Praktiker schrieb: > Das, und nur das ist immer wieder das Kernproblem - auch bei so manchen > "genialen" Vorstellungen auf so manchen Internetauftritten die alles > zeigen - nur den Sourcecode geschweige den das gut kommentierte Programm > (in C, Assembler, C++, "Adruinosprache", what ever) [nicht zur} Verfügung > stellen..." Hi, Beitrag "Re: Restauration abgefaulter IC-Beine" um nicht zu "off-topic" zu werden, mach ich mal 'nen neuen Thread auf. Es geht mir nicht darum, die manchen sehr leicht über die Lippen gehenden Formulierungen, wie "...ja, das kann heute ja jeder ATtiny mit links...", zu kritisieren, sondern darum, wie man das Geheimnis des UAA1003- Sprechende Uhr - 40-poligen Chips ein wenig "lüften" kann. Also, alle mir bekannten Lösungen, eine Uhr mit Sprachausgabe per Chip nachzubilden, waren nicht so gut wie der besagte UAA1003. Da gibt es auch ältere MMs, die Sprache synthetisieren. OK. Wie kann überhaupt Sprache synthetisiert werden. Die Belgier Lernout and Hauspie haben sich ja durch ihre Sprachengines berühmt gemacht. Die Text-to-Speech Engines arbeiten ganz grob nach dem Prinzip: Phoneme werden aus einem der jeweiligen Sprache zugrundeliegenden Thesaurus geholt und syntaxmäßig plausibel zusammengefügt. Das kann beim UAA1003 allein schon wegen der für heutige Chips geradezu extrem niedrige Taktfrequenz von 230,4 kHz (!) nicht funktionieren, ohne zu große Latenzen und Gestottere in Kauf nehmen zu müssen. Also ist dieser Ansatz schlichtweg falsch. Wie nun wird dann eigentlich die Uhrzeiten-Spreche generiert? Das kann nur so erfolgen, dass die "Phoneme" selbst recht einfache Impulsmuster sind, die in sich noch einmal variiert/berechnet werden. Das ist dann wohl das Kern-Geheimnis des UAA1003. Den gibt es auch in Englisch und Französisch. Weitere Denkanstöße willkommen. ciao gustav
Karl B. schrieb: > Wie nun werden die Uhrzeiten-Spreche generiert? Ich weiß es nicht, aber wäre einfaches Abspielen von Samples nicht auch eine Möglichkeit?
Angehängte Dateien:

Christian H. schrieb: > einfaches Abspielen von Samples Hi, das wurde ja schon ausgeschlossen. aufgrund der schlechten Verarbeitungsgeschwindigkeit und der (nicht vorhandenen) "Rechenleistung". Ich versuche nochmal, etwas über den Ingenieur Notzek etwas herauszufinden. Der hatte so etwas damals für die Stimme beim "Hausfrauenfunk" entwickelt. Das Ding hat aber mehrere Eproms drinne. ciao gustav
Wenn nur die Zeit angesagt werden soll, hält sich der Aufwand in Grenzen: https://www.youtube.com/watch?v=4aMqKr0D-7o Und zum Abspeichern im Flash des MC eignet sich z.B.: https://hackaday.com/2011/09/03/pic-based-voice-recorder/ Das gleiche gibt es auch mit einem ATtiny, find grad den Link nicht.
Peter D. schrieb: > Und zum Abspeichern im Flash des MC eignet sich z.B.: > https://hackaday.com/2011/09/03/pic-based-voice-recorder/ > Das gleiche gibt es auch mit einem ATtiny, find grad den Link nicht. http://elm-chan.org/works/sd20p/report.html
Hm, es gab Ende der Achziger/Anfang der 90er ein IC, das mit einem DRAM im Gespann ein Sprachrecorder für ein paar Sekunden war. Ein DRAM repräsentiert nur ein einzelnes Bit, nicht wie ein EPROM ein Byte. Das lief, glaube ich, per PCM
Das Datenblatt ist sehr bescheiden wenn es um die Funktion geht: > Jedes von Sprachgenerator produzierte Wort besteht aus einer Anzahl > treppenförmiger Impulse, die eine feste Periodendauer von 10 ms haben. Entspricht 100 Hz Abtastfrequenz. Dann wird es schon unklar: > Ein Impuls setzt sich aus 128 verschiedenen Amplitudenwerten zusammen. Beim ersten Lesen dachte ich "Ok, 7-Bit Samples. Wertebereich 0-127". Beim nochmaligen Lesen macht mich der Satz nervös. Das "setzt sich zusammen" stört mich. Reden die etwa davon, dass ein 10 ms Impuls aus 128 "Teilimpulsen" (12,8 kHz Abtastfrequenz) zusammengesetzt ist? Dann geht es weiter mit: > Der kleinste Amplitudensprung beträgt 1/16 der Maximalamplitude. Das > entspricht einer 4-Bit-Amplitudeninformation. Also Wertebereich 0 - 7 für die Amplituden. Warum also wird zuvor von 128 Amplitudenwerten geredet? Karl B. schrieb: > Das kann beim UAA1003 allein schon wegen der für heutige Chips geradezu > extrem niedrige Taktfrequenz von 230,4 kHz (!) nicht funktionieren, ohne > zu große Latenzen und Gestottere in Kauf nehmen zu müssen. 230,4 kHz wäre ja Luxus. Das Datenblatt sagt 25,6 kHz.
Kann es sein, dass dort mit Alaw/µlaw oder ADPCM in Hardware decodiert wird?
Hannes J. schrieb: > Reden die etwa davon, dass ein 10 ms Impuls aus > 128 "Teilimpulsen" (12,8 kHz Abtastfrequenz) zusammengesetzt ist? Ja.
"Im UAA1003 stehen aber als datenspeicher nur 25 Kbit zur Verfugung. Daraus resultiert eine notige Datenreduktion im Verhaltnis von 50 :1. Diese starke Reduktion wurde durch die Kombination verschiedener Verfahren zur Datenreduktion und Redundanzminderung erreicht. Die Sprachvorlage wird bandbegrenzt, digitalisiert und in den Arbeitsspeicher eines ProzeBrechnersystemseingelesen. Diese Daten werden dann 'offline' verarbeitet. Die Naturlichkeit der Sprache wird dabei durch Beseitigung der prosodischen Informationsanteile (Betonung, Grundfrequenzschwankungen usw.) beeintrachtigt, nicht aber die relevante Sprachinformation." https://sites.google.com/site/analogvocoderinfo/miscellaneous/uaa1003-in-german
Karl B. schrieb: > Also, > alle mir bekannten Lösungen, eine Uhr mit Sprachausgabe per Chip > nachzubilden, waren nicht so gut wie der besagte UAA1003. Das ist "nur" eine Frage des Aufwands. Der Hauptaufwand besteht dabei aber nicht etwa in der Programmierung. Das ist mit genug Flash eine wirklich überaus triviale Programmieraufgabe. Sie hat kaum noch etwas mit Programmieren zu tun, im Wesentlichen geht es dabei nämlich nur um die Erstellung zweier Lookup-Tabellen. Input->Patternlist und Pattern->Soundcharacter. Der Hauptaufwand besteht darin, einen "Soundfont" in guter Qualität bereitzustellen. Das ist deshalb schwierig, weil die einzelnen "Zeichen" dieses Fonts nicht nur jeweils für sich gut klingen müssen, sondern auch in jeder Kombination, in der sie verwendet werden. Es soll also möglichst gerade nicht hörbar sein, dass der Sound aus einzelnen Schnipseln besteht. Sprich: Die Zeit, die man mit Audacity verbringt, wird weit die Zeit übersteigen, die man mit dem Atmel-Studio verbringt...
c-hater schrieb: > Der Hauptaufwand besteht darin, einen "Soundfont" in guter Qualität > bereitzustellen. Hast Du Dir das Beispiel im zugehörigen Nachbarthread mal angehört? Von "guter Qualität" ist das schon etwas mehr als nur ein bisschen entfernt.
Rufus Τ. F. schrieb: > Hast Du Dir das Beispiel im zugehörigen Nachbarthread mal angehört? > > Von "guter Qualität" ist das schon etwas mehr als nur ein bisschen > entfernt. Es ist gerade noch so verständlich. Mal die Jungs von "Kraftwerk" fragen ;-) Die waren ja Vorreiter und haben das technisch mögliche aus Comutern und sonstiger Elektronik rausgeholt.
Es ist grauselig. Sowas will heute keine mehr hören. Selbst Roboter nicht ;-)
Rufus Τ. F. schrieb: > Hast Du Dir das Beispiel im zugehörigen Nachbarthread mal angehört? Jetzt ja. :o/ > Von "guter Qualität" ist das schon etwas mehr als nur ein bisschen > entfernt. Auf jeden Fall. Diese Qualität ließe sich sicherlich innerhalb eines einzigen Bastel-Nachmittags weit überbieten.
c-hater schrieb: > Auf jeden Fall. Diese Qualität ließe sich sicherlich innerhalb eines > einzigen Bastel-Nachmittags weit überbieten. Nun, es ist schon erstaunlich, wie man damals eine derart komplexe Schaltung in ein einziges IC "giessen" konnte. Heutzutage bekommt man aber Speicher "fürn Appel undn Ei" sodas es überhaupt kein Problem ist, sämtliche benötigten Wörter in einem Speicher abzule- gen und dort nach Bedarf aufzurufen. http://elm-chan.org/works/sd8p/report.html
Das UAA1003 kostete damals bei Conrad 40 DM, wenn ich mich richtig erinnere. MfG
Christian S. schrieb: > Das UAA1003 kostete damals bei Conrad 40 DM, wenn ich mich richtig > erinnere. Irgendwie mussten die ja Ihre hohen Entwicklungskosten wieder reinkriegen.
Lustig ist immer die Verstellung des Taktes. Schnell eingestellt klingt sie übereifrig, langsam wie ein Waal oder alternder Elefant. So eine selbstgebaute sprechende Uhr habe ich noch immer aufgestellt. MfG
Kann sich noch jemand an S.A.M. erinnern? Das passte in 6kB, konnte genug Phoneme für beliebige englische Texte und klang auch nicht viel anders. Jemand hats dann später mal nach C portiert, da kann man sich anschauen wie das funktioniert: https://simulationcorner.net/index.php?page=sam https://github.com/s-macke/SAM/wiki
Bernd K. schrieb: > Kann sich noch jemand an S.A.M. erinnern? Du meinst das hier? https://en.wikipedia.org/wiki/Software_Automatic_Mouth
hinz schrieb: > Du meinst das hier? > > https://en.wikipedia.org/wiki/Software_Automatic_Mouth Jetzt ist mir klar, warum ich das nicht kenne. Hatte damals einen Atari 800XL. Und die Restriktionen sind lt. Wikipedia-Artikel genau dafür so übelst, dass es niemals auch nur andeutungsweise für eine nützliche Verwendung in Frage gekommen wäre. Beherrschte der Typ, der die Atari-Variante implementiert hat, etwa nur das mitgelieferte Basic? Sieht irgendwie fast so aus...
Ich erinnere mich an "Say" auf dem Amiga (Workbench 1.3). Klang damals ganz gut. Für damals.
Angehängte Dateien:
-

Taktfrequenz__.jpg
50 KB -

Testfrequenz_Ausgang16_.jpg
50 KB
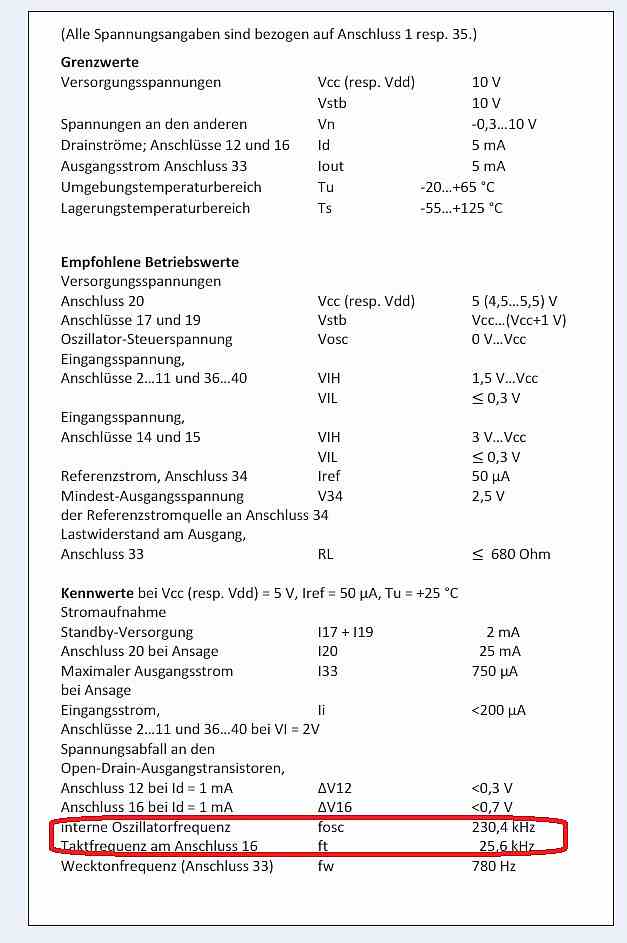

Hannes J. schrieb: > 230,4 kHz wäre ja Luxus. Das Datenblatt sagt 25,6 kHz. Hi, ja, Datenblatt ...Etliche grobe Schnitzer habe ich da schon gefunden und korrigiert. (Beziehe mich auf das ITT-Originaldatenblatt.) Was die meinen, zeige ich nochmal im Bild. Damit man den Oszillator nicht vielleicht noch durch den "Mess"-Aufbau verstimmt, wurde die Frequenz heruntergeteilt/gepuffert am Ausgang 16. Das aber ist nicht die interne Oszillatorfrequenz selbst. Dieser Anschluss dient zur Justage auf "optimale" Sprachverständlichkeit über das Poti an Anschluss 18. Übrigens, mein alter TI1000 hatte auch mit Extended Basic einen "call speech" Befehl. Aber sehr eingeschränkter Wortschatz und buchstabierte meistens. Nur Englisch. ciao gustav
Walter T. schrieb: > Ich erinnere mich an "Say" auf dem Amiga (Workbench 1.3). Klang damals > ganz gut. Für damals. Einen Amiga konnte ich mir als Zoni erst leisten, als ich keiner mehr war, also 1990. Die Amiga-Sprachausgabe habe ich tatsächlich 1990 ein mal benutzt. Da ging es darum, dass das aus dem Amiga-Magazin abgetippte Listing nicht das erhoffte Ballerspiel produziert hat, sondern einen Absturz. Da habe ich dann mit dem mitgelieferten Microsoft-Basic ein kleines Programm geschrieben, was mir den Scheiß vorgelesen hat, den ich eingetippt hatte, so dass ich mich auf das Mitlesen im Heft konzentrieren konnte. Hat tatsächlich geholfen, ich habe den (es war tatsächlich nur ein einziger!) Tippfehler gefunden und dann mindestens eine Woche lang "DFS" (Deathbringers from Space) gespielt. Hurra... Die Sprachausgabe hatte aber aber einen ganz fürchterlichen amerikanisch-englischen Akzent, wenn ich mich richtig erinnere... Naja, nach dieser Woche habe ich dann lieber 68k-Assembler gelernt... So wie immer, wenn ich ein neues Hardware-System in Besitz nehme, ich lerne die Sprache, mit der man es optimal nutzen kann...
Angehängte Dateien:
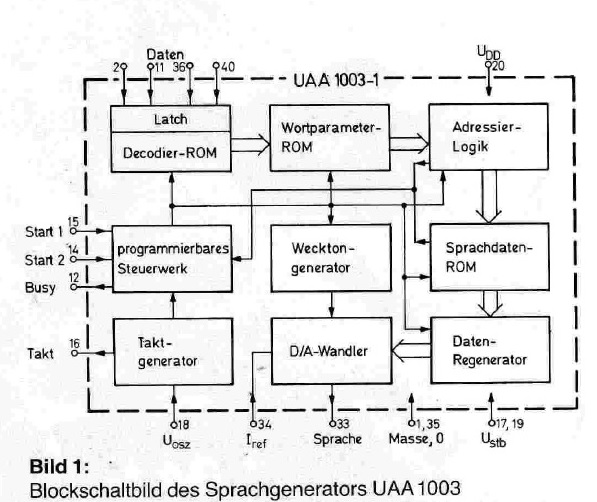
c-hater schrieb: > Wesentlichen geht es dabei nämlich nur um die Erstellung zweier > Lookup-Tabellen. Input->Patternlist und Pattern->Soundcharacter. > > Der Hauptaufwand besteht darin, einen "Soundfont" in guter Qualität > bereitzustellen. Das ist deshalb schwierig, weil die einzelnen "Zeichen" usw.. Hi, im Blockschaltbild ist noch Black-Box mit Daten-Regenerator bezeichnet, was immer darunter zu verstehen sein mag. ciao gustav
Karl B. schrieb: > im Blockschaltbild ist noch Black-Box mit Daten-Regenerator bezeichnet, > was immer darunter zu verstehen sein mag. Sehr wahrscheinlich ein Sprach-Synthesizer. Für gesampelte Klänge war der Speicher echt zu knapp. Wäre es auch noch mit heutigen hochentwickelten Audio-Kompressoren. Für die allerdings sowieso die "Rechenleistung" nicht gelangt hätte. So ein Sprach-Synthesizer ist garnicht so schwierig zu implementieren, schließlich bildet er nur das ab, was ein blödes Stück Gewebe (Stimmband) in einem Luftstrom zu produzieren vermag und das, was wir mit Zunge, Lippen und Kehlraum daran wiederum stören können. Sprache halt. Auf der einen Seite. Reine, recht triviale Physik auf der anderen. Man muss sich halt beim Modell auf das für das Signal wesentliche beschränken, wenn die Steuersignale für das Modell klein bleiben sollen. Genau das werden die damals wohl auch gemacht haben, denn die Physik hat sich seit damals meines Wissens nach nicht geändert...
Angehängte Dateien:
-

UAA1003_Bestueckungsseite.jpg
130 KB -

_UAA1003_Loetseite_.jpg
130 KB


c-hater schrieb: > So ein Sprach-Synthesizer ist garnicht so schwierig zu implementieren, Hi, Vokalherstellung geht mit zwei Ringmodulatoren relativ simpel. Hier mal gemacht. Analog. (Und "digital" mit XOR-Gliedern, soweit ich weiß.) Aber beim Transponieren merkt man, wie "synthetisch" das dann klingt. Nur mit sehr viel Phantasie erkennt man, dass es vielleicht Vokale wie "a", "e", "i", "o", "u" sein könnten. Ist hier mit Rechteck Duty cycle 1:1 an und ausgeschaltet worden. Da merkt man schon, dass auch Artikulationen wichtig sind. Aber auch ein Erwartungsschema ergänzt das, was im Signal zur Erkennung von Sprache fehlt. (Das "Genudel" von Smartphone Noise Reduction braucht man nicht zu erwähnen. Das mutet man den Leuten heute einfach zu. Telefonqualität von früher fand ich persönlich aber besser.) Nehme an, die "Black Box" birgt das wesentliche Geheimnis. Dann mal die Taktfrequenz halbieren. OK. Die Filter sind dann nicht drauf eingestellt. Aber pfeifen tut es noch nicht. (Der Rest sind Kameradreckeffekte. Der Sekundentaktgeber da im Hintergrund.) Christian S. schrieb: > Das UAA1003 kostete damals bei Conrad 40 DM, wenn ich mich richtig > erinnere. Der Bausatz wurde 1982 bei Völkner für 120 DM gekauft. Später noch einen kleineren, der hat die Widerstände nicht drauf und kleinere Steckverbinder. ciao gustav
Da kann meine Kreissäge offensichtlich auch sprechen, ha ha.
Hat schon jemand versucht, die dem Chip zugrundeliegenden Patente ausfindig zu machen? Die dürften sich recht interessant lesen und einige Fragen beantworten. Zeitlich plus minus 2 Jahre um das Erscheinen des Chips, und Hersteller zur Suche verwenden.....
Der UAA1003 ist alter Schnarpel. Ausser man hat einen Karton voll zu Hause im Regal stehen, heute voellig irrelevant. Keiner will heute in die geistigen Niederugen abtauchen, sowas mit dem absolutem Minimum an Speicher zu realisieren und zu fertigen. Mein Dummfon hat ein TTS, mein Schlaufon auch. Beides gerne benutzt. Vom Teatimer bis zur Kuckucksuhr ohne Kuckuck. Beides kommt ohne "Mehrverbrauch" daher, weil bereits vorhanden...
Jochen F. schrieb: > Zeitlich plus minus 2 Jahre um das Erscheinen des Chips, und Hersteller > zur Suche verwenden..... Vielleicht kann man das eingrenzen mit dem Erscheinen der "Musik Postkarten". Digital waren die sicher nicht. Mitte der 70' ziger??? Im Moment habe ich ältere Chip von Analoguhren beim Wickel. Und dabei bin ich auf einen Chip gestoßen, welcher eine Melodie als Weckton ausgeben konnte. Es ist der KB1004 von so etwa 1987. Gehört der zur Familie des UAA1003? Mit der Zusatzbezeichnung CHL 7-4-06 soll er Berlin Poutpouri abgespielt haben.
michael_ schrieb: > Vielleicht kann man das eingrenzen mit dem Erscheinen der "Musik > Postkarten". Da es dabei nur auf simple Melodien ankommt, ist die Technik eine noch viel simplere. Sprache ist komplexer zu modellieren als Pieptöne, auch wenn sie verzerrt sind oder gar mehrere gleichzeitig ausgegeben werden (Polyphonie). Das ist obendrein komplett analog lösbar, wie diverse Synthesizer-Ansätze schon sehr lange zeigen.
michael_ schrieb: > Vielleicht kann man das eingrenzen mit dem Erscheinen der "Musik > Postkarten". > Digital waren die sicher nicht. > Mitte der 70' ziger??? Außerdem waren die ICs für Postkarten und Geräuschmodule auch als "Dreibeiner" im TO92 Gehäuse für ca. 1 DM erhältlich. In einem TO92 Gehäuse ist nicht viel Platz an Chipfläche. Im DIL40 ist quasi Platz ohne Ende. Der Preis von 40 DM spricht auch dafür, das dort ein fingernagelgroßer Chip verbaut wurde. Das Einzige, was ich etwas befremdlich finde, ist das die Ziffernsegmente auf die Pins geführt wurden. Dabei versucht man ja immer Pins zu sparen, weil die ein wesentlicher Kostenreiber sind. BCD, wie bei Zählern üblich, würde nur 4, statt 7 Leitungen pro Ziffernstelle benötigen. Mit Multiplex ließe sich noch mehr sparen.
Angehängte Dateien:
-

VFD_mpx_mode_interf.jpg
50 KB
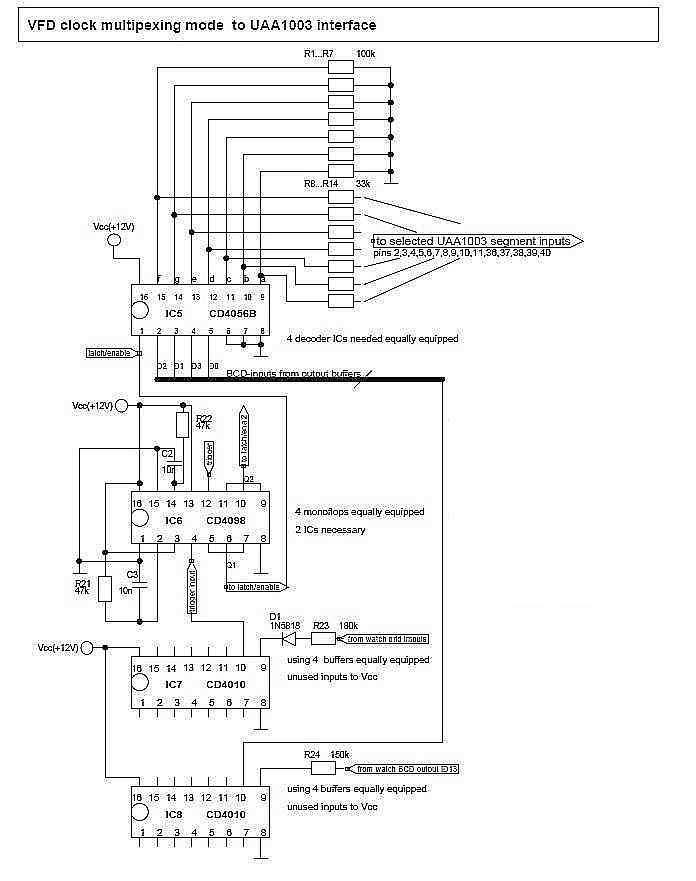
Gerald B. schrieb: > Das Einzige, was ich etwas befremdlich finde, ist das die > Ziffernsegmente auf die Pins geführt wurden. Hi, liegt schlicht und ergreifend daran, dass die damaligen Digitaluhren kein "Interface" hatten, außer den Anschlüssen am Display selbst. Und da brauche ich 13 Leitungen. Gerald B. schrieb: > Mit Multiplex ließe sich noch mehr sparen. Dann mit Multiplexing klappt es so wie so nicht so leicht. Man brauchte Uhrenanzeigen, die "statisch" arbeiteten. Aber es geht: Bis ca. 128 Hz Abtastfrequenz mit Pegelwandlern, Monoflops und BCD-zu Siebensegmenttreiber mit Latch. Sonst kommen die Lottozahlen Eins aus 59 ;-) ciao gustav
Gerald B. schrieb: > BCD, wie bei Zählern üblich, würde nur 4, statt 7 Leitungen pro > Ziffernstelle benötigen. Wenn Du Dir das Ding genau ansiehst, wirst Du feststellen, daß es weniger als 7 Leitungen verwendet. Hier findet sich eine ziemlich ausführliche Beschreibung: Beitrag "Re: Applikationsschaltung UAA 1003" Für die beiden Einerstellen verwendet es sechs Leitungen, für die Minuten-Zehner nur drei und für die Stunden-Zehner sogar nur zwei Leitungen. Das sind in Summe siebzehn Leitungen, also nur eine mehr als für vollständiges BCD bei vierstelligem Wert (was natürlich überflüssig wäre, auch im BCD-Betrieb könnte man die Minutenzehner auf drei und die Stundenzehner auf zwei Leitungen reduzieren).
Weiß jemand, wie die musikalischen Geburtstagskarten funktionierten? Meine Oma hatte mal erzählt, da sind Tonbänder drin. Und wenn man das Papier so auseinander gefaltet hat, konnte man tatsächlich zwei kleine Metallzylinder erkennen.
Marek N. schrieb: > Weiß jemand, wie die musikalischen Geburtstagskarten > funktionierten? Maskenprogrammierter Melodiegenerator. > Meine Oma hatte mal erzählt, da sind Tonbänder drin. Süß. > Und wenn man das Papier so auseinander gefaltet hat, konnte man > tatsächlich zwei kleine Metallzylinder erkennen. Das waren die Batterien.
Angehängte Dateien:
-

Busy_Ausgang_.jpg
89 KB
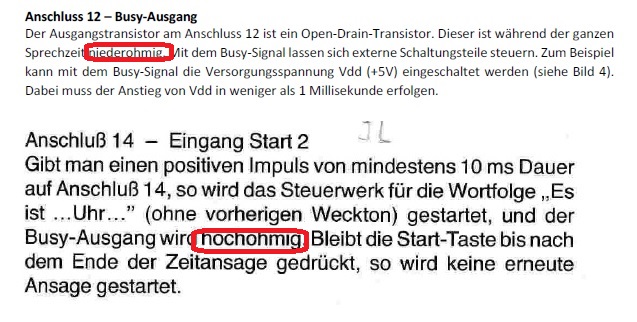
Hi, Die meisten damals handelsüblichen Uhren-ICs selbst hatten keine Schnittstellen-Pinne für BCD-Format extra herausgeführt. Sie waren für den UAA1003 oder sonstige Peripherie, außer Piezo-Wecker und Stellfunktionen überhaupt nicht konzipiert. Ich kenne jedenfalls auch keinen "normalen" Wecker, der Zusatzmodule für Weckzeitenerweiterung gehabt hätte, da wäre das nämlich auch sehr sinnvoll. Also musste man notgedrungen an die vorhandenen Anoden der VFD-Röhren (oder LED-Siebensegmentanzeigen) gehen. Und da eben auf Redundanz verzichten, so weit da eben geht. Interessant auch, wie man die Doppelte Null bei Mitternacht als Doppeldeutigkeit logisch gelöst hat. Es gab Uhren, die unterdrückten die "führende" Null nämlich nicht. Sie zeigten 00:00 und nicht 0:00 Auch hieran konnte man den UAA1003 anschließen, ohne dass er "Es ist Null Uhr Null" sagt, er sagt "es ist Null Uhr" Könnte man als logisches "Vielleicht" bezeichnen: Stunden Zehner: entsprechend abgegriffene Segmente: Sprachausgabe: d c 0 0 0 0 1 1 1 0 1 2 1 0 ciao gustav P.S.: Rufus Τ. F. schrieb: > Hier findet sich eine ziemlich ausführliche Beschreibung: > > Beitrag "Re: Applikationsschaltung UAA 1003" Übrigens, genau dieselbe Beschreibung nur ohne die Fehler findet man hier: https://www.mikrocontroller.net/attachment/424095/UAA1003_description.zip Nur die schönen Zeichnungen fehlen. Zum Beispiel: Der Busy-Ausgang funktioniert so nicht, wie im ITT-PDF beschrieben.
Karl B. schrieb: > Hi, > das wurde ja schon ausgeschlossen. > aufgrund der schlechten Verarbeitungsgeschwindigkeit und der (nicht > vorhandenen) "Rechenleistung". Ich zweifle das an! Zum Abspielen von Samples ist fast gar keine Rechenleistung nötig. Wir reden hier vermutlich von Mono, mit niedriger Samplerate. Konzept: Man nehme ein 8-Bit-Speicher (ich tippe auf Masken-ROM) und einen parallelen 8-Bit-DAC. Man verbinde die Datenleitungen von RAM und DAC. An die Adressleitungen des Speichers kommt ein Zähler. DAC und Zähler bekommen den gleichen Takt. Schon läuft das vollautomatisch: Mit jedem Takt zählt der Zähler hoch (und damit wird die Adresse inkrementiert), ein neues Sample liegt am DAC an, der gibt das aus. Jaja, ein paar Steuerleitungen brauchts schon noch, schon klar ;-) Keine Rechenleistung nötig, kein hoher Takt nötig. 11kHz reichen. Um verschiedene Sprachsamples abspielen zu können, benötigt man noch weitere Logik, aber keine Raketentechnik. Ich denke, nicht einmal ein Prozessorkern ist nötig. Was die Rechenleistung angeht: Über ein Sprachsample mit 11kHz / 8Bit (was für einen verständliche Ansage reicht) lacht selbst der müdeste 8-Bit-µc aus den 80ern. Auch mit nur um die 200kHz.
Mit deinem primitiven Konzept kommt man aber nicht auf den geringen Speicherbedarf des Original-ICs. Könnte mir vorstellen, daß der DAC sogar noch weniger Bits hat.
Karl B. schrieb: > Weitere Denkanstöße willkommen. https://en.wikipedia.org/wiki/Phonetics Ersetzt jetzt zwar kein Studium, aber hier stehen schon einige schöne Grundlagen. Vor allem findet man Suchbegriffe (Formant, Vokal, Konsonant, ...). Wie bei Wikipedia üblich - öfter mal die Sprache wechseln, die Inhalte der Artikel sind stark unterschiedlich. Ich selber habe leider nur englische Linguistik/Phonetik gehört, daher fällt mir das Englische hier leichter. Mein erster Suchtreffer zum UAA1003, in dem auch der Begriff Vocoder fällt: https://sites.google.com/site/analogvocoderinfo/miscellaneous/uaa1003-in-german https://de.wikipedia.org/wiki/Vocoder Auch in älterer Science Fiction reden Aliens ohne passenden Sprachtrakt gerne mal per Vocoder. Fritz Leiber - The Big Time, um nur mal ein Beispiel zu nennen, das mir grad in den Kopf kommt. Brauchst Du noch populärwissenschaftliche Literatur zu Phonetik? G.B.Shaw - Pygmalion - gibt es auch als Hollywood-Film ;)
http://www.redcedar.com/sc01.htm den SC01 von Votrax habe ich damals auch benutzt, das Speak%Spell von TI habe ich noch und den SP0256-AL2 auch. Mein Professor war damals (1982/83) begeistert, dass der Votrax seinen Vornamen aussprechen konnte.
Abdul K. schrieb: > Könnte mir vorstellen, daß der DAC sogar noch weniger Bits hat. Eventuell einen 1-bit Delta Sigma Wandler? Ich hatte vor einiger Zeit für den C64 einen 2-bit AD-Wandler aus dem C64-Magazin 10/86 nachgebaut und damit einige 2-bit-Samples aufgenommen. https://www.c64-wiki.de/wiki/Audiodigitizer http://www.idealine.info/emuecke/index_quereinstieg.htm?/emuecke/hardware/_2_bitdigitizer.htm
Abdul K. schrieb: > Mit deinem primitiven Konzept kommt man aber nicht auf den > geringen > Speicherbedarf des Original-ICs. Mir ist der Original-IC nicht geläufig. Aber hoch ist der Speicherbedarf nicht wie jeder glaubt. Sagen wir, du musst alle Zahlen aufsagen können. Ich brauche dazu 4-6 Sekunden. Dann nehmen wir an, wir haben 8Bit/11kHz da kommen wir mit <64kBytes hin. Das ist definitiv ausreichend, um einfache Sprache abzuspielen. Und das ist schon unkomprimiert, es gibt bestimmt irgenwelche einfachen Komprimieralgorithmen, die man in Hardware leicht umsetzen kann. Oder die Auflösung ist geringer gewesen. Oder man interpoliert irgenwie, z.B. analog oder so. Der Speicher wäre dann wohl Masken-ROM, aus Kostengründen. Mir ist so nicht klar, wieviel Masken-ROM man damals unterbringen konnte, aber mehr als ein paar kBytes bis zig kBytes ist nicht nötig für diese Funktion. Ich behaupte nicht, das wäre bei dem Chip so umgesetzt, sondern nur, dass es generell auch damals technisch problemlos möglich war.
Siehe weiter oben - 1 Kb. Mit Speicher und Rechenleistung läßt sich das Problem recht einfach "erschlagen", aber mit 1 Kb und der damaligen Fertigungstechnik ist es eben nicht trivial gewesen.
Das war der "Speak&Spell" 1978: https://en.wikipedia.org/wiki/Speak_%26_Spell_(toy) https://en.wikipedia.org/wiki/Texas_Instruments_LPC_Speech_Chips "Speech synthesis data (phoneme data) for the spoken words were stored on a pair of 128 Kbit metal gate PMOS ROMs. 128 Kbit was at the time the largest capacity ROM in use."
Die üblichen Ansätze sind hier ganz gut beschrieben... https://en.m.wikipedia.org/wiki/Linear_predictive_coding
Ich hatte früher für meinen Schneider CPC folgendes Gerät: http://www.cpcwiki.eu/index.php/Dk%27tronics_Speech_Synthesizer Den konnte man auch gerade so verstehen…
Weil weiter oben jemand S.A.M. erwähnte ... ich habe mal den C64 Emulator angeworfen und SAM (bzw. RECITER) die Uhrzeit ansagen lassen. Resultat anbei. Weil SAM auf Englisch geeicht ist, muß man deutsche Wörter ein bißchen kreativ schreiben. Hier: "es ist tsehn oor und dry und drysig minooten"
Christoph db1uq K. schrieb: > http://www.redcedar.com/sc01.htm > den SC01 von Votrax habe ich damals auch benutzt, das Speak%Spell von TI > habe ich noch und den SP0256-AL2 auch. > Mein Professor war damals (1982/83) begeistert, dass der Votrax seinen > Vornamen aussprechen konnte. Wie alt bis du denn? Das ist ja das reinste Museum. Wahrscheinlich bist du der Bruder im Geiste von Rafael aus der d.s.e. ;-) Der hat auch ein Riesenlager. Einfach unglaublich. Warum nicht noch einen Schritt weiter in die Vergangenheit. Damals lief die Hobbythek und stellte einen maskenprogrammierten TMS1000 mit diversen Klingeltönen vor. Das Heft hatte mir meine Mutter besorgt und damit fing gefühlt für mich Elektronik damals an.
Angehängte Dateien:
-

EMUF_Talker01.jpg
150 KB -

EMUF_Talker02.jpg
150 KB
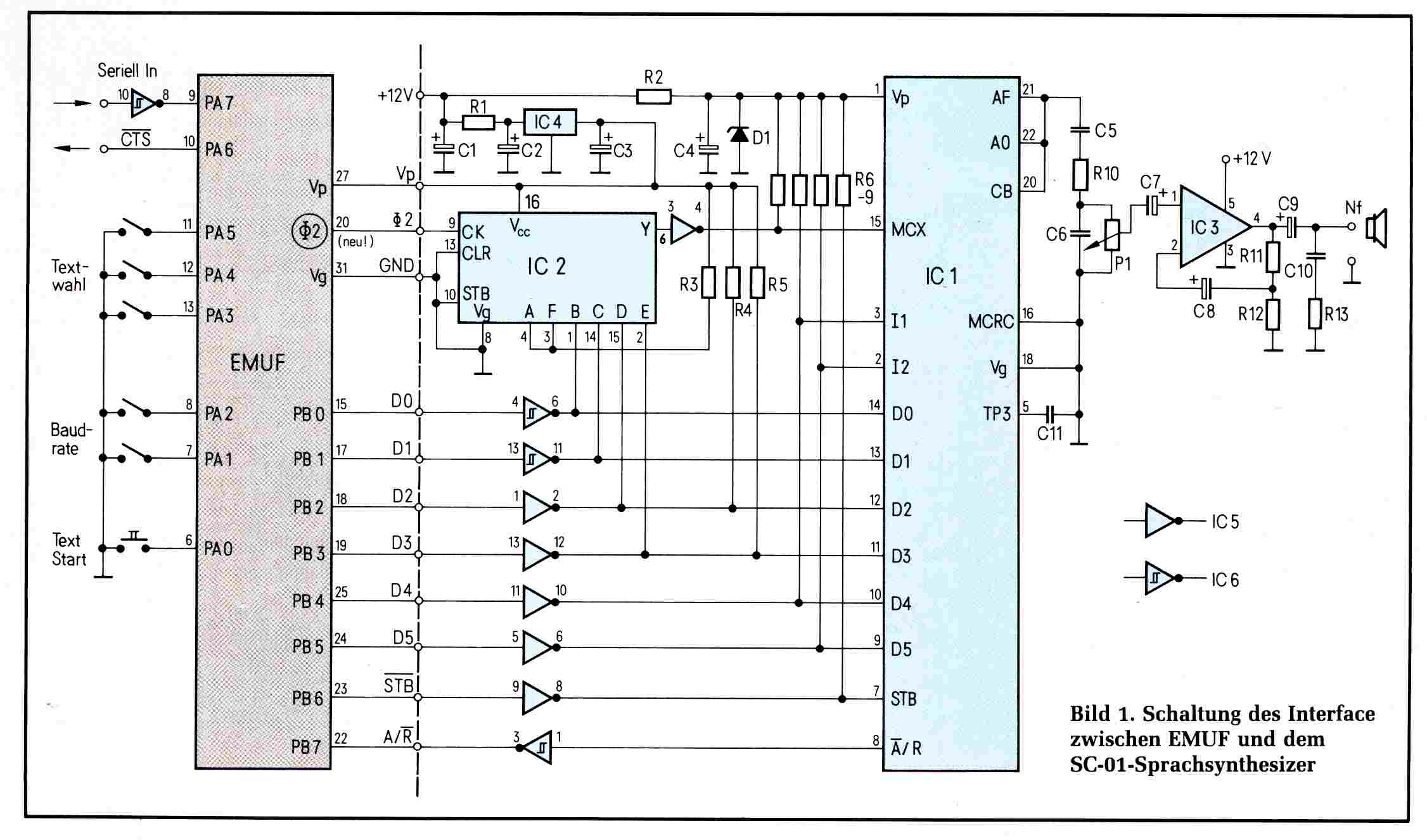
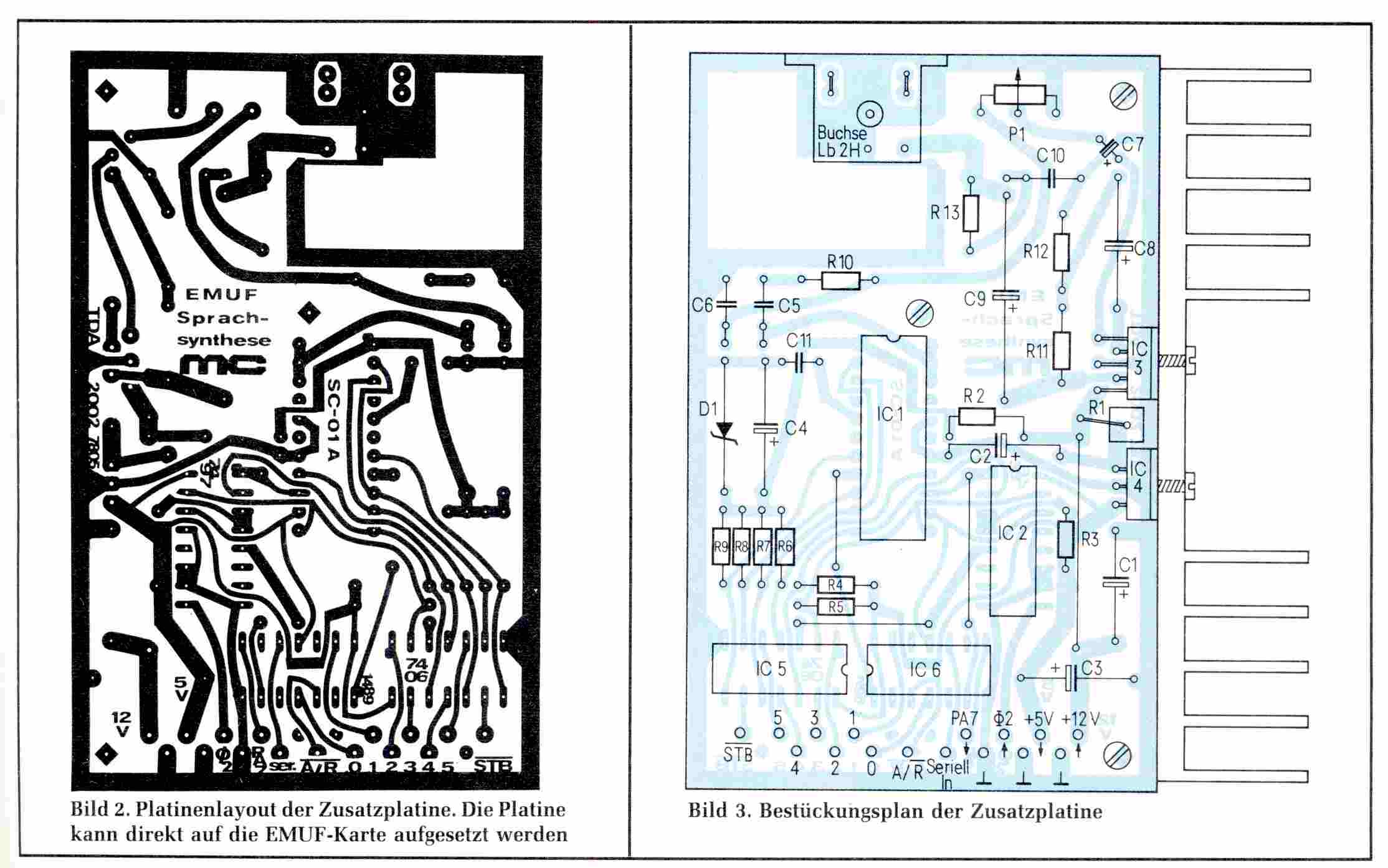
Die Elektronik fing bei mir mit dem Philips-Kasten EE20 Ende der 60er an, http://www.hansotten.com/electronic-kits/ee-series/ee8-ee20-a20/ und z.B. einem Franzis-Buch von Heinz Richter https://www.amazon.de/Neues-Bastelbuch-Elektronik-Selbstbauger%C3%A4te-Versuche/dp/B002DU1TBY Den Votrax-Sprachsynthesizer habe ich zusammen mit einem Klassenkameraden im "EMUF-Sonderheft" 1983 veröffentlicht, vom mir stammt die Hardware, also das Platinenlayout. Ein 7497 bit-rate-multiplier konnte die Tonhöhe verändern. Eingabe über die serielle Schnttstelle. Ich hatte das Teil mal in die Uni Karlsruhe mitgenommen, dort gab es als Spende von Siemens einen 8080-Rechner, der konnte das Ding ansteuern. Zuhause war bei uns beiden der Rockwell AIM-65 vorhanden. Damals hatte der Chefredakteur der Funkschau Feichtinger denselben Rechner und veröffentlichte viele Amateurfunkprogramme dazu, Funkfernschreiben, Morsedecoder usw.
Absolut goil, @Christoph!! Das muß ne Zeit des Aufbruches gewesen sein! Auch in der DDR wurde damals mit Spracherkennung / Synthese ( Auf nem Z80) experimentiert. Gab es da nicht auch ne Platte für den Z80 "Micro Professor" im Westen? mfg
Christoph db1uq K. schrieb: > vom mir stammt die Hardware, also das Platinenlayout. Von Hand mit Klebestreifen erstellt?
Harald W. schrieb: > Christoph db1uq K. schrieb: > >> vom mir stammt die Hardware, also das Platinenlayout. > > Von Hand mit Klebestreifen erstellt? Bestimmt damit: https://pico-systems.com/photoplot.html ;-)
Wie wär's mit einem Arduino oder Atmega328 als Sprachgenerator: https://github.com/going-digital/Talkie
Warum nicht einfach den Quellcode eines Schneider cpc odr C64 und dessen Soundchip z.B oder einen neueren besseren Beitrag "ATMega328-basierter Sprach-Synthesizer für den CPC 464 - Schnelles Byte-weises Lesen mit dem 328?" https://www.youtube.com/watch?v=C5BnD1NPwGw&feature=youtu.be
Herbert schrieb: > Wie wär's mit einem Arduino oder Atmega328 als Sprachgenerator: > > https://github.com/going-digital/Talkie ...und wie wärs damit? http://www.elm-chan.org/works/sd8p/report.html
Ja das waren Kreppapier-Klebestreifen speziell zum Leiterplattenlayout, Abreibelötaugen und -Buchstaben. Hier noch der Quelltext dazu.
Christoph db1uq K. schrieb: > Ja das waren Kreppapier-Klebestreifen speziell zum Leiterplattenlayout, Ja, nur damit bekommt man so schön geschwungene Leiterbahnen hin. :-)
AIM65 war interessant, aber teuer und damit unerreichbar für mich. Außerdem stand ich mehr auf Z80 als auf 6502.
Harald W. schrieb: > Christoph db1uq K. schrieb: > >> Ja das waren Kreppapier-Klebestreifen speziell zum Leiterplattenlayout, > > Ja, nur damit bekommt man so schön geschwungene Leiterbahnen hin. :-) Nicht ausschließlich. Ich habe meine Leiterplatten entworfen, auf Millimeterpapier dann masstabsgetreu gezeichnet, auf das Basismaterial geklebt, die Löcher vom Kupfer aus gebohrt, die Leiterplatte mit Scheuermilch gereinigt und dann mit einer Schreibfeder und lötbarem Leiterplattenlack von Hand gezeichnet. Ich hatte auch Bögen :D
Das war übrigens 2:1 geklebt, und dann auf orthochromatischem Film verkleinert. Als Reprokamera diente das Dunkelkammergerät für Rollfilm. Erst ein quadratisches Stück 6*6cm oben eingelegt und das geklebte Layout auf dem Selbstbau-Leuchttisch darunter etwa 2-4 Sekunden eingeschaltet. Mit Lith-Entwickler dieses Negativ entwiclkelt und später an gleicher Stelle wieder eingelegt. Projektor auf halbe Größe umgestellt und dieses Mal den Lithfilm unten drunter wieder ein paar Sekunden belichtet. Das alles bei trüber rötlicher Dunkelkammerbeleuchtung über der Badewanne. Für den AIM65 hatten wir noch ein zweites Programm veröffenlicht, SSTV-Empfang. Der Kassettenrecodereingang als "Soundkarte", und den Thermodrucker mit Grauwerten durch veränderliche Impulsbreite der Thermoköpfe.
Da gibt es die Hefte der "mc" aus den 80ern als PDF: https://ntxdhxgzadrdathx.myfritz.net/mc-zeitschriften/ Speziell den EMUF: https://ntxdhxgzadrdathx.myfritz.net/mc-zeitschriften/1981/mc-1981-02.pdf#page=20 1MHz Takt, max. 2kByte Eprom, zwei 8-Bit-Ports, ein Timer und 128 Byte RAM. Auf Seite 15 ist eine Anzeige meines damaligen Händlers, dort habe ich den AIM65 gekauft, 1149 DM mit 1k RAM und 8k "Betriebssystem" im ROM. Der "SSTV-Empfang mit AIM65" stand schon in Heft 14/1980 der Funkschau.
Christoph db1uq K. schrieb: > Der "SSTV-Empfang mit AIM65" stand schon in Heft 14/1980 der Funkschau. Wenn man die Heftnummern kennt, kann man sich Kopien solcher Artikel auch verhältnismäßig einfach über den sog. auswärtigen Leihverkehr über die nächste Leihbücherei besorgen.
Ich muss den Artikel mal raussuchen. Von mir war nur die Grundidee, ausserdem habe ich damals in München die Amateurfunktagung besucht, und bei der Gelegenheit einen Besuch in der Funkschauredaktion in der Karlstrasse gemacht. Herwig Feichtinger war begeistert von den SSTV-Ausdrucken, was man auch seinen Bildkommentaren anmerkt. Das abgedrucktes Beispielbild war immerhin vom Odenwald nach Mannheim (beinahe Sichtverbindung) im 2m-Band übertragen worden und stammte aus einem Video-Normwandler ohne Bildspeicher. Hajo Pietsch hat den in seinem RPB-Band zu SSTV (Band 154 - 1. Auflage 1980) beschrieben. Eine normale Schwarz-Weiß-Videokamera wurde um 90 Grad gekippt, sodaß die Zeilen senkrecht standen. Mittels Sample-and-Hold wurden aus dem Videosignal Bildpunkte geholt und zum SSTV-Videosignal umgewandelt. Ein Nachteil war, dass man 7,2 Sekunden stillhalten musste. Ich schweife vom Thema ab. Hab erst jetzt das oben von Herbert genannte github-Projekt angeschaut, das macht ja Linear Predictive Coding auf dem Arduino, wie es auch der Speak&Spell benutzt hat. Die Windows-Emulation zum Speak&Spell wirkt recht lebensecht mit sämtlichen Nebengeräuschen. "Spell it: LICORICE L-I-C-O-R-I-C-E, you are right, now spell FIELD..." "wrong, the correct spelling of... is..."
Karl B. schrieb: > Es geht mir nicht darum, die manchen sehr leicht über die Lippen > gehenden Formulierungen, wie "...ja, das kann heute ja jeder ATtiny mit > links...", zu kritisieren, sondern darum, wie man das Geheimnis des > UAA1003- Sprechende Uhr - 40-poligen Chips ein wenig "lüften" kann. Da müsste man mal Ken Shirriff drauf ansetzen. Der hat schon viele Chipdesigns aus den '80ern reverse-engineered. http://www.righto.com/
soul e. schrieb: > Da müsste man mal Ken Shirriff drauf ansetzen. Der hat schon viele > Chipdesigns aus den '80ern reverse-engineered. > http://www.righto.com/ Damals waren die Strukturgrößen noch im Bereich der Wellenlänge sichtbaren Lichtes, da reichte noch ein einfaches Mikroskop ;-)
Gerald B. schrieb: > Damals waren die Strukturgrößen noch im Bereich der Wellenlänge > sichtbaren Lichtes, da reichte noch ein einfaches Mikroskop ;-) Erstaunlicherweise werden aber m.W. auch moderne ICs nach wie vor optisch vervielfältigt.
Harald W. schrieb: > Erstaunlicherweise werden aber m.W. auch moderne ICs > nach wie vor optisch vervielfältigt. Hier wird das erklärt. https://de.wikipedia.org/wiki/Immersionslithografie Bei unter 12nm werden dann noch ganz andere Klimmzüge fällig.
Den SP0256 gab es nicht nur als Phonemsynthesizer sondern auch ähnlich dem UAA1003 zur Aussprache von Uhrzeiten. Ein zusätzliches ROM brachte mehr Speicherplatz.
https://ntxdhxgzadrdathx.myfritz.net/mc-zeitschriften/1983/mc-1983-03.pdf#page=42 Der EMUF-Votrax-Artikel stand nicht nur im Sonderheft, hier (in schwarz-weiß) das Original aus mc 4/1983
Die Suche nach dem SP0256 bringt einiges zutage, der scheint mir noch am bekanntesten zu sein. Es gibt sogar eine Nachbau im FPGA: https://github.com/trcwm/Speech256 Family Cyclone III, Device EP3C16F484C6 mit Quartus auf einem DE0-Board aufgebaut. https://en.wikipedia.org/wiki/General_Instrument_SP0256 http://www.speechchips.com/shop/item.aspx?itemid=3 Wer also unbedingt eine nostalgische "Roboterstimme" sucht, hat ein paar Möglichkeiten.
Den SP0256 hatte ich "seinerzeit" als Bastelkarte für den Apple IIc gebaut. Der klang so gruselig, damit waren deutsche Texte schier unmöglich zu synthetisieren. War aber lustig zu sehen, was alles ging...
Der SP0256 hat meine eingetippten Hex-Dumps korrekturgelesen. Zu CP/M-Zeiten hab ich noch lange HEX-Listings aus Zeitschriften abgetippt und danach von der Sprachausgabe wieder vorlesen lassen, um Tippfehler zu finden. Dafür reichte die Sprachqualität allemal. Schaltung war ein SP0256 am Printer-Port mit NF-Verstärker, wahrscheinlich aus der Elektor.
Der amerikanische Zungenschlag ist den Phonemsynthesizern kaum abzugewöhnen. Das Emufprogramm nahm als Schluss-"er" ein "EA", da das Original eher nach "E-ÖH" klang. Der Adobe-Reader hat heute noch dieses Problem, der ist außer für englischer Texte unbrauchbar.
Christoph db1uq K. schrieb: > Der Adobe-Reader hat heute noch dieses > Problem, der ist außer für englischer Texte unbrauchbar. Vor langem hatte ich zufällig eine ziemlich gute Alternative fürs deutsche Vorlesen entdeckt: RealSpeak Solo fur Deutsch - Steffi. War damals frei im Netz erhältlich.
gerade erst gefunden........ hier noch was los? in den 80ern hatte ich mal ein sprachausgabe prog. für diverse AFU-anwendungen gebaut und über das damalige PR-netz veröffentlich. as prog. hat texte in silben zerlegt und diese dann aus einzelnen samplen und später durch eine FFT-synthese als sound ausgegeben. hatte es LESE genannt. die ausgabe ging per soundkarte oder delta-signa am drucker port. das ganz war in C geschrieben.
Gibt es nicht so etwas von Microchip als library? Vermutlich bekommt man heute überall Lösungen. Nur die Qualität ist halt die Frage. Ob das was da herauskommt eher wie ein Zahnrad oder eher wie die Alexa klinngt?
Karl B. schrieb: > Übrigens, mein alter TI1000 hatte auch mit Extended Basic einen "call > speech" Befehl. Aber sehr eingeschränkter Wortschatz und buchstabierte > meistens. > Nur Englisch Yep, altes Band wieder aufgetaucht. Also, TV auf Kanal 34, die Blechbüchse anstöpseln und zeilenweise Bascic-Befehle-Listing eintippen und "RUN". Hatte keinen Cassetten-Interface-Speicher. Das Modul steckte noch nicht drin. ciao gustav
...womit wurde die mp3 synthetisiert? Das hört sich ja zml gut an, wär geil für...irgend ein "Gerät", hauptsache es spricht :) Klaus.
Klaus R. schrieb: > womit wurde die mp3 synthetisiert? Hi, für den Mitschnitt hier? Der "lame" wie gewohnt. Schneidet ab ca. 10 kHz aber ab. Der Texas Instruments TI 1000 war schon irgendwie was Extras. Aber irgendwie gab es außer den Rechenprogrammen und "Tischtennis" keine Spiele mehr, wenn auch schon Farbe, falls Fernseher Farbe konnte. War wohl auch zu teuer. Ist dann von den Amigas und Commodores abgehängt worden. Ich bekam den TI in die Finger wegen Fehlern für 'nen 100-er. Später war auch noch die Bus-Kontaktierung kaputt. Die, wo man die Module reinstecken konnte. Das eXtended Basic Modul brauchte man für die "Speech". Wie die da synthetisiert wird, darüber habe ich keine Info. Der "Thesaurus" ist auch nicht so umfangreich gewesen. ciao gustav
...ne ich meinte den konkreten chip - also "irgendwas" im TI1000? Schön wäre ja wenn der chinese sowas wie den DF player hätte. Wort-Wahl oder HEX-Zeichen hinschicken, "der Gerät" gibt es in einer Qualität ähnlich dem sample aus... Klaus.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.