Hallo zusammen, ich habe es gerade satt, bei einem Bastelprojekt mit 320 x 240 TFT auf Umlaute, "ß" und "µ" im Text zu verzichten. Die Monospaced-Schritftart, die ich aus einer Arduino-Library entnommen habe, ist auch keine Schönheit. Früher™ habe ich beim 8 Pixel hohen Font diese Zeichen selbst gemalt. (irgendwann einmal auch einen 5 Pixel hohen Font komplett selbst auf kariertem Papier ...). Aber: Das nervt. Ich bin kein Typograph, und das sieht man. Irgendwo im Forum habe ich einen Zeichengenerator für Schriftarten-Quelltext mal gefunden - finde es aber nicht wieder. Ich weiß auch nicht, ob diese für Sonderzeichen brauchbar war. Außerdem stellt sich bei Schriftarten immer die Frage nach dem Urheberrecht, was allerdings erst dann interessant wird, sollte man das Projektchen als abschreckendes Beispiel Open Source stellen. Hat jemand einen Tipp für mich? Viele Grüße W.T.
Angehängte Dateien:
-

Screenshot.png
2,6 KB
>Früher ... selbst gemalt. >Aber: Das nervt. >die Frage nach dem Urheberrecht Selber machen -> man hat selbst das Urheberrecht von anderen kopieren -> jemand anders hat das Urheberrecht Open Source nutzen -> der geschenkte Gaul ist nicht gut genug Selber machen und open Source verschenken -> umsonst für andere gearbeitet Das Dilemma ist, was machen zu wollen, aber halt nicht alles, sondern nur das was man selbst für interessant empfindet oder bereits gut kann. Man macht aber nur persönliche Fortschritte, wenn man die eigenen Schwächen ausbügelt. Also, kariertes Papier auspacken und den perfekten Font für Umlaute erstellen und den Ruhm der Community ernten. Fonts ohne Umlaute scheinen ja schon länger ein Ärgernis zu sein.
qwertz schrieb: > Also, kariertes Papier auspacken Es ist schon viel bequemer, die Kästchen am Bildschirm auszufüllen, und man muss das dann nicht mehr extra in Daten umsetzen. Das lässt sich auch ohne Spezialsoftware mit Assemblerbefehlen wie DEFB (Define Byte) umsetzen:
1 | DEFB 00000000 |
2 | DEFB 00000100 |
3 | DEFB 00001010 |
4 | DEFB 00010001 |
5 | DEFB 00011111 |
6 | DEFB 00010001 |
7 | DEFB 00010001 |
Ich hatte auch mal einen netten kleinen Fonteditor, aber der Entwickler ist verstorben und die Software hat niemand weitergeführt - das scheint mir nicht untypisch, mit Windows und Truetype entstand vorübergehend eine grosser Hype um Schriften und Typografie, heute interessiert das kein Schwein mehr. Georg
Wo ist das Problem? kopier das u über irgendein Zeichen aus deinem Font das du nicht brauchst und setz 2 punkte drauf.
Hallo, danke für die sinnvollen Antwortteile. georg schrieb: > mit Windows und Truetype entstand vorübergehend > eine grosser Hype um Schriften und Typografie, heute interessiert das > kein Schwein mehr. Wie das für jedes Problem ist, das zufriedenstellend gelöst ist: Irgendwann vergißt man den vorherigen Zustand. grundschüler schrieb: > kopier das u über irgendein Zeichen aus deinem Font > das du nicht brauchst und setz 2 punkte drauf. qwertz schrieb: > Also, kariertes Papier auspacken und den perfekten Font für Umlaute > erstellen und den Ruhm der Community ernten. Typografie ist eine Arbeit, die entsprechende Fähigkeiten erfordert. Beim "ü" mag das ja halbwegs einfach sein (wobei da auch einzelne Pixel über gutes oder schlechtes Aussehen entscheiden), das "µ" als verlängertes gespiegeltes "u" zu machen ist schon brutal, und das "ß"? Als Mischung aus "f" und "s" zusammenstückeln? Typografie, Lackieren und Knochenbrüche gehören zu den Sachen, bei denen ich lieber jemanden frage, der sich damit auskennt. Auch wenn er schwer zu finden ist.
Walter T. schrieb: > Wie das für jedes Problem ist, das zufriedenstellend gelöst ist: > Irgendwann vergißt man den vorherigen Zustand. Ich habe für meine Steuerungen damals einen ganzen kyrillischen Font programmiert, und ich habe auch noch Fontlab, die führende Software, aber die habe ich glaube ich seit mindestens 10 Jahren nicht mehr benutzt - einfach kein Bedarf mehr. Kleine LCDs sind die einzigen Anzeigegeräte für die sich noch die Frage nach einem passenden Font stellt. Georg
Walter T. schrieb: > ich habe es gerade satt,... Glaub ich dir. Ich hatte bei der Lernbetty einige Eigenbau-Fonts dabei. Die brauchen aber auch zumindest den Rumpf des dortigen gdi.c, weil meine Fonts variable Breite und Höhe haben können und man sogar bei Bedarf sich monochrome Icons und kleine Grafiken damit machen kann. Ich häng dir mal ein paar Fonts als Quelle (*.txt) und fertig übersetzt (*.c) dran, dazu den Fontcompiler, den ich mir vor gefühlten 20 Jahren mal selber geschrieben habe, dazu auch ein passendes GDI, wo du dir das rauskopieren kannst, was du haben willst. Um sich nen Font zu machen, lädst du dir eine der *.txt in deinen Editor und änderst dort, was du haben willst. Da siehst du sinngemäß folgendes:
1 | FACE_NAME "Simple5x7" |
2 | Height= 7 |
3 | CapHeight=0, Ascent= 6, Descent= 1 |
4 | |
5 | ...
|
6 | |
7 | Ch_41: { "A" } |
8 | .MM... |
9 | M..M.. |
10 | M..M.. |
11 | MMMM.. |
12 | M..M.. |
13 | M..M.. |
14 | -- ...... |
15 | ;
|
16 | |
17 | ...
|
18 | |
19 | Ch_AB: { "guillemotleft" } |
20 | ......
|
21 | ......
|
22 | .M..M. |
23 | M..M.. |
24 | .M..M. |
25 | ......
|
26 | -- ...... |
27 | ;
|
Jeder Punkt steht für ein nicht gesetztes Pixel und jedes M für ein
gesetztes Pixel. Nach meinem Empfinden ist das die beste Kombination, um
sich aus dem Erscheinungsbild die rechte Vorstellung über das spätere
Aussehen machen zu können.
Was ist was?
Im Header braucht es den Namen und die Angabe der Höhe. Ascent, Descent
usw. sind nett, aber für die Übersetzung nicht so wichtig.
Ch_XX: { Bezeichnung }
Das ist der Start eines Zeichens, hexadezimaler Wert des Zeichens und in
Klammer die verbale Bezeichnung.
Dann folgen soviele Zeilen, wie die o.g. Höhe vorgibt. In jeder Zeile
stehen dann so viele Punkte und M's, wie man für das aktuelle Zeichen
haben will. Muß für alle Zeilen des Buchstaben gleich sein.
Anschließend ne Zeile, wo nur ein Semikolon drin ist, als Endmarke.
Die beiden Striche (links) geben nen optischen Eindruck für die gedachte
Schreiblinie.
Übersetzt wird das mit fm.exe und dann kommt ne fertig benutzbare
C-Quelle bei heraus - oder ne Fehlermeldung vom fm.exe
Die erzeugte C-Quelle ist übrigens sowohl für Little Endian als auch für
Big Endian Systeme geeignet. Deshalb byte DispHi und ..Lo und kein
int_ oder _word.
Die Funktion CgCh_at zeichnet einen Buchstaben. Dabei zeichnet sie NUR
die gesetzten Pixel. Die nichtgesetzten Pixel im Font bleiben unberührt.
Deshalb muß man den Hintergrund zuvor ablöschen. Das ist deshalb, weil
diese Funktion logisch (also per Definition in gdi.h) für verschiedene
Umgebungen da ist: vom einfachen monochromen Display bis hin zu
TrueColor-TFT.
W.S.
Typographie-Bauchschmerzen bei 5x7-, oder auch 8x12-Fonts... Genaauuu! Ich kann garnicht S-Bahn fahren, wegen der grausigen Laufschrift für die Stationen. - Aber Taxi ist genauso schlimm! Die Taxameter-Darstellung hat ja auch keine Kultur nicht...
Wenn es ein paar tausend Zeichen mehr sein sollen, und 8/16x16 OK sind, Google Mal czybiora unifont.
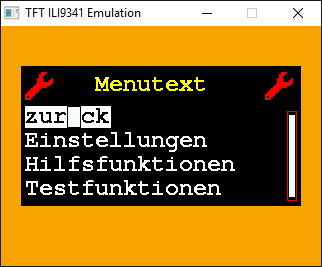
Giaccomo schrieb: > Typographie-Bauchschmerzen bei 5x7-, oder auch 8x12-Fonts... Sieh Dir mal den Screenshot am Anfang des Threads an: https://www.mikrocontroller.net/attachment/354542/Screenshot.png Um so kleine Fonts geht es ganz offensichtlich nicht.
Mir ging das ähnlich. Als typographischer Laie kam das Selber-Zeichnen nicht in Frage. Und als Programmierer habe ich lieber meine Zeit in einen Konverter gesteckt. Als Ausgangsformat dient BDF, das einerseits noch per Text-Editor erstellt werden kann, in dem aber auch viele Fonts noch im Netz verfügbar sind (beispielsweise der oben erwähnte Unifont). Ausserdem ist BDF weitestgehend standardisiert. Wie auch immer, ich sammele seit mehreren Jahre gute Pixel Fonts und erweitere damit meine eigene Graphics-Lib. Die Fonts kann man u.a. hier anschauen: https://github.com/olikraus/u8g2/wiki/fntlistall Ausserdem ist das Copyright jeweils sorgfältig dokumentiert. Die Roh-Daten (BDF-Fonts) liegen hier: https://github.com/olikraus/u8g2/tree/master/tools/font/bdf Das ist sozusagen das "best of" Bitmap Font aus 4 Jahren. Praktisch alle dieser Fonts enthalten auch die europäischen Sonderzeichen (das war eines der Kriterien für die Aufnahme in meine Sammlung). Grüße, Oliver (u8g2 lib)
u8g2 schrieb: > Das ist sozusagen das "best of" Bitmap Font aus 4 Jahren. Das Beste aus 4 Jahren? Und wie soll man das anwenden? Soweit ich das beim Drüberschauen sehen konnte, befaßt du dich zu allererst mit diversen Displays und deren Display-Controller-Chips. Deine Fonts scheinen mir schlichtweg jeweils auf ein bestimmtes Display, einen bestimmten Displaycontroller und einen bestimmten µC ausgerichtet zu sein. Siehe "https://github.com/olikraus/u8g2/wiki/setup_tutorial"; und "https://github.com/olikraus/u8g2/wiki/Porting-to-new-MCU-platform"; Wieso eigentlich? Ein Font hat ja schließlich GARNICHTS mit irgend einem konkreten Display und dessen physischer Ansteuerung zu tun, sondern ein Font ist ein Satz von Daten, mittels dessen eine Zeichenroutine auf einer Fläche aus Pixeln an einer vorgebbaren Stelle einen Buchstaben o.ä. erscheinen lassen kann. Das ist reine Programmierung und sollte von der Ebene der Lowlevel-Treiber strikt getrennt werden, sonst eckt man ständig an seinen eigenen Rahmenbedingungen an. Zitat: "You need to know the controller and the size of your display (Note: "Controllerless" displays are not supported by U8g2)" Für einen Font ist es doch egal, wie groß und wie bunt der Bildschirm ist, falls zu klein, dann wird eben nur ein Teil des Buchstaben angezeigt werden können. Und warum sind Displays, die Refresh benötigen, ausgeschlossen? Mir kommt dein Konzept doch recht unpraktisch vor. W.S.
qwertz schrieb: > Also, kariertes Papier auspacken und den perfekten Font für Umlaute > erstellen ich mache das in einer Exel Tabelle erst mal sieht man an den gesetzten X schon den Buchstaben, weiter wird das gesetzte X in C-Code überführt um die ich meine C-Font .h Datei erweitern kann
Joachim B. schrieb: > ich mache das in einer Exel Tabelle O ha! Ja, ich kenne das, denn meine Frau macht auf diese Weise ihre Strickmuster. Im Ö.D. wird Excel sehr gern verwendet, weil man damit so schöne Text-Kästchen machen kann... W.S.
W.S. schrieb: > O ha! Ja, ich kenne das, denn meine Frau macht auf diese Weise ihre > Strickmuster. aber das gibt keinen Code für die Strickmaschine oder doch? :)
W.S. schrieb: > Ein Font hat ja schließlich GARNICHTS mit irgend einem konkreten Display > und dessen physischer Ansteuerung zu tun Natürlich nicht. Die von Dir zitierten Seiten haben auch nichts mit den Fonts zu tun. Die Fonts sind nur Teil der Lib. Das von mir angegebene Directory ist eine Sammlung von display unabhängigen Fonts. Nicht mehr und nicht weniger. Die Fonts liegen im Klartext als hex-code vor (BDF Format) und könnten per copy und paste relativ einfach in eigene Projekte übernommen werden. Grüße, Oliver
Guten Morgen zusammen, W.S. schrieb: > Ich häng dir mal ein paar Fonts als Quelle (*.txt) und fertig übersetzt > (*.c) dran, dazu den Fontcompiler, den ich mir vor gefühlten 20 Jahren > mal selber geschrieben habe, danke an W.S. für die Verfügungsstellung seines kleinen Werkzeugs und vor allem der Font-Liste. Joachim B. schrieb: > ich mache das in einer Exel Tabelle Achim S. schrieb: > Google Mal czybiora unifont. Ich glaube, so ein Werkzeug hat jeder, der mit GLCDs zu tun hat, mal geschrieben. Bei mir war/ist es ein Konverter zwischen BMP-Dateien und C-Array, der Einfachheit halber in Matlab geschrieben. Da paßt der Unifont natürlich direkt (wenn auch beschränkt auf 16 x 16). u8g2 schrieb: > Wie auch immer, ich sammele seit mehreren Jahre gute Pixel Fonts und > erweitere damit meine eigene Graphics-Lib. > > Die Fonts kann man u.a. hier anschauen: > > https://github.com/olikraus/u8g2/wiki/fntlistall > > Ausserdem ist das Copyright jeweils sorgfältig dokumentiert. Danke für Deinen Hinweis und Deine Font-Sammlung. Was ich allerdings nicht verstehe: Wo finde ich die Copyright-Hinweise zu den Schriftarten? Viele Grüße W.T.
Walter T. schrieb: > Danke für Deinen Hinweis und Deine Font-Sammlung. Was ich allerdings > nicht verstehe: Wo finde ich die Copyright-Hinweise zu den Schriftarten? erster Link oben (fntlistall), auf einen Font klicken, jeweils 2. Link oben heisst dann ‚Copyright‘...
u8g2 schrieb: > Die Fonts liegen im > Klartext als hex-code vor (BDF Format) und könnten per copy und paste > relativ einfach in eigene Projekte übernommen werden. Na, so einfach mit Copy&Paste wohl doch nicht. Schließlich sind die Zahlen nach BITMAP zeilenorientiert und haben Byte-Grenzen. Um daraus einen wirklich benutzbaren Font zu machen, muß man noch einiges dazwischen tun, insbesondere das Padding rauszuschmeißen und ein im µC benutzbares Font-Format zu etablieren. W.S.
W.S. schrieb: > muß man noch einiges > dazwischen tun Ausserdem ist die Frage, ob man die Pixeldaten zeilen- oder spaltenweise angibt - für CRT-artige Bildschirme ist es zwar logisch, Zeilen zu speichern, aber ein Naturgesetz ist das nicht, und z.B. bei einer Laufschrift wären Spalten geeigneter. Eine Umwandlung ist aber programmtechnisch kein Hexenwerk. Georg
u8g2 schrieb: > Wie auch immer, ich sammele seit mehreren Jahre gute Pixel Fonts und > erweitere damit meine eigene Graphics-Lib. Ich hatte das Thema "Schriftarten" erst einmal zurückgestellt, weil andere Teile des Projektchens dringender der Aufmerksamkeit bedurften. Ich habe mich gestern mal durch die U8G2-Sachen gewühlt. In u8g2.h findet sich die Struktur der Zeichensaetze (u8g2_font_info_t), so richtig schlau werde ich daraus allerdings nicht. Gibt es irgendwo noch eine übersichtlichere Beschreibung des Datenformats?
Der interessante Teil scheint sich in u8g2_font.c abzuspielen. Ich finde allerdings lustigerweise keine Stelle, wo irgendwelche Daten in einen Pixelpuffer kopiert werden. Gefühlt bestehen alle XX_draw_XX-Funktion und alles, was davon aufgerufen wird, nur aus dem Zusammenstellen irgendwelcher Offsets.
Hallo Walter, wenn du mit bis 8x8 großen Zeichnen zu recht kommst kann Dir als Alternative das von mir entwickeltes Programm empfehlen wo man selbst definierte Zeichensätze erstellen kann: Beitrag "Charaktergenerator" Srolle hinunter bis zu Version 1.01 mfG
Angehängte Dateien:
-

Screenshot.png
2,1 KB
Ozvald K. schrieb: > wenn du mit bis 8x8 großen Zeichnen zu recht kommst Hallo Ozwald, danke, aber damit kann ich nichts anfangen. Eine gute 8x8-Zeichen-Nichtproportionalschrift mit der kompletten Codepage 850 habe ich schon eingebunden. Was mir jetzt fehlt, ist eine gute "Brot- und Butter"-Proportionalschrift mit Umlauten.
Ah, jetzt ja. Die u8g2_font.c scheint ein BDF-Interpreter zu sein. Ich finde zwar immer noch nicht die Stelle, wo etwas in den Pixelpuffer kopiert wird, aber so langsam ergibt das Sinn. Wie genau die BDF-Daten (die ja normalerweise ASCII sind) serialisiert sind, kriege ich heraus. Die Makro-Geschichte scheint den Zweck zu haben, dass die Font Descsription zur Section in der Memory Map wird.
Ich hab mal das Programm FontForge benutzt. Gerade um die fehlenden Umlaute zu basteln.
https://unix.stackexchange.com/questions/119236/bitmap-font-data-as-array-in-c Bin mir aber nicht sicher obs das war, aber damit konnte man sich mittels Skript sehr einfach eine Zeichentabelle erstellen mit Sonderzeichen usw.
Naja. Ich finde, die U8G2-Geschichte ist es durchaus wert, sich damit mal zu befassen. Auch wenn mich der Display-Ansteuerungs-Teil, der den Hauptteil ausmacht, nicht interessiert. Der Grafik-Teil auch nicht. Die Möglichkeit, auf den riesigen Pool der zudem auch noch sehr kompakten BDF-Fonts zuzugreifen, finde ich sehr reizend. Wahrscheinlich komme ich am Wochenende mal dazu, das Ganze auf die acht nötigen Schriftarten-Schnittstellenfunktionen herunterzubrechen.
Walter T. schrieb: > Die Möglichkeit, auf den riesigen Pool der zudem auch noch sehr > kompakten BDF-Fonts zuzugreifen, finde ich sehr reizend. Das fand ich auch, weshalb ich mich mittlerweile vollständig auf das BDF Format verlasse. Viele Editoren (u.a. auch fontforge) können Fonts im BDF Format ablegen. Das automatisierte Einlesen der BDF Dateien und das Konvertieren der BDF Daten in das eigene Datenformat ist aus meiner Sicht kein großes Problem. Das Datenformat von BDF ist jedenfalls gut erklärt: https://en.wikipedia.org/wiki/Glyph_Bitmap_Distribution_Format Für U8g2 bin ich einen Schritt weitergegangen und habe die Pixeldaten komprimiert. Deshalb ist auch die Interpretation der Daten im u8g2_fonts.c etwas schwierig. Leider bin ich bisher auch nicht dazugekommen das Ganze zu dokumentieren. Die Frage nach der existierenden Dokumentation kam aber letzthins auch mal im Arduino Forum auf: https://forum.arduino.cc/index.php?topic=535040.msg3655518#msg3655518 Vielleicht helfen meine Antworten dort etwas weiter. Ich hätte dann auch noch zwei weitere Ideen: 1. @OP: Es besteht die Möglichkeit die U8g2 auf die Zielplattform zu portieren. U8g2 ist eine C-library mit einer C++ Wrapper für die Arduino Welt. Aber der C Kern läuft auf jedem System. 2. Es gibt noch das bdfconv.exe tool, das die Daten aus dem BDF herausliest. Man könnte hier vor der Komprimierung die Daten in seinem eigenen Format ablegen. bdfconv.exe liegt hier: https://github.com/olikraus/u8g2/tree/master/tools/font/bdfconv Grüße, Oliver
Hallo Oliver, danke für die ausführliche Antwort. u8g2 schrieb: > Für U8g2 bin ich einen Schritt weitergegangen und habe die Pixeldaten > komprimiert. OK, RLE erklärt einiges. u8g2 schrieb: > https://forum.arduino.cc/index.php?topic=535040.msg3655518#msg3655518 > > Vielleicht helfen meine Antworten dort etwas weiter. Das führe ich mir mal in Ruhe zu Gemüte. u8g2 schrieb: > 1. @OP: Es besteht die Möglichkeit die U8g2 auf die Zielplattform zu > portieren Genau das ist mein Ziel. Für jede Schriftarten-Schnittstelle habe ich bisher genau acht Funktionen benötigt:
1 | typedef int exit_t; // EXIT_SUCCESS oder EXIT_FAILURE; |
2 | typedef int codepage_t; // Enum |
3 | typedef struct { int16_t x, y, w, h; } Rect_t; |
4 | typedef int_fast16_t ifast16_t; |
5 | |
6 | codepage_t XXXfont_init(parameters); |
7 | exit_t XXXfont_deinit(void); |
8 | |
9 | typedef struct |
10 | {
|
11 | Rect_t (*getBoundingBox)(void); |
12 | ifast16_t (*getLinePitch)(void); |
13 | ifast16_t (*char_getCharPitch)(char c); |
14 | ifast16_t (*char_getWidth)(char c); // Breite auf Basislinie kann kleiner als Breite BoundingBox sein |
15 | Rect_t (*char_getBoundingBox)(char c); |
16 | exit_t (*char_copyBitmapToPixelbuffer)(uint8_t *pxbuf, char c); |
17 | }
|
18 | Font_vtable_t; |
Damit lassen sich alle Ausrichtungs-Geschichten (und theoretisch sogar Kerning - aber ich habe keine Schriftart, bei der das Implementiert wäre) abdecken. Wenn ich das richtig sehe, gibt es in der Library zu allen Funktionseinheiten Äquivalente - nur ein wenig mit dem Display-Treiber verquickt. Das sollte sich ja trennen lassen. Wenn der Wetterbericht für das Wochenende stimmt, weiß ich schon, wann ich das ausprobiere. Viele Grüße W.T.
Walter T. schrieb: > Wenn ich das richtig sehe, gibt es in der Library zu allen > Funktionseinheiten Äquivalente - nur ein wenig mit dem Display-Treiber > verquickt. Das sollte sich ja trennen lassen. Auf Wunsch der Arduino Community hab ich die Font-Render Proceduren aus U8g2 herausgelöst und eine eigene Library erstellt: https://github.com/olikraus/U8g2_for_Adafruit_GFX Die einzige Schnittstelle zum Display sind die Routinen zum Zeichnen horizontaler und vertikaler Linien: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/master/src/U8g2_for_Adafruit_GFX.cpp#L229 Der Rest besteht aus den reinen Font-Render-Routinen: Dekodierung und UTF-8 Handling und ein paar Features wie 90 Grad Rotation und Transparenz/Solid Rendering. Gerne nehme ich auch weitere Wünsche in der Lib entgegeben (wie beispielsweise BBX Berechnung etc...). Einfach ein GitHub Issue anlegen... Grüße, Oliver
Angehängte Dateien:
-

Font_BoundingBox.png
8,3 KB
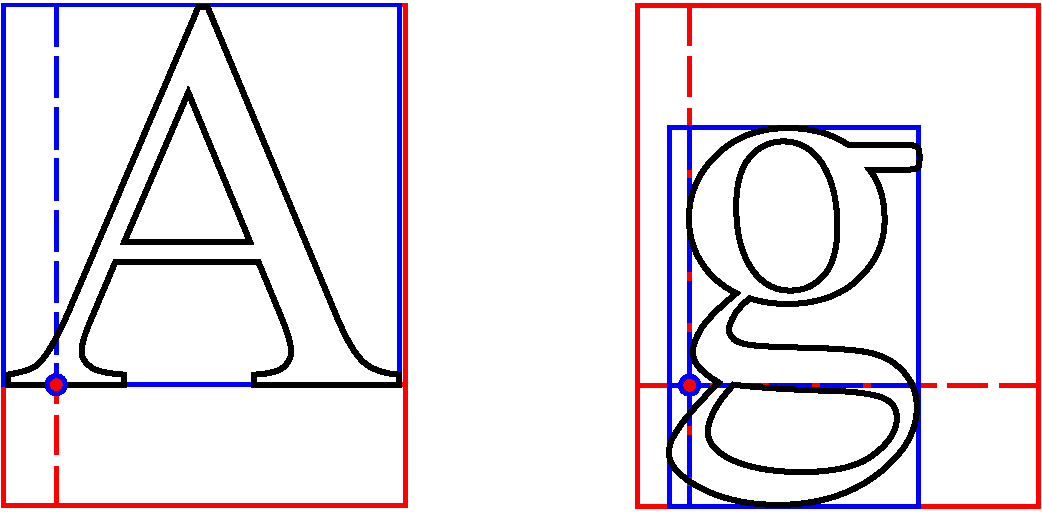
u8g2 schrieb: > Auf Wunsch der Arduino Community hab ich die Font-Render Proceduren aus > U8g2 herausgelöst Danke nochmal für den Hinweis! Ich habe gerade ziemlich lange im oben verlinkten Github-Repository gesucht... Dann führe ich mir den Teil mal zu Gemüte. u8g2 schrieb: > Gerne nehme ich auch weitere Wünsche in der Lib entgegeben (wie > beispielsweise BBX Berechnung etc.. Den Teil verstehe ich nicht. Wie kannst Du Zeichen darstellen, ohne die Bounding-Box zu kennen? Irgendwie muss doch die Basislinie ausgerichtet, der Zeichenvorschub durchgeführt und das Ganze irgendwie in einen Grafikspeicher (ob jetzt auf dem LCD oder in der MCU sei mal dahingestellt) kopiert werden. Zumindest für das einzelne Zeichen müßte es doch soetwas schon geben (in der Skizze blau dargestellt)? Oder wird das wie in der Adafruit-Library gemacht, wo jedes Pixel einzeln zum LCD kopiert wird? Edit: Hab's gefunden. Die andere Library ist ja recht kompakt. Verstehe ich das richtig: Als zusammenhängend erkannte Pixel werden als Linie gezeichnet, und die Ausrichtung (H/V) bestimmt, ob die Linie waagerecht oder senkrecht ist? Edit 2: Es wird klarer....die Linie steckt ja schon in der RLE. An eine geometrische Interpretation habe ich noch nie gedacht. Edit 3: Ich sollte mehr Energie in Quelltext-lesen als in Foren-Posts stecken :-).
u8g2 schrieb: > Auf Wunsch der Arduino Community hab ich die Font-Render Proceduren aus > U8g2 herausgelöst und eine eigene Library erstellt: Oliver, vielen Dank dafür, da ich mich auch gerade damit beschäftige die u8g2-Lib für meine Zwecke anzupassen und da ist das Ziel das Ganze in den Speicher zu zeichnen, denn den habe ich immer und dann von da auf das entsprechende Display. Walter T. schrieb: > Edit: Hab's gefunden. Die andere Library ist ja recht kompakt. > Verstehe ich das richtig: Als zusammenhängend erkannte Pixel werden als > Linie gezeichnet, und die Ausrichtung (H/V) bestimmt, ob die Linie > waagerecht oder senkrecht ist? > > Edit 2: Es wird klarer....die Linie steckt ja schon in der RLE. An eine > geometrische Interpretation habe ich noch nie gedacht. > > Edit 3: Ich sollte mehr Energie in Quelltext-lesen als in Foren-Posts > stecken :-). Walter, danke dafür, das Du uns an deinen Gedanken der Erkenntnis teilhaben lässt. Sowas finde ich sehr hilfreich, da ich diese Erkenntnisse selbst machen müsste, so aber Zeit gespart habe und mich auf die anderen Dinge konzentrieren kann. Siehe oben Edit: Typo
Ein sehr schönes Tool ist auch das hier: http://www.eran.io/the-dot-factory-an-lcd-font-and-image-generator/ Es generiert Dir Font-Daten für genau die Zeichen, die Du brauchst. Das spart Platz. Und zugreifen kannst Du trotzdem einfach über den ASCII-Code.
Walter T. schrieb: > Den Teil verstehe ich nicht. Wie kannst Du Zeichen darstellen, ohne die > Bounding-Box zu kennen? Doch doch, die BBX kenne ich schon und die ist natürlich auch in den Font-Daten der u8g2 lib gespeichert. Ich dachte Du wolltest die Werte der BBX über die API auslesen. Das ist noch nicht implementiert. Pro Zeichen werden fünf Informationen gespeichert, die hintereinander im Speicher liegen, aber im Code an zwei verschiedenen Stellen ausgelesen werden: Zwei Daten hier: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/1.0.0/src/U8g2_for_Adafruit_GFX.cpp#L350 glyph_width & glyph_height Das sind (grob gesagt) Breite und Höhe der Bounding Box (BBX). Genauer gesagt, sind das Breite und Höhe der abgespeicherten Bitmap. Dann drei Daten hier: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/1.0.0/src/U8g2_for_Adafruit_GFX.cpp#L381 x und y Offset der Bitmap bezüglich des Referenzpunktes des Zeichens. Der Referenzpunkt ist der Punkt auf der Gundlinie links unten vom A. Beispiel: Für das Hochkomma wird eigentlich nur eine kleine Bitmap benötigt. Diese Bitmap befindet sich recht weit oberhalb der Grundlinie, entsprechend ist der y Offset recht groß und gibt eben die Stelle an, wo die Bitmap zu liegen hat. Entsprechendes gilt für den x Offset, der sogar negativ sein kann (wie in dem A vom obigen Bild zu erahnen). Schließlich gibt das delta-x an, wo der Referenzpunkt des nächsten Zeichens liegt. Viele Implementierungen benutzen hier einfach die Breite der BBX um die Position des nächsten Zeichens zu berechnen, das ist aber eigentlich falsch, da ja die Breite des aktuellen Zeichens nicht unbedingt darauf schließen lässt, wo das nächste Zeichen beginnt. Ein Beispiel wäre der Satzpunkt, nach dem üblicherweise eine etwas größere Lücke gelassen wird. Nur der Vollständigkeit halber: Pro Zeichen ist dann in der U8g2 noch Größe des komprimierten Zeichens und der Unicode abgelegt: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/1.0.0/src/U8g2_for_Adafruit_GFX.cpp#L458 Somit sind pro Zeichen folgende Informationen in einem U8g2 Font abgelegt: Unicode (1 oder 2 Bytes) Anzahl Bytes des komprimierten Zeichens (1 Byte) Breite der Bitmap des Zeichens (variable Bitanzahl) Höhe der Bitmap des Zeichens (variable Bitanzahl) X-Verschiebung des Zeichens (variable Bitanzahl) Y-Verschiebung des Zeichens (variable Bitanzahl) Horizontaler Abstand des nächsten Zeichens (variable Bitanzahl) Danach folgt direkt die Run-Length Codierung des der Bitmap: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/1.0.0/src/U8g2_for_Adafruit_GFX.cpp#L400 Das ist jeweils ein Ziffernpaar aus "Anzahl der Hintergrundpixel (0)" und "Anzahl der Vordergrundpixel (1)". Beide Werte beschreiben die Länge einer horizontale Linien aus nicht gesetzten und gesetzten Pixel. Bei sehr langen Linien nicht gesetzter Pixel, ist der zweite Wert (1) dann einfach immer 0. Also beispielsweise 7 0 2 3 beschreibt eine 9 Pixel lange Linie in der Hintergrundfarbe mit anschließend 3 Pixel in der Vordergrundfarbe. Auch diese Werte sind alle bitkomprimiert, d.h. die Werte liegen nicht einfach auf Bytegrenzen und sind auch nicht notwendigerweise 8 Bit breit. Sollte das Zeichen um 90 Grad gedreht sein, werden statt horizontalen Linien einfach vertikale Linien gezeichnet. Vielleicht noch kurz der Zusammenhang zum BDF Dateiformat. Der dortige BBX Befehl entspricht exact den oben genannten Werten (bis auf das Delta-X, das aus einem anderen Befehl gewonnen wird). Bevor ich aber die Bitmap des BDF files im U8g2 Font ablege, entferne ich noch überflüssge Kanten aus der Bitmap des BDF files. Wenn Beispielsweise die erste Spalte der Bitmap im BDF file aus lauter nicht gesetzten Pixel besteht, dann wird diese Spalte gelöscht und der X-Offset um eins erhöht. Auch das spart natülich wieder Speicher. All das führt dazu, dass man in den U8g2 Fonts sogar recht große Bilder ablegen kann: https://github.com/olikraus/u8g2/wiki/fntgrpiconic#open_iconic_all_8x Jedes dieser 220 Icons ist 64x64 Pixel groß. Es würden also 64x64/8*220 = 110KB benötigt. Tatsächlich belegt dieser Icon-Font aber nur 24515 Bytes, also nur ca. 25% der unkomprimierten Daten. Grüße, Oliver
Angehängte Dateien:
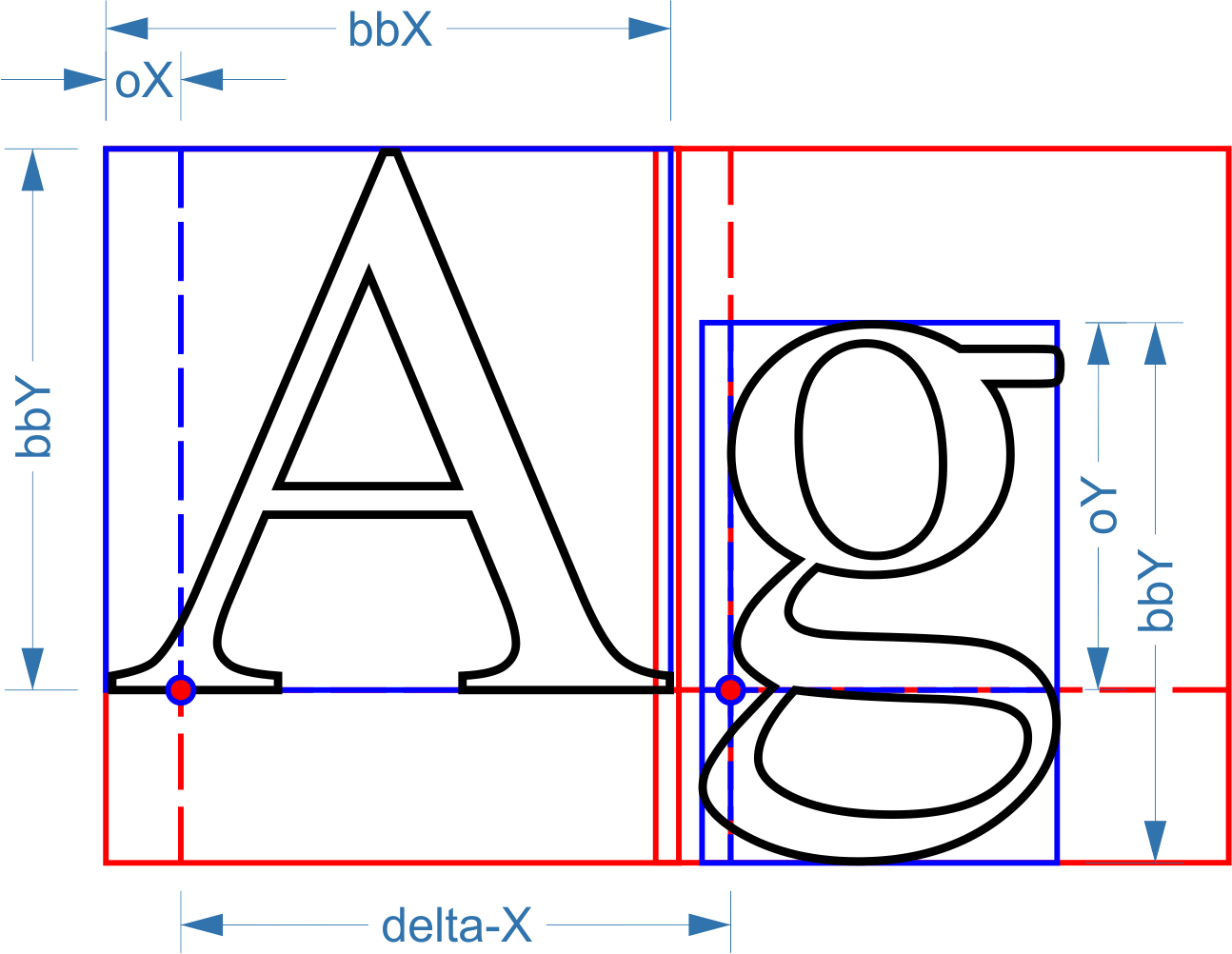
Danke für die "Foren-Doku". Ich habe mal Deine Worte und mein Verständnis des Quelltextes in eine kleine Skizze gepackt (dass der Basislinienpunkt des großen "A"s in meiner Skizze etwas weiter rechts liegt, ist ja nur Font-Sache, da durch die Kombination X-Offset und Laufweite delta-X frei festlegbar). Bei meinen bisher verwendeten Schriften habe ich die große, rote BoundingBox auch immer aus den Einzel-Boundingboxen aller Zeichen im Zeichensatz zur Laufzeit berechnet. Solange der Umfang der Schriftzeichen bekannt ist, ist das ja kein Problem. u8g2 schrieb: > All das führt dazu, dass man in den U8g2 Fonts sogar recht große Bilder > ablegen kann: Das ist natürlich eine feine Sache, an die ich vorher noch gar nicht gedacht habe. Wie man an den Bildern oben sieht, habe ich mir bislang mit häßlichen um den Faktor zwei hochskalierten Piktogrammen geholfen.
Walter T. schrieb: > Das ist natürlich eine feine Sache, an die ich vorher noch gar nicht > gedacht habe. Wenn es sich nur um einige wenige und monochrome Icons oder Piktogramme handelt, ist der Weg ja OK. Aber sobald man etwas größeres macht, ist eine geeignete Kompression angesagt. Hab ich beim Thema "Landkarten auf dem µC" oder so mal durchexerziert. Ich glaub, ich hatte zu dem Thema hier schon mal was gepostet. W.S.
Angehängte Dateien:
-

u8g2_first_light.png
5 KB
Das Dunkel fängt an zu lichten. Momentan zeichne ich noch mit Linien-Zeichen-Funktionen durch, aber ich fange an, Land zu sehen. Woran im momentan noch etwas rätsel, ist u8g2_font_get_glyph_data(). Es scheint, als enthielte der Block ab Byte 23 hintereinander a) den Unicode für ein Zeichen b) den Sprung-Abstand zum nächsten Zeichen c) die Pixeldaten des Zeichens. Die Funktion springt also Zeichen für Zeichen durch, bis der passende Zeichencode gefunden wird. Dabei gibt es zwei Abkürzungen für Groß- und Kleinbuchstaben, damit nicht so viele Zeichen durchwühlt werden müssen. Für die Zeichen ab Unicode 255 hat der Zeichencode dann 16 Bit, so dass sich die Offsets etwas verschieben. Dafür gibt es dann keine Abkürzungen mehr. Habe ich das richtig verstanden?
Walter T. schrieb: > Habe ich das richtig verstanden? Ja, genau, jedoch noch mit einer kleinen Bemerkung hierzu: > a) den Unicode für ein Zeichen > b) den Sprung-Abstand zum nächsten Zeichen > c) die Pixeldaten des Zeichens. Zwischen b) und c) liegen noch 5 wichtige Werte: 1. Breite der Bitmap des Zeichens 2. Höhe der Bitmap des Zeichens 3. X-Verschiebung des Zeichens 4. Y-Verschiebung des Zeichens 5. Horizontaler Abstand des nächsten Zeichens Ich bin beeindruckt, dass Du dich so tief in das Format hinein arbeitest. Grüße, Oliver
Angehängte Dateien:
-

Font_RLE_naiv.jpg
37 KB

Hallo Oliver, u8g2 schrieb: > Zwischen b) und c) liegen noch 5 wichtige Werte: Danke! Das wäre die übernächste Funktionalität gewesen, nach der ich gesucht hätte. u8g2 schrieb: > Ich bin beeindruckt, dass Du dich so tief in das Format hinein > arbeitest. Tief...naja. Aber wenn ich etwas auf links krempeln will, sollte ich schon nachsehen, dass ich nicht versuche, alles durchs Knopfloch zu ziehen. Der Vorteil: Wir basteln hier gerade zusammen die Doku :-). Wo wir gerade beim Datenformat sind: Die Glyphen-Bitmaps sind zeilenweise von links nach rechts und oben nach unten gespeichert. Naiv fallen mir da vier Möglichkeiten ein (wenn man das Escaping kurzer Sequenzen mal außen vor läßt). Für mich ist eigentlich erst einmal nur die Frage relevant: Sind Elemente zeilenübergreifend gespeichert? So ganz schlau werde ich aus den get_unsigned_bits()/get_signed_bits() nämlich noch nicht. Viele Grüße W.T.
Walter T. schrieb: > Der Vorteil: Wir basteln hier gerade zusammen die Doku :-). Ja, das stimmt. Vielleicht übersetze ich das ganze mal ins Englische und hänge es an das Projekt Wiki an. Walter T. schrieb: > Wo wir gerade beim Datenformat sind: Die Glyphen-Bitmaps sind > zeilenweise von links nach rechts und oben nach unten gespeichert. Genau. Walter T. schrieb: > Sind > Elemente zeilenübergreifend gespeichert? Ja, sind sie. Diese for-Schleife bricht eine dekodierte Linie wieder in einzelne Zeilen für das Zeichen herunter: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/master/src/U8g2_for_Adafruit_GFX.cpp#L290 Beispielsweise, wenn das Zeichen 5 Pixel breit ist und eine Linie von 11 Pixel gezeichnet werden sollte, dann werden sozusagen zwei Zeilen und ein Pixel gezeichnet (naja, jenachdem wo angefangen wurde). Walter T. schrieb: > So ganz schlau werde ich aus > den get_unsigned_bits()/get_signed_bits() nämlich noch nicht. Diese beiden Funktionen sind sozusagen das Herz der Dekodierung. Über diese beiden Funktionen werden die Werte der Lauf-Längen-Kodierung zurückgewonnen. Das hat aber nichts mit dem oben beschriebenen Zeilenumbruch zu tun. Bezüglich deines Bildes müsste eigentlich a) die richtige Kodierung sein. Oliver
Joachim B. schrieb: > W.S. schrieb: >> O ha! Ja, ich kenne das, denn meine Frau macht auf diese Weise ihre >> Strickmuster. > > aber das gibt keinen Code für die Strickmaschine oder doch? :) Nicht lustich und nicht abwegig. Ich wurde quasi "gebeten" einen Strickmustervisualiserer zu schreiben. Strickmuster in Excel rein (mit Kästchen und X-sen) und gerenderte Ansicht des gestrickten Teils hinten wieder raus. Mal im Ernst: traut sich jemand so etwas zu?
Angehängte Dateien:
-

Seite_46.png
17 KB

u8g2 schrieb: > Vielleicht übersetze ich das ganze mal ins Englische und > hänge es an das Projekt Wiki an. Wir können auch auf Englisch weiterdiskutieren. Dann entfällt das übersetzen. u8g2 schrieb: > Ja, sind sie. Dann habe ich das Prinzip langsam verstanden. In jedem Glyph sind der Unicode und der Sprung-Abstand zum nächsten Zeichen die einzigen unkomprimierten Daten. Danach sind alle Informationen RLE-kodiert, wobei die Kodierungslänge im Header in den ersten 23 Bytes steckt. Das sorgt für die kleinen Daten. Was mich etwas Zeit gekostet hat, war eine Übersicht zu bekommen, welche Daten wo im Dekoder gesetzt und verändert werden. Aber jetzt passt das. Ein paar Kleinigkeiten sind mir noch unklar: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/master/src/U8g2_for_Adafruit_GFX.cpp#L311 Warum wird hier x mit der Höhe der Zeichen-Boundingbox inkrementiert? Ansonsten sehe ich langsam Land. Der Pixelpuffer funktioniert schon. Jetzt geht es nur noch darum, die zustandsabhängigen Klamotten (Dekoder) und die zustandsunabhängigen Sachen (Rest) etwas zu trennen. Viele Grüße W.T.
Walter T. schrieb: > Wir können auch auf Englisch weiterdiskutieren. Dann entfällt das > übersetzen. Ach, deutsch passt schon. Walter T. schrieb: > In jedem Glyph sind der > Unicode und der Sprung-Abstand zum nächsten Zeichen die einzigen > unkomprimierten Daten. Danach sind alle Informationen RLE-kodiert Also, ich würde das mal so sagen (im Sinne von https://de.wikipedia.org/wiki/Laufl%C3%A4ngenkodierung): Ich verwende zwei verschiedene Kodierung: 1. Eine Bit-Kodierung, bei der Werte als Bitfolge, unabhängig von den Bytegrenzen, abgelegt sind. Hier werden für die Werte oft weniger als 8 Bit benötigt. 2. Eine RLE Kodierung der Bitmap. Wobei hier die notwendigen Daten der RLE Kodierung zusätzlich Bit-kodiert sind (im Sinne von 1.). Also ist die Bitmap erstmal RLE kodiert und dann noch Bit-kodiert. Die fünf Daten zwischen Sprungdistanz und Bitmap würde ich in diesem Sinne nicht als RLE kodiert, sondern als Bit-kodiert bezeichnen. Walter T. schrieb: > https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/master/src/U8g2_for_Adafruit_GFX.cpp#L311 > > Warum wird hier x mit der Höhe der Zeichen-Boundingbox inkrementiert? Das hat mit der Boundingbox nicht mehr viel tun. Es ist eine Vektor-Addition, die die endgültigen Pixel-Koordinaten berechnet. Die ergeben sich aus der linken oberen Ecke der Bitmap auf dem Display (target_x und target_y) sowie der aktuellen Position in der Bitmap (lx, ly). (lx, ly) ist am Anfang in der linken oberen Ecke (0, 0) und läuft dann in die rechte untere Ecke. Der Punkt (target_x, target_y) bleibt konstant bis das nächste Zeichen an der Reihe ist. Die Summe dieser beiden Werte ist dann die Pixel-Position auf dem Display. Grüße, Oliver
Angehängte Dateien:
-

Screenshot.png
4,1 KB -

Font_BoundingBox_Forenfrage.png
26 KB -
Font_BoundingBox_Forenfrage.svg
2,8 KB
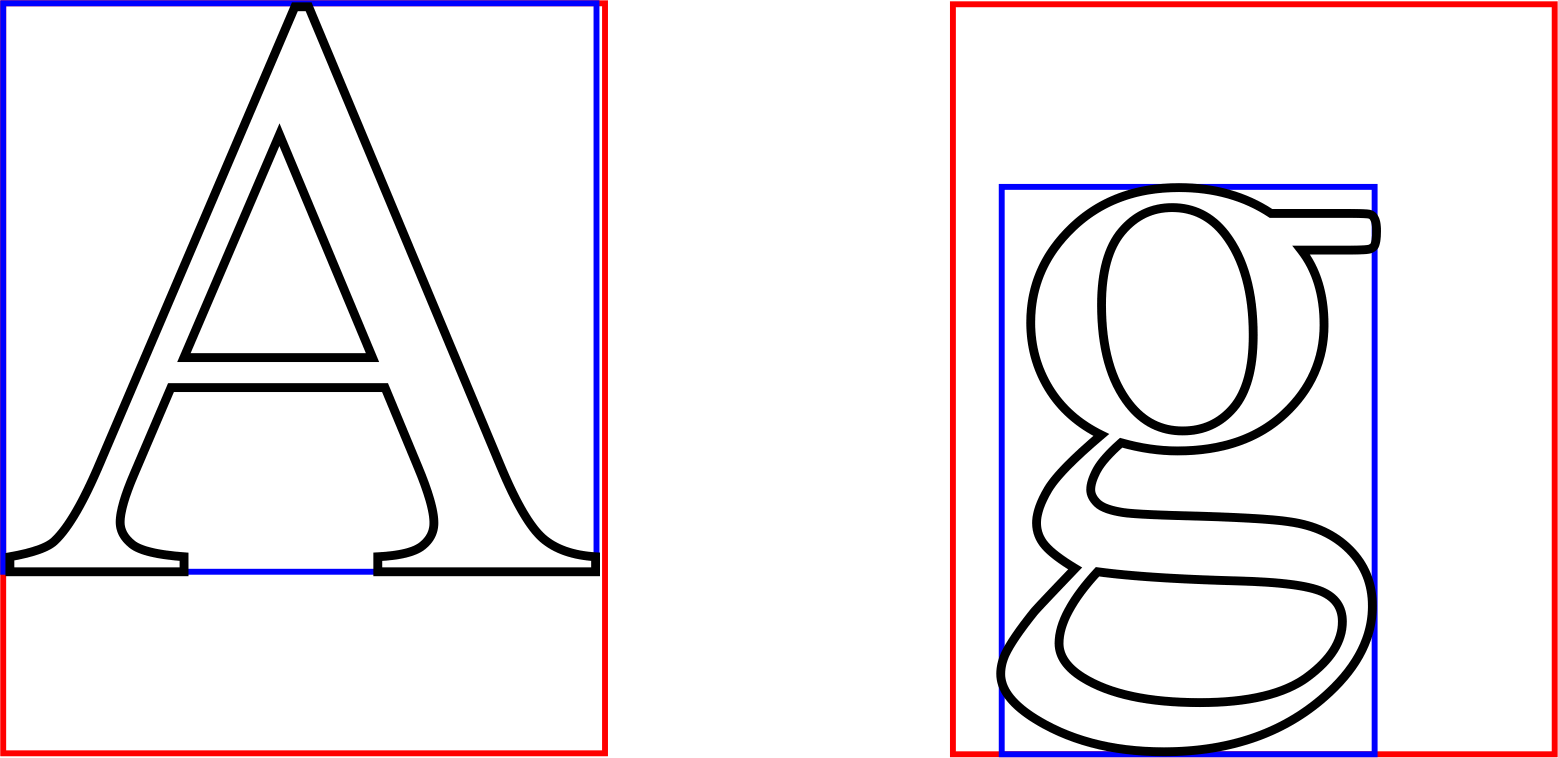
Hallo Oliver, danke für Deine Unterstützung. Und noch viel mehr Dank für Deine absolut wunderbare Library! Vor mir öffnet sich gerade die wunderbare Welt einer gut lesbaren Darstellung auf dem LCD mit Umlauten und Sonderzeichen, ohne daß ich mich um jedes Zeichen einzeln kümmern muß. Wie man im Screenshot sieht, bin ich mit den Offsets und den Boundingboxen noch nicht ganz im Reinen. (Das halbe "M" liegt allerdings nur daran, daß zu ich noch Debug-Zwecken Delays im Zeichenaufbau habe - mit dem Auge sieht man nichts.) Aber im Großen und Ganzen bin ich schon sehr glücklich damit. Jetzt also die Feinheiten. Die müßten ja alle in _u8g2_font_info_t stecken:
1 | struct _u8g2_font_info_t |
2 | {
|
3 | /* offset 0 */
|
4 | uint8_t glyph_cnt; /* Number of Glyphs/characters */ |
5 | uint8_t bbx_mode; /* ????? */ |
6 | uint8_t bits_per_0; /* Encoding run lenght */ |
7 | uint8_t bits_per_1; /* Encoding run length */ |
8 | |
9 | /* offset 4 : Encoding lengths of glyph bounding box components */
|
10 | uint8_t bits_per_char_width; |
11 | uint8_t bits_per_char_height; |
12 | uint8_t bits_per_char_x; |
13 | uint8_t bits_per_char_y; |
14 | uint8_t bits_per_delta_x; |
15 | |
16 | /* offset 9 : Font Bounding box*/
|
17 | int8_t max_char_width; |
18 | int8_t max_char_height; /* overall height, NOT ascent. Instead ascent = max_char_height + y_offset */ |
19 | int8_t x_offset; |
20 | int8_t y_offset; |
21 | |
22 | /* offset 13 */
|
23 | int8_t ascent_A; /* Oberlaenge Buchstabe 'A'; Abstand Basislinie zur oberen Kante Font-Boundingbox ? */ |
24 | int8_t descent_g; /* usually a negative value */ /* Unterlaenge; Gilt acent_A - descent_g = max_char_height ? */ |
25 | int8_t ascent_para; /* ???? */ |
26 | int8_t descent_para; /* ???? */ |
27 | |
28 | /* offset 17 : Start Pos
|
29 | Offset of specific Glyphs ('A', 'a', 255) in Font Array.
|
30 | This accelerates search for the correct glyph. Would still work, if all
|
31 | zeroes, thus slower */
|
32 | uint16_t start_pos_upper_A; /* Glyphs starting from 'A' */ |
33 | uint16_t start_pos_lower_a; /* Glyphs starting from 'a' */ |
34 | uint16_t start_pos_unicode; /* Glyphs starting from 255 */ |
35 | };
|
(für bessere Lesbarkeit auch als Datei angehängt) Einige Sachen sind mir unklar geblieben: bbx_mode: Scheint nirgendwo verwendet zu werden. Ist das eine Altlast, die Vorbereitung zu einer Erweiterung, ein Rest aus dem BDF-Standard oder habe ich einfach nicht gründlich genug gesucht? Bei den Parametern unter Offset 13 bin ich mir auch nicht so recht über ihre Bedeutung klar: - ascent_A : Abstand Basislinie zur Oberkante der Font-BoundingBox? - descent_g: Abstand Basislinie zur Unterkante ? Sind diese beiden Größen Erweiterungen des BDF-Standards? - ascent_para; - descent_para; Diese beiden Parameter sind Teil des Standards und scheinen die gleiche Bedeutung zu haben (mit descent_para = - descent_g) ? Viele Grüße W.T.
Walter T. schrieb: > Vor mir öffnet sich gerade die wunderbare Welt einer gut lesbaren > Darstellung auf dem LCD mit Umlauten und Sonderzeichen, ohne daß ich > mich um jedes Zeichen einzeln kümmern muß. Sehr nett auf den Punkt gebracht. Danke dafür. Walter T. schrieb: > uint8_t bbx_mode; Das ist der Mode mit dem der Font durch bdfconv.exe generiert wurde. Wir haben bisher nur den "t" (transparent) Mode besprochen. Es gibt noch den "h" mode und den "m" mode. Die unterscheiden sich nicht im Format, aber in der Art und Weise der Vorverarbeitung. Im "h" und "m" Mode haben alle Bitmaps im Font die gleiche Höhe und das Delta-x entspricht der Breite des Zeichens. Im "m" Mode haben zusätzlich alle Zeichen die gleiche Breite (mono-spaced). Ich glaube die Werte waren so: t = 1, h = 2, m = 3. t, h und m sind jeweils die vorletzten Buchstaben der U8g2 Font-Namen hinterlegt. h und m Fonts belegen entsprechend mehr Speicher, da die Bitmap größer ist. Die Idee der h und m Fonts ist, dass man auf dem Display einen bereits vorhandenen Text "überschreiben" kann. Bei einem t font muss man einen Rechteckigen Bereich vorher löschen. Man hat das auf einem deiner Bilder ganz gut gesehen (25.3.). Der rote Buchstabe war in einem blauen Rechteck eingebettet. Dieses blaue Rechteck ist minimal bei den t Fonts und entsprechend größer bei den h und m Fonts. Walter T. schrieb: > /* offset 13 */ > int8_t ascent_A; /* Oberlaenge Buchstabe 'A'; Abstand > Basislinie zur oberen Kante Font-Boundingbox ? */ > int8_t descent_g; /* usually a negative value */ /* > Unterlaenge; Gilt acent_A - descent_g = max_char_height ? */ > int8_t ascent_para; /* ???? */ > int8_t descent_para; /* ???? */ Das sind eigentlich die wichtigsten Werte um "bounding" Boxen zu berechnen. ascent_A: Die Höhe des großen A, gerechnet ab der Baseline. Es ist also die tatsächliche Höhe des großen A in Pixel. ascent_g: Das ist sozusagen das Gegenteil von ascent_A, nämlich wie weit das kleine g unter die Baseline ragt. Der Wert ist normalerweise negativ! Aus diesen beiden Werten kann man dann die Höhe einer Box berechnen, die die üblichen Zeichen einschließt: ascent_A - descent_g Achtung: Das Minus ist hier wichtig, weil ja ascent_g negativ ist. Bemerkung: Ich bin mir jetzt nicht ganz sicher ob es nicht "ascent_A - descent_g + 1" lauten sollte. ascent_para: Wie ascent_A, aber für die runde Klammer (Paranthesis) descent_para: Wie descent_g, aber auch hier für die runde Klammer. Hintergrund für das Verwenden der runden Klammer ist, dass die runden Klammern noch höher als das große A sind und noch tiefer ragen als das kleine g. Der Wert ascent_para - descent_para ergibt üblicherweise einen optisch ganz guten Zeilenabstand. Wenn es enger sein darf, ist ascent_A - descent_g sozusagen die Untergrenze des Zeilenabstands. Nehmen wir mal an, Du willst an die Stelle (x,y) den Text "Abcdefg" schreiben und um den Text eine Box zeichnen. Dann ist die obere linke Ecke der Box bei (x, y-ascent_A). Die untere linke Ecke wäre (x, y+descent_g)... ok auch hier bin ich mir nicht ganz sicher, ob es nicht y+descent_g-1 ist. Die Breite der Box kann mit der Funktion getUTF8Width() Näherungsweise berechnet werden. Die exakte Berechnung ist etwas komplizierter, weil das Delta-X des ersten Zeichens und die Breite des letzten Zeichens berücksichtigt werden müssen (Ausserdem gibt es noch einen Sonderfall mit dem Leerzeichen): https://github.com/olikraus/u8g2/blob/master/csrc/u8g2_font.c#L1096 Danke für die vielen Fragen. Ich denke es ist eine ganz gute Dokumentation geworden. Aber ich befürchte, nur wenige werden wirklich so tief abtauchen müssen. Grüße, Oliver
Angehängte Dateien:
-

Screenshot.png
6,4 KB
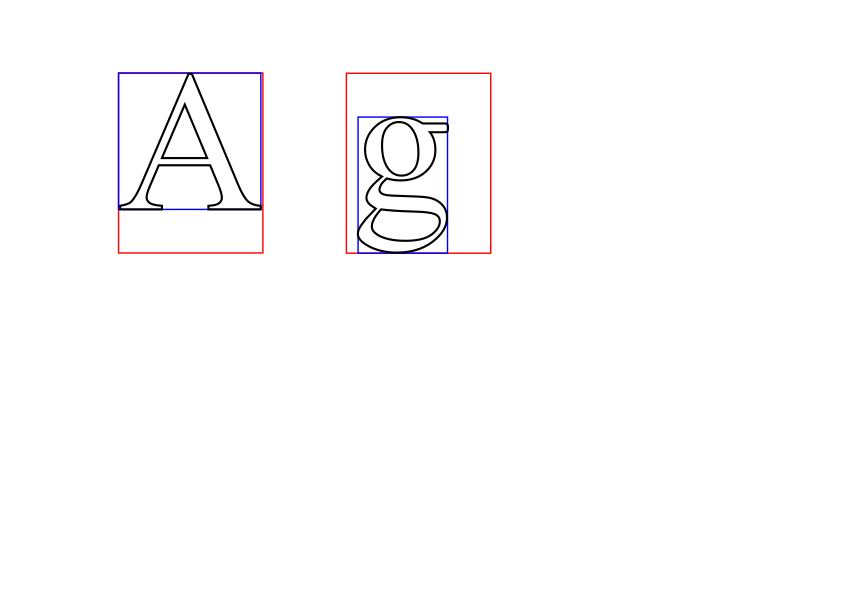
{kind=link}
{kind=link}
Hallo Oliver, danke für Deine ausführliche Beschreibung der Offsets. Es wird wohl ein paar Tage brauchen, bis ich alle Implikationen daraus verarbeitet habe, da ich in den nächsten Tagen eher nicht dazu komme, aber es ist für die nächsten (letzten?) Schritt extrem hilfreich. Mir ist nämlich immer noch nicht ganz klar, wie sich die Font-Bounding-Box berechnet - oder anders: Warum sie so riesig ist. (Ich habe sie mal im Screenshot gelb dargestellt.) Wenn ich eine eigene BoundingBox als minimales Rechteck, das alle Glyph-Boundingboxen von 0x20 bis 0xFF umschließt, berechne, ist das Ergebnis bei allen getesteten Schriftarten kleiner. u8g2 schrieb: > Ich denke es ist eine ganz gute Dokumentation geworden. Ich habe mal in den vergangenen Tagen die Ergebnisse unserer Diskussion ins Englische übersetzt (momentan als Quelltext-Kommentare vorliegend). Wenn ich das richtig sehe, kann in Deinem Wiki nicht jeder schreiben. Ich würde Dir also die entsprechenden Texte zukommen lassen, sobald der Quelltext nicht mehr peinlich ist. (Momentan sieht es sehr wüst aus, weil sich unsere Stile doch sehr stark unterscheiden.) u8g2 schrieb: > Aber ich befürchte, nur wenige werden wirklich > so tief abtauchen müssen. Ist doch erst einmal ein gutes Zeichen. Das heißt, daß die Funktionalität gut gekapselt ist. Ich habe den Vorteil des Laien: Mit sitzt weder ein Produktmanager noch ein Abgabetermin im Nacken. Viele Grüße und ein schönes Osterwochenende wünscht Nicolas (aka W.T.)
Walter T. schrieb: > Mir ist nämlich immer noch nicht ganz klar, wie sich die > Font-Bounding-Box berechnet - oder anders: Warum sie so riesig ist. Sie dürfte den nötigen Zeilenabstand mit beinhalten, was man bei Deiner Glyphenkombination "Ag" sehen kann, da steckt unterhalb der Unterlänge des "g" noch etwas Luft. Oder sind die Boxen auch deutlich breiter als nötig?
Rufus Τ. F. schrieb: > Sie dürfte den nötigen Zeilenabstand mit beinhalten Nein, der Zeilenabstand ist deutlich kleiner - wie ja oben geschrieben wurde, ist er sinnvoll eher bei abs(ascent_A)+ abs(descent_g) oder abs(descent_A)+ abs(descent_g) oder abs(ascent_para) + abs(descent_para). Viel breiter sind sie auch. Was ich noch nicht betrachtet habe, ist ob es evtl. noch deutlich größere Zeichen als '@' gibt. Es kann natürlich auch sein, daß sich die Bounding-Box auf das umhüllende Rechteck von Zeichen im Zeichensatz bezieht, deren Glyphen in der Teilmenge des vorliegenden Fonts gar nicht mehr enthalten sind. Oder daß es für BDF noch eine ganz andere Definition gibt. P.S.: Der angezeigte Zeilenabstand im Screenshot entspricht noch der Höhe der Boundingbox. Das ist typographisch Unsinn, aber die BoundingBoxen lassen sich so noch gut darstellen. P.P.S: Der Abstand der Basislinie zur Oberkante der Font-Boundingbox ist noch etwas willkürlich. Wie man sieht, paßt der '|' auch noch nicht ganz hinein.
Ich habe es. Bei mir war ein Fehler drin. Wenn ich von allen enthaltenen Zeichen das umhüllende Rechteck berechne, komme ich auf exakt die im Font hinterlegte Bounding-Box hinaus. Vor allem der riesige Klammeraffe trägt jede Menge zur Breite bei.
Walter T. schrieb: > Wenn ich das richtig sehe, kann in Deinem Wiki nicht jeder schreiben. Kein Problem, stelle mir einfach einen issue dazu: https://github.com/olikraus/u8g2/issues Oliver
Meine Frage passt zwar zu einem grafischen LCD, hat aber zunächst nichts mit Umlauten/Sonderzeichen zu tun. Hoffe trotzdem auf Tipps. Ich habe das grafische LCD DEM240160A mit dem IS UC1698u. Hier möchte ich neben der Darstellung einer EKG-Kurve (funktioniert schon) etwas Text für z. B Puls, Batteriespannung einblenden. Meine Frage: Wenn ich (Programmierlaie) mir z.B. mit den "Ozvald–Zeichengenerator" die „Zeichen-Datei, *.h" erzeugt habe, wie geht es dann weiter. Oder, wo könnte man dazu nachlesen? µC: MSP430F1611, LCD: siehe oben
wolle g. schrieb: > [...] das paßt tatsächlich nicht zum Thema. Da ist es sinnvoll, einen eigenen Thread aufzumachen.
Hallo Oliver, es hat ein wenig gedauert (manche Sachen sieht man einfach besser, wenn man ein paar Tage Pause macht), aber der einfache Teil ist jetzt für mich geschafft: Am Anfang dachte ich, es würde ein kleiner Wrapper ausreichen, aber letztendlich habe ich den BDF-Dekoder aus der U8G2-Lib teilweise re-implementiert. Das war aus folgenden Gründen sinnvoll: - Arbeiten mit einem zeichenweisen Bitmap-puffer anstelle direkter Darstellung auf dem Display - wahlfreier Zugriff auf Font-Geometrie-Daten (BoundingBoxen und Zeichenabstand) ohne komplette Dekodierung oder gar Darstellung der Zeichen, um die Ausrichtung in Tabellen und Textfeldern zu erleichtern. (Nebenbei: Hut ab vor Deiner Arbeit! Ich habe noch nie eine echte Quelltext-Library gemacht. Insbesondere finde ich es eindrucksvoll, die Du die Anzahl einzubindender Fremd-Header fast auf Null herunterbekommst.) Der Stand ist also: Ich habe jetzt einen Klumpen Quelltext, der eine Mischung aus Deiner und meiner Arbeit ist. An sich enthält er von meiner Seite nicht viel Schöpfungshöhe. Er ist nur besser an meinen Verwendungszweck angepaßt. Jetzt kommt die Überlegung, wie ich jetzt sinnvoll weiter vorgehe, um mir nicht den Weg abzuschneiden, das Projektchen irgendwann einmal open source machen. Wenn ich das jetzt richtig sehe, gibt es außer der "Copyright"-Notiz keine Lizenzinformation. Sprich: Ich kopiere ich also Deinen dicken "Copyright"-Header auf meinen Misch-Quelltext-Klumpen, und darf das dann veröffentlichen/behalten/verkaufen? Oder wie ist das gedacht? Viele Grüße Nicolas P.S.: Nein, das ist keine Abschlußarbeit. Es geht um ein kleines großes Hobbyprojekt Beitrag "Re: Zeigt her eure Kunstwerke (2017)" P.P.S.: Jetzt habe ich in den Copyright-Headern auch Deine Emailadresse entdeckt. Die war so riesig, daß ich sie nicht gesehen habe. Ich lasse die Frage trotzdem mal im Forum stehen, da ich denke, daß die Antwort nicht nur für mich interessant ist.
Walter T. schrieb: > Wenn ich das jetzt richtig sehe, gibt es außer der "Copyright"-Notiz > keine Lizenzinformation. Sprich: Ich kopiere ich also Deinen dicken > "Copyright"-Header auf meinen Misch-Quelltext-Klumpen, und darf das dann > veröffentlichen/behalten/verkaufen? Oder wie ist das gedacht? Nun es gibt diese Lizenz Datei: https://github.com/olikraus/U8g2_for_Adafruit_GFX/blob/master/LICENSE Grundsätzlich muss man leider zwischen dem (Quell-) Code (2-clause BSD-Lizenz) und den Fonts unterscheiden. Die 2-clause BSD Lizenz ist hier ganz gut erklärt: https://www.fakten-gegen-vorurteile.de/de/lizenzen/simplified-bsd/ Insgesammt sollte diese Lizenz recht liberal sein. Auch eine kommerzielle Nutzung ist ok, solange die Lizenzbedingungen eingehalten werden. Bei den Fonts ist das nicht so einfach. Bei allen Fonts muss letztlich die ursprüngliche Lizenz der BDF oder TTF Datei beachtet werden. Das ist jeweils in der u8g2 Lib dokumentiert für jeden einzelnen Font. Ein Auswahlkriterium für den Font war durchaus auch die Lizenz, so dass sich hier auch keine großen Hürden ergeben dürften, aber es kann eben doch sein, dass man den Font Author nennen muss. Über den Master Index der Fonts kommt man zu den jeweiligen Copyright Bedingungen: https://github.com/olikraus/u8g2/wiki/fntlistall Grüße, Oliver
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.