Hallo Leute,
Ich möchte eine CRC berechnen von einem 64 bit datenstrom. Da aber nicht
immer alle bits gültig sind, möchte ich das in meiner crc berechnung
berücksichtigen. Hier mein Code:
In meiner For schleife habe ich eine Bedingung eingebaut. Mit einem
zusätzlichem Parameter "valid_bits" sollen nur über diesen bereich die
CRC berechnet werden. Falls valid_bits z.b. auf 31 steht, soll auch nur
über die ersten 32 bit die crc berechnet werden.
Das Problem ist, dass ich wenn ich das synthetisiere, immer Timing
Verletzungen bekomme...
Er kommt mit der Bedinung in der for schleife nicht klar. Ich bekomme
eine zulange kombinatorische Kette.
Kann mir jemand sagen wie ich das anders lösen kann?
Danke vielmals
mfg
Paul
So schlimm ist's nun auch wieder nicht.
Ich hab' das gerade mal ins Quartus gesteckt und das ist der Meinung,
450 MHz (Cyclone III) wären kein Problem (solange man die nicht auf die
Pins schickt).
Wie schnell soll das Ding denn auf was laufen?
Markus F. schrieb:> Muss die CRC-Summe unbedingt in einem Takt fertig werden?
Ja die muss leider in einem Takt fertig werden.
Meine einzige idee ist es jetzt, für alle möglichen Fälle eine Funktion
zu bauen.
z.b. so:
Markus F. schrieb:> So schlimm ist's nun auch wieder nicht.>> Ich hab' das gerade mal ins Quartus gesteckt und das ist der Meinung,> 450 MHz (Cyclone III) wären kein Problem (solange man die nicht auf die> Pins schickt).>> Wie schnell soll das Ding denn auf was laufen?
mit 200 Mhz
Wenn der Datenstrom seriell ist, dann gehe ich davon aus, dass du ihn
seriell im FPGA empfängst.
Warum rechnest du die CRC nicht einfach während des Empfangs?
Das sehe ich wie Schlumpf. Einfach beim Empfang schon rechnen.
Aber mal was anderes:
Ich würde Dir raten, Paul, Dir mal eine konkrete Schaltung zu skizzieren
und die zu beschreiben.
Du machst es im Augenblick umgekehrt und bist offenbar überrascht, was
dabei herauskommt. Vermutlich, weil Du in gewisser Weise, ein Programm
schreibst, und nicht eine Schaltung beschreibst.
Konkreter, weil Dir nicht klar ist, was Du mit einer for-Schleife für
eine Schaltung beschreibst.
Die Antwort ist: Eine Kette von Operationen deren Durchlaufzeit
natürlich proportional zu der Länge dieser Kette ist.
Es ist natürlich (oft) möglich, äquivalente flache Strukturen zu
beschreiben - aber nur relativ flache, weil im FPGA nur eine begrenzte
Anzahl von Bits tatsächlich auf einmal verknüpft werden können. Siehe
mal in der Doku nach, wie viele Inputs eine LUT in Deinem FPGA hat. Oder
wie viele Addressen ein evtl. vorhandener Speicher.
Dazu kommt, dass die (mir bekannte) Synthesesoftware bei relativ großen
Strukturen, gar nicht mehr versucht, logisch äquivalente, aber flachere
Strukturen zu erzeugen, wenn Timing-Constraints nicht eingehalten
werden. Du kannst also nicht einfach irgendeine Struktur beschreiben,
und erwarten, dass die SW sämtliche logisch äquivalenten Möglichkeiten
durchrechnet. Um das Timing einzuhalten, wird nur die von Dir
vorgegebene Struktur in Varianten auf die im FPGA vorhanden Pfade
verteilt, so das es passt - und das geht eben nicht immer.
Theor schrieb:> Das sehe ich wie Schlumpf. Einfach beim Empfang schon rechnen.>> Aber mal was anderes:> Ich würde Dir raten, Paul, Dir mal eine konkrete Schaltung zu skizzieren> und die zu beschreiben.> Du machst es im Augenblick umgekehrt und bist offenbar überrascht, was> dabei herauskommt. Vermutlich, weil Du in gewisser Weise, ein Programm> schreibst, und nicht eine Schaltung beschreibst.> Konkreter, weil Dir nicht klar ist, was Du mit einer for-Schleife für> eine Schaltung beschreibst.>> Die Antwort ist: Eine Kette von Operationen deren Durchlaufzeit> natürlich proportional zu der Länge dieser Kette ist.>> Es ist natürlich (oft) möglich, äquivalente flache Strukturen zu> beschreiben - aber nur relativ flache, weil im FPGA nur eine begrenzte> Anzahl von Bits tatsächlich auf einmal verknüpft werden können. Siehe> mal in der Doku nach, wie viele Inputs eine LUT in Deinem FPGA hat. Oder> wie viele Addressen ein evtl. vorhandener Speicher.>> Dazu kommt, dass die (mir bekannte) Synthesesoftware bei relativ großen> Strukturen, gar nicht mehr versucht, logisch äquivalente, aber flachere> Strukturen zu erzeugen, wenn Timing-Constraints nicht eingehalten> werden. Du kannst also nicht einfach irgendeine Struktur beschreiben,> und erwarten, dass die SW sämtliche logisch äquivalenten Möglichkeiten> durchrechnet. Um das Timing einzuhalten, wird nur die von Dir> vorgegebene Struktur in Varianten auf die im FPGA vorhanden Pfade> verteilt, so das es passt - und das geht eben nicht immer.
Danke für die Hilfe. Der Eingang ist zwar Seriell (LVDS) aber dieser
geht direkt zu einem IP. Von diesem bekomme ich dann die Daten in 64 Bit
packeten. Diese sind aber nicht immer vollständig gültig.
Ich habe zusätzlich einen 8 bit vektor der mir markiert welche bytes
gültig sind.
Und ich darf natürlich nur über die gültigen bytes den crc rechnen.
Das ganze erstmal mit einer Schaltung zu realisieren wäre hier doch sehr
aufwendig.
Wenn ich das so mache wie oben beschrieben, sprich für jeden typ eine
eigene Funktion, klappt das mit dem timing. Aber wie gesagt, ist das
keine schöne Lösung.
Danke
mfg
Paul
Paul schrieb:> Das ganze erstmal mit einer Schaltung zu realisieren wäre hier doch sehr> aufwendig.
Du realisierst das aber in einer Schaltung. Denn dein FPGA kennt nur
Schaltungen und in VHDL beschreibst du das Verhalten einer Schaltung,
die dann der Synthesizer "baut".
Genau deswegen auch meine Frage:
Schlumpf schrieb:> Ist dir bewusst, was der Synthesizer aus einer For-Schleife baut?> Schau es dir mal im RTL an :-)
Die Logiktiefe wird eben recht groß, wenn du 64 Bit auf einmal
berechnest.
Kommt dann noch die Lgik für Verknüpfung mit "valid_bits" hinzu, wird
die Logiktiefe noch größer.
Die Information, welche Bits du in die Betrachtung einbeziehen musst,
kommt vermutlich auch aus dem IP-Core nachdem die Daten bereits
empfangen sind.
Damit ist das serielle Berechnen direkt am Eingangsstrom so nicht
möglich.
Du könntest aber folgendes überlegen:
Zapfe den Datenstrom an und errechne die CRC während des Empfangs.
Und bei allen möglichen Bitbreiten, die in Frage kommen könnten, ziehst
du eine Kopie des Ergebnis.
Damit liegen dir nach Empfang des Datenpaketes die CRCs für alle
möglichen größen vor und du musst dir nur die Korrekte raus fischen.
Die Logiktiefe wäre hier extrem gering.
Andere Option:
Du sagst, es muss innrerhalb eines Taktes errechnet sein.
Warum ist das so? Würde es stören, wenn du z.B. 8 Takte Latenz hättest
und einfach dein Datenpakt auch um 8 Bit verzögerst, bevor du es weiter
gibst?
Dann sind Daten und CRC im korrekten zeitlichen Bezug zueinander, aber
halt insgesamt um 8 Takte verzögert.
Wenn ich das richtig überschaue, dann wird die CRC Checksumme aus einem
1bit breiten seriellen Datenstrom errechnet und dieser dann entsprechend
in einer Schleife mit 64 Iterationen zu einem 64bit breiten Strom
parallelisiert.
Lösung 1: Du nimmst eine 64x höhere Clock und verwendest statt einer
Schleife einen Prozess der nach 64 Taktzyklen deine 64 bit breite
Checksumme liefert.
Lösung 2: Du berechnest die Checksumme gleich parallel. Ich greife gerne
auf folgendes online Tool zurück
http://outputlogic.com/?page_id=321
Das ist ziemlich geschmeidig, einfach Datenbreite und Generator-Polynom
angeben, "Generate VHDL" klicken und fertig.
Ein Buch was ich zu dem Thema empfehlen kann ist "Scrambling Techniques
for Digital Transmission" von Gi Lee Byeong und Chang Kim Seok. Der
Stoff setzt zwar mindestens ein Mathematik Grundstudium voraus, ist aber
fachlich unschlagbar. Es wird zwar die Theorie von Daten Scrambling
beschrieben, jedoch lässt sich ein Großteil des Inhalts auch auf CRC
anwenden. Die Mathematik dahinter ist sehr ähnlich.
Tobias B. schrieb:> dieser dann entsprechend> in einer Schleife mit 64 Iterationen zu einem 64bit breiten Strom> parallelisiert.
Nein, das Datum liegt als 64 Bit breites paralleles Konstrukt vor...
Tobias B. schrieb:> Lösung 2: Du berechnest die Checksumme gleich parallel.
Genau das tut er ja und die Logiktiefe ist deshalb so groß, dass er es
nicht mehr in einem Takt schafft.
Zumindest habe ich das so verstanden
Paul schrieb:> Ich habe zusätzlich einen 8 bit vektor der mir markiert welche bytes> gültig sind.
Und auf diese Bemerkung sollte besonders achten.
Im Code wird das VALID-Bit für jeden CRC-Schritt
abgefragt, nicht für jeden 8ten. Was ist jetzt richtig?
Ansatz für jeden 8ten: Je Länge eine Schaltung, aus deren
Ergebnisse werden dann per MUX die gewünschte Lösung
ausgewählt. Das ergibt aber nich immer eine gewisse
Tiefe. Schaut man sich aber einen CRC-Schritt an bzw.
wendet mehrere Schritte an, dann entdeckt man bestimmt
eine Vereinfachung.
Und zum Oben erwähnten "Seriellen Ansatz", der parallel
zur IP eine Auswertung machen soll: Ist es nicht möglich,
den Datenstrom vorher abzugreifen und ach festzustellen,
wann ein Datenpacket von 64 Bits beginnt und endet?
ist crc_iteration rückgekoppelt in die Funktion calc_serial_crc16. Die
Ausgabe ist zwar parallel, die Berechnung an sich bildet jedoch die
Rechnvorschrift ab, wie bei einer seriellen CRC Ermittlung.
Richtig parallel wäre etwas in der Form:
Die 16 crc16 Funktionen bestehen aus einfachen xor Verknüpfungen
zwischen crc_iteration und data, abhängig vom entsprechenden
Generatorpolynom. Genau diese 16 crc16 Funktionen zu bestimmen ist nun
die Kunst. Ich mache es mir immer einfach und verwende das online Tool
auf http://outputlogic.com/?page_id=321
Wenn das Synthese Tool natürlich gut genug ist, dann bricht es die
serielle Rechnung runter und es kommt das gleiche Ergebnis raus.
Btw: Auch die parallel Berechung ist bei 64 bit Daten noch ziemlich
dick.
Tobias B. schrieb:> ist crc_iteration rückgekoppelt in die Funktion calc_serial_crc16. Die> Ausgabe ist zwar parallel, die Berechnung an sich bildet jedoch die> Rechnvorschrift ab, wie bei einer seriellen CRC Ermittlung.
Ich sehe hier keinen Takt.
Daher IST das parallel.
Ein Schleifenkonstrukt in VHDL ist in keinster Weise seriell.
Tobias B. schrieb:> Wenn das Synthese Tool natürlich gut genug ist, dann bricht es die> serielle Rechnung runter und es kommt das gleiche Ergebnis raus.
Dem Synthesizer bleibt gar nichts anderes übrig, als ein paralleles
Konstrukt daraus zu bilden, das die gleiche kombinatorische Funktion
ergibt wie mit dem Schleifenkonstrukt beschrieben wird.
Aber niemals kann er daraus etwas Serielles bauen.
Schlumpf schrieb:> Ein Schleifenkonstrukt in VHDL ist in keinster Weise seriell.
Das habe ich auch in keinster Weise geschrieben. Die Art der Berechnung
ist seriell, siehe seine CRC Funktion, welche genau ein Datenbit möchte.
Und diese Operation wird 64 mal in einer Schleife ausgeführt. Das ist
nichts anderes als eine serielle Berechnung und anstatt diese zu Takten
(wodurch es seriell in deinem Sinne wird), packt er halt das ganze in
eine Schleife, was eine elendslange Kette von XOR Verknüpfungen ergibt.
Und wie bereits geschrieben, wenn das Synthese Tool ordentlich
optimiert, kommt das gleiche raus, wie in meinem Ansatz, dass man direkt
eine parallel arbeitende CRC Funktion verwendet. Natürlich nur unter der
Prämisse, dass das Synthese Tool gute Arbeit leistet. Das möchte ich
nicht kommentieren.
Ich habe entsprechende Literaturangaben weiter oben gemacht, kann nur
empfehlen da mal rein zu schauen.
Tobias B. schrieb:> Die Art der Berechnung> ist seriell
Aha... und was ist eine "Art der Berechnung"? Wer berechnet das? der
Synthesitzer? Das FPGA rechnet garantiert nichts seriell...
Tobias B. schrieb:> Und diese Operation wird 64 mal in einer Schleife ausgeführt.
Ne, der Synthesizer instanziiert die Anweisung in der Schleife 64 mal
und baut sie als riesen paralleles Konstrukt zusammen.
Tobias B. schrieb:> was eine elendslange Kette von XOR Verknüpfungen ergibt
richtig
Tobias B. schrieb:> Natürlich nur unter der> Prämisse, dass das Synthese Tool gute Arbeit leistet
Die Loop Anweisung ist eine Anweisung an den Synthesizer, das, was
innerhalt der Loop steht, n mal zu instanziieren und entsprechend zu
verknüpfen. Das hat nichts mit "gute Arbeit" oder "ordentlich
optimierten Tools" zu tun.
Schlumpf schrieb:> Tobias B. schrieb:>> Die Art der Berechnung>> ist seriell>> Aha... und was ist eine "Art der Berechnung"? Wer berechnet das? der> Synthesitzer? Das FPGA rechnet garantiert nichts seriell...
Die "Art der Rechnng" ist die Mathematik dahinter. Und die ist erstmal
so formuliert, dass seriell berechnet wird, siehe die CRC Funktion,
welche genau ein Datenbit möchte. Interessant wie man aus der eigenen
Unwissenheit heraus, jemanden falsche Behauptungen unterstellt. Ganz
mieser Stil.
> Tobias B. schrieb:>> Und diese Operation wird 64 mal in einer Schleife ausgeführt.>> Ne, der Synthesizer instanziiert die Anweisung in der Schleife 64 mal> und baut sie als riesen paralleles Konstrukt zusammen.
Richtig, mir ist bewusst was das Synthesewerkzeug aus einem
Schleifenkonstrukt erzeugt.
> Tobias B. schrieb:>> was eine elendslange Kette von XOR Verknüpfungen ergibt>> richtig
Gut
> Tobias B. schrieb:>> Natürlich nur unter der>> Prämisse, dass das Synthese Tool gute Arbeit leistet>> Die Loop Anweisung ist eine Anweisung an den Synthesizer, das, was> innerhalt der Loop steht, n mal zu instanziieren und entsprechend zu> verknüpfen. Das hat nichts mit "gute Arbeit" oder "ordentlich> optimierten Tools" zu tun.
Wenn es ordentlich arbeitet, dann optimiert es diese elendlange Logik
von Xor Verknüpfungen soweit runter, als würde man von Beginn an die
optimale Berechnung mit einem parallelen Ansatz durchführen. Und ob das
gegeben ist, möchte ich nicht beurteilen, das kann sein, muss aber
nicht. Da hilft nur beides mal zu implementieren und das Result der
Synthese zu begutachten.
Schlumpf schrieb:> Die Information, welche Bits du in die Betrachtung einbeziehen musst,> kommt vermutlich auch aus dem IP-Core nachdem die Daten bereits> empfangen sind.> Damit ist das serielle Berechnen direkt am Eingangsstrom so nicht> möglich.
Ja genau
> Du könntest aber folgendes überlegen:> Zapfe den Datenstrom an und errechne die CRC während des Empfangs.> Und bei allen möglichen Bitbreiten, die in Frage kommen könnten, ziehst> du eine Kopie des Ergebnis.> Damit liegen dir nach Empfang des Datenpaketes die CRCs für alle> möglichen größen vor und du musst dir nur die Korrekte raus fischen.
Klingt interessant. Werde ich mal probieren, Danke
> Die Logiktiefe wäre hier extrem gering.>> Andere Option:> Du sagst, es muss innrerhalb eines Taktes errechnet sein.> Warum ist das so? Würde es stören, wenn du z.B. 8 Takte Latenz hättest> und einfach dein Datenpakt auch um 8 Bit verzögerst, bevor du es weiter> gibst?>> Dann sind Daten und CRC im korrekten zeitlichen Bezug zueinander, aber> halt insgesamt um 8 Takte verzögert.
Ja das stimmt. Wahrscheinlich wäre es gar nich so schlimm wenn man das
ganze um ein paar takte verzögert....
Sigi schrieb:> Paul schrieb:>> Ich habe zusätzlich einen 8 bit vektor der mir markiert welche bytes>> gültig sind.>> Und auf diese Bemerkung sollte besonders achten.> Im Code wird das VALID-Bit für jeden CRC-Schritt> abgefragt, nicht für jeden 8ten. Was ist jetzt richtig?>> Ansatz für jeden 8ten: Je Länge eine Schaltung, aus deren> Ergebnisse werden dann per MUX die gewünschte Lösung> ausgewählt. Das ergibt aber nich immer eine gewisse> Tiefe. Schaut man sich aber einen CRC-Schritt an bzw.> wendet mehrere Schritte an, dann entdeckt man bestimmt> eine Vereinfachung.>> Und zum Oben erwähnten "Seriellen Ansatz", der parallel> zur IP eine Auswertung machen soll: Ist es nicht möglich,> den Datenstrom vorher abzugreifen und ach festzustellen,> wann ein Datenpacket von 64 Bits beginnt und endet?
Ich rechne einfach nur die gültigen Bytes in Bits um. Das ist alles.
Damit ich jedes bit eizeln in der Schleife prüfen kann.
Dein erster Ansatz klingt interessant. Werde mir mal dazu Gedanken
machen. Danke
Die Daten vor dem IP abzugreifen stelle ich mir schwierig vor. Das
Problem ist auch noch das ich nur die CRC über die Payload rechnen will.
Das heisst ich müsste den Header beim Eingang vom IP erkennen und
verwerfen.
Zum Thema "serielle Verarbeitung".
Da war ich auch der Meinung, dass ich sowieso alles parallel rechne.
Danke
Paul
Tobias B. schrieb:> Interessant wie man aus der eigenen> Unwissenheit heraus, jemanden falsche Behauptungen unterstellt. Ganz> mieser Stil.
Unwissenheit und ganz mieser Stil ist es eher, wenn man behauptet, eine
Lösung zu haben, und dabei nicht kapiert, dass das gar keine Lösung ist,
sondern das IDENTISCHE "Problemkonstrukt" beschreibt, dafür aber nur
eine andere Beschreibungsform wählt.
Tobias B. schrieb:> Lösung 2: Du berechnest die Checksumme gleich parallel. Ich greife gerne> auf folgendes online Tool zurück
Das, was du als Lösung vorschlägst, ist keine Lösung. Denn beide
Lösungen sind parallel und führen zu einer großen Logiktiefe, die
wiederum hier das Timing Problem hervorruft.
Tobias B. schrieb:> Wenn es ordentlich arbeitet, dann optimiert es diese elendlange Logik> von Xor Verknüpfungen soweit runter, als würde man von Beginn an die> optimale Berechnung mit einem parallelen Ansatz durchführen.
Ok, da stimme ich dir zu. Es könnte eventuell sein, dass das parallele
Konstrukt, welches aus einer seriellen Darstellungsform generiert wird,
nicht so weit vom Synthesizer optimiert werden kann, als wenn man ihm
gleich das (manuell) optimierte parallele Konstrukt beschreibt.
Tobias B. schrieb:> Und die ist erstmal> so formuliert, dass seriell berechnet wird
Eine Behauptung aus Unwissenheit heraus, so wie du es mir ja auch
unterstellst, was ich übrigens auch einen ganz miesen Stil finde.
Ich bleibe dabei! Hier berechnet niemand irgendwas irgendwie seriell!
Weder der Synthesizer noch sonst irgendjemand.
Es ist nur die Darstellungsform, wie du es in den Rechner klimperst
und dem Synthesizer mitteilst, welche Funktionalität du gerne haben
möchtest.
Tobias B. schrieb:> als würde man von Beginn an die> optimale Berechnung mit einem parallelen Ansatz durchführen.
Na ja, was soll ich sagen... du berechnest die CRC nicht.
du beschreibst eine Schaltung, die eine CRC berechnen kann.
Ob du diese Schaltung als in einer seriellen Darstellungsform
beschreibst, oder in einer parallelen Darstellungsform ist dir
überlassen.
BERECHNEN tut dann die Schaltung, die du beschrieben hast.
Mal ein vereinfachtes Beispiel:
1
ENTITYtestIS
2
PORT(
3
x:INstd_logic_vector(7downto0);
4
y:INstd_logic_vector(7downto0);
5
z:OUTstd_logic_vector(7downto0)
6
);
7
ENDtest;
Hier die serielle Darstellung der identischen Anweisung:
1
ARCHITECTUREseriellOFtestIS
2
BEGIN
3
process(x,y)
4
variablei:integerrange0to7:=0;
5
begin
6
foriin0to7loop
7
z(i)<=x(i)andy(i);
8
endloop;
9
endprocess;
10
ENDseriell;
Hier lautet die Anweisung:
Baue ein UND mit Vektor X Bit 0 und Vektor Y Bit 0 als Eingang
Baue noch ein UND mit Vektor X Bit 1 und Vektor Y Bit 1 als Eingang
Baue noch ein UND mit Vektor X Bit 2 und Vektor Y Bit 2 als Eingang
Du gibst dem Synthesizer also "seriell" die Anweisung, ein paralelles
Konstrukt aufzubauen, mit dessen Hilfe im FPGA zwei Vektoren bitweise
verUNDed werden können.
Paul schrieb:>> Dann sind Daten und CRC im korrekten zeitlichen Bezug zueinander, aber>> halt insgesamt um 8 Takte verzögert.>> Ja das stimmt. Wahrscheinlich wäre es gar nich so schlimm wenn man das> ganze um ein paar takte verzögert....
Dann könntest du es so aufbauen, dass du eine kleine FSM schreibst, mit
der du dir 8 Bit weise die Daten aus dem Vektor holst und dann mit einer
überschaubaren Logiktiefe die CRC ermittelst.
Oder du baust ein vollständig paralleles Konstrukt auf und arbeitest mit
pipelining und/oder multicycle-constraints
Schlumpf schrieb:> Unwissenheit und ganz mieser Stil ist es eher, wenn man behauptet, eine> Lösung zu haben, und dabei nicht kapiert, dass das gar keine Lösung ist,> sondern das IDENTISCHE "Problemkonstrukt" beschreibt, dafür aber nur> eine andere Beschreibungsform wählt.
Also ein letzter Versuch, dann ist es mir auch egal.
Beispiel: CRC mit 4 bit Datenbreite und Generatopolynom x^4 + x^3 + 1
(ob das ein sinnvolles Polynom ist? - keine Ahnung)
Passende parallele mathematische Verknüpfung:
Wenn ich eine serielle Funktion aufbaue (die passenden f0 bis f3 habe
ich für das Beispiel nicht zur Hand), dann bekomme ich etwas in der Form
(D ist 1 bit breit)
1
crc(0):=f0(crc,D);
2
crc(1):=f1(crc,D);
3
crc(2):=f2(crc,D);
4
crc(3):=f3(crc,D);
Das in einer Schleife von 0 bis 3 ergibt etwas in der Form
Sollte dieses Konstrukt nun durch das Synthesetool nicht auf die obige
Form reduzieren, dann hast du nunmal eine Logik die trotz des gleichen
Resultates einen deutlich erhöhten Logikaufwand benötigt.
In diesem Beispiel
1
x<=yandy;
2
x<=y;
sind die beiden x auch erst nach Optimierung identische Lösungen. Ohne
optimierung braucht die erste Anweisung eine LUT mit 2 Eingängen,
während die zweite Anweisung ohne LUT auskommt. Und ob das fette 64 bit
CRC Konstrukt vernünftig optimiert wird, wage ich zu bezweifeln, nicht
mehr und nicht weniger habe ich behauptet.
Ich verstehe nicht was daran so schwierig ist und wie man sich an dem
Wort seriell aufgeilen kann, obwohl das hier streng im mathematischen
Sinne ausgelegt wird.
Schlumpf schrieb:> Ich bleibe dabei! Hier berechnet niemand irgendwas irgendwie seriell!> Weder der Synthesizer noch sonst irgendjemand.> Es ist nur die Darstellungsform, wie du es in den Rechner klimperst> und dem Synthesizer mitteilst, welche Funktionalität du gerne haben> möchtest.
Wenn ich von einem digitalen System erwarte, die Funktion f(x) = x²/x
anzuwenden, dann ist das nicht identisch zur Anwendung von f(x) = x.
Erst wenn das System so smart ist zu erkennen, dass x²/x auf x reduziert
werden kann, sind beide Lösungen identisch. Genau das gleiche gilt für
das Synthesetool.
Aber ich vermute ich verstehe dein Problem: Du behauptest dass zwei
unterschiedliche Darstellungen zur selben Lösung, auch eine dientische
Implementierung zur Folge haben. Das ist im Allgemeinen einfach nur
korrekt. Und dein Schleifen Beispiel ist auch korrekt wie du es
formuliert hast, hat aber nicht im geringsten etwas mit dem CRC Fall zu
tun. Du versteifst dich viel zu sehr auf die Schleife an sich. Der
Knackpunkt sind aber die einzelnen Operanden in der CRC Funktion. Lese
am besten mal ein vernünftiges Buch zum Thema.
Ich habe ja gesagt, dass es möglich ist, dass die Logiktiefe
unterschiedlich sein kann, je nachdem, ob es als Loop beschrieben wird
oder die Kombinatorik manuell optimiert parallel codiert wird.
Ich behaupte sogar mittlerweile, dass wir vom gleichen reden, aber die
Begriffe 'seriell' und 'parallel' anders benutzen.
Ich wollte zum Ausdruck bringen, dass beide Darstellungen zu einer
parallelen Struktur großer Logiktiefe führen. Egal, ob du es seriell
oder parallel beschreibst.
Und daher die von dir genannte Lösung wieder eine parallele Struktur
großer Tiefe erzeugt. Die eventuell etwas kleiner sein könnte, als die
Beschreibung über das Schleifenkonstrukt.
Dieser Unterschied könnte natürlich im konkreten Fall das Zünglein an
der Waage sein.
Aber dann portierst du das Design auf ein FPGA mit weniger inputs an den
LUTs und schon ist wieder Essig.
Unter einem guten Design verstehe ich jedenfalls auch, dass nicht alles
auf Kante genäht ist.
Denn sowas holt einen irgendwann ein. Daher sollte eine gescheite Lösung
her. Und ich denke, du gibst mir recht, dass ein voll paralleler 64 Bit
CRC-Kalkulator immer ein fettes Teil ist, was man vermeiden sollte,
wenn es irgendwie geht. Man quält damit PaR unnötig.
Mich hat im Wesentlichen gestört, dass du Begriffe wie serielle
Berechnung verwendet hast, oder gesagt hast, dass das Datum als ein
Bitstrom mit 1 Bit breite ankommt und in der Funktion verarbeitet wird.
Das stimmt einfach nicht. Und das weißt du auch. Es wird lediglich eine
Beschreibung verwendet, die so tut, als wäre es so. Im FPGA ist es aber
nicht so.
Das ist genau der Punkt, wo ständig Leute drüber stolpern, vorallem,
wenn sie aus der Software Ecke kommen. Darum reite ich da auch so
penibel drauf rum, dass das korrekt formuliert wird.
Ich gehe davon aus, dass du letztendlich genau das gleiche Bild im Kopf
hast, wie ich. Es aber vielleicht ein wenig unpräzise formuliert hast,
was eventuell für Verwirrung sorgen könnte.
Zu deinem Vorschlag wegen eines Buches.. Man lernt natürlich nie aus,
aber die Grundlagen habe ich in 20 Jahren Berufserfahrung verstanden
(behaupte ich zumindest mal).
Peace
Schlumpf schrieb:> Ich habe ja gesagt, dass es möglich ist, dass die Logiktiefe> unterschiedlich sein kann, je nachdem, ob es als Loop beschrieben wird> oder die Kombinatorik manuell optimiert parallel codiert wird.>> Ich behaupte sogar mittlerweile, dass wir vom gleichen reden, aber die> Begriffe 'seriell' und 'parallel' anders benutzen.
Davon bin ich auch überzeugt. Meine Interpretation in diesem
Zusammenhang ist einfach: Die serielle Operation wird N mal auf ein Bit
angewandt, die parallele Operation wird einmal auf N Bits angewandt. Was
das Tool daraus macht ist hinterher alles parallel, nur die
mathematische Grundoepration halt nicht. Diese Terminologie wird auch in
dem von mir zitierten Buch verwendet und in dem gibt es keine Zeile
Code, keine Schaltung, bloß reine Mathematik. An diesem orientiere ich
mich, weil ich das Buch an sich super finde - bis auf die Tatsache dass
ich lineare Algebra hasse und das Buch sit voll davon. ;-)
> Ich wollte zum Ausdruck bringen, dass beide Darstellungen zu einer> parallelen Struktur großer Logiktiefe führen. Egal, ob du es seriell> oder parallel beschreibst.> Und daher die von dir genannte Lösung wieder eine parallele Struktur> großer Tiefe erzeugt. Die eventuell etwas kleiner sein könnte, als die> Beschreibung über das Schleifenkonstrukt.
Dem stimme ich auch zu. Ich gehe sogar soweit dass das Ergebnis das
gleiche sein könnte. Daher muss ich auch nochmal meinen ersten Beiträg
revidieren. Da habe ich in der Tat von Lösung 1 und Lösung 2 gesprochen.
Das ist falsch, korrekt wäre Lösung 1 und Idee 2. :-(
> Dieser Unterschied könnte natürlich im konkreten Fall das Zünglein an> der Waage sein.> Aber dann portierst du das Design auf ein FPGA mit weniger inputs an den> LUTs und schon ist wieder Essig.
Auch richtig. 64 bit sind in allen belangen doof. Durch den direkten
Feedback des Ergebnisses, kann man auch ohne die Schleifenstruktur nicht
vernünftig pipelinen. Egal was man macht, es bleibt eklig.
> Unter einem guten Design verstehe ich jedenfalls auch, dass nicht alles> auf Kante genäht ist.> Denn sowas holt einen irgendwann ein. Daher sollte eine gescheite Lösung> her. Und ich denke, du gibst mir recht, dass ein voll paralleler 64 Bit> CRC-Kalkulator immer ein fettes Teil ist, was man vermeiden sollte,> wenn es irgendwie geht. Man quält damit PaR unnötig.
Full ACK
> Mich hat im Wesentlichen gestört, dass du Begriffe wie serielle> Berechnung verwendet hast, oder gesagt hast, dass das Datum als ein> Bitstrom mit 1 Bit breite ankommt und in der Funktion verarbeitet wird.> Das stimmt einfach nicht. Und das weißt du auch. Es wird lediglich eine> Beschreibung verwendet, die so tut, als wäre es so. Im FPGA ist es aber> nicht so.
Richtig seriell ist in dem Zusammenhang nur die Rechenoperation der
Funktion calc_serial_crc16 welche 64 mal ein Bit verarbeitet. Ich mag
den Begriff seriell trotzdem, weil in dem der Begriff Serie/Reihe
steckt, was im mathematischen Sinne ja auch korrekt ist. Macht man die
Schleife weg und arbeitet Bit für Bit pro Takt ab, dann hat man auch
eine echte serielle Verarbeitung. Durch die Schleife zwingt man halt die
Synthese dazu da alles in einem Zyklus zu erledigen.
> Das ist genau der Punkt, wo ständig Leute drüber stolpern, vorallem,> wenn sie aus der Software Ecke kommen. Darum reite ich da auch so> penibel drauf rum, dass das korrekt formuliert wird.>> Ich gehe davon aus, dass du letztendlich genau das gleiche Bild im Kopf> hast, wie ich. Es aber vielleicht ein wenig unpräzise formuliert hast,> was eventuell für Verwirrung sorgen könnte.
Im Sinne der digitalen Signalverarbeitung unpräzise, im mathematischen
nicht. Für den Author des Anfangsposts aber sicher verwirrend, das gebe
ich zu.
> Zu deinem Vorschlag wegen eines Buches.. Man lernt natürlich nie aus,> aber die Grundlagen habe ich in 20 Jahren Berufserfahrung verstanden> (behaupte ich zumindest mal).
Dito, auch wenn es nur etwas mehr als 10 Jahre sind. ;-)
> Peace
Danke dir auch! :-)
Schön, dass wir das klären konnten...
Was wären jetzt tatsächlich gute Lösungen für den TO?
1.)Super wäre es natürlich, die Funktion in den IP-Core zu bauen. Da
kann dann die CRC seriell (im Schaltungstechnischen Sinn) ermittelt
werden.
Setzt aber voraus, dass die Sourcen des Core vorliegen.
2.)Sich zwischen Pin und Core zu klemmen wäre auch eine Möglichkeit,
aber dann muss der Datenstrom analysiert werden, um Header etc zu
erkennen und entfernen.
3.)Die CRC voll parallel (Schaltungstechnisch) zu ermitteln wäre auch
möglich, führt aber zu großer Logiktiefe. Diese könnte man durch
Pipelining aufbrechen, was aber ein nicht ganz triviales Unterfangen
wird, angesichts der Logik. (Wo bricht man die auf?)
4.)CRC mehrstufig parallel ermitteln (z.B. in 8 oder 16 Bit Blöcken in 8
oder 4 Takten) und die Daten dazu passend "verzögern" oder den Takt für
den CRC-Rechner entsprechend hoch setzen (was aber kontraproduktiv ist,
da dann auch nur kleinere Logiktiefen möglich sind)
5.) wie 4.) aber die Daten nicht parallel zum CRC-Rechner über eine
8-stufige (64 Bit breite) FIFO-Struktur führen, sondern die Daten in
8-Bit Häppchen durch den CRC-Rechner schubsen und am Ausgang des
CRC-Rechners wieder zusammensetzen.
Spart gegenüber Möglichkeit 4) Register bzw RAM (je nach Implementierung
des FIFO)
Hat außerdem den Vorteil, dass diese Lösung ganz einfach auf größere
Datenbreiten angepasst werden kann, falls das mal nötig sein sollte.
Wenn ein paar Takte Verzögerung im Design kein Problem darstellen, dann
tendiere ich zu Ansatz 5)
Wenn man mal dieses Paper zur Hand nimmt:
http://www.ijsret.org/pdf/121757.pdf
dann wird Vorschlag 3.) nachgegangen, kombiniert mit 4.) und Lookup
Tables. Es scheint auch, das der Lookup Table Ansatz bei solchen breiten
CRC Berechnungen einen gewissen Stand hat, siehe z.B.:
https://ieeexplore.ieee.org/document/7839009/
Erfahrung habe ich damit jedoch keine und detailiert bin ich das Paper
auch nicht durchgegangen.
Aber auch die vorgeschlagene Lösung im ersten Paper schafft es nicht in
einem Taktzyklus.
Auf alle Fälle gibt es massig Material im Netz und alle Lösungen sind
alles andere als trivial. :-(
Hier noch ein Beispiel:
http://www.jocm.us/uploadfile/2013/0209/20130209010226752.pdf
für peace bin ich auch ;)
Schlumpf schrieb:> 5.) wie 4.) aber die Daten nicht parallel zum CRC-Rechner über eine> 8-stufige (64 Bit breite) FIFO-Struktur führen, sondern die Daten in> 8-Bit Häppchen durch den CRC-Rechner schubsen und am Ausgang des> CRC-Rechners wieder zusammensetzen.> Spart gegenüber Möglichkeit 4) Register bzw RAM (je nach Implementierung> des FIFO)> Hat außerdem den Vorteil, dass diese Lösung ganz einfach auf größere> Datenbreiten angepasst werden kann, falls das mal nötig sein sollte.>> Wenn ein paar Takte Verzögerung im Design kein Problem darstellen, dann> tendiere ich zu Ansatz 5)
Ich denke diesen Ansatz werde ich als erstes ausprobieren.
@Tobias B.
Danke für die Links. Werde ich mir auf jeden fall mal durchlesen.
Und danke nochmal an alle anderen für die Vorschläge und Hilfen.
mfg
Paul
Tobias B. schrieb:> Wenn man mal dieses Paper zur Hand nimmt:
Auch ein möglicher Ansatz mit den LUT, aber ob das unter´m Strich so
viel bringt? Müsste man sich mal genauer anschauen. Aber ich denke, auch
hier wird es so sein, dass man entweder mit kleinen LUTs und vielen
Iterationen arbeitet oder mit großen LUTs und wenig Interationen. (Hab
das Dokument aber grad echt nur schnell diagonal gelesen)
Aber unter dem Hintergrund, dass beim Problem des TO die CRC nicht immer
über die kompletten 64 Bit berechnet werden muss, werden die Verfahren
noch komplizierter.
Wenn man mal davon ausgeht, dass die Anzahl der relevanten Bits nicht
beliebig ist, sondern z.B. nur ganzzahlige Vielfache von 8 sein darf,
dann würde sich eine CRC-Berechnung in 8 Schritten à 8 Bit (parallel)
über XORs anbieten.
Damit wäre man in maximal 8 Takten durch, die Logiktiefe ist gering und
die Anzahl der benötigen Register ist auch überschaubar.
Paul schrieb:> @Tobias B.> Danke für die Links. Werde ich mir auf jeden fall mal durchlesen.
Gerne, mehr kann ich zum Thema leider nicht beitragen. Bin am Ende aber
echt gespannt ob und wie du es hinbekommen hast. :-)
Schlumpf schrieb:> Auch ein möglicher Ansatz mit den LUT, aber ob das unter´m Strich so> viel bringt? Müsste man sich mal genauer anschauen. Aber ich denke, auch> hier wird es so sein, dass man entweder mit kleinen LUTs und vielen> Iterationen arbeitet oder mit großen LUTs und wenig Interationen. (Hab> das Dokument aber grad echt nur schnell diagonal gelesen)
Ja, da bin ich auch noch nicht ganz sicher. Man findet eine gewisse
Tendenz Richtung LUTs, mehr kann ich auch nicht dazu sagen.
Das letzte Paper fand ich auf den ersten Blick am vielversprechendsten,
da sieht man auch wie problematisch das Pipelining bei CRC ist. Eine
generische Lösung bekommt man wahrscheinlich mit VHDL Hausmitteln auch
nicht wirklich sauber hin, da wird man sich eher einen Core-Generator
programmieren müssen.
Tobias B. schrieb:> Man findet eine gewisse> Tendenz Richtung LUTs, mehr kann ich auch nicht dazu sagen.
Sagen wir mal so: In einem FPGA ist ein XOR auch nur ein LUT ;-)
Tobias B. schrieb:> Das letzte Paper fand ich auf den ersten Blick am vielversprechendsten,
Ich lese da unter anderem:
"Lookup tables can be replaced by XOR trees to achieve
smaller area and to reduce pipeline latency"
Ob ich dem so pauschal zustimmen würde?
Eine große LUT in einem BRAM hat garantiert ne kürzere Latency als das
äquvalente XOR-Grab.
Eigentlich braucht man daraus doch gar keine so große Wissenschaft
machen.
Es gibt einen einfachen Zusammenhang:
Je mehr Bits pro Interation verrechnet werden, desto tiefer wird die
Logik.
Ob das jetzt ne riesen LUT ist oder ein XOR-Grab sei mal dahin gestellt.
Also muss man ein gutes Mittelmaß finden.
Ganz ohne komplizierte Mathematik oder wissenschaftliche Abhandlungen
von chinesischen Nerds ;-)
Aus dem Bauch heraus würde ich sagen, dass bei den geforderten 200 MHz
auf einem günstigen FPGA eine parallele Verarbeitung von 16 oder 32 Bit
problemlos möglich sein sollten.
Falls die Granularität der zu betrachteten Daten aber 8Bit beträgt, dann
einfach aus praktischen Gründen in 8 Bit Blöcken.
Hier ( http://www.easics.com/webtools/crctool ) oder auf vergleichbarer
Seite den Code generieren lassen, mit ner kleinen FSM den 64 Bit Vektor
in 8 Bit-Häppchen durch diesen Code nudeln und abbrechen, wenn die
Anzahl der relevanten Bits erreicht ist.
Paar Takte später stehen CRC und die 64 Bit Daten gleichzeitig zur
Weiterverarbeitung bereit.
Geht halt nur, wenn das nächste Datenpaket erst dann kommt, wenn die CRC
fertig berechnet ist.
Schlumpf schrieb:> Je mehr Bits pro Interation verrechnet werden, desto tiefer wird die> Logik.> Ob das jetzt ne riesen LUT ist oder ein XOR-Grab sei mal dahin gestellt.>> Also muss man ein gutes Mittelmaß finden.> Ganz ohne komplizierte Mathematik oder wissenschaftliche Abhandlungen> von chinesischen Nerds ;-)
Das ist der Unterschied zwischen Theorie und Praxis. :-)
Schlumpf schrieb:> Falls die Granularität der zu betrachteten Daten aber 8Bit beträgt, dann> einfach aus praktischen Gründen in 8 Bit Blöcken.
Eines dieser Papaer liefert sogar den mathematischen Beweis, dass man
das darf. Da fühlt man sich wieder richtig ins Mathegrundstudium
zurückversetzt schwelg.
Schlumpf schrieb:> Paar Takte später stehen CRC und die 64 Bit Daten gleichzeitig zur> Weiterverarbeitung bereit.>> Geht halt nur, wenn das nächste Datenpaket erst dann kommt, wenn die CRC> fertig berechnet ist.
Ist halt doof, wenn man Daten als unterbrechungsfreien Stream hat. Da
fand ich das Paper mit dem Pipelinig beim überfliegen ganz interessant.
Pauschal hab ich alle nur überflogen, ist dann doch zu schwere Kost um
seine Freizeit damit zu verbringen. :-(
Es ist ein CSI2 Stream. Ich bekomme Bilddaten Zeile für Zeile. Und
innerhalb einer Zeile bekomme ich dann ununterbrochen Daten. Danach
gibts eine Pause.
Das heisst, ich müsste mit der CRC fertig werden bis die nächste Zeile
wieder beginnt. Das muss ich noch herausfinden wieviel luft ich da
minimal habe.
Es hängt halt immer vom Bildformat ab wie groß ein Datum dann ist. Bei
RAW12 habe ich dann (12 Bit pro pixel * 4 pixel pro clk) 48Bit. Diese
48 Bit hole ich mir dann aus dem 64 bit vektor vom IP raus.
Bisher habe ich das so gemacht, dass ich einen Daten_breiten_converter
IP dran gehängt habe der mir immer volle 64 bit zusammengebaut hatte.
Danach hab ich die CRC immer auf die vollen 64 bit gerechnet.
Und das hat ohne Timing verletzungen auch funktioniert. Also in einem
Takt über 64 bit gerechnet.
Das blöde ist nur das ich so einen Converter für jeden einzelnen CSI2
Datentyp instanzieren muss. Sprich von 32 auf 64, von 48 auf 64 usw...
Ich hab mich gefragt ob das nicht ohne diesem Converter funktioniert.
Und das war der Grund für diesen Post.
mfg
Paul
Mal ne blöde Frage :
Du rechnest über jedes Pixel ne CRC, wenn ich das jetzt korrekt
verstanden habe?
Und gegen was vergleichst du die?
Hängt an jedem Pixel ne CRC, wenn du es empfängst?
Det IP Core spuckt dir also immer 64 Bit aus und ne Info, wieviele Bits
davon gültig sind?
Und du machst durch Padding daraus wieder 64 Bit und rechnest dann die
CRC?
Mit was 'füllt' der IP die unbenutzen Bits und mit was füllst du sie?
Und warum rechnest du über jedes Pixel eine CRC?
Schlumpf schrieb:> Mal ne blöde Frage :> Du rechnest über jedes Pixel ne CRC, wenn ich das jetzt korrekt> verstanden habe?
Ne ich rechne eine CRC über das gesamte Bild
> Und gegen was vergleichst du die?
Die CRC wird am PC von einer Intel CPU gegengerechnet.
Die "calc_serial_crc16" funktion ist auch nicht wirklich die richtige.
Ist nur ein Beispiel
> Hängt an jedem Pixel ne CRC, wenn du es empfängst?
Der IP Core liefert mir keine CRC
> Det IP Core spuckt dir also immer 64 Bit aus und ne Info, wieviele Bits> davon gültig sind?
Das hatte ich vielleicht falsch beschrieben. Eigentlich bekomme ich nur
die Info welcher CSI2 Datentyp das ist. Und aus dem 64 Bit Vektor hole
ich mir dann die 4 Pixel raus. bei RAW12 wären das dann 48 Bit. Bei Raw8
sind es 32 Bit usw.
Es kann aber laut Spec nur ein vielfaches von 8 Bit sein.
Ich rechne die CRC für die 4 Pixel und speichere mir den Wert. Beim
nächsten Datenpacket wird der gespeicherte Wert dann als Startwert
genommen usw.
Im Endeffekt ist es aber so wie ich es beschrieben hatte. Ich habe einen
IP der mir einen Datenstrom liefert und mir gleichzeitig sagt Wieviele
Bytes vom den 64Bit vektor gültig sind (welcher CSI2 Datentyp).
Mehr ist es aus meiner Sicht nicht. Da ist es für mich nicht wichtig ob
es pixel oder sonst was sind...
> Und du machst durch Padding daraus wieder 64 Bit und rechnest dann die> CRC?> Mit was 'füllt' der IP die unbenutzen Bits und mit was füllst du sie?>> Und warum rechnest du über jedes Pixel eine CRC?
Ein Padding mache ich nicht. Ich hänge den CRC einfach in den stream
ganz am Ende als Footer an. Das wars.
mfg
Paul
Da bleibt dir in der Tat nichts anderes übrig, als das in einem Takt
irgendwie hinzubekommen, gegebenfalls mit Pipelining. Es sei den, du
kannst die Daten irgendwie puffern.
Du schreibst, dass du die CRC Rechnung mit 64 bit bei 200 MHz
hinbekommen musst. Machst du 4K Video? RAW12 wären bei 4K@60Hz knapp 6
Gb/s. Wenn du es schaffst die Daten geschickt mit einem externen
Speicher mit genug Bandbreite zu puffern, hast du theoretisch 2 Zyklen
pro 64 bit Word Zeit. Bei FullHD würde sich das sogar auf 8 Zyklen
erhöhen.
Ist allerdings ein hoher Preis den man für die CRC Rechnung zahlt.
Zumindest hast du theoretisch bis 12 bit bei 60Hz, bzw. 24bit bei 30Hz
die Chance das nicht in einem Zyklus schaffen zu müssen.
Tobias B. schrieb:> Da bleibt dir in der Tat nichts anderes übrig, als das in einem> Takt> irgendwie hinzubekommen, gegebenfalls mit Pipelining. Es sei den, du> kannst die Daten irgendwie puffern.>> Du schreibst, dass du die CRC Rechnung mit 64 bit bei 200 MHz> hinbekommen musst. Machst du 4K Video? RAW12 wären bei 4K@60Hz knapp 6> Gb/s. Wenn du es schaffst die Daten geschickt mit einem externen> Speicher mit genug Bandbreite zu puffern, hast du theoretisch 2 Zyklen> pro 64 bit Word Zeit. Bei FullHD würde sich das sogar auf 8 Zyklen> erhöhen.>> Ist allerdings ein hoher Preis den man für die CRC Rechnung zahlt.> Zumindest hast du theoretisch bis 12 bit bei 60Hz, bzw. 24bit bei 30Hz> die Chance das nicht in einem Zyklus schaffen zu müssen.
Es ist schon so das zwischen 2 Datenpacketen immer 1 oder 2 clk zylken
Pause ist. Das Problem ist nur das es variiert. Es ist eher zufällig.
Ich weiss nie genau wieviel Pause ist. Es kommt auch vor das 2 Packete
ohne Pause kommen und dann dafür 3 Zyklen Pause ist.
Ja ich denke ohne zu Puffern wirds wohl nicht klappen.
mfg
Paul
Tobias B. schrieb:> Du schreibst, dass du die CRC Rechnung mit 64 bit bei 200 MHz> hinbekommen musst. Machst du 4K Video? RAW12 wären bei 4K@60Hz knapp 6> Gb/s. Wenn du es schaffst die Daten geschickt mit einem externen> Speicher mit genug Bandbreite zu puffern, hast du theoretisch 2 Zyklen> pro 64 bit Word Zeit. Bei FullHD würde sich das sogar auf 8 Zyklen> erhöhen.
Bisher kriegen wir Full HD bei 60 fps. Es ist so das der IP auf 200 MHz
eingestellt werden muss um den vollen Speed zu schaffen. Das wären max
1,5 Gbit/ pro Lane. Wir haben 4 Lanes.
Dementsprechend schaufelt er die Daten mit 200Mhz raus.
mfg
Paul
Paul schrieb:> Bisher kriegen wir Full HD bei 60 fps. Es ist so das der IP auf 200 MHz> eingestellt werden muss um den vollen Speed zu schaffen. Das wären max> 1,5 Gbit/ pro Lane. Wir haben 4 Lanes.> Dementsprechend schaufelt er die Daten mit 200Mhz raus.
Ok, das macht die Sache aber schon deutlich angenehmer. Wenn du es
schaffst die CRC Berechnung so zu implementieren, dass Sie nur ein paar
wenige Zyklen braucht, dann sollte ein bisschen BRAM als Zeilenspeicher
sogar ausreichen. Das wäre dann doch wieder ein fairer Mittelweg.
Sollte das Ganze aber mal auf 4K hochgehen wirds wieder eng.
Paul schrieb:> Ein Padding mache ich nicht. Ich hänge den CRC einfach in den stream> ganz am Ende als Footer an. Das wars.
Ich meinte mit Padding auch nicht, dass du am Ende des Streams irgendwas
machst, sondern Folgendes:
Der IP-Core, hat ja anscheinend 64 Bit Datenbreite. Von diesen 64 Bit
werden aber u.U. nicht alle genutzt. Nachdem der Core aber nicht
dynamisch seine pyhsikalische Datenbreit am Ausgang anpassen kann,
müssen die nicht benutzten Bits ja mit irgendeinem Wert belegt werden.
Wieviele dieser Bits gültig sind, gibt der Core in einem 8 Bit Wort aus.
Dann hast du einen Core geschrieben, der die gültigen Bits rausfischt
und dann was damit macht?... Das habe ich nicht ganz kapiert.
Paul schrieb:> Ich rechne die CRC für die 4 Pixel und speichere mir den Wert. Beim> nächsten Datenpacket wird der gespeicherte Wert dann als Startwert> genommen usw.
Letztendlich kannst du die Berechnung einfach weiter laufen lassen. Du
musst nicht einen Wert zwischenspeichern und dann für eine neue
Berechnung als Startwert nehmen.
Statte deinen CRC-Rechner mit zwei Steueringängen aus: calc_next und
crc_restart.
Wenn ein neues Datenpaket da ist fütterst du damit den Rechner und
triggerst die Berechnung mit "calc_next". Das machst du so lange, bis
der Stream zuende ist. Und dann geht es mit "crc_restart" von vorne los.
Die Größe der Häppchen ist für die Berechnung erst mal uninteressant.
Die Mindestgröße wird aber durch die Zeit vorgegeben, die du für die
Berechnung hast (evtl unter Berücksichtigung der Puffergröße)
Wie lange ist ein Stream? Also WANN hängst du die CRC dran? Immer nach
einem Bild?
Ich gehe mal davon aus, dass die Anzahl der benutzen Bits (von den 64)
sich nicht innerhalb eines Streams ändert, oder?
Wenn in einem Stream z.B. immer nur 48 der 64 Bit verwendet werden, wie
baust du dann intern den Stream neu zusammen?
48+48+48+48+CRC oder 48+16+48+16+48+16+CRC ?
Ich vermute mal, dass du die unnötigen Bits nicht weiter im Stream mit
führst, oder?
Könntest du nicht einfach erst den neuen Stream zusammen bauen und DANN
über den die CRC-Berechnung machen? Dann kannst du mit einer fixen
Blockgröße arbeiten. Für die Berechnung sollte es keine Rolle spielen,
ob die "Häppchen" für den CRC-Rechner sich mit den logischen Symbolen
decken.
ggf musst du am Ende des Frames noch ein Padding machen, um ihn auf ein
ganzzahliges Vielfaches der "CRC-Häppchengröße" zu bringen.
Weitere Möglichkeit:
Nachdem du geschrieben hast, dass ein paralleler CRC-Rechner für 64 Bit
vom Timing noch passt, könntest du für jede mögliche Datenbreite einen
parallelen CRC-Rechner bauen und dann so verfahren, wie ich oben
geschrieben habe.
Dann entscheidest du am Ende des Frames, welche CRC du verwendest.
Oder du arbeitest mit den Puffern, wie Tobias vorgeschlagen hat.
Allerdings musst du dann sicherstellen, dass der ausreichend groß ist...
Schlumpf schrieb:> Paul schrieb:>> Ein Padding mache ich nicht. Ich hänge den CRC einfach in den stream>> ganz am Ende als Footer an. Das wars.>> Ich meinte mit Padding auch nicht, dass du am Ende des Streams irgendwas> machst, sondern Folgendes:>> Der IP-Core, hat ja anscheinend 64 Bit Datenbreite. Von diesen 64 Bit> werden aber u.U. nicht alle genutzt. Nachdem der Core aber nicht> dynamisch seine pyhsikalische Datenbreit am Ausgang anpassen kann,> müssen die nicht benutzten Bits ja mit irgendeinem Wert belegt werden.> Wieviele dieser Bits gültig sind, gibt der Core in einem 8 Bit Wort aus.>> Dann hast du einen Core geschrieben, der die gültigen Bits rausfischt> und dann was damit macht?... Das habe ich nicht ganz kapiert.
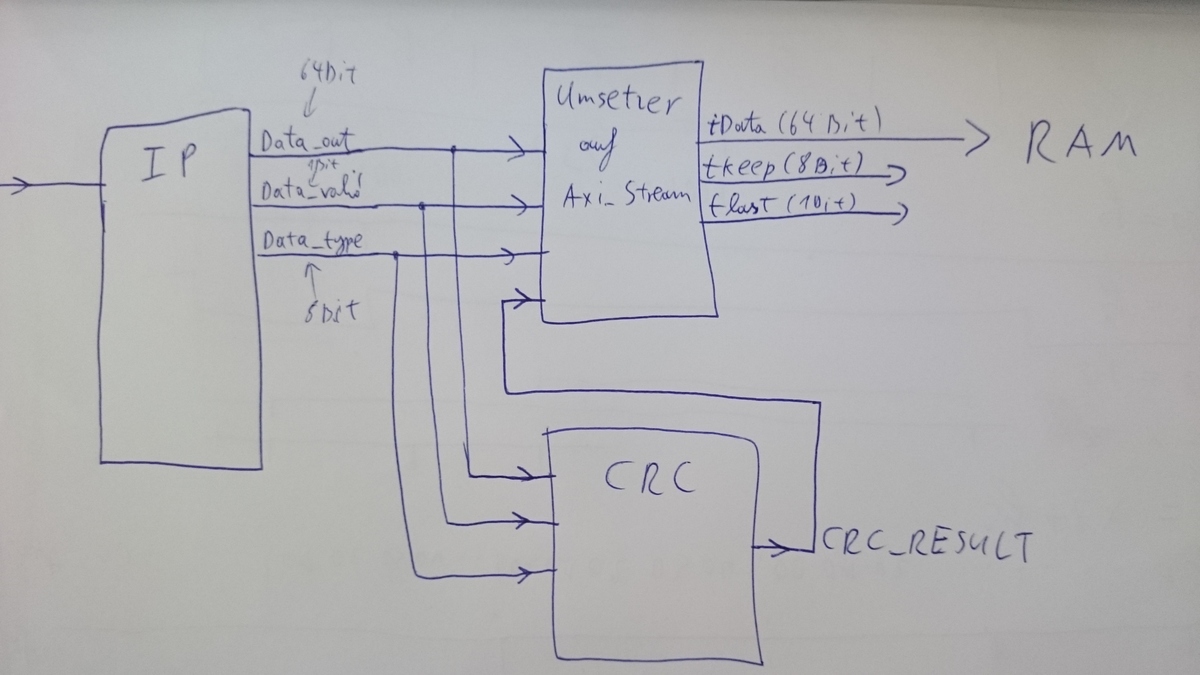
Ja genau so ist es. Ich hab mal eine Skizze angehängt. Ich habe einen
Umsetzer auf ein anderes Interface(Axi Stream) geschrieben. In diesem
Umsetzer wird der CRC wert in den stream dann zum schluss angehängt.
Immer am Bild Ende. Ich bekomme vom IP Core die Info wann ein Bild
zuende ist.
> Paul schrieb:>> Ich rechne die CRC für die 4 Pixel und speichere mir den Wert. Beim>> nächsten Datenpacket wird der gespeicherte Wert dann als Startwert>> genommen usw.>> Letztendlich kannst du die Berechnung einfach weiter laufen lassen. Du> musst nicht einen Wert zwischenspeichern und dann für eine neue> Berechnung als Startwert nehmen.> Statte deinen CRC-Rechner mit zwei Steueringängen aus: calc_next und> crc_restart.>> Wenn ein neues Datenpaket da ist fütterst du damit den Rechner und> triggerst die Berechnung mit "calc_next". Das machst du so lange, bis> der Stream zuende ist. Und dann geht es mit "crc_restart" von vorne los.
Klingt logisch danke.
> Die Größe der Häppchen ist für die Berechnung erst mal uninteressant.> Die Mindestgröße wird aber durch die Zeit vorgegeben, die du für die> Berechnung hast (evtl unter Berücksichtigung der Puffergröße)>> Wie lange ist ein Stream? Also WANN hängst du die CRC dran? Immer nach> einem Bild?
Ja
> Ich gehe mal davon aus, dass die Anzahl der benutzen Bits (von den 64)> sich nicht innerhalb eines Streams ändert, oder?
Ja genau. Erst wenn eine andere Kamera angeschlossen wird oder die
aktuelle Kamera neu konfiguriert wrid und sich auch das Datenformat
ändert . Das kann aber während der Laufzeit passieren.
> Wenn in einem Stream z.B. immer nur 48 der 64 Bit verwendet werden, wie> baust du dann intern den Stream neu zusammen?> 48+48+48+48+CRC oder 48+16+48+16+48+16+CRC ?
Dazu müsste ich kurz erklären wie der AXI_STREAM bus funktioniert. Er
hat einen Datenvektor (tdata), ein flag das ein gültiges Datum markiert
(tvalid), ein flag das das letzte datum markiert(tlast) und einen Vektor
der die gültigen bytes vom Datenvektor marktiert.
Also im prinzip schon ähnlich wie das CSI IP Core Interface.
Der Datenvektor vom IP wird durchgeleitet zum Axi_stream datenvektor.
Das einzige was ich mache ist, dass ich das tkeep in Abhängigkeit vom
CSI2 Datentyp setze.
Bei RAW12 sieht das so aus:
tdata: 64+64+64+64+CRC
tkeep: 06+06+06+06+04
tlast: 0 + 0+ 0+ 0+ 1
das tkeep ist auf 6 weil es die 6 gültigen bytes markiert. Das sind die
4 pixel aus dem IP. Also 48 bit. das letzte ist der CRC der in dem Fall
32 Bit groß ist. Der wird mit tkeep = 4 markiert. Zusätzlich wird der
Frame abgeschlossen mit tlast = 1.
> Ich vermute mal, dass du die unnötigen Bits nicht weiter im Stream mit> führst, oder?
erstmal führe ich sie mit aber sie werden später vom DMA nicht weiter
verarbeitet.
> Könntest du nicht einfach erst den neuen Stream zusammen bauen und DANN> über den die CRC-Berechnung machen? Dann kannst du mit einer fixen> Blockgröße arbeiten. Für die Berechnung sollte es keine Rolle spielen,> ob die "Häppchen" für den CRC-Rechner sich mit den logischen Symbolen> decken.> ggf musst du am Ende des Frames noch ein Padding machen, um ihn auf ein> ganzzahliges Vielfaches der "CRC-Häppchengröße" zu bringen.
Das Problem ist ja das ich nach meinem Umsätzer auch nur einen
Datenstrom bekomme, bei dem nicht alle bytes vom Datenvektor gültig sind
:P
Das könnte ich nur so lösen wenn ich einen IP baue der mir die daten
immer zu vollen 64 bit zusammenpackt. Nur beim letzten wirds dann
schwieriger.
> Weitere Möglichkeit:>> Nachdem du geschrieben hast, dass ein paralleler CRC-Rechner für 64 Bit> vom Timing noch passt, könntest du für jede mögliche Datenbreite einen> parallelen CRC-Rechner bauen und dann so verfahren, wie ich oben> geschrieben habe.> Dann entscheidest du am Ende des Frames, welche CRC du verwendest.>> Oder du arbeitest mit den Puffern, wie Tobias vorgeschlagen hat.> Allerdings musst du dann sicherstellen, dass der ausreichend groß ist...
Genau das ist ja meine aktuelle Lösung. Siehe mein zweiter Post. Ich
habe für jeden Datentyp eine eigene CRC funktion.
Meine Frage war ja anfangs ob sich das eleganter lösen lässt.
Ich habe bisher 4 parallele CRC Funktionen für 4 verschiedene
Datentypen.
Und das funktioniert ja auch, aber es gefällt mir nicht weil ich so mehr
recouren brauche :P
So ich hoffe ich hab das verständlich erklärt :)
mfg
Paul
Ich denke, ich hab es jetzt soweit verstanden, wie die Daten
umhergeschubst werden :-)
Paul schrieb:> Das könnte ich nur so lösen wenn ich einen IP baue der mir die daten> immer zu vollen 64 bit zusammenpackt. Nur beim letzten wirds dann> schwieriger.
Genau, wenn du in 64 Bit Blöcken die CRC berechnest, muss die Anzahl der
Bits im Frame durch 64 teilbar sein. (Hab ich ja geschrieben, dass du
das dann ggf "auffüllen" musst)
Paul schrieb:> Und das funktioniert ja auch, aber es gefällt mir nicht weil ich so mehr> recouren brauche :P
Ob das mehr Ressourcen braucht, als ein riesen CRC-Rechner, der über
Steuereingänge auf verschiedene Blockgrößen angepasst werden kann,
bleibt mal dahin gestellt.
Schau doch mal in den Report, wieviel Ressourcen deine vier parallelen
CRC Rechner benötigen und dann, wieviel dein CRC-Rechner mit
Steuereingängen benötigt.
Ist es erlaubt en letzten 64bit Datenblock, der evtl. nicht vollständig
wird, mit Nullen zu füllen und über diesen dann die CRC zu berechnen?
Falls ja, dann würde ich folgendes vorschlagen (unter der Annahme, dass
die 64bit CRC Berechnung doch in einem Zyklus funktioniert - diese Info
ist völlig an mir durchgegangen):
1.) CRC Funktion bekommt ein Clock enable Signal
2.) 128bit Buffer aus Registern bauen.
3.) Die einzelnen Bytes des Streams in den Buffer schieben. Sozusagen
ein dynamisches Schieberegister bei dem 1-8 Bytes pro Zyklus geschrieben
werden.
4.) Jedesmal wenn mindestens 64 unberechnete Bits im Buffer sind, wird
über den Clock Enable die CRC Berechnung angeschmissen.
5.) Falls der letzte Block nicht mehr auf 64 bit gefüllt werden kann,
diesen mit Nullen füllen und die letzte Operation durchführen.
Dadurch bräuchtest du auch nur einen CRC Rechner.
Ähnliche Technik verwende ich z.B. auch, wen ich z.B. 24 bit Daten in
einen Speicher mit 32 bit Datenbreite schreiben will. Durch das packen
der Bits kann man seine Bandbreite optimieren, in vielen Fällen ist es
den Aufwand wert.
Vielleicht noch eine kleine Idee: Wenn es doch nochmal eng werden sollte
mit den Timings, bietet sich vielleicht doch ein Zeilen-FIFO an. Dann
kannst du für die CRC Berechnung evtl. ein Multicycle Constraint
angeben. Von der Datenrate sollte es lässig reichen den CE nur jeden
zweiten Takt auf High zu setzen.