Ich war überrascht von der Neuankündigung des Propeller 2, war davon ausgegangen das die schon ewig pleite sind. Wo wird der controller eingesetzt und warum? Welche Daseinsberechtigung hat er noch? Nutzt ihn hier noch jemand? Welche Vorzüge hat er?
Die Vorzüge wird dir sicher der Hersteller in epischer Breite beschrieben. Hast du mal in seine Doku geschaut? Nach meinem Kenntnisstand zum Propeller (1) wird der ausschließlich von wenigen Hobbybastlern verwendet, die glauben, damit sei Multitasking viel einfacher und besser umsetzbar, als auf die herkömmliche Art. Ist es natürlich nicht. Zwar bringt der Chip einen praktischen Task Scheduler mit, aber der bietet zu wenig Einstellmöglichkeiten um den Chip sinnvoll auszunutzen und die Probleme des gemeinsamen Datenzugriffs nebenläufiger Threads löst er gar nicht. Aber genau das ist der komplizierteste Teil. Alle Produkte, wo ich diesen Chip drin gesehen habe, waren Experimentier-Boards für Bastler. Offenbar ist dieser Chip so interessant wie eine achtköpfige Schlange, aber auch genau so unattraktiv für die reale Anwendung. (Disclaimer für die beiden Lügen-Jäger: Das ist meine persönliche Meinung. Ich behaupte nicht, hiermit eine wissenschaftlich korrekte Wahrheit zu vertreten.)
Stefan ⛄ F. schrieb: > Die Vorzüge wird dir sicher der Hersteller in epischer Breite > beschrieben. Hast du mal in seine Doku geschaut? Wenn man sich die Story von Parallax anschaut, dann ist klar, dass die ihr Geld mit dem Bestandsgeschäft verdienen (Education). Wenn die ihre Designs einfach auf irgendeinen Standard CM4 portieren würden, würde das Geschäft einfach weiter laufen... Der Propeller 2 ist wohl eher eine Art Hobbyprojekt des Gründers. Warum auch nicht? Man kann mit einem kleinen und dedizierten Team auch ICs entwickeln, und das häufig zu einem Bruchteil der Kosten bei einer großen Firma.
Ich hab mir den mal angesehen weil ich überlegt habe, mich ernsthaft in das Teil einzuarbeiten. Es ist bisher bei den Überlegungen geblieben, aber das liegt nicht am Propeller. Ich fand das Konzept sehr interessant. Wenn ich das damals richtig verstanden habe war die Intention hinter dem Design, sich seine Controllerperipherie selber schnitzen zu können. Wenn du insgesamt nur geringe Anforderungen hast, aber ein besonders leistungsfähiges Peripherieelement brauchst das es sonst nur in größeren Controllern gibt, bist du mit dem Konzept vom Propeller besser dran. Ich denke da z.B. an den High-Resolution-Timer von ST, oder wenn du zwei spezielle Kommunikationskanäle brauchst die es in dieser Kombination nicht oder nur in größeren Controllern gibt.
Wühlhase schrieb: > Wenn ich das damals richtig verstanden habe war die Intention hinter dem > Design, sich seine Controllerperipherie selber schnitzen zu können. Wenn > du insgesamt nur geringe Anforderungen hast, aber ein besonders Ja, so etwas ähnliches gibt es auch von XMOS und von Padauk. XMOS hat sich in der Audio-Nische etabliert. Padauk scheint nur wenige typen mit mehreren Cores/Threads zu haben, ein wirklicher Durchbruch scheint es nicht zu sein.
Tim . schrieb: > Der Propeller 2 ist wohl eher eine Art Hobbyprojekt des Gründers. Immerhin scheint er ja doch noch irgendwie damit fertig geworden zu sein. Das war komplett an mir vorbei gegangen, ich dachte, das Teil wäre immer noch in der "Entwicklung", was es ja so ungefähr seit 2007/2008 war, als es das erste Mal angekündigt wurde... Wie auch immer, ich werde mir das auf jeden Fall mal genauer anschauen, insbesondere unter dem Aspekt, inwieweit die offensichtlichen konzeptionellen Schwächen des ersten Propeller ausgemerzt wurden. Aber selbst, wenn das perfekt passen würde: der Preis für das Teil ist weit jenseits von Gut und Böse. $150 für ein "Evalboard", was außer dem Controller selber so gut wie nichts enthält, das ist schon heftig und läßt darauf schließen, dass der Controller viel zu teuer ist, um im Wettbewerb bestehen zu können, selbst wenn er wirklich gut brauchbar wäre. Aber ich denke sowieso, dass das Konzept keine wirkliche Chance hat, da es mittlerweile schon in der Unterstufe der µC recht verbreitet Teile mit "FPGA"-Units gibt, die eine andere (meist schnellere und bessere) Lösung für das gleiche Problem bieten können, was der Propeller adressiert, nämlich die Bereitstellung frei programmierbarer Einheiten statt fest "verdrahteter" Peripherie. Und auch die "fest verdrahtete" Peripherie hat sich doch massiv gewandelt, seitdem die Propeller-Idee geboren wurde. Inzwischen ist die vielfach so wandelbar und anpassbar geworden, dass sie fast alles Denkbare an Funktionalität erschlagen kann, insbesondere, wenn man sie auch noch mit diesen eingebauten "FPGA"-Einheiten kombiniert. Also zusammengefaßt: Ich glaube, dass der Propeller2 keine große Zukunft haben wird, weil es das Problem einfach nicht mehr gibt, was das Propeller-Konzept lösen sollte.
Alleine schon die Idee, ihn mit einer ganz speziellen Programmiersprache zu programmieren die nur auf diesem einen Controller läuft, halte ich für ein No-Go. Selbst um Java und LUA (auf Mikrocontrollern) ist es ziemlich ruhig geworden.
> Nach meinem Kenntnisstand zum Propeller (1) wird der ausschließlich von > wenigen Hobbybastlern verwendet, die glauben, damit sei Multitasking > viel einfacher und besser umsetzbar, als auf die herkömmliche Art. Naja, echtes Multitasking mit dedizierten Cores ist schon besser wenn du sehr spezielle sehr timingkritische Anwendungen hast. Wo du die Wahl hast es entweder mit einem Propeller hinzubekommen oder ein FPGA (teuer) zu nehmen. Vergleich das mal mit der TPU bei einem 68332 oder den im vergleich dazu armseligen Versuchen von Silabs/Gecko Interaktion ohne laufenden Core zu ermoeglichen. Und wenn du siehst das NXP sich ja auch die Muehe macht Controller mit mehreren Cores zu entwickeln dann wird es dafuer Anwendungen geben. Ich kenne sogar eine aber ohne NDA kann ich darueber nicht reden. .-) > Alleine schon die Idee, ihn mit einer ganz speziellen Programmiersprache > zu programmieren die nur auf diesem einen Controller läuft, halte ich > für ein No-Go. Ich auch wenn man es aus dem Blickwinkel eines Durchschnittsprogrammierers sieht. Aber wenn die Alternative FPGA heisst wo du eine Haelfte in Verilog und die andere in der Spraches deines Softcores programmierst dann kann das wieder interessant werden. Ich wuerde nicht davon aussehen das in so einem Propeller fette Monsteranwendungen programmiert werden. Allerdings denke ich auch das sowas wie der Propeller es schwer haben wird. Das passt nicht zum aktuellen Zeitgeist von Abschreibern und Codecopy. Olaf
Vielleicht nur so ein obsoletes Ding wo die Energie-überschäumenden Jungspunde sich austoben können.
Gängige Compilersprachen passen nicht gut auf die Architektur und spezielle Sprachen führen zu einer Insellösung. Um Assembler für einige Module kommt man wohl kaum herum. Nicht skalierbar. Die sehr spezielle Architektur führt zu sehr speziellen Lösungen. Reichen die Ressourcen nicht, fängt man anderswo praktisch von vorne an. Wer sich beruflich darauf einlässt, muss schon ein sehr spezielles Szenario im Auge haben, das nur damit wirklich gut und günstig lösbar ist. Die meisten Entwickler (-Büros) werden sich lieber eine oder zwei Controller-Familien ausgucken, mit denen sie in weitem Bereich arbeiten können, von klein bis gross. Vereinfacht Knownow-Aufbau und erleichtert Code-Reuse. Lösungen auf viele Threads aufzuteilen kann bei manchen Aufgaben notwendig werden. Allerdings handelt man sich dadurch eine Klasse von Problemen ein, die man ohne diese Technik nicht hätte. Nebenläufigkeit hat Nebeneffekte, das ist ja schon bei einfachen Interrupts der Fall, erst recht bei parallelen Threads.
Stefan ⛄ F. schrieb: > Nach meinem Kenntnisstand zum Propeller (1) wird der ausschließlich von > wenigen Hobbybastlern verwendet, die glauben, damit sei Multitasking > viel einfacher und besser umsetzbar, als auf die herkömmliche Art. und der Vorteil liegt klar auf der Hand, zumal es ja gute Projekte gibt: https://hive-project.de/ > Ist es natürlich nicht. Zwar bringt der Chip einen praktischen Task > Scheduler mit, aber der bietet zu wenig Einstellmöglichkeiten um den > Chip sinnvoll auszunutzen und die Probleme des gemeinsamen Datenzugriffs > nebenläufiger Threads löst er gar nicht. Aber genau das ist der > komplizierteste Teil. das Teil ist vor allen Dingen für Retro-Emulatoren gut und dann macht es durchaus auch Sinn.
Vielleicht sollte man erwähnen, dass der "II" ein Forth-System mitbringt, sodaß man mitnichten in der Sprache von Parallax programmieren muß. Ob das ein Versuch ist, eine weitere Fangemeinde zu erobern, kann ich nicht abschätzen, aber wer jemals mit Forth interaktiv mit einem Controller gearbeitet hat, könnte sich da schon angesprochen fühlen. Daß die Hardware preislich sowohl Bastler als auch Profis nicht gerade lockt, muß trotzdem kein KO-Kriterium sein! Gruß Rainer
Auf den ersten Propeller bin ich reingefallen. Alles schien erstmal ziemlich cool bis ich dann den Chip aufm Breadboard hatte und nicht mehr klar kam. Da gab es diese komische Sprache, SPIN glaube ich und der C Compiler war nicht verfügbar.
Der Propeller 2 ist zwar vom Propeller 1 abgeleitet, aber ausser dem Konzept der parallelen Prozessoren und dem gemeinsamen grossen RAM hat er nicht mehr viel mit dem Ur-Propeller zu tun. Es gibt jetzt viel mehr RAM und viel schnellere Prozessoren, aber das ist nicht so entscheidend, das wirklich spezielle am P2 sind die Analogfunktionen in jedem der 64 Pins. Die heben ihn auch deutlich von FPGAs ab. Jeder Pin hat einen Highspeed DAC eingebaut, der bei 8-Bit Auflösung mit bis zu 300 MHz wandeln kann, oder bei 16 Bits mit etwa 1 MHz. Ausserdem eine SigmaDelta ADC Einheit mit Sinc2 und Sinc3 Hardwarefiltern, die z.B. eine Audio Wandlung mit 18 Bit und 384 kHz zulassen. Gesteuert werden diese Analogfunktionen von einer Smartpin Zelle pro Pin, die sich vielfältig Konfigurieren lässt und neben Dingen wie DDS für die DACs auch so profane Periferie wie PWM, SPI oder UART, aber auch USB (FS und LS) ermöglicht, man muss dafür nicht mehr Prozessoren opfern, und alles in Software machen, wie beim P1. Eine DMA ähnliche "Streamer" Einheit ermöglicht Video, VGA, und beschränkt auch HDMI Ausgabe, sowie den Transfer zwische RAM und Ports mit voller Geschwindigkeit, z.B. für Logic Analyzer oder DSO Anwendungen. Eine Cordic Einheit ist zuständig für präzise trigonometrische und logarithmische Funktionen, Quadratwurzel, aber auch Multiplikation und Division, alles in Integer oder Festkomma, eine FPU gibt es nicht. Ausser in Spin2 kann man den P2 schon heute in C, BASIC und Forth programmieren, auch ein MicroPython wurde schon gesichtet, und C++ ist über den Umweg eines Risc-V Emulators möglich, wenn es denn sein muss. Allerdings stammt nur 'Spin' von Parallax selbst, und auch das ist noch eher spärlich mit Bibliotheken für die zahlreichen Features ausgestattet. Auch die Dokumentation zum neuen Propeller ist noch sehr rudimentär, und Parallax ist da auf die Mithilfe der recht aktiven Community angewiesen, da die Firma doch ziemlich geschrumpft ist in den letzten Jahren. An der ganzen Entwicklung des Propeller 2 war die Community beteiligt, alle Ideen des Entwicklers wurden diskutiert, und man konnte durchaus mitreden. Dadurch, und weil Parallax nichts mit Fremdkapital finanzieren wollte, hat es auch etwas länger gedauert. Der Chip ist natürlich ein Nischenprodukt, und das war auch immer klar. Parallax könnte niemals mit den grossen Prozessorherstellern mithalten, und versucht es auch gar nicht. Der Preis mag für viele Anwendungen zu hoch sein, aber verglichen mit XMOS z.B. ist da kein grosser Unterschied. Entwicklungsboards muss es natürlich noch günstigere, und bessere geben, damit sich mehr Leute auf den Chip einlassen.
> Der Chip ist natürlich ein Nischenprodukt, und das war auch immer klar.
Ich glaub das wollen sie auch so. Ich konnte jedenfalls gerade kein
Datenblatt von dem Teil finden. Das fand ich sehr erstaunlich.
Olaf
Damals[tm] hab ich für mich was mit dem Propeller gemacht. Es war ein Modbus-Interface für das Handrad meiner Fräsmaschine. Der Propeller ist von der Idee her ganz interessant und nur desshalb hab ich es mit ihm gemacht. Die ursprünglich dafür vorgesehene Sprache "Spin" hab ich probiert, aber dann bleiben lassen. Das ist dann doch zu verquer. Formatierungsabhängige Sprachen sind mir zu blöd. Es gab damals einen C-Compiler zu kaufen (Imagecraft), der hat sich aber wieder zurückgezogen aus dem Markt wg. nicht wirtschaftlich. Jedenfalls war der Compiler brauchbar (hatte aber auch Fehler die umschiffbar waren). Mit Spin oder C hat man nicht gemerkt, dass jeder Kern nur 256 (??) Worte Speicher hat, das wurde immer vom Kernspeicher nachgeladen. Programme bei denen die Daten als Strom durchlaufen lassen sich ganz gut parallelisieren (wie Transputer). Diese shared Memory ist leicht zu handhaben, man muss halt semaphoren setzen. Ah, dann hab ich noch was gemacht, wurde aber nie ganz fertig: Eine Zündungsteuerung für Mehrzylindermotoren. Die hatte ziemlich absurde Randparameter (Drehzahl, Zylinderzahl), einfach weil es ging. Da hab ich wesentliche Teile in Assembler geschrieben. Der Befehlssatz ist sehr angenehm für handcodierten Assembler, so schön wie 68000er. Und in den 256 (??) Worten bringt man viel unter. Problem bei dem Ding ist: Es gibt nur eine Variante. Speicher aus? Was anderes verwenden! Fürs Hobby oder nur aus reinem Interesse ist das wirklich mal spannen auszuprobieren. Kommerziell: Finger weg, ausser man hat eine ganz spezielle Aufgabe. Da würde ich lieber einen XMOS verwenden. Es scheint aber, dass XMOS die Weiterentwicklung seiner Prozessoren eingestellt hat. Letztes Jahr wollte ich ein Projekt damit machen, aber es gab nicht mal mehr DevBoards. In XDev nachgefragt ist eine maximal schwammige Antwort von offizieller Seie gekommen die mich davon abgehalten hat noch irgendwas mit den Prozessoren zu machen. Leider ist die IDE von XMOS auch stehengeblieben, Bugs werden da nicht mehr beseitigt. Die IDE läuft auch nur wirklich unter Linux, MacOS und Win haben Speicherprobleme. Ich hab nebenbei auch die Propeller II Entwicklung verfolgt. Da gab es paar Leute die den Entwickler immer neue schräge Sachen aufgequatscht haben. Und inzwischen ist das wohl ein arges Kommitee-Design geworden. Von Anfang an wurde das parallel auf einem FPGA implementiert (Board >> 1000 €). Irgendwelche Sachen gehen besser, die Taktfrequenz schein deutlich höher zu sein. Aber das gleiche Problem: Nur eine Variante.
Nick M. schrieb: > Mit Spin oder C hat man nicht gemerkt, dass jeder Kern nur 256 (??) > Worte Speicher hat, das wurde immer vom Kernspeicher nachgeladen. Kernspeicher??? https://de.wikipedia.org/wiki/Kernspeicher
René K. schrieb: > Kernspeicher??? Du kannst gerne selbst versuchen das Rätsel aufzulösen. Es hilft, sich mit der Architektur des Propeller zu beschäftigen.
René K. schrieb: > Nick M. schrieb: >> Mit Spin oder C hat man nicht gemerkt, dass jeder Kern nur 256 (??) >> Worte Speicher hat, das wurde immer vom Kernspeicher nachgeladen. > > Kernspeicher??? > https://de.wikipedia.org/wiki/Kernspeicher Eigentlich Hub-Memory (32k geshared). Im Gegensatz zu Cog-Memory (1k oder 256 32-Bit Worte)
Andi schrieb: > das wirklich spezielle am P2 sind die > Analogfunktionen in jedem der 64 Pins. Die heben ihn auch > deutlich von FPGAs ab. Jeder Pin hat einen Highspeed DAC eingebaut, der > bei 8-Bit Auflösung mit bis zu 300 MHz wandeln kann, oder bei 16 Bits > mit etwa 1 MHz. Ausserdem eine SigmaDelta ADC Einheit mit Sinc2 und > Sinc3 Hardwarefiltern, die z.B. eine Audio Wandlung mit 18 Bit und 384 > kHz zulassen. Gesteuert werden diese Analogfunktionen von einer Smartpin > Zelle pro Pin, die sich vielfältig Konfigurieren lässt und neben Dingen > wie DDS für die DACs auch so profane Periferie wie PWM, SPI oder UART, > aber auch USB (FS und LS) ermöglicht, man muss dafür nicht mehr > Prozessoren opfern, und alles in Software machen, wie beim P1. Na gut, dann konkurriert das Teil also weniger mit FPGAs als vielmehr mit DSPs. Auch die haben allerdings mittlerweile Einzug in viele übliche µC-Architekturen gehalten. Und dazu kommt: bei praktisch allen aktuellen µC-Familien gibt es zwar auch integrierte ADCs, aber praktisch sind die alle mehr oder weniger huppse, wenn auch noch Genauigkeit eine Rolle spielt. Der Störnebel der räumlich sehr nahen MCU-Kerne mit extremen Transienten (praktisch der gesamte Leistungsumsatz geschieht nur an den Taktflanken) verhindert, dass damit wirklich genaue Einzelmessungen gemacht werden können. Und das wird vermutlich beim P2 nicht viel anders sein. Auch Parallax muss sich wohl am Ende den Gesetzen der Physik beugen.
Stefan ⛄ F. schrieb: > Nach meinem Kenntnisstand zum Propeller (1) wird der ausschließlich von > wenigen Hobbybastlern verwendet, die glauben, damit sei Multitasking > viel einfacher und besser umsetzbar, als auf die herkömmliche Art. Das möchte nicht in meinen Kopf reingehen, für die paar Bastler wird es sich doch garantiert nicht lohnen einen eigenen Chip fertigen zu lassen, und mit den geringen Preisen < 10€ pro Chip scheint sich das Teil doch gut genug zu verkaufen. Ich gehe davon aus, das es einige Produkte damit gibt, vielleicht keine Massen-Consumer-Ware aber doch Produkte mit halbwegs rentablen Stückzahlen.
René F. schrieb: > und mit den geringen Preisen < 10€ pro Chip Das war vielleicht mal gering, heute ist es das nicht mehr. Schau mal in den Markt, was du für 10€ heutzutage für Rechenknechte kaufen kannst... Der einzige Grund, 10€ für einen P1 auszugeben dürfte sein, dass eine fertige Lösung für ein bestimmtes Problem damit existiert. Alles andere ergibt keinen wirtschaftlichen Sinn.
c-hater schrieb: > Und dazu kommt: bei praktisch allen aktuellen µC-Familien gibt es zwar > auch integrierte ADCs, aber praktisch sind die alle mehr oder weniger > huppse, wenn auch noch Genauigkeit eine Rolle spielt. Der Störnebel der > räumlich sehr nahen MCU-Kerne mit extremen Transienten (praktisch der > gesamte Leistungsumsatz geschieht nur an den Taktflanken) verhindert, > dass damit wirklich genaue Einzelmessungen gemacht werden können. > > Und das wird vermutlich beim P2 nicht viel anders sein. Auch Parallax > muss sich wohl am Ende den Gesetzen der Physik beugen. Ja, der Analogteil wurde auch mit Rücksicht darauf als 'Custom-Silicon' designt, und Gruppen von 4 Pins haben je einen eigenen Spannungsversorgungspin erhalten, so dass man diese einzeln entkoppeln kann. Trotzdem erreicht der ADC "nur" eine Genauigkeit von etwa 13.5 Bits für absolute Spannungsmessungen. Für dynamische Signale, wie Audio, geht die Auflösung aber bis 18 Bits. --- Übrigens hat schon der P1 512 Worte Programmspeicher pro Prozessor gehabt, und nicht 256, der P2 hat einen zusätzlichen RAM Block von 512 Worten, der auch zur Programmausführung benutzt werden kann. Ausserdem kann nun Programmcode auch vom grossen Hauptram direkt ausgeführt werden, nur Sprünge benötigen dabei etwas mehr Zeit, da ein FIFO nachgeladen werden muss.
Bis jetzt fehlt hier noch der Link: https://www.parallax.com/propeller-2/ Die Seite braucht aber ewig zum laden.
(prx) A. K. schrieb: > Lösungen auf viele Threads aufzuteilen kann bei > manchen Aufgaben notwendig werden. Allerdings > handelt man sich dadurch eine Klasse von Problemen > ein, die man ohne diese Technik nicht hätte. Ich würde es eher umgekehrt formulieren: Das unerschütterliche Festhalten am Begriff des Algorithmus, der sequenziell ausgeführt wird, ist schon seit mindestens 20 Jahren ein Anachronismus. Man handelt sich dadurch Probleme ein, die man ohne diese Technik nicht hätte :)
Ich wollte gerade mal schauen wie viel der Chip kostet, konnte aber nur das teure Eval Board finden. Hat der Chip keinen darüber hinaus gehenden Sinn, als evaluiert zu werden?
(prx) A. K. schrieb: > Problemlos zu finden: $14.95 Ach, danke. Ich hatte bei Mouser und Digikey nach P2X8C4M64P-ES gesucht. Ist viel billiger als ich befürchtet hatte.
(prx) A. K. schrieb: > Problemlos zu finden: $14.95 Hast du zufällig auch ein "nicht docs.google" Datenblatt gefunden?
Stefan ⛄ F. schrieb: > Ist viel billiger als ich befürchtet hatte. Aber trotzdem immer noch viel teuerer als angemessen für die Leistung...
Tim . schrieb: > Der Propeller 2 ist wohl eher eine Art Hobbyprojekt des Gründers. Warum > auch nicht? Man kann mit einem kleinen und dedizierten Team auch ICs > entwickeln, und das häufig zu einem Bruchteil der Kosten bei einer > großen Firma. Genau, ist doch schön wenn mal jemand andere Konzepte usw. probiert, der Markt regelt es doch sowieso. So sinnlos wird das Teil auch nicht sein, sonst gäbe es die Firma ja nicht. Muss ja nicht immer alles ST oder Microchip sein. Ich bin in dem Konzept auch nicht so sehr drinnen, allerdings könnte der Propeller schon für manche Nischenanwendung sinnvoll sein, vorallem auf CORDIC scheint hier ein direkter Fokus liegen. Also evtl. VR Geschichten oder Roboter. Ein paar Industriekunden muss es jedenfalls geben, sonst kann ich mir das kaum vorstellen.
von c-hater (Gast)
28.12.2020 15:50
>Aber trotzdem immer noch viel teuerer als angemessen für die Leistung...
Kommt auf das Problem an. Mit dem Propeller lassen sich zeitsynchrone
Designs realisieren, die mit konventionellen Prozessoren so gut wie
nicht realiserbar sind.
A. K. schrieb: > Ich bin in dem Konzept auch nicht so sehr drinnen, allerdings könnte der > Propeller schon für manche Nischenanwendung sinnvoll sein, Ich kann nur empfehlen, sich den mal anzuschauen. Leider nicht für den Preis von $150 für ein EvalBoard. Der ist interessant. Z.B. gibt es keine Interrupts und keinen USART (wie beim XMOS auch). Einen kommerziellen Einsatz würd ich mir aber dreimal überlegen.
Ich hatte mir den ersten Propeller angesehen, als er neu war. Fazit: Interessante Lösung auf der Suche nach einem passenden Problem. Der verwandte Ansatz von XMOS gefiel mir besser.
(prx) A. K. schrieb: > Interessante Lösung auf der Suche nach einem passenden Problem. Der > verwandte Ansatz von XMOS gefiel mir besser. Nur hat der XMOS auch so seine Problemchen: Man kann nicht direkt auf das Shared Memory zugreifen. Untereinander können die Prozessoren nur mit zwei Methoden kommunizieren. Die eine ist schnell und verbraucht sehr begrenzte Resourcen, die Andere ist arg langsam. Ich hab die Namen der Methoden vergessen.
chris_ schrieb: > Kommt auf das Problem an. Mit dem Propeller lassen sich zeitsynchrone > Designs realisieren, die mit konventionellen Prozessoren so gut wie > nicht realiserbar sind. Hmm... Kannst du für so etwas ein Beispiel liefern? Muss jetzt nicht die Umsetzung sein, sondern nur eine Art "Prinzipschaltbild", welches das Problem beschreibt.
c-hater schrieb: > Kannst du für so etwas ein Beispiel liefern? Während ein Prozessor z.B. über die Schnittstelle Daten einliest, kann ein zweiter parallel schon anfangen die Daten in einzelne Datensätze zu zerlegen und die bis jetzt schon vollständig erhaltenen vom nächsten Prozessor ausführen lassen.
Nick M. schrieb: > Während ein Prozessor z.B. über die Schnittstelle Daten einliest, kann > ein zweiter parallel schon anfangen die Daten in einzelne Datensätze zu > zerlegen und die bis jetzt schon vollständig erhaltenen vom nächsten > Prozessor ausführen lassen. Sowas kann man mit jedem gängigen µC mit nur einem Core machen, indem man die Interrupts der Peripherie benutzt. Also das allein kann's ja nun wirklich nicht sein.
Es gibt ja noch mehr Ansätze, welche auf massive Parallelverarbeitung setzen Z.B. http://www.greenarraychips.com/home/products/index.html Aber der scheint den wirtschaftlichen Arsch auch nicht hoch zu bekommen
c-hater schrieb: > Also das allein kann's ja nun > wirklich nicht sein. Sagt dir Transputer und Occam was? Nein? Dann lies das bitte auf Wikipedia nach. Ja? Warum frägst du nach Beispielen?
Arduino Fanboy D. schrieb: > Es gibt ja noch mehr Ansätze, welche auf massive Parallelverarbeitung > setzen Interessant!
Ein CPU-Kern mit x-facher Geschwind. kann eine CPU mit x Kernen ersetzen, wenn für ContextSwich, ISR usw, nicht zu viele Clocks verschwendet werden. Unbedingt mehr Kerne macht man nrm. nur, wenn man mit der f am Anschlag ist.
chris_ schrieb: > von c-hater (Gast) > 28.12.2020 15:50 >>Aber trotzdem immer noch viel teuerer als angemessen für die Leistung... > > Kommt auf das Problem an. Mit dem Propeller lassen sich zeitsynchrone > Designs realisieren, die mit konventionellen Prozessoren so gut wie > nicht realiserbar sind. Inwieweit wäre dann eine FPGA Lösung eine theoretische sinnvolle Alternative zum Propeller wenn es darauf ankommt? Irgendwie finde ich den FPGA Ansatz prinzipiell sauberer. Wie oft kommen solche Fälle vor wo ein schneller uC nicht mehr klar kommt? Was mich betrifft hatte ich noch nie Anwendungen zu erstellen die ein schneller uC nicht bewältigen konnte. Aber meine Anwendungen sind alle in Richtung Kommunikation und MSR. Ich kannte in der Stadt eine Firma wo Propeller serienmäßig kommerziell eingesetzt wurden. Allerdings wurde dem Ingenieur (Firmeninhaber) nachgesagt es wäre eine persönliche eigenwillige Marotte von ihm gewesen. Die Kollegen wollten eigentlich von dem Teil eher nichts wissen und entwickelten lieber mit konventionellen uC.
Gerhard O. schrieb: > Inwieweit wäre dann eine FPGA Lösung eine theoretische sinnvolle > Alternative zum Propeller wenn es darauf ankommt? Irgendwie finde ich > den FPGA Ansatz prinzipiell sauberer. Daher kommt ja die Aussage, dass das wie ein FPGA ist. Wobei jeder der das sagt weiß, dass es maßlos übertrieben ist. Gilt auch für den xmos. Man hat halt 8 Prozessoren die entweder völlig autark oder auch beliebig zusammen arbeiten können. Das ist nie so schnell wie FPGA, das ist nie so wirklich parallel wie FPGA, das ist nie so kombinatorisch wie FPGA. Aber jeder der C programmieren kann bekommt das hin. Beim xmos ist es etwas schwieriger, das XC braucht etwas Einarbeitung. Also hängt der Propeller (oder der xmos) irgendwo zwischen µC und FPGA. Aber deutlich näher am µC als am FPGA. xmos ist etwas näher am FPGA, aber auch nicht mal auf halber Strecke.
c-hater schrieb: >> Während ein Prozessor z.B. über die Schnittstelle Daten einliest, kann >> ein zweiter parallel schon anfangen die Daten in einzelne Datensätze zu >> zerlegen und die bis jetzt schon vollständig erhaltenen vom nächsten >> Prozessor ausführen lassen. > > Sowas kann man mit jedem gängigen µC mit nur einem Core machen, indem > man die Interrupts der Peripherie benutzt. Also das allein kann's ja nun > wirklich nicht sein. Eigentlich jedes Problem, wo man zwei sehr zeitkritische Protokolle gleichzeitig bearbeiten muss. Ich hatte mal einen USB AtXmega Programmer basierend auf einem Atmega nachgebaut (fertiges Projekt). Das ganze basierte auf Software USB und einem Programmierprotokoll in Software. Nur funktioniert der USB Stack (VUSB) nur, wenn der Interrupt auch innerhalb von ~10 Taktzyklen mit der Bearbeitung beginnt. Umgekehrt verliert der Xmega nach wenigen µs ohne Takt (der USB Interrupt braucht länger) die Verbindung. Das angeblich fertige Projekt reichte um in 30% der Fällen zumindest die Xmega Signaturbits zu lesen - an eine Programmierung war damit nicht zu denken. Nach zu vielen Stunden und Versuchen das Xmega Protokoll im Interrupt des USB Handlers mit Assembler weiter auszuführen, bin ich zu dem Schluss gekommen, dass man zwei AVRs bräuchte. Jeder der ein zeitkritisches Protokoll handelt und ein zeitunkritisches Protokoll zwischen den beiden. Hier wäre ein Chip mit mehr als einem Kern genau richtig gewesen. Alternativ hätte man das ganze natürlich auch mit purer Rechenleistung erschlagen können. Am Ende hab ich aber einfach für 30€ einen fertigen Xmega Programmer gekauft.
Gerhard O. schrieb: > Irgendwie finde ich den FPGA Ansatz prinzipiell sauberer. Übersehen darauf noch einzugehen. Kommt drauf an wo man steht. Es geht schon was mit parallelen Prozessoren. Wenn Reaktionszeit kritisch ist (Hausnummer 100 ns) kommt man noch tw. hinterher. Muss man sich aber schon gut überlegen. Beim FPGA ruft das nur ein müdes Lächeln hervor. Wenn man gleichzeitig rechnen kann / muss, wirds beim FPGA schwieriger / teuerer. Prinzipiell lässt sich deine Frage nicht beantworten. Fallspezifisch schon.
Malte _. schrieb: > Das ganze basierte auf Software USB und > einem Programmierprotokoll in Software. Nur funktioniert der USB Stack > (VUSB) nur, wenn der Interrupt auch innerhalb von ~10 Taktzyklen mit der > Bearbeitung beginnt. Umgekehrt verliert der Xmega nach wenigen µs ohne > Takt (der USB Interrupt braucht länger) die Verbindung. [...] Hier wäre ein Chip mit mehr als einem Kern genau > richtig gewesen. Alternativ hätte man das ganze natürlich auch mit purer > Rechenleistung erschlagen können. Oder man könnte einfach einen 0815-µC mit USB in Hardware nehmen?
Gerhard O. schrieb: > Was mich betrifft hatte ich noch nie Anwendungen zu erstellen die > ein schneller uC nicht bewältigen konnte. Aber meine Anwendungen sind > alle in Richtung Kommunikation und MSR. Ich hab spaßeshalber (für eine Bewerbung) einen PID-Regler mit FF0..FF2 und roll up auf xmos implementiert. Der hat 750 kHz geschafft. Ich denk der Wert dürfte überzeugen.
Stefan ⛄ F. schrieb: > damit sei Multitasking viel einfacher und besser umsetzbar Es gibt nur zwei Möglichkeiten, zwei Threads echt nebenläufig zu machen, und das ist AMP ohne OS mit zwei Kernen mit Shared Memory - oder das Propeller Konzept Da sich das Propeller Konzept nicht durchgesetzt hat, bleiben nur noch zwei Kerne, und daher finden sich inzwischen in allen uC Familien dafür welche mit zwei Kernen z.B. https://www.nxp.com/products/processors-and-microcontrollers/arm-microcontrollers/general-purpose-mcus/lpc5500-cortex-m33:LPC5500_SERIES Mit DMA oder ART geht keine echte Nebenläufigkeit.
Lothar schrieb: > das ist AMP ohne OS mit zwei Kernen mit Shared Memory Wie wird denn da der gemeinsame Zugriff aufs RAM geregelt? Mir geht es hier nicht um nicht-atomare Zugriffe. Was ich meine ist das interlaced, wird eine CPU angehalten, ist das dual ported RAM oder wie läuft das? Denn "shared memory" kann man ja auch mit nur einer CPU und mit Task-switching (ohne FSM) machen.
Nick M. schrieb: > Wie wird denn da der gemeinsame Zugriff aufs RAM geregelt? Hier geht es um einen älteren Dual-Core uC - hat sich aber nichts geändert: https://www.nxp.com/company/blog/an1117-ipc-on-lpc43xx-managing-inter-processor-communications-in-the-dual-core-lpc4300:BL-AN1117-IPC-ON-LPC43XX
c-hater schrieb: > Nick M. schrieb: > >> Während ein Prozessor z.B. über die Schnittstelle Daten einliest, kann >> ein zweiter parallel schon anfangen die Daten in einzelne Datensätze zu >> zerlegen und die bis jetzt schon vollständig erhaltenen vom nächsten >> Prozessor ausführen lassen. > > Sowas kann man mit jedem gängigen µC mit nur einem Core machen, indem > man die Interrupts der Peripherie benutzt. Also das allein kann's ja nun > wirklich nicht sein. Nein. Gänge µCs mit einem Kern kannst du nur von jeder der Aufgaben nur eine erledigen lassen. Entweder Daten einlesen oder Daten verarbeiten oder Daten ausgeben. Aber niemals gleichzeitig. War hier nicht vor einigen Wochen ein Thread, wo jemand einen "gängigen µC" als SPI-Slave laufen lassen wollte? Wenn ich mich recht erinnere haben ihm die meisten davon abgeraten, er solle das bitte möglichst anders lösen. Der Propeller wäre für so etwas jedoch richtig gut. Da kann sich ein Kern ganz gemütlich auf die Lauer nach dem Chip-Select-Signal legen und der Rest kann nach Belieben seinen zeitkritischen Aufgaben nachgehen. Es ist ja nicht so, daß Interrupts nie stören würden und man da stets immer jederzeit darauf reagieren mag. Ich verstehe die Gegenwehr, die das bei einigen auszulösen scheint, absolut nicht. Kennt ihr nur einen Hammer und seid mit Schrauben überfordert?
Wühlhase schrieb: > Nein. Gänge µCs mit einem Kern kannst du nur von jeder der Aufgaben nur > eine erledigen lassen. Entweder Daten einlesen oder Daten verarbeiten > oder Daten ausgeben. Aber niemals gleichzeitig. Das ist ne ziemlich extreme Aussage. Und ich würd sagen, die ist extrem falsch. Wühlhase schrieb: > War hier nicht vor einigen Wochen ein Thread, wo jemand einen "gängigen > µC" als SPI-Slave laufen lassen wollte? Wenn ich mich recht erinnere > haben ihm die meisten davon abgeraten, er solle das bitte möglichst > anders lösen. Ich frage mich, warum es dann µC gibt, die SPI-Slave in Hardware machen. Was spricht dagegen? Wühlhase schrieb: > Der Propeller wäre für so etwas jedoch richtig gut. Da kann sich ein > Kern ganz gemütlich auf die Lauer nach dem Chip-Select-Signal legen und > der Rest kann nach Belieben seinen zeitkritischen Aufgaben nachgehen. Der Propeller ist also gut, weil er ein Problem löst, das man auch anders, einfacher und günstiger lösen kann? Um auf einen etwas älteren Post zurück zu kommen. Andi schrieb: > Es gibt jetzt viel mehr RAM und viel schnellere Prozessoren, aber das > ist nicht so entscheidend, das wirklich spezielle am P2 sind die > Analogfunktionen in jedem der 64 Pins. Die heben ihn auch > deutlich von FPGAs ab. Jeder Pin hat einen Highspeed DAC eingebaut, der > bei 8-Bit Auflösung mit bis zu 300 MHz wandeln kann, oder bei 16 Bits > mit etwa 1 MHz. Ausserdem eine SigmaDelta ADC Einheit mit Sinc2 und > Sinc3 Hardwarefiltern, die z.B. eine Audio Wandlung mit 18 Bit und 384 > kHz zulassen. Gesteuert werden diese Analogfunktionen von einer Smartpin > Zelle pro Pin, die sich vielfältig Konfigurieren lässt und neben Dingen > wie DDS für die DACs auch so profane Periferie wie PWM, SPI oder UART, > aber auch USB (FS und LS) ermöglicht, man muss dafür nicht mehr > Prozessoren opfern, und alles in Software machen, wie beim P1. Der P2 kann also ~60 ADCs oder DACs haben? Das wäre praktisch, aber irgendwie glaub ich das nicht.
mh schrieb: > Entweder Daten einlesen oder Daten verarbeiten >> oder Daten ausgeben. Aber niemals gleichzeitig. > > Das ist ne ziemlich extreme Aussage. Und ich würd > sagen, die ist extrem falsch. Nun ja, auf einer sequenziellen Maschine ist die Aussage sogar per definitionem richtig.
Und dann wären da noch Maschinen mit rein sequentiellen Programmen, aber parallel arbeitender I/O. Also die weitaus meisten Controller, denn schon eine simple eingebaute UART kann gleichzeitig rein wie raus. Der Unterschied zu Propeller oder XMOS liegt in deren Fähigkeit, I/O-Module in Software zu implementieren, womit man sich auch Aufgaben nähern kann, für die es keine Hardware-Module gibt, und die konventionelle Mikrocontroller mangels Echtzeit-Tempo nicht zuwege bringen. Sonst müsste man ein FPGA verwenden. Krasses Beispiel ist Ethernet in Software bei XMOS. Das ist zwar in diesem Fall eigentlich Unfug, weil man mit einem echten Ethernet-Modul besser dran ist, zeigt aber, was damit geht.
(prx) A. K. schrieb: > Und dann wären da noch Maschinen mit rein sequentiellen > Programmen, aber parallel arbeitender Hardware. Also > die weitaus meisten Controller, denn schon eine simple > eingebaute UART kann gleichzeitig rein wie raus. Hmpf. Eine UART ist aber nicht "programmierbar" im Sinne der Turing-Vollständigkeit -- auch wenn sie natürlich zahlreiche Betriebsarten kennt, unter denen man auswählen kann. Andernfalls wird jeder Prozessor mit Hardware-Multiplizierer zum massiv parallelen System -- bedenke nur, wieviele Halb- und Volladder da parallel arbeiten... > Der Unterschied zu Propeller oder XMOS liegt in deren > Fähigkeit, I/O-Module durch Software implementieren, > womit man sich auch Aufgaben nähern kann, für die es > keine Hardware-Module gibt, und die Mikrocontroller > mangels Echtzeit-Tempo nicht zuwege bringen. Das waren ja wohl die Punkte, um die es hier ging. Das übliche Programmiermodell geht halt von einer sequenziellen Maschine aus, aber letztlich zeigt sich m.E. an allen Ecken und Enden, dass das ergänzungswürdig ist.
Interessanter Thread. Eigentlich kommt es im praktischen Kontext vielleicht eher darauf an datenintensive Peripherien wie USB, Ethernet, USARTS, U.Ä. mit entsprechenden Puffern auszurüsten, so daß multithreaded Betrieb mittels DMA und Interrupts bequem abgearbeitet werden können ohne den eigentlichen uC Instruktionsablauf zu sehr zu bedrängen. Deshalb wären auch bekannte existierende uC mit Multi-Core a la Propeller, aber mit schon bekannten Cores und Werkzeugen praktisch gesehen für größere Anwendungen eine bessere Lösung um die Arbeitslast den Anforderungen gemäß aufteilen zu können. Was es da diesbezüglich in diese Richtung schon gibt ist mir im Augenblick nicht bekannt weil ich bis jetzt noch keinen Grund hatte viel über den Tellerrand zu schauen. Bis jetzt war es mit RTOS und Cortex Core immer bequem möglich Multitasking befriedigend durchsetzen zu können. Mehr als gleichzeitige Bearbeitung von TFT, USB und Ethernet und sonstigen nativen IO brauchen wir eigentlich nicht. Und die erwähnten Funktionen werden ja alle von dedizierter HW erledigt, so daß der Haupt-Prozessor damit bequem klarkommt. Einmal brauchten wir ein großes CPLD um genügend Bus Funktionen zu haben. Sonst gab es nie Engpässe. Naja, wir haben ja alle mit den verschiedensten Anforderungen umzugehen und ist dann immer sehr individuell zu bewerten. Ist ja gut, daß es so viele verschiedene Möglichkeiten gibt, obwohl gerade das die Qual der Wahl verschlimmern kann. Wünsch Euch all noch einen guten Rutsch ins neue Jahr! Gerhard
mh schrieb: > Wühlhase schrieb: >> War hier nicht vor einigen Wochen ein Thread, wo jemand einen "gängigen >> µC" als SPI-Slave laufen lassen wollte? Wenn ich mich recht erinnere >> haben ihm die meisten davon abgeraten, er solle das bitte möglichst >> anders lösen. > > Ich frage mich, warum es dann µC gibt, die SPI-Slave in Hardware machen. > Was spricht dagegen? z.B. die 8 Bit AVR? Prächtig, als Master. Unangenehm als Slave. Denn das Päuschen, zwischen 2 Byte, welches der Master einlegen muss, damit die Slave ISR das Datentransferregister beschreiben/lesen kann, das stört. Unangenehm.
Beitrag #6528396 wurde von einem Moderator gelöscht.
Arduino Fanboy D. schrieb: > z.B. die 8 Bit AVR? Es gibt noch eine Welt außerhalb von AVR ... Egon D. schrieb: > Eine UART ist aber nicht "programmierbar" im Sinne der > Turing-Vollständigkeit -- auch wenn sie natürlich > zahlreiche Betriebsarten kennt, unter denen man > auswählen kann. Wo ist das Problem, wenn die UART macht was man möchte? Warum nen ganzen Kern mit ner Software UART belegen, wenn ich auf einem anderen µC nen Hardware UART haben kann (UART ist hier nur ein Beispiel)?
Vielleicht erinnern sich die die "alten Hasen" noch an den Hype der Parallelrechner...Parsytec z.B... da wurden Megacluster zusammen geklöppelt und leider mußten auch Programme geschrieben werden, die mit der massiven Parallelisierung etwas anfangen konnten. Das war eindeutig eine Sackgasse...und ging auch nicht in die Richtung, zeitkritische Peripherie gleichzeitig zu handeln. Man versprach sich einfach schnellere Bearbeitung des (Rechen-)Problems. Klappt ja auch...bis der eine Prozess Ergebnisse des anderen benötigt...und da ist im Prinzip das Serielle wieder durch die Hintertür drin! Theoretisch, falls es geeignete Algorithmen gibt, kann ich natürlich die vorletzte und die letzte und...Stelle von PI auf einem eigenen Core berechnen lassen, aber letztlich ist es doch nur blöd! Eben weil die meisten Algorithmen nach dem simplen Schema "n + 1 = n" arbeiten. Mir bliebe jetzt auch nur noch die parallele Peripherie, aber ohne Idee für einen konkreten Anwendungsfall :-) Gruß Rainer
mh schrieb: > Egon D. schrieb: >> Eine UART ist aber nicht "programmierbar" im Sinne >> der Turing-Vollständigkeit -- auch wenn sie natürlich >> zahlreiche Betriebsarten kennt, unter denen man >> auswählen kann. > > Wo ist das Problem, wenn die UART macht was man möchte? Keins. Wenn man eine UART hat und eine UART braucht, ist alles paletti. > Warum nen ganzen Kern mit ner Software UART belegen, Gegenfrage: Warum sich zwischen UART, SPI, I2C, USB, ... entscheiden müssen, wenn man einfach ein oder zwei Kerne entsprechend programmieren kann? Wenn freie Programmierbarkeit keine praktischen Vorteile hat -- warum sind dann Gatterschaltungen nahezu ausgestorben, Mikrocontroller aber allgegenwärtig?
Egon D. schrieb: > Gegenfrage: Warum sich zwischen UART, SPI, I2C, USB, ... > entscheiden müssen, wenn man einfach ein oder zwei > Kerne entsprechend programmieren kann? Gegengegenfrage: Warum muss ich mich dazwischen entscheiden? Antwort: Muss ich nicht, ich nutze einen µC der mehrere von den Schnittstellen in Hardware hat (Ok, USB nur einmal, aber davon hab ich noch nie mehr als eine gebraucht)
Rainer V. schrieb: > Vielleicht erinnern sich die die "alten Hasen" noch > an den Hype der Parallelrechner...Parsytec z.B... da > wurden Megacluster zusammen geklöppelt und leider > mußten auch Programme geschrieben werden, die mit > der massiven Parallelisierung etwas anfangen konnten. Und das ist heute in der Top500 der Supercomputer anders? > Das war eindeutig eine Sackgasse... Ach ja. > und ging auch nicht in die Richtung, zeitkritische > Peripherie gleichzeitig zu handeln. So. Und was ist eine aktuelle Graphik"karte" mit ihren mehreren hundert oder tausend parallel arbeitenden Prozessorelementen? Richtig: Ein massiv paralleles System. Und das in jedem Standard-PC. Schöne "Sackgasse". INMOS, Parsytec usw. waren m.E. einfach ihrer Zeit voraus -- und hatten vielleicht auch nicht die richtige Vorstellung von dem Marktsegment, das sie erfolgreich besetzen können. Soweit ich weiss, ist Parsytec primär deshalb baden gegangen, weil der T9000 ewig nicht lieferbar war und wohl auch "vaporware" geblieben ist... > Theoretisch, falls es geeignete Algorithmen gibt, > kann ich natürlich die vorletzte und die letzte > und...Stelle von PI auf einem eigenen Core berechnen > lassen, aber letztlich ist es doch nur blöd! Du weisst, warum (unter anderem) die Enigma gebrochen werden konnte? Durch Parallelisierung. > Eben weil die meisten Algorithmen nach dem simplen > Schema "n + 1 = n" arbeiten. Du weisst, was eine sich selbst erfüllende Prophezeiung ist? Das ist zum Beispiel, wenn man fast die ganze Informatik auf dem Begriff des Algorithmus aufbaut, diesen durch die Turing-Maschine (eine sequenzielle Maschine!) definiert und sich dann wundert, wieso die Studenten nur sequenzielle Abläufe programmieren können!
Ich möchte den xmos // Propeller-Zweiflern // Kritikern nochmal nahelegen sich ein bisschen mit dem Transputer zu beschäftigen. Das Konzept ist sehr ähnlich zum xmos, ist aber deutlich älter. Kommerziell konnte auch er sich auf Dauer nicht durchsetzen, da lag es aber wohl eher an der Sprache Occam. Dennoch wurde der Transputer in der Rüstung und für die Video / Bildbearbeitung verwendet. Die Kommunikationskanäle findet man im xmos so auch wieder, sogar über mehrere Chips hinweg (was beim Transputer wesentlich war). Beim xmos lassen sich auch beliebige cluster bilden die untereinander (chip to chip) mit schnellen Kanälen kommunizieren. Man kann also so lang parallelisieren, bis die Kommunikation nicht mehr hinterherkommt. Beim Propeller geht das so nicht. Und schaut euch da die Namensliste der Anwender an, nicht bloß paar Hobbyisten die sich irgendwas erträumen. https://de.wikipedia.org/wiki/Transputer Ich weiß nicht ob ich mir das einbilde, aber ich glaub einer der Entwickler des Transputers ist der Gründer von xmos (aber jetzt nicht mehr dort dabei).
mh schrieb: > Egon D. schrieb: >> Gegenfrage: Warum sich zwischen UART, SPI, I2C, >> USB, ... entscheiden müssen, wenn man einfach >> ein oder zwei Kerne entsprechend programmieren >> kann? > > Gegengegenfrage: Warum muss ich mich dazwischen > entscheiden? Du musst nicht. Du kannst auch immer ein deutlich luxuriöseres System kaufen und einen Teil der Hardare ungenutzt lassen. Das beantwortet meine Frage aber noch nicht: Wenn spezialisierte Hardware so toll ist -- warum ist dann für komplexe Aufgaben Gatterlogik am Aussterben, während programmierbare Systeme überall zu finden sind?
Beitrag #6528497 wurde von einem Moderator gelöscht.
Nick M. schrieb: > Ich möchte den xmos // Propeller-Zweiflern // Kritikern nochmal > nahelegen sich ein bisschen mit dem Transputer zu beschäftigen. Das > Konzept ist sehr ähnlich zum xmos, ist aber deutlich älter. Kommerziell Das ist Schwachsinn, sorry. Die Idee hinter XMOS ist die gleiche, die hinter SMT (Simultaneous Multithreading) steckt, welches es seit dem Pentium 4 auch in PC Prozessoren gibt: Es gibt für jeden Thread ein eigenes Registerfile aber nur eine Pipeline, die reihum die Threads abarbeitet. Der Transputer ist eine echte Multiprozessormaschine.
Egon D. schrieb: > Du kannst auch immer ein deutlich luxuriöseres > System kaufen und einen Teil der Hardare ungenutzt > lassen. Wie definierst du luxuriös? Wie teuer ist nochmal ein Propeller? Egon D. schrieb: > Das beantwortet meine Frage aber noch nicht: Wenn > spezialisierte Hardware so toll ist -- warum ist > dann für komplexe Aufgaben Gatterlogik am Aussterben, > während programmierbare Systeme überall zu finden sind? Es hat deine erste Frage beantwortet ... Ok dann auf zur zweiten Fragen ... Es war mir nicht bewusst, dass Gatterlogik am Aussterben ist. Besteht der Parallax nicht auch zum Großteil aus Gatterlogik?
Tim . schrieb: > Das ist Schwachsinn, sorry. Wenn du dich nicht selbst informieren willst, mach ich es ausnahmsweise mal für dich und die Mitleser: "XMOS wurde im Juli 2005 von Ali Dixon, James Foster, Noel Hurley, David May und Hitesh Mehta gegründet, unter anderem mit Startkapital der Universität Bristol. Der Name XMOS lehnt sich an Inmos[1] an, einige grundlegende Konzepte fanden bereits beim Transputer Anwendung.[2] " Inmos war Transputer. Hurra! Jetzt hab ich auch wieder gefunden wer am Transputer und der xmos-CPU gearbeitet hat: David May https://en.wikipedia.org/wiki/Inmos
Egon D. schrieb: > Richtig: Ein massiv paralleles System. > Und das in jedem Standard-PC. Schöne "Sackgasse". Ja, egon, es ist eben ein paralleles System an der Stelle, wo es "schon passt", wie der Österreicher gern sagt. Parsytec war seinerzeit unser Nachbar im Technologiezentrum und was mir vom Fachsimpeln auf dem Flur in Erinnerung geblieben ist, war der große Mangel an "parallelen" Algorithmen. Natürlich war auch die reine Hardware ein Alptraum...und "Code-knacken" kann natürlich in einzelne Prozesse verlagert werden...du kriegst aber erst ein Ergebnis, wenn du alle Einzelergebnisse zusammenführen konntest! Man erkennt den Unterschied :-) Gruß Rainer
mh schrieb: > Wühlhase schrieb: >> War hier nicht vor einigen Wochen ein Thread, wo jemand einen "gängigen >> µC" als SPI-Slave laufen lassen wollte? Wenn ich mich recht erinnere >> haben ihm die meisten davon abgeraten, er solle das bitte möglichst >> anders lösen. > > Ich frage mich, warum es dann µC gibt, die SPI-Slave in Hardware machen. > Was spricht dagegen? Z.B. die Tatsache daß du ständig eine Unterbrechung hast auf die du sehr wenig Einfluß hast und die du kaum nach hinten legen kannst. Wenn der Master mit 3MHz Daten anfordert und du die evt. vorverarbeiten willst, z.B. FFT o.ä., dann hast du nicht mehr allzuviel Zeit für andere Dinge. Ich arbeite gerade an etwas mit Leistungselektronik, ein bisschen Datenauswertung, etwas Regelung, und später soll das Teil mal noch kommunizieren können und auf Anfrage ein paar Daten liefern. Die ganze Kommunikation einfach auf einen - gerne auch kleineren - Kern auslagern wäre durchaus praktisch und allemal sauberer, als seinen schönen Regelalgorithmus unvorhergesehen unterbrechen zu müssen. Ein Kern macht Datenakquise und -verarbeitung, einer regelt entspannt und einer kümmert sich um das Kommunikationsgeraffel...wäre eine technisch saubere Lösung, die mir gut gefallen würde. Ja, geht auch mit einem F3. Trotzdem würde mir das Propellerkonzept besser gefallen. mh schrieb: > Wühlhase schrieb: >> Der Propeller wäre für so etwas jedoch richtig gut. Da kann sich ein >> Kern ganz gemütlich auf die Lauer nach dem Chip-Select-Signal legen und >> der Rest kann nach Belieben seinen zeitkritischen Aufgaben nachgehen. > > Der Propeller ist also gut, weil er ein Problem löst, das man auch > anders, einfacher und günstiger lösen kann? Nun, das war EIN Beispiel - und sogar für ein reales Problem das hier kürzlich auftauchte. Der Propeller ist nicht interessant weil man damit besser einen SPI-Sklaven bauen kann, sondern weil man damit weitaus flexibler ist um z.B. einen SPI-Sklaven zu bauen. Mal davon abgesehen daß das Teil differentielle Ausgänge hat könntest du z.B. auch so etwas wie den LTM900x-14 ansteuern. Ja, das Teil ist eigentlich für FPGAs gedacht, aber das kann einem egal sein. Mir deucht, einige sollten mal wieder einen Controller ohne RTOS verwenden. :)
...und rein interessenhalber...welcher Programmieralgorithmus ist mehr als eine Touringmaschine? Bin echt gespannt! Aber vielleicht auch nur zu doof... Gruß Rainer
Rainer V. schrieb: > Natürlich war auch die reine Hardware ein Alptraum...und > "Code-knacken" kann natürlich in einzelne Prozesse verlagert werden...du > kriegst aber erst ein Ergebnis, wenn du alle Einzelergebnisse > zusammenführen konntest! Man erkennt den Unterschied :-) Kurz: Die ganzen massiven Multiprozessoren-Rechner sind kompletter Unfug. Und wieder: Man konnte es zuerst auf µC.net lesen. Die Fachwelt braucht wohl noch 7 Jahre bis sie es kapieren.
Wühlhase schrieb: > Z.B. die Tatsache daß du ständig eine Unterbrechung hast auf die du sehr > wenig Einfluß hast und die du kaum nach hinten legen kannst. Wenn der > Master mit 3MHz Daten anfordert und du die evt. vorverarbeiten willst, > z.B. FFT o.ä., dann hast du nicht mehr allzuviel Zeit für andere Dinge. Wenn man die Daten verarbeiten will, muss man die Rechenleistung dafür haben, das ist klar. Das gilt aber auch für einen Propeller, wenn der auf einem Kern auf die SPI Schnittstelle warten muss, kann er die Daten auf diesem Kern nicht verarbeiten. Wühlhase schrieb: > Ja, geht auch mit einem F3. Trotzdem würde > mir das Propellerkonzept besser gefallen. Das ist deine Meinung, da kann man nichts gegen sagen. Wühlhase schrieb: > Nun, das war EIN Beispiel - und sogar für ein reales Problem das hier > kürzlich auftauchte. Der Propeller ist nicht interessant weil man damit > besser einen SPI-Sklaven bauen kann, sondern weil man damit weitaus > flexibler ist um z.B. einen SPI-Sklaven zu bauen. Das Argument funktioniert aber nur, wenn du etwas brauchst, das nicht genauso auf einem herkömmlichen µC funktioniert, ob in Hardware oder Software. Wühlhase schrieb: > daß das Teil differentielle Ausgänge hat könntest du z.B. auch so etwas > wie den LTM900x-14 ansteuern. Ja, das Teil ist eigentlich für FPGAs > gedacht, aber das kann einem egal sein. Das ist doch tatsächlich mal ein echter Vorteil, wenn man sowas braucht. Wühlhase schrieb: > Mir deucht, einige sollten mal wieder einen Controller ohne RTOS > verwenden. :) Mir deucht, einige sollten weniger mutmaßen. Rainer V. schrieb: > ...und rein interessenhalber...welcher Programmieralgorithmus ist mehr > als eine Touringmaschine? Bin echt gespannt! Aber vielleicht auch nur zu > doof... > Gruß Rainer Hier nicht wirklich relevant, aber du solltest mal bei den Quantencomputer gucken gehen, wenn dich das wirklich interessiert.
Nick M. schrieb: > Kommerziell > konnte auch er sich auf Dauer nicht durchsetzen, da lag es aber wohl > eher an der Sprache Occam. Weshalb damals auch andere Compiler entstanden, darunter ein C Compiler, der auf mein Konto ging. Die Hardware war zwar etwas sehr mit Occam korreliert, aber bekanntere Sprachen liessen sich durchaus implementieren. Das wars nicht. Der Transputer war prima für Unis. Neue Ideen eignen sich immer gut für Unis, geben mehr her als ausgetretene Pfade. Mindestens eine kommerzielle Anwendung fand er sogar auch, allerdings entgegen seiner Natur als Einzelprozessor, auf AVMs ISDN S2M Karten. Der einzelne Transputer war vom Tempo her ok, aber nicht überragend. Erst im massiven Verbund wurde er wirklich interessant. Aber es dauert eine ziemliche Weile, bis man mit solchen parallelen Strukturen konstruktiv arbeiten kann. In dieser Zeit hätte der Transputer sich hardwareseitig weiterentwickeln müssen. Indes, der Nachfolger verzögerte sich und verzögerte sich ..., wohl zu ambitioniert für ein kleines Unternehmen.
Tim . schrieb: > Die Idee hinter XMOS ist die gleiche, die hinter SMT (Simultaneous > Multithreading) steckt, welches es seit dem Pentium 4 auch in PC > Prozessoren gibt: Es gibt für jeden Thread ein eigenes Registerfile aber > nur eine Pipeline, die reihum die Threads abarbeitet. Der Peripherieprozessor der CDC 6600 aus den 60ern arbeitete ähnlich wie XMOS. 10 Kontexte, reihum abgearbeitet. Allerdings hatte jeder Kontext seine eigenen 4K Worte RAM.
(prx) A. K. schrieb: > Indes, der Nachfolger verzögerte > sich und verzögerte sich ..., wohl zu ambitioniert für ein kleines > Unternehmen. Die Architektur war allerdings für damalige Verhältnisse nur schwierig weiterzuentwickeln. Eine Stack-Architektur hat oft inhärente Abhängigkeiten von Folgebefehlen. Sowas wie Pipelining von aufeinander folgenden Multiplikationen ist damit ziemlich witzlos. Oder zumindest ausgesprochen schwierig, wie Intel feststellen musste, als sie die 8087 FPU im Pentium beschleunigten. Ein weiteres Problem war die Prozess-Synchronisation innerhalb der Cores. Es gab kein effektives Verfahren zur Synchronisation beliebiger Prozesse. Also sowas einfaches wie eine Mutex für gemeinsamen Speicher - nada. Damit muss man erst einmal zurecht kommen.
Rainer V. schrieb: > Egon D. schrieb: >> Richtig: Ein massiv paralleles System. >> Und das in jedem Standard-PC. Schöne "Sackgasse". > > Ja, egon, es ist eben ein paralleles System an der > Stelle, wo es "schon passt", wie der Österreicher > gern sagt. Zugestanden. Aber was beweist das? GraphikAUSgabe ist gut parallelisierbar; also ist das der Punkt, an dem massiv parallele Hardware den Weg in den Mainstream gefunden hat. Aber steht schon fest, dass es die EINZIGE gut parallelisierbare Aufgabe ist? Was ist z.B. mit Bewegtbildcodierung, oder mit Texterkennung? Es gab immer wieder Versuche, Numerik auf Graphik- prozessoren zu betreiben. So, wie ich das verstehe, hängt es weniger an den Algorithmen oder der Hardware, sondern an geeigneten Werkzeugen. > Parsytec war seinerzeit unser Nachbar im > Technologiezentrum Tatsächlich? Du warst im TCC -- WIMRE auf der Annaberger Straße? Was hast Du da so getrieben? Ich habe im selben Städtchen an der Uni studiert... > und was mir vom Fachsimpeln auf dem Flur in Erinnerung > geblieben ist, war der große Mangel an "parallelen" > Algorithmen. Ich bestreite den Fakt gar nicht -- aber ich finde ihn in Anbetracht der Tatsache, dass die sequenzielle Maschine die Informatik jahrzehntelang beherrscht hat, auch nicht weiter verwunderlich. > und "Code-knacken" kann natürlich in einzelne Prozesse > verlagert werden...du kriegst aber erst ein Ergebnis, > wenn du alle Einzelergebnisse zusammenführen konntest! > Man erkennt den Unterschied :-) Ehrlich gesagt: Nein -- ich verstehe nicht, worauf Du hinauswillst.
(prx) A. K. schrieb: > Der einzelne Transputer war vom Tempo her ok, aber > nicht überragend. Erst im massiven Verbund wurde er > wirklich interessant. Du magst mich korrigieren, wenn ich mich irre, aber das Alleinstellungsmerkmal am Transputer war m.E. die Kombination aus lokalem RAM (das unterscheidet ihn vom gewöhnlichen Mikroprozessor), externem Bus (das unter- scheidet ihn vom Mikrocontroller) und on-Chip-Links (das unterscheidet ihn von allem). > Aber es dauert eine ziemliche Weile, bis man mit > solchen parallelen Strukturen konstruktiv arbeiten > kann. Das ist m.E. der Knackpunkt. Das Programmiermodell war einfach zu ungewohnt, der Leidensdruck noch nicht hoch genug und die Vorteile noch nicht überzeugend genug. > In dieser Zeit hätte der Transputer sich hardwareseitig > weiterentwickeln müssen. Indes, der Nachfolger verzögerte > sich und verzögerte sich ..., Die Ankündigung vom T9000 las sich gut, aber dann...
Nick M. schrieb: > "XMOS wurde im Juli 2005 von Ali Dixon, James Foster, Noel Hurley, David > May und Hitesh Mehta gegründet, unter anderem mit Startkapital der > Universität Bristol. Der Name XMOS lehnt sich an Inmos[1] an, einige > grundlegende Konzepte fanden bereits beim Transputer Anwendung.[2] " > > Inmos war Transputer. > > Hurra! > Jetzt hab ich auch wieder gefunden wer am Transputer und der xmos-CPU > gearbeitet hat: David May > https://en.wikipedia.org/wiki/Inmos Ja und? Nichts von dem weist darauf hin, dass es sich um eine vergleichbare Architektur handelt.
Tim King hat ja auch nur das Amiga Betriebsystem entworfen. Und dann noch Transputer. Kinderkram
Wühlhase schrieb: > Ein Kern macht Datenakquise und -verarbeitung, einer regelt > entspannt und einer kümmert sich um das Kommunikationsgeraffel... > wäre eine technisch saubere Lösung Genau so wird das mit den Multicore Cortex-M gemacht - hier z.B. 1x M4 und 2x M0 https://www.mikrocontroller.net/part/LPC4370 http://thomasweldon.com/tpw/lpc4370/lpc4370tutorial1/index.html
>Egon D. schrieb: >> Eine UART ist aber nicht "programmierbar" im Sinne der >> Turing-Vollständigkeit -- auch wenn sie natürlich >> zahlreiche Betriebsarten kennt, unter denen man >> auswählen kann. >Wo ist das Problem, wenn die UART macht was man möchte? Warum nen ganzen >Kern mit ner Software UART belegen, wenn ich auf einem anderen µC nen >Hardware UART haben kann (UART ist hier nur ein Beispiel)? Immer diese "Touring-Vollständigkeit". Mikrocontroller sind es mangels unendlichem Speicher definitiv nicht. Das sie es wären ist ein weit verbreiteter Irrtum.
Egon D. schrieb: >Du weisst, was eine sich selbst erfüllende Prophezeiung >ist? >Das ist zum Beispiel, wenn man fast die ganze Informatik >auf dem Begriff des Algorithmus aufbaut, diesen durch >die Turing-Maschine (eine sequenzielle Maschine!) definiert >und sich dann wundert, wieso die Studenten nur sequenzielle >Abläufe programmieren können! Egon, ich bin genau Deiner Meinung. Ich finde es erstaunlich, dass es so wenig Leute gibt, die das erkennen. Was den Propeller angeht: Dort liegt das Geheimnis der zeitlichen Präzision in der "Propeller" Architektur. Es läuft ein Zeiger auf die Speicher der 8 Cores im Kreis und in jedem 8.ten Zyklus hat der Core Zugriff auf den gemeinsamen Speicher. Der einzelne Kern läuft ohne Interrupts absolut deterministisch. Die Architektur hat auch Einschränkungen: Die einzelnen Cores haben wenig Speicher, was den Einsatz von C-Compiler schwieriger macht bzw. die Geschwindigkeit runter bremst, wenn der C-Code im Shared-Memory steht. Schade, dass es keinen 16-Core M0-ARM mit Propeller Prinzip und ohne Interrupts gibt.
>Parsytec war seinerzeit unser >Nachbar im Technologiezentrum und was mir vom Fachsimpeln auf dem Flur >in Erinnerung geblieben ist, war der große Mangel an "parallelen" >Algorithmen Das dürfte wohl eher der damaligen Zeit geschuldet gewesen sein. Probleme, die mit parallelen Algorithmen zu lösen sind dürften wohl deutlich zahlreicher als andere sein. Beipiele: FEM-Simulation Wetter Simulation Spiele Simulation Partikel Simulation Graphik-Shading Automobile: Man kann gleichzeitig fahren, Radio hören, den Blinker einschalten, den Abstandregler benutzen, den Bremsassistent benutzen, den Einparkassistent, den Rückfahrultraschall, die Motorsteuerung usw .... Alles parallel arbeitende Embedded-Systeme.
Tim . schrieb: > Nick M. schrieb: >> Der Name XMOS lehnt sich an Inmos[1] an, einige >> grundlegende Konzepte fanden bereits beim Transputer Anwendung.[2] " > Ja und? Nichts von dem weist darauf hin, dass es sich um eine > vergleichbare Architektur handelt. Wirklich nichts? Nicht mal grundlegende Konzepte?
mh schrieb: > Wühlhase schrieb: >> Nun, das war EIN Beispiel - und sogar für ein reales Problem das hier >> kürzlich auftauchte. Der Propeller ist nicht interessant weil man damit >> besser einen SPI-Sklaven bauen kann, sondern weil man damit weitaus >> flexibler ist um z.B. einen SPI-Sklaven zu bauen. > Das Argument funktioniert aber nur, wenn du etwas brauchst, das nicht > genauso auf einem herkömmlichen µC funktioniert, ob in Hardware oder > Software. Von deiner Übergeneralisierung mal abgesehen: Jedes Sachargument sollte doch so funktionieren...oder nicht? Jedes Konzept hat Stärken und Schwächen, und mir ist kein Konzept bekannt das in jedem Fall und unter allen Umständen das Beste ist. Kennst du eins? Niemand hier hat je behauptet, daß das Propellerkonzept immer und überall überlegen ist, sondern nur das es Probleme gibt die sich mit dem Propellerkonzept besser lösen lassen als mit dem Wald- und Wiesenkonzept. Niemand hat gesagt, daß es mit einem herkömmlichen µC gar nicht gehen würde. Ich persönlich habe gern mehrere Werkzeuge im Werkzeugkasten, um Probleme zu lösen. Allein deshalb gebe ich alternativen Konzepten gerne mal eine Chance und schaue sie mir wohlwollend an. Klar kann ich einen Nagel (um mal bei der Metapher zu bleiben) auch mit einem Ziegelstein in die Wand donnern, aber in meinen Augen wäre das Stümperei. Ich nehme lieber das eigens für diese Problemklasse entworfene Werkzeug: einen Hammer. Und dann natürlich nicht die 15kg-Abbruchramme, und auch nicht das 50g-Präzisionshämmerchen, Gummihammer oder Fäustel - welche ich nach Möglichkeit trotzdem habe. Und nichts davon werde ich benutzen, wenn es um Probleme der Klasse 'Schraube' geht. Ich persönlich brauche nicht erst ein Problem, das sich nur mit dem Propeller lösen läßt und auf einem normalen Mikrocontroller gar nicht zu machen wäre. Mir reicht es schon, wenn sich ein Problem zwar mit beiden, aber auf dem Propeller besser lösen läßt (wie auch immer man 'besser' definieren mag). Dann denke ich zumindest mal darüber nach, es zu benutzen, oder ich befasse mich mit dem Teil einfach schon deshalb, um mal etwas anders machen zu können. Ob es brauchbar ist, wird sich dann in Zukunft zeigen.
Ein CPU-Kern kann Perif.teile (bsp. Interface usw) nicht ersetzen, weil die erreichbare CPU-f dafür zu gering ist. Mit 100 MHz FFs lässt sich keine 100 MHz CPU-f erreichen.
mh schrieb: > Wo ist das Problem, wenn die UART macht was man möchte? Warum nen ganzen > Kern mit ner Software UART belegen, wenn ich auf einem anderen µC nen > Hardware UART haben kann (UART ist hier nur ein Beispiel)? Ich denke, dass die Entwickler des Chips Schnittstellen im Sinn hatten, die weniger weit verbreitet sind und deswegen oft in Software implementiert werden müssen.
Beitrag #6528795 wurde von einem Moderator gelöscht.
mh schrieb: > Der P2 kann also ~60 ADCs oder DACs haben? Das wäre praktisch, aber > irgendwie glaub ich das nicht. Stimmt auch nicht. Die Aussage von Andi war bewusst irreführend. Der P2 hat 4 DACs, von denen sich jeder auf 1/4 aller IO Pins mappen lässt. Steht auch so im Datenblatt hust wenn man das Dokument in dem nicht Mal der Bereich der Versorgungsspannung beschrieben steht und in dem die volle DAC Funktionalität es auf genau 3 Sätze bringt so nennen darf.
Wühlhase schrieb: > mh schrieb: >> Wühlhase schrieb: >>> Nun, das war EIN Beispiel - und sogar für ein reales Problem das hier >>> kürzlich auftauchte. Der Propeller ist nicht interessant weil man damit >>> besser einen SPI-Sklaven bauen kann, sondern weil man damit weitaus >>> flexibler ist um z.B. einen SPI-Sklaven zu bauen. >> Das Argument funktioniert aber nur, wenn du etwas brauchst, das nicht >> genauso auf einem herkömmlichen µC funktioniert, ob in Hardware oder >> Software. > > Von deiner Übergeneralisierung mal abgesehen: Jedes Sachargument sollte > doch so funktionieren...oder nicht? Was genau habe ich übergeneralisiert? Was genau ist "so funktionieren"? Wühlhase schrieb: > Niemand hier hat je behauptet, daß das Propellerkonzept immer und > überall überlegen ist, sondern nur das es Probleme gibt die sich mit dem > Propellerkonzept besser lösen lassen als mit dem Wald- und > Wiesenkonzept. Niemand hat gesagt, daß es mit einem herkömmlichen µC gar > nicht gehen würde. Bis jetzt ist die Liste mit konkreten Beispielen, die auf dem Propeller besser gelöst werden können relativ dünn. Ich kann mich an kein überzeugendes Beispiel in diesem Thread erinnern. Wühlhase schrieb: > um mal bei der Metapher zu bleiben Warum immer diese schlechten Metaphern? Ein Ziegelstein ist das perfekte Werkzeug, um einen Nagel in die Wand zu hämmern, wenn der Ziegelstein gerade in Reichweite ist und der passende Hammer 10€ kostet, im nächsten Baumarkt in 2h Entfernung. Stefan ⛄ F. schrieb: > mh schrieb: >> Wo ist das Problem, wenn die UART macht was man möchte? Warum nen ganzen >> Kern mit ner Software UART belegen, wenn ich auf einem anderen µC nen >> Hardware UART haben kann (UART ist hier nur ein Beispiel)? > > Ich denke, dass die Entwickler des Chips Schnittstellen im Sinn hatten, > die weniger weit verbreitet sind und deswegen oft in Software > implementiert werden müssen. Möglich, aber welche? Ich habe kein Problem mit den Propeller und Co, aber ich sehe bis jetzt keinen Grund sie einzusetzen. Ich würde mich freuen, wenn jemand ein konkretes gutes Beispiel hat.
Schnittstellen in Software zu implementieren, bringt zweifellos mehr Flexibilität, als HW Module vom Hersteller zu verwenden. Aber diese zu entwickeln kostet auch Zeit und bringt die Gefahr mit sich, unnötige Fehler zu machen. Dann sollte man auch bedenken, dass neue Kollegen sich mit selbst gebautem Code (versus Standard-Hardware) schwer tun, insbesondere wenn er komplex ist. Das gleiche Dilemma hat man ja auch bei der Frage: Nehme ich eine Bibliothek, oder programmiere ich es selber neu? Nehme ich ein Framework wo ich von 1000 Funktionen nur 20 scheinbar triviale brauche, oder schreibe ich mir diese 20 trivialen Funktionen selbst. Wie hoch ist das Risiko, dass sie am Ende doch nicht so trivial sind, wie anfangs gedacht? Wie hoch ist das Risiko, dass meine Leute das Framework missverstehen und dadurch schwerwiegende Fehler machen, die erst Wochen nach der Inbetriebnahme auffallen (z.B. bei der Abrechnung von Kommunikations-Diensten). Was mache ich, wenn sich nach Monaten der Entwicklung herausstellt, dass die Anlage in der technischen Umgebung des Kunden nicht funktioniert, weil es dort irgendeine Sonderlocke gibt, die von der gewählten Hardware/Bibliothek/Framework nicht unterstützt wird? Das ist oft der Moment, wo man sich wünscht: Hätte ich es doch alles selbst programmiert, dann hätte ich es auch voll im Griff. Soll man demnächst wirklich alles selbst machen, während der Rest der Welt weiterhin diese Standardkomponenten verwendet? Wer bezahlt solche Fehlentscheidungen?
> Ich denke, dass die Entwickler des Chips Schnittstellen im Sinn hatten, > die weniger weit verbreitet sind und deswegen oft in Software > implementiert werden müssen. Gut denkbar. Man denke nur an die Verrenkungen die notwendig sind um die kranken Neopixel anzusteuern. Oder du brauchst SPI mit einer exotischen Wortgroesse. Und es gibt in der Industrie eine reihe von sehr schraegen Bussen von denen noch nie einer gehoert hat der nicht zufaellig damit arbeitet. > Gegenfrage dazu: Warum soll ich eine Schnittstelle selber entwickeln, > wenn ich sie fertig kaufen kann? Wer bezahlt denn die Arbeitszeit? Ich kenne eine Anwendung wo I2C in Software drin ist weil das einfacher war als die Hardware im Chip komplett zu durchschauen. Oder ich hab auch schon mal einen IRDA-Master komplett selber geschrieben weil mir gegen Ende eines Projektes aufgefallen ist das der STM32 da einen echt schraegen Bug in der Hardware hatte. Aber manchmal macht es auch einfach Spass ungewoehnliche Hardware zu nutzen und ungewohnte Wege zu beschreiten. Ich staune da immer ueber die griesgraemigen Besserwisser die gleich Schaum vor dem Mund bekommen. Schaut mal hier ab 2:17: https://www.youtube.com/watch?v=31xA9p3pYE4 Dem was Fefe da sagt kann ich nur 100% zustimmen. Eine der Folgen, wir haben halt viele Leute die sind von ungewohnte Konzepten oder neuen Ideen gleich ueberfordert. Die noergeln dann sofort anstatt es als Spielwiese zu begreifen. Die eine Haelfte denkt, oh das ist ja interessant, was kann ich daraus machen? Die andere Haelfte: Iiih! Das ist ja gar nicht wie immer, das geht gar nicht. Olaf
Stefan ⛄ F. schrieb: > Schnittstellen in Software zu implementieren, bringt zweifellos mehr > Flexibilität, als HW Module vom Hersteller zu verwenden. Das ist aber, wie gesagt, nur ein Vorteil, wenn man diese Flexibilität auch braucht. Olaf schrieb: >> Ich denke, dass die Entwickler des Chips Schnittstellen im Sinn hatten, >> die weniger weit verbreitet sind und deswegen oft in Software >> implementiert werden müssen. > > Gut denkbar. Man denke nur an die Verrenkungen die notwendig sind um die > kranken Neopixel anzusteuern. Oder du brauchst SPI mit einer exotischen > Wortgroesse. Und es gibt in der Industrie eine reihe von sehr schraegen > Bussen von denen noch nie einer gehoert hat der nicht zufaellig damit > arbeitet. Dann ist der Propeller aber nur im Vorteil, wenn man es nicht genauso einfach auf einem herkömmlichen µC umsetzen kann. Olaf schrieb: > Ich kenne eine Anwendung wo I2C in Software drin ist weil das einfacher > war als die Hardware im Chip komplett zu durchschauen. Oder ich hab auch > schon mal einen IRDA-Master komplett selber geschrieben weil mir gegen > Ende eines Projektes aufgefallen ist das der STM32 da einen echt > schraegen Bug in der Hardware hatte. Und der Propeller ist sicher bugfrei? Olaf schrieb: > Aber manchmal macht es auch einfach Spass ungewoehnliche Hardware zu > nutzen und ungewohnte Wege zu beschreiten. Ich staune da immer ueber die > griesgraemigen Besserwisser die gleich Schaum vor dem Mund bekommen. > [...] > Die andere Haelfte: Iiih! Das ist ja gar nicht wie immer, das geht gar > nicht. Das kannst du gerne machen. Du kannst auch gerne jeden, der nach einem praktischen Nutzen fragt, beleidigen.
Wünschenswert wäre, das der Propeller für so ziemlich alle Standard Schnittstellen entsprechende Software-Module mit bringt, die gründlich getestet wurden. Ich habe leider die Erfahrung gemacht, dass Hardware-Hersteller sich mit Software eher schwer tun. Und das nicht nur im Mikrocontroller-Umfeld.
>Ich habe leider die Erfahrung gemacht, dass Hardware-Hersteller sich mit >Software eher schwer tun. Und das nicht nur im Mikrocontroller-Umfeld. Das ist beim Propeller anders, weil er ein echtes Freak-Projekt. Die Freaks sind im Schnitt Leute ab 40 mit 20 Jahren Berufserfahrung.
mh schrieb: > Was genau habe ich übergeneralisiert? Was genau ist "so funktionieren"? Lies doch deinen eigenen Post noch einmal. Und zum zweiten: Jedes (Sach)Argument geht allgemein von bestimmten Annahmen aus (hier: Man nehme eine Alternative, wenn es damit besser geht). mh schrieb: > Bis jetzt ist die Liste mit konkreten Beispielen, die auf dem Propeller > besser gelöst werden können relativ dünn. Ich kann mich an kein > überzeugendes Beispiel in diesem Thread erinnern. Dem Beispiel mit dem ADC vorhin hast du doch zugestimmt? mh schrieb: > Warum immer diese schlechten Metaphern? Ein Ziegelstein ist das perfekte > Werkzeug, um einen Nagel in die Wand zu hämmern, wenn der Ziegelstein > gerade in Reichweite ist und der passende Hammer 10€ kostet, im nächsten > Baumarkt in 2h Entfernung. Nur weil man mangelhaft vorbereitet ist, macht das einen zweckentfremdeten Gegenstand keineswegs zu einem besseren Werkzeug. Wenn du in einer Weltgegend wärst wo ein Hammer auch mit viel Aufwand einfach nicht zu beschaffen ist, z.B. in irgendeinem sozialistischen Dritte-Welt-Land, dann wäre das ein Argument. Dann ist die Ausführung immer noch Stümperei, aber dann geht es halt nicht anders, im Gegenteil: Da würde ich für die Improvisation Respekt zollen. So aber hast du zwar mit Stümperei um vernünftiges Werkzeug herumimprovisiert, aber was machst du beim nächsten Mal? Hoffen daß dann wieder ein Ziegelstein in der Nähe ist? Steckst du den Ziegel zum Werkzeug und arbeitest jetzt immer so? Und Stümperei, die ich bei 10€ und einem 2h entfernten Baumarkt nicht akzeptieren würde, bleibt es ja immer noch.
Stefan ⛄ F. schrieb: > mh schrieb: >> Warum nen ganzen >> Kern mit ner Software UART belegen, wenn ich auf einem anderen µC nen >> Hardware UART haben kann (UART ist hier nur ein Beispiel)? > > Ich denke, dass die Entwickler des Chips Schnittstellen im Sinn hatten, > die weniger weit verbreitet sind und deswegen oft in Software > implementiert werden müssen. @mh: Am Propeller kann ein Kern wimre 4 USART machen. Und das wohl bis 115 kBaud. @ Stefan: Nein, Ziel ist möglichst viel der gebräuchlichen implementieren zu können. Und das hat ja auch geklappt. Hätte man z.B. USART per Hardware implementiert, wäre der Zgriff auf die Daten ein ziemlicher Bruch mit der Architektur geworden und damit irgendwie seltsam und zweifelhaft ob man dadurch eine CPU sparen kann. XMOS ist zunächst den gleichen Weg gegangen, hat dann aber eine Familie um Ethernet und eine Andere um USB erweitert.
Stefan ⛄ F. schrieb: > Schnittstellen in Software zu implementieren, bringt zweifellos > mehr Flexibilität, als HW Module vom Hersteller zu verwenden.Aber > diese zu entwickeln kostet auch Zeit und bringt die Gefahr mit > sich, unnötige Fehler zu machen. Da hatte Parallax eine echt revolutionäre Idee: Sie stellen den Code für die Schnittstellen zur Verfügung. Irre gell?!
Egon D. schrieb: > GraphikAUSgabe ist gut parallelisierbar; also ist das > der Punkt, an dem massiv parallele Hardware den Weg > in den Mainstream gefunden hat. Das ist vor allem der Punkt, an dem man damit gutes Geld verdienen und eine Industrie (Spiele!) füttern konnte. > Aber steht schon fest, dass es die EINZIGE gut > parallelisierbare Aufgabe ist? Was ist z.B. mit > Bewegtbildcodierung, oder mit Texterkennung? Beides lässt sich sehr gut parallelisieren. Ich sehe jetzt kein Problem darin, eine Textseite in Streifen zu schneiden und diese mit etwas Überlappung parallel auszuwerten. Die aktuell in Videocodecs (oder z.B. auch JPEG) verwendeten Verfahren arbeiten mit Blöcken, die ebenfalls parallel verarbeitet werden können. Ein relevanter Teil des Verfahrens ist damit parallelisierbar, auch wenn am Ende ein serialisierter Datenstrom rausfällt. Zukünftige Algorithmen auf KI-Basis sind grundsätzlich auf Parallelisierbarkeit ausgelegt, man denke z.B. an neuronale Netze. > Es gab immer wieder Versuche, Numerik auf Graphik- > prozessoren zu betreiben. So, wie ich das verstehe, > hängt es weniger an den Algorithmen oder der Hardware, > sondern an geeigneten Werkzeugen. Wenn man versucht, eine fixed function 3D-Pipeline, wie sie in frühen 3D-Grafikkarten verbaut war, für Numerik zu benutzen, dann ist das naturgemäß schwierig. Die größten Numerikprobleme, mit denen ich zu tun hatte (Fluidsimulation mit Lattice-Verfahren) werden real ausschließlich auf Grafikprozessoren gerechnet, weil die deutlich schneller sind und weniger Energie verbrauchen. Dazu brauchte man natürlich Grafikprozessoren mit flexiblen Pipelines, wo die Verfahrensschritte nicht fest ins Silizium gegossen wurden. Die kamen aber so vir 10-15 Jahren auf den Markt. Ich habe so ein bisschen das Gefühl, dass dein Wissen recht stark veraltet ist. Was du sagst, war einstmals wahr, ist es aber nicht mehr. Damit sind deine Schlüsse missweisend bis falsch. Olaf schrieb: > Ich kenne eine Anwendung wo I2C in Software drin ist weil das einfacher > war als die Hardware im Chip komplett zu durchschauen. Ich habe auch schon einige einfache Protokolle erst mit Bitbanging in Betrieb genommen. Einen GPIO kann man wesentlich einfacher in Betrieb nehmen, vor allem bei schlecht dokumentierter Hardware. Witzigerweise reicht das oft genug auch aus.
Stefan ⛄ F. schrieb: > Ich habe leider die Erfahrung gemacht, dass Hardware-Hersteller sich mit > Software eher schwer tun. Und das nicht nur im Mikrocontroller-Umfeld. Es bleibt Parallax garnichts anderes übrig als alle Standardschnittstellen in Software zu implementieren und auch zu testen. Weil danach sofort geschrien wird. Und wenn die SW nicht funktioniert, dann wird der Fehler behoben. Die Quellen dafür sind offen und die user nützen das.
Nick M. schrieb: > @mh: Am Propeller kann ein Kern wimre 4 USART machen. Und das wohl bis > 115 kBaud. Wenn du so speziell werden willst ... bedeutet das, dass die Flexibilität am Ende ist, wenn ich 1M Baud brauche? Sind die 4 USART mit "Hardwareflussteuerung" RTS/CTS? Wühlhase schrieb: > mh schrieb: >> Was genau habe ich übergeneralisiert? Was genau ist "so funktionieren"? > > Lies doch deinen eigenen Post noch einmal. Ich habe das Argument nochmal von Anfang an gelesen und sehe nicht, wo ich etwas übergeneralisiert habe. Du musst also etwas genauer werden in deinen Vorwürfen. Wühlhase schrieb: > Und zum zweiten: Jedes > (Sach)Argument geht allgemein von bestimmten Annahmen aus (hier: Man > nehme eine Alternative, wenn es damit besser geht). Exakt das habe ich doch geschrieben. Zur Erinnerung: du hattest geschrieben: Wühlhase schrieb: > Nun, das war EIN Beispiel - und sogar für ein reales Problem das hier > kürzlich auftauchte. Der Propeller ist nicht interessant weil man damit > besser einen SPI-Sklaven bauen kann, sondern weil man damit weitaus > flexibler ist um z.B. einen SPI-Sklaven zu bauen. Meine Antwort darauf war mh schrieb: > Das Argument funktioniert aber nur, wenn du etwas brauchst, das nicht > genauso auf einem herkömmlichen µC funktioniert, ob in Hardware oder > Software. Das ist eine Einschränkgung deines Arguments. Was willst du also von mir? Wühlhase schrieb: > Und Stümperei, die ich bei 10€ und einem 2h entfernten Baumarkt nicht > akzeptieren würde, bleibt es ja immer noch. Wenn du weiter auf dieser unsinnigen Metapher rumreiten willst ... Ich benutze halt die Werkzeuge die ich habe und wenn der Nagel nach 10 Sekunden in der Wand ist, hast du nichtmal die Schuhe angezogen auf dem Weg zum Baumarkt. Du kannst nach 2h gerne stolz sein, dass du einen Hammer hast.
mh schrieb: > Wenn du so speziell werden willst ... Wenn Du spezielle und klare Anforderungen hast, solltest du einfach nachschauen.
Angehängte Dateien:

Achtung: Der Nick ist wieder da. Er verwickelt euch in sinnlose Endlos-Diskussionen. Gestern bin ich auf ihn herein gefallen.
Ja Stefan, auch wenn es dir nicht passt. Ich bin da. Der Grund ist ganz einfach: Ich hab sowohl mit dem Propeller als auch mit xmos eigene Erfahrungen. Aus deiner und der ersten Antwort (Beitrag "Re: Wofür Propeller von Parallax ?") schließe ich, dass du zu dem Thema leider nicht wirklich was beitragen kannst ausser irgendwas. Das ist aber nicht meine Schuld. Aber auch hier, danke für die erhellende Graphik. Jetzt ist klar wie der xmos funktioniert (aus deiner sicht). Edit: Ich hoffe dein Beitrag bleibt stehen. So können die Leute eigene Schlüsse ziehen.
Nick M. schrieb: > Ich hab sowohl mit dem Propeller als auch mit xmos eigene Erfahrungen. Für die interessieren wir uns auch, aber nicht für deine persönlichen Angriffe auf einzelne Personen.
Stefan ⛄ F. schrieb: > Für die interessieren wir uns auch, aber nicht für deine persönlichen > Angriffe auf einzelne Personen. Ähhhhh ... verstehst du was du so schreibst?
Geiler Thread! Dann heißt der Propeller also Propeller, da er round robin in Hardware macht, hab ich das richtig vertanden? mfg
~Mercedes~ . schrieb: > da er round robin in Hardware macht, > hab ich das richtig vertanden? Ja, das ist der Grund. Im Hub (der Nabe) geht ein Zeiger rundrum von Prozessor zu Prozessor und gibt dem jeweilgen Proz den Zugriff auf das Hub-RAM. Die Drehrichtung ist auch definiert, weil man dadurch noch etwas Geschwindigkeit rauskitzeln kann.
Das ist ein Ding. Ist da das Ram für alle Prozzis gemeinsam? Kann jeder Prozzi im Ram für den nächsten was hinterlassen? mfg
Angehängte Dateien:
-

parallaxPropeller.png
810 KB
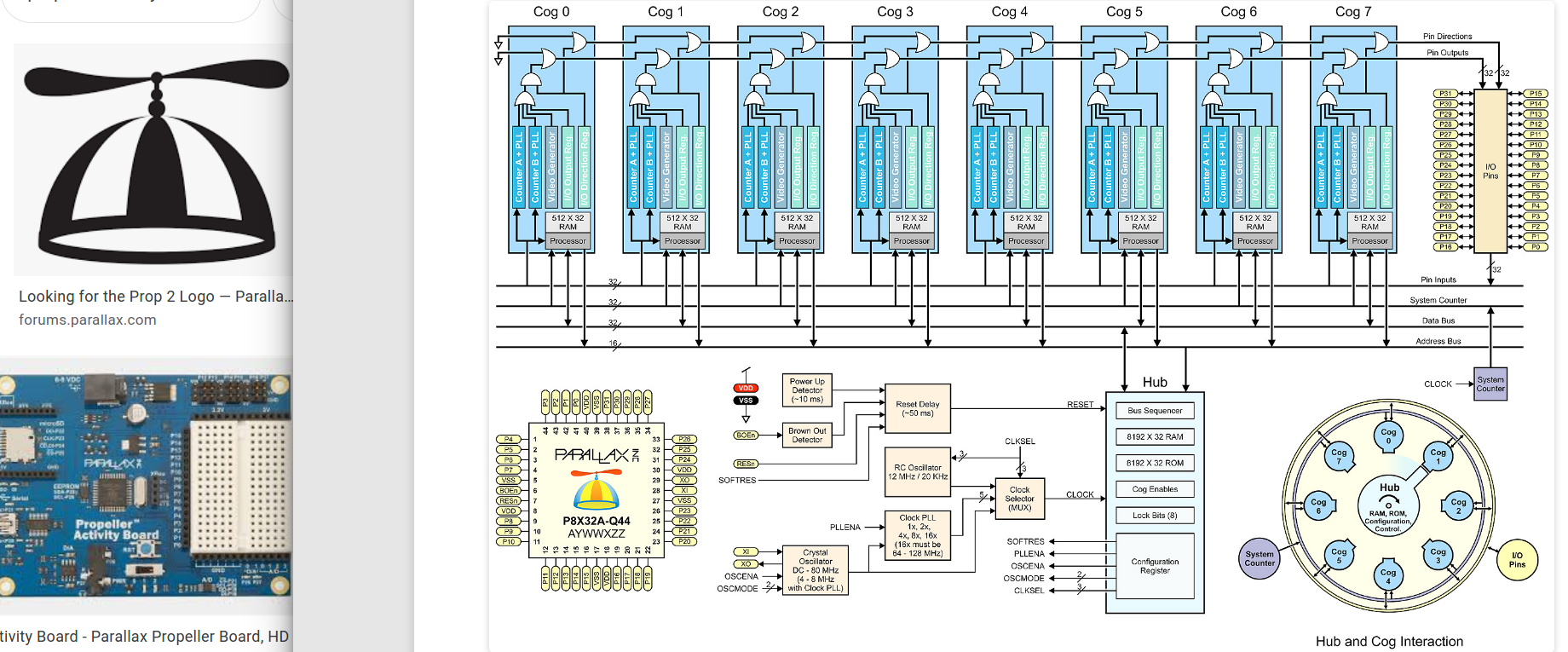
>da er round robin in Hardware macht
Dies betrifft aber den "shared memory".
~Mercedes~ . schrieb: > Kann jeder Prozzi im Ram für den nächsten was hinterlassen? Ja. Das Bild vom chris_ zeigt das ganz gut. Zusätzlich hat jeder Proz sein eigenes RAM für code oder Daten. Hub ist gemeinsam, cog Proz-spezifisch. Zugriffskollisionen sind per HW verriegelt.
~Mercedes~ . schrieb: > Dann heißt der Propeller also Propeller, > da er round robin in Hardware macht, Wobei die 8 Cores (COGs) des Propellers getrennt arbeiten, es werden also keine verschiedenen Kontexte durch die gleiche Ausführungseinheit rotiert. Rotieren tut der Zugriffs-Slot der 8 COGs auf den zentralen Speicher. Demgegenüber gab es bei den Peripherieprozessoren der CDC 6600 eine einzelne Ausführungseinheit, die sich nacheinander 10 getrennten Kontexten aus Register+Speicher widmete. Dafür verwendete man den Begriff "Barrel", also Fass. Das SMT (Hyperthreading) aktueller x86 Prozessoren und die Arbeitsweise von XMOS ähneln eher dem Verfahren der CDC als dem Propeller. Vereinfacht ausgedrückt kümmert sich eine gepipelinete Ausführungseinheit um mehrere Kontexte, bei gemeinsamem Speicher. Bei XMOS bedeutet es, dass das in 4 Stufen erfolgende Pipelining der Ausführungseinheit dafür genutzt wird, 4 Threads in diesen 4 Stufen ohne Performanceverlust abzuarbeiten. Möglich sind bis zu 8 Threads, das bremst dann entsprechend aus. Obwohl sowohl XMOS als auch die Transputer auf David May zurückgehen, ist die Arbeitsweise der Cores völlig verschieden. Deren Gemeinsamkeit ist die von Haus aus vorgesehene schnelle Verbindung vieler Knoten matrixartig untereinander, ohne gemeinsamem Speicher.
(prx) A. K. schrieb: > ~Mercedes~ . schrieb: >> Dann heißt der Propeller also Propeller, >> da er round robin in Hardware macht, > > Wobei die 8 Cores (COGs) des Propellers getrennt arbeiten, es werden > also keine verschiedenen Kontexte durch die gleiche Ausführungseinheit > rotiert. Rotieren tut der Zugriffs-Slot der 8 COGs auf den zentralen > Speicher. Also gibt es keine gemeinsame Instanz, man müßte also nen Core zur Verwaltung abstellen? Für nen Enigma-Cracker etwa, der ja praktich ein Vignere- Cracker mit mod26 sein müßte ( das Alphabet hat ja 26 Buchstaben) hätte man dann 7 Cracker und eine Verwaltung. :-P > > Demgegenüber gab es bei den Peripherieprozessoren der CDC 6600 eine > einzelne Ausführungseinheit, die sich nacheinander 10 getrennten > Kontexten aus Register+Speicher widmete. Dafür verwendete man den > Begriff "Barrel", also Fass. > > Das SMT (Hyperthreading) aktueller x86 Prozessoren und die Arbeitsweise > von XMOS ähneln eher dem Verfahren der CDC als dem Propeller. > Vereinfacht ausgedrückt kümmert sich eine gepipelinete > Ausführungseinheit um mehrere Kontexte, bei gemeinsamem Speicher. Da wird ja auch Prioritäten-Multitasking gemacht, oder? > > Bei XMOS bedeutet es, dass das in 4 Stufen erfolgende Pipelining der > Ausführungseinheit dafür genutzt wird, 4 Threads in diesen 4 Stufen ohne > Performanceverlust abzuarbeiten. Möglich sind bis zu 8 Threads, das > bremst dann entsprechend aus. Hmmm.... :-P > > Obwohl sowohl XMOS als auch die Transputer auf David May zurückgehen, > ist die Arbeitsweise der Cores völlig verschieden. Deren Gemeinsamkeit > ist die von Haus aus vorgesehene schnelle Verbindung vieler Knoten > matrixartig untereinander, ohne gemeinsamem Speicher. Der Transputer, der oben auf den ISDN Karten erwähnt wurde, was hat der gemacht? Das ISDN-Protokoll? Hast Du im Kopf, wie der Chip hieß?
~Mercedes~ . schrieb: > Der Transputer, der oben auf den ISDN Karten erwähnt wurde, > was hat der gemacht? Das ISDN-Protokoll? Hast Du im Kopf, wie der Chip > hieß? Fritz ? :-)
Stefan meinte:
> Fritz ? :-)
Deshalb frag ich ja, die DSL-FPGA hatten ja
ne Butterfly-Aufschrift.
ich muß mich jetzt ausklinken, meine Zimmergenossin
und ich haben für 20 Leuts Käse-Erdbeertorten gebacken,
die tragen wir jetzt auf. :-P
mfg
Man muß vielleicht bedenken, dass es schon einen Unterschied macht, ob man von Parallelisierung oder von massiver Parallelisierung spricht. Sicher wird niemand mit einem Propeller einen Graphikprozessor aufbauen wollen oder ein neuronales Netz mit x Knoten. Die Frage ist dann einfach, was man mit dem Propeller besser machen könnte, als mit einem "einfachen" Controller. Unter den Stichworten zeitkritisch oder gar gleichzeitig sehe ich einen gewissen Verwaltungsaufwand im Hauptprogramm, der durch unabhängige Hardware entlastet werden kann, aber nicht muß. Und wie schon gesagt wurde, erst wenn ich mit f am Anschlag bin, denke ich über weitere Recheneinheiten nach. Ob das nun ein Symptom für die Unfähigkeit ist, über den sequentiellen Tellerrand zu schaun, kann ich auch nicht abschätzen. Also bleibt (für mich) die Suche nach dieser Community mit ihren Projekten...möglicherweise harren dort ja echte Schätze der Entdeckung... Gruß Rainer
~Mercedes~ . schrieb: > Also gibt es keine gemeinsame Instanz, man müßte also nen Core > zur Verwaltung abstellen? Verwaltung von was?
~Mercedes~ . schrieb: > Der Transputer, der oben auf den ISDN Karten erwähnt wurde, > was hat der gemacht? Das ISDN-Protokoll? Hast Du im Kopf, wie der Chip > hieß? https://www.ebay.de/itm/Transputer-Inmos-IMST400B-T400-AVM-B1-active-ISDN-ISA-/114079187728
Arduino Fanboy D. schrieb: > z.B. die 8 Bit AVR? > Prächtig, als Master. > Unangenehm als Slave. Das trifft für die aktuellen Nachkommen (Tiny0..2, Mega0, DA ,DB series nicht mehr zu. Die SPI-Einheit ist bei denen "buffered". Ja, das war schon lange überfällig, ist aber nunmehr auch für die AVR8 geschehen. Abgehakt! > das stört. > Unangenehm. Damit hinfällig. Genau das ist, was man bedenken sollte, bevor man sich auf sowas wie den Propeller einläßt: die Peripherie aller üblichen µC-Familien wird immer besser und immer vielfältiger anpassbar. Genau damit schließt sich zunehmend die Lücke, die vor 1,5 Jahrzehnten mal der Ansatz für das Propeller-Konzept war. Damals berechtigt, heute einfach mal aus der Zeit gefallen. Höchstens noch für ganz exotische Probleme die optimale Lösung.
c-hater schrieb: > Das trifft für die aktuellen Nachkommen (Tiny0..2, Mega0, DA ,DB series > nicht mehr zu. Das ist doch schön!
> Im Hub (der Nabe) geht ein Zeiger rundrum von Prozessor zu Prozessor und > gibt dem jeweilgen Proz den Zugriff auf das Hub-RAM. Bloss das haben die nicht erfunden. Multiprozessor-Systeme kann man mit MCUs/CPUs bauen, wie man sie braucht. > ...Am Propeller kann ein Kern wimre 4 USART machen. Und das wohl bis > 115 kBaud. Das ist wirklich "atemberaubend". >> Das trifft für die aktuellen Nachkommen (Tiny0..2, Mega0, DA ,DB series >> nicht mehr zu. > Das ist doch schön! Und die FIFOs?
Das meiste, was da über den Propeller geschrieben wurde, bezieht sich auf den Propeller 1. Der Propeller 2 hat viele der Einschränkungen des P1 nicht mehr. Beim P2 ist es nun nicht ein Zeiger der sich dreht, sondern es sind 8, die jeweils auf 8 separate RAM Blöcke zeigen, und bei jedem Takt auf den nächsten Block weitergeschaltet werden. Ein 8 flügliger Propeller also, statt einem 1 Flügler. Das bewirkt, dass jeder Prozessor nun den Speicher in jedem Takt lesen kann, solange die Adresse fortlaufend aufsteigend ist, was zu 99% der Fall ist. Das ermöglicht z.B. erst die schnelle Ausführung von Code direkt aus dem gemeinsamen Hauptspeicher. Jeder Pin hat nun eine konfigurierbare Peripherie für UART und solche Sachen, man muss nicht mehr alles in Software machen. Ein Prozessor kann nun leicht viele UART Kanäle verwalten mit Baudraten bis 30 MHz (geschätzt), wenn es sein muss.
void schrieb: > mh schrieb: >> Der P2 kann also ~60 ADCs oder DACs haben? Das wäre praktisch, aber >> irgendwie glaub ich das nicht. > > Stimmt auch nicht. Die Aussage von Andi war bewusst irreführend. Der P2 > hat 4 DACs, von denen sich jeder auf 1/4 aller IO Pins mappen lässt. > Steht auch so im Datenblatt hust wenn man das Dokument in dem nicht > Mal der Bereich der Versorgungsspannung beschrieben steht und in dem die > volle DAC Funktionalität es auf genau 3 Sätze bringt so nennen darf. Mit Glauben und Irreführung hab ich nichts am Hut. Fakt ist, dass beim Propeller alle Pins grundsätzlich gleich aufgebaut sind, genauso wie die 8 Prozessoren. Das war dem Entwickler des Chips sehr wichtig. Die Ansteuerung der Pins geschieht manchmal in Gruppen z.B. für USB oder HDMI. Auch die DACs können vom Prozessor, oder vom Streamer in 4er Gruppen beschrieben werden, zum Beispiel für VGA, um alle Farbkanäle gleichzeitig umzuschalten. Das bedeutet aber nicht, dass da nur 4 DACs vorhanden sind, die irgendwie den Pins zugeschaltet werden. Man kann den DAC jeden Pins einzeln mit einem 8 oder 16 Bit Wert beschreiben, wenn gewünscht. Auch wenn es für manche unglaublich klingen mag, der Propeller 2 kann bis zu: - 64 DACs - 64 ADCs - 32 USB Schnittstellen (Host oder Device) - 64 UART Kanäle (RX oder TX) - 64 PWM Ausgänge - 64 Frequenzzähler - und vieles mehr, alles natürlich nur einmal pro Pin/Pinpaar einsetzbar, aber in fast jeder Kombination. Dazu all die Softwareperipherie die man selber programmiert. Manches wird durch die Anzahl Prozessoren begrenzt, so lassen sich "nur" 8 Video Ausgänge realisieren, diese aber als Component- oder Composite Video oder VGA oder HDMI, auch gemischt.
Ab Minute 14 erklärt der Erfinder sein Zielpublikum https://embedded.fm/episodes/2015/2/4/87-make-my-own-steel-foundry
> Fakt ist, dass beim Propeller alle Pins grundsätzlich gleich aufgebaut > sind, genauso wie die 8 Prozessoren. Das war dem Entwickler des Chips > sehr wichtig. Das finde ich grundsaetzlich sehr sympathisch. Ich denke sobald der Chip fertig ist, es also ein Datenblatt als PDF gibt welches einen kompletten Eindruck hinterlaesst schau ich mir das nochmal an. > Auch die DACs können vom Prozessor, oder vom Streamer in 4er > Gruppen beschrieben werden, zum Beispiel für VGA, um alle Farbkanäle > gleichzeitig umzuschalten. Das verwundert mich etwas an der Kiste. Ich meine ein DAC gut und schoen, ein schneller auch gut. Aber ich hab den Eindruck als wenn die mehr Aufwand und Liebe in DACs als in ADCs gesteckt haben. Wieso? Und VGA? Was soll der Quatsch? VGA ist Geschichte. > Auch wenn es für manche unglaublich klingen mag, der Propeller 2 kann > bis zu: > - 64 DACs > - 64 ADCs > - 32 USB Schnittstellen (Host oder Device) > - 64 UART Kanäle (RX oder TX) > - 64 PWM Ausgänge > - 64 Frequenzzähler Fuer mich klingt das auch ueberraschend. Aber wie schon gesagt, das liegt am Mangel an Datenblatt. Ausserdem waeren vielleicht 2-3Applikationen nicht schlecht. Aber 32USB-Schnittstellen ist ja schonmal super. Damit koennte man damit schonmal einen dicken USB-Hub bauen. Das koennen andere Prozessoren nicht. :-D Was mich auch interessieren wuerde, Stromverbrauch? Sleepmodi? Und was mich ganz besonders interessieren wuerde, wenn man alle Schnittstellen in Software nachbilden muss, koennte man damit einen paralleln Datenbus als Slave nachbilden? Also als Beispiel(!) mal einen kompletten 8255 simulieren? Olaf
> Das bewirkt, dass jeder Prozessor nun den > Speicher in jedem Takt lesen kann, solange die Adresse fortlaufend > aufsteigend ist,.. jeder Prozessor in jedem Takt ??? Bezweifele ich. Schneller als das zentrale RAM es erlaubt wird RD/WR nicht möglich sein. Und wie geschrieben, man kann das mit MCUs/CPUs bauen, wie man es haben will. (auch mit MB's an RAM) > ... mal einen kompletten 8255 simulieren? ... Klar geht das; die Frage ist, wie schnell der das hin bekommt?
> Genau damit schließt sich zunehmend die Lücke, die vor 1,5 Jahrzehnten > mal der Ansatz für das Propeller-Konzept war. Umfangreiche Periph-Einheiten in MCUs gibt es schon seit den 90ern.
Wie ist es eigentlich mit der Geschwindigkeit? Die Cores werden wohl mit 180MHz getaktet. 180MHz x 8= 1440MHz
> Klar geht das; die Frage ist, wie schnell der das hin bekommt?
Das ist ja im Prinzip die Frage. Der Controller muesste dann ja bei
Anfragen schnell genug Daten Bereitstellen oder abolen. Genau
das geht ja bei einem normalen Mikrcontroller nicht weil du dort
ja immer irgendeinen IRQ oder was anderes laufen hast das sowas
verzoegert.
Fuer solche Spielchen koennte ein Multicore im Vorteil sein.
Olaf
Olaf schrieb: > Genau > das geht ja bei einem normalen Mikrcontroller nicht weil du dort > ja immer irgendeinen IRQ oder was anderes laufen hast das sowas > verzoegert. Das lässt sich oft ganz schnell beantworten ob ein single-core schnell genug für eine Aufgabe ist: Wie lange dauert ein Interrupt bis man überhaupt in der IRQ-Routine gelandet ist? IRQ heißt ja auch Interupt request. Es kann sein, dass ein höherer IRQ aktiv ist, oder ein IRQ gesperrt wurde, weil im Moment nicht-atomare Daten bearbeitet werden. Das IRQ-Problem entfällt beim xmos und Propeller komplett, weil es keinen IRQ gibt. D.h. es gibt keine Timing-Überaschungen. Beim xmos gibt es das nicht-atomar-Problem überhaupt nicht. Es gibt kein shared memory auf das man direkt zugreifen kann.
Nick M. schrieb: > Beim xmos gibt > es das nicht-atomar-Problem überhaupt nicht. Es gibt kein shared memory > auf das man direkt zugreifen kann. Die bis zu 8 Threads eines XMOS Cores haben gemeinsamen Speicher und können sich über entsprechende Hardware synchronisieren. Nur nicht die über Links kommunizierenden verschiedenem Cores.
Andi schrieb: > Auch wenn es für manche unglaublich klingen mag, der Propeller 2 kann > bis zu: > - 64 DACs > - 64 ADCs > - 32 USB Schnittstellen (Host oder Device) > - 64 UART Kanäle (RX oder TX) > - 64 PWM Ausgänge > - 64 Frequenzzähler > - und vieles mehr, alles natürlich nur einmal pro Pin/Pinpaar Das hab ich beim überfliegen jetzt auch so verstanden. Wobei das eher "64 - Anzahl Versorgungspins" ist. Allerdings ist das Datenblatt so mies, dass ich nach ein paar Minuten aufhören musste und keine eindeutige Antwort gefunden habe. Wenn das Datenblatt irgendwann mal fertig ist, gucke ich mir das vielleicht nochmal an. Mal davon abgesehen, dass der Inhalt eher mau ist, die docs.google Idee ist eine Katasrophe. Ich konnte nichmal nach pdf exportieren, obwohl es die Option gibt, es ist einfach nichts passiert. Und ich kann nur das Chip-Datenblatt oder das Io-Zellen-Datenblatt öffnen, nicht beides gleichzeitig? Die Pins, wenn es denn tatsächlich stimmt und so funktioniert, sind sehr interessant. Schön wäre es, wenn es die Pins mit einem ordentlichen Kern geben würde, dann wäre das Zielpublikum sicher deutlich größer. Bei dem Preis greif ich vermutlich eher zum FPGA, dann muss ich nix neues lernen und hab noch mehr "Flexibilität" ;-). chris_ schrieb: > Wie ist es eigentlich mit der Geschwindigkeit? > Die Cores werden wohl mit 180MHz getaktet. Keine Ahnung, auf der Webseite konnte ich nichts finden. Im Datenblatt wollte ich nicht suchen.
(prx) A. K. schrieb: > Die bis zu 8 Threads eines XMOS Cores PS: Das bezieht sich auf die erste Generation, die XS1, von 2008.
(prx) A. K. schrieb: > Die bis zu 8 Threads eines XMOS Cores haben gemeinsamen Speicher und > können sich über entsprechende Hardware synchronisieren. Es ändert aber nichts daran, dass man nicht auf den gemeinsamen Speicher direkt zugreifen kann. Direkt im Sinne von: Ich greif direkt auf Daten eines anderen cores oder threads zu. Man muss immer über ein Interface gehen, es gibt keinen address-operator (&). By reference geht in XC anders:
1 | void swap(int &a, int &b) { |
2 | int tmp = x; |
3 | x = y; |
4 | y = tmp; |
5 | }
|
6 | |
7 | swap(a, b); |
Es kann auch nur eine Referenz auf ein und das selbe Objekt generiert werden.
>> Genau >> das geht ja bei einem normalen Mikrcontroller nicht weil du dort >> ja immer irgendeinen IRQ oder was anderes laufen hast das sowas >> verzoegert. > Das lässt sich oft ganz schnell beantworten ob ein single-core schnell > genug für eine Aufgabe ist: > Wie lange dauert ein Interrupt bis man überhaupt in der IRQ-Routine > gelandet ist? Sofern diese Anfragen-Beantwortung nicht an der CPU vorbei (DMA, sep Hardware etc.) gehen könnte. Je schneller es sein muss, desto eher ist sep. Hardware erforderlich. (die CPU mit unendl. f gibt es nicht) > Das IRQ-Problem entfällt beim xmos und Propeller komplett, weil es > keinen IRQ gibt. Und dadurch ist das doch vorhandene IRQ-Problem unlösbar (!), wenn man mehr als 8 äussere Anfragen (Threads) hat (die wegen Komplexität von einer CPU gemacht werden müssen). (Einige CPUs haben bereits 16 oder mehr INT-Prioritäten) > D.h. es gibt keine Timing-Überaschungen Doch, Timing-Katastrophen. Eine CPU(Kern), die nichtmal mit INTs umgehen kann, ist (meist) unbrauchbar. > Die bis zu 8 Threads eines XMOS Cores haben gemeinsamen Speicher und > können sich über entsprechende Hardware synchronisieren. Auch diese Cores können m.W. nicht gleichzeitig auf den gemeinsamen Speicher zugreifen.
MCUA schrieb: > Eine CPU(Kern), die nichtmal mit INTs umgehen kann, ist (meist) > unbrauchbar. Es ist nur die Frage, ob der Propeller2 mit IRQs umgehen kann. Ich habe etwas von Eventsystem gelesen. Aber um mehr darüber herauszufinden, müsste ich in der miesen Doku lesen ...
MCUA schrieb: > Und dadurch ist das doch vorhandene IRQ-Problem unlösbar (!), wenn man > mehr als 8 äussere Anfragen (Threads) hat (die wegen Komplexität von > einer CPU gemacht werden müssen). Fehlende Interrupts bedeuten nicht unbedingt, dass man Ereignisse explizit abfragen muss. Beim Propeller mag das notwendig sein, aber das hängt mit deren fester Zuordnung von Threads zu Cores zusammen. Wenn ein Thread mit einem Core untrennbar verknüpft ist, kann man darin ebensogut pollen, warten spart höchstens Strom. Wenn Threads jedoch freier zugeordnet werden können und inaktive Threads keine Cores belegen, sieht das anders aus. Bei Transputern war das nur anders abgebildet: Threads konnten auf Hardware-Ereignisse warten, und trat das Ereignis ein, hat der Hardware-Scheduler den Thread aktiviert. Wird bei XMOS vmtl ähnlich sein.
(prx) A. K. schrieb: > Threads konnten auf Hardware-Ereignisse warten, und > trat das Ereignis ein, hat der Hardware-Scheduler den Thread aktiviert. > Wird bei XMOS vmtl ähnlich sein. Ja, das ist genau so. Man muss nicht mal pollen, es wartet Hardware auf ein Muster am Eingang. Sobald das da ist geht es los. Man kann einen thread exklusiv einem core zuweisen, damit der nicht mehrere threads übernimmt. Umgekehrt kann man "unwichtiges" im Hintergrund laufen lassen. xmos ist deterministisch, die Reaktionszeiten lassen sich berechnen. Dazu gibt es die Software XScope.
mh schrieb: > MCUA schrieb: >> Eine CPU(Kern), die nichtmal mit INTs umgehen kann, ist (meist) >> unbrauchbar. > Es ist nur die Frage, ob der Propeller2 mit IRQs umgehen kann. Ich habe > etwas von Eventsystem gelesen. "16 unique event trackers that can be polled and waited upon 3 prioritized interrupts that trigger on selectable events" Von der Shopseite: https://www.parallax.com/product/propeller-2-multicore-microcontroller-chip/
MCUA schrieb: > Eine CPU(Kern), die nichtmal mit INTs umgehen kann, ist (meist) > unbrauchbar. Ein Programmierer der nicht ohne INTs auskommt ist unbrauchbar.
Laie schrieb: > "16 unique event trackers that can be polled and waited upon > 3 prioritized interrupts that trigger on selectable events" > Von der Shopseite: Schön, das sagt nun wirklich nichts aus, außer dass es 16 von irgendwas und 3 von was anderem gibt und dass man irgendwas damit machen kann.
mh schrieb: > Laie schrieb: >> "16 unique event trackers that can be polled and waited upon >> 3 prioritized interrupts that trigger on selectable events" >> Von der Shopseite: > Schön, das sagt nun wirklich nichts aus, außer dass es 16 von irgendwas > und 3 von was anderem gibt und dass man irgendwas damit machen kann. Ja, wollte deine Aussage nur in einen Zusammenhang bringen. Interrupts zu Pollen ("polled and waited upon 3 prioritized interrupts") scheint mir auch ein Widerspruch zu sein.
Andi schrieb: > der Propeller 2 kann bis zu: > - 64 DACs Steht aber anders im Datenblatt. mh schrieb: > Allerdings ist das Datenblatt so mies, Genau. Und ohne ordentliche Dokumente ist das Teil für die Tonne.
Laie schrieb: > Ja, wollte deine Aussage nur in einen Zusammenhang bringen. Interrupts > zu Pollen ("polled and waited upon 3 prioritized interrupts") scheint > mir auch ein Widerspruch zu sein. Man "polled" ja auch nicht die Interrupts, sondern die Events, steht da doch auch so. Die möglichen Events und was man damit machen kann wird im Dokument doch beschrieben, halt nicht in der Einleitung, sondern im entsprechenden Kapitel. Wenn man als Event z.B. die negative Flanke eines Pins setzt, dann hat man 3 Möglichkeiten es (ihn?) zu nutzen: 1) Per Softwareloop den Status zu pollen - eher langsam, dafür kann man noch anderes im Loop machen. 2) Einen Interrupt auslösen zu lassen - Reaktionszeit hängt davon ab was der Prozessor gerade abarbeitet, manches kann nicht sofort unterbrochen werden. 3) Den Prozessor in einen Wartezustand zu versetzen, indem er nur auf das Ereignis wartet. Die Reaktionszeit ist dann ein einzelner Takt! Das ist nur mit wirklich parallel laufenden Cores, wie beim Propeller möglich. Wenn man also den P2 als Peripherie Baustein an einen Bus hängen will, dabei auf die fallende Flanke des ChipSelect wartet, wird der nächste Befehl zum einlesen der Daten und/oder Adresse innerhalb von 2 Taktzyklen ausgeführt. Das dauert also 10ns, wenn man den P2 mit 200 MHz taktet. Die maximale Taktfrequenz des P2 liegt offiziell bei 180 MHz, das ist aber ein sehr vorsichtiger Wert von OnSemi, dem Chipfertiger. In der Praxis hat sich gezeigt das man bis etwas über 300 MHz gehen kann. Die meisten Befehle benötigen 2 Takte, also erreicht ein Prozessor etwa 100..150 MIPs. Olaf schrieb: > Und > VGA? Was soll der Quatsch? VGA ist Geschichte. Ja, da wurde der Chip leider im laufe der langen Entwicklungszeit von der digitalen Realität überholt. Immerhin hat man noch eine HDMI Schnittstelle eingebaut, als sich abzeichnete, dass der Chip auch mit 250 MHz läuft. Damit ist Digitalvideo mit 640 x 480 Pixel möglich. Für Computerverwöhnte vielleicht lächerlich, aber es handellt sich ja auch um einen Microcontroller. Und der Bildspeicher füllt bei 16bit Farben mit dieser Auflösung auch schon fast das ganze RAM.
Andi schrieb: > Damit ist Digitalvideo mit 640 x 480 Pixel möglich. > Für Computerverwöhnte vielleicht lächerlich, aber es handelt > sich ja auch um einen Microcontroller Da der Hersteller in der Werbung gerade die Videoausgabe als Highlight/Anwendungsbeispiel hervor hebt sollte der Punkt auch überzeugen. Wenn ich ein Auto bewerben würde, würde ich ja auch nicht schreiben: Erreicht bis zu 100 km/H in 30 Sekunden. Da fehlt einfach die Begeisterungsfähigkeit mit 640x480 Punkten.
void schrieb: > Andi schrieb: >> der Propeller 2 kann bis zu: >> - 64 DACs > > Steht aber anders im Datenblatt. > > mh schrieb: >> Allerdings ist das Datenblatt so mies, > > Genau. Und ohne ordentliche Dokumente ist das Teil für die Tonne. Hier der Mitschnitt des Zoom Meetings von heute Nacht. Da erklärt der Entwickler Aufbau und Funktion der DACs. Auch das Dithering von 8 auf 16 Bits wird gezeigt. https://www.youtube.com/watch?v=N1Yj9_Dq49E Ich konnte das GoogleDoc Datenblatt als PDF runterladen, Online ist es in der Tat ungeniessbar. Datenblatt ist wahrscheinlich die falsche Bezeichnung, es ist mehr eine Beschreibung der Möglichkeiten und eine Referenz.
Stefan ⛄ F. schrieb: > Da fehlt einfach die Begeisterungsfähigkeit mit 640x480 Punkten. Wird oft genug in kleinen Steuerungen als viel zu groß bewertet. Z.B. Kaffeemaschinen, WaMa, Telefon, ... Wie viel kann denn der Arduino so an Pixeln?
Nick M. schrieb: > Ein Programmierer der nicht ohne INTs auskommt ist unbrauchbar. Das würde ich doch stark in Frage stellen wollen. Ja klar, es gibt viele Interrupts, die vorhersehbar eintreten und somit bei optimaler Programmierung quasi überflüssig werden. Aber: es gibt eben auch die unvorhersehrbare Interrupts aus externen Quellen. Und für diese ist nunmal die Nutzung des Interrupt-Mechanismus meist (aber auch nicht immer) die beste Lösung. Unbrauchbar ist nur ein Programmierer, der nicht die optimale Wahl für das Target und das Problem treffen kann, also auf jeden Fall schonmal jeder, der nur "Hochsprachen" beherrscht, die das Timing abstrahieren (also diesbezüglich rein garnix garantieren). Weil: er kann darauf dann schlicht keinen Einfluss mehr nehmen, das gibt sein Werkzeug nicht her...
Stefan ⛄ F. schrieb: > Da der Hersteller in der Werbung gerade die Videoausgabe als > Highlight/Anwendungsbeispiel hervor hebt sollte der Punkt auch > überzeugen. Werbung? Wo denn? Über HDMI lassen sich immerhin die kleinen Monitore ansteuern, wie sie für den RasPi verkauft werden. Per VGA oder Component Video gehen viel höhere Auflösungen, und das auch noch mit weniger Pins und Leitungen. Digital hat nicht nur Vorteile...
Andi schrieb: > Olaf schrieb: >> Und VGA? Was soll der Quatsch? VGA ist Geschichte. > Ja, da wurde der Chip leider im laufe der langen Entwicklungszeit > von der digitalen Realität überholt. VGA gibt es seit 1987, taucht noch immer an vielen Stellen auf und ist erstaunlich kompatibel. Es wird wahrscheinlich länger gelebt haben als jede ihm nachfolgende Digitalschnittstelle. > Immerhin hat man noch eine HDMI Schnittstelle eingebaut, als sich > abzeichnete, dass der Chip auch mit 250 MHz läuft. Damit ist > Digitalvideo mit 640 x 480 Pixel möglich. Wenn ich sehe, dass die automatischen Tankstellen hier mit 640x480 Auflösung und geschätzten 1fps laufen (fällt bei der PIN-Eingabe schon deutlich auf) und auf der Gegenseite sehe, wie die Kaffeemaschinen in der Firma bei gleicher Auflösung an Animationen scheitern...
c-hater schrieb: > der nur "Hochsprachen" beherrscht, die das Timing abstrahieren > (also diesbezüglich rein garnix garantieren). Hochsprachen abstrahieren also das Timing. Und eine ISR in Hochsprache garantiert überhaupt nichts. Das kann teilweise Stunden dauern. Man lernt nie aus. Besonders hier.
Andi schrieb: > Hier der Mitschnitt des Zoom Meetings von heute Nacht. Die können Videos machen solange sie wollen, bis es kein ordentliches Datenblatt als pdf gibt, werd ich mich damit nicht weiter beschäftigen.
mh schrieb: > Die können Videos machen solange sie wollen, bis es kein ordentliches > Datenblatt als pdf gibt, werd ich mich damit nicht weiter beschäftigen. Ich vermute, dass das hier durchaus auf Gegenliebe stoßen würde.
Beitrag #6530673 wurde von einem Moderator gelöscht.
Beitrag #6530769 wurde von einem Moderator gelöscht.
Beitrag #6530787 wurde von einem Moderator gelöscht.
Stop! Bitte aufhören. Das Thema "ISR besser in Hochsprache oder nicht" ist nicht Thema dieses Threads. Schlagt euch bitte in einem anderen Thread den Kopf ein.
Beitrag #6530795 wurde von einem Moderator gelöscht.
Beitrag #6530800 wurde von einem Moderator gelöscht.
Andi schrieb: > Hier der Mitschnitt des Zoom Meetings von heute Nacht. Da erklärt der > Entwickler Aufbau und Funktion der DACs. blub schrieb: > Ab Minute 14 erklärt der Erfinder sein Zielpublikum > https://embedded.fm/episodes/2015/2/4/87-make-my-own-steel-foundry Verstehe. Als unter 50 Jähriger gehöre ich wohl nicht zur Zielgruppe, welche sich 2 Stunden per Zoom einen 8-bit R2R DAC vorlesen lässt und dann immer noch glaubt das es sich um eine PWM-Ausgabe handelt. Geräusch von Kopf auf Tischplatte Nick M. schrieb: > Ich vermute, dass das hier durchaus auf Gegenliebe stoßen würde. Du meinst die Zielgruppe der unter 20 Jährigen nach Youtube-Video Schaltung Zusammenstecker? Ja, da könnte der P2 in der Tat gross einschlagen. Datenblatt wird da ja auch nicht benötigt für. mh schrieb: > bis es kein ordentliches Datenblatt als pdf gibt, > werd ich mich damit nicht weiter beschäftigen. Dem kann ich mich nur anschliessen.
Beitrag #6530808 wurde von einem Moderator gelöscht.
Beitrag #6530818 wurde von einem Moderator gelöscht.
Beitrag #6530821 wurde von einem Moderator gelöscht.
Beitrag #6530823 wurde von einem Moderator gelöscht.
Beitrag #6530831 wurde von einem Moderator gelöscht.
Beitrag #6530833 wurde von einem Moderator gelöscht.
Beitrag #6530834 wurde von einem Moderator gelöscht.
Beitrag #6530835 wurde von einem Moderator gelöscht.
Beitrag #6530837 wurde von einem Moderator gelöscht.
Beitrag #6530839 wurde von einem Moderator gelöscht.
Beitrag #6530854 wurde von einem Moderator gelöscht.
Beitrag #6530867 wurde von einem Moderator gelöscht.
Beitrag #6530868 wurde von einem Moderator gelöscht.
Nick M. schrieb im Beitrag #6530769: > Der Aufruf einer ISR dauert immer gleich lang, egal ob die ISR in > Assembler oder einer Hochsprache geschrieben ist. Auf welche Plattform beziehst du dich dabei? > Ausser du schreibst > alles in Assembler und weißt, welche Register nicht gesichert werden > müssen. Denn das kann ein Compiler auch.
(prx) A. K. schrieb: >> Ausser du schreibst >> alles in Assembler und weißt, welche Register nicht gesichert werden >> müssen. > > Denn das kann ein Compiler auch. :-)) Natürlich, er kann nicht nur, er muss auch. Ich meinte, dass er, wenn er alles in Asm schreibt, noch ein paar Register sparen könnte. (prx) A. K. schrieb: > Auf welche Plattform beziehst du dich dabei? Auf welcher ist es nicht so? Ich sprech von µCs.
Beitrag #6530904 wurde von einem Moderator gelöscht.
Beitrag #6530912 wurde von einem Moderator gelöscht.
Nick M. schrieb: > Auf welcher ist es nicht so? Ich sprech von µCs. Ob es wohl bei jedem Compiler für Z80 vorgesehen ist, ggf den zweiten Registersatz in Interrupts zu nutzen? Allerdings wollte ich damit nur absichern, dass konventionelle ISRs gemeint sind. Eventbasierte Aktivierung von Hardware-Threads hat mehr mit solchen alternativen Registersätzen gemein, weniger mit Stack-Push.
(prx) A. K. schrieb: > Eventbasierte Aktivierung von Hardware-Threads hat mehr > mit solchen alternativen Registersätzen gemein, weniger mit Stack-Push. Ah OK! Nein, die nicht. "Ganz normale INTs", wenn das eine qualifizierte Beschreibung ist. :-/
Nick M. schrieb: > Natürlich, er kann nicht nur, er muss auch. Beim Interrupt von 6800&Co hat schon die Hardware alles gesichert (war ja nicht viel). Bei TIs 9995 waren Interrupts komplette Kontextwechsel, weil Register im RAM. Da muss er nicht, denn für einen Compiler gibts diesbezüglich nichts zu tun. ;-)
Junge, Junge! Ihr macht mir echt Sorgen;-) Irgendwie kann ich mir trotz aller Nischenvorteile als eingefleischter Pragmatiker nicht wirklich vorstellen, daß die Propellerarchitektur groß Fuß fassen wird. Da müssen die Planeten wirklich zueinander richtig stehen um einen klaren Vorteil in einer spezifischen Situation zu haben. Ansonsten kommt man in der realen Welt wahrscheinlich mit herkömmlichen, bewährten Lösungen weiter. Sicherlich, die Konzepte der Propellerarchitektur sind teilweise "intriguing", aber die Industrie frisst doch lieber von dem das sie kennt. Wenn in der Firma erst gelernt werden muß um praktisch Produkte entwickeln zu können, kostet das Geld und hat schon deshalb einen Nachteil. Abgesehen davon gibt es viele Branchen wo SW aus sicherheitstechnischen Gründen schon einen Stammbaum haben muß um abgenommen werden zu können. Ich bin der Meinung, daß Propellerarchitektur nicht besser oder schlechter ist, sondern grundsätzlich anderes konzeptionelles Denken im Ansatz bedarf und Grenzen in der Skalierbarkeit da sind, die die Größe der Anwendung limitieren. Das sind einfach verschiedene Welten die aber durchaus nebeneinander existieren können. Da ich aber alt, lernfaul und gefrässig bin, werde ich höchstwahrscheinlich bis zum Ende meiner Tage beim althergebrachten bleiben; unintuitiv wie ich einfach bin, die bekannten Wege beschreiten bis man mich als altes Eisen dann aussondert. Bis dahin werde ich auf herkömmlichen uC mein Unwesen treiben;-) Schönes Neues Jahr noch! Gerhard
Gerhard O. schrieb: > Irgendwie kann ich mir trotz aller Nischenvorteile als eingefleischter > Pragmatiker nicht wirklich vorstellen, daß die Propellerarchitektur groß > Fuß fassen wird. Ich auch nicht, aber warum sollte man nicht über die Architektur diskutieren?
Groß Fuß wird weder der Propeller noch xmos fassen. Propeller oder xmos sind auch nicht besser oder schlechter. Sie sind aber besser oder schlechter für einzelne Aufgaben geeignet. Und oft genug komplett ungeeignet. Der Propeller ist überhaupt nicht skalierbar, xmos einigermaßen. Gerhard O. schrieb: > Da ich aber alt, lernfaul und gefrässig bin, werde ich > höchstwahrscheinlich bis zum Ende meiner Tage beim althergebrachten > bleiben; Alt bin ich auch. Das ist genug. :-)
>Der Propeller ist überhaupt nicht skalierbar, xmos einigermaßen.
Hängt von der Software ab und wie gut einer der Prozessorkerne als
Kommunikationsprozessor zum nächsten Propeller programmiert ist.
chris_ schrieb: >>Der Propeller ist überhaupt nicht skalierbar, xmos einigermaßen. > > Hängt von der Software ab und wie gut einer der Prozessorkerne als > Kommunikationsprozessor zum nächsten Propeller programmiert ist. Unter skalierbar verstehe ich "Den gibts auch mit mehr RAM oder im 16-poligen Gehäuse". Wenn du die aber durch aneinanderhängen skalieren willst: Ja das ginge natürlich. Mit handshake und allem schätze ich etwa 40 MByte / sec peak, dauerhaft 5 MByte / s
Bei den Xmos nennt man das Channels die können 100Mbit/s. Das Konzept ist schon interessant, erfordert aber schon ein umdenken. Man gewöhnt sich an den XC den Rest kann man man mit C/C++ erledigen. XC umfasst nur das was sich auf C/C++ nicht abbilden lässt. Der Umfang ist nicht sehr groß und Hardware bezogen. Channels, I/Os,Takt, Prozess etc. VHDL ähnlich... Nachteil ist das man alle Schnittstellen in der Software bauen muss. Es gibt zwar Bibliotheken aber die machen er einen ungepflegten Eindruck. Voll mit Fehlern... Ich würde ehrlich heute nicht mehr mit Xmos eine Neuentwicklung starten, sondern mir einen ARM suchen...
Ich hab nochmal ne Frage zum Hubmemory. So wie ich das verstanden habe, kann jeder Cog nur in jedem 8. Takt auf diesen Speicher zugreifen. Wie genau funktioniert das? Wenn man einen Zugriff zum falschen Zeitpunkt startet, dauert der Zugriff dann im schlimmsten Fall 8 Takte? Muss man dann in seinem Code die Takte zählen, um die maximale Geschwindigkeit zu erreichen? Wenn ja, übernimmt der Compiler das, wenn man in einer höheren Sprache arbeitet? Die Frage geistert seit heut morgen in meinem Kopf rum, nachdem ich einen "bank conflict" in einem CUDA Kernel fixen musste. Ich konnte auf die schnelle keine zufriedenstellende Antwort finden.
mh schrieb: > Wenn man einen Zugriff zum falschen Zeitpunkt > startet, dauert der Zugriff dann im schlimmsten Fall 8 Takte? Ja, keine Arbitrierung, sondern Rotation wie bei einem Propeller. Dadurch wird es deterministisch. Mit Arbitrierung käme ein faktisch unbestimmbarer Zeitfaktor hinein. Das Konzept vom Propeller 1 sah die Programmierung zeitkritischer Module direkt in COG-Assembler vor. Die Hochsprache SPIN wird interpretiert, nicht compiliert.
mh schrieb: > dauert der Zugriff dann im schlimmsten Fall 8 Takte? Muss man dann in > seinem Code die Takte zählen, um die maximale Geschwindigkeit zu > erreichen? Beim P1 dauert das, ja Beim P2 scheint es anders zu sein. Dadurch welchen Code man wo laufen lässt kann man die Zugriffe optimieren (interleaving) Man kann etwas Daten lokal halten, direkt von Proz zu Proz kann man keine Daten austauschen (P1).
(prx) A. K. schrieb: > mh schrieb: >> Wenn man einen Zugriff zum falschen Zeitpunkt >> startet, dauert der Zugriff dann im schlimmsten Fall 8 Takte? > > Ja, keine Arbitrierung, sondern Rotation wie bei einem Propeller. > Dadurch wird es deterministisch. Mit Arbitrierung käme ein faktisch > unbestimmbarer Zeitfaktor hinein. Das bedeutet dann, man muss beim ersten Zugriff warten bis man dran ist und kann von da Takte zählen, wenn man schnell sein will?
mh schrieb: > Das bedeutet dann, man muss beim ersten Zugriff warten bis man dran ist > und kann von da Takte zählen, wenn man schnell sein will? Üblicherweise wird man per Timer arbeiten. Aber wenn es auf jeden Takt ankommt, kann zählen angesagt sein.
Beim Propeller 1 kann ein Prozessor nur alle 16 Takte auf das HubRAM zugreifen, da jeder Zugriff 2 Takte dauert. Takte zählen muss man nicht gross, man kann einfach 2 Befehle zwischen zwei Hub Zugriffen ausführen, ohne dass diese zusätzlich Zeit benötigen. Da alle höheren Programmiersprachen des P1 den Code aus dem HubRAM lesen und ausführen, gibt es da leider nicht viel zu optimieren.
> Takte zählen muss man nicht gross, man kann einfach 2 Befehle zwischen > zwei Hub Zugriffen ausführen, ohne dass diese zusätzlich Zeit benötigen. Ich wuerde sowas nicht ueberbewerten. Ich kenne sowas aehnliches vom SH2A. Also einem Microcontroller der Superscalar ist. (er kann mehrere Befehle gleichzeitig ausfuehren) Da ist es dann Aufgabe des Compilers seinen Code so anzuordnen das dies moeglichst gut klappt. Als Programmierer merkt man davon nichts solange man nicht im Debugger im Singlestep durch den Code wandert. BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten die nicht mittlerweile auch Superscalar sein? Olaf
Olaf schrieb: > BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten > die nicht mittlerweile auch Superscalar sein? Auf der Mikrokontrollerebene hat der ARM Cortex-M7 Superskalarität. Die großen Cortex-A schon länger, aber auch nicht jeder. Beispiele: Cortex-A5 ist es nicht, aber Cortex-A8 schon.
Olaf schrieb: > BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten > die nicht mittlerweile auch Superscalar sein? Konsequenter Smartphoneverächter? ;-) Aber auch auch der Microcontroller-Core Cortex-M7 ist superskalar. > Da ist es dann Aufgabe des Compilers > seinen Code so anzuordnen das dies moeglichst gut klappt. Wenn es darum geht, exakte Zeitbedingungen einzuhalten, bei denen ein Takt mehr oder weniger bereits eine Rolle spielt, wirds etwas aufwändiger und der Compiler ist keine Hilfe.
> Wenn es darum geht, exakte Zeitbedingungen einzuhalten, bei denen ein > Takt mehr oder weniger bereits eine Rolle spielt, wirds etwas > aufwändiger und der Compiler ist keine Hilfe. Das stimmt natuerlich. Wenn man sowas echt braucht dann wird es Zeit die Aermel hochzukrempeln und wieder mal Assembler zu machen. Allerdings kann man das dann dem Propeller nicht vorwerfen. Nur bei einem Singlecore wird man es kaum schaffen auf IRQs zu verzichten und die kann man sich auch nicht erlauben. Bei so einem Multicore wie dem Propeller schon. Olaf
Olaf schrieb: > Allerdings kann man das dann dem Propeller nicht vorwerfen. Wem soll man es dann vorwerfen? Multiprozesskommunikation ist normalerweise kompliziert genug. Da kann ich gut darauf verzichten den Teil in Asm zu schreiben, um die volle Kontrolle über jeden Takt zu haben.
mh schrieb: > Die Frage geistert seit heut morgen in meinem Kopf rum, nachdem ich > einen "bank conflict" in einem CUDA Kernel fixen musste. Ich konnte auf > die schnelle keine zufriedenstellende Antwort finden. Naja, beim P2 ist der Haupt-RAM in 8 Bänke aufgeteilt..So können alle Cores gleichzeitig im RAM lesen oder schreiben, jedoch nur jeweils in ,,ihrer" Bank, welche nach jedem 2. Takt weiterrotiert zum nächsten...Also im Schlimmsten Fall heisst das 7 Slots abwarten , im Optimalfall (sequenzielles Zugreifen auf aufeinanderfolgende Speicheradressen) muss garnicht gewartet werden. Wenn ich jetzt Code ausführe und dann ein Branch kommt muss also im Mittel 3,5 Slots abgewartet werden. Trotzdem kann aber zwischendrin jeder Core auf seinen eigenen kleinen Speicher zugreifen. DMA macht hier also Sinn..Ganze Streams können flott in den Core-Speicher verschoben werden und dort anschliessend bearbeitet werden, wie ein Cache im Grunde, nur zu Fuß programmiert
Aber auch hier wird, wenn ich es richtig verstanden habe, die Zugriffszeit eines COGs auf das Hub-Memory nicht von Zugriffen anderer COGs beeinflusst.
Olaf schrieb: > BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten > die nicht mittlerweile auch Superscalar sein? Aber nur in der A-Reihe. Die Cortex-M nicht. Und das ist meiner Meinung nach auch für die typischen Anwendungen ganz passend. Matthias
zonk schrieb: > Naja, beim P2 ist der Haupt-RAM in 8 Bänke aufgeteilt..So können alle > Cores gleichzeitig im RAM lesen oder schreiben, jedoch nur jeweils in > ,,ihrer" Bank, welche nach jedem 2. Takt weiterrotiert zum > nächsten...Also im Schlimmsten Fall heisst das 7 Slots abwarten , im > Optimalfall (sequenzielles Zugreifen auf aufeinanderfolgende > Speicheradressen) muss garnicht gewartet werden. Es wird also noch komplexer. Wenn ich daraus einen Nutzen ziehen möchte, muss ich meine Datenstrukturen über die Bänke verteilen und muss dann trotzdem auf auf den richtigen Startpunkt warten. (prx) A. K. schrieb: > Aber auch hier wird, wenn ich es richtig verstanden habe, die > Zugriffszeit eines COGs auf das Hub-Memory nicht von Zugriffen anderer > COGs beeinflusst. Wenn das nicht der Fall wäre, könnte man die Zugriffszeiten auch per Zufallszahlengenerator erzeugen ;-)
Μαtthias W. schrieb: > Aber nur in der A-Reihe. Die Cortex-M nicht. Wie schon aufgeführt wurde, ist der Cortex M7 Kern sehr wohl superskalar mit bis zu 2 Befehlen pro Takt. Allerdings im Unterschied zu vielen Cortex A Kernen ist er in-order.
(prx) A. K. schrieb: > Μαtthias W. schrieb: >> Aber nur in der A-Reihe. Die Cortex-M nicht. > > Wie schon zweimal aufgeführt wurde, ist der Cortex M7 Kern sehr wohl > superskalar mit 2 Befehlen pro Takt. Allerdings im Unterschied zu vielen > Cortex A Kernen ist er in-order. Den muss ich mir demnächst auch mal angucken. Sorgt der Kern selbst dafür, dass die beiden Befehle keine Konflikte auslösen und tatsächlich in-order sind?
Olaf schrieb: > BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten > die nicht mittlerweile auch Superscalar sein? Arm an sich bezeichnet in diesem Zusammenhang nur eine ISA. Die konkrete Implementierung setzt diese ISA um. Dabei kann alles mögliche gemacht werden. Z.b. ist ein Cortex M0 sicher nicht superskalar, ein M7 aber schon. Als Anwender merkt man davon nichts, außer dass der M7 wesentlich mehr Instructions per clock (IPC) hat als der M0. Wenn man darauf von Hand optimiert geht sicher noch was, allerdings wird es dann schnell Controller-spezifisch, weil die Anbindung und Geschwindigkeit von RAM und flash manchmal sehr unterschiedlich sind. Der CM7 von atmel kann hier ganz anders sein als der von ST. Dazu kommt, dass die effektive Nutzung der Peripherie wichtiger ist als der Code selbst. Die ITCM und DTCM und ihre zugreifbarkeit per DMA sind hier beispielsweise zu nennen. Sorry für OT.
mh schrieb: > Den muss ich mir demnächst auch mal angucken. Sorgt der Kern selbst > dafür, dass die beiden Befehle keine Konflikte auslösen und tatsächlich > in-order sind? Zweifellos.
(prx) A. K. schrieb: > Μαtthias W. schrieb: >> Aber nur in der A-Reihe. Die Cortex-M nicht. > > Wie schon aufgeführt wurde, ist der Cortex M7 Kern sehr wohl superskalar > mit bis zu 2 Befehlen pro Takt. Allerdings im Unterschied zu vielen > Cortex A Kernen ist er in-order. Tatsächlich. Da lag ich falsch. Danke für den Hinweis.
mh schrieb: > Es wird also noch komplexer. Wenn ich daraus einen Nutzen ziehen möchte, > muss ich meine Datenstrukturen über die Bänke verteilen und muss dann > trotzdem auf auf den richtigen Startpunkt warten. das Konzept ist eben daraufhin optimiert, komplette Datenpakete zu händeln. Per DMA kann auch direkt vom HUB-RAM auf die I/O-Pins gestreamt werden(SPI,VGA, oder Ähnliches) oder ein Audiostream von einem der ADCs eingelesen werden. Also Datenverarbeitung, sagen wir FFT wäre nur sinnvoll wenn es innerhalb des COG-RAMs passiert.(das sind je 4kByte wenn ich das hier richtig sehe)
zonk schrieb: > das Konzept ist eben daraufhin optimiert, komplette Datenpakete zu > händeln. Das verstehe ich nicht. Ich würde sagen für den Propeller2, wurde der erreichbare Speicherduchsatz des Hubs maximiert. Vielleich verstehe ich das aber noch immer falsch. Wenn ich ein Array mit 10 Werten von cog1 effizient in den hub kopieren will kann ich entweder: -Warten bis cog1 an der Reihe ist, in die Ziel Bank des hubs zu schreiben. Ab da muss cog1 für jeden weiteren Wert 8 Takte warten, (gültig für Propeller1 und 2), oder -die 10 Werte über mehrere Speicherbänke im Hub verteilen und dann in jedem Takt in die richtige Bank schreiben (nur Propeller2). Das würde für mich mehr Sinn ergeben, wenn im Hubspeicher die Bank mit jeder Adress wechselt, also Bank = Adresse % 8. Ist das vielleicht der Ausweg?
Es gibt 8 COGs und 8 Speicherbänke. Das rotiert durch. Die Daten sind verteilt Adresse 0 auf Bank 0, Adresse 1 auf Bank 1......Adresse 7 auf Bank 7..Adresse 8 wieder auf Bank0...Somit wird durch das weiterschalten der Bänke erreicht, dass jeder COG ohne Verzögerung auf ganze Arrays/Strings/Streams mit aufsteigenden Speicheradressen zugreifen kann. Auch könnten 8 COGS auf die selbe Adresse zugreifen jedoch zeitlich versetzt eben....
Könnte evtl für jemand interessant sein: https://propeller.parallax.com/p2.html Praxisbericht: Ich habe mir vor ca. 1 Jahr das Eval Board und die Zusatzplatinen besorgt. (z.B. die VGA Zusatzplatine beinhaltet nur Mechanik, nämlich die VGA - Buchse, 4x Cinch, eine Audio IN und eine Audio OUT Buchse) Als Programmiersprachen standen damals das proprietäre SPIN, ASM, C, Forth und BASIC zur Verfügung. Als einen der ersten Versuche habe ich ein simples ping- game mit ausgabe auf einem VGA Monitor umgesetzt. Die elementaren Graphicroutinen sind in SPIN geschrieben und mir von einem Forummitglied zur Verfügung gestellt worden. Dann gibt es einen C-Wrapper der mir die Funktionen für C zur Verfügung stellt. Das Hauptprogramm habe ich in C implementiert. Es werden 2 cogs benutzt, einer für Graphic und einer für die Spiellogik. Das Spiel läuft absolut zügig und ruckelfrei. Ich habe mich dann längere Zeit nicht mehr mit dem P2 beschäftigt, werde aber demnächst wieder weitermachen (HOBBYMÄSSIG!)
Das ist der Punkt. Als Hobby ist das super aber bevor das eine Firma hernimmt, setzt sie eher auf ein FPGA
zonk schrieb: > Es gibt 8 COGs und 8 Speicherbänke. Das rotiert durch. Die Daten sind > verteilt Adresse 0 auf Bank 0, Adresse 1 auf Bank 1......Adresse 7 auf > Bank 7..Adresse 8 wieder auf Bank0...Somit wird durch das weiterschalten > der Bänke erreicht, dass jeder COG ohne Verzögerung auf ganze > Arrays/Strings/Streams mit aufsteigenden Speicheradressen zugreifen > kann. Auch könnten 8 COGS auf die selbe Adresse zugreifen jedoch > zeitlich versetzt eben.... Ok, also wirklich Bank = Adresse % 8 oder ähnlich. Vielen Dank!
(prx) A. K. schrieb: > Ja, keine Arbitrierung, sondern Rotation wie bei einem Propeller. > Dadurch wird es deterministisch. Mit Arbitrierung käme ein faktisch > unbestimmbarer Zeitfaktor hinein. Glückwunsch (prx) A. K., du hast soeben Round-robin Arbitrierung erfunden. Olaf schrieb: > BTW: Ich hab mich noch nie auf dem Level mit ARM beschaeftigt. Sollten > die nicht mittlerweile auch Superscalar sein? Solltest du aber mal machen Olaf. Wie üblich gilt da die Antwort: "kommt drauf an". Oder genauer ARM Cortex M/R/A: fast-nein*/ja-aber**/ja***. * Cortex-M nein, nicht superscalar. Ausnahme M7 bestätigt die Regel. ** Cortex-R ja, aber nur in-order execution *** Cortex-A ja, out-of-order execution. Das erhebt keinen Anspruch auf Vollständigkeit/Richtigkeit. Es mag im ARM Zoo, wie schon beim M7 gesehen, noch ein paar mehr Ausnahmen von der Regel geben...
Da habe ich mit meiner Sinnfrage zum Propeller echt was losgetreten haha
void schrieb: > Glückwunsch (prx) A. K., du hast soeben Round-robin Arbitrierung > erfunden. Danke der Ehre. Der Begriff Arbitrierung wird üblicherweise für Fälle verwendet, bei denen mehrere wollen, aber nicht gleichzeitig können. Hier hingegen wird auch verteilt, wenn niemand will und COGs müssen u.U. warten, obwohl Zugriff möglich wäre.
R.M. schrieb >Praxisbericht: >Ich habe mir vor ca. 1 Jahr das Eval Board und die Zusatzplatinen >besorgt. >... Danke dafür, dass Du etwas Code gepostet hast, da bekommt man eine echten Eindruck. War das Eval Board vor einem Jahr schon verfügbar? Ich dachte, das sei jetzt erst raus gekommen. >Die elementaren Graphicroutinen sind in SPIN geschrieben und mir von >einem Forummitglied zur Verfügung gestellt worden. >Dann gibt es einen C-Wrapper der mir die Funktionen für C zur Verfügung >stellt. >Das Hauptprogramm habe ich in C implementiert. Beim SPIN-Teil müsste man eventuell erwähnen, dass dort die schnellen Routinen in Propeller-Assembler geschrieben sind. Welcher C-Compiler wird den verwendet? Beim Propeller1 war das Catalina, aber lief auf Grund der damaligen Architektur eher langsam.
Das Board welches es jetzt gibt ist das mit der finalen Revision des Chips(Rev.C), bei dem alle Mängel und bugs behoben wurden. chris_ schrieb: > War das Eval Board vor einem Jahr schon verfügbar? Ich dachte, das sei > jetzt erst raus gekommen.
zonk schrieb: > bei dem alle Mängel und bugs behoben wurden Sowas gibts wirklich? Das wäre ein echtes Plus. ;-)
Naja, der Propeller 2 war in Fankreisen schon seit Jahren als fpga-Modul unterwegs. Der Entwickler setzt halt auf Transparenz und auf seine Community. Deshalb gab's da jetzt relativ gute Ergebnisse mit den Chips. Paar Fehler gab's aber halt doch bei der Konvertierung in's Silizium, weshalb 2 ,,respins" gemacht wurden mussten. Alles in Vollendung bis in's Detail;)
chris_ schrieb: > R.M. schrieb >>Praxisbericht: >>Ich habe mir vor ca. 1 Jahr das Eval Board und die Zusatzplatinen >>besorgt. >>... > > Danke dafür, dass Du etwas Code gepostet hast, da bekommt man eine > echten Eindruck. > War das Eval Board vor einem Jahr schon verfügbar? Ich dachte, das sei > jetzt erst raus gekommen. > >>Die elementaren Graphicroutinen sind in SPIN geschrieben und mir von >>einem Forummitglied zur Verfügung gestellt worden. >>Dann gibt es einen C-Wrapper der mir die Funktionen für C zur Verfügung >>stellt. >>Das Hauptprogramm habe ich in C implementiert. > > Beim SPIN-Teil müsste man eventuell erwähnen, dass dort die schnellen > Routinen in Propeller-Assembler geschrieben sind. > Welcher C-Compiler wird den verwendet? Beim Propeller1 war das Catalina, > aber lief auf Grund der damaligen Architektur eher langsam. Das Evalboard war/ist Revision B, ich habe es über Beziehungen aus USA bekommen. Der C-Compiler heißt (unglücklicher) Weise fastspin. Ich verwende die Kommandozeilenversion. Es gibt aber auch eine IDE. Der gcc, wie beim P1, ist leider noch nicht soweit. edit: ach ja, der Compiler liegt als Source vor, ich habe Linux, für Windows glaube ich auch als binary. Es ist sehr einfach den Compiler zu bauen: make ist alles
Wie schon erwähnt, ich hatte eine längere Pause und habe heute die aktuellste Version geholt und gebaut.
1 | reinhard@reinhard-TUXEDO:~/Schreibtisch/Propeller2/spin2cpp-5.0.3$ make |
2 | mkdir -p ./build |
3 | bison -Wno-deprecated -D parse.error=verbose -D api.prefix={spinyy} -t -b ./build/spin -d frontends/spin/spin.y |
4 | frontends/spin/spin.y: Warnung: 26 Schiebe/Reduzier-Konflikte [-Wconflicts-sr] |
5 | bison -Wno-deprecated -D parse.error=verbose -D api.prefix={basicyy} -t -b ./build/basic -d frontends/basic/basic.y |
6 | frontends/basic/basic.y: Warnung: 15 Schiebe/Reduzier-Konflikte [-Wconflicts-sr] |
7 | bison -Wno-deprecated -D parse.error=verbose -D api.prefix={cgramyy} -t -b ./build/cgram -d frontends/c/cgram.y |
8 | frontends/c/cgram.y: Warnung: 3 Schiebe/Reduzier-Konflikte [-Wconflicts-sr] |
9 | gcc -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/lexer.o -c frontends/lexer.c |
10 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/symbol.o -c symbol.c |
11 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/ast.o -c ast.c |
12 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/expr.o -c expr.c |
13 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/dofmt.o -c util/dofmt.c |
14 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/flexbuf.o -c util/flexbuf.c |
15 | gcc -MMD -MP -g -Wall -I. -I./build -DFLEXSPIN_BUILD -o build/lltoa_prec.o -c util/lltoa_prec.c |
16 | ... ... ... |
1 | reinhard@reinhard-TUXEDO:~/Schreibtisch/Propeller2/spin2cpp-5.0.3$ PATH="$HOME/Schreibtisch/Propeller2/spin2cpp-5.0.3/build:$PATH" |
2 | reinhard@reinhard-TUXEDO:~/Schreibtisch/Propeller2/spin2cpp-5.0.3$ fastspin |
3 | fastspin: Befehl nicht gefunden. |
4 | |
5 | FASTSPIN HEISST JETZT FLEXSPIN !!!! |
6 | |
7 | reinhard@reinhard-TUXEDO:~/Schreibtisch/Propeller2/spin2cpp-5.0.3$ flexspin |
8 | Propeller Spin/PASM Compiler 'FlexSpin' (c) 2011-2020 Total Spectrum Software Inc. |
9 | Version 5.0.3 Compiled on: Jan 1 2021 |
10 | usage: flexspin [options] filename.spin | filename.bas |
11 | [ -h ] display this help |
12 | [ -L or -I <path> ] add a directory to the include path |
13 | [ -o <name> ] set output filename to <name> |
14 | [ -b ] output binary file format |
15 | [ -e ] output eeprom file format |
16 | [ -c ] output only DAT sections |
17 | [ -l ] output DAT as a listing file |
18 | [ -f ] output list of file names |
19 | [ -g ] enable debug statements |
20 | [ -q ] quiet mode (suppress banner and non-error text) |
21 | [ -p ] disable the preprocessor |
22 | [ -D <define> ] add a define |
23 | [ -u ] ignore for openspin compatibility (unused method elimination always enabled) |
24 | [ -2 ] compile for Prop2 |
25 | [ -O# ] set optimization level: |
26 | -O0 = no optimization |
27 | -O1 = basic optimization |
28 | -O2 = all optimization |
29 | [ -H nnnn ] set starting hub address |
30 | [ -E ] skip initial coginit code (usually used with -H) |
31 | [ -w ] compile for COG with Spin wrappers |
32 | [ -Wall ] enable warnings for language extensions and other features |
33 | [ -Werror ] make warnings into errors |
34 | [ -C ] enable case sensitive mode |
35 | [ -x ] capture program exit code (for testing) |
36 | [ --code=cog ] compile for COG mode instead of LMM |
37 | [ --fcache=N ] set FCACHE size to N (0 to disable) |
38 | [ --fixedreal ] use 16.16 fixed point in place of floats |
39 | [ --lmm=xxx ] use alternate LMM implementation for P1 |
40 | xxx = orig uses original flexspin LMM |
41 | xxx = slow uses traditional (slow) LMM |
42 | [ --version ] just show compiler version |
43 | |
44 | |
45 | |
46 | reinhard@reinhard-TUXEDO:~/Schreibtisch/Propeller2/testbench2/pong$ flexspin -2 pingpong.c graphictools.c |
47 | Propeller Spin/PASM Compiler 'FlexSpin' (c) 2011-2020 Total Spectrum Software Inc. |
48 | Version 5.0.3 Compiled on: Jan 1 2021 |
49 | pingpong.c |
50 | |-p2videodrv.spin2 |
51 | graphictools.c |
52 | |-p2videodrv.spin2 |
53 | memset.c |
54 | pingpong.p2asm |
55 | Done. |
56 | Program size is 347256 bytes |
>von R. M. (n_a_n) >01.01.2021 10:26 >Wie schon erwähnt, ich hatte eine längere Pause und habe heute die >aktuellste Version geholt und gebaut. Interessant ... könntest Du mal diesen Benchmark hier laufen lassen?: Beitrag "Re: STM32 Arduino" Mich würde der Vergleich zu den genannten Prozessoren interessieren.
chris_ schrieb: > Interessant ... könntest Du mal diesen Benchmark hier laufen lassen?: > Beitrag "Re: STM32 Arduino" > > Mich würde der Vergleich zu den genannten Prozessoren interessieren. Der Propeller hat keine Hardwareunterstützung für Float, daher ist dieser Benchmark etwas unfair. Ein schnelles IIR Filter würde man wohl von Hand optimieren und die 16 Bit DSP Befehle oder ein Pipelined Cordic verwenden. Der C Compiler erlaubt FixedPoint (16.16) statt Float zu verwenden, was erheblich schneller ist, wenn's die Anwendung erlaubt. Einfach so von deinem C Source compiliert erhalte ich folgende Ergebnisse für time/sample: Float library mit 250 MHz: 38 us FixedPoint library mit 250 MHz: 9 us
chris_ schrieb: > Mich würde der Vergleich zu den genannten Prozessoren interessieren. Das ist eher ein Compilervergleich, mit der Hoffnung, dass der Compiler den Inhalt von millis() nicht kennt, wenn er loop compiliert.
chris_ schrieb: > Interessant ... könntest Du mal diesen Benchmark hier laufen lassen?: > Beitrag "Re: STM32 Arduino" > > Mich würde der Vergleich zu den genannten Prozessoren interessieren. Hallo chris, ich habe momentan die Hardware nicht bei mir in der Wohnung. Aber hier sind einige benchmark Ergebnisse beschrieben (Laufzeit und Speicher), die die verschiedenen vorhandenen Compiler für P2 vergleichen. https://forums.parallax.com/discussion/171960/c-and-c-for-the-propeller-2
Was ich auf die Schnelle noch zeigen kann: Ich habe ein IIR HP Filter für Audiobereich implementiert und gemessen. Das waren meine ersten Versuche mit dem neuen chip. https://forums.parallax.com/discussion/171100/fastspin-is-really-fast#latest
Ach ja, da hab ich noch was gefunden. Das waren wirklich die allerersten Schritte, noch in Assembler. https://forums.parallax.com/discussion/170987/simple-iq-modulation-with-cordic-finished#latest
R. M. (n_a_n) >Hallo chris, ich habe momentan die Hardware nicht bei mir in der >Wohnung. Danke für die Antwort. Falls Du mal an die Hardware kommen solltest, würde mich genau das Ergebnis für den genannten C-Code interessieren.
>Einfach so von deinem C Source compiliert erhalte ich folgende >Ergebnisse für time/sample: >Float library mit 250 MHz: 38 us >FixedPoint library mit 250 MHz: 9 us Ahh ... hab's nicht richtig gelesen. Das Ergebnis ist also time/sample us: Arduino UNO ( 16Mhz ) us: 127 STM32 BluePill ( 72MHz ) us: 16 Propeller2 ( 250MHz ) us: 9 STM32F4 Discovery ( 168MHz? ) us: 4
> Ein Programmierer der nicht ohne INTs auskommt ist unbrauchbar. Völliger Quatsch. INTs/Events (von aussen kommend) sind durch das Gesamt-System bestimmt. Ohne solch INTs/Events-Bearbeitung wäre viel höhere CPU-Rechenleistung (oder sep. Hardware, DMA usw (*)) erforderlich. Selbst dann stellt sich die Frage wie genau diese Werte in den zentr. Speicher kommen; darin liegt der Flaschenhals (auch wenn man es Propeller nennt). > Wenn man also den P2 als Peripherie Baustein an einen Bus hängen will, > dabei auf die fallende Flanke des ChipSelect wartet, wird der nächste > Befehl zum einlesen der Daten und/oder Adresse innerhalb von 2 > Taktzyklen ausgeführt. Innerh. 2 Cycl. wird die CPU es nicht hinkriegen. (Die ist da nicht besser als andere auch, eher schlechter)
Interrupt kann man eben HW-seitig unterschiedlich implementieren. Entweder man baut eine CPU, die auf Kommando mal pausieren kann, um schnell mal ein anderes Stück Code auszuführen, oder man hat mehr als eine CPU und "Interrupt" realisiert man durch "Polling". Man hat dann zwar das neue Problem den Zugriff der mehreren Kerne auf gemeinsame Resourcen in den Griff zu bekommen, dafür hat man entweder extrem schnell reagierende ISRs, die brauchen nämlich weder "Context-Save", noch müssen sie zwingen auf Shared Resoutcen zugreifen. Oder man braucht nicht alle 8 Cores für ISRs und kann sie einfach zum parallel rechnen nutzen. Das Shared Resourcen-Problem hat man übrigens auch wenn Peripherie per DMA selbstständig Daten vom/zum Speicher transferiert. Nur muß man zum Bus-Zyklus stehlen keine CPU-Register benutzen und natürlich sicher/wiederherstellen. Welcher Ansatz besser ist, hängt eher vom Problem ab. Und von der Frage, mit was man mehr Erfahrung hat.
> gemeinsame Resourcen in den Griff zu bekommen, dafür hat man entweder > extrem schnell reagierende ISRs, die brauchen nämlich weder > "Context-Save", noch müssen sie zwingen auf Shared Resoutcen zugreifen. Der Context Switch ist kein Problem. Es gibt CPUs die koennen einfach ihren Registersatz umschalten. (SH2A, Z80) Allerdings musst du bei echt parallel Cores natuerlich kein Gedanken daran verschwenden was du alles in der Reaktion auf eine externes Ereignis an Zeit verbraten tust. Deshalb hat das seinen Charme. Olaf
I brauche nicht noch eine Platine aber ich habe so gute Erfahrungen mit dem P1 gemacht... Cluso's Platinen sind so schön, ich mag daß für VGA schon eine Footprint auf der Platine gibt. ManAtWork's Platine hat alle PINs auf .1" raster... schwer sich zu entscheiden...
MCUA schrieb: >> Ein Programmierer der nicht ohne INTs auskommt ist unbrauchbar. > Völliger Quatsch. Ich hab das nicht aus Versehen geschrieben. So ein Programmierer ist geistig so festgefahren, dass er sich nichts Anderes vorstellen kann. Flexibel geht Anders. Wenn schon die Zweifel kommen, dass ein INT nicht besser gehandhabt wird, wie ist es denn bei 5 INTs gleichzeitig? Die 5 müssen dann auch noch ihre Daten wegbekommen. Da nützen die INT-Prioritäten beim klassischen µC dann auch nichts mehr, denn 4 INT-Ebenen blockieren die mit der niedrigsten Priorität. Und dazu eine belastbare Aussage bzgl. Latenzzeit für den niedrigsten INT zu machen, mit der Hoffnung dass nicht noch ein INT zwischenfeuert ... das witz witzig!
> Da nützen die INT-Prioritäten beim klassischen µC dann auch nichts mehr, > denn 4 INT-Ebenen blockieren die mit der niedrigsten Priorität. Du hast wohl das INT-Konzept nichtmal verstanden. Der INT mit niedrig(st)er Prio KANN warten, eben weil die Bearbeitung nicht so dringend ist. Und wenn mehrere mit sehr hoher Prio bearbeitet werden müss(t)en, geht das (wie bereits geschrieben) mit sep. Hardware (was aber definitiv aufwändiger und teurer ist). Also, je mehr INTs / INT-Ebenen eine CPU verarbeiten kann, desto besser.
> Der Context Switch ist kein Problem. Es gibt CPUs die koennen einfach > ihren Registersatz umschalten. Die Anzahl der Registersätze ist (oft nur auf 2) begrenzt.
> Allerdings musst du bei echt > parallel Cores natuerlich kein Gedanken daran verschwenden was du alles > in der Reaktion auf eine externes Ereignis an Zeit verbraten tust. 100 Cores sind nicht schneller als einer, wenn ein Event einem bestimmten Thread (damit einem bestimmten Core) zugewiesen werden muss.
Die Reaktionszeit ist bei wartenden Cores (Propeller) oder Kontexten (XMOS) kürzer als bei klassischen Interrupts.
MCUA schrieb: > Die Anzahl der Registersätze ist (oft nur auf 2) begrenzt. Das war der Charme von TIs 9900 Architektur. Genau genommen gab es nur einen Registersatz, aber das waren gerade einmal 3 Stück: Program Counter, Status Register, Workspace Pointer. Was in den Befehlen als Register angesprochen wurde lag im RAM, via Workspace Pointer. Also nur von der RAM-Kapazität begrenzt. Dementsprechend flott waren Interrupts.
..sozusagen Definitionssache, was 'Register' ist. Wenn die CPU (CISC) als Source/Destination jeweils auch MEM-Bereich nutzen kann/könnte (für alle Befehle, nicht nur für wenige) hätte man quasi unendl. viele Register. ... ist also Frage des CPU-Befehls-Satzes (wobei nat. ein grosser MEM-Bereich weniger schnell angesprochen werden kann als ein sehr kleiner Bereich (die man dann womöglich 'Registersatz' nennt))
MCUA schrieb: > Der INT mit niedrig(st)er Prio KANN warten, eben weil die Bearbeitung > nicht so dringend ist. KANN, und wie lange? Falls du das mit den INTs wirklich verstanden hast. Denn wenn er könnte, warum ist er dann ein INT?
MCUA schrieb: > wenn ein Event einem > bestimmten Thread (damit einem bestimmten Core) zugewiesen werden muss. Dieser eine ganz bestimmte wartet nur auf diese eine ganz bestimmte Event. Beim xmos ist das noch flexibler.
(prx) A. K. schrieb: > Die Reaktionszeit ist bei wartenden Cores (Propeller) oder Kontexten > (XMOS) kürzer als bei klassischen Interrupts. Das hängt wohl ganz stark vom verwendeten Core und dessen Takt ab. Nick M. schrieb: > MCUA schrieb: >> Der INT mit niedrig(st)er Prio KANN warten, eben weil die Bearbeitung >> nicht so dringend ist. > > KANN, und wie lange? Falls du das mit den INTs wirklich verstanden hast. > Denn wenn er könnte, warum ist er dann ein INT? Der Entwickler sollte es wissen. Genauso wie der Entwickler auf einem Propeller wissen muss, auf wieviele Events er maximal gleichzeitig warten muss. 8 Kerne bringen nichts, wenn man auf 9 Events direkt reagieren können muss.
mh schrieb: > 8 Kerne bringen nichts, wenn man auf 9 Events direkt > reagieren können muss. Zumindest wenn diese 9 Events voneinander unabhängig und zeitkritisch sind. Wenn einige davon nur bei verschiedenen Zuständen derselben Statusmaschine auftreten, lassen sie sich prinzipiell in einem Core zusammenfassen. Aber natürlich ist gerade eine Architektur wie bei den Propellern mit einer harten Grenze versehen. Die erwähnte fehlende Skalierbarkeit.
(prx) A. K. schrieb: > mh schrieb: >> 8 Kerne bringen nichts, wenn man auf 9 Events direkt >> reagieren können muss. > > Zumindest wenn diese 9 Events voneinander unabhängig und zeitkritisch > sind. Wenn einige davon nur bei verschiedenen Zuständen derselben > Statusmaschine auftreten, lassen sie sich prinzipiell in einem Core > zusammenfassen. Klar, das gleiche gilt aber genauso für Interrupts. Das ganze hängt halt von der Anwendung ab. Und ich habe hier immer noch kein Beispiel für eine Anwendung gesehen, wo der Propeller duch seine Architektur im Vorteil ist.
mh schrieb: > 8 Kerne bringen nichts, wenn man auf 9 Events direkt > reagieren können muss. Diese 8 Kerne können jedenfalls 8 Events sofort abarbeiten. Interruptgesteuert werden die 9 Events sequentiell abgearbeitet. Wer der Beiden braucht länger?
Nick M. schrieb: > mh schrieb: >> 8 Kerne bringen nichts, wenn man auf 9 Events direkt >> reagieren können muss. > > Diese 8 Kerne können jedenfalls 8 Events sofort abarbeiten. > Interruptgesteuert werden die 9 Events sequentiell abgearbeitet. > > Wer der Beiden braucht länger? Ach Nick, ich habe keine Lust mehr mit dir zu diskutieren, wenn du dir immer nur einzelne Sätze herauspickst, statt komplette Aussagen.
mh schrieb: > Ach Nick, ich habe keine Lust mehr mit dir zu diskutieren, wenn du dir > immer nur einzelne Sätze herauspickst, statt komplette Aussagen. Ich hab mich auf eine Kernaussage von dir bezogen. Ob du über deine eigenen Aussagen diskutieren willst oder nicht, überlass ich dir gerne. Allerdings würde ich dir dann auch mehr Konsequenz in bezug auf "ich hab keine Lust" nahelegen.
> > Die Anzahl der Registersätze ist (oft nur auf 2) begrenzt. > Das war der Charme von TIs 9900 Architektur. Genau genommen gab es nur > einen Registersatz, aber das waren gerade einmal 3 Stück: Program SH2A: 16Banks Olaf
mh schrieb: > Und ich habe hier immer noch kein Beispiel für > eine Anwendung gesehen, wo der Propeller duch seine Architektur im > Vorteil ist. Wir können uns zumindest auf eines einigen: Die Dokumentation ist ohne Zweifel ungenügender, unprofessioneller Mist. So, hier ein ganz konkretes Beispiel: Eine 3-Achs Digitalanzeige (einer Fräsmaschine). Die Positionssignale kommen von Glasmaßstäben mit Quadraturencoder-Ausgängen. Die Auflösung der GMS ist 1µm. Es werden also 3 QE-Eingänge benötigt. Mir ist bekannt, dass es dafür vom ic-haus schöne Chips gibt, die sind aber zusätzlich. Das hat der Propeller: Quadrature decoding with 32-bit counter, both position and velocity modes 1*) 320 MHz Taktfrequenz 2*) Befehl SPM_CNT_QUAD setzt QE-Decoder Eingang 3*) Ich konnte nur ein Bsp für den QE-Eingang im Velocity-mode finden *4). Ich will aber position mode, velocity mode wäre für die innere Regelschleife eines PID-Reglers für ein Servo ideal. 32 Bit counter genügt (bei 1 µm) für etwa 4,3 km, was deutlich über dem üblichen Bereich von GMS ist. Ich kann jetzt nur annehmen was die maximale Eingangsfrequenz für den QE-Eingang ist. Ich nehme 80 MHz an, 1/4 er max. Taktfrequenz. Daraus ergibt sich eine maximale Verfahrgeschwindigkeit von 4800 m/min. 80 m/min ist schon absurd hoch, 20 m/min gilt als sehr schnell. Der Abstand zu realistischen Grenzen ist mehrere Größenordnungen. Der Rest um die Werte auf einem Display darstellen zu können sollte ohne Diskussion mit 5 weiteren Kernen wohl machbar sein. 1*) https://www.parallax.com/propeller-2/ Reiter 64 Smart I/O Pins 2*) https://forums.parallax.com/discussion/170380/new-p2-silicon 3*) https://forums.parallax.com/discussion/170380/new-p2-silicon/p25 4*) https://forums.parallax.com/discussion/171659/baffled-by-prop-2-quadrature-encoder // ======================================================== Noch ein Beispiel, weil ich das eben gefunden habe: PID-Regler für einen DC-Servomotor, innere Regelschleife. Der Servomotor hat einen QE-Ausgang. Das Eingangssignal ist Geschwindigkeit mit +/- 10V. Der Regler soll die P-, I-, D-, FF1- und FF2- Terme bearbeiten. Die Terme bekommen je einen Kern, das Ist-Signal wird von einem Kern im QE-Velocity-Mode verarbeitet. Die Rechnerei ist wenig aufwändig. Im I-Term kann man noch ein wind-up implementieren. Ein Kern liest den Sollwert über seinen AD-Eingang, ein weiterer Kern gibt den Stellwert über den DA-Wandler aus. Sind 8 Kerne. Ich hatte mal Gaudihalber auf einem XMOS einen genau gleichen Regler geschrieben, bei dem ich auf 666 KHz gekommen bin, allerdings mit rein scaled integer und ohne DA/AD. Ich kann im Moment nicht nachvollziehen, wie lange Fixed Float auf dem Propeller dauert, aber durch den Geschwindigkeitsvorteil vom Prop 2 beim AD/DA wage ich zu sagen, dass man auf 50 KHz mit dem Regler hinkommt. Damit könnte der äussere Regelkreis mit mindestens 5 kHz arbeiten. Genügt das jetzt den Zweiflern? Oder haben sie eine CPU die das auch locker hinbekommt? Gut beim zweiten Bsp. ist das möglich, 8 kHz hab ich schon auch gesehen, es geht bestimmt schneller als die 8 kHz.
>> Der INT mit niedrig(st)er Prio KANN warten, eben weil die Bearbeitung >> nicht so dringend ist. > KANN, und wie lange? Lange genug, um noch bearbeitet zu werden (auch wenn höher prior. INTs das System beanspruchen). Derjenige, der das System baut (bzw die Schaltung für die Anforderung baut) muss das nat. im Blick haben (Worstcase-Berechnung usw). (wenn's zu viele hochprio' sind, auf Hardware ausweichen) > Wer der Beiden braucht länger? Das interessiert gar nicht!, solange das System (CPU.. was auch immer) es in der geforderten Zeit hinbekommt. Man nimmt nicht tonnenweise Hardware-Gatter, wenn man es mit nem simplen CPU-Konzept schon machen kann. > Wenn einige davon nur bei verschiedenen Zuständen derselben > Statusmaschine auftreten, lassen sie sich prinzipiell in einem Core > zusammenfassen. Eben. Das läuft ja auf INTs hinaus. > SH2A: 16Banks Ja! M16C:2Banks. RX:keine (für Fast-INT können spez. Register benutzt werden)
Nick M. schrieb: > Genügt das jetzt den Zweiflern? Oder haben sie eine CPU die das auch > locker hinbekommt? Gut beim zweiten Bsp. ist das möglich, 8 kHz hab ich > schon auch gesehen, es geht bestimmt schneller als die 8 kHz. Bei deinem ersten Beispiel nutzt du nichtmal einen Vorteil des Propeller? Warum sollte das nicht auch ein gleich schnell getakteter µC mit Interrupt hinbekommen? Der kann doch im Zweifel, genauso in Software pollen. Genauso das zweite Beispiel. Das beruht 100% auf der Rechenleistung.
mh schrieb: > Bei deinem ersten Beispiel nutzt du nichtmal einen Vorteil des > Propeller? 3 schnelle QE-Eingänge sind nicht genug? Nenn mir bitte einen µC der 3 QE-Eingänge hat, welche mit einem sind kein Problem. Was ist deren Taktfrequenz? mh schrieb: > Genauso das zweite Beispiel. Das beruht 100% auf der Rechenleistung. Auf paralleler Rechnenleistung. Es werden 5 Terme parallel bearbeitet, gleichzeitig ein AD-Eingang der noch skaliert und ein DA-Ausgang der die 5 Terme aufsummiert und skaliert und ausgibt. Und nebenher ein QE-Eingang der die Frequenz ermittelt, das ist nämlich der Velocity mode. Also ein QE-Eingang mit Berechnung. Und das mit 300 MHz. Welcher µC kann das deiner Meinung nach leisten. Nenn nur den Typen, mehr nicht.
MCUA schrieb: >> KANN, und wie lange? > Derjenige, der das System baut (bzw die Schaltung für die Anforderung > baut) muss das nat. im Blick haben (Worstcase-Berechnung usw). > (wenn's zu viele hochprio' sind, auf Hardware ausweichen) Oder eben, statt zusätzliche HW dazu entwickeln, auf einen Kern auslagern. Abgesehen davon, dass die worst-case-Berechnung nur auf Annahmen basieren kann. Denn INTs haben nun mal die Eigenschaft unberechenbar aufzutreten. Wenn genügend INT-Quellen vorhanden sind, wird das ganze ein Lotteriespiel. Sowohl vom Zeitverhalten her, als auch von der Berechenbarkeit.
..Motor-Control-uCs...(mit jeder Menge ADCs, DACs, Timer..) > Ich kann jetzt nur annehmen was die maximale Eingangsfrequenz für den > QE-Eingang ist. Ich nehme 80 MHz an, 1/4 er max. Taktfrequenz. Dafür braucht man mit Sicherheit nicht mehrere CPU-Kerne.
MCUA schrieb: > ..Motor-Control-uCs...(mit jeder Menge ADCs, DACs, Timer..) Es ging aber ganz konkret um QE-Eingänge. Noch konkreter um 3 QE-Eingänge. Ich denke, das ließe sich auch ganz konkret mit einem µC beantworten. > >> Ich kann jetzt nur annehmen was die maximale Eingangsfrequenz für den >> QE-Eingang ist. Ich nehme 80 MHz an, 1/4 er max. Taktfrequenz. > Dafür braucht man mit Sicherheit nicht mehrere CPU-Kerne. Nein, da genügt ein Kern. Und 3 QE-Eingänge. Ich hab dafür aber 3 Kerne veranschlagt, einer pro QE-Eingang. Einfach weil der dann jeweils seinen Zählerwert ins HUB-RAM schreiben kann. Ich vermute, dass bei denen die hier sagen dass man QE-Eingänge mit INT erschlagen kann, die prinzipielle Problematik der QEs nicht ganz geläufig ist. Ich erkläre das mal: QE-Ausgänge prellen. Nicht nur manchmal, sondern zuverlässig. Das tritt dann auf, wenn die Position genau so ist, dass man genau auf der Grenze steht und die kleineste Bewegung entweder die Position als H oder L dedektiert. Das Prellen schadet aber nicht. Das sieht am Ausgang so aus: A B 0 1 1 1 // Prellendes Signal 0 1 Behandelt man das per INT, gibt es beliebig schnell einen INT, bei dem die Position zwischen zwei Lagen hin & herpendelt. Aus dem Grund haben GSM die eigentlich zur Positionsbestimmung von 1 µm sind, eine Auflösung von 0.5 µm. Da kenn das Signal gerne hin & herwackeln, es wird nur 1 µm ausgewertet. Eine tatsächliche Positionsänderung in dem Sinne tritt nur auf, wenn sich 2 Bits im Vergleich zur zuletzt gelesenen Position ändern. A B 0 1 1 1 // Prellen 0 1 1 0 // Hier ändert sich "wirklich" was. Die ersten 3 Zeilen waren wieder nur Wackeln, die 4 Zeile eine "wirkliche" Änderung. Die 4 Änderungen können innerhalb kürzester Zeit auftreten, denn der Verfahrweg waren dann nur 0.5 µm. Und das dann bitte für die 3 Kanäle gleichzeitig mit INT behandeln. In dem Fall geht es um 6 Eingänge. Denn 3 Achsen können problemlos gleichzeitig verfahren. Spaßiger wird es bei einer 5-Achs-Fräsmaschine. Mit Port Change-INT ist das aussichtslos. Welchen Typ von INT würdet Ihr stattdessen verwenden?
Nick M. schrieb: > Ein Kern liest den Sollwert über seinen AD-Eingang, ein weiterer Kern > gibt den Stellwert über den DA-Wandler aus. Hatte eben noch eine Idee: Statt den Stellwert per DA auszugeben, kann der Kern gleich die H-Brücke ansteuern und auch ein Enable Signal auswerten das den Regler an/abschaltet.
>>> Ich kann jetzt nur annehmen was die maximale Eingangsfrequenz für den >>> QE-Eingang ist. Ich nehme 80 MHz an, 1/4 er max. Taktfrequenz. >> Dafür braucht man mit Sicherheit nicht mehrere CPU-Kerne. > Nein, da genügt ein Kern. Und 3 QE-Eingänge. Dafür kein CPU-Kern nötig (80 MHz-Int wäre auch zuviel für CPU, also (irgent eine) sep. Hardware nutzen). Die Encoder-Ergebnisse kann dann eine kleine 8BitCPU ganz gemächlich abrufen.
MCUA schrieb: > (irgent eine) sep. Hardware nutzen). Ging es also bei der Diskussion darum, wie man durch Zusatzhardware einen Propeller ersetzen kann? Dann bitte ich um Entschuldigung, ich hab das komplett falsch verstanden!
Gut, du willst einen Propeller benutzen um einen Propeller zu benutzen.
MCUA schrieb: > Gut, du willst einen Propeller benutzen um einen Propeller zu benutzen. Nein, bloß keinen Propeller! Das kann man doch alles per TTL mit weitaus mehr Aufwand bauen. Ahwa! Machma mit ECL, damit der Solarstrom endlich wegkommt. Und dass jetzt keiner mit FPGA daherkommt, die sind ausschließlich für paar Spezialfälle vorbehalten, eigentlich völlig sinnlos.
Ich frag mich ja immer: Was ist der Antrieb für diese Miesmacher, sei es nun der Propeller oder seien es FPGAs. Man braucht es nicht, man kann es auch anders lösen, ja es gibt gar keine Anwendung. Sie könnten ja einfach denken: "Nichts für mich", und sich dann mit etwas anderem beschäftigen, etwas das sie interessiert. Statt dessen suchen sie tagelang nach Argumenten wieso das neue Ding unnötiger Blödsinn ist. Liegt es daran, dass es für sie zu kompliziert ist, und sie nicht wollen, dass andere es dann benutzen könnten? Oder dass der Chef auf die Idee kommen könnte, das einzusetzen, und sie vielleicht etwas neues lernen müssen, nachdem sie sich endlich mit dem Alten einigermassen auskennen? Ich versteh es nicht. Mann muss es doch nicht benutzen, wenn man nicht will, und es macht auch keinen Sinn es anderen ausreden zu wollen. Die haben nämlich eine Anwendung dafür, sonst würden sie es nicht benutzen.
Nick M. schrieb: > Es ging aber ganz konkret um QE-Eingänge. Noch konkreter um 3 > QE-Eingänge. > Ich denke, das ließe sich auch ganz konkret mit einem µC beantworten. Microcontroller mit 3 QE Eingängen gibts bei ST genug. z.B. STM32F051 hat 3 STM32F103 hat 4 STM32G431 hat 5
Alex D. schrieb: > Microcontroller mit 3 QE Eingängen gibts bei ST genug. z.B. Herzlichen Dank für die weiterführende Antwort!
Andi schireb > Ich frag mich ja immer: Was ist der Antrieb für diese Miesmacher, sei es > nun der Propeller oder seien es FPGAs. Man braucht es nicht, man kann es > auch anders lösen, ja es gibt gar keine Anwendung. > Sie könnten ja einfach denken: "Nichts für mich", und sich dann mit > etwas anderem beschäftigen, etwas das sie interessiert. Statt dessen > suchen sie tagelang nach Argumenten wieso das neue Ding unnötiger > Blödsinn ist. > Liegt es daran, dass es für sie zu kompliziert ist, und sie nicht > wollen, dass andere es dann benutzen könnten? > Oder dass der Chef auf die Idee kommen könnte, das einzusetzen, und sie > vielleicht etwas neues lernen müssen, nachdem sie sich endlich mit dem > Alten einigermassen auskennen? > Ich versteh es nicht. Mann muss es doch nicht benutzen, wenn man nicht > will, und es macht auch keinen Sinn es anderen ausreden zu wollen. Die > haben nämlich eine Anwendung dafür, sonst würden sie es nicht benutzen. Locker sein Modus : An ! Es könnte sein daß du hier nicht genug Threads gelesen hast und nicht bemerkt hast daß voll mit Leute ist die genau so denken wie du beschrieben hast. Muss du nur irgendwie, auch wenn tangenziell, von der Seite oder umgedreht ein Thema ansprechen die nicht "Mainstream" ist: Arduino (ist nicht ein uC), gibts andere Prozesoren als AVRs und STM32s, andere FPGAs als (die große X) usw. Und bitte alles nur in Perfektes Deutsch schreiben ! oh gott rettet uns von diesen die die Artikeln falsch deklinieren (wie ich), neben Sätze nicht richtig nutzen usw. Nicht alle haben DE als Muttersprache, leben trotzdem in dem DE-Sprächige Raum... Locker sein Modus : Aus ! Seriöse Modus : An ! Trauring :). Der Propeller 1 kann ganz locker VGA Signalen erzeugen ohne zu schwitzen und bleibt genug Luft für einiges, und in 2006 und für ~18 €. Und der XMOS is nicht nur ein multithread und multicore (in einige Fälle), hat auch Kommkanäle mit FIFOs, Ports mit konfigurierbare Breite mit FIFOs, mit clocks, Timers die Teil der Programmiersprache sind ! Aber wie du gesagt hast die können es nicht, deswegen machen es kaputt, die Menscheit is doomed doooooooomed :(
Angehängte Dateien:
chris_ schrieb: >>von R. M. (n_a_n) >>01.01.2021 10:26 > >>Wie schon erwähnt, ich hatte eine längere Pause und habe heute die >>aktuellste Version geholt und gebaut. > > Interessant ... könntest Du mal diesen Benchmark hier laufen lassen?: > Beitrag "Re: STM32 Arduino" > > Mich würde der Vergleich zu den genannten Prozessoren interessieren. chris_ schrieb: > R. M. (n_a_n) >>Hallo chris, ich habe momentan die Hardware nicht bei mir in der >>Wohnung. > > Danke für die Antwort. Falls Du mal an die Hardware kommen solltest, > würde mich genau das Ergebnis für den genannten C-Code interessieren. Das ist jetzt schon ziemlich OT, aber erst jetzt habe ich die Platine wieder verfügbar. Zumindest kann ich die Messung von Andi bestätigen: time/sample 14µs @160MHz 9µs @250MHz In der Praxis ist aber noch viel Luft für Optimierungen. Ohne jetzt den Original Benchmark zu viel zu verändern und auf C-Ebene zu bleiben habe ich mal die Filterkoeffizienten nicht in einem Array gehalten sondern als Makros definiert. das bringt schon 7µs @250MHz. Vermutlich wirkt sich das bei den anderen Prozessoren auch so aus, ich weis es nicht.
>Das ist jetzt schon ziemlich OT, aber erst jetzt habe ich die Platine >wieder verfügbar. Zumindest kann ich die Messung von Andi bestätigen: >time/sample >14µs @160MHz >9µs @250MHz Dankeschön. Das sieht doch gar nicht schlecht aus. Ich habe nach dieser Art der Umsetzung gefragt, weil man oft keine Zeit in Optimierungen stecken will oder kann. Nehmen wir als 8 Cores, käme theoretisch auf 14µs/8 @160MHz 9µs/8 @250MHz Hat eigentlich schon mal jemand das Arduino-Framework auf den Propeller portiert? Das könnte die Verbreitung ordentlich fördern.
chris_ schrieb: > Hat eigentlich schon mal jemand das Arduino-Framework auf den Propeller > portiert? Ich wüsste nicht, wie das Sinn ergeben sollte. Das Framework kann nichts mit den CPUs anfangen, außer mit ihnen PWM Timer und UART zu implementieren. Das wäre wie Perlen vor die Säue geworfen.
Ich würd mal auch sagen, die Nische zwischen schneller als ein üblicher MC und deutlich langsamer als ein FPGA ist schon recht schmal. Das erklärt die geringe Verbreitung des Propeller.
>Ich wüsste nicht, wie das Sinn ergeben sollte. Das Framework kann nichts >mit den CPUs anfangen, außer mit ihnen PWM Timer und UART zu >implementieren. Es gibt die Frameworks für alle möglichen Prozessoren. Aus diesem Grund spricht überhaupt nichts gegen den Propeller. Der große Vorteil: Arduino-Libraries, die keinen hardwarespezifischen Code benutzen, können ohne Probleme verwendet werden. z.B. diese hier: https://github.com/TKJElectronics/KalmanFilter ;-)
chris_ schrieb: > Der große Vorteil: Arduino-Libraries, die keinen hardwarespezifischen > Code benutzen, können ohne Probleme verwendet werden. Weitaus schöner daran ist, dass es glücklicherweise keine Arduino-libs sein müssen. Denn platformunabhängiger Code wurde schon lange vorm Arduino geschrieben und gepflegt und nicht von den Arduinisti verhunzt.
Angehängte Dateien:
-

ArduinoPropeller.png
790 KB
>Weitaus schöner daran ist, dass es glücklicherweise keine Arduino-libs >sein müssen. Das kann sein. Nur gibt es leider einige tausend Arduino-Libs und die Portierung kann durchaus einen Haufen Aufwand bedeuten, den man vermeiden kann. Aber ich sehe, die Diskussion läuft: https://forums.parallax.com/discussion/165942/prop-2-languages-c-c-arduino-ide " I think providing an Arduino-compatible HAL would benefit Parallax significantly. My guess is that moving to a new IDE is not as difficult as porting code to a new HAL. Aiming for Simple Library v2.0 to be Arduino compatible would be a very good goal, rather than carrying forward the C interface from Simple Library v1. " https://forums.parallax.com/discussion/170108/what-the-propeller-2-can-learn-from-the-arduino
chris_ schrieb: > Aber ich sehe, die Diskussion läuft: TOLL!!! Ein "me too"-Produkt. Oder Österreichisch: Adabei-Produkt. Egal. Die sollten die 4-fache Anzahl Arduino-Anschlüsse haben. Arduino Quadro. In der Mitte der Platine eine stehende Klinkenbuchse um die man das Alles rotieren lassen kann. Dann hat es was mit Propeller zu tun und ist was neues. Abklatsch kann jeder.
Stefan ⛄ F. schrieb: > Das wäre wie Perlen vor die Säue geworfen. Da kommt der Arduino Basher wieder aus den Büschen gesprungen! Stefan ⛄ F. schrieb: > Das Framework kann nichts > mit den CPUs anfangen, außer mit ihnen PWM Timer und UART zu > implementieren. Keine Ahnung von dem Thema! Aber einen dummen Basher Spruch raus rocken. An anderer Stelle hast du die Behauptung aufgestellt, Arduino User dürfen/sollen nur die Arduino Framework API nutzen. Nicht bis auf die Hardware durchgreifen. Denn das wäre nicht "vorgesehen". Aus der Ecke kommt das wieder, oder? Stefan ⛄ F. schrieb: > Ich wüsste nicht, wie das Sinn ergeben sollte. Das ist genau der Punkt! Du weißt es nicht! Und weil du es nicht weißt, ist es Perlen vor die Säue. Warum bist du nicht ehrlich? Wenn du sagen würdest: > Ich habe keinen Bock auf Arduino! > Darum sehe ich auch keinen Sinn, > in einer Propeller zu Arduino, Portierung. > Eigentlich, in keiner einzigen "zu Arduino" Portierung. Aber aus deiner Arduino Ablehnung ein allgemeines Urteil zu formen: > Das wäre wie Perlen vor die Säue geworfen. Ist gründlich daneben. Das ist weit jenseits von irgendeinem fachlichen Argument! Siehe: chris_ schrieb: > Es gibt die Frameworks für alle möglichen Prozessoren. Aus diesem Grund > spricht überhaupt nichts gegen den Propeller. Natürlich wird die Portierung nicht einfach. Aber deine Vorstellungen/Projektionen/Fantasien sind einfach Irre. Obwohl, die Vorstellungen darfst du haben. Gerne sogar. Privat. Aber die öffentliche Projektion ist schlicht falsch. Da nicht die Realität abbildend, sondern nur deiner Fantasie entsprungen. Die sich daraus ergebene, hier präsentierte Beurteilung, ist gründlich daneben. --- Klar, jetzt kommts wieder(ich höre es schon): > Du hast mich auf dem Kieker. Oder: > Wäre besser, wenn du aus dem Forum verschwinden würdest. Einsicht, in den Irrtum, darf ich von dir nicht erwarten.
Arduino Fanboy D. schrieb: > Da kommt der Arduino Basher wieder aus den Büschen gesprungen! Ich bashe Arduino schon lange nicht mehr. > An anderer Stelle hast du die Behauptung aufgestellt, Arduino User > dürfen/sollen nur die Arduino Framework API nutzen. Wo denn? > Und weil du es nicht weißt, ist es Perlen vor die Säue. Ja genau, das ist meine Meinung. Stell dir vor, auch ich darf eine Meinung haben. Ich darf sie auch öffentlich kund tun, denn Deutschland ist ein freies Land und dieses Diskussionsforum dient unter anderem dazu, Meinungen zu diskutieren. Wenn dem nicht so wäre, wärst du längst lebenslänglich weg gesperrt worden. > Warum bist du nicht ehrlich? > Wenn du sagen würdest: >> Ich habe keinen Bock auf Arduino! >> Darum sehe ich auch keinen Sinn, >> in einer Propeller zu Arduino, Portierung. >> Eigentlich, in keiner einzigen "zu Arduino" Portierung. > Klar, jetzt kommts wieder(ich höre es schon): >> Du hast mich auf dem Kieker. >> Wäre besser, wenn du aus dem Forum verschwinden würdest. Bitte unterlasse gefälschte bzw. frei erfundene Zitate! Du handelst hier wie meine Schwiegermutter. Die denkt sich auch mit großem Eifer Dinge aus, die andere sagen oder tun könnten, um sich dann über die Person aufregen zu können und sie genau für diese frei erfundenen Unterstellungen zu verurteilen. Bist du auch schon so senil?
Stefan ⛄ F. schrieb: > wie meine Schwiegermutter Du diffamierst hier deine Schwiegermutter öffentlich! Dass du zu solchen Mitteln greifen musst, ist aus meiner Sicht mehr als armselig. Schämen, solltest du dich!
> Ich würd mal auch sagen, die Nische zwischen schneller als ein üblicher > MC und deutlich langsamer als ein FPGA ist schon recht schmal. Sofern man (wegen der bekannten Nachteile des Propeller) von Nische überhaupt sprechen kann. > Es gibt die Frameworks... Die Geschindigkeits-Nachteile von Frameworks sind aber bekannt. Und schon garnicht kann ein Framework Nachteile einer CPU ausbügeln.
MCUA schrieb: > Die Geschindigkeits-Nachteile von Frameworks sind aber bekannt. Richtig: Jede Abstraktion kostet mindestens tendenziell Performance. Auch wenn einige C/C++-Apologeten immer mal wieder behaupten, dass ihre bevorzugte Sprache gegen solche Grundgesetze der Informatik nicht nur immun ist, sondern sie sogar in ihr Gegenteil verkehren kann: Das ist und bleibt natürlich Quatsch. Und davon, dass man mehrere solcher Abstraktionen übereinander stapelt, wird es natürlich niemals besser, sondern (im allerbesten Fall) nur nicht wesentlich schlechter...
c-hater schrieb: > Auch wenn einige C/C++-Apologeten immer mal wieder behaupten, dass ihre > bevorzugte Sprache gegen solche Grundgesetze der Informatik nicht nur > immun ist, sondern sie sogar in ihr Gegenteil verkehren kann Was soll der Blödsinn? Wer sagt das?
Arduino Fanboy D. schrieb: > Was soll der Blödsinn? > Wer sagt das? Passt schon. Mancher Code ist nach der Optimierung durch einen Compiler schneller als subptimal geschriebener Assembler-Code, selbst bei gleichem Algorithmus. Besonders wenn der Asm-Code nicht speziell für den eingesetzten Prozessor geschrieben wurde, unter Kenntnis all seiner teils mässig oder nicht dokumentierten Stärken und Schwächen. Wer wie c-hater sich die Mühe macht, alle in Frage kommenden Prozessoren in- und auswendig zu kennen, und für jeden davon das Programm im relevanten Kern neu schreibt, für den gilt das natürlich nicht. ;-)
(prx) A. K. schrieb: > Passt schon. Mancher Code ist nach der Optimierung durch einen Compiler > schneller als subptimal geschriebener Assembler-Code Das kann natürlich sehr gut passieren. Aber der Goldstandard ist optimaler Assemblercode. Jeder sinnvolle Vergleich kann und muss sich genau darauf beziehen. Alles andere ist Selbstbetrug. > Wer wie c-hater sich die Mühe macht, alle in Frage kommenden Prozessoren > in- und auswendig zu kennen Das ist wohl kaum möglich, schon garnicht in Bezug auf jedes beliebige Problem. Auch für mich natürlich nicht. Aber auch in C/C++ geht das natürlich nicht. Denn die Makros der Codegeneratoren haben von dem konkreten Problem auch keine Ahnung, genau genommen wissen sie über das Gesamtproblem sogar immer sehr viel weniger als der Programmierer. Da müssen dann Profiling-Iterationen folgen. Die allerdings in Assembler viel einfacher sind. Da muss man nicht immer überlegen, wie man irgendeinem konkreten Comiler nun beibiegt, dass diese oder jene Optimierung hier die bessere Wahl wäre (was natürlich bei einem anderen Compiler sicher nicht funktioniert und oft nichtmal beim gleichen Compiler in einer anderen Version). Nö, man schreibt die für das konkrete Problem als besser erkannte Code-Variante einfach hin und der Drops ist gelutscht.
c-hater schrieb: > Das kann natürlich sehr gut passieren. Aber der Goldstandard ist > optimaler Assemblercode. Jeder sinnvolle Vergleich kann und muss sich > genau darauf beziehen. Alles andere ist Selbstbetrug. Es wäre Selbstbetrug, davon auszugehen, dass handgeschriebener Assembler Code immer perfekt ist. Alle höheren Programmiersprachen wären in diesem Fall sinnlos. Ihr Erfolg zeigt, dass sie sinnvoll sind.
Stefan ⛄ F. schrieb: > Es wäre Selbstbetrug, davon auszugehen, dass handgeschriebener Assembler > Code immer perfekt ist. Du hast scheinbar die unangenehme Eigenschaft, den Leuten die Worte im Mund umzudrehen. c-Hater hat vom optimalen Assembler gesprochen. Nicht vom handgeschriebenen Assembler. Das ist ein kleiner aber feiner Unterschied! Stefan ⛄ F. schrieb: > Alle höheren Programmiersprachen wären in diesem Fall sinnlos. Ihr > Erfolg zeigt, dass sie sinnvoll sind. Wie kommst du jetzt zu der sinnlosen Erkenntnis?
Stefan ⛄ F. schrieb: > Es wäre Selbstbetrug, davon auszugehen, dass handgeschriebener Assembler > Code immer perfekt ist. Deswegen nimmt das auch kein gestandener Assemblerprogrammierer an. Der weiß, das er niemals perfekt ist und das bei genauerer Betrachtung immer noch der eine oder andere Takt rauszukitzeln wäre. Umso erstaunlicher ist die Attitüde der C/C++-Programmierer. Die bauen ja nur auf Bausteine auf, die mal irgendein Assemblerprogrammierer in den Codegeneratoren verewigt hat. Dieser Programmierer unterlag grundsätzlich erstmal denselben Einschränkungen, denen auch jeder andere Assemblerprogrammierer ausgesetzt ist. ZUSÄTZLICH musste er aber bei der Gestaltung seiner Bausteine mit dem Problem der sehr unvollständigen Information klarkommen. Der Codegenerator weiß nämlich fast nichts über das Gesamtwerk, denn er arbeitet auf der Ebene von Funktionen... > Alle höheren Programmiersprachen wären in diesem Fall sinnlos. Nein, das sind sie natürlich nicht. Das hat auch niemals jemand behauptet. Sie produzieren halt in sehr vielen Fällen hinreichend schnellen Code. Aber eben nicht in allen Fällen. Immer dann, wenn's eng wird, dann hilft Assembler. Und genau dieser, in unendlich vielen Fällen nachgewiesene, Sachverhalt zeigt, dass die Lüge, dass C/C++ schon alles optimal macht eben genau das ist: ein Lüge. Und sie wird auch durch gebetsmühlenartige Wiederholung nicht wahrer.
Stefan ⛄ F. schrieb: >> Wie kommst du jetzt zu der sinnlosen Erkenntnis? > > Mit dir diskutiere ich nicht. Die für dich bis jetzt einzige sinnvolle Erkenntnis!
c-hater schrieb: > Sie produzieren halt in sehr vielen Fällen hinreichend > schnellen Code. Aber eben nicht in allen Fällen. Immer dann, wenn's eng > wird, dann hilft Assembler. Ja. Ich bin positiv überrascht, das von dir in so klaren Worten zu lesen.
c-hater schrieb: > Sie produzieren halt in sehr vielen Fällen hinreichend > schnellen Code. Aber eben nicht in allen Fällen. Immer dann, wenn's eng > wird, dann hilft Assembler. Das genügt ja auch. Meistens. c-hater schrieb: > dass die Lüge, dass C/C++ schon alles optimal macht eben genau > das ist: ein Lüge. Sagt das eigentlich ein halbwegs vernünftiger C-Programmierer? Ich nicht! Der C-Programmierer greift dann weiter oben an und feilt an den Algorithmen. Und dann ist es meistens erledigt. Wenn das nicht genügt kommt spätestens jetzt der Profiler und man kann qualifiziert und geziehlt zum Assembler übergehen. Ich seh das alles nicht so verbissen.
> Besonders wenn der Asm-Code nicht speziell für den > eingesetzten Prozessor geschrieben wurde, Das ist dann Quatsch-Comedy. Abstraktion ist immer langsamer, weil untere Ebenen auch bearbeitet werden müssen. Das Programmiersprachen benutzt werden, sagt nichts drüber aus, dass das Ergebnis auch effizienter ist. (klar kann man auch völlig unsinnig in ASM schreiben) Der Compiler (was ja nichts anderes als ein vorgefertigtes Stück Software ist) hat jedoch definitiv vom wirklichen Problem keine Ahnung.
MCUA schrieb: > Der Compiler (was ja nichts anderes als ein vorgefertigtes Stück > Software ist) hat jedoch definitiv vom wirklichen Problem keine Ahnung. Umso verblüffender ist, wenn er dann ab und zu ein Teilproblem erkennt und dafür einen besseren Algorithmus einsetzt. Beispielsweise wenn er eine verschachtelten Rechenschleife mit vollständig bekannten Daten durch "return 42;" ersetzt. ;-)
>von c-hater (Gast) >MCUA schrieb: >> Die Geschindigkeits-Nachteile von Frameworks sind aber bekannt. >Richtig: Jede Abstraktion kostet mindestens tendenziell Performance. >Auch wenn einige C/C++-Apologeten immer mal wieder behaupten, dass ihre >bevorzugte Sprache gegen solche Grundgesetze der Informatik nicht nur >immun ist, sondern sie sogar in ihr Gegenteil verkehren kann: Das ist >und bleibt natürlich Quatsch. Das ist wohl war. Handoptimierter Assemblercode kann fast in jedem Fall schneller sein als vom C-Compiler erzeugter Code, der immer irgendwelche Generalisierungen enthält. Aber es wäre natürlich etwas aufwendig die oben erwähnte Kalmam-Filter Library für den Beschleunigungssensor auf die jeweilige Prozessorarchitektur anzupassen. Deshalb ist es so schön, dass das Arduino-Framework so viele Libraries anbietet, mit denen man in wenigen Schritten einen funktionierenden Prototypen basteln kann ( oft, aber natürlich nicht immer ). Viel schlimmer ist die Verwendung von Java auf dem PC. Da wird die Leistung in den Wind geblasen ( OK ich weiss es gibt Jit-Compiler ). Aber Python nähert sich ja auch schon den Mikrocontrollern ... für den Propeller gibt es MicroPython.
Nick M. schrieb: > Sagt das eigentlich ein halbwegs vernünftiger C-Programmierer? Nein, natürlich nicht. Das Problem ist nur: es gibt ganz offensichtlich Unmassen C/C++(only)-Programmierer, die nichtmal in die Kategorie "halbwegs vernünftig" fallen. Die sind es, die diese Lüge immer und immer wieder als Schutzbehauptung verbreiten, um ihre eigene dramatische Inkompetenz zu bemänteln. Und genau das ist, was mir so dermaßen stinkt, dass ich mich gezwungen gesehen habe, eigens eine Persona zu erfinden, um dagegen argumentativ vorzugehen. Natürlich mit recht wenig Erfolg bezüglich genau dieser Zielgruppe, aber hoffentlich mit etwas mehr Erfolg bezüglich des Nachwuchses. Wenigstens einige von denen glauben dann hoffentlich diese Lüge nicht mehr unbesehen und verschaffen sich ein eigenes Bild, indem sie selber Assembler lernen und anwenden...
.. dann wurde die "verschachtelte Rechenschleife" schon falsch eingegeben. Die Eingabemöglichkeiten in einen Compiler sind extrem! begrenzt.
MCUA schrieb: > Abstraktion ist immer langsamer, weil untere Ebenen auch bearbeitet > werden müssen. Das ist falsch. Da die Abstraktion vor der Komilezeit erfolgt, und im besten Fall zur Komilezeit aufgelöst wird, ist die Aussagen, dass immer Laufzeitnachteile zu erwarten sind falsch.
c-hater schrieb: > Das Problem ist nur: es gibt ganz offensichtlich > Unmassen C/C++(only)-Programmierer, die nichtmal in die Kategorie > "halbwegs vernünftig" fallen. Stimmt. Und genau diese Leute werden also bessere Programme auswerfen, wenn sie statt dessen Assembler nutzen. ;-)
c-hater >Natürlich mit recht wenig Erfolg bezüglich genau dieser Zielgruppe, aber >hoffentlich mit etwas mehr Erfolg bezüglich des Nachwuchses. Der Nachwuchs? Vergiss es. Ich habe mich vor kurzem mit den jüngeren Kollegen unterhalten. Die sind von der Bitnahen Assemblerwelt Lichtjahre entfernt. Bei uns werden für's LED-Blinken mittlerweile STM32H7 eingesetzt ...
(prx) A. K. schrieb: > Umso verblüffender ist, wenn er dann ab und zu ein Teilproblem erkennt > und dafür einen besseren Algorithmus einsetzt. Beispielsweise wenn er > eine verschachtelten Rechenschleife mit vollständig bekannten Daten > durch "return 42;" ersetzt. ;-) Oder wenn der Java Compiler eine Reihe von String Konkatenierungen durch die StringBuilder Klasse und ihre Methoden ersetzt. Aus
1 | String s="Hallo "; |
2 | if (vorname!=null) |
3 | {
|
4 | s+=vorname; |
5 | s+=" "; |
6 | }
|
7 | s+=nachname; |
8 | return s+","; |
(Das ist deswegen blöd, weil Strings unveränderbar sind, was hier zum Anlegen von insgesamt 5 Objekten führt) Daraus macht er:
1 | StringBuilder sb("Hallo"); |
2 | if (vorname!=null) |
3 | {
|
4 | sb.append(vorname); |
5 | sb.append(' '); |
6 | }
|
7 | sb.append(nachname); |
8 | return sb.append(',').toString(); |
Aber auch der avr-gcc hat solche Tricks drauf. Zum Beispiel wandelt er
1 | printf("Hallo\n"); |
in
1 | puts("Hallo"); |
um.
>> Abstraktion ist immer langsamer, weil untere Ebenen auch bearbeitet >> werden müssen. > Das ist falsch. > Da die Abstraktion vor der Komilezeit erfolgt, und im besten Fall zur > Komilezeit aufgelöst wird, ist die Aussagen, dass immer > Laufzeitnachteile zu erwarten sind falsch. Ja es wird zur Compilezeit gemacht. Und? Mit Sicherheit wird es nicht schneller... ... also wird es (in Realität) langsamer. (und wenn ich mir anhöre, wieviele Takte ein Pin-Set-Befehl bei manchen "Frameworks" braucht, wird mir schlecht)
chris_ schrieb: > Viel schlimmer ist die Verwendung von Java auf dem PC. Da wird die > Leistung in den Wind geblasen ( OK ich weiss es gibt Jit-Compiler ). C Programme sind etwa doppelt so schnell wie Java. Bei C++ ist der Unterschied noch geringer, also nicht so groß, wie man (ich) spontan vermuten würde.
c-hater schrieb: > Natürlich mit recht wenig Erfolg bezüglich genau dieser Zielgruppe, aber > hoffentlich mit etwas mehr Erfolg bezüglich des Nachwuchses. Glaubst du, dass die Jüngeren das besser verstehen? Die freuen sich doch eher über Python auf dem Propeller. Für die Jungen ist i.A. C völlig nutzlos. Die können Libraries zusammenstöpseln. Das Ergebnis ist dann ein Arduino der vor einem Raspberry hängt, weil der Arduino schneller zählen kann (Parallel-Thread Fluxgate; aber keiner der Teilnehmer). Ich versteh den K(r)ampf sowieso nicht. Jede Sprache hat seinen Platz. Das Wissen wann was sinnvoll und wirtschaftlich einzusetzen ist sollte man von einem Entwickler verlangen können.
c-hater schrieb: > Die sind es, die diese Lüge immer und immer wieder als Schutzbehauptung > verbreiten, um ihre eigene dramatische Inkompetenz zu bemänteln. > > Und genau das ist, was mir so dermaßen stinkt, dass ich mich gezwungen > gesehen habe, eigens eine Persona zu erfinden, um dagegen argumentativ > vorzugehen. Merkt man. Aber du kannst die Welt nicht verbesern. Akzeptiere sie lieber, dann lebst du glücklicher.
>> Das Problem ist nur: es gibt ganz offensichtlich >> Unmassen C/C++(only)-Programmierer, die nichtmal in die Kategorie >> "halbwegs vernünftig" fallen. > Stimmt. Und genau diese Leute werden also bessere Programme auswerfen, > wenn sie statt dessen Assembler nutzen. ;-) Nein, die sind auf Compiler angewiesen.
Beitrag #6543318 wurde von einem Moderator gelöscht.
Beitrag #6543319 wurde von einem Moderator gelöscht.
Beitrag #6543348 wurde von einem Moderator gelöscht.
Beitrag #6543349 wurde von einem Moderator gelöscht.
Beitrag #6543369 wurde von einem Moderator gelöscht.
Beitrag #6543397 wurde von einem Moderator gelöscht.
Beitrag #6543413 wurde von einem Moderator gelöscht.
Beitrag #6543425 wurde von einem Moderator gelöscht.
Beitrag #6543439 wurde von einem Moderator gelöscht.
Beitrag #6543499 wurde von einem Moderator gelöscht.
Beitrag #6543546 wurde von einem Moderator gelöscht.
Beitrag #6543566 wurde von einem Moderator gelöscht.
Beitrag #6543620 wurde von einem Moderator gelöscht.
Beitrag #6543626 wurde von einem Moderator gelöscht.
Beitrag #6543641 wurde von einem Moderator gelöscht.
Beitrag #6543645 wurde von einem Moderator gelöscht.
Beitrag #6543646 wurde von einem Moderator gelöscht.
Beitrag #6543648 wurde von einem Moderator gelöscht.
Beitrag #6543663 wurde von einem Moderator gelöscht.
Gerade beim Propeller, wo man oft Softwareperipherals schreibt, ist ein optimierender Compiler manchmal sehr störend. Da muss man ein bestimmtes Timing einhalten, das der Compiler nicht kennt, und wenn da einfach Schleifen optimiert und Befehle in eine andere Reihenfolge gebracht werden führt das eben dazu das es nicht mehr funktioniert. Auch ist höchste Geschwindigkeit dabei nicht immer das Ziel. Konkretes Beispiel: Schreibe ich eine I2C Routine in Spin weiss ich, der Clock wird nicht schneller sein als 400 kHz, da Spin Bytecode erzeugt, der dann interpretiert wird. Übersetzte ich den gleichen Code in C wird er viel zu schnell sein, und ich muss überall Delays einbauen.
Andi (Gast) >Gerade beim Propeller, wo man oft Softwareperipherals schreibt, ist ein >optimierender Compiler manchmal sehr störend. Deshalb gibt es ja beim Propeller für die unterschiedlichen Peripherieemulationen fertige Code Blöcke. Diese bindet man dann in eigene Projekte ein, so wie man auch eine seriellen Treiber in eigene Projekte einbindet und nicht jedes mal neu schreibt. Das Prinzip schnelle Signalverarbeitungsblöcke als Module zu programmieren und dann mit einer Skript artigen Sprache zu verbinden, ist weit verbreitet ( z.B OpenCV und Python oder Lua als Script Sprache in Spieleengines ). Aus diesem Grunde ist ein Arduine-Framework für den Propeller extrem sinnvoll falls dort die Peripherie schon ins Framework eingebunden ist.
> Das Prinzip schnelle Signalverarbeitungsblöcke als Module zu > programmieren und dann mit einer Skript artigen Sprache zu verbinden, Interessant finde ich das es das Prinzip schon sehr lange gibt. Ich bin da vor 20Jahren das erstemal drauf gestossen. Und zwar in Form der TPU eines 68332. https://www.mikrocontroller.net/articles/MC68332#TPU Hier mal eine Anwendung: https://www.jstor.org/stable/44611720?seq=1 Es hat mich immer gewundert das sich diese geniale Idee nicht mehr verbreitet hat. Daher denke ich das der Durchnittsprogrammierer dafuer einfach nicht bereit ist. Das uebersteigt seine Vorstellung. Man sieht ja auch wie oft hier jemand aufschlaegt und jammert das er eine fertige Libarie fuer irgendeine banale Funktion eines STM32 braucht. Oder das man auch nur darueber nachdenkt sowas wie arduino auf so einem System zu implementieren. Im professionellem Umfeld sehe ich ausserdem das grosse Problem der Inkompatibilitaet. In der Firma ziehen wir ohne Probleme auch umfangreichste Projekte von einem Mikrocontroller eines Herstellers auf einen anderen um wenn das aus Hardware oder Kostengruenden notwendig ist. Das wird dir bei einem Propeller ziemlich schwer fallen. Und es ist vermutlich auch das Problem das den PSoC von Cypress immer etwas behindert hat. Daher denke ich das Hauptproblem des Propeller, neben seiner schlechten Dokumentation, ist vor allem: Wat de Buer nich kennt, dat frett he nich Olaf
>Interessant finde ich das es das Prinzip schon sehr lange gibt. Ich bin >da vor 20Jahren das erstemal drauf gestossen. Und zwar in Form der TPU >eines 68332. Auch interessant ist, dass sie die TPUs bis in die modernen PPC-MCUs übernommen haben. Sie sind mir zum ersten mal vor ca. 8 Jahren aufgefallen: https://de.wikipedia.org/wiki/Liste_der_Freescale-Produkte
MCUA schrieb: > 20 Beiträge gelöscht Ja, ist doch gut so! Die Java Nebelkerze gestartet, damit eine Eskalation ausgelöst und jetzt ist der Dreck weg. Alles ok so. Es wäre natürlich schöner, wenn .......
MCUA schrieb: > Da ging es nicht nur um Java Ja, das stimmt! Irgendwelche Überlegenheitsfantasien waren da auch im Spiel. Das alles macht doch in einer "Propeller Diskussion" wenig Sinn.
Andi schrieb: > Gerade beim Propeller, wo man oft Softwareperipherals schreibt, ist ein > optimierender Compiler manchmal sehr störend. Da muss man ein bestimmtes > Timing einhalten, das der Compiler nicht kennt, und wenn da einfach > Schleifen optimiert und Befehle in eine andere Reihenfolge gebracht > werden führt das eben dazu das es nicht mehr funktioniert. Wenn die Software, nicht mehr funktioniert, wenn der Compiler optimiert, liegt das am Entwickler und nicht an der Sprache oder dem Compiler. Es gibt klare Regeln an die man sich halten muss und die muss der Entwickler lernen.
mh schrieb: > Andi schrieb: >> Gerade beim Propeller, wo man oft Softwareperipherals schreibt, ist ein >> ... > > Wenn die Software, nicht mehr funktioniert, wenn der Compiler optimiert, > liegt das am Entwickler und nicht an der Sprache oder dem Compiler. Das gilt aber nicht bei zeitkritischen Routinen. Wenn eine neue Compiler-Version oder eine andere Optimierungsoption einen Zyklus mehr oder weniger braucht kann ein zeitkritisches Interface einfach nicht mehr funktionieren. Auch wenn alle Signale rein von den Pegeln her stimmen.
Andi schrieb: > Auch ist höchste Geschwindigkeit dabei nicht immer das Ziel. Das ist ein weiterer wesentlicher Grund, der an vielen Stellen für Assembler spricht: berechenbares Timing. Selbst in modernen Architekturen, die oft schon auf Hardware-Ebene durch Caches und Out-Of-Order-Pipelines das Timing verwürfeln können ist es fast immer möglich, mit entsprechenden Assembler-Instruktionen dann doch wieder ein berechenbares Timing zu produzieren. Das ist natürlich typischerweise für den theoretischen Durchsatz suboptimal, aber für das konkrete Problem optimal. Solche Sachen laufen letztlich auf die Entscheidung hinaus: geht nicht (liefere das falsche/unbrauchbare Ergebnis aber maximal schnell) oder geht. Jedem normalen Programmierer fällt da die Wahl dann doch sehr leicht... Wenn er die Wahl hat, weil er mehr als nur C/C++ kann...
c-hater schrieb: > Das ist ein weiterer wesentlicher Grund, der an vielen Stellen für > Assembler spricht: berechenbares Timing. Ja. Wenn man Schnittstellen in Software implementiert ist das sicher ein ganz wichtiger Aspekt. Als PC Programmierer bin ich eher gewohnt, mit Hochsprachen und Frameworks Hardwaremodule zu programmieren, die das Timing selbst erzeugen. Das kann in ein einfachen z.B. ein PCA9685 (16 Channel PWM) sein. Wenn ich nun den PCA9685 zum Beispiel durch einen Mikrocontroller ersetzen würde, der nur einfache dumme I/O Pins hat, dann würde wohl kaum ein Weg an Assembler vorbei führen. Wie soll er sonst exakte Timings machen? Und wenn ich meine PWM Signale direkt mit dem PC erzeugen wollte, müsste ich einen Parall-Port verwenden und das ganz sicher auch in Assembler ohne Windows programmieren. Wenn man nun im Propeller diverse I/O Schnittstellen in Software implementieren muss, ist da sicher viel Assembler mit dabei. Wahrscheinlich viel mehr, als man heute von anderen Mikrocontrollern gewohnt ist. So sehr ich unsere Compiler und Hochsprachen schätze, eins erwarte ich von ihnen überhaupt nicht: Exakte Timings erzeugen zu können.
Stefan ⛄ F. schrieb: > So sehr ich unsere Compiler und Hochsprachen schätze, eins erwarte ich > von ihnen überhaupt nicht: Exakte Timings erzeugen zu können. Deswegen verspricht das ja auch ehrlicherweise keine dieser Sprachen. > Als PC Programmierer bin ich eher gewohnt, mit Hochsprachen und > Frameworks Hardwaremodule zu programmieren, die das Timing selbst > erzeugen. Solange du entsprechende Hardware zur Verfügung hast, ist das ja auch der normale Weg. Niemand (schon garkein gelernter Asm-Programmierer) kommt auf die abstruse Idee, verfügbare und für den Zweck auch nur halbwegs brauchbare Hardware nicht irgendwie nutzbringend zu verwenden. Nur manchmal gibt es halt keine geeignete Hardware. Oder es gibt sie zwar, sie wird aber für einen anderen, noch timing-kritischeren Zweck benötigt.
> schon garkein gelernter Asm-Programmierer
Ist das ein anerkannter Lehrberuf?
Carl D. schrieb: > Ist das ein anerkannter Lehrberuf? Nein. Aber OK: Gehirnchirurg ist auch kein anerkannter Lehrberuf. Es soll trotzdem welche geben, die sich damit auskennen und zu durchaus nützlichen Ergebnissen kommen (wenn auch nicht in jedem Fall)...
c-hater schrieb: > Carl D. schrieb: > >> Ist das ein anerkannter Lehrberuf? > > Nein. > > Aber OK: Gehirnchirurg ist auch kein anerkannter Lehrberuf. Es soll > trotzdem welche geben, die sich damit auskennen und zu durchaus > nützlichen Ergebnissen kommen (wenn auch nicht in jedem Fall)... Die haben aber eine medizinische Ausbildung hinter sich. Zudem versuchen Mediziner nicht jedes Problem mit einer Gehirnoperation zu lösen. Manchmal benutzen sie z.B. zum bekämpfen von Kopfschmerzen lieber weniger ultimative Mittel wie Acetylsalicylsäure. Sowas wäre aus Sicht eines "echten Hirnchirurgen" völlig inakzeptabel. Zum Thema: Propeller ist ein Konzept, das Peripherie durch Software ersetzt. Quasi Microcode, der in jeden der Cogs geladen werden kann. Um diese programmierte "HW" zu "scripten", wurde Microcode für den SPIN-Interpreter im ROM hinterlegt. Damit können auch "verweichlichte Nichtskönner" (wie mancher/einer hier gerne zum Ausdruckt bringt) diese Teil benutzen. Der Ansatz könnte auch der Tatsache geschuldet sein, daß damit die HW einfacher aufgebaut sein könnte, was der Größe des Entwicklungsteams (Prop1 -> einer) entgegen kommt. Alle, die damit ein Problem haben sollten das Ding einfach nicht beachten. Ich hab hier einen rumliegen, der für ein Projekt gedacht ist, das es früher mal im Netz gab: eine "Emulation" einer Hammond B3. Klingt nach den mp3's nicht schlecht. Ich hab auch mal versucht den Code zu analysieren, die B3 läuft quasi auf einem Kern, ein weiterer bildet einen Leslie-Turm nach, einer wartet auf MIDI-Kommandos, ... Ich benutze aber trotdem auch andere "Rechner", wo diese besser geeignet sind.
Carl D. schrieb: > Zudem versuchen Mediziner nicht jedes Problem mit einer Gehirnoperation > zu lösen. Gehirnchirurgen lösen Probleme die mit Gehirnchirugie lösbar sind. Gehirnchirurgen lösen in der Regel keine Probleme die der Orthopäde mit einem Gipsverband löst. Nicht alles was hinkt ist ein Vergleich.
c-hater schrieb: > Stefan ⛄ F. schrieb: > >> Es wäre Selbstbetrug, davon auszugehen, dass handgeschriebener Assembler >> Code immer perfekt ist. > > Deswegen nimmt das auch kein gestandener Assemblerprogrammierer an. Der > weiß, das er niemals perfekt ist und das bei genauerer Betrachtung immer > noch der eine oder andere Takt rauszukitzeln wäre. Na und? Deine Haterei geht einem wirklich mit der Zeit auf den Wecker. Neimand, ich meine absolut gar Keiner, verbietet jemand Anderem das Werkzeug zu benutzen das er für am besten geeignet für den Job hält. > > Umso erstaunlicher ist die Attitüde der C/C++-Programmierer. Die bauen > ja nur auf Bausteine auf, die mal irgendein Assemblerprogrammierer in > den Codegeneratoren verewigt hat. Dein Fehler liegt bei "nur". Teilweise bauen die auch auf Bausteine auf die irgendwann mal von Fortran Programmierern geschaffen wurden (numerische Bibliotheken). Sie bauen halt auf Bausteinen auf die auch Jemand Anderes geschaffen haben kann. > Dieser Programmierer unterlag > grundsätzlich erstmal denselben Einschränkungen, denen auch jeder andere > Assemblerprogrammierer ausgesetzt ist. > > ZUSÄTZLICH musste er aber bei der Gestaltung seiner Bausteine mit dem > Problem der sehr unvollständigen Information klarkommen. Der > Codegenerator weiß nämlich fast nichts über das Gesamtwerk, denn er > arbeitet auf der Ebene von Funktionen... Ich möchte Dich mal sehen wenn Du einen X-Server in Assembler schreiben sollst, über Performance redet da erst mal Niemand, Interessant wäre ob Du die Funktion alleine gewährleisten könntest. > >> Alle höheren Programmiersprachen wären in diesem Fall sinnlos. > > Nein, das sind sie natürlich nicht. Das hat auch niemals jemand > behauptet. Sie produzieren halt in sehr vielen Fällen hinreichend > schnellen Code. Aber eben nicht in allen Fällen. Immer dann, wenn's eng > wird, dann hilft Assembler. Es sollte nicht eng werden, denn die von C Programmierern ja ständig benutzen Bausteine schließen überhaupt nicht aus das man Assembler Routinen für zeitkritische Stellen einbaut, aber beispielsweise halt komplexe GUI Funktionen benutzt die Jemand in C oder in wasweisich geschrieben hat. Bitte erst mal die Funktion gewährleisten, danach über Performance reden! "If it doesn't fit, use a bigger hammer!" ist doch der Grundsatz nach dem heute Programmierung läuft, jede beschissene Textverarbeitung fordert heute Gigabytes an RAM und mehrere GHz als Taktfrequenz um genau das zu tun was auf einem IBM XT mit 640K und 4,77Mhz möglich war. > > Und genau dieser, in unendlich vielen Fällen nachgewiesene, Sachverhalt > zeigt, dass die Lüge, dass C/C++ schon alles optimal macht eben genau > das ist: ein Lüge. Das hat Niemand behauptet, es wird nur erklärt das die Performance im Vergleich zu handoptimiertem Assembler so schlecht gar nicht ist. Was wofür eingesetzt wird entscheidet doch kein "Gut oder Böse", sondern wieviel Aufwand man in die Hardware und wie viel in die Software stecken will. Jemand der länglich einen Atmga16 mit Assembler auswringt um damit unbedingt seine Anwendung durchziehen zu wollen ist doch nur als krank zu bezeichnen wenn weltweit für deutlich geringere Preise um ein vielfaches schnellere 32Bit MCUs verfügbar sind, die selbst bei Programmierung mit Basic Interpreter um ein Vielfaches schneller sind, als der handoptimierte AVR. Kannst Du Deine Agitation an jeder möglichen und unmöglichen Stelle also bitte mal einstellen? Es nervt nur noch, universell wahr sind Deine Behauptungen aber auch nicht. > > Und sie wird auch durch gebetsmühlenartige Wiederholung nicht wahrer. Was auch auf Deine Behauptungen exakt paßt. Pille
Nick M. schrieb: > Carl D. schrieb: >> Zudem versuchen Mediziner nicht jedes Problem mit einer Gehirnoperation >> zu lösen. > > Gehirnchirurgen lösen Probleme die mit Gehirnchirugie lösbar sind. > Gehirnchirurgen lösen in der Regel keine Probleme die der Orthopäde mit > einem Gipsverband löst. > Nicht alles was hinkt ist ein Vergleich. Das Trifft aber auch auf das ultimative "besser" von Assemblercode zur Programmierung zu. Ich kenne Wissenschaftler die nach wie vor Fortran nutzen und das Zeug auf Vectorrechnern durchdrehen. Wie Ihr Fortran auf die Maschine paßt..darum mögen sich doch bitte die Compiler auf den Konzentrator-Workstations kümmern.. Pille
Pille schrieb: > Das Trifft aber auch auf das ultimative "besser" von Assemblercode zur > Programmierung zu. Prinzipbedingt kann handoptimierter Assemblercode besser sein als das was ein C-Compiler generiert hat. Die Betonung liegt auf kann. Ausser: Irgendwann kommt mal einer drauf mit dem Monte-Carlo-Verfahren so lange Assembler-code zu produzieren bis er den schnellsten Code gefunden hat. So lang will ich aber nicht warten. :-) Zum Assembler mit/statt/gegen C bleib ich dabei: Beitrag "Re: Wofür Propeller von Parallax ?"
Nick M. schrieb: > Irgendwann kommt mal einer drauf mit dem Monte-Carlo-Verfahren so lange > Assembler-code zu produzieren bis er den schnellsten Code gefunden hat. > So lang will ich aber nicht warten. :-) Musst nicht warten. Gibts schon seit Jahrzehnten: https://www.gnu.org/software/superopt/ https://en.wikipedia.org/wiki/Superoptimization
(prx) A. K. schrieb: > Musst nicht warten. Gibts schon seit Jahrzehnten: Mein Schicksal. Ich erfind immer Sachen die es schon gibt. :-( Danke für die Links.
Nick M. schrieb: > Pille schrieb: >> Das Trifft aber auch auf das ultimative "besser" von Assemblercode zur >> Programmierung zu. > > Prinzipbedingt kann handoptimierter Assemblercode besser sein als das > was ein C-Compiler generiert hat. > Die Betonung liegt auf kann. > Ausser: > Irgendwann kommt mal einer drauf mit dem Monte-Carlo-Verfahren so lange > Assembler-code zu produzieren bis er den schnellsten Code gefunden hat. > So lang will ich aber nicht warten. :-) > > Zum Assembler mit/statt/gegen C bleib ich dabei: > Beitrag "Re: Wofür Propeller von Parallax ?" Genauer gesagt meinst Du: "Es wurde von Dir zwar Alles schon gesagt, nur von mir noch nicht"? Pille
Dann wollen das die C Quellen "MISRA" compliant sind und wenn man ein bisschem assembler benutzt hat weil es schneller/kleiner muss wird schief angeguckt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.