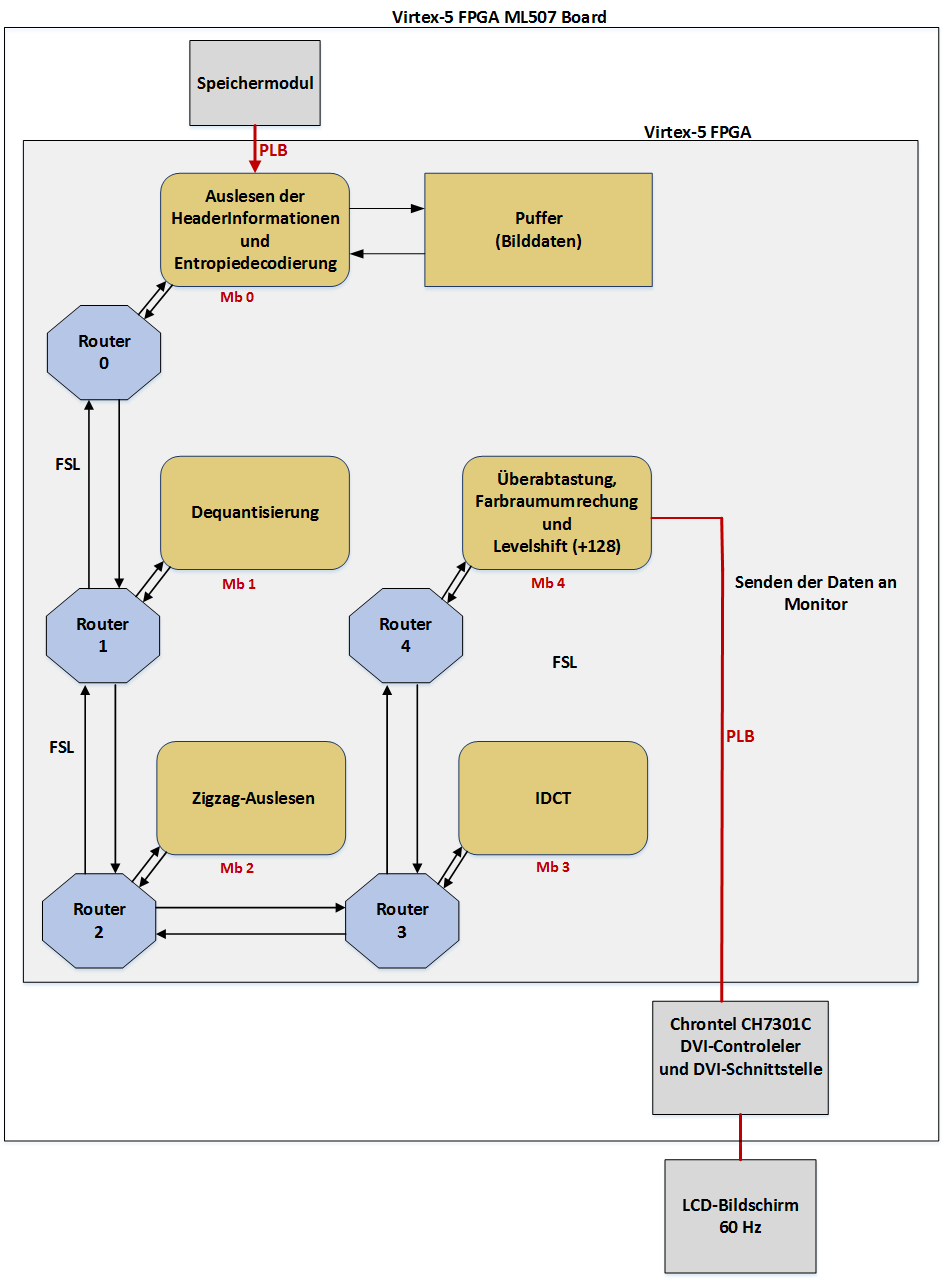
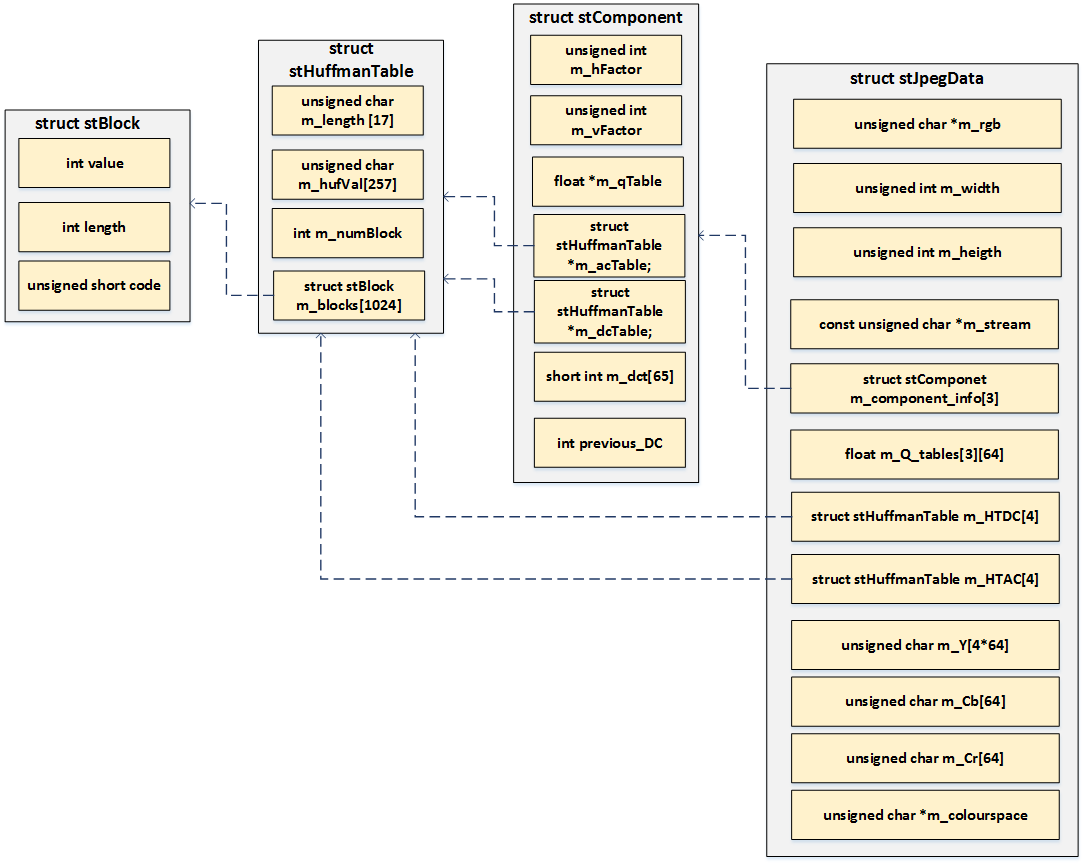
Hallo, in meiner Bachelorarbeit realisiere ich den MJPEG-Decoder auf dem Virtex-5-FPGA der Firma Xilinx (ML507-Board) unter Verwendung von Network-on-Chip-Kommunikation (siehe Anhang). Die Netzwerkarchitektur (MicroRouters und Protokoll) ist bereist realisiert und es implementiert die Schichten von 1 bis 4 des OSI-Models. Die Kommunikation zwischen beteiligten Komponenten (MicroBlazes und Routers) erfolgt über 4-Byte-Pakete, wobei lediglich zwei Bytes davon die Nutzlast ist. Die Quellcode in C für den JPEG-Decoder ist auch schon vorhanden.Nun will ich die einzelnen Dekodierungsschritte des MJPEG-Decoders über jeweilige MicroBlazes verteilen (siehe Anhang). Die Funktionsweise meiner Quellcode ist so, dass zuerst ein ganzes dekodiertes Bild erst eingelesen und zwischengespeichert wird. Nun werden die Bilddaten bearbeitet und der Stukturdatentyp stJpegData (siehe Anhang) initialisiert und dessen Komponenten während des Auslesens der Header- und Tabelleninformationen mit entsprechenden Werten initialisiert. Somit brauchen die Funktionen für entsprechende Dekodierungsschritte in MicroBlazes nur Zeiger auf Puffer mit Bilddaten und auf Strukturdatentyp stJpegData. Meine Frage ist, ob meine Vorgehensweise auf FPGA realisierbar ist. Ich brauche zwei Puffer, wobei im ersten Puffer zuerst alle kodierten Daten von SOI bis EOI und im zweiten Puffer der Stukturdatentyp mit allen Headerinformationen sowie DQT-und Huffman-Tabellen gespeichert werden. Die Zeiger auf diese Puffer sollten dann beim Funktionsaufruf an entsprechenden MicroBlaze übergeben werden, sodass jeder MicroBlaze dem Zugriff auf diese Speicherbereiche hat. Ich bin ganz neu in der FPGA-Welt und für jeden Vorschlag oder Idee von ihrer Seite würde ich sehr dankbar sein. Viele Grüße Nohchi
Angehängte Dateien:
-

Designentwurf.png
52 KB -

Struktur_JpegData.png
45 KB
Nohchi V. schrieb: > Ich bin ganz neu in der FPGA-Welt und für jeden Vorschlag oder Idee von > ihrer Seite würde ich sehr dankbar sein. Prinzipiell sehe ich erstmal keine Bedenken. Ist die ganze FPGA-Struktur schon fertig und es fehlt nur noch Software? (Ich hoffe doch für eine Bachlorarbeit zumindest :) Ich rate dir es erstmal zu probieren. Prinzipiell sollte mit einem NoC ein MB sich ja von überall die Daten holen können. Am Ende ist die Effizienz/Geschwindigkeit das andere Problem.
Was genau soll der FPGA tun? Soll der nur die Prozessoren und deren Kommunikation hosten, und die MJPEG-Dekodierung ist dann Hardware, oder soll er auch aktiv beim Dekodieren helfen?
Die Prozessoren sind IM FPGA. Ja aber gute Frage wieso man das Dekodieren nicht in Hardware macht sondern in C. Für mich sieht das eher so aus als wäre die Aufgabe ein Network-on-Chip mit mehreren CPUs zu bauen.
> Prinzipiell sehe ich erstmal keine Bedenken. Ist die ganze FPGA-Struktur > schon fertig und es fehlt nur noch Software? (Ich hoffe doch für eine > Bachlorarbeit zumindest :) Die Network-on-Chip-Architektur ist bereits vorhanden. Die MikroRouters sind in VHDL implementiert. Die Softwareschnittstelle zu MikroRoutern, die die Schicht 4 implementiert, ist auch vorhanden. In Meiner Arbeit muss ich nun diese Network-on-Architektur anwenden. Dabei implementiere ich MJPEG-Decoder und verteile die Funktionalitäten der einzelnen Dekodierungschritte über MicroBlazes, die dann die Dekodierung sequentiell durchführen. Die Software habe ich bereits implementiert und die Funktionsweise habe ich schon teils in meiner Frage erläutert. Ich weißt jetzt einfach nicht, wo ich meine Daten zwischenspeichern soll, sodass jeder MB beim Funktionsaufruf die Zeiger auf die entsprechenden Speichern als Parameter bekommen und auf diese Daten zugreifen.
HM. Musst Du das mit den Microblazes und in C machen? Ich kenne mich damit nicht aus aber bei FPGA und Dekoder habe ich doch sehr erwartet, dass da viel direkt in Hardware gemacht wird. Vielleicht noch mit CPU zur Steuerung aber eben nicht für rechenintensive Aufgaben. Was ist denn der Grund wieso das mit CPUs gerechnet werden soll? Finde ich auch spannend weil ungewöhnlich.
Nohchi V. schrieb: > Ich weißt jetzt einfach nicht, wo ich meine Daten zwischenspeichern > soll, sodass jeder MB beim Funktionsaufruf die Zeiger auf die > entsprechenden Speichern als Parameter bekommen und auf diese Daten > zugreifen. Wie sieht es aus wenn du ein allgemeines BRAM ans NoC hängst? Dann kopieren sich die MB das notwendige in ihren eigenen RAM. Hier weiß ich nun nicht wie dynamisch die Sache abläuft. Es könnte dann zuviel Traffic am BRAM anliegen. Außerdem kann ich die Größe dieser ganzen Zeiger Daten noch nicht abschätzen und Synchronisierung ist auch wichtig.
Dann schlage ich vor, du löst dich erstmal von dem Wort "FPGA". Du hast nämlich eigentlich keinen FPGA, sondern einfach mehrere MicroBlaze-Prozessoren, die miteinander über ein Netzwerk (Network-on-chip) verbunden sind. Dass die in einem FPGA implementiert sind, ist relativ egal. Viel wichtiger sind die klassischen Fragen der Mikrocontrollerei: - Wie ist die Aufteilung des Adressraums aus Sicht jedes MicroBlaze? --- Wo befindet sich der RAM (welche Adressen) und was für RAM ist es? --- Hat jeder MicroBlaze eigenen RAM? ----- Können die anderen MicroBlazes darauf zugreifen? --- Gibt es einen gemeinsam genutzten RAM irgendwo? ----- Ist der auch schnell genug für parallele Zugriffe? --- Findet zwischen den MicroBlazes Message Passing statt? ----- Mit oder ohne DMA? ------- Wie mächtig ist der DMA-Controller? Wenn es keinen RAM gibt, auf den alle MicroBlazes zugreifen können, dann kannst du schlicht keinen Zeiger auf die Daten bauen, sondern du musst vorher die Daten in die richtige CPU kopieren. Dabei ändert sich natürlich die Adresse. Wenn es einen gemeinsamen RAM gibt (oder der Speicher in einem gemeinsamen Adressraum verteilt ist), kannst du zwar mit einem Pointer arbeiten, aber Zugriffe auf "fremden" Speicher können deutlich langsamer sein als Zugriffe auf "eigenen" Speicher. Dann willst du trotzdem kopieren, und zwar je nach Datenmenge mit DMA. Wenn zwei CPUs gleichzeitig auf einen RAM zugreifen, musst du die Zugriffe synchronisieren (z.B. durch Locks oder sowas wie Transaktionen, z.B. FIFOs). Im Zweifelfall brauchst du dafür spezielle CPU-Instruktionen (test-and-set o.ä.), um das implementieren zu können. Oder du garantierst atomische Zugriffe und kannst lock-free synchronisieren. Hängt vom NoC ab, was du brauchst und was du kannst.
> Dann schlage ich vor, du löst dich erstmal von dem Wort "FPGA". Du hast > nämlich eigentlich keinen FPGA, sondern einfach mehrere > MicroBlaze-Prozessoren, die miteinander über ein Netzwerk > (Network-on-chip) verbunden sind. Dass die in einem FPGA implementiert > sind, ist relativ egal. So verstehe ich es auch. Ich habe mich von Anfang an mit C und JPEG-Standard gründlich beschäftigt, um die Softwarelösung zu erarbeiten und natürlich das Xilinx-ML507-Board mit EDK noch kennen gelernt. > Viel wichtiger sind die klassischen Fragen der Mikrocontrollerei: > --- Hat jeder MicroBlaze eigenen RAM? > ----- Können die anderen MicroBlazes darauf zugreifen? > --- Gibt es einen gemeinsam genutzten RAM irgendwo? Genau diese Fragen interessieren mich jetzt und das ist der Grund, warum ich diesen Thread geöffnet habe. Ich habe es versucht mit "MicroBlaze Processor Reference Guide" von Xilinx herauszufinden, aber da ist alles irgendwie verwirrend für mich. > ----- Ist der auch schnell genug für parallele Zugriffe? Da die Dekodierungsschritte von MicroBlazes sequentiell durchgeführt werden, fällt auch der Bedarf an parallelen Speicherzugriffen von MicroBlazes aus. > --- Findet zwischen den MicroBlazes Message Passing statt? Die einzelnen Dekodierungsschritte (Entropiedekodierung, DeZigZag, Dequantizierung, IDCT usw.) sind als Funktionen in entsprechenden MicroBlazes implementiert und bei Aufruf benötigen diese Funktionen Zeiger auf Tabellen und Bilddaten, wofür ich jetzt einen gemeinsamen Speicher brauche, und die Zeiger auf diese Speicherbereiche werden zwischen MicroBlazes unter Hilfe von NoC ausgetauscht. > Wenn es keinen RAM gibt, auf den alle MicroBlazes zugreifen können, dann > kannst du schlicht keinen Zeiger auf die Daten bauen. Genau das ist mein Problem, ich weiß jetzt einfach nicht, ob es einen gemeinsamen RAM gibt oder nicht und dafür suche ich hier Hilfe. > Wenn es einen gemeinsamen RAM gibt (oder der Speicher in einem > gemeinsamen Adressraum verteilt ist), kannst du zwar mit einem Pointer > arbeiten, aber Zugriffe auf "fremden" Speicher können deutlich langsamer > sein als Zugriffe auf "eigenen" Speicher. Es gibt von der Seite des Betreuers keine Randbedingungen oder bestimmte Anforderungen, daher kommt die Optimierung erst als nächstes in die Frage. Ich muss jetzt den Dekoder einfach laufen lassen.
Nohchi V. schrieb: >> Viel wichtiger sind die klassischen Fragen der Mikrocontrollerei: >> --- Hat jeder MicroBlaze eigenen RAM? >> ----- Können die anderen MicroBlazes darauf zugreifen? >> --- Gibt es einen gemeinsam genutzten RAM irgendwo? > > Genau diese Fragen interessieren mich jetzt und das ist der Grund, warum > ich diesen Thread geöffnet habe. Diese Fragen können wir dir aber nicht beantworten, weil die nicht vom MicroBlaze abhängen, sondern davon, wie konkret das Netzwerk implementiert ist. Da musst du den Designer des Systems fragen. >> ----- Ist der auch schnell genug für parallele Zugriffe? > > Da die Dekodierungsschritte von MicroBlazes sequentiell durchgeführt > werden, fällt auch der Bedarf an parallelen Speicherzugriffen von > MicroBlazes aus. Du hast 4 MicroBlazes, also können pro Taktzyklus bis zu 4 Speicherzugriffe auftreten, wenn die 4 MicroBlazes auf einem Speicher arbeiten und der nur einen Port hat. >> Wenn es keinen RAM gibt, auf den alle MicroBlazes zugreifen können, dann >> kannst du schlicht keinen Zeiger auf die Daten bauen. > > Genau das ist mein Problem, ich weiß jetzt einfach nicht, ob es einen > gemeinsamen RAM gibt oder nicht und dafür suche ich hier Hilfe. Frag den Designer des Systems, denn der hat das entschieden. Der muss eine Dokumentation abgeliefert haben. >> Wenn es einen gemeinsamen RAM gibt (oder der Speicher in einem >> gemeinsamen Adressraum verteilt ist), kannst du zwar mit einem Pointer >> arbeiten, aber Zugriffe auf "fremden" Speicher können deutlich langsamer >> sein als Zugriffe auf "eigenen" Speicher. > > Es gibt von der Seite des Betreuers keine Randbedingungen oder bestimmte > Anforderungen, daher kommt die Optimierung erst als nächstes in die > Frage. Ich muss jetzt den Dekoder einfach laufen lassen. Ich habe mit einer ähnlichen Architektur gearbeitet und für eine Iteration meines Algorithmus lag der Zeitunterschied zwischen "unter eine Sekunde" und "ich habe die erste Iteration nach 30 Minuten abgebrochen". Du musst dir vorher überlegen, was wo ausgeführt werden soll und wo die dazugehörigen Daten liegen müssen. Es hängt von der Systemarchitektur ab, was sinnvoll und was überhaupt möglich ist. Diese Entscheidung kannst du so ohne weiteres auch nicht ändern (viel Arbeit). Fange klein an und baue Programme, die eine Zahlenfolge (1, 4, 7, ...) von A nach B schicken und lasse sie dir von B ausgeben.
Also wenn ich das richtig verstehe. Dafür wird ein "Netzwerk on chip" mit mehreren layern eingesetzt. Wer ist denn auf den Quatsch gekommen? Das ist typischer akademischer Müll. Der Datenstrom ist nur in eine Richtung und für die Flowkontrolle ist eine einfach Busy Leitung als Handshake notwendig.
dose schrieb: > Wer ist denn auf den Quatsch gekommen? Ein universelles System ist halt kein MJPEG-Beschleuniger.
Denke mal, dass der MJPEG Decoder eher als Demo gedacht ist um zu zeigen, dass das System sowas prinzipiell kann.
Das glaube ich auch, da so ein Sinn (Softcore!) keinen Sinn macht, besonders auch, weil die Virtex-Familie einen PowerPC anbietet, der das geringfügig schneller erledigen könnte.
> Denke mal, dass der MJPEG Decoder eher als Demo gedacht ist um zu > zeigen, dass das System sowas prinzipiell kann. Genau, die mein Arbeit soll nun einfach die Anwendbarkeit in einer vorherigen Diplomarbeit implementierten NoC-Architektur zeigen.
Auweia... Mal abgesehen davon, dass der Microblaze schlecht skaliert und gleich mit einem Virtex aufgefahren werden muss, um eine Kanonen-auf-Spatz-Lösung zu schaffen, dürften sich die Probleme zunächt beim Datenfluss manifestieren. Und dabei dürfte auch die Erkenntnis gewonnen werden, dass das eine von-hinten-durch-die-Brust Idee ist (so vernichtend wie User dose wollma mal nicht sein...). Ich gehe mal davon aus, dass der clevere Diplomand die Geschichte erst in einer Multithread-Umgebung im Trockentest durchspielt und sich dann Gedanken machen muss, wie die FIFOs/Pipes zwischen den Prozessen umgesetzt werden sollen. Eigentlich braucht ab dem Punkt man für diese "Idee" kein FPGA mehr. Übrigens: Ein hart gepipelin'ter MJPEG-Accelerator passt gerade mal auf einen Spartan3e/250.
Strubi schrieb: > Übrigens: Ein hart gepipelin'ter MJPEG-Accelerator passt gerade mal auf > einen Spartan3e/250. Schon mal gebaut, nehme ich an?
Jau. Der ENcoder ist hier etwas dokumentiert: http://tech.section5.ch/news/?p=219 Beim Decoder sieht die Sache ähnlich aus, das habe ich aber nicht mehr dokumentiert (die Anzeige macht schlussendlich eh der Browser). Sollte dazu allerdings sagen, dass nur ein JPEG-Kanal (Y/UV gemuxt) in den genannten Spartan passt (deswegen 'Accelerator', der ohne externe CPU nicht auskommt). Für vollen YUV422-Durchsatz brauchts entsprechend doppelt, und für MJPEG am besten noch eine integrierte CPU für das browser-kompatible Streaming. Vielleicht sollte man für diese Übung auch mal das "M" weglassen :-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.