Hallo, ich habe hier ein Design das ich für einen Spartan3 gemacht habe. Jetzt soll es auf einem Spartan6 laufen. Den DCM habe ich neu generieren lassen und ich habe alle Projektdateien entfernt die irgendwie mit dem Spartan3 in Verbindung standen. Ja und jetzt baut XST endlos. Ohne Fehlermeldung und nix. Hab das komplett neu erstellt und alles, habe auch ordentlich CPU-Last aber keine Meldung und nix. Für den Spartan3 hat das nur wenige Sekunden gedauert ... Kann es an der BRAM Beschreibung liegen? Die ist wie bei Lothar und es soll DP-BRAM draus werden. Hat am Spartan3 auch prima geklappt, muss ich da am Spartan6 was besonderes beachten? Danke!
Am RAM liegts sicher nicht, Lothars Beschreibung ist die gleiche wie im XST User Guide. Ich hab auch mehrere Projekte mit dem S6, bei denen ich den DP-RAM so beschreibe. Je nach Designgröße kann das aber schon dauern, ISE ist ja nicht die schnellste.
Hm, um das für den Spartan3 zu bauen braucht der Rechner keine Minute. Und jetzt für den Spartan6 rechnet der immernoch. Ist ISE generell beim Spartan6 deutlich langsamer oder sieht das so aus als würde ich was falsch machen?
So, meine Vermutung war richtig, habe das über Nacht rechnen lassen und XST hat keine BRAMs verwendet sondern LUTs. Und ist jetzt bei über 6000% FPGA Belegung. Ganz toll! Wie gesagt, ich habe an der RAM Beschreibung nichts verändert und die gleiche ISE Version nutzt auch schön die BRAMs am Spartan3.
Poste doch mal die Beschreibung des BRAMs oder schau im Spartan 6 XST User Guide nach, ob das passt. BRAM wird erst, wenn die Leseadresse getaktet wird. Außerdem muss natürlich die Breite irgendwie sinnvoll zu den 9/18 Bit Modulen passen und die Tiefe muss 2^n sein. Oder nutzt du <= 9 Bit Breite und Initialwerte aus einem File? Da hat der S6 einen riesen Bug, kann sein dass XST in dem Fall automatisch drum herum rudert.
Ja ... ich verwende "untypische" Längen, aber wie gesagt, für den Spartan3 wird es verwendet. Im Anhang mal die Nötigsten Dateien, aber ohne den DCM, den kannst Du wenn Du testen willst weglassen und die CLK Clock verwenden.
Solchen Schnulli mit generischer VHDL Beschreibung von BRAMs hab ich nie verwendet. Einfach einen BRAM per IP-Generator erstelln, fertig. Da weiß man was man bekommt und kann auch spezielle Features DIREKT nutzen, ohne ein Ratespiel mit dem VHDL-Compiler. Beim Wechsel der Familie oder gar des Herstllers kann man das leicht neu erstellen und ggf. anpassen. Fettig.
:
Bearbeitet durch User
Also ich habe mit das nie als IP-Core generieren lassen und bin bis jetzt auch immer gut klargekommen. Wurde immer so umgesetzt wie ich es wollte. Mit dem IP-Core wird das ja auch umständlicher und mehr Schreibarbeit die ich mir bisher immer gut sparen konnte. Also hier weiß ich eben nicht wieso das der XST für den Spartan3 in BRAMs packt, und beim Spartan6 nicht. Klar weiß ich wie ich das sondt lösen kann und zur Not werde ich auch einen IP-Core verwenden oder einfach einen Spartan3, aber es geht mir hier ums Verständnis wie ich BRAMs beschreiben muss damit XST die auch für den Spartan6 verwendet. Anpassen der Größe auf Zweierpotenzen zu
1 | type FELD is array (0 to (128*256)-1) of std_logic_vector(3 downto 0); |
2 | signal frame0,frame1,frame2: FELD; |
hat auch nicht geholfen.
naja, du hast da 3 RAMs mit jeweils ca. 80kBit definiert. Vlt. kommt die Toolchain damit nicht wirklich klar und wie schon weiter oben bemerkt wurde: Der S6 ist ein wenig buggy diesbezueglich. Pack doch dein RAM einfach mal in eine extra Komponente (generisch), instantiiere das 3x, und schau nach was dann rauskommt. Ein Dual-Ported RAM im S6 funktioniert bei mir prima mit folgender Beschreibung (aus den Xilinx Guidelines):
1 | --
|
2 | -- Generic dual port BRAM 256x16bit (from 'xst_v6s6.pdf', page 252) for a Spartan6
|
3 | --
|
4 | |
5 | library ieee; |
6 | use ieee.std_logic_1164.all; |
7 | use ieee.numeric_std.all; |
8 | |
9 | entity ram256x16 is |
10 | port ( |
11 | clk : in std_logic; -- FPGA clock |
12 | -- Port A
|
13 | rea : in std_logic; -- read enable port A |
14 | wea : in std_logic; -- write enable port A |
15 | addra : in std_logic_vector (7 downto 0); -- read/write address port A |
16 | dia : in std_logic_vector (15 downto 0); -- write data port A |
17 | doa : out std_logic_vector (15 downto 0) := (others => '0'); -- read data port A |
18 | -- Port B
|
19 | reb : in std_logic; -- read enable port B |
20 | web : in std_logic; -- write enable port B |
21 | addrb : in std_logic_vector (7 downto 0); -- read/write address port B |
22 | dib : in std_logic_vector (15 downto 0); -- write data port B |
23 | dob : out std_logic_vector (15 downto 0) := (others => '0') -- read data port B |
24 | );
|
25 | end ram256x16; |
26 | |
27 | architecture rtl of ram256x16 is |
28 | |
29 | type t_ram is array (0 to 255) of std_logic_vector (15 downto 0); |
30 | shared variable ram : t_ram := ( |
31 | 0 => x"0000", -- Init-data for address 0 |
32 | 1 => x"0000", -- Init-data for address 1 |
33 | others => x"0000" -- Init-data for the rest... |
34 | );
|
35 | |
36 | begin
|
37 | |
38 | --
|
39 | -- Port A, read/write
|
40 | --
|
41 | proc_a : process (clk) |
42 | begin
|
43 | if rising_edge (clk) then |
44 | if rea = '1' then |
45 | doa <= ram (to_integer (unsigned (addra))); |
46 | if wea = '1' then |
47 | ram (to_integer (unsigned (addra))) := dia; |
48 | end if; |
49 | end if; |
50 | end if; |
51 | end process; |
52 | |
53 | --
|
54 | -- Port B, read/write
|
55 | --
|
56 | proc_b : process (clk) |
57 | begin
|
58 | if rising_edge (clk) then |
59 | if reb = '1' then |
60 | dob <= ram (to_integer (unsigned (addrb))); |
61 | if web = '1' then |
62 | ram (to_integer (unsigned (addrb))) := dib; |
63 | end if; |
64 | end if; |
65 | end if; |
66 | end process; |
67 | |
68 | end rtl; |
Da ich meistens nur 1xRead und 1xWrite brauche, funktioniert das bei mir sogar mit Lattice und Altera nach dieser Beschreibung...
Falk Brunner schrieb: > Solchen Schnulli mit generischer VHDL Beschreibung von BRAMs hab ich nie > verwendet. Einfach einen BRAM per IP-Generator erstelln, fertig. Da weiß > man was man bekommt und kann auch spezielle Features DIREKT nutzen, ohne > ein Ratespiel mit dem VHDL-Compiler. Beim Wechsel der Familie oder gar > des Herstllers kann man das leicht neu erstellen und ggf. anpassen. > Fettig. Naja, der Charme, solche Sachen 'generisch' in VHDL zu beschreiben liegt darin, dass jeder VHDL Simulator auch ohne kompilieren der Vendor-Libs damit zurecht kommt. Und die meisten Simulatoren sind damit auch schneller. Wenn du gleiche Designs/Komponenten auf verschiedenen Plattformen verwenden willst, dann hat das 'generische VHDL' schon eine Menge Vorteile. Ich kapsele sowas ueblicherweise in eine Komponente, wenn mal eine Plattform 'rumzickt' kann ich immer noch eine direkte Instantiierung nach Herstellervorschrift machen (Stichwort DCMs, PLLs, DLLs...). Wenn es auf diesem Weg funktioniert, dann macht das halt weniger Stress. Und die IP-Generatoren versuche ich, wo ich kann, zu meiden (klappt halt nicht immer).
Mit der angepassten Beschreibung auf Zweierpotenzen sind das genau 128*256*4/8=16kBytes. Das sind 4 volle 18k BRAMs. Werde wohl doch mal mit IP-Core probieren oder Spartan3 verwenden ...
@ berndl (Gast) >Naja, der Charme, solche Sachen 'generisch' in VHDL zu beschreiben liegt >darin, dass jeder VHDL Simulator auch ohne kompilieren der Vendor-Libs >damit zurecht kommt. Wenn es denn immer funktioniert. >Wenn du gleiche Designs/Komponenten auf verschiedenen Plattformen >verwenden willst, dann hat das 'generische VHDL' schon eine Menge >Vorteile. Ich kapsele sowas ueblicherweise in eine Komponente, wenn mal >eine Plattform 'rumzickt' kann ich immer noch eine direkte >Instantiierung nach Herstellervorschrift machen (Stichwort DCMs, PLLs, >DLLs...). EBEN! >Und die IP-Generatoren versuche ich, wo ich kann, zu meiden (klappt halt >nicht immer). Warum? Sie haben schon ihre Berectigung. Ausserdem kannst du nur mit IP-Modulen die spezifischen Besonderheiten der Komponenten nutzen.
hm, probier's mal mit der generischen Beschreibung. Wie oben angemerkt, du definierst in deiner Komponente 3 RAMs die du generisch beschreiben willst. Mein Vorschlag: 1.) Pack' die RAMs mal in eine eigene Komponente (so wie das 256x16 von oben, halt angepasst auf deine Verhaeltnisse) 2.) Schau mal was die Synthese daraus macht (BRAM oder distributed RAM) 3.) Und falls das nicht hilft, dann in der RAM-Komponente mal nach XST Guide das BRAM 'hart' instantiieren Ich glaube aber, dass du Schritt 3 nicht brauchen wirst wenn du das sauber trennst (Logik vom RAM). Und das muss auch mit dem S3 sowie dem S6 funktionieren...
Achso, manchmal/oft sehr wichtig wenn man SRAMs in VHDL beschreiben will: Die Sache mit der 'shared variable'... Ich nutze normalerweise keine 'variable' und schon gar nicht 'shared variable', aber um ein RAM generisch zu beschreiben braucht's das halt manchmal. Und deshalb auch gekapselt in einer Komponente...
Vielen Dank für die Antworten, das hat mir zum Teil auch bestimmt geholfen. Im Wesentlichen geht es mit um die Frage warum XST einen Unterschied macht zwischen Spartan3 und Spartan6. Aber ok, ist wohl eben so. Glaubt ihr ich kann meine Beschreibung sonst wie so bauen lassen, dass BRAMs verwendet werden? Also gibt es Tricks wie den neuen Parser zu verwenden die da helfen könnten? Oder macht Vivado das richtig? Will das mal Jemand testen?
Mein Gott, in der Zeit, in der hier über Gott und die FPGA-Welt philosophiert wirde, hättest du den BRAM als IP-Core 100 mal erschaffen können!
-gb- schrieb: > Im Wesentlichen geht es mit um die Frage warum XST einen Unterschied > macht zwischen Spartan3 und Spartan6. Sieh dir mal das da an: http://www.lothar-miller.de/s9y/archives/79-use_new_parser-YES.html defaultmäßig wird für den S3 der "alte" Parser im Synthesizer verwendet. Evtl. ist im neuen Parser noch ein Feature ("its not a bug..."). Falk Brunner schrieb: > Mein Gott, in der Zeit, in der hier über Gott und die FPGA-Welt > philosophiert wirde, hättest du den BRAM als IP-Core 100 mal erschaffen > können! Ich instantiiere das Ding dann gleich komplett von Hand, dann muss ich nicht noch mit irgendwelchen Cores im Projekt rumturnen. Die Templates dafür lassen sich einfach im Editor abrufen.
:
Bearbeitet durch Moderator
Angehängte Dateien:
-

gen0.jpg
190 KB
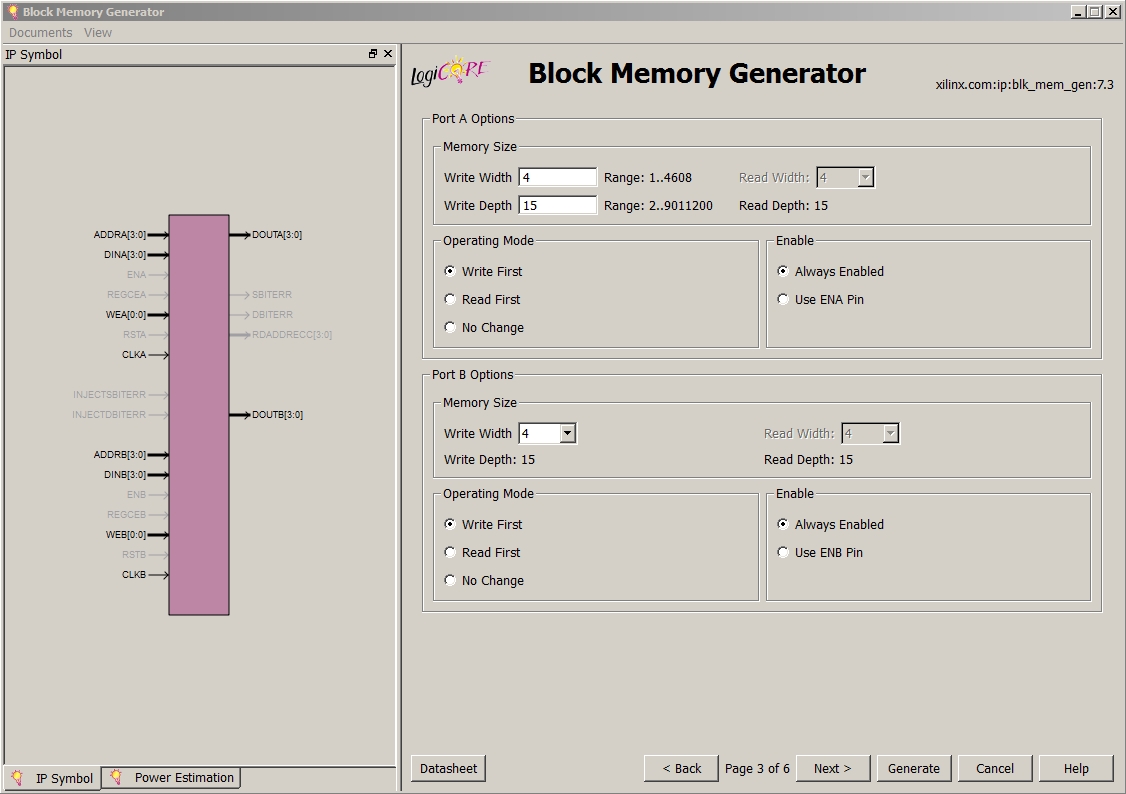
Dieser Coregen ist auch eher witzig. Siehe Anhang, ich kann da keinen Speicher generieren der 15 Bit Adresse und 4 Bit Daten hat. Seltsam ...
Update, es klappt und zwar ist fast kein Unterschied zur Beschreibung mit Spartan3 (der Rest ist vollkommen identisch): Spartan3:
1 | bit_adr <= to_integer(screen_h(1 downto 0)); |
2 | read_adr <= 80*to_integer(screen_v) + to_integer(screen_h(8 downto 2)); |
3 | |
4 | pixel_vec(0) <= frame0(read_adr)(bit_adr); |
5 | pixel_vec(1) <= frame1(read_adr)(bit_adr); |
6 | pixel_vec(2) <= frame2(read_adr)(bit_adr); |
Spartan6:
1 | bit_adr <= to_integer(screen_h(1 downto 0)); |
2 | read_adr <= 80*to_integer(screen_v) + to_integer(screen_h(8 downto 2)); |
3 | |
4 | DATA_out0 <= frame0(read_adr); |
5 | DATA_out1 <= frame1(read_adr); |
6 | DATA_out2 <= frame2(read_adr); |
7 | |
8 | pixel_vec(0) <= DATA_out0(bit_adr); |
9 | pixel_vec(1) <= DATA_out1(bit_adr); |
10 | pixel_vec(2) <= DATA_out2(bit_adr); |
Ja, die Daten aus dem BRAM müssen noch explizit einmal gepuffert werden. Ob das einen weiteren Takt kostet oder das beim Spartan3 auch irgendwie gemacht wurde muss ich noch testen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.