Ich poste die Frage hier, da sie eher zu FPGAs passt, als zu Controller, da sie sich auf den Zynq und artverwandte on-Chip-Systeme bezieht. Ich möchte viele Ausgänge in sehr hoher Geschwindigkeit schalten und die Muster autark rotieren. Für Quermuster würden sich reine Schieberegister eigenen, für die Längsmuster allerdings brauche ich Speicher, der sich nicht mit Latches machen lässt. Benötigt werden 64 Ausgänge mit Daten für die intelligenten Schieberegister / Matrix-Zellen sowie weitere Steuerleitungen für die Kanäle. Es braucht demnach eine Anordnung aus kleinen FPGAs mit internem RAM und vielen Ausgängen, die durch einen Master befüllt werden. Für das Rotieren würden die internen Block-Rams reichen, allerdings nicht für die Musterlänge. Dafür braucht es mindestens 4GB Speicher insgesamt. Da das Einschreiben in den Zwischenpausen erfolgen soll, müsste die RAMs schnell befüllt werden, was für alle Schalter eine Bandbreite von 1GB/s am RAM ergibt. Ich bin nun für den Master auf die Zynq-Chips gekommen und fand Anbieter die Module haben, welche schon genug Speicher integriert haben. Ich kenne mich mit denen nicht aus, habe nur die Specs durchgelesen und stelle mir eine Frage: Wie schnell kann das RAM tatsächlich gelesen werden? Die Bandbreiten die angegeben sind, werden durch das Zynq-System sicher nicht weiterzugeben sein. Ich frage mich vor allem, wie das funktioniert, wenn das RAM nur an dem Rechnerteil, nicht aber am FPGA-teil angeschlossen ist. Wie schnell bekommt man die Daten vom Prozessor auf die Logik um sie dann weiterzuverteilen? In den User-Groups liest man von Interruppt-Zugriffen und DMA finde aber nirgends ein konkretes Beispiel mit realen Werten, die erzielt werden können.
Mr. T. schrieb: > Ich frage mich vor allem, wie das funktioniert, wenn das RAM nur an dem > Rechnerteil, nicht aber am FPGA-teil angeschlossen ist. Es gibt genug Module/Boards mit Zynq bei denen auch RAM am FPGA Teil angeschlossen ist.
Mr. T. schrieb: > Es braucht demnach eine Anordnung aus kleinen FPGAs mit internem RAM und > vielen Ausgängen, die durch einen Master befüllt werden. Falsche Herangehensweise. Beschreibe verständlich und mit konkreten Zahlen (nicht "schnell"), was du machen willst. Nicht womit.
Ich weis was ich bauen will und wie es funktionieren soll :-) Es geht in der Tat darum, ein ausgewähltes Modul zu verwenden, welches nur ein RAM angeschlossen hat und dieses eben an am "Computerteil", also der PS. Die Idee dahinter ist, dass der Controller, der an der PS benutzt wird, eine ausreichend hohe Bandbreite hat. Schaue ich mir die Specs an, sehe ich, dass die Verbindung zu der PL langsamer ist, weil dort FPGA-Zellen benutzt werden, die (meine Interpretation) offenbar weniger schnell arbeiten können. Das nächst passende Systemmodul das PL-Verbindung hat, bringt weiter noch den Nachteil mit, dass IOs verloren gehen. Es müsste das übernächste genutzt werden, was deutlich teurer und größer ist.
Leider zu wenig Details. Welches Modul willst du verwenden? Wieso Zynq und nicht Spartan/Artix/... mit Microblace? Die Anbindung zwischen PS und PL ist doch eher sehr schnell. Das ist zwar kein so irre hoher Takt, aber sehr breit. 128 Bit AXI oder so.
Gustl B. schrieb: > Spartan/Artix/... mit Microblace? Spartan und Artix müssen mit RAMs versehen werden, wahrscheinlich müsste man etwas selbst konstruieren und dann bleibt das Problem der wegfallenden IOs. Das geht nur mit den großen Bausteinen. > Die Anbindung zwischen PS und PL ist doch eher sehr schnell. Wie schnell? > Das ist zwar kein so irre hoher Takt, aber sehr breit. > 128 Bit AXI oder so. Der AXI liefert aber nur, was die interne Logik und die Brücke dorthin hergeben. So wie ich die Dokumentation verstehe, gibt es eine Brücke zu dem PS-System mit/per DMA-Controller. Die Dokumentation schweigt sich aber darüber aus, wie schnell das ist. Angenommen, das wären im Durchschnitt 100MHz, wären das 1,6GB/s, was reichen würde. Aber kommen so viele Daten? Nehmen wir beispielsweise das "Bora-Som" oder "ALINX AC7Z020", beide mit einem Xilinx Zynq-7000 XC7Z020 FPGA. Die angeschlossenen RAMs haben theoretisch 1,6 / 2,6 GB/s. Für den zweiten Fall würde der AXI mit 100 MHz schon nicht reichen. Mit welchen Verzögerungen kann man bei dem DMA rechnen? Die Prozessorlast liegt bei unter 30% und es wäre rechnerisch möglich, die Arbeit des Prozessors in dem kurzen Moment, wo die Bandbreite gebraucht wird, auf gut die Hälfte zu senken. Die Zugriffe des Prozessors brauchen dann geschätzt 0,3 statt 0,5 GB/s. Ich rechne nun einen AXI mit 150MHz. Der könnte 2,4GB/s (mehr kommt vom Exemplar 2 sowieso nicht). Rechnen wir 2,0. Abzüglich 0,5 bleiben 1,5. Davon müsste ich mindestens 70% abgekommen. Klappt das?
Manni T. schrieb: > Spartan und Artix müssen mit RAMs versehen werden, wahrscheinlich müsste > man etwas selbst konstruieren und dann bleibt das Problem der > wegfallenden IOs. Auch da gibt es genug fertige Module. Auch mit vielen IOs. Es gibt auch kleine FPGAs mit einem großen Package und vielen IOs. Ja sonst kann ich da leider nicht helfen. Ich weiß nicht was du vor hast. Woher kommen die Daten denn überhaupt? Ethernet? Werden die lokal errechnet? Wenn es möglich ist die Daten zu errechnen wie eine Sinustabelle oder so, dann geht das auch im FPGA Teil und man kann sich den Speicher vielleicht sparen.
Reicht das Budget fuer ein UltraScale+ MPSoC Modul? Der macht die angestrebten 1GB/s aus dem PS DDR ohne Probleme, da geht auch mehr. Und nebenbei kannst du noch ein Linux laufen lassen um die Daten zu betanken.
Angehängte Dateien:
-

ZynqMemoryInterface..PNG
96 KB -

ZynqMemoryInterconnect..PNG
76 KB
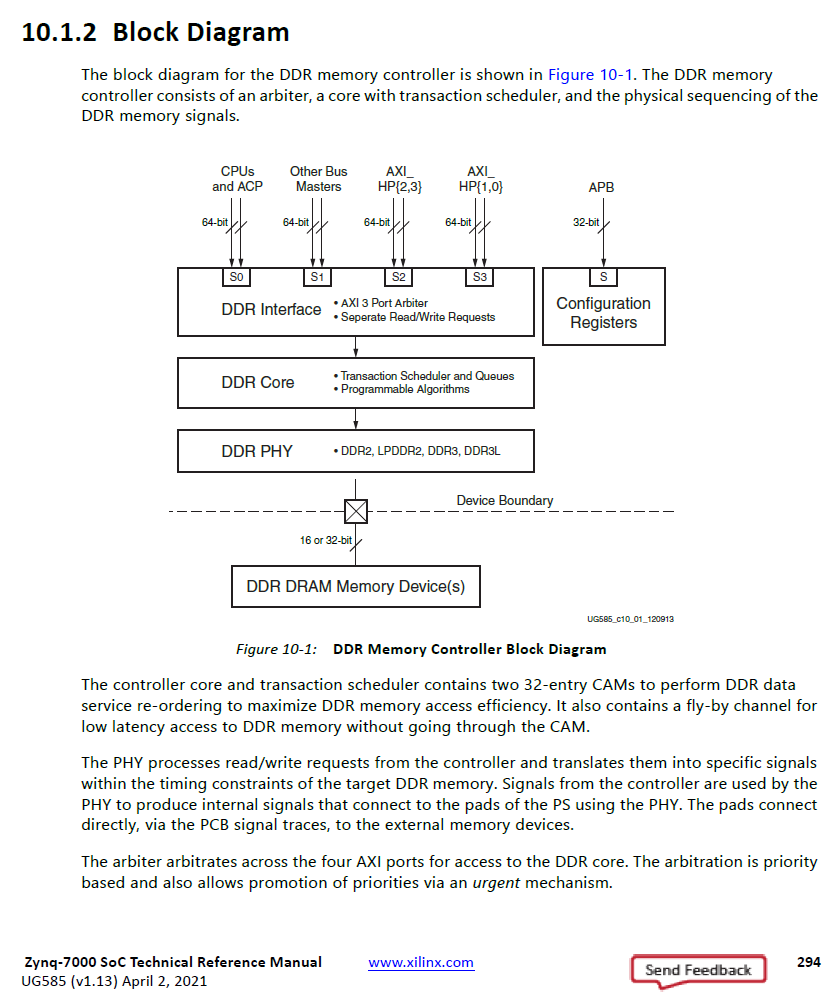
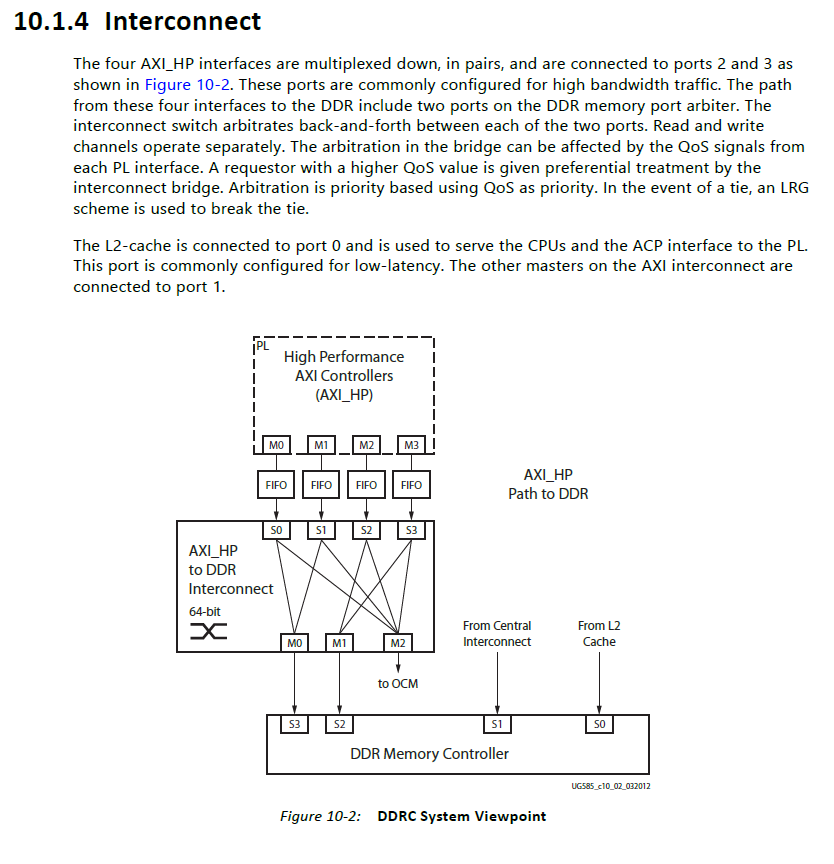
Letztlich ist das doe Frage was der Memorycontroller an den Userports an Datenrate zur Verfügung stellt. Du musst also mal einen passenden DDR-Controller Konfigurieren, das steht in der Beschreibung der "Memory interface solution - MIS, früher auch MiG - Memory Interface Generator. https://docs.xilinx.com/v/u/1.4-English/ug586_7Series_MIS Die Angaben für den userport sind meist isochrounous über eine längere consecutive Blocklänge gemeint, währen DDR-RAM burstartig arbeitet, also nur kurze Blöcke schnell liefert, nachdem diese erst addressiert werden. DRAM-typisches-Refresh muss auch noch automatisiert werden. Da muss also einiges an Cache/Buffer-speicher dazwischen, das könnte man auch im Memory-controller konfigurieren. Natürlich sollte man auch ein paar FIFO's zwischen Memory-Controller-Userport und deinen Bitgeschubse einbauen. Anbau Auszüge aus der Zynq-Doc die die Blöcke mit einer konhreten Realisierung der UserPorts als AXI-Stream-Interface aufzeigen. Das Ganze ist kein triviales PLD-Gebastel, wielleicht besorgst du dir zuerst das kostenlose Zynq-book und arbeitest das Thema DDR-Controller und Grundlagen durch. Für einen FPGA-Anfänger, auch mit passender Uni-Qualifikation als Elektrotechniker/Informationstechnik (notfalls technische Informatik) wären dafür vier Wochen Intensiv anzusetzen. https://github.com/Lauro199471/CECS-461/blob/master/The%20Zynq%20Book%20ebook.pdf
Manni T. schrieb: > Ich weis was ich bauen will und wie es funktionieren soll :-) Dann mal ein Blockbild davon und präsentiere das hier.
Manni T. schrieb: > Ich weis was ich bauen will und wie es funktionieren soll :-) Das ist schön für dich, aber leider vollkommen unbrauchbar für eine sinnvolle, technische Diskussion. Siehe Netiquette. > Es geht in > der Tat darum, ein ausgewähltes Modul zu verwenden, welches nur ein RAM > angeschlossen hat und dieses eben an am "Computerteil", also der PS. PS? Die > Idee dahinter ist, dass der Controller, der an der PS benutzt wird, eine > ausreichend hohe Bandbreite hat. Schaue ich mir die Specs an, sehe ich, > dass die Verbindung zu der PL langsamer ist, weil dort FPGA-Zellen PL?
Du müsstest mal dokumentieren, was du unter Längsmuster, Quermuster, intelligenten Schieberegistern und Matrixzellen verstehst. Das hört sich alles ganz toll nach Startrek-Technobabbel an, hat aber irgendwie keinen Inhalt. Ich versuche mal etwas Struktur in das Wirrwar zu bringen. Du willst 64bit breite Bitmuster mit hoher Geschwindigkeit aus einem Speicher auslesen, mit Schiebregistern hin- und her schieben und dann parallel über 64 Pins ausgeben. Dazu brauchst du einen großen und schnellen Speicher. Wie groß und wie schnell, hast du uns nicht verraten. Bei einem Zynq kannst du den DDR-Speicher auch direkt aus der PL auslesen, ohne die CPU. Wie schnell das geht, hängt vom verwendeten Zynq ab und wie gut optimiert das FPGA-Design ist. Ich würde mal schätzen, dass du den DDR-Speicher über die PL mit maximaler Geschwindigkeit auslesen kannst, zumindest bei den neueren Zynqs. Du könntest genauso gut z.B. einen Artix mit angeschlossenem DDR-Speicher nehmen, wie z.B. auf dem Arty-Board von Digilent. Davon abgesehen kannst du noch die Blockrams der PL verwenden, wenn die groß genug sind. Ob sie das sind, kann dir niemand beantworten.
Angehängte Dateien:
-

Zynq_block.png
47 KB
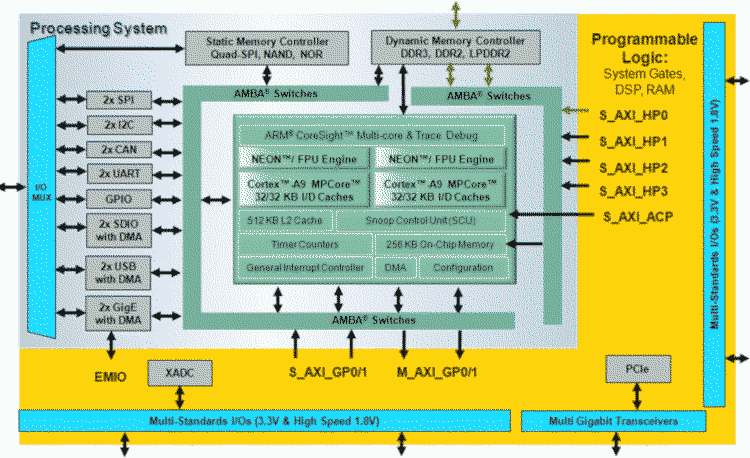
> PL? > PS? Ich spring mal für den TO ein... Der Zynq als System-on-a-(FPGA)-Chip besteht in der Xilinx-Sprache aus zwei Teilen: PL und PS (siehe Anhang) PL programmable-Logic (gelber Hintergrund) enzhält LUT's FF und den ganzen Kram die alte recken aus Zeiten von Spartan-2 bis Spartan-6 kennen. PS (Processing system -grauer Hintergrund) dagen bezeichnet das System aus (Hard-silicon)Dual-ARM-Core, diverse Priphereals (i.e I2C), dynamic memory controller, ..., vielen dieser Komponenten sind Pins fest zugeordnet.Es kann also sein das der DDR-Speicher auf einem Zynq-Eval-Board fest nur über das PS (eben als Speicher für die ARM-Core) angesprochen werden kann und nicht direkt vom (in HDL-) geschriebenen Memory-controller im PL-Teil. Es gibt natürlich auch verbindungen zwischen PS und PL Teil; * AXI_GP ((Registerzugriff basierte general purpose) AXI-Bridges aber auch * AXI_HP_schnelle (streamfähige) Highperformance Interface eben um auch vom DDR um PS ans PL zu kommen. Dieser (umständliche weg übers PS) zum PL hat aber verständlicherweise eine höhere Latenz.
Falk B. schrieb: >> und dieses eben an am "Computerteil", also der PS. > PS? Ja, das "programmierbare System". Die Dokumentation unterscheidet PS und PL beim Zugriff auf den Controller. >> die Verbindung zu der PL langsamer ist, weil dort FPGA-Zellen > PL? die "programmierbare Logic". In der englischen Dokumentation sind die Begriffe im Übrigen dieselben. Vancouver schrieb: > Ich würde mal schätzen, dass du den DDR-Speicher über die PL mit > maximaler Geschwindigkeit auslesen kannst ja das würde ich auch schätzen, aber die Schaltmatritzen der AXI-Busse suggerieren mir eine Bandbreitenbremse. Dem Bild oben z.B. ist zu entnehmen, dass auf dem PHY 4 Teilnehmer arbeiten (können) während nur 2 davon über eine Matrix an die 4 PS-Teilnehmer angeschlossen sind. Frage der Frage: Welche Bandbreite bleibt für einen einzelnen übrig, wenn die anderen gerade nichts tun? Sicher keine 100%. Ferner ist dem Diagramm zu entnehmen, dass es 64 Bit-breite Busse sind. Das würde auch bei 250MHz nicht reichen. > Du könntest genauso gut z.B. einen Artix mit angeschlossenem > DDR-Speicher nehmen, wie z.B. auf dem Arty-Board von Digilent. Das wird mit 16 Bit angeschlossen und mit 600 MHz ausgelesen. Der Zynq im avisierten board kann 1GHz und 32 Bit.
Manni T. schrieb: > Falk B. schrieb: >>> und dieses eben an am "Computerteil", also der PS. >> PS? > Ja, das "programmierbare System". Nein, nicht programmierbar sondern "processing System". "Programmierbar" ist alles auf den SoC wenn man nicht gerade ein Schmalspur-Software-Entwickler ist, der nur C kann. Als unqualifizierter deutschsprachiger Halb-Laie würde man aus dem Bauch wohl eher zum Logic-Teil "processing (verarbeitend) sagen, das ist hier aber nicht gemeint. Vielleicht konzentriert man sich eher auf die Begriffe Logik und System. Dann ist PS das System das die Logik am Laufen (processing) hält. Xilinx betont das mit der Bezeichnung als "close coupled" SoC, während die SoftCore SoC Geschichten als loose coupled bezeichnet werden. > Die Dokumentation unterscheidet PS und > PL beim Zugriff auf den Controller. Welcher Controller? Es gibt PL, PS und die Bridges GeneralPurpose (GP) und HP (high performance) dazwischen. Aber keinen Controller daneben. Die ARM-Cores gehören zum PS, ebenso der dynamic memory controller. PS: A bisserl zu den verschiedenen Möglichkeiten der Speicheranbindungen am Zynq wurde im dortigen thread erötert: Beitrag "Re: Terasic DE10-Nano & weitere Fragen" . Wobei, dort geht es im Retro-Computing, wo es, im Unterschied zu deinem hingekaspelten Systembeschreibung, keine "Zwischenpausen" im Speicherzugriff gibt.
DSGV-Violator schrieb: > Nein, nicht programmierbar sondern "processing System". "Programmierbar" > ist alles auf den SoC wenn man nicht gerade ein An einer Diskussion um die sprachlichen Spitzfindigkeiten möchte ich mich nicht beteiligen. "processing" oder nicht - der folgende Satz ist sicher nicht richtig interpretiert: DSGV-Violator schrieb: > Dann ist PS das System das die Logik am > Laufen (processing) hält. Die Logik läuft auch ganz alleine, ohne dass die Prozessoren aktiviert sind. DSGV-Violator schrieb: > AXI_HP_schnelle (streamfähige) Highperformance Interface eben um auch > vom DDR um PS ans PL zu kommen. Dieser (umständliche weg übers PS) zum > PL hat aber verständlicherweise eine höhere Latenz. Die Latzen wäre zu verkraften. Alles was unter 2-3ms liegt, ist im externen Bereich transparent. Es geht ausschließlich um die Bandbreite. Ich habe den Hersteller kontaktiert um eine Aussage zu bekommen. Diese lautet, dass die Bandbreite für unsere Anwendung nicht reicht, und ein alternatives Modul angeboten, das in Entwicklung ist und welches passt. Der Hersteller ist im Übrigen sehr deutlich mit der Firma X ins Gericht gegangen, was Qualität an Dokumentation anbelangt und die Verprechungen, die selbige macht.
> Der Hersteller ist im Übrigen sehr deutlich mit der Firma X ins Gericht > gegangen, was Qualität an Dokumentation anbelangt und die Verprechungen, > die selbige macht. Dann haste ja die für Dich bequemste Antwort bekommen, Xilinx ist Schuld und du hast alles richtig gemacht ... IMHO die Lösung dagegen ein Blockbild, das genau zeigt, wie die Daten durch die Daten-senken/quellen fliessen sowie eine Spezifikation der erforderlichen Datenraten. Ein Anfang wäre bespielsweise nachvollziehbar aufzu zeigen, wie man aus den Angaben von 64 ausgängen und 4 GB Speicher auf 1 Gbit/s Transferate kommt um dann später zu behaupten, die wären nicht erreichbar. (Nur mal so als Beispiel schon mit Spartan6 & Co kann man Videauausgaben realisiern, die rechnerisch eine Transferrate von 10 GBit/s ergeben: Beitrag "HDMI Signalaufbau/Pinbelegung") Daraus könnte man dann eine erste Implementierung in Vivado zusammklicken. Das erfordert, das man die Turorials abarbeitet und es hilft sich mit 3rd party literatur wie dem Zynq-book auseinanderzusetzen. Dazu bedarf es aber mehr als ein Wochenende und ein paar unillustrierte Beiträge in einem Hobbyisten-Forum.
DSGV-Violator schrieb: > Dann haste ja die für Dich bequemste Antwort bekommen, Xilinx ist Schuld > und du hast alles richtig gemacht ... Bitte korrekt lesen: Das war die Aussage des Modulkartenherstellers. Der plagt sich mit der XI-Dok herum und hat Supportanfragen laufen. Ich nehme das natürlich zur Kenntnis und deshalb muss beim Planen solcher Systeme zuvor etwas gerechnet werden. > IMHO die Lösung dagegen ein Blockbild, das genau zeigt, wie die Daten > durch die Daten-senken/quellen fliessen das liegt vor, wird aber hier sicher nicht pubiliziert! > sowie eine Spezifikation der erforderlichen Datenraten. Siehe Eingangspost: Die erforderliche Datenrate wurde berechnet: Manni T. schrieb: > was für alle Schalter eine Bandbreite von 1GB/s > am RAM ergibt. -> 1 GBps am RAM sind Man(n)ifest. > Ein Anfang wäre bespielsweise nachvollziehbar aufzu zeigen, wie man > aus den Angaben von 64 ausgängen und 4 GB Speicher auf 1 Gbit/s > Transferate kommt ist im internen Dokument genauestens gezeigt. > (Nur mal so als Beispiel schon mit Spartan6 & Co kann man Videauausgaben Dieses Beispiel ist keines, weil es sich auf die Ausgaben mit Transceivern bezieht. Woher die Daten kommen, bleibt offen. Der Spartan war zudem kein SOC, sondern hatte die RAMs direkt angeflanscht, wenn ich mich richtig entsinne. Es muss also nicht geprüft werden, ob meine 1GBps richtig sind, sondern ob und mit welchem Steckkartenmodul sie erzielbar sind. Und natürlich muss es wie immer das billigste sein.
Wieso kein Spartan/Artix/Kintex mit uBlaze und mehreren DRAM Kanälen?
Weil auf Spartanen mit Softcores kein Linux effektiv läuft und Kintex viel zu teuer ist. Ist alles geprüft und quergecheckt. Der Zynq ist gesetzt. Es ging mir hier nur um einen eventuellen Tipp von jemandem, der sich zufällig auskennt, mit welchen Datenraten man rechnen kann. Möglicherweise ist das einfach das falsche Forum für solche anspruchsvollen Fragen. Das Thema ist erledigt. Module sind geordert! Es gibt aber ein Anschlussthema: Beitrag "Lebensdauerverlängernde Maßnahmen für Flash-LEDs"
Manni T. schrieb: > Weil auf Spartanen mit Softcores kein Linux effektiv läuft und Kintex > viel zu teuer ist. Ist alles geprüft und quergecheckt. Der Zynq ist > gesetzt. > > Es ging mir hier nur um einen eventuellen Tipp von jemandem, der sich > zufällig auskennt, mit welchen Datenraten man rechnen kann. Diese Frage hast Du nie gestellt und diese Frage stelltsich Dir auch nicht. Deine Frage wäre gewesen: "wie und welche erreiche LED-Schaltraten (Bereich <= 10 Mbit/sec erreicht man über ein LowCost FPGA?" Bei OSRAM in München hab ich vor ca. 10 Jahren mal dergleichen gesehen, die technische Herausforderung ist nicht die Ansteuerung sondern das Schalten des Laststromes. LIDAR war da auch im Gespräch. Der Prototyp war wohl ein Virtex weil das aufgekaufte (Schwedische?) StartUp ein solches verwendet hat. Aktuell findet man Publlikationen aus dem Chinesischen Kanton: https://www.mdpi.com/2073-8994/14/6/1256 und mit ein bißchen Gehirnschmalz sicher noch weitere. Wobei deren Schwerpunkt eher das DSP nach dem RX ist und nicht das bisserl TX-Steuerung wie hier angefragt. > Möglicherweise ist das einfach das falsche Forum für solche > anspruchsvollen Fragen. Eher ist die Formulierung eine verständlichen Frage für Dich zu anspruchsvoll. Vielleicht weil es hier eben nicht um reine Ja/Nein Frage geht sondern um den Entwurf eine Architektur unter Berücksichtigung mehrerer IC-Varianten und Bewertung derselben geht.Um die "dritte Meinungen" abzufragen, muss man eben wenigstens Blockbilder der Varianten vorlegen.
Manni T. schrieb: > mit welchen Datenraten man rechnen kann. Zwischen PS und PL ist AXI und schnell, aber je nachdem was du im PS machst limitiert dann auch die CPU. Wenn es nur vom RAM an IOs gehen soll dein Muster, dann nimm doch ein Board mit schnellem/mehreren RAMs am PL selbst. Dann ist der Durchsatz klar aus dem Datenblatt ersichtlich. Dort steht noch etwas dazu: https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/18842244/Zynq-7000+AP+SoC+Performance+Benchmarks Manni T. schrieb: > Weil auf Spartanen mit Softcores kein Linux effektiv läuft Und das brauchst du zwingend? Außerdem gibt es Softcores mit RISCV und Linux.
>> Weil auf Spartanen mit Softcores kein Linux effektiv läuft > > Und das brauchst du zwingend? Außerdem gibt es Softcores mit RISCV und > Linux. Naja, die Aussage "kein Linux läuft darauf effektiv " kann man kommentarlos in die Tonne kloppen. Was meint effektiv ? Das erste Linux lief auf einem i386-PC mit 4 MByte und 33MHz, einen mikroblaze auf einem Spartan kann man locker mit 80 MHz takten. Letzlich braucht man nur ein bisserl Shell und console, da braucht es kein HiPerformance ServerLinux mit deepPaketInspection und HeavyDuty WebServer.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.