Generell bin ich nicht der Freund der Softcores, da klassische Softwareverarbeitung das FPGA-Silizium nicht sonderlich gut auslastet. Ich sehe aber im Markt Anwendungsbedarf für 128Bit Applikationen, die sich mit aktuellen CPUs nicht machen lassen und auch nicht so schnell machen lassen werden. Daher würde ich die Frage stellen, ob jemand weiss, ob und wo bereits 64b/128b Softcores in der Entwicklung sind. Oder: Welche Softcore liesse sich mit vertretbarem Aufwand hochskalieren?
Ich will ja nicht sinnlos rumnörgeln, aber moderne CPUs haben 128 Bit breite Register (die SSE Register). Ich glaub kaum das ein Softcore in einem FPGA, der annähernd soviel kostet wie ein Quad Core von AMD oder Intel, auch nur annähernd die gleiche Rechenleistung erzielen könnte.
Klar, was es zu kaufen gibt, ist ohnehin billiger, als der Nachbau. aber es gibt eben die Möglichkeit, die Architektur zu manipulieren. Z.B. kann man bei Auslieferung der Hardware einen Softcore branden und Daten Verschlüsseln, sodass eine bestimmte Software nur auf einem einzigen System laufen kann. Damit wird dem SW-Klau vorgebeugt. Wofür 128 Bit? Je mehr Bitbreite der Bus, desto mehr Daten bekommt man gleichzeitig über den Bus ins RAM. Es gibt IO-lastige Applikationen, die man nur im FPGA machen kann. Der Schritt hin zur Software ist mit weniger Latenz belastet. Auch einfache Rechenoprationen sind effektiver: Um einn unskalierten Ausgang einer FFT zu normalisieren, musste ich z.B. 34 Bit qudrarieren. Das geht in 64er Architekturen nicht mehr rein. Wenn ich immer noch einen Schritt zum Skalieren brauche, dauert der Transport über den Prozessor eben nicht 1x4096 Takte sonden 2x4096 Takte. Macht 40us mehr Bedarf. >Quad Core Dass Softcores mit steigender Größe im Vergleich immer unwirtschaftlicher werden, ist klar. Cores im FPGA müssen aber sehr leistungsfähig sein, damit es von der Systemplanung her Sinn mach. Irgendwelche Sonderbedingungen müssen exisitieren. Wenn der Bedarf für dieses maximale Timing nicht da wäre, könnte man solche Operationen wieder in die billigeren hardDSPs auslagern.
Andreas Fischer schrieb: > Wofür 128 Bit? Je mehr Bitbreite der Bus, desto mehr Daten bekommt man > gleichzeitig über den Bus ins RAM. Es gibt IO-lastige Applikationen, die > man nur im FPGA machen kann. Der Schritt hin zur Software ist mit > weniger Latenz belastet. nicht wirklich, eine normale 32bit CPU kann auch mit 256bit auf dem Ram zugreifen. Grafigkarten haben auch eine 512bit Speicheranbindung und dort ist meines Wissens keine 512Bit CPU drin.
CPU-Neuling schrieb: >> mit 256bit auf dem Ram zugreifen > Welche RAMs haben denn 256bit??? Typ GDDR3 Taktfrequenz 1632 MHz Speicheranbindung 512 Bit http://www.alternate.de/html/product/PNY/Quadro_FX5800/574426/?
Bei Bedarf kann man sich ja auch selbst eine CPU aus ALU und dergleichen zusammenkloppen. So schwierig ist das nun auch wieder nicht.
CPU-Neuling schrieb: >> mit 256bit auf dem Ram zugreifen > Welche RAMs haben denn 256bit??? Man kann RAMs auch parallel schalten...
Hi, Du kannst im Prinzip auch einen 8051 core mit speziellen n-bit-Instruktionen aufbohren. Stichwort: SIMD oder Vektor-Operationen. Am kniffligsten wird vermutlich, die Pipeline so zu designen, dass diese Instruktionen in (bevorzugt) Hardwareschleifen in einem Takt abgearbeitet werden. Da würde ich mir doch eher die Berechnungen in einen separaten Coprozessor verfrachten, da das Aufbohren so einige Probleme schaffen könnte.
Peter II schrieb: > eine normale 32bit CPU kann auch mit 256bit auf dem Ram > zugreifen. ...und was macht die 32-Bit ALU dann mit den 256 Bits im nächsten Taktzyklus??? EBEN!
Stefan Wimmer schrieb: > und was macht die 32-Bit ALU dann mit den 256 Bits im nächsten > Taktzyklus??? sich den Cache füllen. Damit gibt es beim nächsten zugriff keine Wartezeit mehr.
Andreas Fischer schrieb: > Ich sehe aber im Markt Anwendungsbedarf für 128Bit Applikationen, Welche wären das?
Strubi schrieb: > Du kannst im Prinzip auch einen 8051 core mit speziellen > n-bit-Instruktionen aufbohren. Hört sich innovativ an: ein (in Zahlen 1) Akku mit 128 Bit Breite...
Gibt es in ASICs schon geraume Zeit. Die Prozessorhersteller haben das wohl nur deshalb nicht drin, weil es keiner nachfragt. (?)
Siebzehn mal Fuenfzehn schrieb: > Bei Bedarf kann man sich ja auch selbst eine CPU aus ALU und dergleichen > zusammenkloppen. So schwierig ist das nun auch wieder nicht. Schon mal gemacht?
Halbleitermann schrieb: > Gibt es in ASICs schon geraume Zeit. Die Prozessorhersteller haben das > wohl nur deshalb nicht drin, weil es keiner nachfragt. (?) Hättest Du ein Beispiel für einen solchen ASIC?
Andreas Fischer schrieb: > Hättest Du ein Beispiel für einen solchen ASIC? Sieh mal eine Grafikkarte aus dem höheren Preissegment genauer an. Andere verwenden übrigens genau solche Grafikkarten zum Rechnen mit großer Wortbreite... Andreas Fischer schrieb: > Ich sehe aber im Markt Anwendungsbedarf für 128Bit Applikationen, die > sich mit aktuellen CPUs nicht machen lassen und auch nicht so schnell > machen lassen werden. Und auf was kommt es da an? Wortbreite oder Geschwindigkeit? > Daher würde ich die Frage stellen, ob jemand weiss, ob und wo bereits > 64b/128b Softcores in der Entwicklung sind Softcores sind LANGSAM. Und was nützt mir eine langsame CPU mit breiten Registern?
Andreas Fischer schrieb: > Wofür 128 Bit? Je mehr Bitbreite der Bus, desto mehr Daten bekommt man > gleichzeitig über den Bus ins RAM. Es gibt IO-lastige Applikationen, die > man nur im FPGA machen kann. Der Schritt hin zur Software ist mit > weniger Latenz belastet. Dafür braucht es aber keinen128 bit cpu core sondern einen entsprechend breiten Memoryxontroller. Dafür gibt es schon einiges am Markt. Wobei solche IO-lastigen Applikationen selten sind. Mir ist noch keine Applikation untergekommen die ADU mit mehr als 16bit Quantisierung nutzen. Für mehrkanalanwendungen z.B Phased Array oder CT gruppiert man eben einige Kanale passend zum Ram-interface und instanziert die Blöcke parallel. > Auch einfache Rechenoprationen sind effektiver: Um einn unskalierten > Ausgang einer FFT zu normalisieren, musste ich z.B. 34 Bit qudrarieren. > Das geht in 64er Architekturen nicht mehr rein. Wenn ich immer noch > einen Schritt zum Skalieren brauche, dauert der Transport über den > Prozessor eben nicht 1x4096 Takte sonden 2x4096 Takte. Macht 40us mehr > Bedarf. Hast du mal ein Beispiel wo eine 34bit FFT nötig ist? Wo liegen die Vorteile - bessere frequenzauflösung - im sub-ppm Bereich? Feinere Betragsquantisierung - aber der Großteil davon ist eh rauschen? MfG,
Bist du sicher, dass Deine APP nur mit einem 128 bitter zu machen ist? Softcores machen bekanntlich nur wirklich Sinn, wenn sie wenig und Langsames zu rechnen haben, weil sie de facto schon sequenziell an die Aufgabe herangehen. Ich meine, dass das geringfügige Aufblähen des Codes gegenüber dem Rechnen mit einer 32Bit-CPU nicht sonderlich ins Gewicht fallen sollte, es sei denn, es ginge jetzt zufällig um 2-3 Takte mehr oder weniger. Es hat schon seinen Grund, warum die keiner baut: Weil's keiner braucht :-) Eher schon machen 64Bit und mehr breite HW-DSPs Sinn, wenn es um das Verarbeiten von hochschnellen Signalen geht. Einmal als VHDL erarbeitet, kann man die ja flux in einen ASIC backen. CERN hat da immer mal wieder was im Gepäck, um die beschleunigten Teilchen erfassen und prozessieren zu können.
Experte schrieb: > Eher schon machen 64Bit und mehr breite HW-DSPs Sinn, wenn es um das > Verarbeiten von hochschnellen Signalen geht. Einmal als VHDL erarbeitet, > kann man die ja flux in einen ASIC backen. So ist es. Wir haben den Tipp dankend aufgenommen: Beitrag "Re: Projekt-Idee 64-Bit RISC CPU in VHDL" Waren noch 2 Studenten mit dran und ja, er wandert nach erfolgreichem Prototyping in einen ASIC rein und zwar an einer Stelle, wo nur für einen Chip Platz ist. Beispiel: Im Vergleich zum derzeit schnellsten Zynq läuft mein RS1-96 Core für jeweils optimierte Taktfrequenzen auf rund einem Drittel der Geschwindigkeit, mit der er z.B. FSMs abarbeiten kann. Er schafft aber bei komplexer Rechnung mit mehr als 36 Bit Auflösung schon 40% ... 160% an Datendurchsatzes gegenüber dem Zynq - kommt so auf 45% der Leistung. Bei komplexen Rechnungen mit Iterationen wie z.B. Mandelbrot mit floating point, die mit den vollen 96 Bit fixed point gerechnet werden, sind bis zum Fünffachen des Datendurchsatzes gegenüber dem Zynq möglich, er ist mit an anderen Operationen zusammen also schon fast gleichwertig. Im Schnitt packt das VHDL rund 60% bis 90% dessen, was der Zynq kann, ich kann aber 20 Stück in den FPGA setzen. Für die ASIC-lösung erwarten wir eine Taktfrequenz von 1500 MHz gegenüber 300 MHz. Da ist dann einer alleine schon 3x schneller.
So jetzt sortieren wir mal: > in einen ASIC rein und zwar an einer Stelle, wo nur für > einen Chip Platz ist. Es geht also um den Platz. Wenn dort ein ASIC hingeht, der Software verarbeiten kann, dann muss dort wenigstens noch ein RAM und ein FLASH hin. Oder sitzt das auch alles im ASIC? > Beispiel: Im Vergleich zum derzeit schnellsten Zynq läuft mein RS1-96 > Core für jeweils optimierte Taktfrequenzen auf rund einem Drittel der > Geschwindigkeit, mit der er z.B. FSMs abarbeiten kann. Der Vergleich bezieht sich also auf eine CPU im FPGA. Was ist mit einer normalen CPU? > Bei komplexen Rechnungen mit Iterationen ... > ... also schon fast gleichwertig. Also so schnell wie eine SOPC-Plattform. Ein echte CPU wäre also immer noch einen Faktor 2 schenller. > Im Schnitt packt das VHDL rund 60% bis 90% dessen, was der Zynq kann, > ich kann aber 20 Stück in den FPGA setzen. Kannst Du auch 20 Stück dieser Prozessoren in den ASIC setzen? Woher bekommen die ihre Daten? Alle brauchen Flash und RAM. > Für die ASIC-lösung erwarten wir eine Taktfrequenz von 1500 MHz > gegenüber 300 MHz. Da ist dann einer alleine schon 3x schneller. 1500 / 300 = Faktor 3 ? Mich beschäftigt Folgendes: Ein CPU, egal wie sie aussieht, setzt jemand ein, wenn er komplizierte Sachen machen will, die als Programm laufen. Wie aber wird das Programm erzeugt? Gibt es ein C-Programm das durch einen Compiler geht, oder ist es Assembler-Code?
Naja. Ich melde mal auch etwas Skepsis an. Butter bei die Fische: 1) Welches FPGA? 2) CPU sauber verifiziert? 3) Was ist neu? 4) Debug-Interface (In Circuit Emulation)? > Waren noch 2 Studenten mit dran und ja, er wandert nach erfolgreichem > Prototyping in einen ASIC rein und zwar an einer Stelle, wo nur für > einen Chip Platz ist. > Das mit den Studenten spricht erfahrungsgemäss leider nicht grade für einen Chip... > > Für die ASIC-lösung erwarten wir eine Taktfrequenz von 1500 MHz > gegenüber 300 MHz. Da ist dann einer alleine schon 3x schneller. Das Ziel kommt mir ein bisschen hochgesteckt vor. Aber wenn Ihr das hinkriegt und eine Bude auftut, werdet ihr bestimmt von NXP gekauft:-) Was die Tools angeht: Es gibt auch durchaus Ansätze, die ohne C-Compiler gut benutzbar sind, wie z.B. Motorola 56k-Klone als DSP-Coprozessoren, oder die gut lesbare Blackfin-Assembler-Syntax mit Vektor/Parallel-Operationen. Wenn einer gut bison kann, kriegt er nen Gnu Assembler-Port in 3-4 Monaten hin. Der letzte Knackpunkt aber ist die Frage: Ist es ein akademisches Spielwiesenprojekt, oder soll es ein richtiger Systemprozessor werden, von dem man auch in Zukunft noch was hören wird? Statistisch: Es gibt nämlich doch eine Menge me2-Projekte, die nach anfänglicher Euphorie schnell wieder der Verwaisung unterliegen, weil die Komplexität einer Industrielösung unterschätzt wurde. Gruss, - Strubi
Wer eine Rock-Stable 128-Bit Plattform sucht: AS/400. Seit 30 Jahren 128 Bit. (Damals noch über switching, mittlerweile echte Busbreite.) ;-) Gruß Jobst
> Experte schrieb: >> Eher schon machen 64Bit und mehr breite HW-DSPs Sinn, wenn es um das >> Verarbeiten von hochschnellen Signalen geht. > Im Schnitt packt das VHDL rund 60% bis 90% dessen, was der Zynq kann, > ich kann aber 20 Stück in den FPGA setzen. hm, auch bei großen FPGAs bleibt nicht viel, wenn man die Resourcen durch 20 teilt. Da ist vielleicht eine CPU bei einer kleinen Architektur möglich, aber die dürfte kaum der Rechenleistung eines Zynq-ARM vergleichbar sein. Allenfalls ist die Aufgabe so gestellt, daß ein ARM qualitativ unterfordert wäre, weil Teile der Funktionen brach lägen. Oder es liegt an vielen Speicherzugriffen, die beim FPGA / ASIC im Ggs zum ARM wegfallen, weil Block-RAM verwendet wird.
Die AS/400 war ne geile Kiste, neben der PDP-11. Wenn die Dinger nur nicht so viel Strom gefressen hätten... (sonst stünden sie noch in meinem alten Kinderzimmer :-) ) Zum Thema "Vollpacken" von FPGAs mit CPU-Kernen kann man sich etwas an den klassischen alternativen Ansätzen orientieren: - Parallax-Architektur - Chucks Forth Prozessoren Obwohl theoretisch diese Kerne immer n-fach in ein großes FPGA reinpassen, manifestiert sich spätestens im P&R das Problem mit einer Gatter-Verstopfung, typischerweise beim shared memory oder den Register Files. Mit alternativen Ansätzen a la J1 und andere Forth-Prozessoren und einer unabhängigen Programm-Pipe geht das bis zu einem gewissen Punkt gut, bei registerbasierten CPUs wie wir sie gewohnt sind (GCC-Support) ist bald mal Schluß. Leider sind in der Industrie die Forth-Sachen nie so recht angekommen, ein robuster C-Compiler gehört heute einfach zum Standard. Einen annehmbaren Kompromiß für "home made" multi core kriegt man mit der ZPU hin, das ist so ein Zwischending zwischen reiner Stack-Maschine und wanderndem Register-Window. Mit distributed RAM als Stack/Register file sieht das dann so aus, daß jede CPU für sich recht kompakte Logik alloziert und die Memory-Interfaces entlastet werden können. Dementsprechend laufen aber auch keine großen Programme auf den Nebenkernen. Bisher habe ich noch keine sinnvolle Anwendung für mehr als drei Kerne gefunden (ein Master, zwei Slave threads). Gegenüber einem ARM mit Linux macht das sowieso keinen Sinn. Nur, wenn man ein beweisbares/stromsparendes Design haben möchte/muß. Für richtig dedizierte Rechenpower sollte man sich lieber an den parallelen Shader-Units von nvidia orientieren. Alles andere klingt mir - verzeiht mir meine ehrliche Meinung - nach akademischer Verträumtheit.
Die Entwickler von RISC-V hatten anfangs als Spielerei in die Spec geschrieben, dass man neben 32 und 64 Bit auch eine 128 Bit-Implementation machen könnte, wenn man denn wollte. Daraufhin wurden sie mit Anfragen so lange zugeschissen, bis sie das auch gemacht haben. Solche Cores scheinen für gewisse Anwendungsfälle (d.h. Bignum, z.B. Krypto) hinreichend nützlich zu sein. Zumindest die 32- und 64-bittigen RISC V-Kerne werden von GCC schon unterstützt, ob das auch für 128 Bit zutrifft, weiß ich nicht. Hat natürlich dann wieder nichts mit Multicore zu tun.
S. R. schrieb: > Solche Cores scheinen für gewisse Anwendungsfälle (d.h. Bignum, z.B. > Krypto) hinreichend nützlich zu sein. Ja, das ist schon richtig. Hatte auch schon APPs, wo 64 gerade nicht ausreichend war. Ließ sich natürlich emulieren. Das Problem bei einem Softcore mit 128 Bit ist der Flächenverbrauch, wenn es dann nur partiell ausgenutzt wird. Daher sind die Einwände im thread absolut berechtigt.
Jürgen S. schrieb: > Das Problem bei einem Softcore mit 128 Bit ist der Flächenverbrauch, > wenn es dann nur partiell ausgenutzt wird. Daher sind die Einwände im > thread absolut berechtigt. Ich kann nicht einschätzen, ob ein einfacher 128 Bit-Core so viel größer ist als ein komplexerer 32 Bit-Core ist, der (im Extremfall) in der gleichen Zeit das Fünffache an Befehlen ausführen können muss.
Vielleicht schafft man es ja, einen Prozessor zu bauen, der aus 4 32Bit Cores besteht, welche jeweils eigene Tasks bearbeiten und mit einem Befehl zu einem 1x 128Bit Core umgeschaltet werden können ... ;-) Gruß Jobst
Ich würde jetzt nicht einen einfachen mit einem komplizierten Core vergleichen, weil Komplexität im FPGA zu einerseits Flächenbedarf- aber auch Zeitbedarf führt, der sich in der maximalen Geschwindigkeit niederschlägt. Aus demselben Grund ist es auch schwierig, den Anstieg des Flächenbedarfs zu schätzen: Da es Teile in einer Schaltung gibt, die von der Wortbreite unabhängig sind, dürfte eine 128er Architektur zunächst deutlich unter dem Doppelten liegen, was einer 64er-Architektur verbraucht. Da aber mit den Worten gerechnet wird, entstehen naturgemäß viel längere Pfade. Will man das klein halten, geht die fmax runter, ansonsten kostet es mehr FFs! Und trotzdem wird es dann noch so sein, dass das Tempo oft nicht ausreichend ist und man mit Architekturverdopplung arbeiten muss, um eine pipe schnell zu kriegen. Es kann daher durchaus sein, dass die 128er Architektur mehr, als doppelt so groß wird. Die 4 32-bit-Systeme bringen da keine Lösung des Problems, weil sie a) schon mal pauschal 4x größer sind und b) noch lange keine 128 bit DSP-OP realisieren. Nehmen wir doch einfach mal die binomische Formel für 32Bit durch 16Bit mit H und L für zwei Faktoren realisiert: ERG_32 = A_32 x B_32 -> wird zu: ERG_32 = (AH_16 x 65536 + AL_16) x (BH_16 x 65536 + BL_16) -> = 65536 x 65536 x (AH_16 x BH_16) + 65536 x (AH_16 x BL_16 + AL_16 x BH_16) + AL_16 * BL_16 Sind also 4 Multiplikationen + 1 Addition und 3 weitere implizite Additionen durch Zusammensetzen der Terme, was durch richtiges Speichern mit explizitem Carry erfolgen kann. Sind also 4 parallele Schritte für jede CPU und einen weiteren wobei 3 im Leerlauf sind. In FPGAs braucht die MUL gfs 2 Taktzyklen, sind also 4x3 time slots bei denen 5 belegt sind. Na Danke. Sowas baut man dann eher als schmale pipeline mit einer mitgeführten Potenz, die die Binärstelle steuert, hängt einen Takt für die Carry-Addition dran und schiebt es sequenziell durch, macht 3+1+(4-1) = 7 Takte im FPGA mit einer Architektur. Beim FPGA hängt man immer irgendwo an den DSP-Breiten fest. Der Spartan z.B. hat 18x25, da kann man sich abzählen, dass er für 36x36 bit noch einigermaßen hinkommt, die absolute Grenze sind 36x50, darüber wird es übel mit dem MUL-Verbrauch und dem Tempo. Ich kann mir schon vorstellen, dass das in einem ASIC super schnell arbeiten könnte.
Angehängte Dateien:
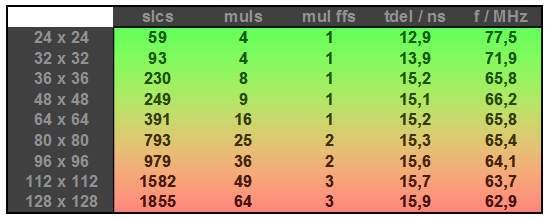
Ein Beispiel für den Flächenverbrauch an slices und MULs, zusätzlichen Registerstufen nach dem Multiplier, um 60 MHz zu erreichen.
Moin, habe in der Vergangenheit mal mit manuell generierten Vektor-ALUs herumgespielt, die in die Richtung der Blackfin-Vektoreinheiten gehen, allerdings mit etwas mehr Genauigkeit, Anwendung: Matrizenmultiplikation. Da sieht man eigentlich ziemlich dasselbe, was die Xilinx-Corengen-Tools für MAC-Units auch ausspucken: Beim Kaskadieren der DSP-Primitiven kommt gezwungenermassen eine Pipeline-Stage dazu, wenn die Fmax noch gelten soll. Bei meiner Anwendung waren das schon 5 Takte Pipeline delay pro Vektor-MAC. Das beisst sich dann prinzipiell mit einer generischen CPU, bei der die Daten irgendwo aus dem RAM kommen, da hat man einfach die ALU-Pipeline nie voll. Das kann man allerdings a la Blackfin parallelisieren, wird aber auf dem FPGA eine wüste Geschichte mit einer Menge Hazard-Szenarien, die man einem Anwender nicht zumuten kann. Geschweige denn demjenigen, der die RTL für den GCC entwerfen muss... Auf einem ASIC mag das schliesslich mit viel Arbeit lösbar sein, aber Hazard-Logik auf dem FPGA neigt fast immer zu lokaler Resourcen-Verstopfung, sprich: bremst. Deswegen kann ich der Idee mit der fetten ALU-Bitbreite unter dem Aspekt des generischen Cores nicht so viel abgewinnen. Der pragmatische Highspeed-Ansatz sieht also nach wie vor so aus, dass der generische Kern nur die DMA-Datenschleuder anschmeisst, die die Rohdaten in die Vector-MAC des unabhängigen Coprozessors schleust (und hinten wieder raus). Beim generischen "inline"-Ansatz, d.h. Berechnung im Programmcode, macht es IMHO mehr Sinn, sich Carry/Adder-Chains sequentiell aufzubauen, wie Jürgen es oben skizziert hat. Warte also noch auf das bahnbrechende Argument pro "generische 64 bit ALU". Denn flexibel gestalten kann man den highspeed-Ansatz mit SIMD-Mikrocode auch. Grüsse, - Strubi
Strubi schrieb: > Warte also noch auf das bahnbrechende Argument pro "generische 64 bit > ALU". Also 64 bit sind schon gebrauchsfähig, habe ich auch schon benutzt, aber 128 sind halt ein bischen fett und schlecht zu handhaben, aber vielleicht kommt das ja noch in Zukunft mit neuen FPGAs. Jetzt, wo die Anforderungen steigen, wäre es eigentlich Zeit, mal breitere Multiplier einzubauen. Oder noch besser: Gleich eine mikroskopische FIR-Struktur mit durchtaktbarem 24Bit-Register und parallel ladbaren Multiplieren bei direkter Summierung, wo man einfach nur noch ein Datum reintaktet und im nächsten Takt direkt das Teilergebnis hat. Wäre für Videofilterung wichtig. So muss man doch einiges an resourcen verwenden und tricksen und oft Register spendieren, weil das Tempo nicht reicht. Mit Bezug zur Grafik oben nochmal einige alternative Werte vom Artix7: Bei 24x24 benötigt er nur 2 statt 4 Multiplier, dafür aber mehr FFs! Offenbar baut die Synthese (welche - anders als oben beim Spartan - auf "balanced" eingestellt sein kann, um das timing zu treffen) einige der Terme direkt in fabric auf! Konkret werden 176 FFs verbraten, dafür packt er standardmässig aber schon mal 80 MHz! Die Geschichte setzt sich nach oben fort! Kontinuierlich eher weniger DSP-Elemente und irgendwann auch weniger FF-Bedarf. Für 128x128 werden 1282 FFs benötigt, aber dann auch 64 MULs bei erreichbaren 80MHz und das jeweils aber mit nur einer FF-Stufe hinter den MULs. Die Architektur beim Artix ist also regelmäßig signifikant kleiner und hat trotzdem eine höhere Grenzfrequenz. Mit "Performance Retiming" und 3 Stufen hinter den MULs, zum balancieren der FFs werden bei jetzt 1634 FFs immerhin 100 MHz erreicht, dann ist aber auch so ziemlich Schluss! Der Artix hat aber im Vergleich zum Spartan schon ein enormes Preis-Leistungsverhältnis, muss man sagen. Meinen ersten Synthesizer den ich vor 10 Jahren für den Spartan3 gebaut habe, packt er für die Zielfrequenz von 50 MHz auf Wunsch OHNE einen einzigen DSP anzutasten! Bei der aktuellen Version mit 200MHz fallen alle DSPs für die langsamen Modulatoren (multi cycle constraint) unter den Teppich und er verbrät weniger als 300 DSP Elemente ( die beim Spartan der Anschlag waren) hat aber über 700 an Board! Wenn ich mir in Erinnerung rufe, was ich mich noch vor Jahren mit dem schnuddeligen Virtex abgequält habe :-) Ich bin eigentlich ziemlich sicher, dass die künftigen FPGAs entsprechende DPSs drin haben werden, vielleicht auch mit dem Fokus Grafk und Video. Nett wären CUDA-ähnliche Strukturen, die man so programmieren könnte, wie Grafikkarten. Auch die CPUs im FPGA werden zulegen. 32 Bit sind eigentlich überholt :-)
Moin, mit generisch meinte ich eben eigentlich den Einsatz als ALU in einer CPU. Aber mal von der anderen Seite aufzäunen: Die Frage, warum sich fast alle Hersteller immer bei den 18 Bit breiten DSP-Slices (MAC-Units) finden, kommt ja immer wieder auf. Im Zusammenhang mit den BRAM-Schnittstellen ist das wohl nach wie vor der beste generische Kompromiss. Warum das überhaupt was mit dem Memory zu tun haben sollte, kann man natürlich in den Raum werfen, aber das klassische Schema sollte für sich sprechen:
1 | [Peripheriegerät] --Rohdatenstrom--> [Interface] -> [FIFO Memory(DMA)] -> |
2 | [DSP unit] |
Wenn man da die Datenworte auf 32 bzw die MAC auf 64 oder 96 bit aufbohrt (mehr macht IMHO keinen Sinn für 'double'-Emulation), kommen halt die weiteren Register (Pipeline-Stages) hinzu, an denen man von der Kaskadierung der Multiplier her schon nicht vorbeikommt. Aber noch kein Problem, die Daten strömen clocksynchron durch, und der Delay tut hier nicht weh. In der CPU allerdings schon, da sich selbige ja die Daten erst besorgen oder evaluieren muss. D.h. um maximale Effizient wie oben zu kriegen, brauchts eine 1-Zyklen-Parallel-Op für den typischen FIR wie:
1 | loop(z0) { ; Hardware loop register 0
|
2 | a1 += r0 * r1 ¦ r0 = [i0]++ ¦ r1 = [i1]++; |
3 | } |
4 | ; TODO: a1 evaluieren |
Wenn die Bitbreite nicht ausreicht, muss man die MUL/MAC softwaremässig kaskadieren und verbrät weitere Zyklen, da ist die breite ALU (in HW) wieder besser dran. Innerhalb der Schleife kriegt man dann auch "1-Zyklen"-Performance. Aber am Ende muss die Pipeline gespült werden, um mit a1 weiter was im Programmcode machen zu können. Und da beisst der Delay. Wer also jetzt generische Operationen in der CPU (noch per bare metal assembler-code) anstrebt, muss einen gehörigen gordischen Knoten lösen. Und da sich schlussendlich nach meinem Feststellen fast immer der Bandbreitenstau an den Memory-Interfaces ergibt, ist IMHO eine generische Lösung als Systemprozessor mit allen Programmierschmankerl bei der Bitbreite fast nicht praktikabel, geschweige denn vom Aufwand, den ein vernünftiger C-Compiler mit sich bringt. Die Entwicklung der ALU-Sektion alleine ist also nicht das Problem, und auch Register lassen sich intern mit Aufbohren des Befehlssatzes kaskadieren. Auf der ZPU(next generation) habe ich den 'DSP-Mode' so implementiert, dass obige MAC-Ops inline im Code per Mikrocode-Emulation abspulen. Ein Escape-Bit im Opcode schaltet sozusagen den Befehlssatz um. Das resultiert in einem (anwendungsspezifischen) Mikrocode-Applet, welches intern die 32 bit breiten Register-shadows jeweils zu 64-Bit Breite zusammenhängt. Also bisschen a la "Trick Jobst single core", oder wie es der Blackfin mit seinen 16-Bit-Registerhälften macht. Ineffizient wird das bloss bei "Immediate loads", die Daten müssen also parallel aus dem 32 Bit-BRAM kommen. Nur generisch ist das Ganze kaum, der Mikrocode wird als langes Bitfeld von parallelisierten/verzögerten Opcodes ausgespuckt, ein Assembler wäre schon zu aufwendig, und GCC-RTL bekäme die 1-Zyklen-Optimierung nicht mal hin. Es läuft also immer öfter auf hybriden Ansatz raus, bei dem Pipeline, Operationsablauf und ALU wie auch zugehöriger Default-Mikrocode für den jeweiligen Zweck aus der HDL generiert wird, und der C-Code bloss Applets lädt/aufruft. D.h. damit lässt sich kein Systemprozessor konzipieren, den die Community brauchen kann (Kennt noch jemand den HiCoVec?). Lasse mich dennoch immer gern überraschen. Ist nur etwas still geworden um den oben angekündigten 64-Bit-RISC... Grüsse, - Strubi
Allein schon, wenn ich versuche, dem Sermon zu folgen, gelange ich zu der Erkenntnis, dass das für den Benutzer nicht machbar ist. Softcores sind ineffektiv und haben nur einen Zweck, nämlich die Entwicklung zu vereinfachen. Alles, was der Compiler nicht automatisch erledigen kann, bleibt dem User und konterkariert die gesamte Idee! Dann lieber in C bauen und in VHDL übersetzen lassen.
Thomas U. schrieb: > Softcores > sind ineffektiv und haben nur einen Zweck, nämlich die Entwicklung zu > vereinfachen. Gegenüber Hardcores (beliebiger Art) ist ein weiterer Vorteil die prinzipielle HW- und Hersteller-unabhängige Verwendbarkeit. Eine generische Beschreibung läuft auch in 50 Jahren noch auf den dann aktuell verfügbaren ICs. Nur scheinbar hat daran leider niemand ein Interesse.
Lars R. schrieb: > Thomas U. schrieb: >> Softcores >> sind ineffektiv und haben nur einen Zweck, nämlich die Entwicklung zu >> vereinfachen. ineffektiv ist nicht ganz richtig. Es lassen sich nicht die Geschwindigkeiten erreichen, die eine HW-CPU erreicht. 200MHz für einen Softcore ist kein Problem. Was viele CPUs durchaus auch im Regen stehen lässt.
Thomas U. schrieb: > Dann lieber in C bauen und in VHDL übersetzen lassen. Schon mal ausprobiert? Ich halte davon gar nichts. Bei 3x3 Filterkernel kann die HLS von Xilinx schon nicht mehr mithalten. Auch sind Softcores nicht ineffektiv, wir haben ein DSP design im FPGA laufen, wo es sonst keine Lösung gibt mit ARM, etc. Kann dazu aber nicht mehr sagen. Es sind hier halt oft Nischenanwendungen, wo es nur wenige Spezialisten gibt. Dort ist auch sehr viel Interesse vorhanden, z.b. für gewisse Sicherheitsanforderungen, wo ein ARM nicht in Frage kommt.
Also dann, wer mag: Eine 64 Bit FPU: https://www.ra.informatik.tu-darmstadt.de/fileadmin/user_upload/Group_RA/main/documents/Dokumenation_FPU.pdf
Thomas U. schrieb: > Also dann, wer mag: Eine 64 Bit FPU: Jo, sieht nach einer ordentlichen Arbeit aus. Aber gerade auf einem FPGA bevorzuge ich wegen verschiedener Faktoren fixed point. Gerade bei Fehlerabschätzung ziemlich essentiell. Macht also IMHO mehr Sinn, mehr Bits zu spendieren und stattdessen die Konversion double <-> FixedPoint nur an den Schnittstellen (d.h. dem Interface zu C) vorzunehmen. Mich würde mal interessieren, was die Xilinx HLS aus einem in C geschriebenem Algo mit double-Werten so an Logik zusammenkaskadiert... Ansonsten sehe ich softcores mit DSP-Erweiterungen als sehr effektiv für den jeweiligen Zweck an. Als konkretes Anwendungsbeispiel: MJPEG-Streamer für HD video. - Strubi
>...und was macht die 32-Bit ALU dann mit den 256 Bits im nächsten >Taktzyklus??? >EBEN! Man merkt, du hast noch nie versucht eine CPU zu designen. Dann wüsstest du nämlich das Zugriffe auf den Ram ewwwwig dauern. Da hat die CPU dreimal die Pipeline geleert und neu befüllt. Gruß Jonas
Strubi schrieb: > Mich würde mal interessieren, was die Xilinx HLS aus einem in C > geschriebenem Algo mit double-Werten so an Logik zusammenkaskadiert... Ich habe mich ein wenig mit der HLS befasst und sage mal so: Ich bin nicht gerade weggerissen. Manche Sachen kann man sich auf diese Weise sehr einfach formulieren und Zeit sparen, aber es sind die einfachen FPGA-Algorithmen und -abläufe, die sich gut umsetzen lassen. Bei allen FPGA-spezifischen Dingen wie pipelining, Parallelisierung, muss dem tool unter die Arme gegriffen werden. Auch habe ich den Eindruck, dass der Resourcenverbrauch höher ist - gerade bei mathematischen Rechnungen. Offenbar hat er Probleme, die ranges zu handhaben und kleinzukürzen. Ist aber Vermutung.
Thomas U. schrieb: > FPGA-Algorithmen und -abläufe, die sich gut umsetzen lassen. Bei allen > FPGA-spezifischen Dingen wie pipelining, Parallelisierung, muss dem tool > unter die Arme gegriffen werden. Da C jetzt nicht wirklich optimal zur Beschreibung von HW ist, bist du doch sehr schnell wieder beim SystemC++-Ansatz und schreibst dir deine eigenen Fixpoint-Klassen, wenn du volle Kontrolle über deine DSP-Arithmetik haben willst. Richtig? Solange man sich nicht auf experimentellem Wege Wissen über die Funktion einer Blackbox-Toolchain aneignen muss, ist das alles ok :-) Und natürlich um eben mal ein paar float-ops zu beschleunigen auch. Aber schon bei Matrizenkram stelle ich mir das schwieriger vor. Spart man sich da wirklich die Zeit? Gerate weil generische CPUs immer flotter werden, muss das FPGA immer mehr mit dediziert optimierten Verarbeitungspipes kontern (oder mit einem echten ALU-Novum). Und die HDL-Apfelmännchen-Messedemos kommen langsam in die Jahre...
Strubi schrieb: > Und die HDL-Apfelmännchen-Messedemos kommen langsam in die Jahre... Welche Vorteil hätten den FPGAs ausgerechnet bei den Appelmännern? Die sind doch Ergebnis einer Iteration. Da muss doch der FPGA auch mehrfach rechnen, bis er ein Ergebnis hat. Sicher nix wo der seine Stärken ausspielen könnte, oder? Oder ließen sich mit so hochaufgelösten Cores die Rechnungen schneller machen? Ich meine, eine gute CPU rennt heute auf immerhin 4GHz.
Freak schrieb: > Die sind doch Ergebnis einer Iteration. Ja. Viele kleine Prozessoren in einem FPGA. Jeder rechnet an einem Pixel. Oder an einer Zeile. Ich denke einige hundert Einheiten bekommt man parallel. Zumal man die Berechnung gleich in HW gießen kann. Gruß Jobst
Moin, mit den nvidia-Shadern konnte man vor Jahren sowas schon in Realtime machen. Lag nahe, das im FPGA nachzubauen, aber da kommt die Anspielung ins Spiel: nach Jahren Messepräsenz ist der Coolness-Faktor in Bezug auf HLS etwas verflogen. Oder war er jemals grösser Epsilon?
Nachtrag: Bevor jemand auf den Gedanken kommt: Bitte keine Mathematikerwitze nachlegen :-) Rot13: [ Frv Rcfvyba xyrvare Ahyy ]
Jonas B. schrieb: >>...und was macht die 32-Bit ALU dann mit den 256 Bits im nächsten >>Taktzyklus??? > Man merkt, du hast noch nie versucht eine CPU zu designen. Dann wüsstest > du nämlich das Zugriffe auf den Ram ewwwwig dauern. Das gilt aber nur, wenn man einen klassischen RAM-Zugriff der CPU auf externe RAMs fokussiert. Im FPGA kann man das so lösen, dass internes RAM adressiert wird. Dann wird die CPU der Limiter sein, weil die RAMs schnell genug sind. Aus einem BRAM kriege ich völlig unregistriert Daten jederzeit mit 50MHz raus, bei schnellen FPGAs mit 100MHz. Das ist die soft-CPU langsamer. Anders herum betrachtet bekommt man mit einer 32Bit-Emulation bei echten RAM--Zugriffen mehr davon, um die Terme zu handhaben und wäre mit einer breiten soft-CPU schneller.
Ich komme nochmals zurück auf meine damals gestellte Frage. Interessant, was es inzwischen als Antworten gab. Das Thema ist jetzt auch wieder aktuell, weil wir im Begriff sind, Grafikchips, die auf 128 Bit angefahren werden, anzusprechen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.