Hi,
anbei findet Ihr einige Routinen, die das Rechnen mit 64 Bit float
Zahlen auch auf den AVRs erlauben. Der Emulator ist in K&R C geschrieben
und angepaßt und getestet für den Einsatz mit gcc. Er erlaubt die
Rechnung mit ca. 15 gültigen Stellen anstelle der 6 Stellen für den
eingebauten 32Bit float Typ. Das Zahlenformat entspricht IEEE754.
Das Headerfile erzeugt einen neuen Typ float64_t , der in einem uint64_t
untergebracht wird. 64Bit floats können von den vorhandenen
standardisierten 32Bit floats konvertiert werden:
(float64_t) x = f_sd((float32_t)a); (sd: single to double).
Umgekehrt gehts so:
(float32_t) x = f_ds((float64_t)a);
Es sind die vier Grundrechenarten und die Kehrwertberechnung
implementiert.
(float64_t) x = f_add ((float64_t) a,(float64_t) b);
(float64_t) x = f_sub ((float64_t) a,(float64_t) b);
(float64_t) x = f_mul ((float64_t) a,(float64_t) b);
(float64_t) x = f_div ((float64_t) a,(float64_t) b);
(float64_t) x = f_inverse((float64_t) a);
Die Leistung für die Division liegt bei ca. 200 flops auf nem Mega 128
@16Mhz, Kehrwertbildung ist ähnlich lahm, der Rest geht schneller.
Die Behandlung von Sonderzahlen (NaN, +/-Infinity, etc.) und
Over/Underflows ist nicht normgerecht implementiert. 1/0 liefert
allerdings Infinity und die Rundung zu 0 für betragsmäßig zu kleine
Ergebnisse ist drin.
Das File avr_f64.c enthält den Rechencode. Im main.c findet sich ein
framework für den Test.
Ich habe diese Routinen erstellt, weil ich für meine Belange mit dem 32
Bit Floatformat nicht genügend Genauigkeit erreichen konnte. Ich habe
relativ viel Aufwand in die Tests gesteckt, wie auch im main.c zu sehen
ist. Trotzdem kann ich natürlich Fehler nicht ausschließen.
Ich würde mich über rege Benutzung und Rückmeldung freuen.
Cheers
Detlef
Gute Arbeit und kompakter Code !
Ich habe deinen Code zum Anlass genommen, die Bibliothek um die
Funktionen sqrt, exp, log, sin, cos, tan, arcsin, arccos, arctan sowie
um die Konvertierung vom und ins Dezimalsystem zu erweitern. Ich
verwende dafür bestimmte Hilfsfunktionen, welche sich auch dazu eignen,
die den Code für 4 Grundrechenarten kompakter zu schreiben. Daher habe
ich +, -, *, / auch entsprechend abgeändert. Andernfalls würden
Code-Teile, die Ähnliches tun, nebeneinander existieren, was man sich
auf einem µC nicht leisten sollte.
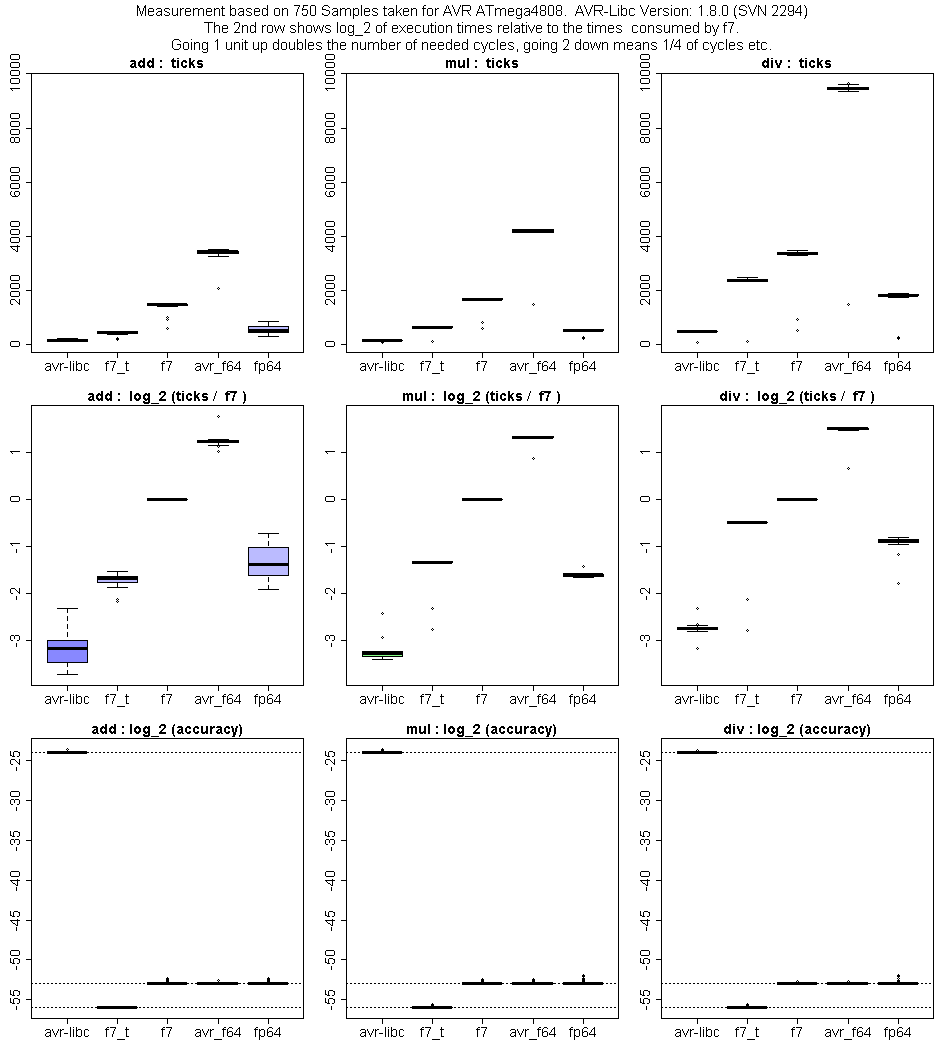
Meine Performance-Messungen auf einem ATMega32 (16 MHz) ergaben ca. 1000
Multiplikationen und 400 Divisionen pro Sekunde. Die Performance von
exp, log, sin, cos, tan, arcsin, arccos, arctan hängt auch vom
übergebenen Argument ab und lag zwischen 50 und 200
Funktionsauswertungen pro Sekunde.
Der Code ist ebenfalls ANSI-C-kompatibel. Bei den math. Fkt. wird in den
meisten Fällen die float64-Zahl geliefert, welche sich durch Rundung des
exakten Ergebnisses ergibt. Manchmal wird in die falsche Richtung
gerundet. Nur in speziellen Fällen kann es vorkommen, dass deutlich
weniger als alle 52 Mantissebits signifikant sind: Wenn x nicht nahe bei
Null, aber sehr nahe einer Nullstelle von sin, cos oder tan liegt, ist
der absolute Fehler zwar in der Größenordnung 2E-16; weil der
Funktionswert aber nahe bei Null liegt, ist der relative Fehler (= abs.
Fehler / Fkt.-Wert) deutlich größer als 2E-16. Größere Fehler treten bei
sin, cos, tan auch auf, wenn x betragsmäßig sehr groß ist, z.B. 1E10.
Für die Praxis dürfte sich der Aufwand nicht lohnen, diese Fehler zu
verkleinern.
Ich habe den Code v.a. nach Compilierung unter Visual C++ und nur
stichprobenartig auf dem eigentlichen Zielsystem (ATMega32) getestet.
Die Funktionen sqrt, exp, log, sin, cos, tan, arcsin, arccos, arctan
habe ich zum einen mit ausgewählten Spezial-Zahlen und zum anderen
jeweils mit 1E9 Zufallszahlen getestet, bei denen sowohl Mantisse als
auch Exponent zufällig waren. Das Ergebnis habe ich mit dem Ergebnis
verglichen, das die double-Arithmetik unter VC++ liefert. Mögliche
Differenzen wurden toleriert, wenn sich jeweils folgende beiden
Intervalle überlappen: Das erste Intervall ergibt sich, indem der von
meinem Code gelieferte Funktionswert einmal auf den nächstkleineren
darstellbaren float64-Wert (untere Intervallgrenze) und zum anderen auf
den nächstgrößeren (obere Grenze) abgeändert wird. Das zweite Intervall
ergibt sich, indem die entsprechende Funktion der PC-math-Bib. mit dem
nächstkleineren Funktionsargument und einmal mit dem nächstgrößeren
Argument evaluiert wird. Bei den 1E9 zufälligen Funktionsargumenten
waren alle Ergebnisse meines Codes mit diesen Kriterien tolerierbar. Das
beweist jedoch nicht, dass es keinen Bug gibt. Bugs können gerade auch
in Spezialfällen auftreten, die auch durch viele Tests mit Zufallszahlen
nicht auftreten.
Als Demo-Applikation benutze ich den mit einer RC5-Fernbedienung
steuerbaren Taschenrechner, den ich auch schon für die
Gleitkomma-Bibliothek Gleitkomma-Bibliothek für AVR verwendet habe.
Man kann alle Funktionen der float64-Bibliothek mit #defines in der
Datei avr_f64.h in die Kompilierung einbeziehen bzw. sie ausschließen.
Wenn nur +, -, *, / sowie die Konvertierung vom und ins Dezimalsystem
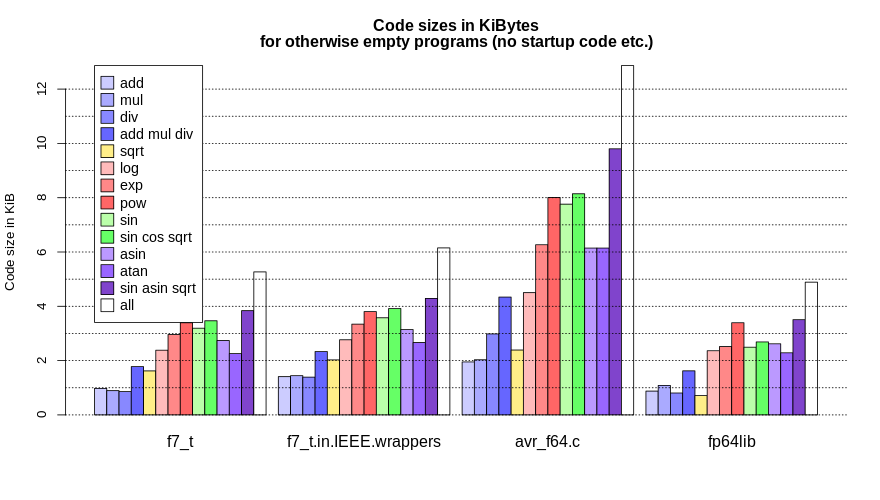
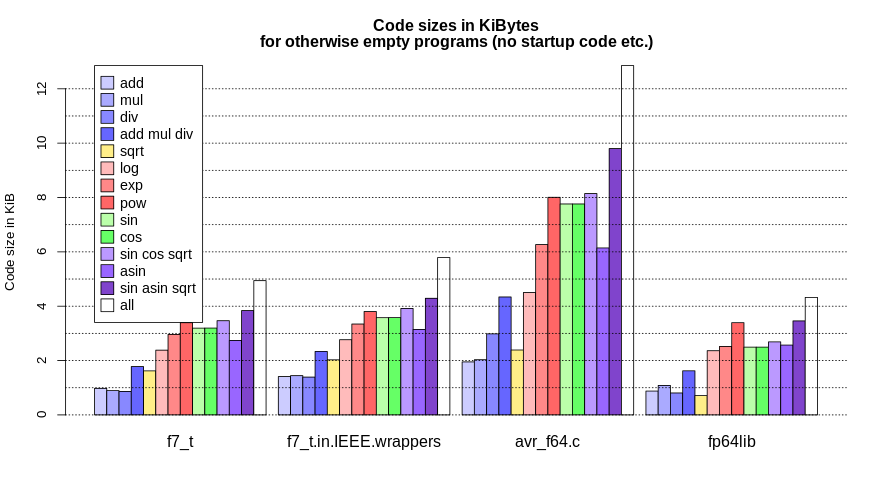
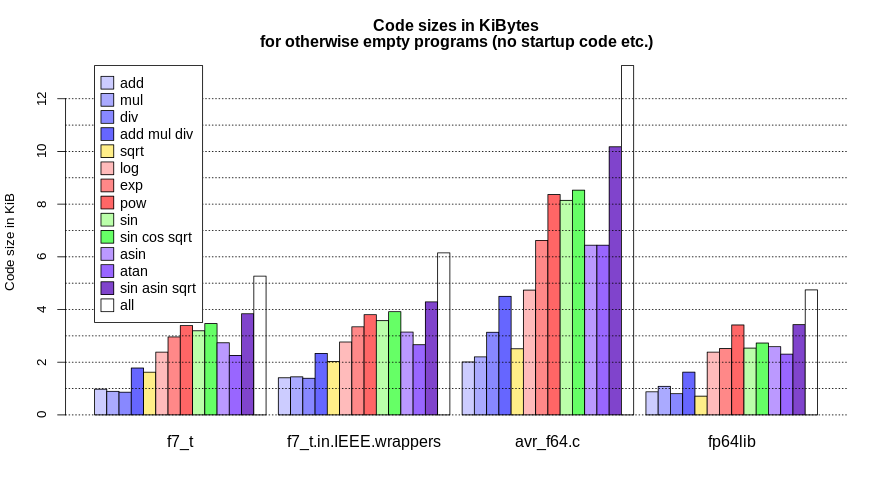
verwendet werden, benötigt die Taschenrechner-Applikation ca. 20 kB. Ich
habe auf meinem ATMega32 noch exp und log aktiviert, was auf 28 kB
führt. Mit allen Funktionen werden ca. 39 kB benötigt -- nichts für
einen ATMega32.
Außer der float64-Bibliothek verwende ich in der
Taschenrechner-Anwendung den RC5-Code von Peter Dannegger, Code für LCDs
von Peter Fleury und USART-Code von Ulrich Radig.
Ich habe festgestellt, dass die Benutzung der vom avr-gcc Compiler zur
Verfügung gestellten 64-Bit-Integer Division ca. 4 kB kostet. Daher habe
ich die float64-Bib. so geändert, dass, falls
#define F_PREFER_SMALL_BUT_SLOWER_CODE
oder
#define F_PREFER_SMALLEST_BUT_SLOWEST_CODE
vorhanden ist, eine eigene primitive Division verwendet wird, mit der
man bis zu 4500 Bytes sparen kann. Dann ist die Performance der Division
allerdings nur noch ca. 100 pro Sekunde bei
F_PREFER_SMALLEST_BUT_SLOWEST_CODE oder 250 pro Sekunde bei
F_PREFER_SMALL_BUT_SLOWER_CODE. Auch die math. Fkt. (exp, log, ...) sind
dann langsamer.
Außerdem ergibt in der neuen Version f_sqrt aus einer negativen Zahl
korrekterweise NaN (komplexe Zahlen gibt es hier nicht).
Florian K. wrote:
> man bis zu 4500 Bytes sparen kann. Dann ist die Performance der Division> allerdings nur noch ca. 100 pro Sekunde
Schön wäre es, wenn man dann noch dem AVR-GCC die long long
Grundrechenarten in Assembler unterjubeln könnte.
Das dürfte neben weiterer Codeeinsparung auch das Tempo massiv
beschleunigen.
Peter
Peter Dannegger wrote:
> Schön wäre es, wenn man dann noch dem AVR-GCC die long long> Grundrechenarten in Assembler unterjubeln könnte.>> Peter
hmmm, für + und - sieht das übel aus, weil die nicht beschrieben sind im
avr-Backend, d.h. gcc expandiert den adddi3 in QImode (char). Das Carry
wird dabei in C ausgetextet...
für * und / wird gegen die libgcc2 gelinkt, da könnte man sich evtl.
reinhängen? ZB in __muldi3 aus _muldi3.o?
Ich habe ein paar Kleinigkeiten geändert, damit der Compiler mit 0
Warnings durchläuft. Das meiste waren "differ in signedness" Warnungen,
und eine Funktion die definiert, aber unter Umständen nicht genutzt
wurde.
Getestet ist das ganze aber erst mit:
f_compare
f_abs
f_atof
f_add
f_mult
f_div
f_atof
f_to_string
Vielleicht kann Florian ja mal einen Blick drauf werfen :)
Ich habe die Funktion approx_inverse_of_fixpoint_uint64() noch etwas
optimiert. Sie ist nun bei ca. 3000 Bytes weniger Speicherbedarf so
schnell wie die originale Funktion, wenn F_PREFER_SMALL_BUT_SLOWER_CODE
und F_PREFER_SMALLEST_BUT_SLOWEST_CODE nicht definiert sind. In der
neuen
Version kann nur noch das #define F_PREFER_SMALL_BUT_SLOWER_CODE und
nicht F_PREFER_SMALL_BUT_SLOWER_CODE angegeben werden. Durch #define
F_PREFER_SMALL_BUT_SLOWER_CODE werden weitere 800 Bytes gespart,
allerdings ist dann die Rechenzeit deutlich länger.
Ich habe wieder mehr nach Compilierung unter Visual C++ und weniger
unter einem ATMega32 getestet.
Außerdem habe ich die Änderungen von Stefan P. berücksichtigt.
Ich habe einen bug gefunden. Nach ANSI C/C++ darf man mit << oder >> nur
um eine Bitzahl schieben, die echt kleiner als die Bitlänge des
Operanden ist, ansonsten ist das Ergebnis undefiniert (tatsächlich
bekommt man dann z.B. nach Kompilierung unter Visual C++ andere
Ergebnisse als unter avr-gcc und oftmals nicht das gewünschte Ergebnis).
In zwei Fällen habe ich eine entsprechende Abfrage vergessen (f_exp(),
f_mod_intern()). Der Fehler tritt z.B. bei f_exp(f_from_double(1E-80))
auf, also eher in Spezialfällen. Ich habe die geänderte Datei avr_f64.c
angefügt.
Hallo,
ich habe heute die neue 64-Bit Lib von PeDa mit dem Projekt übersetzt
und das spart einige Bytes.
Alt
20584 bytes
mit der neuen 64-Bit Lib
20118 bytes
http://www.avrfreaks.net/index.php?name=PNphpBB2&file=viewtopic&t=113673
Einfach die Datei dannis64bit.S kopieren und in das Makefile eintragen
- fertig !
Hello
Excuse me for bad english - ( and that i dont khnow German _ but I
translate your page and use it).
GOOD JOB
Thank u very much for your try and building library f64
but
I can not use it
as default i use code vision avr (But i can not use this library in code
vision)
NOW
for this project i add this library to my project In ATMEL STUDIO 6.2
But the compiler not allow me that use this library
for any of functions it has ERROR: Undefined reference to "f_add"
Can you help me?
thank u. Have Good time.
Hallo,
vielen dank für die Lib.
ich habe mal ein paar Stellen korrigiert, bei der ein aktueller gcc
Fehler und Warnungen produzierte, so dass sie sich jetzt wieder
übersetzen lässt.
Die Datei basiert auf der Version von Florian K.
Ich brauche die Präzision nur einmal zum Ausrechnen eines Werts nach
einer einmaligen Kalibrierung. Somit spielt die Geschwindigkeit für mich
keine Rolle.
Was mir persönlich fehlt, wäre eine Funktion um den double64_t direkt in
einen uint64_t zu konvertieren ohne den Umweg über einen float gehen zu
müssen.
Detlef _. schrieb:> Ich würde mich über rege Benutzung und Rückmeldung freuen.
Tolle Arbeit!
Vielen Dank!
Gerade das habe ich gesucht!
Ich finde es nicht normal, daß in GCC double wie float behandelt wird.
Nun kann ich auch bei Messungen double nutzen! Diese Bibliothek sollte
zusammen mit GCC gleich installiert werden!
Einzige Vorschlag: es wäre gut, wenn im Archiv auch die letzte
korrigierte Version von avr_f64.c gleich steht. Sonst will Compiler ohne
das Wort "const" an einigen Stellen nicht arbeiten.
Viele Grüße.
Maxim B. schrieb:> Ich finde es nicht normal, daß in GCC double wie float behandelt wird.
Nicht GCC allgemein, sondern das ist eine Konfiguration von AVR-GCC.
Derjenige, der damals die GCC-Portierung für den AVR vorangetrieben hat,
sah offenbar zum damaligen Zeitpunkt (ist nun fast 20 Jahre her) keinen
großen Sinn darin, auf so einem kleinen Prozessor (das war m. M. n. noch
vor dem Erscheinen eines ATmega128!) solch pompöse Operationen wie
64-Bit-Gleitkomma zu implementieren. Daher hat er alles so verbogen,
dass es auf 32 bit zeigt. Damals gab es sogar noch eine Option -mint8,
bei der alle "int" in 8 bit abgelegt worden sind.
Ja, hätte man sicher anders angehen können, aber wie immer: es lief dann
erstmal, die Leute hatten damit überhaupt Gleitkomma (und zwar mit einem
durchaus passablen memory footprint), und kaum einer hatte mehr Elan,
daran noch was zu ändern.
Hallo,
zuerst mal riesigen Dank an detlef_a und makrokontroller für die lib.
Die verwendeten Algorithmen sind wirklich gut. Ich habe die Lib benutzt,
um einen HP-kompatiblen RPN Rechner zu bauen. Leider kommt man relativ
schnell mit einem AVR328 Mikroprozessor an die 32K-Grenze, trotz aller
Optimierungen. Ich habe dann angefangen, das ein oder andere in
Assembler zu optimieren.
Zum Schluss ist dann eine mehr order weniger math.h- und
avr_f64.c-kompatible Bibliothek herausgekommen, fp64lib, die zu 100% in
Assembler geschrieben ist. Dabei war eure Bibliothek für mich der
"Gold-Standard" um meine Bibliothek zu testen.
Bibliothek ist ab heute unter http://fp64lib.org verfügbar und soll
demnächst auch direkt als "fp64lib" im Arduino-Library-Manager
auftauchen.
Um die Portierung von Code zu erleichtern, der mit avf_f64 geschrieben
wurde, gibt es ein eigenes Header-file "avr_fp64.h", das anstatt von
"avr_f64.h" #included werden soll. Damit werden Calls von f_... Routinen
auf fp64... Routinen umgeleitet. Die Ergebnisse müssen trotzdem
überprüft werden, da fp64lib in Details abweicht (z.B. werden Subnormals
implementiert).
Also nochmal besten Dank für eure Bibliothek, ohne die wäre fp64lib
nicht entstanden!
Uwe B. schrieb:> um einen HP-kompatiblen RPN Rechner zu bauen.
hi, wo finde ich dein project?
die fp64lib gefällt mir sehr und kann ich gerade auch gut gebrauchen, um
eine astronomische berechnung jetzt endlich genauer zu implementieren.
vielen dank!
mt
Hi,
Du findest fp64lib unter https://fp64lib.org. Die lib installierst du
dir am einfachsten direkt in der arduino IDE über den Punkt Bibliothek
einbinden, da sie auch über den arduino library Manager verteilt wird.
Viel Erfolg,
Uwe
fp64lib.h:215:41: warning: 'const' attribute on function returning 'void' [-Wattributes]
2
void __fp64_cordic( void ) __ATTR_CONST__;
Und dann hatte ich ein übles Problem mit den Sections: per default
landen alle Funktionen in Section MLIB_SECTION, was eine Orphan-Section
ist. Diese werden nicht gemäß Linker-Skript lokatiert sondern nach einer
Heuristik. Im konkreten Fall landete der Code nach .text aber vor
.rodata, was bei Devices mit linearem Speichermodell dazu führt, dass
der Offset zwischen diesen beiden Sections nicht mehr 0x4000 ist bzw.
nicht mehr korrekt vom Linker bestimmt werden kann. Resultat ist, dass
Konstanten von falschen Adressen gelesen werden.
M.E. ordnet man die Sections am besten fest an, z.B. .text.libfp64.sqrt
oder .text.libfp64.asm.fp64_sqrt für fp64_sqrt; auf jeden Fall aber mit
Präfix ".text."
Uwe B. schrieb:> Für welchen Prozessor hast du das compiliert?
Für avr{5,51,6}, avrxmega{2,3,4,5,6,7} aber ohne -mmcu=avrxmega3
-mshort-calls.
Eine wirkliche Core-Abhängigkeit hat man ja nicht: MUL und MOVW sind
vorhanden, weil Du enhanced Core forderst. Ansonsten unterscheiden sich
die Cores nur darin, ob sie CALL / JMP haben.
Noch eine allgemeine Frage zu pi: Du verwendest
Wikipedia ist absolut korrekt. Der Unterschied kommt aus dem Standard
52(53)-bit Signifikand einer IEEE 754 64-bit Zahl:
PI/2 ist gepackt 0x3f f9 21 fb 54 44 2d 18
Ausgepackt ergibt das genau die Bytefolge mit C0:
__pi_o_2: .byte 0xC9, 0x0F, 0xDA, 0xA2, 0x21, 0x68, 0xC0
Natürlich hätte man ausgepackt 3 Bits mehr zur Verfügung, d.h. aus C0
könnte man jetzt C2 machen.
Ich prüfe mal, ob das negative Seiteneffekte hat, wenn ich das auf C2
ändere, was durchaus sein kann, denn da wo PI/2 benutzt wird, wird das
Argument von sin(x) auf den Bereich 0-PI/2 reduziert und das Vorzeichen
bestimmt. Und x kommt ja nur mit 53-bit Genauigkeit rein. Da könnte ein
Vergleich mit einer Zahl mit 56-bit Genauigkeit Fehler verursachen, denn
auf einmal ist PI/2 < PI/2, da 0xC0 < 0xC2.
Ich hab's überprüft, und tatsächlich ergeben sich Fehler. Mit der
"C2-Variante" ist auf einmal sin(PI) 1.11E-16 und SIN(2*PI) -2.22E-16,
während in der "C0-Variante" beides exakt 0 ergibt. Danke für's
kritische Überprüfen, ich werde im nächsten Release einen entsprechenden
Kommentar einfügen.
Uwe B. schrieb:> Ich hab's überprüft, und tatsächlich ergeben sich Fehler. Mit der> "C2-Variante" ist auf einmal sin(PI) 1.11E-16 und SIN(2*PI) -2.22E-16,
Das soll doch so sein (sic!):
Bei sin(PI) enthält PI nicht den Wert π (pi) sondern zwangsläufig eine
Näherung. Ist PI 0xC90FDAA22168C, dann ist dieser Wert etwa
0x00000000000002 kleiner als π, d.h. sin(PI) ist effektiv ca.
sin (π - 2^{-53}) ~ 2^{-53} ~ 1.11E-16 (wegen sin'(pi) = -1)
Für sin(PI) als Ergebnis 0 zurückzuliefern sieht zunächst besser aus,
ist aber schlechter als der exaktere Wert 2^{-53}. Und bei sin(2·PI)
ist 0 schon doppelt so weit vom korrekten Ergebnis weg.
> während in der "C0-Variante" beides exakt 0 ergibt.
Johann L. schrieb:> ist aber schlechter als der exaktere Wert 2^{-53}. Und bei sin(2·PI)> ist 0 schon doppelt so weit vom korrekten Ergebnis weg.
Das Problem ist die Interpretation von “exakt“. Eine Fließpunktzahl
repräsentiert nicht nur eine Näherung, sondern ein komplettes Intervall
von Zahlen: [x-1/2ulp, x+1/2ulp), wobei ulp die niedrigwertigste Stelle
ist. Und das Ergebnis einer Funktion sollte dieses Intervall
berücksichtigen.
Daher ist sin(PI)=~2^{-53} nicht “exakter“ als sin(PI)=0. Vielmehr
berücksichtigt die momentane Umsetzung, dass der exakte Wert von pi in
dem Intervall liegt, und 0 daher ein valides Ergebnis ist.
Ein weitere Punkt für die Beibehaltung ist die Erwartbarkeit bei
typischen Einsatzgebieten. Wenn es um die Rechnung mit GPS-Koordinaten
oder die Bestimmung von Sternpositionen, liegen die Rohdaten in Grad
(0-360 oder -180 - +180) vor. Da fp64lib nur Bogenmaß “versteht“, muss
umgerechnet werden. Da wäre es unerwartet, wenn aus einem tatsächlich
exakten sin(180Grad)=0 ein sin(PI)=1,11E-16 wird, denn die Umrechnung
(x/180*PI) liefert ja die bestmögliche Näherung für pi.
Apollo M. schrieb:> und wo findet man dein "HP-kompatiblen RPN Rechner" project?
Noch nirgends. Unter fp64lib.org findest du ein Bild und etwas dazu
hinter history, aber ich habe erst jetzt wieder angefangen, den weiter
zu entwickeln. Wird wohl noch ein paar Wochenenden dauern :-)
Uwe B. schrieb:> Johann L. schrieb:>> ist aber schlechter als der exaktere Wert 2^{-53}. Und bei sin(2·PI)>> ist 0 schon doppelt so weit vom korrekten Ergebnis weg.>> Das Problem ist die Interpretation von “exakt“. Eine Fließpunktzahl> repräsentiert nicht nur eine Näherung, sondern ein komplettes Intervall> von Zahlen: [x-1/2ulp, x+1/2ulp), wobei ulp die niedrigwertigste Stelle> ist. Und das Ergebnis einer Funktion sollte dieses Intervall> berücksichtigen.>> Daher ist sin(PI)=~2^{-53} nicht “exakter“ als sin(PI)=0. Vielmehr> berücksichtigt die momentane Umsetzung, dass der exakte Wert von pi in> dem Intervall liegt, und 0 daher ein valides Ergebnis ist.
Da hab ich immer noch ein Verständnisproblem:
IEEE legt doch als Ergebnis einer Operation folgendes fest:
1) Korrektes Ergebnis berechnen
2) Gemäß Rounding-Mode runden:
>> "Each of the computational operations that return a numeric>> result specified by this standard shall be performed as if it>> first produced an intermediate result correct to infinite>> precision and with unbounded range, and then rounded that>> intermediate result, if necessary, to fit in the destination's>> format"
Im Falle von PI = 0xC90FDAA22168C ist das korrekte Ergebnis ca. y =
1.225E-16 ~ 1.1*2^{-53}. Die Mantisse hat 53 Bits. Der relative
Fehler, der durch Rundung bedingt ist, wird also nicht größer als
2^{-54}. Umgerechnet in absoluten Fehler macht das ca. 2^{-53} *
2^{-54} = 2^{-107}.
Die Null ist in diesem Intervall nicht enthalten, d.h. Null für
sin(0xC90FDAA22168C) zurückzugeben entspricht nicht IEEE. Oder wo ist
da mein Verständnisproblem?
Johann L. schrieb:> IEEE legt doch als Ergebnis einer Operation folgendes fest:>> 1) Korrektes Ergebnis berechnen>> 2) Gemäß Rounding-Mode runden:> [...]> Die Null ist in diesem Intervall nicht enthalten, d.h. Null für> sin(0xC90FDAA22168C) zurückzugeben entspricht nicht IEEE. Oder wo ist> da mein Verständnisproblem?
Dein Verständnis und das daraus abgeleitete Ergebnis ist absolut
korrekt, wenn du das Argument PI = 0xC90FDAA22168C als einen exakten
Wert betrachtest.
Man kann das Argument aber auch als Intervall betrachten, d.h. PI =
[0xC90FDAA22168B8, 0xC90FDAA22168C7) (hier mal nur 1 Stelle rangehängt,
geht natürlich beliebig weiter mit 0 bzw. F). Alle Zahlen in diesem
Intervall werden zu PI = 0xC90FDAA22168C gerundet. In diesem Intervall
ist auch die "exaktere" Näherung PI = 0xC90FDAA22168C2 enthalten.
Wenn du jetzt sin(PI) für das Intervall berechnest, erhältst du ein
Intervall, das ungefähr von 1.7E-16 (für 0xC90FDAA22168B8) bis -0.6E-17
(für 0xC90FDAA22168C7) gehen müsste (weiß nicht, ob die Zahlen genau
stimmen, da ich momentan unterwegs bin mit beschränktem Equipment). In
diesem Intervall liegt 0 als Ergebnis.
Bzgl. Intervallbetrachtung gibt es im "Handbook of Floating-Point
Arithmetic" von Jean-Michel Muller et.al. einige interessante Kapitel.
Insbesondere ist das wichtig bei der Umwandlung von/zum Dezimalsystem.
Es bleibt aber klar ein Widerspruch mit dem von dir zitierten Grundsatz
von IEEE 754
>>>>1) Korrektes Ergebnis berechnen>>>>2) Gemäß Rounding-Mode runden:
Wahrscheinlich ist der Grundsatz auch höher zu werten. Zumindest spricht
dafür, dass z.B. python3 auf x86 ebenfalls 1.2E-16 zurückliefert:
1
>>> format(math.pi,'.20f')
2
'3.14159265358979311600'
3
>>> math.sin(math.pi)
4
1.2246467991473532e-16
Werde da noch etwas recherchieren, ob ich die bisherige
Interpretation/Umsetzung ändere.
Uwe B. schrieb:> Johann L. schrieb:>> IEEE legt doch als Ergebnis einer Operation folgendes fest:>>>> 1) Korrektes Ergebnis berechnen>>>> 2) Gemäß Rounding-Mode runden:>> [...]>> Die Null ist in diesem Intervall nicht enthalten, d.h. Null für>> sin(0xC90FDAA22168C) zurückzugeben entspricht nicht IEEE. Oder wo ist>> da mein Verständnisproblem?>> Dein Verständnis und das daraus abgeleitete Ergebnis ist absolut> korrekt, wenn du das Argument PI = 0xC90FDAA22168C als einen exakten> Wert betrachtest.
Ein Wert ist ein Wert ist ein Wert :-)
> Man kann das Argument aber auch als Intervall betrachten, d.h. PI => [0xC90FDAA22168B8, 0xC90FDAA22168C7) (hier mal nur 1 Stelle rangehängt,> geht natürlich beliebig weiter mit 0 bzw. F). Alle Zahlen in diesem> Intervall werden zu PI = 0xC90FDAA22168C gerundet. In diesem Intervall> ist auch die "exaktere" Näherung PI = 0xC90FDAA22168C2 enthalten.>> Wenn du jetzt sin(PI) für das Intervall berechnest, erhältst du ein> Intervall, das ungefähr von 1.7E-16 (für 0xC90FDAA22168B8) bis -0.6E-17> (für 0xC90FDAA22168C7) gehen müsste (weiß nicht, ob die Zahlen genau> stimmen, da ich momentan unterwegs bin mit beschränktem Equipment). In> diesem Intervall liegt 0 als Ergebnis.
Die Wert = Intervall Interpretation von IEEE wird aber schnell
problematisch, z.B. wenn wir Cosecans statt Sinus nehmen. Das Bild des
Intervalls ist dann ganz R weil csc in pi einen einfachen Pol hat. Nach
deiner Logik wäre es also korrekt, für csc(PI) irgendeine beliebige
Zahl als Ergebnis zuliefern. Oder +Inf. Oder -Inf.
> Wahrscheinlich ist der Grundsatz auch höher zu werten. Zumindest spricht> dafür, dass z.B. python3 auf x86 ebenfalls 1.2E-16 zurückliefert:>
1
>>>> format(math.pi,'.20f')
2
> '3.14159265358979311600'
3
>>>> math.sin(math.pi)
4
> 1.2246467991473532e-16
5
>
Dies gehört eben zu den Eigenarten dieser Arithmetik, genauso wie sie
weder assoziativ noch distributiv ist. M.E. ist es vergebens, zu
versuchen, in einer Implementation da drumrum programmieren zu wollen.
In vergleichbar gelagerten Fällen wie sqrt(2)^2 oder exp(log(2)) kommt
evtl. auch was anderes raus als ein Anwender erwartet oder als natürlich
empfindet. Das Problem ist dann aber auf Seiten des Anwenders.
Johann L. schrieb:> Die Wert = Intervall Interpretation von IEEE wird aber schnell> problematisch, z.B. wenn wir Cosecans statt Sinus nehmen. Das Bild des> Intervalls ist dann ganz R weil csc in pi einen einfachen Pol hat. Nach> deiner Logik wäre es also korrekt, für csc(PI) irgendeine beliebige> Zahl als Ergebnis zuliefern. Oder +Inf. Oder -Inf.
In der Tat muss für jede Funktion genau geschaut werden, wie die
Spezialfälle gehandhabt werden. Es geht nicht darum, irgendeinen,
beliebigen Wert zurückzuliefern, sondern einen sinnvollen. Bei den
Polstellen, z.B. csc(PI) oder TAN(PI/2) wird daher oft NaN
zurückgeliefert, da +Inf genau so falsch wäre wie -Inf oder wie jede
andere Zahl.
> Dies gehört eben zu den Eigenarten dieser Arithmetik, genauso wie sie> weder assoziativ noch distributiv ist. M.E. ist es vergebens, zu> versuchen, in einer Implementation da drumrum programmieren zu wollen.
Ganz im Gegenteil: eine sorgfältige Umsetzung muss mit den Eigenarten
dieser Arithmetik so umgehen, dass sie unerwartete Effekte minimiert.
> In vergleichbar gelagerten Fällen wie sqrt(2)^2 oder exp(log(2)) kommt> evtl. auch was anderes raus als ein Anwender erwartet oder als natürlich> empfindet. Das Problem ist dann aber auf Seiten des Anwenders.
Ich glaube, der Vergleich mit assoziativ/distributiv passt nicht, denn
es geht ja hier (und auch bei der sin(PI)) um Funktionen und ihre
Umkehrfunktion, und da ist der Anspruch schon, dass f_inv(f(x))=x ist.
Bzgl. sin ist bei der jetzigen Implementierung asin(sin(PI))=0, was
korrekt und exakt ist (wg. PI mod PI = 0).
Aber wie gesagt: danke für den Hinweis bzgl. PI/2. Du hast mich auf
einen interessanten Konflikt aufmerksam gemacht, ich fand sie Diskussion
darüber gut. Ich werde da noch ein wenig recherchieren - die evtl.
notwendige Anpassung ist ja dann einfach und schnell durchgeführt.
Inzwischen hab ich asin implementiert und kann so zumindest halbwegs die
Genauigkeit der Ergebnisse messen, und zwar gemäß
f_inv(f(x)) ~ x
mit f in { asin, atan, log, exp, sqrt } sowie f und f_inv jeweils aus
der gleichen Implementierung (z.B. fp64lib).
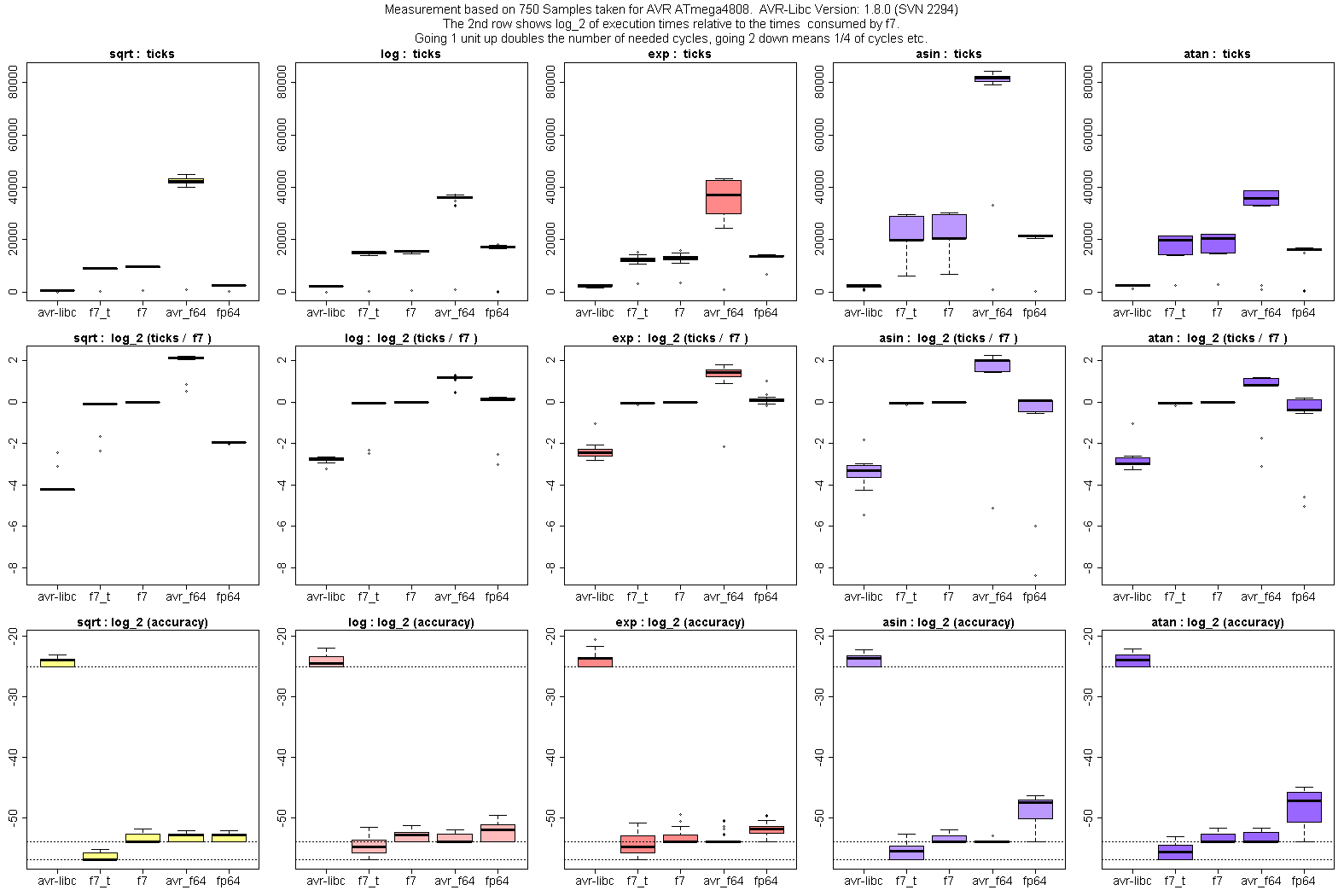
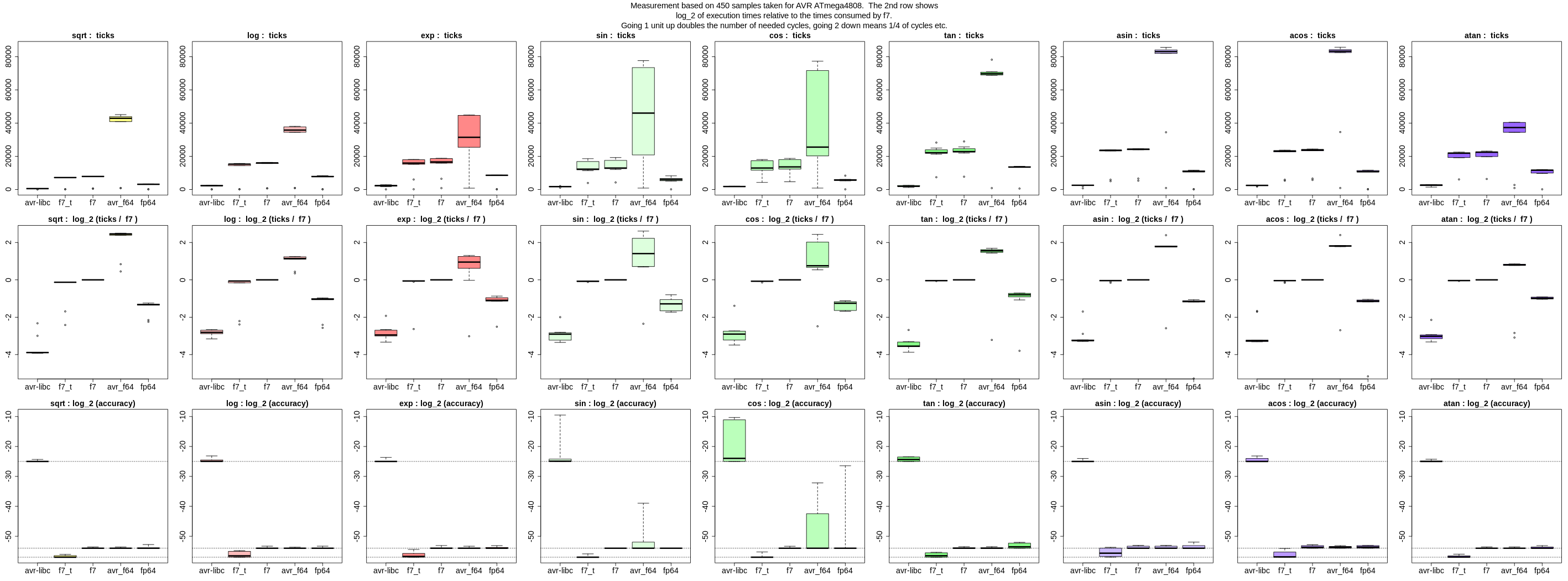
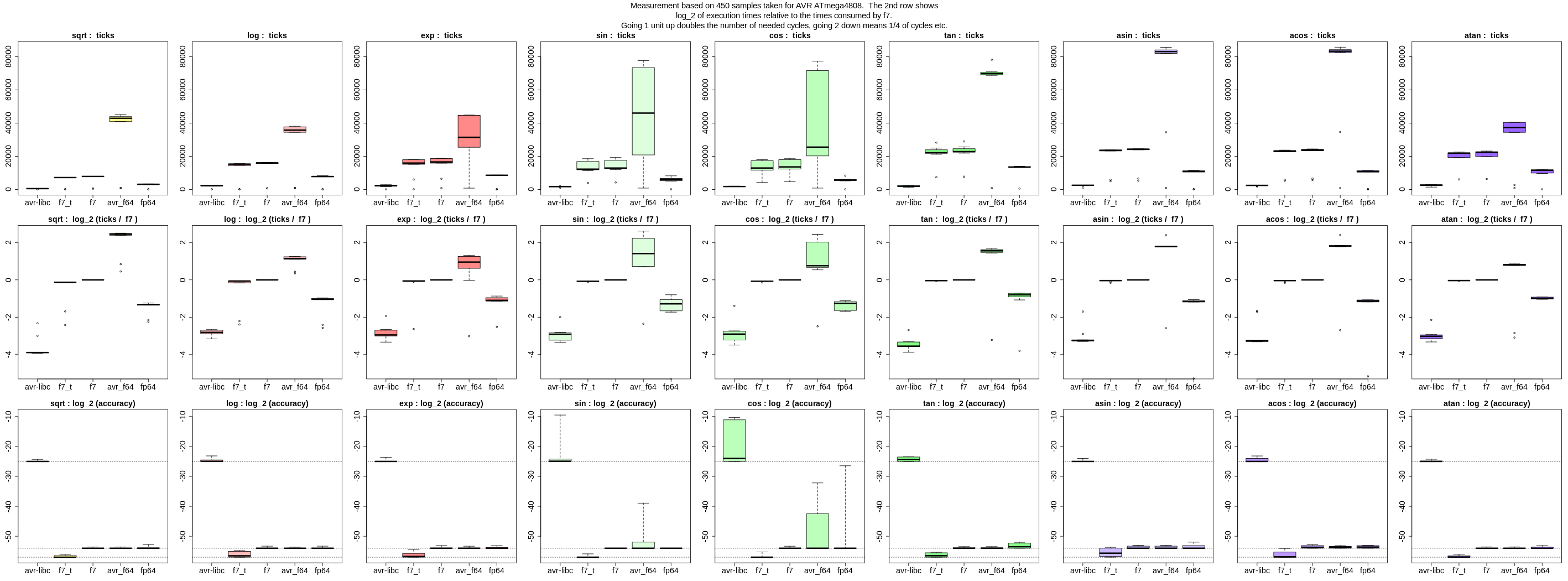
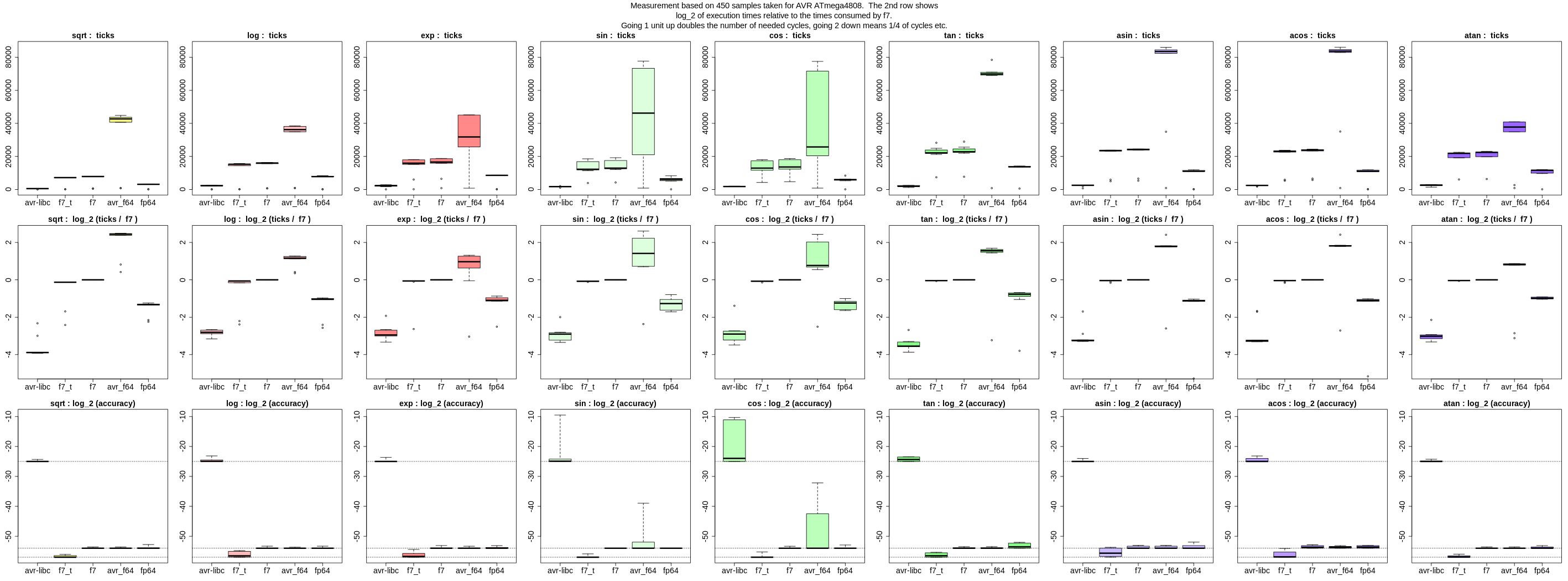
Die Genauigkeit ist in den Diagrammen der unteren Zeile zu sehen, bzw.
log_2 davon, also Bits an relativer Genauigkeit. fp64lib hat Label
"fp64".
Nach unten hin habe ich die Ergebnisse auf -54 saturiert (gestrichelte
Linie), weil man mit 53-Bit Mantisse und Rundung das Ergebnis bis auf
1/2 LSB kennt. (Für die avr-libc / float ist die Linie bei -25, für
meine f7_t mit 56-Bit Mantisse bei -57).
Vor paar Wochen hatte ich eine double-Implementierung (C + (inline) Asm)
für AVR angefangen weil ich evtl. standardkonformen double-Support in
die avr-Tools einbauen will wenn die Zeit es zulässt.
Mein Favorit ist momentan deine fp64lib: die Implementierung scheint
i.w. vollständig und hat vernünftige Performance. Wenn Routinen fehlen
hab ich auch kein Problem damit, wenn die Tools nicht linken und zB.
fehlende Multiplikation für Devices ohne MUL anmeckern (wer sowas will
kann die __muldf3 selbst implementieren und sein Code dagegen linken).
Was ich momentan nicht beurteilen kann ist ob es von der Lizenz passen
würde und wie gut der Code von anderen Entwlicklern zu supporten wäre
falls es Probleme gibt.
Johann L. schrieb:> Vor paar Wochen hatte ich eine double-Implementierung (C + (inline) Asm)> für AVR angefangen weil ich evtl. standardkonformen double-Support in> die avr-Tools einbauen will wenn die Zeit es zulässt.
Gute Übersicht - könntest du die noch erweitern um den Platzbedarf?
Interessant ist, dass die Geschwindigkeit von fp64lib gut mithalten
kann, obwohl ich für minimalen Code optimiert habe. Aber bzgl.
Genauigkeit muss ich mir tan/atan mal genauer anschauen, wo der Fehler
herkommt. Bei Cordic ist ja eine atan-table die Grundlage, daher sollte
atan sehr genau sein. Und intern wird mit 64 Bit gerechnet, so dass
selbst mit dem Cordic-Verlust von ~5 Bit bei 53 Schritten noch mehr als
53 Bits übrig bleiben.
Mich würden deine f7-Algorithmen interessieren: hast du Taylor, Padé
oder Chebyshev genommen? Und mit wie viel Bits hast du intern gerechnet?
>> Mein Favorit ist momentan deine fp64lib: die Implementierung scheint> i.w. vollständig und hat vernünftige Performance. Wenn Routinen fehlen> hab ich auch kein Problem damit, wenn die Tools nicht linken und zB.> fehlende Multiplikation für Devices ohne MUL anmeckern (wer sowas will> kann die __muldf3 selbst implementieren und sein Code dagegen linken).
Danke für die Blumen. Geschwindigkeit stand ja nicht im Fokus, sondern
minimaler Platzbedarf. Ich habe ebenfalls bewusst die Devices ohne MUL
nicht unterstützt, da in die 8KB eines ATTiny schon float Probleme
erzeugt. Falls noch mathematische Routinen fehlen, unterstützte ich
gern.
>> Was ich momentan nicht beurteilen kann ist ob es von der Lizenz passen> würde und wie gut der Code von anderen Entwlicklern zu supporten wäre> falls es Probleme gibt.
Meine Lizenz ist 1:1 dieselbe wie von AVR-Libc, habe die bewusst
genommen, um später die Integration in die AVR-Standards zu ermöglichen.
Sollte also kein Problem sein.
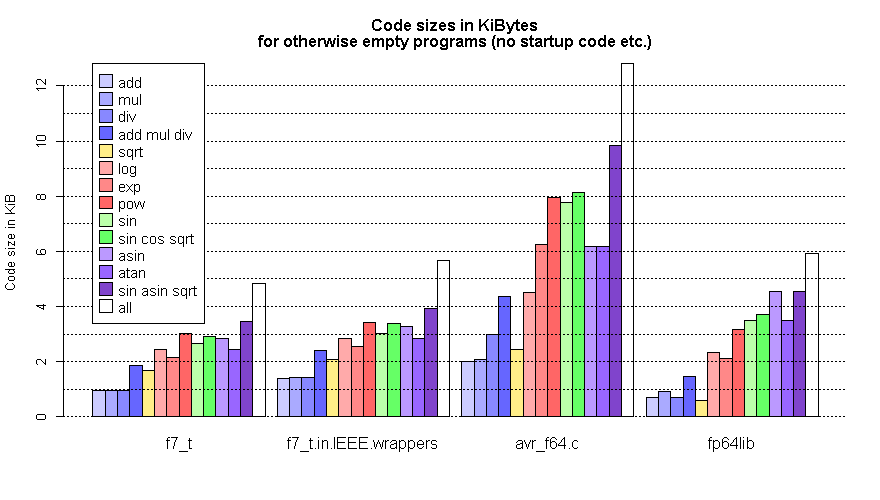
Uwe B. schrieb:> Gute Übersicht - könntest du die noch erweitern um den Platzbedarf?
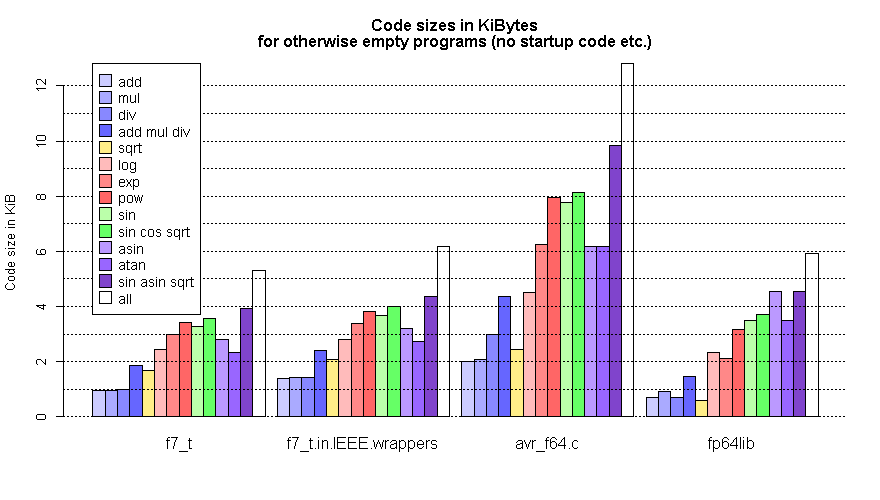
Siehe Grafik. Übersetzt wurde mit
-Os -mcall-prologues -mstrict-X
-ffunction-sections -fdata-sections -Wl,--gc-sections -mrelax
-nostartfiles -Wl,--defsym,main=0
und -Wl,-u<func> für die zu bewertende(n) Funktion(en).
> Interessant ist, dass die Geschwindigkeit von fp64lib gut mithalten> kann, obwohl ich für minimalen Code optimiert habe.
Ist eben Assembler; die Geschwindigkeit wird da durch die Algorithmen
bestimmt, weniger durch die konkrete Umsetzung — wobei ich nicht die
teilweise exorbitanten Zeiten von avr_f64.c untersucht habe; jedenfalls
ist deren Code durch uint64_t extrem aufgeblasen...
> Mich würden deine f7-Algorithmen interessieren: hast du Taylor, Padé> oder Chebyshev genommen? Und mit wie viel Bits hast du intern gerechnet?
Die Basis-implementierung auf den Mantissen ist 58..64 Bit; bei Division
z.B. 58 Bits (7*8 Bits Mantisse + 1 Bit für Rundung + 1 Bit für
Normalisierung).
Ergebnisse der Routinen wie Addition (f7_add), Division (f7_div) etc.
sind aber alle f7_t (56-Bit Mantisse), und alle darauf aufbauenden
Routinen wie Quadratwurzel, Horner, exp, sin, asin, atan etc. rechnen
intern mit solchen Zwischenergebnissen und verwenden auch f7_t zur
Parameterübergabe. Dito für Darstellung von Konstanten wie pi oder ln2.
Algorithen:
Quadratwurzel: Newton-Raphson. Startwert sqrt(uint16_t) + 3
Iterationen.
sin: Taylor Grad 17 um 0 (9 Terme), Intervall [0, pi/4]
cos: Taylor Grad 16 um 0 (9 Terme), Intervall [0, pi/4]
exp: Taylor Grad 8 um 0 (9 Terme), |x| < ln2 / 16 ~ 0.044
ln: artanh Taylor Grad 19 um 0 (10 Terme), |x| <= (sqrt2 - 1) / (sqrt2 +
1) ~ 0.172
atan: Padé [9/10] um 0 (11 Terme), |x| < 2 - sqrt3 ~ 0.268. Oder auf
dem gleichen Intervall atan(sqrt)/sqrt rationale [4/4] (10 Terme),
vermutlich MiniMax, von
Beitrag "Re: Näherung für ArcusTangens?"
asin/acos: func_a Padé [7/7] um 0 (16 Terme), x in [0, 1/2] mit
func_a(x) = acos(1-x) / sqrt(2x). Mit einer rationalen MiniMax könnte
man die Grade bestimmt noch reduzieren, ich hab aber keine
Implementierung, die rationale MiniMax berechnen kann.
> Ich habe ebenfalls bewusst die Devices ohne MUL nicht unterstützt,> da in die 8KB eines ATTiny schon float Probleme erzeugt.
Na, da geht schon einiges. Siehe zum Beispiel [[4000 Stellen von Pi mit
ATtiny2313]]
> Meine Lizenz ist 1:1 dieselbe wie von AVR-Libc, habe die bewusst> genommen, um später die Integration in die AVR-Standards zu ermöglichen.> Sollte also kein Problem sein.
Für avr-gcc würde eher GPL + Runtime-Exception passen. Problem mit der
avr-libc ist aber erst mal technischer Natur, weil 1) die math.h nicht
passt und 2) die avr-libc die Multilib-Struktur hartcodiert statt
1
avr-gcc --print-multi-lib
zu verwenden. Das bedeutet dann, dass jede Anpassung der
Multilib-Struktur (wie z.B. bei Support von avrxmega3) in die avr-libc
händlisch reingeklöppelt werden muss, teilweise abhängig von der
Compilerversion...
Johann L. schrieb:> Siehe Grafik. Übersetzt wurde mit> [...]> und -Wl,-u<func> für die zu bewertende(n) Funktion(en).
Danke! Falls kein Fehler in der Auswertung ist, musst du ja
höchst-kompakte Umsetzungen für Taylor und Padé haben, denn deine
kombinierte sin/asin/sqrt ist ja kaum 600 Byte (per Augenintegral
geschätzt) größer als sin allein.
> teilweise exorbitanten Zeiten von avr_f64.c untersucht habe; jedenfalls> ist deren Code durch uint64_t extrem aufgeblasen...
Stimmt, hier kommt aber auch die Kombination gcc und AVR an ihre
Grenzen, teilweise durch die Hardware (fast keine Befehle, die mehr als
ein Register betreffen), teilweise durch die Konfiguration des ABIs, das
(natürlich) mehr auf die kleineren Datentypen ausgelegt ist.
> Die Basis-implementierung auf den Mantissen ist 58..64 Bit; bei Division> z.B. 58 Bits (7*8 Bits Mantisse + 1 Bit für Rundung + 1 Bit für> Normalisierung).
Das erklärt die höhere Genauigkeit. Außer bei Multiplikation (72 bit)
ist die Basisroutinen bei mir immer 56 Bit (7*8 Bit) (+16 bit für
Exponenten).
> Ergebnisse der Routinen wie Addition (f7_add), Division (f7_div) etc.> sind aber alle f7_t (56-Bit Mantisse), und alle darauf aufbauenden> Routinen wie Quadratwurzel, Horner, exp, sin, asin, atan etc. rechnen> intern mit solchen Zwischenergebnissen und verwenden auch f7_t zur> Parameterübergabe. Dito für Darstellung von Konstanten wie pi oder ln2.
Gleiches bei fp64lib bei den Basis-Routinen, bei den komplexeren
Routinen nutze ich oft nur die Standard IEEE 754-Darstellung (64-bit)
zur Übergabe, da ich dadurch auch wieder Flash-Platz sparen konnte -
natürlich zu Lasten der Genauigkeit.
> exp: Taylor Grad 8 um 0 (9 Terme), |x| < ln2 / 16 ~ 0.044
Das ist ja ein relativ kleines Intervall und ein kurzes Polynom. Wie
reduzierst bzw. expandierst du da und hältst den Fehler unter Kontrolle
für |x| > ln2/16, insbesondere |x| > 1? float32 braucht für seine 24 bit
schon 7 Terme für |x|<1, ich habe wg. der. einfacheren Skalierung
(Platzbedarf) |x| < ln2 genommen und brauchte 17 Terme, damit auch im
Worst-Case (300 < |x| < 700) die Genaugkeit noch einigermaßen ist.
> Das bedeutet dann, dass jede Anpassung der> Multilib-Struktur (wie z.B. bei Support von avrxmega3) in die avr-libc> händlisch reingeklöppelt werden muss, teilweise abhängig von der> Compilerversion...
Es gibt definitiv schönere Arbeiten! Und so viel tut sich ja auf der
Projektseite von avr-libc auch nicht mehr, als dass man von dort auf
Unterstützung hoffen könnte :-(
Uwe B. schrieb:> Und so viel tut sich ja auf der Projektseite von avr-libc auch nicht> mehr, als dass man von dort auf Unterstützung hoffen könnte :-(
Unabhängig von der Projektseite: außer Johann gibt es dort wohl einfach
niemanden, der überhaupt dazu in der Lage wäre, derartiges zu
implementieren.
Aber ich würde mich natürlich freuen, wenn es mehr aktive Beteiligung am
Projekt gäbe … Mit 0,01 Entwicklern (also derzeit nur mich mit 1 %
meiner Zeit) ist nicht viel zu reißen.
Jörg W. schrieb:> Aber ich würde mich natürlich freuen, wenn es mehr aktive Beteiligung am> Projekt gäbe … Mit 0,01 Entwicklern (also derzeit nur mich mit 1 %> meiner Zeit) ist nicht viel zu reißen.
Auch wenn 1% deiner Zeit und Johanns Zeit deutlich mehr bringt als von
vielen anderen, ist mir klar, dass das keine stabile Lösung ist und dass
es breiteres Engagement braucht...
Hier ein Patch damit avr-gcc 64-bit double unterstützt. configure mit
--with-double64 und dann mit -mdouble64 compilieren.
Aber Obacht: die avr-libc und deren math.h passen nicht zu diesem
Compiler. double64-Multilibs werden nur für Cores erzeugt, die MUL
unterstützen. Mit dem Patch werden (teilweise) libgcc Funktionen für
double generiert, falls diese unerwünscht sind müsste man die händisch
per objcopy o.ä. entfernen.
Falls man eine eigene Funktion einklinken will, dann so:
Mit double a + b bekommt man dann einen Fehler vom Linker weil __adddf3
fehlt. Hat man eine eigene Implementierung my_add mit korrektem ABI,
dann kann man diese nutzen per -Wl,--defsym,__adddf3=my_add.
Uwe B. schrieb:> Johann L. schrieb:>> Siehe Grafik. Übersetzt wurde mit>> [...]>> und -Wl,-u<func> für die zu bewertende(n) Funktion(en).>> Danke! Falls kein Fehler in der Auswertung ist, musst du ja> höchst-kompakte Umsetzungen für Taylor und Padé haben, denn deine> kombinierte sin/asin/sqrt ist ja kaum 600 Byte (per Augenintegral> geschätzt) größer als sin allein.
Basiert eben alles auf Polynomen; die auszuwerten ist ja nicht sooo
aufwändig wenn man die Basisarithmetik erst mal hat. Der rest sind dann
Fallunterscheidungen bei sin etc. Und Wurzel ist Newton; macht sie zwar
langsam aber es verwendet eben nur Grundarithmetik. (add + div).
>> Die Basis-implementierung auf den Mantissen ist 58..64 Bit; bei Division>> z.B. 58 Bits (7*8 Bits Mantisse + 1 Bit für Rundung + 1 Bit für>> Normalisierung).>> Das erklärt die höhere Genauigkeit.
Glaub ich eigentlich nicht; bei mir sind ja auch alle Zwischenergebnisse
56-Bit Mantisse. Und was Genauigkeit angeht, machen bei Grundarithmetik
alle Implementationen eine Punktlandung; siehe Anhang.
>> exp: Taylor Grad 8 um 0 (9 Terme), |x| < ln2 / 16 ~ 0.044>> Das ist ja ein relativ kleines Intervall und ein kurzes Polynom. Wie> reduzierst bzw. expandierst du da und hältst den Fehler unter Kontrolle> für |x| > ln2/16, insbesondere |x| > 1? float32 braucht für seine 24 bit> schon 7 Terme für |x|<1, ich habe wg. der. einfacheren Skalierung> (Platzbedarf) |x| < ln2 genommen und brauchte 17 Terme, damit auch im> Worst-Case (300 < |x| < 700) die Genaugkeit noch einigermaßen ist.
Getestet hab ich nur für halbwegs zivile Exponenten — Werte sind
randomisiert aber natürlich identisch für alle Implementationen.
Inzwischen bin ich auf |x| < ln2 / 8 umgestiegen, Grad 8 MiniMax.
Johann L. schrieb:> Hier ein Patch damit avr-gcc 64-bit double unterstützt. configure mit> --with-double64 und dann mit -mdouble64 compilieren.>> Aber Obacht: die avr-libc und deren math.h passen nicht zu diesem> Compiler. double64-Multilibs werden nur für Cores erzeugt, die MUL> unterstützen. Mit dem Patch werden (teilweise) libgcc Funktionen für> double generiert, falls diese unerwünscht sind müsste man die händisch> per objcopy o.ä. entfernen.
Anbei eine erweiterte Version des GCC Patches, der auch
--with-long-double64 anbietet, so dass nur long double ein 64-Bit Typ
ist:
1
configure | compile | float | double | long double
Eine Einschränkung auf Devices mit MUL gibt es nicht mehr: Beim Build
werden einfach die libgcc.a in die Multilib-Verzeichnisse double64 (bei
--with-double64) bzw. long-double64 (mit --with-long-double64) kopiert.
Damit ist der Build dann nicht langsamer als sonst obwohl sich die
Anzahl der Multilibs verdoppelt hat. Annahme ist weiterhin, dass alles
DFmode Zeug (also 64-Bit double und 64-Bit long double) extern gehostet
wird, also z.B. avr-libc oder Implementation des Anwenders.
> Falls man eine eigene Funktion einklinken will, dann so:>> Mit double a + b bekommt man dann einen Fehler vom Linker weil __adddf3> fehlt. Hat man eine eigene Implementierung my_add mit korrektem ABI,> dann kann man diese nutzen per -Wl,--defsym,__adddf3=my_add.
Geht mit --with-long-double64 genauso, nur dass man eben long double a +
b braucht. Mit double a + b wird weiterhin __addsf3 referenziert, d.h.
die gleichen Funktionen wie mit float.
--with-long-double64 hat den Vorteil, dass double weiterhin ein 32-Bit
Typ ist und damit nicht mit avr-libc und math.h etc. kollidiert.
Weil der Build der libgcc so lange dauert, kann man auch configure
--with-fixed-point=no angeben, so dass die libgcc ohne die tausende
Fixed-Point Funktionen generiert wird, was den Build- bzw.
Entwicklungsprozess deutlich schneller macht.
Johann L. schrieb:> Anbei eine erweiterte Version des GCC Patches, der auch> --with-long-double64 anbietet, so dass nur long double ein 64-Bit Typ> ist:> [...]> Geht mit --with-long-double64 genauso, nur dass man eben long double a +> b braucht. Mit double a + b wird weiterhin __addsf3 referenziert, d.h.> die gleichen Funktionen wie mit float.>> --with-long-double64 hat den Vorteil, dass double weiterhin ein 32-Bit> Typ ist und damit nicht mit avr-libc und math.h etc. kollidiert.
Wow, super! Ist eine sehr smarte Lösung, da es eine Menge Avr-Code gibt,
die unreflektiert double statt float nutzen und die mit dem Patch keine
Probleme bekommen. Und wer long double benutzt, weiß was er will.
Uwe B. schrieb:> bzgl. Genauigkeit muss ich mir tan/atan mal genauer anschauen,> wo der Fehler herkommt. Bei Cordic ist ja eine atan-table die> Grundlage, daher sollte atan sehr genau sein. Und intern wird mit> 64 Bit gerechnet, so dass selbst mit dem Cordic-Verlust von ~5 Bit> bei 53 Schritten noch mehr als 53 Bits übrig bleiben.
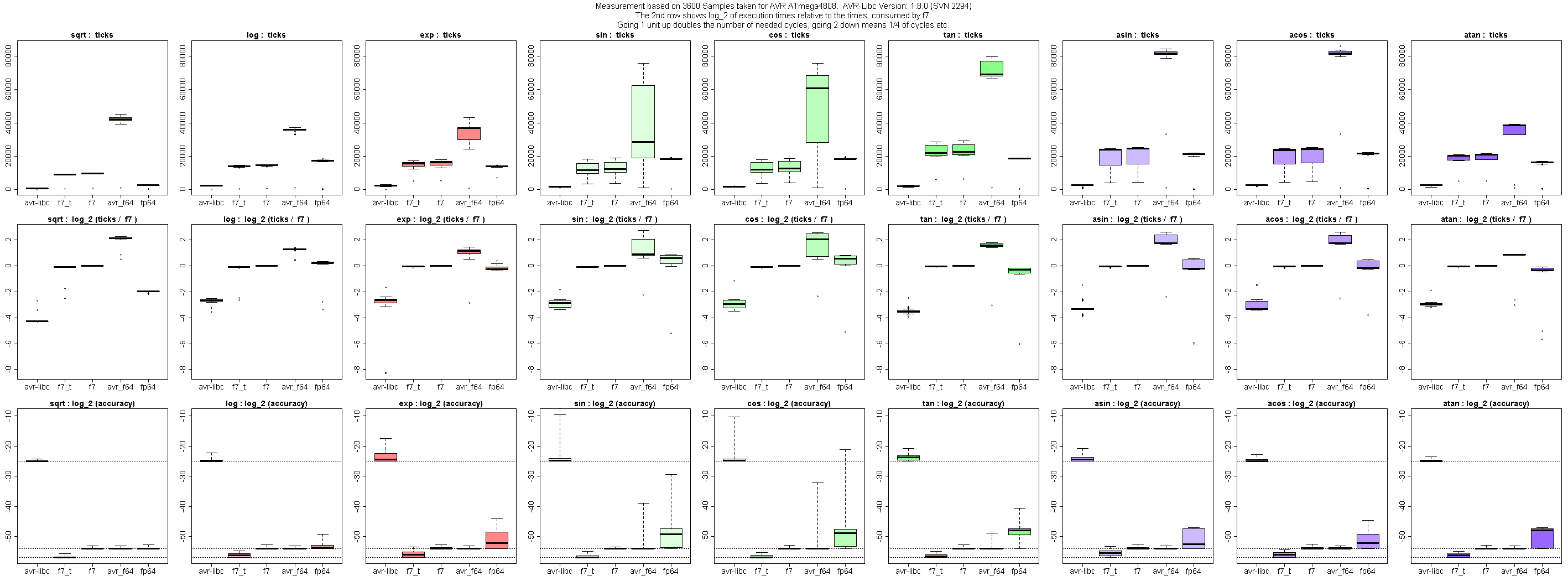
Hi, inzwischen hab ich die Beurteilung der Genauigkeit vom AVR zum PC
verlagert, so dass ich nicht mehr darauf angewiesen bin per f^-1 o f zu
werten. Stattdessen kommt natürlich Host-Arithmetik zum Einsatz.
Hier ein paar Findings bzgl. fp64lib:
Genauigkeit von sin / cos scheint vor allem durch Auslöschung bei
Argument-Reduktion begrenzt. Der Median der Bitgenauigkeit liegt bei
ca. -48, d.h. bei der Hälfte der Testfälle ist die Genauigkeit nicht
besser als 48 Bits. Wenn das Ergebnis betragsmäßig klein ist, lassen
sich die Fehler fast beliebig in die Höhe schrauben. Beispiele:
1
-0x1220a29f6ebbf00p-63 = f_sin(22), genau auf 43.2 Bits
2
-0x1220a29f6eb9f3ep-63 ~ sin(22)
3
4
-0x1f9bd030bb49300p-72 = f_sin(355), genau auf 31 Bits
5
-0x1f9bd0307d1de2cp-72 ~ sin(355)
6
7
+0x1921fb542000000p-56 = x1
8
+0x12168c41641e290p-87 = f_cos(x1), genau auf 23.2 Bits
9
+0x12168c234c4c662p-87 ~ cos(x1)
10
11
+0x1921fb546000000p-56 = x2
12
-0x1bd2e882cb70b90p-88 = f_cos(x2), genau auf 21.1 Bits
13
-0x1bd2e7b9676733ap-88 ~ cos(x2)
Die Arcus-Funktionen schneiden besser ab
1
+0x1bafdcde82a51d0p-57 = x3
2
+0x10bab68b3951290p-56 = f_asin (x3), genau auf 47 Bits
3
+0x10bab68b3951098p-56 ~ asin(x3)
4
5
+0x10ce899215b7de0p-57 = f_acos (x3), genau auf 46 Bits
6
+0x10ce899215b81dap-57 ~ acos(x3)
7
8
-0x1b65d4d82e7d400p-56 = x4
9
-0x10acfc5c96b6aa0p-56 = f_atan(x4), genau auf 47 Bits
10
-0x10acfc5c96b68a8p-56 ~ atan(x4)
> Mich würden deine f7-Algorithmen interessieren: hast du Taylor, Padé> oder Chebyshev genommen? Und mit wie viel Bits hast du intern gerechnet?
Bei Argument-Reduktion von sin und cos verwende ich nun Multiply-Add
bzw. -Sub, um die Genauigkeit weiter zu erhöhen. Und ich verwende jetzt
andere Polynome. Ursprünglich hatte ich MiniMax für
1
cos (π·√x)
2
sin (π·√x) / √x
3
x in [0, 1/16]
Jetzt verwende ich wie üblich die Versionen ohne π
1
cos (√x)
2
sin (√x) / √x
3
x in [0, π²/16]
was die Genauigkeit erhöht. Allerdings wird die Implementierung dadurch
komplizierter, und der Codeverbrauch für die trigonometrischen
Funktionen ist nun gleich dem von fp64lib.
Johann L. schrieb:> Hi, inzwischen hab ich die Beurteilung der Genauigkeit vom AVR zum PC> verlagert, so dass ich nicht mehr darauf angewiesen bin per f^-1 o f zu> werten. Stattdessen kommt natürlich Host-Arithmetik zum Einsatz.
Hi, ich weiß nicht, ob das eine gute Idee war ;-) Bei mir kommen auf der
AVR-Hardware doch sehr andere Werte raus (jeweils fp64lib vs. avr_f64):
Schon deinen ersten Wert kann ich nicht nachvollziehen, denn egal auf
welcher Plattform ich rechne, sin(22) ist immer ~ -0.00885 = ~
-0x9105..p-7, was ewig weit weg ist von -0x1220..p-63:
x1 = fp64_int32_to_float64(22); //
((float64_t)0x4036000000000000LLU)
fp64_sin( x1 ) = -8.851309290404E-3 //
((float64_t)0xBF8220A29F6EBA30LLU)
f_sin( x1 ) = -8.8513092904039E-3 //
((float64_t)0xBF8220A29F6EB9F5LLU)
fp64_sin( x1 ) = -0x910514FB75D180p-7
f_sin( x1 ) = -0x910514FB75CFA8p-7
Ähnlich ist es bei sin(355): Da ist das Ergebnis ~ -3.014e-5, d.h.
~0xFCDE8 p-16 und nicht -0x1f9bp-72.
Darüber hinaus werfe ich die Cordic-Maschine gar nicht an, wenn das
Argument < 2^-26 =~1.49E-8 ist, da ab hier mit der darstellbaren
Genauigkeit sin(x)=x bzw. cos(x) = 1 ist, was sich ja auch leicht aus
der Taylor-Reihenentwicklung um 0 herleiten lässt:
sin(x) = x - x^3/6 + x^5/120...
Bei x = 2^-26 ist der zweite Term 2^-78/120, d.h. etwas größer als
2^-85, was mehr als 53 bits von 2^-26/3 entfernt ist. Damit trägt schon
der 2. term nichts mehr zu einem 53-bit Signifikant bei.
Ähnlich ist es bei cos, wo ich analog ab x < 2^-26 direkt 1
zurückliefere. Im Sourcecode sind die Stellen zu finden bei fp64_sin.S,
Zeile 199-206.
Auch bei acos und asin wende ich die Abkürzung an, aber erst ab 2^-32,
da ich hier, um Flash zu sparen, über asin(x) = atan(1/sqrt(1-x^2))
berechne.
Irgendwo muss daher bei deinen Analysen ein Fehler passiert sein, z.B.
bei
>+0x1921fb546000000p-56 = x2>-0x1bd2e882cb70b90p-88 = f_cos(x2), genau auf 21.1 Bits>-0x1bd2e7b9676733ap-88 ~ cos(x2)
sollte das Ergebnis eigentlich 1 sein. Vielleicht hättest du doch bei
deinem Statement von früher bleiben sollen ;-)
>Getestet hab ich nur für halbwegs zivile Exponenten — Werte sind
Trotzdem hast stimme ich dir in zu bei:
> Der Median der Bitgenauigkeit liegt bei> ca. -48, d.h. bei der Hälfte der Testfälle ist die Genauigkeit nicht> besser als 48 Bits.
Wenn ich avr_f64 als meinen Goldstandard nehme, dann weiche im
Durchschnitt 4,87 bits davon ab, was etwas besser wird auf 4,72 bits,
wenn ich PI/2 auf C2 korrigiere (du erinnerst dich an die Diskussion
weiter oben).
> Genauigkeit von sin / cos scheint vor allem durch Auslöschung bei> Argument-Reduktion begrenzt.
Den Punkt sehe ich nicht. Selbst ohne die Argument-Reduktion, d.h. wenn
ich im Bereich 0 bis PI/2 bin, steigert sich die Genauigkeit nicht und
bleibt im Durchschnitt bei 48bit, wobei ca. 25% auf mindestens 52 bit
genau sind. Meine Vermutungen für die Ursache dafür haben sich noch
nicht bestätigt:
- Fehler in den Konstanten-Tabellen
- Limitierung/Aufschaukeln von Rundungsfehlern durch die interne 64-bit
Fixpunkt-Artithmetik
Andere Ursachen konnte ich bis jetzt ausschalten, weil darin genügend
Fehler waren, die ich korrigiert und mehrfach überprüft habe, wie z.B.
Umrechnung IEEE zu 64-bit Fixpunkt und zurück, Umsetzung des
Cordic-Algorithmus.
> Bei Argument-Reduktion von sin und cos verwende ich nun Multiply-Add> bzw. -Sub, um die Genauigkeit weiter zu erhöhen.
Interessant, d.h. du hast die Reduktion wahrscheinlich iterierend per
Newton–Raphson gemacht, wo du pro Iterationsschritt dann 1 fma und 1
multiplikation brauchst.
> Jetzt verwende ich wie üblich die Versionen ohne π> cos (√x)> sin (√x) / √x> x in [0, π²/16]was die Genauigkeit erhöht. Allerdings wird die> Implementierung dadurch> komplizierter, und der Codeverbrauch für die trigonometrischen> Funktionen ist nun gleich dem von fp64lib.
Die Version mit √x haben natürlich den großen Vorteil, dass du in den
Reihen nur mit x multiplizieren musst und dadurch die Genauigkeit länger
erhalten kannst, clever, aber natürlich zu Lasten der Vor- und
Nachbereitung der Reihe.
Uwe B. schrieb:> Johann L. schrieb:>>> Hi, inzwischen hab ich die Beurteilung der Genauigkeit vom AVR zum PC>> verlagert, so dass ich nicht mehr darauf angewiesen bin per f^-1 o f zu>> werten. Stattdessen kommt natürlich Host-Arithmetik zum Einsatz.>> Hi, ich weiß nicht, ob das eine gute Idee war ;-) Bei mir kommen auf der> AVR-Hardware doch sehr andere Werte raus (jeweils fp64lib vs. avr_f64):>> Schon deinen ersten Wert kann ich nicht nachvollziehen, denn egal auf> welcher Plattform ich rechne, sin(22) ist immer ~ -0.00885 = ~> -0x9105..p-7, was ewig weit weg ist von -0x1220..p-63:
> x1 = fp64_int32_to_float64(22); //> ((float64_t)0x4036000000000000LLU)> fp64_sin( x1 ) = -8.851309290404E-3 //> ((float64_t)0xBF8220A29F6EBA30LLU)> f_sin( x1 ) = -8.8513092904039E-3 //> ((float64_t)0xBF8220A29F6EB9F5LLU)> fp64_sin( x1 ) = -0x910514FB75D180p-7> f_sin( x1 ) = -0x910514FB75CFA8p-7
Irgendwas stimmt da nicht mit der Normierung?
1
voidausgabe(void)
2
{
3
floatf=-0x910514FB75D180p-7;
4
floaty=-0x1220a29f6ebbf00p-63;
5
printf("f = %f\n",f);
6
printf("y = %f\n",y);
7
}
8
// Simuliert mit avrtest:
9
f=-318902030000000.000000
10
y=-0.008851
> Ähnlich ist es bei sin(355): Da ist das Ergebnis ~ -3.014e-5, d.h.> ~0xFCDE8 p-16 und nicht -0x1f9bp-72.
Das ist auch nicht der von mir angegebene Wert, der war
Zur Referenz hier nochmal mein Datensatz zu sin(355):
1
avr-libc sin 9 1610 0x163000000000000p-48 -0x1f9f80000000000p-72
2
f7_t sin 9 15886 0x163000000000000p-48 -0x1f9bd0307d1de28p-72
3
f7 sin 9 16508 0x163000000000000p-48 -0x1f9bd0307d1de30p-72
4
avr_f64 sin 9 29333 0x163000000000000p-48 -0x1f9bd0307d23990p-72
5
fp64 sin 9 19102 0x163000000000000p-48 -0x1f9bd030bb49300p-72
4. Spalte = Laufzeit in Ticks.
5. Spalte = Eingabe 0x163000000000000p-48 = 0x163p0 = 355.
6. Spalte = Ausgabe
Die Werte sind etwas ungewohnt normiert auf 56-Bit Mantisse, so dass bei
Darstellung in einer Spalte leicht erkennbar ist, ab welcher Stelle
Unterschiede auftreten.
> Darüber hinaus werfe ich die Cordic-Maschine gar nicht an, wenn das> Argument < 2^-26 =~1.49E-8 ist, da ab hier mit der darstellbaren> Genauigkeit sin(x)=x bzw. cos(x) = 1 ist
Soweit ok, aaaber: man muss ja erst mal zum Arument im Zielbereich
hinkommen. Im Falle von sin(355): sin(355) = sin(355-113·π) was
bedeutet, dass jeder Fehler in der Darstellung von π mit 113
multipliziert wird.
Weil sin(355) klein ist, wird der relative Fehler von sin(355) dann
wesentlich durch Ungenauigkeiten in der Darstellung von π (mit)bestimmt.
Für den Wert von sin(355) folgendes Beispiel in Python:
y = 0.00003014435335948844921412288013245859093451
4
y = 0x1f9bd0307d1de29p-72
wobei hier das Vorzeichen nicht angepasst wurde (113 ist ja ungerade).
Dies bestätigt den Wert vom AVR-Programm von -0x1f9bd0307d1de28p-72 für
sin(355).
> Im Sourcecode sind die Stellen zu finden bei fp64_sin.S,> Zeile 199-206.
Hatte ich auch mal überlegt, aber im Endeffekt kostet das nur unnötig
Resourcen: Je kleiner der Bereich, desto unwahrscheinlicher, dass er
getroffen wird. Damit der Term 3. Ordnung vernachlässigbar ist, muss
bei n-Bit Arithmetik gelten:
|x|^3 / 6 < |x| / 2^n <=> |x| < √6·2^(n/2) ~ 9E-9 bei 56-Bit Arithmetik
> Irgendwo muss daher bei deinen Analysen ein Fehler passiert sein, z.B.> bei>>+0x1921fb546000000p-56 = x2>>-0x1bd2e882cb70b90p-88 = f_cos(x2), genau auf 21.1 Bits>>-0x1bd2e7b9676733ap-88 ~ cos(x2)> sollte das Ergebnis eigentlich 1 sein.
x2 = 0x1921fb546000000p-56 = 0x1921fb546p-32 = 6746518854 / 2^32 ~
1.5707963271997869014739990234375
x2 liegt damit in der Nähe von π/2, einer Nullstelle von cos.
Wieder in Python:
1
from__future__importprint_function
2
fromdecimalimport*
3
4
getcontext().prec=40
5
x2=Decimal(0x1921fb546000000)/2**56
6
pi=Decimal(0x3243F6A8885A308D313198A2E)/16**24
7
8
x=x2-pi/2
9
y=x-x**3/6
10
print("pi =",pi)
11
print("x2 =",x2)
12
print("x =",x)
13
print("y =",y)
14
print("y = 0x%xp-88"%long(y*2**88))
1
pi = 3.141592653589793238462643383279333315644
2
x2 = 1.5707963271997869014739990234375
3
x = 4.04890282242677331797833342178E-10
4
y = 4.048902822426773317867706504681003354057E-10
5
y = 0x1bd2e7b9676733ap-88
und das stimmt (wieder bis aufs Vorzeichen) mit dem obigen überein:
>> -0x1bd2e7b9676733ap-88 ~ cos(x2)> Vielleicht hättest du doch bei deinem Statement von früher> bleiben sollen ;-)>> Getestet hab ich nur für halbwegs zivile Exponenten — Werte sind
Das bezog sich auf exp().
>> Bei Argument-Reduktion von sin und cos verwende ich nun Multiply-Add>> bzw. -Sub, um die Genauigkeit weiter zu erhöhen.> Interessant, d.h. du hast die Reduktion wahrscheinlich iterierend per> Newton–Raphson gemacht,
Nein, N-R nehme ich nur bei Quadratwurzel (weshalb asin und acos je nach
Argument mit 24k Ticks noch relativ langsam sind). Argumentreduktion
für sin und cos sind Addition / Subtraktion von ganzzahligen Vielfachen
von 2π, π, π/2 bis das Argument in [0,π/4] ist. Es ist also ein
ganzzahliges Vielfaches N von π/2. Danach wird korrigiert mit N·(π-pi)
wobei pi meine Darstellung für π ist; daher ist eine weitere Konstante
Δπ = π-pi zu speichern.
>> Jetzt verwende ich wie üblich die Versionen ohne π>> cos (√x)>> sin (√x) / √x>> x in [0, π²/16]was die Genauigkeit erhöht. Allerdings wird die>> Implementierung dadurch komplizierter, und der Codeverbrauch für>> die trigonometrischen Funktionen ist nun gleich dem von fp64lib.> Die Version mit √x haben natürlich den großen Vorteil, dass du in den> Reihen nur mit x multiplizieren musst und dadurch die Genauigkeit länger> erhalten kannst, clever, aber natürlich zu Lasten der Vor- und> Nachbereitung der Reihe.
√ meint eigentlich nur die Darstellung der Reihe (bei Taylor für cos)
als
1, -1/2!, 1/4!, ... statt
1, 0, -1/2!, 0, 1/4!, 0, ...
Inzwischen verwende ich MiniMax, da geht die Symmetrie dann verloren
weil die Funkionen im verwendeten Intervall nicht symmetrisch sind. Hab
mir noch keine Gedanken darüber gemacht, welche Konsequenzen das hätte
bezüglich cos(√x) vs. cos(x). Die Genauigkeit von sin und cos ist aber
exzellent, und daher mach ich mir da keinen Kopf drum.
Was ich hingenen nicht wirklich in den Griff bekomme ist exp für große
Argumente.
Sorry, mein Fehler. Ich hatte deine Zahlen als das Ergebnis von
printf("%a",x) interpretiert, was standardmäßig auf 1 Stelle vor dem
Komma ausgibt, z.B. printf("%a\n", 3.14) ergibt 0x1.91eb86p+1. Der
fehlende Dezimalpunkt hätte mich eigentlich stutzig machen sollen :-[ .
> Soweit ok, aaaber: man muss ja erst mal zum Arument im Zielbereich> hinkommen. Im Falle von sin(355): sin(355) = sin(355-113·π) was> bedeutet, dass jeder Fehler in der Darstellung von π mit 113> multipliziert wird.>> Weil sin(355) klein ist, wird der relative Fehler von sin(355) dann> wesentlich durch Ungenauigkeiten in der Darstellung von π (mit)bestimmt.
Der Auslöser war ja der Unterschied zwischen 0 und 2 (bzw. C0 und C2) in
Bits 54-56 in der Konstante PI/2. Ich habe mir den Wert von 355 mod pi
mal rausgegriffen, direkt nach der Berechnung.
Mit C2: +0xFCDE8184BC0000p-71 = 71176341990146048*2^-71
Mit C0: +0xFCDE8186800000p-71 = 71176342019768320*2^-71
Natürlich ist das Ergebnis bei C2 etwas näher dran. Das eigentliche
Problem ist aber die fehlende (interne) Genauigkeit bei der
Modulo-Berechnung: wie man oben sieht, sind die letzten 16 bzw. 20 bit
alle 0. Der auf 56bit genaue Wert müsste sein:
+0xFCDE81848D6A49p-71
Mit C2: +0xFCDE8184BC0000p-71
Insoweit geht bei x > 2*PI doch einiges an Genauigkeit verloren.
> Danach wird korrigiert mit N·(π-pi)> wobei pi meine Darstellung für π ist; daher ist eine weitere Konstante> Δπ = π-pi zu speichern.
Den Weg muss ich wohl auch gehen, um eine einigermaßen zuverlässige
Argumentreduktion zu haben.
> Inzwischen verwende ich MiniMax, da geht die Symmetrie dann verloren> weil die Funkionen im verwendeten Intervall nicht symmetrisch sind. Hab> mir noch keine Gedanken darüber gemacht, welche Konsequenzen das hätte> bezüglich cos(√x) vs. cos(x). Die Genauigkeit von sin und cos ist aber> exzellent, und daher mach ich mir da keinen Kopf drum.
Bin gespannt, wann du deine f7 bzw. f7_t Routinen mal veröffentlichst.
Würde sie gerne an Stelle von avr_f64 als "Goldstandard" nutzen beim
tunen der Genauigkeit meiner Routinen.
> Was ich hingenen nicht wirklich in den Griff bekomme ist exp für große> Argumente.
Ich bin auch über das Problem gestolpert. Im "Handbook of Floating-Point
Arithmetik" von Jean-Michel Müller et. al. beschreibt er in Kapitel
11.3.1 (1. Auflage) einen 2-stufigen Reduktionsansatz, mit dem man wohl
die Genauigkeit besser in den Griff bekommt. Ich hab's nicht
ausprobiert, sondern hab's bei einmaliger Reduktion e^x = e^(n*ln(2)+y)
belassen, da man damit mit wenig Code die Expansion machen kann - ist ja
dann nur eine Multiplikation mit 2^n.
Uwe B. schrieb:> Bin gespannt, wann du deine f7 bzw. f7_t Routinen mal veröffentlichst.> Würde sie gerne an Stelle von avr_f64 als "Goldstandard" nutzen beim> tunen der Genauigkeit meiner Routinen.
Am besten ist das aufm PC zu checken. Dann hat man zwar keine direkte
Rückmeldung (wenn man z.B. Werte mit maximaler Abweichung sucht), aber
dafür hat man keine Begrenzung in der Genauigkeit. Das oben verwendete
Format lässt sich ja leicht (ohne printf) und bitgenau basierend auf der
internen Darstellung serialisieren, und es ist auch einfach zu
decodieren. Zum Beispiel mit Python; da hat man auch genaue Type von
Haus aus: long (Arithmetik in Z), Fraction (Arithmetik in Q), Decimal
(Arithmetik in R). Decimal kann sogar sqrt, exp und ln; und sin und
asin etc. mit vorgegebener Präzision sind damit nur n paar Zeilen Code.
Mein Code sieht momentan noch aus wie bei Hempels unterm Sofa, vor allem
das Makefile. Hab's mal halbwegs aufgerämt und hochgeladen:
http://sourceforge.net/p/winavr/code/HEAD/tree/trunk/libf7/
oder
>> Was ich hingegen nicht wirklich in den Griff bekomme ist exp für große>> Argumente.> Ich bin auch über das Problem gestolpert. Im "Handbook of Floating-Point> Arithmetik" von Jean-Michel Müller et. al. beschreibt er in Kapitel> 11.3.1 (1. Auflage) einen 2-stufigen Reduktionsansatz, mit dem man wohl> die Genauigkeit besser in den Griff bekommt. Ich hab's nicht> ausprobiert, sondern hab's bei einmaliger Reduktion e^x = e^(n*ln(2)+y)> belassen, da man damit mit wenig Code die Expansion machen kann - ist ja> dann nur eine Multiplikation mit 2^n.
Momentan hab ich nen 3-stufigen Ansatz:
1) Reduktion auf |x| < 4.
2) Reduktion mod ln2 d.h. auf |x| <= ln2 / 2.
3) Reduktion auf |x| <= ln2 / 8.
Für große Argumente bedeutet das wegen 1) dann entsprechend viele
Quadrierungen, und bei jeder davon verdoppelt sich der Fehler...
Uwe B. schrieb:> Johann L. schrieb:>> Was ich hingenen nicht wirklich in den Griff bekomme ist exp für große>> Argumente.> Ich bin auch über das Problem gestolpert.
Auch gelöst: Problem war analog zu sin / cos: nach mod ln2 muss man
nachkorrigieren.
Johann L. schrieb:> Auch gelöst: Problem war analog zu sin / cos: nach mod ln2 muss man> nachkorrigieren.
Sehr gut. Wie stark ist mit dem 3-stufigen Ansatz die Genauigkeit
gestiegen für große Exponenten, auch gegenüber fp64lib?
Uwe B. schrieb:> Johann L. schrieb:>> Auch gelöst: Problem war analog zu sin / cos: nach mod ln2 muss man>> nachkorrigieren.> Sehr gut. Wie stark ist mit dem 3-stufigen Ansatz die Genauigkeit> gestiegen für große Exponenten, auch gegenüber fp64lib?
Den 3-stufigen Ansatz hatte ich ursprünglich, war wie gesagt nicht so
toll und nur 1-3 Bit besser als fp64lib.
Inzwischen hab ich exp neu geschrieben und verwende nen 2-stufigen
Ansatz, der allerdings langsamer und größer ist da er Division braucht:
1) Reduktion mod ln2 im betragsmäßig kleinsten Restsystem, d.h. |x mod
ln2| <= ln2 / 2. x mod ln2 ist i.d.R. betragsmäßig kleiner als x, so
dass die Differenz genau wie bei sin und cos nachkorrigiert wird.
2) Reduktion auf |x| < ln2 / 8 ~ 0.087, was der Urbilbereich des
MiniMax Polynoms ist (Grad 8).
Damit ist die Genauigkeit dann besser als 53 Bits.
fp64lib.exp hat Mediangenauigkeit von ca. 52 Bits, Worst-case liegt bei
ca. 45 Bits, siehe 3. Zeile im Anhang. Die Darstellung ist etwas
anders: Bei der Genauigkeit werden keine Ausreißer mehr dargestellt,
sondern die Whisker reichen bis zum Worst-Case.
Johann L. schrieb:>>> Genauigkeit von sin / cos scheint vor allem durch Auslöschung bei>>> Argument-Reduktion begrenzt.>> Danach wird korrigiert mit N·(π-pi)>> wobei pi meine Darstellung für π ist; daher ist eine weitere Konstante>> Δπ = π-pi zu speichern.>Den Weg muss ich wohl auch gehen, um eine einigermaßen zuverlässige>Argumentreduktion zu haben.
Ich habe inzwischen die Argumentreduktion mit dem obigen Ansatz
korrigiert, zuerst mal in C. Ich konnte damit tatsächlich die Genaugkeit
erhöhen, z.B. bei sin(355):
fp64lib vorher: 0x1F9BD030ABC966p-72
fp64lib korrigiert: 0x1F9BD0307D491Dp-72
f7_t: 0x1f9bd0307d1de2cp-72
Darüber hinaus war aber bei sin(355) keine Steigerung mehr möglich, was
jetzt nicht mehr an der Argumentreduktion liegt (außer ich habe noch
einen Fehler übersehen), sondern wohl eher an der
Cordic-Implementierung: Damit die effizient läuft und pro Iteration
tatsächlich nur 2 Shifts und 2 Additionen braucht, rechnet sie intern
mit Festpoint-Arithmetik mit 2 Stellen vor dem (impliziten) Komma und 62
Stellen danach. Bei sin(355) = sin(355-113*pi) ~ sin(3,01E-5) gehen sind
davon aber die ersten 2+15 bits 0. Demenstprechend ist der Ausgangswert
hier maximal auf 47bit genau. Analog fehlen die Stellen auch bei der
Rückumwandlung.
Dieses prinzipielle Problem liese sich nur lösen mit größerer
Genauigkeit (in Fixpunkt), Wechsel auf Fließkomma-Arithmetik - oder man
wechselt den Algorithmus. Vielleicht läst man auch dem Anwender die
Chance: reduzierte Genuigkeit/konstantes Timing bei fp64lib vs. volle
Genauigkeit/variables Timing bei f7_t.
Trotzdem müssen die Worstcases besser werden. Werde daher jetzt die
genauere Argumentreduktion in Assembler kodieren und sie
veröffentlichen, so dass du sie auch testen kannst.
>> Johann L. schrieb:> 1) Reduktion mod ln2 im betragsmäßig kleinsten Restsystem, d.h. |x mod> ln2| <= ln2 / 2. x mod ln2 ist i.d.R. betragsmäßig kleiner als x, so> dass die Differenz genau wie bei sin und cos nachkorrigiert wird.>> 2) Reduktion auf |x| < ln2 / 8 ~ 0.087, was der Urbilbereich des> MiniMax Polynoms ist (Grad 8).>> Damit ist die Genauigkeit dann besser als 53 Bits.
Der Ansatz ist ähnlich zu dem im "Handbook of Floating Point
ARithmetik", nur ich frage mich, wo die "magische" Konstante 0.087
herkommt.
> fp64lib.exp hat Mediangenauigkeit von ca. 52 Bits, Worst-case liegt bei> ca. 45 Bits, siehe 3. Zeile im Anhang.
Der Wort-Case liegt wahrscheinlich ebenfalls an der Argumentreduktion x
mod ln(2). Ich werde auch hier analog zu sin/cos hier nachkorrigieren,
das sollte die Ausreißer reduzieren, da ich bei exp ansonsten nur
normale Arithmetik benutze, und die funktioniert ja auf 53bit genau.
> Die Darstellung ist etwas> anders: Bei der Genauigkeit werden keine Ausreißer mehr dargestellt,> sondern die Whisker reichen bis zum Worst-Case.
Gefällt mir besser, man sieht eher wo der Schwerpunkt ist und auf was
man sich "einlässt" bzgl. Worst-Case Szenarien.
Uwe B. schrieb:> Ich habe inzwischen die Argumentreduktion mit dem obigen Ansatz> korrigiert, zuerst mal in C. Ich konnte damit tatsächlich die Genaugkeit> erhöhen, z.B. bei sin(355):> fp64lib vorher: 0x1F9BD030ABC966p-72> fp64lib korrigiert: 0x1F9BD0307D491Dp-72> f7_t: 0x1f9bd0307d1de2cp-72>> Darüber hinaus war aber bei sin(355) keine Steigerung mehr möglich, was> jetzt nicht mehr an der Argumentreduktion liegt (außer ich habe noch> einen Fehler übersehen), sondern wohl eher an der> Cordic-Implementierung: Damit die effizient läuft und pro Iteration> tatsächlich nur 2 Shifts und 2 Additionen braucht, rechnet sie intern> mit Festpoint-Arithmetik mit 2 Stellen vor dem (impliziten) Komma und 62> Stellen danach. Bei sin(355) = sin(355-113*pi) ~ sin(3,01E-5) gehen sind> davon aber die ersten 2+15 bits 0. Demenstprechend ist der Ausgangswert> hier maximal auf 47bit genau. Analog fehlen die Stellen auch bei der> Rückumwandlung.>> Dieses prinzipielle Problem liese sich nur lösen mit größerer> Genauigkeit (in Fixpunkt), Wechsel auf Fließkomma-Arithmetik - oder man> wechselt den Algorithmus. Vielleicht läst man auch dem Anwender die> Chance: reduzierte Genuigkeit/konstantes Timing bei fp64lib vs. volle> Genauigkeit/variables Timing bei f7_t.
Mit Wechsel auf Fließkomma würde die Ausführungszeit wohl durch die
Decke gehen. sin und cos per Polynom sind ja schon jetzt schneller als
Cordic (ich hab immer noch die v1.0.5). Konstantes Timing finde ich
jetzt nicht wirklich spannend; ist ja nicht so, dass man einzelne Takte
zählen würde um irgendwas zu erreichen. Was m.E. interessiert ist:
* Genauigkeit (Worst-Case und Median bzw. Mittel)
* Laufzeit (Worst-Case und Medial bzw. Mittel)
* Flash-Verbrauch
* RAM-Verbrauch
Wobei mein Fokus bei der Genauigkeit immer beim Worst-Case war; Grafiken
wie in Beitrag "Re: Taschenrechner: ATmega1284p - 15x 7-Segmentdisplay" sind zwar
ganz nett, aber wenig aussagekräftig weil der Worst-Case fast ganz unter
den Teppich gekehrt wird.
>>> Johann L. schrieb:>> 1) Reduktion mod ln2 im betragsmäßig kleinsten Restsystem, d.h. |x mod>> ln2| <= ln2 / 2. x mod ln2 ist i.d.R. betragsmäßig kleiner als x, so>> dass die Differenz genau wie bei sin und cos nachkorrigiert wird.>>>> 2) Reduktion auf |x| < ln2 / 8 ~ 0.087, was der Urbilbereich des>> MiniMax Polynoms ist (Grad 8).>>>> Damit ist die Genauigkeit dann besser als 53 Bits.>> ich frage mich, wo die "magische" Konstante 0.087 herkommt.
Mathe ist magisch :-)
ln2 / 2 ist klar. Von da ab kann man das Argument (mehrfach) durch 2
teilen, wenn man exp entsprechend oft quadriert. Durch die
Verkleinerung des Arguments kommt man also evtl. mit einer Approximanten
kleineren Grades aus, allerdings kostet das dann Quadrierungen, und mit
jedem Quadrieren verdoppelt sich der Fehler.
Es ist also abzuwägen, wie oft durch 2 zu teilen ist. Ursprünglich
hatte ich ln2 / 16, was aber nicht besser war als ln2 / 8. Ob ln2 / 4
oder gar ln2 / 2 noch besser sind hab ich noch nicht ausprobiert; ich
wollte erst die Genauigkeit im Griff haben.
~ steht für ≈.
Johann L. schrieb:> Uwe B. schrieb:> Mit Wechsel auf Fließkomma würde die Ausführungszeit wohl durch die> Decke gehen. sin und cos per Polynom sind ja schon jetzt schneller als> Cordic (ich hab immer noch die v1.0.5).
Stimmt beides, leider. Es zeigt sich einfach in der Praxis, dass -
zumindest auf dem AVR - der theoretische Vorteil von "nur" 3 (Fixpoint)
Additionen und 2 Shifts nicht ausgespielt werden kann, da dafür
mindestens 5*8=40 8-bit Register benötigt würden, aber nur 32 vorhanden
sind. Ein Teil der Performance geht schlichtweg verloren im Overhead,
die entsprechenden Variablen in den Speicher auszulagern bzw. wieder zu
laden. Im Gegensatz dazu können beim Polynom problemlos die Variablen
für die je eine Fließpunkt-Addition und Multiplikation in 3*9 (7 für
Signifikand, 2 für Exponent) = 27 Registern gehalten werden. Obwohl die
Fließpunkt-Operationen länger brauchen, sind es in Summe selbst im
Worst-Case weniger Register-Operationen.
> Konstantes Timing finde ich> jetzt nicht wirklich spannend; ist ja nicht so, dass man einzelne Takte> zählen würde um irgendwas zu erreichen.
Es geht nicht um das Zählen einzelner Takte, sondern darum
Displays/Sensoren/Schnittstellen zuverlässig z.B. alle 10ms anzusteuern.
Das macht die Auswertungen einfacher (sprich weniger Flash) und als
Benutzer siehst du auch weniger bis gar kein Flackern. Ich nutze
Arduinos auch zum Ansteuern via MIDI, und da brauchst du konstantes
Timing. Zugegeben, bei MIDI brauche ich aber auch keine
double-Arithmetik. Und: Was hilft mir das, wenn mein konstantes Timing
nicht besser ist als dein Timing selbst im Worst-Case. :-/
Werde trotzdem zuerst mal eine Variante von fmod machen, die mit
erweiterter Genauigkeit x mod y berechnet, z.B. für y = π bzw. ln(2).
Das brauche ich so oder so, egal ob für Cordic oder für
Polynom-Berechnung von sin oder für exp. Damit sollten auch ein paar
Worst-Case-Zahlen runtergehen.
> Was m.E. interessiert ist:>> * Genauigkeit (Worst-Case und Median bzw. Mittel)>> * Laufzeit (Worst-Case und Medial bzw. Mittel)>> * Flash-Verbrauch>> * RAM-Verbrauch
Für mich waren es immer die letzten beiden entscheidend, Ziel war es so
wenig Speicher in Summe wie möglich zu verbrauchen. Scheint nach deinen
Auswertungen nicht überall geklappt zu haben :-(
> Wobei mein Fokus bei der Genauigkeit immer beim Worst-Case war; Grafiken> wie in Beitrag "Re: Taschenrechner: ATmega1284p - 15x 7-Segmentdisplay" sind
zwar
> ganz nett, aber wenig aussagekräftig weil der Worst-Case fast ganz unter> den Teppich gekehrt wird.
Ich habe auch immer den Fokus auf die Abweichung in bits gelegt, und
mich dort zuerst um die Worst-Cases gekümmert. Verbesserungen im Median
waren auch interessant, aber der Anspruch ist und war nach wie vor, mit
vertretbarem Aufwand zuverlässlich so nah wie möglich an die 53-bit
Genauigkeit zu kommen. Zumindest sollte es für jede Operation eine
Aussage geben: Genauigkeit mindestens x bit - und da muss ich zuerst auf
die Worst-Cases schauen.
Nur das Problem fängt ja schon da an, in welchem Wertebereich man testet
und mit welchem Ansatz. Beispielsweise hatte ich sin/cos ziemlich
intensiv zwischen 0 und PI/2 getestet, aber die Bereichsreduktion nur
punktuell bei Vielfachen von PI/n mit 2 <= n <= 6. Du dagegen hast ganz
andere Werte genommen, die z.B. aus der Approximation von Pi kommen, wie
355/113.
Speziell bei Worst-Case-Tests muss ich eigentlich viel Whitebox-Testen
machen, d.h. den Test sauber auf den Algorithmus abstimmen, um gezielt
die Schwachstellen abzuklopfen, z.B. bei dir rund um ln(2) und ln(2)/2
bei exp, bei mir rund um PI/2 und PI/4 bei sin. Und dann noch genügend
Blackbox-Tests, die ohne Kenntnis des Algorithmus verifizieren, dass die
Implementierung sauber ist und in der Regel eine bessere Genauigkeit
liefert als die Worst-Cases.
> Mathe ist magisch :-)>> ln2 / 2 ist klar. Von da ab kann man das Argument (mehrfach) durch 2> teilen, wenn man exp entsprechend oft quadriert. Durch die> Verkleinerung des Arguments kommt man also evtl. mit einer Approximanten> kleineren Grades aus, allerdings kostet das dann Quadrierungen, und mit> jedem Quadrieren verdoppelt sich der Fehler.>> Es ist also abzuwägen, wie oft durch 2 zu teilen ist. Ursprünglich> hatte ich ln2 / 16, was aber nicht besser war als ln2 / 8. Ob ln2 / 4> oder gar ln2 / 2 noch besser sind hab ich noch nicht ausprobiert; ich> wollte erst die Genauigkeit im Griff haben.>> ~ steht für ≈.
War wohl etwas zu spät gestern abend für mich, als ich das geschrieben
habe. Für mich hieß das ln 2 / 8 - 0.087, statt ln 2 / 8 ~ 0.087. Wer
lesen kann, ist klar im Vorteil :-]
Uwe B. schrieb:> Johann L. schrieb:>> Uwe B. schrieb:>> Mit Wechsel auf Fließkomma würde die Ausführungszeit wohl durch die>> Decke gehen. sin und cos per Polynom sind ja schon jetzt schneller als>> Cordic (ich hab immer noch die v1.0.5).>> Stimmt beides, leider. Es zeigt sich einfach in der Praxis, dass -> zumindest auf dem AVR - der theoretische Vorteil von "nur" 3 (Fixpoint)> Additionen und 2 Shifts nicht ausgespielt werden kann, da dafür> mindestens 5*8=40 8-bit Register benötigt würden, aber nur 32 vorhanden> sind. Ein Teil der Performance geht schlichtweg verloren im Overhead,> die entsprechenden Variablen in den Speicher auszulagern bzw. wieder zu> laden. Im Gegensatz dazu können beim Polynom problemlos die Variablen> für die je eine Fließpunkt-Addition und Multiplikation in 3*9 (7 für> Signifikand, 2 für Exponent) = 27 Registern gehalten werden. Obwohl die> Fließpunkt-Operationen länger brauchen, sind es in Summe selbst im> Worst-Case weniger Register-Operationen.
Die libf7 lädt und speichert die Operanden auch bei jeder Operation: 3
Operanden à 10 Byte à 2 Ticks/Instruktion à 2 Instruktionen/Byte macht
120 Ticks nur für LD und ST bei jeder Grundrechenart.
f7_add + f7_mul, was zusammen ca. 1000 dauern, könnte also 20% schneller
sein. Und damit dann auch Horner, der ja praktisch nur aus einer
mul+add Schleife besteht.
Wirklich gut wartbar wäre so ein Code aber wohl nicht; i.W. ist man da
nur mit Register-Juggling beschäftigt. Und in C ist das auch nicht
auszudrücken.
> Und: Was hilft mir das, wenn mein konstantes Timing> nicht besser ist als dein Timing selbst im Worst-Case. :-/
Wohl wahr.
> Werde trotzdem zuerst mal eine Variante von fmod machen, die mit> erweiterter Genauigkeit x mod y berechnet, z.B. für y = π bzw. ln(2).> Das brauche ich so oder so, egal ob für Cordic oder für> Polynom-Berechnung von sin oder für exp. Damit sollten auch ein paar> Worst-Case-Zahlen runtergehen.>>> Was m.E. interessiert ist:>>>> * Genauigkeit (Worst-Case und Median bzw. Mittel)>>>> * Laufzeit (Worst-Case und Median bzw. Mittel)>>>> * Flash-Verbrauch>>>> * RAM-Verbrauch>> Für mich waren es immer die letzten beiden entscheidend, Ziel war es so> wenig Speicher in Summe wie möglich zu verbrauchen. Scheint nach deinen> Auswertungen nicht überall geklappt zu haben :-(
Wobei die fp64lib beim RAM-Verbrauch klar vorne liegt weil sie zum Teil
direkt mit der IEEE-Darstellung hantiert. libf7 muss immer zwischen
10-Byte f7_t und double hin-und-her wandeln was Stack kostet, weil die
Prototypen wie void f (f7_t*, const f7_t*, const f7_t*) sind. War
ursprünglich so angedacht, damit Anwender direkt auf der internen
Darstellung arbeiten können, aber wenn das alles unter der Haube einer
lib(gc)c läuft, spielt das natürlich keine Rolle mehr.
Johann L. schrieb:> Genauigkeit von sin / cos scheint vor allem durch Auslöschung bei> Argument-Reduktion begrenzt. Der Median der Bitgenauigkeit liegt bei> ca. -48, d.h. bei der Hälfte der Testfälle ist die Genauigkeit nicht> besser als 48 Bits. Wenn das Ergebnis betragsmäßig klein ist, lassen> sich die Fehler fast beliebig in die Höhe schrauben. Beispiele:
Hi, ich habe inzwischen an der Argumentreduktion gearbeitet und neue
Assembler-Routinen entwickelt, die fmod(x,y) für y = pi/2 mit 96 bit
interner Genauigkeit berechnen und die ohne zusätzliches
Register-Shuffling auskommen. Durch die 96 bit erspare ich mir eine
Korrektur für N·(π-pi). 96 bit ist auch das Maximum, was ohne Ein- und
Auslagern von Registern geht; die zusätzlchen 43 bit (gegenüber 53 bit
Signifikant bei IEEE) reichen aber meiner Meinung nach auch locker für
die "üblichen" (bezogen auf Einsatzzwecke auf einem Mikroprozessor)
Wertebereiche, mit denen sin, cos und tan aufgerufen werden. Damit hat
sich in den Grenzfällen die Genauigkeit um 7 bit gesteigert:
> -0x1220a29f6ebbf00p-63 = f_sin(22), genau auf 43.2 Bits> -0x1220a29f6eb9f3ep-63 ~ sin(22)>> -0x1f9bd030bb49300p-72 = f_sin(355), genau auf 31 Bits> -0x1f9bd0307d1de2cp-72 ~ sin(355)>
> +0x1921fb542000000p-56 = x1> +0x12168c41641e290p-87 = f_cos(x1), genau auf 23.2 Bits> +0x12168c234c4c662p-87 ~ cos(x1)>> +0x1921fb546000000p-56 = x2> -0x1bd2e882cb70b90p-88 = f_cos(x2), genau auf 21.1 Bits> -0x1bd2e7b9676733ap-88 ~ cos(x2)
Bei den Cosinus-Fällen ist der beobachtbare Fehler aber nicht durch
ungenaue Argument-Reduktion ausgelöst, sondern liegt, wie schon früher
oben ausgeführt, an den Grenzen der Festpunkt-Arithmetik und der
Rückumwandlung in das IEEE Format mit max. 53 Bit Signifikand:
PI/2 - x1 ~ 5.26432E-10 ~ 1.13050 / 2**31
--> Die erwartbare Genauigkeit liegt bei 54-31 = 23bit
dito bei x2:
PI/2 - x2 ~ 4.04890E-10 ~ -1.73899 / 2**32 --> --> Erwartbare
Genauigkeit 54-32 = 22bit
Dementsprechend hat die Umstellung auf 96bit bei fmod hier keine
Verbesserung ergeben.
Die Zeit für sin und cos hat sich minimal um 0.9% verschlechtert von
1.283ms auf 1.295ms.
Johann L. schrieb:> Die libf7 lädt und speichert die Operanden auch bei jeder Operation: 3> Operanden à 10 Byte à 2 Ticks/Instruktion à 2 Instruktionen/Byte macht> 120 Ticks nur für LD und ST bei jeder Grundrechenart.>> f7_add + f7_mul, was zusammen ca. 1000 dauern, könnte also 20% schneller> sein. Und damit dann auch Horner, der ja praktisch nur aus einer> mul+add Schleife besteht.>> Wirklich gut wartbar wäre so ein Code aber wohl nicht; i.W. ist man da> nur mit Register-Juggling beschäftigt. Und in C ist das auch nicht> auszudrücken.
In Assembler hat man da natürlich etwas mehr Freiheiten, allerdings war
ich jetzt auch ungefähr die Hälfte der Zeit damit beschäftigt, mir eine
schlaue Registerverteilung zu überlegen, die ohne LD und ST auskommt und
so wenig Stack wie möglich verbraucht.
> Wobei die fp64lib beim RAM-Verbrauch klar vorne liegt weil sie zum Teil> direkt mit der IEEE-Darstellung hantiert. libf7 muss immer zwischen> 10-Byte f7_t und double hin-und-her wandeln was Stack kostet, weil die> Prototypen wie void f (f7_t*, const f7_t*, const f7_t*) sind. War> ursprünglich so angedacht, damit Anwender direkt auf der internen> Darstellung arbeiten können, aber wenn das alles unter der Haube einer> lib(gc)c läuft, spielt das natürlich keine Rolle mehr.
Dazu kommt noch, dass Datentypen, die mehr als 8 Bytes belegen, beim AVR
GCC ABI nicht mehr in Registern übergeben werden, sondern nur als
Pointer. Dementsprechend werden Dutzende von LD und ST Anweisungen
erzeugt, um die Daten dann in Registern zu haben und darauf zu
operieren. Das kann man natürlich in Assembler umgehen, wobei es schon
bei 8 Byte gepackt = 10 Byte ausgepackt anstrengend ist, 3 Zahlen
gleichzeitig im Zugriff zu haben, denn meistens braucht man ja daneben
noch ein paar Variablen, z.B. Zähler für Schleifen oder Flags für den
Status.
>> fp64lib.exp hat Mediangenauigkeit von ca. 52 Bits, Worst-case liegt bei>> ca. 45 Bits, siehe 3. Zeile im Anhang.>> Der Wort-Case liegt wahrscheinlich ebenfalls an der Argumentreduktion x> mod ln(2).
Bin gerade dabei, die oben erwähnte 96-bit Implementierung von fmod auch
auf exp anzuwenden. Damit sollte auch dort die Genauigkeit etwas besser
werden. Darüber hinaus werde ich die Umsetzung des Horner-Schemas in
fp64_powser anpassen, dass sie die internen Routinen für * und + nutzt,
die alle mit 56-bit Genauigkeit arbeiten. Damit sollte die Genauigkeit
sowohl für den Worst-Case als auch für den Media steigen und
gleichzeitig die Ausführungsgeschwindigkeit etwas sinken - allerdings
bei etwas mehr Flash-Space für die Tabellen. Davon können exp und ln
direkt profitieren und indirekt die Funktionen, die sich darauf
abstützen, wie sinh, cosh, tanh oder log10.
Von daher gibt es die oben erwähnte V1.0.7 auf Github noch nicht. Ich
werde sie erst releasen, wenn das Paket in Summe funktioniert. Trotz der
Nachteile wird es zuerst mal bei Cordic bleiben für die
trigonometrischen Funktionen. Das abzulösen ist ein größeres Projekt, da
ich dann auf einen Schlag sin, cos, tan und atan neu aufsetzen muss.
Johann L. schrieb:> Und wer es für Linux will:>> [...]>> 3) Executables x-Flag setzen:>> ./devtools/gen-avr-lib-tree.sh
Ist stattdessen für ./devtools/mlib-gen.py
Johann L. schrieb:> http://gcc.gnu.org/gcc-10/changes.html#avr
Super! Muss ich ausprobieren, sobald ich wieder etwas Zeit habe. Ich bin
mitten in der Umstellung, weg von Cordic hin zu Polynomen. Dazu musste
ich zuerst einmal die Grundroutinen +, -, * und / so umschreiben, dass
die das interne 56-bit-Ergebnis zurückliefern. Darauf aufbauend dann
die Taylor-Approximation und dann die Routinen der "höheren" Mathematik.
Inzwischen habe ich exp, sin, cos und tan komplett umgestellt und
intensiv getestet, jeweils Approximation mittels Taylorpolynomen vom
Grad 16. Das Ergebnis kann sich sehen lassen: Genauigkeit teilweise
deutlich gesteigert, z.B. ist jetzt fp64_sin(355) auf alle 53 Bits
exakt. Gleichzeitig wurde gegenüber der Cordic-Implementierung die
Geschwindigkeit um mehr als den Faktor 2 gesteigert (-53%).
Jetzt sind gerade die Arcus-Funktionen dran. Da Taylor sich hier ja
relativ langsam sich annähert, nehme ich ebenfalls MiniMax. Hat sich ja
auch bei dir bewährt.
Uwe B. schrieb:> Inzwischen habe ich exp, sin, cos und tan komplett umgestellt und> intensiv getestet, jeweils Approximation mittels Taylorpolynomen vom> Grad 16.
Taylor ist schlecht bzw. nie besser als MiniMax Polynom (bzgl.
Polynomgrad) weil letztere optimal sind. Falls man Symmetrie verlieren
würde, muss man diese dann eben explizit reinbringen, z.B. indem man
sin(√x)/√x approximirt statt sin(x). Ok, braucht dann 2
Multiplikationen mehr, aber ein Versuch ist's auf jeden Fall wert.
Uwe B. schrieb:> Von daher gibt es die oben erwähnte V1.0.7 auf Github noch nicht. Ich> werde sie erst releasen, wenn das Paket in Summe funktioniert. Trotz der> Nachteile wird es zuerst mal bei Cordic bleiben für die> trigonometrischen Funktionen. Das abzulösen ist ein größeres Projekt, da> ich dann auf einen Schlag sin, cos, tan und atan neu aufsetzen muss.
Endlich, V1.1.0 ist verfügbar, und ich habe Cordic doch rausgeschmissen
und große Teile neu implementiert und/oder angepasst, und ich wurde
belohnt mit echten 52-53 Bit Genauigkeit und nochmal 40-70% höherer
Geschwindigkeit. fp64_sin dauert damit auf einem Standard 16MHz Arduino
Mega2560 600-650 Microsekunden, d.h. 9500-10500 Ticks.
Basis war, dass ich bei allen Grundrechenarten, sqrt und fmod jeweils
die internen, auf 56-bit genauen Routinen von außen aufrufbar gemacht
habe. Darauf haben dann die Routinen für Polynomberechnung nach Horner
(fp64_powser, fp64_powsodd) aufgesetzt.
sin und cos habe ich ganz normal per Taylor approximiert, x/1 - x^3/3! +
x^5/5! -+ ... +x^33/33! , wobei die Berechnung natürlich bei x^33/33!
anfängt und x auf den Bereich [0,pi/2[ reduziert wird. Dank deiner
Beobachtung (Stichwort "sin(355)") findet die Reduktion mit auf 96-bit
erweiterter Genauigkeit statt, was die Auslöschung von signifikanten
Stellen effektiv verhindert.
Wie bei dir, gibt es keine eigene Entwicklung für tan, sondern tan wird
als sin/cos berechnet.
Bei asin und acos habe ich auch das von dir schon optimierte [5,4]
Minimax Polynom genommen,
Beitrag "Re: Näherung für ArcusTangens?", for |x| in
[0,0.5].
Bei atan habe ich mich ebenfalls auf deine Vorarbeit abgestützt:
Beitrag "Re: Näherung für ArcusTangens?".
Bei log blieb es bei der atanh-Taylorentwicklung,
log(x)=2*atanh(y)=2*(y+y^3/3+y^5/5+...+y^33/33) für y=(x-1)/(x+1) für x
in [0.5,1[. Reduktion auf diesen Bereich log(x*2^n)=log(x)+n*log(2).
Auch bei exp blieb es bei Taylor, d.h. exp(x) = 1/0!*1 + 1/1!*x +
1/2!*x^2 + 1/3!*x^3 + ... + 1/16!*x^16 für 0 <= |x| < ln(2). Die
Reduktion hier wurde ebenfalls mit 96-bit Genauigkeit durchgeführt, was
auch nochmal etwas gebracht hat - nicht so viel wie bei sin, denn mehr
wie exp(709.78...) geht nicht, weil dann das Ergebnis >1.79E308 ist.
Bei meinen Tests bin ich damit überall auf die Genauigkeit von avr_f64
gekommen und teilweise auch besser. Viellicht kannst du mal das aktuelle
Release durch deinen "Comparator" jagen :-) ? Du testest doch teilweise
andere Edge-Cases, da ist sicher noch Optimierungspotential vorhanden.
Uwe B. schrieb:> Endlich, V1.1.0 ist verfügbar, und ich habe Cordic doch rausgeschmissen> und große Teile neu implementiert und/oder angepasst, und ich wurde> belohnt mit echten 52-53 Bit Genauigkeit und nochmal 40-70% höherer> Geschwindigkeit. fp64_sin dauert damit auf einem Standard 16MHz Arduino> Mega2560 600-650 Microsekunden, d.h. 9500-10500 Ticks.>> Basis war, dass ich bei allen Grundrechenarten, sqrt und fmod jeweils> die internen, auf 56-bit genauen Routinen von außen aufrufbar gemacht> habe. Darauf haben dann die Routinen für Polynomberechnung nach Horner> (fp64_powser, fp64_powsodd) aufgesetzt.>> sin und cos habe ich ganz normal per Taylor approximiert, x/1 - x^3/3! +> x^5/5! -+ ... +x^33/33!
Grad 33 ???
Für sin genügte mit Grad 6; wobei das für sin√/√ ist. Entspricht Grad
13 für sin.
> x auf den Bereich [0,pi/2[ reduziert wird.
Reduktion auf [0,π/2) hatte ich nicht angetestet. Gibt vermutlich
kleineren Code als Reduktion auf [0,π/4)?
> atan [...] y^33/33
Da genügte Grad 7 (effektiv Grad 15).
> y=(x-1)/(x+1) für x in [0.5,1[.
Wenn man nicht im kleinsten nicht-negativen Restsystem rechnet sondern
im betragsmäßig kleinsten, dann kommt man auf [1/√2,√2] was symmetrisch
um1 liegt und besser konvergiert. Symmetrisch deshalb, weil x und 1/x
gleich schnell konvergieren.
> Auch bei exp blieb es bei Taylor, d.h. exp(x) = 1/0!*1 + 1/1!*x +> 1/2!*x^2 + 1/3!*x^3 + ... + 1/16!*x^16 für 0 <= |x| < ln(2).
Auch hier besser Reduktion auf's betragsmäßig kleinste Restsystem.
> Viellicht kannst du mal das aktuelle Release durch deinen> "Comparator" jagen :-) ?
Momentan leider keine Zeit...
Was mir an deinem Code noch aufgefallen ist: große Pro- und Epiloge zum
Speichern / Sichern von Registern brauchen viel Code und könnten durch
die Prolog-Funktionen der libgcc kleiner Werden.
Definition:
https://gcc.gnu.org/viewcvs/gcc/trunk/libgcc/config/avr/libf7/asm-defs.h?revision=279994&view=markup#l156
Verwendung:
https://gcc.gnu.org/viewcvs/gcc/trunk/libgcc/config/avr/libf7/libf7-asm.sx?revision=279994&view=markup#l785https://gcc.gnu.org/viewcvs/gcc/trunk/libgcc/config/avr/libf7/libf7-asm.sx?revision=279994&view=markup#l1545
Johann L. schrieb:> Uwe B. schrieb:>> sin und cos habe ich ganz normal per Taylor approximiert, x/1 - x^3/3! +>> x^5/5! -+ ... +x^33/33!>> Grad 33 ???
Nein, Grad 16, Polynom geht ja mit 2n+1.
> Für sin genügte mit Grad 6; wobei das für sin√/√ ist. Entspricht Grad> 13 für sin.
Bin zuerst mal auf Nummer sicher gegangen, jetzt den Grad zu reduzieren
ist ja so gut wie kein Aufwand.
>> x auf den Bereich [0,pi/2[ reduziert wird.>> Reduktion auf [0,π/2) hatte ich nicht angetestet. Gibt vermutlich> kleineren Code als Reduktion auf [0,π/4)?
Ja genau. In jeweils 10 Byte bekomme ich problemlos jeweils einen
weiteren Polynomgrad rein (siehe oben), aber kaum eine
Fallunterscheidung oder eine Nachkorrektur.
>> atan [...] y^33/33>> Da genügte Grad 7 (effektiv Grad 15).
Danke für den Hinweis. Auch hier gilt: jetzt, wo's funktioniert, kann
ich problemlos mit minimalen Aufwand den Grad reduzieren.
>> y=(x-1)/(x+1) für x in [0.5,1[.>> Wenn man nicht im kleinsten nicht-negativen Restsystem rechnet sondern> im betragsmäßig kleinsten, dann kommt man auf [1/√2,√2] was symmetrisch> um1 liegt und besser konvergiert. Symmetrisch deshalb, weil x und 1/x> gleich schnell konvergieren.
Stimmt natürlich. Die Reduktion bei [1/√2,√2] ist etwas aufwändiger als
bei [0.5,1[, aber die Nachkorrektur ist identisch. Mal ausprobieren, was
das bringt.
>> Auch bei exp blieb es bei Taylor, d.h. exp(x) = 1/0!*1 + 1/1!*x +>> 1/2!*x^2 + 1/3!*x^3 + ... + 1/16!*x^16 für 0 <= |x| < ln(2).>> Auch hier besser Reduktion auf's betragsmäßig kleinste Restsystem.
Allerdings ist das bei exp ja schon deutlich aufwändiger. Habe deinen
Ansatz gesehen bzgl. zuerst Reduktion auf |C| < ln(2) und dann weiter
<Ln(2)/2 und ln(2)/8 mit entsprechender Nachkorrektur durch Quadrieren.
Dafür braucht es einiges an zusätzlichem Code. Da ich mit dem simpleren
Verfahren aber schon auf der Genauigkeit von avr_f64 bin (d.h. 53 bit,
worst case 52 bit, siehe deine Auswertung), habe ich keinen praktischen
Vorteil vom besseren Modell.
> Was mir an deinem Code noch aufgefallen ist: große Pro- und Epiloge zum> Speichern / Sichern von Registern brauchen viel Code und könnten durch> die Prolog-Funktionen der libgcc kleiner Werden.
Das ist ja ein cooler Hack, macht ja damit Platz für die ein- oder
andere Reduktion bzw. Nachkorrektur ;-) Danke für den Hinweis.
Uwe B. schrieb:> Johann L. schrieb:>> Uwe B. schrieb:>>> sin und cos habe ich ganz normal per Taylor approximiert,>>> x/1 - x^3/3! + x^5/5! -+ ... +x^33/33!>>>> Grad 33 ???>> Nein, Grad 16, Polynom geht ja mit 2n+1.>>> Für sin genügte mir Grad 6; wobei das für sin√/√ ist. Entspricht Grad>> 13 für sin.>> Bin zuerst mal auf Nummer sicher gegangen, jetzt den Grad zu reduzieren> ist ja so gut wie kein Aufwand.
Hab mal meinen Remez angeworfen für sin√x/√x mit x in [0,π²/4]:
Polynom hat Grad 8, also Grad 17 für sin:
Uwe B. schrieb:
> Bei log blieb es bei der atanh-Taylorentwicklung,> log(x)=2*atanh(y)=2*(y+y^3/3+y^5/5+...+y^33/33) für y=(x-1)/(x+1) für x> in [0.5,1[. Reduktion auf diesen Bereich log(x*2^n)=log(x)+n*log(2).
Folgendes Polynom vom Grad 10 in [1,1/9] tut:
also "nur" Grad 21 für artanh. Das gibt ln in [1/2,1] (und auch in
[1,2]):
ln(x) = w·p(w^2) mit w = (x-1)/(x+1)
Relativer Fehler ist ca. 1.25E-18, siehe Plot.
Johann L. schrieb:> also "nur" Grad 21 für artanh. Das gibt ln in [1/2,1] (und auch in> [1,2]):>> ln(x) = w·p(w^2) mit w = (x-1)/(x+1)>> Relativer Fehler ist ca. 1.25E-18, siehe Plot.
...dass dieses Näherung sowohl über [1/2,1] als auch über [1,2]
funktioniert, aber nur über einem dieser Intervall gebraucht wird, ist
Verschwendung.
Stattdessen kann man [1/√2,√2] verwenden, was ebenfalls Intervallgrenzen
mit Quotient 2 hat. Durch die Symmetrie braucht man das Polynom jetzt
nur noch über [0,w²] mit w = (√2-1)(√2+1) = 3-2√2, d.h. w² < 0.03 (siehe
aber p.s.):
Das Polynom hat also nur noch Grad 7; der relative Fehler ist mit
1.36E-18 nur unwesentlich größer als beim Grad-10 Polynom.
Im Fehler-Plot sieht man das daran, dass der Fehler 17 mal ein lokales
Maximum annimmt; für Grad 7 würde man 9 Maxima erwarten (bis zur 1 sind
es tatsächlich nur 9 Stück). Die restlichen Maxima ergeben sich durch
Spiegelung per ln(x) = -ln(1/x).
p.s.: Nachdem man x auf [1,2] (oder [1/2,1]) reduziert hat, genügt ein
einfacher Vergleich, ob x größer √2 (1/√2) ist. Wobei "einfach" heißt,
dass nur die Exponenten verglichen werden müssen. Sind diese gleich,
genügt es, nur die high-Bytes der Mantissen zu vergleichen. Dies wurde
ins Polynom dadurch eingepreist, dass es ln auf [1/z,z] approximiert mit
z = √2·(1+1/256) d.h. w² ≈ 0.0301 also auf einem minimal größeren
Intervall.
Johann L. schrieb:> Durch die Symmetrie braucht man das Polynom jetzt nur noch über [0,w²]> mit w = (√2-1)(√2+1) = 3-2√2, d.h. w² < 0.03
Soll natürlich heißen: w = (√2-1)/(√2+1)
Johann L. schrieb:> Das Polynom hat also nur noch Grad 7; der relative Fehler ist mit> 1.36E-18 nur unwesentlich größer als beim Grad-10 Polynom.
Den Grad um 9 zu reduzieren bei im Wesentlichen gleicher Genauigkeit,
zumindest für 64-bit IEEE, und dazu mit wenig Aufwand bei der Reduktion,
sind einfach unwiderstehliche Argumente :)
Ich habe fp64_log nach deinen Hinweisen optimiert für x in [1/√2,√2],
und das Ergebnis ist:
- Identische Genauigkeit, außer in 1 Testfall - dort besser
- Ausführungszeit von 0,720ms aus 0,437ms reduziert, d.h. -39%
- Ausführungszeit in Ticks: von ~11500 auf ~7000
- 84 Byte eingespart
Ist als V1.1.4 released. Die push/pop-Optimierungen via gcc-prologue
habe ich da noch nicht drin. Die möchte ich in Summe in ein Release
einsteuern, wo ich in Summe nochmal doppelte Code-Stellen rauswerfe.
Johann L. schrieb:> Hab mal meinen Remez angeworfen für sin√x/√x mit x in [0,π²/4]:>> Polynom hat Grad 8, also Grad 17 für sin:
Hab mir das auch lange angeschaut, auch bei libf7, mit folgendem
Ergebnis:
- Das eigentliche Polynom ist deutlich kleiner, allerdings brauchst du
eines für sin(x) und eines für cos(x).
- In Summe wären das (7*10+2)+(8*10+2)=154 Byte vs. 17*10+2=172 Byte für
die Tabellen.
- Die 18 eingesparten Bytes gehen mindestens 8 Byte für die
Fallunterscheidung zwischen sin und cos und den Aufruf des dazugehörigen
Polynoms drauf.
- Die restlichen 10 Byte reichen nicht, um x auf [0,π²/4] zu reduzieren
und dabei die ganzen Fälle zu tracken, wie z.B. pi/2 > x > pi/4, sin(x)
= cos(pi/2-x).
- Ich habe mal ein paar Fallunterscheidungen probehalber implementiert,
bin aber ganz schnell bei 14-20 Byte gelandet pro Fall.
In Summe braucht dein Vorschlag für sin√x/√x mit x in [0,π²/4] mehr
Speicher, wird aber natürlich schneller sein. Da ich aber nach
Speicherverbrauch optimiere, ist das für mich keine Lösung - zudem die
Ausführungszeit jetzt schon ganz gut ist.
Uwe B. schrieb:> - Die restlichen 10 Byte reichen nicht, um x auf [0,π²/4] zu reduzieren> und dabei die ganzen Fälle zu tracken, wie z.B. pi/2 > x > pi/4, sin(x)> = cos(pi/2-x).
Da ist was falsch angekommen: Ich bin davon ausgegangen, dass du
sin([0,π/2]) berechnest:
1) Reduziere x auf [0,π/2].
2) Berechne sin(x) ≈ x·p(x²). Wegen x in [0,π/2] muss die Approximation
für p(y) ≈ sin(√y)/√y für y = x² in [0,π²/4] taugen.
libf7 macht hingegen:
1) Reduziere x auf [0,π/4].
2) Je nach Anwendung, berechne sin(x) ≈ x·p(x²) und / oder cos(x) ≈
q(x²). Polynome p und q müssen für [0,π²/16] taugen wobei p ≈ sin√/√
und q ≈ cos√.
> Hab mir das auch lange angeschaut, auch bei libf7, mit folgendem> Ergebnis:> - Das eigentliche Polynom ist deutlich kleiner, allerdings brauchst du> eines für sin(x) und eines für cos(x).
Im ersten Fall muss p über [0, 2.467] approximiert werden, im zweiten
Fall p und q über [0, 0.6168].
Außerdem bin ich davon ausgegangen, dass bei dir 53 Bit Genauigkeit
ausreichend sind, bei libf7 verwende ich 56 Bit Genauigkeit. Die beiden
Fälle sind also nicht gut miteinander vergleichbar.
Ob 53 Bit beim Polynom für sin√/√ bzw. 2·artanh√/√ für 53 Bit
Zielgenauigkeit bei sin und cos bzw. log ausreichnd sind, hab ich nicht
untersucht. ggf. kann ich auch genauere Polynome berechnen, was
natülich den Polynomgrad größer werden lässt.
Johann L. schrieb:> Da ist was falsch angekommen: Ich bin davon ausgegangen, dass du> sin([0,π/2]) berechnest:>> 1) Reduziere x auf [0,π/2].>> 2) Berechne sin(x) ≈ x·p(x²). Wegen x in [0,π/2] muss die Approximation> für p(y) ≈ sin(√y)/√y für y = x² in [0,π²/4] taugen.
Ja, in der Tat haben wir aneinander vorbeigeredet. Die Approximation mit
sin(√y)/√y geht natürlich nach vorheriger Reduktion auf [0,π/2] ohne
Probleme und ohne Zusatzaufwand.
> Ob 53 Bit beim Polynom für sin√/√ bzw. 2·artanh√/√ für 53> Zielgenauigkeit bei sin und cos bzw. log ausreichnd sind, hab ich nicht> untersucht. ggf. kann ich auch genauere Polynome berechnen, was> natülich den Polynomgrad größer werden lässt.d ohne großen Zusatzaufwand.
Nach einem ersten Quick-Check ist die Genauigkeit fast ausreichend. Im
Intervall [-2π;2π] gibt es bei 512 Werten nur 4 Abweichungen, 3x ist
dabei die neue Approximation x·p(x²) um 1 Bit schlechter, 1x ist sie
besser, die anderen 508 Fälle stimmen "exakt" (d.h. auf 53bit) überein.
Von daher glaube ich nicht, dass genauere Polynome da noch helfen. Es
ist jetzt schon so, dass die Konstanten oft auf 56bit schon genau sind.
Ich habe deine Approximation in V1.1.6 released. Ergebnis:
- Ausführungszeit für sin & cos reduziert um 45%, von ca. 0,62ms auf
0,34ms
- In Ticks von ca. 10000 auf 5400
- 80 Bytes eingespart
Uwe B. schrieb:> um einen HP-kompatiblen RPN Rechner
hi, ich hoffe immer noch, dass du dein rpn nerdcal project noch
irgendwann veröffentlichst.
keep going and thanks for flib64, mt
Hallo,
die Library hört sich gut an, ich wollte mir mal ein handheld-GPS bauen,
und stiess dort auf die Ungenauigkeit von float32.
Also wollte ich die fp64lib eben ausprobieren, und stiess auf ein
Problem. Ich mag die Arduino IDE nicht, also verwendete ich Eclipse.
Was ich veranstaltet hab:
* Library direkt von https://github.com/fp64lib/fp64lib runtergeladen
* mit eclipse+avr-plugin ein neues AVR Projekt erstellt, atmega328P
* Dateien aus fp64lib in das Projekt übertragen
* Minimale main.c angelegt:
1
#include<avr/io.h>
2
#include"fp64lib.h"
3
4
intmain(void){
5
float64_tfloat1=float64_NUMBER_PLUS_ZERO;
6
while(1){
7
float1=fp64_add(float64_NUMBER_ONE,float1);
8
}
9
}
Dann kompilieren.
Ich erhalte die Fehlermeldung beim linken:
1
relocation truncated to fit: R_AVR_13_PCREL against `no symbol'
.. in fp64_modf.S Zeilen 63, 73, 91. Dort sieht alles wunderbar aus.
Googlen empfahl die Verwendung von "-mrelax" als Parameter, aber das
fruchtete nicht.
Ich könnte die von eclipse generierte Makefile anbieten. Wenn ich eine
Lösung finde, teil ich die mit.
Zum Vergleich mal doch in der Arduino IDE getestet, das example sketch
"Double". Kompilierte anstandslos:
Sketch uses 6236 bytes (20%) of program storage space. Maximum is 30720
bytes.
Global variables use 253 bytes (12%) of dynamic memory, leaving 1795
bytes for local variables. Maximum is 2048 bytes.
N.N. schrieb:> Ich könnte die von eclipse generierte Makefile anbieten. Wenn ich eine> Lösung finde, teil ich die mit.
Mach doch bitte einen issue auf dem fp64lib github auf und lade Makefile
und Sourcecode hoch und die Info über deine Umgebung (linux, Windows,
GCC Version). Ich schau es mir dann abends mal an.
N.N. schrieb:> Ich erhalte die Fehlermeldung beim linken:relocation truncated to fit:> R_AVR_13_PCREL against `no symbol'.. in fp64_modf.S Zeilen 63, 73, 91.> Dort sieht alles wunderbar aus.
Ich habe eine Vermutung, woran es liegen könnte, kann es leider aber
mangels makefile nicht nachvollziehen. Aber probier doch mal aus, dass
du in Zeile 59 von fp64_modf.s folgendes einfügst:
1
FUNCTION fp64_modf
Damit wird das Standard-Segment geändert, um zu verhindern, dass sich
die Bibliothek in dem Standard .text Segment einnisted.
Uwe B. schrieb:> Mach doch bitte einen issue auf dem fp64lib github auf und lade Makefile> und Sourcecode hoch und die Info über deine Umgebung (linux, Windows,> GCC Version). Ich schau es mir dann abends mal an.
Fehler bei fp64lib und bei dir sind beide gefunden, siehe
https://github.com/fp64lib/fp64lib/issues/7#issuecomment-594689924
Johann L. schrieb:>> Viellicht kannst du mal das aktuelle Release durch deinen>> "Comparator" jagen :-) ?>> Momentan leider keine Zeit...
Kein Problem, ich habe mal das Wochenende investiert und libf7 samt
Auswertungstoolset installiert (alles noch auf Basis gcc 9.2.0), auf das
neueste Release 1.1.10 von fp64lib angepasst und auswerten lassen. Anbei
im bekannten Format die Vergleichsdiagramme für Größe, Geschwindigkeit
und Genauigkeit.
In Summe läßt sich sagen, dass die Genauigkeit und Geschwindigkeit von
fp64lib sich deutlich gesteigert haben. In der Regel bin ich jetzt bei
53 Bit Genauigkeit, nur bei acos gibt es noch einen
Worst-Case-Ausreisser, den muss ich mir anschauen. Und bei tan streut es
etwas stärker zwischen 54 und 52 Bit Genauigkeit.
Uwe B. schrieb:> bei acos gibt es noch einen Worst-Case-Ausreisser,
Ist bei cos, nicht acos?
Irgendwas kann da nicht stimmen. Deine sqrt Implementierung ist
deutlich kleiner als meine (elementar vs. Newton-Raphson), dass müsste
sich doch analog für deine asin und acos ergeben?
Johann L. schrieb:> Ist bei cos, nicht acos?
Natürlich bei cos. Habe den Ausreisser auch schon gefunden, es ist
cos(PI/2). Du hast bei lib_f7 für cos ein eigenes Polynom, während ich
platzsparend cos(x) = sin(x+PI/2) implementiert habe. Und da das
Ergebnis nahe 0 ist (ca. 10^-10, wg. PI/2+PI/2 != π), ist der relative
Fehler recht groß.
Johann L. schrieb:> Irgendwas kann da nicht stimmen. Deine sqrt Implementierung ist> deutlich kleiner als meine (elementar vs. Newton-Raphson), dass müsste> sich doch analog für deine asin und acos ergeben?
asin/acos habe ich noch nicht platz-optimiert, da sind immer noch die
großen push/pop-Strecken drin, die ich ansonsten an vielen Stellen schon
ersetzt habe nach deinem Tipp bzgl. gcc-Prologue-Funktionen.
Uwe B. schrieb:> asin/acos habe ich noch nicht platz-optimiert,
Inzwischen habe ich asin & acos ebenfalls optimiert, um weniger
Flash-Space zu brauchen. Anbei die neuesten Auswertungen. Während es für
asin/acos nur wenig bringt (32 Byte), macht sich die Einsparung
deutlicher bemerkbar, wenn man mehrere fp64lib-Routinen in einem
Programm hat, da es inzwischen relativ viele gemeinsam genutzte
Hilfs-Routinen gibt.
Uwe B. schrieb:> Auswertungstoolset installiert
Hi, kannst du mal was schreiben wie diese gute Auswertung erzeugt wird?
Was/wo kommt das Auswertungstoolset her oder so ...
Danke!
HutaufHutab schrieb:> Hi, kannst du mal was schreiben wie diese gute Auswertung erzeugt wird?> Was/wo kommt das Auswertungstoolset her oder so ...
Das Auswertungstoolset ist Teil von libf7. Daher gebührt Johann
(@gjlayde) dein Lob, das ich uneingeschränkt teile. Wie er etwas weiter
oben
gepostet hat, gibt es libf7 hier:
> http://sourceforge.net/p/winavr/code/HEAD/tree/trunk/libf7/>> oder> $ svn checkout svn://svn.code.sf.net/p/winavr/code/trunk/libf7
Das Toolset ist im Unterordner .scripts. Damit es funktioniert, brauchst
du neben einer aktuellen avr-Toolchain noch mindestens python, avrtest
und R.
Das Toolset hat als Referenz die mathematischen Routinen auf mindestens
40 Stellen genau in Python implementiert. Dann werden aus einem Set von
Testdaten jeweils Testprogramme für die 4 zu testenden Bibliotheken
erzeugt, die mit den Testdaten gefüttert werden und deren Ergebnisse
gegen die Python-Referenz getestet werden. Aus dem Vergleich werden dann
komprimierte Ergebnisse erzeugt, die mithilfe von Rscript dann in die
sehr prägnanten Graphiken übersetzt werden.
Auch ohne Doku kann man da durchsteigen, vorausgesetzt, man hat etwas
Erfahrung in Entwicklung unter Linux, denn die Kombination von make,
avr-gcc-Toolchain, python, R(script) und avrtest ist hervorragend
gelöst, jedes Tool genau für den richtigen Zweck und keine unnötigen
Schnörkel.
Uwe B. schrieb:> Natürlich bei cos. Habe den Ausreisser auch schon gefunden, es ist> cos(PI/2). Du hast bei lib_f7 für cos ein eigenes Polynom, während ich> platzsparend cos(x) = sin(x+PI/2) implementiert habe.
Problem ist nicht extra Polynom oder nicht, sondern Argument-Reduktion?
> Und da das Ergebnis nahe 0 ist (ca. 10^-10, wg. PI/2+PI/2 != π),> ist der relative Fehler recht groß.
Das Problem hattest du doch gelöst?
sin ist doch relativ genau um 0, damit dann doch auch cos(x) = sin(pi/2
- x) um pi/2 vorausgesetzt Argument-Reduktion ist hinreichend genau,
z.B. 128 Bit oder so.
Johann L. schrieb:> Das Problem hattest du doch gelöst?
Ja, das Problem hatte ich tatsächlich gelöst, zeigen auch die
Auswertungen mit deinem Toolset.
Nur habe ich bei cos(x) einen wie ich dachte smarten Trick angewandt:
Ich führe die Addition in cos(x)=sin(x+PI/2) nicht physisch aus, sondern
ich sage nur, dass ich im nächsten Quadranten bin.
Nun passiert folgendes:
Zuerst wird die Argumentreduktion auf x durchgeführt auf 96 Bit genau.
Da x=PI/2 (52 bit) < π/2 ist, gibt es aber nichts zu reduzieren, d.h. x
bleibt PI/2.
Wg. cos sind wir aber trotzdem in 2. Quadranten, d.h. sin(x)=sin(PI/2-x)
(x reduziert, d.h in [0,π/2) )
Die Rechnung PI/2-x wird mit Standard 56 Bit Genauigkeit ausgeführt. Das
ist für sin(x) auch kein Problem für x um π/2, da das Ergebnis von
sin(x) nahe 1 ist und der Unterschied zwischen sin(PI/2-x) und
sin(π/2-x) sich erst nach 53 Bit bemerkbar macht.
Für cos ist das sehr wohl ein Problem, da cos(x) nahe 0 ist. Und da sin
um 0, wie du richtig feststellst, sehr genau berechnet wird, ist der
Unterschied zwischen sin(PI/2-x) und sin(π/2-x) deutlich zu sehen.
Und damit war der Trick doch nicht so smart. Das Problem hast du
umgangen, in dem du für cos(x) ein eigenes Polynom genommen hast. Die
verbesserte Argumentreduktion hilft da leider gar nicht, da sie erst gar
nicht getriggert wird wg. x=PI/2 < π/2.
Uwe B. schrieb:> ... cos(x)=sin(x+PI/2) ...> ... sin(x)=sin(PI/2-x) ...
Hä?
> Das Problem hast du umgangen, in dem du für cos(x) ein eigenes> Polynom genommen hast.
Das Polynom für cos dient dazu, x bei Berechnung von sin und cos auf
[0,π/4] reduzieren zu können anstatt nur bis auf [0, π/2]. Wegen cos(x)
= sin(π/2-x) ist ja cos(π/4-x) = sin(π/4+x), h.d. x=π/4 ist
Symmetrieachse. Vorteil ist, dass die Polynome dann kleineren Grad
haben.
Uwe B. schrieb:
gibt es libf7 hier: [...]
Und auch hier:
https://gcc.gnu.org/git/gitweb.cgi?p=gcc.git;a=tree;f=libgcc/config/avr/libf7;
Allerdings ohne Skripte und unter etwas anderer Lizenz.
> Das Toolset hat als Referenz die mathematischen Routinen auf mindestens> 40 Stellen genau in Python implementiert.
Die Genauigkeit ist dynamisch anpassbar, am einfachsten global per
1
import decimal
2
decimal.getcontext().prec = ...
Die Genauigkeit kann auch den Routinen mitgegeben werden:
1
def get_asin (x, n):
2
""" Compute asin (x) to n binary figures."""
3
...
decimal ist Teil von Python:
https://docs.python.org/2/library/decimal.html
Zu beachten ist allerdings, dass diese Funktionen die Genauigkeit
"bumpen", d.h. global auf mindestens die erforderliche Genauigkeit
einstellen und diese dort belassen.
Johann L. schrieb:> Uwe B. schrieb:>> ... cos(x)=sin(x+PI/2) ...>> ... sin(x)=sin(PI/2-x) ...>> Hä?
War etwas reduziert dargestellt:
cos(x) = sin(x+π/2) gilt universell für alle x in R, das sollte
unstrittig sein
Jetzt sei x1 = fmod(x, π/2), d.h. Argument-Reduktion
Damit ist x1 in (-π/2, π/2) und ich kann sin(x1) annähern durch sin(x1)
≈ x1·p(x1²)
Vorher muss ich allerdings den Parameter korrigieren, je nachdem in
welchem Quadranten x vorher war:
Im 1. Quadranten ist keine Korrektur nötig, d.h. sin(x) = sin(x1)
Für ein x im 2. Quadranten, d.h. π/2<x< π gilt sin(x)=sin(π/2-x1)
Kurzer Plausicheck für die Grenzen des 2. Quadranten für ein kleines
eps>0:
x=π/2+eps -> x1 = eps -> sin(π/2+eps)=sin(π/2-eps)~sin(π/2)=1
x=π-eps -> x1=π/2-eps -> sin(π-eps) = sin(π/2-(π/2-eps)) =
sin(eps)~sin(0)=0
Uwe B. schrieb:> Die Rechnung PI/2-x wird mit Standard 56 Bit Genauigkeit ausgeführt.
Behoben, in V1.1.12 korrigiere ich mit π/2-PI/2 nach, et voilà: sin(x)
ist jetzt immer auf voller Genauigkeit und cos(x) ist in der Regel auf
53 Bit und im worst case auf 52 Bit, und das mit minimaler Penalty bei
der Geschwindigkeit.
Uwe S. schrieb:> ich habe heute die neue 64-Bit Lib von PeDa mit dem Projekt übersetzt> und das spart einige Bytes. [...]>> http://www.avrfreaks.net/index.php?name=PNphpBB2&file=viewtopic&t=113673>> Einfach die Datei dannis64bit.S kopieren und in das Makefile eintragen> -- fertig !
Seit Microchip avrfreaks übernommen hat funktionieren Links wie oben
leider nicht mehr.
Hat jemand nen aktuellen Link zu dem entsprechenden Beitrag?
Was ich finden kann ist
[C][UTIL] Efficient 64 bit support
https://www.avrfreaks.net/s/topic/a5C3l000000UNh2EAG/t104870
was im Archiv my64bit.zip eine Datei dannis64bit.S enthält, die aber nur
einige long long Routinen hat.
Gibt es da eine neuere Version mit 64-Bit double?