Ich brauche einen neuen PC - speziell für FPGA-Synthese, weil der alte so langsam in Grätsche macht und ewig vor sich hin rödelt. Teilweise dauern die Synthesen 3-4h und mehr! Außerdem soll der auch pSPICE können. Wer kennt sich aus, was diese Softwarepakete so brauchen? Momentan läuft Quartus, es kommt aber auch Xilinx hinzu. Als CPU ist Intel angedacht. 1) Skylake oder Haswell? Skylake ist schneller auf 4 Kernen wegen der Frequenz, Haswell kann aber 6 Kerne, WENN sie verwendet werden und ist dann schneller. Kann die Synthese-Software das nutzen? Sollte man den Haswell nehmen? 2) Kann man die Mehrkerne wenigstens dann effektiv nutzen, wenn ich im Hintergrund synthetisiere und im Vordergrund arbeite, z.B. Simulation? Ist es also so, wie ich vermute, dass das OS das verteilt, wenn man konkret z.B. 3 Softwarepakete laufen ließe, die selber nur jeweils 2 Kerne können? Ich habe leider zur Mehrkernnutzung bei den Herstellern nur unklare Angaben gefunden und selber keine Erfahrung. Mein PC hat 2 Kerne und 4 threads. 3) Bringen SSDs einen Vorteil? Nutzt es also, schnellen Plattenspeicher zu haben? Ich habe den Eindruck, dass Quartus schon ziemlich viel auf der Platte macht. Momentan habe ich 2 HDD-SATAs mittlerer Geschwindigkeit. Machen M2 einen Sinn? 4) Wieviel RAM kann man ansetzen? Kann man eine RAM-Disk nehmen? Oder wären M2 besser, weil der Speicher parallel zum RAM liegt? Meine Befürchtung ist, dass der Haswell das RAM gar nicht genug auslasten könnte, damit eine RAM-DISK Sinn macht. 5) Können die Pakete schon GPU nutzen? Gibt es einen SPICE Simulator, der das kann? Ich benutze momentan viel LTSpice und meine Simlationen dauern auch schon mal 30min und mehr, was ich mehr akzeptabel ist, weil ich warten muss. Frage also: WIE STELLT MAN EINEN PC ZUSAMMEN UND KONFIGURIERT IHN, UM OPTIMAL SIMULIEREN ZU KÖNNEN?
Skylake-Prozessoren haben wohl einen ganz üblen Bug, siehe heise.de: "Bei komplexer Rechenlast mit AVX-Befehlen wie beim Primzahlprogramm Prime95 kann es zu Abstürzen bei Skylake-Prozessoren der Serien Celeron G3900, Pentium G4000, Core i3/i5/i7-6000 und Xeon E3-1200 v5 kommen." https://communities.intel.com/thread/96157?start=0&tstart=0 http://www.computerbase.de/forum/showthread.php?t=1545912
Meiner Erfahrung nach bringen schnellere Kerne mehr als viele aber dafür langsamere. SSD nutzt allgemein viel - Software startet viel viel schneller und man kann auch mal während der Rechner am rödeln ist noch eine weitere komplexe Software starten... Aber sobald die Software mal läuft bringts dann nicht mehr soviel weil das wichtigste eh im RAM liegt. Den Bug hat Intel schon behoben per Microcode update.
Harry Hirsch schrieb: > Teilweise > dauern die Synthesen 3-4h und mehr! Außerdem soll der auch pSPICE > können. Ich kenne noch Zeiten, da hat es auch 8h gedauert. Inzwischen sind meine Designs aber kleiner. Ich kann nur für Xilinx sprechen: > 1) Skylake oder Haswell? Bisher nutzt die Xilinx-Synthesesoftware nur in bestimmten Abschnitten mehr als einen Kern. Ich weiß nicht wie es bei Vivado aussieht. Gefühlt würde ich sagen: Lieber schnellere Kerne, als mehr Kerne. > 2) Kann man die Mehrkerne wenigstens dann effektiv nutzen, wenn ich im > Hintergrund synthetisiere und im Vordergrund arbeite, z.B. Simulation? Ja, definitiv. Outlook + Virenscanner + Webbrowser + Simulation + Synthese ist auf einem entsprechenden Rechner gut nutzbar. > 3) Bringen SSDs einen Vorteil? Nutzt es also, schnellen Plattenspeicher Ich nutze die SSD nur als Programmspeicher. Als Datenspeicher ist sie mir zu wertvoll. > 4) Wieviel RAM kann man ansetzen? Kann man eine RAM-Disk nehmen? Mit RAM-Disk hab ich seit Ewigkeiten nichts mehr gemacht. Wieviel RAM Du für die Synthese brauchst, dazu gibt es Angaben beim Hersteller. Hängt Hauptsächlich vom Chip und der Größe des Designs ab. Mehr ist immer besser. > 5) Können die Pakete schon GPU nutzen? Gibt es einen SPICE Simulator, > der das kann? Nicht das ich wüßte. > Ich benutze momentan viel LTSpice und meine Simlationen > dauern auch schon mal 30min und mehr, was ich mehr akzeptabel ist, weil > ich warten muss. Mehr Zeit zum Nachdenken. Frag mal die Alten, wie die ohne Simulator ausgekommen sind... Duke
Hallo, da der Skylake bug hat mich auch irritiert. Tendiere trotz Behebung zum Haswell. Der Händler meint auch, dass das board stabiler sei. Hm.. Wegen der Simulationszeiten: Sicher haben die "alten" einen mieseren PC gehabt, aber die hatten auch weniger board-grösse und es wurde weniger simuliert. Heute sind die Designs grösser und schneller. Auch bei den FPGAs.
also bei mir lass ich große Sachen über einen Linux-Server laufen. Für ein großes Geschoss mit zwei Implementierungen gleichzeitig werden gerade ca. 21G RAM gebucht. Kerne werden nur einzeln ausgelastet. Manche schritte vertragen auch 4-8 kerne.
Tim schrieb: > Kerne werden nur einzeln ausgelastet. Manche schritte vertragen auch 4-8 > kerne. Der Xilinx Mapper kann z.B. mehrere Kerne nutzen, allerdings fallen dann einige Möglichkeiten der Optimierung weg. Komischerweise auch solche, die es meines Erachtens nicht wirklich müssten. Ich kann mir aber gut vorstellen, dass man bei Xilinx noch gar nicht so weit ist, vollparalleles Rechnen durchzuführen, denn machbar wäre da so einiges. Z.B. die Generierung der RTL-views nach der Synthese, sowie der Modelle ohne Timing, können komplett parallel laufen. Auch der Placer wäre ein target für das Verwenden mehrerer Ansätze und damit für vollparallelem Arbeiten. Was in jedem Fall geht: Synthetisieren und gleichzeitig weiterbauen mit Simulieren. Da hängt es oft an der CPU-Reserve und dem RAM. Interessant wäre das mal im Zusammenspiel mit Speicherfresser Nummer 1, namens MATLAB zu probieren, wobei einem da gfs der work flow einen Strich durch die Rechnung macht, weil man in dem Design, das man gerade simuliert, nicht so ohne Weiteres synthetisieren oder gar verändernd weiterarbeiten kann.
Harry Hirsch schrieb: > Hallo, da der Skylake bug hat mich auch irritiert. Tendiere trotz > Behebung zum Haswell. Schaun wir mal ob du am Ende der Diskussion beim 8088 landest. Haswell hat nämlich auch einen Bug. Intel musste deshalb eine ganze Befehlsgruppe abschalten. ;-)
Wie andere schon gesagt haben gesagt. Eher weniger dafür schnellere Kerne. Speicherbedarf hängt stark von der Größe des FPGA ab, schau dir mal das an: http://dl.altera.com/requirements/15.1/ Für den Arria 10 werden da bis zu 48 GB Ram empfohlen. Falls du eh Cyclones wegen der kostenlosen Liteversion benutzen willst dürften 8 GB reichen. Xilinx dürfte auch so eine Tabelle haben.
Quartus kann seit einigen Versionen auch in der kostenlosen Variante "Multithreading" (= auf zwei Prozessoren beschränkt, aber immerhin). Eine schnelle SSD möchte ich auch nicht mehr missen, Synthese ist langsam genug.
Ok, also RAM ist doch nicht so kritisch, aber wenn man andere Anwendungen am Laufen hat, ist es vielleicht hilfreich. Jetzt lese ich beim Altera, dass die virtuelle Disk entsprechend gross sein muss. Ergo nutzen die das. Ergo: Schnelle SSD als Auslagerungsdatei? Was wäre denn, wenn man noch zusätzlich eine RAM-Disk anlegt und das Projekt für die Bearbeitung dort hin kopiert? Dann legt er doch auch die gesamten Unterverzeichnisse und Zwischendateien dort an, oder?
Wenn du ein Projekt für quartus hast, kann ich das bei meinem i7 4790 durchlaufen lassen und dir die Zeit sagen. Vielleicht findet sich noch jemand der die neue Architektur hat, zum vergleichen. Virtuelle Kerne werden (aus guten Gründen) ignoriert.
das ist nett, aber ich kann das nicht senden. Man könnte höchstens eine von Altera gelieferte Demo APP laufen lassen. Also ein Demoprojekt für eine bekannte Plattform, das man von denen lädt und dann als Referenz verwendet. Das wäre interessant. Hier ist das für Xilinx http://www.xilinx.com/design-tools/vivado/memory.htm Brauchen auch nur 4 / 8 GB.
4/8 GB mag die Mindestanforderung sein. 16 sind besser. Eine SSD brachte bei mir die Synthesezeiten (der Fitter ist der lahmste Teil) um fast die Hälfte runter. Auf meinem i7 Laptop sind meine (Hobby-) Projekte fast doppelt so schnell durch als auf meinem i5 Desktop. Wer die Web-Edition nutzt, braucht noch was anderes, auf das man so ohne weiteres nicht gleich kommt: eine schnelle Internetverbindung. Will man mehrere Prozessoren nutzen, muß TalkBack an sein. Dann telefoniert Quartus bei jedem Einzelschritt erst mal nach Hause. Wenn mein Laptop kein WLAN hat, fällt er noch deutlich hinter den (eigentlich langsameren) Desktop zurück, weil erstmal der http-Request auf seinen Timeout laufen muss...
Zur Orientierung: Bei uns laufen die Xiinx-Projekte auf Xeon-Servern mit 8 Cores/16Threads unter Linux. Ich habe allerdings noch nie gesehen, dass Vivado mehr als 4 Threads anwirft, und das auch nur beim Mapping bzw. Routing und nicht bei der Synthese. Die 20GB Speicher sind hingegen immer gut ausgelastet. Die Platten sind keine SSDs sondern schnelle Serverplatten, aber sicher würden SSDs nochmal einen guten Schub bringen. In dieser Konfiguration dauert ein Virtex-7-Projekt mit sehr starker Konnektivität zwischen 9 und 12 Stunden. Swapfiles auf SSDs sind keine gute Idee, dauerhaft viele kleine Schreiboperationen mögen die nicht. Besser in einen gut ausgebauten Speicher investeren. Wenn ich mir einen Syntheseknecht bauen wollte, würde ich einen schnellen 4-Core mit Hyperthreading oder 8-Core ohne HT nehmen und erst mal 32GB reinstecken. Als Datenspeicher eine SSD und noch eine schnelle Magnetplatte für den Swap, falls die 32GB nicht ausreichen. Wenn das öfter vorkommt, Speicher aufrüsten. Kostst ja zum Glück nicht mehr so die Welt. Wenn Du Vivado verwendest: trenne Dich möglichst schnell von der GUI und packe Dein Projekt in ein TCL-Script. Das wirkt manchmal Wunder, besonders,w enn Du Speichermäßig am Anschlag bist.
Ein Vergleich von vor einer Woche: Ein simples Quartus-Design (NIOS, DDR2, etwas Peripherie, Zielplattform Cyclone V). Beides als Win7x64 vmWare unter Ubuntu 14.04 (Host): Ein Haswell i7-4790 @ 3.60 GHz, 32 GByte RAM, M2-SSD. Synthese-Zeit: 7 min 30 sec. Ein Xeon 1275v5 @ 3.60 GHz, 32 GByte DDR4 ECC, NVe SSD (Samsung 950 Pro): Synthese-Zeit: 5 min Bei beiden Maschinen sind alle Kerne gut ausgelastet. Woher der große Unterschied kommt, weiß ich nicht. Kest
Kest schrieb: > Ein Haswell i7-4790 @ 3.60 GHz > Ein Xeon 1275v5 @ 3.60 GHz Für den Xeon ist eine höhere maximale Speicherbandbreite angegeben, d.h. 34,1 GB/s vs. 25,6 GB/s. Weiterhin ist der Xeon schon aus einer moderneren Baureihe aus der Haswell. Ist es korrekt, dass der Haswell mit 3,6 GHz betrieben wird, obwohl er für 4,0 GHz spezifiziert wurde? http://ark.intel.com/de/products/80806/Intel-Core-i7-4790-Processor-8M-Cache-up-to-4_00-GHz http://ark.intel.com/de/products/88177/Intel-Xeon-Processor-E3-1275-v5-8M-Cache-3_60-GHz
Beide CPU Takten sicherlich bis auf 4GHz hoch (Turbo). Trotzdem ist der Sprung ganz schön hoch, finde ich. Kest
Kest schrieb: > Beide CPU Takten sicherlich bis auf 4GHz hoch (Turbo). Trotzdem > ist der > Sprung ganz schön hoch, finde ich. > > Kest Wenn der Speicher 1/3 schneller ist, laufen speicherintensive Anwendungen auch ca. 1/3 schneller. Klingt logisch finde ich ;-)
Kest schrieb: > Beides als Win7x64 vmWare unter Ubuntu 14.04 (Host) Warum läuft das Ubuntu und nicht direkt unter Win7? Ich habe gelesen, dass Altera für Linux teilweise nicht verfügbar ist. Ist das der Grund?
Harry Hirsch schrieb: > Kest schrieb: >> Beides als Win7x64 vmWare unter Ubuntu 14.04 (Host) > > Warum läuft das Ubuntu und nicht direkt unter Win7? > > Ich habe gelesen, dass Altera für Linux teilweise nicht verfügbar ist. > Ist das der Grund? Altera stellt Quartus II für Linux (zumindest, wenn man ältere Cyclone füttern möchte) nur für ältliche RedHat Linuxe zur Verfügung, die eigentlich keiner mehr auf seinem Rechner haben will. Damit das auf aktuellen Ubuntus läuft, muß man leider ein wenig fummeln. Lohnt sich aber, das Gefummle, finde ich. Meine Versuche mit vmware waren geschwindigkeitsmäßig eher enttäuschend.
Also bei Xilinx hilft ein schneller 4 Kerner, unter Windows kann auch Vivado nicht mehr Threads benutzen und das auch nur beim Implement. Dazu eine schnelle SSD und min 16GB Ram, speziell wenn man größere FPGAs machen will. Xilinx hat dafür eine Tabelle. Ich arbeite an einer Z620 mit Dual Xeon und insgesamt 8 Kernen und 16GB, das geht schon gut, aber leider hat die Kiste keine SSD sondern nur eine blöde SAS Platte. Könnte ssn Admin jetzt noch shlagen dafür aber es ging kein Weg rein. Zu Hause am A8 5500 mit SSD und 8GB sind die Desings fast genauso schnell bzw. langsam. Simulation profitiert im.Normalfall gar nicht von mehr Kernen, Modelsim, Spice, alles single Thread. Wenn dann noch verschlüsselte Verilog IP Cores zu simulieren sind wird es völlig albern. MGT am Artix 7 kann man komplett vergessen.
Christian R. schrieb: > Simulation profitiert im.Normalfall gar nicht von mehr Kernen, Garnicht? Im ModelSim läuft je wenigstens die GUI mit dem WAVE und die Simulation selber. Datenbasis ist das aktuelle WLF. Da sehe ich wenigstens 3 unabhängig threads die parallel laufen könnten.
Harry Hirsch schrieb: > Warum läuft das Ubuntu und nicht direkt unter Win7? > > Ich habe gelesen, dass Altera für Linux teilweise nicht verfügbar ist. > Ist das der Grund? nein, ich habe alles in VMs: diverse Versionen von Quartus und SoC-Arm Umgebungen, mal für Windows mal für Linux (Ubuntu). Bis jetzt hat alles funktioniert bzw. ich habe alles zum Laufen gebracht. Manchmal logge ich mich über ssh ein, dann geht nur Ubuntu. Von früher weiß ich, dass Quartus über Windows-Remote nicht funktioniert hat (hat lizenztechnische Gründe). Ob das immer noch so ist, keine Ahnung Kest
Warum holst dir nicht ne dicke Maschine und betreibst sie als Server mit ESXi? Per Remotedesktop kannst darauf auf Win zugreifen und arbeiten. So kannst du deinen jetzigen PC weiter nutzen und stellst den Server zur Synthese neben hin.
Ein ESXi ist gerplant, aber jetzt ist meine Workstation (oder sogar zwei Workstations) noch vollkommen ausreichend. Das mit Windows-Remote-Desktop habe ich früher gemacht, jetzt greife ich auch mit VM-Ware darauf zu.
Hey Vancouver, hast du einen Werte zum Vergleich zwischen GUI und TCL ? Mich würde interessieren wieviel man damit wirklich rausholen kann.
Das sind die Ergebnisse für mein relativ großes Cyclone V Projekt (also im vergleich zu den High-End FPGAs eher klein) mit Quartus. Wenn ich mir die Spalte "Average Processors used" anschaue, würde ich auch zu weniger Kernen mit mehr Geschwindigkeit tendieren. Mein System ist ein i7 mit 4 Kernen (8 mit HT), 3.4GHz und 16GB RAM. Quartus ist gekauft und auf "Use all processors" eingestellt. Die Spalten wie folgt: Elapsed Time, Average Processors used, Peak Virtual Memory, Total CPU Time (on all processors) Analysis & Synthesis 00:02:54 2.0 1820 MB 00:04:34 Fitter 00:18:09 1.9 4709 MB 00:38:03 Assembler 00:00:33 1.0 1285 MB 00:00:33 TimeQuest Timing Anal.00:02:25 2.6 2809 MB 00:04:52 EDA Netlist Writer 00:00:25 1.0 1757 MB 00:00:25 Total 00:24:26 -- -- 00:48:27
eingast schrieb: > Mein System ist ein i7 mit 4 Kernen (8 mit HT), 3.4GHz Dito. Und dazu noch eine SSD und insgesamt 32GB RAM... Damit gehts zügig.
Harry Hirsch schrieb: > Kann man eine RAM-Disk nehmen? Das habe ich schon mal probiert, brachte aber nicht so arg viel. Die Zugriffe gehen sicher nochmal schneller, aber er macht das Meiste wohl im RAM und wenn die jeweilige Datei erst mal drin ist, ist der Vorteil weg. Ich habe auch gesehen, dass der RAM-Speicher bei großen Designs ziemlich voll lief und dann die RAM-Disk zuviel Speicher verbrauchte, was vom benötigten echten Speicher abging. Könnte also sogar gebremst haben. Allerdings war das ein freeware-Programm und ich hatte da nur 8GB. Werde das nochmal auf der 32GB-Maschine probieren. Ich würde aber sagen, dass es irgendwann nicht mehr viel bringt, wenn man eh schon eine M2-PCIe Disk drin hat.
Welches Motherboard wäre denn momentan so empfehlen für eine aktuell 4 Kern-CPU 4GHz?
Hab nochmal geschaut: Bei der zwischenzeitlich installierten ISE läuft auch beim Mapper bei mir nur EIN Prozessorkern und dies nicht einmal ständig mit 100%. Auch die Auslagerungsdatei wird nicht voll ausgelastet. Kann das am Win Home Premimum liegen?
Angehängte Dateien:
-

cpu.gif
5 KB
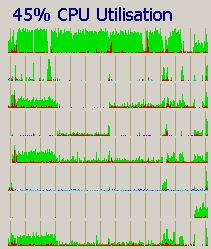
{kind=link}
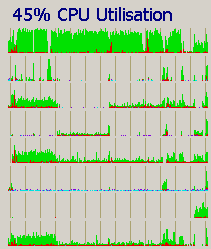
Kommando zurück: Habe nun unter dem Vivado ein Demoprojekt machen lassen und das erzeugt: Am Anfang macht er rund 30% usage, also mehr, als ein Viertel, wobei der 1. am Meisten tut. Dann gibt es nur 13%, also 1/8 + ein bischen was, es ist also nur einer aktiv. Gegen Ende rennen erst 4 und dann alle 8 threads mit zuletzt 45%.
Harry schrieb: > Skylake ist schneller auf 4 Kernen wegen der Frequenz, Haswell kann aber > 6 Kerne, WENN sie verwendet werden Äpfel mit Birnen verglichen, würde ich mal sagen. Beide gibt es als 4-Kerner. Da dürfte ein Skylake schneller sein. Kommt auf die CPU an. Genereller Unterschied: Skylakes haben (meistens) Grafik mit drin, Haswell mehr Cache. Wenn Du richtig viele parallele Rechnungen hast, dann ist mehr L3-Cache gut wegen der mehr Kerne. Haswell haben auch oft eine höhere Speicherbandbreite wegen Quad Channel. Fragt sich wo Dein Schwerpunkt ist! pSPICE kann z.B. Multi/Hyperthreading. Bei aufwändigen Simulationen mit selbstgeschriebenen Modellen sollte sich das schon auswirken!
Gerade was Passendes zum Thema entdeckt: Wenn Xilinx neue Cores baut oder diese Resynthetisiert, ist es schon mal nicht in der Lage, mehre threads zu starten, um zu übersetzen. Obwohl es ja unterschiedliche Tasks sind, sein könnte.
Doch, bei Vivado klappt das seit ein paar Versionen, da baut er dann mehrere Cores parallel neu.
Vancouver schrieb: > Swapfiles auf SSDs sind keine gute Idee, dauerhaft viele kleine > Schreiboperationen mögen die nicht. Chip hat dazu mal einen Artikel, der lautet, dass das SWAP file genau dahin soll, nämlich auf die SSD. Ich habe es auch nicht mehr genau vor Augen, warum, aber die Argumentation war schlüssig. Mac G. schrieb: > Meiner Erfahrung nach bringen schnellere Kerne mehr als viele aber dafür > langsamere. Was irgendwo logisch ist, weil Mehrkernrechnen immer Verwaltung mit sich bringt. Ein Vergleich 8 Kerne gegen 4 mit doppelter Frequenz, geht also zu Gunsten der 4 Kerne aus. Allerdings liegen die Unterschiede ja eher bei 20% in der Frequenz. Mehr Kerne sind immer besser, als weniger. Aber wer will für eine 8 Kern-Xeon zahlen? Da bekomme ich 2 PCs!
Ralf schrieb: > Mehr Kerne sind immer besser, als weniger. Aber wer will für eine 8 > Kern-Xeon zahlen? Da bekomme ich 2 PCs! Richtig, wobei es eben Applikationen gibt, die sich gegenseitig sehen müssen. Beispiel: Audio-Sequencer, Klangsynthese, Sampler, Recording und Mixing, Mastering. Läuft nur unzureichend, wenn es auf mehrere Maschinen verteilt wird. Bei mehreren Cores dagegen sehr wohl.. Das Mehr an Kernen macht sich vor allem bei wirklich parallelen Applikationen bemerkbar. Da reicht es schon, wenn man 2 unterschiedliche Programme gleichzeig laufen lässt, die beide weniger, als 4 Kerne belegen. Besonders effektiv ist es, wenn sich die Programme komplementär ergänzen, also das eine z.B. viel CPU benötigt und das andere richtige Speicherbandbreite. Man merkt den Vorteil, wenn man z.b. einen Winrar parallel zu einem Autorouter und einer Simulation ablaufen lässt, oder auch installiert und viel ausgepackt werden muss. Da gilt wirklich, je mehr, desto besser. Außerdem kann man immer schön weiter Editieren und mit Excel arbeiten. Ansonsten geht der Rechner so dermaßen in die Knie, dass er nicht einmal mehr Mausklicks annimmt. Einzelne Programme werden die Kerne aber nur selten dauerhaft effektiv ausnutzen. Auch mein 3D-Renderer muss immer mal wieder "denken" und neue threads berechnen, es sei denn ich rendere die Bildansicht und auch im Hintergrund. Es ist in jedem Fall sehr erbaulich, zu sehen, wenn statt der üblichen 4 oder 8 gleich mal 12 Linien anspringen und das Bild verrechnen. Dann rennen die in der Tat mit 100% CPU. Bei meinem neuen Rechner habe ich eine Super-Kühlung drinnen, sodass die unter Volllast trotzdem nur 70 Grad (ohne Lüfter) haben und ungebremst lautlos laufen. Sehr angenehm! Auch der Speicher ist relevant: Je mehr, desto besser. Hier die Ergebnisse des RAM-Disk-Versuchs: a)3D-Renderer 100 Bilder = 4sec, mit Spiegelungen und Fresnel-Optikberechnung, Projekt mit Ergebnis auf ... ... neuer SATA HD : 7min35, ... M.2 PCI-E SSD : 7min02, ... RAMDISK 16GBB : 6min55 b) Xilinx ISE, Spartan 6 Projekt, Alles inklusive Ergebnis auf ... ... neuer SATA HD : 1h24min ... M.2 PCI-E SSD : ausgelassen ... RAMDISK 16GBB : 1h13min c) ModelSIM, VA-Synthesizer, 128 Stimmen, 3 Sekunden Audio ... neuer SATA HD : 34min20s ... M.2 PCI-E SSD : ausgelassen ... RAMDISK 16GBB : 26min15sec Beim ModelSim ist vor allem zu beobachten, dass das Blättern im WAVE schneller läuft. Das fallen die Plattenzugriffe auf die physische Disk weg. Das ist schon ein ziemlicher Vorteil. Ich würde sagen, dass sich das teilweise schon lohnt. Man muss halt das Projekt entsprechend ins RAM kopieren.
Ich weiß jetzt zwar nicht, ob der TE sich schon entschieden hat aber ich würde auch noch die beiden verfügbaren Broadwell CPUs in den Raum werfen. Der Vorteil ist, dass beide übertaktbar sind und recht wenig verbrauchen. Das interessanteste ist aber, dass beide eine Iris Grafik und damit auch einen 128MB großen L4-Cache integriert haben, der in manchen Anwendungen für einen ordentlichen Leistungsschub sorgen soll, da der L4-Cache nicht exklusiv vom Grafikchip verwendet wird. Mit einem Z97-Board kannst du eine Broadwell CPU ebenfalls auf 4GHz über den Multiplikator übertakten. Ebenfalls interessant ist der i7-5820k. Er bietet 6 Kerne und hat ein 4-Kanal-Speicherinterface, so dass du mit 16GB Modulen auf maximal 128GB RAM kommst. Wie die Broadwells hat auch der i7-5820k nur einen geringen Basistakt. Du kannst ihn aber auch mithilfe des Multiplikators übertakten. In den gängigen Computer-Foren habe ich schon öfter von Usern gelesen, dass sie ihn ohne Probleme auf 4GHz übertaktet haben, selbst bei niedriger Core-Spannung von ca. 1V. Für die Skylakes hat Intel mittlerweile ein Microcode-Update zur Behebung des AVX2-Fehlers ausgeliefert.
Wieviel bringt Übertakten? 10%? Lohnt sich das?
Wie hoch kann man da gehen, ohne Material zu zerstören? Bzw zu
riskieren, dass einem die Kiste alle 10min abschmiert?
Und was ist mit der Kühlung?
Soweit mir bekannt, arbeiten die Overclocker mit Wasserkühlungen und
drücken u.a. nicht nur die CPU und GPU, sondern auch Northbridge und
RAMs in der Temperatur runter, damit sie stabil laufen.
>I5820
Beim 5820 sind nominell 3,3 GHz angegeben. Kriegt man den gfs auf 4 GHz?
Das wären ja immerhin schon 20%
Beim Übertakten kann nur was kaputtgehen, wenn du die Core-Spannung zu stark erhöhst. Wenn du nur den Takt und nicht die Core-Spannung erhöhst, dann erhöht sich die Chiptemperatur nur im geringen Maße. Den i7-5775C und den I7-5820k kann man, ohne die Core-Spannung großartig zu erhöhen, sehr gut mit 4GHz betreiben. Beide CPUs lassen sich dann noch sehr gut mit einem vernünftigen Tower-Kühler kühlen. Manche CPUs machen sogar bei niedrigerer Core-Spannung mehr Takt, manche eben nicht. Bevor man produktiv mit dem System arbeitet sollte man aber erstmal ein paar Stabilitätstest mit prime95 machen, um spätere Systemabstürze ausschließen zu können. Eine Wasserkühlung wird erst für das extreme Übertakten benötigt, wo es dann darum geht, soviel Takt wie möglich rauszuholen. Dafür werden aber auch Core-Spannungen von 1,2V und mehr benötigt und die CPUs verbauchen dann 150W und mehr. Das geht dann aber eher so in den Bereich von ca. 4,5GHz und höher. Bei 4GHz ist dann noch entspannter.
>5820 Ich habe genau den Prozessor! Die Taktfrequenz beträgt maximal 100x34. Habe noch nicht rausgefunden, wo ich das modifizieren kann. Ich bin auch nicht sicher, ob ich das möchte, denn der hat schon ohne irgendeine Übertaktung 145 Watt bei 1.0V. >nur geringe Erhöhung Wenn man den auf 4GHz hochzieht, wären das in der Tat 20% und entsprechend geht auch die Leistung hoch. Ob das die Kühlung mitmacht, sei mal dahingestellt. Ich habe vor 15 Jahren viel mit Wasserkühlung gemacht und selbst die hat Grenzen. Am Ende braucht man immer laute Lüfter oder ist begrenzt. Ich habe jetzt einen käuflichen Silent-PC mit Passivkühlung. Komplett lautlos. Völlig neues Arbeitsgefühl, besonders für Musik :-) Der CPU Kühler ist extrem leistungsfähig, andererseits muss er das auch sein, weil die begrenzte Eigenkonvektion zu einem Wärmestau und damit einer starken Überhöhung der Temperatur führt. Habe mal getestet, was drin ist, wenn man das mit einem externen Ventilator wegbläst: Beispiele bei gut 20° Umgebung: Alle CPUs im Leerlauf, passive Kühlung : 43° Alle CPUs im Leerlauf, ext. Ventilator : 24° Alle CPUs bei Volllast, passive Kühlung : 74° Alle CPUs bei Volllast, ext. Ventilator : 52° Alle CPUs bei Prime95, passive Kühlung : bei 85° manuell abgebrochen Alle CPUs bei Prime95, ext. Ventilator : 68° Prime95 ist schon ein ziemlicher Killer! Die CPUs rennen mit 33x100 auf 140W, aber dafür alle Vollgas ohne Pause, was es praktisch nicht gibt. Cinema 4D ist da eher ein Maß: Maximal 34x100 = 3400 auf 145 Watt, aber immer wieder Pausen vor jedem Bild zum Planen und wegspeichern. Macht am Ende nur maximal 75° eingeschwungen (bei langen Bildrechnungen) und rund 70 bei normalen Bildfolgen. Werde mir wohl einen lautlosen Lüfter drauflegen und mal schauen, wohin es geht. Immerhin werden ja auch die anderen Bauelemente mitgeheizt, wenn die Innenraumtemperatur höher ist. Und die mögen das bekanntlich nicht.
Zum Übertakten der CPU brauchst du nur den Multiplikator hochsetzen. Das geht entweder im BIOS oder im Tool XTU von Intel, manche Mainboard-Hersteller stellen auch eigene Tools zur Verfügung, mit denen man das machen kann. Zum Übertakten solltest du aber auf jeden Fall Lüfter verbauen. Es ist so schon erstaunlich, dass die CPU passiv gekühlt nur 75° warm wird. Das die CPU bei Prime95 wärmer wird, ist kein Wunder, da das Tool auch verstärkt die AVX-Einheit verwendet, die dafür bekannt ist, dass sie den Verbrauch nochmal ordentlich steigert. Womit hast du eigentlich den Verbrauch gemessen? Was hast du für einen CPU-Kühler? Lüftermäßig kann ich dir die bequiet Silent Wings mit PWM empfehlen. Die haben ein sehr gutes PL-Verhältnis. Ich hab 2 davon an meinem CPU-Kühler(Alpenföhn Matterhorm) befestigt und die sind sehr leise und mein i7-4770 wird nicht mal 50° warm.
Stephan C. schrieb: > Zum Übertakten der CPU brauchst du nur den Multiplikator hochsetzen. Das geht aber nur bei manchen boards. Wenn du alle over clocking Funktionen nutzen willst, brauchst Du ein OC-board! Viele Hersteller erlauben nur wenige Funktionen diesbezüglich und lassen das board den Prozessor auslesen und stellen sich passend ein. Mein board kann: *CPU-Takt 150 MHz, läuft mit 101,01 statt 100 *CPU-MULT 40, läuft mit 45 max statt mit 40 max *CPU-VOLT 1.25V, läuft mit 1.125 statt mit 1.0 *CPU-POWER, läuft mit 180W statt 130W *CPU-CURR, läuft mit 135A statt 130A weiter *RAM-TAKT, *RAM-VOLT, *IO-TAKT, etc Im Mittel ist er rund 15% schneller, weil er auch länger im Turbomodus bleiben darf.
Also ich habe das Tool ausprobiert - das board nimmt nichts von den Einstellungen an. Auch temporär geht es nicht. Weder Multiplier noch Ströme oder gar Spannungen können per Software geändert werden. Ist ein Fujitsu Server board 3348D. Wahrscheinlich auch gut so ;.)
Jürgen S. schrieb: > Ist ein > Fujitsu Server board 3348D. Wahrscheinlich auch gut so ;.) Server Boards sind ja auch nicht für "Gamer" gedacht wo es egal ist wenn die Kiste abschmiert oder doch mal ein Bit zuviel im Speicher kippt... ;-)
Gibt es eigentlich eine Möglichkeit, eine FPGA-Symthese auf zwei PCs ausführen zu lassen? Oder kann man die Erzeugung des fertigen Chips nur auf eine andere Maschine im Serverraum auslagern, um den eigenen wieder frei zu bekommen? Wie ist das mit der Lizenz? Wird eine weitere Lizenz benötigt um entfernt zu generieren? Können dort mehrere Leute gleichzeitig mit einer Lizenz bauen lassen? Ich kenne es mit der ASIC-Synthese. Man schickt seinen Job auf die Maschine und die nutzt mehrere physische Workstations mit einer Lizenz. Kann aber eine Mehrplatzlizenz sein, wie mir gerade einfällt.
Soweit das bei uns gehandhabt wird (und soweit es mir bekannt ist) geht das nicht auf mehreren Rechnern und wenn ich lese, daß ohnehin nur 4 Kerne zum Einsatz kommen, macht es auch wenig Sinn. Was Sinn macht, ist sicher, die komplizierten langen Tasks in der Erzeugung auf einen anderen Rechner zu versenden, besonders, wenn mit MATHWORKS designed wird. MATLAB und sein Gedöhns ist extrem Speicher anfordernd. MATHWORKs selber hat dazu ja schon eine Lösung geliefert und stattet Kunden mit einer Art Serverfarm aus, auf der die umständlichen Task dann offline laufen können. Man mietet sich quasi mit einem thread darauf ein. Ich hätte aber einen anderen Punkt: Wie verhält es sich eigentlich mit Xilinx unter Linux? Ich mache viel mit embedded Linux, früher auch mit Server-Linux und wir alle wissen, daß Linux mit den Rechnerresourcen sehr viel schonender umgeht, als Windows. Besonders multithreading/tasking wird da erheblich besser und stabiler gehandhabt. War zumindest früher so. Ok, das heutige Windows kann auch gut multi und stabil ist es ja nun inzwischen. Ich meine aber, daß man für solche Operationen wie FPGA-Synthese mit Linux durchaus gewinnen müsste, oder? Mich interessiert es privat und beruflich, weil ich privat ein bischen was mit FPGAs mache (momentan nur Altera+Windows) - beruflich aber im Bereich Projektmanagement unterwegs bin, wo es öfters um den Einsatz hochrechenintensiver Plattformen geht. Die Frage ist, ob man bei Synthesis-Prozessen unter Linux nennenswert an Zeit gewinnen könnte. ?
Andreas F. schrieb: > Die Frage ist, ob man bei > Synthesis-Prozessen unter Linux nennenswert an Zeit gewinnen könnte. Nein, meiner Erfahrung nach nicht nennenswert. Vor ein paar Jahren, gab es noch den Vorteil, das Linux schon 64 Bit konnte, und Windows noch nicht. Damit liefen große Synthese nur unter Linux. Duke
Andreas F. schrieb: > Bereich Projektmanagement unterwegs bin, wo es öfters um den Einsatz > hochrechenintensiver Plattformen geht. Die Frage ist, ob man bei > Synthesis-Prozessen unter Linux nennenswert an Zeit gewinnen könnte. Der Vorteil verpufft sobald man die platformübergreifende GUI am Laufen hat oder anders ausgedrückt Linux bringt Vorteile bezüglich effizientes Aufsetzen Toolchain (make,tcl-scripting,automatisierte Regressionstest in der Simu) die aber von Entwicklern die nur GUI können vergebens ist. Deshalb in Projekten einen Mensch/Person einplanen die sich zu 100-50% um die Toolchain und CAD-Support kümmert.
Bit Wurschtler schrieb: > Deshalb in Projekten einen Mensch/Person einplanen die sich zu 100-50% > um die Toolchain und CAD-Support kümmert. Da ist was dran. Wenn ich sehe, was ich an Zeit mit toolchain verbrate, kommt das hin. War mal in einer Abteilung aktiv, wo es zwei Leute hatte, die nur Sripte gemacht haben und die Synthesplattform und Tools managten. Da waren aber auch 20 Männeken aktiv am bauen.
Bei uns haben sie wegen solcher Probleme die FPGA-Entwicklung nahezu vollständig ausgelagert. Unter anderem wegen dieses Themas hier: Beitrag "Embedded Linux Cluster im FGA testen und ASIC draus machen" Nun befasse ich mich noch privat damit, vor allem im Kontext mit Linux und embedded processing. Ich benutze eine HP-Workstation, älteren Datums. Da ich auch viel mit Grafik mache, mal kurz von mir die Frage in die Runde: FPGA-Synthese auf MAC? Geht das? Ich überlege, komplett auf MAC umzusteigen.
Georg B. schrieb: > FPGA-Synthese auf MAC? Geht das? Klar, in der VM ;) Nativ hab ich zumindest bei den großen nix in Erinnerung.
Georg B. schrieb: > FPGA-Synthese auf MAC? Geht das? Ja, auch ohne VM. Xilinx ISE lässt sich mittels wine installieren/starten. Bei Vivado scheiterte die Installation unter wine am Java-Installer... Eigentlich wird's mal Zeit, das die Hersteller ihre Tools auch für MacOS rausbringen. Duke
Da sehe ich wenig Chancen. Mal ehrlich: Wer momentan mit FPGAs arbeitet und im Büro sitzt: Schaut euch mal um: Wieviele MACs seht ihr gerade? Ich denke, das Beste ist nach wie vor eine eigene Linuxmaschine, mit schlankem Core, ohne viel Schnickschnack drauf und vor allem keine normale PC-Software zur Nutzung als Office-PC, der ins Internet muss, damit man Virtenscanner und anderes Zeug getrost abschalten kann. Dann sollte das schnell genug sein. Solange die Tools keine echte verteilte Anwendung darstellen, die man auf einer Serverfarm verteilen kann, macht es eh nicht viel Sinn.
Ich kann bestätigen, dass Vivado die CPUs voll auslasten kann. Einfach alle Cores neu machen lassen und alle threads aktivieren. Und "Auslasten" meine ich hier durchaus wörtlich: Meine Kiste startet mit 100MHz x 39 Turbo und rennt dann auf allen 8 Kernen mit x36 weiter. Nach allerdings 1 Minute sind die CPU-Temperaturen schon jenseits der 95 Grad und er fängt an, zu drosseln! Am Schluss brutzelt er mit durchschnittlich 98 Grad dahin und erlaubt nur noch den Multiplier von z.T. 31! Fehlen also schon >10% CPU-Dauer-Leistung! Beim Synthetisieren sind es dann wieder an die 4GHz, mit maximal 1-2 weitgehend aktiven Cores. Der Rest dümpelt mit wenigen %ten vor sich hin, sind aber trotzdem alle bei Faktor 35 und verbrutzeln Energie. Komisch. Erst, wenn die Synthese vorbei ist, fahren für alle Kerne die Multiplier runter. Sieht aus, als ob da sporadisch irgendwelche Sachen angeworfen werden, die verhindern, dass die CPUs runtergeregelt werden können. Kann man das irgendwie steuern?
Markus F. schrieb: > CPU-Temperaturen schon jenseits der 95 Grad und er fängt an, zu > ... brutzeln Pass auf, dass Dir die CPU nicht "wegbruzzelt". Du weißt um die maximale Temp deines Systems? 95 Grad scheint mir definitiv zu viel. Normal sind maximale Temperaturen von 100°, die man aber nicht messen kann. Die Dauertemperatur am Case sollten unter 75° sein! Was ist das für ein Typ?
Ich habe aufgrund des Beitrags weiter vorn (m)einen alten Rechner mal dahingehend inspiziert und vorgefunden, dass auch auf diesem über 90°C erreicht werden, wenn alle Kerne arbeiten! Es ist ein I7-2600K (Sandy) mit 3.4GHz. Die Berechnung von Cores dauert nicht sonderlich lange, aber während der Implementierung geht es auch ordentlich nach oben. Waren ebenfalls gut 85°C, die aber läuft an die 15min. Muss ich mir Sorgen machen?
Markus F. schrieb: > Solange die Tools keine echte > verteilte Anwendung darstellen, die man auf einer Serverfarm verteilen > kann, macht es eh nicht viel Sinn. Ich habe ohnehin den Eindruck, dass speziell bei Vivado ein Großteil der Leistung in der GUI verschleudert wird. Selbst wenn man demnächst noch leistungsstärkere Rechner haben wird, dann werden es die Programmierer der Betriebssysteme und Anwendungen mit ihrem GUI-Wahn schon irgendwie schaffen, die Hardware auszubremsen. Beitrag "Re: Xilinx Vivado ist wirklich so langsam!"
Thomas der Vivadohasser schrieb: > Ich habe ohnehin den Eindruck, dass speziell bei Vivado ein Großteil der > Leistung in der GUI verschleudert wird. Hm, kann ich objektiv nicht bestätigen. Wir bauen unsere Projekte immer per TCL Script, auf meinem Rechner dauert der Build ohne GUI nur wenige Sekunden weniger als mit. Bei über 30 min fällt das nicht ins Gewicht. Aber die Vivado GUI nervt schon, das stimmt. Hätten sie mal lieber einen ordentlichen Editor integriert oder das ganze Ding in Eclipse gepackt. Aber nee, muss ja jeder das Rad noch 3 mal neu erfinden.
D.h. es würde gar keinen Vorteil bieten, auf die GUI zu verzichten?
Bei mir bringt es fast nix. Ich arbeite lokal mit der Gui und auf dem Teamcity Server läuft es per Script.
Christian R. schrieb: > Bei mir bringt es fast nix. Das ist interessant, zumal es ja auch andere Meinungen zu geben scheint, denn: Vancouver schrieb: > Wenn Du Vivado verwendest: trenne Dich möglichst schnell von der GUI und > packe Dein Projekt in ein TCL-Script. Das wirkt manchmal Wunder, > besonders,w enn Du Speichermäßig am Anschlag bist. Ich meine aber auch, dass die GUI keinen großen Einfluss haben sollte / kann, wenn genug Kerne zur Verfügung stehen. Nach meiner Beobachtung ist das maximal dann relevant, wenn das tool alle der 4 typischen Kerne belegt und dann noch was anderes laufen muss. Ich habe jetzt mal Vergleiche angestellt mit den Synthesen bei ISE und Vivado: Rennt auf meinem 12-Kerner gefühlt ungebremst, d.h. dem Vivado ist es ziemlich egal, ob im Hintergrund noch die ISE routet oder nicht. Erste Ergebnisse: Vivado ist bei gleichem Projekt etwas langsamer! Vergleiche dazu dieses Thema: Beitrag "Ist Xilinx (Vivado) wirklich so langsam?"
Christian R. schrieb: > Hätten sie mal lieber einen > ordentlichen Editor integriert oder das ganze Ding in Eclipse gepackt. Ich glaube, die investieren schon lange nichts mehr in Editoren, weil sie genau wissen, dass die halbe Welt was Eigenes nimmt. Ist wohl dasselbe, wie mit dem Symbol Based Design. Das scheinen sie jetzt wohl beerdigt zu haben. Andererseits haben sie jetzt einen TCL Store aufgemacht. Da kann man wohl eigene Sachen machen und sogar in die GUI-Teile andocken. Gehört aber wohl besser in einen anderen Beitrag.
Dieses symbolorientierte Eingaben haben die keineswegs beerdigt. Die nennen es jetzt nur Blockdesign und es sieht anders aus. Ist aber so anfällig und kaputt wie das Gemale vorher. Leider addieren sich zu den vielen kleinen Sauereien, die man sich mit sowas einhandelt, auch noch die vielen Probleme, die Vivado noch macht: Beitrag "Klicki-Bunti-Manie der Softwareentwickler"
Ich komme nochmals zurück auf das Thema Xilinx unter Linux! Ich habe einen sagenn wir mittelalten PC, der noch mit Win7 lief auf ein Linux64 umgestellt und finde, dass Sript gesteuerte Synthesen maximal knapp 10% schneller ablaufen. Der Versuch, 2 Rechner zu clustern und eine Virtuelle Maschine auf beiden zu erstrecken, hat leider nicht funktioniert. Dies als Einwurf zu meinem Vorschlag oben, mehrere Rechner ins Spiel zu bringen. Werde da aber dranbleiben. Ich meine, dass es möglich sein müsste.
Moin, Andreas F. schrieb: > Ich komme nochmals zurück auf das Thema Xilinx unter Linux! Ich > habe > einen sagenn wir mittelalten PC, der noch mit Win7 lief auf ein Linux64 > umgestellt und finde, dass Sript gesteuerte Synthesen maximal knapp 10% > schneller ablaufen. > Ich habe mir Vivado nicht allzu lange angesehen, aber so viel hat sich bezüglich der Effizienz doch nicht gegenüber ISE verändert. Bei ISE lief der ganze Prozess (Syn bis P&R) unter Linux im Makefile-Betrieb fast doppelt so schnell gegenüber Windows aus der Cygwin shell, ganz zu schweigen von den 50% CPUlast, die das QT-'Busy'-Windrad verbraten hat. Ich gehe mal davon aus, dass noch eine Menge alten Codes unter der Haube werkelt, der noch auf Sun-Kisten entworfen wurde. Posix-Emulate sind unter Windows nun einmal nicht sonderlich schnell. Beim exzessiven Disk-I/O der Xilinxtools konnte ich zwischen den zwei OS keine Unterschieden messen. > Der Versuch, 2 Rechner zu clustern und eine Virtuelle Maschine auf > beiden zu erstrecken, hat leider nicht funktioniert. Dies als Einwurf zu > meinem Vorschlag oben, mehrere Rechner ins Spiel zu bringen. > > Werde da aber dranbleiben. Ich meine, dass es möglich sein müsste. Du kannst ja ansich pragmatisch dein Design manuell partitionieren und auf verschiedenen Rechnern backen, das finale P&R kann aber doch nur eine Instanz (womöglich nur ein Core) wirklich effizient, bzw. können nur die Money-Tools so partitionieren, dass sich Mehrkerne auch wirklich nutzen lassen. Also für mich haben sich jegliche Mehrkern-Tricks nur bedingt gerechnet. Besser ist, im richtigen Moment Kaffee trinken zu gehen oder genug Speicher zu haben, um in der Zeit was anderes machen zu können.
Dann muss man aber auch ausreichend CPU-Power haben. Schon gleichzeitig zu simulieren haut oft nicht hin, wenn zwar Speicher da wäre, aber die CPUs voll mit Gedöhns belastet sind. Wenn ich mit ISE gearbeitet habe, war ModelSIM -zumindest auf Rechnern, der 2010er Generation - kaum möglich. Von MATLAB will ich gar nicht reden. Deine Aussage bestätigt aber meine Haltung zu dem GUI-Getöse. Dort wird unverstänlich viel Zeit verbraten.
Dann lohnt wirklich die Nutzung von 2 PCs, womit man auch ein bischen das Problem umgeht, dass man z.B. durch das Weiterentwickeln unter Modelsim unachtsam files ändert, was während einer Synthese negativ aufgeschlagen ist. Als die PCs noch nicht so leistungsfähig waren, hatten die meisten Entwickler eine zweite Maschine rumstehen, die die Synthesen macht, während z.B. ein MATLAB auf einem Hauptrechner läuft. Bei einer ausreichenden Zahl von Kernen und RAM geht es aber auch mit einem: Trotz GUI ist der meistens nicht voll belastet: Beitrag "Re: Ist Xilinx (Vivado) wirklich so langsam?"
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.