Ich muss 4 AD7980 parallel einlesen und mir ist folgende idee gekommen um Hardware zu sparen. Zu aller erst möchte ich diesen AD wandler im 3-wire modus betreiben, sprich ich benötige CNV,SCLK und Miso Leitungen. anstatt dass ich jetzt aber ein SPI interface implementiere und es dann für jeden AD wandler instanziere, kann ich doch einfach ein SPI interface mit 4 MiSO Leitungen verwenden. die SCLK,CNV können sich die 4 AD Wandler ja teilen da es für alle ADs das selbe ist und somit könnte ich diese 4 AD Wandler mit 6 Leitungen ansteuern. könnte das so gehen oder gibt es probleme?
Natürlich geht das. Ich wundere mich eher, warum du dir unsicher bist. Grüße, Uwe
S.G schrieb: > Ich muss 4 AD7980 parallel einlesen Wir reden aber schon von FPGA und VHDL, oder? Ich bau in solchen Fällen trotzdem n Instanzen ein, verwende dann aber nur die Steuerleitungen der 1. Instanz. Der Rest wird von der Synthese wegoptimiert und ich brauche kein Spezialmodul. Duke
Hallo Duke, genau so sehe ich das auch. So etwas habe ich erst in den letzten Tagen verglichen, allerdings mit 1 bzw. 4 I2S-Signalen. Das hat, wie erwartet, geklappt. 4 Instanzen verbrauchen weniger Ressourcen als das 4-fache der Einzel-Instanz. Ich wollte wissen, ob die 4 noch in ein bestimmtes CPLD passen. Die 4 Instanzen werden, zumindest bei mir in Quartus, mit unterschiedlichem Ressourcenverbrauch angezeigt, also nicht eine Instanz "mit allem" und die anderen drei minimal und gleich groß. Ist ja auch egal, welcher Instanz was vom gemeinsamen Teil zugeordnet wird. Grüße, Uwe
naja, wenn ich meinem SPI modul nur 4 zusätzliche leitungen und register gebe hab ich nicht gleich das 4 fache an hardware als wenn ich 4 einzelne Instanzen mit jeweils eigener hardware erstelle. PS: ja wir reden über vhdl und FPGA xD
Wenn es wirklich so knapp mit den Ressourcen ist, dann würde ich ein einfaches SPI schlicht auf 4 MISO-Leitungen aufbohren. Das braucht mit Sicherheit weniger Ressourcen als 4 eigene SPI-Instanzen. Denn die FSM der einzelnen Instanzen wird die Synthese nicht wegoptimieren. Also ich persönlich würde eine klitzekleine Modifikation an meinem normalen SPI vornehmen. Einfach aus MISO ein MOSI(3 downto 0) machen und eben dann in der FSM die Daten in vier getrennte Register empfangen. Der "Umbauaufwand" in einem normalen SPI dürfte sich auf ne Handvoll stellen beschränken und ist in 10 min gemacht. Dafür benötigt man dann auch wirklich nur die zusätzlichen Datenregister und das ganze Drumrum ist nur einmal vorhanden. Also in der FSM beim Empfang statt:
1 | Data_Register(i) <= MISO; |
einfach
1 | Data_Register(0)(i) <= MISO(0); |
2 | Data_Register(1)(i) <= MISO(1); |
3 | Data_Register(2)(i) <= MISO(2); |
4 | Data_Register(3)(i) <= MISO(3); |
schreiben.
Schlumpf schrieb: > Das braucht mit Sicherheit weniger Ressourcen als 4 eigene > SPI-Instanzen. Denn die FSM der einzelnen Instanzen wird die Synthese > nicht wegoptimieren. Doch macht sie. Hab ich auch schon gemacht, da bleibt nur das Schieberegister übrig. So "schlau" ist der Optimierer schon...
Christian R. schrieb: > Doch macht sie. Hab ich auch schon gemacht, da bleibt nur das > Schieberegister übrig. So "schlau" ist der Optimierer schon... Davon bin ich auch überzeugt. Die 4 FSMs werden auf eine reduziert, weil sie identische Abläufe (bzw. identische Eingänge) haben werden. Aber im Prinzip hat der Schlumpf auch recht. Was er vorschlägt, ist auch sehr naheliegend. Aber es geht hier im Forum wohl weniger um die optimale Lösung, sondern mehr um den Gedankenaustausch zur Funktion der Optimierer anhand dieses Beispiels. Uwe
Uwe schrieb: > Davon bin ich auch überzeugt. Die 4 FSMs werden auf eine reduziert, weil > sie identische Abläufe (bzw. identische Eingänge) haben werden. Gilt aber nur, wenn die FSM auch gleichzeitig loslaufen.... sonst kracht es definitiv.
Schlumpf schrieb: > Gilt aber nur, wenn die FSM auch gleichzeitig loslaufen.... sonst kracht > es definitiv. Im Prinzip kein schlechter Einwand. In der Praxis, wenn man 4 FSMs hat, die alle die selben Eingangssignale bekommen, könnte passieren, dass sie unterschiedlich laufen, weil sie beim Start in unterschiedlichen States sind. Bei der Synthese im FPGA/CPLD ist das aber nicht der Fall: Der Compiler nimmt für alle Register den selben Ausgangszustand = 0 an (was man wahrscheinlich irgendwo überschreiben kann, aber hier gar nicht will). Da auch das FPGA/CPLD mit 0 startet, laufen alle FSMs identisch, und der Compiler weiß das und kann reduzieren. Grüße, Uwe
Uwe schrieb: > Der Compiler > nimmt für alle Register den selben Ausgangszustand = 0 an (was man > wahrscheinlich irgendwo überschreiben kann, aber hier gar nicht will). Stimmt, aber auch dann gilt das nur, wenn die Instanzen keinen "Start"-Eingang haben.. Oder man diesen dann auch für alle Instanzen gleichzeitig aktiviert. Weiterhin gibt es zwei Möglichkeiten, den Übernahmezeitpunkt für MISO festzulegen. Entweder rein in Abhängigkeit von Systemtakt oder indem man die Flanke von SCK erkennt. Hat man zweite Möglichkeit gewählt, dann braucht die FSM den SCK und kann ihn nicht weg optimieren. Also wird SCK in jeder Instanz erzeugt (selbst, wenn er nicht nach außen verdrahtet wird). Oder liege ich da falsch?
Schlumpf schrieb: > Der Code würde mich interessieren :-) Ist einfach der (leicht modifizierte) SPI Master von Lothar Miller. Der State zu Beginn ist definiert und das Start-Signal liegt an allen parallel an. Dann schmeißt der Synthesizer alles weg, was nicht unbedingt gebraucht wird. Sicher geht es mit einem 4-fach SPI Master auch, aber dann hat man wieder ein extra Modul für genau einen Spezielfall...
Schlumpf schrieb: > Entweder rein in Abhängigkeit von Systemtakt oder indem man die Flanke > von SCK erkennt. Weil das FPGA ja Master ist und einen gemeinsamen SCK für alle Slaves erzeugt, kann man aus der (einzigen) FSM auch das "Abtastsignal" erzeugen. Selbst wenn man die Flanke von SCK detektiert (FPGA ist Slave), können, weil nur ein gemeinsamer SCK vorgesehen ist, alle FSMs auch nur das selbe "Abtastsignal" erzeugen. Bei asynchronem SCK und Systemtakt gilt das zwar nicht, aber das wird den Compiler nicht daran hindern, nur eine FSM zu instanziieren. Schlumpf schrieb: > Oder liege ich da falsch? Wenn verschiedene SCKs vorliegen, natürlich nicht. Aber, wie gesagt, bei diesem Beispiel ist per Definition nur ein Satz Steuerleitungen vorhanden, siehe ganz oben, und damit gilt, dass alle Instanzen der FSM die selben Signale und die selben Start-Voraussetzungen haben. So habe ich es jedenfalls verstanden. Wäre es anders, wäre die Frage von Duke und diese Diskussion hinfällig. Uwe
Christian R. schrieb: > Ist einfach der (leicht modifizierte) SPI Master von Lothar Miller. Genau das habe ich gerade getan. Sendeteil rausgeschmissen, 8 Bit konfiguriert. zweimal Instanziiert und bei dem einen das SCK nicht nach außen geführt. Und siehe da: Bei zwei Instanzen werden doppelt so viele Register benötigt, wie bei einer Instanz. Ganz so, wie ich es auch erwartet habe, da Lothar in seinem Code die Flanke des von ihm selbst generierten SCK wieder prüft, um den Zeitpunkt der Datenübernahme festzulegen. Uwe schrieb: > kann man aus der (einzigen) FSM auch das "Abtastsignal" Aha! Es ging aber darum, dass man mehrere Instanzen eines SPI verwendet und die Steuersignale nur aus einer der Instanzen verwendet. Und sich dann darauf verlässt, dass die Synthese das schon richtet und alles überflüssige wegschmeißt. Und das ist eben nicht so. Uwe schrieb: > Selbst wenn man die Flanke von SCK detektiert (FPGA ist Slave), FPGA ist aber in diesem Fall Master Ich habe es so verstanden: Man beschreibe eine SPI mit MISO und SCK. Instanziiere die 4 mal und führe aber nur einen SCK nach außen. Betreibe mit dem alle vier SPI-Slaves und führe an jede der vier Instanzen je eine MISO-Leitung von den Slaves und hoffe darauf, dass die Synthese erkennt, dass die der SCK nur in einer Instanz erzeugt wird und deswegen von den anderen 3 Instanzen alles wegschmeißt, bis auf das Schieberegister zum Empfang. Falls das so gemeint war, dann funktioniert das nicht. Die Synthese optimiert (verifiziert an Lothars Code) nicht ein einziges Register weg.
Wer es gerne selbst ausprobieren möchte, anbei die VHDL-Files Eine Instanz benötigt 20 Register: rx_reg : 8 Register bitcounter : 4 Register delay : 4 Register spitxstate : 2 Register spiclk : 1 Register spiclklast : 1 Register -------------------------- 20 Register Wenn die Behauptung, dass die Synthese alles bis auf die Empfangsregister rausschmeißt, stimmt, dann sollten also bei zweimaliger Instanziierung unter Nichtanschließen von SCK 28 Register benötigt werden. Tatsächlich werden aber 40 Register benötigt.
Ergänzung: Habe das Ganze jetzt sogar noch so getestet, dass ich die Übernahme von MISO nicht in Abhängigkeit von SCK mache, sondern einfach an der Stelle in der FSM, in der die Flanken für den SCK erzeugt werden. Auch hier ist die Synthese nicht imstande, irgendwas zusammenzufassen. @ Christian: Mich würde daher wirklich brennend interessieren, wie dein Master aussieht, dass die Synthese es schafft, die FSM mehrerer Instanzen zusammenzufassen.
Hm, da hab ich mich anscheinend auf eine falsche Erinnerung verlassen. Ich hab das Projekt eben nochmal synthetisieren lassen, und es wird tatsächlich nicht wegoptimiert. Ich könnte schwören, dass der das mal erkannt hat, aber da trügt mich anscheinend die Erinnerung. Ich muss also alle Behauptungen zurücknehmen....sorry. Auch VIVADO erkennt nicht, dass es identisch ist. Schon komisch. Funktionieren tut´s auf jeden Fall auch so zuverlässig.
Na ja, mich hätte es, ehrlich gesagt, gewundert, wenn die Synthese so gescheit gewesen wäre :-)
Vielleicht hat es auch was mit "keep hierachy" oder so zu tun. Eigentlich müsste die das doch nach dem ausrollen der FSM erkennen, dass das alles doppelt ist. Oder der extrahiert die FSMs nach dem Optimieren...mich wunderts eher dass sowas nicht erkannt wird. Auf RTL Ebene ist es doch wirklich identisch.
Ich weiß nicht, wie Ihr Euren Synthesizer parametriert habt, bei mir steht folgendes im Log:
1 | INFO:Xst:2261 - The FF/Latch <spi_sender_i6/r_bitcount_0> in Unit <top> |
2 | is equivalent to the following 6 FFs/Latches, which will be removed : |
3 | <spi_sender_i5/r_bitcount_0> <spi_sender_i4/r_bitcount_0> |
4 | <spi_sender_i3/r_bitcount_0> <spi_sender_i2/r_bitcount_0> |
5 | <spi_sender_i1/r_bitcount_0> <spi_sender_i0/r_bitcount_0> |
Die Zeile taucht für jedes Bit von r_bitcount einzeln auf... Das funktioniert sogar modulübergreifend, selbst wenn die Module auf Systemebene nix miteinader zu tun haben, aber zufällig die 'gleiche' Logik brauchen:
1 | INFO:Xst:2261 - The FF/Latch <debug_tracer/r_timestamp_0> in Unit <top> is |
2 | equivalent to the following 7 FFs/Latches, which will be removed : |
3 | <spi_sender_i6/r_sclk_count_0> <spi_sender_i5/r_sclk_count_0> |
4 | <spi_sender_i4/r_sclk_count_0> <spi_sender_i3/r_sclk_count_0> |
5 | <spi_sender_i2/r_sclk_count_0> <spi_sender_i1/r_sclk_count_0> |
6 | <spi_sender_i0/r_sclk_count_0> |
Wenn dem nocht so wäre, hätte ich mir schon lange einen anderen Designstil angewöhnt. Duke
Hmm, erstaunlich. Aber ohne deinen Code gesehen zu haben, vermute ich anhand der Namen, dass es sich um einen Sender handelt, der insgesamt sieben mal instanziiert wurde, oder? Und diese Sender laufen alle absolut gleichzeitig? Und versenden sie auch alle immer das identische Byte? Im hier diskutierten Beispiel handelt es sich ja um einen Empfänger. Wenn du Zeit und Lust hast, lass doch mal den von mir geposteten Code durch deine Synthese. Würde mich echt interessieren, was die dazu sagt.
Mit Synplify Pro (Lattice Diamond Version) klappt es mit dem Beispiel von Schlumpf auch nicht, d.h. es werden 40 Register. In den ganzen Optionen rumzustochern (z.B. syn_hier attribute auf Toplevel) hat auch nichts gebracht. In eigenen Projekten klappt es jedoch, zwar fast alle in Verilog aber es gibt keinen Vernünftigen Grund warum es mit VHDL nicht gehen sollte. Irgendetwas bei dem Beispiel verhindert es.
Kann es vielleicht daran liegen, dass das Design einen Eingang hat, der asynchron zum Systemtakt ist (MISO)? Ist nur mal so daher gefragt. Irgendwo muss es ja einen Unterschied geben, wenn das bei vielen Designs klappt und bei diesem eben nicht. Aber ganz abgesehen davon ging es ja darum, dass man einfach eine Komponente mehrfach instanziieren kann und bei der Synthese dann alles rausfliegt. Wie es sich jetzt herausstellt, ist es offensichtlich etwas gewagt, so eine Aussage pauschal zu treffen. Das heißt, wenn man sowas macht, ist es auf jeden Fall angebracht, die Synthese-Reports genau zu lesen. Ich persönlich bevorzuge es grundsätzlich, das zu beschreiben, was ich gerne hätte und nicht der Synthese zu viel zu überlassen. Also konkret hätte ich in diesem Beispiel definitiv ein SPI um 3 MISO-Leitungen erweitert. Wäre aber trotzdem interessant, ob wir rausbekommen, WANN die Synthese die Logik zusammenfasst und wann nicht.
Schlumpf schrieb: > Kann es vielleicht daran liegen, dass das Design einen Eingang hat, der > asynchron zum Systemtakt ist (MISO)? > Ist nur mal so daher gefragt. > Habe ich probiert, keine Änderung. > Irgendwo muss es ja einen Unterschied geben, wenn das bei vielen Designs > klappt und bei diesem eben nicht. > > Aber ganz abgesehen davon ging es ja darum, dass man einfach eine > Komponente mehrfach instanziieren kann und bei der Synthese dann alles > rausfliegt. > Wie es sich jetzt herausstellt, ist es offensichtlich etwas gewagt, so > eine Aussage pauschal zu treffen. Das heißt, wenn man sowas macht, ist > es auf jeden Fall angebracht, die Synthese-Reports genau zu lesen. > > Ich persönlich bevorzuge es grundsätzlich, das zu beschreiben, was ich > gerne hätte und nicht der Synthese zu viel zu überlassen. > Also konkret hätte ich in diesem Beispiel definitiv ein SPI um 3 > MISO-Leitungen erweitert. Zustimmung. Sich auf den Synthesiser zu verlassen kann immer zu Überraschungen und unerwünschten Nebenwirkungen führen. Z.B. bei in den Code verwursteten RAM Beschreibungen, eine kleine Ämderung und schon wird es ein Registergrab. > > Wäre aber trotzdem interessant, ob wir rausbekommen, WANN die Synthese > die Logik zusammenfasst und wann nicht. Ja.
Lattice User schrieb: > Habe ich probiert, keine Änderung. Ich auch... gleiches Ergebnis.. Lattice User schrieb: >> >> Wäre aber trotzdem interessant, ob wir rausbekommen, WANN die Synthese >> die Logik zusammenfasst und wann nicht. > > Ja. Vielleicht probiert ja Duke das mal anhand des von mir geposteten Beispiels aus und berichtet. Wenn das bei ihm klappt, dann hätten wir den gleichen Code mit unterschiedlichen Ergebnissen, was dann auf unterschiedliches Verhalten der Synthesizer schließen lässt.
Angehängte Dateien:
-

multi_spi.png
110 KB
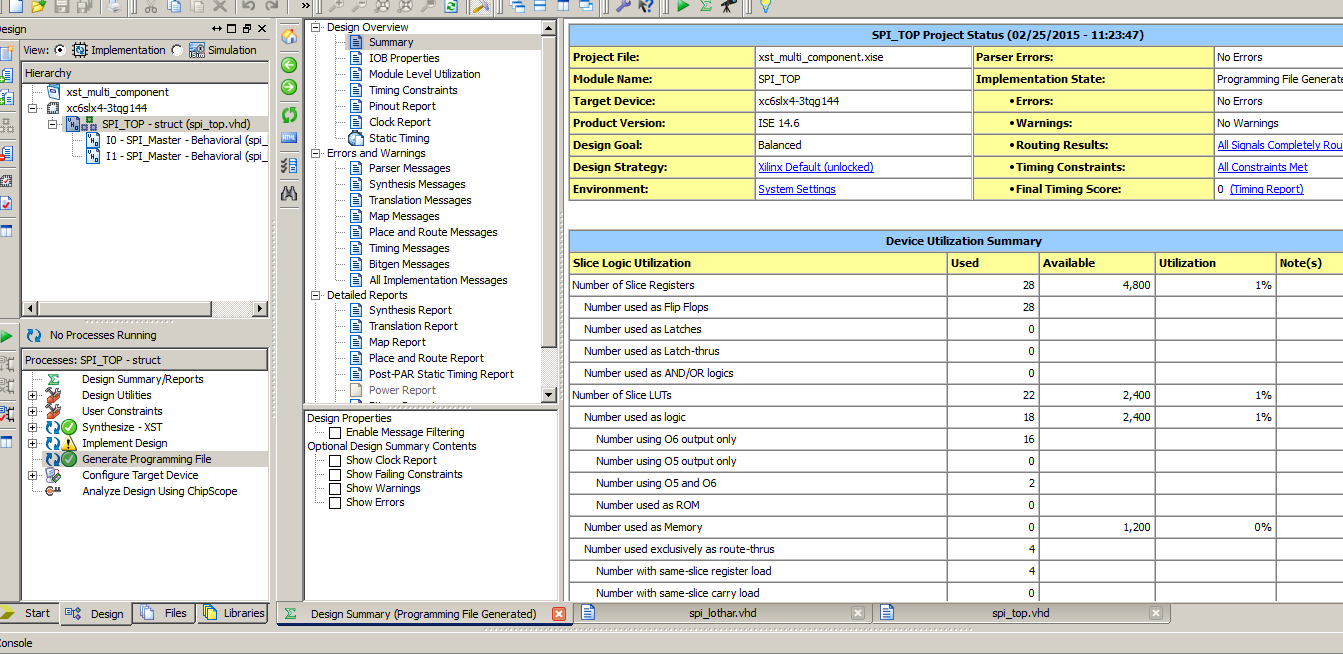
Schlumpf schrieb: > Wenn die Behauptung, dass die Synthese alles bis auf die > Empfangsregister rausschmeißt, stimmt, dann sollten also bei zweimaliger > Instanziierung unter Nichtanschließen von SCK 28 Register benötigt > werden. > > Tatsächlich werden aber 40 Register benötigt. Ich habe das mal eben schnell mit ISE 14.6 und Spartan 6 probiert. Der Synthesereport sagt:
1 | Optimizing unit <SPI_Master> ... |
2 | INFO:Xst:2261 - The FF/Latch <I1/spiclklast> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/spiclklast> |
3 | INFO:Xst:2261 - The FF/Latch <I1/delay_0> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/delay_0> |
4 | INFO:Xst:2261 - The FF/Latch <I1/delay_1> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/delay_1> |
5 | INFO:Xst:2261 - The FF/Latch <I1/delay_2> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/delay_2> |
6 | INFO:Xst:2261 - The FF/Latch <I1/delay_3> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/delay_3> |
7 | INFO:Xst:2261 - The FF/Latch <I1/bitcounter_0> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/bitcounter_0> |
8 | INFO:Xst:2261 - The FF/Latch <I1/bitcounter_1> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/bitcounter_1> |
9 | INFO:Xst:2261 - The FF/Latch <I1/bitcounter_2> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/bitcounter_2> |
10 | INFO:Xst:2261 - The FF/Latch <I1/bitcounter_3> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/bitcounter_3> |
11 | INFO:Xst:2261 - The FF/Latch <I1/spiclk> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/spiclk> |
12 | INFO:Xst:2261 - The FF/Latch <I1/spitxstate_FSM_FFd1> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/spitxstate_FSM_FFd1> |
13 | INFO:Xst:2261 - The FF/Latch <I1/spitxstate_FSM_FFd2> in Unit <SPI_TOP> is equivalent to the following FF/Latch, which will be removed : <I0/spitxstate_FSM_FFd2> |
Es kommen auch die geforderten 28 Register zusammen. Schlumpf schrieb: > Aber ohne deinen Code gesehen zu haben, vermute ich anhand der Namen, > dass es sich um einen Sender handelt, der insgesamt sieben mal > instanziiert wurde, oder? Richtig. > Und diese Sender laufen alle absolut gleichzeitig? Ja. > Und versenden sie auch alle immer das identische Byte? Nein. Dann hätte ich nur einen DAC verbaut und dafür einen Fan-out Buffer. So wie es jetzt ist, kann ich 7 verschiedene Signale ausgeben. Allerdings alle mit der gleichen Samplerate. Duke
Danke fürs Ausprobieren, Duke. Interessantes Ergebnis. Es scheint da also gravierende Unterschiede zwischen den einzelnen Synthesizern zu geben. (Oder in den Default-Settings). Auf jeden Fall sehr interessant, dass deiner wirklich erkennt, dass die komplette Steuerung (FSM, Counter etc..) identisch sind, während andere das nicht schaffen. Für mich ist das definitiv eine Bestätigung, dass man gut beraten ist, sich nicht zu sehr auf die Leistungsfähigkeit seiner Tools zu verlassen, sondern besser das codiert, was man tatsächlich auch haben will. Oder man im Nachgang genau die Reports anschauen muss. Danke nochmal an alle, die es ausprobiert haben.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.