Multitasking
Multitasking bedeutet ein quasi paralleles Ausführen von mehreren Prozessen auf einem Prozessor.
Einleitung
Da eine echte parallele Ausführung von mehreren Prozessen (Programmen, Funktionen) auf einer einzelnen CPU (genauer: einem CPU-Kern) nicht möglich ist, wird ein "Trick" angewendet. Er besteht darin, einzelne Prozesse jeweils nur für kurze Zeit (ungefähr 1...50 ms) zu bearbeiten und danach auf einen anderen Prozess umzuschalten. Man spricht auch von einer verschachtelten Bearbeitung (engl. interleaving).
Das Herz jedes Multitasking-Systems ist der Scheduler. Dies ist ein Programm, das nach bestimmten Algorithmen überprüft, welcher Prozess als nächstes die CPU (also Rechenzeit) zugeteilt bekommt. Es gibt verschiedene Schedulingstrategien:
- "First come first served": Prozesse bekommen Rechenzeit zugeteilt in der Reihenfolge, in der sie rechenbereit werden.
- "Shortest job first": Der Prozess mit der kürzesten Rechenzeit wird als erstes bearbeitet. Dazu muss die Rechenzeit natürlich im Voraus bekannt sein.
- "Shortest remaining time next": Der Prozess mit der kürzesten verbleibenden Rechenzeit wird jeweils als nächstes bearbeitet. Auch hier muss diese Zeit bekannt sein.
- Round robin: Alle Prozesse bekommen gleich viel Zeit zugeteilt. Der Scheduler lässt jeden Prozess für dieselbe Dauer rechnen und übergibt die CPU dann an den nächsten Prozess.
- Priority Scheduling: Die Prozesse sind nicht gleichwertig (wie beim Round-Robin-Verfahren), sondern haben Prioritäten. Der Scheduler sorgt dafür, dass höher priorisierte Prozesse bevorzugt behandelt werden.
Soweit die "reine Lehre". Scheduler in freier Wildbahn implementieren oftmals komplizierte Hybriden der genannten Techniken. Jene der "echten" Betriebsysteme (Windows, Linux, MacOS, *BSD) sind im Prinzip prioritäten-basierte Round-Robin-Scheduler. Generell hat ein Betriebssystem zwei Möglichkeiten, Multitasking zu realisieren: kooperativ oder präemptiv.
Egal welche Art von Multitasking implementiert wird, Aufrufe von _delay_ms() sollten tabu sein. Selbst wenn man präempptives Multitasking vorfindet ist das keine Einladung zum Rechenleistung vergeuden, sondern es gehört zum guten Ton auch da kooperativ zu sein. Die folgenden Implementierungen erscheinen für Mikrocontroller sinnvoll je nach weiteren Umständen:
- Der Kode ist komplett in Interruptserviceroutinen (ISRs), das Hauptprogramm ruft nur noch sleep_cpu() auf. Dieser Ansatz wird verwendet, wenn die Rechenaufgaben kurz sind (= keine langen Sequenzen) und Energie sparen ganz oben auf der Agenda steht. Also für Batteriebetrieb. Von Vorteil ist dass die ISRs keine Register retten müssen (ISR_NAKED und reti() verwenden), solange sie sich nicht verschachteln. Es handelt sich um kooperatives Multitasking, da eine hängende ISR weitere ISRs sperrt.
- Eine lang rechnende Interruptroutine (meistens: ADC) gibt Interrupts frei und ermöglicht Verschachtelung. Es entsteht so eine Art DPC (Deferred Procedure Call, Windows-Sprech) oder ein Bottom Half (Linux-Sprech). Das Hauptprogramm darf (aber sollte nie) lange _delay_ms()-Aufrufe tätigen, die je nach Interruptlast dann deutlich länger brauchen. Entweder man trifft Vorsorge, dass sich die DPCs nicht verschachteln, oder die Zeitverhältnisse lassen das nicht zu. Das Hauptprogramm kann eine lange Sequenz sein oder auch nur aus sleep_cpu() bestehen.
- Sämtliche Warteschleifen des Hauptprogramms (= lange Sequenz) rufen eine Idle-Prozedur auf, die anstehende Aufgaben erledigt, die nicht in Interrupts erledigt werden können. _delay_ms() ist tabu und Zeitmessungen müssen anders gelöst werden. Die Hintergrundaufgabe darf keine (allzu) lange Sequenz sein und darf ihrerseits nicht idle() aufrufen. Da die Idle-Prozedur im main()-Kontext aufgerufen wird entfallen die Probleme des Register-Rettens und -Wiederherstellens. Für Mikrocontroller die erstrebenswerteste Struktur, da die Idle-Prozedur zum Energie sparen wiederum sleep_cpu() aufrufen kann, wenn alle interruptgetriggerten DPCs abgearbeitet sind.
- Ist der Hintergrundprozess eine lange Sequenz, empfiehlt sich eine Stackumschaltung. Für nur zwei Threads ist der dazu erforderliche Kode besonders einfach. Die beiden (kooperativen) Threads spielen sich ihre Rechenzeit mittels yield() zu — das ist die Stackumschaltprozedur. Für mehr als zwei Threads geht es besser mittels yieldTo()-Prozedur. Für eine variable Thread-Anzahl, wie das typischerweise für Webserver erforderlich ist, braucht es eine dynamische Speicherverwaltung und damit viel RAM. Diese Art von Multitasking ist so wie man sie von Windows 3.1 oder alten Macs her kennt. Aber nur wenige Mikrocontroller-Projekte benötigen eine solche Struktur; mir fällt da prompt nichts ein. Ein oder auch beide Threads dürfen idle() aufrufen für DPCs, es ist aber besser für die Stack-Dimensionierung, wenn das nur /ein/ Thread tut.
- Aus dem kooperativen Multithreading entsteht sofort präemptives Multithreading, wenn yield() vom Timer-Interrupt aufgerufen wird. Präemptiv ist hier nicht mit „absturzsicher“ gleichzusetzen, da ein Thread den Timer-Interrupt abschalten oder mit cli() unterbinden kann. Der Stack-Bedarf steigt erheblich, und man muss sich ernsthaft um Synchronisierungsmaßnahmen kümmern! Denn der Interrupt kann überall zuschlagen, und cli() verhindert Kooperation. Lohnt sich nicht so recht.
- Schließlich entsteht aus präemptiven Multithreading präemptives Multitasking, wenn Prozessor-Features das Umschalten zwischen User-Mode und God-Mode zulassen. Im User-Mode werden irrlaufende Speicherzugriffe und das Herumspielen an den Interrupts mit "kill -9" bestraft. Die richtige Wahl für Prozesse, die aus externen oder dubiosen Quellen stammen: Plugins, Server-Side Scripting usw. Und aus dem Stack-Umschalter wird etwas, was man /Betriebssystem/ nennen darf.
Kooperatives Multitasking
Beim kooperativen Multitasking gibt der Scheduler die Kontrolle komplett an den Prozess ab. Als Konsequenz davon ist das Betriebssystem darauf angewiesen, dass der Prozess seinerseits die Kontrolle "freiwillig" wieder zurückgibt. Geschieht das nicht, wird der Scheduler nicht wieder aufgerufen und damit auch kein anderer Prozess mehr ausgeführt - das System "hängt". Das Betriebssystem ist also auf die Kooperation der Prozesse angewiesen. Bekannte Beispiele für Betriebssysteme mit kooperativem Multitasking sind Windows 3.x und MacOS vor Version 10.
Dennoch ist kooperatives Multitasking keineswegs überholt oder schlecht. Gerade im Bereich der Mikrocontroller und Echtzeitanwendungen gibt es viele gute Argumente dafür: Kooperatives Multitasking ist deterministischer, also besser zeitlich und logisch vorhersagbar. Es ist besser simulierbar, d. h. für ein gegebenes System ist leichter nachweisbar, dass es funktioniert. Zudem ist kooperatives Multitasking ressourcenschonender, ein wichtiger Grund auch für die älteren Betriebssysteme. Da es sich um geschlossene Systeme handelt, tritt das Problem, dass „irgendein“ Prozess das System anhält, nicht auf. Es laufen ja im Gegensatz zum PC nicht „irgendwelche“ Prozesse, sondern nur die, deren Korrektheit (im Idealfall) verifiziert und validiert wurde.
Ein einfaches Beispiel für den AVR
Hier soll ein einfaches Beispiel den Weg in die Programmierung von parallel bearbeiteten Aufgaben zeigen.
Wichtigster Grundsatz ist die Herangehensweise! Viele Programmieranfänger haben damit Schwierigkeiten, was unter anderem an den schlecht vermittelten Grundlagen liegt. Oft sieht man Funktionen zum Warten in Form von
while(1) {
PORTD ^= (1<<PD0);
_delay_ms(500);
}
um beispielsweise eine LED blinken zu lassen. Will man dann noch andere Dinge erledigen, wundert sich der Programmierer, warum der Mikrocontroller so langsam reagiert, trotz 16 MHz Taktfrequenz.
Einfacher Ansatz
Stellen wir uns vor, wir wollen drei Dinge gleichzeitig tun.
- Eine Taste abfragen
- Eine LED blinken lassen, in Abhängigkeit der gedrückten Taste
- Daten vom UART empfangen und zum PC zurücksenden
Ein einfacher Ansatz für die drei Dinge sieht etwa so aus. Die Beispiele wurden mit WinAVR Version 20081006 in der Optimierungsstufe -Os kompiliert.
/*
Multitasking Demo, erster Versuch
ATmega32 @ 3,6864 MHz
LED + 1KOhm Vorwiderstand an PB0
Taster nach GND an PA0
UART an RXD und TXD
*/
#define F_CPU 3686400
// Baudrate, das L am Ende ist wichtig, NICHT UL verwenden!
#define BAUD 9600L
#include "avr/io.h"
#include "util/delay.h"
// Berechnungen
// clever runden
#define UBRR_VAL ((F_CPU+BAUD*8)/(BAUD*16)-1)
// Reale Baudrate
#define BAUD_REAL (F_CPU/(16*(UBRR_VAL+1)))
// Fehler in Promille
#define BAUD_ERROR ((BAUD_REAL*1000)/BAUD-1000)
#if ((BAUD_ERROR>10) || (BAUD_ERROR<-10))
#error Systematischer Fehler der Baudrate grösser 1% und damit zu hoch!
#endif
uint8_t taste_lesen(void) {
if (PINA & (1<<PA0))
return 1;
else
return 0;
}
void led_blinken(uint8_t taste) {
PORTB ^= (1<<PB0);
if (taste)
_delay_ms(1000); // 1 s warten
else
_delay_ms(100); // 0,1 s warten
}
void uart_lesen(void) {
uint8_t tmp;
while (!(UCSRA & (1<<RXC))); // Warte auf empfangenes Zeichen vom UART
tmp = UDR;
while (!(UCSRA & (1<<UDRE))); // Warte auf freien Sendepuffer vom UART
UDR = tmp;
}
int main(void) {
int8_t taste;
// IOs initialisieren
PORTA = 1; // Pull Up für PA0
DDRB = 1; // PB0 ist Ausgang
// UART initialisieren
UBRRH = UBRR_VAL >> 8;
UBRRL = UBRR_VAL & 0xFF;
UCSRB = (1<<RXEN) | (1<<TXEN);
// Endlose Hauptschleife
while (1) {
taste = taste_lesen();
led_blinken(taste);
uart_lesen();
}
}
Wenn man das Programm nun laufen lässt, wird man feststellen dass
- das Hyperterminal sehr langsam reagiert und bisweilen Zeichen verschluckt
- die LED auf Tastendrücke nur dann reagiert, wenn man per Hyperterminal Zeichen eingibt
Dieser Ansatz ist also untauglich. Egal wie schnell unser AVR auch ist, er reagiert sehr langsam.
Verbesserter Ansatz
Will man mehrere Dinge gleichzeitig bearbeiten, muss man die Aufgaben in kleinste Häppchen zerteilen. Diese kleinsten Häppchen werden dann verschachtelt abgearbeitet, also ein Häppchen von Aufgabe A, ein Häppchen von Aufgabe B, ein Häppchen von Aufgabe C.
Das Auslesen der Taste geht immer sehr schnell, kein Ansatz zum optimieren. Das Blinken der LED dauer entweder 1s oder 100ms, eine Ewigkeit für einen Mikrocontroller! Hier muss man was ändern. Am schlimmsten ist die UART-Nutzung. Der AVR wartet solange, bis ein Zeichen empfangen wurde! Das kann ewig dauern! Unser Programm steht! Das darf nicht sein!
/*
Multitasking Demo, zweiter Versuch
ATmega32 @ 3,6468 MHz
LED + 1KOhm Vorwiderstand an PB0
Taster nach GND an PA0
UART an RXD und TXD
*/
#define F_CPU 3686400
// Baudrate, das L am Ende ist wichtig, NICHT UL verwenden!
#define BAUD 9600L
#include "avr/io.h"
#include "util/delay.h"
// Berechnungen
// clever runden
#define UBRR_VAL ((F_CPU+BAUD*8)/(BAUD*16)-1)
// Reale Baudrate
#define BAUD_REAL (F_CPU/(16*(UBRR_VAL+1)))
// Fehler in Promille
#define BAUD_ERROR ((BAUD_REAL*1000)/BAUD-1000)
#if ((BAUD_ERROR>10) || (BAUD_ERROR<-10))
#error Systematischer Fehler der Baudrate grösser 1% und damit zu hoch!
#endif
uint8_t taste_lesen(void) {
if (PINA & (1<<PA0))
return 1;
else
return 0;
}
void led_blinken(uint8_t taste) {
static uint16_t zaehler=0;
if (taste) {
if (zaehler>=999) {
PORTB ^= (1<<PB0);
zaehler=0;
}
}
else {
if (zaehler>=99) {
PORTB ^= (1<<PB0);
zaehler=0;
}
}
zaehler++;
}
void uart_lesen(void) {
uint8_t tmp;
if((UCSRA & (1<<RXC))) { // empfangenes Zeichen abholbereit im UART ?
tmp = UDR;
while (!(UCSRA & (1<<UDRE))); // Warte auf freien Sendepuffer vom UART
UDR = tmp;
}
}
int main(void) {
int8_t taste;
// IOs initialisieren
PORTA = 1; // Pull Up für PA0
DDRB = 1; // PB0 ist Ausgang
// UART initialisieren
UBRRH = UBRR_VAL >> 8;
UBRRL = UBRR_VAL & 0xFF;
UCSRB = (1<<RXEN) | (1<<TXEN);
// Endlose Hauptschleife
while (1) {
taste = taste_lesen();
led_blinken(taste);
uart_lesen();
_delay_ms(1); // 1 ms warten
}
}
Dieses Programm reagiert ganz anders! Schnell wie der Wind und vollkommen unabhängig von anderen, parallel laufenden Prozessen. Warum ist das so?
Die einzelnen kleinen Häppchen sind verdaulicher als die großen. Die maximale Durchlaufzeit der einzelnen Funktionen ist drastisch reduziert. Anstatt in der LED-Ausgabe einmal 1000 ms zu warten wird nun 1000 mal 1 ms gewartet. Zwischendurch werden aber 1000 mal die anderen Prozesse bearbeitet. Echte Demokratie sozusagen. Noch viel besser ist die Handhabung des UARTs. Anstatt eine Ewigkeit auf ein ankommendes Zeichen zu warten, wird nur dann etwas bearbeitet, wenn auch wirklich etwas zur Bearbeitung vorliegt. Klingt eigentlich logisch. Also nur dann, wenn schon ein Zeichen empfangen wurde wird es auch bearbeitet, ansonsten geht es zurück zur Hauptschleife. Das ist praktisch der ganze "Trick" eines kooperativen Multitaskings. Auch wenn die Verwendung von _delay_ms(1) noch ein kleiner Schönheitsfehler ist, den die Profis lieber mit einem Timer erledigen, so wird das Prinzip klar.
- Prozesse eines kooperativen Multitaskingsystems warten nicht (lies: niemals) auf das Eintreten von Ereignissen, sondern bearbeiten nur bereits eingetretene Ereignisse.
- Größere Aufgaben werden in kleine Teilaufgaben zerlegt, welche nur durch mehrfaches Aufrufen der Funktion abgearbeitet werden. Das erreicht man meist am besten mit einer State machine.
- Prozesse eines kooperativen Multitaskings haben eine garantierte, maximale Durchlaufzeit, welche möglichst klein ist.
Damit ähneln die Prozesse einem Interrupt, auch wenn sie als ganz normale Funktionen außerhalb eines Interrupts ausgeführt werden. An diesem Beispiel erkennt man die Vor- und Nachteile des kooperativen Multitaskings:
Vorteile
- einfacher Scheduler mit geringster CPU Belastung
- Deterministische Arbeitsweise, damit einfach prüfbar und strenges Timing möglich
Nachteile
- eine andere Programmierweise zur Zerlegung größerer Aufgaben in kleine Teilaufgaben muss manuell vorgenommen werden
Verbesserter Ansatz mit Timer
Zum Abschluss die noch bessere Version mit Timer. Diese hat mehrere Vorteile.
- Das Zeitraster der Hauptschleife ist exakt, unabhängig von der Laufzeit der Aufgaben, weil der Timer unabhängig eine feste Interruptfrequenz generiert. Im vorherigen Beispiel war das Zeitraster die Summe aus Laufzeit aller Funktionen/Tasks und dem _delay_ms(1).
- CPU-Rechenleistung wird zu 100% in der Abarbeitung der Task verwendet und nicht für nutzlose Warteschleifen verschwendet.
- Es kann leicht im realen System geprüft werden, ob die Laufzeit der Tasks klein genug ist, um den Anforderungen des Timers zu genügen.
Diese Überprüfung kann an zwei Stellen durchgeführt werden.
- Am Ende der Hauptschleife nach Abarbeitung aller Ausgaben. Wenn hier die Variable flag_1ms schon wieder aktiv ist, dauerte die Abarbeitung länger als 1ms. Wenn man ein sehr strenges Timing sicherstellen möchte, ist das ein Fehler, der erkannt und signalisiert werden kann.
- In der ISR. Wenn hier die Variable immer noch aktiv ist, wurde sie von der Hauptschleife noch nicht erkannt und zurück gesetzt. Das ist definitiv ein Fehler, denn jetzt würde ohne Fehlererkennung ein Timerdurchlauf von der Hauptschleife verschluckt werden. Diese Prüfung ist etwas entspannter, weil zwischenzeitlich ein Durchlauf der Hauptschleife mehr als 1ms, jedoch nicht länger als 2ms dauern darf. Siehe auch den Abschnitt Interrupt#Zeitverhalten_eines_Timerinterrupts. Man muss sich für eine der beiden Prüfungen entscheiden.
/*
Multitasking Demo, dritter Versuch
ATmega32 @ 3,6468 MHz
LED + 1KOhm Vorwiderstand an PB0 und PB1
Taster nach GND an PA0
UART an RXD und TXD
*/
#define F_CPU 3686400
// Baudrate, das L am Ende ist wichtig, NICHT UL verwenden!
#define BAUD 9600L
#include "avr/io.h"
#include "util/delay.h"
#include "avr/interrupt.h"
// Berechnungen
// clever runden
#define UBRR_VAL ((F_CPU+BAUD*8)/(BAUD*16)-1)
// Reale Baudrate
#define BAUD_REAL (F_CPU/(16*(UBRR_VAL+1)))
// Fehler in Promille
#define BAUD_ERROR ((BAUD_REAL*1000)/BAUD-1000)
#if ((BAUD_ERROR>10) || (BAUD_ERROR<-10))
#error Systematischer Fehler der Baudrate grösser 1% und damit zu hoch!
#endif
uint8_t taste_lesen(void) {
if (PINA & (1<<PA0))
return 1;
else
return 0;
}
void led_blinken(uint8_t taste) {
static uint16_t zaehler=0;
if (taste) {
if (zaehler>=999) {
PORTB ^= (1<<PB0);
zaehler=0;
}
}
else {
if (zaehler>=99) {
PORTB ^= (1<<PB0);
zaehler=0;
}
}
zaehler++;
}
void uart_lesen(void) {
uint8_t tmp;
if((UCSRA & (1<<RXC))) { // empfangenes Zeichen abholbereit im UART ?
tmp = UDR;
while (!(UCSRA & (1<<UDRE))); // Warte auf freien Sendepuffer vom UART
UDR = tmp;
}
}
volatile uint8_t flag_1ms;
int main(void) {
int8_t taste;
// IOs initialisieren
PORTA = 1; // Pull Up für PA0
DDRB = 3; // PB0/1 sind Ausgang
// UART initialisieren
UBRRH = UBRR_VAL >> 8;
UBRRL = UBRR_VAL & 0xFF;
UCSRB = (1<<RXEN) | (1<<TXEN);
// Timer 0 initialisieren, CTC, Presacler 64
TCCR0 = (1<<WGM01) | (1<<CS01) | (1<<CS00);
OCR0 = 56; // 1ms
TIMSK |= (1<<OCIE0);
// Interrupts global freigeben
sei();
// Endlose Hauptschleife
while (1) {
if (flag_1ms) {
flag_1ms=0;
taste = taste_lesen();
led_blinken(taste);
uart_lesen();
if (flag_1ms) {
// Strenge Zeitprüfung
// Laufzeit der Tasks >1ms, Fehlersignalisierung
// PB1 auf HIGH, Programm stoppen
PORTB |= (1<<PB1);
while(1);
}
}
}
}
// Interruptserviceroutine für Timer 0
// hier 1ms
ISR(TIMER0_COMP_vect) {
/*
if (flag_1ms) {
// entspannte Zeitpruefung
// Laufzeit der Tasks >2ms, Fehlersignalisierung
// PB1 auf HIGH, Programm stoppen
PORTB |= (1<<PB1);
while(1);
}
*/
flag_1ms = 1;
}
Message passing Framework
Im vorangegangenen Abschnitt wurde erklärt, wie man die einzelnen Tasks in kleine "Häppchen" zerlegen kann und diese alle innerhalb der Main Loop aufruft. Dieses kooperative System hat aber noch einige Nachteile:
- Alle Häppchen werden gleich oft aufgerufen und nicht nur bei Bedarf
- Für die Timeouts gibt es noch keine befriedigende Lösung
Wenn man diese beiden Nachteile auch noch beseitigen möchte, wird das ganze noch ein klein wenig komplizierter. Da man das Grundprinzip aber für viele Mikrocontroller-Projekte immer wieder verwenden kann, lohnt es sich und man kann die Entwicklung für diese Art des Multitasking in einem Framework zusammenfassen.
Ein Framework, das sind einige Dateien, die den Rahmen (Frame=Rahmen) für ein Programm bilden und den Teil enthalten, den man immer wieder braucht.
Message
Die Basis des Frameworks bildet die "Message". Immer wenn wir für einen unserer "Tasks" etwas zu tun haben, schicken wir eine "Message". Die "Messages" werden in eine Warteschlange einsortiert und der Reihe nach abgearbeitet. Dadurch kommt ein Task der viel zu tun hat (viele Messages bekommt) öfter dran, als ein "Task" der nicht so viel zu tun hat. Außerdem kann eine Message noch Daten enthalten (z. B. ein empfangenes Zeichen). So können die einzelnen Tasks sogar Daten austauschen.
Message Receiver
Unsere "Tasks" werden immer dann aufgerufen, wenn Arbeit für sie da ist. Das wissen wir, weil sie eine Message empfangen sollen. Deshalb heißen die "Tasks" ab jetzt "Message Receiver"
Timeout
In diesem System wird jeder Message Receiver aufgerufen, wenn jemand Arbeit für ihn hat und er deshalb eine Message bekommt. Was aber, wenn keine Message kommt, oder ein Message Receiver selbst aktiv werden soll?
Aus diesem Grund braucht es die Timeouts. Mit Hilfe eines Hardware Timers wird eine "Systemzeit" programmiert. Jeder Message Receiver kann die Zeit angeben, wann er wieder aufgerufen werden muss. Das Framework verwaltet alle Timer und sendet den Message Receivern eine "Timeout" message, wenn ihre Zeit gekommen ist.
Beispiel
Hier der Sourcecode eines solchen Framework Datei:ACF.zip Das Framework implementiert die Message Warteschlange und die Timer Warteschlange. Die Prozessor spezifischen Dinge sind in der Datei "ACF_Hal.c" zusammengefasst und für Linux Desktop und atMega128 implementiert. In dieser Datei kann man das ganze auch auf andere Prozessoren anpassen.
Ein "main" sieht dann z.B. so aus:
#include "ACF.h"
int main(int argc, char** argv)
{
ACF_init();
ACF_loop();
return 0; // we will never arrive here
}
Tracing
Es gibt noch einen weiteren Grund, sich ein "Framework" zu erarbeiten, oder ein fertiges Framework zu verwenden. Da der Ablauf der Software und der Aufruf aller Teile vom Framework bestimmt wird, kann das Framework auch einen sehr detaillierten Trace über das Verhalten des Codes anfertigen. Das Framework aus vorstehendem Beispiel enthält bereits entsprechenden Code.
Solche Traces von laufendem Code können gerade dann sehr hilfreich sein, wenn viele Dinge gleichzeitig ablaufen (und das war schließlich der Sinn des ganzen).
Nachstehendes Bild zeigt den Trace eines Reglers, der mit dem Framework realisiert wurde. Sequenzdiagramm
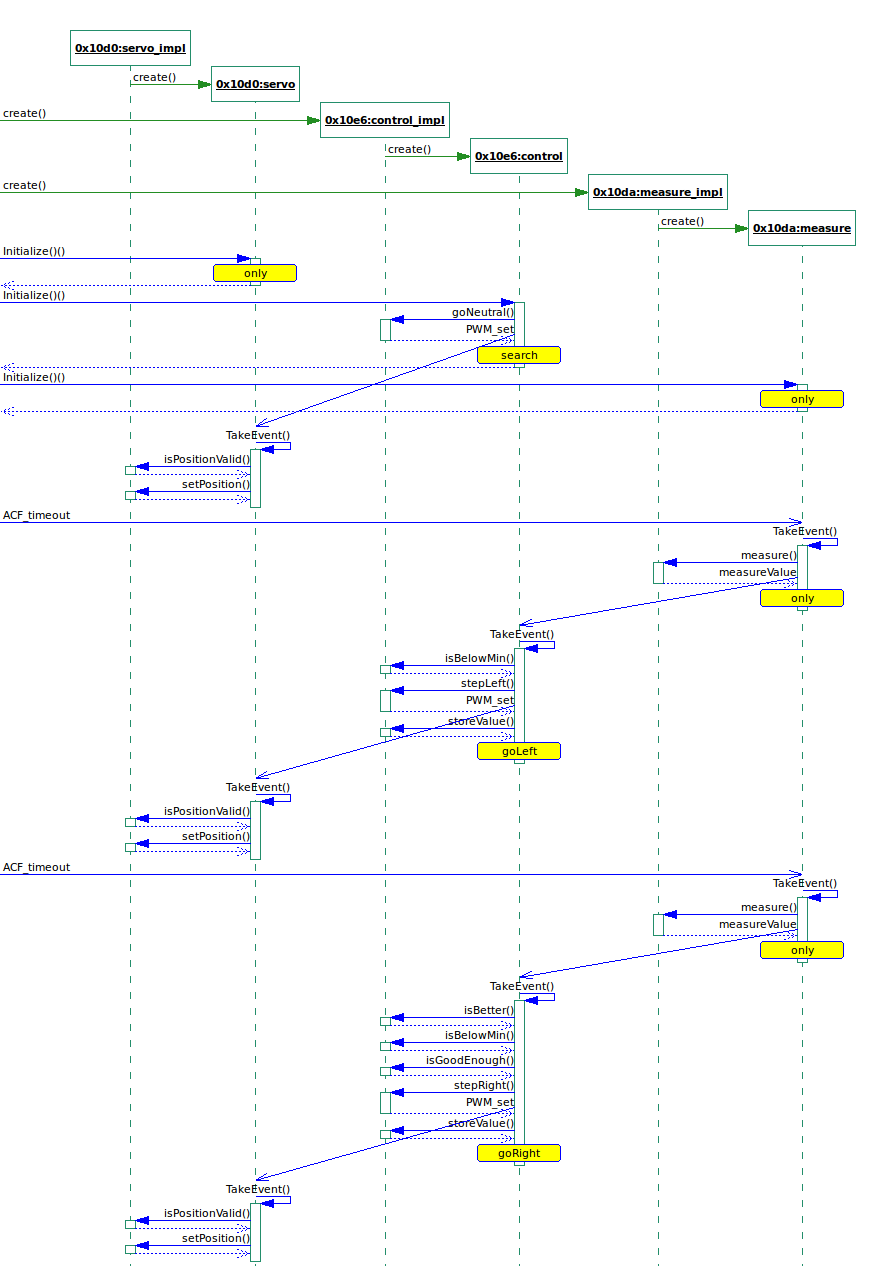{kind=link}
Präemptives Multitasking
Beim präemptiven oder verdrängenden Multitasking gibt das Betriebssystem die Kontrolle zu keinem Zeitpunkt auf. Ein Prozess, der gerade die CPU nutzt, kann jederzeit wieder vom Betriebssystem unterbrochen werden. Daher muss bei der Entwicklung für ein präemptives System immer damit gerechnet werden, dass ein Prozess jederzeit unterbrochen werden kann. Das kann z. B. zu Problemen beim Zugriff auf limitierte Betriebsmittel führen. Beispiel:
- Prozess A sucht freien Speicher und findet einen freien Block
- Prozess B wird vom Scheduler gestartet und sucht ebenfalls einen Speicherblock. Der gefundene Block wird von Prozess B reserviert und benutzt
- Der Scheduler teilt wieder Prozess A die CPU zu. Prozess A wird fortgeführt, d.h. er reserviert jetzt den im letzten Systemcall gefundenen Speicherblock
Jetzt haben also beide Prozesse den gleichen Speicherblock reserviert. Entweder arbeiten jetzt beide Prozesse mit dem gleichen Speicher, und überschreiben daher gegenseitig die Daten, oder das Betriebsystem hat etwas gemerkt und zieht die Notbremse. In jedem Fall passieren schreckliche Dinge. Sowas nennt man eine Race-Condition.
Die Lösung nennt sich Semaphore: Dieser Mechanismus wird vom Betriebsystem bereitgestellt und erlaubt es einem Prozess eine bestimmte Ressource zu sperren. Wenn also Prozess A aus obigem Beispiel Speicher haben möchte, setzt er vor Beginn der sogenannten "Kritischen Sektion" einen Semaphor für "Speicher reservieren". Dieser Semaphor wird erst wieder aufgehoben, sobald Prozess A den Speicher für sich reserviert hat. Wenn der Prozess B zwischendurch gestartet wird und ebenfalls versucht den Semaphor zu setzen, wird er solange warten müssen, bis Prozess A den Semaphor wieder freigibt. Speziell für derartige Locking Mechanismen bieten die meisten Prozessoren sogenannte TAS-Befehle (Test And Set), die in einem Prozessorbefehl eine Variable testen und je nach Ergebnis setzen können. Das ist nötig um das Setzen von Semaphoren unteilbar (atomar) zu machen. Könnte der Scheduler das Setzen eines Semaphors unterbrechen, wäre ja der ganze Aufwand umsonst.
Präemptive Multitasking Systeme sind sehr flexibel und kommen mit einer Vielzahl an Tasks klar. Amok laufende Prozesse können das System bei korrekter Implementierung nicht blockieren. Damit aber das System crash-sicher ist, muss es Systemresourcen geben, die nur der Scheduler verteilen kann (z. B. kein anderer Prozess darf in den Speicherbereich des Schedulers schreiben; kein anderer Prozess darf den Timerinterrupt des Schedulers ändern). Diese Möglichkeiten sind in Mikrocontrollern normalerweise gar nicht vorhanden, wodurch dieser Vorteil des Präemptiven MT weniger ins Gewicht fällt. Beispiele für Systeme mit präemptivem Multitasking sind Linux, *BSD und Windows XP.
Vorteile
- sehr flexibel in der Verwaltung von dynamisch ausgeführten Prozessen
- einzelne Prozesse können einfach linear programmiert werden, ohne die Aufgabe in kleine Teile zerlegen zu müssen
Nachteile
- Der Scheduler ist aufwändiger und benötigt mehr CPU-Zeit
- Höherer Resourcenbedarf zu Verwaltung des Systems und Bereitstellung der Semaphore etc.
- nicht streng deterministisch, somit kann kein festes Timing garantiert werden
- nicht explizit debug- und prüfbar, da die Prozesse nicht fest gekoppelt sind
Multithreading
Multithreading ist eine meist softwarebasierende Möglichkeit moderner Betriebssysteme, innerhalb eines Prozesses mehrere Tasks (threads) parallel auszuführen. Der Vorteil dieser weiteren Unterteilung ist, dass sich die Threads eines Tasks den Speicherbereich teilen können und eine Aufteilung in logische nebeneinander laufende Teile möglich ist. Je nach Betriebssystem kann der Übergang von Multithreading zu Multiprocessing fliessend bis starr sein.
Das Hyperthreading eines Intel Pentium 4 folgt dem Konzept des Multithreadings auf Hardwarebasis und teilt den CPU-Kern zeitlich in zwei logische Prozessoren ein.
Umsetzung auf Prozessoren
Unabhängig davon, ob Multitasking oder -threading auf einem Prozessor konkret unterstützt wird, lässt es sich immer in Form von Software realisieren. Dies wird in modernen Systemen durch das OS geleistet, das standardisierte Funktionen und Strukturen zur Verfügung stellt. Besonders C++ bietet ein stark abstrahiertes Programmiermodell und Methoden-Set an, um effektiv untereinander kompatible Programmmodule erstellen zu können. Nutzt man diese nicht, wie z.B. bei der Programmierung in C, müssen Strukturen manuell erzeugt und gehandhabt werden, was aufwändiger ist, aber auch geringeren overhead bewirkt. Das Programm ist dann fast immer erheblich kleiner, in den meisten Fällen strukturell einfacher, bezüglich komplizierter Änderungen jedoch auch unflexibler und träger.
Bei Mikrocontrollern findet man je nach Komplexität und Struktur der Appliation praktisch alle denkbaren Kombinationen:
System mit real-time OS und Entwicklung in C++
- Programmentwicklung stark an abstrakte Interfaces und Standards gebunden
- Starke Abhängigkeit an das OS im Bezug auf RT-Funktionalität
- Innerhalb gleicher OS-Landschaft gut portierbar
- Sehr geringe Abhängigkeit vom Prozessortyp
- Multitasking muss über OS-Schicht ausprogrammiert werden
- Multithreading muss/kann durch Programmierleistung optimiert werden
- Laufzeiteffizienz ist niedrig durch relativ hohen Anteil des OS-Bedarfs
- Datendurchsatz regelt sich selbst und ist gleichmäßig am relativen Maximum
- Programmiereffizienz ist niedrig durch sehr viel Arbeit an Formalismen
- Planungsaufwand ist noch überschaubar
- Planungseffizienz ist relativ hoch durch viele Standards
- Erweiterung um komplexe Module einfach möglich, Timing regelt sich selber
System mit real-time OS und Entwicklung in C
- Programmentwicklung stark an Interfaces und weniger an Standards
- Starke Abängigkeit an das OS im Bezug auf RT-Funktionalität
- Innerhalb aber auch ausserhalb gleicher OS-Landschaft gut portierbar
- Geringe Abhängig von dem Prozessortyp
- Multitasking muss über OS-Schicht und eigene Strukturen programmiert werden
- Multithreading muss/kann durch Programmierleistung optimiert werden
- Laufzeiteffizienz ist höher durch geringeren Anteil des OS-Bedarfs
- Datendurchsatz regelt sich selbst und ist gleichmässig am relativen Maximum
- Programmiereffizienz ist höher durch weniger Arbeit mit Formalien
- Planungsaufwand ist etwas höher, je nach Applikation
- Planungseffizienz ist relaiv niedriger durch weniger Standards
- Erweiterung mit akzeptablem Aufwand möglich, Timing muss beachtet werden
System ohne real-time OS und Entwicklung in C
- Programmentwicklung stark an Interfaces und kaum an Standards gebunden
- Ausprägung und Gestaltung der RT-Funktionalität absolut frei
- nur ausserhalb von OS-Landschaft portierbar, dafür prinziepiell sehr gut
- Stärkere Abhängig von dem Prozessortyp, kann die Portierbarkeit einschränken
- Multitasking muss auschlieslich durch eigene Strukturen programmiert werden
- Multithreading muss durch umständliche Programmierung ermöglicht werden werden
- Laufzeiteffizienz kann sehr hoch sein, ist aber stark von der Progr. abhängig
- Datendurchsatz muss selbst ins Maximum gesteuert werden, das aber höher liegt
- Programmiereffizienz ist hoch, dank Wegfall von Konventionen
- Planungsaufwand ist stark Applikations abhängig, gfs sehr viel grösser
- Planungseffizienz ist gering, da RT Konzept selber optmiert werden muss
- Erweiterung nur möglich, wenn Timing weitestgehend überarbeitet wird
System ohne real-time OS und Entwicklung in ASM
- Programmentw. nur an physische Interfaces gebunden und frei von Standards
- Ausprägung und Gestaltung der RT-Funktionalität absolut frei
- nur innerhalb der Prozessorlandschaft gut portierbar
- Volle Abhängig vom Prozessortyp, Portierbarkeit auf andere aufwändig
- Multitasking muss auschlieslich durch eigene Strukturen programmiert werden
- Multithreading muss durch umständliche Programmierung ermöglicht werden werden
- Laufzeiteffizienz sehr hoch, jedoch stark von Programmierung abhängig
- Datendurchsatz muss selbst ins Maximum gesteuert werden, das aber höher liegt
- Programmiereffizienz ist hoch, dank Wegfall von Konventionen
- Planungsaufwand ist stark applikationsabhängig, ggfs. sehr viel grösser
- Planungseffizienz sehr gering, RT Konzept nur für einfache System machbar
- Erweiterung nur möglich, wenn Timing komplett überarbeitet wird
Weblinks
- Scheduler mit Erweiterung zum Mini-Betriebssystem
- Präemptives Multitasking bei Wikipedia
- Femto OS, ein ultrakompaktes Mulitaskingbetriebssystem für kleine Mikrocontroller
- FreeRTOS, ein freies Echtzeitbetriebssystem für Mikrocontroller
- Get by Without an RTOS Ein schönes Beispiel wie man ohne ein RTOS auch Multitasking hinbekommt.
- TNKernel, freier Multitasking-Kernel.
- i-hate-rtoses Blog zum Thema RTOS
- Multitasking mit Arduino Multithreading in C und Arduino
- Für ATtiny geeignete einfache Stackumschaltung für 2 Threads