Hi, kennt jemand eine praktikable Näherungsformel für atan (Arcus
Tangens) im Intervall [0,1]?
Anzunähern ist in double-Präzision, also mit (mindestens) 53 Bits
Genauigkeit. Intern wird mit 56 Bits gerechnet.
Bekanntlich hat die Taylor-Reihe um 0 schleichte Konvergenz weil der
Konvergenzradius nur 1 ist, d.h. in der Nähe von 1 hat man (praktisch)
keine Konvergenz mehr. Daher untersuche ich gerade Padé-Approximation,
also eine Entwicklung als rationale Funktion, die ansonsten die gleichen
Nebenbedingungen im Entwicklungspunkt hat wie eine Taylor-Reihe: dort
stimmen die ersten n Ableitungen der Approximante mit den ersten n
Ableitungen der Funktion überein.
Entwicklungspunkt 0 hat wegen der Symmetrie von atan den Vorteil, dass
bei gleicher Anzahl Terme der Grad der Approximation doppelt so groß
ist. Die Padé Approximation um 0 konvergiert zwar bis jenseits von 1,
aber man immer noch zu viele Terme.
Daher hab ich das Intervall [0,1] aufgespalten in 2 Teilintervalle: Eine
Approximation vom Grad [13/14] um 0 (15 Terme) approximiert in [0,
0.55], und im Intervall [0.55, 1] wird mit Grad [7/7] um 191/256
approximiert (ebenfalls 15 Terme).
Konkret für die 2. Approximante für [0.55, 1] um 191/256:
1
atan(191/256) +
2
(1109278398945277954552108998515656949760x
3
+3190014013046549743618019835405171425280x^2
4
+4409271226637051705982201724529121689600x^3
5
+3567894272956348772810533213265356390400x^4
6
+1761790565199680283994647188193675313152x^5
7
+498498185308650458726160978418683871232x^6
8
+62925645331517674324275193263427682304x^7)
9
/
10
(1726764746478277909691505488610409165095
11
+5793379763241549317328788011779036491520x
12
+9481302008830900338634583261911194992640x^2
13
+9412956020430072773739129723727695052800x^3
14
+6049687104603154491828695341359484108800x^4
15
+2495103530011474195120698950231953244160x^5
16
+608983183658054509908458581941561589760x^6
17
+67669375374053976356851630199244062720x^7)
Für einen ATmega4808 ergeben sich dabei in etwa folgende Kosten:
* 400 Ticks pro Addition
* 600 Ticks pro Multiplikation
* 6000 Ticks pro Division
insgesamt also 2*div + 14*add + 14*mul = ca. 26000 Ticks. Zu speichern
sind 31 Terme à 10 Bytes pro Term.
Gibt es da effizientere Alternativen? Im Netz hab ich nicht wirklich
viel dazu gefunden.
Cordic hab ich noch nicht angetestet; der liefert pro Schritt 1 Bit; bei
56 Bits intern braucht's also 56 Schritte. Und man braucht 1 Konstante
zur Korrektur pro Schritt, also 560 Bytes an Lookup für die Konstanten.
Außerdem verliert Cordic pro Schritt mindestens 1/2 LSB, insgesamt also
56/2 LSB ~ 5 Bit. Daher ist zu erwarten, dass mit Cordic der Fehler
nicht kleiner als 2^-51 zu bekommen ist.
Padé liefert im schlechtesten Falle (x = 0.55) hingegen einen Fehler von
2^-55.2 (theoretisch), womit die Genauigkeit für 53 Bit double-Mantisse
zu erreichen sein sollte.
Ideen?
Sinustabelle 0...90° und der Observer aus der NXP AppNote hier:
https://www.google.com/search?q=resolver+observer+an3943
Siehe auch Anhang.
Da musst du halt schauen, wieviele Iterationen der braucht, man kann den
Winkel aber je Quadrant mit einer Schätzung schon vorbereiten, dass die
Zielwinkelabweichung mit <±45° oder <±22,5° startet. Das Ding lässt sich
ohne Division aufbauen :)
Add1 die Sinustabelle lässt sich Unterpolieren, damit kommst du evtl.
mit 2k Sinustabelle aus
Add2 beim sin und cos, die du rein fütterst, macht dir die float sowieso
eine Normierung auf maximal große Zahlen. Kommst du mit 64bit integer
aus? Dann reicht zur Berechnung eine 128bit Integerarithmetik.
Add3 muss es float64 sein?
Johann L. schrieb:> Gibt es da effizientere Alternativen? Im Netz hab ich nicht wirklich> viel dazu gefunden.
Darüber habe ich erst gestern was gelesen. Da stand auch nur dass man
sich auf 0..1 beschränken solle wenn es geht, besser wäre sein Problem
nochmal anzuschauen und ob man es ohne arctan lösen kann,
quadrantenweise Fallunterscheidung, Steigung,... das geht für viele
Probleme aber eben nicht für alle.
Zum Trost: arcsin, arccos sind noch schlimmer.
A. S. schrieb:> Als wieviel Takte braucht atan dort?
Pro Zyklus Observer
6x Mul
4x Add
Pro Zyklus Sin und Cos mit linearer Interpolation y =
y1+((x-x1)*((y2-y1)*(1/dx)))
4x Table-Lookup
6x Add
4x Mul
Summe pro Zyklus also
4x Table-Lookup
10x Mul
10x Add
Ergo 10kTicks
Mit Vorbesetzen des Winkels einmalig 4 Fallunterscheidungen und 0-2
Multiplikationen
Hmmm, sieht gar nicht mal so gut dagegen aus...
Johann L. schrieb:> Cordic hab ich noch nicht angetestet; der liefert pro> Schritt 1 Bit; bei 56 Bits intern braucht's also> 56 Schritte.
Korrigiere mich, wenn ich mich irre, aber CORDIC ist
doch im Prinzip ein Iterationsverfahren auf Basis der
Intervallhalbierung, oder?
Was wäre mit einem Sender-Jerewan-CORDIC: Im Prinzip
ja, aber erstens verwenden wir eine bessere Start-
näherung, zweitens versuchen wir, mehr als ein Bit
je Schritt zu gewinnen, und drittens verwenden wir
ein Iterationsverfahren von höherer Konvergenzordnung.
Nur mal spekuliert: Startnäherung mittels Taylorreihe
auf z.B. 16bit; das müsste noch recht fix gehen.
Iterationsverfahren mit quadratischer Konvergenz
braucht nochmal zwei Schritte, um in die Nähe von
64 geltenden Bit zu kommen.
> Außerdem verliert Cordic pro Schritt mindestens 1/2 LSB,> insgesamt also 56/2 LSB ~ 5 Bit. Daher ist zu erwarten,> dass mit Cordic der Fehler nicht kleiner als 2^-51 zu> bekommen ist.
Das Problem entfällt bei einem echten Iterationsverfahren.
minifloat schrieb:> Add3 muss es float64 sein?Franko S. schrieb:> besser wäre sein Problem nochmal anzuschauen und ob man es ohne> arctan lösen kann,
In dem Fall nicht, Fernziel wäre Implementierung als Teil der
Standard-Lib im Rahmen von avr-gcc, d.h. als Teil der libgcc und / oder
avr-libc. Von daher hab ich auch kein Problem mit salted Code.
A. S. schrieb:> Was ist denn die Referenz? Als wieviel Takte braucht atan dort?
Als Referenz hab ich momentan nur avr_f64.c/h von
Beitrag "Re: 64 Bit float Emulator in C, IEEE754 compatibel"
Zu der Implementierung kann ich bisher sagen, dass sie Out-of-the-Box
problemlos funktioniert. Bei PROGMEM fehlen const und für C++ braucht's
ein extern "C" Wrapper, das war's. Die Implementierung ist vanilla C,
also prinzipiell einfach portabel. Leider ist die Implementierung
stellenweise etwas kryptisch; zumindest for mich.
avr_f64.c::f_arctan() belegt folgende Resourcen:
* Ticks: 40000
* Stack: 216 Bytes
* Code: 6 KiB
Für ein paar Funktionen, die ich bereits habe, hab ich mit avr_f64
verglichen um sicher zu sein, dass ich nicht kompletten Unsinn treibe.
Meine Implementierung hat nicht Portierbarkeit als Ziel, sonder vor
allem Effizienz in den 3 wesentlichen Bereichen
* Ausführungszeit
* Code- bzw. Flash-Verbrauch
* Stack- bzw. RAM-Verbrauch
und zwar auch im Hinblich auch die anderen double-Funktionen, d.h.
Wiederverwendbarkeit anderer Routinen wie Polynom-Auswertung, die vom
Anwender ebenfalls (implizit) verwendet werden, spielt auch eine Rolle.
siehe dazu die Anhänge. Übersetzt wird i.W. mit:
-Os -ffunction-sections -fdata-sections -mcall-prologues -mstrict-X
-mrelax -Wl,--gc-sections
und für Messung der Codegröße zusätzlich
-nostartfiles -Wl,--defsym,main=0
f7_t ist die expandierte 10-Byte Darstellung (1 Byte Flags, 7 Byte
Mantisse, 2 Byte Exponent). f7 sind Werte für C/C++ IEEE
double-Wrapper; hier kommen Resourcen für f7_t <-> double hinzu.
Als Resourcen für Padé atan erwarte ich 100-150 Bytes Stack, 3-4 KiB
Code (bei ansonsten leerem Programm) und 20000-30000 Ticks je nachdem,
ob 1 oder 2 Divisionen gebraucht werden. Was die Codegröße betrifft, so
werden viele Routinen verwendet, die auch von anderen Funktionen
gebraucht werden: add, sub, mul, div, Vergleiche und Polynom-Auswertung,
so dass der effektive Codezuwachs in realer Anwendung deutlich kleiner
ausfallen wird.
Wie asin und acos implementiert werden sollten, weiß ich auch noch
nicht. Via atan hätte den Vorteil von Code-Sharing, allerdings kämen
mindestens 1 Division und 1 Quadratwurzel hinzu, also nochmal 20000
Ticks...
Franko S. schrieb:> Zum Trost: arcsin, arccos sind noch schlimmer.
Die stehen dann als nächstes auf der Liste.
Konkret kann ich nur einen Literaturvorschlag beisteuern: Computer
Approximations, John F. Hart, Wiley, 1968
Das Buch hatte ich in einer Bibliothek zu solchen Themen einmal in den
Händen und durchgeblättert. Darin gibt es auch Kapitel über die Näherung
von trigonometrischen Funktionen und den Inversen. Verschiedene
Approximationsmethoden werden auch beschrieben. Ist schon etwas älter,
ob die Methoden noch "state of the art" sind oder ob es mittlerweile
bessere gibt, weiß ich nicht. Ich habe die darin beschriebenen Methoden
auch nie selber verwendet und das Buch nur aus Interesse
durchgeblättert.
Wenn eine gute (genau und schnell) Quadratwurzelfunktion schon da ist,
kann man mittels
arctan(x)=2*arctan(x/(1+sqrt(1+x^2)))
den problematischen Bereich von [0.5, 1.0] so etwa auf [0.25, 0.42]
reduzieren. Ggf. auch gleich ohne Fallunterscheidung [0, 1.0] auf [0,
0.42].
Ansonsten würde ich mal Entwicklung nach Legendre- oder
Chebyscheff-Polynomen versuchen.
Nein. Es ist ja schoen, wenn man das machen moechte. Und dafuer eine
Library aufblasen moechte. Minimale Codegroesse und Ausfuehrungszeit ist
auch nett.
Nur soll die auf den ATMega festgelegt werden. Dann kann ich in einen
grossen ATMega die Library linken plus 2 Operationen und dann ist voll.
Ungeachtet dem, muss man eben alle Moeglichkeiten abklopfen. Taylor,
stueckweise Taylor, cordic, invers iterativ usw. Und nicht gleich alles
was ineffizient erscheint verwerfen. Allenfalls kann ein Algorithmus
aufgrund der Rahmenbedingungen auch beschleunigt werden.
Das gibt's auch noch wissenschaftliche Publikationen. Das Problem wurde
schon behandelt, sonst waere es nicht in Hardware in einer Floating
point einheit implementiert. Der Intel 8087 konnte das schon vor 35
Jahren.
Als Anwender muss man sich sowieso ueberlegen, ob man diese Genauigkeit
benotigt... eine Floatlibrary wird ja immer als Ganzes geladen.
An dieser Stelle: Jetzt nicht.
In der Allgemeinheit stimmen die Ausführungen zwar - hätte ich nicht den
Namen des Fragestellers gekannt, wäre mir die angestrebte Genauigkeit
auch zweifelhaft erschienen.
Aber jetzt und hier können wir davon ausgehen, daß der TO genau weiß,
was er bezweckt.
Joggel E. schrieb:> eine Floatlibrary wird ja immer als Ganzes geladen.
Gut, du kennst also nicht nur Johann nicht, sondern du hast auch nicht
den blassesten Schimmer, wie ein Linker mit Libraries umgeht.
Das disqualifiziert dich in dieser Hinsicht komplett.
Joggel E. schrieb:> Trollalarm !!!>> wer benotigt einen Arctan mit 53 bit Praezision ... Leute, die das> benoetigen haben ueblicherweise eine Floatingpointeinheit.
Abgesehen davon, dass der Trollalarm eher auf Ignoranz beruht:
mich würde auch sehr ehrlich interessieren, wofür man das brauchen kann,
also für welche konkrete Applikation.
Kann da jemand zu meiner Wissensmehrung beitragen? Danke!
Dieter R. schrieb:> mich würde auch sehr ehrlich interessieren, wofür man das brauchen kann,> also für welche konkrete Applikation.
Wenn man (weil man wie Johann halt Mit-"Anbieter" der Toolchain ist)
eine komplette Standardbibliothek aufbauen möchte, dann muss eben auch
ein Arcustangens mit dabei sein. Dann ist es recht und billig, sich um
die Effizienz der Implementierung Gedanken zu machen.
Jörg W. schrieb:> Dieter R. schrieb:>> mich würde auch sehr ehrlich interessieren, wofür man das brauchen kann,>> also für welche konkrete Applikation.>> Wenn man (weil man wie Johann halt Mit-"Anbieter" der Toolchain ist)> eine komplette Standardbibliothek aufbauen möchte
Eine Standardbibliothek und die Arbeit daran ist aber nur nützlich, wenn
es auch Applikationen dafür gibt. Danach hatte (nicht nur) ich gefragt.
Dieter R. schrieb:> Eine Standardbibliothek und die Arbeit daran ist aber nur nützlich, wenn> es auch Applikationen dafür gibt.
… oder wenn es eben ein Hobby ist.
Applikationen finden sich immer. :) Ich bin zumindest schon in
Situationen gelaufen, wo die Rundungsfehler der 32-bit-FP-Arithmetik
schon deutlich wurden, und ich mir die Option von 64-bit-FP gewünscht
hätte. Wenn Johanns Implementierung ähnlich effizient ist wie die
existierende 32-bit-FP (logischerweise zuzüglich Mehrbedarf für die
höhere Genauigkeit), dann wird sie durchaus ihre Anwender finden. Die
existierende 32-bit-FP-Arithmetik in der AVR-GCC-Toolchain hat
jedenfalls aus meiner Sicht sehr eindrücklich gezeigt, dass das alte
Dogma "Gleitkomma macht man auf einem 8-bit-Prozessor nicht" (*) getrost
ad acta gelegt werden kann.
(*) Das stimmte ja schon mit Turbo-Pascal auf CP/M nicht mehr.
Allerdings hat man dort als Kompromiss eine 48-Bit-Implementierung
gewählt, was übrigens sogar C-Standard-konform als "double" durchgehen
würde. Nur 32 bit tut's nicht.
Jörg W. schrieb:> @Johann>> Kennst du das hier?>> Beitrag "64 Bit float Emulator in C, IEEE754 compatibel">> Keine Ahnung, wie genau oder schnell es ist.
Ja, kenn ich. Dient wie gesagt als Basis für den Vergleich von hier:
Beitrag "Re: Näherung für ArcusTangens?"Dieter R. schrieb:> mich würde auch sehr ehrlich interessieren, wofür man das brauchen kann,> also für welche konkrete Applikation.
Eine Anwendung ist Auswertung von GPS-Daten, wo Genauigkeit von float
nicht ausreicht. Üblicherweise sind das Bereichnungen aus der
sphärischen Geometrie: Zuerst Winkelfunktionen, Berechnugen auf deren
Werten und dann eine Arcus-Funktion so wie hier:
Beitrag ""echter" double mit AVR-GCC"
Da wird zwar asin verwendet, zeigt aber dass float nicht ausreicht und
dass gelegentlich, wenn auch selten, Bedarf für double besteht.
Außerdem ist an avr-gcc prinzipiell anzumäkeln, dass double nicht
standardkonform ist. Wäre ein rein theoretisches Problem wenn niemand
double brauchen würde; aber auch der Autor der o.g. avr_f64.c/h hat
seine double-Implementierung gemacht weil er sie brauchte, um ein
konkretes Problem zu lösen. AFAIR gab es auch bei avrfreaks
entsprechende Anfragen.
Johann L. schrieb:> Eine Anwendung ist Auswertung von GPS-Daten, wo Genauigkeit von float> nicht ausreicht. Üblicherweise sind das Berechnungen aus der> sphärischen Geometrie
Ah, danke. Endlich mal eine kompetente Auskunft dazu!
Johann L. schrieb:> Cordic hab ich noch nicht angetestet; der liefert pro Schritt 1 Bit; bei> 56 Bits intern braucht's also 56 Schritte. Und man braucht 1 Konstante> zur Korrektur pro Schritt, also 560 Bytes an Lookup für die Konstanten.
Dann lies erstmal die Literatur zum CORDIC.
Kurz gesagt, wenn du keine Schritte ausläßt, sondern jeden Schritt
ausführst (mit wechselnder Richtung, so daß der Restwinkel gegen Null
läuft), dann ist dein Rest nach endlich vielen Schritten in seiner
Amplitude determiniert (da ja alle Schritte ausgeführt werden und jeder
einen Faktor 1/cos(d) einbringt).
Dann kannst du den Rest zum Berechnen des Endwertes heranziehen, da du
ihn mit dem konstanten Produkt aus allen 1/cos(dn) wieder normalisieren
kannst.
Der Rest enthält so etwa die doppelte Stellenzahl wie das, was du in den
Drehschritten errechnet hast.
In Wahrheit ist es ein bissel weniger, aber man spart sich trotzdem 2/3
der Schritte ein. Also brauchst du für 56 Bit nur 19 Cordic-Schritte,
dann eine Multiplikation des Restes mit o.g. 1/cos.. Korrekturfaktor und
Addition des Restes.
W.S.
W.S. schrieb:> Dann kannst du den Rest zum Berechnen des Endwertes> heranziehen, da du ihn mit dem konstanten Produkt aus> allen 1/cos(dn) wieder normalisieren kannst.>> Der Rest enthält so etwa die doppelte Stellenzahl wie> das, was du in den Drehschritten errechnet hast.
Sehr hübsch.
Hast Du zufällig auch eine ungefähre Quellenangabe zur
Hand?
whitespace schrieb:> Konkret kann ich nur einen Literaturvorschlag beisteuern: Computer> Approximations, John F. Hart, Wiley, 1968>> Das Buch hatte ich in einer Bibliothek zu solchen Themen einmal in den> Händen und durchgeblättert. Darin gibt es auch Kapitel über die Näherung> von trigonometrischen Funktionen und den Inversen. Verschiedene> Approximationsmethoden werden auch beschrieben. Ist schon etwas älter,> ob die Methoden noch "state of the art" sind oder ob es mittlerweile> bessere gibt, weiß ich nicht. Ich habe die darin beschriebenen Methoden> auch nie selber verwendet und das Buch nur aus Interesse> durchgeblättert.
Ich habe mir das Buch interessehalber heute mal angeschaut. Das sieht
gut aus.
arctan(x) = x*P(x^2)/Q(x^2)
Es werden also nur x, x^3, x^5, .... verwendet.
Es gibt auch ein Polynom x*P(x^2) aber nur bis 10 Dezimalstellen.
Wenn die Zahl unter Precision wirklich Dezimalstellen sind, was ich auch
annehme, dann reichen 6 Koeffizienten im Zähler und 6 Koeffizienten im
Nenner um die 53bit Genauigkeit zu erreichen. Da wird man aber nicht
umhin kommen mit 64bit Mantisse zu rechnen. Das Buch liegt z. B. in der
UB Stuttgart im Magazin.
Jörg W. schrieb:>> (*) Das stimmte ja schon mit Turbo-Pascal auf CP/M nicht mehr.> Allerdings hat man dort als Kompromiss eine 48-Bit-Implementierung> gewählt, was übrigens sogar C-Standard-konform als "double" durchgehen> würde. Nur 32 bit tut's nicht.
Schon vorher gab es unter cp/m von MS BASIC80 als Compiler und Mbasic
als Interpreter - zumindest letzterer eher lahm, und die
"Assembler-Schnittstelle" beschränkte sich (bei Mbasic) auf PEEK und
POKE, aber IO-Befehle gehörten zur Sprache ebenso wie 8-byte-reals - nur
leider keine transzendenten Funktionen über 4-byte-reals hinaus, iirc.
Percy N. schrieb:> Schon vorher gab es unter cp/m von MS BASIC80 als Compiler und Mbasic> als Interpreter
Mit denen hatte ich nicht viel zu tun. Turbo-Pascal war so viel schöner
und bequemer und eben – wie der Namen nicht nur versprach – verdammt
schnell.
Alexander S. schrieb:> Hallo,>> ganz unten auf dieser Seite ist ein code atan_137 für ca. 13.7> Dezimalstellen: http://www.ganssle.com/approx.htm
Dieses Programm verwendet exakt eines der Polynome aus dem bereits
zitierten Buch "Computer Approximations, John F. Hart, Wiley, 1968".
Die angegebene Genauigleit von 13,7 Stellen dieser Approximation gilt
aber nur bis zum Winkel pi/12. Gefordert wird aber der Winkelbereich 0
bis pi/2 - entspricht arctan(0 bis 1).
Helmut S. schrieb:> Die angegebene Genauigleit von 13,7 Stellen dieser Approximation gilt> aber nur bis zum Winkel pi/12. Gefordert wird aber der Winkelbereich 0> bis pi/2 - entspricht arctan(0 bis 1).
Dafür wird auf den "range reduction code" weiter oben auf der Seite
verwiesen: "atan_137 computes the arctangent to about 13.7 decimal
digits of accuracy using a simple rational polynomial. It's input range
is 0 to Π /12; use the previous range reduction code."
Alexander S. schrieb:> Helmut S. schrieb:>> Die angegebene Genauigleit von 13,7 Stellen dieser Approximation gilt>> aber nur bis zum Winkel pi/12. Gefordert wird aber der Winkelbereich 0>> bis pi/2 - entspricht arctan(0 bis 1).>> Dafür wird auf den "range reduction code" weiter oben auf der Seite> verwiesen: "atan_137 computes the arctangent to about 13.7 decimal> digits of accuracy using a simple rational polynomial. It's input range> is 0 to Π /12; use the previous range reduction code."
OK. Das hatte ich übersehen.
Statt einem "range reduction code" könnte man auch gleich mit 5
Koeffizienten im Zähler und 5 Koeffizienten im Nenner arbeiten. Damit
bekäme man 14,5 Stellen.
Der Fragesteller hätte gerne mindestens 16 Stellen (53bit). Dazu
benötigt man 6 Koefizienten im Zähler und 6 Koeffizienten im Nenner.
Nachtrag zu meiner vorherigen Antwort - dort sollte pi/4 statt pi/2
stehen.
Alexander S. schrieb:> "atan_137 computes the arctangent to about 13.7 decimal> digits of accuracy using a simple rational polynomial.
Wobei man da aufpassen muss, denn soweit ich sehe sind für atan_137
absolute Fehler angegeben. Bei Floats zähl aber der relative Fehler,
d.h. in der Nähe von 0 muss der absolute Fehler dann nochmal kleiner
sein.
Jack Ganssle:
> All of the approximations here are polynomials, or ratios of> polynomials. All use very cryptic coefficients derived from> Chebyshev series and Bessel functions.
Wie werden hier Besselfunktionen eingesetzt?
Bzw. wie bekommt man beste (im Sinne der max-Norm) rationale
Approximationen? Für Polynome ist es Chebyshev, aber für rationale
Funktionen kenn ich nur das Analogon zu Taylor (Padé), was ist das
rationale Analogon zu Chebyshev?
und zur Kontrolle den mit bc berechneten atan Werten:
1
0
2
.0499583957219427
3
.0996686524911620
4
.1488899476094972
5
.1973955598498807
6
.2449786631268641
7
.2914567944778670
8
.3366748193867271
9
.3805063771123648
10
.4228539261329407
11
.4636476090008061
12
.5028432109278608
13
.5404195002705841
14
.5763752205911836
15
.6107259643892086
16
.6435011087932843
17
.6747409422235526
18
.7044940642422177
19
.7328151017865065
20
.7597627548757708
21
.7853981633974483
Auf der Seite der Ganssle Group mit den auf Hart, "Computer
Approximations" basierenden Routinen http://www.ganssle.com/approx.htm
gibt es auch den source code der Routinen
http://www.ganssle.com/approx/sincos.cpp
Die Ausgabe habe ich angehängt. Die erste Spalte ist der Winkel in Grad.
Das wird intern in rad gewandelt. Dabei habe ich nur die fehlende
Ausgabe der atan Werte korrigiert. g++ gibt noch einige Warnungen aus.
Hab noch dieses Paper von Castellanos und Rosenthal gefunden: "Rational
Chebyshev Approximations of Analytic Functions"
https://www.fq.math.ca/Scanned/31-3/castellanos.pdf
Danke erstmal für all die Hinweise und Links, ist vorerst mal einiges an
Hirnfutter...
Alexander S. schrieb:> Auf der Seite der Ganssle Group
Ist das in Zeiten von viel RAM und schneller Interpolation noch
zeitgemäß? Hier hammse schon normale Sinusfunktionen in Tabellen und
interpolieren, weil es schneller ist ..
Hamburger schrieb:> Ist das in Zeiten von viel RAM und schneller Interpolation noch> zeitgemäß? Hier hammse schon normale Sinusfunktionen in Tabellen und> interpolieren, weil es schneller ist ..
Ich glaube, du wirfst da was durcheinander....
Gruß Rainer
Liebe Rechenfreunde, hallo Johann,
ich brauchte ein wenig Spass und habe den atan Algorithmus für den
Argumentbereich [0 , 1] in Cordic und reiner 64 Bit integer Rechnung
implementiert.
Beitrag "Atan function implementation"
Die gemessene Genauigkeit sollte besser als 51 Bit sein, mehr kann ich
nicht messen weil die double Implementierung von atan nicht besser ist.
Ausgelegt ist der Algo auf 61 Bit damit man mit dem 64 Bit integer Type
rechnen kann. Ich habe jetzt nicht ausufernd testen können, vllt. kommt
da noch ein Korken hoch aber so komplex ist die Sache am Ende auch
nicht, der Weg war etwas steinig gewesen wie man am auskommentierten
Code erahnen kann.
Jederzeit gerne Kommentare und Anmerkungen.
War grosser Spaß jewesen!
math rulez!
Cheers
Detlef
Hallo Johann,
ich habe den ArcTan für meine Teleskopsteuerung benötigt, programmiert
habe ich damals in Assembler, weil es für den AtMega128 in der C-Library
nur Fließkommazahlen in einfacher Genauigkeit gab.
Basis für die Algorithmen war eine C-Library ('Cephes Mathematical
Library') von Steve Moshier.
http://www.netlib.org/cephes/index.html und
http://moshier.net/#Cephes
Hier meine Implementation in Asm, die seit Jahren zuverlässig
funktioniert:
http://martin-cibulski.de/atm/mount_controller_4/mc_4_asm_main/float_atan.asm
Wenn ich mich richtig erinnere, läuft die Routine in ca. einer
Millisekunde durch; ich habe damals gegen einen PC mit Zufallszahlen
getestet.
Gruß,
Martin
Detlef _. schrieb:> Jederzeit gerne Kommentare und Anmerkungen.
Na denn wolle mer mal.
Ich hatte vor ein paar Jahren mir den Cordic mal näher angesehen, um mir
über die Nützlichkeit des restlichen Drehwinkels nach getaner
CORDIC-Arbeit klar zu werden.
Ergebnis: siehe Anlagen.
Ursprünglich mit Delphi 6 (jaja, immer noch), hab's grad eben mal nach
XE3 umgesetzt, deswegen die Umfänglichkeit der EXE.
Also: du verschwendest in deinem Code Rechenzeit und Speicherplatz. Wie
ich schon weiter oben geschrieben habe, braucht man nur so etwa 1/3 der
Durchläufe. Also für 30 Bit 10 Runden CORDIC, die restlichen Stellen
stecken im Restwinkel.
Es ist aber wirklich WICHTIG, im CORDIC nicht bedingt zu drehen,
sondern immer und die Richtung geht immer in Richtung Abszisse. Dann
wird jede DrehStreckung ausgeführt und jede fügt für die Zeigerlänge
einen Faktor 1/cos(drehwinkel) hinzu. Deshalb ist die finale Zeigerlänge
und eben auch der Restwinkel mit einem simplen Faktor wieder normierbar
und der Restwinkel kann danach auf das Ergebnis einfach addiert werden.
Ach ja: die Tafel mit all den Konstanten hab ich mir hier verkniffen,
aber das siehst du ja in der Quelle selber.
W.S.
>>>>>>>
Also: du verschwendest in deinem Code Rechenzeit und Speicherplatz. Wie
ich schon weiter oben geschrieben habe, braucht man nur so etwa 1/3 der
Durchläufe.
<<<<
Nein, das stimmt nicht, die Behauptung wird auch durch nachdrückliches
Vertreten nicht wahr.
Angehängtes Bild zeigt für Zufallszahlen in blau die Anzahl der
Drehungen bis der Imaginärteil 0 wird wenn man den Imaginärteil immer
positiv läßt, in rot wenn man auch ins negative dreht. Beide Zahlen sind
ungefähr gleich, nix Drittel.
Das liegt daran, dass Zufallszahlen die gleiche mittlere Anzahl von
'Einsen' als Binärzahl haben, ob negativ oder positiv.
Ausserdem kann ich billig drehen, das kostet in meinem Code zwei
Additionen und zwei shifts.
math rulez!
Cheers
Detlef
clear
pluss =zeros(1,100);
minuss=zeros(1,100);
for(k=1:100000)
ph=1;
zz=1+i*rand(1,1);
zz1=zz;
nd=0;
while(abs(angle(zz1))>1E-16)
if(angle(zz1*(1-i*ph))>0)
zz1= zz1*(1-i*ph);
end;
nd=nd+1;
ph=ph/2;
end;
pluss(nd)=pluss(nd)+1;
zz1=zz;
nd=0;
ph=1;
while(abs(angle(zz1))>1E-16)
ph;
if(angle(zz1)>0)
zz1= zz1*(1-i*ph);
else
zz1= zz1*(1+i*ph);
end;
nd=nd+1;
ph=ph/2;
end;
minuss(nd)=minuss(nd)+1;
end;
plot(1:100,pluss,'b.-',1:100,minuss,'r.-');
Detlef _. schrieb:> Nein, das stimmt nicht, die Behauptung wird auch durch nachdrückliches> Vertreten nicht wahr.
Guck einfach in die Datei, um es zu sehen. Mit nur 8 Drehungen plus Rest
kommt man auf 5 gültige Nachkommastellen des Winkels (im Gradmaß 0..359
Grad) - und wieviele Drehungen brauchst du für diese Genauigkeit, he?
Ich habe eher den Eindruck, daß du über was ganz anderes redest als ich.
W.S.
Aaaalso...
Ein wichtiger Tipp war der Link von Alexander zu Ganssle und der dort
verwendeten Reduktion des Arguments:
Nachdem das Argument auf [0, 1] reduziert ist, spaltet man das Intervall
auf in 2 Intervalle [0, a] und [a, 1], und zwar so, dass per
Addttionstheorem
atan(x) - atan(y) = atan((x - y) / (1 + xy))
das Intervall [a, 1] auf [-a, a] abgebildet wird. Das ergibt ein
Gleichungssystem in 2 Variablen, aus dem alle Schikanen ausfallen und
das liefert: y = 1/sqrt(3), atan(y) = pi/6, a = (1 - y) / (1 + y) ~
0.268.
Für dieses reduzierte Intervall genügt dann
(14549535x+29609580x^3+19801782x^5+4813380x^7+307835x^9)
/
(14549535+34459425x^2+28378350x^4+9459450x^6+1091475x^8+19845x^10)
um auf 58 Bits Genauigkeit zu kommen (auf dem PC bestimmt). Außerdem
hab ich die Division jetzt in Assembler, so dass Divisionen nicht mehr
ganz so weh tun was Laufzeit angeht (vorher hatte ich aus Bequemlichkeit
Newton-Raphson, was ca 3× langsamer war).
Laufzeit ist ca. 18000 Ticks bei 2.5 KiB Code (inclusive aller
Konstanten und Abhängigkeiten wie Code für Division etc.) bzw. < 450
Bytes Code (mit Konstanten aber ohne sonstige Abhängigkeiten).
Franko S. schrieb:> Zum Trost: arcsin, arccos sind noch schlimmer.
Hab ich inzwischen auch, war garnicht sooo schlimm :-)
Man beginnt mit der Beobachtung, dass acos in 1 i.w. die Quadratwurzel
ist. Die Singularität kann man also einfach rausfaktorisieren:
acos(1-x) = sqrt(2x) * a(x)
wobei sich a() als rationale McLaurin-Reihe darstellen lässt.
Konvergenzradius von a() ist 2 und a(0) = 1 (d.h. a(0) ist ungleich 0),
also schon mal nicht schlecht.
Ist eigentlich auch klar: 1 - x^2/2 ist Asymptote an cos in (0,1),
folglich ist sqrt(2-2x) Asymptote an acos in (1,0).
Implementiert ergibt das:
1
Genauigkeit: ca. 52-53 Bits
2
Code: ca. 3 KiB (inclusive aller Abhängigkeiten und Konstanten)
3
Laufzeit: ca. 30000 Ticks (worst case), 20000 Ticks (Median)
Quadratwurzel ist momentan Newton-Raphson, die frisst schon 10000 Ticks
:-/
Als Referenzen hab ich avr_f64.c/h (C):
1
Genauigkeit: ca. 54 Bits
2
Code: ca. 6 KiB
3
Ticks: 80000 / 80000
sowie fp64lib (Assembler):
1
Genauigkeit: ca. 47-48 Bits
2
Code: ca. 4.5 KiB
3
Ticks: 20000 / 20000
Evtl. ergibt sich eine vorteilhaftere Näherung für a() wenn man nicht um
0 entwicklelt sondern um ein x0 > 0 irgendwo im Intervall (0, 1/4).
Helmut S. schrieb:> Statt einem "range reduction code" könnte man auch gleich mit 5> Koeffizienten im Zähler und 5 Koeffizienten im Nenner arbeiten. Damit> bekäme man 14,5 Stellen.> Der Fragesteller hätte gerne mindestens 16 Stellen (53bit). Dazu> benötigt man 6 Koefizienten im Zähler und 6 Koeffizienten im Nenner.Johann L. schrieb:> Wobei man da aufpassen muss, denn soweit ich sehe sind für atan_137> absolute Fehler angegeben. Bei Floats zähl aber der relative Fehler,> d.h. in der Nähe von 0 muss der absolute Fehler dann nochmal kleiner> sein.
Im Buch "Computer Approximations" von Hart, auf das sich auch
http://www.ganssle.com/approx.htm bezieht, gibt es u.a.
arctan-Approximationen für 13.70 (2/3), 16.06 (3/3) bis 25.51 (5/5)
Dezimalstellen
im Bereich [0, tan pi/12]. (N/M) bezeichnet den Grad der Polynome (in
x^2) in Zähler und Nenner. Mit "range reduction" geht auch [0, tan pi/4]
oder weiter. Die arctan-Approximationen basieren auf dem relativen
Fehler.
Die angegebene "precision", z.B. 16.06 bezeichnet aber absolute
Dezimalstellen. Das 3/3-Polynom für 16.06 Stellen liefert z.B. für x =
0.05 einen relativen Fehler von
Die Werte für x = 0.05 bis 2.0 für atan_13.70 und atan_16.06 und die
Polynomkoeffizienten (ohne Gewähr) für diese beiden Approximationen
finden sich im Anhang. Die Fehler in atan_double.txt beziehen sich auf
die Werte der C libmath.
Alexander S. schrieb:> Im Buch "Computer Approximations" von Hart, auf das sich auch> http://www.ganssle.com/approx.htm bezieht, gibt es u.a.> arctan-Approximationen für 13.70 (2/3), 16.06 (3/3) bis 25.51 (5/5)> Dezimalstellen im Bereich [0, tan pi/12].
Ich hab das
1
p00 = 12.82297680061262709335
2
p01 = 16.2428078151342213662
3
p02 = 4.923443373635526899
4
p03 = .205608723964456163
5
q00 = 12.82297680061262821474
6
q01 = 20.517133415336848884
7
q02 = 9.197892485655692716
8
q03 = 1.0
mal eingebaut, sieht ganz gut aus. Die Genauigkeit[1] mit der neuen
Funktion "swift" ist etwas schlechter als meine aktuelle "old" (Jeweils
die untere Teilgrafik). Umgerechnet in die interne Darstellung hab ich
mit Python/Decimal, ich hoff mal ich hab da keinen Fehler gemacht.
Argument-Reduktion ist wie gehabt auf 2-sqrt3 ~ 0.26795.
Hast du auch die [5/5] Näherung?
[1] Wird monemtan bestimmt aus tan(atan(x)) - x, kommt also noch die
Rundungsfehler von tan dazu.
Johann L. schrieb:> Hast du auch die [5/5] Näherung?
Ich habe das Buch vor mir liegen. Ich habe jetzt auch noch die
Koeffizienten für atan_20.78 (4/4) und atan_25.51 (5/5) abgetippt. In C
reicht auch "long double" auf x86 nicht mehr. Für Kontrollen hänge ich
auch noch die mit bc und "scale=26" berechneten Werte an. Ich habe die
abgetippten Koeffizienten einmal zur Kontrolle gelesen, aber weiterhin
"keine Gewähr".
Hallo Jörg W.,
Jörg W. schrieb:> Joggel E. schrieb:>> Trollalarm !!!>> [ ] Du weißt, über wen du gerade sprichst.Beitrag "wer is Gjlayde"
hat mir auch nicht weitergeholfen.
Wer ist er und was macht er?
Ich hätte auf GCC-Programmierer getippt, kann aber seinen Vornamen nicht
auf der Contributor-Seite finden.
Was ich mal gebrauchen könnte, wäre eine Implementierung, die ohne
Real-Divisionen auskommt. Lässt sich der Nenner gfs so umformen, dass
nur Binärdivisionen auftauchen?
Alexander S. schrieb:> Johann L. schrieb:>> Hast du auch die [5/5] Näherung?>> Ich habe das Buch vor mir liegen. Ich habe jetzt auch noch die> Koeffizienten für atan_20.78 (4/4) und atan_25.51 (5/5) abgetippt.
Vielen Dank für die (Tipp)Arbeit! Ich meinte eigentlich das [4/4], also
5 Terme in Zähler und Nenner. Mit dem (4/4) komme ich auf die
Genauigkeit meiner bisherigen Näherung (11 Terme, d.h. [9/10] für atan
bzw. [4/5] für atan(sqrt)/sqrt). Sieht also so aus als hätte sich kein
Tippteufel eingeschlichen :-)
Bei Gelegenheit werd ich mal nen anderen Test als f_inv(f(x)) - x
einbauen um Genauigkeit besser beurteilen zu können.
Klaus E. schrieb:> Was ich mal gebrauchen könnte, wäre eine Implementierung, die ohne> Real-Divisionen auskommt. Lässt sich der Nenner gfs so umformen, dass> nur Binärdivisionen auftauchen?
Was meinst du denn mit "Binärdivision"? Im Nenner steht ja ein Polynom.
Johann L. schrieb:> Was meinst du denn mit "Binärdivision"? Im Nenner steht ja ein Polynom.
Das ist das Problem. Etwas MicroController-unfreundlich.
Die Taylor-Entwicklung erlaubt nach meiner Erinnerung die Entwicklung um
jeden Punkt. Könnte man das nicht irgendwie umformen?
Detlef _. schrieb:> Jederzeit gerne Kommentare und Anmerkungen.
Wie die Zahl Pi schon vermuten läßt, gibt es im Gegensatz zum Quadrat
auch mathematisch keinen perfekten Kreis.
Klaus E. schrieb:> Johann L. schrieb:>> Was meinst du denn mit "Binärdivision"? Im Nenner steht ja ein Polynom.>> Das ist das Problem. Etwas MicroController-unfreundlich.
Na, Division ist ja kein Hexenwerk. Für die Reduktion des Arguments
braucht's eh Division(en).
Und man kann auch dividieren ohne zu dividieren:
https://en.wikipedia.org/wiki/Newton-Raphson_division#Newton–Raphson_division> Die Taylor-Entwicklung erlaubt nach meiner Erinnerung die Entwicklung um> jeden Punkt. Könnte man das nicht irgendwie umformen?
Man nimmt deshalb rationale Approximationen weil die i.d.R. besser
funktionieren als Taylor bzw. weniger Terme brauchen. Du kannst auch
Taylor nehmen und um 0 entwickeln: x - x^3/3 + x^5/5 - x^7/7 ...
Konvergenzradius ist 1, d.h. die Summanden werden nur kleiner weil man
höhere Potenzen vo x nimmt; die Koeffizienten leisten praktisch keinen
Beitrag. Hat man das Intervall wie oben beschrieben auf 2-sqrt3 ~ 1/4
reduziert, dann gewinnt man an der Intervallgrenze ca. 4 Bit pro Term.
Für double-Genauigkeit (53Bits) brauch man also mindestens ca. 14 Terme:
bis -x^27/27.
Du kannst auch um andere Punkte entwickeln, wobei du aber Symmetrie
verlierst, d.h. es ist nicht jeder 2. Term der Entwicklung 0 wie bei der
Entwicklung um 0 (wegen atan(-x) = -atan(x)). atan hat Singularitäten
bei i und -i, der Konvergenzradius bei Entwicklung um 1 ist also sqrt2.
Falls du damit Werte in [0.5, 1.5] nähern willst, dann gewinnst du pro
Term ca. 1.5 Bit. Für double-Genauigkeit braucht's alo schon 36 Terme
an der Intervallgrenze... und da ist Rundung und Auslöschung noch nicht
drinne.
Sinnvoll ist um Unendlich zu entwickeln — das macht man effektiv per
atan(x) + atan(1/x) = sgn(x)*pi/2 wenn man Argumente |x|>1 auf |x|<1
reduziert.
Klaus E. schrieb:> aha(?)
Die Perfektion der Mathematik existiert nur für den Betrachter außerhalb
der mathematischen Welt. Innerhalb der mathematischen Welt existiert
kein Betrachter.
Der Betrachter eines Gegenstandes existiert nur innerhalb dieser Welt.
Außerhalb dieser Welt existiert kein Betrachter.
Zur Welt der Rechenmaschinen fällt mir jetzt grade nichts Anständiges
ein.
Christoph db1uq K. schrieb:> Die Numerical Recipies wurden noch nicht erwähnt, ich dachte, das ist> ein Standardwerk:
Wobei bei den "Numerical Recipes" die Nutzungsrechte der Rezepte nicht
unproblematisch sind.
Sven B. schrieb:> Blöde Frage, warum funktioniert denn an mehreren Punkten> taylorentwickeln und dann den passenden auswählen nicht?
Zunächst mal weil, egal wo man entwickelt, der Konvergenzradius immer
endlich ist. Heißt: Um ganz R zu überdecken bräuchte man oo viele
Taylor-Reihen. Außerdem verliert man die Symmetrie wenn man nicht um
(0,0) entwickelt, d.h. in einer Umgebung von 0 hat man doppelt zu viele
Terme auszuwerten.
Wenn man sich auf der reellen Achse von (0,0) entfernt wird der
Konvergenzradius zwar größer (der Radius ist sqrt(1+|x0|) wenn x0 der
Entwicklungspunkt ist), aber man muss eben nen ganzen Zoo von Reihen
speichern.
Wenn die geforderte Präzision nicht allzu groß ist, und man z.B. mit
linearen oder kubischen Teilstücken hinkommt, entspricht das im
Endeffekt einer linearen Approximation bzw. einer mit kubischen Splines,
wobei Splines und lineare Approximation den Vorteil haben, dass die
stetig sind und im Idealfall den Fehler im Teilintervall minimieren (was
Taylor nicht macht).
Hier noch die Reihe um 1 (Konvergenzradius ist wie gesagt sqrt2):
atan(x+1) - atan(1) = 1/2x - 1/4x^2 + 1/12x^3 - 1/40x^5 + 1/48x^6 -
1/112x^7 + 1/288x^9 - 1/320x^10 + 1/704x^11 - 1/1664x^13 + 1/1792x^14 -
1/3840x^15 + 1/8704x^17 - 1/9216x^18 + 1/19456x^19 ...
Für x=-1 ergibt das -atan(1) = -pi/4. Wertet man bis zu der gezeigten
Ordnung aus, ergibt sich:
-130023561/165541376 ~ -pi/4 - 4.6E-5
das sind 14.5 Bits. Warum auch immer verschwindet jeder 4. Term, d.h.
man braucht nur ca. 3N/4 Terme für Ordnung N.
whitespace schrieb:> Konkret kann ich nur einen Literaturvorschlag beisteuern: Computer> Approximations, John F. Hart, Wiley, 1968>> Das Buch hatte ich in einer Bibliothek zu solchen Themen einmal in den> Händen und durchgeblättert. Darin gibt es auch Kapitel über die Näherung> von trigonometrischen Funktionen und den Inversen. Verschiedene> Approximationsmethoden werden auch beschrieben. Ist schon etwas älter,> ob die Methoden noch "state of the art" sind oder ob es mittlerweile> bessere gibt, weiß ich nicht.
Erstmal Danke für den Literaturhinweis. Wie die Beiträge weiter oben
zeigen, sind die Approximationen in dem Buch schon noch "state of the
art". Mit heutigen Computer-Algebra-Systemen (CAS) kann man sich die
Koeffizienten, passend zu den Anforderungen, auch berechnen lassen. Für
das CAS Maple ist das z.B. hier beschrieben:
Maplesoft Online Help numapprox minimax rational approximation
https://www.maplesoft.com/support/help/Maple/view.aspx?path=numapprox/minimax
Das Abtippen der Koeffizienten, wie ich das gemacht habe, ist eigentlich
nicht mehr zeitgemäß. In den freien CAS, wie Axiom oder Maxima habe ich
aber noch nicht nach Funktionen wie "minimax" geschaut.
Hier mal die Lösung mit 6 Koefitienten im Zähler und im Nenner. Der Plot
zeigt die Differenz zwischen dem approximierten Wert und der normalen
atan()-Funktion von Cpp. die normale atan()-Funktion hat vermutlich nur
"double" und kein "long double".
/* atan(x) x-range 0...1
y = x*P(x^2)/Q(x^2)
Approximations, John F. Hart, Wiley, 1968
*/
Es ist schon verblüffend, dass es bereits 1968 so genaue Approximationen
gab.
Helmut S. schrieb:> die normale atan()-Funktion hat vermutlich nur> "double" und kein "long double"
Hallo, daher habe ich Dein Programm mal so modifiziert, dass es die mit
bc (bc - An arbitrary precision calculator language) auf 22
Dezimalstellen berechneten atan-Werte in ein array einliest und dann die
Differenz zur Approximation mit Polynomgraden (in x^2) 6/6, d.h. 7/7
Koeffizienten für das Intervall [0; tan pi/4] mit precision 17.24 im
Buch von Hart ausgibt. Für die gewählten x-Werte stimmt die precision
ganz gut.
Alexander S. schrieb:> Helmut S. schrieb:>> die normale atan()-Funktion hat vermutlich nur>> "double" und kein "long double">> Hallo, daher habe ich Dein Programm mal so modifiziert, dass es die mit> bc (bc - An arbitrary precision calculator language) auf 22> Dezimalstellen berechneten atan-Werte in ein array einliest und dann die> Differenz zur Approximation mit Polynomgraden (in x^2) 6/6, d.h. 7/7> Koeffizienten für das Intervall [0; tan pi/4] mit precision 17.24 im> Buch von Hart ausgibt. Für die gewählten x-Werte stimmt die precision> ganz gut.
Hallo Alexander,
vielen Dank für die Tabelle mit den genauen Werten.
Der Fehlerplot sieht jetzt richtig gut aus. Besonders gut finde ich,
dass der absolute Fehler ungefähr proportional mit dem Wert von x
steigt. Damit ist auch der relative Fehler nicht viel schlechter. Hut ab
vor John F. Hart.
Hallo Alexander,
ich habe jetzt deinen Code genommen und die Approximation atan1(x) mit
der atan(x)-Standard-Funktion verglichen. Die Approximation ist wirklich
Spitze verglichn mit der eingebauten atan()-Funktion.
PS:
#include <stdio.h>
Diese Zeile hat mich eine halbe Stunde gekostet.
Mit stdio.h kamen nur xxx-317 Werte heraus, egal ob printf() oder
fprintf(). Irgendwann fiel mir auf, dass ich <iostream> verwendet hatte.
Nach dieser Änderung hat alles wieder funktioniert -
main3_long_double.cpp
//#include <stdio.h>
#include <iostream>
Helmut S. schrieb:> Hallo Alexander,> ich habe jetzt deinen Code genommen und die Approximation atan1(x) mit> der atan(x)-Standard-Funktion verglichen. Die Approximation ist wirklich> Spitze verglichn mit der eingebauten atan()-Funktion.
Kannst du auch mal den relativen Fehler plotten? Da hat die rote Kurve
wohl konstante Amplitude.
Hat eigentlich jemand ein CA System verfügbar, mit dem man solche
rationalen minimax Approximationen bestimmen kann? Die Numerik ist ja
nicht ganz trivial, siehe z.B. https://arxiv.org/pdf/1705.10132
Konkret würde mich arcsin(sqrt(x/2)) / sqrt(x/2) im Intervall [0, 1/2]
mit relativem Fehler -55 Bits oder kleiner interessieren.
Hallo Alexander,
der screenshot zeigt den relativen Fehler.
Die Frage ist jetzt ob der konstante Anstieg eventuell mit der endlichen
Genauigkeit von long double (80bit) zusammenhängt.
Johann L. schrieb:> Kannst du auch mal den relativen Fehler plotten? Da hat die rote Kurve> wohl konstante Amplitude.Helmut S. schrieb:> Hallo Alexander,> der screenshot zeigt den relativen Fehler.
Helmut war schneller. Trotzdem hier noch meine Variante (siehe
Diagramm).
1
if(i>0){
2
e=(y-z)/z;
3
fprintf(file2,"%28.20Le %28.20Le\n",x,e);
4
}
Helmut S. schrieb:> #include <stdio.h>> Diese Zeile hat mich eine halbe Stunde gekostet.
Entschuldigung. Aber eigentlich ist der Code komplett C und nicht C++.
Johann L. schrieb:> Hat eigentlich jemand ein CA System verfügbar, mit dem man solche> rationalen minimax Approximationen bestimmen kann?
Ich habe unter Linux Axiom, Maxima und Octave u.v.m. Habe aber noch
nicht geschaut, ob es dafür schon die Routinen gibt.
Etwas offtopic: Ich überlege gerade mir einen RaspberyPi4 zu holen.
Dafür gibt es Mathematica für privaten Gebrauch kostenlos.
Hier noch ein Link auf "Function Approximation" bei Wolfram:
https://reference.wolfram.com/language/FunctionApproximations/tutorial/FunctionApproximations.html
Johann L. schrieb:> Konkret würde mich arcsin(sqrt(x/2)) / sqrt(x/2) im Intervall [0, 1/2]> mit relativem Fehler -55 Bits oder kleiner interessieren.
Hallo Johann, ich habe mir mal erlaubt Deine Frage auf dem Matheplaneten
www.matheplanet.de im Unterforum "Mathematica" zu stellen. Der Benutzer
HyperG hat mit Mathematica dieses Polynom erzeugt:
Alexander S. schrieb:> Johann L. schrieb:>> Konkret würde mich arcsin(sqrt(x/2)) / sqrt(x/2) im Intervall [0, 1/2]>> mit relativem Fehler -55 Bits oder kleiner interessieren.>> Hallo Johann, ich habe mir mal erlaubt Deine Frage auf dem Matheplaneten> www.matheplanet.de im Unterforum "Mathematica" zu stellen. Der Benutzer> HyperG hat mit Mathematica dieses Polynom erzeugt:>
1
> (0.999999999999985 - 0.795192955982834 x + 0.180219557964123 x^2 -
> Wieder abgetipt, d.h. ohne Gewähr. Die Genauigkeit ist ca. 3E-14.>> https://www.matheplanet.de/matheplanet/nuke/html/viewtopic.php?topic=243737&post_id=1775475
Hi, vielen Dank für dein Engagement!
Inzwischen hab ich meine eigene Approximation zusammengeklöppelt weil
mich das Rumgesuche genervt hat...
Just bestimmt und ausgetestet ist folgende rationale [5/4] MiniMax für
o.g. Funktion in [0, 1/2]:
...zurück zu atan.
Mit meiner MiniMax hab ich folgende [3,4] für a(x) = atan(sqrt(x)) /
sqrt(x) bestimmt:
1
p(x) =
2
+ 0.999999999999999998080178351225003952632
3
+ 1.51597040589722809277543885223133087789x
4
+ 0.636928974763539784860899545005247736093x^2
5
+ 0.0638944455799886571709448345524306512048x^3
6
7
q(x) =
8
+1
9
+ 1.84930373923056200945453682584178320362x
10
+ 1.05336355450697082895016644607427716580x^2
11
+ 0.188012025422931152047197803304030906006x^3
12
+ 0.00507310235929401206762490897042543192106x^4
Damit ergibt sich folgender Algorithmus zur Berechnung von atan:
Argument-Reduktion
1) auf [0,oo]
2) auf [0,1]
3) auf [-w,w] mit w = 2 - sqrt3 ~ 0.268
wie ausgeführt in Beitrag "Re: Näherung für ArcusTangens?"
In [-w^2,w^2] verwendet man dann g(x) = p(x) / q(x) als Näherung für
a(x) und bestimmt atan gemäß
atan(x) = x·a(x^2) ~ x·g(x^2); x in [-w,w]
d.h. a() wird genähert in [-w^2,w^2] mit w^2 = 7 - 4sqrt3 ~ 0.072.
Der Plot im Anhang zeigt den relativen Fehler von x·g(x^2) zu atan(x) in
[-w,w]. Der Graph ist nicht komplett symmetrisch weil rechts noch für
paar Werte > w geplottet wurde.
Der Fehler ist (fast) genau wie erwartet. (Bei 0 und w sind keine Maxima
weil a() auf einem minimal größeren Intervall als [-w^2,w^2] genähert
wurde, d.h. bei 0 und w hat der Fehler von g() kein Maximum.)
p.s: Der linke Plot mit x in [0..0.3] kann gelöscht werden.
Zwischenfrage: Weshalb werden hier Näherungsreihen so wesentlich
diskutiert. Ich würde CORDIC verwenden um an das Ziel zu kommen. Ein zu
hoher RAM-Verbrauch? .. Eine zu hohe Rechenzeit?
Christoph db1uq K. schrieb:> Die Numerical Recipies wurden noch nicht erwähnt, ich dachte, das ist> ein Standardwerk:> https://de.wikipedia.org/wiki/Numerical_Recipes> Zum Lesen muss man allerdings eine Software installieren, die ich noch> nicht kannte. "Empanel" oder "OpenFile"
Hallo, auch wenn die ursprüngliche Frage bereits beantwortet ist, hier
ein Kommentar zu den Numerical Recipes.
Die 2. Aufl. der Numerical Recipes in C kann man sich als flash-Datei
hier anschauen: http://numerical.recipes/oldverswitcher.html
In dem Buch gibt es im Abschnitt 5.13 Rational Chebyshev Approximation
auf S. 206 die Routine ratlsq, die f(x) mit R(x) =
(p0+p1*x+...)/(1+q1*x+...)
approximiert.
Für die Funktion f(x) = asin(sqrt(x/2)) / sqrt(x/2) erhalte ich mit Grad
3 / Grad 4 und Intervall [0:0.5] eine Näherung mit einer Polstelle bei x
= 0.3.
Bei Einschränkung auf das Intervall [0:0.25] kommt eine ganz brauchbare
Näherung heraus.
1
ratlsq iteration= 1 max error= 4.821e-06
2
ratlsq iteration= 2 max error= 2.017e-06
3
ratlsq iteration= 3 max error= 7.303e-04
4
ratlsq iteration= 4 max error= 3.086e-04
5
ratlsq iteration= 5 max error= 1.670e-02
6
[0.000001 : 0.500000]
7
0 1.000038095717036946
8
1 202244301.401464492082595825
9
2 -735806100.350590467453002930
10
3 186583373.451535642147064209
11
4 202244323.917425632476806641
12
5 -752661211.566265940666198730
13
6 245531641.993888765573501587
14
7 -7564721.532575584016740322
15
16
ratlsq iteration= 1 max error= 2.618e-08
17
ratlsq iteration= 2 max error= 4.140e-10
18
ratlsq iteration= 3 max error= 1.186e-07
19
ratlsq iteration= 4 max error= 3.762e-08
20
ratlsq iteration= 5 max error= 1.565e-05
21
[0.000001 : 0.250000]
22
0 1.000001887400718825
23
1 8925421822.914939880371093750
24
2 369595154.398652076721191406
25
3 -870760035.829437494277954102
26
4 8925421821.023189544677734375
27
5 -374189577.714669704437255859
28
6 -1006942402.749973297119140625
29
7 41261209.496030598878860474
Siehe die beiden angehängten Diagramme.
Für den atan in [0:pi/12] habe ich keine brauchbare Näherung erhalten.
sin scheint auch ganz gut zu gehen.
Jens G. schrieb:> Zwischenfrage: Weshalb werden hier Näherungsreihen so wesentlich> diskutiert. Ich würde CORDIC verwenden um an das Ziel zu kommen. Ein zu> hoher RAM-Verbrauch? .. Eine zu hohe Rechenzeit?
Wenn der Prozessor einen Hardwaremultiplizierer mit großer Bitbreite
hat, dann ist man mit Polynomen schneller als mit CORDIC.
Alexander S. schrieb:> Helmut S. schrieb:>> die normale atan()-Funktion hat vermutlich nur>> "double" und kein "long double">> Hallo, daher habe ich Dein Programm mal so modifiziert, dass es die mit> bc (bc - An arbitrary precision calculator language) auf 22> Dezimalstellen berechneten atan-Werte in ein array einliest und dann die> Differenz zur Approximation mit Polynomgraden (in x^2) 6/6, d.h. 7/7> Koeffizienten für das Intervall [0; tan pi/4] mit precision 17.24 im> Buch von Hart ausgibt. Für die gewählten x-Werte stimmt die precision> ganz gut.
"ganz gut"? Fast ideal würde ich sagen! Hab's mal nachgerechnet,
relativer Fehler siehe Anhang. Der größte Max-Abstand ist 5.809E-18,
der kleinste 5.413E-18. Deren Quotient ist 1.073 und erreicht damit
fast das theoretische Minimum von 1.
Irgendwo muss sich bei dir nen Fehlerteufel eingeschlichen haben; so
ansteigende Fehlerkurven sind ein Indiz dafür, dass die interne
Genauigkeit dem Ende zugeht.
Zur Referenz hier nochmal die Polynome (Style=Gnuplot):
Jens G. schrieb:> Zwischenfrage: Weshalb werden hier Näherungsreihen so wesentlich> diskutiert. Ich würde CORDIC verwenden um an das Ziel zu kommen. Ein zu> hoher RAM-Verbrauch? .. Eine zu hohe Rechenzeit?
Polynome bzw. rationale Funktionen sind eben ziemlich allgemein, sie
können auf unterschiedliche Anforderungen angepasst werden
(darzustellende Funktion, Intervall, Genauigkeit), und sie sind einfach
auszuwerten.
Momentan ist meine auf rationalen Approximationen basierende
Implementierung aber auch besser als die Konkurrenten, als da wären
avr-f64 und fp64lib von Beitrag "64 Bit float Emulator in C, IEEE754 compatibel"
Von der Genauigkeit bin ich bei asin, atan in etwa wie avr-f64 (Cordic)
und besser als fp64lib (ebenfalls Cordic). Siehe untere Zeile von
(meine Implementierung hat Labels f7)
https://www.mikrocontroller.net/attachment/430317/test-f7.png
Und Codegröße ist auch besser, siehe
https://www.mikrocontroller.net/attachment/430869/size.png
Laufzeit meiner Implementierung (C+Asm) ist etwas schlechter als fp64lib
(Asm).
Johann L. schrieb:> Irgendwo muss sich bei dir nen Fehlerteufel eingeschlichen haben; so> ansteigende Fehlerkurven sind ein Indiz dafür, dass die interne> Genauigkeit dem Ende zugeht.
Hallo Johann,
das Diagramm atan3.png im Beitrag
Beitrag "Re: Näherung für ArcusTangens?" mit dem relativen
Fehler für die atan-Näherung auf 17.24 Dezimalstellen zeigt den Fehler
der Polynomberechnung in C mit long double, d.h. nur 18 bis 19
Dezimalstellen. Die Referenz für die Fehlerberechnung wurde mit bc auf
22 Stellen genau berechnet.
Das der Anstieg mit der begrenzten Genauigkeit von long double
zusammenhängt, hat Helmut bereits vermutet.
Helmut S. schrieb:> Die Frage ist jetzt ob der konstante Anstieg eventuell mit der endlichen> Genauigkeit von long double (80bit) zusammenhängt.
Wenn ich das rationale Näherungspolynom (Grad 6 / Grad 6) auch in bc mit
26 Dezimalstellen Genauigkeit berechne, erhalte ich den gleichen
relativen Fehler wie Du. Siehe atan_17_24.png
Alexander S. schrieb:> Hallo Johann,> das Diagramm atan3.png im Beitrag> Beitrag "Re: Näherung für ArcusTangens?" mit dem relativen> Fehler für die atan-Näherung auf 17.24 Dezimalstellen zeigt den Fehler> der Polynomberechnung in C mit long double, d.h. nur 18 bis 19> Dezimalstellen. Die Referenz für die Fehlerberechnung wurde mit bc auf> 22 Stellen genau berechnet.
Ah, ok. Kann sogar die Kurve nachvollziehen, dazu genügt es, die
Koeffizienten der Polynome auf float(Python) zu casten. Gerechnet wird
mit höherer Präzision.
1
>>> import sys
2
>>> print (sys.float_info.mant_dig)
3
53
float(Python) entspricht also dem üblichen double(C/C++).
> Das der Anstieg mit der begrenzten Genauigkeit von long double> zusammenhängt, hat Helmut bereits vermutet.> Helmut S. schrieb:>> Die Frage ist jetzt ob der konstante Anstieg eventuell mit der endlichen>> Genauigkeit von long double (80bit) zusammenhängt.
Sieht eher danach aus, dass da irgendwie (teilweise?) mit double
gerechnet wurde, ansonsten kann ich mir nicht vorstellen, dass ich die
Kurve so gut mit 53-Bit Mantisse nachvollziehen kann.
> Wenn ich das rationale Näherungspolynom (Grad 6 / Grad 6) auch in bc mit> 26 Dezimalstellen Genauigkeit berechne, erhalte ich den gleichen> relativen Fehler wie Du. Siehe atan_17_24.png
Gibt's da eigentlich nen Hinweis, wie die Näherungen bestimmt wurden?
Mit rationalem Remez kann ich atan in [0,1] annähern per 5/4 oder 4/5,
bei 5/5 gibt es kaum noch Konvergenz, und für 6/6 ist das Verfahren so
instabil, dass es nichtmehr funktioniert.
Eine Möglichkeit könnte Carathéodory-Féjer sein, d.h. Approximation auf
dem Einheitskreis in C und dann Teil des Randes auf [a,b] in R abbilden.
Alles sehr interessant, aber meine ursprüngliche Frage ist ja durch die
tollen Beiträge in diesem Thread zu meiner Zufriedenheit beantwortet.
Und rational Remez zu implementieren war einfach, die meiste Arbeit war
QR-Zerlegung.
Alexander S. schrieb:> Für den atan in [0:pi/12] habe ich keine brauchbare Näherung erhalten.
Wenn man die Symmetrie von atan berücksichtigt und atan(sqrt(x)) /
sqrt(x) approximiert, erhält man auch mit ratlsq aus den Numerical
Recipes "brauchbare" Näherungen für den
1
atan x = x * (p0 + p1*x^2 + p2*x^4 + ...) / (q0 + q1*x^2 + q2*x^4 + ...)
Z.B. mit Grad 4 / Grad 4 in [0:tan pi/12]
1
ratlsq iteration= 1 max error= 3.617e-06
2
ratlsq iteration= 2 max error= 6.183e-07
3
ratlsq iteration= 3 max error= 1.008e-03
4
ratlsq iteration= 4 max error= 1.937e-05
5
ratlsq iteration= 5 max error= 1.340e-01
6
[0.000001 : 0.518000]
7
0 1.000013216745146760
8
1 132475496.082246452569961548
9
2 -559127738.893114686012268066
10
3 -455648453.819097280502319336
11
4 -33228001.094260059297084808
12
5 132475502.845357134938240051
13
6 -514969853.801637709140777588
14
7 -653785760.688392877578735352
15
8 -129374889.419161975383758545
Der absolute Fehler in [0:tan pi/12] ist kleiner 5e-09, der relative
eine Größenordnung höher. Im Bild ist der absolute Fehler gezeigt.
Johann L. schrieb:> Gibt's da eigentlich nen Hinweis, wie die Näherungen bestimmt wurden?
John F. Hart gibt in seinem Buch "Computer Approximations" nicht für
jede der zahlreichen Näherungen Quellen an. Am Anfang vom Abschnitt 6.5
zu arcsin und arctan schreibt er: "Coefficients for expansions of
arcsin(x) and arctan(x) in a series of Chebyshev polynomials are given
to 20D by Clenshaw [1962]; Vionnet [1960] gives 24D values.
Clenshaw [1962] "Chebyshev series for mathematical functions," National
Physical Laboratory Mathematical tables, 5.
https://www.worldcat.org/title/chebyshev-series-for-mathematical-functions/oclc/60945199
Vionnet [1959] Approximation de Tchebycheff d'ordre des functions sin
x,x-1 sin x, cos x, et exp x.
Alexander S. schrieb:> Alexander S. schrieb:>> Für den atan in [0:pi/12] habe ich keine brauchbare Näherung erhalten.
Soweit nachvollziehbar; mit Nullstelle im Approximationsintervall
funktioniert Optimieren auf relativen Fehler i.d.R. nicht.
> Wenn man die Symmetrie von atan berücksichtigt und atan(sqrt(x)) /> sqrt(x) approximiert, erhält man auch mit ratlsq aus den Numerical> Recipes "brauchbare" Näherungen für den> [...]> Z.B. mit Grad 4 / Grad 4 in [0:tan pi/12]> [code]> ratlsq iteration= 1 max error= 3.617e-06> ratlsq iteration= 2 max error= 6.183e-07> ratlsq iteration= 3 max error= 1.008e-03> ratlsq iteration= 4 max error= 1.937e-05> ratlsq iteration= 5 max error= 1.340e-01
Mit brauchbar in Gänsefüßchen :-/ Problem ist wohl, einen Startpunkt
zu finden, von dem aus die Iteration konvergiert.
Übrigens reicht hier bis tan²pi/12 zu approximieren: g(x) =
atan(sqrt(x)) / sqrt(x) wird bei Reduktion des atan-Arguments auf [-z,z]
mit z = tan pi/12 = 2-sqrt3 nur im Intervall [0,z²] mit z² < 0.0718
ausgewertet.
In diesem Fall hat ein [3/3] Proximum Abstand < 8.75E-17 zu g. (Höhere
Grade schafft meine Implementierung auch nicht, eben wegen des Problems
einen geeigneten Startpunkt für die Iteration zu finden.)
Zum Abschluss noch meine Näherung für asin und acos:
1
p(x) =
2
+ 0.9999999999999999944249107313502758620
3
- 1.0352340338921976278427312087167692142 x
4
+ 0.3529020623298151981342259189772057401 x^2
5
- 0.0433348317064168570561235180136569466 x^3
6
+ 0.0012557428614630796315205218507940285 x^4
7
+ 0.0000084705471128435769021718764878041 x^5
8
9
q(x) =
10
+ 1
11
- 1.1185673672255329236623716486696411533 x
12
+ 0.4273660095987244885409833401675833351 x^2
13
- 0.0635558848496317165994214838980137828 x^3
14
+ 0.0028820878185134035637440105959294542 x^4
a(x) = p(x) / q(x) in [0, 1/2]
x in [0, 1/2] => Berechne asin(x) = x·a(2x²)
x in [1/2, 1] => Berechne acos(x) = sqrt(2-2x)·a(1-x)
alle anderen Fälle von asin / acos lassen sich so auf diese beiden Fälle
zurückführen, dass nur Vorzeichenwechel und/oder Addition eines
ganzzahligen Vielfaches von pi/2 benötigt werden.
Diese Formel gefällt mir besser als das, was ich so in der Literatur
gefunden habe, denn dort war die Wurzel immer im Argument von asin bzw.
acos und oft sogar im Nenner.
Relative Fehler siehe Grafiken.
Johann L. schrieb:> Kann sogar die Kurve nachvollziehen, dazu genügt es, die> Koeffizienten der Polynome auf float(Python) zu casten. Gerechnet wird> mit höherer Präzision.
Hallo Johann, dazu passt dieser Artikel, insbesondere Fig. 2, gut:
Frithjof Blomquist, "OPTIMIZATIONOF RATIONAL APPROXIMATIONS BY CONTINUED
FRACTIONS", SerdicaJ. Computing 1 (2007), 433{442
http://sci-gems.math.bas.bg:8080/jspui/bitstream/10525/355/1/sjc033-vol1-num4-2007.pdf
Johann L. schrieb:> Hat eigentlich jemand ein CA System verfügbar, mit dem man solche> rationalen minimax Approximationen bestimmen kann? Die Numerik ist ja> nicht ganz trivial, siehe z.B. https://arxiv.org/pdf/1705.10132Johann L. schrieb:> ...zurück zu atan.>> Mit meiner MiniMax hab ich folgende [3,4] für a(x) = atan(sqrt(x)) /> sqrt(x) bestimmt:> p(x) => + 0.999999999999999998080178351225003952632> + 1.51597040589722809277543885223133087789x> + 0.636928974763539784860899545005247736093x^2> + 0.0638944455799886571709448345524306512048x^3>> q(x) => +1> + 1.84930373923056200945453682584178320362x> + 1.05336355450697082895016644607427716580x^2> + 0.188012025422931152047197803304030906006x^3> + 0.00507310235929401206762490897042543192106x^4>> Damit ergibt sich folgender Algorithmus zur Berechnung von atan:>> Argument-Reduktion>> 1) auf [0,oo]> 2) auf [0,1]> 3) auf [-w,w] mit w = 2 - sqrt3 ~ 0.268>> wie ausgeführt in Beitrag "Re: Näherung für ArcusTangens?">> In [-w^2,w^2] verwendet man dann g(x) = p(x) / q(x) als Näherung für> a(x) und bestimmt atan gemäß>> atan(x) = x·a(x^2) ~ x·g(x^2); x in [-w,w]Johann L. schrieb:> Mit rationalem Remez kann ich atan in [0,1] annähern per 5/4 oder 4/5,> bei 5/5 gibt es kaum noch Konvergenz, und für 6/6 ist das Verfahren so> instabil, dass es nichtmehr funktioniert.
Hallo Johann,
falls es noch von Interesse ist: ich habe den atan jetzt mit Mathematica
in [0;0.268] mit Grad 3 durch Grad 4 und mit Grad 4 durch Grad 5
approximiert. Erst habe ich die Koeffizienten für ftmp(x) =
atan(sqrt(x))/sqrt(x) bestimmt und dann atan durch atapp(x) =
x*ftmp(x^2) approximiert.
Die Koeffizienten für die 3/4 Approximation liegen sehr nahe an Deinen
Koeffizienten.
Mit 3/4 liegt der max. relative Fehler bei 4e-19 und mit 4/5 bei 7e-24
(siehe Diagramme). D.h. Mathematica scheint einen guten Algorithmus
implementiert zu haben.
Johann L. schrieb:> Relative Fehler siehe Grafiken.
Spontan wäre ich versucht, diese sehr "sinusförmigen" Fehler
wegzurechnen, indem man den gefundenen Wert noch nachprozessiert. Sieht
auf den ersten Blick nach leicht komprimierter (quadratischer) X-Achse
aus, für die man einen Fehlerterm sin(k(x*x)) bestimmen könnte.
?
Auch der A-TAN-rel error direkt hier drüber schreit fast nach weiterer
Reduktion.
Alexander S. schrieb:> Hallo Johann,>> falls es noch von Interesse ist: ich habe den atan jetzt mit Mathematica> in [0;0.268] mit Grad 3 durch Grad 4 und mit Grad 4 durch Grad 5> approximiert. Erst habe ich die Koeffizienten für ftmp(x) => atan(sqrt(x))/sqrt(x) bestimmt und dann atan durch atapp(x) => x*ftmp(x^2) approximiert.
Für atan verwende ich momentan die [6/6] in [0,1], die du oben gepostet
hattest.
> Mit 3/4 liegt der max. relative Fehler bei 4e-19 und mit 4/5 bei 7e-24> (siehe Diagramme).
Die [6/6] hat ausreichende Genauigkeit und den Vorteil, dass
Argument-Reduktion auf [0,1] ausreicht.
Für Genauigkeit siehe in der 1. Grafik ganz unten rechts in
Beitrag "Re: 64 Bit float Emulator in C, IEEE754 compatibel"
Zur Auswertung eines Polynoms vom Grade n braucht's n Additionen und n
Multiplikationen. Nach Reduktion auf [0,1] ergeben sich also folgende
Kosten bei aktuell folgenden mittleren Laufzeiten in Ticks (ATmega4808):
Add = 400
Mul = 600
Div = 2400 = 4×Mul
[6/6] kostet: 12×Add + 12×Mul + 1×Div = 14400
Weil Reduktion à la atan(x) - atan(y) = atan((x - y) / (1 + xy)) 3×Add +
1×Mul + 1×Div kostet, ergibt sich:
[3/4] kostet: 10×Add + 8×Mul + 2×Div = 13600
[6/6] - [3/4] kostet: 2×Add + 4×Mul - 1×Div = 2×Add = 800
Mit [3/4] wäre atan also etwa 6% schneller als mit [6/6].
[6/6] braucht 14 Konstanten à 10 Bytes, [3/4] hingegen nur 11 Stück,
also 30 Bytes weniger, was 15 AVR-Instruktionen entspricht. [6/6]
schneidet hier wegen des einfacheren Codes also besser ab, denn ein
Funktionsaufruf kostet bereits mindestens 8 Bytes: 3×MOVW + 1×RCALL.
Hinzu kommen bei [3/4] Vergleich und Fallunterscheidung vor Reduktion
und Fallunterscheidung danach.
Johann L. schrieb:> Für atan verwende ich momentan die [6/6] in [0,1], die du oben gepostet> hattest.
Ok.
Johann L. schrieb:> Zum Abschluss noch meine Näherung für asin und acos:> p(x) => + 0.9999999999999999944249107313502758620> - 1.0352340338921976278427312087167692142 x> + 0.3529020623298151981342259189772057401 x^2> - 0.0433348317064168570561235180136569466 x^3> + 0.0012557428614630796315205218507940285 x^4> + 0.0000084705471128435769021718764878041 x^5>> q(x) => + 1> - 1.1185673672255329236623716486696411533 x> + 0.4273660095987244885409833401675833351 x^2> - 0.0635558848496317165994214838980137828 x^3> + 0.0028820878185134035637440105959294542 x^4>> a(x) = p(x) / q(x) in [0, 1/2]>> x in [0, 1/2] => Berechne asin(x) = x·a(2x²)> x in [1/2, 1] => Berechne acos(x) = sqrt(2-2x)·a(1-x)
Zum Vergleich hier die von Mathematica berechneten Werte:
I passed this problem to a befriended mathematician.
His quick answer was:
an effcient accurate formula for arctan not too close to 1 is the arctan
Bailey Borwein Plouffe formula.
Geert H. schrieb:> I passed this problem to a befriended mathematician.> His quick answer was:> an effcient accurate formula for arctan not too close to 1 is the arctan> Bailey Borwein Plouffe formula.
This formula has a slowly converging series. Thus I think it's a bad
choice for compuation.
Jürgen S. schrieb:> Johann L. schrieb:>> Relative Fehler siehe Grafiken.>> Auch der A-TAN-rel error direkt hier drüber schreit fast nach weiterer> Reduktion.
Ich höre da noch nichtmal ein Flüstern :o)
Mal angenommen wir hätten eine (einfach zu berechnende) Näherung h(x)
des relativen Fehlers r(x). Dann gilt:
r = (g-f)/f ≈ h <=> g ≈ f·(1+h)
In Worten: Um h dazu zu verwenden, eine bessere Näherung g für f zu
finden, muss man f kennen.
> Sieht auf den ersten Blick nach leicht komprimierter (quadratischer)> X-Achse aus, für die man einen Fehlerterm sin(k(x*x)) bestimmen> könnte.
Meine OFR [*] sagt: Polynom :-)
> Spontan wäre ich versucht, diese sehr "sinusförmigen" Fehler> wegzurechnen, indem man den gefundenen Wert noch nachprozessiert.
Der Fehler ist ja bereits unter dem erforderlichen Limit. Eine
Nachkorrektur wäre also dann sinnvoll, wenn der Fehler größer wäre, etwa
wenn man eine Approximation kleineren Grades wählt.
In diesem Falle hätte man folgende Gemängelage:
Für den (relativen oder absoluten) Fehler eines Proximums vom Grade N
gilt der Alternantensatz.
Proximum: Hier ein Polynom vom Grade N, das im Sinne der Maximumsnorm
möglichst dicht (proximal) an der Zielfunktion liegt. Für rationale
Funktionen gilt das Gleiche, nur dass der Grad sich aus dem Grad von
Nenner- und Zählerpolynom ergibt.
Alternantensatz: Der Absolutwert des Proximum-Fehlers hat genau N+2
lokale Maxima. Sind x_k die N+2 x-Werte zu diesen lokalen Maxima mit
x_k < x_{k+1}, dann gilt für den Fehler: r(x_k) = E·(-1)^k. Der Fehler
oszilliert also mit konstanter "Amplitude" um 0. Es kann der seltene
Fall auftreten, dass es mehr als N+2 solcher Maxima gibt: Dann gilt E =
0, d.h. das Proximum stimmt mit der anzunähernden Funktion überein. Das
tritt zum Beispiel auf, wenn man ein Polynom vom Grad M durch Polynome
vom Grade <= M annähert.
Folgerung: Hat man ein gutes Näherungspolynom vom Grad N gefunden, dann
hat der Fehler die Alternenteneigenschaft. Will man den Fehler durch
ein Polynom vom Grad N+1 darstellen — oder gleichbedeutend damit, ein
(besseres) Näherungspolynom vom Grad N+1 finden — dann sollte dieses
ebenfalls die Alternanteneigenschaft haben. Polynome mit dieser
Eigenschaft sind die Tschebyschow-Polynome 1. Art T_n:
https://de.wikipedia.org/wiki/Tschebyschow-Polynom#Tschebyschow-Polynome_erster_Art
Im Intervall [-1,1] haben diese folgende kompakte Darstellung:
T_n(x) = cos(n·arccos(x))
Will man also den Fehler als Polynom darstellen, dann ist das nächste
T_n eine gute Wahl. Und nach Korrektur ist der Fehler immer noch
oszillierend, und zwar ungefähr wie
cos((n+1)·arccos(x))
Wenn die Approximation also nicht genau genug ist, dann geht man einfach
einen Grad höher usw. und fertig ist der Lack.
Analog für rationale Approximationen, nur dass man hier die Wahl hat,
Nenner- und/oder Zähler-Grad zu erhöhen. Die besten Ergebnisse erhält
man i.d.R für grad(Nenner) ≈ grad(Zähler).
Und wie immer: cum granum salis. Dass der Fehler fast wie
cos(n·arccos(x)) aussieht, gilt natürlich nur dann, wenn die
Zielfunktion leicht zu approximieren ist, d.h. bei Entwicklung nach T_n
werden die Koeffizienten der T_n rasch kleiner mit n, so dass höhere T_n
nur einen sehr kleinen Beitrag leisten. Wenn die Zielfunktion nicht
gutartig ist, z.B. nicht glatt wie |x| in 0, dann ist der Fehler zwar
immer noch eine Alternante, sieht aber ganz anders aus als die obigen
Grafiken vermuten lassen.
[*] Optical Function Recognition
Johann L. schrieb:> Wenn die Approximation also nicht genau genug ist, dann geht man einfach> einen Grad höher usw. und fertig ist der Lack.
Das ist klar, allerdings impliziert ein höherer Grad bei den hier
vorgestellten Methoden immer auch mehr Divisionen. Ich suche z.B. nach
Implementierungen, die mit einfachen Divisionen / ohne Wurzelbildungen
auskommen. Da sind oszillierende Korrekturen sehr viel einfacher zu
applizieren. Ich mache das z.B. bei Berechnungen nach CORDIC.
Jürgen S. schrieb:> Johann L. schrieb:>> Wenn die Approximation also nicht genau genug ist, dann geht man einfach>> einen Grad höher usw. und fertig ist der Lack.>> Das ist klar, allerdings impliziert ein höherer Grad bei den hier> vorgestellten Methoden immer auch mehr Divisionen.
Nicht mit rationalen Approximationen. Da hat man immer genau eine
Division: Polynom durch Polynom. Der Grad von Nenner- und Zählerpolynom
ist dabei unerheblich.
Einen Grad höher zu wählen kostet also 1 Multiplikation, 1 Addition und
das Speichern 1 Konstante mehr.
> Ich suche z.B. nach Implementierungen, die mit einfachen> Divisionen / ohne Wurzelbildungen auskommen.
Also etwa Polynom (z.B. Taylor oder MiniMax) oder rationale Funktion
(z.B. Padé oder rationale MiniMax).
Bei arccos und arcsin wirst du um Quadratwurzel schwerlich herumkommen,
denn die Singularitäten in -1 und 1 sind i.W. Quadratwurzeln, und diese
bekommst du anders nicht vernünftig approximiert.
> Da sind oszillierende Korrekturen sehr viel einfacher zu> applizieren. Ich mache das z.B. bei Berechnungen nach CORDIC.
??? Aber wenn du zur Korrektur zum Beispiel ein Polynom vom Grad N
brauchst, dann kannst die Funktion doch direkt per Polynom vom Grad N
approximieren und CORDIC in die Tonne kloppen. Ich seh da den Sinn und
Zweck von CORDIC nicht. Außerdem hat CORDIC wohl kaum diesen hübschen
Fehlerverlauf, sondern meine Erfahrung mit CORDIC ist, dass die
Ergebnisse ziemlich verrauscht sind.
Johann L. schrieb:> Jürgen S. schrieb:
Außerdem hat CORDIC wohl kaum diesen hübschen
> Fehlerverlauf, sondern meine Erfahrung mit CORDIC ist, dass die> Ergebnisse ziemlich verrauscht sind.https://www.mikrocontroller.net/attachment/431573/atan_02.png
Ich verwende CORDIC mit 63-bit. Nach 32 Iterationen kann ich das
Ergebniss direkt ausrechnen. Hintergrund dazu. Nach der Hälfte der
Iterationen ändert sich der Radius nicht mehr. Das nennt man
Nano-Stepping.
Jens G. schrieb:> Johann L. schrieb:>> Außerdem hat CORDIC wohl kaum diesen hübschen>> Fehlerverlauf, sondern meine Erfahrung mit CORDIC ist, dass die>> Ergebnisse ziemlich verrauscht sind.>> https://www.mikrocontroller.net/attachment/431573/atan_02.png> Ich verwende CORDIC mit 63-bit. Nach 32 Iterationen kann ich das> Ergebniss direkt ausrechnen.
Wenn ich die Heuristik richtig lese, ist das Maximum des absoluten
Fehlers bei 1E-14, d.h. nicht besser als 47 Bits?
Da möchte ich doch nochmal in aller Bescheidenheit auf diese, meine
Implementation des atan in Cordic hinweisen, die mehr als 51 Bit macht:
Beitrag "Atan function implementation"
Cheers
Detlef
Zur Info: Ich habe den relativen Fehler in meiner Grafik. Aber gut,
beinahe jede Funktion meiner "Sammlung" sieht ähnlich aus. Mein
Zahlenformat kann zuverlässig "nur" maximal 31 Bit darstellen.
Johann L. schrieb:> Jens G. schrieb:> Wenn ich die Heuristik richtig lese, ist das Maximum des absoluten> Fehlers bei 1E-14, d.h. nicht besser als 47 Bits?
Ich habe diesen Randgebieten, weniger als "1 von 1000 Berechnungen",
bisher keine Beachtung geschenkt.
Mehr Grafiken auch zu anderen Funktionen findet man hier.
Beitrag "Taschenrechner: ATmega1284p - 15x 7-Segmentdisplay"
Jens G. schrieb:> Johann L. schrieb:>> Jens G. schrieb:>> Wenn ich die Heuristik richtig lese, ist das Maximum des absoluten>> Fehlers bei 1E-14, d.h. nicht besser als 47 Bits?>> Ich habe diesen Randgebieten, weniger als "1 von 1000 Berechnungen",> bisher keine Beachtung geschenkt.
D.h. man muss nur für viele genügend Werte testen, damit der
Maximalfehler untem Teppich landet :o)
> Mehr Grafiken auch zu anderen Funktionen findet man hier.> Beitrag "Taschenrechner: ATmega1284p - 15x 7-Segmentdisplay"
Die Histogramme sagen mir nicht viel; ob die Verteilung von log(Fehler)
eine Normalverteilung ist oder Poisson-verteilt oder eine spezielle
Gamma-Verteilung bringt m.E. keinen Erkenntnisgewinnn.
Die wesentliche Metrik, wenn es um Genauigkeit geht, ist da der maximale
Fehler — je nach Anwendung relativ (wie bei der hier diskutierten
Floating-Point Anwendung) oder absolut. Interessant sind vielleicht
noch Mittelwert oder Median und evtl. noch Quartile wenn man
verschiedene Implementationen miteinander vergleicht.
Wenn man eine Berechnug hat wie z.B. atan(a-b) und wissen will, ob das
Ergebnis einer geforderten Genauigkeit genügt, dann gehen in diese
Betrachtung die Maxmalfehler ein. Dass die Genauigkeit "im
Durchschnitt" oder "meistens" eingehalten wird, reicht da nicht.
Und wenn man die Genauigkeit verbessern will, ist oft zielführend, sich
nen bösen Buben anzuschauen der einen großen Fehler verursacht, um zu
sehen wo es knirscht in der Berechnung.
Anbei ein recht aktueller Plot der auch das Fehlerbild verschiedener
Implementierungen zeigt (Grafiken der 3. Zeile). Die Box-and-Whiskers
Plots dieser Zeile sind so erstellt, dass die Whiskers bis zu den
Extremwerten reichen, d.h. es gibt keine Ausreißer jenseits der Whisker
(im Gegensatz zur Ausführungszeit, wo Ausreißer (z.B. bei Input 0 oder
NaN) nicht wirklich interessieren). Die Boxen umfassen den Bereich vom
25%- bis zum 75%-Quantil, der dicke Strich ist das 50%-Quantil (Median).
Schönes Beispiel sind die Genauigkeiten der sin-Implementierungen:
avr_f64 etwa hat einen sehr guten Mittelwert, aber ein paar Extremwerte
verhageln die Qualität.
Interessanterweise gibt es bereits 4 Implementierungen von atan, die
CORDIC verwenden, aber keine erreicht die Werte der
Polynom-Implementierung (f7_t bzw. f7), was dan auch deine Frage von
oben beantwortet:
Jens G. schrieb:> Zwischenfrage: Weshalb werden hier Näherungsreihen so wesentlich> diskutiert. Ich würde CORDIC verwenden um an das Ziel zu kommen. Ein zu> hoher RAM-Verbrauch? .. Eine zu hohe Rechenzeit?
avr_f64: Genauigkeit ist seht gut, aber Ausführungszeit ca 50% länger,
Codegröße ca 100% mehr.
fp64lib: Genauigkeit ca. 7 Bits schlechter; Codegröße und
Ausführungszeit etwa gleich. Uwe arbeitet an besserer Genauigkeit, die
i.W. durch 64-Bit Fixpunkt-Arithmetik begrenzt ist. Ausführungszeit und
Codegröße werden aber steigen, und Uwe zieht in Betracht, komplett auf
Polynome umzusteigen (dann auch für sin, asin, etc.).
Taschenrechner ATmega1284p: Design-Ziel ist nicht mehr als 31 Bits
Genauigkeit.
Implementierung von Detlef: Genauigkeit wird limitiert durch 64-Bit
Fixed-Point, d.h. Problem ähnlich wie bei fp64lib: In der Nähe von
Nullstellen kann die für double erforderliche relative Genauigkeit nicht
erreicht werden. Codegröße und Ausführungszeit hab ich mir nicht
angeschaut.
Johann L. schrieb:> Taschenrechner ATmega1284p: Design-Ziel ist nicht mehr als 31 Bits> Genauigkeit.
Besten Dank für die Zusammenfassung der Unterschiede. Mein verwendetes
Zahlenformat hat offensichtlich die Eigenschaft einen statistischen
Fehler nach oben (genauer, etwa +2 Dezimalstellen) oder nach unten
(ungenau, etwa -4 Dezimalstellen) zu haben.
In meiner Anwendnung ist es ein Vorteil. Mit einem Byte mehr als double
(8 Byte - "54 bit in der Mantisse") erreiche ich eine etwas höhere
Grundgenauigkeit von etwa "61 bit in der Mantisse" .. mit etwas mehr
statistischen Fehlern.
Mit welchem Programm wurden die Statistiken erzeugt?
Jens G. schrieb:> Johann L. schrieb:>> Taschenrechner ATmega1284p: Design-Ziel ist nicht mehr als 31 Bits>> Genauigkeit.> Besten Dank für die Zusammenfassung der Unterschiede. Mein verwendetes> Zahlenformat hat offensichtlich die Eigenschaft einen statistischen> Fehler nach oben (genauer, etwa +2 Dezimalstellen) oder nach unten> (ungenau, etwa -4 Dezimalstellen) zu haben.
Das Zahlenformat? Oder die verwendeten Algorithmen?
> In meiner Anwendnung ist es ein Vorteil.
???
Wieso ist Rauschen ein Vorteil?
> Mit welchem Programm wurden die Statistiken erzeugt?
Das Programm ist in C/C++ und wird simuliert mit avrtest. Auf dem PC
bestimmt dann ein Python-Skript die Genauigkeiten der Ergebnisse und
erzeugt eine Tabelle, die dann von R gelesen und dargestellt wird.
Leider ist R ziemlich langsam und ein Flaschenhals, so dass es nicht
praktikabel ist, größere Stickproben zu nehmen. Liegt aber vermutlich
daran, dass ich irgendein Anti-Pattern verwende. Mit den R Interna bin
ich nicht vertraut.
Johann L. schrieb:> Jens G. schrieb:> Wieso ist Rauschen ein Vorteil?
Weil im Ergebniss auch in die richtige Richtung gerundet wird.
Beispiel: asind( acosd( atand( tand( cosd( sind(9)))))) - 9 = 0
> Das Zahlenformat?
Mantisse: Zähler_31_bit / Nenner_31_bit + expo_7_bit
Die Mantisse hat den Bereich 0,3..3,0
Hier eine Idee - Bereichsreduktion: arctan (x) = arctan(c) + arctan((x -
c) / (1 + x*c))
Mit c=-1/3, c=0, und c=1/3 lässt sich der Bereich zur Berechnung auf
0,3..0,7 eingrenzen, und damit sind in meinem Fall auch die Fehler
größer 1e-15 weg.
Hi, bin mir nicht sicher, ob ich was Erhellendes sagen kann. Als
"Forthler" rechne ich "eh" mit Ganzzahlen, egal wie skaliert. Und wenn
ich einen ARCT berechnen muß, dann mache ich das nach Anforderung. Mir
ist klar, dass das nicht euer Ansatz ist, aber warum für jede Anwendung
immer das Optimum bereitstellen??
Klar, nicht jeder möchte ARCT aktuell in seiner Anwendung jeweils neu
berechnen...aber dennoch...
Gruß Rainer und ich habe mit Respekt und Vergnügen mitgelesen!
Jens G. schrieb:> Johann L. schrieb:>> Jens G. schrieb:>> Wieso ist Rauschen ein Vorteil?> Weil im Ergebniss auch in die richtige Richtung gerundet wird.> Beispiel: asind( acosd( atand( tand( cosd( sind(9)))))) - 9 = 0
Also asind(...) = 9.
Für asin verwende ich wie üblich den Hauptwert, d.h. asin in [-pi/2,
pi/2].
Oder rechnest du in Altgrad?
mit x = 9*pi/180 und y = asin(acos(atan(tan(cos(sin(x))))))
bekomme ich |x - y| ~ 1.18e-16 ~ 2^{-53} bei 56-Bit Mantisse für diese
9 Operationen (inclusive *, /, -).
Wie gesagt ist mein Ziel einen möglichst kleinen Maximalfehler zu
erreichen. Ob eine singuläre Berechnung mathematisch exakt ist, ist
weder kein Design-Zeil noch Design-Kriterium. Interessant wäre so eine
Berechnung dann, wenn sie den etablieren Maximalfehler überschreiten
würde: dann wäre es ein Testfall, anhand dessen die Algorithmen
verbessert werden könnten.
Hier zeigt sich ein weiterer Vorteil von MiniMax: Die erhaltenen
Polynome bzw. rationalen Funktionen haben bekannten Abstand (in der
Maximumsnorm) von den zu approximierenden Funktionen. D.h. egal für
welchen Wert approximiert wird, der Maximalfehler ist nie größer als
durch den MiniMax-Algorithmus bestimmt. Die einzige verbleibende Quelle
für Genauigkeitsverlust ist die verwendete Grundarithmetik (+, -, *, /)
und im Falle von asin und acos ggf. noch Quadratwurzel.
>> Das Zahlenformat?> Mantisse: Zähler_31_bit / Nenner_31_bit + expo_7_bit> Die Mantisse hat den Bereich 0,3..3,0
Also ein Float, der (effektiv) noch durch eine ganze Zahl geteilt wird?
Was bringt das? Nicht-eindeutige Zahlenformate sind doch lästig bei
Vergleichen, und man vergeudet Darstellungen:
a / b = n·a / n·b
a / b · 2^n = 2a / b · 2^{n-1} = a / (2b) · 2^{n+1} etc.
> Hier eine Idee - Bereichsreduktion: arctan (x) = arctan(c) + arctan((x -> c) / (1 + x*c))>> Mit c=-1/3, c=0, und c=1/3 lässt sich der Bereich zur Berechnung auf> 0,3..0,7 eingrenzen, und damit sind in meinem Fall auch die Fehler> größer 1e-15 weg.
Mit 2-maliger Reduktion kommt man bis auf |x| <= 2-sqrt3 < 0.268
Beitrag "Re: Näherung für ArcusTangens?"
Bringt in meinem Falle aber kein Vorteil gegenüber 1-maliger Reduktion
auf 0 <= x <= 1:
Beitrag "Re: Näherung für ArcusTangens?"
Johann L. schrieb:> Jens G. schrieb:> mit x = 9*pi/180 und y = asin(acos(atan(tan(cos(sin(x))))))>> bekomme ich |x - y| ~ 1.18e-16 ~ 2^{-53} bei 56-Bit Mantisse für diese> 9 Operationen (inclusive *, /, -).
Das ist ein sehr guter Wert. Wesentlich besser als es die Routinen in
"C" sind. Excel bekommt bei diesem Test eine schlechte Note.
|x - y| ~ 5.39e-10
Hier gibt es noch einen Algorithmus mit (4,4). Wertebereich 0..0,66. Das
lässt sich leicht umrechnen.
https://golang.org/src/math/atan.go
Es sind in diesem Dokument noch Verweise zu "C"-Quellen.
CORDIC ist genauer als ihr Ruf - Ich habe mein Algorithmus mal direkt
getestet. Nach 32 von 63 Iterationen berechne ich direkt das Ergebniss.
Hinweis dazu: Nach 32 Iterationen ändert sich der Radius nicht mehr.
Jens G. schrieb:> Hintergrund der Berechnung von .. asind( acosd( atand( tand( cosd(> sind(9)))))) - 9> .. ist die "Calculator Forensik":> http://www.rskey.org/~mwsebastian/miscprj/forensics.htm
Nach Umwandlung in Altgrad liefert mein Algorithmus
9.000000000000006661338147750939242541790008544921875
= 9 + 15·2^{-51}
= 0x9.000000000001e
Was sagt mir das?
Jens G. schrieb:> CORDIC ist genauer als ihr Ruf - Ich habe mein Algorithmus mal direkt> getestet. Nach 32 von 63 Iterationen berechne ich direkt das Ergebnis.
Also auf 58 Bit genau, was man von CORDIC erwarten würde: 63-ld(32) =
58.
Ist die Genauigkeit relativ, d.h. gilt sie so auch für Float?
Johann L. schrieb:> Jens G. schrieb:> 9.000000000000006661338147750939242541790008544921875> = 9 + 15·2^{-51}> = 0x9.000000000001e>> Was sagt mir das?
Hier eine kleine Gegenüberstellung.
1
x = asind( acosd( atand( tand( cosd( sind(9)))))) - 9
2
3
PlanMaker 2018 -3,1247e-08
4
Excel 2013 -1,6732E-10
5
snc98 -2,4181e-11
6
Genie 92SC 3,1389e-13
7
xxx 6,6613e-15
8
Win-98 Calc 3,3056e-32
Bei "normaler Berechnung verliert man über Alles etwa 6-7
Dezimalstellen.
In deiner Rechnung muss irgendwie intern mit höherer Genauigkeit
gerechnet worden sein. ... weil das Ergebniss dem entspricht, was
Float64 hergibt (53-bit).
>> CORDIC ist genauer als ihr Ruf - Ich habe mein Algorithmus mal direkt>> Nach 32 von 63 Iterationen berechne ich direkt das Ergebnis.>> Also auf 58 Bit genau, was man von CORDIC erwarten würde: 63-ld(32) => 58.>> Ist die Genauigkeit relativ, d.h. gilt sie so auch für Float?
Hier die Kommandozeile für x = 0,7500.
Die Implementierung hab ich vorerst mal abgeschlossen, für atan wird wie
gesagt [6/6] MiniMax in [0,1] verwendet.
Zur Integration hab ein paar Makefile-Schnipsel und Wrapper drum gemacht
und alles in die libgcc eingebaut. Wer's ausprobieren möchte:
https://sourceforge.net/projects/mobilechessboar/files/avr-gcc%20snapshots%20%28Win32%29/avr-gcc-10.0.0_2019-12-16_-mingw32.zip/download
ist ein ZIP mit avr-gcc.exe für Windos. Es braucht nichts installiert
werden, einfach ZIP auspacken und ./bin-Verzeichnis zu PATH hinuifügen,
oder avr-gcc / avr-g++ per absolutem Pfad aufrufen. Das Verzeichnis
kann nach dem Auspacken verschoben oder umbenannt werden.
Es gibt 2 neue Optionen
-mlong-double=32/64 (default: 64)
-mdouble=32/64 (default: 32)
so dass das Layout von (long) double zur Compilezeit gewählt werden
kann.
Wer sich die Toolchain selbst aus den Quellen generieren will, zum
Beispiel für Linux:
1) ZIP runterladen und auspacken.
2) Patches aus ./patch auf die Quellen von GCC trunk bzw. avr-libc trunk
anwenden.
3) Executables x-Flag setzen für:
./libgcc/config/avr/libf7/f7renames.sh (gcc)
./libgcc/config/avr/libf7/f7wraps.sh (gcc)
./devtools/mlib-gen.py (avr-libc)
4) Tools wie üblich aus den Quellen generieren.
Der double-Support ist unvollständig, es fehlen: lround, lrint, atan2,
Gamma- und Besselfunktionen. Außerdem gibt es keine
Konvertierungsfunktionen von / nach String für 64-Bit Floats.
Der Support von 64-Bit Floats in der avr-libc beschränkt sich darauf,
dass math.h korrekte Prototypen hat, keine double Aliase für 64-Bit
double definiert werden, es Multilib-Varianten für double = 64 und long
double = 32 gibt, und xprintf für 64-Bit Floats 8 Bytes überliest (und
"?" ausgibt).
Ausgabe von 64-Bit Floats wird im avrtest Core-Simulator unterstützt,
und zwar für double (LOG_DOUBLE), long double (LOG_LDOUBLE), sowie für
uint64_t, dessen Bits als 64-Bit IEEE 754 double interpretiert werden
(LOG_D64: 11-Bit Exponent, 52-Bit reduzierte Mantisse, little Endian).
https://sourceforge.net/p/winavr/code/HEAD/tree/trunk/avrtest/
avrtest kann also auch mit avr-Tools verwendet werden, die keinen
nativen 64-Bit Float support haben. Zum Beispiel mit Uwes fp64lib oder
mit Detlefs Implementierung von
Beitrag "64 Bit float Emulator in C, IEEE754 compatibel"
Schau an: Es gibt doch noch produktive und brauchbare Beiträge hier!
Eine Frage hätte ich:
Jens G. schrieb:> CORDIC ist genauer als ihr Ruf
Cordic kann beliebig genau sein, wenn man die hinterlegte Tabelle
entsprechend umfangreich macht. Die Frage wäre aber, wie es mit dem
Zeitbedarf und dem Aufwand aussieht. Wie würdest du deine Methode
gegenüber der üblichen Cordic-Leistung / Geschwindigkeit einschätzen?
Markus W. schrieb:> Jens G. schrieb:>> CORDIC ist genauer als ihr Ruf> Cordic kann beliebig genau sein, wenn man die hinterlegte Tabelle> entsprechend umfangreich macht. Die Frage wäre aber, wie es mit dem> Zeitbedarf und dem Aufwand aussieht. Wie würdest du deine Methode> gegenüber der üblichen Cordic-Leistung / Geschwindigkeit einschätzen?
Interessant ist natürlich auch der Vergleich mit anderen Methoden, zum
Beispiel mit rationalen Funktionen.
Meine Implementierung von atan mit Float-Darstellung mit 56-Bit Mantisse
hat eine Worst-Case Genauigkeit von etwa 55 Bits relativ.
Berechnung dauert ca. 20000 Ticks, das entspricht ca. 1.7 ms bei 12MHz
(20000 / 12000000).
Jens G. schrieb:> Zur Zeit verwende ich CORDIC "nur" im Rotationsmodus für jede> Winkelfunktion: sin, cos, tan, asin, acos, atan. Und das in Radiant> (Vollkreis = 2 x Pi) und Degrees (Vollkreis = 360°). Um eine andere> Funktion verwenden zu können wird der Vollkreis intern auf 1> umgerechnet.>> Die Berechnungen dauert etwa 120ms bei einer 8-bit CPU bei 12Mhz Takt.> Gefühlsmäßig ist das etwas schneller als etwa bei beim TI-30.
Aus der Heuristik ergibt sich eine Worst-Case Genauigkeit von ca. 57
Bits, also 2 Bit besser, allerdings dauert eine Berechnung ca. 120ms
also 0.120 * 12000000 Ticks = 1440000 Ticks. Das wäre über 70 mal
langsamer als mit rationalen Funktionen für 2 zusätzliche Bits an
relativer Genauigkeit.
Bist du sicher, dass es da keinen Messfehler gibt? Dass z.B. Zeiten für
Ausgabe / String-Konvertierung mit gemessen wurden?
Bei mir ist alles dabei. Sring-Konvertierung zur Ausgabe an die serielle
Schnittstelle, ein Betriebssystem auf Basis von Arduino und die interne
Umrechnung auf mein verwendetes Zahlenformat (Continued Fraction).
Wie man mit professionellen Werkzeugen umgeht - um diese Ticks zu
messen, ist mir völlig unbekannt. Mein Vorschlag - meinen Quelltext
holen und selber prüfen.
Die Tastatur wird abgefragt, die LED werden angesteuert, und es gibt ein
Interrupt 3800 mal in der Sekunde.
Damit ich auf die hohe Grundgenauigkeit komme, muss bei der
Zahleneingabe zu CORDIC mit höherer Genauigkeit gerechnet werden. In
meiner Arithmetic war eine Multiplikation mit einem Zwischenergebniss
von 96-bit dabei.
http://www.naughter.com/int96.html
Besten Dank Johann. Super Arbeit.
@Jens.
Die einfachste Methode die Ticks zu messen waere mit einem Oszilloskop
oder Zaehler. Vorher einen Pin wackeln und nachher wieder. Moderne
Zaehler koennen gleich ein Histogramm von Zeitdauern anzeigen.
Joggel E. schrieb:> @Jens.> Die einfachste Methode die Ticks zu messen waere mit einem Oszilloskop> oder Zaehler. Vorher einen Pin wackeln und nachher wieder. Moderne> Zaehler koennen gleich ein Histogramm von Zeitdauern anzeigen.
Die Rechenzeit kann ich bei Arduino bestimmen und auch ausgeben.
Der Messfehler ergibt sich aus der Umwandlung der Rational_64bit auf
Rational_32bit. Da gibt es erhebliche Streuung in der Rechenzeit -- ist
jetzt nicht Thema hier bei diesem Thread.
Bitte hier nachschauen:
Beitrag "Re: Taschenrechner: ATmega1284p - 15x 7-Segmentdisplay"
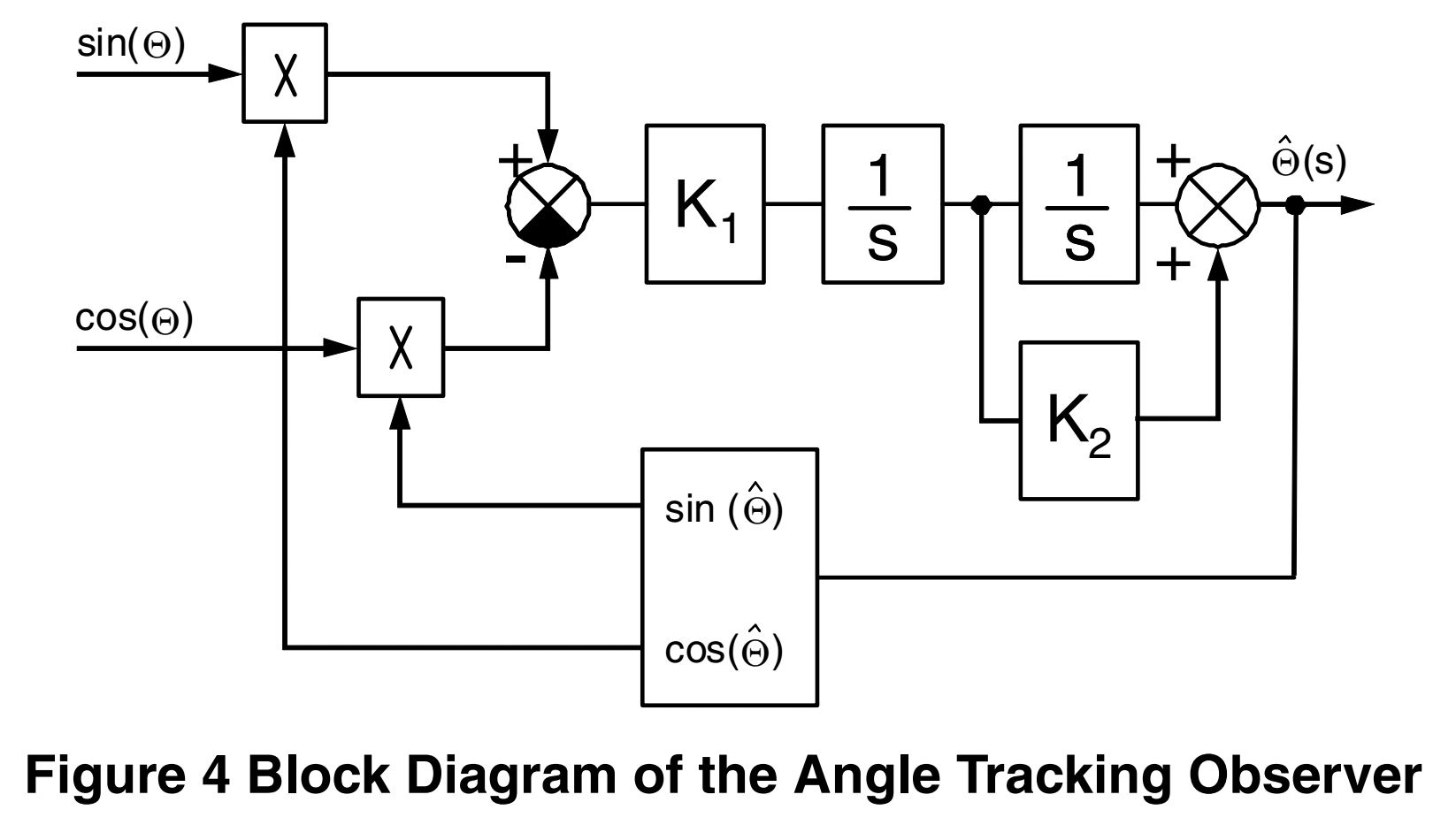
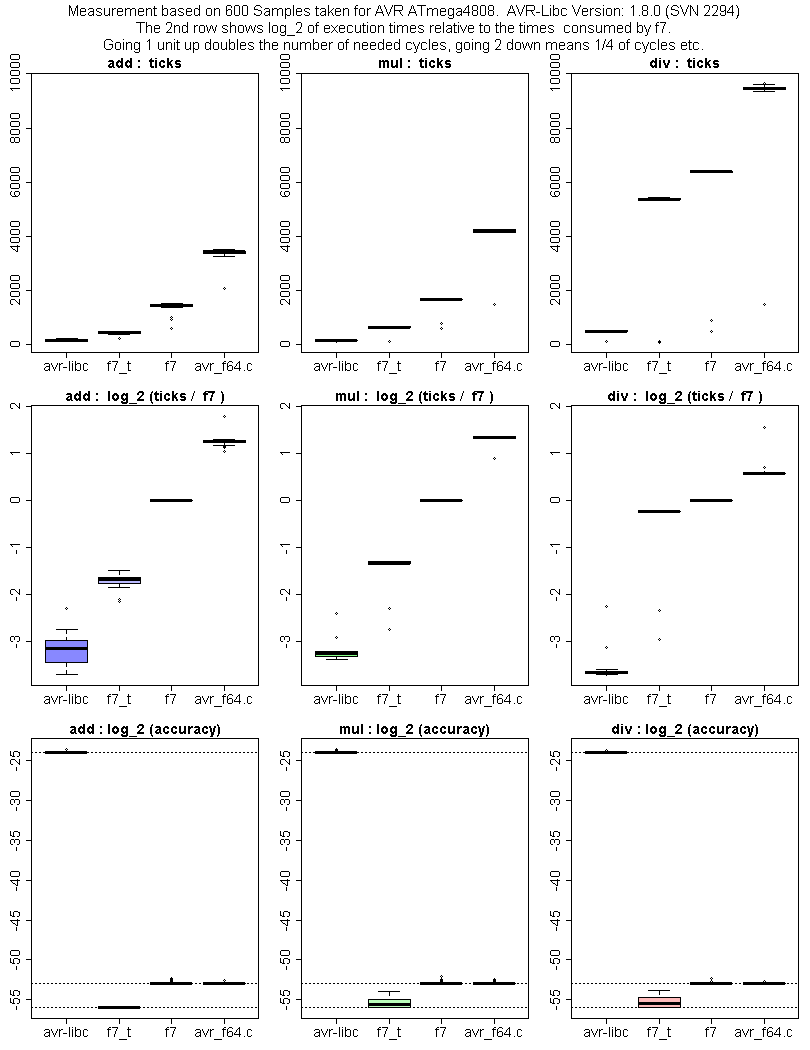
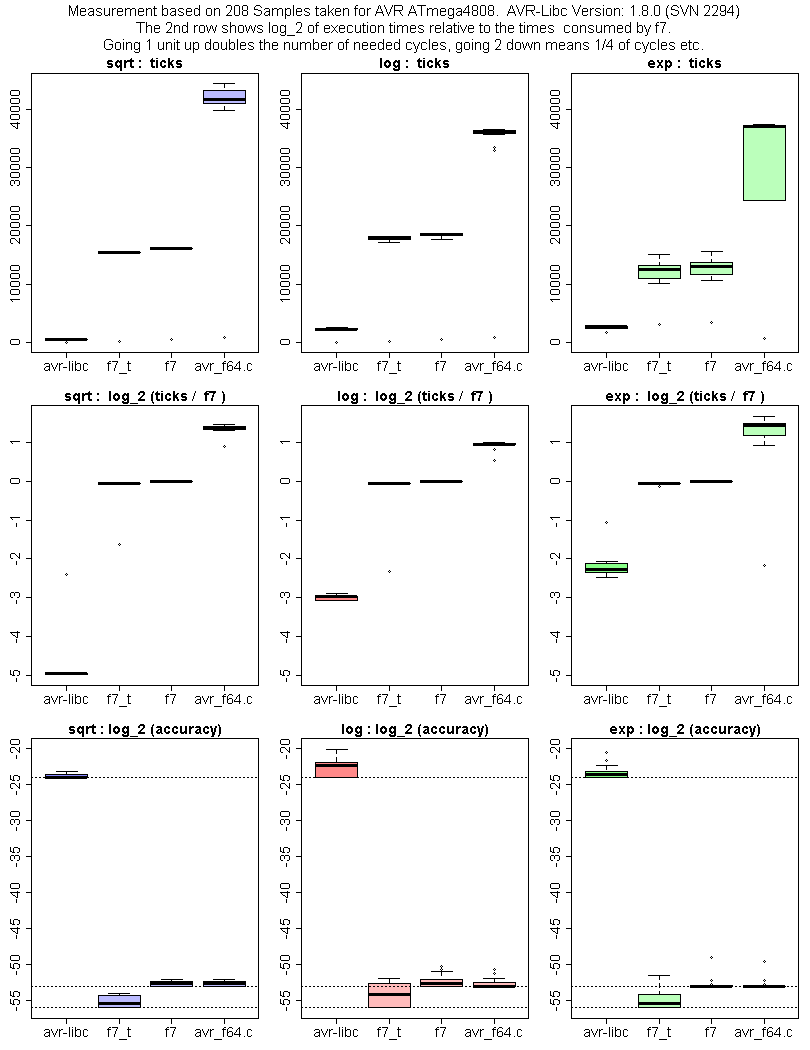
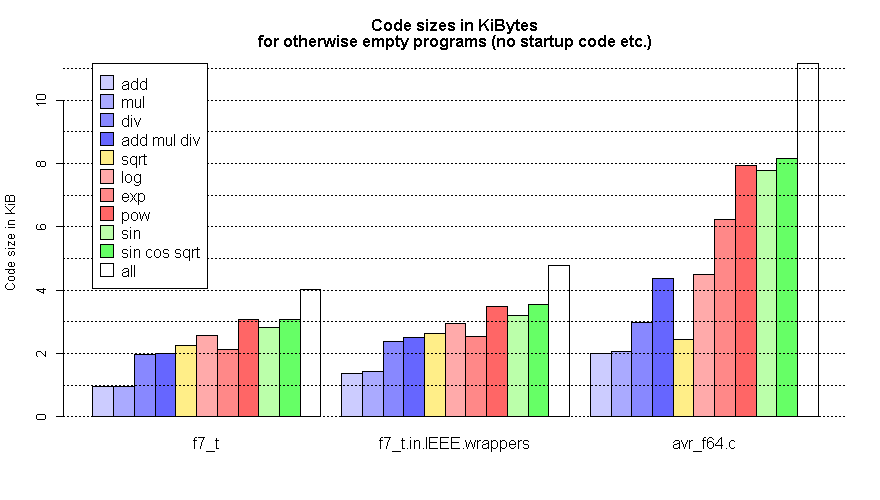
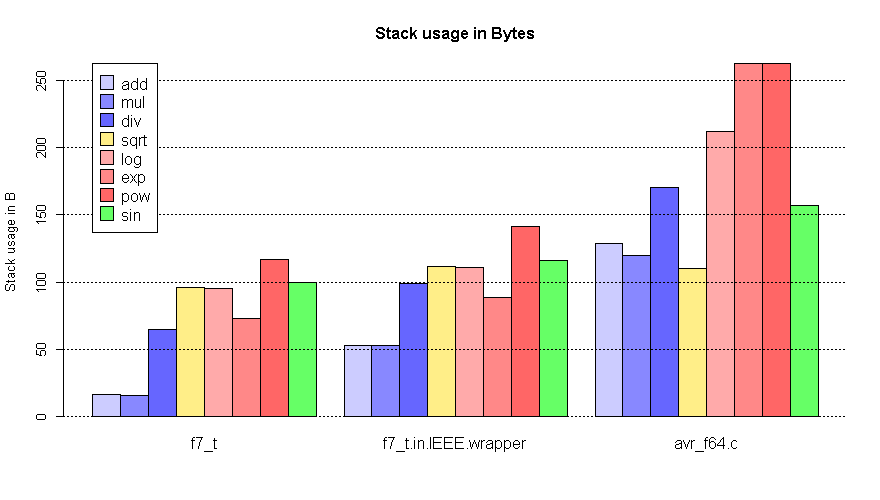
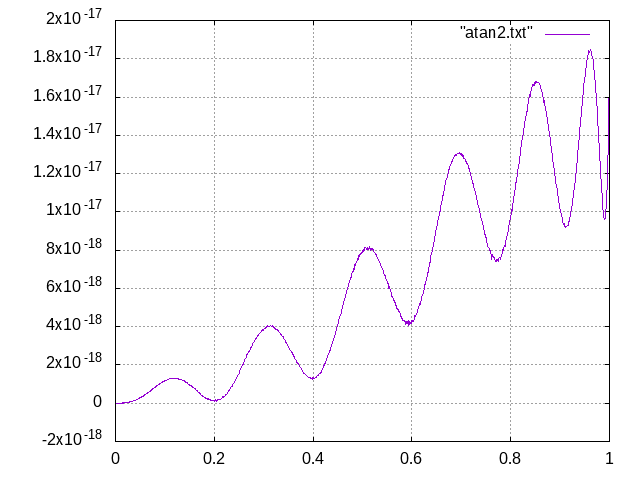
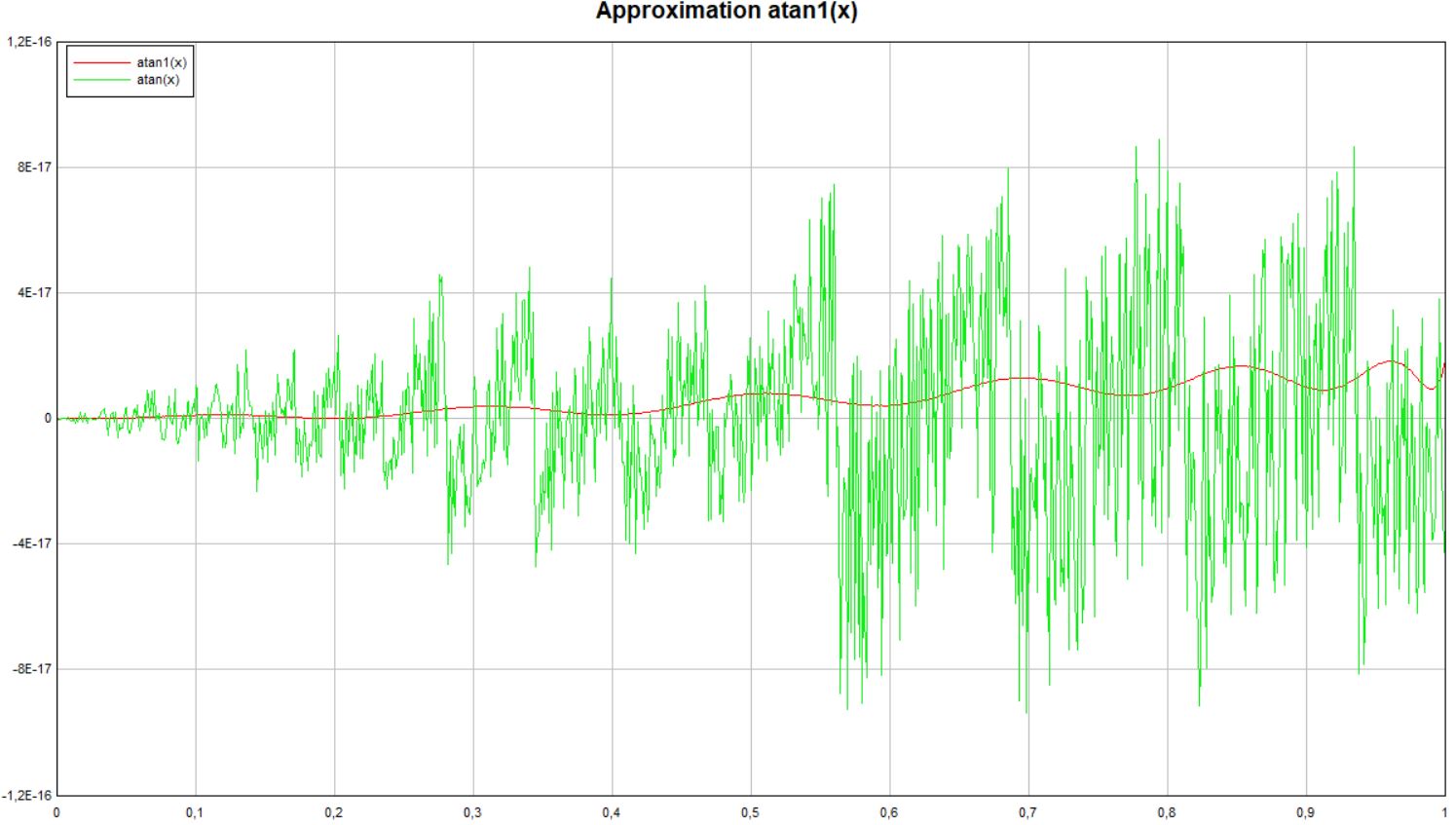
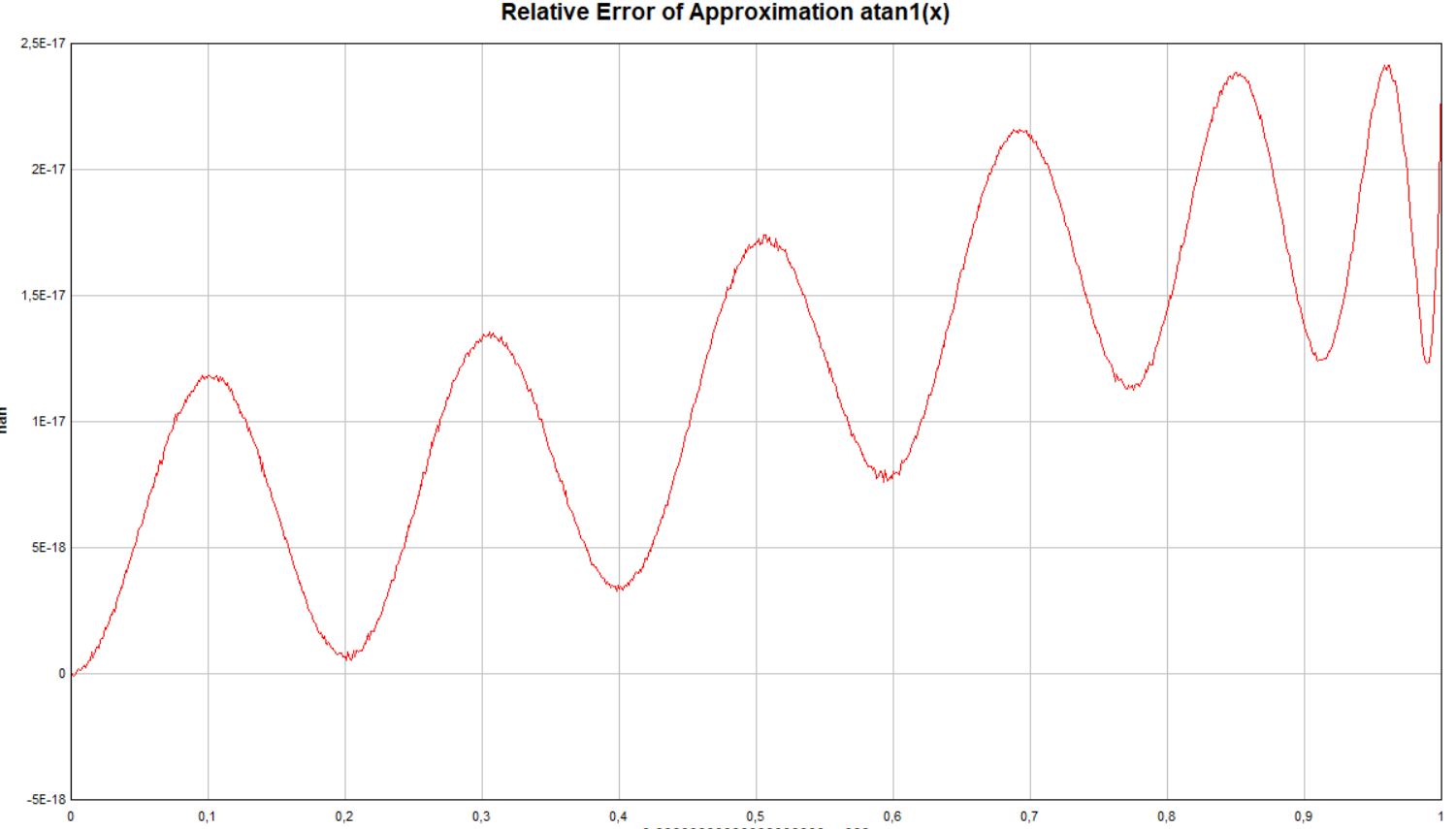
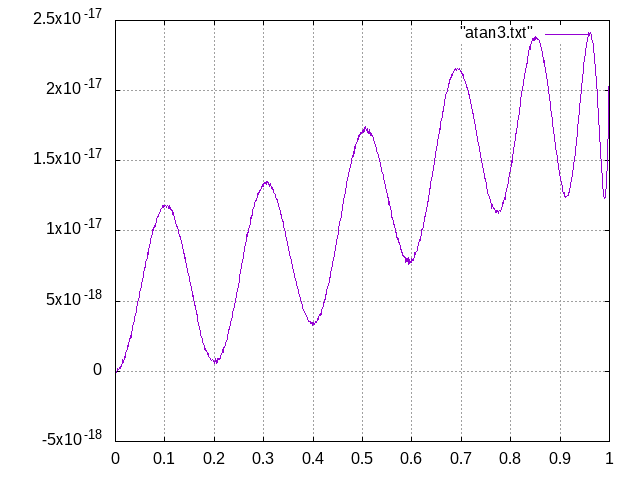
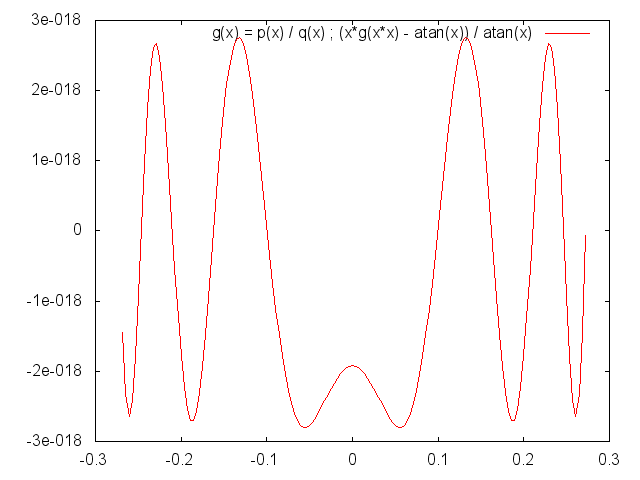
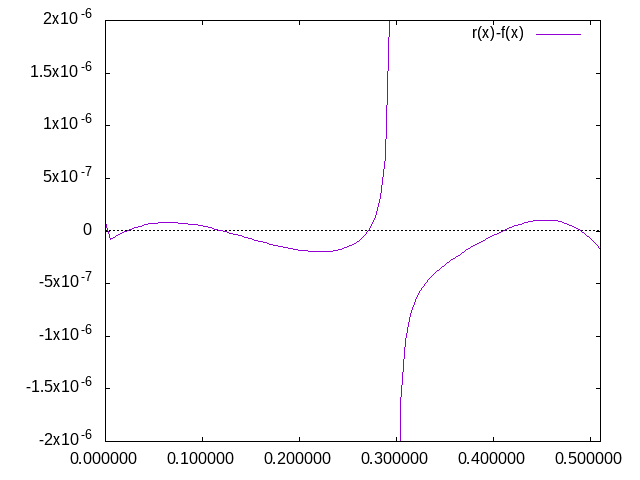
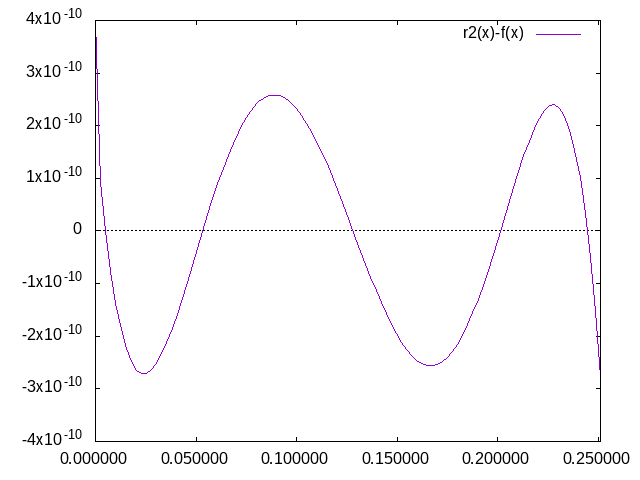
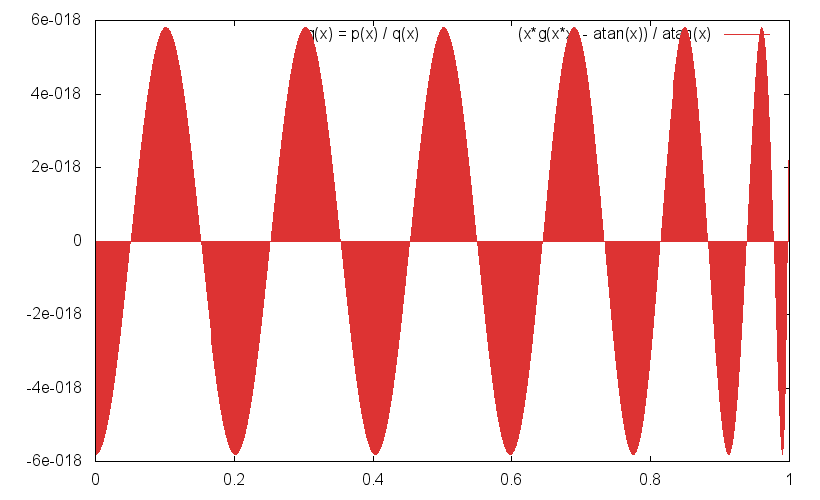
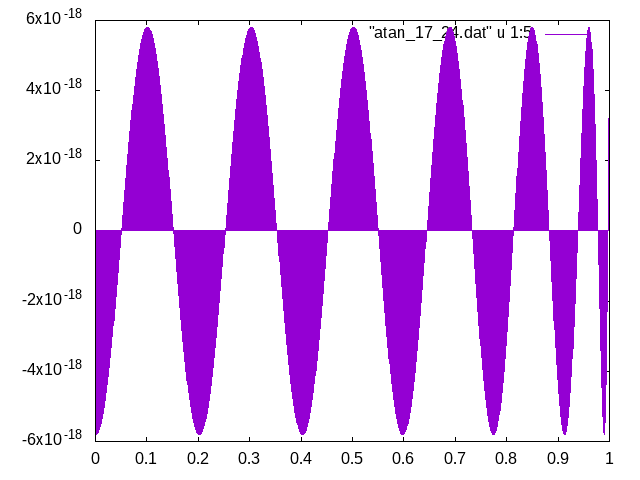
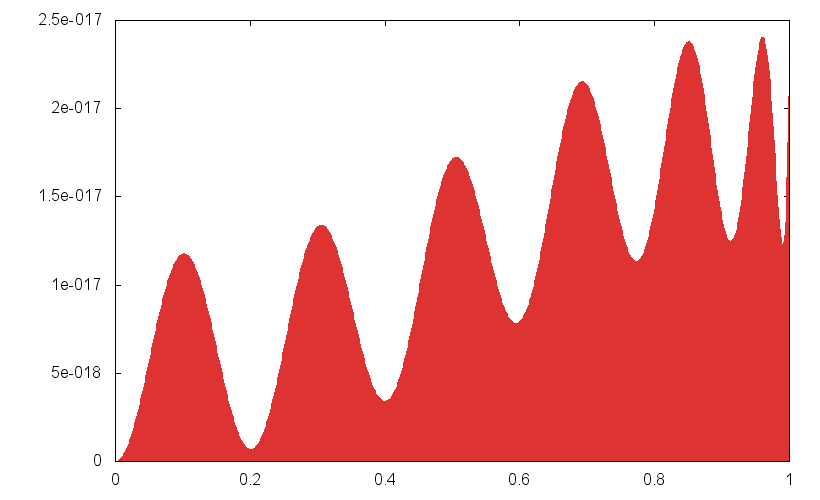
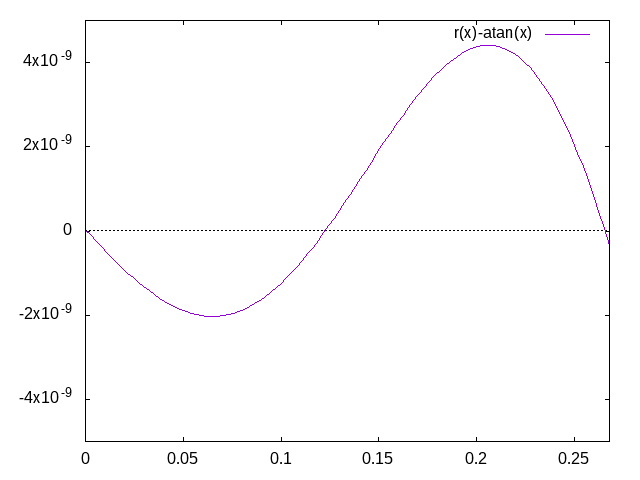
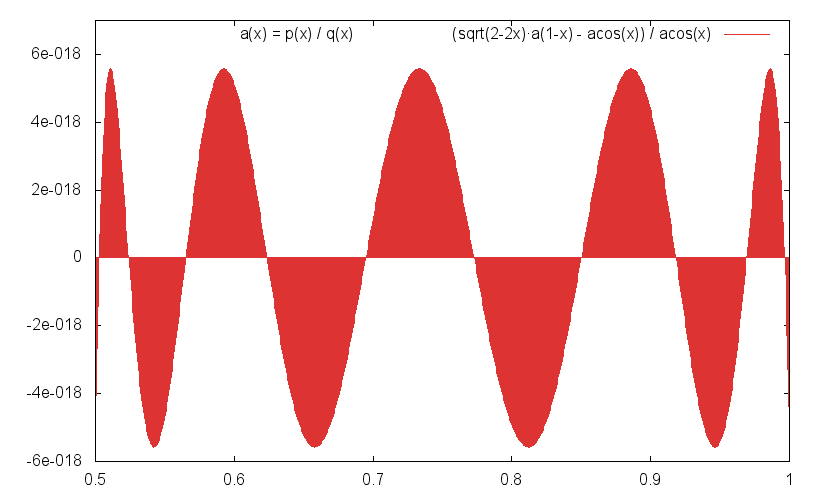
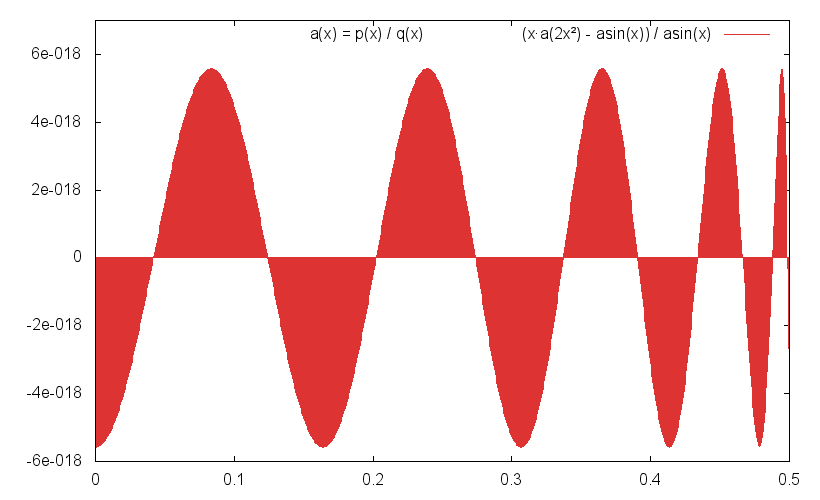
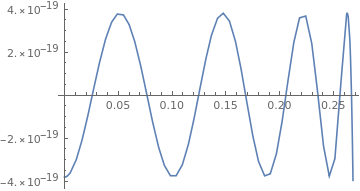
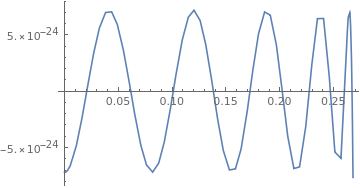
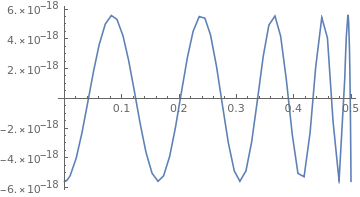
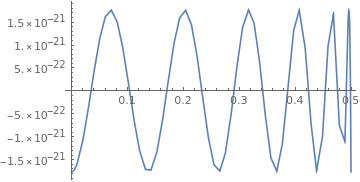
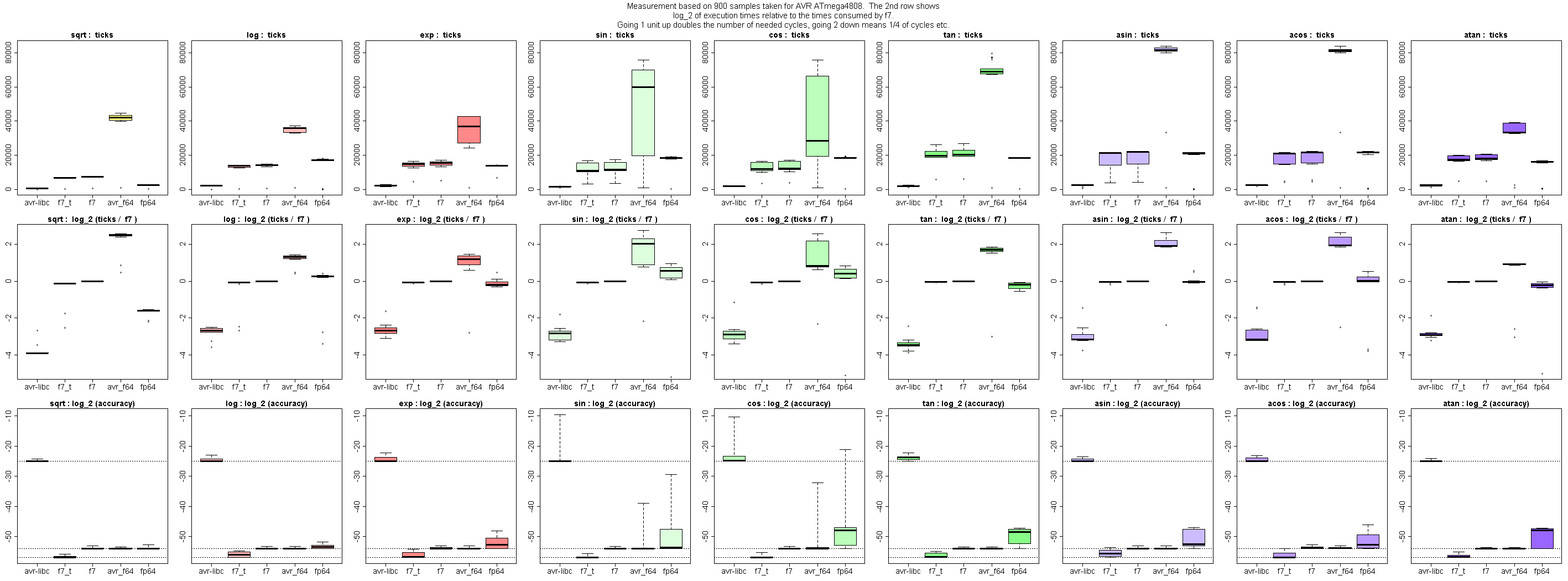
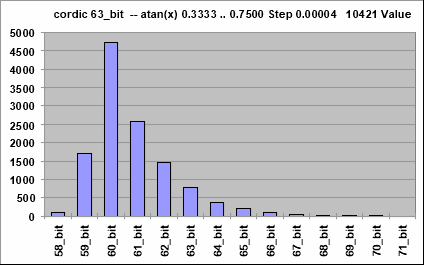
{kind=link}
{kind=link}
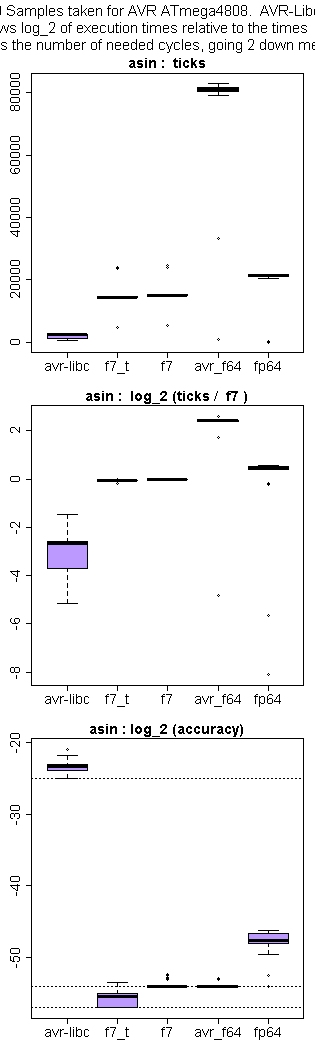{kind=link}
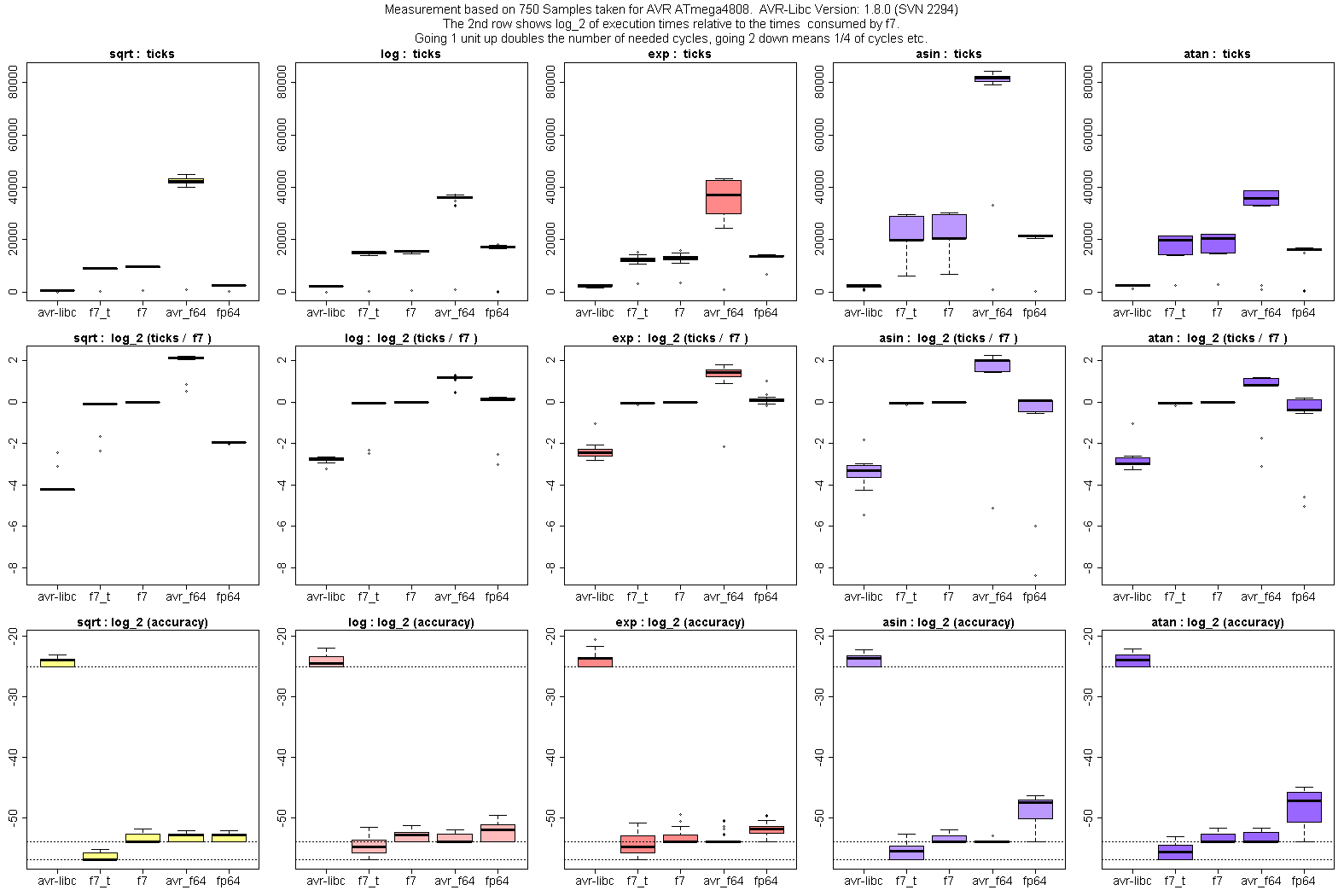{kind=link}
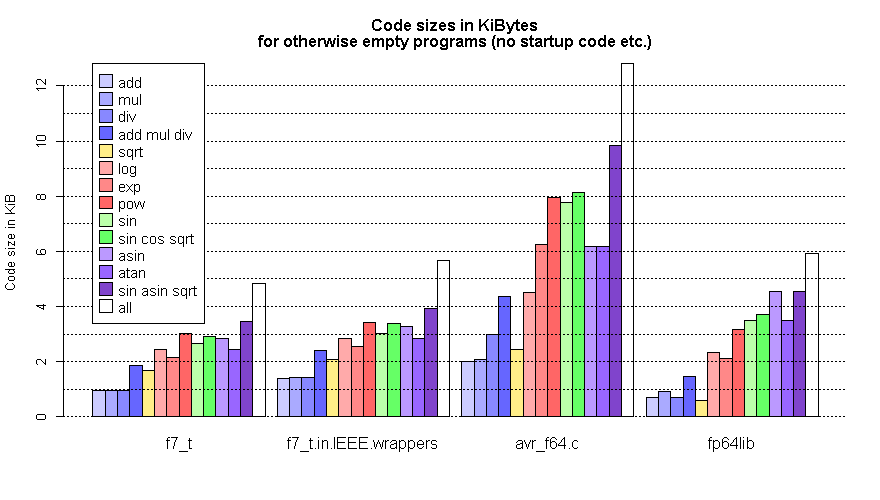{kind=link}
{kind=link}
{kind=link}