Dieser Artikel erschien im Embedded Projects Journal 15 auf Seite 7.
Im Rahmen einer Lehrveranstaltung an der Hochschule Merseburg ist das Projekt im Sommer 2012 enstanden. ...
|
|
Forum: FPGA, VHDL & Co. EPJ15 S. 7: PWM mit FPGADieser Artikel erschien im Embedded Projects Journal 15 auf Seite 7. Im Rahmen einer Lehrveranstaltung an der Hochschule Merseburg ist das Projekt im Sommer 2012 enstanden. ...
Angehängte Dateien:
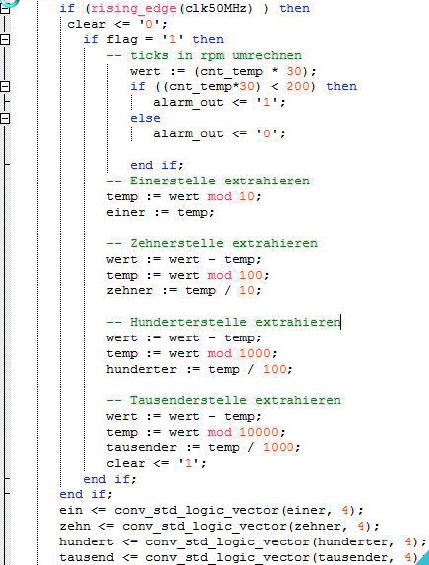
Modulo-Operationen und Divisionen zuhauf, fallende Flanken auf einem Taster, der dann einen Vergleichswert asynchron ändert. Jungs, das hat Niveau. Sowas kommt, wenn Programmierer mit VHDL auf ein FPGA losgelassen werden. Stimmts? > an der Hochschule Merseburg Kennt sich da keiner mit den Grundlagen von FPGA-Design aus? :-o Habt ihr analysiert, was euch diese Divisionen kosten? Warum zählt ihr nicht einfach gleich dekadisch? Ist der Schalter entprellt? Wie war das mit dem Einsynchronisieren? Lothar Miller schrieb: > Habt ihr analysiert, was euch diese Divisionen kosten? Die Chiphersteller wird es freuen, so können sie größere FPGAs verkaufen ;-) Duke Ui, da gibt es aber Haue :-) So schlimm sind die Divisionen nicht, es gibt Anwendungen für schnelle und breite Operationen, die auch Platz beanspruchen dürfen - wenn auch nicht im Umfeld der PWM-Erzeugung :-) Ich hätte da eine PWM anzubieten, die eine nichtlineare Vorverzerrung, eine Kompression und eine AGC integriert und zudem die Totzeiten und Überlappung der Schalttransistoren in der H-Brücke mitberechnet. Wo kann ich die publizieren? ja was habe ich mal auf einer VHDL Schulung gehört: Es gibt in Deutschland keinen einzigen Prof der VHDL kann - auch wenn sie meinen Bücher darüber schreiben zu können... Vigo schrieb: > Wo kann ich die publizieren? Am besten: mach einen Artikel dazu und wenn du Glück hast kannst du was gewinnen. Siehe dazu den https://www.mikrocontroller.net/topic/artikelwettbewerb-2012-2013 Vigo schrieb: > es gibt Anwendungen für schnelle und breite Operationen, die auch Platz > beanspruchen dürfen - wenn auch nicht im Umfeld der PWM-Erzeugung :-) Es geht dabei nicht mal um die Erzeugung einer (recht simplen) PWM, sondern darum, einen Zählerstand zu skalieren und für eine Anzeige in die Zehnerstellen aufzutrennen... Weil das Auge aber sowieso nicht 50 Millionen Aktualisierungen pro Sekunde verdauen kann, wäre es sinnvoll, das ganze zur Ressourcensparung zu serialisieren. SOWAS müsste man an einer Hochschule lernen (können)... Nur mal ein paar Ansätze, wie man platzsparend von Binär in BCD wandeln kann: http://www.lothar-miller.de/s9y/categories/44-BCD-Umwandlung 1) Hoho! Mein Knowhow kostenlos unter die Leute bringen, um dann eine Option auf den Gewinn eines Oszilloskops zu haben, mit dem ich meine PWM nicht mal ausmessen kann? ***lol*** 2) Es gibt durchaus Bedarf für vollparallele bin2dec mit maximaler Bandbreite, z.B. bei int2float conversion, wenn man bestimmte Cores anbinden möchte. Vigo schrieb: > 1) Hoho! Selber Hohoho. Warst nicht DU es, der freundlich nachgefragt hat, wie DU deinen Gedankenblitz veröffentlichen könntest. Konnte ja keiner wissen, dass das für DICH ein kleiner Scherz war. Mach doch wenigstens einen Smiley dran... :-/ > Es gibt durchaus Bedarf für vollparallele bin2dec Gut, dass niemand das Gegenteil behauptet hat. Nur wird man die dann mit mehr Hirnschmalz pipelinen und nicht so brachial mit zig Divisionen (die es ja nun auch nicht umsonst gibt) aufbauen... An Hochschulen wird eben meistens mit Kanonen auf Spatzen geschossen. Logik kostet da nichts, die hat man einfach ... daher sind die Divisionen kein Problem. Ich persönlich bin zwar auch geizig was die Verschwendung angeht, aber wenns mal eben schnell gehn muss ;-) Auf VHDL-Schulungen hört man so einigen Stuss. Mit einer Aussage, dass es KEINEN EINZIGEN Prof gibt der VHDL beherrscht disqualifiziert man sich selbst. Denn das setzt voraus, dass man ALLE kennt. Meinen Profs macht hier keiner etwas vor. Keine Theoretiker von der Uni, sondern einschlägige Industrieerfahrung ist das Stichwort. Ansonsten muss ich Lothar völlig recht geben. Es gibt elegantere Wege eine PWM zu realisieren. Modululo und Divisionen sind auch in Hardware kein Problem. So lange man es zur richtigen Basis macht ;-) Arno Nühm schrieb: > So lange man es zur richtigen Basis macht ;-) Wie heißt es so schön? Es gibt 10 Arten von Menschen: 1. die das Dualsystem kennen und 2. die anderen... Lothar Miller schrieb: > Es gibt 10 Arten von Menschen: > 1. die das Dualsystem kennen und > 2. die anderen.. Lol...Und die restlichen Acht?;) Reto schrieb: > Und die restlichen Acht? Hmm, dann eben so: Es gibt 10 Arten von Menschen: 01. die das Dualsystem kennen und 10. die anderen... Und der ist auch gut: Es gibt 2 Arten von Menschen: 1. die, die basierend auf unvollständigen Angaben extrapolieren können. Bei FPGA/VHDL ist es bei mir immer leider öfter so: “There are two rules for success. 1) Never tell everything you know.” Lothar Miller schrieb: > Nur wird man die dann > > mit mehr Hirnschmalz pipelinen und nicht so brachial mit zig Divisionen > > (die es ja nun auch nicht umsonst gibt) aufbauen... Wenn "man" es korrekt macht, braucht man keine einzige Division, denn es sind lediglich funktionelle Teilung. Tatsächlich sind es ja Multiplexer, also reine (schnelle) Kombinatorik, die zudem noch stark zusammengefaltet werden kann, wenn man es in einem Takt macht, also gerade NICHT pipelined, weil dann Teilterme mitgenutzt werden können. Wenn es sequenziell sein soll, dann kann man das mittels Partialbruchzerlegung im Übrigen auch geschickter lösen. Es hat niemand vorgeschrieben, dass man das im Zehnersystem rechnen muss. Hexa, mit je zwei look-ahead-Zweigen pro Stufe ist einfacher und braucht nur halb soviele Schritte. Vigo schrieb: > Wenn es sequenziell sein soll, dann kann man das mittels > Partialbruchzerlegung im Übrigen auch geschickter lösen. Hast du mal ein Beispiel? > Es hat niemand vorgeschrieben, dass man das im Zehnersystem rechnen muss. Aber das Ergebnis muss im Zehnersystem sein. Das ist von den meisten Menschen am besten lesbar... Euch ist aber klar, dass das ein Student gemacht hat, dem eventuell noch einiges an Erfahrung fehlt. Ich finds nicht gut, wie in diesem Forum zerrissen wird. Konstruktive Kritik ist hier aber sicher angebracht. Eventuell liest der Author das hier ja auch mal... Ich möchte nur daran erinnern, dass die meisten von euch im Studium auch noch keine Profis waren. Lothar Miller schrieb: > Es gibt 10 Arten von Menschen: Kenne das so: Es gibt 10 Arten von Menschen. Die die Binärcode verstehen und die die ihn nicht verstehen. Spart einem die 01/10 10.2.8 etc. Haarspalterei ;-) Lothar Miller schrieb: > Kennt sich da keiner mit den Grundlagen von FPGA-Design aus? Genau, dafür benutzt man einen Softcore! ;-) Hallo und Danke für die teilweise konstruktive Kritik. @Lothar Danke für die Verlinkung zur Binär BCD Wandlung. Ich habe das eben mal implementiert und komme von 1,3% Auslastung auf 1,1% Auslastung des FPGA. Das erscheint mir nich viel?! Ich sehe jedoch ein, dass das eventuell für größere Projekte Sinn macht. Eine Frage hätte ich zu deiner Kritik der Tasterabfrage: Warum darf ich nicht auf die fallende Flanke des Tasters abfragen? Der Taster ist LOW-Aktiv angebunden und selbstverständlich entprellt. Christian Kähler schrieb: > Warum darf ich nicht auf die fallende Flanke des Tasters abfragen? Der > Taster ist LOW-Aktiv angebunden und selbstverständlich entprellt. Darfst du schon, aber nicht so, wie du es da gemacht hast. Du verwendest den Taster dort als Takt, das ist absolut tödlich. Richtig wäre beispielsweise:
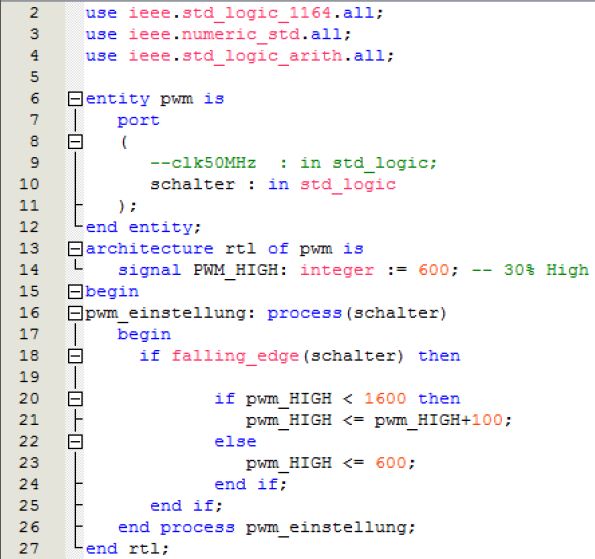
Die std_logic_arith-Bibliothek ist auch schon eher scheintot als empfehlenswert. Sven P. schrieb: > das ist absolut tödlich Was genau ist daran absolut tödlich. Mir ist bekannt, dass eigentlich alles synchron getaktet sein muss. In diesem Fall sehe ich allerdings nicht die Notwendigkeit?!? Die Idee dahinter ist eigentlich nur, dass egal wie lange die Taste gedrückt wird, nur "eine" Erhöhung des Wertes stattfindet. Dachte, dass ich das so am schnellsten/einfachsten realisiere. Sonst ist in dem Prozess ja auch nichts drin, was irgendwie synchron zum Rest sein muss (mMn). Wäre nett, wenn du mir erklären könntest, was da jetzt genau so schlimm ist?! Arno Nühm schrieb: > Ansonsten muss ich Lothar völlig recht geben. Es gibt elegantere Wege > eine PWM zu realisieren. Modululo und Divisionen sind auch in Hardware > kein Problem. So lange man es zur richtigen Basis macht ;-) Die Modulo und Divisionen sind eigentlich nur für die Anzeige auf den 7Seg Anzeigen wichtig. Mit der PWM-Erzeugung haben die eigentlich nichts zu tun. Die Verwendung der 7SEG war vorgegeben. :-( Ich sehe ein, dass Lothars Weg eleganter ist. Ich werde diesen in Zukunft auch so verwenden. Zeig doch interessehalber mal her, was die Synthese daraus macht. Also ein Bildschirmphoto vom RTL wäre schön.
Angehängte Dateien:
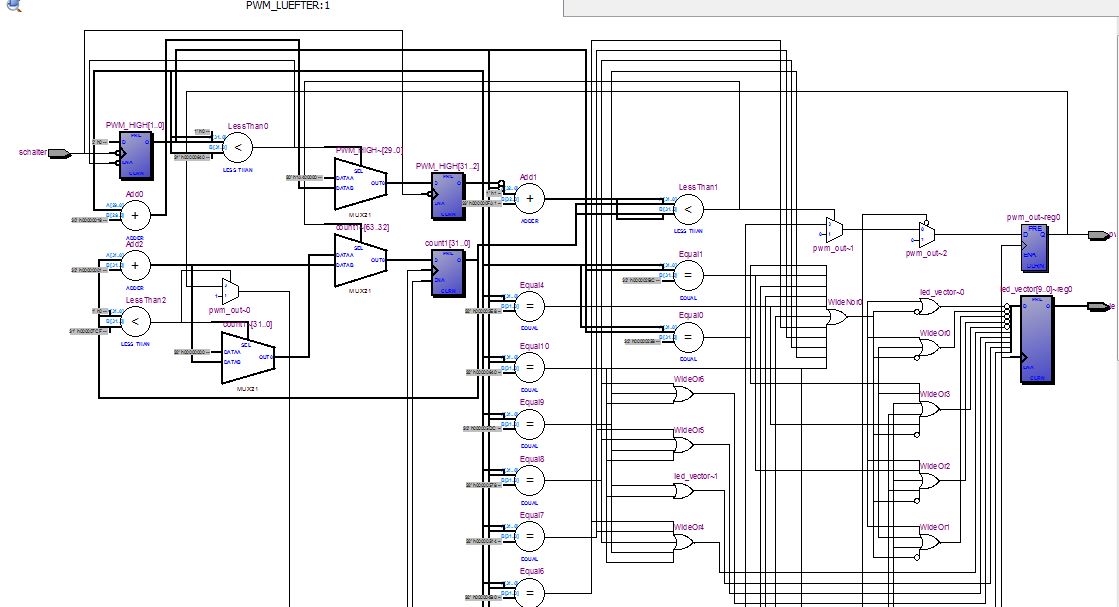
Hmm... Irgendwie macht die Synthese da gar nichts draus...
Angehängte Dateien:
Für den gesamten Block (Code) sieht das so aus Christian Kähler schrieb: > use ieee.numeric_std.all; > use ieee.std_logic_arith.all; aehm, wozu bitte das? Und dann: In deinem process (schalter) verwendest du ein Clock-Netz des FPGAs. Warum, wozu, ist 'schalter' ein FPGA Eingang oder ein einsynchronisiertes Signal? Dein process 'pwm_ausgabe' ist etwas gewoehnungsbeduerftig. Entweder benutze ich in einem getakteten process einen asynchronen Reset oder halt die Flanke einer Clock. So wie du das da machst und hinschreibst, naja, grenzwertig... Summasummarum: Schoen geht anderst. Mag sein, dass das ganze sogar funktioniert. Aber gib diese Beschreibung mal jemand anderem und erwarte, dass der versteht was du da machen willst... Stimmt...
Und bitte(!) korrigier das mit 'falling_edge(schalter)'... Wie erwartet synthetisiert es den Schalter unmittelbar auf einen Takteingang zweier Flipflops. Das SCHREIT geradezu nach metastabilen Zuständen und all den hässlichen Dingen, die in einem FPGA so passieren können :-O Harald schrieb: > Ich finds nicht gut, wie in diesem Forum zerrissen wird. > Konstruktive Kritik ist hier aber sicher angebracht. Meine Kritik war durchaus konstruktiv und Christian hat das offenbar auch so aufgefasst. Christian Kähler schrieb: > use ieee.numeric_std.all; > use ieee.std_logic_arith.all; Dazu den Beitrag "Re: Parallel/Seriel Wandler, mit Convertierung von BIT_VERTOR zu STD_LOGIC" Christian Kähler schrieb: > Ich habe das eben mal > implementiert und komme von 1,3% Auslastung auf 1,1% Auslastung des > FPGA. Das erscheint mir nich viel?! Nicht viel? Auf einem Xilinx 7V2000T würde das ca. 3900 Logic Cells bedeuten! Auf einem Spartan3E-500 entsprechen die 0,2% Unterschied ca. 21 "Equivalent Logic Cells". Ohne Angabe des Devices ist Deine Aussage nicht brauchbar. Außerdem ist es günstig, den Ressourceverbrauch auf LUTs (Kombinatorik), FFs (Register), BRAM (Speicher) und DSP-Blöcke (Multiplizierer) aufzuschlüsseln. Duke Duke Scarring schrieb: > den Ressourceverbrauch auf LUTs (Kombinatorik), > FFs (Register), BRAM (Speicher) und DSP-Blöcke (Multiplizierer) > aufzuschlüsseln. Und die Zielarchitektur anzugeben. Denn ein logiklastiges Design wird auf einem Spartan 6 mit 6er-Luts deutlich besser dastehen, als auf einem Spartan 3 mit seinen 4er-Luts... Lothar Miller schrieb: > Habt ihr analysiert, was euch diese Divisionen kosten? Werden die in FPGAs nicht einfacher durch invertierte Multiplikationen? Statt durch 100 oder zu dividieren, liesse es sich doch sicher schneller und direkter rechnen, wenn man einen entsprechenden Vektor genügender Auflösung mit 1/100 multipliziert? Also 2hoch32/100 => 42949673 und dann 32 Bit wegziehen. Lothar Miller schrieb: > Modulo-Operationen und Divisionen zuhauf, fallende Flanken auf einem > Taster, der dann einen Vergleichswert asynchron ändert. Jungs, das hat > Niveau. Sowas kommt, wenn Programmierer mit VHDL auf ein FPGA > losgelassen werden. Stimmts? Krass ... ich bin sprachlos ... Aber naja, dafür ist's ja kostenlos ;) Hmm ... gab es da nicht mal eine effiziente Methode, wie man binär nach BCD umwandelt? Fetz schrieb: > Hmm ... gab es da nicht mal eine effiziente Methode, wie man binär nach > BCD umwandelt? Kommt drauf an, wie schnell du das brauchst. Serielle Wandler kann man ziemlich simpel und kompakt aufbauen aus Schieberegister und Addierer. Aber der braucht halt etwas länger. Davon ab, einen Dividierer kann man auch relativ kompakt bauen. Riesig werden die erst, wenn man das Ergebnis mit wenig Latenz braucht, d.h. der Dividierer parallel gebaut wird. Martin Kluth schrieb: > Statt durch 100 oder zu dividieren, liesse es sich doch sicher schneller > > und direkter rechnen, wenn man einen entsprechenden Vektor genügender > > Auflösung mit 1/100 multipliziert? Das wird praktisch ja auch gemacht, zumal dann, wenn man es in Logik baut, weil es Wurscht ist, wie man es formuliert. Spätestens bei der Benutzung der Funktionen "restructure multiplexers" und "register balancing" wird die tool chain zu denselben Ergebnissen kommen (wenn sie was taugt). Solche BCD Wandler wurden hier nebenbei auch schon des öfteren diskutiert, siehe hier: Beitrag "Schnelle Conversion bin2dec" Lothar Miller schrieb: > Und die Zielarchitektur anzugeben. Denn ein logiklastiges Design wird > > auf einem Spartan 6 mit 6er-Luts deutlich besser dastehen, als auf einem > > Spartan 3 mit seinen 4er-Luts... Und zudem braucht man in einer schnelleren Technologie auch noch weniger zusätlziche FFs, um ein schnelles timing zu schaffen. Ich habe dazu gerade einen Vergleich mit meinem Audiodesign angestellt. Sobald man in die Nähe der Taktreserven kommt, passieren 2 Dinge: 1) Man schafft nicht mehr viel Kombinatorik zwischen 2 Taktflanken, weswegen es zwei Teile gibt, wo vorher nur ein Teil war, was sofort dazu führt, dass die Termmehrfachnutzung und Optimierung nicht mehr so ausgeprägt funktioniert und die Kombinatorik grösser wird (oder "bleibt"). 2) Desweiteren lässt sich die 2 erzeugte Kombi-FF-Architaktur auch nicht mehr gut ins BRAMs verschieben, wie ich beobachten durfte und wenn, dann braucht das RAM gleich mal weitere Ausgangs-FFs als Puffer. Das Mehr an FFs erzeugt also sozusagen noch weiteren FF-Bedarf und der geht nicht immer in den ungenutzten Silces, die bisher kombinarotisch waren, unter. Wie sich das dann darstellt, ist sehr unterschiedlich!! Die kleinen Versionen der DAW, für simple Musik in 8-10 Bit Güte, laufen z.B. auf 10MHz FPGA-Frequenz, weil die erreichbare GF der Filter bei knapp 9kHz liegen muss, um zu taugen. Das Ganze passt locker in einen Spartan 3, weil auch dieser langsame Chip viel Kombinatorik in die 100ns reinpacken kann. Beim Spartan 6 ist das Design dann gerade 5%-10% kleiner, hat aber die doppelte Geschwindigkeitsreserve. Eine CD-kompatible DAW mit mindestens 16 Bit Audiogüte, braucht bei denselben Filtern schon 18kHz Grenzfrequenz und 48kHz Abtastung, somit sind 50 MHz für alle 1024 Soundkanäle Pflicht. Trotzdem brauche ich teilweise schon 5-10% zusätzliche Register, da das Timing zu treffen ist und ich einige einige Softmultipliere in echte HW-MULs verschieben muss, was nicht viel Kombinatorik spart, aber mehr slices für die örtlich fixen MULs verbrät. Damit steigt die Latenz, weswegen ich streng genommen, mit mehr als 50MHz takten muss. In den Spartan 6 geht es ohne Zusatzregister rein und ist 25 kleiner! Die full scale DAW mit 96kHz ist nicht mit 100MHz zu betreiben, wie man denken könnte, sondern braucht wegen des timings sicher 120 oder so, womit mehr Register anfallen und noch mehr Latenz entsteht und noch mehr Tempo eingebaut werden muss, um im Sample fertig zu werden. Der "Hase und Igel" Effekt beschert einem hier 130-140 MHz, möchte ich mal schätzen. Das fliegt einem im Spartan 3 sofort um die Ohren - in den 6er passt es rein. Da ich ich ohnehin genauere Filter und mehr Auflösung brauche - habe ich noch mehr Bedarf an Timingreserven - gleichzeitig aber noch weniger zur Verfügung, also baue ich auf 200MHz für 1024 timeslots. Da ist dann Ende der Fahnenstange, weil noch mehr Tempo zuviele Register brauchen würde, um es zu schaffen und die Latenz mehr Verzögerung aufwirft, als die Taktgeschwindigkeitssteigerung einspart. Trotz "nur" einer Verdopplung der Leistung des Systems und einiger Bits mehr an Auflösung, braucht die Grundschaltung fast 2/3 mehr an slices und Multiplier ohne Ende. Bei einem Spartan 3 wäre es auch in den 1500er nicht reinzubringen. Bei Weitem nicht. Selbst in einen Virtex 4 gleicher Grösse geht es nicht rein. Tenor: Neben Angabe der Technologie sind auch die Syntheserandbedingungen anzugeben, um ein Design zu beurteilen. Genau genommen ergibt sich ja von links nach rechts ("area", "balanced" to "speed") eine Art von Hyperbel, die man angebeben könnte. Ich mache mir für meine VHDL-Module seit einiger Zeit jetzt immer Testsynthesen, indem ich das Modul wrappe, mit mehrfachen FF-Ketten versehe und in einige FPGAs testweise reinsetze. Die FFs sorgen dann aussen für ein enspanntes Timing und ich erhalte einen Eindruck, welche Resourcen an Zeit und Fläche für das eigentliche Design jeweils benötigt werden. Bei Modulen, in denen sehr viel Kombinatorik ooptimiert werden kann, wenn alles in einem Takt läuft, ist es z.B. manchmal am Besten, manlässt pipeline FFs weg und nutzt zwei Konstrukte parallel mit multicycle constraint. Hab mir den Bericht nochmal angesehen: Der Artikel ist wohl mehr ein Beispiel für die Implementierung traditioneller Vorgehensweisen in C und anderen Programmen in einem FPGA, also die Emulation von Software in Hardware am Beispiel der DDS. Eigentlich hätte man sich gezielte Tricks erwünscht, die die Vorteile des FPGAs ausreizen und zwar so, dass es resourcenschonend geschieht. Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.
|
|