Hallo zusammen, ich bräuchte eure Hilfe, ich komme gerade nicht weiter. Ich spiele wieder mit meinem Evalboard herum. Ich möchte eine MAC Einheit bauen um ein Skalarprodukt zu berechnen. Die Werte für die Multiplikation kommen von Input und Konstanten aus einem RAM. Die Eingangswerte korrekt einspeisen funktioniert richtig. Ich verwende einen Multiplizierer und einen Addierer. Beide Cores habe (zugunsten höherer Durchgangsgeschwindigkeit) eine Latency von 6 Takten. Ich habe den Multiplizierer und den Addierer hintereinander geschaltet. Ich versuche die Latency zu warten, bevor ich das Ergebnis an den Ausgang übergebe, aber durch die zeitlich verschobenen Ergebnisse ist das Resultat am Ausgang nicht richtig. (Richtig, das ist mein erster Versuch für eine Pipeline Struktur) Die Anwendung sollte mit der Beschreibung auch klar sein, das ist für ein neuronales Netz. Ich hänge euch meine Lösung mit an. Meine Frage ist nun, wie muss ich die Pipeline für den Multiplizierer und den Addierer richtig machen? Grüße, Jens
Was ich sehe ist, dass das ready nicht benutzt wird. Du timest also händisch. Das passt aber nicht nur funktionell- sondern auch technisch nicht, weil das keine echte pipeline ist. Irgendwie hast du da noch eine FSM drüber laufen die auch getaktest ist und es sieht fuer mich so aus, als ob damit timing -Anforderungen entstehen, d.h. es wird nach dem erwarteten Ende der Berechnung sofort ein Ergebnis weitergeschrieben, das noch nicht da ist. So ganz werde ich aus dem Konstrukt eh nicht schlau. Eigentlich schreibt man einfach ein Y = A * B und setzt genügend FFs dahinter, dass es technisch passt. Das Gemurkse mit Adder-Cores ist an der Stelle eigentlich unnötigt.
Hallo Rolf, danke für deine Antwort. Allerdings ist es nicht möglich einfach zu schreiben: Y = A * B. Es müsste heißen Y <= A * B, aber das wird trotzdem nicht funktionieren. Wenn du genau schaust, verwende ich die Cores, da die Berechnungen in Float16 laufen. In einer Signed-Arithmetik würde ich das eh ganz anders machen. Die FSM brauche ich, da hier die Multiplexer versteckt sind, die die Daten zu den richtigen Cores schieben. Durch die Latenz kann ich das nicht durchverdrahten, sonst kommt nur Murks raus. Außerdem fehlt noch die Aktivierungsfunktion und da will ich die beiden Cores nochmal verwenden. Aber wenn die Pipeline bei mir nicht richtig ist, wie geht es denn richtig? Grüße, Jens
1 | Component instance "/Neuron/My_Weight_Memory : Weight_Memory" is not bound. |
2 | Component instance "/Neuron/My_Float_Multiply : Float_Multiply" is not bound. |
3 | Component instance "/Neuron/My_Float_Addition : Float_Addition" is not bound. |
Wäre es möglich die fehlenden Komponenten nachzureichen? Dann könnte ich das in der Simulation evtl. nachvollziehen...
Hallo Rick, klar, die kann ich auch bereitstellen. Allerdings sind Float_Multiply und Float_Addition Cores von Xilinx. Was brauchst du da? Da habe ich ja keine Sourcen. Ich hänge dir den Ordner, den Core Generator anlegt, an. Und ich lege dir die Testbench mit dazu, die ich verwende. Dann hast du für die Simulation ein paar Werte. Zu Weight_Memory: Das ist als Dual-Port Ram gemacht, dass man später von außen an die Werte kommt. Der zweite Port ist noch nicht verbunden. Aber für das Problem hier, ist das kein Thema. Danke dir! Grüße, Jens
Für eine Pipeline brauchst du eigentlich nur ein durchgereichtes Enable-Signal, damit hakt man dann auch allfällige Start/Stop-Bedingungen ab. Wenn du gemultiplext mehrere Datenströme quasi-gleichzeitig durch die Pipe schieben willst, ist eine FSM eher fehl am Platz, da für die einzelnen Stufen ein Zeitversatz des Zustands gelten muss, besser ist ein Slot/Lane-Konzept mit rotierenden Indizes per Pipeline-Stufe. Den Slot-Index nimmst du dann auch für die Adressierung von Koeffizienten in der entsprechenden Stufe. Wenn du an die Sourcen nicht rankommst: Es kann auch fürs Lernen helfen, händisch Dummies zu schreiben (zu lassen), die intern die laufenden Indizes und Latenzen mitführen. Dann kannst du für die finale Verifikation immer noch die erzeugten Netzlisten per "netgen" in HDL umwandeln und gegen dein Dummy co-verifizieren (also feststellen, dass es richtig rechnet). Vordergründig springt mir zumindest bei deinem Code keine Pipeline-Struktur ins Auge. Ich würde mir da eine andere Notation überlegen und gerade bei extern eingeschleiften Cores per Kommentar kennzeichnen, wann ein Resultat gültig ist. Per explizite Ausformulierung oder Skizzierung einer Pipeline auf Häuschenpapier siehst du auch sofort, wo Delays nötig sind und man allenfalls die Resourcen besser nutzen kann.
:
Bearbeitet durch User
Angehängte Dateien:
-

simu.png
44 KB
Jens W. schrieb: > klar, die kann ich auch bereitstellen. Danke. > Allerdings sind Float_Multiply und Float_Addition Cores von Xilinx. Was > brauchst du da? Da habe ich ja keine Sourcen. Da sind doch Sourcen dabei (z.B. Float_Multipy.vhd). Das sind aber nur Wrapper für die XilinxCoreLib. Die ist bei mir vorhanden. Mich wundert nur die vhd-Dateien aus ipcore_dir.rar haben kein ce-Signal, aber in Neuron.vhd wird es mit angesteuert. Außerdem bemängelt Modelsim noch ein paar Kleinigkeiten:
1 | -- Compiling architecture behavior of Neuron_tb |
2 | ** Warning: Neuron_tb.vhd(170): (vcom-1207) An abstract literal and an identifier must have a separator between them. |
3 | ** Warning: Neuron_tb.vhd(172): (vcom-1207) An abstract literal and an identifier must have a separator between them. |
4 | ** Warning: Neuron_tb.vhd(176): (vcom-1207) An abstract literal and an identifier must have a separator between them. |
5 | -- Compiling entity Weight_Memory |
6 | -- Compiling architecture Behavioral of Weight_Memory |
7 | ** Warning: Weight_Memory.vhd(142): (vcom-1074) Non-locally static OTHERS choice is allowed only if it is the only |
8 | choice of the only association. |
Ansonsten ist nach 350 ns Schluß und die Simulation crasht mit:
1 | # ** Fatal: (vsim-3421) Value 10 is out of range 0 to 9. |
2 | # Time: 357500 ps Iteration: 1 Process: /neuron_tb/uut/line__157 File: Neuron.vhd Line: 186 |
Dann würde ich int_execute in der Testbench noch initialisiern:
1 | signal int_execute : std_logic := '0'; |
Damit sieht das ready-Signal etwas besser aus. Wie und wo kann ich in der Simulation Dein Latency-Problem finden?
:
Bearbeitet durch User
Angehängte Dateien:
-

Neuron_Timing.JPG
290 KB
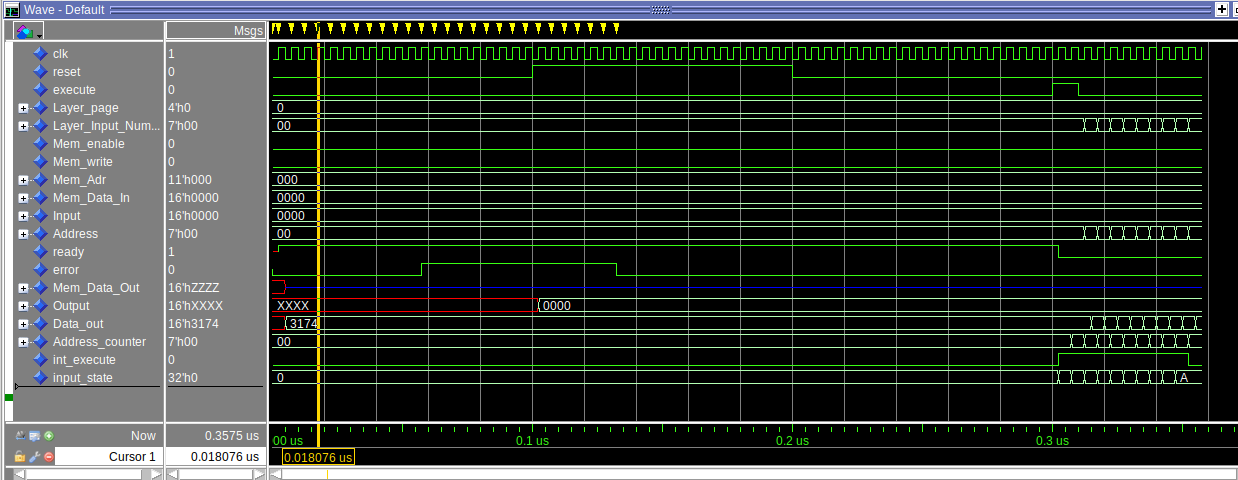
Hallo Rick, danke, dass du dir die Mühe machst. Ich habe dir nochmal das aktuelle File angehängt. Da ist das CE-Signal nicht mehr drin. Ich probiere natürlich weiter und als ich die Cores zusammengepackt habe, war ich schon weiter, als mein Post vom Anfang. Sorry, dafür, das habe ich nicht gemerkt. Ich habe dir noch ein Bild aus meiner Simulation mit angehängt und da kann man das Problem gut erkennen. Rot unterstrichen ist die Latency aus dem Mult-Core. Man kann gut erkennen, dass das erste Ergebnis 6 Takte später geliefert wird. Für die Multiplikation ist das kein Problem, das funktioniert. Blau unterstrichen ist die Latency aus dem Addierer und da ist das Problem. Da das ein Akkumultor sein soll, wird das Ergebnis an den Eingang zurückgeführt. Dabei sollen die Eingangswerte mit dem Ergebnis der Multiplikation jeweils aufaddiert werden. Da die ersten Ergebnisse des Addierers aber erst 6 Takte später zurück kommen (Durchlauf durch den Addierer), werden die ersten 6 Eingangswerte jeweils mit Null addiert. Somit ist das Ergebnis später falsch. Es sind zu wenig Werte addiert (gelber Kasten). Man muss wohl die ersten 6 Eingangswerte in einem kleinen lokalen Speicher festhalten und sie am Ende nochmal auf den Addierer geben. Die Reihenfolge der Werte, die addiert werden sollen, spielt ja keine Rolle. Hauptsache jedes Signal wird addiert. Im aktuellen File ist der Buffer dafür schon angelegt, jedoch bin ich noch am Anfang, dass das Timing passt. Ich möchte das nicht für einen Fall (ein Wert für die Latency) fest codieren, da später die Cores vielleicht angepasst werden und dann mehr oder weniger Latency haben, oder ich mehr Eingänge verwende (und das werde ich), dann möchte ich nicht mehr am Timing fummeln müssen. Ich hoffe das Problem ist damit nochmal deutlicher beschrieben. Grüße, Jens
Ich komme mit der Simulation gar nicht so weit wie Du:
1 | entity Neuron is |
2 | generic
|
3 | (
|
4 | ...
|
5 | INPUTS : integer := 10; --Number of used inputs |
6 | ...
|
7 | );
|
8 | |
9 | architecture Behavioral of Neuron is |
10 | |
11 | ...
|
12 | signal counter : integer range 0 to INPUTS-1; |
13 | ...
|
14 | |
15 | when load => |
16 | ...
|
17 | counter <= counter + 1; |
18 | if(counter = INPUTS) then |
19 | counter <= 0; |
20 | ...
|
21 | end if; |
Warum darf counter nur Werte von 0 bis INPUTS-1 annehmen, wird aber auf INPUTS abgefragt? Und war fällt das in deinem Simulator nicht auf? Abgesehen davon wird die Endbedingung nicht funktionieren, da Signalzuweisungen erst am Ende vom Prozess (und damit hier im nächsten Takt) wirksam werden.
Angehängte Dateien:
Was ich gerne bei solchen Berechnungen mache: ein enable bzw. valid-Signal mit an die Datenleitungen geben. Da kann man 1. in der Simulation sehen, wann die Werte gültig sind und viel wichtiger 2. die nachfolgende Stufe kann dieses Signal verwenden um die eigene Berechnung zu starten Hier scheint es ja für die Multiplikation an sich zu funktionieren. Wenn man bei der Addition aufintegrieren möchte, muß man immer erst fünf Takte auf das Ergebnis warten bevor man die nächste Addition starten kann. Im FPGA laufen die Addition i.d.R. in einem Takt, aber das gilt für Ganzzahlen und nicht für fp-Zahlen. Wenn möglich würde ich intern nur mit Ganzzahlen rechnen und floating-points nur an den Schnittstellen verwenden.
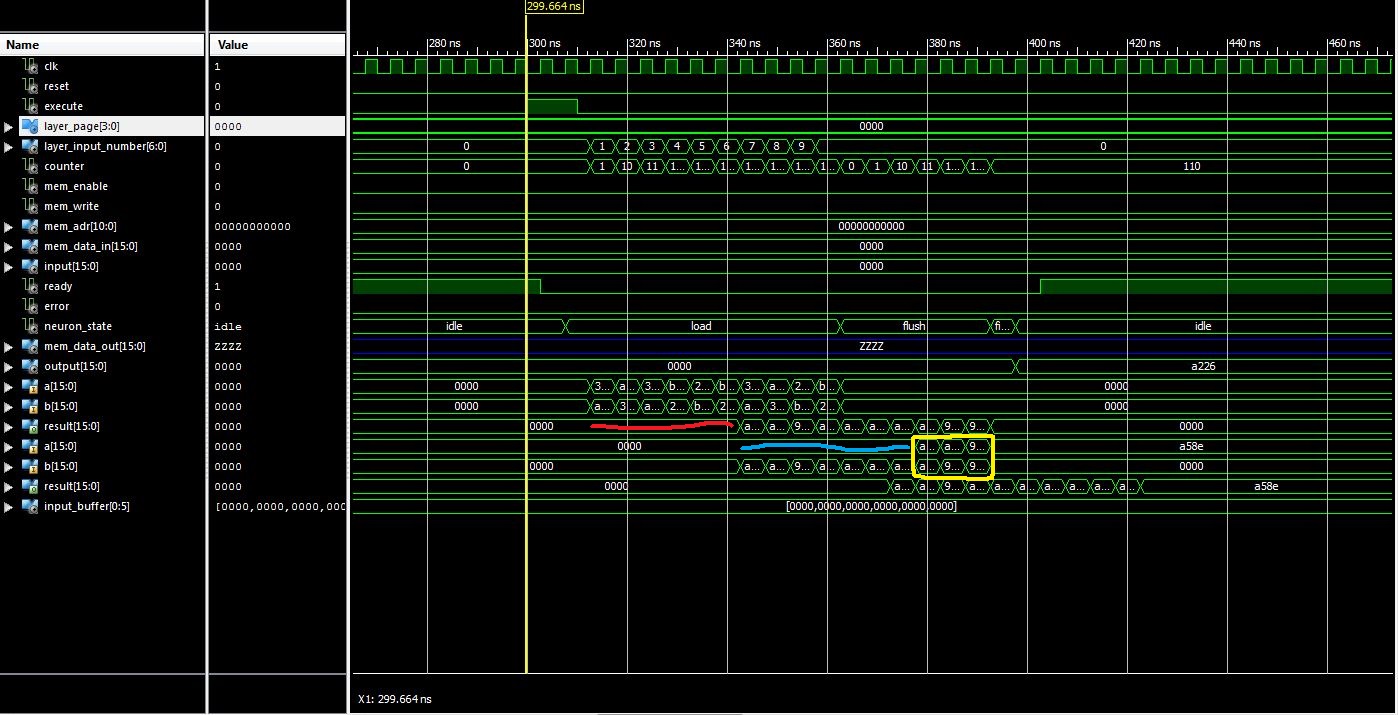
Hallo Rick, da hast du Recht, das ist natürlich falsch. Und wird nicht funktionieren. Warum mein Simulationstool hier deutlich toleranter ist als deines, ist auch sehr interessant. Ich verwende noch ISE14.7 für den alten Kram und den eingebauten Simulator in ISE. Aber am eigentlichen Problem ändert das nichts. Ist zwar falsch, aber mir geht es ja um die Latenz der Cores. In meinem Ansatz ist alles in einen Prozess gequetscht und das macht es schon unübersichtlich. Ich habe nun angefangen das ein bisschen aufzuteilen. Einen Prozess als reiner Counter. Der zählt die Eingänge und die Latenzzeiten durch. Den Timer will ich nun dafür nehmen um die anderen darauf zu synchronisieren. Wie ein enable-Signal im Prinzip. Dann habe ich jeweils einen Prozess für Multiplikation und Addition. Und das funktioniert auch ganz gut. Und der Ansatz, den ich oben schon anpeilte, dass man die ersten Ergebnisse in einem Speicher zwischenzuspeichern, scheint auch das Richtige zu sein. Zusätzlich habe ich die Multiplexer für die Dateneingänge des Addierers auch rausgezogen in eine nebenläufige Select-Anweisung. Das funktioniert besser als im Prozess selbst. Laut Simulation spart man sich hier sogar noch einen Takt. Was mir jetzt noch fehlt ist die zwischengespeicherten Signale noch auf den Addierer zu geben, so dass das Ergebnis wieder stimmt. Ich lade später noch das Source-File dazu hoch, ich bin gerade an einem anderen Rechner. Grüße, Jens
Angehängte Dateien:
-

Neuron_Timing2.JPG
240 KB
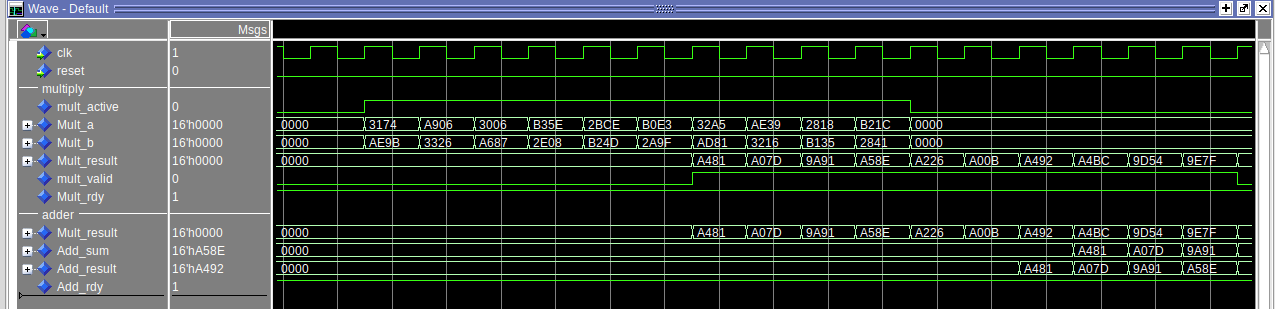
Rick D. schrieb: > Wenn man bei der Addition aufintegrieren möchte, muß man immer erst fünf > Takte auf das Ergebnis warten bevor man die nächste Addition starten > kann. Das stimmt nicht ganz. Man muss bei den Cores, die ich verwende, nicht auf jedes Ergebnis 5 Takte warten. Die Cores haben eine Pipeline. Man bekommt nach der Latenz (hier 6 Takte) das erste Ergebnis und dann mit jedem Takt das nächste. Daher verwende ich die auch, da man so den großen Datendurchsatz bekommt. So sieht es im Moment aus (Anhang). Es ist noch nicht fertig. Durch den Multiplizierer laufen die Daten sauber durch. Die ersten Ergebnisse werden auch im Buffer richtig abgelegt. Das Finish fehlt noch, wo die Werte aus dem Buffer nochmal angehängt werden. Die Signale für die Select-Anweisung sind als Vektoren. Die könnte man kürzen, aber ich weiß noch nicht was ich noch brauche. Kürzen kann ich später, wenn das Timing insgesamt passt. Den Weg, den ich einschlagen will, ist klar. Aber ist das auch der effektivste? Oder übersehe ich was und man kann das ganz elegant machen? Wichtig ist nur: ich möchte nicht von den IP-Cores weggehen. Also ein Umbau auf Integer kommt für mich nicht in Frage. Ich möchte die Berechnungen unbedingt in Float16 behalten. Grüße, Jens
Jens W. schrieb: > Die Cores haben eine Pipeline. Man > bekommt nach der Latenz (hier 6 Takte) das erste Ergebnis und dann mit > jedem Takt das nächste. Richtig. Wenn Du aber die Ergebnisse der Multiplikation aufsummieren möchtest, solltest Du immer erst auf die Zwischensumme warten, bevor der nächste Wert addiert werden kann.
Hallo Rick, ich bin einen Schritt weiter, aber der wirft mich leider weit zurück! Also einfach mit einem Buffer und die Werte nochmal oben drauf und gut ist es, so wird das nichts. Man bekommt ein Ergebnis, das zwar einzelne Eingänge miteinander addiert, aber die echte Summe über alle Werte bekommt man nicht. Dafür müsste man mehrere Durchläufe machen. Ähnlich wie in einem Adder-Tree und dann jede Ebene extra durch den Core quetschen. Dann hätte ich zwar eine hohe Taktrate, aber der effektive Durchsatz ist dann auch nicht so groß, da ich durch die Durchläufe im Addierer, das wieder zu nichte mache. Es gibt einiges an Veröffentlichungen, die sich genau mit diesem Problem beschäftigen. Leider veröffentlichen sie nicht die Lösung als Code... Jetzt weiß ich noch nicht, wie ich weitermache. Ich will noch nicht einsehen, dass der Core so vielleicht nicht einsetzbar ist, für meinen Zweck. Grüße, Jens
Ich würde ja erstmal eine langsame Lösung bauen, bevor ich gar keine Lösung habe...
Jens W. schrieb: > da hast du Recht, das ist natürlich falsch. Und wird nicht > funktionieren. Warum mein Simulationstool hier deutlich toleranter ist > als deines, ist auch sehr interessant. Ich verwende noch ISE14.7 für den > alten Kram und den eingebauten Simulator in ISE. Oergs. isim ist "broken by design", d.h. es hat seit Jahren diverse VHDL-Standardverletzungen mitgeschleppt, damit's irgendwie mit der Legacy funktioniert. Das sorgt dann gern dafuer, dass manche Cores falsch rechnen (das alte signed/resize-Thema). Wenn du portablen sauberen Code entwickeln willst, tust du dir mit GHDL den besseren Gefallen. Sollte auch mit der XilinxCoreLib weitestgehend tun, kann sein, dass man ab ein illegales Statement auf den Standard trimmen muss. IMHO kommt man von dem CoreGen-Geraffel einfach am besten weg, ausser es nutzt strikt numeric_std. Zum Pipelining: Der Knoten steckt offensichtlich in deinem "Akkumulator", den du haendisch aus einem (latenz > 1) behafteten Addierer strickst. Das verletzt das 1-cycle-Akkumulatorprinzip grundsaetzlich :-) Dir bleibt noch: * (N-1) Addierer instanzieren (N = len(vector)). Das ist aber eher ungut: Zuviele Resourcen und allenfalls unnoetige Totzeiten. * Wie schon oben vorgeschlagen die stumpfe float16-Pipeline durch Fixpoint-Arithmetik oder gar vereinfachte rationale Darstellung emulieren, also keine float16-Werte innerhalb der Pipeline nutzen. Spart auch massiv Resourcen und du hast mehr Kontrolle ueber allfaellige Fehlerabschaetzung. Damit schaffst du den 1-cycle-Akkumulator. * Den Datenstrom per Interleaving so zu zerschnipseln und in L Bahnen und entsprechend L Zustaende (slots) deines Akkumulators aufzuteilen, dass du die volle Auslastung erreichst (L = Latenz deiner Verarbeitungs-Stufengruppe) Das wird dann zu einem mehrdimensionalen Problem, wo es wirklich hilft, sich erst mal alles auf Karopapier aufzumalen, bevor du dir gleich eine ganze Latte an potentiellen Stolperfallen im Code schaffst. Skalarprodukt ist 'nur' ein Spezialfall einer Matrixmultiplikation. Dazu gibt es haufenweise Ansaetze und Loesungen im Netz. Die Frage ist immer, wie genau deine Daten reintrudeln, und wie/wann du die Resultate brauchst. Das sind deine Priority 1-Randbedingungen, die du skizzieren solltest, dann machst du dir typischerweise Gedanken zur Serialisierung/Interleaving/Multiplexing der Datenstroeme.
Angehängte Dateien:
-

Neuron_Timing.JPG
300 KB
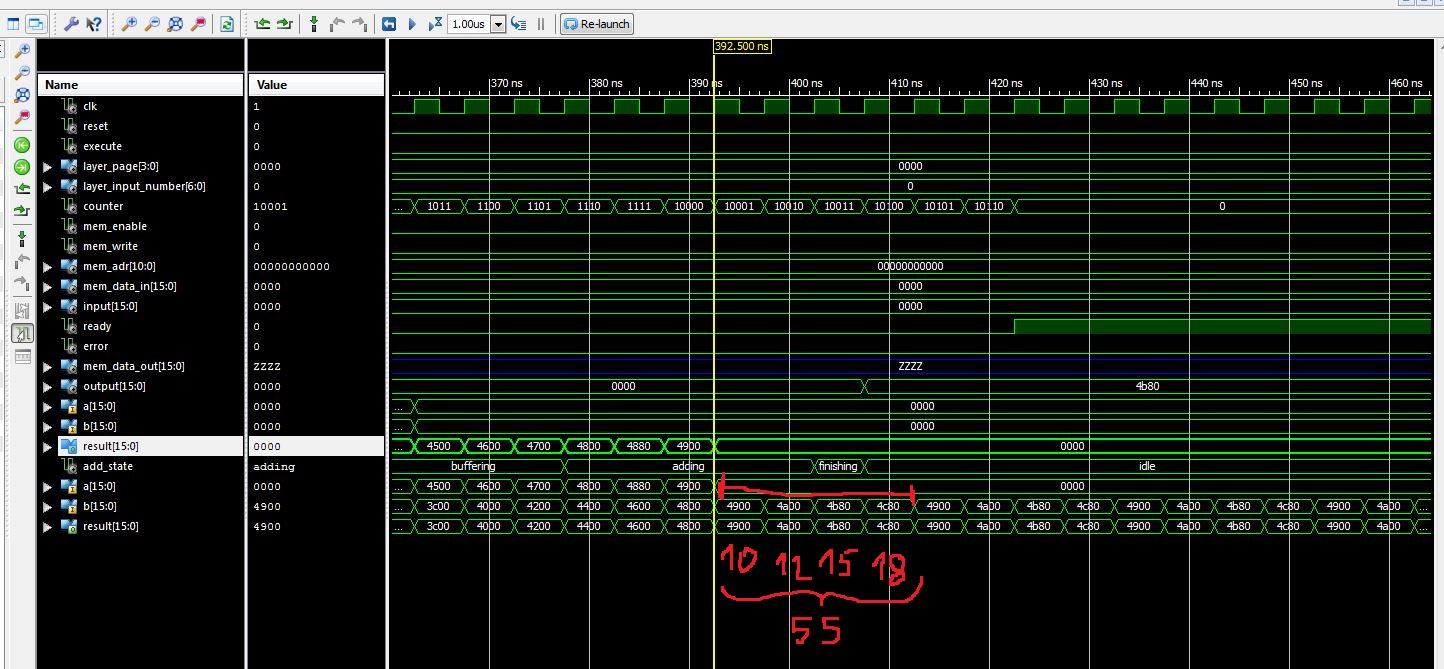
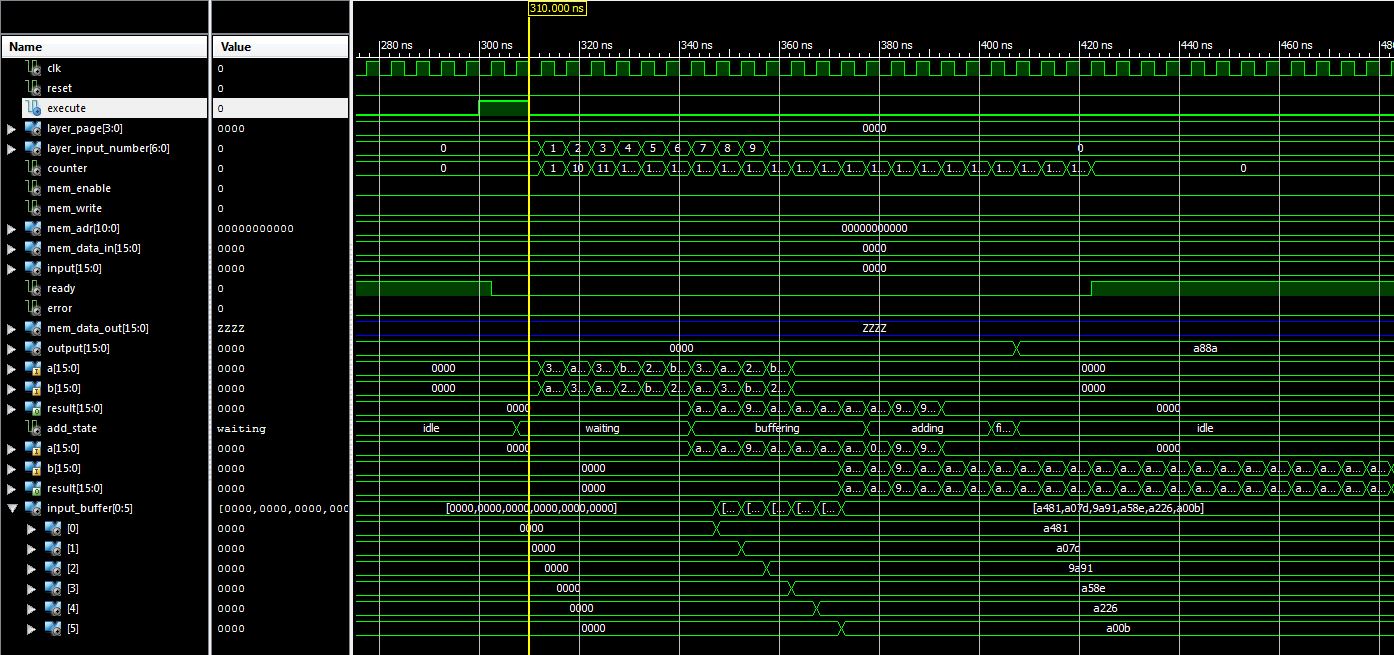
Hallo Martin, du scheinst mit ISIM schon deine Erfahrungen gemacht zu haben! ;-) Das hat mich auch schon ordentlich geärgert, aber für meine Zwecke tut es das meist. Das Problem, das ich hier habe, ist auch eher ein Architektur-Problem und keines, dass die Cores nicht richtig funktionieren. In der Simulation tun sie genau das, was das Datenblatt verspricht. Ein Ersatz der float16 in Fixpoint kommt nicht in Frage und macht auch in diesem Design keinen Sinn. Um eine ähnliche Auflösung zu bekommen bräuchte man irgendwas mit 30bit. Das ist bei der Multiplikation auch wieder schwierig, da die DSP48 nur 18x18bit können. Somit bräuchte ich für eine Multiplikation mehr als einen DSP48. Somit verringert sich direkt die Zahl der parallelen Berechnungen. Und wenn die Verschaltung der ganzen Geschichte von 16bit auf 30bit anwächst, kostet das auch Ressourcen, die nicht verfügbar sind im Chip. Martin S. schrieb: > Zum Pipelining: > Der Knoten steckt offensichtlich in deinem "Akkumulator", den du > haendisch aus einem (latenz > 1) behafteten Addierer strickst. Das > verletzt das 1-cycle-Akkumulatorprinzip grundsaetzlich :-) Das ist der Kern der Geschichte. Allerdings muss man nur das 1-cycle-Prinzip auf ein LATENZ-cycle-Prinzip erweitern, dann funktioniert es wieder. Ich habe nochmal von vorne angefangen. Bei Latenz=1 gilt das normale Akkumulator-Prinzip. Im nächsten Takt ist das Ergbenis aus In1+In2 am Ausgang vefügbar. Wenn man sich nun eine 6-Stufige Pipeline vorstellt, dann kommt am Ausgang etwas raus wie, In1+In7, im nächsten Takt In2+In8 und so weiter. Das heißt man kann die Werte am Ende in einer Adder-Tree-Methode addieren und man hat das richtige Ergebnis. Und genau das ist der Punkt! Es sind schon alle Werte im Akku drin (man hat ja auch alle reingefüttert), nur die kommen nicht in einem Ergebnis raus, sondern aufgeteilt in (in diesem Beispiel) sechs Werte. In dem Bild im Anhang kann man es erkennen: Hier ist die Pipeline 4 Stufen und am Eingang habe ich die Eingangswerte zur einfacheren Kontrolle geändert zu (1,2,3,4,5,6,7,8,9,10 --> Summe 55). Die Gewichte sind immer 1, so dass die Multiplikation nicht reinspuckt. Ich habe das mit mehreren Latenzen durchgespielt und das Ergebnis ist immer richtig, wenn ich, sobald alle Eingangswerte reingefüttert sind, die nächsten Werte, die der Latenz entsprechen, addiere. Das Zusammenfassen, der Ausgangswerte ist jetzt noch nicht implementiert, das kommt als nächstes. Grüße, Jens
Jens W. schrieb: > Ein Ersatz der float16 in Fixpoint kommt nicht in Frage und macht auch > in diesem Design keinen Sinn. Um eine ähnliche Auflösung zu bekommen > bräuchte man irgendwas mit 30bit. Das ist bei der Multiplikation auch > wieder schwierig, da die DSP48 nur 18x18bit können. Somit bräuchte ich > für eine Multiplikation mehr als einen DSP48. Somit verringert sich > direkt die Zahl der parallelen Berechnungen. Und wenn die Verschaltung > der ganzen Geschichte von 16bit auf 30bit anwächst, kostet das auch > Ressourcen, die nicht verfügbar sind im Chip. Betr. "Auflösung" wird es eben lustig und richtig non-deterministisch mit float, du gewinnst zwar Dynamik, aber auf Kosten non-uniformer Auflösung. Und pikanterweise spielt es dann eine Rolle, in welcher Reihenfolge dein "interleaved Akkumulator" die Werte addiert. Kann man schon so machen, aber wo die Namensgebung Experimente mit Neuronalen Netzwerken suggeriert, würde ich sowas nur bedingt auf einer solchen Architektur aufbauen. Um dann auftretendes erratisches Verhalten bei Differenzierungen wieder zu kompensieren, brauchst du deutlich mehr Resourcen wegen zusätzlich nötiger Layer. Aber first things first. Für deinen neuen Ansatz oben gilt also der Abschnitt "Interleaving". Innerhalb deiner gesamten Pipeline hast du ja beliebig die Möglichkeit, einen Datenstrom in mehrere Spuren aufzuteilen und wieder zusammenzuführen, indem du in den nachgeschalteten N-1 Pipeline-Stufen deine interleaved-Akkumulationen fürs Resultat addierst - unter den Randbedingungen deiner Vektorenlänge (die mir noch nicht ins Auge gesprungen ist). ABER: Wegen des Verlusts der Assoziativität unterscheidet sich das Resultat u.U. gröber von dem einer anderen Implementierung, z.B. Akkumulation (a0 + a1 + a2 + ...) statt (a0 + a6 + a1 + ...). Das sollte man in der Verifikation im Auge behalten.
Angehängte Dateien:
-

idn1538085553005.gif
18 KB
{kind=link}
Jens W. schrieb: > Ein Ersatz der float16 in Fixpoint kommt nicht in Frage und macht auch > in diesem Design keinen Sinn. Das wage ich immer noch zu bezweifeln. > Um eine ähnliche Auflösung zu bekommen > bräuchte man irgendwas mit 30bit. Das ist bei der Multiplikation auch > wieder schwierig, da die DSP48 nur 18x18bit können. Somit bräuchte ich > für eine Multiplikation mehr als einen DSP48. Ja, mit drei Stück DSP48 bekommt man einen 36x36 Bit Multiplizieren. Hier hat sich mal jemand hingesetzt und geschaut, wie man für noch größere Bitbreiten die DSP48 effizient einsetzen kann: https://ens-lyon.hal.science/ensl-00356421v1/document Außerdem bekommst Du mit den DSP-Blöcken den Addierer gratis mit dazug: https://docs.amd.com/r/2021.2-English/ug1483-model-composer-sys-gen-user-guide/DSP48E Zum Thema Genauigkeit von float habe ich gerade die Tage erst ein schönes Beispiel bekommen:
1 | #include <stdio.h> |
2 | #include <math.h> |
3 | |
4 | int main( void) |
5 | {
|
6 | const int n = 1000; |
7 | const float step = 0.1; |
8 | float summe = 0.0; |
9 | |
10 | for( int i = 0; i < n; i++) |
11 | {
|
12 | summe += step; |
13 | }
|
14 | printf( "%d * %f = %f\n", n, step, summe); |
15 | }
|
Bei mir sieht das so aus:
1 | $ cc float_rundung.c && ./a.out |
2 | 1000 * 0.100000 = 99.999046 |
Rick D. schrieb: > Zum Thema Genauigkeit von float habe ich gerade die Tage erst ein > schönes Beispiel bekommen: Und noch schöner wird das Beispiel, wenn du `summe` auf einen sehr grossen Anfangswert setzt und dann damit das Endresultat vergleichst.. (Sei
..) Was DSP-Blöcke angeht, kann man auch sparsame truncated multiplication implementieren. Je nach Architektur sind die daraus entstehenden Pipelines deutlich besser zu routen als mit den Haudrauf-Cores der klassischen Xilinx-FPGAs, die ihre DSP-Elemente eher auf periphere Verarbeitung von Daten ausgerichtet haben als auf kaskadierte Netze im "Fabric". Aber das ist eher eine fortgeschrittene Geschichte, wo man ohne HLS nicht effektiv vorankommt. Vorerst würde ich mich bei dem obigen Problem mal rein auf die Untersuchung der Pipeline fokussieren, dann auf die Arithmetik. Soll ja ein Lernprojekt sein, oder?
Hallo Rick, danke für die Links! Der Hintergrund, warum ich bei float bleibe, ist der, dass es sonst eben mehr DPS-Blöcke werden. Ich will ja parallel arbeiten und das so breit, wie es geht. Das FPGA, das ich nutze, hat 96 DSP-Blöcke. Die will ich nutzen um parallel zu arbeiten. Wenn ich pro Multiplikation 3 bräuchte, dann kann ich nur noch 30 Einheiten parallel laufen lassen. Daher bleibe ich bei Float. Das bietet mir alles, was ich will. Die Auflösung passt, und da ist die Genauigkeit auch nicht so dramatisch, da es eh nur um Statistik geht und der Fehler ist einkalkuliert. Ich brauche mir keine großen Gedanken machen über Überläufe. Und die Cores laufen, wenn ich den Addierer fertig habe, mit 225Mhz (laut Tool, das ist natürlich noch nicht getestet). Da wird der Datendurchsatz sehr groß. Wenn ich das mit nur 30 Einheiten parallel machen will, bräuchte ich die dreifache Frequenz und das wird auch nicht funktionieren. So schnell sind die Berechnungen in Fixpoint auch nicht. Und, wenn man so viele Einheiten parallel verbinden will, macht es einen großen Unterschied, ob ich 16bit verbinden muss, oder 30bit. Aber ich will keine Grundsatzdiskussion über Sinn und Unsinn von float anfangen. Hier habe ich mich entschieden, das so zu machen. Ob ich damit auf die Nase falle, das werde ich dann auch sehen ;-) Aber ohne blutige Nase lernt man ja nichts. Bei deinem Beispiel kommt es auf die Implementierung an, also wie es im µC oder was auch immer umgesetzt ist. Bei meinen kleinen µCs erhalte ich immer 6 gültige Stellen. Danach wird gerundet. Allerdings würde ich mir schon erwarten, dass da dann 1000.00 als Ergebnis steht. Nicht 99,irgendwas. Da könnte auch was anderes faul sein... Grüße, Jens
Martin S. schrieb: > Vorerst würde ich mich bei dem obigen Problem mal rein auf die > Untersuchung der Pipeline fokussieren, dann auf die Arithmetik. Soll ja > ein Lernprojekt sein, oder? Hallo Martin, genau so ist es! Es geht rein ums Lernen. Ich mache das rein privat, daher habe ich auch kein Problem meinen Code zu posten. Sobald ich das implementiert habe, melde ich mich mit dem Ergebnis. Dann stelle ich mich auch gerne einem Benchmark ;-) Wenn ihr Ideen habt, gerne her damit. Danke euch! Viele Grüße, Jens
Jens W. schrieb: > Bei deinem Beispiel kommt es auf die Implementierung an, also wie es im > µC oder was auch immer umgesetzt ist. Bei meinen kleinen µCs erhalte ich > immer 6 gültige Stellen. Danach wird gerundet. Allerdings würde ich mir > schon erwarten, dass da dann 1000.00 als Ergebnis steht. Nicht > 99,irgendwas. > Da könnte auch was anderes faul sein... Nein, das ist ein inhärentes Problem der float-Arithmetik. Wenn die nach IE³-754 implementiert ist, ist das auf jedem uC/CPU gleich "falsch". Deswegen spielt es bei float eine grosse Rolle, in welcher Reihenfolge du die Produkte addierst. Wird dir dann nämlich passieren, dass:
wenn (a viel kleiner als A). Ich würde mal schwer wetten, dass du mit der Duplizierung deiner Pipeline die f_max rapide nach unten drücken musst und die DSP48-Resourcen so gar nicht optimal nutzen kannst. xst macht dann u.U. ab einem Punkt auch nur noch nerviges Zeug, was man nicht will. Aber kannst ja dann mal Bilder vom PnR posten, wenn die Flaschenhälse auftreten. Du nutzt ja hoffentlich nicht einen alten Spartan3E, oder?
Martin S. schrieb: > Du nutzt ja hoffentlich nicht einen alten Spartan3E, oder? Nee, das nicht. Aber so viel neuer ist es auch nicht. Ich verwende ein Virtex-4. ;-) Ich hab das mal günstig auf ebay gefunden und für meine Gehversuche tut es das hoffentlich. https://www.ebay.com/itm/186917057793 Grüße
Beitrag #8039481 wurde vom Autor gelöscht.
Hallo zusammen, also ich habs! Man muss die restlichen Ergebnisse in einem Addertree zusammenfassen. Ich will hier keine zusätzlichen Addierer verwenden, da bei float zusätzliche Ressourcen notwendig sind und ich dann das gleiche Problem wie am Anfang habe. Da käme man nicht über 50MHz hinaus. Also verwende ich den vorhandenen Addierer. Jetzt muss man aber auf die Ergebnisse warten, da kann man nicht mehr kontinuierlich reinstreamen. Für die Struktur empfiehlt sich eine ungerade Anzahl der Latenz (=Ergebnisse, die zusammengefasst werden müssen). Ich habe auf 5 reduziert. Dann kommt man auf mögliche 200MHz. Schon deutlich mehr als die 50MHz, wenn alles in einem Takt ausgeführt werden soll. Verteilt man die zusätzlichen Takte vom Addertree über die Anzahl der Werte, die berechnet werden sollen, dann kommt man bei 96 Eingängen auf eine resultierende Frequenz von 168MHz. Umso mehr Eingänge es werden, desto besser wird das Verhältnis und desto näher kommt man an die 200MHz ran. So werde ich es erstmal lassen. Für mich der beste Kompromiss aus Ausführungsgeschwindigkeit und Ressourcenverbrauch (bei Verwendung aller 96 DSP-Einheiten, ist das FPGA erst zu 60% gefüllt). Danke an euch! Grüße und ein schönes langes Wochenende!
> Ich verwende ein > Virtex-4. ;-) > Ich hab das mal günstig auf ebay gefunden und für meine Gehversuche tut > es das hoffentlich. Günstig, wenn man eine Lizenz für die Entwicklungssoft hat. Meines Wissens wird der gezeigte LX100 nicht von der kostenlosen Webpack Lizenz unterstützt. Da wäre man mit einem Spartan-3 besser dran. * https://www.xilinx.com/publications/matrix/Software_matrix.pdf Virtex-4 war Xilinx nicht besonders gelungen (bspw. wegen Problemen mit den RocketIO) und wurde rechte flott durch den Virtex5 abgelöst.
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.