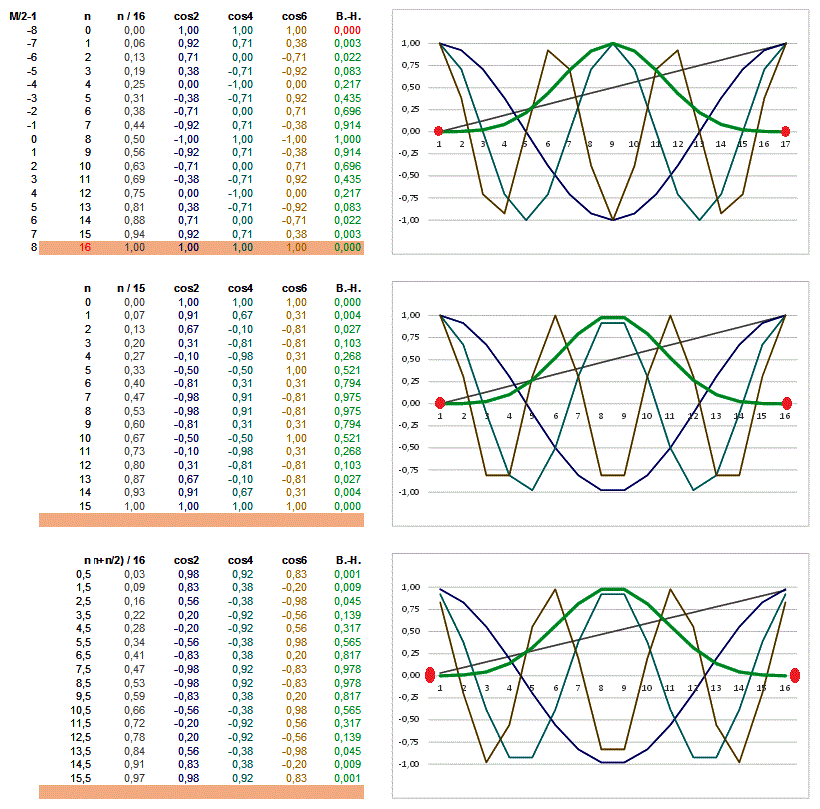
Die Formulierung in der WP ist schon richtig. Die Unsymmetrie erzeugt nur eine Verschiebung der Wirkung der Samples wie schon gesagt. Das ist hier deshalb der Fall, weil eine gerade Anzahl von Samples genutzt wird, während die Kurve auf eine ungerade ausgelegt ist, bzw der Cosinus eben so tickt. Da bei Audio eine ungerade Anzahl günstiger ist, kannst du einen Punkt weglassen und mit 15 rechnen. Dann gibt es eine "echte" Mitte mit 7 Nachbarn zu jeder Seite. In der Bildverarbeitung wird das regelmäßig so gemacht (strikt ungerade Anzahl) und das Fenster entsprechend angepasst. Siehe dazu auch den N/2 + 1 - Shift in meiner [Digitale Sinusfunktion]. Dort wird es genutzt, um die ungerade Sinus-Funktion auf eine gerade Zahl von Samples zu mappen und dabei in 2 Achsen symmetrisch zu werden. Generell kann man durch ein leichtes Verschieben der Kurve mit weniger als einem Sample, die Signale unterhalb der Samplegrenze schieben. Z.B. mit einem MOVE von 25% , 50%, 75% schlagartig in einer Rechnung die Werte erhalten, die ein upsampler im Zeitbereich durch oversampling produzieren würde. Um das Problem also vereinfacht zu beantworten: Die Formeln im WIKI sind auf einen Fall ausgelegt, den anderen musst du dir denken. Das ist ja bei der Veranschlagung von Filterlängen generell der Fall. Beispiele siehe Bild. Unten wieder meine Empfehlung mit dem N/2-Shift. Mathematisch / Funktionell ist beides richtig. Die Windowfunktionen an sich sind vollständig überlagerbar, d.h. die Punkte einer verschobenene Kurve passen genau in die einer Nichtverschobenen. Wenn man unterschiedlich lange Kurven für mehr Samples richtig skaliert, passen auch diese ineinander. Es sind halt andere Punkte derselben Kurve. Es muss immer das Gleiche rauskommen. Da aber die Nutzung von einem Sample mehr oder weniger zu etwas mehr oder weniger "Information" führt, gibt es automatisch leicht andere Ergebnisse. Auch sind manche etwas recheneffizienter, wegen perfekter Symmetrie und Nulldurchgängen. Nähert man die Punkteanzahl gegen Unendlich, gleichen sich alle Kurven einander an.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.