Hi guys, meine Frage betrifft Audio Profiling - vielleicht kennt jemand Kemper-Amps (https://www.kemper-amps.com/profiler/overview) Wäre prinzipiell auch eine Charakterisierung von SW-Effekten wie z.B. Guitar Rig mit anschließender Realisierung als HW-Filter möglich? (MCU->FPGA). Bin kein DSP-Experte, aber als erster Problemaspekt fällt mir z.B. IIR time-invariance (Delay-Effekte) ein.
Du solltest vielleicht erst nochmals genauer erklären, was du genau wissen willst und Deine Gedanken ordnen: bla schrieb: > meine Frage betrifft Audio Profiling Profiling != Modelling > - vielleicht kennt jemand > Kemper-Amps (https://www.kemper-amps.com/profiler/overview) ... betreibt kein audio modelling, sondern amp modelling. D.h. es wird ein Gerät und dessen Funktion nachgebildet. > Wäre prinzipiell auch eine Charakterisierung von SW-Effekten "Charakterisierung" von Software oder Effekten bedeutet, sie zu gruppieren und in ihrer Bedeutung zu klassifizieren. Du meinst was komplett anderes, nämlich, Software nach zu bilden. > wie z.B. > Guitar Rig mit anschließender Realisierung als HW-Filter möglich? > (MCU->FPGA). Es gibt keine HW-Filter in FPGAs. Die gibt es nur in Analogelektronik. FPGAs sind digitale Bausteine, die allenfalls zum Rechnen gebracht werden können und DANN in der Lage wären, durch diese Software Allesmögliche zu Rechnen. Damit wäre es Software, die Filter und anderes leisten könnte. Dann: Die Programme, auf die Du abzielst, sind allesamt Software und sie lassen sich damit IMMER in anderer Software nachbilden. > Bin kein DSP-Experte Mit DSPs hat das wiederum gar nichts zu tun. Einen DSP müsstest Du im FPGA erst mal bauen. Konkret einen Audio-DSP, der sowas kann. Und dann hättest Du nichts anderes, als das, was deine Winsoftware schon macht. > aber als erster Problemaspekt fällt mir z.B. IIR > time-invariance (Delay-Effekte) ein. Wo genau soll das das Problem sein? Was an Filtern in Windoof läuft, läauft auf DSPs 10mal und auf FPGAs 100mal, sobald Du sie dazu gebracht hast. Das allerdings sollte nicht einfach sein.
Als kleiner Nachtrag ein Ergebnis einer Suche hier im Forum: Beitrag "Röhrenklang nachbilden" Beitrag "VHDL-Effektgerät für Gitarre und andere Instrumente" Beitrag "Effektgeräte selber bauen" Beitrag "USB MIDI Controller mit Effekt Software f. Gitarre" Du darfst die Sucher auch gerne selbst mal verwenden :-)
Audiomann schrieb: > Mit DSPs hat das wiederum gar nichts zu tun. Einen DSP müsstest Du im > FPGA erst mal bauen. Konkret einen Audio-DSP, der sowas kann. Der TO meinte hier offensichtlich nicht DSP(rocessor) sondern DSP(rocessing). Letzteres kann man auf einem FPGA mit oder ohne einen Prozessor-Core betreiben, die benötigten Algorithmen (Filter, FFT, DWT, NCO usw.) lassen sich auch unmittelbar in HW realisieren. bla schrieb: > Wäre prinzipiell auch eine Charakterisierung von SW-Effekten wie z.B. > Guitar Rig mit anschließender Realisierung als HW-Filter möglich? Grundsätzlich lässt sich jedes Signal mit einem beliebigen Profil falten. Wenn ich Kempers Werbesprech richtig deute, sind Amps als lizensierte Profile im Gerät hinterlegt. In diesem Fall steckt das Geschäftsgeheimnis weniger im "wie" (Effekten) sondern im "was" (den Amp-Profilen).
Danke Burkhard, also ist glaube ich klar was gemeint ist. der praktische Vorteil einer Modellierung von SW-Effekten mittels FGPA ist offensichtlich: - Latenz - Stromverbrauch - Formfaktor - Kosten Ev. ist die Frage berechtigt, warum HW-modeling eines SW-models eines HW-models... - SW ist schon in der digitalen Domäne - große Preset-Auswahl. Daß es geht, zeigt sich ja am Beispiel Kemper. Ich hatte gehofft, jemand hat mehr zum Thema theoretische Machbarkeit zum sagen, also wie gesagt. z.B. Zeit-Varianz... Faltung mit IIR ist ja invariant, und inwieweit sich der Prozeß automatisieren läßt.
Ich bin wirklich der Allerletzte, der einen Nutzen von FPGAs im Bereich Audio bestreiten würde ;-) aber diese von Dir genannten Punkte "Latenz, Stromverbrauch, Formfaktor und Kosten" sind alles andere, als Pro-Argumente für FPGAs. Die Kosten sind sowohl bezüglich der Bauteile höher, als auch für die Entwicklung, dasselbe gilt für Formfaktor und vom Strom wollen wir gar nicht erst reden. Was die Latenz angeht, so muss berücksichtigt werden, daß man hier sample-orientiert denken muss. Wenn Du eine Basswelle bearbeiten willst, musst Du wenigstens mal 10ms aufgreifen und das sind auch bei 192kHz nicht allzuviele Samples, dass sie einen DSP ins Schwitzen bringen müssen, von der Seite her gibt es da kaum Raum für einen großen Latenzvorteil bei FPGAs. Die Latenzthematik spielt sich auch eher im Umfeld "Windows, Treiber, Realtime, USB, Masterkeyboard und MIDI" ab und dafür habe ich ja Lösungen geliefert, die auch führend waren, solange es noch kein USB 2.0 und ASIO gab. Wenn Du aber wie in Deinem Fall Echtzeit für Audio forderst, also "Gitarrensignal rein und wieder raus", wird es kaum ein Problem sein, einen ausreichend schnellen DSP zu finden, der das Benötigte kann, zumal hier ja nur ein oder zwei Kanäle zu prozessieren sind und DSPs mithin ausreichend sind, um mehrere Stimmen parallel zu prozessieren, wie z.B. beim Hall und dem Vocoder im (ebenfalls von C.K. entwickelten) Access Virus. Es kommt darauf an, was man da konkret an Software laufen lassen will und wie rechenintensiv es ist. Im Zweiffelsfall packt man einen fetteren DSP mit drauf. Man darf davon ausgehen, dass im Kemper-Amp ausreichend Power verbaut ist. Ich habe zwar keine Ahnung von dessen Innenleben, vermute aber stark, dass da nicht mal der dickste DSP drinsitzen dürfte, der zum Zeitpunkt der Entwicklung verfügbar war, sondern eher was Kostenoptimiertes. Um einen FPGA bei Audio ins Spiel zu bringen, braucht es ganz andere Anforderungen, wie z.B. Echtzeitmodellierung von Elektronik und dies auch a) parallel für b) für mehrere Kanäle. Das impliziert z.B. dass, man solche Filter wie sie mit Oszillatoren gebildet werden, mikrogranular in Echtzeit rechnet, als mit ns-Auflösung. Das erfordert wiederum gewaltige Auflösungen und Resourcen, wenn es genau(er) werden sollen, die sich nicht unbedingt in einem Mehr, an Qualität abbilden. Wenn man die Filter stärker diskretisiert, also gröber abtastet, bekommt man praktisch dieselbe Qualität am analogen Ausgang. Ich habe dazu Messungen an den OSCs meines Drumcomputers gemacht und betreibe diese mit maximal 768kHz Abtastfrequenz. Mehr bringt nix, zumindest solange nicht, solange es keine erschwinglichen DA-Wandler gibt, die mehr als, 192kHz verarbeiten können. Mit FPGAs ist es natürlich möglich, Filterung und Klanggeneration auf höchstem Niveau für z.B. 256 Kanäle gleichzeitig zu betreiben. (200MHz FPGA). Will man aber nur EINEN Kanal erzeugen, lägen 99% der time slots im FPGA brach. Dann reicht auch ein normaler DSP. Daher sitzen in den ganzen Audiogeräten in der Regel auch normale DSPs. Um da die Rechenleistung zu senken, wird z.B. kein rt-modelling betrieben, sondern es wird eine beschreibende Gleichung eines Filters ermittelt und diese abstrakt durchgerechnet. In den VA-Synthesizern "schwingen" also die Oszillatoren nicht wirklich, wie echte Elektronik, sondern nur gerade so schnell, wie die Abtatsfrequenz es erlaubt. Wie genau das dann ist, steht auf einem anderen Blatt. Meine in HW nachgebauten OSCs lösen freilich sehr viel feiner auf und lassen solche Effekte wie Energieaustausch und Intermodulation in Echtzeit zu, wozu man bei klassischen VA-OSCs erst die Gleichung finden müsste, so überhaut möglich. Richtig ist auch, dass man mit einem FPGA z.B. einen FIR-Filter bauen kann, der mit Maximalgeschwindigkeit abtastet und für jedes Sample z.B. gleich mehrere Tausende Filter-TAPs berücksichtigt. Ich habe einen solchen EQ as Mastering-Tool gebaut und in Verwendung: Auch hier wären wieder 10ms Tonmaterial mit 192kHz anzunehmen, was zu 2048 TAPs führt. Da muss man schon zweifach parallel rechnen, um mit einem FPGA hinzukommen. Die Auflösung ist grandios, aber das "Gerät" belegt schon locker einen halben mittleren FPGA. Passender Beitrag dazu: Beitrag "Re: Faltung mit Xilinx FIR compiler 5.0" Erfahrungsgemäß will die Audiogemeinde aber solche Qualität nicht bezahlen - zumal der Vorteil eben halt auch nicht so direkt hörbar ist. Der Weg geht ja eher weg von den Geräten und man begnügt sich mit Windows-Plugins. > Ev. ist die Frage berechtigt, warum HW-modeling eines SW-models > eines HW-models... Es wird kein Software in Hardware modelliert. Wie ich beschrieben habe, gibt es entweder a) eine Abbildung einer Hardware in Form eine konkreten aus elektronischen Bauteilen bestehenden Schaltung, deren Einzelelemente so gerechnet werden, wie sie physikalisch funktionieren (bei den OSCs eine numerische Integration, bei der sich der Sinus ergibt). b) eine Formel, bei der das äussere Verhalten schon vorweggenommen ist und einfach nur parametrisch gerechnet wird, um die Funktion nachzubilden. In beiden Fällen muss gerechnet werden! Womit das geschieht, ist eine kostenfrage, bzw Geschmackssache. Nur bei meinen rückgekoppelten OSCs im FPGA gab es wirklich und tatsächlich schwingende Hardware. Das baut aber keiner, weil es nicht gut beherrschbar ist.
Was den Kemper-Amp angeht, bin ich nicht informiert, wie der genau arbeitet, aber letztlich wird es auch dort einen Satz von Formeln geben, welche jeweils über eine Anzahl von Freiheitsgraden verfügt, mit denen man sich an den Klang von AMPs anpassen kann. Wie realistisch das ist, weiß ich nicht. Ich bin kein AMP-Experte und halte es für fraglich, ob man die vielen Details völlig unterschiedlicher Geräte wirklich genau erfassen kann. Der Verlauf solcher nichtlinearer Übertragungssysteme (und die Nichtlinearität ist ja im Wesentlichen das Klangbestimnende) ist theoretisch in Form von Faltungen in FPGAs abzubilden, aber um an die Parametersätze zu gelangen, müsste man sehr aufwändige Messungen durchführen, weil diese 4-Dimensional wären (ein sich über die Zeit änderndes komplexes Amplituden-Spektrum mit Frequenz und Phase, jeweils in Abhängigkeit der Spektrenhistorie): Ich habe nämlich mal Röhren vermessen und gefunden, dass deren tolle Klangeigenschaften hauptsächlich darin begründet liegen, dass sich ihre Ü-Kennlinie rasch ändert, wenn sie wärmer wird. Wärmer wird sie z.B. differenziell bei hohen Pegeln, d.h. bot das Klangmaterial in den Milliekunden vorher eine hohe Enrgiedichte, nahm die Oberwellenempfindlichkeit anders ab, was zu einem weniger aggressiven Klang führte. Die Sättigung ist also nicht statisch, sondern dynamisch. Röhren klingen damit deshalb "weich", weil sie im entscheidenden Moment weniger Oberwellen zusetzen, als es bei den statischen Röhrenemulationen oft der Fall ist. Bei geringen Lautstärken ist es entsprechend mehr, weil die dynamische Sättigun geringer ist. Ich habe das bei meinem Modell durch einen Multibandkompressor emuliert, der die Verstärkung und die Oberwellen zugabe steuert. Bei Lautsprechern wiederum hat man einen gegenteiligen Effekt: Hohe Elongationen der Membran infolge z.B. eines Basses, bewirken einen rauheren Klang, daher sind Obertöne mit hohem NF-Anteil stärker gefärbt. Hinzu kommen die Partialschwingungen von Membranen und die des Gehäuses, die ja resonieren. All das für einen kompletten AMP in eine Ü-Kennlinie zu packen, ist schon mal theoretisch nicht möglich. Es brächte getrennte nichtlineare Regelsystem-Gleichungen mit Sättigungsverhalten für jeweils die Röhren, die Vorverstärker, die Effekteinheiten mit Limiter und auch Eumlationsgleichungen für das Verhalten der Lautsprecher mit ihrem komplexen Abstrahlverhalten. Dann braucht es eine Modellierung des Raumes, weil solche Amps in verschiedene Richtungen verschieden Strahlen und damit sich eine Überlagerung von Spektren ergibt. Somit muss man sich fragen, wo man da anfängt und wo man da aufhört, denn letztlich wird das Signal, was aus dem AMP-Modeller rauskommt, ja auch wieder irgendwo wiedergegeben und damit mit diesem letzten Lautsprecher in der Kette klanglich gefaltet. Ich habe diese Thematik schon mehrfach im Rahmen von Diskussionen bei Studiomonitoren durchgekaut, wo es auch Exemplare gibt, die vorgeben, man könne per Umschaltung den Klang anderer Monitore emulieren. Man kann mathematisch zeigen, dass das grundsätlzich nicht geht, bzw nur ein dem theoretischen Spezialfall, wo sich Mischprodukte der Faltung zufällig alle so aufheben, dass man mit einer inverten 3D-LaPlacegleichung das Verhalten korrekt vorverzerren könnte, sodass sich der Klang der eigenen Monitore und des Raums drauf-"addieren" kann, und dann das richtige Ergebnis entsteht.
Aha, aha, sehr interessant. Danke mal für die ausführliche Antwort. Zum Thema Systemidentifikation, d.h. Ermittlung der Übertragungsfunktion: Jürgen S. schrieb: > Wie ich beschrieben habe, gibt es entweder > a) eine Abbildung einer Hardware [...] (a.k.a physical modeling) > b) eine Formel [...] c) Impulse-Response? Vom Aspekt Automatisierung wahrscheinlich am einfachsten zu realisieren. Wie am Röhren-Beispiel schön beschrieben, wäre dann soweit ich das verstehe eine mehrdimensionale Kennlinie notwendig (nichtlinear, zeitvariant). -> Repräsentation? Kann der Laplace-Transform auch für non-LTI-Systeme verwendet werden? Auch das Impuls-Signal müßte dann mehrdimensional sein, d.h. den Raum der harmonischen Kombinationen zeitlich aufgelöst möglichst abdecken, im Gegensatz zu einem Dirac-Impuls oder Sine-sweep. (Wavelets?) Soweit sehe ich theoretisch noch keine konkreten Grenzen. (und wenn, vielleicht ein Fall für Peter Neubäcker: "Es ist zwar theoretisch nicht möglich, aber praktisch durchaus machbar" :) > [...] Monitore emulieren. Man kann mathematisch zeigen, dass das > grundsätzlich nicht geht [...] Grundsätzlich im Bezug auf convolution nicht oder nur im Zusammenhang mit Raumklang?
>physical modelling Schon klar, aber es fragt sich, WAS und WIEVIEL modelliert wird. Ich habe das bei meinem V-Piano gesehen, wie aufwändig das werden kann, wenn man versucht, 3-D-Gehäuse aus z.B. Holz genau zu emulieren und deren Partialschwingungen nachzubilden. Das ist trotz enormen Recheneinsatz oft sehr realitätsfern. Genau diese Erkenntnis hat mich bewogen, die viel zitieren Monitoremulationsversuche in ihrer Sinnhaftigkeit ausdrücklich zu verneinen. > Grundsätzlich im Bezug auf convolution nicht oder nur im Zusammenhang > mit Raumklang? Von der Physik her ist das schon im Regelfall nicht machbar, weil bei einem nichtlinearen System jede einzelne Sinuswelle ihre Oberwellen erzeugt und es im Regelfall = 99,9% nicht möglich ist, negative Oberwellen immer so einspeisen, dass sich jeweils alle daraus neu erzeugten allesamt wegheben. Für ein einzelnes Ü-System ist das theoretisch noch möglich, aber für zeitvariante Gekoppelte nicht mehr. Man hat einfach das letzte Glied in der Kette nicht genügend gut an der Angel. >noch keine konkreten Grenzen. Das Problem mit solchen Profilingversuchen ist generell, ein dedziertes Modul in der gesammten Signalkette gezielt und vollständig auszutauschen. Das ist hier so ohne Weiteres nicht möglich, weil Du in dem Fall ja einen Lautsprecher mit abscannen musst. Klar kann man den Verstärker auch vor oder nach der Endstufe anzapfen und das Signal elektronisch aufnehmen, aber immer, wenn die Tonmänner kommen und ein Signal auf diese Weise ins Mischpult geben, kommt der Bassist und sagt, dass der Klang nicht ok ist, weil der Lautsprecher nicht mit dabei ist. Ergo stellt man oft ein Mikro hin und das addiert wieder seinen Klang. Das betrifft sowohl das Frequenz- und Ansprechverhalten, als auch den Raumklang, weil so ein AMP als 3D-Gebilde klingt und aus Erfahrung weiß ich, wie wenig davon man authentisch ist Mikro bekommt. Beim Profiling müsste man nun vom Mikro rückrechnend auf den Klang des Lautsprechers schließen und eine Übertragsungsfuktion so bilden, daß der eigene Lautsprecher "abgezogen" wird. Keine Ahnung, wie man das bewerkstelligen will. So, läuft es darauf hinaus, daß Herr Müller "seinen" AMP mit seinem konkreten LS unter Nutzung seines Mikros "profiled", das Setup an Herrn Mayer sendet, der dann den AMP Modeller Mit Müllersetup und darin inbegriffenem Müllermikroklang auf das Signal loslässt, auf das dann der Meyer-Lautsprecher wirkt. Hm .... Wenn, müsste man Lautsprecher und Mikros komplett weglassen und alles durch den Modeller ersetzen. Das bewirkte dann zwar kein Auseinanderlaufen der Abspielketten, erforderte aber eine funktionierende Lautsprecheremulation durch den Modeller. Diese ist zwar theoretisch möglich, erfordert aber wie schon erklärt verfärbungsfreie eigene Lautsprecher und eine gewaltige Messkette, gepaart mit entsprechendem Rechenaufwand. Für möglich und sinnvoll hingegen halte ich es, den Klang eines irgendwie gearteten Systems durch subjektive Parametrierung nachzubilden, also Sounddesign zu betreiben und dann das jeweils auf trockene Signale loszulassen, um sich den Kauf von Hardware zu sparen. Da sind wir aber genau genommen bei Klangprozessoren und Klangsynthese und genau das wird mit solchen Geräten letztlich gemacht. Die Parameter werden so justiert, dass es "gut" klingt. Was "gut" ist, ist dann Geschmacksfrage. Ich hatte Teile meines Modellers ja mal in ein Design gepackt und zur Verfügung gestellt. Es bleibt dem Nutzer überlassen, festzustellen, wie am(p)tlich das klingt :-)
Jürgen S. schrieb: > Für ein einzelnes Ü-System ist das theoretisch noch möglich, aber für > zeitvariante Gekoppelte nicht mehr. Das betrifft jezt aber nur Emulationen im Sinne von rechn. Lösung von Gleichungssystemen, aber nicht IR-Faltung. Interessante Frage in dem Zusammenhang natürlich, sind die beiden äquivalent. Klar, ein profiliertes 'eingefrorenes' System läßt sich anschließend schwer entsprechend den Originalmodell-Parametern verändern, es bleibt aber wie erwähnt die Möglichkeit, einzelne Module getrennt einzufangen und - unter Vernachlässigung von Koppelungseffekten - zu kombinieren. Dafür tun sich aber völlig neue Klangbeeinflussungsmöglichkeiten in Form der direkten Manipulation der Übertragungsfunktion auf. Capybara hat glaube ich direkt mit der Spektralrepräsentation gearbeitet. (Wundert mich, daß niemand entsprechende Software geschrieben hat - war ein HW-System, sollte heute rechnerisch kein Problem mehr sein.) Also der Engpaß bei convolution scheint der große Eingangsparameter-Raum zu sein, sollte sich mit z.B. Interpolation aber in den Griff bekommen lassen... Hab leider kein fpga, kann man den Modeller irgendwo anhören?
Das Problem der IR-Faltung ist das der Auflösung. Die Transformation der gealteten Signale wieder in den Zeitbereich ist auch mit hochaufgelösten iFFTs nichtartefaktfrei. Solche Sachen sind ja mehrfach probiert wurden, z.B. bei den Variosamplern und Variophrase von Roland. Das klingt immer entweder metallisch oder sonst wie steril gekünstelt. Selbst, wenn Du ein Signal nur über FFT und iFFT mit dem Spektum a(f)=konst prozessierst, bekommst Du Artefakte, weil Du aus praktischen Gründen an beiden Stellen fenstern musst. Je komplexer das Material, desto schlimmer :-) >Engpaß Da kommt so oder so noch ein Calculation Power Problem. Echtzeitfaltungen sind nur mit HW praktikabel. Bei Video und Radar ist das Tagesgeschäft, beim Audio scheitert es aber an der benötigten Auflösung. >irgendwo hören Ursprünglich war der mal in C für einen TMS320 entwickelt worden. So, wie er heute aussieht, geht das aber nur im FPGA, oder man müsste neuen Code schreiben.
Jürgen S. schrieb: > Selbst, wenn Du ein Signal nur über FFT und iFFT mit dem Spektum > a(f)=konst prozessierst, bekommst Du Artefakte, weil Du aus praktischen > Gründen an beiden Stellen fenstern musst. Und wie machen das die ganzen Geräte, die die Tonhöhe verändern und Harmonien erzeugen? Die nehmen die Klänge ja doch auch auseinander, filtern Frequenzen weg und setzen das neu zusammen. Auf anderen Gebieten der Datenverarbeitung werden Signale auch so prozessiert, also per FFT in den Frequenzbereich überführt und dann wieder rücktransformiert.
Ja, ja - freilich tun sie das, aber eben nur im Rahmen einer gewissen Genauigkeit. Bei der FFT z.B. greift sowohl durch das Fenstern als auch durch die Auflösung eine Bandbeschränkung. Die Auflösung ist dabei sowohl in der Frequenzachse, als auch auf der Zeitachse gegeben. Theoretisch könnte man natürlich samplegenau Analysieren und Synthetisieren, aber dann kann man nicht mehr fenstern. Es läuft also immer auf einen Kompromiss hinaus. Was bei Bildverarbeitungsthemen mit Echoauswertung wie Radar, Lidar und Ultraschall noch sehr gut hinkommt, ist beim Audio nicht machbar: Zwar gäbe es grundsätzlich keine Probleme, das limitierte Spektum von 20Hz ... 20kHz einzufangen, aber von der Amplituden- und Frequenzauflösung ist das Gehör einfach viel zu fein. Das Gehirn hat genau gelernt, was wie klingt und es reichen minimale Artefakte, um einen Klang als künstlich zu entlarven. Selbst, wenn man einen durchschnittlichen Audiodatenstrom unverändert nur etwas schneller abspielt, hört man sofort die Formantenverschiebung und nimmt einen Mickey Mouse Effekt war. Auch die Artefakte von Samplern die durch das Loopen entstehen, sind deutlich zu hören. Geschulte Ohren hören auch Defizite bei Tonaufnahmen, infolge von Frequenzverzerrungen. Genau genau genommen, ist das in der Bildverarbeitung allerdings auch der Fall: Wenn Du eine 2D-Analyse eines Bildes machst und es wieder zusammensetzt, kannst Du deutlich erkennen, dass der Bildausschnitt manipuliert wurde. Um es genau zu sagen, ist er total verhunzt! Das sieht noch schlimmer aus, als viele MPEG-Kompressionseffekte, mit denen wir heute leben müssen. Bei Bildern haben wir uns aber dran gewöhnt, dass das, was wir sehen, aus einem Kasten kommt und man erkennt selbst mit einem Auge und bei UHD sofort, dass man nicht durch ein Fenster nach draußen schaut. Mit guten Mikros und Studiomonitoren hingegen ist es hingegen heute möglich, Geräusche so zu transportieren, dass der Laie nicht mehr hört, ob ein Lautsprecher oder eine Person hin ihm spricht. Von daher sind die heutigen Aufnahme-Wiedergabe-Systeme auch bei Konservenmusik absolut geeignet, Klangverluste infolge von exzessiver Datenverarbeitung zu offenbaren - zumindest bei natürlichen Klängen, für die im Gehör ein Erfahrungshintergrund existiert. Wenn es allerdings bei der Smartphone-Generation mit der Gehör-Verarmung durch zuviel plattkomprimierte Konservenklänge und MP3 so weiter geht, dann könnte man in einigen Jahren möglicherweise aber (wieder) dichter rankommen :-)
Wie machen die das eigentlich, wenn sie Elektronik modellieren? Die Abtastrate der Signalprozessoren ist doch auch begrenzt. In pSPICE kann Ich jederzeit kleine Schritte einsetzen, um genaue Ergebnisse zu erhalten, aber in der Realität kann ich mir kaum vorstellen, daß es möglich ist, eine Elektronik, die schwingt, genau genug zu berechnen. Nehmen wir eine normale Frequenz von 15kHz, die noch jeder hören kann, dann muss man mindestens auf Faktor 1000 genauer rechnen, um sie überhaupt genau abzubilden, wenn es Dreckeffekte geben soll und nicht nur einfach den theoratischen Sinus. Einen Selbstschwinger in einer analogen Oszialltorschaltung muss man mit mindestens Faktor 10.000 auflösen, wenn es genau werden soll und er von einem anderen beeinflusst wird. pSPICE rechnet da mit Auflösungen von 0.1us und genauer. Geht also irgendwie nicht, oder?
Der Unterschied ist, dass man es nicht mit diskreten immer gleichen Abständen berechnet, sondern die Zeit mit in die Gleichung nimmt und dann den richtigen Wert berechnet. Die Auflösung in Y muss dann entsprechend genau sein, Dann reichen generell Abtastraten von etwa dem 10-fachen der benötigten Höchstfrequenz, um sie gut darzustellen. Wer Zeit hat und in der Nähe ist: http://www.isi.ee.ethz.ch/teaching/courses/sip.html
> sondern die Zeit mit in die Gleichung nimmt und dann den richtigen Wert
berechnet.
... was erfordert, dass eine analytische Gleichung vorliegt und im
Weiteren bedingt, dass so nur bestimmte Systeme berechenbar sind.
Numerische Integrale bedürfen da schon einer höheren Auflösung. Da liegt
auch ein bisschen der Hund begraben, wenn es ums Audio geht:
Das klanglich Entscheidende zwischen der komplexen Realität und der
meistens einfachen Mathematik ist eben das nichtlineare Moment in den
Gleichungen. Und das kostet neben Modellierungsaufwand auch Rechenzeit
und stellt Anforderungen an die Genauigkeit.
Habe ich auch lernen müssen ...
Jürgen S. schrieb: > ... was erfordert, dass eine analytische Gleichung vorliegt und im > Weiteren bedingt, dass so nur bestimmte Systeme berechenbar sind. Der Trick liegt vielmals darin, die Gleichungen zu finden, die dem Realen nahekommen, also sie überhaupt erst aufzustellen. Bei dem, was der TE machen möchte, müssten erst einmal genaue Messungen herbei, die zeigen, was das zu berechnende Gerät überhaupt zu leisten in der Lage ist. Bei den sogenannten Amps sind oft auch verzerrende Effekte mit drin. Die müsste man wohl abziehen. Oder extra Modellieren.
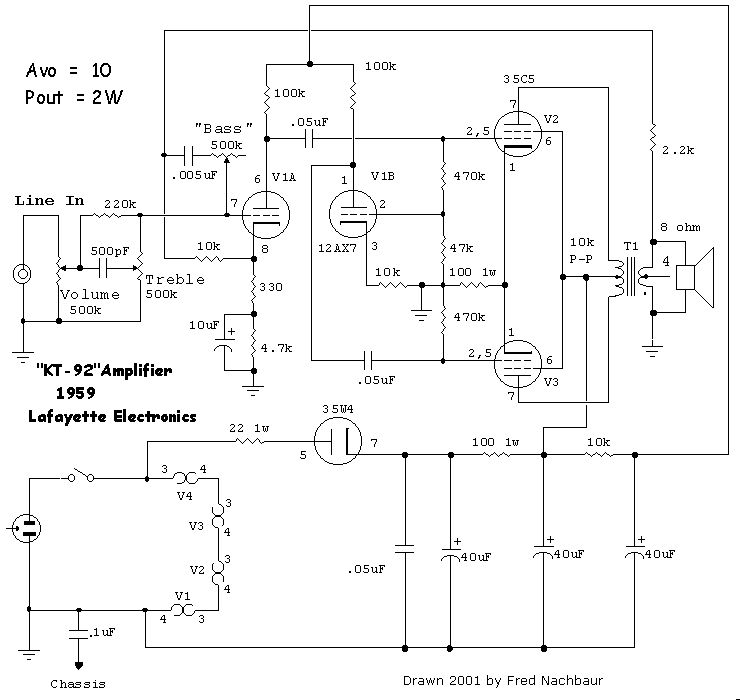
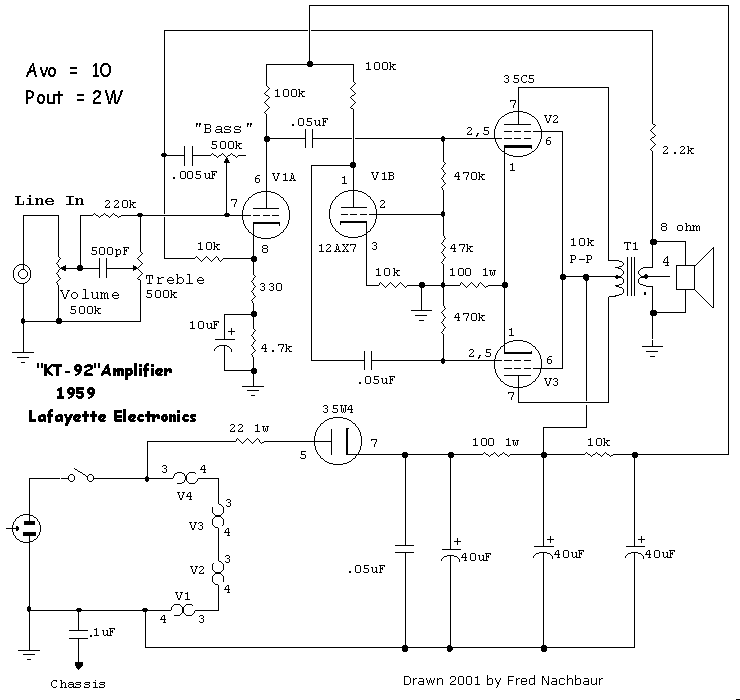{kind=link}
Klar, kann man. Da die Software aber nur ein Modell der Wirklichkeit ist, stellt sich die Frage wie genau das Modell sein soll. Was ist Dein Qualitätskriterium? Im einfachsten Fall implementiert man nur die nichtliniearen Kennlinien der Röhrenstufe. Aber natürlich spielt auch das warme Licht der Röhren eine Rolle für die Wahrnehmung. Als Ketzer würde ich sagen: Da nimmt man einfach noch ein paar orange Leuchtdioden dazu.
Guter Tipp das mit den LEDs. Aber für den Klang braucht es wohl doch noch etwas mehr. Immerhin ist noch ein Ausgangstrafo vorhanden und es sind mehr, als ein Röhre verbaut. Die beeinflussen sich ja auch über die Wärme. Ich finde aber bisher kein Modell einer Röhre, in dem das eingeflossen ist. Wie simuliert man die Widerstände? Auch die sind bekanntlich wärmeabhängig. Und sie rauschen.
Wie gesagt: Du brauchst ein Gütekriterium. Es nützt wenig, jedes Detail zu simulieren, wenn man es nicht hört. Die Frage ist: Was willst Du hören? Was ist der Maßstab?
Ich sehe mich momentan nicht in der Lage, ein solches Gütekriterium aufzustellen. Technisch könnte ich jetzt sagen: zu 90% an der Realität. Also ein Klangverlauf soll bis auf maximal 10% Abweichung dargestellt werden. Für mich wäre es in einem ersten Ansatz aber erst einmal von Interesse, zu höhren, was machbar ist.
>Technisch könnte ich jetzt sagen: zu 90% an der Realität.
Tja, jetzt wird es echt schwierig: Was ist Realität?
Audiobastler schrieb: > Wie simuliert man die Widerstände? Auch die sind bekanntlich > wärmeabhängig. Und sie rauschen. Nicht nur die. Schaue Ich mir die hochohmigen Potis an, dann wird da alles reinpfeifen, was in der Luft verfügbar ist. Zum Zeitpunkt der Entwicklung dieser Schaltung gab es noch keine Funkgeräte, Telefone oder WLAN und für all diese Störer, sind solche Analogkisten perfekte Empfänger. Röhrenemulation gibt es unterschiedlich Genaue. Mein Ansatz dazu ist ein musikalischer, das heißt er modelliert das, was herauskommen soll. Das ist nicht unbedingt zur Schaltungssimulation geeignet. Wenn man sowas exakt machen will, braucht man pSPICE-ähnliche Modelle z.B. in C und kann sie verhaken. Sowohl für Röhren als auch für Trafos gibt es da Einiges. Zu der Erwärmung: Röhren und Widerstände ändern ihre Temperatur geringfügig, wenn die Musik laut wird und mehr Leistung durch die Schaltung fließt. Das kann man durch eine Kennlinienschar simulieren. Röhren neigen z.B: dazu den Klang weicher zu machen und nicht mehr mit der vollen Dynamik mitzugehen. Macht einige Prozente aus. Bei Widerständen sind das aber eher Promille und die ziemlich linear. Das Besondere bei Wärmeeffekten ist, dass sie sich zu einem Zeitpunkt auf das Spektrum auswirken, wenn die Ursache schon längst wieder vorbei ist. Die Klangmodulation ist also nicht vom Pegel-, sondern dem zeitlichen Integral des Pegels abhängig. Höher ist oft der Einfluss der Spannungsversorgung und der Verdrahtung: Hohe Ausgleichsströme auf den Leiterbahnen und Zuleitungen werden durch parasitäre Induktivitäten gedämpft, die auch etwas Zeitverhalten in die Schaltung bringen . Das einknickende Netzteil tut sein Übriges. Ich habe schon mal einen Röhrenverstärker eines Audioenthusiasten vermessen, der mich bat, die Kennlinien seines Wundergerätes aufzunehmen. Heraus kam, dass bei hohen Pegeln das Netzteil in die Knie ging und den Klang deutlich veränderte. Mit einem stabilen NT mit ausreichend Elkos aber waren dann die wundersamen analogen Effekte der Röhrentechnik wieder wech. Das passiert auch bei vielen analogen Vorverstärkern, Endstufen und vor allem den einschlägig bekannten elektronischen Klangerzeugern, die mit Steckernetzteilen versorgt werden. Hängt man die an die 12V Autobatterie, klingen die plötzlich ganz anders, weil das Einbrechen der Versorgung erstens nicht vollständig linear ist und zweites der Wiederanstieg infolge der Pufferung durch Elkos, zeitversetzt an die Schaltung zurückgegeben wird. Eine hochfrequente Sinuswelle hoher Amplitude wird dadurch in den ersten Momenten noch gut gestützt, bricht dann aber etwas weg. Musikalisch gesehen löst sie in der Schaltung eine tiefpassgefilterte Welle aus. Das kann man sehr schon testen, wenn man knackige, gegatete Bässe mit starkem Oberwellenspektrum ohne große Mitten auf die Verstärker gibt. Gute Verstärker gehen da sehr sauber mit, die schwachbrüstigen produzieren Verzerrungen ohne Ende. Der Klang wird schärfer und zugleich mitteltöniger. Da diese Oberwellen aber spätestens ab der dritten Harmonischen nicht mehr perfekt zu denen der Restmusik passen, wird es schwammig, klingelig und brummelig.
Solche Erzählungen wunderm mich kein bischen. 90% der esotherischen HiFi-Spinnereien, die manche zu hören glauben, sind dahin, sobald eine richtige Verkabelung zur Anwendung kommt. Ich entsinne mich noch deutlich an einen $3000,- Audiohochkaräter einer Edelschmiede aus den USA, deren musikalischer hightech-Klang verschwand, wenn man das Gerät richtig geerdet und die innen frei in der Lusft verlegten Kabel abschmirmte und verdrillte, wie es jeder Hobbyaudiphreak tut. Nun aber zur eigentlichen Frage der Nachbildung von Systemverhalten. Vielleicht ist Folgendes ein Ansatz: Im Bereich 4D-Object-Profiling wird die Bewegung eines Objektes mit 2D-FFT erfasst und der Verlauf der FFT-Amplituden über die Zeit modelliert. Das kann analystisch geschehen, oder mit Geradenabschmitten oder besser Wavelets. Bei der Rekonstruktion bekommt der Generator dann nur die Wavelet-Vorschriften übermittelt und erzeugt das Objekt per IFFT. Das müsste bei Audio auch gehen, zumal es eine Dimension weniger hat. Also engmaschige FFT, Analyse des normierten Amplitudenverlaufes und Übersetzen in eine vektorielle Darstellung. Dann könnte dieses Datenmaterial mit jeder denkbaren Geschwindigkeit und Tonhöhe abgespielt werden.
Das gibt es ja schon und wurde hier auch schon erwähnt. Die meisten Autotune-Geräte arbeiten mit solchen Algorithmen. Erwähnt wurde auch schon, dass es hierbei zu hörbaren Klangveränderungen kommt. Das gilt für die polyphone Synthese a la "Variophrase" genau so wie die für die Granularsynthese. Richtig sauber resynthetisierbar ist immer nur die Grundwelle, weil sich Fensterung, Abtastintervall und Filterung auf diese beziehen. Die Oberwellen spielen nebenher. Die sind es aber, die klanggebend sind und die bei der iFFT moduliert werden: Bei einem strikten Synthesizersound mit statischen Oberwellen, die langsam verlaufen, kann das theoretisch mathematisch noch gut stimmen, aber bei natürlichen Instrumenten wie der menschlichen Stimme, Klavieren, Orgeln, den Saiteninstrumenten und auch Schlagwerk sind die Obertöne fast nie exakt auf den ganzzahligen Vielfachen und damit hat praktisches jedes Instrument, in einer anderen Tonlage oder Oktave ein anderes relatives Oberwellenspektrum und was das zeitliche angeht, einen wiederum anderen Spektralverlauf. Da kann man zwar subjektiv viel hindrehen und filtern, aber es bleibt unvollständig. Genau stimmt es nach wie vor nur, wenn exakt das gemacht wird, was auch im Erzeugergerät passiert. Wenn also im Gitarren-AMP eine Clipdiode für Oberwellen sorgt, dann ein Kompressor wirkt und danach eine Resonanz agiert, dann muss das exakt so nachgebildet werden. Schon wenn man Kompressor und Clipper austauscht, funktioniert es nur noch für einen Fall und eine Frequenz, da das Verhalten eben nicht linear über die Zeit und den Pegel ist. Daher müsste man also nicht nur den 3D-Spektralverlauf, also den Frequenz-Pegel-Spektrum-Verlauf über die Zeit, sondern alles auch noch über den Gesamt-Pegel aufzeichnen. Das, was da rauskommt, kannst Du nicht mehr in einfache analytische Funktionen packen und wenn, bekommst Du kein plausibles Faltungsprodukt mehr mit Deinem Eingang hin, der es dann ja erst ermöglichen würde, jedes Eingangssignal mit jedem zurechtzubiegen. Genau kannst Du es also nur noch Samplen und abspielen. :D
Wo Ich das so lese: Unser Bassist stellt den Amp gerne vor die Heizung. Nicht dass, er warm wird, sondern weil die Heizung mitjault. Kann man das auch simulieren? :-D
Ein kleines Gedankenspiel: Ein Operationsverstärker hat ein Frequenzbandbreiteprodukt von nur einem 10 MHz, d.h. er kann durchaus Audio mit hohen Versträkungen bewältigen. Um das genau zu berechnen, muss es sicher auch fein genug angeschaut werden. Wie genau geht das? Eine Schaltung besteht es vielen zeitabhängigen Bauelementen und die prägen ihr Verhalten ein. Diese erhöhen die Zahl der Rechenschritte pro Zeiteinheit. Wie genau geht das dann noch?
> Eine Schaltung besteht es vielen zeitabhängigen Bauelementen und die > prägen ihr Verhalten ein. Diese erhöhen die Zahl der Rechenschritte pro > Zeiteinheit. Nicht unbedingt. Wenn nicht an irgendwelchen Abgriffen zwanghaft Zwischenergebnisse benötigt werden, weil es echte Knoten sind, kann man die Funktion der Bauelemente zusammenfassen und in deutlich weniger Rechenschritten berechnen. Die diskrete Berechnung erfolgt auch nicht notwendigerweise in equidistanten Zeitschritten. Spice macht das ja auch.
Hier hat einer den Kemper-AMP getestet: https://recording.de/threads/kemper-profiling-amp-erfahrungsbericht.208821/
Bastler schrieb: > Eine Schaltung besteht es vielen zeitabhängigen Bauelementen und die > prägen ihr Verhalten ein. Diese erhöhen die Zahl der Rechenschritte pro > Zeiteinheit. Wie genau geht das dann noch? Nicht so sehr weit, wenn es so genau sein will, wie es die bisher entwickelten Beschreibungen der Bauteile theoretisch zulassen. Das geht nur für sehr kleine Schaltungen und einfachen Modellen. Modellierung analoger Schaltungen
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.