ist es möglich, mit dem xilinx fir ip core ein komplexes signal (amplituden + phasengang) mit einer impulsantwort zu falten? im manual ist dazu nichts zu finden. ben
ben schrieb: > welche einstellung ist zu wählen? Die Einstellung, erst mal das Problem ausführlich zu beschreiben.
ok. ich habe ein basisbandsignal (i,q), dass ich falten möchte. die impulsantwort ist reell. eine anwendung liegt nicht vor. ich möchte nun wisse, ob und wie sich der ip core einstellen lässt, um das signal zu falten. für ein reelles signal ist das kein problem. für ein komplexes schon. es ist auch im frequenzbereich umsetzbar (faltungstheorem), dass weiß ich. der vorteil vom fir ist die verzögerung, der nachteil die rechenoperationen.
ich find es nicht. für die hilbert transformierte ist ein i ausgang definiert. anders nicht. von einem i,q eingang (den möchte ich verwenden) lese ich nichts. strubi, es ist hilfreich, wenn du mich auf die richtige stelle im manual verweisen kannst.
ben schrieb: > ich habe ein basisbandsignal (i,q), dass ich falten möchte. Und das muß im FPGA passieren? Kannst Du das nicht offline auf dem PC mit einer Hochsprache Deiner Wahl machen? > eine anwendung liegt nicht vor Genau deswegen würde ich es nicht im FPGA machen... Duke
ok. meine frage zielte lediglich darauf ab, OB und mit welchen einstellungen (falls ja) es mit dem ip core möglich ist. eine hochsprache ist geeigneter, keine frage.
Für eine Faltung brauchst Du nicht notwendigerweise den (FIR-)CoreGen zu bemühen. Die Faltung selber ist ja die Filterung und daher verkommt das Ganze zu einer iterativen Multiplikation. Im Komplexen sind es eben 4 Multiplikationen mit Summierung für REAL und IMAG getrennt. Wenn der Faltungsvektor kurz genug ist, bekommst Du die sogar als full speed pipeline hin, kannst also für jeden Takt ein neues Datum eingeben und ein Faltungsergebnis generieren. Bei Radar und der Pulskompression sowie beam forming wird das so gemacht. Das geht bis etwa zu einer Menge von 6-8 Vektorelementen voll sequenziell, ab da parallel mit mehreren units. Für größere Filterbreiten läuft es bei einer unit auf eine state machine mit Akumulation hinaus, die für jedes Sample neu angestossen wird. Beim Audio kommt das häufig vor, z.B. beim Faltungs-Hall. Der war in den 90ern mal groß in Mode. Habe das selber schon realisiert: http://www.96khz.org/htm/convolutionreverb.htm Das ist eigentlich mit das Einfachste in einem FPGA. (?). Du brauchst nur ein RAM mit den Daten, eines mit dem Vektor und eine Zählschleife.
ben schrieb: > für die hilbert transformierte ist ein i ausgang > definiert. anders nicht. von einem i,q eingang (den möchte ich > verwenden) lese ich nichts Dieser konkrete FIR-Compiler ist für den (Standard-Hilbert) Use-Case gedacht: "Aus reell mach komplex". So steht es auch (implizit) auf Seite 4 des Guides. Der Nachteil dieses Vorgehens ist, dass nur der Q-Anteil mit den Filter-Koeffizienten gefaltet wird - das Ergebnis ist hinsichtlich der Signaleigenschaften nicht "symmetrisch".
Das geht nicht für alle Anwendungsfälle, weil die Transformation in den Zeitbereich nicht präzise genug möglich ist. Bei Audio ist das z.B. so. Zudem erfordert es, die Tranformation in den F-Bereich auch der Eingangsdaten. Damit geht Kontinuität verloren und / oder man braucht overlapping. Und dann ist der Vorteil weg. Die kontinuierliche Faltung in Zeitbereich ist das Einfachste und Genaueste, zumal es ja mit der Geschwindkeit reicht. Daher nimmt man ja überhaupt FPGAs :-)
einen fir filter (vier koeffizient, reell) habe ich umgesetzt. die benötigten mac operationen werden parallel ausgeführt. der xilinx fir compiler 5.0 benötigt einen dsp slice. es wird somit sequentiell gearbeitet. mit steigender anzahl an koeffizienten steigt die latenz. wie setze ich den fir filter mit einem dsp slice um? eine möglichkeit besteht darin, den clk für den mac befehl zu vervierfachen. ist für viele koeffizienten keine lösung. Generelles vorgehen?
ben schrieb: > einen fir filter (vier koeffizient, reell) habe ich umgesetzt. die > benötigten mac operationen werden parallel ausgeführt. der xilinx fir > compiler 5.0 benötigt einen dsp slice. es wird somit sequentiell > gearbeitet. mit steigender anzahl an koeffizienten steigt die latenz. > wie setze ich den fir filter mit einem dsp slice um? eine möglichkeit > besteht darin, den clk für den mac befehl zu vervierfachen. ist für > viele koeffizienten keine lösung. Generelles vorgehen? Divide et impera und die Pipeline von Hand stricken? Du kannst ja die FIR-Instanzen durch geeignetes Parallelisieren deiner Daten parallel schalten, und am Schluss ein paar Adder kaskadieren. Genügend Slices sollten doch vorliegen. Erstaunt mich bisschen, dass der Coregen-Ansatz nicht auch was parallelisiertes ausspucken kann, aber da er damals in die Ecke flog, bin ich auch nicht auf dem Stand.
ok. wie ich den filter parallelisiere ist mir klar. wie ich die eingangsdaten aufteile, um dsp slices zu sparen nicht. minimalbeispiel?
ben schrieb: > ok. wie ich den filter parallelisiere ist mir klar. wie ich die > eingangsdaten aufteile, um dsp slices zu sparen nicht. minimalbeispiel? Du sprichst in Rätseln! Einmal behauptest Du, der Compiler arbeite mit einem slice, dann willst Du aber auf einen slice reduzieren. Also muss der Compiler doch auf 4 umgesetzt haben, oder? Und dann das Sparen! Wozu? 3 DSP slices einsparen? Haben wir die nicht mehr? Du kannst doch jederzeit die Direktive benuzten, DSPs zu limitieren und in fabric zu bauen.
ben schrieb: > wie ich die > eingangsdaten aufteile, um dsp slices zu sparen nicht. Typischer Fall von RTFM! Keine Ahnung wozu Du unbedingt einen DSP-Slice einsparen willst, aber wenns unbedingt so sein soll, dann nimm "Distributed Arithmetic" - ist garantiert DSP-Slice frei - trägt halt etwas bei der Latenz auf. BTW: Den "Implementation"-Tab hast Du schon entdeckt?
danke. zusammenfassend. meine frage war, ob der xilinx fir compiler 5.0 die faltung komplexer signale unterstützt (falls ja, wo finde ich informationen dazu im manual). die frage wurde verneint. danke. meine anschließende intention. ich möchte den fir filter selber in vhdl umsetzen. zu begin habe ich die taps parallel ausgeführt. funktioniert. dann die frage, wie es sich mit weniger harwareaufwand lösen lässt (dass der xilinx fir compiler 5.0 nur einen dsp verwendet, war nur ein beispiel. ungünstig von mir ausgedrückt. entschuldigt). falls man einen fir filter mit zb. 256 koeff. (beispiel!) realisieren möchte, benötigt man bei einem parallelen ansatz 256 dsp (für komplexe eingangswerte und koeff ohne ausnutzung von symmetrien sogar 3*256 bzw. 4*256 dsp blöcke und entsprechende add.). daher suche ich nach einer möglichkeit dsp blöcke einzusparen (klar, man kann dsp blöcke mit lut einspraren). mir ist nicht klar, wie ich die eingangswerte anordne um dsp blöcke einzusparen (im extremfall nur einen dsp block zu verwenden). ich habe daher um ein minimalbeispiel gebeten. noch offen die frage. kommentar "RTFM". wenn du mir einen link zu einem manual (bzgl. serieller fir etc.) zu verfügung stellst, werde ich es durcharbeiten. hoffe, dass ich nicht mehr in rätseln spreche. danke.
Naja die Frage ist halt wie schnell die Daten reinkommen. Also ob du die Pipeline weglassen kannst und das seriell funktioniert. In meinem FIR Block brauche ich so viele MACs wie Koeffizienten. Also Beispiel jetzt mal n Stück. Dafür funktioniert es wenn in jedem Takt ein neuer Samplewert vom ADC rein kommt. Wenn ich jetzt statt n MAC nur noch 1 MAC haben will, muss ich das seriell hinschreiben und brauche jetzt n Takte, kann also nur alle n Takte einen neuen Samplewert verarbeiten. Am Ende muss man eben gucken was die Aufgabenstellung und Hardware zulässt und was die Ziele sind.
So ist es. Leider sind die meisten Entwickler heute aus mir nicht erklärlichen Gründen kaum noch in der Lage, Anforderungen zu verstehen, zu formulieren und umszusetzen: Beitrag "Welcher DSP für Realtimesignalverarbeitung bei 2 MHz Abtastrate" Da wird einfach schnell was aufgesetzt, ein Core aufgerufen und dann drauf los designed. Uns hat man beigebracht, erst mal ein Zeitdiagramm anzufertigen, dann sich zu überlegen, welche Datenraten und welcher Durchsatz entsteht. Dann weiss man auch was man nehmen kann. Ob es eine echte hardware sein muss, oder ob es in Software geht und wie. Wenn ich mir z.B. allein diesen Strang ansehe, dann habe ich keinen blassen Schimmer, warum hier ein FIR-Compiler benötigt wird.
Na der FIR-Compiler wird verwendet weil er da ist. Der kann bestimmt auch coole Sachen, also sowas wie Koeffizienten mit Matlab berechnen, ... Weil mir Matlab zu teuer ist verwende ich https://github.com/chipmuenk/pyFDA Ja, kann weniger aber ist frei. Mittlerweile kann das glaube ich sogar HDL schreiben.
Moin, Bei zu teuerem Matlab nehm' ich gerne GNU Octave her; das ist auch frei und mit dem "Signal" Package gibts da schon auch das ein oder andere sinnvolle Tool zum Filterbasteln. Um die Verwirrung weiter zu steigern: Wenn die Impulsantwort des Filters nur reell ist, und's die Taktfrequenz hergibt, kann man auch die I und Q Komponenten einfach immer hintereinander in ein Filter reintakten, das dann nur mit ein paar Nullen gestreckt werden muss. Wenn das Originalfilter die Koeffizienten [a b c d e] hat, dann sieht das Modifizierte so aus: [a 0 b 0 c 0 d 0 e] So kommen sich die I und Q Komponenten nicht ins Gehege und nach dem Filter kann man sie auch wieder leicht "auseinandernehmen". Gruss WK
> Weil mir Matlab zu teuer ist verwende ich > https://github.com/chipmuenk/pyFDA > Ja, kann weniger aber ist frei. Mittlerweile kann das glaube ich sogar > HDL schreiben. Was tut das tool? Die Koeffizienten bestimmen? Das gibt es schon wie Sand am Meer. Gustl B. schrieb: > Na der FIR-Compiler wird verwendet weil er da ist. Man sollte mitnichten tools verwenden, nur "weil sie da sind", sondern sich Gedanken machen, ob es an dieser Stelle nutzbringend ist. Ich verstehe ehrlich gesagt, noch immer nicht, wieso hier ausgerechnet ein FIR-Filter zu Einsatz kommen soll.
Weltbester FPGA-Pongo schrieb im Beitrag #4784841: > Ich verstehe ehrlich gesagt, noch immer nicht, wieso hier ausgerechnet > ein FIR-Filter zu Einsatz kommen soll. Ich auch nicht und ich bin hier auch nicht der der den FIR-Compiler verwendet. Weltbester FPGA-Pongo schrieb im Beitrag #4784841: > Was tut das tool? Die Koeffizienten bestimmen? Das gibt es schon wie > Sand am Meer. Ja, genau. Aber ich finde es eben praktisch.
Dergute W. schrieb: > Wenn die Impulsantwort des Filters nur reell ist > hergibt, kann man auch die I und Q Komponenten einfach immer > hintereinander in ein Filter reintakten, das dann nur mit ein paar > Nullen gestreckt werden muss. Ich denke, das ist wohl eher der seltenere Fall und hier besonders scheint mir das nicht die Lösung. Ich sehe auch generell nicht den Vorteil der erhöhten Taktfrequenz, weil besonders in FPGAs das sehr viel "teuer" ist, als eine Parallelisierung. Außerdem sind die DSP-Elemente der dickeren FPGAs durchaus auf komplexe Rechung mit IQ designed, weil das bei fast jeder SV-APP auftritt. Gustl B. schrieb: > Na der FIR-Compiler wird verwendet weil er da ist. Der kann bestimmt > auch coole Sachen, also sowas wie Koeffizienten mit Matlab berechnen, Die Koeffizienten kann man auch ohne solche Tools erzeugen. Ich mache das mit Excel. Da steckt die Limitierung und Optimierung auf die digitale Auflösung mit drin, die MATLAB automatisch nicht leistet. Bei dieser Anwendung hier, braucht es auch nicht mal ein Filterdesign, da der Faltungsvektor ja von Aussen kommt und vorgegeben wird, wenn ich den TE richtig verstehe. Für mich bleibt das hier bei zwei "lumpigen" Multipliern, bzw bei 4, wenn es komplexes Signal reinkommt.
Moin, Jürgen S. schrieb: > Ich denke, das ist wohl eher der seltenere Fall und hier besonders > scheint mir das nicht die Lösung. Ich sehe auch generell nicht den > Vorteil der erhöhten Taktfrequenz, weil besonders in FPGAs das sehr viel > "teuer" ist, als eine Parallelisierung. Daher schrub ich auch nicht: "Hier praesentiere ich die einzig und alleineseeligmachende Implementierung", sondern ich schreibte: > Um die Verwirrung weiter zu steigern Ob's sinnvoll ist, haengt natuerlich massgeblich von den dafuer noch vorgesehenen Ressourcen im FPGA und vom Takt und nicht zuletzt von der nicht vorliegenden Anwendung ab. ;-) Gruss WK
Angehängte Dateien:
{kind=link}
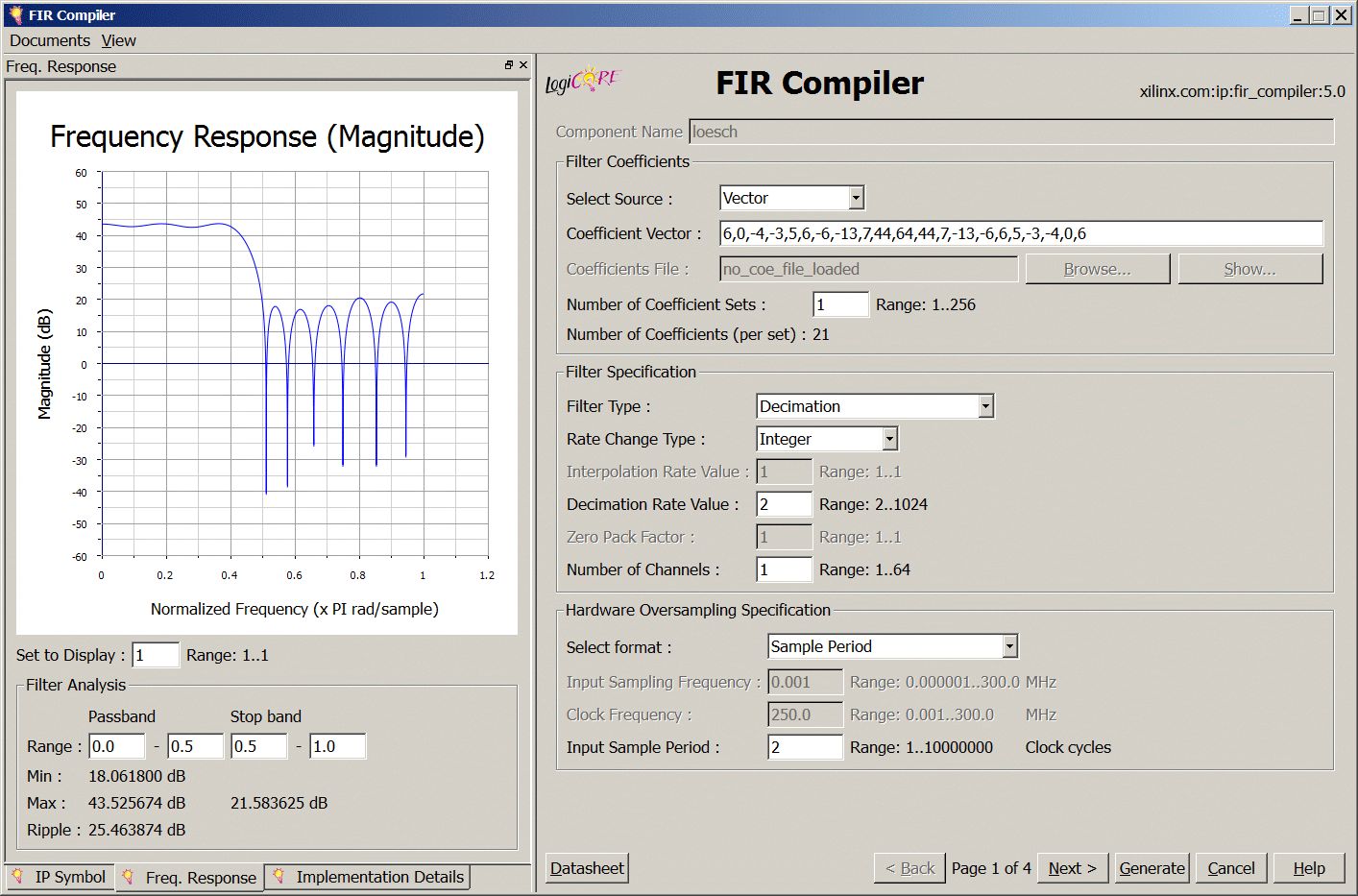
Ich möchte mich in den Schlagabtausch der Signalverarbeitungsprofis hier nicht einmischen, stelle aber doch zur Diskussion, wo überhaupt die Möglichkeit besteht, die Faltungsfunktion in den Core einzubringen? Ich sehe nur die Möglichkeit mit mehreren Koeffizientensätzen zu arbeiten, um die Funktion anzupassen. Dann: Wie rechnet der komplex? WEKA's Lösung scheint mir da doch recht interessant zu sein. Welchen Vorteil hätte die komplexe Rechnung? Ich kenne es so, dass damit die Phase ignoriert werden kann, bzw sie keinen Einfluss auf das Ergebnis hat. Wäre das im vorliegenden Fall überhaupt erwünscht? Die Phase soll ja sicher berücksichtigt werden bei der Faltung, oder? > schrub > schreibte Neue Rechtschreibung? :-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.