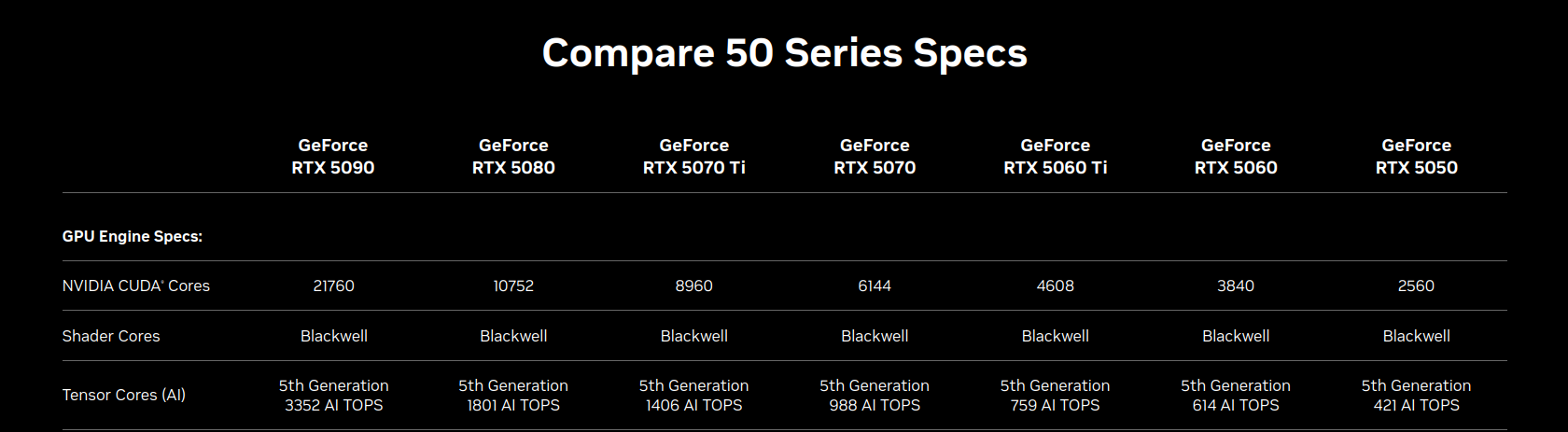
Es gibt immer mehr KI-Hardware. Sei es nun Graphikarten, CPUs oder MCUs. In diesem Thread will ich die Anforderung an die Hardware für bestimmte Anwendungen diskutieren. Das kann z.B. die Ausführung eines LLMs auf dem eigenen Rechner bedeuten. Eine Nvidia RTX5090 hat z.B. 3352 AI TOPS, ist allerdings nicht ganz billig. Die Frage stellt sich auch, welchen Einfluss die Archtektur des KI-Beschleunigers auf die Ausführungsgeschwindigkeit hat. Wir hatte schon einmal eine Diskussion hier zur Anforderung an die PCs: Beitrag "PC: das Zeitalter neuer Hardware"
Angehängte Dateien:
:
Verschoben durch Moderator
> Es gibt immer mehr KI-Hardware. Sei es nun Graphikarten, CPUs oder MCUs.
Heise hat mal ein Video gemacht welches du bei Youtube finden kannst wo
Keno spezielle Grafikkarten mit spezieller Hardware verglichen hat.
Vanye
Würde mich sehr interessieren. Auch welche Modelle jeweils geeignet sind, und welche sonstige Software-Infrastuktur (Agent-Runtime IDE Chatbot etc.). Auch wie man die integrierte NPU von den "AMD Ryzen AI" Prozessoren für sowas nutzt (welches Modell etc).
Naja, da gibt es auch die "AI on the edge" die kommt mit den normalen Embedded prozessoren aus. https://www.emft.fraunhofer.de/de/kompetenzen/systemloesungen-ki/ai-on-the-edge.html Und auch bei den Sprachmodellen gibt es clevere Ansätze, die die Hardwareanforderungen auf ein Bruchteil zusammenschrumpeln lassen. https://www.heise.de/select/ct/2025/7/2504911435670065158 Siehe auch Deep-seek. Ich hatte auch mal ne komplette Offline .de Wikipedia auf dem Handy (Kiwix), braucht halt nur ne gescheit große SDCard (~100 GB). Ist halt oft wie beim Opel Manta, die dümmsten Nüße haben die dicksten Motoren. SCNR

Vanye R. schrieb: > Heise hat mal ein Video gemacht welches du bei Youtube finden kannst wo > Keno spezielle Grafikkarten mit spezieller Hardware verglichen hat. Ich meine, das Video gesehen habe. Er hatte eine relativ schnelle Graphikkarte mit viel Speicher. Der Speicher scheint wichtig zu sein, weil das ganze Modell rein passen muss, sonst fängt die Graphikkarte an, den Speicher zu swappen und dann wird das ganze sehr langsam. Die meisten Graphikarten scheinen wohl nur 16GB Speicher zu haben. Da stellt sich die Frage: Passt die Modelle wie z.B. Qwen3.5-122B-A10B da rein Beitrag "KI-Modelle Deep Dive" A10B heißt hier wohl 10Giga aktive Gewichte, was sich so anhört, als wenn es passen könnte.
Angehängte Dateien:
-

Minifloat.png
86 KB

Mittlerweile ist man bei den Gewichten wohl bei "Minifloat FP4" angekommen. Das ist eine 4Bit "Fließkommazahl" mit dem Wertebereich -6 bis 6. Eine offene Frage ist, ob man ein echtes FP32 Modell einfach in ein FP4 Modell umwandeln könnte. Dann würde in eine Graphikkarte mit 16GB ingesammt 32GB Gewichte reinpassen. Ein lustiger Nebeneffekt von FP4: Auf einem Mikrocontroller könnte man die Multiplikation mit einer 256 Byte Look-Up-Table realisieren und damit würde es auch auf Mikrocontroller ohne Hardwaremultiplizier zügig laufen.
Angehängte Dateien:
-

JetsonOrin.png
140 KB
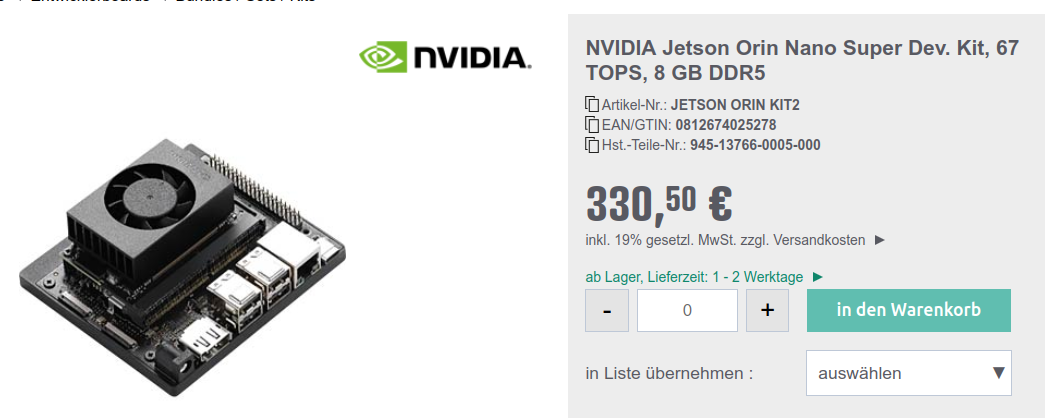
Das Jetson Orin könnte eine schöne Platform zum experimentieren sein. Leider hat es nur 76TOPs und 8GB Ram, was nur für kleine Modelle reichen dürfte. Das schöne ist, dass das Board ein Linux beinhaltet, so dass es eigenständig laufen kann.
Christoph M. schrieb: > Eine Nvidia RTX5090 hat z.B. 3352 AI TOPS, ist allerdings nicht ganz > billig. Die Frage stellt sich auch, welchen Einfluss die Archtektur des > KI-Beschleunigers auf die Ausführungsgeschwindigkeit hat. Es stellt sich eher die Frage, was du denn überhaupt mit der KI machen willst und wie oft. Wahrscheinlich ist es in den meisten Fällen sinnvoll, für die sehr rechenintensiven Schritte (Modell trainieren oder so) auf einen Clouddienst zurückzugreifen wie den von Google oder Amazon und bei sich vor Ort für die Ausführung nur eine moderat ausgestattete Maschine anzuschaffen. So kann man beispielsweise 8x Nvidia A100 mit 640GB VRAM für USD 20.- pro Stunde mieten (Google). 8x Nvidia H200 mit 1128GB VRAM für USD 40.- pro Stunde (Amazon).
:
Bearbeitet durch User
> Ich meine, das Video gesehen habe. Er hatte eine relativ schnelle > Graphikkarte mit viel Speicher. > Der Speicher scheint wichtig zu sein, weil das ganze Modell rein passen > muss, sonst fängt die Graphikkarte an, den Speicher zu swappen und dann > wird das ganze sehr langsam. Ganz so einfach ist es nicht. Du willst moeglichst viel Speicher haben damit du ein moeglichst grosses Modell nutzen kannst das dann halt moeglichst intelligente Antworten liefert. Damit du auf diese Antworten aber nicht zu lange warten musst brauchst du halt auch noch moeglichst schnellen Speicher. Jetzt ist das aber so das die Entwickler der Modelle immer die aktuellste coole Hardware haben die sie sich gerade so leisten koennen. Schliesslich ist das ganze ja ihr Hobby oder so. Wenn du also nicht das kleinere Modell von vorgestern nutzen willst und immer vorne dabei sein willst dann brauchst du eigentlich immer das was heute am teuersten ist und es wird in ein paar Monaten total veraltet sein. :-D Vanye
Die Hardwareanforderungen sind ganz unterschiedlich, je nach dem, ob ein fertiges Modell nur offline verwendet werden soll, oder aktiv gelernt werden soll aus weiteren Beispielen.
Wir haben in der Firma extra einen Experimentier-Rechner für lokale KI eingerichtet, für rel. kleines Geld: Intel i7 3,2GHz, MSI Gamingboard mit 32GB RAM und eine Radeon RX3090 mit 24GB. Alles vor ca Jahr einzeln gebraucht gekauft, noch vor der Speicherkrise, für weniger als 600,- Derzeit laufen dort LM Studio mit verschiedenen Modellen im Server-Mode, sowie Paperless NGINX und OpenClaw. Ziel ist eine KI-basierte Dokumenten-Klassifizierung - das Projekt eines Praktikanten. Wenn die KI nicht gerade damit beschäftigt ist, die OCR-Ergebnisse in 4...6 Dokumenten gleichzeitig zu optimieren, kommen auch Chat-Antworten übers Netzwerk mit nahezu der gleichen Geschwindigkeit, wie man das von ChatGPT oder Grok gewohnt ist. Bei den gigantischen Harware-Anforderungen der "Großen" muss man immer auch daran denken, dass dort hunterttausende User gleichzeitig dranhängen, was lokal eher nicht vorkommt :-) Übrigens: Ein aktueller MacMini mit M4 Prozessor (z.B. 10 CPU-Kerne und 10 GPU Kerne, 32GB RAM) soll für lokale KI richtig gut geeignet sein. Preis neu um die 1600,- - da kostet derzeit alleine eine PC-Grafikkarte mehr ...
:
Bearbeitet durch User
32GB RAM? Da bekommt man aber kein wirklich nützliches LLM rein. Zum Rumspielen reicht es vielleicht... Derzeit wären 512 GB RAM der Sweetspot, um z.B. ein Minimax 2.5 laufen zu lassen. Das kann richtig was (etwa auf Claude 4.6 Niveau).
Frank E. schrieb: > Radeon RX3090 mit 24GB Danke für deinen nützlichen, ausführlichen Beitrag. Bist du sicher, dass es eine RX3090 und keine RTX3090 ist?
> Ganz so einfach ist es nicht. Du willst moeglichst viel Speicher haben > damit du ein moeglichst grosses Modell nutzen kannst das dann halt > moeglichst intelligente Antworten liefert. Damit du auf diese Antworten > aber nicht zu lange warten musst brauchst du halt auch noch moeglichst > schnellen Speicher. Beides (intelligenz und schnell) sind Wunschträume und letzterer ist eher unnötig. Wenn man weiss, das es mit der Antwort dauern wird, formuliert man seine Anfrage präziser. Und nicht selten erkennt man, das in der gut formulierten Frage, die halbe Antwort steckt (macht die KI auch nicht anders). Und dann ist dann noch wie man "intelligent" definiert, die KI presentiert halt nur schlau aussehende Suchergebnisse (OK, das ist manchen genug). Aber ein Schachcomputer ist kein guter Sparringspartner, der macht den menschen nicht besser sondern setzt seine Wissenslücken gnadenlos im Spiel ein. BTW: wer an Maschinen glaubt sollte sich mal mit der Herkunft der Antwort auf alles (""forty-two") beschäftigen.
Bradward B. schrieb: > Beides (intelligenz und schnell) sind Wunschträume und letzterer ist > eher unnötig. In diesem Thread geht es um KI-Hardware von kleinen Embedded-Systemen bis zu Systemen, auf denen LLMs laufen können. Das ist kein Thread für KI-Meinungsgelaber. Kannst du deinen eigenen Thread im Offtopic-Forum aufmachen?
Frank E. schrieb: > Übrigens: Ein aktueller MacMini mit M4 Prozessor (z.B. 10 CPU-Kerne und > 10 GPU Kerne, 32GB RAM) soll für lokale KI richtig gut geeignet sein. > Preis neu um die 1600,- - da kostet derzeit alleine eine PC-Grafikkarte > mehr ... Das klingt interessant. Kann es sein, dass es sich um den Mac-Mini-Pro handelt? Ich vermute, dass der Mac Mini Pro auch weniger Strom als die NVIDIA-Grafikkarten bei gleicher KI-Performance braucht, was ein Vorteil wäre. Allerdings haben die NVIDIA-Graphikkarten einen großen Vorteil: CUDA Das ist für reine Anwender vielleicht nicht wichtig, aber für Leute im Entwicklungsbereich, die sich auch mit dem ein- oder anderen Algorithmus beschäftigen, könnte das ein Ausschlusskriterium für den MAC sein. Welche Entwicklungstools für Programmierung der KI-Einheiten gibt es dort? #
Christoph M. schrieb: > Frank E. schrieb: >> Radeon RX3090 mit 24GB > > Danke für deinen nützlichen, ausführlichen Beitrag. > Bist du sicher, dass es eine RX3090 und keine RTX3090 ist? Nö ... bzw ja, hast recht. Macht es der eine Buchstabe wirklich aus? :-) War spät ...
Bernd schrieb: > 32GB RAM? Da bekommt man aber kein wirklich nützliches LLM rein. > Zum > Rumspielen reicht es vielleicht... > > Derzeit wären 512 GB RAM der Sweetspot, um z.B. ein Minimax 2.5 laufen > zu lassen. Das kann richtig was (etwa auf Claude 4.6 Niveau). Das LMM läuft im VRAM der Grafikkarte, deshalb ist sie (auch) drin, nicht nur wegen der GPUs. Und das ist mehrfach schneller als das System-RAM. Es muss (dürfte aber) auch nich tgrößer sein, als das LMM selbst. Und für eine lokale KI sind 20GB+ schon recht ordentlich. Ich vermute mal, du hast selbst noch keinerlei praktische Versuche gemacht, klingt jedenfalls so. Selbst auf einem "mickrigen" Macbook M2 mit 16 GB antwortet ein (kleines) LMM (unter Ollama) erstaunlich flüssig.
Christoph M. schrieb: > Frank E. schrieb: >> Übrigens: Ein aktueller MacMini mit M4 Prozessor (z.B. 10 CPU-Kerne und >> 10 GPU Kerne, 32GB RAM) soll für lokale KI richtig gut geeignet sein. >> Preis neu um die 1600,- - da kostet derzeit alleine eine PC-Grafikkarte >> mehr ... > > Das klingt interessant. Kann es sein, dass es sich um den Mac-Mini-Pro > handelt? > Ich vermute, dass der Mac Mini Pro auch weniger Strom als die > NVIDIA-Grafikkarten bei gleicher KI-Performance braucht, was ein Vorteil > wäre. Jein ... noch ist es bei uns tatsächlich nur ein "Wald-und-Wiesen-PC", wie beschrieben. Ein Mac Mini wäre aber sicher besser. Wir prüfen derzeit noch, wozu man den sonst noch gebrauchen könnte, nicht nur für KI-Experimente, dafür alleine ist er mir zu teuer. Wir prüfen derzeit noch, ob die in verschidenen Foren und Fachzeitschriften versprochene Performance beim Einsatz als Server für das Datenbanksystem "Filemaker Pro" hält, was sie verspricht ... dann werden wir einen kaufen. Ich dachte zunächst an den hier z.B.: https://www.mactrade.de/cto-apple-mac-mini-m4-10-core-cpu-10-core-gpu-32gb-256bssd-ethernet/69741.0017 "Pro" wäre natürlich noch besser ... nach Oben geht immer :-)
:
Bearbeitet durch User
Auch interessant, allerdings ohne persönliche Erfahrung diesbezüglich, wollte es nur mal in die Runde werfen: Für den Raspberry gibts auch verschiedene "KI-Beschleuniger", z.B. "Coral" von Google. Bildverarbeitung und Objekterkennung scheinen damit ganz brauchbar zu laufen ... Immerin 4 TOPS bei 2 Watt für weniger als 80,- https://www.mouser.de/datasheet/2/963/Coral_M2_datasheet-3237151.pdf https://www.youtube.com/watch?v=iNSahfWDXZA
Christoph M. schrieb: > Frank E. schrieb: >> Übrigens: Ein aktueller MacMini mit M4 Prozessor (z.B. 10 CPU-Kerne und >> 10 GPU Kerne, 32GB RAM) soll für lokale KI richtig gut geeignet sein. >> Preis neu um die 1600,- - da kostet derzeit alleine eine PC-Grafikkarte >> mehr ... > > Das klingt interessant. Kann es sein, dass es sich um den Mac-Mini-Pro > handelt? > Ich vermute, dass der Mac Mini Pro auch weniger Strom als die > NVIDIA-Grafikkarten bei gleicher KI-Performance braucht, was ein Vorteil > wäre. Das Optimum wäre der Mac Studio M3 Ultra. Der hat einen Prozessor, wo zwei Chips direkt intern miteinander verbunden sind. Dadurch sind hier bis zu 512GB RAM möglich. Jeff Geerling hat 4 von diesen Teilen per Thunderbolt miteinander verbunden, und dieser Cluster hat schon exterm erstaunliches geleistet. Ok, das waren auch 50k$, aber andere gleichwertige Lösungen lagen eher bei 200k$ oder so. > Allerdings haben die NVIDIA-Graphikkarten einen großen Vorteil: CUDA Dann wäre der DGX Spark oder einer seiner Clones das bessere. Der hat 128GB schnelles Unified Memory und als NVidia-System natürlich vollen CUDA-Support. https://www.nvidia.com/de-de/products/workstations/dgx-spark/ fchk
Frank K. schrieb: > Das Optimum wäre der Mac Studio M3 Ultra Was haltet ihr von sowas: https://de.gmktec.com/products/gmktec-evo-x2-amd-ryzen%E2%84%A2-ai-max-395-mini-pc-1 Wenn man 128 GB RAM nimmt kann man mit der NPU ziemlich große Modelle rechnen. Halt nicht so schnell wie bei einer Nvidia GPU, aber immerhin einigermaßen "schlau". Frank K. schrieb: > Dann wäre der DGX Spark oder einer seiner Clones das bessere. Ausgerechnet der soll für LLMs nicht so geeignet sein, hab leider vergessen warum (Memory Speed?).
Frank E. schrieb: > Christoph M. schrieb: >> Frank E. schrieb: >>> Radeon RX3090 mit 24GB >> >> Danke für deinen nützlichen, ausführlichen Beitrag. >> Bist du sicher, dass es eine RX3090 und keine RTX3090 ist? > > Nö ... bzw ja, hast recht. Macht es der eine Buchstabe wirklich aus? :-) > War spät ... Eine RTX kenne ich von AMD nicht. Sicher, dass es Radeon und nicht Geforce war? ;-)
Niklas G. schrieb: > Was haltet ihr von sowas: > > https://de.gmktec.com/products/gmktec-evo-x2-amd-ryzen%E2%84%A2-ai-max-395-mini-pc-1 Tja, die schreiben 126 TOPS total, 2.2× RTX 4090 efficiency Wobei ich das mit den Angaben der RTX4090 mit https://www.spheron.network/blog/rtx-4090-for-ai-ml/ FP16 Tensor (TFLOPS) 165.2 71 AI TOPS (FP8/INT8) 1321 Nicht so recht in Einklang bringen kann. Oder bezieht sich "efficiency" auf Stromverbrauch?
:
Bearbeitet durch User
Christoph M. schrieb: > Oder bezieht sich "efficiency" auf Stromverbrauch? Ja vermutlich, die NPU soll sehr energieeffizient sein. Weniger TOPS bei viel RAM (statt viel VRAM) -> langsam aber schlau. Ist vielleicht besser als ein gleich teures System mit GPUs und wenig VRAM, welches schnell aber dumm ist, oder so... Allerdings sind die Ryzen AI CPUs eigentlich für Notebooks; eine "große" Version mit mehr (NPU-)Leistung für Desktop/Server gibt's nicht. Dort soll man die dedizierten Beschleunigerkarten (AMD Instinct) nehmen, die natürlich Größenordnungen teurer sind...
:
Bearbeitet durch User
Niklas G. schrieb: > Ja vermutlich, die NPU soll sehr energieeffizient sein. Weniger TOPS bei > viel RAM (statt viel VRAM) -> langsam aber schlau. Für mich stellt sich die Frage, wie gut die NPU von Frameworks wie Tensorflow 2 unterstützt werden und wie aufwändig die Installation ist.
Christoph M. schrieb: > Für mich stellt sich die Frage, wie gut die NPU von Frameworks wie > Tensorflow 2 unterstützt werden und wie aufwändig die Installation ist. Software ist wohl das Hauptproblem ja... Für LLMs kann man "Lemonade AI" oder FastFlowLM nehmen, aber die Auswahl der fertig quantifizierten Modelle ist gering. Zum selbst Quantifizieren braucht man wieder eine Nvidia GPU 😁
Frank E. schrieb: > Auch interessant, allerdings ohne persönliche Erfahrung diesbezüglich, > wollte es nur mal in die Runde werfen: > > Für den Raspberry gibts auch verschiedene "KI-Beschleuniger", z.B. > "Coral" von Google. Bildverarbeitung und Objekterkennung scheinen damit > ganz brauchbar zu laufen ... > > Immerin 4 TOPS bei 2 Watt für weniger als 80,- Ich habe hier noch ein Unhiker K10 mit ESP32-S3 liegen. https://www.unihiker.com/products/k10 Das wäre dann eine noch günstigere Möglichkeit, sich mit KI-Anwendungen auf dem Mikrocontroller zu beschäftigen. Die KI-Fähigkeiten des ESP32-S3 werden aber nicht durch eine eingebaute NPU bestimmt, sonder durch eine Erweiterung des Befehlssatzes. Zur schnellen Berechnung der Neuronalen Netze gibt es extra SIMD Befehle mit einer Datenbreite von 128Bit, die parallele 8Bit Multiplikation und andere wichtige Befehle für die Signalverarbeitung beinhalten. Das sind ziemlich kompliziert klingende Assembler Befehle wie
1 | EE.VMULAS.S8.ACCX.LD.IP |
2 | an instruction that performs a fused multiply + add + load, |
https://hackaday.io/project/196067-running-a-pytorch-model-on-the-esp32-s3/details
Frank E. schrieb: > da kostet derzeit alleine eine PC-Grafikkarte > mehr ... Wenn man geeignete Boards für mehrere Grafikkarten hat, warum nicht auch mehrere Grafikkarten nutzen, wenn die kostengünstig zu bekommen sind?
Rbx schrieb: > Frank E. schrieb: >> da kostet derzeit alleine eine PC-Grafikkarte >> mehr ... > > Wenn man geeignete Boards für mehrere Grafikkarten hat, warum nicht auch > mehrere Grafikkarten nutzen, wenn die kostengünstig zu bekommen sind? Die Grafikkarten werden ja nicht für die Grafik-Ausgabe benutzt, sondern als Rechenknecht und schnelles Speicher-Resevoir. Theoretisch kann ich mir vorstellen, dass sich das auch auf mehrere GK aufteilen lässt - die Frage ist, ob die Software (LLM) das derzeit mitmacht ...
:
Bearbeitet durch User
Frank E. schrieb: > Theoretisch kann ich > mir vorstellen, dass sich das auch auf mehrere GK aufteilen lässt - die > Frage ist, ob die Software (LLM) das derzeit mitmacht .. Ja das geht und wird gemacht, aber die Performance leidet weil Daten hin-und hergeschoben werden müssen.
> EE.VMULAS.S8.ACCX.LD.IP > 2an instruction that performs a fused multiply + add + load, Klingt doch eigentlich so als wenn man das super fuer FFT oder sowas verwenden kann. Ich hab mich naemlich schon gefragt was wir alle mit den ganzen EdgeAI Mikrocontroller machen sollen die auf der Embedded ueberall rumhingen. Fuer irgendwas muss das Zeug ja gut sein. :) Vanye
Vanye R. schrieb: >> EE.VMULAS.S8.ACCX.LD.IP >> 2an instruction that performs a fused multiply + add + load, > > Klingt doch eigentlich so als wenn man das super fuer FFT oder sowas > verwenden kann. Ich hab mich naemlich schon gefragt was wir alle mit den > ganzen EdgeAI Mikrocontroller machen sollen die auf der Embedded > ueberall rumhingen. Fuer irgendwas muss das Zeug ja gut sein. :) Ja, der ESP32-S3 ist für Signalverarbeitungsaufgaben optimiert. Hier gibt es eine FFT-Library, welche die Funktionen nutzt: https://github.com/johnny49r/ESP_DSP_FFT Bezüglich der KI-Anwendungen kannst du in meinem letzten Post den Link zum Unhiker K10 anklicken. Dort sieht man die typischen "AI" Anwendungen für den ESP32: - Einfache Worterkennung - Gesichterkennung - einfache Katze/Hund Erkennung - QR-Code Detection Hier hat einer ein Sprachprodukt gemacht: https://www.tindie.com/products/abbycus/watt-iz-speech-enabled-embedded-hardware/ Die Library gehört wohl dazu: https://github.com/johnny49r/watt-iz
Angehängte Dateien:
-

LLM_RTX_Speed.png
110 KB
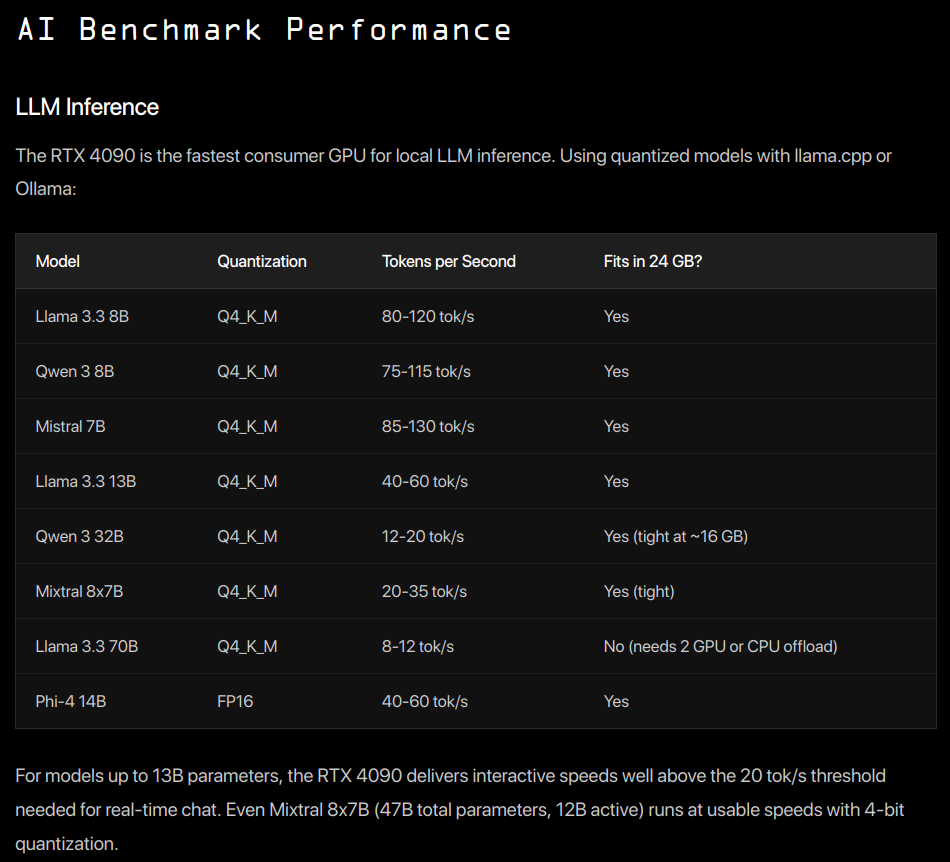
Eine sehr interessante Frage ist, welche Rechenleistung braucht man, um ein brauchbares LLM-Modell auf einem Rechner lokal laufen zu lassen. In dem oben erwähnten Blog https://www.spheron.network/blog/rtx-4090-for-ai-ml/ Scheint Token/Sekunde eine passende Metrik. Das Limit für eine brauchbare Antwortzeit scheint bei 20 Token/Sekunde zu liegen.
> https://de.gmktec.com/products/gmktec-evo-x2-amd-ryzen%E2%84%A2-ai-max-395-mini-pc-1 > > Wenn man 128 GB RAM nimmt kann man mit der NPU ziemlich große Modelle > rechnen. Halt nicht so schnell wie bei einer Nvidia GPU, aber immerhin > einigermaßen "schlau". Aus der Praxis: Die NPU ist langsamer als die GPU, die Modelle für die NPU sind eher die kleinen. Dann lieber Nemotron, Qwen3/3.5, GLM oder gpt-oss auf die GPU. Klappt mit 96GB problemlos. Bleiben noch 32GB übrig, damit kann nebenher problemlos noch Redis & pgvector laufen lassen, fertig ist die Agentic AI Büchse.
:
Bearbeitet durch User
1N 4. schrieb: > auf die GPU. Klappt mit 96GB problemlos Also das bezieht sich auf die integrierte Radeon 8060S GPU?
> Scheint Token/Sekunde eine passende Metrik. > Das Limit für eine brauchbare Antwortzeit scheint bei 20 Token/Sekunde > zu liegen. Da hab ich so meine Zweifel, das "Token" pauschal ein vernünftiges Maß zur Leistungsbestimmung ist. Beispielsweise Vergleich zwischen Analyse von Menschlicher Sprache und Analyse von Programmcode oder Analyse von log-Dateien. Wichtig ist, neben der Gesamtzahl der möglichen Token, die Konfidenz ("glaubhaft/Vertrauen") der gemachten Aussage. Beispielsweise gibt es bei der Linux-Sourceverwaltung eine Unmenge von KI-generierten "bug-reports" die sich im Nachhinein als "false alarm" o.ä. herausstellen. https://www.heise.de/news/Bis-zum-Burn-out-Open-Source-Entwickler-von-KI-Bug-Reports-genervt-10195951.html Wobei "sachliche Fehlentscheidung wegen zu schnellen Textpassagen" macht auch die natürliche Intelligenz. Sieht man auch hier im Forum, da macht man sich selten die Mühe alle "Token" des Posts zu parsen sondern begnügt sich mit dem "Token Autor" um Posts willkürlich in Schubladen zu versenken. So nach der Devise "von dem User mit diesem Nick kommt nur Müll - hat der Rudelführer mal gesagt".
:
Bearbeitet durch User
1N 4. schrieb: >> Also das bezieht sich auf die integrierte Radeon 8060S GPU? > > Jup Cool danke, hast du so ein Setup schon für sowas benutzt? Wie gut funktioniert das in der Praxis?
> Cool danke, hast du so ein Setup schon für sowas benutzt? Wie gut > funktioniert das in der Praxis? Benutze das Setup täglich, es kommt darauf an, was du damit machen willst. Die meisten Leute die sich auf so eine Kiste ein 120B Modell packen werden enttäuscht sein, weil da ein OpenAI/Gemini/Claude-Abo schneller und günstiger ist. Sobald es aber über einen Chatbot hinausgeht, langchain, langgraph, Agentic-Graph RAG etc. amortisiert sich die Kiste schneller als man denkt. Kenne einige KMU die auf solchen Kisten mittlerweile mehr produktive Agentic AI machen als Großunternehmen.
1N 4. schrieb: > Sobald es aber über einen Chatbot hinausgeht, langchain, langgraph, > Agentic-Graph RAG etc. amortisiert sich die Kiste schneller als man > denkt. Für welche Use-Cases ist das konkret? Interaktive Code-Generierung bei Softwareentwicklung oder ist es dafür zu langsam? Eher für Batch-Prozesse bei denen die Latenz egal ist, wie Support-Emails beantworten? 1N 4. schrieb: > Kenne einige KMU die auf solchen Kisten mittlerweile mehr produktive > Agentic AI machen als Großunternehmen. Mit ist noch nicht so ganz klar welche Art von Arbeit in einem gewöhnlichen KMU so gemacht werden kann...
Arschteuer!
> Für welche Use-Cases ist das konkret? Das muss man sich vermutlich so vorstellen. Deine Effizienz als Programmierer verdoppelt sich bei gleichzeitig halben Arbeitseinsatz. Du musst also mehr Kaffee trinken. :-D Ich hab mir auf der Embedded das hier angeschaut: https://embedder.com Mein Eindruck, es ist schon sinnvoll, aber sicher hier und da noch neu und was hackelig. Noch 2-3Jahre und man wird von Programmierern den doppelten Output erwarten den sie mit solchen Systemen auch liefern koennen. Privat wird das wohl nicht so einfach weil sowas davon lebt das da im Hintergrund Spezialisten die Probleme wegbueglen und man dafuer Kohle rueberschieben muss. Gespannt bin ich mal auf was anderes. Das grosse Computerproblem unserer Zeit besteht darin das es fuer alles droelfzigtausend Programme gibt und in der Softwareentwicklung und deren Tooling ist es sogar noch extremer. In dem Moment wo der Computer aber auch die Entwicklung uebernimmt erwarte ich da etwas Konsolidierung. Vanye
Angehängte Dateien:
-

RTX5060_unboxing.png
890 KB

Die Hardware für meine KI-Experimente ist eingetroffen .. Der Speicher ist mit 8GB etwas klein, aber für CUDA-Experimente und einfache Modelle wird es wohl reichen.
Angehängte Dateien:
-

nvidia_smi.png
83 KB
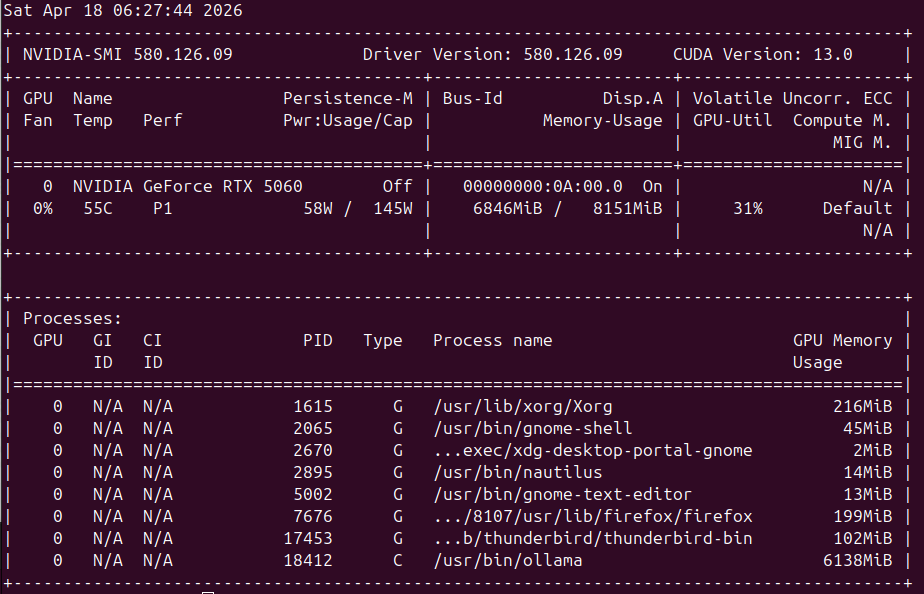
Hier die ersten Versuche mit der RTX5060. Obwohl die Graphikkarte 145Watt verbraten könnte, werden doch wohl nur 58W gebraucht. Quen3.5:9B läuft wohl auf meiner 8GB Karte. Die CPU wird wohl auch noch zu 30% gebraucht.
1 | docker exec -it ollama ollama run qwen3.5:9b |
>>> Can you make an Arduino blink program blinking with 10Hz ?
1 | ... |
2 | |
3 | docker exec -it ollama ollama ps |
4 | NAME ID SIZE PROCESSOR CONTEXT UNTIL |
5 | qwen3.5:9b 6488c96fa5fa 8.8 GB 28%/72% CPU/GPU 4096 59 seconds from now |
Die Anfrage war ein Arduino-Blink-Programm mit 10Hz. Interessanterweise wird auch blink without delay mit ausgegeben.
1 | const int ledPin = 13; |
2 | unsigned long previousMillis = 0; |
3 | const long interval = 100; // 100ms per cycle (10Hz) |
4 | |
5 | void setup() { |
6 | pinMode(ledPin, OUTPUT); |
7 | }
|
8 | |
9 | void loop() { |
10 | unsigned long currentMillis = millis(); |
11 | |
12 | // Toggle the pin based on current time
|
13 | if (currentMillis - previousMillis >= interval) { |
14 | // Flip the state of the pin
|
15 | if (digitalRead(ledPin) == LOW) { |
16 | digitalWrite(ledPin, HIGH); |
17 | // To keep it simple, we just toggle the pin,
|
18 | // but in non-blocking code you usually track the state.
|
19 | }
|
20 | }
|
21 | |
22 | // Actually, for pure 10Hz on/off switching, the 'delay' method is cleaner to read.
|
23 | // The millis method above requires a state flag to toggle correctly without delay.
|
24 | }
|
Angehängte Dateien:
-

StrixHaloNPU.png
210 KB

Es ist interessant, dass CPUs mit KI-Unterstützung noch eine relativ kleine Chipfläche dafür verwenden. Strix Halo Review https://www.youtube.com/watch?v=vMGX35mzsWg
Christoph M. schrieb:1 | const int ledPin = 13; |
2 | unsigned long previousMillis = 0; |
3 | const long interval = 100; // 100ms per cycle (10Hz) |
4 | void setup() { |
5 | pinMode(ledPin, OUTPUT); |
6 | }
|
7 | void loop() { |
8 | unsigned long currentMillis = millis(); |
9 | if (currentMillis - previousMillis >= interval) { |
10 | if (digitalRead(ledPin) == LOW) { |
11 | digitalWrite(ledPin, HIGH); |
12 | }
|
13 | }
|
14 | }
|
1. Das soll blinken? Mit LED>ein aber niemals LED>aus? 2. Würde es blinken, dann mit der falschen (halben) Frequenz. Du scheinst eine zu komplexe Aufgabenstellung gewählt zu haben. ;-)
Norbert schrieb: > Du scheinst eine zu komplexe Aufgabenstellung gewählt zu haben. ;-) Oh ja, das geht schief. Bei der Aktion geht es aber mehr um die Geschwindigkeitstests bei der Tokenverarbeitung, als um die Nützlichkeit des Codes.
aber, das muss man der KI zugute halten, die Interval-Berechnung ist richtig ausgeführt, ohne das es beim Integer-Overflow zu Problemen führt.
> Es ist interessant, dass CPUs mit KI-Unterstützung noch eine relativ > kleine Chipfläche dafür verwenden. Da gilt es zu unterscheiden: Dein Bild zeigt die NPU. Die kann kleine Modelle ausführen, ist energieeffizient aber nicht schnell (ok, schneller als CPU). Dann gibt es noch die iGPU, da laufen auch große Modelle drauf, mit ordentlicher Performance.
Christoph M. schrieb: > Speicher scheint wichtig zu sein, weil das ganze Modell rein passen > muss So ist es. Mit weniger RAM kommt nichts brauchbares heraus. Die Leistung der Grafikkarte bestimmt dann, wie viele User damit parallel arbeiten können. Für einen reicht jede Grafikkarte. Als langsame Zwischendung kommen mehrere Grafikkarten in Frage, deren RAM mit einem eigenen Link-Kabel zusammen geschaltet werden kann. Manche Nvidia Modelle können das.
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.